
Abstract
Loop closure detection is a key module in visual SLAM. During the robot’s movement, the cumulative error of the robot is reduced by the loop closure detection method, which can provide constraints for the back-end pose optimization, and the SLAM system can build an accurate map. Traditional loop closure detection algorithms rely on the bag-of-words model, which involves a complex process, has slow loading speeds, and is sensitive to changes in illumination or viewing angles. Therefore, aiming at the problems of traditional methods, this paper proposes an algorithm based on the Siamese capsule neural network by using the deep learning method. We have designed a new feature extractor for capsule networks, and in order to further reduce the parameter count, we have performed pruning based on the characteristics of the capsule layer. The algorithm was tested on the CityCentre dataset and the New College dataset. Our experimental results show that the proposed algorithm in this paper has higher accuracy and robustness compared to traditional methods and other deep learning methods. Our algorithm demonstrates good robustness under changes in illumination and viewing angles. Finally, we evaluated the performance of the complete SLAM system on the KITTI dataset.
Similar content being viewed by others
Introduction
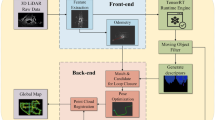
Robots, such as sweeping robots and Automated Guided Vehicles (AGVs), have become ubiquitous in daily life. These robots rely on perceive their surroundings and determine their positions through the utilization of Simultaneous Localization and Mapping (SLAM) technology. With the advancement of robotics, SLAM technology has also evolved significantly1. Based on the sensing technique, SLAM can be categorized into Lidar (Light detection and ranging) SLAM and Visual SLAM. The framework of visual SLAM consists of sensor data acquisition, front-end visual odometry, back-end nonlinear optimization, loop closure detection and mapping2, as depicted in Fig. 1. The front-end primarily handles initial feature extraction and localization by processing images captured by the robot’s camera, the back-end module acquires information provided by the front-end visual odometry and the results of loop closure detection to conduct global optimization, producing globally consistent trajectories and maps.
Loop closure detection is a fundamental issue in SLAM research3. The purpose of loop closure detection is to ascertain whether the robot has revisited a location it previously encountered and subsequently aid in map construction. While the robot moves, it necessitates precise map information to localize itself and plan its trajectory. In the early stages of robotics development, the focus was primarily on building 2D maps, and prevalent solutions were filter-based, such as the Extended Kalman Filter (EKF)4, which is considered a landmark for loop closure detection5.

The framework for visual SLAM.
Loop closure detection methods can be categorized into odometry-based6 and appearance-based7. The appearance-based method is a commonly employed loop closure detection technique, as it can mitigate the accumulation of errors in contrast to odometry-based methods. It enables the imposition of constraints on the back-end pose optimization and plays a pivotal role in the establishment of precise maps8, rendering loop closure detection an independent module. Most appearance-based loop closure detection methods take advantage of Bag-of-Visual-Words (BoVW)9,10. These methods are employed to store visual scene information as a visual dictionary. Visual data is organized into clusters represented as “words,” and the current scene’s information is conveyed through a “word” vector. DBOW (Direct Bag-of-Words) methods rely on the precomputed offline generation of vocabularies. This implies that vocabularies need to be trained in advance when the robot is operational, allowing the robot to understand the environmental elements and subsequently perform loop closure detection. In cases where pretraining is not feasible, it can adversely impact the accuracy of loop closure, resulting in more biased maps.
Deep learning is now widely used in computer vision. It has achieved excellent results in the field of image classification11,12,13,14,15 and target detection16,17,18. Especially in dynamic environments, SLAM methods based on multi-sensor and deep learning have been widely studied and applied19,20,21. Based on target recognition and semantic information, the front-end odometer can effectively extract static features as landmarks; based on multi-sensors, it can bring more scale information as well as supplementary data for localization; deep learning can provide new technical solutions for loop closure detection. With the development of deep learning, more and more learning-based visual SLAM methods have been proposed in the last few years22,23,24. CNN-extracted features exhibit robustness to changing environmental conditions. CNNs do not require training for a specific environment during robot operation, indicating that CNN-based loop closure detection methods possess superior generalization capabilities.
In this paper, we propose a loop closure detection method based on Siamese network architecture and investigate the variation of accuracy and robustness under different Siamese branching strategies. The main contributions are as follows:
-
1.
We utilized a Siamese architecture in conjunction with a novel capsule network for loop closure detection tasks. The Siamese network structure is well-suited for image matching, while the capsule network is effective in extracting inter-image feature relationships. To address the issue of algorithm robustness in loop closure detection tasks, which are often affected by changes in lighting, viewpoint, and occlusion, we propose a new approach. Experimental results demonstrate that our method outperforms other deep learning-based loop closure detection methods in terms of accuracy. Additionally, compared to conventional convolutional neural networks, our approach exhibits superior robustness in complex environments.
-
2.
