
Abstract
To address the problems of complex cloud features in satellite cloud maps, inaccurate typhoon localization, and poor target detection accuracy, this paper proposes a new typhoon localization algorithm, named TGE-YOLO. It is based on the YOLOv8n model with excellent high-low feature fusion capability and innovatively achieves the organic combination of feature fusion, computational efficiency, and localization accuracy. Firstly, the TFAM_Concat module is creatively designed in the neck network, which comprehensively utilizes the detailed information of shallow features and the semantic information of deeper features, enhancing the fusion ability of features at each layer. Secondly, the GSConv convolution is used to replace traditional convolution to reduce the computational cost of the model and effectively aggregate global information. Finally, the Efficient Intersection over Union (EIoU) loss function is improved to enhance its sensitivity to positional errors and optimize the error distribution, thereby improving the model’s accuracy in capturing the position at the center of the typhoon. The experimental results show that the proposed TGE-YOLO model outperforms Faster R-CNN, YOLOv5s, YOLOv9s, and YOLOv11n, with the typhoon identification mean average precision (mAP) reaching 87.8%, the mean square error (MSE) of typhoon center localization at 0.115, and the detection speed at 416.7 frames per second (FPS). The model’s rapid inference capability and efficient performance provide technical support for typhoon monitoring, which is expected to improve the timeliness and accuracy of typhoon warnings in practical applications.
Similar content being viewed by others


Introduction
Typhoon is a natural disaster with extreme suddenness and destructive power, which brings serious and extensive harm to human society, economy and ecology. Its strong winds and heavy rains often lead to building collapses, transportation disruptions, large-scale power outages, as well as huge losses in agriculture and fisheries, and even human casualties1. When facing the threat of typhoons, it is crucial to accurately detect and locate the position of the typhoon so that protective measures can be taken in time to reduce the damage caused by the disaster.
Traditional typhoon center localization mainly relies on morphological methods and the use of wind field structures as an aid. Among the morphological methods, Hu et al.2 used an azimuthal spectrum analysis method to locate the center of a typhoon by obtaining the maximum symmetry component of the encircling center. Zhang et al.3 proposed an algorithm based on the gradient of the bright temperature and rotational symmetry, which takes into account the radial symmetry characteristics of the typhoon and uses a numerical optimization method to improve the accuracy of the estimation of the typhoon center. Shin et al.4used the enhanced logarithmic spiral band (LSB) and scoring matrix (SCM) to determine the center of a typhoon. However, the morphological method performs poorly in situations where there are no obvious spiral cloud bands and eyewall features, and where the meteorological field is complex and rapidly changing. Using satellite inversion of ocean surface wind or cloud-guided wind data to find the zero value of wind speed or the vorticity extreme point in the typhoon wind field structure as the center of the typhoon is suitable for typhoons during the formation and weakening phases5. It also helps determine the location of the typhoon center when the center of circulation is unclear and can complement the method of locating the center of the cloud system morphology of a tropical cyclone. However, the wind field inversion method is affected by resolution and heavy rainfall areas when the tropical cyclone intensity level is high, making it inaccurate for localizing strong typhoons.
In recent years, deep learning technology has been widely applied across various fields. In the domain of image segmentation, frameworks such as UNet6 and Transformer have demonstrated remarkable performance. Liu et al.7 have proposed the Swin Transformer model, which has significantly enhanced the model’s representational power and computational efficiency through its hierarchical design and sliding window attention mechanism, offering a novel solution for visual tasks like image segmentation. Ruan et al.8 have addressed the limitations and computational complexity of remote modeling by introducing the Visual State Space (VSS) block, which is based on the State Space Model (SSM) and designed to capture a wide range of contextual information. They proposed the Vision Mamba UNet (VM-UNet) model, incorporating an asymmetric encoder-decoder structure to enhance performance. However, these methods face certain limitations when applied to typhoon localization tasks. Typhoons, as mesoscale weather systems, exhibit irregular shapes and diffuse boundaries, which differ significantly from the segmentation requirements of general objects. Traditional image segmentation methods emphasize pixel-level segmentation and precise boundary delineation. In contrast, typhoon localization prioritizes overall recognition and accurate center positioning, making it challenging for pixel-level segmentation methods to simultaneously achieve precise center localization and shape recognition. This discrepancy limits the applicability of traditional image segmentation frameworks in addressing typhoon localization tasks.
The successful application of object detection technology in remote sensing imagery has demonstrated the significant advantages of deep learning-driven object detection methods in complex scenes. Unlike traditional segmentation approaches, object detection methods predict object categories as a whole and directly output bounding boxes along with their center points. Integrating object detection technology into typhoon localization research not only effectively addresses the challenge of fuzzy typhoon boundaries but also shows strong potential and promising results. This technique is not only able to locate the center of a typhoon more accurately, but also handles complex and rapidly changing meteorological scenarios more effectively. Target detection techniques are categorized into single-stage and two-stage algorithms. The two-stage algorithms first generate candidate regions and then perform classification and location regression, characterized by high accuracy but slow speed. The representative algorithms are Faster R-CNN9and Mask R-CNN10. Kızıloluk et al.11 combined Faster R-CNN with an artificial jellyfish search (JS) optimizer to construct a system for typhoon detection by optimizing the hyperparameter settings of Faster R-CNN, significantly improving the model’s performance. Pal et al.12proposed a Mask R-CNN-based typhoon center localization method, significantly improving the accuracy of the model by segmenting and labeling the eye of the typhoon and combining it with an eye detection index. The single-stage algorithm predicts the target position and category directly at each position and scale of the image with high real-time performance, represented by the YOLO13,14,15,16,17series. The latest release, YOLOv1118, features an improved backbone and neck architecture with new components such as C3k2 and C2PSA, which enhance feature extraction but do not significantly improve object detection accuracy. He et al.19 used YOLOX combined with morphological knowledge to achieve the localization of typhoon centers, addressing the problem of the high resolution of the satellite images but the high noise characteristics of the non-typhoon clouds. Long et al.20 used the YOLOv4 model to identify the typhoon center based on the satellite cloud map data and achieved good results.
