
Abstract
Online hate speech has become a major social problem owing to the rapid growth of Internet communities. Relying on anonymity, people use hateful or abusive language for groups who are different from them. As these terms vary by region and are reflected in local languages, it is important to build robust hate speech detection models for each local language. We propose an ensemble of several Bidirectional Encoder Representations from transformers (BERT)-based models to enhance English and Korean hate speech detection. Parallel Model Fusion (PMF) requires the results of BERT-based models and a final estimator called meta-learner. During each cross-validation, validation and testing results were used to train and test the PMF data. PMF test data are calculated using Majority Voting Integration or Weighted Probabilistic Averaging. Popular machine learning algorithms such as Random Forest, Logistic Regression, Gaussian Naïve Bayes, and Support Vector Machine are employed as meta-learners for PMF. The proposed model outperformed previous studies and the single-model approach in English and Korean, with accuracies of 85% and 89%, respectively, for each dataset. This study demonstrates improved automatic hate speech detection and encourage not only studies on English hate speech detection but also further work on non-English hate speech detection.
Similar content being viewed by others

Introduction
The rapid growth in online communication has enabled people to share their experiences and opinions instantly and anonymously. Anonymity often contributes to an increase in hate speech, which can cause significant harm, both online and in the real world. 7.4 million instances of hate speech were removed from Facebook and 8.6 million from Instagram, reflecting a substantial rise compared to previous data1,2. The consequences of hate speech extend beyond digital platforms, with a previous study revealing that half of those exposed to hate speech experience serious psychological effects, including stress and depression3,4. With the exponential growth of online text data, manual hate speech detection methods have become inefficient, highlighting the need for automated real-time detection systems5.
Recent advances in natural language processing (NLP) using transformer models, particularly BERT, have shown promise for addressing these challenges. These models enable context-aware multilingual detection, thereby improving the ability to identify nuanced hate speech across languages6. Despite these improvements, detecting hate speech, particularly in non-English contexts such as Korean, remains a significant challenge7,8. This study addresses these challenges by proposing an ensemble-learning approach using multiple BERT-based models to enhance detection in both English and Korean, demonstrating the benefits of combining various models to address each model’s weaknesses9.
Related works
Need for hate speech detection
Hate speech frequently targets groups perceived as “different” by the speaker, and the nature of such speech varies significantly across regions10. Addressing these regional and cultural differences in hate speech detection remains a significant challenge in natural language processing (NLP)11. While considerable research has been conducted on hate speech detection in English, there is growing interest in developing models for other languages. English benefits from an abundance of NLP resources, including extensive datasets and pre-trained models, which are often unavailable for many other languages such as Korean12.
Korean poses unique linguistic challenges due to its use of honorifics and context-dependent meanings. The meaning of a word or sentence can shift significantly depending on the social context or intent of the speaker, complicating the development of accurate hate speech detection models13. For instance, phrases that appear neutral, such as “그 사람 참 안됐어” (“That person is really unfortunate”), may carry sarcastic or hateful undertones depending on the context. These linguistic subtleties underline the need for culturally and linguistically sensitive hate speech detection models.
To address these challenges, multilingual models like mBERT have been developed to detect hate speech across multiple languages14. These models attempt to bridge the gap by utilizing shared linguistic structures across languages. Additionally, language-specific models like KoBERT have been tailored to accommodate the unique characteristics of Korean, demonstrating the importance of language-specific adaptations for handling local linguistic features15. By leveraging these advancements, this study aims to enhance hate speech detection for both high-resource (e.g., English) and low-resource (e.g., Korean) languages, addressing gaps in current research and ensuring more comprehensive coverage16.
Recent studies have demonstrated that hybrid approaches combining transformer models like BERT with traditional embedding techniques (e.g., FastText) significantly improve hate speech detection accuracy. By leveraging complementary strengths of each method, these hybrid models are particularly effective for handling nuanced text classification tasks in multilingual settings17.
Hate speech detection approaches
Traditional machine learning methods
Traditional approaches to hate speech detection initially relied on keyword-based methods. While these methods are simple and computationally efficient, they struggle to detect nuanced or implicit hate speech that does not rely on explicitly offensive terms18. Machine learning techniques such as Naïve Bayes (NB), Logistic Regression (LR), and Support Vector Machines (SVM) have been employed to overcome these limitations. These methods use labeled datasets to extract features, enabling improved detection accuracy compared to keyword-based methods19,20,21. However, despite their improvements, these models often fail to capture deeper contextual meanings, particularly in complex or multilingual settings.
Deep learning methods, such as CNN and Bi-LSTM, have shown enhanced performance in hate speech detection tasks by capturing both sequential and localized text patterns. Recent works suggest that combining Bi-LSTM with CNN yields higher classification accuracy, especially in multilingual datasets20.
BERT-based models and recent advances
The advent of transformer-based large language models (LLMs) has redefined the standards for NLP tasks, including hate speech detection. Models such as Bidirectional Encoder Representations from Transformers (BERT), Robustly Optimized BERT Pretraining Approach (RoBERTa), and Bidirectional and Auto-Regressive Transformers (BART) have achieved state-of-the-art performance in various NLP tasks by utilizing advanced bidirectional transformer architectures22,23,24,25.
BERT, in particular, leverages a multi-head self-attention mechanism to capture both left and right contexts within a sentence, enabling a more nuanced understanding of linguistic structures. This ability to assign varying levels of importance to words within a sentence significantly improves the model’s capacity to detect subtle semantic nuances, which are crucial for hate speech detection. When fine-tuned on hate speech datasets, BERT and its derivatives, such as RoBERTa and xlm-RoBERTa, have consistently outperformed traditional machine learning models in terms of accuracy and robustness23,24.
Multilingual models like mBERT have further demonstrated their effectiveness in low-resource languages, such as Urdu, by leveraging shared linguistic features across languages. Similarly, language-specific models like KoBERT have been designed to address the unique linguistic challenges of Korean, such as morphological variations and honorifics. These adaptations make them particularly effective in handling hate speech detection for low-resource languages like Korean26,27,28.
In this study, BERT-based models were fine-tuned using carefully optimized hyperparameters, including a learning rate of 1e-5, batch size of 128, and training epochs up to three. These parameters were determined through extensive experiments to ensure optimal performance across both English and Korean datasets. By building on these advancements, this research highlights the potential of combining multilingual and language-specific models to improve hate speech detection.
