
Abstract
Semantic segmentation of remotely sensed images is crucial for urban planning and change detection, yet faces issues like sample imbalance and low data quality. This study compiles a GF-2 image dataset and refines the PSPNet model. Weights of different class samples were adjusted to prioritize minority classes, mitigating sample imbalance’s impact on classification. Data augmentation enhanced dataset quality. By replacing ResNet with the STFF network for better global feature extraction, adding attention modules, and using a combined loss function, the improved model shows excellent performance. It achieves a mAcc of 90.32 \(\%\), mIoU of 76.04 \(\%\), and a Dice coefficient of 85.15 \(\%\). Comparison with other models verifies its superiority, and tests on public datasets prove strong generalization, offering valuable insights for remote sensing image processing.
Similar content being viewed by others
Introduction
Over the last few years, with the fast progress of remote sensing technology, the availability of high-resolution satellite images has greatly increased1. This has led to a growing research interest in the field of semantic segmentation of remotely sensed images. The goal is to classify and label various types of land cover and land use in images2. It plays a crucial part in diverse applications like urban planning3, land change detection4, water body monitoring5, and road extraction6. However, due to the lack of high-quality information, recognizing feature types only from images can still be limited for problems such as obscure boundaries and overlapping regions, which makes the classification task increasingly difficult and affects the accuracy of the classification results7. In addition, it may be the case that the distribution of features in each category within the image is not uniform. This leads to a significant disparity in the number of samples in each category. Consequently, the generalization ability of the semantic segmentation model is reduced. Furthermore, in the process of acquisition, remote sensing images are covered by clouds, so there is a problem of partial information loss8. Therefore how to efficiently and accurately recognize feature types using computer vision methods has become the focus of research.
Against the current research backdrop, numerous intractable issues are faced, such as sample imbalance and low data quality. Datla et al.9 innovatively proposed a scene attribute-focused modeling approach. By skillfully integrating the Gaussian Mixture Model (GMM) and factor analysis techniques, they successfully overcame these difficulties and accurately and efficiently extracted highly discriminative scene vectors from remote sensing images. He et al.10 proposed using the MMSE framework to address the multi-class imbalance problem. Through selective integration and multiple undersampling rates, the computational cost was reduced, and various optimal solutions for decision-makers to weigh among different classes were provided. Regarding the problem of low data quality, Shorten et al.11 through the analysis of various augmentation techniques, constructed better deep learning models by enhancing the size and quality of the training dataset. These methods have proposed effective solutions to the problems existing in the dataset.
Traditional land cover classification methods for remote sensing images, which rely on pixel-based classification techniques, have limited ability to accurately capture spatial and contextual information of land cover categories. In contrast, semantic segmentation is able to categorize each pixel point, which can determine the location and shape of features more accurately12. There are two main learning methods, namely the traditional semantic segmentation algorithm and the full convolutional neural network algorithm. The traditional semantic segmentation methods include the commonly used and classical segmentation methods based on threshold13, edge14, and region. However, the traditional methods have the disadvantages of low accuracy and time-consuming.
Based on the deep learning develops and progress, the field of computer vision has achieved breakthrough progress. Convolutional Neural Networks(CNNs) have already turned into an important method for image processing. Using CNNs semantic segmentation can fully make use of the semantic information of images to accomplish the segmentation process15. Among them, Liu et al.16 proposed a method which employs the spatial residual truncation module to acquire and fuse multi-scale contextual features based on the Fully Convolutional Network(FCN)-based segmentation approach. Moreover, this method can successfully extract buildings in high-resolution remote sensing images.Guo et al.17 put forward a graph theory-based remote sensing image segmentation method. It can be applied to image segmentation by replacing the standard convolution of FCN with null convolution. It refines the boundary of the segmentation result through the utilization of the fully connected conditional random field, finally obtaining a more accurate segmentation result. In addition, the encoder-decoder based method has been used by many scholars, and its structure is a derived model structure. It is composed of two parts: encoder and decoder, the encoder part extracts the feature information from the original image, and the decoder part carries out the reconstruction of the feature information. Based on this structure, Hu et al.18 used the Unet algorithm to successfully identify water bodies that are threatening to ecological water systems such as eutrophication and green ponds by employing a cross-entropy loss function as well as referencing the improvement of the attention mechanism. Datla et al.19 developed a multi-modal semantic segmentation method combining panchromatic remote sensing images and digital elevation models. Through the integration of U-Net and Transformers, this method can effectively identify and delineate airport runways. Swetha et al.20 proposed a novel network architecture, MS-VACSNet, which enhanced the segmentation accuracy for volcanic eruptions of different scales by introducing dilated convolutions into the U-Net architecture and verified its superior performance compared with existing techniques. Since traditional convolution has a relatively small receptive field in the shallow layer of the neural network, a convolution method with a larger scope-cavity convolution has been proposed21. Zhao et al.22 proposed Pyramid Scene Parsing Network (PSPNet), which averages feature maps with different sizes through the pooling to obtain more global semantics. Chen et al.23 presented the cavity convolution Deeplab model, which boosts the precision of pixel localization and enlarges the receptive field by making use of dilated convolution and conditional random fields.
