
Abstract
Air as an inert gas is usually applied for homogenization and mixing liquids. In the current research, we study a 3-D bubble column reactor (BCR) filled with water by using an Artificial intelligence algorithm (AI) and CFD. We used one of the adaptive networks and fuzzy inference systems (ANFIS) to study fluid flow and see its effect on the accuracy of the AI. Therefore, the Gaussian membership function was used to have a prediction in the 3-D BCR. Also, the grid partition system was used to cluster the data. The number of membership functions increases in the training process of the AI system, from 2 to 5. The influence of input numbers on AI data prediction is analyzed. The four inputs in the training process included air velocity and pressure, as well as the x-direction and z-direction. Finally, air vorticity was considered as the output parameter of the study in the predictions. Correlations were developed to predict the air vorticity in each node using x and z direction, air velocity, and pressure. The results showed the AI accuracy increased by the rise of membership and input numbers. The AI intelligence level was found by five memberships and four inputs. The AI and CFD were in suitable agreement (regression number around 1). The developed correlations could simplify the calculation of air vorticity instead of using the complicated and time-consuming CFD simulation. As far as the authors know, there are no studies that have developed correlations to find the air vorticity in bubble column reactors.
Similar content being viewed by others

Nomenclature.
Roman symbols.
\(\:{\text{M}}_{\text{I}}\) Interfacial force,\(\:\left(\text{N}\right)\)
\(\:{\text{M}}_{\text{T}\text{D}}\) Turbulent dispersion force,\(\:\left(\text{N}\right)\)
\(\:{\text{M}}_{\text{D}}\) Drag force,\(\:\left(\text{N}\right)\)
\(g\) Gravitational acceleration,\((\text{m}/\text{s}2\:)\)
\(k\) Turbulent kinetic energy,\(({\text{m}}^{2}/{\text{s}}^{2})\)
\(p\) Static pressure,\(({\text{N}}/{\text{m}}^{2})\)
\(\:{\text{u}}_{k}\) bubble or liquid velocity,\((\text{m}/\text{s})\)
Greek Symbols.
\(\:{\in\:}_{k}\) bubble or liquid volume fraction
\(\:\epsilon\:\) Dissipation rate of turbulence kinetic energy,\(\:({\text{m}}^{2}/{\text{s}}^{3})\)
Subscripts.
\(\:G\) gas/bubble phase
\(\:L\) Liquid phase
Introduction
Feeding air in a cylindrical water reservoir is applied as a tool for mixing and homogenizing hydrodynamics parameters. A two-phase bubble column is a multiphase reactor with a gas phase spread in a liquid phase as the “coalescence-induced” or dispersed bubbles. An interface separates the two phases in which the interfacial transport phenomena might happen. A vertical cylinder is included in the simplest bubble column configuration where the gas is inserted at the bottom via a gas sparger while supplying the liquid phase in a batch manner. However, it might result in counter-currently or co-currently toward the upward gas stream. In spite of the simple bubble column plan, coupling, and multifaceted fluid dynamics contacts exist within the phases, revealing in the dominant flow trends1.
A bubble column has many benefits, including decent mass and heat transfer, ease of operation, no moving parts, and low maintenance and operating expenses. Back mixing is the main shortcoming of bubble column reactors, adversely affecting product conversion. Momentum is conveyed in these reactors from the faster gas phase moving upward to the slower liquid or slurry phase. The acting liquid superficial velocity (within 0–2 cm/s) is slower compared to the superficial gas velocity (1–50 cm/ s). Therefore, the gas flow mainly controls such as reactors’ hydrodynamics. Mostly, two flow regimes exist in the bubble columns with relatively big diameters, i.e., heterogeneous and homogeneous2.