Additionally, recent studies have explored the use of BERT embeddings in combination with ensemble learning techniques to enhance model robustness. These approaches utilize diverse ensemble methods such as Weighted Averaging and Majority Voting to improve classification accuracy across varied datasets.
Hybrid models that integrate BERT with other techniques have shown significant improvements in text classification tasks, including rumor and fake news detection. For example, combining BERT embeddings with optimized convolutional neural networks (OPCNN) and FastText embeddings has demonstrated higher classification accuracy by leveraging complementary strengths of each embedding method29.
Adaptive ensemble and Thompson sampling
Ensemble learning has proven to be a powerful approach for enhancing model accuracy by combining the predictions of multiple models. In this study, various ensemble techniques were employed, including Majority Voting Integration (MVI), Weighted Probabilistic Averaging (WPA), and Thompson Sampling (TS). These methods were integrated to optimize hate speech detection performance.
Thompson Sampling dynamically adjusts the weights of individual models during training based on their performance, ensuring that the ensemble adapts to variations in the data and achieves better overall accuracy. Additionally, Parallel Model Fusion (PMF) was utilized to efficiently process real-time inputs, further enhancing the robustness and accuracy of the ensemble model. By combining these techniques, this study demonstrates the effectiveness of ensemble learning in addressing the challenges of multilingual hate speech detection.
Hybrid ensemble approaches using BERT-OPCNN with advanced optimization techniques, such as FastText embedding fusion, have demonstrated higher accuracy and robustness in text classification tasks29,30.
Methodology
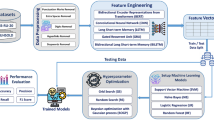
This study aims to enhance the performance of hate speech detection by utilizing an ensemble of BERT-based models with both Korean and English datasets. As shown in Fig. 1, the text from the datasets is first tokenized using a tokenizer, after which the BERT-based models are fine-tuned. Each fine-tuned BERT model is trained in different ways, and TS is applied to adaptively adjust the weights of each model. During this process, stratified 3-fold cross-validation is performed, and the resulting data is used for training and testing the meta-learner, PMF. The ensemble approach incorporates MVI, WPA, TS, and PMF to optimize the performance across multilingual datasets.

Architecture of the proposed model. Overview of the ensemble strategy employed for hate speech detection. This figure illustrates the sequence of steps including tokenization, BERT model fine-tuning, integration with Majority Voting Integration (MVI), Weighted Probabilistic Averaging (WPA), Thompson Sampling (TS), and Parallel Model Fusion (PMF).
Dataset
Korean dataset (Unsmile dataset and hate score dataset)
The Unsmile dataset31 is a collection of approximately 18,700 Korean sentences from various social media platforms and news comments, categorized into “hate” and “non-hate” speech. This dataset was designed to handle the complex vocabulary and grammar of Korean, with multiple annotators ensuring consistent labeling. BERT-based models can be fine-tuned on this dataset to improve the understanding of Korean texts. The dataset was divided into training and test sets in an 8:2 ratio. For binary classification, the “clean” label was applied, where a value of 1 indicates non-hate and 0 indicates hate. As shown in Fig. 2, the label distribution of the Unsmile dataset provides insight into how hate speech is represented in the data.

Distribution of labels in the Unsmile dataset. Stratified 3-fold cross-validation process. This figure details the process where the dataset is divided into three folds, with each iteration showing one fold used for validation while the remaining folds are used for training.
English dataset (measuring hate Speech dataset)
The Measuring Hate Speech dataset32 contains 1.36 million English samples labeled with attributes such as sentiment, respect, insult, hate speech, and humiliation. The “hatespeech” label is categorized as 0, 1, or 2, where 2 represents hate speech, 0 indicates no hate speech, and 1 indicates neutral speech. During the preprocessing stage, all neutral sentences (labeled 1) were removed because they could not be directly classified as hate or non-hate speech. The features representing the categories of hate speech were excluded from the dataset since the aim of this study is to determine whether a given text contains hate speech. The dataset was randomly divided into training and test sets with 20% of the data selected for the test set. Approximately 36% of the total data were labeled as hate speech and 64% were labeled as non-hate speech. Figure 3 illustrates the distribution of labels within the English dataset, offering a clear visualization of the dataset composition.

Distribution of labels in the Measuring Hate Speech dataset. Performance comparison of individual models vs. ensemble model for hate speech detection across Korean and English datasets. The figure highlights accuracy and F1 scores for each model.
Addressing dataset imbalance
Imbalanced data is a common challenge in hate speech detection tasks, as it can lead to overfitting on the majority class and underperformance on the minority class. To address this issue, we employed stratified 3-fold cross-validation as our primary method for managing class imbalance without altering the dataset.
Stratified 3-fold cross-validation ensures that the proportion of labels in the training and validation sets remains consistent with the original dataset’s distribution. This approach divides the dataset into three folds, with each fold containing a balanced representation of both majority and minority classes. During the validation process, the model is trained on two folds and tested on the remaining fold, repeating this process three times to ensure that every instance in the dataset is used once for validation. This methodology not only preserves the integrity of the dataset but also avoids introducing synthetic data or removing existing samples.
This method provides several advantages. First, it ensures that minority class instances are adequately represented in both training and validation sets, mitigating bias towards the majority class. Second, it facilitates robust model evaluation by validating on every fold, offering a comprehensive assessment of the model’s performance across all data. Finally, by avoiding oversampling, undersampling, or class weight adjustments, stratified cross-validation maintains the dataset’s natural distribution and context.
While alternative techniques, such as oversampling, undersampling, or class weight adjustments, were considered, stratified 3-fold cross-validation was selected for its simplicity and effectiveness in addressing class imbalance. As demonstrated in the experimental results, this approach was sufficient to ensure balanced evaluation and robust model performance across the datasets.
Data processing
The datasets used in this study are in text form, and various preprocessing steps are necessary to convert them into a suitable format for training the hate speech detection models. Preprocessing is a vital step to ensure the consistency of the text and reduce noise, ultimately improving the performance of the model. This process includes text normalization, stopword removal, and the handling of special characters.
Text normalization
In the text normalization step, all characters were converted to lowercase forms to ensure consistency because the uppercase and lowercase forms of the same word could otherwise be treated as distinct words by the model. Additionally, unnecessary white space was removed to reduce the amount of irrelevant data processed by the model. This normalization helps eliminate variables that do not contribute to the learning of the model and leads to better generalization during training.
