
Abstract
Cross-document event coreference resolution (CD-ECR) is a fundamental task in natural language processing (NLP) that seeks to determine whether event mentions across multiple documents refer to the same real-world occurrence. However, current CD-ECR approaches predominantly rely on trigger features within input mention pairs, which induce spurious correlations between surface-level lexical features and coreference relationships, impairing the overall performance of the models. To address this issue, we propose a novel cross-document event coreference resolution method based on Argument-Centric Causal Intervention (ACCI). Specifically, we construct a structural causal graph to uncover confounding dependencies between lexical triggers and coreference labels, and introduce backdoor-adjusted interventions to isolate the true causal effect of argument semantics. To further mitigate spurious correlations, ACCI integrates a counterfactual reasoning module that quantifies the causal influence of trigger word perturbations, and an argument-aware enhancement module to promote greater sensitivity to semantically grounded information. Within a unified end-to-end framework, ACCI delivers reliable support for coreference decisions. Extensive experiments demonstrate that ACCI achieves state-of-the-art performance, with CoNLL F1 scores of 88.4% on ECB+ and 85.2% on GVC. The implementation and materials are available at https://github.com/era211/ACCI.
Similar content being viewed by others
Introduction
Event coreference resolution (ECR) is a fundamental task in deep semantic understanding, aiming to identify different textual expressions that refer to the same real-world events. It underpins applications such as knowledge graph construction1, information extraction2, and question answering3. As illustrated in Fig. 1, suppose two documents \(\mathscr {D}_1\) and \(\mathscr {D}_2\) jointly contain four event mentions, denoted as \({e}_1\), \({e}_2\), \({e}_3\), and \({e}_4\). ECR pairs these mentions (e.g. (\(e_1\), \(e_4\)), (\(e_3\), \(e_4\))) to determine coreference, grouping coreferent mentions into event chains via clustering. ECR can be categorized into within-document (WD-ECR), where mentions are from the same document, and cross-document (CD-ECR), where mentions span multiple documents. This work primarily focuses on event coreference resolution in the cross-document setting.

Examples of event mentions in within-document and cross-document scenarios under the ECR task.

Distribution of ”trigger word matching” between mention pairs in the ECB+ and GVC training sets. The left is ECB+ and the right is GVC, with C and NC denoting coreferential and non-coreferential pairs, respectively. LexSim vs. LexDiv indicate lexically similar vs. dissimilar trigger words.
Most existing approaches to the CD-ECR task formulate it as a similarity assessment between event mentions4,5. A commonly adopted paradigm is pairwise representation learning6, in which pre-trained language models jointly encode event mentions and their surrounding contexts. From these contextualized embeddings, salient features are extracted to train a coreference scorer that estimates the likelihood of two mentions referring to the same event. However, such methods primarily rely on the lexical properties of trigger words and their correlation with coreference labels. As a result, the scorer often exhibits a strong bias towards superficial lexical matching, at the expense of a deeper understanding of event arguments. As illustrated in Fig. 2, coreferential mention pairs tend to share lexically similar triggers, while non-coreferential pairs usually do not. This distributional asymmetry can induce spurious correlations between trigger word similarity and coreference labels, thereby undermining the model’s accuracy.
To address the challenge of spurious correlations induced by lexical triggers, we introduce a new perspective based on structural causal modeling. By conceptualizing the CD-ECR decision process through a causal graph, we reveal how confounding factors—such as trigger matching—can obscure the genuine semantic relationships between event mentions. This causal view exposes the limitations of previous approaches5,7 and motivates the design of principled intervention strategies to disentangle superficial correlations from true semantic signals.
Building upon this insight, we propose a cross-document event coreference resolution method based on Argument-Centric Causal Intervention (ACCI), a novel framework that leverages causal intervention and counterfactual reasoning to explicitly mitigate confounding influences in CD-ECR. Specifically, ACCI models the dependencies among triggers, event arguments, and coreference labels within a structural causal graph, and applies targeted interventions to isolate the genuine causal effect of argument semantics. To implement this intervention and enhance the model’s focus on argument semantics, ACCI incorporates two key components: a counterfactual reasoning module quantifies the impact of hypothetical changes to trigger words (such as replacement or masking) on coreference predictions, thereby disentangling the confounding effect of trigger matching while holding argument information constant. An argument-aware enhancement module is introduced to refine the model’s internal representations and attention mechanisms, encouraging greater sensitivity to the semantic roles and contextual interactions of event arguments. It thus reinforces the model’s reliance on causal cues rather than surface-level lexical signals. ACCI achieves this effective debiasing within a unified end-to-end framework by operating on the model’s inference process, without altering the underlying model training procedure. Specifically, our contributions are as follows:
-
We are the first to introduce causal intervention and counterfactual reasoning into the CD-ECR task. The proposed ACCI framework is designed to mitigate spurious correlations in the representation of event mention pairs, without necessitating modifications to the original training paradigm.
-
We apply the back-door criterion to causally disentangle event constituents from confounding factors. By quantifying the semantic divergence between factual and counterfactual representations. It mitigates spurious correlations introduced by superficial trigger word matching and enhances the model’s ability to capture the causal semantics of event arguments.
-
Extensive experimental results show that ACCI outperforms existing methods, achieving state-of-the-art performance.
Related work
Cross-document event coreference resolution
In recent years, deep learning-based approaches have driven notable progress in CD-ECR. Caciularu et al.8 proposed CDLM, an extension of Longformer that combines global attention for masked label prediction with local attention elsewhere. Some studies have explored end-to-end approaches. Cattan et al.9 extended a within-document coreference model to an end-to-end framework that resolves cross-document coreference directly from raw content. Lu et al.10 proposed an end-to-end method for predicting event chains directly from raw text.
Some studies have also adopted pairwise representations for coreference prediction. Barhom et al.4 proposed a model for joint cross-document entity and event coreference, using a learned pairwise scorer for clustering. Event and entity mention representations are enriched via predicate-argument structures to incorporate related coreference clusters. Held et al.11 proposed a two-stage approach for cross-document entity and event coreference, inspired by discourse coherence theory. It models attentional states as mention neighborhoods for candidate retrieval, then samples hard negatives to train a fine-grained classifier using local discourse features. Yu et al.6 proposed PAIRWISERL, a pairwise representation learning method that jointly encodes sentence pairs containing event mentions, enhancing the model’s ability to capture structured relationships between events and their arguments. Ahmed et al.5 decomposed ECR into two subtasks to address computational challenges and data distribution skew. The method filters non-coreferent pairs using a heuristic, then trains a discriminator on the balanced dataset for pairwise scoring and coreference prediction. Ding et al.12 introduced LLM-RCDA, a rationale-centric counterfactual data augmentation method that intervenes on triggers and context, reducing reliance on surface trigger word matching and emphasizing causal associations between events. Graph-based methods have also been applied to the CD-ECR task. Chen et al.13 incorporated discourse structure as global context into CD-ECR to better capture long-distance event interactions. They modeled documents using rhetorical structure trees and represented event mention interactions via shortest dependency paths and lowest common ancestors. Gao et al.14 constructed document-level RST trees and cross-document lexical chains to model structural and semantic information, using Graph Attention Networks to learn event representations. This approach improves the modeling of long-distance dependencies in CD-ECR. Chen et al.15 introduced the ECD-CoE task to generate coherent cross-document text for event mentions, addressing limitations in capturing long-distance dependencies and contextual coherence. They encoded the generated text using rhetorical relation trees to extract global interaction features for coreference resolution. Zhao et al.16 proposed HGCN-ECR, a hypergraph-based method for CD-ECR. It uses BiLSTM-CRF for semantic role labeling, constructs a multi-document event hypergraph centered on triggers, and employs hypergraph convolution and multi-head attention to capture higher-order semantic relations. Ahmed et al.17 introduced X-AMR, a graphical event representation, and applied a multi-hop coreference algorithm to linearize ECR over event graphs. Apart from the aforementioned approaches, Nath et al.18 used Free-Text Rationales (FTRs) from LLMs as distant supervision for smaller student models. Through Rationale-Oriented Event Clustering (ROEC) and Knowledge Distillation, their method significantly improved performance on the ECB+ and GVC corpora.
While foundational ECR research has predominantly focused on English, the field is increasingly expanding to address the challenges in other languages. Recognizing the scarcity of multilingual resources, Pouran Ben Veyseh et al.19 introduced MCECR, the first large-scale, manually annotated dataset for cross-document ECR covering five languages: English, Spanish, Hindi, Turkish, and Ukrainian. Research is also deepening in specific, morphologically rich languages; for example, Aldawsari and Dawood20 developed AraEventCoref, the first public event coreference dataset for Arabic, highlighting unique linguistic challenges such as complex syntax.
Causal inference
Causal inference21, as a potential statistical theory originating from statistics and data science, aims to determine whether one variable causes another through statistical and experimental methods. Its core lies in clarifying causal relationships between variables rather than superficial correlations. Causal inference primarily encompasses structural causal graph22, causal intervention23, and counterfactual reasoning24, which can scientifically identify causal relationships between variables and eliminate potential biases in data. Causal intervention25 focuses on altering the natural tendency of independent variables to change with other variables to eliminate adverse effects. Counterfactual reasoning26 describes the imagined outcomes of factual variables in constructed counterfactual worlds.
In recent years, causal inference has been increasingly applied to various down-stream tasks such as recommendation systems27, natural language inference28, computer vision29, and multimodal modeling30. Mu et al.31 employed counterfactual reasoning in event causality identification to estimate the impact of contextual keywords and event pairs on model predictions during training, thereby eliminating inference biases. Chen et al.32 proposed a multimodal fake news debiasing framework based on causal intervention and counterfactual reasoning from a causal perspective. They first eliminated spurious correlations between textual features and news labels through causal intervention, then imagined a counterfactual world to apply counterfactual reasoning for estimating the direct effects of image features.
Although existing research has achieved significant progress in improving cross-document event coreference resolution (CD-ECR) performance, discussions on mitigating spurious correlations caused by the over-reliance on trigger words in current ECR systems remain insufficiently explored. While Ding et al.12 alleviated such biases at the data level through counterfactual data augmentation, this approach inevitably incurs additional data annotation costs. Current research trends favor leveraging causal inference to eliminate spurious correlations a strategy that avoids the need for extra labeled data compared to data augmentation methods. In our work, we adopt a causal perspective and use causal intervention to mitigate these correlations without additional labeled data, enhancing the model’s focus on argument-level semantics across documents. Furthermore, our application of counterfactual reasoning is specific. Its function is to implement the back-door adjustment, quantifying the confounding effect of lexical triggers to isolate the true causal effect of argument semantics.

