
Abstract
This paper intends to solve the limitations of the existing methods to deal with the comments of tourist attractions. With the technical support of Artificial Intelligence (AI), an online comment method of tourist attractions based on text mining model and attention mechanism is proposed. In the process of text mining, the attention mechanism is used to calculate the contribution of each topic to text representation on the topic layer of Latent Dirichlet Allocation (LDA). The Bidirectional Recurrent Neural Network (BiGRU) can effectively capture the temporal relationship and semantic dependence in the text through its powerful sequence modeling ability, thus achieving a more accurate classification of emotional tendencies. In order to verify the performance of the proposed ATT-LDA- Bigelow model, online comments about tourist attractions are collected from Ctrip.com, and users’ emotional tendencies towards different scenic spots are analyzed. The results show that this model has the best emotion classification effect in online comments of scenic spots, with the accuracy and F1 value reaching 93.85% and 93.68% respectively, which is superior to other emotion classification models. The proposed method not only improves the accuracy of sentiment analysis, but also provides strong support for the optimization of tourism recommendation system and provides more comprehensive, objective and accurate tourism information for scenic spot managers and tourism enterprises. This achievement is expected to bring new enlightenment and breakthrough to the research and practice in related fields.
Similar content being viewed by others
Introduction
Research background and motivations
Driven by digitalization and internet technology, tourism has become an important part of the global economy and plays an important role in promoting local economic development, cultural exchanges and enhancing international competitiveness1,2,3. Tourism not only directly promotes the development of transportation, accommodation, catering and other related industries, but also indirectly promotes exchanges and cooperation in culture, education, science and technology and other fields. According to statistics, the global tourism industry creates more than hundreds of millions of direct and indirect employment opportunities every year, making great contributions to the global economy4,5,6.
Driven by internet technology, the tourism industry has ushered in a wave of digitalization and being online. Online travel platforms have sprung up, providing consumers with more convenient and rich tourism products and services7,8,9. The rise of online travel platform has provided consumers with convenient and rich tourism products and services, and also spawned a large number of user comments. These comments are not only an important way for consumers to express their travel experiences, but also an important basis for potential tourists to obtain travel information and make travel decisions10. Traditional emotional analysis methods are often difficult to accurately capture and distinguish subtle emotional differences in user comments, especially in the face of complex and changeable user comments. For example, comments may contain both positive and negative emotional expressions, or the emotional tendency is not obvious, which makes emotional detection more difficult. Many existing methods fail to fully consider the time dependence in comments, so they cannot capture the contextual information and semantic dependence in comments.
In recent years, the rapid development of artificial intelligence (AI) technology brings new opportunities and challenges to the field of text mining. As a technology to extract useful information from a large number of text data, text mining has been widely used in many fields11,12,13. However, the traditional text mining method has many limitations when dealing with online comments of tourist attractions, such as the inability to accurately identify the emotional tendency in comments and the poor effect of topic classification14,15. In order to solve these problems, researchers begin to explore the method of combining AI technology with text mining to realize more in-depth analysis and mining of online comments in tourist attractions.
In this context, this paper proposes the ATT-LDA-BiGRU model, which extracts potential topics through LDA, dynamically calculates topic weights by using attention mechanism, and captures temporal relations and semantic dependencies in comments by using BiGRU network. On the theoretical level, this paper aims to fill the gaps in the existing research and provide a new theoretical perspective and method for the study of online comments on tourist attractions. This not only helps to enrich and develop the theoretical system in the field of text mining, but also provides new theoretical support for the study of tourism. On the practical application level, this paper helps the managers of tourist attractions and tourism enterprises to understand the needs and satisfaction of tourists more comprehensively to formulate more effective management and marketing strategies.
Research objectives
The main goal of this paper is to explore a text mining method for online comments of tourist attractions under the background of AI. In section one, this paper describes the research background, objectives and necessity. The second section summarizes the current research status of text mining and sentiment analysis. The third section mainly describes the problem of online comment analysis in the current tourist attractions to capture tourists’ needs, and puts forward a text mining model integrating attention mechanism to improve the emotional analysis effect of tourists’ comments in scenic spots. In the fourth section, experimental design is carried out to verify the feasibility of the text mining model proposed in this paper in specific applications. The fifth section summarizes the research contribution, limitations and future research direction. The LDA model is used to model the topic of comment data, and the potential topics related to tourism are extracted. The attention mechanism is used to calculate the weight of different words’ contribution to the topic to capture and distinguish the emotional tendency in comments more accurately. By introducing BiGRU network structure, ATT-LDA BiGRU model can efficiently process and analyze large-scale review data, reduce the consumption of computing resources and improve the processing speed, thus supporting real-time travel recommendation services.
Literature review
With the rapid development of the Internet and the popularity of social media, online text data has exploded. These text data contain rich information, which is of great significance for understanding users’ needs and mining potential value. At present, scholars have made some achievements in the study of online comments on tourist attractions. In the aspect of sentiment analysis, researchers used machine learning algorithm and deep learning model to classify and judge the sentiment of comments, and achieved certain results16. Wahyudi (2021)17 used TF-IDF and K-means algorithm in text mining tasks. TF-IDF algorithm was used to extract features from text data, and then K-means algorithm was used to cluster the extracted features to realize automatic text classification and topic extraction. Zeberga et al. (2022)18 proposed a text classification method based on Convolutional Neural Network (CNN). By embedding words into the text, and then using CNN model for feature extraction and classification, the high-precision text classification task was realized.
