
Abstract
To address the challenges of low detection accuracy of small objects and weak applicability of the multi-person fall action recognition applications, we propose a hybrid fall detection method based on modified YOLOv8s and AlphaPose called HFDMIA-Pose. Firstly, we use the modified Yolov8s as object detector. It uses SPD-Conv to preserve small object features and adds a small object detection layer, while using BCIOU as the loss function. These methods can effectively improve the accuracy of small object detection and significantly reduce the model size. Secondly, we improve the fall recognition accuracy by introducing a hybrid fall detection algorithm based on human skeletal nodes. Lastly, we build a multi-person fall detection dataset (MPFDD) to test the model’s effectiveness in multi-person scenarios. Validated on datasets Le2i and MPFDD, our method improves accuracy by 4.30%, F1 by 4.57%, and FPS by 37.50% faster than the AlphaPose. Compared with other models, our model improves accuracy by 5.33% on average, F1 by 5.51%, and FPS by 43.05% faster on average. Therefore, HFDMIA-Pose has significantly improved performance compared to the original model and it also demonstrates strong competitiveness over other advanced human fall detection models. Furthermore, it has the advantages of high detection accuracy, fewer model size, and fast speed, which makes it more suitable for resource constrained edge environments and can meet industrial and daily scenarios.
Similar content being viewed by others
Introduction
The damage to human health caused by falls is severe, especially for older people. In recent years, the elderly population has been growing faster than any other age group, and as of October 2022, 10% of the world’s total population will be over 65 years of age1. Related studies predict that older adults will increase to 1.5 billion by the end of 20502. Physical, cognitive, and motor skills of older adults decline with age. Falls are a significant challenge for them and can significantly reduce the life expectancy of older adults. Approximately 35% of people (65 years and older) fall one or more times yearly3. In addition to age, other factors such as the environment, physical activity, and cardiovascular disease can contribute to falls. It is a significant source of bodily injuries, and these injuries usually require hospitalization4. Every year, 37.3 million falls require medical attention, and 650,000 falls result in death5. Medical investigations have shown that prompt treatment after a fall reduces the risk of death by 80% and significantly improves survival in older adults. Therefore, the rapid detection of fall events is critical6.
With the development of deep learning technology, computer vision-based human action recognition models and model optimization techniques are crucial to achieving the above goal. However, there are some problems, such as significant differences in the structure and performance of each different model, low detection accuracy for small objects, poor robustness, and weak applicability at the edge end7. In this paper, we propose a novel human pose estimation method called HFDMIA-Pose. Based on the improved Yolov8s and AlphaPose (IA-Pose) and a hybird fall detection algorithm (HFDA) that combines fall instantaneous feature and fall state feature. HFDMIA-Pose has the advantages of high detection accuracy, a small number of parameters, and fast inference speed ,which is able to meet the application requirements of deploying multi-person fall detection at the edge end. The primary advantages of the scheme are summarized as follows:
-
1.
Firstly, IA-Pose used modified YOLOv8s to replace the object detector of AlphaPose, which improves the accuracy of small object detection and significantly reduces the parameter scale so that the model can be adapted to the edge end environment.
-
2.
Secondly, HFDA combines the human’s fall instantaneous feature and fall state feature to comprehensively analyze and judge the fall action, which is less computationally intensive and has a higher accuracy.
-
3.
Lastly, we constructed our own fall detection dataset (MPFDD), which is for multi-person fall detection and analyzed the reasons for missed and false detections to provide a reference for subsequent research.
The rest of the paper is organized as follows: “Related works” section reviews related studies on fall detection and human pose estimation. “Hybrid fall detection method based on modified HPE model (HFDMIA-Pose)” section presents the proposed model’s general design framework and each component’s functions, including the design details of the object detection model and the fall detection method. “Experiments and analysis” section presents the construction method of the multi-person fall detection dataset and gives experiments and results to validate the effectiveness and feasibility of the proposed scheme. Finally, the paper discusses conclusions and directions for future work.
Related works
Currently, three main human fall detection methods exist (1) Environmental device fall detection methods, which are based on the environmental noise formed when a human falls, such as sensing changes in object pressure and sound to detect falls8. This method is rarely used and has a high false alarm rate and cost. (2) Wearable sensor fall detection methods. Falls are detected using accelerometers and gyroscopes9. This method requires wearing the sensors for a long time, which affects the comfort of human life and increases the burden on the body of older people. The false alarm rate is high in complex environments. (3) Computer vision-based fall detection methods10. It can be categorized into two types: traditional machine vision methods for extracting fall features with low hardware requirements. They are susceptible to environmental factors such as background and light changes and have poor robustness. The other category is deep learning-based human pose estimation (HPE), which aims to predict the coordinates of each pedestrian’s human skeleton nodes from 2D images captured by a camera. As a fundamental model in the field of pedestrian analysis and understanding, HPE can support several downstream tasks in the field of computer vision, such as human re-recognition11, human parsing12, human action recognition13, etc. Since computer vision-based HPE does not require additional wearable devices and is more cost-effective and flexible than wearable motion capture techniques, it is widely used in various real-world applications, including virtual reality, human-computer interaction, and digital entertainment. For these reasons, human fall detection based on HPE has become an essential fundamental task in computer vision. It has attracted the attention of many researchers.
There are two types of HPE: single-person pose estimation and multi-person pose estimation. Among them, there are regression methods and body part detection methods for single-person pose estimation. This method has high detection accuracy but is unsuitable for complex environments. Traditional multi-person pose estimation methods are primarily based on heat maps and are categorized into top-down and bottom-up methods. The top-down method is a two-stage detection algorithm, in which the first stage identifies the human object through the object detection method and labels the rectangular box of the human object region. Then, the labeled region is detected at the skeleton nodes. and the representative algorithms include JC-SPPE14, AlphaPose15, Mask-RCNN16 and FCPose17. The bottom-up approach is an end-to-end detection algorithm that first extracts all the human body skeleton nodes and then determines which human object it belongs to by the correlation relationship between the skeleton nodes, represented by algorithms such as OpenPose18, PifPaf19, and HigherHRNet20. Some recent works have introduced a feature transformer (Transformer) to the pose estimation task for direct regression of skeleton nodes coordinates. Li et al.21 designed an end-to-end multi-person pose estimation transformer for simultaneous pedestrian detection and skeleton nodes regression. Compared to the heat map-based pose estimation method, the regression-based method can predict pedestrian centroid and skeleton nodes offsets. Shi et al.22 proposed a multilevel transformer model, including a pose decoder to obtain coarse-grained human poses and a key point decoder to augment and optimize the coarse-grained poses. Benefiting from the strong characterization capability of the transformer, it can achieve excellent performance on multiple pose estimation datasets.
In general, the top-down methods offer the advantage of enhanced accuracy by processing each human body in isolation, thereby mitigating the conflation of poses among distinct individuals. However, this approach incurs a linear increase in computational complexity with the number of subjects, which can diminish efficiency in scenarios characterized by a multitude of individuals, and the precision of human detection is pivotal to the accuracy of pose estimation outcomes. Conversely, the bottom-up methods exhibit a computational complexity that does not escalate significantly with an increase in the number of people, rendering them adept at managing large-scale crowd scenarios with commendable efficiency. Nevertheless, in dense or heavily occluded settings, the accurate aggregation of joints poses a challenge, potentially leading to a marginal decrease in accuracy compared to top-down methods. Furthermore, Transformer-based methods, exemplified by their self-attention mechanism, enable the concurrent computation of inter-dependencies across the entire sequence, effectively modeling long-range dependencies. Such methods are adept at capturing intricate joint relationships and are well-suited for environments demanding the processing of extended sequences and complex dependencies. Their strengths are underpinned by robust generalization capabilities and parallel computing efficiency, albeit with the caveat that they necessitate substantial computational resources and fine-tuning to be optimally aligned with specific HPE tasks.
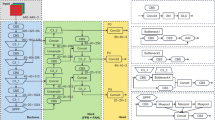
Even the bottom-up and transformer-based methods have higher detection accuracy, especially for crowded scenes. However, the large model size make them difficult to migrate the model to the edge and suffer from poor detection of small objects. On the contrary, although the top-down approach is easily affected by the number of detected objects in terms of detection accuracy and processing speed, this scheme can perform better in terms of detection accuracy and speed in scenarios that are not relatively sparse. Moreover, by improving the object detector, it is often possible to improve the model’s detection accuracy for small objects and reduce the parameter scale significantly, so this scheme is more friendly to the edge end. In Fig. 1, we show the processing flow of the top-down representative model AlphaPose, which, thanks to the five-stage pipeline mechanism, enables the model to process in parallel, thus overcoming the problem of inference speed limitation of the two-stage detection method, and therefore realizing the need for fast processing of large-scale data. Consequently, we will adopt AlphaPose as the backbone model and improve the accuracy and inference speed by optimizing the object detector and the integrated fall detection algorithm.