Although feature classification of high-resolution images using deep learning has been extensively studied, there are limitations in its research for the mountainous and hilly terrain that dominates the Hunan region of China. The primary motivation of this study is to propose an enhanced PSPNet algorithm aimed at achieving precise classification. This addresses the challenges of inadequate recognition of intricate features by existing semantic segmentation algorithms in satellite remote sensing images, as well as the issues related to low segmentation accuracy. The main contributions of this study are summarized as follows.
-
(1)
Creating datasets, that include complex feature types, provides an important resource to support research and development in related fields. In addition, validate the migration capabilities of improved models using publicly available datasets.
-
(2)
An improved semantic segmentation algorithm for PSPNet model is proposed using STFF. The accuracy (mAcc), intersection and concatenation ratio (mIoU), mDice coefficient, and detection speed of STFF-PSPNet algorithm as well as other algorithms (such as U-Net, DeepLabV3+, and Segformer) are compared.
-
(3)
The Combined Loss(CL) function is applied in the improved PSPNet network instead of the original loss function, which is better adapted to the dataset created in this study. In addition, an attention, specifically, CBAM (Convolutional Block Attention Module) was added to both the backbone and head layers to enhance feature extraction and improve detection accuracy.
Materials and methods
Research area
The study area is located in Yueyang City, Hunan Province, China, as shown in Fig. 1. It is located in the northeastern part of Hunan Province, with the city surrounded by mountains on two sides, a hilly area in the Southeast, the Dongting Lake plain in the Northwest, and a transitional shallow hilly area around the lake in the center, with a variety of feature types. The study mainly distinguishes between buildings, water bodies, cultivated land, woodland and grassland. Therefore, the test area selected for this study is representative, making the data diverse and rich.

(a) Left: The green frame denotes China’s geographical coordinates, and the yellow part represents Hunan Province. (b) Right: The yellow region indicates Yueyang City’s location in Hunan Province. (Maps created in ArcGIS 10.2, http://www.esri.com Boundaries made with free vector data provided by National Catalogue Service for Geographic Information, https://www.webmap.cn/commres.do?method=dataDownload).
Data
Data sources
-
(1)
Data Acquisition of Remote Sensing Images: In this research, high-resolution remote sensing images collected by Gaofen-2 are utilized, as shown in Fig. 2. These images were subjected to a series of preprocessing operations, including radiometric calibration, atmospheric correction, geometric correction, band fusion and enhancement, as well as image stitching and mosaicking, which were used to boost the accuracy and definition of the remote sensing images, etc24. The preprocessed image contains RGB three channels and position information channels, but only RGB channels are used based on the purpose of this study.
-
(2)
Auxiliary data: this paper uses the publicly available dataset LandCover.ai25 on the web, with feature type information including background, buildings, woodlands, water and roads. The purpose is to compare the improved algorithm of this study with other algorithms on public datasets, analyze the results, and verify the generalization ability and migratability of the algorithm.

Remote sensing image of Yueyang (The satellite imagery data source: Gaofen-2, https://data.cresda.cn/#/home. Maps created in ArcGIS 10.2, http://www.esri.com).
Dataset
This study is dedicated to the classification of feature types in Yueyang City, through the preprocessed data as a block of image data, the features were classified and labeled using ArcMap 10.2. With the aim of labeling samples, we generated vector files and annotated images whose size was the same as that of the original images. Due to the large images, we used a sliding window to crop for processing the image and its corresponding labeled samples. First cropping out the square image with pixel value of 9216 size, which is not free from cloud cover, etc. We processed or deleted the images with cloud cover, blankness, and lack of clarity and verified the accuracy of the remaining labels26. Then the remaining images are cropped to 512 × 512 size as shown in Fig. 3.