We employed depthwise separable convolutions and dilated convolutions to design a novel feature extractor. This approach effectively reduces network parameters while maintaining a substantial receptive field, capturing both local and global correlations in image features.
-
3.
We have designed a pruning layer for the capsule network to further compress the required parameters. This allows the algorithm to be feasible for real-time operations, even at the cost of sacrificing a certain level of accuracy.
This article is organized as follows: Sect. 1 centers on our loop closure detection method and provides experimental details, Sect. 2 reviews the current relevant literature, Sect. 3 presents our model’s structure and methodology, Sect. 4 evaluates the experimental results of different Siamese branch networks, traditional bag-of-words models, other deep learning methods, and loop closure detection performance using publicly available datasets, and Sects. 5 and 6 summarize the entire article.
Related work
Traditional loop closure detection methods
Loop closure detection methods can be categorized into odometry-based and appearance-based approaches. The odometry-based method relies on precise robot motion trajectory information. It operates under the assumption that the robot has returned to a previous location and then initiates loop closure detection. However, due to cumulative errors in practice, the robot may not accurately determine its return to a previously visited location, leading to a causal inversion in this assumption. In the field of visual SLAM, appearance-based loop closure detection algorithms are more commonly used. The appearance-based loop closure detection method lacks direct correlation with the front-end and back-end components of the SLAM system. It typically consist of four key elements: key feature extraction, feature matching, frame similarity calculation, and determination. By comparing image similarities, this method evaluates whether the robot has revisited a location. Despite its advantages, the bag-of-words model still possesses certain limitations: it is computationally intensive, unable to capture feature relationships, and sensitive to changes in lighting and environmental conditions. Consequently, it often underperforms in real-world applications, demonstrating weak generalization capabilities and causing SLAM systems with higher-than-expected errors in loop closure detection.
Deep learning loop closure detection methods
Studies have shown that the generic descriptors extracted by convolutional neural networks outperformed artificially extracted features. Features extracted by convolutional neural networks are more robust to environmental and illumination changes19,25,26,27,28. At the same time, deep learning methods, when compared to traditional methods, can extract the abstract features of the original image and capture deeper image information, as well as perform more robustly when dealing with complex scene changes. Gao et al.29 first proposed to apply Autoencoder in SLAM experiments, using neural network for feature extraction, and then using similarity matrix to evaluate image similarities. Arandjelovic30 addressed large-scale location recognition by designing a new CNN architecture that leverages CNN models as feature extractors, employing an end-to-end training approach. He Yuanlie et al.31 used the FLCNN network to extract the features of an image and confirm whether loop closure was generated by the similarity matrix. This method has improved the accuracy and effectiveness of loop closure detection. Xia et al.32 compared the performances of CNN methods and traditional methods in loop closure detection and the results showed that loop closure detection based on deep learning methods had better performance, whereas the traditional bag-of-words model loop closure detection method had only 62% accuracy on the New College dataset. Ahmad Khaliq et al.33 proposed a lightweight region feature combined with VLAD coding, which is capable of low computational cost to achieve high performance of the system and maintain higher accuracy under viewpoint and appearance variations. Yuan et al.34 proposed an LCD algorithm based on semantic-visual-geometric information, referred to as SVG-Loop. To reduce interference from dynamic features, they established a semantic bag-of-words model by connecting visual features with semantic labels. Similarly, Qin et al.35 endeavored to combine the semantic information extracted by the object detection model with geometric information to form a semantic subgraph, achieving excellent results.
In summary, the deep learning-based loop closure detection approach utilize neural networks instead of the conventional manual feature extraction. However, these methods exhibit a degree of vulnerability and reduced accuracy in dynamically changing environments. We observe that these approaches primarily rely on convolutional neural networks, which suffer from information loss due to the current pooling operations. Loop closure detection approaches should account for not only image similarity assessments but also the integration with the visual SLAM system, which is a pivotal factor. SLAM systems emphasis not only on accuracy but also on real-time performance, which is a crucial performance metric.
Proposed method
In this section, we present the details of the proposed method in two parts: (1) The extraction of different Siamese branch features and the learning process of the neural network. (2) The determination method of loop closure detection. The differences in loop closure detection accuracy variation and computation time due to different Siamese branches are explored.
Siamese convolution architecture
The Siamese network36, first proposed by Yann LeCun in 2005, was initially designed for face recognition. The Siamese network achieved significant success in signature verification, face recognition37 and other similarity metric tasks. The structure of the Siamese network is shown in Fig. 2. The Siamese network consists of two Siamese branches that share the weights W. According to this structure, a Siamese network requires a pair of similar or dissimilar images as input, for INPUT1 and INPUT2, respectively, into the neural network to obtain the similarity of the two inputs.

Siamese network structure.
