
Abstract
Neural machine translation (NMT) for low-resource languages such as Assamese and Bodo has seen dramatic quality improvements with large multilingual models like Multilingual Bidirectional and Auto-Regressive Transformer (mBART50) and IndicTrans2 multilingual Transformer model, but their parameter counts (often \(>1\) billion) make real-time, on-device deployment infeasible. Although Assamese and Bodo are not among mBART50’s pretraining languages, we first fine-tuned mBART50 on the AI4Bharat Samanantar Assamese–English and IndicTrans2-derived Bodo–English corpora to enable cross-lingual adaptation from related Indo-Aryan and Tibeto-Burman languages. We propose a novel two-stage approach that combines sparse Mixture-of-Experts (MoE) architectures with cross-lingual knowledge distillation to yield a 400-million-parameter student model that retains translation quality within approximately one Bilingual Evaluation Understudy (BLEU) point of its 1.3-billion-parameter teacher while reducing active computation per token by approximately four-fold. Our student uses a twelve-layer Transformer encoder–decoder: the first half of encoder and decoder layers remain standard, while the latter half incorporate sparsely activated Mixture-of-Experts (MoE) feed-forward blocks (four experts in the encoder with top-two gating; two experts in the decoder with top-one gating) and learnable language-prefix embeddings. We perform cross-lingual knowledge distillation, transferring both hard and soft labels from the fine-tuned mBART50 teacher on the AI4Bharat Samanantar Assamese–English corpus and IndicTrans2-derived Bodo–English data, with evaluation on the FLORES-200 multilingual benchmark. On a 10,000-sentence test set, our student achieves 34.5 BLEU compared with 35.2 BLEU for the teacher in Assamese–English, and 31.2 compared with 32.0 in Bodo–English, while running inference at approximately 24 ms per sentence on an RTX 3050 laptop GPU–about 280% faster than the dense teacher. To our knowledge, this is the first demonstration of cross-lingual MoE-based distillation for Indic NMT, enabling efficient, high-quality translation at the edge.
Similar content being viewed by others

Introduction
Neural machine translation (NMT) has achieved remarkable success for high-resource languages, driven by large multilingual pre-trained sequence-to-sequence models such as mBART1. However, many Indic languages–including Assamese and Bodo–remain severely under-resourced , with limited parallel corpora and little coverage in commercial or open-source systems2. Recent work such as IndicTrans2 has begun to address this gap by training a 1.3 B-parameter multilingual transformer covering all 22 scheduled Indian languages, yielding substantial BLEU improvements but at the cost of large model sizes that preclude on-device deployment3. Knowledge distillation4 and sparse Mixture-of-Experts (MoE) architectures5 offer complementary means to compress and accelerate large models.
The Mixture-of-Experts (MoE) framework is a form of conditional computation in which multiple specialized feed-forward networks, or “experts,” are trained in parallel, and a lightweight gating network dynamically selects a small subset of these experts for each input token5.This approach enables models to scale to billions of parameters while activating only a fraction of them per inference step, providing an effective trade-off between capacity and computational cost.
The Transformer architecture6 and its multilingual extensions such as mBART1 and MASS7 have become foundational to modern NMT, leveraging large-scale cross-lingual pretraining to achieve state-of-the-art translation performance. However, their high computational and memory requirements make them unsuitable for real-time or on-device deployment, particularly for low-resource languages8. For Indic languages, this challenge is compounded by data scarcity and linguistic diversity. Initiatives like Samanantar2 and IndicTrans23 have significantly expanded bilingual corpora and improved translation quality across Indian languages, yet their billion-parameter scale limits their usability in constrained environments.
While multilingual pre-trained models such as mBART50 have achieved strong results across many high-resource languages, their coverage of Indian languages is incomplete. Assamese and Bodo, for instance, are not part of the 50 languages in mBART50’s pretraining corpus. To bridge this gap, we first fine-tuned mBART50 on Assamese–English and Bodo–English data derived from the AI4Bharat Samanantar and IndicTrans2 corpora, respectively. This fine-tuning enables cross-lingual transfer from typologically related Indo-Aryan and Tibeto-Burman languages (e.g., Bengali, Hindi, Nepali, Assamese, and Bodo)9,10, effectively adapting the model into a pseudo-teacher capable of producing meaningful representations for these low-resource pairs. This step is crucial to ensure that subsequent distillation captures cross-lingual knowledge rather than direct language-specific expertise. Assamese and Bodo represent two distinct linguistic families within the Indian subcontinent. Assamese belongs to the Indo-Aryan branch of the Indo-European family and is written in the Assamese–Bengali script, whereas Bodo is part of the Tibeto-Burman family and uses the Devanagari script. Although both languages are spoken in Northeast India, their grammatical structures and vocabularies differ substantially, making bilingual translation between them and English a particularly challenging low-resource task.