The overall architecture of the ACCI framework.
Methodology
In this paper, we introduce an argument-centric causal intervention framework, named ACCI, to mitigate bias in cross-document event coreference resolution. Built upon two widely adopted backbone architectures5,11, our approach integrates causal intervention with counterfactual reasoning to effectively alleviate spurious correlations arising from lexical matching of trigger words. Simultaneously, we enhance the model’s perception capabilities regarding event arguments based on counterfactual reasoning principles. During the training phase, this approach calibrates model biases by contrasting the semantic differences between factual and counterfactual features. And it strengthens the alignment capabilities among events mention arguments. It significantly improves the model’s accuracy in complex semantically ambiguous scenarios. The architecture of the proposed model is illustrated in Fig. 3.
Task definition
Given a document set \(\mathscr {D}=\{{d}_1,{d}_2,\dots ,d_{m}\}\), where \(m=|\mathscr {D}|\). Each document \({d}_i\) contains multiple event mentions. The set of all event mentions in \(\mathscr {D}\) constitutes the event mention set \(E = \{e_1, e_2, \ldots , e_{n}\}\). For candidate event mention pairs \((e_i,e_j)\) from the same subtopic, the goal of the ECR is to learn a mapping function \(\mathscr {F}\) to predict the coreference relation between these two event mentions: \(\mathscr {F}:(e_i,e_j) \rightarrow {y}\), where \(y\in Y=\{\Upsilon ,\Theta \}\). Here, \(y=\Upsilon\) indicates that \(e_i\) and \(e_j\) refer to the same events, and \(y=\Theta\) indicates that they refer to different events. Subsequently, event mention pairs predicted to be coreferent are clustered to represent distinct events.
Pairwise event coreference
The base pairwise event coreference model serves as the foundation of our proposed ACCI framework. This approach typically consists of two main stages: candidate mention retrieval and coreference resolution. The architecture of the pairwise event coreference model is illustrated in Fig. 4.
Candidate mention retrieval phase: To ensure fair comparison with previous work, we employ two candidate event mention pair retrieval strategies: (1) a discourse coherence theory-based approach for generating event mention pairs11; and (2) a heuristic algorithm for the efficient filtering of non-coreferential pairs5.
Coreference resolution phase: To enable fine-grained evaluation of candidate mentions, a pairwise classifier is constructed and trained accordingly. Specifically, for each event mention pair \((\mathscr {A},\mathscr {B})\), the trigger words of both mentions are enclosed with a special marker \((<\text {m}> \text {and} </\text {m}>)\) to explicitly signal their roles. Formally, for each event mention, It can be denoted as:
where \(\mathscr {M}\) denotes event mention, the symbol \(\oplus\) denotes concatenation, and \(\mathscr {T}_\mathscr {A}\) is the trigger word of event \(\mathscr {A}\). Next, the textual content of the marked mentions \(\mathscr {A}\) and \(\mathscr {B}\) is combined into a joint sequence as input to a model. The input sequence is structured as:
where [CLS] and [SEP] are standard special tokens. This sequence is fed into a PLM-based cross-encoder to obtain hidden state representations:
where \(H\in \mathbb {R}^{L\times d}\), L is the sequence length and d denotes the dimension of the feature representation, with \(x_i\in X\) representing different event mention pairs.

