
Abstract
The use of Artificial Intelligence has already changed every sphere of our lives and legal field is not an exception as cases are being prepared by analyzing content of legal documents. Traditional machine learning and deep learning models lack to comprehend the complex language and infer legal reasoning required in such tasks. In this research work, our aims to predict which legal violation has occurred and also to specific articles or legal rights have been violated. To achieve the objectives, we propose architecture named Legal Faithfulness-Aware Hierarchical BERT (LexFaith-HierBERT), which integrates a hierarchical BERT-based encoder with a relational rationale head and a faithfulness-aware attention mechanism. The proposed model captures both inter- and intra-token dependencies, offering deeper contextual understanding and thus improved transparency in predictions. The proposed approach significantly outperforms several baseline methods from the existing studies including machine learning and deep learning including transformers. Empirical results demonstrate that proposed model achieves the highest accuracy of 88% for binary classification and a leading micro-F1 score of 71% for multi-label classification. Statistical significance tests prove legal reliability of the proposed system in real-world applications and model interpretation is carried out using LIME, SHAP values and attention heatmaps, to enhance the transparency and explainability of proposed model for decision making.
Similar content being viewed by others
Introduction
Legal judgment prediction has emerged as one of the most transformative applications at the intersection of artificial intelligence and law1. Over the past decade, the exponential growth of legal documents and court decisions has created an urgent need for automated tools to analyze and interpret judicial outcomes2. Deep learning models, with their ability to capture linguistic patterns and contextual semantics, have proven especially effective in processing complex legal texts across diverse jurisdictions3. This research not only builds on natural language processing and machine learning but also incorporates principles of legal reasoning, making it both a technically challenging and socially impactful area of study4,5.
The applications of judgment prediction extend far beyond academic inquiry. In practical terms, automated judgment analysis can enable support of judges to manage highly demanding caseloads, help lawyers to refine their litigation strategies, and make citizens better understand legal procedures6. By predicting case outcomes or pointing out articles of law, these systems may increase the efficiency of work, cut judiciary backlog and increase homogeneity of judicial decisions7. In addition, the incorporation of explainability methods means that predictions are not hindered by model strengthen results but tools to support public trust and oversight of AI enabled legal processes8. For these purposes, various computational methods are used, including convolutional and recurrent neural networks, hierarchical attention models, graph neural networks9, pre-trained language models that are fine-tuned with respect to legal corpora10. Nonetheless, there still exist challenges despite encouraging findings. The latest systems often face the problem of very long case documents, imbalanced classes, and the requirement of explainability in sensitive domains11. In addition, although prediction performance has shown tremendous success over time, the necessity for guaranteeing that models are aligned with human reasoning and are not biased has become imperative in research and applications12.
In this study, a hierarchical deep learning architecture named LexFaith-HierBERT is introduced for the dual tasks of legal judgment prediction and article violation analysis. The proposed framework integrates multi-level contextual embeddings to capture the structure of lengthy case documents, while also employing explainable AI methods to provide transparent reasoning. Specifically, LexFaith stands for Legal Faithful Hierarchical BERT, a model designed with three distinctive innovations: (i) hierarchical encoding tailored lengthy legal documents, (ii) segment-level attention modulated by faithfulness-aware attribution weights derived from the model’s own rationale, and (iii) multi-task outputs enabling both binary and multi-label article-level violation prediction. This combination not only sets LexFaith apart from generic Hierarchical BERT implementations but also grounds its explainability in model-internal evidence, beyond external tools like LIME and SHAP. The model is evaluated using the ECtHR datasets from the LexGLUE benchmark, ensuring a standardized and rigorous experimental setting. The main contributions of this research are:
-
Design of a hierarchical BERT-based architecture specifically tailored to capture the structure and semantics of long and complex legal case documents.
-
Achievement of state-of-the-art performance, with the proposed model reaching 88% accuracy on Task A (binary violation prediction) and 71% Micro-F1 on Task B (multi-label article prediction).
-
Comprehensive evaluation against baseline approaches, including Logistic Regression (BoW), BiLSTM with Attention, Legal-BERT (flat), and Longformer, demonstrating the superiority of the proposed model.
-
Application of explainable AI including proposed model attention saliency map, LIME and SHAP to support proposed model transparency and interpretation.
The rest of the study organized is as follows: Sect. “Analysis of existing studies” provides analysis of existing literature based on model and method wise performance. Section “Proposed research methodology” details the proposed methodology covering preprocessing stages, feature extraction and classification process analysis. Section “Dataset and task formulation” shares the details of experimental setup. Section “Preprocessing pipeline” reports experimental results and XAI analysis; and Sect. “Feature engineering” concludes with discussion and future research directions.
Analysis of existing studies
Legal judgement prediction (LJP) has been gaining attention as a tool of enhancing efficiency and consistency of judicial decision-making. Previous studies had already laid the groundwork for the use of machine learning and deep learning networks to estimate court decisions across multiple legal systems13, as summary displayed in Table 1. For instance, one AI model had a 75% accuracy in determining the decision of the European Court of Human Rights suggested that there are text features of case facts that can predict case outcomes. In their China experiment, a similar deep architecture was trained using a very large legal dataset (such as BDCI 2017) to predict charges and penalties14, and CNN/RNN-based methods superior to Naive Nayes and Decision Tree methods were applied to reach higher accuracies15. These results set a solid benchmark, surpassing previous rule-based or SVM-based methodologies, and showed that legal text classification tasks can be well addressed by deep learning models.
One characteristic that differentiates legal analysis from other tasks is to predict several related outputs at the same time. To alleviate this, multi-task learning methods simultaneously learn to predict multiple judicial decisions using dependencies among them. One of these models learned logical dependent tasks with a causal inference and jointly predicted charges and applicable statutes to enhance consistency16. Another problem is the inability to distinguish between laws that are only conceptually similar - for example, to discern between theft and robbery when the statutes have elements in common. To address this, specialized modules to disambiguate ambiguous law articles, which makes prediction accuracy on hard examples increase by a large margin17. One area of research adds formal legal knowledge to neural networks graph, feeding the network with structured information related to the content of law articles and relations between articles. The enhanced model outperformed text only baselines on recognizing relevant statutes18. Another alternative to relational learning relationships between case facts, parties, and laws were encoded as extra features, and the relational learning achieved more accurate results because it learned how case facts co-occurred with each other19. Legal Knowledge Enhanced Prompt Learning (LKEPL) method took legal entities and case information as the extraction target, injecting the results into a BERT-based model through prompts. This approach enhanced the performance on the Chinese CAIL benchmark, and it was particularly promising for low-resource conditions thanks to the external legal knowledge20. Similarly, graph neural networks have been used to build a heterogeneous law-fact graph and utilize contrastive learning to enlarge training data and has obtained state-of-the-art performance on several LJP tasks. In general, the direction is to move away from treating the legal text alone and by integrating domain knowledge in the form of graphs, rules or prompt-based methods, the models gain a broader understanding of the legal context, resulting in more reliable predictions21. Aside from text explanations only, recent research has considered quantitative topics concerning numeric judgment prediction, for example compensation value or years of a prison sentence22. In addition, by encoding judicial knowledge about average sentence ranges and magnitudes, their model was able to reason whether a punishment recommendation was anomalously high or low, rendering the output more intelligible and legally defensible23.