Stopword removal and special character handling
Stopwords, words that appear frequently but do not significantly contribute to meaning, were removed to make the model’s learning process more efficient. Special characters and punctuation, which typically have a minimal impact on sentence structure, were either removed or replaced as necessary. These included emojis and username tagging. Handling special characters is particularly important for mixed-language texts, such as those containing both Korean and English, because each language requires a different preprocessing approach for its unique character systems. These preprocessing steps streamline the data, making it more concise and consistent, and improving the model’s ability to learn effectively.
Through these systematic pre-processing techniques, the dataset was prepared in a way that optimized the model’s ability to interpret and detect hate speech, which in turn improved its overall performance and robustness across different languages.
Tokenization & BERT-based models
In this study, tokenization plays a crucial role in preprocessing the text data for both the Korean and English datasets. Figure 4 shows how each base model employs different tokenization methods based on the language used. Tokenization methods such as WordPiece, Byte Pair Encoding (BPE), and SentencePiece are applied base on the language structure and model requirements, ensuring that BERT-based models can efficiently handle linguistic variations and nuances in hate speech detection tasks.

Tokenization method for each base model. This figure shows the tokenization methods used for each BERT-based model in processing the Korean and English datasets, including techniques like Sentence Piece, Word Piece, and Byte-Level BPE.
Tokenization for the Korean dataset
As depicted on the left side of Fig. 4, the Korean tokenization methods are designed to handle the complex morphological structure of a language. Models, such as KoBERT, KcBERT, and KoRoBERTa apply WordPiece and BPE, breaking down text into morpheme-based subwords to address the out-of-vocabulary (OOV) problem and flexibly manage the morpheme structure of Korean words. These tokenization methods ensure that the models can effectively process Korean sentences and capture the linguistic features that are critical for hate speech detection.
Furthermore, KoBERT and DistilKoBERT utilize the SentencePiece tokenization method, which reduces the vocabulary size to 8,000 tokens. This enables the models to handle a wide range of morphemes and context-dependent meanings that are crucial for understanding Korean sentences on social media and other contexts in which hate speech frequently appears.
Tokenization for English dataset
The tokenization of the English datasets is illustrated on the right side of Fig. 4. Models such as RoBERTa and DistilBERT use BPE, which merges frequently occurring character pairs to form subwords, optimizes the handling of rare words, and reduces the vocabulary size. BERT applies WordPiece tokenization, which splits text into subwords to ensure that rare words are effectively managed, thereby helping the model detect subtle forms of hate speech.
In addition, xlm-RoBERTa uses SentencePiece tokenization, which directly processes Unicode character sequences without requiring pre-tokenization. This provides a more generalized tokenization approach that works effectively across multiple languages including Korean and English. Using SentencePiece, xlm-RoBERTa overcomes the tokenization challenges faced by models, such as mBERT and XLM-100, including handling inconsistencies in multilingual vocabularies and subword representations.
Ensemble strategy
The ensemble strategy implemented in this study integrates predictions from multiple models to enhance the overall performance of hate speech detection. Specifically, three techniques, MVI, WPA, and TS, were employed to optimize the prediction accuracy. Additionally, a meta-learning-based stacking approach called PMF was incorporated to further improve the performance by leveraging the strengths of different models.
A stratified three-fold cross-validation was applied to train and validate the ensemble models. As illustrated in Fig. 5, the dataset is divided into three folds: two folds are used for training and the remaining fold is reserved for validation. The validation process is critical because the weights for each BERT-based model and training data for the meta-learner are derived from the validation results. During testing, meta-learner test data is gathered from the results of MVI and WPA on the test data for each validation fold, whichever method has higher accuracy. The TS algorithm is employed in each validation step to dynamically update the weights of the individual models based on their performance. This ensures that models with superior performance receive more weight, whereas models with lower performance are still being explored for potential improvement.

Ensemble learning with K-3 fold, MVI, WPA, and TS. This diagram illustrates the ensemble learning process, combining K-3fold cross-validation, Majority Voting Integration (MVI), Weighted Probability Averaging (WPA), and Thompson Sampling (TS) to enhance hate speech detection accuracy.
Stratified 3-fold cross-validation ensures that the label distribution (hate and non-hate) is consistent across all folds, maintaining balance during both the training and validation phases. This method enhances the robustness of the ensemble model by ensuring that label distribution discrepancies do not skew the performance. For each fold, two-thirds of the dataset is allocated for training and one-third is reserved for validation, as depicted in Fig. 5. This process is repeated for each model in the ensemble strategy to enable comprehensive training.
Figure 5 shows the data partitioning in training, validation, and testing phases. This iterative cross-validation approach is crucial for optimizing the ensemble strategy. It dynamically adjusts the weights of each model and improves prediction accuracy by ensuring that all data points are included in the final model evaluation.
Majority voting integration (MVI)
In MVI, the final prediction is determined by selecting the class that the majority of the models have predicted. Specifically, for each input, the predictions from all models are collected, and the class with the highest frequency of votes is selected as the final output. If multiple classes receive the same number of votes, the prediction is determined by combining confidence scores and predefined rules to resolve ties. When performance varied across models, we updated the confidence score by weighting it based on the overall F1-score of the models. In addition, in multilingual models, we use additional metadata or contextual information to establish predefined rules, such as weighting the predictions of models that are better suited to a particular language if the text is written in a specific language. In this way, the methodology combines confidence scores and predefined rules to design and apply a more robust tie-breaking mechanism.
To enhance the robustness of MVI, additional strategies were employed in this study. First, when model performances differed significantly, weights were assigned to the predictions based on the overall F1-score of each model. This weighting mechanism dynamically adjusted the confidence scores of the predictions, ensuring that more reliable models had a greater influence on the final output. Second, in multilingual scenarios, the weighting naturally reflected the performance differences among models without requiring explicit adjustments based on the language of the text. For example, for Korean text, models specifically trained on Korean data, such as KoBERT, tended to receive higher weights due to their superior accuracy, rather than deliberate prioritization. This organic weighting mechanism allowed the ensemble to leverage the strengths of each model without introducing biases.
In this study, MVI was applied to combine the predictions of both single-language and multilingual models. For example, if three models predicted a sentence as ‘hate’ while two models predicted it as ‘non-hate,’ the final prediction was ‘hate.’ By integrating confidence scores, predefined rules, and weighting mechanisms, the MVI approach effectively aggregated model outputs to balance predictions and mitigate biases, particularly in cases where model performances were heterogeneous.
Weighted probabilistic averaging (WPA)
WPA calculates the final prediction by taking the weighted average of each model’s predicted probabilities. In this study, the predicted probabilities provided by BERT-based models were weighted and averaged, and the class with the highest probability was selected as the final prediction. WPA provides a more nuanced combination than MVI by reflecting the confidence level of each model’s predictions, thus generating more accurate results in complex scenarios.