The architecture of the pairwise event coreference model.

Structural causal graph for ECR. This figure illustrates the causal relationships in ECR via SCM. Key variables include event mention pairs (X), coreference labels (Y), and trigger word matching (T) as a confounder. The details are shown: (a) the baseline causal structure, (b) the confounding bias from T, and (c) the results after controlling for confounding factors.
Through average pooling operations, we derive event representations \(E_\mathscr {A}\) and \(E_\mathscr {B}\) centered on trigger words, representing the hidden layer embeddings corresponding to the triggers in event mentions \(\mathscr {A}\) and \(\mathscr {B}\), respectively. Simultaneously, we extract the global pooled representation \(H_{[CLS]}\) to capture the global semantic context of the entire input. These representations are then concatenated to form a unified event mention pair representation:
where \(W^T\) is a learnable weight matrix, the symbol || denotes concatenation. The symbol \(\odot\) denotes element-wise multiplication, which is used to capture fine-grained interactions between event mentions. The concatenated representation is fed into a MLP layer to predict the coreference probability:
where \(W^T_p\) is the weight matrix, and \(P_{ECR}\) denotes the predicted coreference score. Then, a clustering algorithm groups event mentions predicted as coreferential to form clusters representing coreferent events. The clustering algorithm is shown in Algorithm 1.

Clustering algorithm.
Causal analysis and intervention for ECR
Based on the structured causal graph shown in Fig. 5, we employ a causal intervention mechanism to systematically analyze the confounding bias present in baseline ECR systems. Specifically, as illustrated in Fig. 5a, the baseline causal structure offers a high-level view of the ECR decision process, in which the prediction Y is directly influenced by the input features X. However, as shown in Fig. 5b, we expect the model to follow a causal path from the input features X via the semantic argument information A to the prediction Y, represented as \(X \rightarrow A \rightarrow Y\), in order to achieve an accurate semantically driven prediction. However, the trigger word matching feature T often influences the input representation X. Subsequently, it affects the model’s decision, thereby forming a path such as \(T \rightarrow X \rightarrow A \rightarrow Y\). This path introduces a non-causal influence on the event coreference prediction Y, causing the model to establish a spurious correlation between trigger word matching and coreference decisions. According to causal theory25, the trigger matching feature T effectively acts as a confounder between the input X and the predication Y. This confounder introduces bias through the backdoor path \(X \leftarrow T \rightarrow Y\), resulting in the model overly relying on superficial semantic similarity during inference while neglecting the modeling of contextual semantic consistency.
Subsequently, we employ the backdoor adjustment principle26, as depicted in Fig. 5c. By intervening on X and blocking the influence of T, we remove the spurious correlation and compel the model to make coreference decisions based primarily on argument-level semantics. Formally, we achieve this by using the do-operator to estimate the interventional distribution:
where the operation \(\text {do}(X)\) sets X independently of T, effectively severing the confounding path. This intervention guides the model to focus on contextual semantic arguments rather than superficial trigger word matches, resulting in more robust and causally valid coreference predictions.
Counterfactual ECR
We first introduce the counterfactual reasoning module, which systematically quantifies and mitigates surface bias induced by trigger word matching through the construction of hypothetical scenarios contrary to observed facts. Subsequently, we elucidate the Argument-Aware Enhancement Module, designed to further improve the model’s ability to determine the coreference relationship of events without interference from trigger words, especially by prioritizing the processing of the core semantic information of event arguments. The overall procedure is outlined in Algorithm 2.
Counterfactual reasoning module
Building on our earlier analysis of confounding effects, we introduce a counterfactual reasoning module designed to quantify and mitigate the spurious correlations caused by trigger word matching. Specifically, we pose the following counterfactual query: ”What would the coreference resolution outcome be if the trigger word information in the event mention pair were unobserved?” By comparing the model’s predictions under both factual and counterfactual conditions, our approach enables precise assessment and effective reduction of spurious biases stemming from trigger word matching. The detailed implementation is described as follows.
Constructing counterfactual event embeddings: We first partition the original input sequence \(X=\{x_1,\ldots ,x_n \}\) into trigger subsequences \(X_{trg}=\{x_t \mid t \in T\}\) and context subsequences \(X_{arg}=X \backslash X_{trg}\) via masking operations. To ensure a clean separation against tokenization artifacts, this masking is performed at the subword level: we identify all subword tokens corresponding to a target trigger and mask them as a complete unit, which prevents partial information leakage. This allows the model to separately learn spurious correlations from triggers and true causal information from context in decoupled subspaces. Using a cross-encoder, we obtain counterfactual event embeddings \(h_{x_t}^{cf}\), which strip away contextual argument information and retain only lexical features of the triggers:
where \(X_{arg}=\emptyset\) denotes unobserved contextual argument information. What distinguishes counterfactual embeddings from conventional ones is that the former primarily omit contextual semantics and instead encode solely trigger-specific lexical features.
Computing bias-aware state representations: We then compute a joint representation space mapping using:
where \(\Phi _c\in \mathbb {R}^d\) is an empty-context placeholder that simulates zero contextual input, \(W_f\in R^{\left( d+2d_{x_t}\right) \times d_h}\) is a trainable weight matrix, and \(d_{x_t}\), \(d_h\) are the embedding and hidden-state dimensions, respectively.
Quantifying Spurious Correlation: Finally, we quantify surface-level bias via linear projection to compute pseudo-association strength between event pairs:
where \(W_E\in \mathbb {R}^{d_h\times 2}\) are the classification weights. The score represents the degree to which spurious correlation arises solely from trigger words.
By applying this approach, we mitigate the spurious signals caused by the lexical similarity of trigger words, allowing the model to concentrate on the genuine causal relationships among events. Thereby it has enhanced the accuracy of cross-document event coreference resolution.
Argument-aware enhancement module
After the counterfactual reasoning module successfully quantified and mitigated the spurious correlations introduced by trigger words, we enhanced the ACCI framework’s argument awareness by developing an argument-aware enhancement path based on event argument information \(X_{arg}\). This path is designed to fully leverage the core semantic information provided by the event arguments. It enables the model to diminish its overreliance on trigger words, while prioritizing the semantic contribution of argument roles in determining coreference relations, thereby achieving more accurate coreference resolution.
Argument-centric embedding extraction: We input \(X_{arg}\) into a cross-encoder to obtain the contextualized embedding of the [CLS] token, denoted as \(\mathscr {C}_{arg}\). The resulting embedding aggregates semantic information from all arguments:
where \(\mathscr {C}_{arg}\) reflects contextual information only, distinct from the [CLS] representation derived from full event pairs.
The input \(X_{arg}\) represents not merely a collection of isolated arguments, but the entire event mention context excluding the trigger word. This rich contextual input preserves the syntactic and semantic structure—such as other verbs, prepositions, and relational phrases—that defines the specific event type and the roles its arguments play. By processing these rich contexts with a cross-encoder, the model is trained to compare the underlying relational frameworks of the events, rather than simply matching the entities themselves. Guided by an event-level training objective, this mechanism learns to differentiate events based on their relational structure, ensuring the model’s focus remains on event coreference, not merely entity coreference.
Simulating argument-only scenarios: To simulate event coreference resolution based solely on argument information, we introduce a learnable constant vector \(\Phi \in \mathbb {R}^d\), which replaces the original trigger representation and serves as a placeholder for an empty event. Concatenate \(\mathscr {C}_{arg}\) with two instances of \(\Phi _E\) (empty trigger placeholders) and apply a nonlinear transformation via shared parameters \(W_f\):
where \(W_f\) denotes a learnable shared parameter, and \(\Phi\) represents a placeholder for event representation.
To support more effective learning of semantic representations, we introduce a learnable placeholder vector \(\Phi \in \mathbb {R}^d\), which substitutes the original trigger embedding. This design encourages the model to rely primarily on argument-related contextual cues, thereby simulating an argument-only inference scenario. Argument-centric embeddings are concatenated with these placeholders and passed through a non-linear transformation parameterized by a shared weight matrix \(W_f\), ensuring consistent representation learning across modules. This shared parameterization ensures consistent representation learning across modules, aligns latent spaces, and prevents divergence within the argument-aware enhancement module while fostering synergistic learning of contextual features.
Training and debiased inference
We design a training and inference strategy that emphasizes argument-centric semantic information and reduces trigger word bias. During training, we jointly optimize the factual prediction loss on complete samples and the semantic enhancement loss focusing on argument information, encouraging the model to attend to event arguments for accurate coreference resolution. The overall training objective is
where \(Loss_F\) is the binary cross-entropy loss over \(P_F\) (predictions based on all input features), and \(Loss_C\) is computed on \(P_C\) to promote reliance on argument semantics. The balancing coefficient is \(\alpha\). Each loss term is defined as
where \(y_i\) and \(\widehat{y_i}\) are ground-truth and predicted coreference probabilities for the i-th training sample.