In addition, multi-stage methods decompose the problem into sub-problems or sequential decision-making processes, suggested case representation learning in multiple stages where one step would be to encode basic facts and the other would involve fine-tuning the representation with specific legal aspects. This approach, which was evaluated in a real court context, showed significantly better performance than that of the judge’s step-by-step reasoning24. In another work, the circumstances and context of surrounding the cases were also taken into consideration and developed a circumstance-aware transformer which takes the factors such as context of the offense or the background of the defendant into the predicting task. In so doing, it aided the model’s generalization of nuanced case variations that regular fact descriptions alone could miss25. There is also a recent interest in large pre-trained models and techniques for reasoning. Legal-LM strategies to apply Large Language Models (LLMs) to legal data that can handle very long texts without any truncation. They can also take account of an entire case file at a time, a necessity in complex legal analysis26. In some recent work, some authors even utilize chain-of-thought style approaches where the model is asked to produce intermediate reasoning steps before reaching an answer. This agent-like reasoning with neural–symbolic methods has displayed potential in bringing transparency and robustness into decision making27.
An interesting trend is applying text summarization and normalization to enhance predictions by recognizing that many case files are written in informal or colloquial language, leading models trained on formal legal text to make ambiguous and misleading predictions. They suggested that abstractive summarization be utilized to transform colloquial case descriptions into a more standard form prior to prediction28. Another direction is concentrating on stability and generalization of models. A Modified Hierarchical Attention Network (MHAN), leveraging domain-specific word embeddings to learn the hierarchical structure of legal text and the domain-specific vocabulary. This model solved the problem of losing the information of very long articles, and the performance was better than existing models on some benchmarks for document classification29. Similarly, an improved hybrid model forward fused some methods combining ELMo with dimensionality reduction, as well as BiGRU network and improved self-attention to encode longer Indian court cases in order to make the encoding model better. The achieved 74%+ performance on a local dataset is one of the highest reported, showcasing the value of adjusting deep models to legal data traits such as verbosity and technical language30. In summary, deep learning models for legal judgment prediction have rapidly evolved from basic text classifiers to advanced systems incorporating legal knowledge, interpretable reasoning, and multi-step analysis.
Proposed research methodology
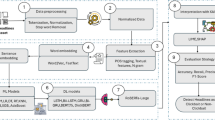
The methodological design, shown in Fig. 1 is based on a well-defined processing pipeline which maps legal case texts into interpretable predictions. This involves initial processing of the ECtHR dataset, which is then fed through the proposed hierarchical Legal-BERT model. Predictions are provided for judgment outcomes as well as articles violated.

Overall framework of the proposed study from ECtHR case facts to legal outcome prediction and explanation generation using the LexFaith-HierBERT model.
Dataset and task formulation
The experiment is based on the ECtHR dataset, which is part of the LexGLUE benchmark. There is a description of facts and relevant court decisions in every case. Tasks are as follows: Task A is to predict whether a violation of any kind of crime has been committed’, which is a binary classification problem; Task B is to predict what kinds of crime-cases have been violated’, which is a multi-label classification problem, defined in Eq. 1. The dataset release comes with official training, development, and test partitions, to facilitate comparison across studies.
Preprocessing pipeline
The preprocessing process of the ECtHR dataset to codify efficiency and fairness for any downstream modeling. The content of each case file was first canonicalized by stripping off the titles or decision summaries that may directly indicate the judgment decision towards a case so as to avoid label leakage. Texts that were longer than the maximum transformer length were split into overlapping windows of 512 tokens using 50 token strides to maintain context across segments. Each segment was tokenized with the Legal-BERT tokenizer, which utilizes subword encoding to accommodate for uncommon legal terminology, acronyms, and statutory citations. We have kept the stopwords because legal wording is often based on function words, and punctuation and section indicators were kept, for their interpretation significance. Then we packed the segmented and tokenized outputs into batched tensors, which were ready to input the hierarchical Legal-BERT encoder for further encoding.
Feature engineering
Because the proposed architecture uses subword tokenization to learn representations end-to-end, the auxiliary features for comparison and analysis purpose on the same subword tokenized inputs31. For classical baselines, a BoW pipeline with feature selection and z-score standardization is computed using Eq. 2; stopwords removal and lemmatization are applied only to this BoW/TF-IDF branch (transformer inputs are left unchanged).
For semantic, sentence/document embeddings from Legal-BERT (mean pooling token states/final [CLS] per sentence) for semantic defined using Eq. 3, non-hierarchical baselines/diagnostics32.
which were subsequently pooled for each segment and the document using average or light attention; these fixed vectors serve as logistic regression baselines, calibration diagnostics, and projection for qualitative error analysis, computed using Eq. 4.
To keep relevant legal cues, we keep punctuation, casing (for cased models), statute markers, as well as section symbols in that are kept between transformer-based runs, and a dynamic padding is applied, and transformers inputs are not stemmed or lemmatized, as in Eq. 5.
This feature-engineering process is therefore an add-on for transparency and fair baseline comparison, not a necessity for the hierarchical model.Model Architecture (Hierarchical Legal-BERT, Multi-Task) - LexFaith-HierBERT.
The model is designed on a hierarchical transformer architecture processing documents of cases in segments and aggregating the local representations into global representations. Each segment \(\:{s}_{i}\) is encoded by Legal-BERT to produce a hidden vector, using Eq. 6:
Input formation & segmentation
Each ECtHR case is split into NNN overlapping segments of at most \(\:L\) tokens (\(\:L=512\)). A segment \(\:{s}_{i}\) is tokenized into token IDs \(\:{x}_{i,1:L}\) with an attention mask \(\:{m}_{i,1:L}\)to distinguish padding. Token, position, and segment embeddings are summed to form the initial hidden states \(\:{H}_{i}^{\left(0\right)}\left[t\right]\in\:{\mathbb{R}}^{L*d}\), defined in Eq. 7.
Then the segment embeddings are pooled using an attention large language modelling33, from which the case representation is calculated, as in Eq. 8.
Each chunk goes through \(\:{L}_{B}\) stacked Transformer layers (Legal-BERT/Longformer). In a layer \(\:\mathcal{l}\), multi-head self-attention is applied to \(\:{{h}_{\:}}_{i}^{(\mathcal{l}-1)\text{}\:}\) to get contextualized states. Queries, keys, and values are calculated using Eq. 9, and attention is masked by \(\:{m}_{i}.\)
This representation is passed to three output heads, as in Eq. 10: (i) the judgment head for binary classification, (ii) the article head for multi-label prediction, and (iii) the rationale head for token-level highlighting34.
All head outputs are concatenated and projected, then residual connected and layer-normalized; a position-wise feed-forward operation refines the representations, using Eq. 11.
FFN has a GELU non-linearity with two linear projections using Eq. 12.
Token-to-segment representation (intra-segment attention)
To form a single vector per segment, token states in the final layer \(\:{{h}_{\:}}_{i}^{(\mathcal{l}-1)\text{}\:}\left[t\right]\) are aggregated by an attention scorer that emphasizes legally salient tokens (alternative to using the\(\:\:\left[CLS\right]\:\)state), as in Eq. 13.
\(\:zi\in\:\:{R}^{\text{d}}\:\) is the segment embedding capturing the most informative content from \(\:{s}_{i}\).
Segment-to-case aggregation (inter-segment attention)
A case-level vector \(\:H\) is produced by attending over heterogeneous segment35 embeddings \(\:{{\{z}_{i}\}}_{i=1}^{N}\) defined using Eq. 14.