(a–d) are Sample datasets. Perform data preprocessing on the remote sensing images obtained from Gaofen-2 (Fig. 2), and crop them into 512 × 512-sized pictures by means of sliding block cutting (Figures created in Visio 2021, https://visio.iruanhui.cn/).
Data augmentation
Data augmentation has a significant influence on deep learning-based semantic segmentation methodologies, improving data multiplicity and regularizing the model. To extract feature information more effectively, guarantee recognition exactness and prevent overfitting during training, various augmentation means were utilized. Using data augmentation tools and OpenCV, the dataset was expanded through operations such as image rotation, image mirroring, random cropping, noise addition, and image stitching. The resulting augmented images, which are the outcomes of these five augmentation operations explained in Table 1, are shown in Fig. 4.

Image augmentation results. (a) Original image. (b) Image rotation. (c) Image mirror. (d) Image cropping. (e) Image add noise. (f) Image mosaic. The methods of data augmentation are implemented by writing Python scripts in combination with OpenCV techniques (Figures created in Visio 2021, https://visio.iruanhui.cn/).
After data augmentation, the dataset comprised 48,708 images (8118 original images augmented sixfold). From this dataset, we utilize a python random assignment strategy to divide the processed images .With a ratio of 6:2:2, allocate the corresponding labeled data into training, validation, and test sets. 29,226 images were used as the training set, 9741 images were taken as the test set, and 9741 images were regarded as the validation set.
Table 2 demonstrates the number of specific datasets.
Improved semantic segmentation algorithm based on PSPNet remote sensing images
PSPNet
Zhao et al.22 proposed Pyramid Scene Parsing Network (PSPNet) deep learning network. The traditional PSPNet algorithm uses pooled pyramids to aggregate contextual information from different regions through the proposed PSPNet, which allows the algorithm to have a large global receptive field. The diagram representing the network structure of PSPNet is exhibited in Fig. 5. For the input image, a pretrained ResNet model with an extended network strategy, using null convolution, is employed to extract feature maps. The primary purpose of the null convolution is to increase the receptive field. The feature map obtained from the last convolution is then passed to the pyramid pooling module. The input feature layer will be divided by the pyramid pooling module into 1\(\times\)1, 2\(\times\)2, 3\(\times\)3 and 6\(\times\)6 regions, reduce the feature latitude to 1/4 of the original by a 1\(\times\)1 convolutional layer, upsample these pyramid features directly to the same size as the input features, and then do a merge, i.e., the Concat operation, with the input features, so as to form the feature layer that contains both the local and global context information. Finally, the feature layer is subjected to convolutional kernel SoftMax classification to obtain prediction results for each pixel in the image.

The architecture of PSPNet network.
Improvement of the PSPNet network
The richness of feature categories and irregular terrain in the Yueyang area, etc. create challenges for accurately recognizing feature types. To cope with these challenges, in order to improve the accuracy of detection, it is necessary to optimize the network relying on PSPNet.
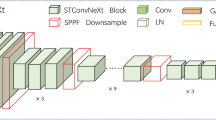
The traditional PSPNet network, that uses ResNet backbone network27 to extract features with deeper layers result in poorer computational efficiency, higher memory consumption, and a larger sensory field, is only available in the deeper stages, which affects the network segmentation accuracy and speed, among others. Therefore, in our study, the PSPNet backbone(ResNet) is replaced with STFF module. STFF contains two structures, one is Swin Transformer28 with Transformer as the underlying architecture, and the other structure is similar to the feature pyramid network FPN structure29 is the Feature Fusion Module (FFM). The STFF-PSPNet network is presented in Fig. 6. The input image is transformed into four feature maps of different sizes, namely 128\(\times\)128, 64\(\times\)64, 32\(\times\)32 and 16\(\times\)16 by Swin Transformer. Then the deeper feature maps are up-sampled and convolved by the feature fusion module, and fused with the upper level feature maps to get the multi-scale feature representation. The feature maps after up-sampling in each layer help the network to better understand and perceive the global and local information of the input image through the CBAM attention mechanism, thus improving the network’s ability to recognize and localize the target. Finally, the convolution operation is performed on the adjusted feature maps through convolutional or fully connected layers to generate feature maps with a size identical to that of the input image.

The architecture of STFF-PSPNet.
By using STFF, the network can be better adapted to targets of different scales and complexity, thus improving the generalization ability of the network. This is great significance for dealing with complex scenes and multi-scale targets, and is conducive to improve the practical application value of the model. In order to enhance feature extraction and attention to relevant targets, the attention mechanism is added to both the backbone and head layers. By incorporating the CBAM attention mechanism, it can help the model better learn the key features as well as the intrinsic structure of the input data, thus improving the model’s representation and generalization ability.