Counterfactual ECR.
During inference, we apply a three-step debiasing procedure: (1) Trigger words are masked to create argument-focused inputs, which are encoded to produce argument-centric predictions \(P_C\); (2) Counterfactual inputs containing only trigger words are used by the counterfactual reasoning module to estimate the bias term \(S_{bias}\), reflecting surface-level spurious signals; (3) The final prediction combines the original prediction \(P_F\), the argument-centric score \(P_C\), and subtracts the bias:
where \(\alpha\) and \(\beta\) balance the contributions of argument-based predictions and trigger-induced bias, respectively. The final scores are fused via a linear combination, a simple yet principled approach chosen for its alignment with causal theory and its analytical transparency. The structure directly mirrors causal adjustment, where the factual prediction (\(P_F\)) is corrected by both the argument-centric score (\(P_C\)) and the estimated spurious bias (\(S_{bias}\)). This linearity prevents the model from learning complex, confounding interactions. Moreover, the additive fusion preserves the framework’s modularity, ensuring the contribution of each causal pathway can be analyzed independently.
Experiments
This section details the datasets, evaluation metrics, baseline models, and experimental setups, followed by comprehensive analysis of results. We further validate the effectiveness of each module through ablation studies and investigate the impact of confounding factors via case studies.
Datasets and evaluation metrics
Datasets
To validate the effectiveness of our proposed method, we conducted experiments on two widely used benchmark datasets: Event Coreference Bank Plus (ECB+)33 and the Gun Violence Corpus (GVC)34. These datasets span diverse topics and linguistic contexts, providing a robust basis for evaluating the generalizability of the ACCI framework.
ECB+: This dataset was introduced by Cybulska and Vossen33 in 2014 and is currently a widely used standard for cross-document event coreference resolution research. It was created as an extension to the original ECB dataset. The expanded ECB+ dataset enhances the study of cross-document event coreference resolution by drawing on a large collection of news articles that cover various types of events, with coreference relations annotated across multiple documents. The corpus includes text spans marking event mentions and information on how these events are linked via coreference. It comprises 982 articles spanning 43 different topics, with 6,833 event mentions connected by 26,712 coreference links.
GVC: Introduced by Vossen et al.34 in 2018, the Gun Violence Corpus is an English dataset specifically designed for event coreference resolution. It comprises texts related to gun-violence incidents collected from multiple sources—news websites, social media platforms, reports, and blogs—all centered on a single theme (gun violence) and exhibiting a wide range of reporting styles, event descriptions, and subsequent reactions. The corpus contains 510 articles and features high lexical variability. In total, GVC includes 7,298 event mentions linked by 29,398 coreference relations. Following previous work, we train and evaluate our method on the annotated event mentions.
Evaluation metrics
In this study, to maintain consistency with previous work12, we adopt the \(\text {B}^3\) F1 metric35 to select the best model during the training phase. For comprehensive comparison with existing research, we also report the F1 for \(\text {LEA}\)36, \(\text {MUC}\)37, and \(\text {CEAFe}\)38, as well as \(\text {CoNLL}\) F1, which is the arithmetic mean of the \(\text {MUC}\), \(\text {B}^3\), and \(\text {CEAFe}\) F1.
Implementation details
Our model is implemented using PyTorch39. We use AdamW40 to optimize the model parameters. To ensure a fair comparison with the main baseline, we followed their experimental setup5. Specifically, we adopt their heuristic method for data construction. We set the model learning rate to \(1e-5\) and the classifier learning rate to \(1e-4\). All experiments are conducted in four NVIDIA Tesla A40 Gpus.
Baseline
To comprehensively evaluate our ACCI model, we conduct comparative experiments with various existing methods on the ECB+ and GVC datasets:
-
Cross-document language modeling (CDLM): Caciularu20218 pretrains multiple related documents to build a general-purpose language model for multi-document settings.
-
End-to-end methods: Cattan20219 develop an end-to-end model that performs cross-document coreference resolution directly from raw text.
-
Graph-structured methods: Chen202313, Gao202414, Chen202515, and Zhao202516 leverage discourse graphs or hypergraph convolutional neural networks combined with structured information across documents to enhance the representation and aggregation of event coreference features.
-
Pairwise representation learning: Barhom20194, Held202111, Yu20226, Ahmed20235, and Ding202412 treat event mention pairs as input and employ a cross-encoder framework to learn fine-grained coreference features between mentions.
-
Large language model (LLM)-based Methods: Nath202418 use a large language model as a teacher via rationale-aware clustering and knowledge distillation for cross-document event coreference resolution. We also compare the performance of Llama and GPT-3.5-Turbo on this task. The prompt is designed as follows:

Experimental results
Results on the ECB+ dataset
To evaluate the effectiveness of the proposed approach, we implemented ACCI within two representative backbone architectures5,11, using RoBERTa41 as the primary encoder. A comparison between ACCI and several established baselines on the ECB+ dataset is reported in Table 1. On the test set, ACCI achieved \(\text {B}^3\) F1 and \(\text {CoNLL}\) F1 of 86.9% and 88.4%, respectively. Compared with the strongest baselines13,18, which previously achieved the highest \(\text {CoNLL}\) F1, our method delivers a notable improvement of 2.0%. For the \(\text {B}^3\) F1 metric, ACCI trails the best-reported score13 by only 0.4%, indicating highly competitive performance. Importantly, ACCI obtains the best scores across all competing methods on additional metrics including MUC, CEAFe, and LEA F1. This comparative evaluation underscores the substantial advantages of our approach. Although it marginally underperforms the optimal reported values on individual metrics, a holistic analysis across all evaluation criteria confirms that ACCI leads to marked improvements in the accuracy of cross-document event coreference resolution, thereby highlighting its efficacy in addressing the inherent challenges of the task.
To more systematically examine the performance differential between ACCI and the baseline models, Table 2 presents an extensive comparison involving two representative backbone networks5,11. Furthermore, we investigate the performance of ACCI when adopting RoBERTa-large as the encoder. The results reveal that, relative to Held202111 and the best-performing variants of Ahmed20235, ACCI using RoBERTa-base achieves significant gains of 1.6% and 1.0% in \(\text {CoNLL}\) F1. When further upgraded with RoBERTa-large, ACCI demonstrates even more pronounced improvements over Ahmed2023, boosting \(\text {B}^3\) F1 and \(\text {CoNLL}\) F1 by 1.9% and 2.3%, respectively.
Notably, even when employing RoBERTa-base, ACCI surpasses all Longformer-based counterparts, indicating that its superiority is not solely attributable to the choice of encoder. Instead, the effectiveness of ACCI arises from its architectural innovation and its tailored optimization strategy. These results also lend strong support to the necessity and effectiveness of incorporating causal intervention and counterfactual reasoning into ECR.
Results on the GVC dataset
To comprehensively evaluate the generalization capability of the proposed method, A detailed comparison of ACCI with existing advanced baseline methods on the GVC dataset is provided in Table 3. In the test set evaluation, the ACCI method achieved \(\text {CoNLL}\) F1 and \(\text {B}^3\) F1 of 85.2% and 86.6%, respectively. Compared to the baseline that reported the best \(\text {CoNLL}\) F115, ACCI demonstrates a highly competitive performance, achieving a score within a small margin of only 0.6% of their result. It is notable that on the \(\text {B}^3\) F1 and \(\text {LEA}\) F1 metrics, ACCI surpassed the best reported baseline results5,12 by 0.8% and 0.9%, respectively. This indicates that this method has advantages in these key evaluation indicators. Although the \(\text {CEAFe}\)F1 of ACCI is lower than that of Chen202515, it remains higher than the scores of other compared models. This discrepancy may stem from ACCI’s strong performance in capturing the causal relationships between local triggers and arguments, contrasted with certain limitations it exhibits in explicitly modeling document-level chain structures, thereby leading to a slight reduction in the \(\text {CEAFe}\) (chain integrity matching) evaluation score. Nevertheless, when considering overall performance, ACCI maintains a highly competitive standing.
A comprehensive comparison between ACCI and two representative backbone architectures5,11 on the GVC dataset is presented in Table 4. The experimental results indicate that, when using RoBERTa-base as the encoder, ACCI achieves significant improvements of 3.1% and 2.9% in \(\text {CoNLL}\) F1 over Held202111 and the strongest versions of Ahmed20235, respectively. While not best on every metric, ACCI remains competitive and excels at mitigating spurious correlations.
Ablation experiment
To evaluate the contribution of each model component to the performance of ACCI, we conducted ablation studies on both the ECB+ and GVC datasets. The examined components include Trigger Bias Mitigation (TBM) and Context Argument Enhancement (CAE), where \(\downarrow\) indicates a decrease in F1. Table 5 reports the detailed results of this analysis.
Specifically, w/o TBM refers to the setting in which the contextual arguments of event mentions are retained while the event trigger words are removed. This corresponds to the counterfactual inquiry: ”What would the model’s coreference decision be if it had not observed the trigger word associated with the event?” Conversely, w/o CAE retains the trigger words while omitting the contextual arguments, representing the question: ”What would the model’s prediction be if it had not seen the surrounding arguments related to the event?” Finally, w/o TBM+CAE removes both components, i.e. without applying either trigger bias mitigation or context argument enhancement.
On the ECB+ dataset, we observe that removing TBM results in a performance drop of 0.6% in \(\text {CoNLL}\) F1 and 0.7% in \(\text {B}^3\) F1, with \(\text {LEA}\) F1 showing the most substantial decline of 0.9%. These findings underscore the importance of TBM in mitigating the adverse impact of lexical trigger bias on coreference decisions. Similarly, removing CAE leads to a 0.8% decrease in \(\text {CoNLL}\) F1 and a 0.5% decrease in \(\text {B}^3\) F1, with \(\text {MUC}\) F1 and \(\text {LEA}\) F1 decreasing by more than 1.0%, indicating the essential role of contextual arguments in event understanding. These results further reveal that conventional ECR systems often overly depend on surface-level lexical cues from triggers, while underutilizing the informative context that arguments provide. When both TBM and CAE are removed, the performance degradation becomes even more pronounced. Overall, these results demonstrate that ACCI effectively enhances the model’s ability to capture the underlying causal relationships between event mentions and coreference decisions, by reducing overreliance on triggers and improving sensitivity to argument-level information.
Analysis
Model generalization