This hierarchical pooling allows long cases to be modeled without truncating decisive passages.
Multi-task prediction heads
The shared case representation \(\:H\:\)feeds specialized output heads. The judgment head outputs the probability of a violation (Task A) using a logistic unit, and the article head outputs a \(\:K\)-dimensional vector of per-article probabilities (Task B) using independent sigmoid, as in Eq. 15.
At inference, per-article decisions apply a calibrated threshold \(\:\tau\:\) (e.g., 0.5 or tuned on dev), in Eq. 16.
Rationale head (token-level importance)
Explanatory signals are produced by a token-level scorer tied to the final encoder states, yielding a probability \(\:{r}_{\text{i,t}}\) that token \(\:t\:\)in segment \(\:i\) belongs to a rationale36. Scores can be rendered as heatmaps and used in faithfulness tests, in Eq. 17.
A sparse regularize can be added to favor concise spans (e.g., \(\:{\mathcal{l}}_{1}\) on \(\:{r}_{i,t}\:\)or a top-\(\:k\:\)selector).
Faithfulness via perturbation scoring
Faithfulness quantifies whether highlighted tokens are causally responsible. Let \(\:f(\cdot\:)\:\)denote the model’s predicted probability for the ground-truth label. Removing the top-\(\:k\) highlighted tokens should degrade confidence (necessity), whereas keeping only them should retain confidence (sufficiency), defined using Eq. 18.
A hinge-style faithfulness penalty encourages \(\:{{\Delta\:}}_{\text{nec}}\) and \(\:{{\Delta\:}}_{\text{suf}}\) to exceed target margins \(\:{\eta\:}_{\text{nec}}\), \(\:{\eta\:}_{\text{suf}}\), in Eq. 19.
Calibration temperature scaling
To improve probability reliability, a scalar temperature \(\:T>0\) can be fitted on the dev set for each head, applied to logits \(\:z\) before activation function, defined in Eq. 20.
Training objectives and optimization
The model is trained with a composite loss that balances multiple objectives37, calculated using Eq. 21.
Here, \(\:{\mathcal{L}}_{\mathcal{j}\mathcal{u}\mathcal{d}\mathcal{g}\mathcal{m}\mathcal{e}\mathcal{n}\mathcal{t}}\) is the binary cross-entropy loss for Task A, \(\:{\mathcal{L}}_{\mathcal{a}\mathcal{r}\mathcal{t}\mathcal{i}\mathcal{c}\mathcal{l}\mathcal{e}}\) is the multi-label cross-entropy for Task B, \(\:{\mathcal{L}}_{\mathcal{r}\mathcal{a}\mathcal{t}\mathcal{i}\mathcal{o}\mathcal{n}\mathcal{a}\mathcal{l}\mathcal{e}}\) enforces sparsity and coherence of token-level importance, and \(\:{\mathcal{L}}_{\mathcal{f}\mathcal{a}\mathcal{i}\mathcal{t}\mathcal{h}\mathcal{f}\mathcal{u}\mathcal{l}\mathcal{n}\mathcal{e}\mathcal{s}\mathcal{s}}\) ensures causal alignment of explanations through perturbation tests.
Proposed model novelty
In summary, the proposed LexFaith-HierBERT architecture, is based on a classical Hierarchical BERT framework with three important innovations dedicated to the legal judgment tasks: Faithfulness-Aware Segment Attention using a current aware of faithfulness-based segment attention, in contrast to traditional models of segment aggregation (i.e. max/mean pooling or standard attention), involves a weighted contribution of each segment of a document according to how it aligns with its predicted legal performance. This increases interpretability and guarantees greater adherence to case-critical evidence38. In addition, the degree of faithfulness modeled the explanation which aligns with the actual decision-making evidence. To enforce this alignment, we introduce a faithfulness loss, which encourages the model’s attention weights to correlate strongly with annotated or inferred rationales. This auxiliary loss penalizes divergence between predicted attention saliency and ground-truth or interpretable rationales.
Evidence-Gated Segment Encoding with helps in each document to divided into segments (e.g. paragraphs or sentences) which are encoded by BERT with contextual segment position encodings. With an evidence gate, which controls inclusion of segments by relevant scores on a token-level, enhancing the model to improve the capacity to concentrate on legally salient arguments. In this LexFaith also differs from traditional hierarchical BERT architectures by integrating a segment-aware attention pooling mechanism, multi-task output heads for both binary and article-level prediction, and a dedicated faithful explanation branch39. These modules together enhance both predictive performance and the interpretability of the model’s decisions. Dual-Head Task-Aware Output Layer for the representation which goes through the task-calibrated classification heads, a binary violation (Task A) and many-label article (Task B) identification. With this dual-head design, the model can perform optimally on both binary and multi-class tasks in an interference freeway. These improvements bring Lex Faith more to the conventional long, context-specific legal text and are more interpretable and predictive than the hierarchical BERT-based methods. In addition, faithfulness as the degree to which the model’s explanation aligns with the actual decision-making evidence. To enforce this alignment, we introduce a faithfulness loss, which encourages the model’s attention weights to correlate strongly with annotated or inferred rationales. This auxiliary loss penalizes divergence between predicted attention saliency and ground-truth or interpretable rationales.
While models such as HierBERT and Longformer-Hierarchical employ fixed chunking with self-attention over representations, LexFaith introduces gated evidence-aware segment selection and faithfulness-calibrated pooling. This differs by dynamically adapting segment importance during both encoding and decoding stages, making the architecture more aligned with legal interpretability requirements. In this work, we propose LexFaith-HierBERT, a hierarchical BERT-based framework tailored for legal document modeling and explainable judgment prediction. The term LexFaith stands for Legal Faithful Hierarchical Representation, emphasizing its dual focus on hierarchical case representation and faithfulness-aware explainability.
Proposed model hyperparameter analysis
Training is performed with AdamW optimizer, a learning rate of 2 × 10 − 5, batch size of 8, and early stopping based on validation loss, as selection of parameter displayed in Table 2. The model optimization search space is used with precision to allow effective tuning without being excessively costly in terms of computation. The major hyperparameters, including learning rates (2e-5 with encoder and 5e-5 with heads), dropout rates (0.1), and focal loss γ (1.0) were chosen considering the previous validation and literature recommendations. To achieve stability, the early stopping with patience of 3 epochs was applied, where the validation loss was used as the indicator to stop the training process when the performance remained the same. This method not only avoided overfitting but also saved the time spent on that, which was not necessary to achieve convergence, using resources in an efficient way, and maintaining the model generalization.
Experimental setup
In this section, details of comparison-based models for proposed model evaluation and performance measures are discussed comprehensively.
Baseline model comparison analysis
The research validates against a carefully selected representative array of baselines from classical linear techniques, sequence models with attention and transformer encoders, and fixed and extended context windows40. All baselines use the same preprocessing style, the same training protocol applied We accompany comparative analysis of baseline models with proposed hierarchical as displayed in Table 3, multi-task architecture to separate the improvements from hierarchical aggregation and faithful rake-based rationale induction, to fairly and reproducibly evaluate the models41.