Although deep learning target detection algorithms have been applied in tropical cyclone center localization, their use remains relatively limited compared to other fields. Current research primarily focuses on the application of these models, with insufficient attention paid to enhancing the underlying algorithmic modules. This lack of focus on algorithmic improvement hinders the full utilization of deep learning target detection algorithms in feature extraction, detection, and localization. In this paper, we address the challenges of complex feature maps in satellite cloud imagery, inaccurate typhoon center positioning, and high computational costs by optimizing the YOLOv8n model. We propose an improved model, TGE-YOLO, specifically for typhoon localization. The main contributions of this paper are as follows:
(1) Designing a new TFAM_Concat feature fusion module. By introducing the TFAM21 module and combining it with the Concat module, the ability of the model to focus on the key information of the target is enhanced. Satellite cloud maps usually have complex backgrounds and multi-scale target features, and the TFAM_Concat module effectively improves the model’s sensitivity to the core area of the typhoon by fully exploiting the differences and commonalities of the features in different layers, so as to accurately extract the key information of the typhoon in the complex feature maps.
(2) Introducing of GSConv22 in Backbone and Neck Networks. To address the problem of high computational cost in typhoon identification, this paper introduces the GSConv convolution instead of the traditional convolution module in the backbone and neck networks.GSConv reduces the computational demand for complex feature maps by adaptively aggregating global information while maintaining efficient feature extraction capability. This innovation enables the model to significantly improve inference speed while maintaining high accuracy, thus solving the computational bottleneck of traditional convolution when dealing with large-scale satellite images.
(3) Enhancing the EIoU23 (E-EIoU) Loss Function. Aiming at the problem of inaccurate typhoon center positioning, the EIoU loss function is optimized in this paper. By assigning a higher weight to the positioning error of the typhoon center, the loss function enhances the penalty of the distance metric, which makes the model pay more attention to accurately capturing the location of the typhoon center. This improvement effectively reduces the localization bias due to the location error in complex backgrounds and improves the accuracy of the model in the typhoon center localization task.
The structure of this paper is as follows: the “Introduction” section introduces the research background of typhoon localization, the problems and the proposed methodology; The “Methodology” section describes the design ideas of the YOLOv8 model and the TGE-YOLO model; the “Experimental Studies” section describes the experimental setup, including the dataset and the evaluation metrics; the “Results” section presents the experimental results; finally, the “Conclusion” section summarizes the main conclusions of the study.
Methodology
Overview of the YOLOv8n model
YOLO is a series of target detection algorithms based on deep learning and convolutional neural networks, with the YOLOv8 model offering significant advantages over previous YOLO versions. YOLOv8 includes five models: YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, and YOLOv8x, which differ in depth and width in that order. The structure of the YOLOv8n model consists of four core components: Input, Backbone, Neck, and Head. The Input utilizes the Mosaic data enhancement method for four-in-one splicing operations and incorporates an adaptive image scaling method. This approach not only increases the complexity of the image background and prevents overfitting but also improves the model’s ability to generalize to different scenarios. The Backbone network primarily comprises the Conv module, the C2f. module, and the Spatial Pyramid Pooling-Fast (SPPF) module. The C2f. module enhances feature extraction capabilities while reducing computational complexity, thereby improving model accuracy. The Neck network integrates multi-scale feature maps from the Backbone network using a Feature Pyramid Network (FPN). Finally, the Head network generates the final detection results, including the target class, bounding box coordinates, and confidence scores.
Network structure of the improved model
YOLOv8 is known for its fast detection speed and high accuracy. However, when dealing with complex cloud scenes in satellite cloud maps, the model is prone to leakage and false detection. These scenes typically contain multi-layered cloud structures, variable morphology, and backgrounds, making accurate detection particularly difficult. Additionally, the computational cost is relatively high. These challenges limit the effectiveness of YOLOv8 in complex meteorological environments.
To address these issues, we select YOLOv8n as the base model and improve its network structure to design the typhoon localization model TGE-YOLO.
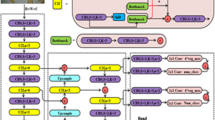
To address the above issue, this paper has adopted YOLOv8n as the foundational research model. By keeping other feature fusion methods unchanged, the network structure has been improved, resulting in the development of the typhoon localization model TGE-YOLO. To solve problems with complex cloud backgrounds, varying typhoon morphology, and poor feature fusion, we design the TFAM_Concat feature fusion module to enhance the effective fusion of global information in the neck network and highlight key parts in the dual features. Next, we introduce the GSConv module, which reduces the number of parameters and computational complexity while maintaining model performance. At the same time, we improve the EIoU to increase the penalty for the distance metric, thus enhancing the accuracy of typhoon localization. The overall network structure of TGE-YOLO is shown in Fig. 1.