STFF
In our study, the STFF consists of two parts, the Swin-Transformer and the Feature Fusion Module. While the traditional ResNet model employs a deep residual linkage structure, the architectural framework of Swin Transformer takes full advantage of the Transformer’s self-attention mechanism and multi-attention mechanism, and also allows the model to extract features and capture long-distance dependencies more efficiently when dealing with large-size images by introducing a local attention mechanism and a sliding-window strategy28. The Swin Transformer architecture is shown in the STFF module in Fig. 7 and is divided into four Stages.Each Stage consists of several Transformer Blocks. Each Transformer Block contains several Multi-Head Self-Attention layers and some fully connected layers dedicated to feature extraction and feature fusion.

STFF architecture overview.
Firstly, the input \(H \times W \times 3\) RGB image is split into non-overlapping equal-sized N patches i.e., \(\frac{H}{4} \times \frac{W}{4} \times 48\) by Patch Partition module(The number of channels changes from 3 to 48), and then the result is passed into Stage1’s Linear Embedding layer i.e. fully connected layer, and then input Swin Transformer Block layer to do self-attention mechanism to complete Stage1.After completing Stage1, then the result is passed into Stage2, Stage3 and Stage4, where Patch Merging layer is the Patch merging layer, which respectively the output feature map dimensions are \(\frac{H}{8} \times \frac{W}{8}\) , \(\frac{H}{16} \times \frac{W}{16}\) and \(\frac{H}{32} \times \frac{W}{32}\) each Stage changes the dimension of the tensor to form a hierarchical representation.
Base on the Transformer Block, each Swin Transformer Block contains a Shift Window Based Multi-head Self-Attention Module (W-MSA/SW-MSA). As shown in Fig. 8, in each Swin Transformer Block, some Multi-Layer Perceptron(MLP) layers are also included for nonlinear transformation and combination of the features of the patches. We modified the architecture of the Swin Transformer by increasing the number of layers in stage 3 from 6 to 18, which can improve the expressive power of the model to capture more complex and detailed features, and thus enhance the performance on visual tasks, but at the same time, we need to pay attention to the training time and the risk of overfitting.

Two successive Swin Transformer Blocks.
The architecture of Swin Transformer has 4 stages, and the output’s dimensions is \(\frac{H}{4} \times \frac{W}{4}\), \(\frac{H}{8} \times \frac{W}{8}\), \(\frac{H}{16} \times \frac{W}{16}\) and \(\frac{H}{32} \times \frac{W}{32}\), where H and W represent the height and width of the input image, respectively. As indicated in Fig. 9, to avoid the model’s over-adaptation to a specific scale and the loss of universality, we make use of top-down pathways and lateral connections to merge feature maps at various resolution levels and combine the outputs and semantic information at different resolutions. During the fusion procedure, a \(1 \times 1\) convolution is initially applied to modify the channels of the previous level’s output. Then, we bring them together and repeat the \(1 \times 1\) and up-sampling process two times to get the final output having the highest resolution. We adopt direct concatenation of each feature map along the channel direction, which retains all the data.

Architecture of feature fusion module. The bi-linear up sampling and the \(1 \times 1\) convolution are adopted to keep the channels and resolutions consistent at all times.
Convolutional block attention module (CBAM)
The utilization of the attention mechanism in image processing aims at seizing the contextual details existing in the image to apprehend the relevance and enable the model to give priority to the significant regions while disregarding the unimportant information.Our algorithm utilizes the CBAM attention mechanism model as depicted in Fig. 10, which comprises two components, namely a channel attention model and a spatial attention model30. The channel attention module, denoted as CAM, facilitates the identification of the vital feature channels relevant to a particular task through analyzing the relationships between diverse channels and optimizing the distribution of feature maps, consequently improving the model performance. The spatial attention module, called SAM, pays more attention to the positional and contextual information of the whole image to better understand the local regions and is especially used to accurately extract edge features. CBAM connects these two modules in tandem, and using the module makes the network to better capture the correlation between the channels and the space, which improves the expression of the features and the performance of the model.

The main structure of CBAM attention module.
