
Abstract
This paper proposes a new strategy for analysing and detecting abnormal passenger behavior and abnormal objects on buses. First, a library of abnormal passenger behaviors and objects on buses is established. Then, a new mask detection and abnormal object detection and analysis (MD-AODA) algorithm is proposed. The algorithm is based on the deep learning YOLOv5 (You Only Look Once) algorithm with improvements. For onboard face mask detection, a strategy based on the combination of onboard face detection and target tracking is used. To detect abnormal objects in the vehicle, a geometric scale conversion-based approach for recognizing large-size ab-normal objects is adopted. To apply the algorithm effectively to real bus data, an embedded video analysis system is designed. The system incorporates the proposed method, which results in improved accuracy and timeliness in detecting anomalies compared to existing approaches. The algorithm’s effectiveness and applicability is verified through comprehensive experiments using actual video bus data. The experimental results affirm the validity and practicality of the pro-posed algorithm.
Similar content being viewed by others

Introduction
In recent years, urban public transportation has gained wide recognition as an important mode of travel for individuals1. The enhancement of public transportation systems has emerged as a primary concern in urban areas, specifically regarding the prevention of public safety risks.
Recently, people have been deeply affected by the coronavirus epidemic, masks have become an important way to protect one’s life. As the new coronaviruses continue to mutate, the infectiousness is increasing. This paper examines the work on masks in two important ways. On the one hand, the motivation for targeting mask testing is to effectively prevent possible future epidemics or other infectious diseases, such as mutated viral strains2. Moreover, the control of wearing masks on buses helps to raise people’s health awareness. It is worth mentioning that although the epidemic has now passed and mask testing has been liberalized in some areas, the mask testing work in this paper has a preventive role in the future3. On the other hand, the mask detection system proposed in this work can be extended for use in other public places. The State Council’s Joint Prevention and Control Mechanism has issued Guidelines on Public Wearing of Masks for Prevention of Novel Coronavirus Infections (April 2023 Edition), which states that masks should be worn in certain places, for example public transportation, confined environments and crowded places4. Therefore, there is a need to develop a system to determine whether passengers wear masks on buses.
The limitations of non-stop and departure times of buses and the lack of specialized X-ray security systems make it difficult to inspect dangerous goods person by person and package by package5,6. In some border areas where riots have occurred, buses with little interior space and substantial foot traffic have become the targets of mobs. Passengers carrying large boxes, long poles, or iron/steel objects pose a potential safety risk7. Therefore, it is necessary to develop a system for detecting abnormal objects.
Currently, several studies have attempted to develop systems for mask and abnormal object recognition. The existing supervised methods to recognize abnormal behaviors are machine learning-based methods8, Haar feature cascade classification9,10, etc., and those based on the unsupervised detection of abnormal behavior and abnormal objects are clustering-based methods (e.g., DBSCAN, K-Means, etc.), and methods based on deep learning11,12,13; the deep learning models are able to learn the complex feature representations of the data and can be used for unsupervised anomaly detection. Examples include RetinaMask-10111 and convolutional neural network models12 as well as the YOLO family of models14.
One study8 proposed a mask detector that uses a machine learning facial classification system to determine whether a person is wearing a mask in busy environments such as hospitals and markets. In addition, other studies9,10 used Haar feature cascade classification for face mask wearing detection. Karim Hammoudi10 used Haar feature descriptors to detect key face features and applied a decision algorithm to design a selfie app to verify whether the face is wearing the correct mask. Jiang and Fan11 proposed a single-stage face detection model that classifies faces based on whether the detected face is wearing a mask. Christine Dewi et al. used the YOLO model to determine whether subjects were wearing masks or not14. A convolutional neural network (CNN) model was proposed by Zhu et al.12 to learn high-level features for saliency detection. In addition, a mask region-based CNN (R-CNN) anomaly target detection method was proposed in the literature13 for logistics management applications.
The contributions of this paper are as follows:
-
A library is established for the analysis of abnormal behavior of people and ab-normal objects. The abnormal behavior includes people boarding the bus without masks and people inside the bus without masks. The anomalous objects include large boxes, long poles, and iron/steel items. Provides rich experimental data for subsequent detection modelling.