In this paper, we investigate the loop closure detection method using AlexNet38 and VGG1639 as Siamese branches. AlexNet played a crucial role in the development of deep learning, this model won the 2012 ISLVRC competition network by a wide margin. VGG has won the 2014 ILSVRC Competition Positioning Contest and placed 2nd in the Classification Contest. AlexNet consists of 5 convolutional layers, 3 pooling layers, and 3 fully connected layers. The specific parameters of AlexNet are shown in Table 1. VGG16 consists of 5 convolutional layers, 3 fully connected layers and a softmax output layer. It uses stacking of multiple small convolutional kernels instead of large convolutional kernels, and the convolutional layers are distinguished from one another using the max pooling layer, the specific parameters of which are shown in Table 2.
We cropped image pairs of 227 × 227 × 3 pixels as the input image, along with the corresponding label. The neural network used a convolutional kernel to extract the features of the input image, and then the feature vectors extracted by the two Siamese branches were stitched together and fed into the fully connected layer. To prevent the gradient from exploding or disappearing and overfitting during training, we added a batch normalization layer between the fully connected layers and normalized each element as shown in Eq. (1):
where\(\:\:{x}_{k}^{{\prime\:}}\) represents the normalized result, \(\:{\mu\:}_{B}\) represents the average value in each batch,\(\:\sigma\:\) represents the variance of each batch, and the sigmoid function was used as the output function as in Eq. (2) to output the result of this prediction.
This function allowed us to control the prediction results in the (0,1) interval and get the Siamese network’s evaluation of whether the two scenes were similar or not. We chose the loss function as in Eq. (3). In the following formula, N stands for batch size, \(\:{y}_{i}\) represents the binary label 0 or 1, \(\:{\widehat{y}}_{\dot{v}}\) represents the probability that this prediction belongs to label\(\:\:{y}_{i}\). We needed to make similar images closer in the feature space; the loss function will reduce the Euclidean distance when the labels of the two input images are 1.
Siamese lightweight capsule architecture
Capsule networks were first proposed in 2017 by Sabour et al.40. Capsule networks, along with routing mechanisms, have been designed to detect part–whole relations, and have emerged as an approach in deep learning with impressive results obtained in image recognition41, speech emotion recognition42 and keyword detection43. Convolutional neural networks use max pooling layers or average pooling layers to compress features while reducing the number of parameters in the network and expanding the receptive field of the neural networks; the pooling operation allows for efficient feature aggregation, but also means that important information such as location information between features may be lost. In order to compensate for this shortcoming of convolutional neural networks, the capsule network uses a dynamic routing algorithm instead of the original pooling layer. Gong et al.44 proved that the aggregation mechanism in a capsule network had obvious advantages over traditional methods such as max pooling. The capsule vector of the capsule network can represent the spatial location relationship between the extracted features.
The capsule network employs 9 × 9 large convolutional kernel for feature extraction from images, providing a richer receptive field and better capability to extract global features and leverage this information for discrimination. However, this strategy introduces a significant computational load, resulting in shortcomings in both time and performance for the capsule network. To address this, we have designed a novel feature extractor for the capsule network, utilizing depthwise separable convolutions to compress the parameter count during feature extraction. Additionally, we have opted to use dilated convolutions to further expand the receptive field while maintaining the network’s lightweight nature. In the capsule layer, a significant number of capsules do not contribute to the final result calculation. Therefore, we have introduced a pruning module within the capsule layer, as illustrated in Fig. 3, in the overall network structure. We have resized the convolutional kernel to 7 × 7 and set the stride to 1. The features extracted by the feature extractor were formed into primary capsules, which were denoted as \(\:{u}_{i}\), \(\:\dot{l\:}\)= 1, 2, 3, … n, where n represents the number of capsules, and a capsule is a set of neurons. By applying the transformation matrix \(\:{W}_{ij}\), which is the affine transformation matrix of the spatial position relation of the encoded features, the input \(\:{u}_{i}\) was transformed into the prediction vector, as shown in Eq. (4):
The total input vector \(\:{s}_{j}\) of the high-level capsule is obtained after weighting and summing all the prediction vectors, as shown in Eq. (5):
In this equation,\(\:{C}_{ij}\) is the coupling coefficient, satisfying\(\:\sum\:_{i}{c}_{ij}\)=1; \(\:{\:\text{c}\text{o}\text{u}\text{p}\text{l}\text{i}\text{n}\text{g}\:\text{c}\text{o}\text{e}\text{f}\text{f}\text{i}\text{c}\text{i}\text{e}\text{n}\text{t}\:C}_{ij}\)can be computed using the softmax function, as shown in Eq. (6):
The predicted prior probability of coupling between \(\:\:{\widehat{u}}_{{\left.j\right|}_{i}}\)and the higher-level capsule \(\:{s}_{j}\) is represented by bij. The formula for bij is as follows:
In the DigitCaps layer, which follows the fully connected layer, the norm of the vector of each capsule represents the probability of the network for a class of predictions. Using the norm length of the capsule vector as the probability of the entity representation requires a nonlinear function squash as shown in Eq. (8):
to compress the vectors so that the short vectors tend to 0 and the long vectors are compressed to below 1.In the formula,\(\:{v}_{\dot{J}}\:\)represents the output vector of capsule j, \(\:{s}_{j}\:\:\)is the total input of the high-level capsule. The size of the capsule was also set to 16 dimensions, and finally the prediction results were obtained. Following the above process, the operation process of the capsule network is shown in Fig. 4.