The numerical methods have been utilized so far in numerous investigations for predicting the bubble column reactors as a result of some problems still existing in scaling up and designing the bubble columns3,4,5. Through computational fluid dynamics (CFD), our partial information regarding the complex hydrodynamic procedures happening in the bubble column is enhanced6. There are several models for interphase turbulence and forces in the literature7,8,9,10. For example, Gupta et al. studied the lift force, turbulent dispersion drag force and added mass model3,11,12. Moreover, various turbulence models such as the standard k–ɛ model, Large Eddy Simulation (LES), and Reynolds Stress Model were utilized for forecasting flow patterns into the bubble column13,14,15,16. RSM and LES models are favored among existing turbulence models as a result of a more precise prediction of the gas hold-up, swirling flow, and velocity into the bubble column. However, using the LES model can be very time-consuming and expensive, and we can not use this model during optimization or scale-up of the bubble column reactor. Recently many studies17,18 have been developed for prediction of bubble column reactors with a combination of CFD and AI with significantly less amount of computational time. This tool is a promising framework for scale-up and optimization of the bubble column reactor.
Currently, adaptive neural network-based fuzzy inference system (ANFIS) was run to simulate the flow pattern within bubble column reactors. Pourtousi et al.19utilized the information regarding the hydrodynamics of the multiphase reactor for the training stage. They indicated that the CFD combined with ANFIS is an excellent instrument for estimating BCR behavior. It was found that the ANFIS algorithm is a proper technique instead of CFD approaches for simulating bubble flow into the BCR for the homogeneous flow regime, indeed with almost equal bubbles with velocity and spherical shape. They specifically model the reactor with different sparger specifications, such as sparger diameter, and they suggested a new framework to optimize the process without participating in the CFD method during optimization. This algorithm has been extended by different researchers, and they optimize the AI by tuning AI parameters20,21. For example, Babanezhad et al.22 found that the number of input parameters can significantly change the accuracy of the AI method and time of training of the CFD data set. However, there is still a question about the impact of functions on the accuracy of the method when the number of input and membership functions is changing.
There is no study to predict the air vorticity in bubble column reactors using CFD and AI learning. The value of air vorticity could help engineers and designers for finding the mixing and disturbance in bubble reactors. In this study, the Difference between two sigmoidal membership functions (dsigmf) was used in the training stage, and four inputs, including x-direction, z-direction, air velocity, and pressure, and one output (air vorticity), were used during training mode. Five membership functions were used to study the system’s accuracy with different patterns of inputs. Data clustering in the system was a grit partition that was used together with the membership function. We also used local node comparison for the data set to compare the AI domain with the CFD domain as a pattern recognition method. After finding the intelligence level of the AI algorithm, correlations are developed for the first time to find the air vorticity as a function of air and pressure for each node.
Method
CFD method
The two-phase model was designed based on the Eulerian-Eulerian approach and was utilized to simulate the gas-liquid interaction using ANSYS CFX23. This approach considers each phase as a continuum in the domain. Ensemble-averaged mass and momentum transport equations for each phase are the bases of the Eulerian modelling framework functions.
Continuity equation:
Momentum transfer equation:
The interphase drag force and turbulent dispersion force rule the total interfacial force between the two phases, which is:
Tabib et al. gave a detailed description of interfacial force models used in the present study11. In addition to the interfacial forces, the turbulence model is among the key factors that represent the hydrodynamic properties of the bubble column. The K–ε model has been widely used in the past two decades to explain the flow pattern in the bubble columns. The model is economical and reliable enough, given its smile design and low computational needs. Here, the turbulence model was used for the whole simulation. The parameters of the model were the same as those of Pourtousi et al.24.
Geometrical structure
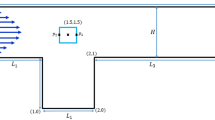
Following Pfleger and Becker13, a cylindrical bubble column reaction, 2.6 m in height and 0.288 m in diameter was used (see Fig. 1). The superficial velocity of the gas was 0.008 m/s at room conditions. Further information about boundary conditions (e.g., walls and outlet pressure) is available in Pfleger and Becker13. Moreover, the boundary condition of the inlet is the same as that of Tabib et al.11.
Figure 1.

Geometry of case study.