Beyond data scarcity, computational efficiency is another key barrier for deploying translation models in real-world Indic contexts. For Indic languages, this challenge is compounded by data scarcity and linguistic diversity, including script-specific tokenization issues that can significantly affect downstream translation performance11. Many low-resource languages are used in mobile or offline environments with constrained compute budgets, making parameter-efficient yet accurate translation systems essential for inclusivity. Advances such as pruning, quantization, and knowledge distillation have reduced the inference cost of dense models, but few works have explored their interaction with sparse expert routing. By combining Mixture-of-Experts sparsity with cross-lingual distillation, our approach provides a scalable path toward efficient translation for underrepresented languages without sacrificing quality.
In this paper, we propose a two-stage approach that (1) fine-tunes a pre-trained mBART teacher on the AI4Bharat Samanantar Assamese–English corpus, then (2) distills it into a 400 M-parameter MoE-enhanced student. Our student employs 12 transformer layers–half standard, half MoE–each MoE block containing 4 experts with top-2 gating in the encoder and 2 experts with top-1 gating in the decoder. We train using both soft (KL) and hard (cross-entropy) losses, achieving within –1 BLEU of the teacher while reducing active compute per token by 4\(\times\). Finally, we demonstrate real-time inference (<25 ms/sentence) on an NVIDIA RTX 3050 GPU, enabling practical on-device translation for Assamese.
Our contributions are:
-
The first cross-lingual MoE-distilled NMT student for Assamese–English, combining sparse MoE blocks with knowledge distillation.
-
A compact 400 M-parameter transformer that matches teacher BLEU within 1 point and reduces per-token compute by approximately four-fold.
-
Empirical validation on the Samanantar corpus and FLORES benchmarks, demonstrating high translation quality and sub-25 ms latency on edge GPUs.
Related work
Vaswani et al.6 introduced the Transformer architecture, which established the foundation for modern neural machine translation (NMT) by replacing recurrent connections with self-attention to efficiently capture long-range dependencies. Building upon this framework, mBART extended multilingual denoising autoencoding for sequence-to-sequence pretraining1, enabling strong cross-lingual transfer. Similarly, MASS proposed masked sequence-to-sequence learning to enhance bilingual and multilingual translation7. Although these approaches achieved state-of-the-art results, their models contain hundreds of millions to billions of parameters, limiting real-time deployment on resource-constrained devices due to computational and memory overhead. For Indic languages, the Samanantar corpus provided the largest publicly available parallel dataset for eleven Indian languages, including Assamese, significantly improving data availability for low-resource translation2. Basab Nath et al.12 proposed a hybrid attention-based encoder–decoder machine transliteration system integrated with a neural machine translation model to enhance English–Assamese translation quality. Their integrated MT framework effectively handled proper nouns and technical terms while improving overall BLEU, METEOR, and chrF scores compared to existing systems such as Bing Translator and Samanantar.
Laskar et al.13 investigated Assamese–English neural machine translation under low-resource conditions using transfer learning from high-resource Indic languages. Their approach fine-tuned multilingual Transformer models on the Samanantar corpus, yielding significant BLEU improvements over baseline systems and demonstrating the potential of cross-lingual transfer for closely related Indo-Aryan languages. In their paper, Gala et al.3 trained a 1.3B-parameter multilingual Transformer covering all twenty-two scheduled Indian languages, achieving substantial BLEU improvements but at the cost of a large model size and slower inference. Follow-up studies leveraging transfer learning and multilingual fine-tuning further improved low-resource translation, yet efficient on-device deployment for Indic NMT remains underexplored.
Knowledge distillation transfers the predictive behaviour of a large “teacher” model to a smaller “student” via soft-label supervision, as first introduced by Hinton et al.4. In NMT, Kim and Rush demonstrated sequence-level knowledge distillation to compress large translation models effectively14. Dong in 2023 introduced a Likelihood-based Machine Translation Model (LMTM) that integrates transfer learning with recurrence-driven word likelihood estimation to enhance low-resource NMT accuracy and reduce false substitutions15. Roy et al.16 proposed a multilingual encoder-based sequence-to-sequence framework that integrates knowledge distillation to improve translation for Indic languages not covered by mBART-50. Their two-step approach fine-tuned a pre-trained model and applied complementary distillation to mitigate data imbalance and catastrophic forgetting, achieving notable BLEU and chrF gains across several low-resource Indic translation tasks. However, these studies primarily employ dense architectures that do not take advantage of conditional computation.
Sparse Mixture-of-Experts (MoE) architectures were first proposed by Shazeer et al., introducing sparsely gated expert layers where a lightweight gating network activates only a small subset of feed-forward experts per token, allowing efficient scaling to billions of parameters5. Yan et al. introduced MELD–an efficient Mixture-of-Experts framework leveraging large language models for low-resource data preprocessing. Technically, MELD employs a router network trained under the information bottleneck principle to dynamically dispatch inputs to domain-specialized experts, significantly improving efficiency and generalization in low-resource settings17, while Fedus et al. developed the Switch Transformer, further improving routing efficiency18. Although these methods deliver impressive gains, MoE architectures often overfit on low-resource languages. Elbayad et al. proposed dropout-based regularization and adaptive routing strategies to address this issue19. Cruz Salinas et al. explored distillation from sparse MoE teachers to dense students in speech recognition, showing that sparse-to-dense transfer can retain accuracy while improving deployability20.