A Siamese network was built using a capsule network as a subnetwork. When two similar samples were obtained, the resulting output capsules were similar and spatially close; when two inconsistent samples were obtained, the spatial distance of the output capsules was larger for the same reason. The capsule network used capsule vectors to express the extracted features, and after obtaining the capsule vectors, the L2 normal form was chosen to measure the similarity of the features, as shown in Eq. (9):
where \(\:x\) represents the capsule vector that needs to be input. The two subnetworks calculated the distance of their respective capsule vectors using the L2 normal form and then performed the calculation as shown in Eq. (10):
Where \(\:{x}_{l}\) is the output result of the first sub-network an-d \(\:{x}_{r}\) is the output result of the second sub-network. Consistent with the Siamese convolutional neural network, we chose the same loss function. When training the Siamese convolutional neural network, an initial learning rate of 0.0003 was used; in training the Siamese capsule network, an initial learning rate of 0.0003 was used; both Adam optimizers were chosen; the batch size was chosen to be 64; and an early stop strategy was adopted to prevent the network from overfitting.

Schematic diagram of capsule network structure.

Capsule network operation process diagram.
Pruning of the capsule network
In the context of handling classification tasks, conventional convolutional neural networks often exhibit parameter redundancy, and capsule networks share a similar characteristic.A subset of primary capsules within the capsule network has a relatively minor impact on the final experimental results while incurring a significant proportion of computational overhead. To further enhance the network’s computational efficiency, we introduced pruning layers.The image undergoes convolutional operations, transforming it into complex feature representations, which are then shaped into primary capsules. These primary capsules exhibit varying levels of activity, and the higher-level capsules are composed of contributions from these primary capsules, with more active primary capsules carrying greater significance in this process. When the coupling coefficients \(\:{C}_{ij}\) are low, it can be inferred that the primary capsules and higher-level capsules are expressing disparate information. Therefore, we can selectively filter out these less active primary capsules. We obtain the coupling coefficients corresponding to the primary capsules and use them as an indicator of capsule activity. We rank the coupling coefficients and perform pruning operations on the bottom 20% of the capsules, as shown in Fig. 5.

Capsule network pruning operation schematic.
We retain only capsules with higher coupling coefficients since these capsules constitute the primary computational components of the network. Simultaneously, the transformation matrix \(\:{W}_{ij}\) corresponding to these capsules are set to 0, and no further updates are performed during the subsequent backpropagation and parameter updating stages. The improved dynamic routing algorithm is shown in Table 3:
The determination of loop closure detection
We design a visual SLAM system inspired by ORB-SLAM2. Instead of using the original ORB-SLAM loop closure detection method, which is based on the bag-of-words model, we adopt the algorithm proposed in this paper as an alternative solution. Finally, we deploy our model in C++.
The essence of loop closure detection is to determine whether the current scene matches a previously observed scene. To achieve this, we search for image information in historical frames that best match the query frame. The Siamese network was applied to determine the similarity of two input images. When performing loop closure detection, the subnetwork received the history frames as INPUT1 and the query frames as INPUT2, and the predicted values were calculated by the Siamese network. Instead of utilizing the similarity calculation method of the bag-of-words model, we employ a Siamese network to directly output the distance between images. Scenes originally represented by words are now expressed through neural network features. The query frame iteratively traverses historical frames to compute matching results and confirm loop closures. When the computed similarity exceeds a predefined threshold (0.9), the scene is considered to correspond to the same location, after which the map fusion process is performed. Meanwhile, we did not modify the keyframe selection strategy and maintained the image database based on keyframes. Additionally, during the validation phase, we use GPS information to determine whether our algorithm has made any misclassifications. The flowchart is shown in Fig. 6.

Flowchart of loop closure detection.
Experiment validation
Dataset processing
We used the Oxford outdoor public datasets NewCollege and CityCentre in our experiments45, as shown in Fig. 7. The images in both datasets are captured by cameras placed on the left and right sides of the wheeled robot, and the robot completes an image acquisition operation every 1.5 m of travel while collecting GPS coordinate information of the images. In the dataset, the robot passes the same place many times, including a large number of loop closure cases; meanwhile, the dataset provides the use of GroundTruth matrix for the labeling of loop closure, and if image i matches with image j, then the elements of the corresponding matrix (i, j) is labeled as 1, otherwise, it is labeled as 0.The image is divided into a set of matched or unmatched samples and a labeled form according to the information of the GroundTruth matrix; while the number of matched as well as unmatched samples is the same. The parameters of the data set are shown in Table 4.