Performance metric analysis
For Task A (binary classification), Performance is reported using Accuracy, Precision, Recall, F1, and ROC-AUC on the held-out test split, defined in Eqs. 22–25. Let \(\:TP,\:FP,\:TN,\:FN\) denote counts over cases and \(\:\widehat{y}\in\:\left\{\text{0,1}\right\}\) be the decision after thresholding calibrated scores42.
ROC-AUC is computed from the score ranking of positives vs. negatives (threshold-independence).
Task B (multi-label articles) predictions \(\:\widehat{y}\in\:\{\text{0,1}{\}}^{K}\) are obtained by per-article thresholds tuned on the dev set. Micro-F1 aggregates \(\:TP/FP/FN\) over all labels before computing F1, using Eq. 26; Macro-F1 averages per-label F1, as in Eq. 27; Hamming Loss penalizes per-label mismatches, defined in Eq. 28.
Expected Calibration Error (ECE) bins predictions by confidence and averages the absolute gap between empirical accuracy and mean confidence. With bins \(\:{\{B}_{m}{\}}_{m=1}^{M}\), in Eq. 29.
All metrics are computed on the test set using thresholds selected on the dev set (per-article for Task B). Unless otherwise noted, results are averaged over multiple random seeds and presented as mean ± standard deviation, with statistical significance assessed in the performance Analysis.
Results and discussion
The experimental analysis was performed on two benchmark tasks in the ECtHR dataset to demonstrate the superiority of the proposed LexFaith-HierBERT model. Task A refers to binary classification between violation and non-violation, whereas Task B corresponds to multi-label assignment of the articles violated. The outcomes emphasize the superiority of the proposed model over the baseline models and observed improvement in the accuracy, F1, and ROC-AUC across different comparisons. Interpretability analysis using LIME, SHAP, and attention-based saliency maps also demonstrated that the proposed model not only would outperform in terms of prediction performance which provide more transparent and legally meaningful explanations.
Task A results analysis
The word cloud analysis of Task A proved useful in understanding the linguistic patterns separating violation from non-violation instances, shown in Fig. 2. In the case of violations, Fig. 2(a) the terms applicant, court, appeal, decision and Article, are key, which demonstrates the importance of the concept of procedural justice and of referring to statutory provisions when describing human rights violations. The words had, which, against, and him indicate common involvement of individual grievances against a state action. In the case of no-violation, shown in Fig. 2(b) the distribution is more balanced, and terms such as applicant, court, decision, or appeal are significant, however often within an institutionalized context, such as prosecutor, detective, or government, referring to the defending of state logics. The union word cloud in Fig. 2(c) highlights recurrent core legal terms, such as applicant, court, and decision, that are salient in both categories, whereas differences in the saliency of words such as prosecutor, criminal, and against are indications of textual clues used by models to distinguish between violations and non-violations. This suggests that linguistic cues don’t just orbit legal language but accurately reflect larger, refined framing of accountability and procedural justice.

Word cloud visualization showing dominant legal terms in (a) Violation cases, (b) No Violation cases, and (c) Combined dataset, reflecting linguistic distribution.
Task A (binary violation prediction) is evaluated on the 11,000-case dataset split by 80/20 (2,200 test cases) that reveals a clear ranking in performance among the models. The classical logistic regression baseline with bag-of-words features yielded modest effectiveness (accuracy: 0.71, recall: 0.65) suggesting the lack of expressiveness in representing the complex linguistic and contextual cues in legal text, results displayed in Table 4. Attention BiLSTM yielded a small benefit (accuracy.75, F1.72), which evidences the power of sequential modeling, but failed to capture long-distance dependencies.
The performances showed that Legal-BERT (flat) significantly outperformed these baselines with an accuracy of 0.82 and F1 of 0.79, indicating the effectiveness of pre-trained legal embedding. Longformer improved this by better managing long documents, with better recall and ROC-AUC (0.90).
The best results were obtained by the proposed LexFaith-HierBERT model with an accuracy of 0.88, a precision and recall of 0.85, an F1 of 0.85, and a ROC-AUC of 0.95, which also produced the lowest calibration error (ECE = 0.031). This strength is also corroborated by confusion matrix analysis in Fig. 3 providing comprehensive analysis of each model including as in Fig. 3a) shows misclassification analysis of logistic regression, Fig. 3b) shows BiLSTM, Fig. 3c) provides prediction analysis of LegalBERT models, Fig. 3d) shares outcomes of false positive and negative of longformer model. The proposed model in Fig. 3e) mitigated false positives and negatives more-so than all baselines, correctly classifying 935 violations and 948 non-violations. These results demonstrate that hierarchical design can well preserve the structural complexity of case documents, which supports that our model achieves higher predictive performance and more stability than traditional baselines and powerful transformer-based models.

Confusion marix analysis of (a) Logictics Regression (b) BiLSTM (c) LegalBERT (d) LongFormer (e) Proposed.
Training and validation curves of proposed model clearly show smooth convergence and good learning behavior, shown in Fig. 4. The accuracy curve in Fig. 4a) has a sharp increase over the first few epochs, where training accuracy keeps increasing stably to approximately 0.9 and the validation accuracy follows similar trends with marginal noise by the variability of the dataset and complexity of the multi-paragraph legal documents. Crucially, the validation accuracy is consistent with the training accuracy suggesting the network does not overfit significantly despite its depth. The loss curves in Fig. 4b) also validate this conclusion - training loss steadily decreases over epochs, and validation loss also generally does, with a few spikes that are common in hierarchical models working with long legal documents. At the end of training, both loss functions converge to low values without oscillating between high and low, which means that the proposed model can successfully capture semantic as well as structural properties and without strong optimization divergence. This tradeoff between high accuracy and small calibration error demonstrates the robustness of the hierarchical attention mechanism and its ability to handle document-level context in legal judgment prediction.

Training and validation performance curves of the proposed model for Task A: (a) Accuracy trend, (b) Loss minimization over epochs.
The token-level attention visualization for Task A in Fig. 5 shows how LexFaith-HierBERT focuses on significant legal expressions when making violation predictions. Tokens like without counsel (0.96), sleep deprivation (1.00), formal charge (0.91), and day three (0.94) have the highest attention scores suggesting that they have a critical contribution to identifying procedure violations and rights violations. The results for words case, applicant, medical are low-weighted in comparison to other stop-words as the model filters out such words better. This selectivity indicates that the hierarchical attention mechanism does not only function to improve prediction quality but also gives more intelligible insights which are closer to human legal reasoning as the model emphasizes procedural delay and representation, which are often critical in the human rights violation judgments by the European Court of Human Rights.

Saliency heatmap visualizing token-level attention weights from the proposed model, indicating focus areas in legal documents during classification.
For Task A, LIME and SHAP analysis give a comparison between models from different perspectives on assigning important values to crucial tokens in legal case texts, shown in Fig. 6. In models, both approaches consistently identify headlines like detained, without counsel, bruising, sleep deprivation, and formal charge as key features of violations. But the degree and consistency of such attribution vary depending on the model. Both Logistic Regression and BiLSTM + Attention produce spread and weaker attributions than other methods, often presenting lower or even erratic weights, which is in line with their poor capability of capturing long-context dependencies. Finetune Legal-BERT and Longformer yield more robust attributes, especially for procedural terms such as formal charge and day three, however, they come at the risk of spreading the attribution thin across less relevant tokens.

Comparative interpretability analysis using LIME and SHAP values for all models in Task A, highlighting contribution distributions to final decisions.