The TGE-YOLO network architecture.
TFAM_Concat feature fusion module
In the YOLOv8 algorithm, the primary role of the neck network is to fuse and process features extracted from the backbone network. However, in practice, the neck network relies solely on the Concat operation for feature fusion. While concatenation is simple and direct, it fails to emphasize key information in the fused features and does not fully leverage the correlations between them. To address this limitation, this paper introduces the TFAM module to enhance feature fusion capabilities for typhoon detection. TFAM achieves effective fusion and enhancement of dual features through its dual-branch structure, improved feature information utilization, attention mechanism, and weight adjustment.
The structure of TFAM is illustrated in Fig. 2 and consists of two branches: the channel branch and the spatial branch. The channel branch enhances channel information attention, while the spatial branch enhances spatial information attention. Input feature maps F1 and F2 are subjected to Avgpool and Maxpool operations along the spatial and channel dimensions, respectively. The results of spatial and channel pooling are then concatenated to obtain aggregated spatial features SC and aggregated channel features SS Convolution operations are performed on these aggregated features to compute the dual temporal channel weights WC1, WC2 and dual temporal spatial weights WS1, WS2 After normalizing these weights using the softmax function, the dual temporal channel weights and dual temporal spatial weights are summed element-wise. These summed weights are then multiplied element-wise with the input feature maps and summed to produce the output feature map \(\widetilde{F}\), computed as follows:

The structure of TFAM.
Equation (1) and Eq. (2) represent the pooling and aggregation operations for the spatial and channel dimensions, respectively, where \({{W}}\), \({{H}}\) and \({C}\) denote the width, height, and number of channels of the feature map, respectively. The notation \(\left[\bullet \right]\) indicates the Concat operation.In Eq. (3), \({{Conv1d}}\left(\bullet \right)\) represents a one-dimensional convolution operation. The value of the convolution kernel kis the same as that of the Eifficient Channel Attention (ECA)24 module, as shown in Equation (4) is taken to be 2, and b is taken to be 1; \({\left|{\text{d}}\right|}_{\text{odd}}\) denotes the nearest odd number to d.
In the following Eq. (5), \({{Conv2d}}\left(\bullet \right)\) represents a two-dimensional convolution operation. After convolution operation, softmax normalization operation is carried out, as shown in Eq. (6) and Eq. (7), \({{{W}}{\prime}}_{{C1}}\) and \({{{W}}{\prime}}_{{C2}}\) denote the dual temporal channel weights after normalization, while \(W^{\prime}_{S1} {\kern 1pt} \,and{\kern 1pt} \,W^{\prime}_{S2} {\kern 1pt}\) denote the dual temporal spatial weights after normalization. weights of the dual time-phase space.
In the following Eq. (8), \(\otimes\) represents an element-by-element multiplication operation; \(\oplus\) represents an element-by-element addition operation.
Next, we combine TFAM to redesign Concat to get TFAM_Concat module, whose structure is shown in Fig. 3. Firstly, using 1 × 1 convolutional kernel, the feature map F2 original 2C channels are compressed to C to get the feature map \({\widetilde{F}}_{2}\); then, the feature maps F1 and \({\widetilde{F}}_{2}\) are inputted into the TFAM module , through spatio-temporal attention, to carry out the fusion of double features to generate the feature map \(\widetilde{F}\); finally, the concat operation is carried out on the feature maps F1, \(\widetilde{F}\)and \({\widetilde{F}}_{2}\) to obtain the final fusion feature FC, which realizes the effective aggregation of the global information.

The structure of TFAM_Concat.
GSConv module
While traditional convolutional methods are effective in extracting image features, they are computationally intensive and time-consuming. The emergence of depth separable convolution (DSC)25 greatly improves the detection speed but sacrifices the detection accuracy of the model. For this reason, the GSConv structure is introduced in this paper to balance the accuracy and complexity of the model. The GSConv structure is shown in Fig. 4, which combines traditional convolution, depth-separable convolution, and Shuffle hybrid strategy. Firstly, using 1 × 1 convolution kernel, the input feature map C1 channels are compressed to half of the output channel number C2; then a depth-separable convolution operation is performed and the two sets of feature maps are spliced according to the channel dimensions; finally, a Shuffle operation is used to mix and arrange the features by channel to obtain a feature map with C2 channel numbers. GSConv can significantly reduce the number of model parameters and strengthen the information connection between feature maps to enrich the feature information.

The structure of GSConv. The DWConv label here denotes Depthwise Convolution, which means that each input channel is convolved with a separate convolution kernel.
By rearranging the output channels after convolution of each group, the GSConv module enables each channel to draw information from different groups of features, which significantly improves the information mobility across groups and the feature expression ability of the network. The TFAM_Concat module, on the other hand, through innovative design, utilizes the TFAM operation to fully mine and fuse the differences and commonalities between the high and low level features, effectively aggregating the features at different levels to generate a richer feature map. The joint application of these two modules not only realizes the fusion of features among different channels, but also fully fuses features at different levels, further enhancing the feature integration and expression capability of the network.
