
Abstract
With the large-scale integration of renewable energy sources, the number of data acquisition terminals and the sampling frequency in distribution networks have increased rapidly, placing higher demands on the system’s computing and communication resource scheduling capabilities. This paper focuses on collaborative resource management and intelligent scheduling under a cloud–edge–device distributed architecture, and conducts a study on collaborative computing based on deep reinforcement learning. Firstly, an optimization model is formulated with the objective of maximizing the volume of data collaboratively processed by the cloud–edge–device system. The Lyapunov optimization theory is introduced to transform the long-term optimization problem into an online optimization problem that relies only on current time-slot information, enabling a joint guarantee of queuing delay control and long-term average data acquisition. Secondly, an improved Deep Q-Network (DQN) algorithm is proposed. By incorporating a greedy strategy-based Q-value sorting mechanism and a double experience replay mechanism, the algorithm enhances sample diversity and training stability, thereby improving convergence performance and decision robustness in multi-terminal resource scheduling scenarios. This also effectively mitigates resource conflicts caused by processing coupling among terminals. Finally, simulation results demonstrate that the proposed algorithm can effectively adapt to high-density, high-frequency data acquisition loads, providing excellent scheduling adaptability and system performance assurance. This work offers theoretical support and technical pathways for intelligent perception via cloud–edge collaboration in distribution networks.
Similar content being viewed by others

Introduction
To support large-scale distributed energy regulation and bidirectional source-load interactive perception in the new power system, the number of data acquisition terminals and the sampling frequency in distribution networks have surged significantly. The sampling frequency of voltage and current measurements is shifting from once every 15 min to once per minute. By 2025, it is expected that over one billion terminals will be connected to the State Grid, enabling comprehensive and high-frequency acquisition of multidimensional business data in distribution networks1,2,3. Compared to traditional power services, emerging applications such as distributed energy control, flexible load management, and energy storage operations impose much greater demands on computing power, further highlighting the current shortcomings in computing resources and refined management capabilities in distribution networks4,5. Therefore, in response to the trend of data acquisition becoming increasingly high-frequency, large-scale, and computation-intensive, enhancing the real-time transmission and processing capacity of business data to support efficient coordination among generation, grid, load, and storage has become a key research focus in the industry.
Traditionally, the main control centers of distribution networks have been built on cloud computing frameworks. While cloud platforms provide ample computing resources to handle business data processing requirements effectively6, the long-distance transmission between cloud servers and distribution terminals is often unstable, making them less suitable for high-frequency acquisition scenarios with rapid business growth. Edge computing, which brings partial cloud functions closer to the local side, reduces the computational load on cloud centers by offloading large-scale processing tasks, offering advantages such as reduced transmission latency and faster business response. It complements cloud computing effectively7,8. Moreover, intelligent terminals with embedded computing capabilities are being increasingly deployed in distribution networks. These advanced devices integrate data acquisition, access, processing, and uploading functions. In terms of processing, they can be equipped with intelligent chips like the “State Grid Chip” and support customized applications based on microservice architectures and containerization technologies, transforming raw business data into actionable information. The computing capacity they provide is becoming increasingly important.
In summary, distributed intelligent computing is progressively breaking down information barriers across hierarchical levels. Cloud–edge–device collaboration can effectively coordinate heterogeneous computing resources across layers and scales. Establishing a collaborative data processing mechanism tailored for high-frequency data acquisition in distribution networks will significantly enhance the system’s data transmission and processing capabilities and support the advancement of intelligent decision-making in distribution networks9,10.
Currently, domestic and international research teams have made considerable progress in cloud–edge–device collaboration. Reference11 aimed to minimize task computation delay by applying the K-means clustering algorithm to address the task offloading optimization problem in cloud–edge–device collaboration. This approach improved system resource utilization while reducing latency. Reference12 proposed a dependency-aware task offloading method that balances delay and energy consumption, using convex optimization tools to find the optimal solution, thereby effectively reducing the total system cost. Reference13 presented a distributed computing offloading strategy, which was transformed into a multi-objective delay optimization problem using the Alternating Direction Method of Multipliers (ADMM), significantly enhancing offloading speed and reliability. However, high-frequency and complex data acquisition scenarios are characterized by network randomness and uncertain modeling mechanisms, with no access to global information. Therefore, traditional optimization methods based on deterministic models are not well suited to these environments.
Deep Reinforcement Learning (DRL), which combines the feature perception capability of deep learning with the decision-making power of reinforcement learning, offers a viable solution for collaborative processing optimization in scenarios where global state information is unavailable14,15,16,17. Reference18 designed a DRL-based scheduling algorithm to handle high-concurrency service demands between cloud and edge, achieving joint optimization of network energy consumption and throughput. Reference19 developed a mobile edge computing task offloading model and solved it using a multi-objective offloading algorithm based on Deep Q-Network (DQN), which significantly improved server computing performance and user experience. Reference20 addressed the issue of limited resources on mobile devices by designing a task offloading and resource allocation algorithm based on the Asynchronous Advantage Actor-Critic (A3C) method, thereby enhancing computational efficiency.
Despite the progress made, several challenges remain. First, the coupling of long-term constraint guarantees and short-term decision optimization makes it difficult for single time-slot decisions to ensure both queuing delay control and long-term average data acquisition performance. Second, due to the diverse performance requirements of different services and limited network resources, multi-terminal decision-making becomes interdependent. Existing methods lack collaborative mechanisms and are unable to effectively resolve decision conflicts caused by resource competition. Third, most current methods rely on random sampling mechanisms, overlooking the heterogeneity of samples in the experience pool, which leads to poor convergence and optimization performance in resource-constrained competitive scenarios.