-
The paper presents a novel Mask Detection and Anomalous Object Detection and Analysis (MD-AODA) algorithm based on the YOLOv5 network structure. By introducing the Convolution and Attention Fusion Module (CAFM), the Spatially Enhanced Attention Module (SEAM), and optimizing the activation function to SELU, the algorithm significantly improves the accuracy of detecting mask-wearing passengers and identifying anomalous objects on buses. The Face Collision Line Detection (FCLC) algorithm is used to detect people wearing masks while boarding the bus; the detection of large-sized objects inside the bus is performed using a geometric scale transformation strategy. The recognition accuracy of the system is up to 92.6%.
-
An embedded video analysis system for abnormal object detection is developed, and the method is proposed to be applied to actual buses through an embedded system, which can detect, monitor and identify abnormal items in buses through surveillance videos while guaranteeing the detection rate and detection accuracy. The effectiveness and applicability of the system are verified through many practical experimental results.
The structure of this paper is as follows. Section “Problem analysis” describes the experimental scenario and system architecture design for the bus. Section “Abnormal behavior of people and abnormal object recognition model design” focuses on presenting the models designed for recognizing abnormal behavior and identifying abnormal objects. Furthermore, Section “Experiment” provides an in-depth description of the implementation results and analysis, covering the development of the video detection system discussed in this paper. The effectiveness of the algorithm is verified using real-world videos. Finally, Section “Conclusion” summarizes the key findings and contributions of this study while also outlining potential avenues for future research.
Problem analysis
Figure 1 shows the library of abnormal behaviors and abnormal objects inside the bus, which is the main focus of this paper. The problem of passengers wearing masks is divided into detection when the passengers board the bus and real-time detection inside the bus, and the detection of abnormal objects inside the bus primarily focuses on identifying large boxes, long poles, and iron/steel objects15. The main aims of existing bus monitoring systems are to monitor and record, and existing systems lack functions such as identification and early warning. Thus, in this work, the detection and analysis of passengers wearing masks and carrying abnormal objects inside the bus are studied.

Library of abnormal behavior of people and abnormal objects in the bus.
Mathematical formulas are used to analyze the above problem. Equation (1) represents the unusual behavior of passengers without masks and unusual object situations in the bus vehicle.
where u denotes the abnormal behaviour of passengers not wearing masks when boarding, v denotes the abnormal behaviour of passengers not wearing masks on the bus, and w denotes the abnormal objects on the bus. The φ function represents the abnormal behaviour of people and abnormal objects on the bus.
In this paper, two detection algorithms are used to identify passengers not wearing masks and abnormal objects inside the bus. Figure 2 illustrates the logical structure of the unmasked and abnormal object recognition system inside the bus16. The real-time status of the passengers is acquired through image acquisition sensors installed at the doors and inside the bus, and the passenger behaviour is detected, recognized and transmitted to detection algorithms A and B. The abnormal behaviour of passengers and abnormal objects inside the bus are recognized in real time based on the surveillance images. Finally, the abnormal behaviour and abnormal object information are displayed through a visualization interface.

Logic structure diagram of unmasked and abnormal object recognition system in the bus (Among them, Algorithm A proposes a face collision detection discrimination algorithm based on the improved YOLOv5; Algorithm B is also based on the improved YOLOv5 with the addition of a geometric scale transformation strategy).
Abnormal behavior of people and abnormal object recognition model design
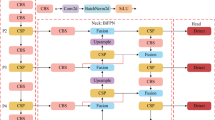
The MD-AODA algorithm structure
Figure 3 illustrates the structural design of the person abnormal behavior and abnormal object detection algorithm, which is divided into input part, backbone, neck and head17. The abnormal behavior of people and abnormal object recognition system in the bus wants to calculate the prediction results in an intuitive form using the data obtained from the video stream. In this paper, the prediction results are presented in the form of pictures and text in the algorithm design.
The input image is enhanced before it is fed into the backbone layer by randomly scaling, masking, and cropping the image18. Anchors are introduced to optimize the width and height prediction of the ground truth boundary (GT) and improve the accuracy of the frame boundary19. The backbone part uses the focus structure (shown in Fig. 3(a)) and the cross-stage partial (CSP) network structure. The focus layer converts the information in the w-h plane to the channel dimension and extracts different features through a 3*3 convolution20. By employing this approach, the loss of information during down-sampling is minimized. The neck layer plays a crucial role in processing and selecting the significant features extracted from the previous step’s backbone layer. This, in turn, facilitates various essential tasks, including classification, regression, and identifying key points, in the subsequent phase21,22. By utilizing the feature map, the prediction layer employs anchors to create bounding boxes, each associated with category probabilities. This process helps to locate and categorize objects in a given environment.