Application of Thompson sampling (TS)
In each validation step, the weights of the models were dynamically updated using TS. The algorithm uses a beta distribution to calculate the likelihood of a particular model producing the best results, based on its past performance. Specifically, α (alpha) represents the number of correct predictions, and β (beta) represents the number of incorrect predictions. By sampling from this distribution, models that perform well are more likely to be selected, whereas underperforming models can still be improved through further exploration.
Thompson Sampling is a probabilistic method that dynamically adjusts the model weights based on their performance during training and validation. In this study, we chose 3-fold cross-validation to strike a balance between sufficient data for training and an appropriate evaluation set for robust testing. 3-fold prevents overfitting compared to fewer folds and is advantageous for measuring the generalization performance of the model. Furthermore, using larger folds, such as 5-fold and 10-fold, increases the computational complexity by requiring multiple splits between the training and validation data. Therefore, 3-fold is simpler and faster to compute, allowing for effective model evaluation by balancing computational cost and performance evaluation. TS prioritizes the selection of models with better performance while continuing to explore underperforming models, allowing for potential improvements and preventing overfitting to only the best-performing models. This method ensures that even models with a lower initial accuracy may still be given the opportunity to improve as the model adapts to new data.
During each validation phase, the TS samples were obtained from the performance distribution of each model, and the corresponding model weights were dynamically updated. This process is captured using a beta distribution that reflects the ratio of correct to incorrect predictions. The beta distribution is formulated as follows:
where\(\:\:{\uptheta\:}\) denotes the probability that the model provides an optimal prediction based on the given data, \(\:X\) represents the input data used for training and validation, α represents the number of correct predictions, and β represents the number of incorrect predictions.
Sampling from this distribution ensures that models with higher performance receive greater weight, whereas models with lower uncertain performance are given reduced but nonzero weights. Thus, models that initially underperform are not completely disregarded but are given a probability of being selected, thus encouraging further exploration.
Thompson Sampling effectively balances exploration (i.e., selecting models with lower performance to test for potential improvement) and exploitation (i.e., prioritizing models with consistently high performance). By sampling from the beta distribution, the algorithm ensures that models with strong track records are favored; however, they remain sufficiently flexible to test models that may show potential in the future. This dynamic process enhances the stability and diversity of the ensemble, leading to greater accuracy and robustness in predictions as the model adapts over time.
Parallel model fusion (PMF)
PMF is an ensemble technique that combines multiple base models with a meta-learner to achieve better performance than individual models. The meta-learner is trained using the predictions from the base models as input, and learns the relationships between the models to improve the final prediction accuracy.
In this study, the predictions of the BERT-based models were used as inputs for the meta-learner, which consisted of traditional machine learning models, such as Random Forest (RF), SVM, Naïve Bayes (NB), and LR. These models were used to reduce the discrepancies between the predictions of the individual base models and to derive the final output. PMF outperformed the individual models by leveraging the complementary strengths of each model, particularly when combined with MVI and WPA, to integrate the base model predictions.
Finally, TS-weighted data were used to train the meta-learner, further optimizing the performance of the ensemble. By combining multiple approaches, PMF reduces the biases present in individual models, thereby improving the overall accuracy of the ensemble.
Meta-learner design
The meta-learner was designed to combine the predictions from the base models (BERT-based and machine learning models) to derive the final prediction. The meta-learner receives the predicted logits and binary outputs from the individual models as input, which are then used to train models, such as Logistic Regression, RF, SVM, and Naïve Bayes. The combination of base models allows the meta-learner to effectively capture complementary patterns and minimize discrepancies between models, thereby improving the overall predictive performance.
How the meta-learner works
-
A.
Collecting Predictions: The predictions generated by each BERT-based model are converted into feature vectors. These vectors serve as input data for the meta-learner, enabling it to learn from the ensemble output.
-
B.
Learning and Final Prediction: The meta-learner identifies complementary patterns in the predictions across different models. By analyzing the overall performance and balancing the strengths and weaknesses of each model, the meta-learner improves the accuracy of the final prediction.
-
C.
Combining Methods: The meta-learner combines the results of and to make the final prediction. MVI selects the class predicted by most models, whereas WPA determines the final prediction by calculating the weighted average of the probabilities predicted by each model.
Meta-Learner Models:
-
Random Forest (RF): This algorithm is an ensemble model comprising multiple decision trees. The predictions from the BERT-based models are transformed into a multidimensional feature vector, X = (x_1, x_2, …, x_n), and then input into the RF, where the final result is determined through majority voting. RF aggregates predictions from each tree to provide stable results.
-
Support Vector Machine (SVM): This algorithm is a binary classification technique that handles nonlinear data by applying a nonlinear transformation to separate them. In this study, the predictions from each BERT-based model were transformed into vectors in an N-dimensional space, and the vectors were input into the SVM to determine the optimal hyperplane \(\:{w}^{T}x+b=0\) for classifying the data. The SVM demonstrated resistance to overfitting and robustness to noise. The decision function for SVM is as follows33:
where \(\:w\) is the weight vector of the hyperplane, \(\:{\xi\:}_{i}\) are slack variables, and \(\:C\) is the regularization constant.
-
Naïve Bayes: This is a probabilistic classification algorithm based on Bayes’ theorem, which simplifies the calculation by assuming that features are independent of each other. In this study, the predictions from the BERT-based models were treated as independent features, and the conditional probability \(\:P\left(X,Y=k\right)\:\)was calculated using the Naïve Bayes model as follows34:
This formula is used to calculate the probability that the given input data belong to a specific class, and the final classification is performed based on these probabilities.
-
Logistic Regression: Logistic regression is an algorithm that predicts the probability of an outcome belonging to a specific class based on a linear combination of independent variables. In this study, the predictions from the BERT-based models were combined linearly, and the sigmoid function \(\:{\upsigma\:}\left(z\right)=\frac{1}{1+{e}^{-z}}\:\) was used to predict the probability that the dependent variable would be 1. The conditional probability for each category \(\:j\:\)is calculated as follows35:
where \(\:{b}_{0j}\) and \(\:{b}_{1j}\) represent the regression coefficients.