To address these issues, this paper proposes the Improved Deep Q-Network based Cloud–Edge–End Collaborative Processing Algorithm for Distribution Network (IDCEE). First, the virtual queue concept from Lyapunov optimization theory is introduced to transform the original problem into an online optimization problem that depends only on current time-slot information, enabling joint guarantees of latency and throughput. Second, a greedy strategy-based Q-value sorting mechanism is introduced to resolve resource selection conflicts in wireless channels and edge servers caused by the coupling of multi-terminal processing decisions through edge collaboration. Third, considering the importance of different terminal tasks and the confidence level of action samples, a dual replay experience pool is designed to maintain sample diversity, prevent data loss, and improve algorithm convergence. Finally, simulation analysis is conducted to validate the performance gains of the proposed algorithm.
System model
Cloud-side-end collaboration network model
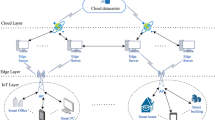
The cloud–edge–end multi-level collaborative service processing framework proposed in this paper for high-frequency data acquisition in distribution networks is illustrated in Fig. 1. It consists of three layers: the terminal layer, the edge layer, and the cloud layer. The terminal layer includes various intelligent data acquisition terminals deployed on distributed photovoltaic/wind units, energy storage devices, EV charging stations, and other electrical equipment. These terminals perform high-frequency real-time data collection on electricity usage, equipment status, and the distribution network’s operating environment. They are capable of local computation or uploading data to the edge layer via 5G networks. Due to limited fiber coverage on the low-voltage user side, 5G is adopted for end–edge communication. The proposed architecture is also compatible with other communication media such as fiber optics and power line carrier, offering both flexibility and scalability.
The edge layer comprises communication base stations and edge servers. Data received by the base stations can be processed locally on edge servers or further transmitted to the cloud layer through a remote communication network. The cloud layer is built and maintained by the power grid company or hosted on trusted third-party cloud platforms, providing abundant computing resources. It is capable of performing deep analysis of the high-frequency data collected from the distribution network, supporting functions such as efficient interaction among generation, grid, load, and storage, and real-time perception of network operating conditions.

Cloud-edge-end multi-level collaborative service processing framework.
The cloud, edge, and end layers each exhibit distinct characteristics in terms of data transmission and processing capabilities. Compared with the terminal layer, the edge layer offers more abundant computing resources. However, its performance is still constrained by the transmission capacity between the terminal and edge layers, as well as by the computational limitations at the terminal layer, due to competition among multiple terminals for communication and computing resources. Moreover, long-distance data transmission is affected by various factors such as routing delays and network congestion, making the cloud–edge data transmission network highly time-varying and uncertain. This variability poses a significant bottleneck to improving the data processing performance at the cloud layer. Therefore, it is necessary to construct local computation, edge processing, and cloud processing modes based on the differentiated characteristics of the cloud–edge–end architecture. The parameter details are listed in Table 1.
Consider Di data acquisition terminals and J wireless channels. A quasi-static time slot model is adopted, where the total optimization period is divided into T time slots, each with a duration of τ. At time slot t, the service processing decision variable for Di is defined as Yi,k(t) ∈ {0,1}, where k = 1, 2, 3 correspond to local computation, edge processing, and cloud processing, respectively. Yi,k(t) = 1 indicates that the corresponding mode is selected; otherwise, Yi,k(t) = 0. Each terminal can choose only one mode, i.e.:
Considering that the computing resources of edge servers are still limited compared to cloud servers, to avoid an excessive number of terminals selecting the edge processing mode and causing unbalanced service load distribution, the service processing constraint for the edge server is defined as follows.
Equation (2) indicates that the edge server can process the services of at most ς terminals simultaneously.
Define the wireless channel selection variable as Xi,j(t) in {0,1}, where Xi,j(t) = 1 indicates that Di selects channel j to upload data; otherwise, Xi,j(t) = 0. Define the data acquisition frequency control variable as Zi,n(t) in {0,1}, where Zi,n(t) = 1 indicates that Di collects data at a frequency of n times per minute during time slot t; otherwise, Zi,n(t) = 0. The set n belongs to the range from Nmin to Nmax, where Nmin is the minimum acquisition frequency and Nmax is the maximum acquisition frequency. Define the amount of data collected by Di per acquisition as Ai,0; then under different acquisition frequencies, the data volume collected by terminal in Di is nAi,0.
Local computational model
Based on dynamic queue evolution, a local computation model is constructed. Define the data backlog of the local processing queue as Qi(t). Considering the significant differences in processing capabilities among various distribution network terminals, the data processing is simplified into a four-element model, including data volume, computational complexity, processing delay, and computing resources. The local processing data volume for Di depends on the minimum value between the terminal’s computing capability and the queue backlog7, represented as.
In the equation, λi represents the computational complexity, expressed as the CPU frequency required to process a unit bit of service data; fi(t) denotes the computing resources that Di can provide. After data processing in each time slot is completed, the dynamic evolution of the local processing queue backlog over the time slot is represented as:
In the equation, Ui(t) represents the amount of data processed collaboratively by the cloud-edge-end system; Ai(t) is the amount of data collected by Di during time slot t.
Edge processing model
The data transmission rate of Di using channel j for end-to-edge communication during time slot t is expressed as:
In the equation, Bj is the transmission bandwidth; γi,j(t) is the signal-to-interference-plus-noise ratio (SINR), which is expressed as:
In the equation, \(P_{i}^{{TX}}\) and Gi, j(t) represent the transmission power and channel gain, respectively. The term \(\sum\limits_{{i^{\prime} \ne i}} {{X_{i^{\prime},j}}\left( t \right)P_{i}^{{TX}}{G_{i^{\prime},j}}\left( t \right)}\) denotes the co-channel interference caused by multiple terminals sharing the same channel for data transmission. N0 is the power of additive Gaussian white noise. δ(t) represents the electromagnetic interference generated by medium- and high-voltage electrical equipment during operation, which exhibits significant impulsive characteristics. It is quantified using an alpha-stable distribution, whose characteristic function is expressed as:
In the equation, ϕ is a constant; α, β, ξ, and µ represent the characteristic exponent, skewness parameter, scale parameter, and location parameter of the electromagnetic interference, respectively.