Generalizability between ECB+ and GVC under the lh_oracle and lh settings.
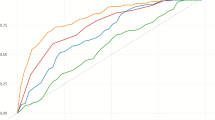
To further assess the out-of-domain generalization of the ACCI method, we conducted cross-dataset experiments in which the model is trained on one dataset and evaluated on another. We selected two distinct datasets: ECB+, which covers a broad range of events such as politics, sports, and disasters, and GVC, which focuses solely on gun violence incidents. Specifically, we train the model on ECB+ and test it on GVC, and then reverse the process. To provide a comprehensive evaluation, we report results under both the lh_oracle and lh settings. The detailed results are shown in Fig. 6.
Compared to baseline models, ACCI consistently outperforms baseline models in all cross-domain scenarios. Under both lh_oracle and lh conditions, ACCI achieves higher F1 scores for both B3 and CoNLL metrics, regardless of whether the source domain is ECB+ or GVC. The improvement is more pronounced when the model is evaluated on the GVC dataset, demonstrating ACCI’s robust generalization to novel event types and domains. By incorporating a structural causal intervention mechanism, ACCI is able to construct representative counterfactual instances from the target dataset, thereby alleviating spurious correlations between event triggers and labels and promoting greater attention to the underlying semantic structures of events. This mechanism not only enhances the model’s generalization ability within the target domain, but also enables ACCI to make robust coreference predictions when presented with new-domain events characterized by changes in structure, context, and modes of expression.
Sensitivity analysis
We systematically analyze the key hyperparameters of the ACCI model and perform sensitivity experiments to assess its performance across varying conditions. A detailed distribution of correctly resolved mentions (True Positives, TP) across varying cluster threshold levels for both the ACCI model and baseline methods on the ECB+ and GVC benchmark datasets is presented in Fig. 7. The quantitative results demonstrate that ACCI consistently outperforms the baselines on both corpora, with its advantage becoming increasingly prominent under higher clustering thresholds. As the clustering threshold increases, a clear upward trend in the number of true positives resolved by ACCI is observed. On the ECB+ dataset, the TP count peaks at a threshold of 16, while the performance gap between ACCI and the best-performing baseline reaches its maximum at threshold 25. On the GVC dataset, the largest disparity occurs at threshold 19. These findings suggest that higher threshold values impose stricter decision boundaries for event clustering, thereby serving as a robust measure of model resilience. The superior performance of ACCI under these challenging settings can be attributed to its ability to integrate rich contextual information, model argument structures more comprehensively, and suppress interference from misleading lexical cues. In contrast, baseline models tend to rely heavily on trigger word matching and superficial lexical similarity, which makes them more susceptible to incorrectly clustering non-coreferent but lexically similar event mentions when stricter thresholds are applied.
To quantitatively assess the impact of the debiasing coefficient \(\beta\), we varied its value from 0.0 to 1.0 in increments of 0.05 and evaluated the resulting \(\text {CoNLL}\) F1 and \(\text {B}^3\) F1 on the ECB+ dataset, and the results are illustrated in Fig. 8. As \(\beta\) increased from 0.0 (no debiasing) to the range of 0.2–0.3, model performance steadily improved, with the \(\text {CoNLL}\) F1 reaching 88.4% and the \(\text {B}^3\) F1 reaching 86.9%. These gains indicate that moderate debiasing effectively suppresses spurious correlations induced by trigger word matching while preserving valuable recall signals, thereby enhancing inference accuracy. As \(\beta\) continued to rise beyond 0.3, both scores began to plateau and slightly declined when \(\beta\) \(\ge\) 0.5. Specifically, at \(\beta\) = 0.5, the \(\text {CoNLL}\) F1 and \(\text {B}^3\) F1 stabilized around 88.1% and 86.7%, respectively. However, as \(\beta\) approached 1.0—corresponding to near-total removal of trigger-based bias—the \(\text {CoNLL}\) F1 dropped sharply to 84.1%, and the \(\text {B}^3\) F1 fell to 85.6%. This suggests that although full debiasing can eliminate false associations, it also removes helpful semantic cues provided by trigger words, causing the model to underperform in event alignment.

Distribution of correctly resolved mentions (True Positives) across cluster-size thresholds on the ECB+ and GVC datasets, comparing the ACCI model with baseline.

Effect of the debiasing coefficient \(\beta\) on \(\text {CoNLL}\) F1 and \(\text {B}^3\) F1 on the ECB+ dataset. Optimal performance is observed when \(\beta\) is set between 0.2 and 0.3.

Training loss curves of BCELoss and BCEWithLogitsLoss under the ACCI framework.
Comparison of loss functions
In classification tasks, the selection of an appropriate loss function is a key determinant of model training efficacy. Under the proposed ACCI framework, we systematically compare two prevalent binary loss functions: Binary Cross-Entropy (BCELoss) and Binary Cross-Entropy with Logits (BCEWithLogitsLoss). The key difference between them lies in output normalization. BCELoss requires the output probabilities to be normalized via a sigmoid function, while BCEWithLogitsLoss operates directly on raw logits and incorporates the sigmoid operation internally to improve numerical stability. As illustrated in Fig. 9, BCELoss consistently demonstrated superior performance throughout the training process in this task. It exhibited a lower initial loss, a faster rate of decrease, and ultimately converged to a smaller training loss with reduced overall fluctuations, indicating a more stable and efficient optimization trajectory. This phenomenon may be attributed to the explicit use of sigmoid activation by BCELoss, which enables the model to learn probability normalization behavior more directly during training, thereby facilitating the establishment of distinct decision boundaries between positive and negative samples. In contrast, while BCEWithLogitsLoss offers better numerical stability, its relatively smooth gradient characteristics might provide insufficient feedback for low-confidence samples during the initial training stages. This could limit the model’s sensitivity to crucial discriminative signals, consequently impacting the overall convergence efficiency.
Confounding factor impact analysis

Case studies illustrating the impact of lexical trigger bias and argument sensitivity. ACCI shows improved robustness over the baseline by correctly handling semantically similar triggers, reducing sensitivity to superficial trigger matches, and detecting changes in event arguments.
In this section, we provide illustrative examples to analyze the influence of potential confounders on the baseline ECR system. A key issue in the baseline model is its overreliance on lexical matching between trigger words in event mention pairs, which prevents it from capturing the underlying causal signals necessary for accurate coreference prediction. Within this context, we identify event triggers as latent confounding variables that bias the model’s decision-making process. In Example 1 (Fig. 10), the two event mentions share semantically equivalent but lexically distinct trigger words: ”acquire” and ”buy”, both referring to the event in which AMD acquires the server company SeaMicro. However, influenced by the lexical discrepancy between the triggers, the baseline model assigns a coreference score of 0.46—below the classification threshold of 0.5, and thus incorrectly labels the pair as non-coreferential (gold label: 1.0). To further examine the model’s susceptibility to confounding effects, we conduct a minimal intervention in Example 2 by replacing the trigger ”buys” with ”acquire”. This slight lexical change significantly increases the model’s confidence, boosting the coreference score from 0.46 to 0.77. Such a sharp shift in prediction, despite identical contextual semantics, highlights the model’s high sensitivity to lexical forms of triggers—an indication of spurious correlations rather than true causal reasoning. In contrast, the proposed ACCI framework effectively attenuates the impact of such confounders, resulting in substantially more robust and context-aware predictions across semantically similar but lexically varied event mentions.
To assess the ACCI model’s sensitivity to event arguments embedded in textual mentions, we introduce a minimal intervention in Example 3, wherein the shared participant ”AMD” in one mention is replaced with ”Intel”. This change alters the ground-truth label from 1 to 0, indicating that the two mentions no longer refer to the same event. As anticipated, ACCI successfully detects the shift in event arguments, with the prediction score dropping markedly from 0.65 to –0.21. This observation provides compelling evidence that ACCI not only mitigates reliance on superficial trigger-word lexical patterns, but also strengthens the model’s capacity to discern semantically meaningful changes in argument structure. Such behavior reinforces the conclusion that causal intervention and counterfactual reasoning embedded within ACCI enable more reliable and context-sensitive predictions, thereby substantially improving the accuracy of the event coreference system.