Qiu et al. (2020)19 introduced the attention mechanism into the emotion analysis model, which improved the accuracy of emotion analysis and enabled the model to automatically focus on words or sentences in the text that have a significant impact on emotion judgment. Li et al. (2020)20 constructed a multi-granularity emotional analysis model, which could capture the emotional information in the text more finely and provide richer dimensions and more accurate judgment results for emotional analysis.
In order to overcome the limitations of RNN and its variants, researchers have proposed a variety of improved neural network architectures in recent years. Among them, Transformer model has made remarkable achievements in the field of natural language processing with its powerful parallel computing ability and self-attention mechanism21. Transformer model can not only process long text data efficiently, but also capture the global dependence in the text, which provides new possibilities for sentiment analysis. Although Transformer model has achieved great success in NLP field, it still needs to be customized and optimized by combining specific domain knowledge and task characteristics in sentiment analysis task.
The existing methods are not effective in dealing with short texts and multi-topic texts. Combining AI text mining model and attention mechanism, this paper proposes a new research method of online comments on tourist attractions. The potential topics in comments are extracted by LDA model to provide contextual information for sentiment analysis. At the same time, the attention mechanism is used to calculate the weight of different words’ contribution to the theme to capture and distinguish the emotional tendency in comments more accurately. BiGRU network structure can capture the temporal dependence of comments and improve the model’s ability to deal with long texts.
Research methodology
Online comment analysis and tourism recommendation of tourist attractions
Online comment data mainly comes from major travel websites and social media platforms. Firstly, by writing a crawler program or using a third-party data service, the online comment data related to tourist attractions are captured from the target website. In the process of data collection, it is necessary to pay attention to the integrity and accuracy of data to ensure the reliability of subsequent analysis. The collected original comment data often contains a lot of noise information, such as advertisements and repeated comments. Therefore, before analysis, it is necessary to preprocess the data. Pretreatment steps include duplicate removal, invalid comments (such as advertisements and spam), text cleaning (such as removing HTML tags and special characters), word segmentation and part-of-speech tagging. These steps are helpful to improve the efficiency and accuracy of subsequent analysis.
Collaborative filtering recommendation is a recommendation method based on user behavior similarity. In tourism recommendation, people can use the historical behavior data of tourists (such as browsing records, collection behaviors, purchase records, etc.) to calculate the similarity between tourists and find other tourists who are similar to the current tourists. According to the preferences and behavior patterns of these similar tourists, this paper recommends tourist attractions that may be of interest to current tourists.
Content recommendation is a recommendation method based on item characteristics and user preferences. In tourism recommendation, matching recommendation is made according to the characteristics of tourist attractions (such as geographical location, type, price, etc.) and tourists’ preferences (such as travel purpose, budget, preferences, etc.)22,23,24. The tourist attractions that best match tourists’ preferences can be found by constructing feature vectors and calculating similarity, and personalized recommendations can be made for them. Table 1 shows the specific online comment analysis methods of tourist attractions. In this stage of emotional evolution analysis, time series analysis is used to track and analyze the changing trend of emotional tendency with time. This paper aims to reveal how tourists’ emotional inclination to different tourist attractions changes with time, provide insights about tourists’ emotional fluctuation for managers of tourist attractions, and help to formulate more effective marketing strategies and management measures. Firstly, the collected comments are sorted according to the date of publication to ensure the chronological order of the data. Next, the review data is divided into several time windows, and the length of each window can be adjusted according to the research needs. The common window lengths are weeks, months and so on. In each time window, the proportion of positive, negative and neutral comments is calculated by using the emotional analysis model. Finally, by drawing a time series diagram, it shows the changing trend of the proportion of positive, negative and neutral emotions in different time periods.
The proportion of positive, negative and neutral comments in each time window is calculated. The specific calculation method is as follows: (1) Positive emotion ratio = number of positive comments/total comments; (2) Negative emotion ratio = number of negative comments/total comments; (3) Proportion of neutral emotions = number of neutral comments/total comments. Record the emotional proportion in each time window to form time series data, and show the changing trend of emotional tendency by drawing a line chart or a histogram.
The BERT model selected here is a pre-training language model based on the Transformer structure, aiming at learning common language expressions through large-scale unsupervised training. Its core idea is to use the encoder in Transformer structure to learn the bidirectional context representation, which makes the model understand the context. The basic principle and process of BERT model are as follows: (1) Model structure: BERT model is based on Transformer architecture, which uses self-attention mechanism to deal with different parts of input sequence, so that it can capture long-distance dependencies. (2) Pre-training task: It covers some words randomly in the input sequence, and then train the model to predict these covered words. This task enables BERT to make better predictions based on the context. Given two sentences, judge whether the second sentence is the next sentence of the first sentence. (3) Input representation: BERT’s input representation includes word embedding, position embedding and paragraph embedding. Word embedding represents the semantic information of words, position embedding represents the position information of words in sentences, and paragraph embedding is used to distinguish different sentences or paragraphs. (4) Training process: After pre-training on large-scale text data, BERT model can adapt to specific applications by fine-tuning on specific tasks, such as text classification and named entity recognition. (5) Multi-attention mechanism: The multi-attention mechanism in the BERT model is a very important part in its processing of text data. By learning multiple groups of self-attention mechanisms in parallel, the model can capture semantic information in different positions simultaneously, thus improving the performance of the model in natural language processing tasks. Multi-head attention mechanism can pay attention to semantic information from different subspaces at the same time, thus improving the model’s ability to model long-distance dependencies and capture different location information.