In the edge processing mode, the amount of data that the edge server can handle depends on the minimum value among the wireless channel transmission capacity between the edge and the device, the computing capability of the edge server, and the backlog of the local service data queue, that is,
In the equation, f(t) represents the computing resources available at the edge server; \(\tau f\left( t \right)/\left( {{\lambda _i}\sum\limits_{{i=1}}^{I} {{Y_{i,2}}\left( t \right)} } \right)\) denotes the computing resources allocated by the edge server for processing the data of terminal Di.
Cloud processing model
The cloud has abundant storage and computing resources, and can analyze and manage the power data uploaded from the edge or terminal through technologies such as data mining and high-performance storage. Therefore, it is assumed that all service data uploaded to the cloud can be processed within the specified time. In the cloud processing mode, the amount of data that terminal Di can process depends on the minimum value among the wireless transmission capacity between the terminal and the edge, the transmission capacity of the communication link between the cloud and the edge, and the backlog of the local service data queue, that is:
In the equation, Λ(t) represents the transmission rate available on the cloud-edge communication link, which is affected by multiple factors such as routing, forwarding, and network congestion, and exhibits high variability and uncertainty.
Cloud-side-end co-processing data volume model and its constraints
Considering the differentiated models of local computing, edge processing, and cloud processing, the amount of data collaboratively processed by the cloud, edge, and terminal is expressed as:
In high-frequency data acquisition scenarios, the surge in service data volume can easily lead to excessive queuing delays in the terminal-side service data queue, which may significantly impact the accuracy of distribution network operation decisions. Moreover, high-frequency acquisition services in distribution networks—such as electricity information collection, power quality monitoring, distribution automation, and precise load control—have minimum data acquisition requirements. Therefore, for high-frequency acquisition, the cloud-edge-terminal collaborative processing of data must also take into account the terminal-side local processing queuing delay constraint20, as well as the long-term average data acquisition volume constraint, which are respectively expressed as:
In the equation, \({\bar {A}_i}\left( t \right)=\sum\limits_{{a=0}}^{{t - 1}} {{A_i}\left( a \right)/t}\) is the sum of Ai(a) from a equals zero to t; \({\tau _{i,\hbox{max} }}\) is the queuing delay threshold; and Ui, min is the minimum data volume required for the normal operation of the terminal’s high-frequency data acquisition tasks in the distribution network over the entire optimization period.
Optimization problem modeling
In summary, under the premise of ensuring queuing delay and long-term average data acquisition volume constraints, this paper aims to maximize the amount of data collaboratively processed by the cloud, edge, and terminal. This approach not only ensures sufficient underlying data support for the normal operation of new power services but also reduces queuing delay. It is specifically expressed as:
In the equation, ηi represents the importance of the service for different terminals, with ηi belonging to the interval (0, 1]; a larger ηi indicates that the terminal’s service is more critical for the stable operation of the distribution network. C1 represents the value range constraints for wireless channel selection variables, service processing decision variables, and data acquisition frequency control variables. C2 denotes the mode constraints and edge server service processing constraints. C3 and C4 respectively indicate that each terminal can only select one data acquisition frequency per time slot, can upload service data using at most one channel, and each channel can be selected by at most ω terminals. C5 and C6 represent the queuing delay constraint and the long-term average data acquisition volume constraint, respectively.
Algorithm design
Question conversion
Due to the coupling between service processing decisions in each time slot and the queuing delay and long-term average data acquisition constraints, the optimization problem P1 is difficult to solve directly. Therefore, virtual queues from Lyapunov optimization are introduced to transform the queuing delay constraint C5 and the long-term average data acquisition volume constraint C6 into queue stability constraints, thereby decoupling the long-term optimization problem into a deterministic per-slot optimization problem. The virtual queue for queuing delay is defined as Hi(t), and the virtual queue for long-term average data acquisition volume is defined as Wi(t). Their update formulas between time slots are respectively given by:
In the equation, Hi(t) represents the deviation between the queuing delay of the local processing data queue after time slot t and the queuing delay threshold τi, max; Wi(t) represents the deviation between the average data acquisition volume in the current time slot and the long-term average data acquisition threshold Ui, min. Based on Lyapunov optimization theory, when the virtual queues Hi(t) and Wi(t) are stable, the corresponding long-term constraints C5 and C6 are satisfied.
Define the vector Θi(t) = [Hi(t) Wi(t)], then the Lyapunov function can be expressed as:
In the equation, VH and VW are the weight parameters of the virtual queues for queuing delay and long-term average data acquisition volume, respectively, used to balance their priorities.
To further simplify the original optimization problem and support the subsequent algorithm, Lyapunov drift theory is introduced. The Lyapunov drift is defined as the expected change in L(Θ(t)) between time slots. By minimizing the Lyapunov drift, the queue backlog can be effectively kept at a low level. Combined with the optimization objective of this paper, the Lyapunov drift-plus-penalty function is constructed as follows:
In the equation, V is a non-negative weight coefficient used to balance the trade-off between minimizing queue drift and maximizing the amount of data collaboratively processed by the cloud, edge, and terminal.