Grid
Throughout the domain, as shown in Fig. 2, a structured grid designed based on a hexahedral grid was utilized. Comparison of local gas hold-up from CFD results (Grids 1, 2, and 3), numerical data from Pfleger and Becker13, and data from Pourtousi et al.25, measured at heights 0 to 0.5 m with a bubble diameter of 4 mm has been done (see Fig. 3). Among several grid sizes, the results show that the number of 1,250,000 control volumes (grid 1) is needed for mesh-independent results.
presents a comprehensive validation study comparing the relationship between gas hold-up and superficial gas velocity across multiple research works. The mathematical correlation developed by Joshi & Sharma26is represented by a solid blue line, showing a nearly linear increase in gas hold-up with superficial gas velocity. This trend is corroborated by both experimental (triangular markers) and numerical (square markers) data from Pfleger & Becker13, which demonstrate good agreement with the theoretical prediction, particularly at lower velocities (0–0.01 m/s), with slight experimental deviations at higher velocities (0.015–0.02 m/s). The more recent numerical simulation by Pourtousi et al.27, depicted by a red line with circular markers, aligns remarkably well with both the historical correlation and Pfleger & Becker’s data, validating the consistency of computational approaches over time. The current study’s results, represented by multiple numerical simulation points, fall precisely along these established trends, particularly matching the numerical predictions of previous studies, thereby demonstrating the reliability and accuracy of the present computational approach in predicting gas hold-up behavior in bubble column systems. Additionally, the current study shows the linear relationship between flow rate and gas bubble concentration in bubble columns, which is in strong agreement with previous experimental, mathematical, and numerical studies.
According to Table 1, the MAE error approaches zero in comparison with Pourtousi et al.‘s27study, while showing an approximate value of 0.003 when compared to the mathematical correlations of Pfleger and Becker13and Joshi and Sharma26.

Grid structure of case study.
Figure 4.
ANFIS (Adaptive network fuzzy inference system)
The network structure of ANFIS includes two sectors known as the consequence and premise parts. Training ANFIS indicates determining the parameters related to these parts using an optimization algorithm. Through ANFIS, the present input-output data pairs are used overtraining, IF-THEN fuzzy rules are then attained to connect these parts28.
The schematic of ANFIS’s structure includes five layers, which are provided in Fig. 5. The ANFIS structure involves two inputs and one output, as well as four rules and four membership functions. Based on the ANFIS structure in the figure, the layer structure of ANFIS is clarified in the following.
Figure 5.
First Layer.
This section is known as the fuzzification layer, which utilizes membership functions to attain fuzzy clusters from input values. The parameters, such as the type of membership function along with these parameters, are known as the premise parameter29. To calculate each membership function’s membership levels, these parameters are used, as provided in (4) and (5). µij represents the membership levels attained from this layer and aij1, cij1, aij2, and cij2 are dsigmf constant parameters where Xi indicates inputs data (X1 = x-direction, X2 = C-direction, X3 = Vg, X4 = P), i is an indicator of inputs (1 to 4) and j is the number of input MFs (1 to 5).
Second Layer.
This layer is known as the rule layer. Firing strengths (wk) for the rules are created utilizing membership values calculated in the fuzzification layer. Multiplication of the membership values results in wk values as follows.
Third Layer.
This layer is termed the normalization layer, which determines normalized firing strengths related to each rule. The normalized value is the ratio of the firing strength of the kth rule to the overall firing strengths, as provided in (7).
Fourth Layer.
This layer is known as the defuzzification layer, where weighted values of rules are determined in each node of this layer as in (8). The first-order polynomial is used to calculate this value.
\(\:\stackrel{-}{{\omega\:}_{k}}\)represents the normalization layer output30.
Fifth Layer.
It is termed the summation layer, where the real output of ANFIS is attained by summation of the outputs attained for each rule within the defuzzification layer.
Results
For the prediction of the fluid in the BCR, we used the dsigmf membership function for the training process. This membership function was studied with various inputs and membership functions to see how the system sends its intelligent signals.