Text mining model integrating attention mechanism
As an important branch of natural language processing, text mining aims to extract valuable information and knowledge from large-scale unstructured text data25. However, traditional text mining methods often face the problems of information redundancy and inaccurate feature extraction when dealing with long or complex texts. In this paper, a text mining model integrating attention mechanism is proposed, which can extract key information from the text more effectively and improve the accuracy and efficiency of text mining by simulating the attention distribution mechanism of human beings when reading.
Attention mechanism originated from the study of human vision, and was gradually introduced into the field of natural language processing. Its core idea is that when processing information, the model can focus on key information and ignore irrelevant information like human beings26,27,28. In text mining, attention mechanism can help the model to filter out important words, phrases or sentences from the text, thus improving the quality and accuracy of text representation.
In the framework of Transformer coding and decoding based on attention mechanism (Fig. 1), the encoder is responsible for encoding the input sequence into one or more fixed-length vectors (usually called context vectors), and the decoder generates a new output sequence according to these vectors and the previous output sequence29,30. Different from the traditional encoder-decoder framework, the attention mechanism allows the decoder to dynamically look at all the words in the input sequence when generating each output, and assign different degrees of attention according to the importance of the words (that is, the attention weight).

Transformer coding and decoding framework based on attention mechanism.
Specifically, the correlation among each word in the input sequence and the current output position is measured by calculating an attention weight vector α. This weight vector is usually obtained by calculating the similarity score (such as dot product, cosine similarity, etc.) between the hidden state of the input sequence and the hidden state of the current output position. Then use softmax function to normalize the weight vector to ensure that the sum of attention weights of all words is 1. Finally, the normalized weight vector is weighted and summed with the hidden state of the input sequence to obtain a context vector c, which contains the most relevant information about the current output position.
Suppose the input sequence is \(x={x_1},{x_2},...,{x_t}\), where \({x_t}\) represents the embedding vector of the t-th input word. The encoder encodes an input sequence into a hidden state \(h={h_1},{h_2},...,{h_t}\) of a sequence, where \({h_t}\) represents the hidden state of the t-th input word.
When the decoder generates the i-th output word, the attention weight of each word in the input sequence is first calculated:
\({e_{ti}}\) is the similarity score between the t-th word in the input sequence and the current output position i.
Calculation of weighted embedding vector matrix:
Embedding layer is the foundation of text mining model, which is responsible for transforming words or phrases in text into vector representations with fixed dimensions. Suppose there is a vocabulary V with the size of |V|, and the task of the embedding layer is to map each word \(w \in V\) into a D-dimensional vector space \({R_d}\) to get an embedding vector \({e_w} \in {R_d}\). This process can be realized by looking up a pre-trained word embedding matrix E∈R|V|×d, that is \({e_w}=E\left[ w \right]\).
The self-attention mechanism assigns an attention weight to each word in the text by calculating the correlation between each word and other words. Specifically, assuming there are n words in the text, their embedding vectors are \({e_1},{e_2},...,{e_n} \in {R_d}\). Firstly, it is necessary to calculate an attention score matrix \(A \in {R_n} \times n\). \({A_{ij}}\) represents the attention score of word \({e_i}\) to word \({e_j}\). Attention score is usually calculated by point product, cosine similarity or bilinear function. Then the attention score matrix is normalized by softmax function, and the attention weight matrix \(\alpha \in {R_n} \times n\) is obtained. \({\alpha _{ij}}\) represents the attention weight of the word \({e_i}\) to the word \({e_j}\). Finally, the attention weight matrix is multiplied by the embedding vector matrix, and the weighted embedding vector matrix \(H \in {R_n} \times d\) is obtained. In this way, the weighted embedding vectors of each word are obtained, which contain the attention information of other words in the text.
The calculation process of attention mechanism can be summarized into three stages, as shown in Fig. 2. Firstly, the similarity between query and key is calculated, then normalized by softmax function, and finally the value is weighted and summed based on the normalized similarity value31,32,33. This mechanism enables the neural network to pay more attention to the information that is more relevant to the current task when processing a large amount of information, thus improving the performance of the model. In Fig. 2, BERT, as a pre-training language model based on Transformer, its core lies in using the self-attention mechanism of Transformer to capture bidirectional contextual information. Different from the traditional coding and decoding framework based on attention mechanism, BERT’s encoder part uses multi-layer Transformer structure, and each layer contains multiple self-attention heads and position feedforward networks. In addition, BERT also pre-trained by masking language model and next sentence prediction task to learn common language representation.

Computational process of attention mechanism.
In the first stage, calculate the similarity between Query and each Key to get the correlation between them:
In the second stage, the weights obtained in the previous stage are transformed by softmax:
L is the length of a given input.
In the third stage, through weighted summation, the attention value for Query is obtained:
After the introduction of attention mechanism, the contribution of each topic to text representation becomes clearer and more dynamic. For a comment that mentions both natural scenery and service quality, the attention mechanism can dynamically adjust the attention weight of natural scenery and service quality according to the specific content of the comment. If the content of natural scenery in comments is more prominent, the attention weight of natural scenery theme will be higher and the influence on text representation will be greater. This dynamic adjustment helps the model capture the key information in comments more accurately and improve the accuracy of emotion classification.