For the input part, three data enhancement methods are used in this paper: mosaic23, cut out and rectangle training. The mosaic method combines four training images in-to one image by random scaling, which helps to improve the detection of small targets24. The rectangular training method resizes the image to a size that is divisible by the step size and closest to the input, thus achieving minimum padding and reducing the amount of redundant information.
The backbone part uses the focus structure (shown in Fig. 3(a)) and the CSP structure25. In the CSP structure, a 3*3 convolution kernel is utilized with a step size of 2, contributing to size reduction and effective feature representation. The input image has a size of 640*640 pixels, and after the CSP structure, a feature map of size 20*20 is obtained26. The CSP structure enhances the learning ability of the CNN, maintaining both accuracy and lightweight structure. In addition, the CAFM (Convolution and Attention Fusion Module) is introduced before the SPPF module to effectively integrate multi-scale feature information by combining convolutional operations and attention mechanisms. Specifically, CAFM employs convolutional layers to extract local features while leveraging attention mechanisms to enhance the expression of key features and suppress redundant information. This approach effectively addresses issues such as information loss or excessive smoothing commonly observed in traditional feature fusion processes. The design of this module not only improves the accuracy of feature fusion but also significantly enhances the performance of downstream tasks, particularly in object detection.
The neck layer processes and determines the important features extracted from the backbone layer in the previous step, which facilitates common tasks such as classification, regression, and key points in the next step12. The FPN + PAN structure, as shown in Fig. 3(b), is used to strengthen the feature fusion ability of the network. The FPN performs a top-down transfer of top-level feature information by up-sampling the fused semantic features to obtain the predicted feature map27. The PAN is a bottom-up feature pyramid that is used to achieve strongly localized features.
Utilizing the feature map, the head layer generates bounding boxes through anchor boxes, accompanied by their corresponding category probabilities. In the detection head, a newly introduced SEAM (Spatially Enhanced Attention Module) the spatial relationships of feature maps to highlight key features in target regions while suppressing background interference. Additionally, it dynamically adjusts the fusion of multi-scale features to accommodate the diversity of target scales and shapes. For the bounding box loss function, nonmaximal suppression (NMS) is the best approach for masked object detection28. The predicted category information and the bounding box coordinate information are used to determine whether the passenger in the vehicle displays the abnormal behavior of not wearing a mask and identify abnormal objects.

MD-AODA algorithm structure diagram (The purple module (CAFM) and the dark green module (SEAM) represent the improved components. Additionally, the activation function in the CBS module has been replaced with SiLU to enhance the overall model performance.)
Behavior detection and recognition algorithm design
-
(1)
Design of algorithm for recognizing the behavior of people boarding the bus without wearing masks.
The face capture algorithm is used to identify the mask wearing condition of the passengers on board the bus. The face capture algorithm first draws a face demarcation line as the passenger boards and then uses the improved YOLOv530 target detection algorithm to detect the passenger’s face and perform a binary classification judgement, i.e., wearing a mask or not wearing a mask. Finally, the tracking algorithm is used to detect the position information of the face without a mask to obtain the collision line, and when the face detection frame coincides with the line, it is uploaded to the system to issue a warning. The specific face collision line discrimination algorithm is formulated as follows:
-
(a)
The position of the target frame of the face is obtained with the improved YOLOv5 target detection algorithm.
-
(b)
The four vertices of the target frame are evaluated to determine their location with respect to the bus demarcation line, and the algorithm determines whether the point is on the left or right side of the line using vector discrimination. As shown in Fig. 4, Q1 and Q4 are on the left side of the vector and Q2 and Q3 are on the right side of the vector.
Definition
The amount of area S of three points\({P_1}({x_1},{y_1}),{P_2}({x_2},{y_2}),{P_3}({x_3},{y_3})\) on the plane:
The starting point of the vector L is Ll the ending point is Lr, and the point of judgment is Q in Eq. (4):
-
(c)
If all four vertices are on the same side of the onboard face demarcation line, it means that the target frame of the face does not intersect with the demarcation line, otherwise it proves that the face collides with the demarcation line. In order to improve the accuracy of the capture, the algorithm captures the entire head region of the person. The face capture algorithm is configured and captured as shown in Fig. 5.