Illumination of AlphaPose’s multi-thread processing flow.
Hybrid fall detection method based on modified HPE model (HFDMIA-Pose)
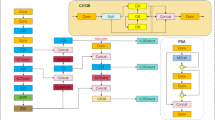
Figure 2 is the framework of overall scheme, and the method processing flow includes the human object detection phase, the human pose estimation phase, and the human recognition phase. Firstly, we use Yolov8s to replace the object detector of Alphapose, and modified Yolov8s by using three methods: the Space-to-Depth Convolution (SPD-Conv), the Improved Small Object Detection Layer (ISOD-Layer), and the Improved Loss Function (BCIoU). Secondly, we use Alphapose’s pose estimation module to extract human skeleton nodes, and the new improved HPE model called IA-Pose. Lastly, we improve the accuracy of HFDA based on the fall instantaneous feature and the fall state feature. In this section, we introduce the IA-Pose in “An enhanced HPE model based on improved YOLOv8s and AlphaPose (IA-Pose)” section and the HFDA in “Improved human fall detection method (HFDM)” section.

Illumination of the HFDMIA-pose processing flow (the human image is from CrowdPose Dataset).
An enhanced HPE model based on improved YOLOv8s and AlphaPose (IA-Pose)
Currently, object detection models mainly include R-CNN series (including Fast R-CNN and Faster R-CNN), YOLO series, SSD, RetinaNet, Anchor-free series (including Corner Proposal Network and FCOS). These models have their own advantages in speed and accuracy, and are suitable for different application scenarios23. Some improvement schemes also significantly improve the model’s performance24,25,26,27. The human object detector used by AlphaPose is YOLOv3. YOLO is an object detection model that makes predictions based on global information from images. It is characterized by high detection accuracy and is lightweight. Since Joseph Redmon and Ali Farhadi proposed the initial model in 201528, researchers have iterated YOLO with several updates, making the model’s performance more and more powerful. The latest version, YOLOv9, was introduced in February 202429, which relies on Programmable Gradient Information (PGI) and Generalized Efficient Layer Aggregation Network (GELAN) and can cope with the deep network to achieve multiple variations required for the goal and achieve excellent results on a lightweight model. Since YOLOv9 has just been introduced and lacks relevant application research and experimental results, we use YOLOv8 to replace AlphaPose’s YOLOv3 module, which would be a good choice.
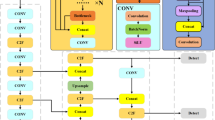
In Table 1, YOLOv5 is a mature and stable version. Compared with it, the most obvious difference of YOLOv8 is replacing the original C3 module with the C2F module. Moreover, YOLOv8 has changed from the original coupled head to a decoupled head in the head section, and it has changed from Anchor-Based to Anchor-Free, significantly improving accuracy and speed in object detection. The accuracy and speed of object detection is considerably enhanced. In addition, according to the scaling factor of the network, YOLOv8 provides five kinds of models with different scales of N/S/M/L/X. Since, in this paper, we wish to strike a trade-off between accuracy and speed, we use YOLOv8s, whose network structure is shown in Fig. 3.