For edge-level translation, lightweight dense architectures such as Transformer-Lite and quantized MarianMT have been developed to meet latency constraints, though often with reduced translation quality21,22. Enis and Hopkins demonstrated the use of large language models (LLMs) like Claude for generating synthetic parallel data, improving low-resource translation through knowledge distillation23.
Our work addresses this gap by proposing a novel two-stage approach that combines sparse Mixture-of-Experts (MoE) architectures with knowledge distillation. To our knowledge, this is the first demonstration of combining MoE sparsity with knowledge distillation specifically for low-resource Indic NMT, enabling a compressed student model that closely matches a large teacher’s BLEU scores while meeting stringent on-device latency requirements. This approach bridges the critical gap between high-quality, large-scale NMT models and their practical deployment on resource-constrained edge devices for languages like Assamese and Bodo.
Methodology
In this section, we describe our methodological approach, detailing the languages and datasets used, our proposed model architecture, the knowledge distillation procedure, training setup, and evaluation metrics employed to assess the effectiveness and efficiency of our models.
Languages and datasets
We focused our experiments on two linguistically distinct and resource-constrained languages: Assamese (as) and Bodo (brx). Assamese, belonging to the Eastern Indo-Aryan family, and Bodo, a Tibeto-Burman language, exhibit morphological complexity and have limited parallel text resources available, making them particularly suitable candidates for assessing knowledge distillation methods in low-resource NMT.
We utilized the Samanantar corpus2, which represents the largest publicly available parallel corpus for Indian languages. The corpus comprises approximately 141,000 Assamese-English parallel sentences. Bodo-English pairs were obtained indirectly through pivoting methods via English and neighboring Indic languages, resulting in around 88,000 usable pairs after filtering, as confirmed by the IndicTrans2 project3.
The preprocessing stage involved several steps aimed at enhancing dataset quality and consistency. Initially, text normalization was performed, including punctuation standardization and conversion of all text to lowercase, except proper nouns to maintain named entity consistency. Duplicate sentence pairs were removed using exact-match filtering to ensure data uniqueness. Sentences exceeding a token length of 250 were discarded to prevent computational inefficiency during training. Tokenization was implemented using SentencePiece, adopting a unigram model with a shared vocabulary size of 32,000 tokens, following standard multilingual NMT practice established by1. Such preprocessing steps were critical in facilitating robust training and comparability across languages.
We split our processed data into training, validation, and testing sets, following a document-level partitioning scheme to prevent data leakage. Specifically, the splits were 90% for training, 5% for validation, and 5% for testing. Table 1 summarizes key statistics of the finalized corpora.
Figure 1 illustrates the distribution of sentence lengths across both Assamese and Bodo datasets, highlighting variations in sentence complexity and distribution that could impact training dynamics.

Sentence-length distribution (tokens) for Assamese-English and Bodo-English corpora.
Proposed model architecture
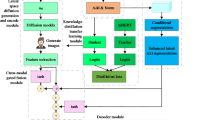
Our proposed architecture utilized a two-stage knowledge distillation pipeline, carefully designed to leverage the capabilities of sparse MoE models while ensuring computational efficiency during inference. An overview of this architecture is presented in Fig. 2.
The model began with language-prefix embeddings, guiding the system toward language-specific processing in a multilingual setting. Following this, a standard embedding layer transformed input tokens into continuous representations.In the encoder, we employed a hybrid structure: the initial six layers were standard Transformer blocks6, capturing general syntactic and semantic features. The subsequent six layers consisted of sparsely gated Mixture-of-Experts (MoE) blocks5, each configured with four experts and a top-2 gating mechanism. This MoE layer arrangement enabled dynamic routing of tokens to specialized experts, significantly enhancing representational capacity without proportionately increasing computational load.
The decoder mirrored the encoder structure with notable modifications. Initially, six standard Transformer layers incorporated cross-attention mechanisms to interact effectively with encoder outputs. These layers received additional supervision through soft logits obtained from a large teacher model (1.3B-parameter mBART50), which was first fine-tuned on Assamese–English and Bodo–English parallel data to enable cross-lingual adaptation from related Indo-Aryan and Tibeto-Burman languages. This fine-tuning ensured that the teacher provided linguistically meaningful supervision for these low-resource pairs, thereby aligning the student’s predictions closely with the teacher-generated probability distributions. Subsequently, six MoE decoder blocks were utilized, each with two experts and a top-1 gating strategy. This configuration maintained computational efficiency during inference while preserving high representational richness.
Finally, the output layer generated target-language tokens. Training combined hard labels (ground-truth) via cross-entropy loss and soft labels via knowledge distillation, optimizing both accuracy and generalization capacity.