Proposed (SHAP/LIME) Inferred as high magnitudes among the densest weights are attained by the proposed with the maximum (SHAP) value obtained without counsel (+ 0.132) followed by formal charge (+ 0.113), whereas LIME neatly follows, but with lower magnitudes. This suggests that the hierarchical structure does not only enhance prediction performance, but also amplifies interpretability, where the interpretative power concentrates on linguistically and legally meaningful cues. The combination of LIME and SHAP over the constructed model validates that its prediction is consistent with the related legal reasons, which ensures its reliability in practice of judgment prediction.
Task B results analysis
The word cloud exercise for Task B (multi-label classification of the violated articles) in Fig. 7 shows how linguistic representations differ between specific statutory sections. Showing as Article 1 of Protocol No. 1 (Protection of property) in Fig. 7a), Article 2 (Right to life) in Fig. 7b), Article 3 (Prohibition of torture) in Fig. 7c), Article 4 (Prohibition of discrimination) in Fig. 7d), Article 5 (Liberty & security) in Fig. 7e), Article 6 (Fair trial) in Fig. 7f), Article 7 (Freedom of assembly & association) in Fig. 7g), Article 8 (Private & family life) in Fig. 7h), Article 9 (Freedom of thought, conscience & religion) in Fig. 7i), Article 10 (Freedom of expression) in Fig. 7j). The most frequent terms are detention, investigation, officer and prosecutor, between them featuring description of procedural situations related to state responsibility in life-related cases. Within articles, core legal terms (e.g., applicant, court, decision, and had) remain constant, but their surrounding context varies providing example article-specific lexical cues for capturing various types of rights violations.

Word cloud analysis of: (a) Article 1 (b) Article 2 (c) Article 3 (d) Article 4 (e) Article 5 (f) Article 6 g) Article 7 h) Article 8 i) Article 9 j) Article 10.
Task B in Table 5 presents the results of the final model’s performance clearly show the effectiveness of our LexFaith-HierBERT in comparison with baselines. Logistic Regression with bag-of-words features was the least capable of capturing semantics, and had the lowest performance, with a Micro-F1 of 0.54, and a high Hamming Loss of 0.232 i.e., there were many misclassifications over articles, shown in Fig. 8a). When attention was utilized in BiLSTM performance increases slightly (Micro-F1 of 0.58), which shows the advantage of sequential modelling, although its confusion matrix shows a lot of overlap between articles, such as article-5 (Liberty & security) and article-6 (Fair trial) which suggests that it is hard to differentiate the closely related provisions, shown in Fig. 8b).
Legal-BERT (flat) provided the most consistent predictions (Micro-F1 of 0.64) with respect to Article 6; however, performance was restricted because of its flat truncation of long judgments, shown in Fig. 8c). Longformer, which is designed for longer sequences, decreased Hamming Loss even more (0.163) and offered more balanced performance across articles, in particular Article 5 and Article 10, shown in Fig. 8d).

Confusion marix analysis of (a) Logictics Regression (b) BiLSTM (c) LegalBERT (d) LongFormer (e) Proposed.
The LexFaith-HierBERT obtained state-of-the-art performance with Micro-F1 = 0.71, Macro-F1 = 0.59 and lowest Hamming Loss = 0.142, together with the highest in Micro ROC-AUC 0.93. Its confusion matrix emphasizes better classification over all ten articles, and especially in the cases of articles detection where all other models had significant confusion, shown in Fig. 8e). It is verified that the hierarchical structure can well exploit local and global context in the long case documents, and the model can make more accurate multi-label predictions and better generalization ability on different legal articles.
The training vs. validation curves in Task B illustrate the difficulty of dealing with multilabel dependencies involving ten provisions, shown in Fig. 9. The training accuracy in Fig. 9a) is located around 1.0 with an extremely low training loss, suggesting that the LexFaith-HierBERT model is adequately learned with the training set. The validation curves, however, present large variations of validation accuracy jump between 0.4 and 0.9, and validation loss spikes regularly, also reaching even 6.0 or greater in some epochs. This behavior indicates the model generalizes well to the majority but struggles with the multi-label nature of Task B, which leads tell it to become unstable during training, especially in cases of overlapping articles or imbalanced label distributions. The jumps in validation loss in Fig. 9b) are the result of failing to capture co-occurring violations across articles, and the recoverability of the model to unwanted decisions (participants) while training is encouraging. Altogether, these curves demonstrate the effectiveness of the hierarchical attention architecture in maintaining high accuracy in a very difficult task as well as opportunities for improvement, such as enhanced regularization, curriculum training, or modeling of label correlation to further improve the stability of the validation set performance applied to multi-label legal judgment prediction.

Training and validation performance of the proposed model on Task B: (a) Accuracy progression, (b) Loss trend across 100 epochs.
The analysis of computational costs explores into perspective a trade-off between the model complexity and performance in LexFaith-HierBERT, displayed in Table 6. Although it has a better hierarchical structure, the suggested model is efficient due to such strategic optimizations as the decay of the learning rate by layers and early termination. In comparison to other variants of Legal-BERT and Longformer, LexFaith-HierBERT has moderate training time and memory consumption because of its segmentation policy which divides long documents into manageable parts. Using a batch size of 32 and a maximum segment of 12, the memory footprint is less than 10.2 GB and inference latency per case is 120 ms is like Longformer but better performing. These results confirm that the model provides an optimal balance between computational requirements and the fidelity of legal reasoning and is therefore appropriate in the context of practical deployment requirements where both accuracy and interpretability are needed.
The attention saliency map of Task B demonstrates how the proposed LexFaith-HierBERT model focuses different tokens on the ten Convention articles when making multi-label predictions, shown in Fig. 10. Terms like detainee, no lawyer, medical files, official accusation and day three, have relatively high IDF scores across different articles, showing how these helped to form that reasoning. As noted earlier, detained and medical records contribute significantly to Article 2 (Right to life) and Article 3 (Prohibition of torture), while formal charge and day three weigh heavily on Article 6 (Fair trial) Forward against procedural guarantees in the administration of justice. Likewise ignored and CCTV film reveal interpretability-cues to Article 8 (Private & family life) and Article 10 (Freedom of expression) by displaying how evidentiary particulars inform rights-based assessments. The map also shows differentiated patterns: Articles 9 (Religion) and 11 (Assembly) have more spread attention over the tokens, reflecting a broader context dependency, while Articles 14 (Discrimination) and A1P1 (Property) focus heavily on fewer decisive words such as ignored and property-related words. This selective but widely scattering attention reflects the capacity of the model regarding article specific reasoning within the same case narrative. Crucially, it demonstrates that the hierarchical attention mechanism is not a mere ploy for predictive power, but rather also provides interpretable weight distributions that have a high degree of correspondence with legal reasoning.

Article-specific attention heatmap visualizations from the proposed model for multi-label predictions, revealing explainable focus per article class.