Loss function
Remote sensing image semantic segmentation for the target task of multiple classification, mainly take the cross-entropy loss, which has a larger penalty for misclassified samples, so it can help the model to learn the classification task better. However, remote sensing image feature terrain is complex, for the segmentation of the image cross entropy loss function is not ideal, so in our method, the improved loss function of PSPNet is used by a combination of the cross entropy loss function31 and the Dice Loss function32 to jointly optimize the feature parameters. The combined loss function (CL) is constituted by summing the cross-entropy loss function (CE) and Dice Loss function (DL) by assigning different weights to them.
The expression for the cross-loss entropy function is:
where p represents the distribution of genuine labels and q denotes the distribution of model outputs.
The expression for the Dice Loss function is:
where p denotes the binarized distribution of the genuine labels, q represents the binarized distribution of the model outputs, and \(\epsilon\) is a small positive number used to avoid the case where the denominator is zero.
The expression for the combined loss function (CL) is:
where \(\alpha\) and \(\beta\) are weighting coefficients used to regulate the share (contribution) of the cross-entropy loss function and the Dice Loss function in the combined loss function to better fit the model.
Model training
Training platforms and parameter settings
In this research, the semantic segmentation model is implemented via the Pytorch deep learning framework. The experiments were deployed on Ubuntu 20.04.2 operating system and the main experimental configurations are shown below: Processor Inter(R) Xeon(R) W-2245 CPU @ 3.90 GHz , RAM is 125G, GPU NVIDIA GeForce RTX 3090(24G). Python 3.11.3 was used as the development language, and PyTorch 2.0.0 + Cuda 11.8 was used as the framework for training and testing the model. The training configuration also included the use of a stochastic gradient descent (SGD) optimizer, with an initial learning rate of \(1 \times 10^{-2}\), a momentum of 0.9, and a weight decay of 0.0005.
The batch size is configured to be 8, the iteration number is set to 160,000 times, which is equivalent to the training epoch of 100, as shown in Equation 4.
The image input size is configured as 512\(\times\)512 pixels. The Poly learning strategy was selected, and the loss function CL weights \(\alpha\) and \(\beta\) were chosen to be 0.6 and 0.4, respectively. Throughout the training process, the log records were saved every 100 steps, and the model was evaluated every 2,000 steps, and the model with the highest mIou metrics was retained as the model weight. Table 3 summarizes the training parameters used in the experiment.
Evaluation indicators of the model
In this study, to assess the performance of the augmented semantic segmentation model, several validation metrics are used, namely, overall accuracy (aAcc)33, intersection over union (IoU), mean intersection over union (mIoU)34, and dice similarity coefficient (Dice)35. These metrics all depend on the confusion matrix as shown in Table 4. It compares the model’s prediction for each pixel with the true label to derive the model’s performance on different categories. By analyzing the confusion matrix, performance metrics such as accuracy, recall, dice coefficient etc. of the model on each category can be derived, thus helping to optimize the model and improve the semantic segmentation.
Results and analysis
Training results
In this study, we tested different backbone networks based on the PSPNet algorithm like the convolution-based Resnet50, Resnet101, the MobileNetV236 with a lighter model, the Resnest network with a new variant of Resnet37, and Swin Transformer. These backbone networks have good classification results on the dataset. The experimental outcomes are presented in Table 5.
According to the obtained results, it is observable that the model MobileNetV2 is more lightweight, with lower number of parameters and faster execution than the traditional Resnet network, however, it brings the price of lower accuracy. For the Resnet network variant of the Resnest network, although the execution of the network becomes faster, but the decline in accuracy is fatal. Swin Transformer as a backbone network achieves optimal results on our dataset because it is based on doing self-attention mechanism within its own sliding window, which reduces computational complexity while not only utilizing Transformer’s ability to extract global semantic information, but also retaining more local information within the window.
In order to better evaluate the performance of the improved PSPNet network for semantic segmentation of remote sensing images, this study compares it with six classical semantic segmentation models such as U-Net35, DeepLabV3+23, Fast-SCNN38, etc. while keeping other training parameters consistent. The precision results of the ameliorated PSPNet and other canonical semantic segmentation models in the task of remote sensing image feature categorization are exhibited in Table 6. The accuracy of our improved model is significantly better than other models when relevant metrics are taken into account. The mean accuracy (mAcc) of the improved PSPNet model is augmented by at least 2.79\(\%\) compared with other models. The mean intersection over union (mIoU) is improved by a minimum of 4.84\(\%\) in comparison with other models. The mean Dice coefficient (mDice) improved by a minimum of 2.58\(\%\) compared to other models. These data indicate that the improved PSPNet model has excellent performance in the task. The Fig. 11 is a confusion matrix based on STFF - PSPNet. STFF-PSPNet performs well in the classification of building and water categories, but there is still room for improvement in the differentiation of categories such as grassland, farmland, and forest land. In subsequent research, for these easily confused categories, the model structure can be further optimized or the parameters can be adjusted to improve the classification accuracy.