Definition example chart.

Face capture algorithm configuration and capture.
-
(2)
The algorithm design for recognizing the behavior of bus occupants not wearing masks.
During the task of identifying abnormal objects and abnormal behavior of people in buses, the people and objects may be obscured by occlusions, which can lead to target misses or target matching errors; therefore, fast and accurate matching algorithms are crucial for effective tracking. We use the complete intersection over union (IOU) (CIOU) loss29, which has faster convergence and better performance than other approaches. This loss expresses the regression of the rectangular bounding box by combining three important geometric measures, namely, the overlap area C, centroid distance d, and aspect ratio l. The CIOU loss is defined as Eq. (5):
Figure 6 illustrates the notation used in this study; A represents the region covered by the target box, B denotes the predicted box, and C denotes the overlapping portion of the predicted box with the target box. Additionally, we define d as the Euclidean distance be-tween the centroids of the two boxes and l as the diagonal distance between the smallest enclosing rectangles of A and B.
In addition, C/(A + B-C) is the evaluation measure for the IOU30 boundary regression, d/l expresses the normalized distance between the centroids of the two bounding boxes A and B, and \(\alpha\nu\) is an impact factor that better reflects the variability between the two boxes A and B.
\(\alpha\)is a weighting function that is expressed in Eq. (6):
\(\nu\)is used to measure the similarity between the aspect ratios in Eq. (7):

Schematic diagram of CIOU.
Equation (5) can be used to address not only the problem of minimizing the normalized distance be-tween the predicted and target frames to achieve faster convergence but also the problem of regressing the predicted frame more quickly and accurately when there is an overlap with the target frame.
-
(3)
Design of an algorithm for identifying abnormal objects in buses.
Passengers may be carrying hazardous materials when boarding the bus, increasing the risk of bus operation31. In the context of this system, the detection of larger or elongated objects within the bus is categorized as detecting suspicious items. An example illustrating this scenario is presented in Fig. 7 for better clarity.
The improved YOLOv5 algorithm framework is employed in the early warning algorithm to detect suspicious items within the bus. To identify the size of these items accurately, an early warning strategy is devised to filter out smaller objects within the image32. An abnormal warning is generated when the ratio of the suspicious item’s occupied area in the im-age to the total image area surpasses a predefined threshold. The explicit calculation method is illustrated in Eq. (8):
where wo indicates the width of the detected suspicious item, \({h_o}\) indicates the height of the detected suspicious item, wi indicates the width of the image, hi indicates the height of the image, and THarea indicates the set ratio threshold. When Srde>THarea, an abnormal warning is output. According to the results of a field test with several boxes of different sizes in a bus, larger boxes can be recognized near the lower edge of the image. The optimal parameters are selected in accordance with the experimental data and the threshold is set to 0.20.

Sample of suspicious items.
In order to detect abnormal objects more adequately, this paper adds the detection of long objects on the basis of the existing large-size object detection and mask detection, taking into account many other factors. Specifically, long objects such as wooden sticks and long guns in buses may hurt the surrounding passengers and have some dangers. Therefore, we add a new definition to realize the recognition and detection of long objects in this system, the judgment logic of the long object detection can be expressed in the following Eq. (9). During the operating process of the anomaly detection system, when Eq. (9) is satisfied, the long stick will be detected as an abnormal object.
Experiment
Experiment platform design
The experimental design flow chart is depicted in Fig. 8, showcasing the structured approach employed in this study. The experimental design consists of three distinct components: the experimental vehicle, the core computing platform, and the visualization interface. Each component plays a crucial role in the overall experimental setup. First of all, the experiment uses a high-performance desktop computer to train the algorithm, and detailed information about the software environment can be found in Table 1.
The process of abnormal object recognition inside the bus is shown in Fig. 8, where the video capture card of the experimental platform is connected to a camera on the experimental bus through wiring. The camera collects real-time monitoring data inside the bus, and the data are input into the Nvidia Jetson Xavier (NX)33 module through a serial port. The NX module transmits images of the video streaming data to the abnormal behavior and abnormal object recognition models. If abnormal behavior and abnormal objects are detected, the visual interface of the system displays transient images and outputs alert messages34.