Quantitative performance comparison between the ACCI model and the baseline model.
To systematically evaluate the robustness of the model from a statistical perspective, we conducted a quantitative analysis of all truly coreferenced event pairs in the test set. Firstly, in terms of overall performance comparison (as shown in Fig. 11a ), our ACCI model has achieved a significant improvement in accuracy from 69.9% to 84.2% compared to the baseline model.
To further understand the source of this improvement, we focused our analysis on the cases where the baseline model failed (false negatives), as shown in Fig. 11b. Among all coreference pairs wrongly judged by the baseline, the ACCI model successfully corrected 57.8% of these errors. This suggests that ACCI’s performance gain is not merely a general improvement, but can be largely attributed to its ability to resolve the systematic flaws we identified. A closer inspection suggests that many of these corrected cases are challenging samples, similar to those in Fig. 10, where the baseline was confounded by lexical diversity (LexDiv). This result provides strong evidence that our causal intervention is working as intended, mitigating the spurious correlations that affect the baseline model.
Case analysis

Three cross-document mention-pair cases from the ECB+ dataset, with event triggers marked between \(<m>\) and \(</m>\), ”Non-Coreference” denoting non-coreferential pairs and ”Coreference” denoting coreferential pairs; A bar chart is included for Case 1 to illustrate the progression of reasoning scores leading to the final prediction.
We construct representative case studies to assess the practical effectiveness of the proposed ACCI model. These cases are drawn from the ECB+ dataset and are selected based on their tendency to induce errors in the baseline model, while being correctly resolved by ACCI.
As illustrated in Fig. 12, Case 1 presents two non-coreferent events extracted from Document A and Document B. While both refer to Scott Peterson, Document A employs the trigger word murder to portray his psychological state and demeanor during the sentencing phase of his trial. In contrast, Document B uses killing to directly reference the act of murdering his pregnant wife and unborn child. Although centered on the same individual, the semantic focus of the triggers clearly diverges: the former emphasizes courtroom proceedings, whereas the latter describes the criminal act itself. The baseline model mistakenly identifies the two as coreferent, reflecting its reliance on lexical similarity. In contrast, ACCI accurately distinguishes between the two, demonstrating a deeper understanding of contextual semantics. The accompanying bar chart visualizes the model’s internal reasoning process that led to its final decision.
In Case 2, the trigger struck is used to report the onset of an earthquake, while rocked captures the resulting tremor in the affected region. Both mentions refer to the same 6.1-magnitude earthquake in Aceh, Indonesia. Despite this, the baseline model incorrectly categorizes them as referring to different events, whereas ACCI successfully resolves them as coreferent.
In Case 3, both mentions share the trigger announced, but differ substantially in their underlying semantics. The first centers on HP’s $13.9 billion acquisition of an outsourcing firm, focusing on the transactional details. The second, however, emphasizes the strategic implications of this cash-based deal. Here, the baseline model again fails by equating the two events, driven by superficial trigger word matching. This example underscores a key limitation of conventional ECR systems: when overly reliant on lexical similarity, they fail to capture fine-grained differences in argument structure and contextual nuance.
Limitations
To make the causal analysis tractable, our framework adopts several simplifying assumptions, which represent important avenues for future research. A central assumption is the procedural separability of triggers and arguments via subword masking; this serves as a necessary approximation of their often-entangled semantic relationship and enables the intervention. This separation mechanism allows our counterfactual module to employ a procedural simulation—using learnable placeholders (\(\Phi _c, \Phi _E\)) and masked inputs—to approximate a true semantic intervention. We posit that this simulation, while presenting the model with input structures not seen in standard pre-training, provides a meaningful contrastive signal for the model to quantify bias. This quantification, in turn, relies on an assumption of effect decomposability, where the spurious and causal effects are treated as distinct components. This streamlines the modeling of what may be complex, non-linear interactions within the model’s representation space. While our approach demonstrates the effectiveness of this simplified causal model, exploring more nuanced interventions that relax these assumptions—alongside addressing other potential confounders like document-level topic bias—remains an important open challenge.
Conclusion
This study introduces an argument-centric causal intervention framework, named ACCI, to mitigate the problem of spurious correlations in CD-ECR. Specifically, a structural causal graph is constructed to identify the confounding effects of trigger words and the causal relationships in the embedded context semantics. Subsequently, backdoor adjustment and counterfactual intervention are employed to guide the model to focus on the causal interaction between event arguments and coreferential relationships, while effectively suppressing the spurious bias caused by the lexical matching of trigger words. Extensive experimental results demonstrate the effectiveness of ACCI compared to the competitive baseline. These results suggest that causal inference and counterfactual reasoning are a promising direction for enhancing model reliability in ECR tasks.
In the future, we aim to expand the capabilities of this framework by tackling more complex challenges, including multilingual and multimodal ECR. This expansion will enhance its universality and practical applicability. Furthermore, we will investigate methods to adapt ACCI to effectively process unstructured and noisy data sources, such as social media posts, news reports, or conversational corpora, which are often characterized by ambiguity and linguistic irregularities.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Vakaj, E., Tiwari, S., Mihindukulasooriya, N., Ortiz-Rodríguez, F. & Mcgranaghan, R. Nlp4kgc: natural language processing for knowledge graph construction. Companion Proc. of the ACM Web Conf. 2023, 1111–1111 (2023).
Perot, V. et al. Lmdx: Language model-based document information extraction and localization. Findings of the Association for Computational Linguistics ACL 2024, 15140–15168 (2024).
Lu, Y. et al. Knowledge editing with dynamic knowledge graphs for multi-hop question answering. Proc. of the AAAI Conference on Artificial Intelligence 23, 24741–24749 (2025).
Barhom, S. et al. Revisiting joint modeling of cross-document entity and event coreference resolution. In Proc. of the 57th Annual Meeting of the Association for Computational Linguistics, 4179–4189 (2019).
Ahmed, S. R., Nath, A., Martin, J. H. & Krishnaswamy, N. 2* n is better than n2: Decomposing event coreference resolution into two tractable problems. Findings of the Association for Computational Linguistics: ACL 2023, 1569–1583 (2023).
Yu, X., Yin, W. & Roth, D. Pairwise representation learning for event coreference. In Nastase, V., Pavlick, E., Pilehvar, M. T., Camacho-Collados, J. & Raganato, A. (eds.) Proc. of the 11th Joint Conference on Lexical and Computational Semantics, *SEM@NAACL-HLT 2022, Seattle, WA, USA, July 14-15, 2022, 69–78, https://doi.org/10.18653/V1/2022.STARSEM-1.6 (Association for Computational Linguistics, 2022).