In the process of text mining, on the topic layer of Latent Dirichlet Allocation (LDA), attention mechanism is used to calculate the contribution of each topic to text representation. As a potential topic model, LDA can extract the potential topic structure from a large number of text data. These topic structures not only help people to understand the text content, but also provide important semantic information for the subsequent emotional analysis and recommendation tasks. Using the results of LDA keywords, text data can be clustered and analyzed, and documents with similar themes can be aggregated together to realize text classification and tagging and optimize the organizational structure of text data. Through LDA, people can capture the associations and differences between different topics in the text to identify the key information and emotional tendencies in user comments more accurately. The attention weight is dynamically calculated according to the text content and task requirements to highlight the topics most related to the current task34,35,36. The structure of LDA theme model is shown in Fig. 3. \(\theta \) represents the topic distribution in each document, and \(\varphi \) represents the word distribution under each topic. \(\alpha \) and \(\beta \) are hyperparameters of Dirichlet distribution. z stands for theme and w stands for word. M represents the number of documents. N represents the number of words, and K represents the number of topics.
LDA mainly focuses on the topic distribution at the lexical level, but may ignore the more complex contextual information and temporal dependencies in the text. In contrast, Hidden Markov Model (HMM) is a statistical model for modeling time series data. It can capture the transition probability between different states in the sequence data, thus revealing the time-series dependence in the data. In the field of text processing, HMM can be used for tasks such as part-of-speech tagging and named entity recognition to capture the temporal and grammatical relationships between words in a text. In this paper, instead of directly using HMM to enhance text embedding, LDA is chosen as the tool of theme modeling. This is because the research focuses on extracting the topic information related to travel recommendations from user comments, and LDA has shown good performance in this respect.

Structure diagram of LDA theme model.
For each document d, the topic distribution of the document is extracted from Dirichlet distribution \({\theta _d}\):
\(\alpha \) is a preset super parameter, which controls the sparsity of topic distribution in the document.
For each topic k, the vocabulary istribution \(Dirichlet(\beta )\) of the topic is extracted from Dirichlet distribution \(\beta \):
\(\beta \) is a preset super parameter, which affects the vocabulary distribution under each topic.
For each word position n in the document d, a topic \({z_{dn}}\) is extracted from the polynomial distribution \({\theta _d}\). A word \({w_{dn}}\) is extracted from conditional distribution .\({\phi _{{z_{dn}}}}\). according to topic \({z_{dn}}\). \({\phi _k}\) is the word distribution of topic kk extracted from Dirichlet distribution \(\beta \).
LDA model discovers potential topics by counting the co-occurrence patterns of words in texts. Each topic consists of a group of words with probability distribution, and these words have a high probability of appearing under a given topic. LDA model can generate a topic distribution for each document, indicating the degree of correlation between the document and each topic. The attention mechanism calculates the attention weight of each topic to the text representation according to the current task requirements37,38,39. These weights are dynamically calculated based on the relevance of the topic to the current task and the importance of the topic in the document. By combining the topic distribution generated by LDA with the attention weight, a weighted topic representation is obtained40.
Tourism recommendation based on emotional analysis
Rich user-generated content not only provides valuable reference information for other users, but also provides a new data source for the tourism recommendation system. Based on the existing emotional dictionaries and domain knowledge, an emotional dictionary suitable for tourism is constructed, including positive emotional words, negative emotional words and neutral emotional words41,42,43. Using emotion dictionary and rule-based method, people can judge the emotional polarity of each user comment, that is, whether the comment is positive, negative or neutral. On the basis of judging the polarity of emotion, the intensity of emotion is further calculated, that is, the user’s satisfaction with tourism products or services. The calculation of similarity can comprehensively consider the basic information of users, interest preferences, emotional tendencies and the basic information and characteristics of tourism products. The thinking framework of tourism recommendation system based on sentiment analysis is shown in Fig. 4. In Fig. 4, BiGRU is used to train the sentiment analysis model, which can capture semantic dependencies in comments and effectively process sequence data. BiGRU can still effectively capture the dependencies in sequences in many tasks, and performs well when dealing with short sequences. For specific tasks, if the sequence length is not very long, BiGRU may be a more economical and effective choice. Through training, the model can learn the emotional characteristics of comments and classify them accurately.

Thinking framework of tourism recommendation system based on emotional analysis.
In this paper, BiGRU neural network combined with attention mechanism is used to classify user comments. The specific steps are as follows: (1) Feature extraction: Use word embedding method to convert words in comments into vector representations; (2) Sequence modeling: BiGRU network captures the temporal relationship and semantic dependence in comments in both directions, and generates the contextual representation of comments; (3) Emotion classification: Use softmax layer to classify the emotional tendency of comments and output positive, negative or neutral probabilities. Table 2 shows a list of emotional tendencies.