E-EIoU Loss
In computer vision and target detection tasks, the choice of the bounding box regression loss function is crucial for the accuracy and stability of the results. YOLOv8 uses a regression loss function based on Complete Intersection over Union (CIoU)26. The CIoU loss function is defined as shown in Eqs. (9) through (11):
where \({\text{b}}\), \({\text{b}}^{\text{gt}}\) represent the center points of the predicted and real frames, respectively; ρ( , ) represents the Euclidean distance calculated between the two points; \(c\) represents the minimum enclosing frame diagonal distance that can encompass both the predicted and real frames; α is a weighting coefficient; IoU is the intersecting and concurrent ratio of the predicted and real frames; v is a similarity used to measure the aspect ratios; w, h, wgt and hgt are the labeled box width and height and the real box width and height, respectively.
Although CIoU takes into account the centroid distance and frame aspect ratio, in typhoon center localization, it is necessary to focus on the loss of the centroid.CIoU may not be able to satisfy the needs in this case. EIoU is an improvement to CIoU, which aims to better handle the bounding box shapes and locations, and further enhances the handling of the centroid. Therefore, in this paper, EIoU is introduced and improved to better fit our needs.The EIoU loss function is shown in Eq. (12).
where \({\text{w}}^{\text{c}}\) represents the width of the minimum enclosing box, and \({\text{h}}^{\text{c}}\) represents the height of the minimum enclosing box.
In the task of typhoon center location, the bounding box regression loss function needs to focus more on the accurate location of the center point. Therefore, in this paper, we increase the penalty on the distance metric of the center point and set the weight coefficient β on the direction loss:
The E-EIoU Loss is shown in Eq. (14), and the influence of the weighting coefficient β on the equation is as follows: the smaller the IoU is, the smaller the β is, and the distance loss is prioritized at this time; the larger the IoU is, the larger the β is, and the direction loss is prioritized at this time. By introducing higher weights, the distance calculation of the center point is further refined, and the influence of aspect ratio is reduced, so that the loss function focuses more on the positioning of the center point.
E-EIoU Loss is better adapted to the needs of typhoon center localization, ensuring bounding box regression while significantly improving focus and accuracy on the center point, and demonstrating higher accuracy and stability when handling typhoon center localization tasks.
Experimental studies
Dataset Creation
In this paper, we have collected the cloud images of the Himawari series of meteorological satellites from 2000 to 2023, and the dataset consists of a total of 11,976 satellite cloud images, including the whole process of each typhoon from generation to dissipation, and the satellite images cover the range of 70 ~ 160°E, 20°S ~ 70°N, and the image size is 640 × 640 pixels. As shown in Fig. 5, although typhoons may exhibit different structural features at different stages of their life cycle, they may also exhibit similar structural features at different stages of intensity27. This similarity, if labeled only by intensity, can easily cause misjudgment of the model and lead to inaccurate results. In the data labeling stage, in order to avoid the loss caused by label misjudgment, we unify the labels of the typhoon and simplify its objective to a binary classification task between the typhoon and the background. With this approach, the errors due to label confusion can be effectively reduced, thus improving the accuracy and robustness of the model in typhoon center detection and localization. According to the China Meteorological Administration tropical cyclone optimal path (CMA)28,29 information, the images are labeled using LabelImg tool, and the data labeling process is as follows: firstly, according to the CMA, obtain the list of files to be labeled; secondly, obtain the cyclone center coordinates of the files to be labeled; and lastly, the cyclone center pixel point is used as the center of the labeling box to label cyclones to generate the labeled files. As shown in Fig. 6, the labeling of the dataset clearly demonstrates its reliability and consistency. As can be seen from Fig. 6(a), the distribution of the labeled centers is consistent with the CMA data, showing a normal distribution pattern; Fig. 6(b) shows that the size of the labeled instances is uniformly distributed without the phenomenon of small targets. The overall labeling effect highlights the high quality and accuracy of our dataset. The experiment divides the dataset into training set, validation set and test set in the ratio of 8:1:1.

Structural characteristics of different intensity stages of the same typhoon.

Labeling of the dataset. (a) Normalized center coordinate distribution of labeled box; (b) labeled box distribution.
Evaluation indicators
In this paper, the main evaluation metrics for the model are mAP, MSE, number of parameters (Params), number of floating point operations per second (FLOPs), and FPS.
The mAP metric assesses the accuracy of the target detection model in terms of both category and location localization. It is calculated based on the combined precision (P) and recall (R). A higher mAP value indicates better detection accuracy of the model. The formulas are given in Eqs. (15) through (17).
where TP represents the number of positive category samples predicted as positive categories by the model; FN represents the number of positive category samples predicted as negative categories by the model; FP represents the number of negative category samples predicted as positive categories by the model; \({\text{P}}_{\text{i}}\) denotes the precision of the target of the i-th category; \({\text{R}}_{\text{i}}\) is the recall of the target of the i-th category; and \({\text{n}}_{\text{c}}\) is the number of categories.
MSE is used to assess the degree of deviation from the centroid, calculating the expected value of the square of the distance between the center of the prediction box and the center of the labeled box, the smaller the MSE, the higher the degree of accuracy of the model localization. The formula is:
where n denotes the number of typhoons.
The number of params refers to the total number of all trainable parameters in the model, usually in millions (M); FLOPs denotes the number of floating-point operations per second, which is used to measure the computational complexity and efficiency of the model; and FPS stands for the number of images detected by the model per second, which is usually considered to be greater than 30 to indicate that the model meets the real-time detection function. With these three metrics, we can more comprehensively evaluate the actual effect of the TGE-YOLO model in terms of performance optimization.
