
Abstract
In visual tasks, image instance segmentation has always been one of the most crucial core technologies in various fields, such as autonomous driving, and medical image analysis. Currently, diffusion models have become the most advanced framework method for research in the field of images. This technology was initially used in the field of image enhancement and made significant progress at one point. In this study, the main discussion revolves around how to use algorithms to improve recognition accuracy when applying diffusion models to image instance segmentation. Here, this paper creatively proposes a Step Noisy Perception (SNP) method. During the inverse denoising process at different stages of the same instance segmentation task, a controllable relationship exists between different step sizes corresponding to different Gaussian distributions. By utilizing the information between different stages of step sizes, the accuracy of the segmentation model can be improved. This research on instance segmentation tasks is valuable. The paper conducts performance tests on instance segmentation models on the COCO and LVIS datasets and compares the segmentation results of the proposed model with those of other traditional classic segmentation methods in recent years. The experimental results show that our method has an overwhelming advantage in the recognition of small and medium-sized objects and is also competitive in recognizing large objects. Additionally, compared to the training of diffusion models, our proposed generative model shows a 2.8% improvement in accuracy, proving that this improved diffusion model method has certain research potential in instance segmentation tasks.
Similar content being viewed by others

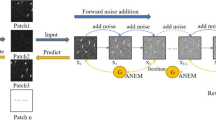
Introduction
The perception of images has gradually shifted from human visual cognition to the processing and analysis of images and multidimensional data by computers. Image segmentation is an application in the field of computer vision, encompassing areas such as object detection, image analysis, image editing, and robotic vision. It involves dividing an image into multiple non-overlapping regions or pixels, with the goal of assigning each pixel to different categories or objects, thereby achieving semantic understanding and region recognition of the image. Image segmentation can extract regions of interest, enabling higher-level image understanding and analysis. Common image segmentation methods include threshold-based, edge detection-based, region-based, image-cutting-based, and deep learning-based approaches1.
Deep learning-based methods, specifically using deep convolutional neural network (CNN), for feature extraction and metric learning, have provided innovative end-to-end solutions. As a result, CNN have become the mainstream approach in visual tasks. Additionally, the inherent generative mechanism in deep learning reveals the significant potential of generative models. During model training, generative models can use latent parameters to randomly generate experimental data samples that meet training requirements but differ in results. In recent years, with the development of computer hardware technology, diffusion models, a type of generative model in deep learning, have gained popularity due to their reliance on powerful GPU computing capabilities. To date, diffusion models have demonstrated excellent performance in numerous application domains, including natural language processing, adversarial purification, time series modeling, multimodal modeling, waveform signal processing, and computer vision.
Generative models are a common learning approach in supervised learning tasks, alongside discriminative models. Generative models aim to randomly generate data information given hidden parameters, thereby establishing similarity information among similar data. During the modeling process, Bayes’ theorem is used to solve the conditional distribution problem in generative models. Unlike discriminative models, generative models focus on understanding how data is generated, whereas discriminative models are more concerned with the differences between classes for classification purposes. Discriminative models do not consider the data generation process; instead, they focus on distinguishing between classes during model training.
In image segmentation, tasks include semantic segmentation and instance segmentation. Semantic segmentation focuses on pixel-level classification, aiming to identify the category of each pixel in an image. It has classic applications in areas such as autonomous driving, medical image analysis, and robotic vision. As early as 1979, Jumiawi2 proposed an image binarization segmentation threshold algorithm, which laid a foundation for future research. The idea of threshold selection based on cross-entropy proposed by Li3 was used to solve the problem of computational extraction between image pixels. Building on this research, Jumiawi4 graded the threshold image segmentation at different intensities and used the average threshold theory for evaluation. In addition, Kittaneh5 further optimized the threshold performance using the minimum variance entropy. Common models for semantic segmentation use an encoder-decoder architecture, such as Fully Convolutional Networks (FCN), U-Net, and DeepLab.Instance segmentation, on the other hand, not only identifies objects in an image but also distinguishes different instances of those objects. It combines semantic segmentation techniques with object detection techniques to segment all object instances in an image. This requires the model to output both the class and location (bounding box) of the objects, as well as pixel-level masks for each object. Applications of instance segmentation place a greater emphasis on distinguishing between individuals, such as different people and objects. Algorithms include Mask R-CNN and YOLOv8, which typically involve components for object detection to locate objects in the image, followed by pixel-level segmentation for each proposed region. Instance segmentation is one of the challenging problems in computer vision, as it requires a more specific and accurate understanding of scene information in the image. The task involves simultaneously determining the differences and relationships between object categories in different regions of the same image.