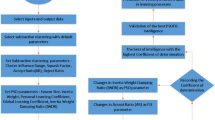
The flowchart in Fig. 6 delineates a methodical approach to utilizing ANFIS for predicting air vorticity surfaces from CFD data, encompassing the selection of critical fluid characteristics (x and z direction, air velocity, and pressure) as ANFIS inputs, the implementation of grid partition clustering for generating the primary Fuzzy Inference System (FIS) and defining input membership functions, the meticulous setting of FIS and clustering parameters (including data allocation for training, iteration counts, and membership function specifications), followed by an iterative process of ANFIS training, error recording, and strategic adjustments to input variables and membership functions, culminating in the selection of the most intelligent model based on error minimization and determination coefficient maximization, which is then validated and applied to predict air vorticity surfaces across diverse input scenarios.
Figure 6.
The bubbles are created from the sparger orifices by using the air pressure inserted into its sparger and the pressure difference in the BCR. The flow can have different forms, such as homogeneous or heterogeneous. If the flow is in the former form, we can see the bubbles that have similar sizes and insignificant interactions with each other, but the latter flow has significant interaction among bubbles, meaning that the amount of merging and breaking up is high. Due to turbulence flow inside the BCR, the pieces of bubbles can have different sizes.
In the current research paper, we study a homogenous flow; therefore, the complexity of the flow in the study is not high. Moreover, we can see how we can perform an AI system entirely in the BCR. Firstly, the BCR could be studied via CFD methods, and the solving is possible through final volume methods designed in parallel. After solving and post-processing the CFD-created data, we could create data sets that are the input and output matrixes, enabling us to have input and output for the data sets. By having the data sets originate from input and output data, we could create a training domain. In the current research, we used the dsigmf function for the training process by using different inputs and membership functions. The errors that originate from AI and CFD could be compared to see the differences in the fluid flow in the AI and CFD domains. For the training process, we used 70% of the data, and for testing the data, the remaining 30% plus the used 70% in the training process was used for comparison of the data in AI and CFD. For the iterative algorithm, we had about 200 steps, and the AI system reached a kind of convergence, meaning that we did not need training for the system anymore. Furthermore, the dsigmf function was used in training, and for data clustering in the system, grid partition was used together with the membership function. As mentioned earlier, we used up to 5 membership functions for studying the accuracy of the system, and we applied four inputs for the training of the system, which are x-direction, z-direction, air velocity, and pressure in the BCR. Moreover, the only output of the study is the vorticity of air.
As shown in Fig. 7a, after considering 70% of the data for the training process, the data was compared to CFD. The purpose was to see the amount of error between the AI and CFD data by the calculation of the regression number (R). As shown in the figure, the different numbers of membership functions were used, including 2, 3, 4, and 5. Figure 7a was considered with two numbers of inputs. As shown in the figure, when there are two numbers of membership functions, the regression number (R) is around 0.65, meaning that the predicted value deviates from the real one. By increasing the membership functions to 5, the measure of R approaches 0.98. This means that by increasing the number of membership functions, the predicted data are closer to the CFD data with less deviation.
Figure 7b shows the testing of the data. The remaining percent of the data (i.e.,30%) and 70% of the data used in training is considered in the testing by using CFD. As the training process, the evaluation is done for different membership functions and two inputs. Similar to the training process, the amount of R increases from 0.68 to 0.98.
Figure 7a and b.
As shown in Fig. 8a, the inputs increased to see the changes in the accuracy of the system. In the training process, the inputs increased to 3, and similar to the previous results, the membership functions were considered from 2 to 5. As shown in the figure, when the number of inputs increased to 3, the value’s R increased slowly from 0.95 to 0.998. The same procedure was done for the testing as well, and as seen in Fig. 8b, the AI system overlapped the training results (regression increases from 0.95 to 0.997).
Figure 8a and b.