The unmasked abnormal behavior and abnormal object analysis system heavily re-lies on the core computer platform. The fundamental structure of this platform comprises three key components: a carrier board, a video capture card, and the NX module. In the system, the RTSO-6002 E carrier board, which is a low-power, high-security industrial-grade carrier board, is used. The video capture card is RTSV-6911 i mini-PCIe35, which meets the requirements of the image processing system. The video capture card offers a multitude of features, including support for a high frame rate, the ability to capture multiple channels of video, and hardware capabilities for color space conversion. Additionally, it possesses the functionality to convert the recorded video data into the necessary format for various applications, such as system display, image analysis, and image processing. Nvidia Jetson Xavier represents a cutting-edge deep machine learning processor developed by Nvidia. The NX module incorporates a comprehensive deep learning inference computing framework that is seamlessly integrated into the broader Jetson platform. This integration enhances the utilization of GPU resources36, resulting in accelerated computational power, efficient processing speed, and a compact module size for the system. Thus, this module enables high computational performance in a compact, modular system.
Additionally, deploying pre-trained models on the Nvidia Jetson platform requires quantization. By utilizing the TensorRT inference engine provided by the Nvidia platform, model inference speed can be significantly improved. The trtexec tool included with TensorRT is used to quantize the trained model into a TensorRT-compatible format, with FP16 precision applied during the quantization process. This approach maximizes the advantages of TensorRT while minimizing accuracy loss.

A block diagram of the experimental design.
Experimental results analysis
-
(1)
MD-AODA experimental results.
The dataset for training the model anomalous behavior and anomalous items in this study was produced from local simulations of specific anomalous behavior. This dataset includes the case of passengers not wearing masks when boarding the bus, the case of people inside the bus not wearing masks, and the case of abnormal items inside the bus.
Remark
In addition, we created a dataset that takes into account multiple factors to verify the validity of the experiment:
-
1.
Anomalous objects under different levels of occlusion (e.g., Fig. 9).
-
2.
Faces under different lighting conditions and facing different directions to detect whether or not people on the bus are wearing masks (e.g., Fig. 10).

Anomalous objects under different degrees of occlusion. (where Fig. (a) shows mild occlusion, Fig. (b) shows moderate occlusion, and Fig. (c) shows heavy occlusion)

Faces under different lighting conditions and facing different directions (where Fig. (a) shows the original data and Fig. (b) shows the recognition results after testing).
The videos are converted into sample images by collecting multiple videos, cutting and framing these videos, and then classifying and annotating the images36. The resulting sample markers were used as the boarding and onboard anomaly datasets. Figure 11 shows examples of annotated images of unmasked people and anomalous items in the dataset. The figure below shows examples of tagged images of unmasked and anomalous items represented in the dataset. There are 1190 samples of faces in the car, 1584 samples of unmasked faces in the car, and 1089 samples of items in the car37. In the data enhancement section, a mosaic data enhancement method is used.

Image annotation of abnormal behavior and abnormal objects on the bus and in the bus.
As shown in Table 2, this study compares the speed and accuracy of the existing algorithms with the newly proposed algorithm using real captured image and video data. In terms of detection accuracy and detection speed, the MD-AODA algorithm is much more effective than the first three algorithms RetinaMask-101, YOLOv5 and Faster R-CNN. Among them, the RT-DETR model has good speed but high complexity and computational overhead, which is not very suitable for the real-time requirement we need. It is worth mentioning that the YOLOv7 model and YOLOv8 are high version models, but the MD-AODA algorithm in this paper still works well.
Through ablation experiments (as shown in Table 3), it was found that the incorporation of the CAFM module significantly enhances the model’s detection performance for targets of varying sizes and occluded objects. The SEAM module further improves classification and localization accuracy. The adoption of the SiLU activation function optimizes the model’s overall detection performance and training stability, outperforming the original YOLOv5. Ultimately, the MD-AODA method achieved a 2.1% improvement in mAP compared to the baseline YOLOv5 model (from 90.5 to 92.6%), demonstrating robust application potential and practical significance.
The specific training hyper-parameter settings for the experimental model are detailed in Table 4.
-
(2)
Experimental test results.
-
a.
Framework deployment and performance metrics definition.
-
a.
The experimental improved YOLOv5 model is small in size and based on the test set, we can detect anomalous behaviors and anomalous objects with a mean average precision (mAP) of up to 92.6%. The proposed model has a fast run speed, with a detection rate of 101 fps on the Tesla P100 processor.