Traditional emotion classification methods are usually based on the feature extraction method of bag-of-words model. Although these methods are simple and easy to understand, they often cannot capture the contextual information and semantic relations in the text. In this paper, BiGRU is used, which can effectively capture the temporal relationship and semantic dependence in the text through its powerful sequence modeling ability, thus achieving a more accurate classification of emotional tendencies. BiRNN captures the context information in sequence data through RNN in both forward and reverse directions44. GRU, through its unique gating mechanism, effectively solves the problems of gradient disappearance and gradient explosion that are easy to occur in the training process of RNN, and improves the training efficiency and performance of the model.
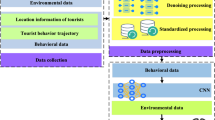
After collecting online comment data of tourist attractions, irrelevant characters, HTML tags, stop words, etc. in comments are firstly removed to improve the text quality. It may also include word segmentation for subsequent analysis. Next, feature extraction is carried out, and the word segmentation list is stop words-removed by loading the preset stop word list. LDA model is used to extract topics, and the contribution of each topic to text representation is calculated by combining attention mechanism. This step is helpful to transform high-dimensional text data into low-dimensional topic vectors, which is convenient for subsequent analysis. In the concrete implementation of the model architecture, LDA model holds that a document is a collection of topics, and each topic is composed of a set of words. Attention mechanism is used to calculate the contribution of each topic to text representation. BiGRU is used to capture the temporal relationship and semantic dependence in the text and realize the classification of emotional tendency.
Figure 5 shows the overall architecture of ATT-LDA-BiGRU model. Firstly, LDA model extracts potential topics from the input text. In LDA model, each topic in a text is represented by a set of keywords and their probability distribution. These topics represent the core content of the text, and the probability of each topic reflects its importance in each text. Next, the attention mechanism calculates the contribution of each topic. The function of attention mechanism is to weight the topics extracted by LDA model and calculate the contribution of each topic to text representation (that is, attention weight). This process helps the model to focus on the topics that are most relevant to the current task and ignore those that have less impact. In this way, the model can focus more accurately on the topics that are most helpful for emotion classification and improve the quality of text representation. Finally, Bidirectional Gated Recurrent Unit (BiGRU) neural network uses the topic representation with attention weight as input to capture the temporal relationship and semantic dependence in the text. BiGRU can extract useful information from the context simultaneously through the mechanism of bidirectional information transmission to understand the emotional trend of comments more comprehensively. BiGRU model can deal with the complex time dependence and semantic dependence in sequence data, and help the model to accurately classify emotional tendencies. This model design, ATT-LDA-BiGRU, can not only improve the accuracy of sentiment analysis, but also provide richer thematic information, which helps people to deeply understand the content and emotional tendency of user comments. Through this way of integration, the model shows higher effect in the task of emotion analysis, especially in the face of complex comments on tourist attractions, which can more accurately capture users’ emotions and evaluation tendencies.

Workflow of ATT-LDA-BiGRU model.
Experimental design and performance evaluation
Datasets collection
The experimental data of this paper comes from Ctrip.com (https://www.ctrip.com/). The reason for choosing Chinese comments is that Ctrip is one of the largest online travel platforms in China, and its users are mainly Chinese mainland residents, so comments are mainly in Chinese. Although this paper mainly focuses on Chinese comments, the proposed method and model have certain language universality. From this website, online comments on tourist attractions are captured, including the text content of online comments on tourist attractions, user ratings and other data. A total of 19,772 comments are collected to explore users’ emotional tendencies towards different scenic spots. The ratio of training set to test set is 8:2. The reason is that it not only ensures that the training set has enough data for model learning, but also ensures that the test set has enough data to accurately evaluate the performance of the model.
The original data is preprocessed, including removing duplicate data, cleaning noise data, text segmentation, removing stop words and other steps to ensure the accuracy and effectiveness of subsequent sentiment analysis.
Experimental environment
Python is adopted as the programming language to realize the model, Python 3.8.2, PyCharm 2021.3 + Jupyter Notebook, and the operating system is Win10 64-bit. NumPy is used for efficient numerical calculation, Pandas is used for data processing and analysis, and Matplotlib is used for data visualization.
Parameters setting
In the ATT-LDA-BiGRU emotional analysis model proposed here, the initial learning rate is set to 0.001, the weight attenuation is set to 0.001, Epoch is set to 100, the maximum number of iterations is set to 15, and the learning rate decline factor is set to 0.1. The word vector dimension is set to 300, and Adam optimizer is chosen.
Performance evaluation
The main topics generated by LDA model, their keywords and probability distribution are shown in Table 3. The attention mechanism highlights the topics that are most relevant to the current task by calculating the contribution weight of each topic to the text representation. These weights are dynamically calculated based on the importance of the topic in the document and its relevance to the task, thus improving the accuracy and depth of sentiment analysis. Specifically, the topic name is inferred by analyzing the high probability words (such as “nature”, “employee” and “facilities”) of each topic in the LDA model. The semantic information of these keywords is used to determine the descriptive name of each topic. For example, for topic 1, the keywords include “nature”, “scenery” and “freshness”, so it is named “Scenic spot environment”. For topic 2, the keywords include “employee”, “attitude” and “specialty”, so it is named “Quality of service”. For topic 3, the keywords include “facilities”, “perfect” and “comfort”, so it is named “Facility equipment”. These names are determined by manual analysis of keywords and matching with topic content, not by preset tags, but based on the output results of LDA model, combined with semantic understanding to name each topic appropriately.
Attention mechanism improves the accuracy and depth of emotional analysis by dynamically calculating the contribution weight of each topic to text representation. Table 4 shows the attention weight of each topic in several typical comments.