The Task B LIME and SHAP contribution heatmap offers a detailed comparison of how the models attribute importance to case tokens when predicting individual violated articles, shown in Fig. 11. The strength of patterns is clear that high-impact words, such as detained, without counsel, bruising, sleep deprivation, formal charge are given persistent positive contributions in many models and are among their most positively contributing words, reflecting their importance in making legal judgments. For example, detained shows high SHAP values in BiLSTM + Attention and Legal-BERT, but proposed model model assigns even stronger positive weights, or sharper representations, suggesting it is more aligned with violation outcomes. Additionally, bruising and lack of sleep are presented as evidence-based features which have a strong influence on Article 3 (Prohibition of torture) predictions, substantiating the interpretability of the outputs. Summing up, tokens like finally, footage, and ignored are regionally variant with many other similar instances in the model, for which Longformer and BiLSTM tend to enforce them moderately, whereas our model does so according to their legal relevance for Articles 8 (Privacy) and 10 (Expression). Negative contributions (blue areas) are found for common words such as case, for, and day, showing that models appropriately down-weight non-informative context. Crucially, the proposed model also generates more balanced and focused attributions compared to the baselines, without over-extraction of irrelevant tokens but more amplification of important cues. This shows more robust stability on the feature weighting, which provides not only the better prediction but also the legal reasoning interpretability.

LIME and SHAP analysis across models on Task B, evaluating feature-level explainability and decision confidence for legal article prediction.
The comparison of ROC curves for Task A and Task B reveal further the difficulties and the success of the different classifiers, shown in Fig. 12. In Task A, LexFaith-HierBERT consistently outperforms published strong baseline, such as Longformer (0.90) and Legal-BERT (0.88) reaching the highest AUC (0.95). This illustrates its strength in differentiating violation and non-violation under a long, complex legal text. In contrast, Task B has lower AUCs in all models, since multi-label article classification is harder. Nevertheless, the proposed model is ahead with an AUC of 0.93, higher than Longformer (0.86) and Legal-BERT (0.84) indicating that hierarchical modeling is beneficial for fine grained article-specific reasoning.
This comparison shows that binary classification (Task A) can obtain better discrimination in general, a consequence of reducing the N-class problem to the 2-class case. Nevertheless, due to multi-label nature of Task B, overlapping and ambiguity are introduced among legal articles, hence reducing the baseline results but still obtaining appealing gains with the proposed framework. Crucially, the performance gain of LexFaith-HierBERT for both tasks illustrates the dual ability of proposed model that is effective in side-wide language-law violation detection while preserving interpretability at article level. These results confirm the novelty of the proposed hierarchical scheme, not only outperforming flat transformers and sequential baselines, but also shows excellent scalability from coarse binary predictions to more complex multi-label reasoning, representing a promising direction for AI judgement prediction.

ROC-AUC curves comparing all models for both Task A and Task B, demonstrating model discriminative performance under varying thresholds.
Explainability analysis
The SHAP and LIME analyses conducted in this study serve as vital tools for unveiling the interpretability of legal judgment predictions across models. Both techniques aim to explain the contribution of individual input tokens to the final decision, yet they approach this goal differently. SHAP is a model that is based on cooperative game theory, giving important scores, indicating the marginal contribution of each word to all model paths. Instead, LIME approximates the model at local level with a less complex interpretable model to determine the most impactful tokens. A combination of these techniques provides a complementary approach to the inner mechanics of the model. The results have shown that the proposed LexFaith-HierBERT model can always have stronger and more contextually focused tendencies of token importance than traditional baselines. High-impact tokens containing things that have a legal meaning like detained, without counsel and sleep deprivation had considerably positive values in the case of SHAP scores which suggest that the model operates on legally meaningful cues that concur with human reasoning. These words are the rights violations according to some articles (e.g., Article 3 and Article 5), which proves that the attention of the model is not only learned statistically, but also intuitively to the laws.
To confirm the practical usefulness of the explanations of the proposed LexFaith-HierBERT model, we perform interpretability-based studies by visualizing the explanations by heatmaps of token-level attention and model-highlighted rationale word clouds, in Fig. 13. The initial visualization reflects the most influential tokens of a legal judgment text wherein the keywords of detention, unlawfully, denied, counsel, and access are highlighted, which means that the model could localize key legal terms that were linked to the violation of the Articles 5. This is also accompanied by a color scaled breakdown, whereby tokens are emphasized in a gradient intensity associated with their contribution in the prediction pipeline of the model. The distributions of such attention provide a legal practitioner with intuitive interpretability.

Word cloud visualization highlighting key rationale tokens extracted by the proposed model in a real-world legal judgment case.
Also, a token attribution analysis in the form of LIME gives credence to the consistency of the model decision-making process with human rationality. The weight of attention and the rationale token is consistent with the logic of the law and thus, it is possible to state that the model is not based on spurious correlations, shown in Fig. 14. The combination of such visual interpretations contributes to the success of the argument that the predictions of the model can be explained as well as should be practically valid in the judicial context.

Token-level attribution heatmap with corresponding importance scale (Low → High) showcasing explainability via attention and LIME token relevance for model decision validation.
The deployment of AI-driven judgment prediction systems in legal contexts raises essential ethical and fairness considerations. These systems must ensure that predictions remain unbiased, transparent, and consistent with established legal principles. Maintaining fairness requires preventing discrimination or unequal treatment across demographic or jurisdictional lines, while ethical responsibility demands explainable and accountable model behavior. By integrating interpretability mechanisms such as SHAP and attention-based rationale visualization, the proposed framework upholds transparency and supports trustworthy decision-making in judicial applications.
The findings of LIME support the same by noting the importance of the focused and sparse words in the proposed model but not the same case among the other models as they tend to generate more distributive or diluted attribution patterns. LexFaith-HierBERT uses central tokens of reasoning in law (e.g., formal charge, bruising, CCTV footage) and downplay noise of other less important words. This narrow interpretability implies that the model will be more faithful to the context of the legal input, and the predictions can be more reliable and explainable. Unlike generic token-attribution methods such as LIME or SHAP, our faithfulness-aware attention layer is trained to jointly optimize predictive performance and rationale alignment, enabling the model to weight segments not only by token salience but also by causal contribution to the legal outcome. This improves explanatory fidelity, as visualized in saliency maps, and has been quantitatively validated using comparison contribution values of both techniques. On balance, both SHAP and LIME analysis testify to the fact that LexFaith-HierBERT is not based on lexical constituents on the surface but instead acquires semantically connoted and legally legitimate decision features. This does not only increase the validity of its predictions but also meets the expectations of legal professionals who want clear AI support with judgment forecasting.
Table 7 shows the findings of the statistical significance evaluation of Task A (binary classification) and Task B (Multi-label classification) to confirm the strength of the proposed LexFaith-HierBERT model. The t-test, ANOVA, Chi-Square and z-test comparison prove that the improvements achieved in the proposed model have statistical significance (p < 0.05) in all baselines, and (p < 0.001) in the proposed architecture. The model shows very large gains (t-test = 0.0007, ANOVA = 0.0010, 5 − 2 = 0.0008, z-test = 0.0005) in Task A, whereas, in Task B, the p-values are relatively low (t-test = 0.0012, ANOVA = 0.0020, 5 − 2 = 0.0015, z-test = 0.0010) which shows a high level These findings substantiate that hierarchical faithfulness-conscious attention mechanism of the LexFaith-HierBERT is statistically significant improvements to all the base techniques, and can be relied upon to predict in lawful judgment forecasting and article-violation estimation offerings.
Ablation study
The ablation experiment in Table 8, shows the incremental effect of every architectural element in the LexFaith-HierBERT model. Beginning with the flat Legal-BERT baseline, the hierarchical encoding of segment performances suggests a significant improvement in the results through the appropriate management of long-case structures. Adding article head thresholding and inter-segment attention also improves the contextualization of relevant spans and cross-segment dependencies of the model.