Confusion matrix based on STFF-PSPNet.
In addition, the experimental results produced by different models on the Yueyang dataset are shown in Fig. 12. We selected three images with representative types, which include feature classes such as water bodies, buildings and woodlands. All the network models recognized the feature types more accurately, but the classical models all suffer from misclassification to a greater or lesser extent, as well as omission problems. The STFF-PSPNet algorithm, proposed in this study, can be clearly seen that its segmentation results are significantly better than the other models, Fig. 12(c). For features with small targets, ourmethods are able to extract them more accurately and more completely and minimize the missing spatial details extracted from the remotely sensed images.

Comparison between predictions generated by different methods on the Yueyang dataset.
Ablation experiments
In order to evaluate the effectiveness of combining the CBAM module of the attention mechanism and the CL module of the loss function, this study formulated four different experimental methods on the original algorithm and compared them. As is shown in Table 7, the specific experimental findings are presented.
Where Scenario 1 is the traditional PSPNet model with Resnet as the backbone network. Scheme 2 is a model that substitutes STFF for the backbone network in Scheme 1. Scheme 3 enlarges Scheme 2 by adding CBAM module to the model. Scheme 4 is a model that only changes the loss function based on Scheme 2. Ultimately, Scheme 5 enlarges Scheme 2 by integrating the CBAM module into the network model and also changing the loss function.
The outcomes in Table 7 suggest that the model’s accuracy is reliant on the combination of the CBAM and CL loss functions. It is easy to see that after replacing the backbone of the traditional PSPNet network, the evaluation metrics are enhanced in all aspects, while the model complexity is augmented. In contrast, the introduction of the CBAM module and the change of the CL loss function led to an improvement in the performance of the model, with an increase in the average accuracy by 1.04% and 0.45%, and in the average intersection and merger set ratio by 1.49% and 0.79%, respectively. It is noteworthy that when both the CBAM module and the CL loss function are employed in Scheme 5, the average accuracy of the model increases by 1.86% and the average intersection over union ratio improves by 2.99%, and the detection results attain the optimal detection performance. Consequently, it can be inferred that the performance of the remote sensing feature classification task can be substantially enhanced by substituting the backbone network with the STFF network and adding the attention mechanism CBAM module as well as combining the CL loss function to the network.
Migrability of the segmentation model
The validation data that is predominantly used for remote sensing image segmentation stems from the same study region as the training data, which consequently fails to effectively reveal the robustness of the segmentation model.
Though a significant number of segmentation models achieve a high level of accuracy on their validation data, their performance undergoes degradation when applied to different geographical regions.Insufficient training samples or limited model generalization capabilities are mainly responsible for this degradation. With the aim of validating the portability of the enhanced model, we performed experiments making use of the publicly accessible dataset LandCover.ai. The experiments additionally utilized GF-2 satellite images as the remote sensing data source, and the images were processed with uniform preprocessing.

LandCover.ai Dataset (Use the free dataset LandCover.ai-Vision 1 provided by Boguszewski et al., https://landcover.ai.linuxpolska.com/#dataset. Figures created in Visio 2021, https://visio.iruanhui.cn/).
We also made targeted adjustments to the model. At the output layer, according to the new four-category task, as shown in Fig.13, we redesigned the number of neurons and activation functions of the output layer to correspond to four categories. At the same time, in order to fully utilize the existing feature extraction capabilities and accelerate the training speed, we froze some of the bottom feature extraction layers of the model. These layers have learned general image features in the five-category task and are expected to continue to play a role in the four-category task. Subsequently, we set appropriate training parameters, such as adopting a smaller learning rate to avoid excessive adjustments to the frozen layers, and reasonably determine the batch size and number of training epochs according to the dataset size and computing resources. Then, we used the adjusted model and the four-category dataset for retraining.
The outcomes of these tests are presented in Table 8. The STFF-PSPNet has considerable accuracy in feature classification, indicating that it is quite transferable and has the potential for wider application and dissemination.
As revealed by Table 9 our empirical findings of transfer learning are compared with the data in the original paper, the overall mIoU reaches 89.32%, which is 3.72% higher than that of LandCover.ai.