The average latitude and longitude error is used as an evaluation metric on the test set to assist in assessing the feasibility of the model, and the average latitude and longitude error is formulated as follows:
where \({\text{c}}_{\text{i}}\) represents the longitude or latitude coordinate of the i-th typhoon predicted by the model, and \({\text{c}}_{\text{i}}^{\text{gt}}\) represents the true longitude or latitude coordinate of the i-th typhoon.
Latitude and longitude represent spherical coordinates, and the average latitude and longitude errors are generally calculated using Haversine’s formula to calculate the spherical distances between each pair of latitude and longitude, and then averaging these distances to obtain a more accurate measure of error. The formula for calculating the average latitude and longitude error is as follows:
Among them, \({\text{R}}\) represents the radius of the Earth, which is generally 6371.009 km. \(lat\) and \({lat}^{gt}\) represent the predicted latitude and true latitude, respectively. \(lon\) and \({lon}^{gt}\) represent the predicted longitude and true longitude, respectively. \({d}_{i}\) represents the error distance of the i-th pair of latitude and longitude coordinates.
Experimental environment configuration
The experimental parameter configuration of this paper is shown in Table 1. The training parameters are set as follows: the image size is 640 × 640, the training epoch is 200, the batch size is 16, and the Stochastic Gradient Descent (SGD) method is used for training, and the other parameters are used as default values.
Results
Ablation experiment
To verify the effectiveness of the improved model proposed in this paper in typhoon localization, YOLOv8n is used as the baseline model, and the results of the ablation experiments are shown in Table 2, where A denotes the YOLOv8n model, B denotes the TFAM_concat module, C denotes the GSConv module, and D denotes the E-EIoU Loss. All ablation experiments have been performed in the same experimental environment with the same experimental configuration parameters. From the results of the ablation experiments, we can see that the After adding TFAM_Concat as the feature fusion module of the model in the neck network to construct the T-YOLO model, the TFAM_Concat module is able to adequately fuse the multi-scale feature information, which enhances the model’s ability to represent the target features, the mAP is improved by 5.8% and the MSE is reduced by 33.3% compared to Baseline, which indicates that the module effectively enhances the model to perform feature fusion and thus improves the accuracy of typhoon localization.
In the G-YOLO model, the use of GSConv instead of the traditional convolutional module, the amount of parameters is reduced by 9.3%, FLOPs are reduced by 6.2%, FPS reaches 476.2, which is an improvement of 9.5%, while mAP is improved by 5%. This indicates that the GSConv module improves feature extraction efficiency by optimizing the grouping strategy and channel mixing of convolution kernels, and preserves or even enhances the model’s expressive power while reducing computational costs. This improvement effectively strengthens the correlation mining between features, enabling the network to achieve lightweight while ensuring performance.
In the E-YOLO model, the improved E-EIoU Loss replaces the CIoU of the original model, and the MSE is reduced by 10.6%. The key to this improvement is that E-EIoU Loss pays more attention to the shape and position characteristics of the target box during the optimization process. By reshaping the error distribution, the deviation of typhoon center positioning is reduced, and the improved loss function is more suitable for typhoon positioning tasks, improving the convergence speed and prediction accuracy of the model.
In the TG-YOLO model, it integrates the advantages of the T-YOLO model in terms of accuracy and the G-YOLO model in terms of lightweighting, and compares it with Baseline, it reduces the computation amount at the same time, the mAP is improved by 7.4% and the MSE is reduced by 35.9%;
TE-YOLO model and GE-YOLO model, the performance is good, compared to Baseline, the mAP is improved by 5.9% and 5.2%, and the MSE is reduced by 30.3% and 35.3%, respectively. This indicates that a single improved module still has a significant effect on improving model performance, but its effect is slightly inferior to joint optimization of multiple modules;
Lastly, the TGE-YOLO model constructed by fusing all the improved modules effectively balances the model’s accuracy and lightweight, without changing the computational amount, sacrificing a small amount of FPS in exchange for a mAP of 87.8% and a reduction of MSE to 0.115. Compared with the Baseline model, the mAP is improved by 11.0%, the MSE is reduced by 41.9%, and the parameter amount is reduced by 3.32%. The model achieves the optimal comprehensive performance between accuracy and lightweighting. The improved TFAM_Concat, GSConv, E-EIoU Loss and other modules work together to enhance the performance of the model from three dimensions: feature fusion, computational complexity, and localization accuracy.
In order to further validate the effectiveness of each module of the TGE-YOLO model, this paper adopts the Grad-CAM30 technique to compare the feature mapping by replacing the network models with different modules, as shown in Fig. 7. Comparing the feature mapping diagrams of T-YOLO, G-YOLO, E-YOLO and Baseline, T-YOLO significantly outperforms Baseline in terms of feature extraction capability.By introducing the TFAM_Concat module, the model further enhances the feature fusion effect, resulting in a richer representation of the feature maps. This improvement not only improves the recognition ability of the model, but also enhances the sensitivity and accuracy of the target object. The GSConv module in G-YOLO significantly improves the detection accuracy while reducing the complexity of network structure and computational load. However, G-YOLO focuses on the target mainly on the edge region of the typhoon, while T-YOLO is able to better focus on the key features of the target. This difference makes T-YOLO perform superior in detecting critical features. In the E-YOLO model, the introduced E-EIoU Loss significantly improves the model’s focus on the typhoon center. Compared to other models, E-YOLO is able to locate and focus on the location of the typhoon center more accurately, which improves the detection accuracy and reliability. This improvement makes E-YOLO more effective and accurate in handling typhoon detection tasks.