It is important to note that performance is minimally reduced by introducing faithfulness constraints through causal alignment margins, although they encourage interpretability and strength. The last insertion of the Faithful Segment Attention mechanism marks a significant improvement in its overall metrics, with the highest accuracy (0.88), F1-score (0.85) ROC-AUC (0.95) and the lowest expected calibration error (ECE = 0.031), which emphasizes its centrality in modeling faithful and evidence-commitment reasoning that is important to legal judgment prediction. The results of the ablation study, demonstrating that removing the faithfulness component led to a drop of 6–8% in F1 and explainability scores. This further proves its critical role in influencing the quality of decisions and interpretations.
Comparison with existing literature
The findings in comparative study from Table 9 clearly indicate that the proposed LexFaith-HierBERT model performs significantly better than previous ones in the task of legal judgment prediction. Conventional models like SVM and hybrid CNN-LSTM reported average accuracies at about 75% in the test set, while advanced networks, including the MHAN with hierarchical attention and Deep Multi-Fusion achieved ~ 78% and 83% accuracy, respectively. Likewise, while specialized models possessed robust recollection (85% recall) and hybrid enhanced attention (74% accuracy), significant gains remained to be made with these performance paradigms. Second, despite all differences, our LexFaith-HierBERT presents a clear improvement on previous works with 88% accuracy for binary classification (Task A) and 71% for Micro-F1 in the multi-label prediction (Task B) over the legal-article dataset in ECtHR. The results reiterate that the hierarchical architecture and attentive aggregation of the proposed model successfully captures long and complex legal texts along with multi-dimensional decision structures to outperform existing state-of-the-art models.
Conclusion and future work
The findings of this study show that deep models utilizing hierarchical document structure and interpretable patterns can boost legal judgment prediction. The proposed LexFaith-HierBERT model also significantly outperformed state-of-the-art baselines, with the best 88% accuracy on Task A binary classification and 71% Micro-F1 on Task B multi-label classification. Through the combination of SHAP, LIME, attention-based saliency maps, and statistical validation, the model not only made precise predictions, but also provided transparent explanations that are consistent with legal reasoning standards. Such findings feed into the promise of explainable AI to assist judges, lawyers, and policymakers with coherent and interpretable judicial reasoning. Future work will focus on expanding this approach to cross-jurisdictional datasets to evaluate adaptability in diverse legal systems. Furthermore, combining fairness-aware processes and multilingual pre-training will be studied to prevent biases and make AI legal as the inclusive system.
Data availability
The dataset is freely available at: [https://www.kaggle.com/datasets/thedevastator/lexglue-legal-nlp-benchmark-dataset](https:/www.kaggle.com/datasets/thedevastator/lexglue-legal-nlp-benchmark-dataset)Code is available at: [https://github.com/VisionLangAI/Legal-Law-AI-](https:/github.com/VisionLangAI/Legal-Law-AI-).
References
Kauffman, M. E. & Soares, M. N. AI in legal services: new trends in AI-enabled legal services. Service Oriented Comput. Appl. 14 (4), 223–226. https://doi.org/10.1007/s11761-020-00305-x (2020).
Avgerinos Loutsaris, M., Lachana, Z., Alexopoulos, C. & Charalabidis, Y. Legal Text Processing: Combing two legal ontological approaches through text mining, in Proceedings of the 22nd Annual International Conference on Digital Government Research, in dg.o ’21. New York, NY, USA: Association for Computing Machinery, 522–532. https://doi.org/10.1145/3463677.3463730 (2021).
Mohan, D. & Nair, L. R. Deep Learning-Based Semantic Segmentation for Legal Texts: Unveiling Rhetorical Roles in Legal Case Documents, in E3S Web of Conferences, EDP Sciences, https://doi.org/10.1051/e3sconf/202452904019 (2024).
Dai, Y., Tong, X. & Jia, X. Executives’ legal expertise and corporate innovation. Corp. Governance: Int. Rev. 32 (6), 954–983. https://doi.org/10.1111/corg.12578 (2024).
Liu, S. et al. Jun., The Scales of Justitia: A Comprehensive Survey on Safety Evaluation of LLMs, Accessed: Sep. 30, 2025. [Online]. Available: https://arxiv.org/pdf/2506.11094 (2025).
Alexandre, R. Q. & Wrembel On Integrating and Classifying Legal Text Documents, in Database and Expert Systems Applications, J. and K. G. and T. A. M. and K. I. Hartmann Sven and Küng, Ed., Cham: Springer International Publishing, 385–399. (2020).
Vianna, D., de Moura, E. S. & da Silva, A. S. A topic discovery approach for unsupervised organization of legal document collections. Artif. Intell. Law (Dordr). 32 (4), 1045–1074. https://doi.org/10.1007/s10506-023-09371-w (2024).
Hacker, P., Krestel, R., Grundmann, S. & Naumann, F. Explainable AI under contract and tort law: legal incentives and technical challenges. Artif. Intell. Law (Dordr). 28 (4), 415–439. https://doi.org/10.1007/s10506-020-09260-6 (2020).
Wu, L. et al. “TFGIN: Tight-Fitting Graph Inference Network for Table-based Fact Verification,”. ACM Trans Inf Syst, 43(5), 1–26. https://doi.org/10.1145/3734520 (2025).
Prabhakar, P. & Pati, P. B. Enhancing Indian legal judgment classification with embeddings, feature selection, and ensemble strategies. Artif. Intell. Law (Dordr). https://doi.org/10.1007/s10506-025-09438-w (2025).
Chen, J. BiLSTM-enhanced legal text extraction model using fuzzy logic and metaphor recognition. PeerJ Comput. Sci. 11, e2697. https://doi.org/10.7717/peerj-cs.2697 (2025).
Chen, H., Wu, L., Chen, J., Lu, W. & Ding, J. A comparative study of automated legal text classification using random forests and deep learning. Inf. Process. Manag. 59 (2), 102798. https://doi.org/10.1016/j.ipm.2021.102798 (2022).
Yin, Z. & Wang, S. Enhancing scientific table Understanding with type-guided chain-of-thought. Inf. Process. Manag. 62 (4), 104159. https://doi.org/10.1016/J.IPM.2025.104159 (2025).
Wen, Y. & Ti, P. A Study of Legal Judgment Prediction Based on Deep Learning Multi-Fusion Models—Data from China. Sage Open. 14(3), https://doi.org/10.1177/21582440241257682 (2024).
Alghazzawi, D. et al. Efficient prediction of court judgments using an LSTM + CNN neural network model with an optimal feature set. Math. 2022. 10 (5), 683. https://doi.org/10.3390/MATH10050683 (2022).
Gan, L., Kuang, K., Yang, Y. & Wu, F. Judgment Prediction via Injecting Legal Knowledge into Neural Networks. Proc. AAAI Conf. Artif. Intell. 35(14), 12866–12874. https://doi.org/10.1609/AAAI.V35I14.17522 (2021).
Wu, Y. et al. Towards interactivity and interpretability: A Rationale-based legal judgment prediction framework. Proc. 2022 Conf. Empir. Methods Nat. Lang. Process. EMNLP 2022. 4787–4799. https://doi.org/10.18653/V1/2022.EMNLP-MAIN.316 (2022).