Discussion
Semantic segmentation of remote sensing images can be helpful in applications such as urban planning and water body change detection. However, the detection accuracy is affected by the intricate terrain and the resolution of remote sensing images. In order to accurately and efficiently recognize the land use types, the paper proposes a semantic segmentation method based on improved deep learning model. The use of STFF features makes the network better adapted to different scales and complex targets and improves the generalization ability of the network. Employing the attention mechanism CBAM in the STFF-PSPNet network and replacing the original loss function with the combined loss function CL enables the model to better seize the feature information of the input data. The results of the comparison test show that, on the one hand, the improved accuracy of the present model is optimal by modifying the backbone module in the PSPNet network while other modules remain unchanged. On the other hand, under comparison with other mainstream semantic segmentation algorithms, the detection speed and accuracy of this model in semantic segmentation for remote sensing image feature classification are superior to other methods. The results of ablation experiments show that the present model is better than other algorithms to obtain optimal detection results.
Our improved semantic segmentation method shows good segmentation performance in both the self-constructed dataset and the LandConver dataset that verifies the migration capability, however, the number of model parameters is enlarged due to the inclusion of STFF, and further improvement is needed in order to increase the detection speed. In future research, the improved PSPNet model can also be used in practical applications such as land change detection and urban planning.
Conclusion
In this study, we propose an improved PSPNet semantic segmentation model to address the challenges in the task of feature type extraction in remote sensing imagery. The model uses STFF as the backbone network, which consists of Swin Transformer and feature fusion model with integrated CBAM module, thus improving the detection accuracy of the model. In addition, we adopt the combined loss function that is more suitable for complex terrain classification, which replaces the cross-entropy loss function commonly used for semantic segmentation and improves the robustness of the model. By consideration, this method effectively solves the problems existing in the existing classical semantic segmentation models, such as inaccurate feature edge extraction and misclassification. By conducting a comparison with the existing classical semantic segmentation models, we found that the model outperforms other algorithms in terms of detection accuracy (mAcc) and Dice coefficient in the application of remote sensing imagery feature classification, reaching percentages of 90.32% and 85.15%, respectively. Although the model has shown good performance in various experiments, there are limitations.The inclusion of STFF makes the network model parameters larger, which leads to an increase in the cost of training. Therefore, for future research we will consider the training cost and accuracy improvement balanced with each other to further come to improve the task.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Li, D., Wang, M. & Jiang, J. China’s high-resolution optical remote sensing satellites and their mapping applications. Geo Spat. Inf. Sci. 24, 85–94 (2021).
Yi, Z. et al. Scene-aware deep networks for semantic segmentation of images. IEEE Access 7, 69184–69193 (2019).
Fan, R. et al. Fine-scale urban informal settlements mapping by fusing remote sensing images and building data via a transformer-based multimodal fusion network. IEEE Trans. Geosci. Remote Sens. 60, 1–16 (2022).
Hu, X. & Zhuang, S. Large-scale spatial-temporal identification of urban vacant land and informal green spaces using semantic segmentation. Remote Sens. 16, 216 (2024).
Weng, L. et al. Water areas segmentation from remote sensing images using a separable residual segnet network. ISPRS Int. J. Geo Inf. 9, 256 (2020).
Dong, S. & Chen, Z. Block multi-dimensional attention for road segmentation in remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 19, 1–5 (2021).
Sui, B., Cao, Y., Bai, X., Zhang, S. & Wu, R. Bibed-seg: Block-in-block edge detection network for guiding semantic segmentation task of high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 16, 1531–1549 (2023).
Li, H., Zhang, L. & Shen, H. A principal component based haze masking method for visible images. IEEE Geosci. Remote Sens. Lett. 11, 975–979 (2013).
Datla, R. et al. Learning scene-vectors for remote sensing image scene classification. Neurocomputing 587, 127679 (2024).
He, Y.-X., Liu, D.-X., Lyu, S.-H., Qian, C. & Zhou, Z.-H. Multi-class imbalance problem: A multi-objective solution. Inf. Sci. 680, 121156 (2024).
Shorten, C. & Khoshgoftaar, T. M. A survey on image data augmentation for deep learning. J. Big Data 6, 1–48 (2019).
Liu, X., Deng, Z. & Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 52, 1089–1106 (2019).
Liu, J., Geng, Y., Zhao, J., Zhang, K. & Li, W. Image semantic segmentation use multiple-threshold probabilistic R-CNN with feature fusion. Symmetry 13, 207 (2021).