The network of YOLOv8s.
To further improve the performance of the object detector, we optimize YOLOv8s. Firstly, we use the SPD-Conv to preserve the small object features. Secondly, we improve the ISOD-Layer of YOLOv8s to reduce the number of parameters and drastically improve the inference speed. Then, we use the BCIoU to improve accuracy.
Space-to-depth convolution (SPD-Conv)
To address the performance degradation of CNNs due to the loss of fine-grained information and inefficient feature representation, Raja30 proposed a new CNN (SPD-Conv) building block to replace each convolutional step and each pooling layer. SPD-Conv comprises a Space-to-Depth (SPD) layer followed by a Non-Strided Convolution (Conv) layer and can be applied in most CNN architectures. Experimental results show that the SPD-Conv method performs well, especially when dealing with more complicated tasks such as low-resolution images and small objects. Specifically, to prevent losing small object features, we use SPD-Conv instead of the convolutional down sampling module with step size 2 in the YOLOv8 model to achieve fine-grained learned features. The structure of SPD-Conv(scale=2) is shown in Fig. 4. In Fig. 5, when the intermediate feature map X size is S \(\times\) S \(\times\) C1, it can specify the down sampling parameter scale to cut out a series of sub-feature maps. When scale=2, the feature map X is sliced. SPD-Conv slices the feature map to obtain four sub-feature maps, whose feature map size becomes S/2 \(\times\) S/2 \(\times\) 4C1, thus extracting the features in a fine-grained manner. The number of channels of the feature map is compressed by convolution with a step size of 1, and downsampling is achieved by joint convolution of the sliced feature map.

The network of Conv (scale=2).

The network of SPD-Conv.
Improved small object human detection layer network (ISOD-Layer)
The existing methods to improve the small object detection effect include increasing the small object detection layer and adding the attention mechanism, etc. However, these approaches increase the number of model parameters and computation, reducing the detection speed. They thus cannot be effectively deployed in real edge-side application scenarios. Inspired by adding a small object layer, we propose an improved small object detection layer(ISOD-Layer) based on reducing the number of network layers and refining the detection network elements. First, we add a small object detection layer to the model. We elicit output from the first C2faster in Backbone (size 160 \(\times\) 160 \(\times\) 64) and add Upsampling, Concat, and C2faster modules in Neck and a Detect module in Head. Second, we reduced Backbone’s 10-layer network to 8 layers and deleted the nearest Convolution module and C2f module in front of the SPPF module. At the same time, we delete the connection to the SPPF with the Upsampling, Concat, C2faster module, and conv module in Neck and delete a Detect module in Head. In addition, the original detection layer divides the 640 \(\times\) 640 input image into 20 \(\times\) 20 detection cells, with each cell size of 32 \(\times\) 32. Since small object human bodies tend to occupy a tiny area, this leads to a significant influence of the feature information of the background on the object feature information when feature extraction information is performed, resulting in a reduction of detection accuracy. The improved detection layer has a cell size of only 4 \(\times\) 4 for the same input image, which can effectively extract the key features of the object, reduce the influence of the background feature information, and improve detection accuracy. The improved YOLOv8 network structure is shown in Fig. 6, where the green part is the new small object detection layer, and the blue area represents the deleted network part.

The network of improved YOLOv8s.
Optimization loss function (BCIoU)
The loss function directly affects the detection accuracy of the model, and we optimize the loss function of YOLOv8s. The classical bounding box-based loss functions based on IoU include GIoU31, DIoU32, and CIoU33 methods. Among them, GIoU solves the bounding box regression problem when the target and prediction boxes do not overlap, the DIoU improves the convergence speed of the loss function by directly minimizing the center distance between the target and prediction boxes, and the CIoU takes into account the aspect ratio of the target and prediction boxes on top of the DIoU, which achieves the optimal performance. The loss function used in YOLOv8s is CIoU, as shown in Eq. (1). Where \(\alpha\) is the trade-off parameter, \(\upsilon\) is used to measure the consistency of the width and height of the target and prediction boxes, as shown in Eqs. (2) and (3).
In Fig. 7, \(w_{gt}\) and \(h_{gt}\) are the width and length of the target box, and w and h are the width and length of the prediction box, respectively.

Illumination of CIoU.
However, when CIoU appears that the aspect ratio of the target frame is equal to the aspect ratio of the prediction frame, it degenerates into DIoU, and the gradient explosion problem occurs when the gradient is solved for the width and height of the prediction frame. Although its authors used some methods to solve the gradient explosion problem, it also changes the size of the gradient and affects the detection accuracy. We used an improved CIoU (BCIoU)34 to solve the above problem. Specifically, BCIoU is based on CIoU and enhances the model’s detection accuracy and convergence speed by introducing the width-height relationship between the overlapping region and the target frame and the normalized distance between the centroids as additional penalty terms.
In Fig. 8, where \(\rho _1\) is the distance between the overlapping region and the center point of the target frame, \(w_{o}\) and \(h_{o}\) denote the width and height of the overlapping region, respectively, \(c_{1}\) is the diagonal length of the target frame, \(\beta\) is a trade-off parameter, and \(v_1^v\) measures the width-height consistency between the overlapping region and the target frame.