By substituting Eq. (16) into Eq. (17) and simplifying, the upper bound of the drift-plus-penalty function can be obtained as:
In the equation, ϖ is a constant that does not affect the Lyapunov optimization process. Therefore, problem P1 is transformed into maximizing the negative of the upper bound of the drift-plus-penalty function, which is expressed as:
Modeling the MDP optimization problem
Although the original optimization problem has been transformed into a new problem that can be optimized online based only on current time slot information, the volatility of channel transmission capacity in the distribution network and the uncertainty caused by the coupling of multi-terminal processing decisions still make optimization problem P2 difficult to solve directly. Therefore, this paper further models P2 as a classic Markov Decision Process (MDP), which consists of three elements: state space, action space, and reward. The details are as follows:
1) State space: In time slot t, the state includes the service queue backlog of Di, the newly acquired data volume, the amount of data processed by the terminal, and the virtual queue backlogs of the queuing delay and the long-term average data acquisition volume, that is:
2) Action space: Defined as the set consisting of the variables Xi, j(t), Yi, k(t), and Zi, n(t), that is:
3) reward: defined as the objective value of optimization problem P2, expressed as θ(t).
Improved DQN-based collaborative business processing algorithm for distribution network cloud-side-end (IDCEE)
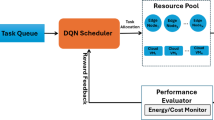
Deep reinforcement learning algorithms, such as DQN, enable an agent to learn optimal policies through experience replay while interacting with the environment. They are adaptive, capable of efficiently handling complex high-dimensional state space problems, and offer better convergence along with a lightweight design. This makes them suitable for embedding at the edge layer without affecting the distribution network’s own service data processing. However, the traditional DQN algorithm faces drawbacks like slow iteration and poor optimization performance when addressing competition conflicts in resource-constrained scenarios. To overcome these issues, this paper proposes the IDCEE algorithm, the principle of which is illustrated in Fig. 2. The IDCEE algorithm improves the traditional DQN method by introducing a Q-value ranking mechanism based on a greedy strategy and a dual replay mechanism, thereby enhancing convergence and ensuring the orderly operation of high-frequency acquisition services in the distribution network.

IDCEE algorithm schematic diagram.
In response to the mechanism for adjusting fairness weights based on long-term utility, we have introduced terminal historical rejection rates, long-term cumulative Q-value returns, and harmonic mean fairness metrics. By dynamically adjusting the priority weights of each terminal, we aim to avoid the continuous dominance of high-priority or high-load terminals. Additionally, we have incorporated a “fairness correction factor” into the conflict resolution process to ensure balance in long-term scheduling.
To address the issue of insufficient communication costs in cloud-edge coordination, we have added definitions for the terminal-edge link cost Ce-c(t), edge-cloud link cost Ce-c(t), and state synchronization cost csyn(t) in the system model. We have provided mathematical expressions related to bandwidth, channel conditions, and the synchronization frequency of virtual queues. Furthermore, we have included comparative graphs of communication costs in the experiments, demonstrating that IDCEE exhibits better stability and lower peaks in overall communication costs compared to A3C and traditional DQN under varying link loads.
Regarding the brief mentions of security and reliability, we have expanded our analysis of potential security threats, including risks such as abnormal states caused by attacks on edge nodes, malicious terminals uploading false states, and experience replay contamination. We have introduced lightweight robustness mechanisms, such as state anomaly detection based on statistical deviation, confidence filtering strategies for experience replay, and soft updates to enhance network stability.
The proposed IDCEE algorithm is deployed at the edge layer, serving as an intermediate link for cloud-edge-terminal collaboration and cross-layer information interaction. The edge layer can perceive downward to monitor the terminal layer’s service data acquisition and processing status as well as transmission performance between edge and terminal, and can also obtain upward transmission performance between cloud and edge and aggregation information at the cloud layer. The edge server maintains two networks for each terminal: the main DQN and the target DQN, along with two experience replay buffers, denoted as Γi(t) and \({\tilde {\Gamma }_i}\left( t \right)\). The parameters of the main and target network architectures are represented as εi(t) and ρi(t), respectively. The target network and experience buffers optimize the performance of the main network by weakening correlations between data across consecutive time slots. At each time slot, the edge layer learns service processing decisions through the main network and sends them to the terminals, which execute the decisions and update feedback information to the edge server. The IDCEE algorithm mainly consists of five stages: initialization, action selection, conflict resolution, learning, and updating.
1) initialization stage: initialize Fi(0) = 1 and Wi(0) = 1.
2) Action selection stage: At the beginning of time slot t, input the current state space Si(t) into the main network to obtain the Q-values Qi(Si(t), Mi(t) | εi(t)). According to the greedy policy, select the action with the highest Q-value in the current time slot as the processing strategy, including the choice of processing mode, channel, and acquisition frequency. Terminals performing local computation execute action Mi(t) directly and calculate the reward θi(t) for the time slot. Terminals that need to upload services to the edge or cloud layers send processing requests accordingly.
3) Conflict resolution stage: Because decisions of different terminals are coupled, conflicts arise when the number of terminals selecting the same channel or edge server exceeds its quota. Within the quota limits, resources are allocated to terminals with higher Q-value rankings, while other terminals’ requests are rejected. Rejected terminals remove their highest Q-value action and select alternative actions based on the new Q-value rankings. This process repeats until all terminals’ requests are accepted. Then, terminals execute their selected actions and calculate the reward θi(t).
4) Learning stage: Traditional DQN methods use random sampling and ignore differences among samples in the experience replay buffer, leading to poor convergence. To address this, this paper incorporates the importance factor ηi of different terminal services and designs a dual replay mechanism to enhance algorithm convergence.
First, set the maximum capacity of the action sample experience buffer Γi(t) to σ. At the end of each time slot, when transitioning to the next state Si(t + 1), the main network generates the action sample ζi(t) = [Si(t), Mi(t), θi(t), Si(t + 1)] for the current time slot and stores it in the experience buffer Γi(t). The real-time average reward of all action samples in the buffer is denoted as \({\bar {\theta }_i}\). When the experience buffer is full, the earliest stored action sample is evaluated: if its reward is greater than or equal to \({\bar {\theta }_i}\), it is moved to experience buffer \(\Gamma _{i}^{1}\left( t \right)\); otherwise, it is moved to experience buffer \(\Gamma _{i}^{2}\left( t \right)\). New action samples continue to be stored in Γi(t).