Li, Y., Liu, Z., Yang, J. & Zhang, H. Wavelet transform feature enhancement for semantic segmentation of remote sensing images. Remote Sens. 15, 5644 (2023).
Yuan, X., Shi, J. & Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 169, 114417 (2021).
Liu, Y. et al. Automatic building extraction on high-resolution remote sensing imagery using deep convolutional encoder-decoder with spatial pyramid pooling. IEEE Access 7, 128774–128786 (2019).
Guo, R. et al. Pixel-wise classification method for high resolution remote sensing imagery using deep neural networks. ISPRS Int. J. Geo Inf. 7, 110 (2018).
Hu, Y. et al. Extraction of eutrophic and green ponds from segmentation of high-resolution imagery based on the EAF-Unet algorithm. Environ. Pollut. 343, 123207 (2024).
Datla, R., Chalavadi, V. & Mohan, C. K. A multimodal semantic segmentation for airport runway delineation in panchromatic remote sensing images. In Fourteenth International Conference on Machine Vision (ICMV 2021) Vol. 12084, 46–52 (SPIE, 2022).
Swetha, G., Datla, R., Vishnu, C. et al. MS-VACSNet: A network for multi-scale volcanic ash cloud segmentation in remote sensing images. In 2023 18th International Conference on Machine Vision and Applications (MVA) 1–6 (IEEE, 2023).
Yu, F., Koltun, V. & Funkhouser, T. Dilated residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 472–480 (2017).
Zhao, H., Shi, J., Qi, X., Wang, X. & Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2881–2890 (2017).
Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K. & Yuille, A. L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 40, 834–848 (2017).
Li, A. & Xia, G. The influence of geometric correction on the accuracy of the extraction of the remote sensing reflectance of water. Int. J. Remote Sens. 42, 2280–2291 (2021).
Boguszewski, A., Batorski, D., Ziemba-Jankowska, N., Dziedzic, T. & Zambrzycka, A. Landcover. ai: Dataset for automatic mapping of buildings, woodlands, water and roads from aerial imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 1102–1110 (2021).
He, Z., Gong, C., Hu, Y. & Li, L. Remote sensing image dehazing based on an attention convolutional neural network. IEEE Access 10, 68731–68739 (2022).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 770–778 (2016).
Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision 10012–10022 (2021)
Lin, T.-Y. et al. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2117–2125 (2017).
Woo, S., Park, J., Lee, J.-Y. & Kweon, I. S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV) 3–19 (2018).
Bahri, A., Majelan, S. G., Mohammadi, S., Noori, M. & Mohammadi, K. Remote sensing image classification via improved cross-entropy loss and transfer learning strategy based on deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 17, 1087–1091 (2019).
Li, X. et al. Dice loss for data-imbalanced NLP tasks. arXiv preprint arXiv:1911.02855 (2019).
Badrinarayanan, V., Kendall, A. & Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 39, 2481–2495 (2017).
Long, J., Shelhamer, E. & Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 3431–3440 (2015).
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5–9, 2015, Proceedings, Part III Vol. 18, 234–241 (Springer, 2015).
Li, X., Ye, H. & Qiu, S. Cloud contaminated multispectral remote sensing image enhancement algorithm based on mobilenet. Remote Sens. 14, 4815 (2022).
Zhang, H. et al. Resnest: Split-attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2736–2746 (2022).
Poudel, R. P., Liwicki, S. & Cipolla, R. Fast-scnn: Fast semantic segmentation network. arXiv preprint arXiv:1902.04502 (2019).
Acknowledgements
The Yueyang data in this article comes from the high-score business department of Hunan Aerospace Yuanwang Technology Co., Ltd. Thanks to all the authors for their contributions to this study.
Funding
Natural Science Foundation of Hunan Province (No. 2024JJ8037)
Author information
Authors and Affiliations
Contributions
H.L.: Author of the main text; involved in data collection and data processing, made tables and figures, methodology, conceived and designed the experiments, research methods, writing and review & editing of the paper. J.G.: Participated in data collection, data processing and other work, and collected information on the working method. Also involved in text writing. Y.L.: Collected information on the working method, data processing and other work. C.H.: Participated in data collection, data processing and other work, and collected information on the working method. L.Z.: Participated in text writing, analyzed the samples. Writing and review & editing. L.L.: Responsible for the revision and correction of grammar and spelling. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, H., Gao, J., Liu, Y. et al. Enhanced remote sensing image feature classification using STFF-PSPNet. Sci Rep 15, 27587 (2025). https://doi.org/10.1038/s41598-025-89094-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-89094-x