Illumination of BCIoU.
Since the relationship between the overlapping region and the target box is considered, the additional penalty term only has an effect when there is an overlapping part between the prediction and target frames. When the prediction box intersects with the target frame but does not entirely overlap, \(w_{o}\ne w_{gt}\), \(h_{o}\ne h_{gt}\), \(\rho \geqslant 0\), at this time, \(\rho _1^2/c_1^2\geqslant 0,\beta v_1^v>0\), at this time, the additional penalty term has a positive effect in the training of the model; when the prediction and the target boxes completely overlap, \(w_{o} = w_{gt}\), \(h_{o} = h_{gt}\), \(\rho = 0\), at this time, \(\rho _1^2/c_1^2=0,\beta v_1^v=0\), the model gets the optimal solution. The additional penalty term also receives the optimal solution. Currently, the model gets the optimal solution, and the extra penalty term also receives the optimal solution. Since the width and height of the overlap region are determined by the centroid of the prediction box and the target box together with the width and height, the additional penalty term provides gradients to the x, y, w, and h of the prediction box, which improves the accuracy of the model and accelerates the convergence.
Imporved human fall detection method (HFDM)
Action recognition algorithms based on human skeleton nodes are highly robust to environmental changes and have more data compression advantages. AlphaPose can extract 18 human joint points containing the face and torso from human body images, as shown in Fig. 9a. Since we only focus on human action recognition applications, facial nodes could be more meaningful for our scheme, so we simplify the original human model. Our human body model contains only 14 skeleton nodes, as shown in Fig. 9b.

Human skeletal model.
After analysis, the complete human fall behavior includes three stages: pre-fall, fall, and post-fall. Among them, the pre-fall state can be walking, standing, sitting, etc., with little change in the upper trunk of the human body. In the fall stage, the human trunk undergoes significant changes. It often occurs abruptly, which results in the fall characteristics of the process not being easily accessible due to the short duration of existence of the fall process. The human body will generally remain in the post-fall stage for some time, especially since older people will continue to fall longer after a fall, and their fall characteristics are more accessible to obtain. Therefore, in the process of falling, in addition to the apparent attributes of the falling stage, reliable and fast detection of the post-fall state is more practical.
Based on this, we designed a hybrid fall detection algorithm based on human skeleton nodes. The algorithm combines the features of instantaneous pose change features of the human fall process and short-term persistent invariant features after the fall to make a comprehensive determination of the fall event. Specifically, it includes (1) fall instantaneous feature and the mathematical relationship between the linear velocity of the head joint point and the linear velocity of the crotch joint point at the instant of human fall. (2) fall state feature, after the human body fell, by calculating the change of the angle between the human body’s mid-plumb line and the X axis of the image (which is divided into the angle between the mid-plumb line of the upper part of the trunk and the X axis of the image, \(\theta _{u}\), and the angle between the mid-plumb line of the lower part of the trunk and the X axis of the image, \(\theta _{d}\)) to judge the occurrence of the fall phenomenon. The fall features are shown in Fig. 10a,b, respectively.

Human fall instantaneous and state feature.
The fall instantaneous feature is based on a specific process in the early stage in fall. Generally, the displacement of the ankle is not apparent, and the human torso falls in a particular direction around the ankle, similar to the human torso rotating with the ankle as the center of a circle, then the further away from the center of the circle the more significant the linear velocity of the point. The fall state feature is based on the human body’s natural standing equilibrium features. When the human torso and the horizontal plane angle exceed a certain angle, there is an excellent possibility of falling. Meanwhile, when a person falls for some time, only then will the posture changes begin to occur, such as hand support on the ground, sitting up, bowing and bending to climb up, etc., so it can be judged by setting the time threshold.
Calculate the fall instantaneous feature
First, we calculate the linear velocity \(V_{0}\) of the human head joint point labeled 0 and calculate the linear velocity \(V_{0}\) of the human chest center of gravity O, where the human chest center of gravity position O is calculated from the image coordinates of the human joint points labeled 1, 8, and 11. Then, the human ankle linear velocities \(V_{10-13}\) are calculated. \(V_{10-13}\) are the average linear velocities of the human joint points labeled 11 and 13. The above linear velocities are the average linear velocities calculated from M consecutive frames of images with N frames of images at each interval. Then, based on the fact that \(V_0,V_0,V_{10-13}\) satisfy (9), it is initially determined as a suspected fall.
Calculate the fall state feature
According to the features of the human body’s standing balance, when the angle between the mid-pendant line of the upper half of the human torso and the horizontal plane satisfies a specific condition, the human body loses balance and falls, but there are also some exceptional cases, such as bending down to pick up something, tying a shoelace, and other actions. Therefore, in combination with Step 2, we simultaneously detect the change of the angle between the plumbline and the horizontal in the lower half of the human torso, and the same is added to the filtering of the time threshold, which is used to determine the human body fall situation. In step 1, we calculate the angle \(\theta _{u}\) between the mid-pendant line and the horizontal line of the upper half of the human torso and determine the fall if \(\theta u<\varepsilon _{1}\) and maintain \(\theta u<\varepsilon _{1}\) within the time threshold \(T_1\) duration. Otherwise, go to step 2. In Step 2, we calculate the angle \(\theta _{d}\) between the mid-pendant line and the horizontal line of the lower half of the human torso and determine the fall if \(\theta u<\varepsilon _{2}\) and maintain \(\theta u<\varepsilon _{2}\) within the time threshold \(T_2\) duration. Otherwise, it is judged that the pedestrian has not fallen. The specific implementation algorithm is shown in Algorithm 1.