In Fig. 9a and b, the number of inputs increased to 4, and as said earlier, input 4 was air velocity, which was also added to the system. When one input was added to the system in the training process, the system suddenly showed intelligence and sent its intelligent signals.
Figure 9a and b.
As shown in the Figure, at the beginning of the process, the regression is very high compared to previous conditions (0.96). Nevertheless, we can still train the system better, and therefore, the system can have better accuracy. By increasing the number of membership functions up to 5, the system’s amount of regression increases significantly (roughly 1). Furthermore, the number of elements whose error was low increased, and therefore, the system became very intelligent. In the testing domain, the same procedure was used, and the same results were achieved in both testing and training processes (the regression is around 0.996). Generally, when the testing and training processes overlapped, we could make sure that the training system was suitable because two different procedures were evaluated and compared, so we could ensure that the system had a suitable capacity.
In Fig. 10, a 3-D plot was used to answer some questions. First, how do CFD and AI data overlap each other? Second, do they completely overlap each other? And finally, do they have some differences? The purpose behind them was to find out how the local data matches with its target value and what the differences are. This condition was considered the best intelligence of the system when the number of inputs was four and the membership function was five. Figure 10 shows that after the training and testing processes, the data was used in the prediction process; consequently, some of the points were not predicted accurately compared to the target point however, these single points related to the boundary condition. The same procedure was done for a variety of inputs. It is worth mentioning that this condition referring to the distance of the local points is closely related to the boundary condition of the system, and we need to introduce and change it in CFD and AI system; therefore, we can consider the error of the system. It is also worth mentioning that in AI, there is no description or boundary condition because AI does not have any understanding of our data set. We need to describe and consider those single local points in AI, which can be done by filtering or boundary condition descriptions in the AI domain.
Figure 10.

Finally, Fig. 11 shows the general prediction of the system to see the differences in internal patterns in the system in CFD and AI domains. As shown in the Figure, the complex data set process in CFD can be predicted by ANFIS, and all the complexity and the relationship among the points could be found by AI when the number of input parameters was four and the number of membership functions was five. This point was when the AI sent its intelligent signals, and the system could be used in different boundary conditions.
Figure 11.
Equation ʄ 10 states that neither the dsigmf parameters nor the resulting parameters are known for each cluster. The number of parameters could be found at the highest level of ANFIS intelligence.
The dsigmf function and its parameters are displayed in Table 2. Table 3 lists the dsigmf parameters at the highest level of ANFIS intelligence. Additionally, Table 4 provides the constant parameters for each of the output’s 625 membership functions, which are constant membership function types. Consequently, all of the parameters required for Eq. ʄ 10 have been acquired. The Air Vorticity as a function of x, z, Vg, and P is provided by the developed equation.
After developing these equations, CFD modeling is no longer necessary for air vorticity predictions. This approach reduces both time and computational costs, leading to simplified engineering design and development.
Conclusion
In the current research paper, we studied a 3-D BCR by using CFD calculation. The BCR made a homogenous flow, leading to similar bubbles without any merging (coalescence), break up, and low rate of bubble interactions in the BCR. The AI learning method was used to map CFD generated data set. After mapping the CFD data, relations could be developed between different fluid dynamics parameters. The adaptive networks and Fuzzy functions (ANFIS) were selected for the AI learning. The Gaussian membership function and the grid partition system were used to cluster the data. The sensitive analysis was done by increasing the number of membership functions and inputs. The x-direction, z-direction, air velocity, and pressure are inputs. Air vorticity was considered the output parameter for finding water disturbances. Correlations were developed to predict the air vorticity in each node using x and z direction, air velocity, and pressure.
The results showed that AI accuracy increased with the rise of membership and input numbers. The AI intelligence level was found by five memberships and four inputs. The AI and CFD were in suitable agreement (regression number around 1). The developed correlations could simplify the calculation of air vorticity instead of using the complicated and time-consuming CFD simulation. As far as the authors know, there are no studies to develop correlations to find the air vorticity in bubble column reactors.