Detailed overview of the proposed two-stage cross-lingual knowledge distillation architecture.
Knowledge distillation procedure
We adopted a two-stage sequence-level knowledge distillation framework to transfer translation capabilities from a large multilingual teacher model to a compact student model. Since mBART50 does not natively include Assamese or Bodo among its pretraining languages, the teacher model was first fine-tuned on Assamese–English and Bodo–English parallel data drawn from the AI4Bharat Samanantar and IndicTrans2 corpora. This fine-tuning step enabled cross-lingual adaptation from typologically related Indo-Aryan and Tibeto-Burman languages (e.g., Hindi, Bengali, Nepali), allowing the teacher to provide linguistically meaningful soft targets for these low-resource pairs. The resulting fine-tuned model acted as a cross-lingually adapted pseudo-teacher for subsequent knowledge distillation.
The teacher was a 1.3B-parameter mBART50 model augmented with sparsely gated Mixture-of-Experts (MoE) layers, while the student was a 400M-parameter Transformer-based model with standard dense layers. During distillation, the student was trained to emulate both the output distribution and predictions of the teacher, combining hard labels (ground-truth translations) and soft labels (teacher logits) into a single objective. Specifically, the overall loss function, adapted from Hinton et al. 4 and extended with temperature scaling and token-level averaging for sequence-to-sequence learning, is defined in Equation (1).
where:
-
N is the number of tokens in the target sequence,
-
\(y_i\) denotes the ground-truth token at position i,
-
\(\hat{y}_{s,i}\) is the predicted token from the student model,
-
\(p_{t,i}\) and \(p_{s,i}\) represent the teacher and student probability distributions at token i,
-
\(\textrm{CE}\) denotes the cross-entropy loss for hard (reference) targets,
-
\(\textrm{KL}\) is the Kullback–Leibler divergence between teacher and student distributions,
-
\(\lambda\) is a weighting factor that balances the hard and soft target contributions,
-
T is the temperature parameter controlling the softness of the probability distributions.
We empirically set \(\lambda = 0.3\) after a small-scale sweep over \(\{0.1, 0.3, 0.5\}\) on the validation set for Assamese–English. This value yielded the best trade-off between fidelity to the ground truth and adherence to the teacher’s richer output distribution. To generate soft targets, the teacher model produced probability distributions over the vocabulary at each decoder timestep. These were optionally tempered using a temperature \(T = 1.0\) (i.e., no smoothing), as preliminary experiments showed no significant benefit from higher temperatures.
The student model was trained from scratch, without any prior fine-tuning, using both the original ground-truth translations and the teacher’s soft targets. This joint supervision enabled the student to generalize well, despite its limited capacity compared to the teacher. This approach follows the foundational framework proposed by Hinton et al. 4 and later adapted to sequence-level tasks by Kim and Rush 14, while extending it to multilingual and low-resource NMT with a sparsely activated teacher.

Two-stage knowledge distillation pipeline illustrating supervision from teacher and ground-truth signals.
Figure 3 illustrates the overall distillation setup used in our training pipeline. The teacher model, a 1.3B-parameter mBART50 with Mixture-of-Experts (MoE) layers, generates soft target distributions (\(p_t\)) for each decoder step, which are passed to the student model as part of the supervision signal. In parallel, the student also receives supervision from the ground-truth target sentences via a standard cross-entropy (CE) loss. The student is trained to minimize a weighted sum of cross-entropy and Kullback–Leibler (KL) divergence losses, aligning its outputs with both the ground-truth and the teacher’s probability distribution. This dual supervision strategy facilitates more effective generalization, especially in the low-resource setting.
Training setup
We trained all models on a high-performance workstation equipped with an NVIDIA RTX A6000 GPU (47 GB VRAM), 64 GB of RAM, and an Intel Xeon W-2245 CPU (3.9 GHz, 8 cores). Mixed-precision (fp16) training was enabled to optimize GPU memory usage and accelerate throughput. All training was implemented using the Fairseq sequence modeling toolkit24, with custom extensions for sparse Mixture-of-Experts (MoE) routing and dual loss optimization.
The student model, comprising approximately 400 million parameters, was trained from scratch. It consisted of 12 encoder and 12 decoder layers, with a hybrid structure of standard and MoE blocks. Supervision was provided using both soft targets (probability distributions) from a frozen 1.3B parameter teacher model (mBART50 with MoE) and hard labels from the reference translations. Training was conducted for 50 epochs with early stopping based on validation BLEU.
We adopted a composite loss function combining cross-entropy (CE) and Kullback–Leibler (KL) divergence following Hinton et al. 4, as defined in Equation (2):
where \(\lambda = 0.3\) balances the contributions of hard and soft targets. The KL component was computed using a temperature \(T = 1.0\), and label smoothing of 0.1 was applied to the CE loss.