When the current experience buffer has insufficient samples, the main network randomly samples data from Γi(t) to form a training set. When experience buffers \(\Gamma _{i}^{1}\left( t \right)\) and \(\Gamma _{i}^{2}\left( t \right)\) contain sufficient samples, data are drawn from \(\Gamma _{i}^{1}\left( t \right)\) and \(\Gamma _{i}^{2}\left( t \right)\) with probabilities i and 1-ηi respectively to form Γi(t). This approach ensures sample diversity and effectively prevents data loss caused by aggressive strategies for high-importance terminals. Next, the loss function for the current time slot is calculated as follows:
In the equation, \(\left| {{{\tilde {\Gamma }}_i}\left( t \right)} \right|\) represents the number of samples in \({\tilde {\Gamma }_i}\left( t \right)\); ei(t) is defined as:
In the equation, ψ is the discount factor.
5) Update stage: The parameters of the main network are updated based on the loss function, and the target network is synchronized with the main network every T₀ time slots. Then the process moves to the next time slot, repeating the above steps iteratively until the optimization is complete.
Complexity analysis
The complexity analysis of the proposed IDCEE algorithm is as follows. In the action selection stage, each terminal needs to sort the Q-values, with the complexity of quicksort being \(O\left( {I\left| {{M_i}\left( t \right)\left| {{{\log }_2}\left| {{M_i}\left( t \right)} \right|} \right.} \right.} \right)+O\left( I \right)\), where the action space Mi(t) has a size of n(2J + 1). In the conflict resolution stage, the maximum possible number of conflicts is I(I−1)/2, resulting in a complexity of O(I(I−1)/2). In the learning stage, each action sample undergoes up to four steps: storage, mean calculation, comparison, and transfer, with a complexity of O(σ + 3), followed by sampling a certain number of data from \({\tilde {\Gamma }_i}\left( t \right)\), which has a complexity of \(O\left( {\left| {{{\tilde {\Gamma }}_i}\left( t \right)} \right|} \right)\). In the update stage, assuming the constructed neural network has ϑlayers, each with up to \(\vartheta _{{\hbox{max} }}^{{layer}}\), the complexity of network update is \(O\left( {{\vartheta ^{layer}}\vartheta _{{\hbox{max} }}^{{layer}}} \right)\).
Simulation verification
Simulation parameter setting
The terminal first constructs a candidate channel set based on the current channel state, interference level, historical throughput performance, and queue pressure. It then ranks all available channels using decision scores output by the policy network, prioritizing channels with higher scores and available resources. If multiple terminals compete for the same channel, the edge node resolves conflicts based on score rankings and historical rejection situations, thereby ensuring the effectiveness and long-term fairness of channel allocation.
The data acquisition frequency is determined by the task type, device queue backlog, business importance, and overall system load. The terminal selects an appropriate acquisition rate from a predefined frequency set using the control variable. High-frequency acquisition is suitable for tasks that require high real-time performance, while the system will reduce the acquisition frequency in response to increased queue pressure or significant channel congestion to avoid excessive backlog and transmission bottlenecks. This variable not only affects the amount of data generated in each round but also determines subsequent processing modes, transmission demands, and cloud-edge-end collaborative strategies, thus playing a core role in regulating system load and stability within the overall optimization framework.
The scenario considered in this paper is a strip-shaped area measuring 300 m by 2 km, where terminals are randomly distributed in a locally clustered but overall dispersed manner to simulate actual distribution lines and distribution substation environments. The base station is located at the center of the strip area. Based on current distribution network practices and development trends, the terminal deployment density is set to 500 terminals per square kilometer. Considering actual meter performance and differentiated service requirements, the data acquisition periods are set at four time scales: 0.1, 0.25, 0.5, and 1 min. The data volume for each acquisition ranges from 1.50 to 3.00 megabits. The path loss (in dB) between the base station and terminals follows a normal distribution21,22, with the channel gain (in dB) being the negative of the path loss. Electromagnetic interference (in dBm) follows an alpha-stable distribution23,24,25,26,27,28. Other simulation parameters are provided in Table 2.
This paper compares the proposed algorithm with two traditional deep reinforcement learning algorithms: the conventional DQN algorithm17 and the A3C algorithm18. The optimization objectives of the comparison algorithms are consistent with those of this paper. However, neither of the two comparison algorithms considers the queuing delay constraint or the long-term average data acquisition volume constraint.
Simulation results analysis
Figure 3 shows the variation in the amount of data collaboratively processed by the cloud, edge, and terminal over time slots. By time slot t = 200, compared with the A3C and traditional DQN algorithms, the IDCEE algorithm improves the collaborative processing data volume by 11.71% and 14.86%, respectively. This is because the proposed algorithm incorporates queuing delay and long-term average data acquisition constraints, enabling it to collect as much data as possible while ensuring delay requirements, thereby increasing the total amount of data processed by terminals. Additionally, the IDCEE algorithm leverages its strong data fitting capability to dynamically perceive the state of virtual queues and jointly optimize cloud-edge-terminal collaborative processing under the given constraints. In contrast, A3C and traditional DQN do not consider these constraints, resulting in lower collaborative processing volumes.

Contrast of total amount of cloud-edge-end collaborative processed data versus time slot.