Dataset image.
These images in the dataset captured by the robot have distortions, which needed to be removed from the images according to the camera parameters. We performed a projection transformation on the validation set to simulate capturing images from different angles of the same location while the robot was moving, as shown in Fig. 8, to test the robustness of the algorithm in this paper under angle-of-view changes, or to train the neural network. To increase the robustness of the loop closure detection algorithm to changes in illumination, we trained the network with random luminance variations on the dataset, as shown in Fig. 9.Additionally, in order to simulate the situation where features are occluded in a dynamic environment, we conducted a control experiment by adding random-sized and -numbered masks to the images, as shown in Fig. 10.

Angle of view change diagram of the data set.

Illumination change diagram of the dataset.

Add random masks to the dataset.
For the evaluation of visual SLAM systems, we tested our algorithm on the KITTI Sequence 00-0546. The KITTI dataset was co-founded by the Karlsruhe Institute of Technology (KIT) in Germany and the Toyota Research Institute in the United States. It is currently the largest benchmark dataset for evaluating computer vision algorithms in the context of autonomous driving scenarios. KITTI encompasses real-world image data collected in various scenarios, including urban areas, rural landscapes, and highways. The image sequences contain multiple instances of pedestrians and vehicles, as well as varying degrees of occlusion and truncation. The data collection platform for the KITTI dataset is equipped with two grayscale cameras, two color cameras, a Velodyne 64-line 3D LiDAR sensor, four optical lenses, and a GPS navigation system. The dataset images of the KITTI dataset are depicted in Fig. 11.
In our experiments, we selected sequences 00–05 as the primary validation datasets. Sequences 00–05 contain multiple loop closure scenarios with closed-loop segments at various map points, enabling the evaluation of the performance of visual SLAM systems and the observation of map construction results.The experimental results show that our method can effectively provide accuracy and robustness for the loop closure detection module.

The KITTI dataset.
Result
Algorithm performance evaluation
We employed two publicly available datasets to assess the performance of the algorithm presented in this paper. The experimental results are presented by Precision-Recall curves to demonstrate the performance of the algorithm. The precision rate and recall rate can be expressed as formulations (11) and (12):
Where TP is true positive; FP is false positive; FN is false negative. A comparison of the P-R curves of the algorithm in this paper and the traditional bag-of-words model is shown in Fig. 12. The larger the area enclosed by the P-R curve, the better the performance of the algorithm. In comparison to other algorithms, the P-R curve of the algorithm proposed in this paper is closer to the upper-right corner, and the overall performance is relatively stable. In this task, precision is more critical than recall; a lower recall may result in the failure to identify some true loops, while a lower precision may lead to errors in the backend optimization and ultimately result in incorrect map construction47. At a recall rate of 70%, the algorithm proposed in this paper maintains a stable level of precision. In contrast, the traditional bag-of-words model shows a significant drop in precision, and the area under the P-R curve is smaller. Overall, neural network-based loop closure detection algorithms outperform traditional methods in terms of performance.

Comparison of the P-R curves of our algorithm and the traditional method in the CityCentre(left) and NewCollege(right) dataset.
Algorithm robustness experimentation
To evaluate the enhanced robustness of capsule networks on algorithms, we selected AlexNet, VGG16, and the capsule network as subnetworks to try the loop closure detection. The experimental results are also shown by P-R curves to demonstrate the performance of the algorithm, the P-R curves are shown in Fig. 13.

P-R curves of different siamese branch networks on the CityCentre dataset.
Based on the results of the P-R curve, it can be seen that the Siamese network achieved the better performance for loop closure detection when the capsule network was used as a subnetwork. When employing capsule networks as branches in a Siamese network, the overall algorithm exhibits a Precision-Recall curve that tends to be closer to the upper-right corner. Even when subjected to variations in viewpoint across the dataset, the performance of the Siamese capsule network surpasses that of alternative architectures. The utilization of capsule networks contributes to a superior ability to capture nuanced patterns, particularly in scenarios where sensitivity to false negatives is critical. In visual SLAM, precision in loop closure is crucial. We evaluated the robustness of various Siamese branches under different environmental influences and documented the results in Table 5.
In addressing changes in illumination, deep learning-based methods show comparable performance. However, when handling variations in viewpoint, capsule networks demonstrate superior robustness. Even in the most complex scenarios, the loop closure detection algorithm based on capsule structures exhibits a precision drop of only 4.4%. However, during experiments involving feature occlusion, the instability of the masked regions significantly affected the performance of all algorithms. The mode of the capsule vector represents the probability of existence of the feature and the direction of the vector represents the pose information of the feature, which will change the capsule vector when the feature is moved without affecting the probability of existence of the feature. Therefore, the capsule network loses less accuracy when the validation set is transformed by projection.