Figure 6 shows the comparison of model results under different values of hidden size. With the increase of hidden size from 128 to 512, the classification performance of the model has indeed been improved to some extent. Specifically, when the hidden size is increased from 128 to 256, the F1 value is increased by 1.36%, which shows the effectiveness of increasing the hidden layer size to improve the model performance. When the hidden size is further increased to 512, although the F1 value is still improved (0.34%), the improvement range is small, which may mean that the improvement of performance is gradually weakened by continuing to increase the hidden layer size. Considering that the large hidden layer size may increase the complexity of the model, lead to over-fitting problems, and be limited by the experimental hardware conditions (such as computing resources and time cost), it is a reasonable choice to set the hidden size to 512 in this experiment. It can not only improve the performance of the model to a certain extent, but also avoid the problems of over-fitting and hardware resource limitation.

Comparison of model results under different values of hidden size.
In order to verify the emotion classification effect of ATT-LDA-BiGRU model proposed in this paper, it is compared with other three emotion classification models, namely BERT-CNN, BERT-BiGRU and BERT-BiLSTM. All three models use BERT to obtain word vectors, and then extract text features through deep learning model. The comparison results of different emotion classification models are shown in Fig. 7. The results show that the proposed model has the best emotion classification effect in online comments of scenic spots, with the accuracy and F1 value reaching 93.85% and 93.68% respectively, which is superior to other emotion classification models.

Comparative results of different emotion classification models.
The ATT-LDA-BiGRU model is superior to other models, mainly due to its attention mechanism’s ability to capture key information, BiGRU’s two-way structure’s comprehensive understanding of contextual information, and LDA’s ability to extract potential thematic information. These factors work together to make the ATT-LDA-BiGRU model achieve better performance in the task of emotional analysis of user comments.
Next, this paper compares the recommendation algorithm without considering emotional tendency (algorithm A) and the recommendation algorithm with considering emotional tendency (algorithm B) to verify the role of emotional analysis in improving the performance of recommendation system. The comparison result is shown in Fig. 8. It shows that the average accuracy of the recommendation algorithm considering emotional tendency reaches 12.28%, which is 9.72% higher than that of algorithm A. This result verifies the important role of sentiment analysis in improving the performance of scenic spot recommendation system, and provides new ideas and methods for future recommendation system research.

Comparative results of different recommendation algorithms.
Discussion
In the analysis of online comments on tourist attractions, traditional text mining methods often only rely on topic models such as LDA to extract topics, but this method ignores the differences in the contribution of different topics to the overall representation of the text. Therefore, attention mechanism is introduced in this paper, and by dynamically calculating the attention weight of each topic to the text representation, the model can focus on the topic most related to the current task. Combined with the powerful sequence modeling ability of BiGRU neural network, the model can capture the temporal relationship and semantic dependence in the text, and further improve the accuracy of emotion classification.
Liu et al. (2020)45 pointed out that BiGRU neural network has powerful sequence modeling ability, which can effectively capture the temporal relations and semantic dependencies in texts. In the task of emotion classification, BiGRU model has shown good performance. The research of Han et al. (2020)46 showed that the attention mechanism can help the model focus on the part of the text that has the most influence on the judgment of emotional tendency. Although BiGRU model performs well in the task of emotion classification, it lacks the introduction of topic model and cannot extract hidden topic information from the text. ATT-LDA-BiGRU model proposed in this paper can not only extract the topic information in the text, but also capture the temporal relationship and semantic dependence by combining LDA topic model and BiGRU neural network, thus achieving better performance in emotion classification tasks. Using the forecasting ability of ATT-LDA-BiGRU model, the development trend of tourism market can be accurately predicted. By analyzing historical data and current market dynamics, people can predict the changing trend of the tourism market in the future, including the increase and decrease of tourism demand and the popularity of tourism products. This is very important for tourism enterprises, which can help them adjust their market strategies in advance, cope with market changes and reduce business risks.
ATT-LDA-BiGRU model has a high computational cost in the process of training and reasoning because it combines a variety of complex components. For large-scale datasets or real-time applications, the scalability and computational efficiency of the model may become a bottleneck. Transformer model effectively processes long sequence data through position coding and self-attention mechanism. In contrast, ATT-LDA-BiGRU model may encounter the problem of gradient disappearance or gradient explosion when dealing with long series, which limits its modeling ability for long series data.
As for dataset deviation, this is a problem that is difficult to completely avoid in the research process. The source, collection method and processing of datasets may all introduce deviations. If the dataset mainly comes from a specific region or a specific population, then the research results may not be representative of the broader situation. In addition, errors or omissions in the process of data collection may also cause the dataset to fail to fully and accurately reflect the actual situation. This deviation may affect the accuracy and reliability of the research results, thus limiting the in-depth understanding of the research problems. In addition, the applicability of the model is also an important limitation of this paper. Any model is a simplification and abstraction of the real world, so its scope of application and accuracy are limited. In the research process, it is necessary to adjust and optimize the model according to the actual situation to ensure that it can better fit the data and explain the phenomenon. Through emotional analysis, people can identify the specific evaluation of tourists on service quality, such as the attitude of employees and the perfection of facilities. According to these feedbacks, scenic spot managers can adjust service strategies in time to improve tourists’ satisfaction. In addition, the results of emotional analysis can also help scenic spot managers to understand the needs and preferences of tourists to optimize product design and provide services and activities that are more in line with tourists’ expectations. Combined with the results of emotional analysis, the recommendation system can recommend interesting spots for tourists more accurately, and improve the personalized degree of recommendation and user satisfaction. Besides in the field of tourism, the proposed model also has great application potential in other fields. E-commerce platform generates a large number of user comments every day, which contain users’ real feedback on goods and services. ATT-LDA-BiGRU model can be applied to the analysis of e-commerce reviews. By extracting the key topics in the reviews, people can understand the focus of users’ attention, such as product quality, price and after-sales service. User-generated content on social media platforms is rich and varied, including news comments, Weibo, forum posts and so on. ATT-LDA-BiGRU model can be applied to emotional analysis of social media, extracting and analyzing hot topics, and understanding the focus and trend of public attention.