Prior to practical application in an actual vehicle, the model had to be deployed in an NVIDIA Jetson Xavier module on an experimental platform. In order to achieve the real-time frame rate of the in-vehicle video, the NX module uses TensorRT, and the computational efficiency can reach up to 14 TOPS in 10 W mode and 21 TOPS in 15 W mode. Using the MD-AODA algorithm in this paper, the whole process from target detection to recognizing the result is between 300ms and 500ms, which has a high efficiency and response speed.
To evaluate the performance of the deployed model on the NX module in Fig. 12, setting the IOU threshold to 0.5, three metrics are computed: the precision rate (PR) (Eq. (10)), the missing rate (MR) (Eq. 11), and the false alarm rate (FR) (Eq. (12)). These metrics serve as quantitative measures for assessing the model’s effectiveness.
PR is defined as the ratio of correctly identified samples (TN + TP) to the total number of samples (TN + TP + FP + FN). It provides a measure of the model’s accuracy in correctly identifying relevant samples.
MR represents the proportion of abnormal samples in the nonalarm data that were incorrectly classified as normal. It is calculated using the number of abnormal samples in the nonalarm data (FP) and the number of abnormal samples in the alarm data (TP). False positives (FP) are cases where normal objects are incorrectly labeled as abnormal objects. MR provides insights into the model’s ability to detect and classify abnormal instances accurately.
FR, which represents the proportion of normal samples in the alarm data that were incorrectly classified as abnormal, is denoted by FR. It is computed using the number of normal samples in the alarm data (FN) and the number of normal samples in the nonalarm data (TN). In this case, False negatives (FN) refer to cases where abnormal objects are not recognized but are incorrectly labeled as normal objects. FR provides insights into the model’s tendency to generate false positives and is an important factor in evaluating its performance.

Nvidia Jetson NX inspection model.
-
b.
Experimental test results.
This experiment was performed to verify the performance of the model on the Nvidia Jetson NX side by randomly selecting data from local scenes several times, as shown in Table 5. Based on 1000 randomly selected images of people in the bus without masks, there was a PR of 96.0%, an MR of 2.0%, and an FR of 6.0%. The model when tested on 1089 randomly selected images of people in the vehicle without masks had a PR of 95.1%, an MR of 7.9%, and an FR of 1.2%. The model when tested on 1193 randomly selected im-ages of suspicious objects in the vehicle had a PR of 98.2%, an MR of 2.1%, and an FR of 1.2%. Thus, the proposed model achieved good results as expected.
We also developed an interface display in the form of an external window to identify abnormal behavior of people and abnormal objects in the bus. Figure 13 shows the visualization interface for the system. The visualization interface can output multiple camera images, display captured video frames of passengers’ abnormal behavior, and output alarm messages in real time. The final accuracy rate was more than 95%.

Nvidia Jetson NX system visualization interface.
Conclusion
In this paper, a method for identifying and analysing abnormal behaviors of people and abnormal objects in buses based on YOLOv5 algorithm is proposed, and the method is applied to real vehicle data. A library of abnormal passenger behavior and abnormal objects on the bus is established for the experimental scenario of the bus. The abnormal behavior includes people boarding the bus without masks and people inside the bus without masks, and the abnormal objects include large boxes, long poles, and iron/steel objects. Then, a new Mask Detection and Abnormal Object Detection and Analysis (MD-AODA) algorithm is proposed. The face collision line detection (FCLC) algorithm is used to detect people wearing masks when boarding the bus. large-size object detection inside the bus is performed using the geometric scale conversion strategy. Furthermore, an embedded system for analysing ab-normal behaviors of people and abnormal objects was developed. The system is to apply to the actual buses. Therefore, the accuracy and speed of the mobile terminal need to be considered in the research. After the practical application test, the accuracy of abnormal behavior and abnormal objects recognition proposed in this paper reaches more than 95%, in addition, the detection speed can meet the real-time requirements.
There are many types of unusual behaviors and unusual objects on buses. In this study, the system did not consider other abnormal behaviors and abnormal objects except two abnormal behaviors and some abnormal object. Meanwhile, many options exist for the identification of different abnormal behaviors and abnormal items.
In the future, additional consideration will be given to abnormal behaviors such as fighting and other types of unusual items on buses, in addition to further research on abnormal behaviors and unusual items on buses based on actual conditions. It is also hoped that the system will have more significant economic significance in terms of improving public safety, reducing costs, and expanding markets.