In recent years, there have been significant advancements in instance segmentation, particularly with the development of deep convolutional neural networks. Driven by large datasets with pixel-level annotations, deep learning-based methods for instance segmentation have made substantial progress. However, the excellent performance of these deep models often depends heavily on large-scale training datasets and expensive pixel-level annotations. This has led to research into ways to increase the volume of training samples and reduce annotation costs while maintaining high-quality performance.So the instance segmentation technology has been widely used in the fields of industry, medical, security, and automatic driving due to its ability of automatically understanding different scenes based on deep learning of images. For example, in the field of automatic driving, the automatic learning and understanding of the road conditions, vehicle driving conditions and pedestrian conditions can be achieved based on the image information, which can be used to obtain the image information of real-time road conditions, provide accurate and timely guidance to the driving of vehicles so as to ensure the normal operation of traffic, and safeguard the safety of vehicles and pedestrians. In the medical field, the boundary of the lesion contour can be accurately located by processing the CT image, and the segmentation and identification of the specific location of the lesion and its shape and size can be implemented, so as to help the doctor to more accurately analyze diagnostic results.
Instance segmentation technology is widely used in various fields, including industrial, medical, security, and autonomous driving sectors, due to its ability to perform deep learning on images and automatically understand different scenes. For example, in the autonomous driving field, instance segmentation can automatically analyze road conditions, vehicle movements, and pedestrian situations from image information. This allows for real-time acquisition of traffic information, providing accurate and timely driving guidance to ensure normal traffic flow and the safety of both vehicles and pedestrians.
In the medical field, instance segmentation is used to accurately delineate the boundaries of lesions in CT images. By precisely locating and identifying the specific position, shape, and size of the lesions, this technology assists doctors in making more accurate diagnostic judgments, thereby enhancing the overall quality of medical care.
In the current instance segmentation researches, the main solution is to localize the target object first and then segment it. At present, the commonly adopted methods mainly include three types. The first type is the instance segmentation method without candidate frames, which mainly relies on the embedded learning between pixel points and clustering according to the relationship between the pixel points, and one method of this type is the classical deep watershed algorithm6. The second type is the candidate frame-based instance segmentation method, which performs object detection first, and then each pixel is predicted to determine whether it is a foreground pixel of the object frame. For example, the classic Mask R-CNN7 uses a full convolutional network to perform semantic segmentation of each candidate frame mask. The third type is the simple and straightforward pixel-level instance segmentation introduced with the proposal of the SOLO algorithm8. In Ref.9 proposes a diffusion model method for instance segmentation, which also presents a new idea and inspires our work. In this paper, on the basis of the above works, an improved method based on the diffusion model for instance segmentation is proposed.
The main work and contributions of this paper can be summarized as follows:
-
(1)
According to the structural characteristics of the diffusion model in the image segmentation task, an improved model framework for the instance segmentation task is designed.
-
(2)
In the image instance segmentation task, the concept of step noisy perception coding is proposed, which is proved to have great significance in the model diffusion process for mask computation in the instance segmentation task.
-
(3)
On the public COCO and LVIS dataset, experiments were carried out to compare the performances of our method and other conventional CNN-based instance segmentation model framework proposed in recent years. The experimental results prove that the learning approach of diffusion model based on the method proposed in this paper has certain research values when applied to the instance segmentation tasks.