BERT architecture and utilization in ensemble strategy
The architecture and application of BERT in this study played a crucial role in improving the accuracy and robustness of hate speech detection. BERT (Bidirectional Encoder Representations from Transformers) employs a bidirectional transformer encoder, which processes textual data by considering the context of a word relative to both its preceding and succeeding words. This bidirectional capability is facilitated by multi-head self-attention layers, enabling BERT to effectively capture nuanced relationships and contextual meanings in text.
In this study, the sentences in the dataset were tokenized into word segments using the BERT tokenizer. The tokenizer applies techniques such as WordPiece or SentencePiece to break down text into subwords or smaller units, which are essential for managing rare or out-of-vocabulary words. These tokenized segments were then encoded into feature vectors by the BERT model, which encapsulate semantic and syntactic information crucial for detecting subtle patterns of hate speech. These feature vectors served as the foundation for downstream processing in the ensemble strategy.
The BERT-based models were fine-tuned on the Korean and English datasets, ensuring that the embeddings produced were tailored to the specific characteristics of each language. For instance, the models captured Korean linguistic features, such as honorifics and morphological variations, while also addressing the structural nuances of English text. Hyperparameters such as learning rate, batch size, and epochs were systematically optimized through experimentation. For the Korean dataset, a learning rate of 1e-5 and batch size of 128 were identified as optimal, while slightly larger batch sizes proved effective for the English dataset.
The ensemble strategy integrated the outputs of these BERT-based models using techniques such as Majority Voting Integration (MVI) and Weighted Probabilistic Averaging (WPA). These methods combined predictions from monolingual models like KoBERT and DistilKoBERT with multilingual models such as mBERT and xlm-RoBERTa. This integration not only mitigated the weaknesses of individual models but also capitalized on their strengths, ensuring robust performance across diverse linguistic contexts.
By leveraging BERT’s contextual embedding capabilities and integrating them into a dynamic ensemble framework, this study demonstrated that combining the strengths of transformer-based models significantly enhances hate speech detection. The use of tokenized word segments as feature vectors further ensured that the models could process text data efficiently and effectively, ultimately leading to improved performance in multilingual and monolingual settings.
Experimental setup and evaluation metrics
Environment
The proposed model was implemented in Python using libraries, such as Hugging Face, PyTorch, and Scikit-learn. All the experiments were conducted on an Intel Xeon Gold 5416 S with 250GB RAM and NVIDIA L40S. For the models implemented using PyTorch, the training objective is to minimize the cross-entropy loss function. The cross-entropy loss for a dataset of N samples, where the true label of the i-th sample is denoted as \(\:{\varvec{y}}_{\varvec{i}}\), is given by the following equation36:
where, \(\:\varvec{\lambda\:}\) is the regularization parameter, and \(\:\varvec{\theta\:}\:\)represents the parameters of the model.
Hyperparameter optimization
For hyperparameter optimization and performance evaluation, ablation studies were conducted to assess how the removal of specific layers, functions, or input variables affects the overall performance. The baseline models used for comparison in both the English and Korean datasets included a single machine learning model and a BERT-based model. In this study, we propose an ensemble of multilingual and monolingual models and evaluate the performance of ensembles limited to multilingual or monolingual models. The hyperparameters and models used in the ablation study were identical to those used in the primary experiments.
The hyperparameters applied to the ensemble models are summarized in Tables 1 and 2.
Evaluation metrics
The accuracy (Acc) and F1 score (F1) were used as primary metrics to evaluate the performance of the models. These metrics are derived from precision (P) and recall (R). The expressions for these evaluation metrics are defined as follows:
where, TP, FP, FN, and TN refer to the true positives, false positives, false negatives, and true negatives, respectively.
In this study, hyperparameter optimization for machine learning models such as SVM, LR, and RF was performed using GridSearchCV. For the BERT-based models, the batch size and learning rate were manually optimized, with batch sizes of 64, 128, and 256, and learning rates ranging from 1e-6 to 1e-4. Owing to computational limitations, the sequence length was truncated to 150 tokens for larger batch sizes (e.g., 256). The range of hyperparameters tested for the machine learning models is listed in Table 3, with the selected optimal parameters highlighted in bold. Because Naïve Bayes has no significant hyperparameters for optimization, its results have not been discussed in detail.
Additional multilingual dataset evaluation
Reason for selecting additional languages and dataset characteristics
To reflect the diversity and complexity of multilingual hate speech detection, we chose two languages with large language populations, Chinese and Portuguese. We chose each language for the following reasons.
-
Chinese: As one of the most widely spoken languages in the world, Chinese was included to evaluate the model’s performance on a high-resource language with a large linguistic population. Its character-based semantics and high context dependency present unique challenges for hate speech detection. Unlike alphabetic languages, Chinese uses logograms, where a single character can represent a word or a concept, depending on the context. This feature introduces a high level of semantic ambiguity, requiring models to rely heavily on contextual information for accurate classification. Additionally, Chinese shares some cultural and linguistic similarities with Korean, such as the use of honorifics and context-dependent meanings, making it an important point of comparison.
-
Portuguese: Portuguese was chosen for its global significance as a widely spoken Romance language. With a linguistic structure distinct from English, Portuguese features significant lexical borrowing from English and other languages, adding to its complexity. Its diverse morphological and syntactical patterns, as well as regional variations, test the model’s ability to adapt to nuanced linguistic features. Additionally, Portuguese provides a valuable opportunity to assess the model’s performance on a language with both high global reach and unique characteristics compared to Korean and English.
Dataset characteristics
The datasets used for this evaluation were sourced from HateSpeechData.com and were designed for hate speech classification tasks. Table 4 summarizes the key characteristics of the datasets used in the evaluation.
-
1.
Chinese: Contains 31,049 samples, labeled as hate or non-hate. The dataset’s reliance on character-based text introduces challenges such as handling polysemous characters and parsing sentence structures without clear word boundaries.
-
2.
Portuguese: Includes 21,000 samples, categorized into 6 distinct hate-speech categories including homophobia, obscene, insult, racism, misogyny and xenophobia which have been processed into binary class label.
to address the multilingual aspect raised by the reviewer, we conducted additional experiments using datasets in Chinese and Portuguese, sourced from the repository recommended by the reviewer and others. Some datasets were evaluated without additional preprocessing to examine the generalization capability of the proposed model while Portuguese dataset has been modified from multiclass to binary classes in order to suit the goal of our study. Table 5 provides an overview of the experimental settings for each language.
Results and observations
The proposed ensemble model demonstrated robust performance on the primary datasets, Korean and English, achieving strong generalization capabilities within these languages. As shwon Table 6, our proposed model also improves the detecting hate speech performnace in Chinese, with 2.5% increase in both Acc and F1 over the model proposed by the authors of COLD dataset. However, when evaluated on additional datasets in Portuguese, the performance was the same. This highlights the inherent challenges of extending hate speech detection models to linguistically diverse datasets without language-specific adaptations.