Data availability
The datasets generated and analyzed during the current study are not publicly available due the data in issue relates to confidentiality agreements but are available from the corresponding author on reasonable request.
References
Soheil Kooraki, A. et al. Coronavirus (COVID-19) outbreak: What the department of radiology should know. J. Am. College Radiol. 17(4), 447–451 (2020).
Siedner, M. J., Gandhi, R. T. & Kim, A. Y. Desperate times call for temperate measures: Practicing infectious diseases during a novel pandemic. J. Infect. Dis. 222(7), 1084–1085. https://doi.org/10.1093/infdis/jiaa209 (2020).
Leung, N. H. L. et al. Respiratory virus shedding in exhaled breath and efficacy of face masks. Nat. Med.
Zhou, S. S. et al. Assessment of a respiratory face mask for capturing air pollutants and pathogens including human influenza and rhinoviruses. J. Thorac. Dis. 10(3), 2059–2069 (2018).
Jinling, L. Research on the security management of public transportation places under the new normal of riot and terrorism prevention. J. Jiangxi Police Acad. 54–58 (2016).
Huang, Z. C. & Wang, J. L. TI DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. Inf. Sci. 241–258 (2020).
Marianne, V. D. S. et al. Professional and Home-Made Face Masks Reduce Exposure to Respiratory Infections among the General Population. PLoS ONE 3(7), e2618 (2008).
Gupta, S. et al. Novel face mask detection technique using machine learning to control COVID’19 pandemic. Mater. Today Proc. (2021).
Cabani, A. et al. MaskedFace-Net – A dataset of correctly/incorrectly masked face images in the context of COVID-19. (Elsevier, 2021).
Hammoudi, H. & Melkemi, M. Validating the Correctwearing of protection mask by taking a selfie: Design of a mobile application “Checkyourmask” to limit the spread of COVID-19. Comput. Model. Eng. Sci. 124(3) (2020).
Fu, C. Y., Shvets, M. & Berg, A. C. RetinaMask: Learning to predict masks improves state-of-the-art single-shot detection for free. https://doi.org/10.48550/arXiv.1901.03353. (2019).
Zhu, D. et al. Image salient object detection with refined deep features via convolution neural network. J. Electron. Imaging 26(6), 1–11 (2017).
Xiong, H. et al. Research on abnormal object detection in specific region based on Mask R-CNN. Int. J. Adv. Robot. Syst. 17(3), 172988142092528 (2020).
Dewi, C., Shun Chen, A. P. & Juli Christanto, H. YOLOv7 for face mask identification based on deep learning. In 2023 15th International Conference on Computer and Automation Engineering (ICCAE), Sydney, Australia 193–197 https://doi.org/10.1109/ICCAE56788.2023.10111427 (2023).
Maohui, L., Chuanping, W. & Yan, B. et al. On the application principle of YOLO algorithm in machine vision. Educ. Modern. 174–176 (2018).
Chuang, C.-W. & Fan, C.-P. Deep-learning based joint iris and sclera recognition with yolo network for identity identification. J. Adv. Inf. Technol. 12(1), 60–65. https://doi.org/10.12720/jait.12.1.60-65 (2021).
Zhao, Z.-Q., Zheng, P., Xu, S.-T. & Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 30(11), 3212–3232 (2019).
Huang, Z. et al. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. Inf. Sci. 522, 241–258. https://doi.org/10.1016/j.ins.2020.02.067 (2020).
Wang, Y.-T. et al. Rain streaks removal for single image via kernel-guided convolutional neural network. IEEE Trans. Neural Netw. Learn. Syst. 32(8), 3664–3676 (2021).
Huang, S.-C., Jaw, D.-W., Chen, B.-H. & Kuo, S.-Y. An efficient single image enhancement approach using luminance perception transformation. IEEE Trans. Emerg. Top. Comput. 9(2), 1083–1094 (2021).
He, K., Zhang, X., Ren, S. & Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 37(9), 1904–1916 (2015).
Too, E. C., Yujian, L., Gadosey, P. K., Njuki, S. & Essaf, F. Performance analysis of nonlinear activation function in convolution neural network for image classification. Int. J. Comput. Sci. Eng. 21(4), 522. https://doi.org/10.1504/IJCSE.2020.106866 (2020).