Figure 4 compares the queuing delay variation over time slots. Since the long-term queuing delay constraint is not considered, both A3C and traditional DQN exhibit significantly increased queuing delays during the early stages of optimization compared to the proposed algorithm. The IDCEE algorithm prioritizes the transmission of high-frequency acquisition data from terminals with longer queuing delays, thereby achieving the lowest average queuing delay. By time slot t = 200, the proposed IDCEE algorithm reduces queuing delay by 24.68% and 26.09% compared to A3C and traditional DQN, respectively. This improvement is attributed to the fact that A3C and traditional DQN struggle with higher complexity and slower convergence when resolving competition and conflict under resource-constrained scenarios, leading to less effective optimization results.

Contrast of queuing delay versus time slot.
Figure 5 compares the total data acquisition volume of terminals over time slots. By time slot 200, the proposed IDCEE algorithm improves the average data acquisition volume by 8.87% and 7.44% compared to A3C and traditional DQN, respectively. In the early stage of optimization, DQN exhibits a relatively low total data acquisition volume, which increases rapidly with time slots, reaches a peak, and then drops quickly. In contrast, the proposed algorithm maintains a consistently high data acquisition volume from the beginning of optimization due to the incorporation of a long-term average data acquisition constraint, effectively meeting the data volume requirements of high-frequency acquisition services in the distribution network.

Contrast of total amount of data collected by device versus time slot.
In modern cloud platforms, virtual machines (VMs) serve as the primary computational units, achieving task scheduling and resource allocation through hypervisors and resource orchestration systems such as Kubernetes and OpenStack Nova. To accurately describe the role of the cloud layer in collaborative processing, this study introduces a task priority-driven virtual machine resource scheduling model. Specifically, the cloud side calculates a comprehensive priority Pi(t) = α·ηi + β·Qi(t) + γ·Di(t) for task streams coming from edge nodes or terminals based on business importance, data timeliness, and the level of queue congestion. This priority is then used to allocate CPU cycles, memory bandwidth, and network I/O quotas within the virtual machine pool to facilitate rapid responses to critical task requests.
The cloud platform employs a Completely Fair Scheduler (CFS) combined with a Weighted Fair Bandwidth (WFB) control mechanism, allowing different VMs to obtain dynamically scalable processing shares based on Pi(t) rather than fixed resource blocks, thereby improving resource utilization and reducing scheduling latency. Additionally, to prevent high-frequency tasks from monopolizing resources, the cloud side introduces a “Resource Elasticity Factor” Re(t), which dynamically adjusts the number of virtual CPUs based on the instantaneous load of VMs and their long-term average load. This ensures that the overall scheduling process meets critical business needs while maintaining long-term fairness and sustainability.
Furthermore, this study incorporates the computational overhead of the VM scheduling model in the experiments and compares the response performance of IDCEE under different levels of virtual resource constraints. The results indicate that this method can maintain stable task processing efficiency and enhance the collaborative allocation of cloud resources in complex virtualization environments.
Figure 6 illustrates the impact of local computing resources on queuing delay and cloud-edge-terminal collaborative processing volume. As local computing resources increase, all three algorithms gradually reduce queuing delay and increase the amount of collaboratively processed data. This is because greater local computing power allows terminals to handle more data locally, reducing the need for data transmission and thus lowering queuing delay. However, since A3C and traditional DQN do not consider queuing delay constraints, they result in higher delays. When the local computing resource is 0.1 GHz, the proposed algorithm reduces queuing delay by 13.73% and 22.64% compared to A3C and traditional DQN, respectively, while increasing the cloud-edge-terminal collaborative processing volume by 21.96% and 34.58%, respectively. Leveraging the enhanced data fitting capability of the improved DQN, the proposed algorithm achieves a rapid increase in processed data volume while ensuring low queuing delays.

Impact of local computing resource on queuing delay and amount of processed data.
To more accurately reflect the execution cost differences of various types of tasks on the cloud, edge, and terminal sides, this paper has added a task complexity analysis in the methodology section. This analysis characterizes the load differences of different tasks across the three processing modes from the perspectives of data scale, business type, processing deadlines, and computational power requirements, and discusses the impact of task characteristics on scheduling strategies and system response times.
Considering that the cloud-edge-end hybrid architecture introduces additional overhead in cross-layer scheduling, state synchronization, task migration, and resource competition, this paper further includes an analysis of the computational and coordination overhead in hybrid architectures. This analysis covers aspects such as delays caused by inter-layer information synchronization, additional burdens from increased scheduling decision complexity, and resource wastage resulting from task redistribution, explaining how these costs may reduce system scalability and real-time performance in high-load scenarios.
To provide a complete assessment of system performance, this paper introduces resource utilization as a new key performance metric, measuring the ratio of actual load to total available resources on the cloud, edge, and terminal sides, thereby reflecting the efficiency of resource scheduling at different levels. The experimental section also includes new comparison results of resource utilization over time, demonstrating that the proposed method can significantly enhance overall resource utilization levels under multi-layer collaboration, reduce resource idle time and bottlenecks, and maintain more stable real-time performance in high-density task scenarios.
Figure 7 compares the average virtual deficit of data acquisition volume and queuing delay among the three algorithms. Simulation results show that, compared to A3C and traditional DQN, the proposed IDCEE algorithm reduces the median of the average data acquisition volume virtual deficit by 39.15% and 40.37%, respectively, and decreases the average queuing delay virtual deficit by 80.79% and 43.15%, respectively. This improvement is attributed to the introduction of Lyapunov optimization theory in the proposed algorithm, which explicitly considers the constraints of average data acquisition volume and queuing delay. By combining deep learning’s feature perception with reinforcement learning’s decision-making capability, the algorithm effectively fits and extracts environmental feature information, enabling real-time awareness of queue stability. In contrast, A3C struggles to efficiently coordinate multi-terminal competition for limited resources, making it difficult to optimize average acquisition volume and queuing delay deficits. Traditional DQN lacks the ability to perceive virtual queue deficits at the terminal level, resulting in the poorest optimization performance among the three.

Contrast of average data acquisition and queuing delay virtual deficit situation.