The Chinese dataset posed unique difficulties due to its character-based structure and context dependency, while Portuguese presented challenges stemming from their morphological complexity and regional variations. These results underscore the importance of dataset-specific preprocessing and fine-tuning to enhance performance on less-studied languages.
Despite these challenges, the additional experiments provide valuable insights into the potential and limitations of the proposed ensemble approach. By addressing these linguistic variations through targeted optimization, future work can improve the scalability of hate speech detection models to truly multilingual tasks.
Result
The experimental results show that the ensemble model outperforms the individual BERT-based models in terms of both accuracy and F1 score. This demonstrates that the use of ensemble learning with MVI, WPA, and TS provides a more robust and accurate approach for hate speech detection across multilingual datasets.
Performance on Korean dataset
To optimize the hyperparameters of the BERT-based models, the accuracy and F1 scores were analyzed across all model and fold combinations, as shown in Fig. 6. In some cases, specific parameter combinations resulted in a significant drop in the F1 score, likely owing to overfitting or inappropriate learning rates that hindered generalization. After the experiment, a learning rate of 1e-5 and batch size of 128 were identified as optimal for the Korean dataset.

Boxplot of both F1-Score and Accuracy for each combination of parameters for all combinations of models and folds.
Table 7 presents the performance of the baseline models on the Unsmile dataset. The results indicate that traditional machine learning models, such as RF and SVM, performed comparably well, whereas the proposed ensemble model outperformed all the others. Specifically, the ensemble model exhibited an F1 score and accuracy of 0.89, indicating a 3% improvement over previous studies
Table 8 presents a comparison of the performance of the proposed model with that of previous studies. Using the Unsmile dataset, the proposed model achieved higher F1 scores and accuracy than the KoBERT and BERT-based models used in prior research. Specifically, the proposed ensemble model recorded an F1 score of 0.89 and an accuracy of 0.89, which represents more than a 3% improvement in performance compared to previous studies. This improvement can be attributed to the application of the ensemble technique, which complements the information that individual models may miss, thereby maximizing the overall performance
Performance on the english dataset
Table 9 presents the performance of the baseline models on the English hate speech dataset. In contrast to the Korean dataset, the machine learning strategies performed well on the English dataset, particularly in terms of SVM and RF, which showed competitive results. However, the performance differences between the BERT-based models were insignificant. The performance differences between the BERT-based models were not significant.
The performance of the nine different ensemble combinations is presented in Table 10. The results show that combining multilingual and single-language models consistently delivered the best performance, with WPA and PMF slightly outperforming MVI. This indicates that ensemble approaches that leverage both multilingual and monolingual models are more effective in improving hate speech detection accuracy.
Table 11 presents a comparison of the performances of the proposed ensemble model and those of previous studies on the English hate speech detection dataset. The proposed model, which used an ensemble of BERT, DistilBERT, and RoBERTa, achieved an accuracy of 0.85, and an F1 score of 0.85, indicating an improvement of more than 2–3% over previous studies. The proposed model performed slightly worse than the studies by Davidson et al.27 and Mozafari et al.26. In cases like the Davidson et al.27 and Lu et al.39 dataset, we see that the accuracy or F1 is high because the dataset is very unbalanced. This dataset consists of 24,783 tweets, of which only 1,430 are classified as “hate” and 23,353 are classified as “non-hate”. This can be attributed to several factors, including the variability of the hate speech patterns, which can cause more noise and ambiguity in large datasets, differences in preprocessing, and the complexity of the ensemble approach. Despite the difficulty of working with datasets of different characteristics and sizes, the ensemble technique was effective in mitigating the individual weaknesses of the models, leading to a more balanced and robust performance across tasks. This highlights the effectiveness of the ensemble technique in complementing the limitations of the individual models and maximizing the overall performance.
Results and error analysis
For the Korean dataset, the ensemble model showed a notable improvement over traditional machine learning models and individual BERT-based models. Specifically, the macro F1 score of the ensemble combining the monolingual and multilingual models improved by 55.6%, 6.3%, and 2.4% over SVM, xlm-RoBERTa, and KcBERT, respectively. In terms of accuracy, improvements of 17.3%, 3.5%, and 1.1% were observed (Fig. 7). These results demonstrate the competitiveness of the ensemble approach for hate speech detection.

Comparison of Accuracy and F1 Score of each best model for the Korean dataset.
Moreover, as shown in Fig. 8, the performances of the monolingual models and their ensembles were compared. The ensemble of monolingual models outperformed the individual models, indicating that combining different models further enhanced the performance.

Comparison of Accuracy and F1 Score of monolingual models and the ensemble of monolingual models for the Korean dataset.
Similarly, Fig. 9 presents a comparison between the multilingual models and their ensembles, where the ensemble approach again delivered superior performance compared to the individual multilingual models.

Comparison of Accuracy and F1 Score of multilingual models and the ensemble of multilingual models for the Korean dataset.
For the English dataset, the ensemble of multilingual and monolingual models outperformed the individual models, as shown in Fig. 10. The multilingual ensemble achieved better results than single multilingual models, confirming the strength of the ensemble technique. Figures 11 and 12 further illustrate the comparison between the monolingual and multilingual model performances in the English dataset, where the ensemble models consistently performed better in terms of both accuracy and F1 score.

Comparison of Accuracy and F1 Score of each best model for the English dataset.

Comparison of Accuracy and F1 Score of monolingual models and the ensemble of monolingual models for the English dataset.

Comparison of Accuracy and F1 Score of multilingual models and the ensemble of multilingual models for the English dataset.
In both the Korean and English datasets, the variation in model predictions emphasizes the complexity of accurately detecting hate speech, particularly in cases involving nuanced or contextually ambiguous languages. For example, the Korean dataset contained cases where even among the 147 samples marked as “non-hate,” models showed differing opinions based on the ambiguity of the context. By leveraging the strengths of multiple models, the proposed ensemble approach enhanced the consistency and accuracy of hate speech detection, thereby effectively addressing these challenges. The process of combining model outputs through MVI allows for a more robust handling of complex linguistic patterns, which individual models might otherwise struggle with. This demonstrates the effectiveness of ensemble learning, particularly in larger datasets, where context and intent can vary widely across instances.