Zhong, Z., Zhang, B., Guangming, L., Zhao, Y. & Yong, X. An adaptive background modeling method for foreground segmentation. IEEE Trans. Intell. Transp. Syst. 18(5), 1109–1121 (2017).
Huang, S. & Chen, B. Highly accurate moving object detection in variable bit rate video-based traffic monitoring systems. IEEE Trans. Neural Netw. Learn. Syst. 24(12), 1920–1931 (2013).
Li, G., Wang, Y. & Shu, W. Real-time moving object detection for video monitoring systems. In 2008 Second International Symposium on Intelligent Information Technology Application 163–166 (2008).
Chengming, Z. & Ronggang, X. YOLOv3 Target detection algorithm combining GIOU and focal loss. Comput. Eng. Appl. (2020).
Xiaoping, Z., Jiahui, J., Li, W., Zhonghe, H. & Shida, L. People’s fast moving detection method in buses based on YOLOv5. Int. J. Sens. Sens. Netw. 9(1), 30. https://doi.org/10.11648/j.ijssn.20210901.15 (2021).
Georgescu, M. et al. Anomaly detection in video via self-supervised and multi-task learning. In Computer Vision and Pattern Recognition IEEE (2021).
Gautam, A. & Singh, S. Deep learning based object detection combined with internet of things for remote surveillance. Wirel. Pers. Commun. 118, 2121 (2021).
Xin Ping, W. & Min Cang, F. Moving target detection based on double model. Adv. Mater. Res. 998–999, 759–762. https://doi.org/10.4028/www.scientific.net/AMR.998-999.759 (2014).
Tian, Y., Duo, S., Lauria, S. & Liu, X. Recent advances on loss functions in deep learning for computer vision. Neurocomputing 497, 129–158. https://doi.org/10.1016/j.neucom.2022.04.127 (2022).
Liu, G. & Zhang, Q. Mask wearing detection algorithm based on improved tiny YOLOv3. Int. J. Pattern Recogn. Artif. Intell. 35(07), 2155007. https://doi.org/10.1142/S0218001421550077 (2021).
Popescu, D. E. An integrated approach for monitoring social distancing and face mask detection using stacked ResNet-50 and YOLOv5. Electronics 10(23), 2996. https://doi.org/10.3390/electronics10232996 (2021).
Jimin, Y. & Zhang, W. Face mask wearing detection algorithm based on improved YOLO-v4. Sensors 21(9), 3263. https://doi.org/10.3390/s21093263 (2021).
Han, S. S. et al. Deep neural networks show an equivalent and often superior performance to dermatologists in onychomycosis diagnosis: Automatic construction of onychomycosis datasets by region-based convolutional deep neural network. PLoS ONE 13(1), e0191493. https://doi.org/10.1371/journal.pone.0191493 (2018).
Zhu, C., He, Y. & Savvides, M. Feature selective anchor-free module for single-shot object detection. (2019).
Batagelj, B. & Peer, P. How to correctly detect face-masks for COVID-19 from visual information?. Appl. Sci. 11(5), 2070. https://doi.org/10.3390/app11052070 (2021).
Funding
This work is supported by national key research and development plan under Grant 2023YFB4704404, Beijing Science and Technology New Star project under Grant 20220484199. R&D Program of Beijing Municipal Education Commission (KM202310009010, KM202210009011).
Author information
Authors and Affiliations
Contributions
“Y.R. and S.L. conceived the paper; Y.B. and S.L. conceived the experimental methodology; S.L. and Y.B. and Q.L. conducted the experiments as well as analysed and validated the experiments; Y.B. and Q.L. and S.L. wrote the text of the manuscript; and H.J. and L.W. edited the images and tables. All authors have read and agreed to the published version of the manuscript.”
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Image Data Statement
Informed consent has been obtained for participants to post identifying information/images in online open access publications.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, S., Bi, Y., Li, Q. et al. A deep learning based detection algorithm for anomalous behavior and anomalous item on buses. Sci Rep 15, 2163 (2025). https://doi.org/10.1038/s41598-025-85962-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-85962-8
Keywords
This article is cited by
-
Detection of anomalous activities around telecommunications infrastructure based on YOLOv8s
Scientific Reports (2025)
-
Multi-camera spatiotemporal deep learning framework for real-time abnormal behavior detection in dense urban environments
Scientific Reports (2025)