Related work
Semantic segmentation
Semantic segmentation involves classifying each pixel in an image. There has been extensive research in this area, primarily focused on improving segmentation performance. For instance, Bing9 proposed using image segmentation techniques to enhance real-time weld seam positioning accuracy, though they did not address the potential issue of reduced accuracy in the backbone network. Similarly, Graham10 proposed achieving model diversity by altering the network scale to address the convergence problem in model training. Additionally, to mitigate the problem of misclassification among similar classes, Bi11investigated the feature mapping relationships of pixel-level and structural-level information, demonstrating the regularization relationship of distances among different pixel representations of different classes.
While the aforementioned studies improved model convergence by altering internal structures, they did not enhance the network’s ability to capture global features. To address this, Xu12 effectively combined CNNs, which struggle to capture global features, with Transformers, which are less adept at capturing local feature details, in lightweight real-time semantic segmentation networks. In the realm of multi-scale object segmentation, Wang13 proposed using distillation to distinguish between the multi-scale differences in outputs between teacher and student models. Similarly, Palanivel14focused on capturing multi-scale contextual information, providing another solution. These methods, which combine different networks to better capture target feature details, can also lead to higher model costs.Moreover, Liu15 suggested using multi-scale information in lightweight perceptual images to address the issue of detail loss. Hui16 applied multi-scale methods to solve sea-land segmentation in remote sensing images, though they did not further optimize the model’s network by integrating actual target conditions. In video segmentation research, Chen17 proposed a dynamic region mask algorithm to enhance the precision of instance segmentation localization, but this approach may lead to over-expansion of the target area, warranting further exploration in future research. In other interdisciplinary fields, there have also been new breakthroughs. For example, Hong18 applied image segmentation techniques to enhance lung CT images, discovering differences between medical image segmentation and traditional natural image segmentation. However, this paper did not delve deeply into these distinctions. In the latest research, Zhu19 applied the concept of dynamic convolution to instance segmentation in industrial systems, aiming to improve the accuracy of global feature mapping. However, this approach also increased the risk of noise corruption in encoding mapping.
Instance segmentation
Instance segmentation combines semantic segmentation techniques with object detection to segment all object instances within an image. Current research on instance segmentation focuses on achieving high-quality segmentation. For instance, Tian20 designed a dynamic instance-aware mask head to improve the resolution of instance masks, speeding up inference and increasing both precision and speed. However, mask data can have various biases, potentially affecting the accuracy of object detection. Similarly, Zhou21 introduced pixel-level instance cues into the segmentation task, utilizing features learned by the backbone network to better locate instance segmentation. Yang22 addressed difficult-to-segment boundaries using branch and ranking loss to produce high-quality segmentation masks. Additionally, some studies use classifier weights to address the long-tail distribution of training samples. For example, Zhao23 designed a weight-guided loss function to enhance model segmentation performance. In teacher-student architecture models, Zhao24 defined the foreground as the teacher end, while the student end focused on segmenting specific object categories. Notably, this method has significant advantages in detecting overlapping objects. Other instance segmentation methods improve upon classic models. For example, Li25 utilized feature details from human aggregation layers to form global contextual features for learning. Rossi26 aimed to further reduce the number of model parameters to capture clues about the relationship between the task to be solved and the layers used.While these methods generally optimize the target feature generation process to improve accuracy, they do not delve deeply into the target generation guidance phase. In the latest research on instance segmentation, Zhu27 used Peak Response Maps to optimize the discrimination region of instance segmentation target objects, aiming to obtain a more complete target region. However, limitations in category discrimination of target regions lead to relatively incomplete instance information.