Conclusion
In this paper, we proposed an ensemble of BERT-based models for multilingual hate speech detection. In our experiments, we compared traditional machine learning methods, transformer-based LLMs, and an ensemble consisting of models such as mBERT, mBART, xlm-RoBERTa, and KoBERT. The results demonstrated that the ensemble approach outperformed individual LLMs in terms of both accuracy and robustness, particularly for multilingual hate speech detection tasks. Thus, the proposed ensemble model is suitable for global social media platforms that require efficient and reliable hate speech detection across multiple languages.
The experiments conducted on Korean and English datasets confirmed the effectiveness of the proposed ensemble approach. These datasets were carefully preprocessed to address linguistic nuances, such as honorifics in Korean and structural nuances in English, resulting in a highly optimized training process. Furthermore, the ensemble approach not only improved classification accuracy but also enhanced the robustness of the model, mitigating the weaknesses of individual models.
To evaluate the generalization capability of the proposed method, additional experiments were conducted using datasets in Chinese and Portuguese, languages from linguistic families distinct from Korean and English. While the performance was slightly reduced due to the lack of advanced preprocessing, the ensemble still demonstrated comparable results to previous studies. These findings emphasize the scalability and adaptability of the proposed approach across diverse linguistic settings.
The ensemble’s ability to combine predictions from monolingual and multilingual models effectively captured complex linguistic patterns and contextual nuances, thereby addressing the inherent challenges of multilingual hate speech detection. This makes the proposed method a strong candidate for real-world applications, particularly on global social media platforms where multilingual data is prevalent.
Limitations and future directions
Despite its promising results, the proposed ensemble approach has limitations. The integration of multiple models increases computational costs and memory usage, posing challenges for large-scale deployment. Future research should prioritize developing lightweight ensemble models and employing techniques such as pruning or quantization to reduce computational overhead without sacrificing performance.
Another limitation lies in the focus on binary classification, which may overlook the intricacies of hate speech, such as overlapping categories or subtle variations in context. Expanding the model to handle multi-label classification would enable the detection of more nuanced forms of hate speech.
Moreover, while this study demonstrated the feasibility of the proposed approach on Chinese and Portuguese datasets, further experiments on additional languages and linguistic families are necessary to fully validate its multilingual capabilities. Incorporating language-specific preprocessing and hyperparameter tuning can further enhance the performance across diverse datasets.
Lastly, alternative ensemble strategies, such as bagging, boosting, or stacking, could be explored to refine the model’s performance. Investigating these methods could reveal more efficient and accurate ways to approach multilingual hate speech detection.
By addressing these limitations, future work can push the boundaries of multilingual hate speech detection, providing a scalable and efficient solution to one of the most pressing challenges in the digital age.
Data availability
The datasets generated and analyzed during the current study are available from the corresponding author upon reasonable request. Any additional data and materials that support the findings of this study are also available upon request.
References
Meta *Community Standards Enforcement Report Meta Platforms, Inc. (2024). https://transparency.fb.com/data/community-standards-enforcement
Vaswani, A. et al. Attention is all you need. Adv. Neural Inf. Process. Syst. 30, 5998–6008. https://doi.org/10.48550/arXiv.1706.03762 (2017).
National Human Rights Commission of Korea. In 2016 Report on Hate Speech and Psychological Effects. Seoul, South Korea (2016).
Raza Ali, U., Farooq, U., Arshad, W., Shahzad, M. O. & Beg Hate speech detection on Twitter using transfer learning. Comput. Speech Lang. 74 https://doi.org/10.1016/j.csl.2022.101365 (2022).
Corazza, M. et al. A multilingual evaluation for online hate speech detection. ACM Trans. Internet Technol. (TOIT). 20 (2), 1–22. https://doi.org/10.1145/3377323 (2020).
Jahan, M., Saroar, M. & Oussalah A systematic review of hate speech automatic detection using natural language processing. Neurocomputing 546 (2023). https://doi.org/10.1016/j.neucom.2023.126232
Agarwal, S., Sonawane, A. & Ravindranath Chowdary, C. Accelerating automatic hate speech detection using parallelized ensemble learning models. Expert Syst. Appl. 230, 120564 (2023).
Raza, S. HarmonyNet: navigating hate speech detection. Nat. Lang. Process. J. 8, 10098. https://doi.org/10.1016/j.nlp.2024.100098 (2024).
Fortuna, P., Sérgio & Nunes A survey on automatic detection of hate speech in text. ACM Comput. Surv. (CSUR). 51 (4), 1–30. https://doi.org/10.1145/3232676 (2018).
Mozafari, M., Farahbakhsh, R. & Crespi, N. Cross-lingual few-shot hate speech and offensive language detection using meta learning. IEEE Access. 10, 14880–14896. https://doi.org/10.1109/ACCESS.2022.3147588 (2022).
Khan, A. et al. Offensive language detection for low resource language using deep sequence model. IEEE Trans. Comput. Social Syst. https://doi.org/10.1109/TCSS.2023.3280952 (2023).
Jeong, Y. et al. KOLD: Korean offensive language dataset. In Proceedings of the Conference on Empirical Methods in Natural Language Processing. 2022. (2022). https://doi.org/10.18653/v1/2022.emnlp-main.744
Sawicki, J., Ganzha, M. & Paprzycki, M. The state of the art of Natural Language Processing—A systematic Automated Review of NLP Literature using NLP techniques. Data Intell. 5, 707–749. https://doi.org/10.1162/dint_a_00213 (2023).
Lee, J. et al. K-MHaS: A multi-label hate speech detection dataset in Korean Online News Comment. In Proceedings of the 29th International Conference on Computational Linguistics (2022). https://aclanthology.org/2022.coling-1.311
Moon, J., Cho, W. I. & Lee, J. BEEP! Korean corpus of online news comments for toxic speech detection. In Proceedings of the Eighth International Workshop on Natural Language Processing for Social Media. (2020). https://doi.org/10.18653/v1/2020.socialnlp-1.4
Park, C. et al. K-HATERS: A hate speech detection corpus in Korean with target-specific ratings. In The Conference on Empirical Methods in Natural Language Processing. (2023). https://doi.org/10.18653/v1/2023.findings-emnlp.952
Arora, R., Singh, S. & Goyal, P. Leveraging transformer models for multilingual hate speech detection. J. Comput. Linguist. (2022). https://doi.org/10.48550/arXiv.2101.03207.