Future study
This work is the study of machine learning applications to predict air vorticity using CFD simulation data. The ANFIS setup could be changed by fluctuating the physical boundary conditions and assumptions. In this study, it was aimed to correlate some parameters like vorticity to other fluid dynamics parameters such as pressure and air velocity. Future investigations are needed to use AI machine learning by considering the other fluid dynamics parameters such as bubble size effect and influence of interfacial forces in a bubble column reactor.


schematic of ANFIS structure for two inputs and two rules.

Flowchart of using ANFIS method for predicting CFD result.

(a)Different number of MFs in ANFIS training process (number of inputs = 2, type of MFs is dsigmf) (b)Different number of MFs in ANFIS testing process (number of inputs = 2, type of MFs is dsigmf).

(a)Different number of MFs in ANFIS training process (number of inputs = 3, type of MFs is dsigmf) (b) Different number of MFs in ANFIS testing process (number of inputs = 3, type of MFs is dsigmf).

(a)Different number of MFs in ANFIS training process (number of inputs = 4, type of MFs is dsigmf) (b) Different number of MFs in ANFIS testing process (number of inputs = 4, type of MFs is dsigmf).

Correlation and comparison of CFD results (ANFIS Target) with ANFIS prediction (output).

Comparison of ANFIS prediction(left) with CFD results(right) using the best of ANFIS intelligence.
Data availability
The datasets used and analysed during the current study are available from the corresponding author upon reasonable request.
References
Majumder, S. K. Hydrodynamics and Transport Processes of Inverse Bubbly flow (Elsevier, 2016).
Shaikh, A. & Al-Dahhan, M. H. A review on flow regime transition in bubble columns. Int. J. Chem. Reactor Eng., 5(1). (2007).
Gupta, A. & Roy, S. Euler–Euler simulation of bubbly flow in a rectangular bubble column: experimental validation with Radioactive particle Tracking. Chem. Eng. J. 225, 818–836 (2013).
Darmana, D., Deen, N. & Kuipers, J. Detailed modeling of hydrodynamics, mass transfer and chemical reactions in a bubble column using a discrete bubble model. Chem. Eng. Sci. 60 (12), 3383–3404 (2005).
Deen, N. G., Solberg, T. & Hjertager, B. H. Large eddy simulation of the gas–liquid flow in a square cross-sectioned bubble column. Chem. Eng. Sci. 56 (21–22), 6341–6349 (2001).
Díaz, M. E., Montes, F. J. & Galán, M. A. Influence of the lift force closures on the numerical simulation of bubble plumes in a rectangular bubble column. Chem. Eng. Sci. 64 (5), 930–944 (2009).
Joshi, J. Computational flow modelling and design of bubble column reactors. Chem. Eng. Sci. 56 (21–22), 5893–5933 (2001).
Rafique, M., Chen, P. & Duduković, M. Computational modeling of gas-liquid flow in bubble columns. Rev. Chem. Eng. 20 (3–4), 225–375 (2004).
Zhang, D., Deen, N. & Kuipers, J. Numerical simulation of the dynamic flow behavior in a bubble column: a study of closures for turbulence and interface forces. Chem. Eng. Sci. 61 (23), 7593–7608 (2006).
Monahan, S. M., Vitankar, V. S. & Fox, R. O. CFD predictions for flow-regime transitions in bubble columns. AIChE J. 51 (7), 1897–1923 (2005).
Tabib, M. V., Roy, S. A. & Joshi, J. B. CFD simulation of bubble column—an analysis of interphase forces and turbulence models. Chem. Eng. J. 139 (3), 589–614 (2008).
Díaz, M. E. et al. Numerical simulation of the gas–liquid flow in a laboratory scale bubble column: influence of bubble size distribution and non-drag forces. Chem. Eng. J. 139 (2), 363–379 (2008).
Pfleger, D. & Becker, S. Modelling and simulation of the dynamic flow behaviour in a bubble column. Chem. Eng. Sci. 56 (4), 1737–1747 (2001).