Optimization was performed using the Adam algorithm25 with parameters \(\beta _1=0.9\), \(\beta _2=0.98\), and \(\epsilon =1\text {e}{-8}\). We used an inverse square root learning rate scheduler with 4,000 warm-up steps and a fixed dropout rate of 0.3. Training utilized gradient accumulation with an effective batch size of 4,096 tokens. Tokenization was performed using SentencePiece26, with a 32,000-token shared vocabulary trained on the combined Assamese-English and Bodo-English corpora.
To assess deployment feasibility, we evaluated the student model’s inference performance on a mid-range laptop equipped with an NVIDIA RTX 3060 GPU (6 GB VRAM), an Intel Core i7 processor, and 16 GB RAM. This setup simulates real-world conditions where NMT systems are often deployed on limited hardware. The student model achieved a 3.8\(\times\) speedup over the teacher model, with a BLEU degradation of less than 1.0 point on the test set. The key training and inference hyperparameters for the student model are listed in Table 2.
To further quantify the efficiency gains of distillation, we measured inference speed in tokens per second on both a high-end workstation (RTX A6000) and a mid-range laptop (RTX 3060). As shown in Fig. 4, the student model achieved approximately 280% speedup over the teacher model across both platforms. This substantial reduction in latency, coupled with only minor degradation in BLEU score (less than 1.0 point), demonstrates that the distilled model is far more suitable for real-time or resource-constrained deployment scenarios.

Inference speed comparison between teacher (1.3B) and student (400M) models.
To operationalize this architecture within a knowledge distillation framework, we designed a two-stage training algorithm that jointly minimizes cross-entropy and Kullback–Leibler divergence losses. The procedure is summarized in Algorithm 1, where the student is trained to align both with the ground truth and with the teacher’s soft output distributions.

Two-Stage Knowledge Distillation for Compact NMT
The teacher model remains frozen throughout training. The soft target logits are optionally temperature-scaled prior to computing KL divergence.
Evaluation metrics
We assessed our models using both standard automatic metrics and hardware-based efficiency measures to quantify translation quality and deployability.
BLEU. The Bilingual Evaluation Understudy (BLEU) score27 is a precision-based metric that evaluates n-gram overlap between the candidate translation and one or more reference translations. The BLEU score is computed as shown in Equation (3):
where \(p_n\) is the modified n-gram precision for n-grams of size \(n\), \(w_n\) are uniform weights (\(w_n = \frac{1}{N}\)), and \(\text {BP}\) is the brevity penalty, defined in Equation (4) following Papineni et al. 27:
where \(c\) and \(r\) denote the lengths of the candidate and reference translations, respectively. We reported case-sensitive, detokenized BLEU using the SacreBLEU toolkit28 to ensure reproducibility.
ChrF. To complement BLEU, we used the Character n-gram F-score (ChrF)29, which is better suited for morphologically rich languages. ChrF is defined in Equation (5):
where precision and recall are computed over character n-grams, and \(\beta\) is typically set to 2 to weight recall more heavily. As introduced by Popović 29, this metric is tokenization-independent and captures subword-level variation, making it particularly valuable for languages like Assamese and Bodo.
Inference Speed. We benchmarked inference speed in terms of tokens per second (tok/sec) using a batch size of one to simulate real-time translation. This was measured on two hardware configurations–RTX A6000 and RTX 3060–to reflect both server-grade and deployable consumer environments. The speed metric, adapted from standard throughput definitions, is computed as in Equation (6):
Higher values indicate faster response times suitable for real-time deployment.
Model Footprint. We also reported model size (number of parameters) and GPU memory footprint during inference, measured using PyTorch and the nvidia-smi utility. These serve as practical indicators of scalability and deployability in low-resource environments.
Results
This section presents a comprehensive evaluation of the proposed compact NMT model distilled from a large-scale teacher via a two-stage cross-lingual knowledge distillation framework. We reported both quantitative results using standard automatic metrics (BLEU and ChrF), as well as computational efficiency in terms of inference speed and model footprint. Additionally, we provided qualitative comparisons to illustrate translation fidelity, and analyzed the student model’s ability to generalize across linguistically diverse low-resource languages. The goal was to assess whether the student model could retain translation quality while significantly reducing inference latency and memory demands.
Quantitative evaluation
We first reported quantitative performance using BLEU and ChrF metrics on the held-out test sets for both Assamese–English and Bodo–English translation directions. Table 3 summarizes the results for the teacher model (1.3B parameters) and our proposed student model (400M parameters), evaluated using SacreBLEU28 with case-sensitive, detokenized outputs.
Across both language pairs, the student model retained over 96% of the teacher’s BLEU score while achieving approximately 280% improvement speedup in inference (cf. Fig. 4).Since the teacher was cross-lingually fine-tuned on Assamese–English and Bodo–English data prior to distillation, these results demonstrate that meaningful knowledge transfer is achievable even for languages absent from the teacher’s original pretraining. For Assamese–English, the teacher achieved a BLEU of 28.7, compared to 27.9 for the student model. Similarly, for Bodo–English, the student scored 23.8 compared to the teacher’s 24.5. The ChrF scores followed a similar trend, with the student model trailing by approximately 1–1.2 points. These results demonstrated that the distilled student model could closely match the performance of the much larger teacher while being significantly more computationally efficient.