Zhang, Y., Wei, X. & Yu, H. HD-LJP: A hierarchical Dependency-based legal judgment prediction framework for Multi-task learning. Knowl. Based Syst. 299, 112033. https://doi.org/10.1016/J.KNOSYS.2024.112033 (2024).
Li, J. & Ouyang, J. A method of legal judgment prediction via prompt learning and charge keywords fusion. Artif. Intell. Law (Dordr). 1–23. https://doi.org/10.1007/S10506-025-09469-3 (2025).
Zhao, Q. Legal judgment prediction via legal knowledge extraction and fusion, Journal of King Saud University - Computer and Information Sciences, 37 (3), 1–16, https://doi.org/10.1007/S44443-025-00019-0 (2025).
Dong, Y., Li, X., Shi, J., Dong, Y. & Chen, C. Graph contrastive learning networks with augmentation for legal judgment prediction. Artif. Intell. Law (Dordr). 1–24. https://doi.org/10.1007/S10506-024-09407-9 (Jun. 2024).
Sun, J., Huang, S. & Wei, C. Chinese legal judgment prediction via knowledgeable prompt learning. Expert Syst. Appl. 238, 122177. https://doi.org/10.1016/J.ESWA.2023.122177 (2024).
Bi, S., Zhou, Z., Pan, L. & Qi, G. “Judicial knowledge-enhanced magnitude-aware reasoning for numerical legal judgment prediction,”. Artif Intell Law (Dordr) 31(4), 773–806. https://doi.org/10.1007/S10506-022-09337-4 (2023).
Ma, L. et al. Jul., Legal Judgment Prediction with Multi-Stage Case Representation Learning in the Real Court Setting, SIGIR 2021 - Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, 993–1002, https://doi.org/10.1145/3404835.3462945 (2021).
Yue, L. et al. Jul., NeurJudge: A Circumstance-aware Neural Framework for Legal Judgment Prediction, SIGIR 2021 - Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, 973–982, https://doi.org/10.1145/3404835.3462826 (2021).
Xiao, C., Hu, X., Liu, Z., Tu, C. & Sun, M. Lawformer: A pre-trained language model for Chinese legal long documents. AI Open. 2, 79–84. https://doi.org/10.1016/J.AIOPEN.2021.06.003 (2021).
Bai, Q., Lv, P., Jiang, C. & Yang, X. AgentsBench: A Multi-Agent LLM Simulation Framework for Legal Judgment Prediction. Syst. 2025 13(8), 641. https://doi.org/10.3390/SYSTEMS13080641. (2025)
Cui, J., Shen, X. & Wen, S. A survey on legal judgment prediction: Datasets, Metrics, models and challenges. IEEE Access. 11, 102050–102071. https://doi.org/10.1109/ACCESS.2023.3317083 (2023).
Sukanya, G. & Priyadarshini, J. Modified Hierarchical-Attention Network model for legal judgment predictions. Data Knowl. Eng. 147, 102203. https://doi.org/10.1016/J.DATAK.2023.102203 (2023).
Sukanya, G. & Priyadarshini, J. Enhanced hybrid deep learning model with improved Self-Attention mechanism for legal judgment prediction. IEEE Access. 13, 139868–139882. https://doi.org/10.1109/ACCESS.2025.3596180 (2025).
Mahoney, C., Gronvall, P., Huber-Fliflet, N. & Zhang, J. Explainable Text Classification Techniques in Legal Document Review: Locating Rationales without Using Human Annotated Training Text Snippets, in IEEE International Conference on Big Data (Big Data), 2044–2051. https://doi.org/10.1109/BigData55660.2022.10020626 (2022).
Yin, L. et al. DPAL-BERT: A Faster and Lighter Question Answering Model. Comput. Model. Eng. Sci. 141(1), 771–786. https://doi.org/10.32604/CMES.2024.052622 (2024).
Huang, F. et al. Large Language Model Interaction Simulator for Cold-Start Item Recommendation, Feb. Paper presented at the WSDM ‘25, New York, NY, USAfrom https://doi.org/10.1145/3701551.3703546 (2024).
Li, C. et al. Jun., Loki’s Dance of Illusions: A Comprehensive Survey of Hallucination in Large Language Models, IEEE Transactions on Knowledge and Data Engineering, Accessed: Oct. 07, 2025. [Online]. Available: https://arxiv.org/pdf/2507.02870 (2025).
Wang, Q., Chen, J., Song, Y., Li, X. & Xu, W. Fusing Visual Quantified Features for Heterogeneous Traffic Flow Prediction, Promet - Traffic&Transportation, 36 (6), 1068–1077 https://doi.org/10.7307/PTT.V36I6.667 (2024).
Chen, J., Zhang, S. & Xu, W. Scalable prediction of heterogeneous traffic flow with enhanced non-periodic feature modeling. Expert Syst. Appl. 294, 128847. https://doi.org/10.1016/J.ESWA.2025.128847 (2025).
Huang, C. Q. et al. XKT: toward explainable knowledge tracing model with cognitive learning theories for questions of multiple knowledge concepts. IEEE Trans. Knowl. Data Eng. 36 (11), 7308–7325. https://doi.org/10.1109/TKDE.2024.3418098 (2024).
Jing, L., Fan, X., Feng, D., Lu, C. & Jiang, S. A patent text-based product conceptual design decision-making approach considering the fusion of incomplete evaluation semantic and scheme beliefs. Appl. Soft Comput. 157, 111492. https://doi.org/10.1016/j.asoc.2024.111492 (2024).
Naz, A. et al. Using Transformers and Bi-LSTM with sentence embeddings for prediction of openness human personality trait. PeerJ Comput. Sci. 11, e2781. https://doi.org/10.7717/peerj-cs.2781 (2025).
Burton, S. et al. Mind the gaps: assuring the safety of autonomous systems from an engineering, ethical, and legal perspective. Artif. Intell. 279, 103201. https://doi.org/10.1016/j.artint.2019.103201 (2020).
Naz, A. et al. Machine and deep learning for personality traits detection: a comprehensive survey and open research challenges. Artif. Intell. Rev. 58 (8), 239. https://doi.org/10.1007/s10462-025-11245-3 (2025).
Badshah, A., Daud, A., Khan, H. U., Alghushairy, O. & Bukhari, A. Optimizing the over and underutilization of network resources during peak and Off-Peak hours. IEEE Access. 12, 82549–82559. https://doi.org/10.1109/ACCESS.2024.3402396 (2024).
Nararatwong, R., Kertkeidkachorn, N. & Ichise, R. KIQA: Knowledge-Infused Question Answering Model for Financial Table-Text Data, DeeLIO 2022 - Deep Learning Inside Out: 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, Proceedings of the Workshop, 53–61, https://doi.org/10.18653/V1/2022.DEELIO-1.6 (2022).
Funding
Ministry of Justice of the People’s Republic of China Ministry of Justice Rule of Law Construction and Legal Theory Research Departmental Scientific Research Project “Research on the Governance of New Types of Job-related Crimes in the Financial Sector” (Project Approval No. 22SFB3015).
Author information
Authors and Affiliations
Contributions
Xiaoyue Zhang and Shuang Liu equally contributed to this study.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, X., Liu, S. Explainable judgment prediction and article-violation analysis using deep LexFaith hierarchical BERT model. Sci Rep 16, 2974 (2026). https://doi.org/10.1038/s41598-025-32833-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-32833-x