Real-time performance experimentation of algorithm
The loop closure detection method based on deep learning has received extensive research attention. We evaluated the performance of various recent methods(DarkNet48, GoogleNet, PCANet49, FLCNN, MobileNet50, VGG51, SqueezeNet52, LSGD53) and compared them with our algorithm. The accuracy and real-time capabilities of the algorithm are presented in Table 6.
According to the experimental results, it can be observed that our algorithm achieved excellent accuracy on two publicly available datasets, demonstrating a significant improvement compared to other neural network methods. However, in terms of computational time, our algorithm is only at an average level compared to other recent methods. By sacrificing a certain level of accuracy, we have enhanced the operational efficiency of the capsule network through lightweight design and pruning, allowing the algorithm to better integrate with real-time SLAM systems. In terms of runtime efficiency, our algorithm achieved a 30.8% improvement after the pruning operation.
Robustness analysis of the visual SLAM system
We tested the visual SLAM system on the KITTI datasets. To assess the robustness of our algorithm to environmental variations, we subjected the KITTI dataset to continuous random changes in brightness. The results of running our algorithm in this paper on the KITTI sequence 00–05 are shown in Table 7.
We chose ORBSLAM2 as a comparative experimental subject. ORBSLAM2 is an exemplary representative among visual SLAM algorithms, relying on the bag-of-words model to construct the loop closure detection module. From the mapping results, it is evident that our visual SLAM system exhibits better robustness in dynamic and uncertain environments with changes in lighting and loop closure positions, aligning more closely with the true trajectory. ORBSLAM2’s loop closure detection confirmation relies on ORB feature, and ORB feature extraction is dependent on pixel disparities, resulting in deviations during the loop closure closure process, which affects the subsequent map fusion and correction. Additionally, in explicit accuracy evaluations, the improvement in accuracy of our VSLAM system compared to the original system is limited. Feature extraction at the front-end and odometry establishment are critical for ensuring the overall accuracy of VSLAM. Since our approach does not modify the front-end of ORBSLAM2, significant improvements in overall accuracy are not expected. However, our method helps the SLAM system reduce accuracy loss in complex environments.
Discussion
In this paper we investigate the traditional loop closure detection method and the deep learning method, respectively. Methods based on the bag-of-words model, such as the loop detection algorithm in ORB-SLAM2, effectively leverage information within visual SLAM systems, demonstrating a high degree of compatibility with the overall framework of visual SLAM systems. The dependency of the loop detection module in ORB-SLAM2 on ORB feature extraction can indeed result in false positives during loop closure determination. As a consequence, both the accuracy and robustness of loop closure detection may be compromised.
Features extracted by neural networks exhibit superior robustness compared to ORB features, particularly in handling variations in illumination. However, features extracted by convolutional neural networks lack rotational invariance, whereas the corresponding ORB features can capture the orientation of features. Convolutional layers do not consider the activity of features when extracting them; however, the concept of feature activity appears in the bag-of-words model. Inspired by this, we aim to better represent the features in an image and enable the method to understand the relationships between features. In convolutional neural networks, there is a stronger emphasis on the presence or absence of features, with less focus on understanding the definition of the features themselves. When handling similar scenes, similar features may appear multiple times, making the relationships between features particularly important in such cases. We adopted a methodology inspired by capsule networks, integrating the strengths of both, allowing our algorithm to simultaneously address variations in illumination and changes in orientation. However, the computational overhead introduced by capsule networks was not aligned with the desired outcomes of the current task. Therefore, based on this, we conducted lightweight optimizations to the overall algorithm.
In summary, the real-time performance of the current algorithm meets the real-time requirements of SLAM. However, in the practical operation of robots, computational resources are often limited. Deploying the algorithm on resource-constrained mobile platforms while maintaining high accuracy and good real-time performance requires further research.
Conclusions
In this paper, we propose a deep learning-based loop detection algorithm. Our objective is to enhance the robustness of the loop detection algorithm to variations in illumination and viewpoint changes by incorporating an improved capsule network as a subnetwork within a siamese network architecture. Specifically, we introduced a siamese structure tailored for the loop closure detection task, utilizing capsule vectors to represent image features. In this process, a novel feature extractor was designed to replace the original convolutional layers. Subsequently, pruning was applied to the capsule layer to reduce network parameters. We proposed a straightforward loop closure verification method as a validation for the loop closure detection results. We evaluated the proposed approach on various publicly available datasets, and the results demonstrate that our algorithm achieves higher accuracy and robustness.
Data availability
We reiterate the accessibility of the data utilized in this study, which is derived from the publicly available NewCollege, CityCentre (https://www.robots.ox.ac.uk/~mobile/IJRR_2008_Dataset/) and KITTI360 (https://www.cvlibs.net/datasets/kitti/).
Code availability
The custom code used in this study is available upon reasonable request.The customized code in this study can be found in the Zenodo repository (https://doi.org/10.5281/zenodo.14623356).