Calculating human pose state.
The fall detection scheme based on deep learning identifies fall behavior through feature extraction and classification. It has significant advantages in analyzing long sequence actions, which is of great significance for identifying coherent actions. However, the low detection speed and high resource consumption make it unfriendly to edge environments. On the other hand, HFDM is a non deep learning based fall detection scheme. It only requires the calculation of the values of \(\theta u\) and \(\theta d\) to determine the fall state, with a small amount of computation and therefore high real-time performance. Furthermore, through the comprehensive analysis of fall instantaneous feature and fall state feature, it is possible to reasonably combine the dynamic and static characteristics of fall actions, making the scheme equally applicable and scientific.
Experiments and analysis
Our experiment consists of two parts, the first part is used to validate the object detection performance of the improved YOLOv8s, and the second part is used to validate the fall detection performance of HFDMIA-Pose. Table 2 shows the experimental hardware environment settings.
Dataset and evaluation metric
Dataset
Multi-person object test dataset
To verify the detection performance of the improved YOLOv8s for multi-person objects, especially for small objects, we use the multi-person crowding dataset (CrowdPose) proposed by the MVIG group of Shanghai Jiaotong University in 201914. In Fig. 11, CrowdPose contains 20,000 images labeled with more than 80,000 pedestrians, including indoor and outdoor scenes. The dataset includes single and more multi-person samples, which total more than 80% of the total samples. In addition, the images in CrowdPose have a uniformly distributed degree of crowding, so it is possible to evaluate both the algorithm’s performance in everyday non-crowded situations and the detection performance of the model in extreme crowding. This dataset is generally used for performance testing of human pose estimation models, while in this experiment, it is only used for human target detection.

CrowdPose dataset (The human images are all from CrowdPose Dataset).
Human fall test dataset
To verify the performance and generalizability of the hybird fall detection algorithm based on the improved AlphaPose, the human fall test datasets we used are divided into two categories: single-person and multi-person. Among them, we use the classical public single-person dataset (Le2i Dataset), which contains a total of 191 video files with a total of 75,911 frames (of which 132 fall videos and 59 non-fall videos), as shown in Fig. 12.

Le2i Dataset (The human images are all from Le2i Dataset).
We constructed our own MPFDD for the multi-person test. The MPFDD has two scenarios, indoor and outdoor, and the number of people is 2 to 5. The dataset consists of 220 videos, including 80 ADL videos and 140 fall videos. The indoor scenes are action room scenes, including chairs, tables, computers, and other accessories. The outdoor scenes are open-ended, with tables and chairs as the main accessories. Specifically, the 2-person scene includes 20 ADL videos, 10 fall videos with 1-person, and 10 fall videos with 2-person. The 3-person scene has 20 ADL videos, 10 fall videos with 1-person, 10 fall videos with 2-person, and 10 fall videos with 3-person. The 4-person scene has 20 ADL videos, 10 fall videos with 1-person, 10 fall videos with 2-person, 10 fall videos with 3-person, and 10 fall videos with 4-person. The 5-person scene has 20 ADL videos, 10 fall videos with 1-person, 10 fall videos with 2-person, 10 fall videos with 3-person, 10 fall videos with 4-person, and 10 fall videos with 5-person. In Fig. 13, we show some of the images in MPFDD.

Multi-person fall detection dataset (MPFDD) (The human images are all from MPFDD, which is owned by the author team of the paper).
Evaluation metric
The confusion matrix is shown in Table 3 which is a unique table arrangement for representing precision evaluation. Based on the confusion matrix, the generic evaluation metrics generally include Precision and Recall, as shown in Eqs. (10) and (11). Among them, Precision refers to the proportion of positive samples whose true values are positive samples, which measures the degree of false detection of the model; Recall represents the proportion of positive samples whose true values are positive samples, which measures the degree of miss detection of the model.
Results and analysis
Results and analysis of multi-person object detection
In addition to the generalized evaluation metrics Eqs. (10) and (11), the average precision AP and mAP are commonly used to measure the model’s overall performance for all classification detections in object detection tasks. AP represents the average accuracy of a particular type, and mAP represents the mean of the average accuracies of all kinds, as shown in Eqs. (12) and (13). In addition, we have used the number of parameters (Parameters) and frame rate (FPS) to measure the lightness and speed of the model.
In the experiments, the hyperparameters used for the training, testing, and validation processes were kept the same for all models. For model training, the models were trained using the SGD optimizer with momentum set to 0.937 and weight decay set to 0.0005. The initial learning rate (Lr0) set to 0.01. All training experiment sets are 300 epochs, the batch size set to 16, and the size of the images input to the model network was rescaled to 640 \(\times\) 640.