Conclusion
Research contribution
In this paper, the AI text mining model is successfully combined with the attention mechanism, and an emotion classification method for online comments in tourist attractions-ATT-LDA-BIGRU model is proposed. Through the experimental analysis of online comment data, the results show that this model has achieved remarkable results in emotion classification tasks.
ATT-LDA-BIGRU model can dynamically calculate the value of each topic to text representation by introducing attention mechanism to capture the most relevant topic information more accurately. Combined with BiGRU neural network, this model can effectively capture the temporal relationship and semantic dependence in the text, and improve the accuracy of emotion classification. The research in this paper can help tourism enterprises to better understand the market demand, optimize product design and service quality, and enhance user satisfaction and loyalty by deeply mining tourism data, accurately predicting market trends and providing personalized services.
Future works and research limitations
This paper mainly focuses on the task of emotion classification in offline state, but in practical application, online comments need to be processed and analyzed in real time. The follow-up research can explore the attention mechanism and try to introduce more advanced attention variants, such as self-attention mechanism or hierarchical attention mechanism to further improve the model’s ability to capture key information in the text. With the popularity of Internet of Things devices, edge computing has become an effective means to deal with a large number of real-time data. Future research can combine edge computing with AI, which can realize real-time data processing and analysis, reduce the delay and improve the response speed of the system.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author Hongbo Wang on reasonable request via e-mail wanghb@pku.edu.cn.
References
Zhang, M. et al. Mining product innovation ideas from online reviews. Inf. Process. Manag. 58 (1), 102389 (2021).
Yang, S., Yao, J. & Qazi, A. Does the review deserve more helpfulness when its title resembles the content? Locating helpful reviews by text mining. Inf. Process. Manag. 57 (2), 102179 (2020).
Sagnika, S., Mishra, B. S. P. & Meher, S. K. An attention-based CNN-LSTM model for subjectivity detection in opinion-mining. Neural Comput. Appl. 33 (24), 17425–17438 (2021).
Li, W. et al. Bidirectional LSTM with self-attention mechanism and multi-channel features for sentiment classification. Neurocomputing 387, 63–77 (2020).
Huang, F. et al. Attention-emotion-enhanced convolutional LSTM for sentiment analysis. IEEE Trans. Neural Netw. Learn. Syst. 33 (9), 4332–4345 (2021).
Kumar, S., Kar, A. K. & Ilavarasan Applications of text mining in services management: a systematic literature review. Int. J. Inform. Manag. Data Insights 1 (1), 100008 (2021).
Lieskovská, E. et al. A review on speech emotion recognition using deep learning and attention mechanism. Electronics 10 (10), 1163 (2021).
Chatterjee, S. D emotion mining approach. IInt. J. Hosp. Manag. 85, 102356 (2020).
Onan, A. Sentiment analysis on massive open online course evaluations: a text mining and deep learning approach. Comput. Appl. Eng. Educ. 29 (3), 572–589 (2021).
Zhao, H. et al. A machine learning-based sentiment analysis of online product reviews with a novel term weighting and feature selection approach. Inf. Process. Manag. 58 (5), 102656 (2021).
Hickman, L. et al. Text preprocessing for text mining in organizational research: review and recommendations. Org. Res. Methods 25 (1), 114–146 (2022).
Onan, A. Mining opinions from instructor evaluation reviews: a deep learning approach. Comput. Appl. Eng. Educ. 28 (1), 117–138 (2020).
Galassi, A., Lippi, M. & Torroni, P. Attention in natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 32 (10), 4291–4308 (2020).
Guo, M. H. et al. Attention mechanisms in computer vision: a survey. Comput. Visual Media. 8 (8), 331–368 (2022).
Dogra, V. et al. A complete process of text classification system using state-of‐the‐art NLP models. Comput. Intell. Neurosci. 1, 1883698 (2022).
de Santana Correia, A. & Colombini, E. L. Attention, please! A survey of neural attention models in deep learning. Artif. Intell. Rev. 55 (8), 6037–6124 (2022).
Wahyudi, M. D. R. Evaluation of TF-IDF algorithm weighting scheme in the qur’an translation clustering with K-means algorithm. J. Inform. Technol. Comput. Sci. 6 (2), 117–129 (2021).
Zeberga, K. et al. [Retracted] A novel text mining approach for mental health prediction using Bi-LSTM and BERT model. Comput. Intell. Neurosci. 1, 7893775 (2022).