Comparison of Feature Maps of each module.
The comprehensive comparison results show that the TFAM_Concat module and the GSConv module are able to effectively integrate the global information and extract more target features, thus generating richer feature maps. And E-EIoU Loss significantly improves the model’s focus on the typhoon center. Finally, by comparing the feature mapping of TGE-YOLO with other modules, it is found that TGE-YOLO can effectively reduce the background interference, and its extracted features are more focused on the target, which indicates that TGE-YOLO has significantly improved its feature extraction and analysis capabilities.
Comparison experiments
Typhoon localization needs to satisfy two requirements: one is to accurately identify the typhoon in complex cloud maps, and the other is to accurately locate the center of the typhoon. In this paper, we have conducted comparative experiments from these two aspects, comparing Faster R-CNN, YOLOv5s, YOLOv8n, YOLOv9s, and YOLOv11n, and evaluating their performance. In order to further demonstrate the advantages of TGE-YOLO’s in typhoon recognition, all experiments are tested on the same hardware equipment and are trained using the typhoon data in this paper to ensure the fairness and reliability of the experiments.
The experimental results are shown in Table 3, TGE-YOLO performs the best in P and mAP, reaching 90.1% and 87.8%, respectively, with P 27.2 percentage points, 11.8 percentage points, 8.8 percentage points, and 3.4 percentage points higher than other models, and mAP improved by 1.6%, 10.2%, 8.7%, and 3.3% compared to other models, which is significantly better than other models, indicating that TGE-YOLO can provide high accuracy and comprehensive coverage in detecting targets with fewer false alarms; in terms of R metrics, TGE-YOLO also performs well at 85.8%, second only to Faster R-CNN, showing its sensitivity to capturing all positive examples and reducing underreporting; In addition, TGE-YOLO’s Param and FLOPs are only 2.91 M and 8.1G, respectively, second only to YOLOv11, indicating that its model is more lightweight and suitable for resource constrained and real-time demanding application scenarios. Taken together, TGE-YOLO significantly reduces the number of parameters and computation volume of the model while maintaining high precision and high recall, demonstrating excellent comprehensive performance. Its excellent performance in various aspects makes it a very promising target detection model in practical applications.
The comparison of the misdetection effect in Fig. 8 shows that the model in this paper demonstrates its excellent performance in dealing with a variety of complex scenarios compared to Faster R-CNN, YOLOv5s, YOLOv8n, and YOLOv9s for typhoon detection in satellite cloud maps. For group (a), the model is able to accurately identify the typhoon under the interference of multiple typhoons and other clouds; in group (b), the model is still able to accurately locate the typhoon even if the typhoon shape is small and inconspicuous and there are other rotating clouds; in group (c), the model is able to identify the typhoon efficiently in a loose cloud environment during the typhoon generation period; and in group (d), faced with the obvious shape of the typhoon and the surrounding loose cloud mass, the model still maintains a very low false detection rate. In terms of false detection, the performance of this model is comparable to the current state-of-the-art YOLOv11.

Comparison of false detection effects of typhoon detection. (a) there are multiple typhoons with interference from other clouds; (b) typhoons with small and inconspicuous shapes and the presence of other rotating clouds; (c) typhoons in the generative phase with loosely shaped clouds; (d) typhoons with conspicuous shapes but surrounded by other loosely shaped clouds.
In the comparison of leakage detection effects in Fig. 9, Faster R-CNN, YOLOv5s, and TGE-YOLO are able to detect loosely shaped typhoons, but Faster R-CNN, and YOLOv5s all show misdetection; when there are typhoons with one obvious shape and one loose shape in the cloud map, YOLOv5s and YOLOv8n pay more attention to the obviously shaped typhoon and ignore the loosely shaped typhoon; when there are multiple cloud masses in the cloud map, TGE-YOLO is less likely to have miss-detections; moreover, TGE-YOLO is effective in detecting the typhoon with a smaller target; the comparison of miss-detection effects in Fig. 7 reveals that the model in this paper is more effective in detecting typhoons in satellite cloud maps compared to the models in Faster R-CNN, YOLOv5s, YOLOv8n, YOLOv9s, and YOLOv9s. for typhoon detection in satellite cloud maps, it shows significant improvement in solving the leakage detection problem. Compared with YOLOv11, the proposed model also demonstrates high stability and notable superiority.

Comparison of missed detection effects of typhoon detection. (a) the clouds are loosely shaped; (b) there are multiple typhoons in the picture, the typhoons are close to each other, and the typhoons are interacting with each other; (c) the clouds are small and their shapes are not obvious; (d) one typhoon has an obvious shape and one has a loose shape.
In order to further verify the feasibility of the TGE-YOLO model proposed in this paper in terms of center location, this paper conducts experiments on the test set to compare the center output of the labeled frame and the latitude and longitude of the typhoon from the CMA, which results in the average error in latitude and longitude of typhoon localization, as shown in Table 4, Compared with Faster R-CNN, YOLOv5s, YOLOv8n, YOLOv9s, and YOLOv11, the proposed model demonstrates the best performance in terms of average longitude and latitude errors. Specifically, the longitude error is the lowest at 0.17, with reductions of 0.2, 0.26, 0.45, 0.24, and 0.12 compared to the other models. Similarly, the latitude error is reduced by 0.12, 0.12, 0.51, 0.03, and 0.01, respectively. These results indicate that the proposed model exhibits significant advantages in center localization accuracy, as well as higher reliability and practicality.