Object detection effect of improve YOLOv8s (The human images are all from CrowdPose Dataset).
Figure 14 shows the detection effect of the improved YOLOv8s on CrowdPose. In a crowded scene with multiple people, the distribution of people in Fig. 14a is more balanced, and the distance of all people from the shooting point is the same, so the model ensures a high detection effect. While the distribution of people in Fig. 14b–d has more layers and the scene is more complex, the model is accurate for the detection of objects in the near view and ensures the detection of objects in the far view. However, the model also suffers from under-detection of heavily occluded objects in the distant view, and such cases are not the focus of this paper. Based on the above results, the improved YOLOv8s can fulfill the detection requirements for small targets. In addition, to further visualize the quantitative gain effect of each module on the network structure of YOLOv8s, we set up several sets of ablation experiments, and the results of the ablation experiments are shown in Table 4.
Table 4 shows that each model is compared with the original model (YOLOv8s). The inference speed of Model 1 has a specific decrease, but the number of parameters is reduced by 18.35%, which indicates that the improved module effectively plays a lightweight role; the model size of Model 2 is only 4.69 M, which is a decrease of 58.01%, the mAP0.5 is increased by 2.90%, and the FPS is increased by 15.49%. It shows that the improved module reduces the model size and improves the accuracy and speed significantly. The mAP0.5 and FPS of model 3 are improved, and the others remain unchanged, which indicates that the improved module has some effect on improving the accuracy and speed. Model 4 is significantly better than the original model in all parameters, especially the model size is reduced by 74.40%. Model 5’s mAP0.5 is improved by 7.80%, and the model size is reduced by 58.01%, and at the same time, the speed is reduced to a certain extent. Model 6 is better than the original model in all parameters. Based on this, compared with the original model (YOLOv8s), the model of this paper is substantially better than the original model in each parameter, and the mAP0.5 of the original model is improved by 7.20%, the number of parameters is reduced by 74.40%, and the speed is improved by 32.72%. Therefore, our improved YOLOv8s is a lightweight model with good performance in terms of accuracy and speed.
Results and analysis of multi-person fall detection
In the fall detection experiments, since the prediction results only contain both fall and non-fall outcomes, we also add Accuracy and F1 to the general evaluation metrics to measure the inference precision of the model. Accuracy is the ratio of the number of correctly predicted samples to the total number of samples, directly reflecting the classification model’s average accuracy. F1 is the precision rate and the reconciled average of Recall, which is used to measure how well the model is balanced between these two metrics and is particularly suitable for datasets with category imbalance, which can provide a more comprehensive assessment of the model performance. In addition, we also use the FPS to measure the inference speed.
Figure 15 shows our model’s experimental results in indoor and outdoor environments. The model can achieve fall detection for both single and multiple people. To validate the algorithm performance, we compare the model with the original AlphaPose and advanced multi-person fall detection algorithms in our experiments.

Fall detection effect of HFDMIA-Pose (The human images are all from Le2i Dataset and MPFDD).
There are various types of skeleton node-based fall detection schemes, we have selected six representative schemes for comparison, and most of these schemes use a hybrid method. Among them, Koo35 used CNN to obtain human pose features and LSTM for human action recognition. Nguyen36 used the YOLOv5+HRNet approach, which improves the accuracy of human object recognition by improving Yolov5 and performing accurate estimation of critical points and poses by HRNet. Dey37 used an approach based on Shifted Patch Tokenization and Locality Self Attention of Transformer. Wei38 used a Mediapipe+LSTM method, which uses Mediapipe to extract human skeleton nodes and analyzes the long-term dependencies of skeleton nodes by LSTM. Gao39 uses a similar scheme to Wei38, except that Openpose and MobileNet are used, respectively. Inturi40 uses a GCN-based model, which uses video segments as recognition objects, analyzes and recognizes the spatial and temporal information of the actions as features, and performs outstandingly in recognition accuracy. In addition, since our scheme is an optimization scheme based on AlphaPose, it is also included in the comparison, and Lee41 uses the Alphapose+LSTM method.
Table 5 shows that on the same dataset, our algorithm has a detection accuracy of 77.5%, which is 10.87%, 7.49%, 2.24%, 8.08%, 6.74%, and 4.30% higher than [35–39] and [41], respectively, but is 2.39% lower than [40], which results in a good accuracy for our scheme. Regarding F1, our scheme performs better with performance improvements of 11.36%, 7.62%, 2.36%, 8.46%, 7.04%, and 4.57%, but 2.84% lower than [40]. In terms of FPS, our scheme has a clear advantage, with performance improvements of 14.45%, 58.40%, 45.58%, 16.47%, 138.55%, and 37.50% compared to [36–41], but 9.58% lower than [35]. Our scheme has higher recognition accuracy compared to [35–37], which relies on the high recognition accuracy of the pose estimation model for human skeletal nodes. Compared to [38,39], our scheme also has higher recognition accuracy, which relies on small target recognition and HFDA advantages. Compared with [40], our scheme does not have a significant advantage in recognition performance. Still, it excels in inference speed, which is 2.18 times higher than [40], mainly due to the larger size of the 2s-AGCN, which consumes more hardware resources for inference. In addition, the comparison results with [41] better show the effect of our improvement scheme for AlphaPose, which is only 58.5% of the original AlphaPose in model parameters but improves the accuracy by 4.30%, the F1 by 4.57%, and the FPS by 37.50%. The above shows that the HFDMIA-Pose has better accuracy and real-time performance.