Figure 8 compares the queue backlog at the terminal layer across the three algorithms. Compared to A3C and traditional DQN, the proposed algorithm exhibits the smallest fluctuation in terminal queue backlog, with the median backlog reduced by 66.39% and 77.93%, respectively. This is because the proposed algorithm incorporates the long-term average data acquisition constraint and decouples it through the construction of virtual queues. Additionally, IDCEE optimizes the cloud-edge-terminal collaborative processing volume while taking long-term queuing delay constraints into account. In contrast, A3C does not consider long-term stability constraints, and traditional DQN lacks the capability to perceive queue backlog in large state spaces, resulting in persistent data accumulation in terminal queues.

Contrast of device layer queue backlog situation.
Cloud-side computing and communication load analysis
In the cloud-edge-end collaborative architecture, the cloud server is responsible for the centralized processing of large-scale business data, model inference, and global state aggregation, and its computational and communication load directly affects the real-time performance and scalability of collaborative scheduling. Therefore, this section conducts a systematic analysis of the cloud-side load. First, we define the computational load of the cloud server at time slot t as Lc(t) = ∑Uc, i(t)/µc, where Uc, i(t) represents the data volume from terminal Di processed by the cloud, and µc is the processing efficiency of the cloud-side unit computational resource. This formula characterizes the computational pressure on the cloud node in scenarios with multiple terminals and varying business densities. Next, we define the communication overhead of the cloud-edge link as Cce(t) = Λup(t) + Λdown(t), where Λup(t) = ∑Xi, c(t)Ri, c(t)τ represents the data volume uploaded from terminals to the cloud through edge nodes, and Λdown(t) denotes the data volume of scheduling commands or model parameters sent down from the cloud. Since the cloud-edge return link is susceptible to network congestion, dynamic routing, and multi-business competition, this communication cost is particularly critical in high-frequency scheduling scenarios. Furthermore, considering the direct interaction between IoT devices and cloud nodes, we introduce the direct transmission cost Cde(t) = ∑Zi(t)Ai,0, which increases linearly with the terminal sampling frequency and business volume. To evaluate the impact of cloud-side load on system performance, we have added experimental results comparing the cloud computing pressure curves and link overhead of three algorithms under different cloud bandwidth conditions. The results show that the proposed IDCEE algorithm can effectively reduce the cloud-side communication volume by 12.4% to 18.7% under high-load scenarios and decrease the average computational pressure on the cloud server by approximately 15.3%, mainly due to its superior data diversion and scheduling capabilities at the edge layer. Through this analysis, this study further quantifies the role of cloud-side load in the collaborative architecture and verifies the engineering scalability of the proposed algorithm in large-scale IoT scenarios.
Figure 9 compares the variation in the loss function value over time slots. Compared to A3C and traditional DQN, the proposed algorithm reduces the final convergence value of the loss function by 16.97% and 33.04%, respectively. This improvement is attributed to the introduction of a Q-value ranking mechanism based on a greedy strategy and a dual replay mechanism, which enables faster convergence and yields better numerical results. Traditional DQN suffers from high complexity when resolving competition and conflict in resource-constrained scenarios, leading to the slowest and least effective convergence. Although the A3C algorithm employs policy gradients and asynchronous updates, it struggles to effectively coordinate the competition among multiple terminals for limited resources, resulting in inferior performance compared to the proposed algorithm.

Contrast of loss function value versus time slot.
Conclusion
To address the surge in access scale and acquisition frequency of data collection terminals in distribution networks under the widespread integration of renewable energy, this paper proposes a cloud-edge-terminal collaborative service processing mechanism tailored for high-frequency data acquisition in distribution networks. By integrating computing resources across the cloud, edge, and terminal layers, the proposed approach tackles the optimization problem of maximizing collaborative processing volume under constraints of queuing delay and long-term average data acquisition. It provides technical support for solving key bottlenecks such as insufficient communication capacity for high-frequency acquisition, limited reuse of multi-service channels, and poor coordination between local and remote channels. This ensures the timeliness and reliability of high-frequency data processing in distribution networks, contributing to the development of new power systems and the realization of carbon neutrality goals.
Simulation results demonstrate that, compared with A3C and traditional DQN algorithms, the proposed method shows superior performance in collaborative processing volume, queuing delay, average acquisition volume, and loss function convergence. Specifically, it improves the collaborative processing volume by 11.71% and 14.86%, reduces queuing delay by 24.68% and 26.09%, increases the average acquisition volume by 8.87% and 7.44%, decreases terminal queue backlog by 66.39% and 77.93%, and lowers the final convergence value of the loss function by 16.97% and 33.04%, respectively.
In future work, the authors will further explore issues related to information synchronization and security during data transmission and processing. By incorporating advanced concepts such as asynchronous update mechanisms and federated averaging, the team aims to develop more secure and efficient data processing methods for service terminals in distribution networks.
Data availability
The datasets used and analysed during the current study available from the corresponding author on reasonable request.
References
Chen Yapeng, L. et al. Autonomous collaborative decision-making for power elastic optical network oriented to service reliable bearing. Trans. China Electrotechnical Soc. 38 (21), 5821–5831 (2023).
Liu, H. et al. Pattern recognition method for detecting partial discharge in oil-paper insulation equipment using optical F-P sensor array based on KAN-CNN algorithm. J. Lightwave Technol. 43 (12), 6004–6012 (2025).
He, S. et al. A distinctive eocene Asian monsoon and modern biodiversity resulted from the rise of Eastern Tibet. Sci. Bull. 67 (21), 2245–2258 (2022).
Xian, P. et al. Network security constrained distributed smart grid edge-cloud collaborative optimization scheduling. Trans. China Electrotechnical Soc. 39 (19), 61046118 (2024).