Typhoon cloud maps of Typhoon Doksuri from 12:00 on July 20 to 00:00 on July 29 and satellite cloud maps of Typhoon Koinu from 00:00 on September 29 to 18:00 on October 9 are selected as experimental samples to visualize and compare the fitting errors of Typhoon Doksuri in 2023, with a total of 79 samples. A total of 79 cloud images are used as experimental samples to visualize and compare the fitting errors. The trans-dimensional error comparison is shown in Fig. 10 and Fig. 11, and it can be seen that compared with other models, TGE-YOLO has the smallest error fluctuation range, which indicates that the model performs more stable and consistent when dealing with data from different situations and different time periods, and the smaller error fluctuation range also indicates that TGE-YOLO has better robustness, which is able to deal with the noises and outliers in the data more efficiently and provide The TGE-YOLO localization fitting results are shown in Fig. 12, (a) for the Doksuri coordinate fitting effect and (b) for the Koinu coordinate fitting effect. The coordinate fitting results show that the model fits best with low deviation during the development and maturity phases of the typhoon, while the model deviation is larger during the generation and demise phases of the typhoon, indicating that the model still needs to be further improved during these phases.

Comparison of longitude error. (a) Doksuri; (b) Koinu.

Comparison of latitude error. (a) Doksuri; (b) Koinu.

Positioning fitting effect. (a) Doksuri; (b) Koinu.
To further demonstrate the significant advantages of the proposed TGE-YOLO model in typhoon localization tasks, this paper has compared and analyzed its performance and detection effectiveness against typical segmentation models, including UNet, Swin-T, and VM-UNet. The performance comparison is presented in Table Table 5.. As shown, TGE-YOLO has achieved the lowest Param and ranks second only to VM-UNet in terms of FLOPs, thereby showcasing its efficiency and lightweight design.
From the typhoon detection comparisons illustrated in Fig. 13, it is evident that the typically blurry boundaries of typhoons have led to significant differences in the segmentation performance of various models. UNet, as a pixel-level segmentation method, struggles to capture the overall contour of typhoons and is prone to over-segmentation at the boundaries. Swin-T and VM-UNet, by contrast, exhibit better control over the overall shape of typhoons and deliver more accurate segmentation results. However, these segmentation models generally fail to effectively locate the center of typhoons, as they primarily focus on boundary segmentation of typhoon areas.

Comparison of typhoon detection effects. (a) UNet; (b) Swin-T; (c) VM-UNet; (d) TGE-YOLO.
In contrast, TGE-YOLO not only identifies typhoon areas but also accurately locates their centers. Combined with its lightweight structure and efficient computational performance, TGE-YOLO better satisfies the practical requirements of typhoon localization tasks, demonstrating superior adaptability and clear advantages for such applications.
Conclusions
In order to accurately and automatically monitor and locate typhoons, and make full use of the features of satellite cloud maps, this paper proposes an efficient typhoon localization algorithm, TGE-YOLO, based on the YOLOv8n model. Firstly, this paper innovatively designs the TFAM_Concat module, through which the differences and commonalities of the features at different levels are fully explored and utilized, thus enhancing the fusion ability of the features at each level; secondly, the GSConv convolution is introduced, which effectively reduces the computational cost of the model, while realizing the efficient aggregation of the global information; and finally with respect to the characteristics of typhoon center positioning, the This paper designs the E-EIOU Loss function, which can capture the center position of the typhoon more accurately and further improve the positioning accuracy. In summary, this paper fully demonstrates the comprehensive innovation results under the synergistic effect of various modules by comprehensively optimizing the three aspects of feature fusion, computational efficiency and positioning accuracy. After a series of experiments, the TGE-YOLO model is used to realize the positioning of the typhoon, which fully verifies the feasibility and effectiveness of the model in this field.
The typhoon model used in this study has been best fitted during the maturation period, showing low deviation. However, the model bias is higher during the generation and decay periods of the typhoon. This phenomenon may be attributed to the following aspects: only satellite cloud map data of the IR1 channel are used in this study, and the typhoon generation and dissipation processes are affected by a variety of factors, which may not be fully reflected by a single IR1 channel data; data of other channels, such as the water vapor channel, the visible channel, and the microwave sounding data, are not included in this study, which leads to the poor performance of the model in these phases; the current models may not adequately consider the complex dynamics of typhoons during the generation and dissipation phases. The generation phase involves the gradual development of tropical depressions, while the demise phase may be affected by a variety of external environmental factors, such as changes in sea surface temperatures, wind shear, etc., which are not adequately represented in the current models. In order to further improve the accuracy of the typhoon model, especially the fitting effect during the generation and dissipation periods, future studies can improve the model in the following aspects: Combine the data from other satellite channels, such as the water vapor channel, the visible channel, and the microwave sounding data, in order to provide more comprehensive information on typhoon characteristics. Introducing more physical parameters, such as sea surface temperature, wind shear, etc., and enhancing the model’s ability to detect typhoons during their generation and dissipation periods by resorting to kinetic methods.
Data availability
Data or code presented in this study are available request from the corresponding author.
References
Wang, K., Yang, Y., Reniers, G. & Huang, Q. A study into the spatiotemporal distribution of typhoon storm surge disasters in China. Nat. Hazards 108, 1237–1256 (2021).
Hu, Y. & Zou, X. Determining tropical cyclone center and rainband size in geostationary satellite imagery. Remote Sens. 14(14), 3499 (2022).