Illumination of false and miss detection (The human images are all from MPFDD).
In Fig. 16, our scheme likewise suffers from false and miss detection in recognizing falls. The main reasons for this are occlusion, illumination, and camera angle. Among them, the illumination and camera angle problems can be mitigated by image processing and camera angle changes, etc., but these problems are not the focus of our scheme. However, we have yet to address the occlusion problem well, especially in crowded scenes with multiple people, where mutual occlusion is the leading cause of wrong and missed detections. In Fig. 16, the red box represents an undetected human object. In short, the main reason for wrong and missed detection is inaccurate feature extraction of human skeletal nodes caused by various environmental factors. It will provide a clear direction for our further research work.
Discussion
We designed a hybrid fall detection method to improve the performance of multi-person fall detection called HFDMIA-Pose. On the one hand, in the object detection comparison experiments, the human object detection performance can be effectively enhanced by three methods: SPD-Conv, ISOD-Layer, and BCIoU. The improved YOLOv8s substantially outperforms the original model in all aspects, with 7.20% increase in mAP50, 74.40% parameter reduction, and 32.72% improvement in inference speed. Therefore, the improved YOLOv8s is a lightweight model with high accuracy and speed, and it has good results as a target detector for AlphaPose. On the other hand, in the fall detection comparison experiment, the model’s recognition accuracy of multi-person fall behavior was improved by designing a hybrid fall detection algorithm combining fall instantaneous feature and fall state feature. HFDMIA-Pose was shown to outperform the comparison algorithms in terms of overall performance. Among them, the accuracy is improved by 5.33% on average, F1 by 5.51% on average, and FPS by 43.05% on average. The above results show that our method has better accuracy and real-time performance in multi-person small object scenarios.
Meanwhile, our algorithm also suffers from the problem of fall and miss detection, and we find that the occlusion is the main reason for the fall detection. To further enhance the detection accuracy of HFDMIA-Pose, we will carry out the following aspects in our future research work:
-
1.
Research on multi-camera detection methods. Multiple cameras should be used for fall detection from different angles to solve the human body occlusion problem.
-
2.
research on more lightweight multi-person pose estimation schemes. Edge AI is an inevitable trend of arithmetic sinking, and we will study the lightweight multi-person pose estimation scheme based on edge AI devices, which provides the basis for realizing edge-side human action recognition applications.
-
3.
Research on fall detection methods for special populations. For example, the problem of elderly falls is a more deserving target. Since there is no publicly available dataset specialized in abnormal movements of older people, our test dataset MPFDD also needs to include such data. Therefore, in our future work, we will gradually collect data on abnormal movements of special populations, such as the elderly, by cooperating with relevant medical organizations and associations of the elderly.
Conclusion
To address the problems of low accuracy of the model for small object detection and weak applicability at the edge end in multi-person fall behavior recognition applications, we propose an improved human pose estimation algorithm, IA-Pose. IA-Pose uses YOLOv8s to replace the object detector of AlphaPose to enhance the model’s performance in object detection and by improving the structure of the model network, significantly reducing the parameter scales. Meanwhile, we design a hybrid fall detection algorithm HFDA that combines fall instantaneous feature and fall state feature to improve the model’s recognition accuracy of fall behavior. The experimental results show that our HFDMIA-Pose has higher detection accuracy and obvious real-time advantages. Therefore, as an attempt at lightweight modeling for multi-person fall detection, our scheme has a certain reference value for subsequent research.
Data availability
The datasets used and analyzed during the current study are available from the corresponding author upon reasonable request. CrowdPose Dataset is https://github.com/Jeff-sjtu/CrowdPose. Le2i Dataset is http://le2i.cnrs.fr/Fall-detection-Dataset. Some experiment data of MPFDD is https://github.com/Hnnuliulei123456/MPFDD/tree/main.
References
WHO. Ageing-and-Health. https://www.who.int/news-room/fact-sheets/detail/ageing-and-health (2024).
CDC. Vision-Loss-Falls. https://www.cdc.gov/visionhealth/resources/features/vision-loss-falls.html (2024).
Usmani, S., Saboor, A., Haris, M., Khan, M. A. & Park, H. Latest research trends in fall detection and prevention using machine learning: A systematic review. Sensors 21, 5134 (2021).
Jung, S.-H., Hwang, J.-M. & Kim, C.-H. Inversion table fall injury, the phantom menace: Three case reports on cervical spinal cord injury. Healthcare 9, 492 (2021).
WHO. Falls. https://www.who.int/news-room/fact-sheets/detail/falls (2024).
Ramirez, H. et al. Fall detection and activity recognition using human skeleton features. IEEE Access 9, 33532–33542 (2021).
Pham, H. H., Khoudour, L., Crouzil, A., Zegers, P. & Velastin, S. A. Video-based human action recognition using deep learning: A review. Preprint at http://arxiv.org/abs/2208.03775 (2022).
Wang, P. et al. A convolution neural network approach for fall detection based on adaptive channel selection of uwb radar signals. Neural Comput. Appl. 35, 15967–15980 (2023).
Yao, F., Kang, Y. & Wei, Y. Research on the detection model of wearable fall detection algorithm. In 2023 International Conference on Integrated Intelligence and Communication Systems (ICIICS) 1–5 (IEEE, 2023).
Newaz, N. T. & Hanada, E. The methods of fall detection: A literature review. Sensors 23, 5212 (2023).
Zhang, G., Zhang, H., Lin, W., Chandran, A. K. & Jing, X. Camera contrast learning for unsupervised person re-identification. IEEE Trans. Circuits Syst. Video Technol. 1, 1 (2023).
Yang, L., Jia, W., Li, S. & Song, Q. Deep learning technique for human parsing: A survey and outlook. Int. J. Comput. Vis. 1, 1–32 (2024).