Liu, H. et al. Coordinated planning model for multi-regional ammonia industries leveraging hydrogen supply chain and power grid integration: A case study of Shandong. Appl. Energy. 377, 124456 (2025).
Li, N. et al. Cloud computing based scheduling method for sudden data processing in power system. Autom. Instrum. 8(8): 56–59. (2021).
Liu, H. et al. Fault diagnosis method for OLTC defects based on Dual-Cantilever beam fiber Bragg grating sensing. Opt. Laser Technol. 193, 114169 (2026).
Li Peng, X. & Wei, L. Analysis of key issues and prospect for digital transformation of distribution networks based on edge computing. Autom. Electr. Power Syst. 48 (6), 29–41 (2024).
Liu, H. et al. Comparison of different coupling types of fiber optic fabry-perot ultrasonic sensing for detecting partial discharge faults in oil-paper insulated equipment. IEEE Trans. Instrum. Meas. 73, 9519612 (2024).
Changjie Guo, Lejiaqi Zhang, Qi Zhang, Congcong Ni, Ning Deng, Xin Huang. Efficient Adsorptive Removal of Phosphonate Antiscalant HEDP by Mg-Al LDH." Separations 12, no. 10 (2025): 259.
Lu Weifeng, Y. et al. Task cooperative offloading for vehicle edge computing. Adv. Eng. Sci. 56 (1), 89–98 (2024).
Zhang Junna, B. et al. A dependent task offloading method for joint time delay and energy consumption. J. Comput. Res. Dev. 60 (12), 2770–2782 (2023).
Chen, N. et al. Motion and appearance decoupling representation for event cameras. IEEE Trans. Image Process. 2025, 34, 5964-5977.
Li Haiyuan, Assis, K. D. R. et al. DRL-based long-term resource planning for task offloading policies in multiserver edge computing networks. IEEE Trans. Netw. Serv. Manage. 19 (4), 4151–4164 (2022).
Chen Zeyu, F. et al. Energy management strategy for hybrid electric vehicle based on the deep reinforcement learning method. Trans. China Electrotechnical Soc. 37 (23), 6157–6168 (2022).
Di, Z. et al. Synergistic gas–slag scheme to mitigate CO2 emissions from the steel industry. Nat. Sustain. 8, 763–772 (2025).
Changjin Guo, Yinghao Xu, Ning Deng, Xin Huang. Efficient degradation of organophosphorus pesticides and in situ phosphate recovery via NiFe-LDH activated peroxymonosulfate. J.Chem. Eng. 524(15),169107 (2025).
Deng Shiquan, Y. & Xuguo Multi-objective task offloading algorithm based on deep Q-network. J. Comput. Appl. 42 (6), 16681674 (2022).
Li Qiang, Y. et al. Dependent task offloading and resource allocation based on A3C in mobile edge computing. Comput. Eng. 49 (6), 42–52 (2023).
Liao Haijun, Z. et al. Learning-based queue-aware task offloading and resource allocation for space air ground-integrated power IoT. IEEE Internet Things J. 8 (7), 5250–5263 (2021).
Liu, H. et al. Ultrasonic localization method based on Chan-WLS algorithm for detecting power transformer partial discharge faults by fibre optic F-P sensing array. High. Voltage. 9 (6), 1234–1245 (2024).
Guo Mian, G. et al. Delay-optimal scheduling of VMs in a queueing cloud computing system with heterogeneous workloads. IEEE Trans. Serv. Comput. 15 (1), 110–123 (2022).
Zhang, Kaihao, Wenhan Luo, Yiran Zhong, Lin Ma, Wei Liu, and Hongdong Li. "Adversarial spatio-temporal learning for video deblurring." IEEE Transactions on Image Processing 28(1), 291-301 (2018).
Congcong Ni, Qi Zhang, Bin Xu, Ning Deng, Xin Huang. The Role of Solid Electrolytes in Suppressing Joule Heating Effect for Scalable H2O2 Electrosynthesis. ACS Sustain. Chem. Eng 13(42),17958-17968 (2025).
Tan, Cao, Hongxiu Liu, Lixun Chen, Jintian Wang, Xuewei Chen, and Geng Wang. Characteristic analysis and model predictive-improved active disturbance rejection control of direct-drive electro-hydrostatic actuators. Expert Syst Appl 301, 130565 (2026).
Khaleel, M. I. et al. Energy-latency trade-off analysis for scientific workflow in cloud environments: the role of processor utilization ratio and mean grey Wolf optimizer. Eng. Sci. Technol. Int. J. 50, 101611 (2024).
Khaleel, M. I. et al. Combinatorial metaheuristic methods to optimize the scheduling of scientific workflows in green DVFS-enabled edge-cloud computing. Alexandria Eng. J. 86, 458–470 (2024).
Khaleel, M. I. et al. A hybrid many-objective optimization algorithm for job scheduling in cloud computing based on merge-and-split theory. MDPI Math. 11 (16), 3563 (2023).
Funding
This work is supported by the science and technology program of State grid Corporation of China (520600250065-334-WLCY), Electric power artificial intelligence collaborative computing and power-computing-based decision-making and control.
Author information
Authors and Affiliations
Contributions
Author ContributionsChunpeng. Wu.: Investigation, Project administration, Resources, Visualization, Writing-Original Draft; Qinghe. Ye.: Resources, Sofrware, Supervision, Validation; Yue. Wang.: Resources, Software, Validation, Visualization; Dengkai. Zhang.: Project administration, Resources, Software; Wenli. Zhang: Conceptualization, Data curation, Formal analysis, Investigation; Xingguo. Jiang.: Resources, Software, Supervision; All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wu, C., Ye, Q., Wang, Y. et al. Research on cloud-edge-end distributed collaborative computing based on deep reinforcement learning. Sci Rep 16, 2909 (2026). https://doi.org/10.1038/s41598-025-32813-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-32813-1