Qiu, J., Wang, B. & Zhou, C. Forecasting stock prices with long-short term memory neural network based on attention mechanism. PloS One 15 (1), e0227222 (2020).
Li, J. et al. Attention mechanism-based CNN for facial expression recognition. Neurocomputing 411, 340–350 (2020).
Liu, H. I. & Chen, W. L. X-transformer: a machine translation model enhanced by the self-attention mechanism. Appl. Sci. 12 (9), 4502 (2022).
Kushwaha, A. K., Kar, A. K. & Dwivedi, Y. K. Applications of big data in emerging management disciplines: a literature review using text mining. Int. J. Inform. Manag. Data Insights. 1 (2), 100017 (2021).
Sun, B., Mao, H. & Yin, C. Male and female users’ differences in online technology community based on text mining. Front. Psychol. 11, 806 (2020).
Minaee, S. et al. Deep learning–based text classification: a comprehensive review. ACM Comput. Surv. (CSUR). 54 (3), 1–40 (2021).
Kumar, A. et al. Sarcasm detection using multi-head attention based bidirectional LSTM. IEEE Access 8, 6388–6397 (2020).
Bigne, E., Chatzipanagiotou, K. & Ruiz, C. Pictorial content, sequence of conflicting online reviews and consumer decision-making: the stimulus-organism-response model revisited. J. Bus. Res. 115, 403–416 (2020).
Brauwers, G. & Frasincar, F. A general survey on attention mechanisms in deep learning. IEEE Trans. Knowl. Data Eng. 35 (4), 3279–3298 (2021).
Ding, Y. et al. Interpretable spatio-temporal attention LSTM model for flood forecasting. Neurocomputing 403, 348–359 (2020).
Suleiman, D. & Awajan, A. Deep learning based abstractive text summarization: approaches, datasets, evaluation measures, and challenges. Math. Probl. Eng. 1, 9365340 (2020).
Qin, R. X. et al. Fine-grained lung cancer classification from pet and ct images based on multidimensional attention mechanism. Complexity 1, 6153657 (2020).
Hassanin, M. et al. Visual attention methods in deep learning: an in-depth survey. Inform. Fusion 108, 102417 (2024).
Liu, H. et al. EDMF: efficient deep matrix factorization with review feature learning for industrial recommender system. IEEE Trans. Industr. Inf. 18 (7), 4361–4371 (2021).
Acheampong, F. A., Wenyu, C. & Nunoo-Mensah, H. Text‐based emotion detection: Advances, challenges, and opportunities. Eng. Rep. 2 (7), e12189 (2020).
Gandhi, A. et al. Multimodal sentiment analysis: a systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions. Inform. Fusion. 91, 424–444 (2023).
Nandwani, P. & Verma, R. A review on sentiment analysis and emotion detection from text. Social Netw. Anal. Min. 11 (1), 81 (2021).
Wang, Y. et al. A systematic review on affective computing: emotion models, databases, and recent advances. Inform. Fusion 83, 19–52 (2022).
Cao, Y. et al. A Novel Temporal Convolutional Network with Residual self-attention Mechanism for Remaining Useful life Prediction of Rolling Bearings, 107813 ( Reliability Engineering & System Safety, 2021).
Jin, Z., Yang, Y. & Liu, Y. Stock closing price prediction based on sentiment analysis and LSTM. Neural Comput. Appl. 32, 9713–9729 (2020).
Kim, Y. & Choi, A. EEG-based emotion classification using long short-term memory network with attention mechanism. Sensors 20 (23), 6727 (2020).
Payrovnaziri, S. N. et al. Explainable artificial intelligence models using real-world electronic health record data: a systematic scoping review. J. Am. Med. Inform. Assoc. 27 (7), 1173–1185 (2020).
Zhou, F. et al. A survey of information cascade analysis: models, predictions, and recent advance. ACM Comput. Surv. (CSUR) 54 (2), 1–36 (2021).
Niu, K. et al. Multichannel deep attention neural networks for the classification of autism spectrum disorder using neuroimaging and personal characteristic data. Complexity 1, 1357853 (2020).
Hameed, Z. & Garcia-Zapirain, B. Sentiment classification using a single-layered BiLSTM mode. IEEE Access 8, 73992–74001 (2020).
Qasim, R. et al. A fine-tuned BERT‐based transfer learning approach for text classification. J. Healthc. Eng. 1, 3498123 (2022).
Liu, Y. et al. Sentiment analysis for e-commerce product reviews by deep learning model of Bert-BiGRU-Softmax. Math. Biosci. Eng. 17 (6), 7819–7837 (2020).
Han, Y., Liu, M. & Jing, W. Aspect-level drug reviews sentiment analysis based on double BiGRU and knowledge transfer. IEEE Access 8, 21314–21325 (2020).
Funding
This work was supported by Program for Innovative Research Team in China University of Labor Relations (Grant No. 24JSTD012).
Author information
Authors and Affiliations
Contributions
Tingting Mou: Conceptualization, methodology, software, validation, formal analysis, investigation, resources, data curation, writing—original draft preparation Hongbo Wang: writing—review and editing, visualization, supervision, project administration, funding acquisition.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Mou, T., Wang, H. Online comments of tourist attractions combining artificial intelligence text mining model and attention mechanism. Sci Rep 15, 1121 (2025). https://doi.org/10.1038/s41598-025-85139-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-85139-3