Song, L., Yu, G., Yuan, J. & Liu, Z. Human pose estimation and its application to action recognition: A survey. J. Vis. Commun. Image Represent. 76, 103055 (2021).
Li, J. et al. Crowdpose: Efficient crowded scenes pose estimation and a new benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 10863–10872 (2019).
Fang, H.-S. et al. Alphapose: Whole-body regional multi-person pose estimation and tracking in real-time. IEEE Trans. Pattern Anal. Mach. Intell. 1, 1 (2022).
Yoon, S. H., Yang, J. J., Kim, C. & Hwang, M. J. Detection and pose estimation of top circular objects using mask r-cnn and overlap handling algorithm. J. Inst. Control Robot. Syst. 29, 1030–1038 (2023).
Mao, W., Tian, Z., Wang, X. & Shen, C. Fcpose: Fully convolutional multi-person pose estimation with dynamic instance-aware convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 9034–9043 (2021).
Hardiyanto, R. A. et al. Empowering elderly care: Innovative fall detection with openpose and yolo. In 2023 6th International Seminar on Research of Information Technology and Intelligent Systems (ISRITI) 451–456 (IEEE, 2023).
Kreiss, S., Bertoni, L. & Alahi, A. Pifpaf: Composite fields for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 11977–11986 (2019).
Cheng, B., Xiao, J., Bin, F. W., Shi, H., Huang, T. S. & Zhang, L. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 5386–5395 (2020).
Li, K. et al. Pose recognition with cascade transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 1944–1953 (2021).
Shi, D., Wei, X., Li, L., Ren, Y. & Tan, W. End-to-end multi-person pose estimation with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 11069–11078 (2022).
Kaur, R. & Singh, S. A comprehensive review of object detection with deep learning. Dig. Signal Process. 132, 103812 (2023).
Shen, J. et al. An anchor-free lightweight deep convolutional network for vehicle detection in aerial images. IEEE Trans. Intell. Transp. Syst. 23, 24330–24342 (2022).
Yi, H., Liu, B., Zhao, B. & Liu, E. Small object detection algorithm based on improved yolov8 for remote sensing. IEEE J. Select. Top. Appl. Earth Observ. Remote Sens. 1, 1 (2023).
Li, Y., Miao, N., Ma, L., Shuang, F. & Huang, X. Transformer for object detection: Review and benchmark. Eng. Appl. Artif. Intell. 126, 107021 (2023).
Shen, J., Liu, N., Sun, H., Li, D. & Zhang, Y. An instrument indication acquisition algorithm based on lightweight deep convolutional neural network and hybrid attention fine-grained features. IEEE Trans. Instrum. Meas. 1, 1 (2024).
Terven, J. & Cordova-Esparza, D. A comprehensive review of yolo: From yolov1 to yolov8 and beyond. Preprint at http://arxiv.org/abs/2304.00501 (2023).
Wang, C.-Y., Yeh, I.-H. & Liao, H.-Y. M. Yolov9: Learning what you want to learn using programmable gradient information. Preprint at http://arxiv.org/abs/2402.13616 (2024).
Sunkara, R. & Luo, T. No more strided convolutions or pooling: A new cnn building block for low-resolution images and small objects. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases 443–459 (Springer, 2022).
Cui, M., Duan, Y., Pan, C., Wang, J. & Liu, H. Optimization for anchor-free object detection via scale-independent giou loss. IEEE Geosci. Remote Sens. Lett. 20, 1–5 (2023).
YiNan, W., Yun, Z., Jia, G. & Yu, Y. Z. Yolov5 detection algorithm of steel defects based on introducing light convolution network and diou function. In 2023 IEEE 12th Data Driven Control and Learning Systems Conference (DDCLS) 118–122 (IEEE, 2023).
Zheng, Z. et al. Distance-iou loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 34, 12993–13000 (2020).
Liu, X., Yang, X., Chen, Y. & Zhao, S. Object detection method based on ciou improved bounding box loss function. Chin. J. Liq. Cryst. Displace. 38, 656–665 (2023).
Koo, B. et al. Tinyfallnet: A lightweight pre-impact fall detection model. Sensors 23, 8459 (2023).
Nguyen, H.-C. et al. Combined yolov5 and hrnet for high accuracy 2d keypoint and human pose estimation. J. Artif. Intell. Soft Comput. Res. 12, 281–298 (2022).
Dey, A., Rajan, S., Xiao, G. & Lu, J. Fall event detection using vision transformer. In 2022 IEEE Sensors 1–4 (IEEE, 2022).
Wei, B., Li, L., Li, A., Meng, Q. & Qu, H. Embedded fall-detection method based on mediapipe and lstm neural network. In 2023 International Conference on Sensing, Measurement & Data Analytics in the era of Artificial Intelligence (ICSMD) 1–5 (IEEE, 2023).
Gao, M. et al. Fall detection based on openpose and mobilenetv2 network. IET Image Proc. 17, 722–732 (2023).
Inturi, A. R., Manikandan, V. & Garrapally, V. A novel vision-based fall detection scheme using keypoints of human skeleton with long short-term memory network. Arab. J. Sci. Eng. 48, 1143–1155 (2023).
Lee, J. & Kang, S.-J. Skeleton action recognition using two-stream adaptive graph convolutional networks. In 2021 36th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC) 1–3 (IEEE, 2021).
Acknowledgements
This study received support from the following sources: the University Natural Science Foundation of Anhui Province (Grant No. 2023AH051542 and Grant No. 2022AH010085), the University Youth Teacher Training Action Funding Project of Anhui Province (Grant No. YQZD2024041), the Science and Technology Plan Project of Huainan (Grant No. 2023A3110).
Author information
Authors and Affiliations
Contributions
Lei Liu: Conceptualization, Methodology, Resources, Validation, Data Curation, Writing—Original Draft, Writing—Review and Editing. Yeguo Sun: Methodology, Formal Analysis, Data Curation, Writing—Review and Editing. Yinyin Li and Yihong Liu: Formal Analysis, Software, Validation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, L., Sun, Y., Li, Y. et al. A hybrid human fall detection method based on modified YOLOv8s and AlphaPose. Sci Rep 15, 2636 (2025). https://doi.org/10.1038/s41598-025-86429-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-86429-6
Keywords
This article is cited by
-
Multi-camera spatiotemporal deep learning framework for real-time abnormal behavior detection in dense urban environments
Scientific Reports (2025)
-
RGE-YOLO enables lightweight road packaging bag detection for enhanced driving safety
Scientific Reports (2025)
-
Dual-branch fall detection algorithm based on multi-scale temporal difference
Signal, Image and Video Processing (2025)