References
Cadena, C. et al. Present, and future of simultaneous localization and mapping: toward the robust-perception age. IEEE Trans. Robot. 32, 1309–1332 (2016).
Gao, X., Zhang, T., Liu, Y. & Yan, Q. In 14 Lectures on Visual SLAM: from Theory to Practice 2nd edn, 19–20 (Publishing House of Electronics Industry, 2019).
Labbe, M. & Michaud, F. Appearance-based loop closure detection for online large-scale and long-term operation. IEEE Trans. Robot. (TRO). 29, 734–745 (2013).
Davison, A. J., Reid, I. D., Molton, N. D. & Stasse, O. Monoslam: real- time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 29 (6), 1052–1067 (2007).
Teslić, L., Škrjanc, I. & Klančar, G. Ekf-based localization of a wheeled mobile robot in structured environments. J. Intell. Robot Syst. 62, 187–203 (2011).
Hahnel, D., Burgard, W., Fox, D. & Thrun, S. An efficient fastslamalgorithm for generating maps of large-scale cyclic environments from raw laser range measurements. In Proc. of the 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003), Las Vegas, NV, USA, 27–31 October, 206–211 (2003).
Cummins, M. & Newman, P. Appearance-only slam at large scale with fab-map 2.0. Int. J. Robot Res. 30, 1100–1123 (2011).
Nistér, D., Naroditsky, O. & Bergen, J. Visual odometry. In Proc. of the Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 (2004).
Gálvez-López, D. & Tardos, J. D. Bags of binary words for fast place recognition in image sequences. IEEE Trans. Robot. 28, 1188–1197 (2012).
Sivic, J. & Zisserman, A. Video google: A text retrieval approach to object matching in videos. In Proc. of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October ; Volume 2, 1470–1477 (2003).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proc. of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June, 770–778 (2016).
Huang, G., Liu, Z., Van Der Maaten, L. & Weinberger, K. Q. July. Densely connected convolutional networks. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26, 4700–4708 (2017).
Xie, S., Girshick, R., Dollár, P., Tu, Z. & He, K. Aggregated residual transformations for deep neural networks. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July, 1492–1500 (2017).
Howard, A. et al. Searching for mobilenetv3. In Proc. of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 1314–1324 (2019).
Tan, M., Le, Q. & EfficientNet Rethinking model scaling for convolutional neural networks. In Proc. of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June, 6105–6114 (2019).
Ren, S., He, K., Girshick, R., Sun, J. & Faster, R-C-N-N. Towards real-time object detection with region proposal networks. In Proc. of the Advances in Neural Information Processing Systems, Montreal, QC, Canada (2015).
Liu, W. et al. Single shot multibox detector. In Proc. of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October, 21–37 (2016).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, real-time object detection. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA; 27–30 June, 779–788 (2016).
Wen, S. et al. CD-SLAM: A Real-Time Stereo Visual-Inertial SLAM for Complex Dynamic Environments with Semantic and Geometric Information (IEEE Transactions on Instrumentation and Measurement, 2024).
Liu, X. et al. Edge-assisted Multi-robot visual-inertial SLAM with efficient Communication. IEEE Trans. Autom. Sci. Eng. (2024).
Yu, Y. et al. A two-stage importance-aware subgraph convolutional network based on multi-source sensors for cross-domain fault diagnosis. Neural Netw. 179, 106518 (2024).
Hou, Y., Zhang, H. & Zhou, S. Convolutional neural network-based image representation for visual loop closure detection. In Proc. of the International Conference on Information and Automation, Lijiang, China, 8–10 August, 2238–2245 (2015).
Chen, Z., Lam, O., Jacobson, A. & Milford, M. Convolutional neural network-based place recognition. Preprint at https://arXiv.org/1411.1509 (2014).
Arroyo, R., Alcantarilla, P. F., Bergasa, L. M. & Romera, E. Fusion and binarization of CNN features for robust topological localization across seasons. In Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Daejeon, Republic of Korea, 9–14 (2016).
Sünderhauf, N. et al. Place recognition with convnet landmarks: Viewpoint-robust condition-robust trainingfree. In Proc. of the Robotics: Science & Systems, Rome, Italy, 13–17 July, 1–10 (2015).
Sharif Razavian, A., Azizpour, H., Sullivan, J. & Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June, 512–519 (2014).
Sünderhauf, N., Shirazi, S., Dayoub, F., Upcroft, B. & Milford, M. On the performance of convnet features for place recognition. In Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September – 2 October, 4297–4304 (2015).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. In Proc. of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 1097–1105 (2012).
XIANG, G. & TAO, Z. Loop closure detection for visual SLAM systems using deep neural networks [C] Chinese Control Conference, 5851–5856 (IEEE, 2015).
ARANDJELOVIC, R. et al. TORII A,. NetVLAD: CNN architecture for weakly supervised place recognition. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 5297–5307 (2016).