Pfleger, D. et al. Hydrodynamic simulations of laboratory scale bubble columns fundamental studies of the eulerian–eulerian modelling approach. Chem. Eng. Sci. 54 (21), 5091–5099 (1999).
Dhotre, M., Niceno, B. & Smith, B. Large eddy simulation of a bubble column using dynamic sub-grid scale model. Chem. Eng. J. 136 (2–3), 337–348 (2008).
Dhotre, M. & Joshi, J. Two-dimensional CFD model for the prediction of flow pattern, pressure drop and heat transfer coefficient in bubble column reactors. Chem. Eng. Res. Des. 82 (6), 689–707 (2004).
Tian, E. et al. Simulation of a bubble-column reactor by three-dimensional CFD: multidimension-and function-adaptive network-based fuzzy inference system. Int. J. Fuzzy Syst., : pp. 1–14. (2019).
Nguyen, Q. et al. Fluid Velocity Prediction Inside Bubble Column Reactor Using ANFIS Algorithm Based on CFD Input Data.
Pourtousi, M. et al. Prediction of multiphase flow pattern inside a 3D bubble column reactor using a combination of CFD and ANFIS. RSC Adv. 5 (104), 85652–85672 (2015).
Xu, P. et al. Flow visualization and analysis of thermal distribution for the nanofluid by the integration of fuzzy c-means clustering ANFIS structure and CFD methods. J. Vis., : pp. 1–14. (2019).
Cao, Y. et al. Prediction of fluid pattern in a shear flow on intelligent neural nodes using ANFIS and LBM. Neural Comput. Appl. 32, 13313–13321 (2019).
Babanezhad, M. et al. Liquid-phase chemical reactors: development of 3D hybrid model based on CFD‐adaptive network‐based fuzzy inference system. Can. J. Chem. Eng. 97, 1676–1684 (2019).
Ansys, I. Ansys. Inc.: Canonsburg, PA, USA, (2018).
Pourtousi, M. CFD Modelling and Anfis Development for the Hydrodynamics Prediction of Bubble Column Reactor ring Sparger (University of Malaya, 2016).
Pourtousi, M. et al. Effect of ring sparger diameters on hydrodynamics in bubble column: a numerical investigation. J. Taiwan Inst. Chem. Eng. 69, 14–24 (2016).
Joshi, J. A circulation cell model for bubble columns. (1979).
Pourtousi, M., Ganesan, P. & Sahu, J. Effect of bubble diameter size on prediction of flow pattern in Euler–Euler simulation of homogeneous bubble column regime. Measurement 76, 255–270 (2015).
Jang, J. S. ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans. Syst. man. Cybernetics. 23 (3), 665–685 (1993).
Thermal storage. In: ASHRAE handbook. American Society of Heating, Refrig- erating and Air Conditioning Engineers, Inc., Atlanta: HVAC Applications; 2007 [chapter 34].
Wang, H. et al. CFD modeling of hydrodynamic characteristics of a gas–liquid two-phase stirred tank. Appl. Math. Model. 38 (1), 63–92 (2014).
Acknowledgements
The authors extend their appreciation to the Deanship of Scientific Research at Northern Border University, Arar, KSA for funding this research work through the project number "NBU-FFR-2025-2947-01".
Author information
Authors and Affiliations
Contributions
“L.K. wrote the main manuscript text, I.B., M.S.D, B.M.A, and T.A. prepared the AI method, figures, and post-processing, M.B. supervised and final check. All authors reviewed the manuscript.”
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kolsi, L., Behroyan, I., Darweesh, M.S. et al. ANFIS algorithm for mapping computational data of water reservoir homogenization with air bubble flows. Sci Rep 15, 5196 (2025). https://doi.org/10.1038/s41598-025-88316-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-88316-6
Keywords
This article is cited by
-
GPT-based lifelong learning and ANFIS-driven reply memory ratio prediction for aspect-based sentiment analysis
Complex & Intelligent Systems (2025)