Ravi, S., Tanner, C., Ng, R. & Shwartz, V. What happens before and after: Multi-event commonsense in event coreference resolution. In Proc. of the 17th Conference of the European Chapter of the Association for Computational Linguistics, 1708–1724 (2023).
Caciularu, A. et al. Cdlm: Cross-document language modeling. Findings of the Association for Computational Linguistics: EMNLP 2021, 2648–2662 (2021).
Cattan, A., Eirew, A., Stanovsky, G., Joshi, M. & Dagan, I. Cross-document coreference resolution over predicted mentions. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 5100–5107 (2021).
Lu, Y., Lin, H., Tang, J., Han, X. & Sun, L. End-to-end neural event coreference resolution. Artif. Intell. 303, 103632 (2022).
Held, W., Iter, D. & Jurafsky, D. Focus on what matters: Applying discourse coherence theory to cross document coreference. In Proc. of the 2021 Conference on Empirical Methods in Natural Language Processing, 1406–1417 (2021).
Ding, B. et al. A rationale-centric counterfactual data augmentation method for cross-document event coreference resolution. In Proc. of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 1112–1140 (2024).
Chen, X., Xu, S., Li, P. & Zhu, Q. Cross-document event coreference resolution on discourse structure. In Proc. of the 2023 Conference on Empirical Methods in Natural Language Processing, 4833–4843 (2023).
Gao, Q. et al. Enhancing cross-document event coreference resolution by discourse structure and semantic information. In Proc. of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 5907–5921 (2024).
Chen, X., Li, P. & Zhu, Q. Improving cross-document event coreference resolution by discourse coherence and structure. Inf. Process. Manag. 62, 104085 (2025).
Zhao, W., Zhang, Y., Wu, D., Wu, F. & Jain, N. Hypergraph convolutional networks with multi-ordering relations for cross-document event coreference resolution. Inf. Fusion 115, 102769 (2025).
Ahmed, S. R. et al. Linear cross-document event coreference resolution with x-amr. In Proc. of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 10517–10529 (2024).
Nath, A., Avari, S. M., Chelle, A. & Krishnaswamy, N. Okay, let’s do this! modeling event coreference with generated rationales and knowledge distillation. In Proc. of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 3931–3946 (2024).
Pouran Ben Veyseh, A., Lai, V. D., Nguyen, C., Dernoncourt, F. & Nguyen, T. MCECR: A novel dataset for multilingual cross-document event coreference resolution. In Duh, K., Gomez, H. & Bethard, S. (eds.) Findings of the Association for Computational Linguistics: NAACL 2024, 3869–3880, https://doi.org/10.18653/v1/2024.findings-naacl.245 (Association for Computational Linguistics, 2024).
Aldawsari, M. & Dawood, O. Araeventcoref: An arabic event coreference dataset and llm benchmarks. ACM Trans. Asian Low-Resour. Lang. Inf. Process. https://doi.org/10.1145/3743047 (2025).
Pearl, J., Glymour, M. & Jewell, N. P. Causal Inference in Statistics: A Primer (Wiley, USA, 2016).
Neuberg, L. G. Causality: models, reasoning, and inference, by Judea Pearl. Econometr. Theory 19, 675–685 (2003).
Lin, X., Wu, Z., Chen, G., Li, G. & Yu, Y. A causal debiasing framework for unsupervised salient object detection. In Proc. of the AAAI Conference on Artificial Intelligence 2, 1610–1619 (2022).
Qian, C., Feng, F., Wen, L., Ma, C. & Xie, P. Counterfactual inference for text classification debiasing. In Proc. of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 5434–5445 (2021).
Pearl, J. Causal inference in statistics: An overview. Stat. Surv. 3, 96–146. https://doi.org/10.1214/09-SS057 (2009).
Pearl, J. Causality (Cambridge University Press, 2009).
Zhang, Y. et al. Causal intervention for leveraging popularity bias in recommendation. In Proc. of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, 11–20 (2021).
Zhang, W., Lin, H., Han, X. & Sun, L. De-biasing distantly supervised named entity recognition via causal intervention. In Proc. of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 4803–4813 (2021).
Yang, D. et al. Context de-confounded emotion recognition. In Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 19005–19015 (2023).
Zhang, L. et al. What if the tv was off? examining counterfactual reasoning abilities of multi-modal language models. In Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 21853–21862 (2024).
Mu, F. & Li, W. Enhancing event causality identification with counterfactual reasoning. In Proc. of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 967–975 (2023).
Chen, Z., Hu, L., Li, W., Shao, Y. & Nie, L. Causal intervention and counterfactual reasoning for multi-modal fake news detection. In Proc. of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 627–638 (2023).
Cybulska, A. & Vossen, P. Using a sledgehammer to crack a nut? lexical diversity and event coreference resolution. In Proc. of the Ninth International Conference on Language Resources and Evaluation (LREC’14), 4545–4552 (2014).
Vossen, P., Ilievski, F., Postma, M. & Segers, R. Don’t annotate, but validate: A data-to-text method for capturing event data. In Proc. of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018) (2018).
Bagga, A. & Baldwin, B. Entity-based cross-document coreferencing using the vector space model. In COLING 1998 Volume 1: The 17th International Conference on Computational Linguistics (1998).
Moosavi, N. S. & Strube, M. Which coreference evaluation metric do you trust? a proposal for a link-based entity aware metric. In Proc. of the 54th annual meeting of the association for computational linguistics, vol. 1, 632–642 (Association for Computational Linguistics, 2016).
Vilain, M., Burger, J. D., Aberdeen, J., Connolly, D. & Hirschman, L. A model-theoretic coreference scoring scheme. In Sixth Message Understanding Conference (MUC-6): Proc. of a Conference Held in Columbia, Maryland, November 6-8, 1995 (1995).
Luo, X. On coreference resolution performance metrics. In Proc. of Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, 25–32 (2005).
Imambi, S., Prakash, K. B. & Kanagachidambaresan, G. Pytorch. Programming with TensorFlow: Solution for Edge Computing Applications 87–104 (2021).
Loshchilov, I. & Hutter, F. Decoupled weight decay regularization. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019 (OpenReview.net, 2019).
Liu, Y. et al. Roberta: A robustly optimized bert pretraining approach. Preprint at arXiv:1907.11692 (2019).
Funding
This work is a research achievement supported by the ”Tianshan Talent” Research Project of Xinjiang (No. 2022TSYCLJ0037), the National Natural Science Foundation of China (No. 62262065), the Key Research and Development Program of Xinjiang (No. 2022B01008), the National Key R&D Program of China Major Project (No. 2022ZD0115800), the National Science Foundation of China (No. 62476233), the Key Research and Development Program of Xinjiang (No. 2023B01005), the Key Research and Development Program of Xinjiang (No. 2024B03028), and the Key Research and Development Program of Xinjiang (No. 2024B03041).
Author information
Authors and Affiliations
Contributions
L. Y., W. Y., Y. Y., L. W. and X. T.: Conceptualization; L. Y.: Software, Writing - original draft, Writing - review & editing, Visualization; W. Y.: Funding acquisition; W. Y., Y. Y., L. W. and X. T.: Supervision; F. W.: Formal analysis, Data curation. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yao, L., Yang, W., Yin, Y. et al. Argument centric causal intervention for cross document event coreference resolution. Sci Rep 16, 2939 (2026). https://doi.org/10.1038/s41598-025-32765-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-32765-6