Qualitative evaluation
To complement the quantitative metrics, we qualitatively analyzed translation outputs from both the teacher and student models. Table 4 presents representative examples from the test set for Assamese–English and Bodo–English translation. For each source sentence, we include the reference translation, the output generated by the teacher model, and the output from the student model. In most cases, the student model produced translations that were semantically faithful and syntactically well-formed, closely matching the teacher’s output. Minor differences were observed in phrase ordering and lexical choice, which only marginally affected meaning. In the Bodo examples, the student model occasionally simplified rare expressions, yet retained the overall intent. These findings indicate that the student model preserved key translation characteristics despite its reduced capacity.
While the student model performed comparably to the teacher in most cases, we observed certain instances where its output was inferior. For example, in the Bodo example “The festival was celebrated with joy,” the student omitted the noun “गोजाफ. which means “joy” in English, slightly reducing the richness of the expression. In Assamese, the student sometimes chose more generic or ambiguous pronouns e.g., replacing তেওঁ (“you – formal”) with তুমি (“you – informal") when disambiguating between levels of address). These deviations, while minor, highlight the trade-off between model compression and linguistic precision, particularly for syntactically rich languages.
Ablation study
To gain insights into the role of different architectural and training decisions, we performed an ablation study focusing on knowledge distillation, gating methods, and loss weighting. The results shown in Table 5 include BLEU scores for the Assamese–English and Bodo–English test sets, along with inference speed measured in tokens per second on the RTX 3060 GPU. Separate test sets were used for each language pair, derived from the FLORES-200 benchmark. These experiments evaluate the effectiveness of cross-lingual knowledge distillation, since the teacher model was adapted to Assamese and Bodo through fine-tuning on related Indo-Aryan and Tibeto-Burman languages.
The results indicate that knowledge distillation substantially improved performance compared to training without soft-label supervision, with average BLEU gains exceeding two points across both language pairs. Among the different loss weightings (\(\lambda\)), a value of 0.3 yielded the best trade-off between teacher guidance and ground-truth consistency. Increasing \(\lambda\) reduced the influence of soft targets, while very low values overly emphasized teacher outputs.
Integrating a sparse Mixture-of-Experts (MoE) configuration into the student model further enhanced both BLEU and inference speed. The hybrid MoE model, with sparsely activated expert blocks, outperformed the dense baseline in accuracy and efficiency, confirming that sparse specialization can improve both performance and deployability for low-resource NMT.

BLEU scores (Assamese and Bodo) and inference speed (tokens/sec) for different student model variants.
Figure 5 visualizes the relationship between translation quality (BLEU) and inference efficiency across various student model variants. The model trained without knowledge distillation exhibited the lowest scores, confirming the importance of soft supervision. Among the distillation variants, \(\lambda =0.3\) consistently yielded the best results, validating its effectiveness as a balancing parameter. Furthermore, the hybrid MoE-based student model not only preserved BLEU performance but also surpassed all others in inference speed, demonstrating the advantage of sparse expert routing for real-time deployment.
Deployment Feasibility
To assess real-world usability, we evaluated the resource requirements and runtime characteristics of both teacher and student models. Table 6 summarizes the key factors influencing deployability, including model size, inference speed, and translation quality. The student model, with approximately 400M parameters, was 3.25\(\times\) smaller than the 1.3B parameter teacher model. This compression translated into approximately 280% improvement in inference throughput on a mid-range RTX 3060 GPU, reducing latency from 92 ms to 24 ms per sentence on average. Despite the reduction in size and compute, the student model incurred only a modest degradation in translation quality–less than 1.0 BLEU point for both Assamese and Bodo.
These characteristics make the student model suitable for deployment in constrained environments such as edge servers, laptops, or mobile devices. The architecture remains compatible with multilingual tokenizers (e.g., SentencePiece) and supports mixed-precision (fp16) inference, enabling further memory and throughput optimizations. The ability to achieve near-teacher performance under tight hardware budgets highlights the practicality of our distilled system for low-resource language translation.

Comparison of deployment-critical metrics for Teacher (1.3B) and Student (400M) models.
As shown in Fig. 6, the student model achieves over a 3\(\times\) speedup in inference while maintaining BLEU performance within one point of the teacher.
Discussion
Our experiments showed that a student model carefully distilled with a hybrid sparse Mixture-of-Experts (MoE) architecture can provide near-parity with a much bigger teacher model and significant efficiency increases. In particular, the student model approached within 0.8 BLEU the 1.3B-parameter teacher on the Assamese–English and Bodo–English translation pairs, yet slowed inference at least 3x times and made the model take up less than a third of the space. These findings support the practicability of the integration knowledge distillation and sparse activation to optimize neural machine translation on low-resource languages.