He, Y., Chen, J. & Zeng, B. Fast Loop closure detectionMethod based on reduced convolutional neural network. Comput. Eng. 44, 182–187 (2018).
Xia, Y., Li, J., Qi, L., Yu, H. & Dong, J. An evaluation of deep learning in loop closure detection for visual SLAM. In Proc. of the IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Exeter, UK, 21–23 June 2017, 85–91 (2017).
Khaliq, A. et al. A holistic visual place recognition approach using lightweight cnns for significant viewpoint and appearance changes. IEEE Trans. Robot. 36 (2), 561–569 (2019).
Yuan, Z. et al. SVG-Loop: Semantic Visual Geometric Information Based Loop Closure Detection. Emote Sens. 13(17), 3520 (2021).
QIN, C. et al. Semantic loop closure detection based on graph matching in multi-object scenes. J. Vis. Commun. Image Represent. 76, 103072 (2021).
Chopra, S., Hadsell, R. & LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proc. of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June, 539–546 (2005).
Cao, Q., Ying, Y. & Li, P. Similarity Metric Learning for Face Recognition. In Proc. of the International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013, 2408–2415 (2013).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. Commun. ACM 60, 84–90 (2017).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. Preprint at https://arXiv.org/1409.1556 (2014).
Sabour, S., Frosst, N. & Hinton, G. E. Dynamic routing between capsules. In Proc. of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December (2017).
Kosiorek, A., Sabour, S., Teh, Y. W. & Hinton, G. E. Stacked capsule autoencoders. In Proc. of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada; 8–14 December, 512–522 (2019).
Wu, X. et al. May. Speech emotion recognition using capsule networks. In Proc. of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17, 6695–6699 (2019).
Xiong, Y., Berisha, V. & Chakrabarti, C. Residual + capsule networks (rescap) for simultaneous single-channel overlapped keyword recognition. In Proc. of the Interspeech 2019, 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 15–19 September, 3337–3341 (2019).
Gong, J., Qiu, X., Wang, S. & Huang, X. Information aggregation via dynamic routing for sequence encoding. Preprint at https://arXiv.org/1806.01501 (2018).
Smith, M., Baldwin, I., Churchill, W., Paul, R. & Newman, P. The newcollege vision and laser data set. Int. J. Robot. Res. 28 (5), 595–599 (2009).
Geiger, A., Lenz, P., Stiller, C. & Urtasun, R. Vision meets robotics: the KITTI dataset. Int. J. Robot Res. 32 (11), 1231–1237 (2013).
Zhu, M. & Huang, L. Fast and robust visual loop closure detection with convolutional neural network. In 2021 IEEE 3rd International Conference on Frontiers Technology of Information and Computer (ICFTIC), 595–598 (IEEE, 2021).
Yu, Y. & Feng, H. Visual SLAM loop detection method based on deep learning. Comput. Eng. Des. 41, 529–536 (2020).
Chan, T. H. et al. A simple deep learning baseline for image classification. IEEE Trans. Image Process. 24, 5017–5032 (2015).
Zhu, Z. et al. LFM: a lightweight LCD algorithm based on feature matching between similar key frames. Sensors 21 (13), 4499 (2021).
Xu, Z. et al. VGG-CAE: Unsupervised Visual Place Recognition Using VGG16-Based Convolutional Autoencoder. In Chinese Conference on Pattern Recognition and Computer Vision (PRCV), 91–102 (Springer, 2021).
Hu, Z. Visual loop closure detection based on SqueezeNet multi-layer feature fusion and adaptive range matching algorithm. J. Intell. Robotic Syst. 108 (3), 55 (2023).
Zhang, B., Xian, Y. & Ma, X. LSGDDN-LCD: an appearance-based loop closure detection using local superpixel grid descriptors and incremental dynamic nodes. Comput. Electr. Eng. 119, 109477 (2024).
Acknowledgements
This work was supported by the Key Research and Development Program of Zhejiang Province [grant number 2022C01139]; the industry university research innovation fund of the Ministry of education of China [grant number 2021JQR012]; Zhejiang Collaboration and Innovation Center for Urban Rail Transit Operation Safety Technology & Equipment; Zhejiang Provincial Key Laboratory of Urban Rail Transit Intelligent Operation and Maintenance Technology & Equipment.
Author information
Authors and Affiliations
Contributions
YuHan Zhou and MingLi Sun, methodology: YuHan Zhou and MingLi Sun, formal analysis: YuHan Zhou , investigation: YuHan Zhou and MingLi Sun, writing—original draft preparation: YuHan Zhou , writing–review and editing: YuHan Zhou and MingLi Sun.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhou, Y., Sun, M. A visual SLAM loop closure detection method based on lightweight siamese capsule network. Sci Rep 15, 7644 (2025). https://doi.org/10.1038/s41598-025-90511-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-90511-4
Keywords
This article is cited by
-
Remotely Operated Robots for Underground Applications
BHM Berg- und Hüttenmännische Monatshefte (2025)