Zhang, G., Xu, C., Li, X., Zhu, Z. & Perrie, W. Tropical cyclone center and symmetric structure estimating from SMAP data. IEEE Transactions Geosci. Remote Sens. 60, 1–11 (2022).
Shin, Y., Lee, J., Im, J. & Sim, S. An advanced operational approach for tropical cyclone center estimation using geostationary-satellite-based water vapor and infrared channels. Remote Sens. 14(19), 4800 (2022).
Wang, Y. et al. An automatic algorithm for estimating tropical cyclone centers in synthetic aperture radar imagery. IEEE Transactions Geosci. Remote Sens. 60, 1–16 (2021).
Ronneberger, O., Fischer, P., & Brox, T. U-net: Convolutional networks for biomedical image segmentation. Medical image computing and computer-assisted intervention–MICCAI 2015. 18, 234–241 (2015).
Liu, Z., et al. Swin transformer: Hierarchical vision transformer using shifted windows. In Proc. of the IEEE/CVF international conference on computer vision. 10012–10022 (2021).
Ruan, J., & Xiang, S. VM-UNet: Vision mamba unet for medical image segmentation. Preprint at https://arxiv.org/abs/2402.02491 (2024).
Ren, S., He, K., Girshick, R. & Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process Sys. 28, 91–99 (2015).
He, K., Gkioxari, G., Dollár, P., & Girshick, R. Mask R-CNN. In Proc. of the IEEE international conference on computer vision. 2961–2969 (2017).
Kızıloluk, S. & Sert, E. Hurricane-Faster R-CNN-JS: Hurricane detection with faster R-CNN using artificial Jellyfish Search (JS) optimizer. Multimed. Tools Appl. 81(26), 37981–37999 (2022).
Pal, S. K., Biswas, S. & Dutta, D. Granulated mask RCNN and eye detection index (EDI) for detection and localization of eye of tropical cyclone from satellite imagery. J. Data, Inf. Manag. https://doi.org/10.1007/s42488-024-00128-x (2024).
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. You only look once: Unified, real-time object detection. In Proc. of the IEEE conference on computer vision and pattern recognition. 779–788 (2016).
Bochkovskiy, A., Wang, C. Y., & Liao, H. Y. M. Yolov4: Optimal speed and accuracy of object detection. Preprint at https://arxiv.org/abs/2004.10934 (2020).
Glenn, J. et al. YOLOv5, http://github.com/ultralytics/yolov5 (2021).
Ge, Z., Liu, S., Wang, F., Li, Z., & Sun, J. Yolox: Exceeding yolo series in 2021. Preprint at https://arxiv.org/abs/2107.08430 (2021).
Wang, C. Y., Yeh, I. H., & Liao, H. Y. M. Yolov9: Learning what you want to learn using programmable gradient information. Preprint at https://arxiv.org/abs/2402.13616 (2024).
Khanam, R., & Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. Preprint at https://arxiv.org/abs/2410.17725 (2024)
He, M. C. & Jiang, G. M. Typhoon identification and positioning using the FY-4A AGRI thermal infrared data. J. Phys: Conf. Ser.IOP Publ. 2400(1), 012027 (2022).
Long, T., Fu, J., Tong, B., Chan, P. & He, Y. Identification of tropical cyclone centre based on satellite images via deep learning techniques. Intl. J. Climatol. 42(16), 10373–10386 (2022).
Zhao, S., Zhang, X., Xiao, P. & He, G. Exchanging dual-encoder–decoder: A new strategy for change detection with semantic guidance and spatial localization. IEEE Transactions Geosci. Remote Sens. 61, 1–16 (2023).
Li, H., et al. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. Preprint at https://arxiv.org/abs/2206.02424 (2022).
Zhang, Y. F. et al. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing. 506, 146–157 (2022).
Wang, Q., et al. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proc. of the IEEE/CVF conference on computer vision and pattern recognition, 11534–11542 (2020).
Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proc. of the IEEE conference on computer vision and pattern recognition. 1251–1258 (2017).
Du, S., Zhang, B., Zhang, P., & Xiang, P. An improved bounding box regression loss function based on CIOU loss for multi-scale object detection. In 2021 IEEE 2nd International Conference on Pattern Recognition and Machine Learning (PRML) .92–98 IEEE, (2021).
Yang, H. Q. & Yang, Y. M. Progress of objective localization methods for satellite remote sensing of tropical cyclones. J. Trop. Oceanogr. 31(2), 15–27 (2022).
Ying, M. et al. An overview of the China meteorological administration tropical cyclone database. J. Atmos. Oceanic Technol. 31(2), 287–301 (2014).
Lu, X. et al. Western North Pacific tropical cyclone database created by the China meteorological administration. Adv Atmos. Sci. 38, 690–699 (2021).
Selvaraju, R, et al. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proc. of the IEEE international conference on computer vision. 618–626 (2017).
Author information
Authors and Affiliations
Contributions
All authors contributed substantially to the manuscript.L.H. designed the experiments and wrote the main manuscript.L.X., P.Y. and S.L. provided some ideas and suggestions, and S.L. helped with the format review and editing of the paper.All authors have read and agreed to the publication of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
He, L., Xiao, L., Yang, P. et al. Typhoon localization detection algorithm based on TGE-YOLO. Sci Rep 15, 3385 (2025). https://doi.org/10.1038/s41598-025-87833-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-87833-8