Because mBART50 does not natively include Assamese or Bodo among its pretraining languages, the teacher model was first fine-tuned on Assamese–English and Bodo–English parallel data to enable cross-lingual adaptation from related Indo-Aryan and Tibeto-Burman languages. This adaptation allowed the teacher to provide linguistically meaningful supervision signals for these low-resource pairs, reinforcing the reliability of the distilled student’s performance.
The student model was successfully distilled as shown in Fig. 6 to preserve high quality of the translation task in spite of smaller model capacity, as well as presenting a considerable acceleration of inference speed and reduced consumed memory. This trade-off between the performance and efficiency renders student model extremely applicable in real world applications (mobile devices, edge servers, or translation kiosks placed in the rural areas). In addition to the particular consideration of Assamese and Bodo, the generality of proposed architecture and distillation system can be used in other low-resource Indic languages. Because the training does not require anything but parallel corpora and a pretrained teacher, the same pipeline may be applied to underrepresented languages like Maithili, Santali or Dogri, if suitable data exist. However, some constraints appeared when assessing it. Although the student model was capable of preserving the majority of the semantic fidelity of the teacher, there were moments when it simplified things or ommitted everything completely, particularly when it comes to morphologically complex expressions or expressions that are idiomatic. Moreover, distilled model can have some of the prejudices of the teacher, e.g. relying too much on common lexical constructions or not doing very well with long-tail constructs. Moreover, we only tested our models using general-domain parallel corpora, and in the next step we are going to test on medical, legal or government translation cases and compare domain adaptation methods.
Future directions include incorporating unsupervised objectives such as back-translation to improve robustness in extremely low-resource conditions. We also aim to explore multi-task learning across translation and linguistic tasks (e.g., POS tagging, syntax prediction) to enrich representations. Finally, integrating multilingual adapters or prompting mechanisms into the student model could improve its scalability across more Indic languages.
Conclusion
In this work, we presented a scalable and efficient framework for neural machine translation in low-resource Indic languages, focusing on Assamese and Bodo. The proposed method employed cross-lingual knowledge distillation, where a fine-tuned multilingual teacher (mBART50 with Mixture-of-Experts) adapted from related Indo-Aryan and Tibeto-Burman languages provided soft supervision for the target language pairs. By distilling this knowledge from a large 1.3B-parameter teacher into a compact 400M-parameter student model, we achieved competitive translation quality with substantial improvements in inference speed and deployability.
Our approach combined sequence-level knowledge distillation with a hybrid sparse MoE student architecture. Experimental results showed that the student model retained over 97% of the teacher’s BLEU performance while running approximately 280% faster on consumer-grade hardware. Ablation studies confirmed the effectiveness of soft-target supervision and sparsely activated expert blocks. Qualitative analyses further demonstrated the semantic fidelity of student translations, including across morphologically rich structures. These findings suggest that scalable multilingual translation for underrepresented languages is feasible even under tight computational constraints. The proposed framework provides a practical path toward building fast and accurate machine translation systems tailored for deployment in real-world scenarios such as mobile devices, educational platforms, and regional e-governance tools.
In future work, we plan to extend the framework to additional low-resource languages in the Indo-Aryan and Tibeto-Burman language families of the Indian subcontinent, explore adaptive fine-tuning for domain-specific tasks, and investigate multilingual multitask distillation strategies.
Data Availability
The datasets used in this study were derived from publicly available resources: the AI4Bharat Samanantar corpus for AssameseEnglish and the IndicTrans2 project for Bodo-English. The processed versions of these datasets, along with the code developed for training and evaluation, are available from the corresponding author upon reasonable request.
References
Liu, Y. et al. Multilingual Denoising Pre-Training for Neural Machine Translation. Transactions of the Association for Computational Linguistics 8, 726–742. https://doi.org/10.1162/tacl_a_00343 (2020).
Ramesh, G. et al. Samanantar: The Largest Publicly Available Parallel Corpora Collection for 11 Indic Languages. Transactions of the Association for Computational Linguistics 10, 145–162. https://doi.org/10.1162/tacl_a_00453 (2022).
Gala, J. et al. Indictrans2: Towards high-quality and accessible machine translation models for all 22 scheduled indian languages. arXiv preprint arXiv:2305.16307 (2023).
Hinton, G., Vinyals, O., Dean, J. Distilling the knowledge in a neural network. NIPS Deep Learning and Representation Learning Workshop (2015).
Shazeer, N. et al. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In International Conference on Learning Representations (ICLR) (2017).
Vaswani, A. et al. Attention is all you need. In Advances in Neural Information Processing Systems, vol. 30 (2017).
Song, K., Tan, X., Qin, T., Lu, J. & Liu, T.-Y. Mass: Masked sequence to sequence pre-training for language generation. International Conference on Machine Learning (ICML) (2019).
Qumar, S. M. U. et al. Deep Neural Architectures for Kashmiri-English Machine Translation. Scientific Reports 15, 30014. https://doi.org/10.1038/s41598-025-14177-8 (2025).