MacAvaney, S. et al. Hate speech detection: Challenges and solutions. PloS one 14 (8), e0221152. (2019). https://doi.org/10.1371/journal.pone.0221152
Zhou, Y. & Zhu, L. Weighted averaging in hate speech detection for addressing dataset bias. In Proceedings of the EMNLP. (2020).
Zhang, Z. & Robinson, D. and Jonathan Tepper. Detecting hate speech on twitter using a convolution-gru based deep neural network. The Semantic Web: 15th International Conference, ESWC Heraklion, Crete, Greece, June 3–7, 2018, Proceedings 15. Springer International Publishing, 2018. (2018). https://doi.org/10.1007/978-3-319-93417-4_48
Badjatiya, P. et al. Deep learning for hate speech detection in tweets. In Proceedings of the 26th international conference on World Wide Web companion. (2017). https://doi.org/10.1145/3041021.3054223
Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). (2019). https://doi.org/10.18653/v1/N19-1423
Lewis, M. et al. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. (2020). https://doi.org/10.18653/v1/2020.acl-main.703
Liu, Y. & RoBERTa a robustly optimized BERT pretraining approach. In Proceedings of the 20th Chinese National Conference on Computational Linguistics(2021). https://aclanthology.org/2021.ccl-1.108
Swamy, S., Durairaj, A., Jamatia, Björn & Gambäck Studying generalisability across abusive language detection datasets. In Proceedings of the 23rd conference on computational natural language learning (CoNLL). (2019). https://doi.org/10.18653/v1/K19-1088
Mozafari, M., Farahbakhsh, R. & Crespi, N. A BERT-based transfer learning approach for hate speech detection in online social media. Complex Networks and Their Applications VIII: Volume 1 Proceedings of the Eighth International Conference on Complex Networks and Their Applications COMPLEX NETWORKS 2019 8. Springer (2020). https://doi.org/10.1007/978-3-030-36687-2_77
Davidson, T. et al. Automated hate speech detection and the problem of offensive language. In Proceedings of the international AAAI conference on web and social media. 11 (1) (2017). https://doi.org/10.1609/icwsm.v11i1.14955
Waseem, Z., Thorne, J. & Bingel, J. Bridging the gaps: Multi task learning for domain transfer of hate speech detection. Online Harassment 29–55. (2018). https://doi.org/10.1007/978-3-319-78583-7_3
Nithya, K. et al. Hybrid approach of deep feature extraction using BERT–OPCNN & FIAC with customized Bi-LSTM for rumor text classification. Alex. Eng. J. 90, 65–75 (2024). https://doi.org/10.1016/j.aej.2024.01.056.
ßWang, J. & Zhang, X. Enhancing robustness of hate speech detection via ensemble models. In Proceedings of the ACL. (2021).
Kang, T. et al. Korean online hate speech dataset for multilabel classification: How can social science improve dataset on hate speech? ArXiv abs/2204.03262 (2022): n. pag. https://doi.org/10.48550/arXiv.2204.03262
Sachdeva, S. P. et al. The measuring hate speech corpus: Leveraging rasch measurement theory for data perspectivism. In Proceedings of the 1st Workshop on Perspectivist Approaches to NLP @LREC2022, pp 83–94, Marseille, France. European Language Resources Association. (2022).
Hearst, M. A. et al. Support vector machines. IEEE Intell. Syst. Their Appl. 13, 18–28. https://doi.org/10.1109/5254.708428 (1998).
Rish, I. An empirical study of the naive Bayes classifier. IJCAI 2001 workshop on empirical methods in artificial intelligence. 3(22). (2001).
LaValley, M. P. Logistic regression. Circulation 117 (18), 2395–2399. https://doi.org/10.1161/CIRCULATIONAHA.106.682658 (2008).
Sohn, H. & Lee, H. Mc-bert4hate: Hate speech detection using multi-channel bert for different languages and translations. In International Conference on Data Mining Workshops (ICDMW). IEEE, 2019. (2019). https://doi.org/10.1109/ICDMW.2019.00084
Deng, J. et al. COLD: A benchmark for Chinese offensive language detection. In Proceedings of the Conference on Empirical Methods in Natural Language Processing. 2022. (2022). https://doi.org/10.18653/v1/2022.emnlp-main.796
João, A., Leite, D., Silva, K. & Bontcheva and Carolina Scarton. Toxic Language Detection in Social Media for Brazilian Portuguese: New dataset and multilingual analysis. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, pp. 914–924, Suzhou, China. Association for Computational Linguistics. (2020). https://doi.org/10.48550/arXiv.2010.04543
Lu, J. et al. Hate speech detection via dual contrastive learning. In IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31, 2787–2795, (2023). https://doi.org/10.1109/TASLP.2023.3294715
Fortuna, P. & Leo Wanner. How well do hate speech, toxicity, abusive and offensive language classification models generalize across datasets? Inf. Process. Manag. 58 (3), 102524. https://doi.org/10.1016/j.ipm.2021.102524 (2021).
Firmino, A. et al. Improving hate speech detection using Cross-Lingual Learning, Expert Syst. Appl., 235, 121115, ISSN 0957–4174. (2024). https://doi.org/10.1016/j.eswa.2023.121115
Lin Liu, D. et al. A cross-lingual transfer learning method for online COVID-19-related hate speech detection. Expert Syst. Appl. 234, 0957–4174. https://doi.org/10.1016/j.eswa.2023.121031 (2023).
Acknowledgements
This work was supported by the National Research Foundation of Korea’s Brain Korea 21 FOUR. And this work was supported the Korea Environmental Industry & Technology Institute (KEITI), with a grant funded by the Korea government, Ministry of Environment (The development of IoT-based technology for collecting and managing big data on environmental hazards and health effects), under Grant RE202101551.
Author information
Authors and Affiliations
Contributions
SH.Y. and JH.C. conceptualized the study and developed the methodology. SH.Y., JS.H., and EB.J. handled software development, while SH.Y., JH.C., JS.H., and EB.J. performed validation and formal analysis. SH.Y., JH.C., JS.H., and EB.J. conducted the investigation, and resources were managed by SH.Y., JS.H., and EB.J. The original draft was written by SH.Y., JH.C., JS.H., and EB.J., with review and editing by all authors. Visualization was managed by SH.Y. and JH.C., and JH.C. provided supervision. Project administration was led by SH.Y. and JH.C. All authors reviewed and approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yoo, S., Jeon, E., Hyeon, J. et al. Adaptive ensemble techniques leveraging BERT based models for multilingual hate speech detection in Korean and english. Sci Rep 15, 19844 (2025). https://doi.org/10.1038/s41598-025-88960-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-88960-y