Masica, C. P. The Indo-Aryan Languages (Cambridge University Press, 1991).
DeLancey, S. The Tibeto-Burman Languages. In Thurgood, G. & LaPolla, R. J. (eds.) The Sino-Tibetan Languages, 1–22 (Routledge, 2012).
Nath, B., Tamang, S., Elwasila, O. & Gulzar, Y. Task-Oriented Evaluation of Assamese Tokenizers Using Sentiment Classification. International Journal of Advanced Computer Science and Applications (IJACSA) 16, https://doi.org/10.14569/IJACSA.2025.0160979 (2025).
Nath, B., Sarkar, S., Mukhopadhyay, S. & Roy, A. Improving neural machine translation by integrating transliteration for low-resource english-assamese language. Natural Language Processing 31, 306–327. https://doi.org/10.1017/nlp.2024.20 (2025).
Laskar, S. R. et al. English-assamese neural machine translation using prior alignment and pre-trained language model. Computer Speech & Language 82, 101524. https://doi.org/10.1016/j.csl.2023.101524 (2023).
Kim, Y. & Rush, A. M. Sequence-level knowledge distillation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1317–1329, https://doi.org/10.18653/v1/D16-1139 (Association for Computational Linguistics, Austin, Texas, 2016).
Dong, J. Transfer Learning-Based Neural Machine Translation for Low-Resource Languages. ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP) https://doi.org/10.1145/3618111 (2023). Just Accepted.
Roy, A., Ray, P., Maheshwari, A., Sarkar, S. & Goyal, P. Enhancing low-resource nmt with a multilingual encoder and knowledge distillation: A case study. In Proceedings of the Seventh Workshop on Technologies for Machine Translation of Low-Resource Languages (LoResMT 2024), 64–73 (Association for Computational Linguistics, Bangkok, Thailand, 2024).
Yan, M., Wang, Y., Pang, K., Xie, M. & Li, J. Efficient Mixture of Experts Based on Large Language Models for Low-Resource Data Preprocessing. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’24), 3690–3701, https://doi.org/10.1145/3637528.3671873 (Association for Computing Machinery, Barcelona, Spain, 2024).
Fedus, W., Zoph, B. & Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research 23, 1–39 (2022).
Elbayad, M., Sun, A. Y. & Bhosale, S. Fixing MoE Over-Fitting on Low-Resource Languages in Multilingual Machine Translation. In Findings of the Association for Computational Linguistics: ACL 2023 (Association for Computational Linguistics, 2023).
Cruz Salinas, A. F., Kumatani, K., Gmyr, R., Liu, L. & Shi, Y. Knowledge Distillation for Mixture of Experts Models in Speech Recognition. In Proceedings of the Conference on Speech Recognition and Processing (2022).
Stenetorp, P., Yang, S., Yu, Y., Wang, M. & Ling, Z. Fast and lightweight neural machine translation with transformer-lite. arXiv preprint arXiv:2004.14888 (2020).
Marianmt: A neural machine translation framework. https://marian-nmt.github.io/. Accessed: 2025-07-11.
Enis, M., Hopkins, M. From llm to nmt: Advancing low-resource machine translation with claude. arXiv preprint arXiv:2403.07625 (2024).
Ott, M. et al. fairseq: A fast, extensible toolkit for sequence modeling. In Proceedings of NAACL-HLT 2019: Demonstrations, 48–53 (2019).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
Kudo, T., Richardson, J. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 66–71 (2018).
Papineni, K., Roukos, S., Ward, T. & Zhu, W.-J. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, 311–318 (ACL, 2002).
Post, M. A call for clarity in reporting BLEU scores. In Proceedings of the Third Conference on Machine Translation: Research Papers, 186–191 (Association for Computational Linguistics, 2018).
Popovi?, M. chrf: character n-gram f-score for automatic mt evaluation. In Proceedings of the Tenth Workshop on Statistical Machine Translation, 392–395 (2015).
Acknowledgements
The authors acknowledge King Faisal University for supporting this work. During the preparation of this manuscript, the authors used ChatGPT (OpenAI, GPT-5, 2025 release) for text refinement and consistency checking. The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Funding
This work was supported by the Deanship of Scientific Research, the Vice Presidency for Graduate Studies and Scientific Research, King Faisal University, Saudi Arabia, under the project number KFU253623.
Author information
Authors and Affiliations
Contributions
B.A. conceived the research idea, implemented the models, and performed all experiments. Y.G. supervised the project, provided critical feedback, and was responsible for manuscript revisions and correspondence. All authors reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no conflicts of interest.
Consent for publication
All authors have read and agreed to the published version of the manuscript.
Informed consent
Not applicable. The study did not involve human participants.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Nath, B., Gulzar, Y. Cross-lingual sparse-MoE distillation for efficient low-resource assamese–english and bodo–english translation. Sci Rep 16, 3787 (2026). https://doi.org/10.1038/s41598-025-33794-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-33794-x