Diffusion model
Diffusion models are a type of generative model based on Markov chains, capable of transforming simple distributions like Gaussian distributions into sampled data from complex distributions. Recently, applying diffusion models to conditional generation for image segmentation has become a new research hotspot. For instance, Rombach28 introduced a class-conditioned generative method using diffusion models, addressing the issue of not requiring re-learning during the image generation process.In the field of image generation, Preechakul29 utilized diffusion models to learn meaningful linear representations, providing a foundation for downstream tasks based on diffusion models. Additionally, in weakly supervised learning, due to the lack of effective label information, Baranchuk30 used the reverse diffusion process of diffusion models to capture semantic information from images, demonstrating its significance for semantic segmentation tasks.In image synthesis, Jain31 advanced high-quality image synthesis techniques using training-weighted methods, contributing to the popularity of diffusion models. Moreover, some improvements to diffusion models have been proposed. For example, Amit32 proposed an end-to-end diffusion model learning framework that extends these models for image segmentation tasks without relying on pre-trained backbone networks. Additionally, Gu33 introduced a diffusion model for instance segmentation tasks, providing significant inspiration for this paper’s research.
Although these methods have applied diffusion models to traditional research work, they have not explored deeper network optimizations for diffusion models to improve model balance, which is also a valuable area for further investigation.In addition to the traditional research work mentioned above, diffusion models have shown impressive performance in interdisciplinary fields. For example, in the medical field, Wu34 integrated lesion area images with diffusion models to provide more effective data information. Similarly, Shao35 utilized diffusion models to address the issue of data scarcity in medical imaging due to privacy and labeling difficulties, enhancing the feasibility of data augmentation. Recent research includes Chen36 applying diffusion models to the problem of tumor image segmentation, achieving significant results. Additionally, image generation techniques have also been employed in pre-segmentation tasks for medical images. For instance, Guo37 described a conditional image generation strategy for medical image segmentation.In the latest research on diffusion models, Gu33 applied diffusion model methods to instance segmentation tasks, highlighting the advantages of generative models in low-level visual tasks and improving segmentation performance across different physical environments. However, it was also noted that the absence of structural information can lead to certain errors in understanding the segmented target areas.
Our method
Network structure
The overall framework of instance segmentation learning under the diffusion model is shown in Fig. 1 in detail. Our work mainly describes how to combine the traditional instance segmentation task with the improved method of diffusion model and apply it to the instance segmentation task, Moreover, the effectiveness of our method is demonstrate through relevant ablation experiments.
Forward propagation process: given a set of data \({x_t}\sim q\left( x \right)\) sampled from the real data distribution, i.e., superimpose the Gaussian noise on the sample in t steps (t is a variable parameter in the training process); finally get a series of samples \({x_1},{x_2}, \ldots ,{x_t}\) obtained by noise superposition, where the size of step T is subject to the constraints of βt: \(\beta =\left\{ {{\beta _t} \in \left( {0,1} \right)} \right\}_{{t=1}}^{T}\), which should also satisfy:
Equation (1) can be understood as a Markov chain, \({x_t}\)indicating the noise state under the state t, \(q({x_{t - 1}}|{x_{t - 2}})\)is the Gaussian distribution under the state\({x_{t - 2}}\), through the above formula to deduce the probability theorem can be obtained:
For the most primitive data bit \({X_0}\), under the iteration of t steps during forward diffusion, it will lose the original feature information due to the addition of noise. Finally, when t->∞, \({x_t}\) is equivalent to the special noise with Gaussian distribution.
In the instance segmentation task, the idea presented in Ref.6 is followed. In this paper, the core idea of the diffusion model is that for time step t, noise is added to the image, which produces a series of noisy images, and a small amount of Gaussian noise is added to the image in the time steps.
Inverse noise reduction process
In the image instantiation task, if the diffusion process is regarded as a process of constantly adding noise labels, then the inverse process can be considered as a process of constantly denoising. In recent years, there have been studies investigating the effect of model noise on model training, such as Ref.7, and the related researches have also proved that the denoising of the model is helpful in improving the model performance. Therefore, the reverse process of diffusion model, which can also be called the reverse noise reduction process, is the reconstruction process for the samples. The sample data after T steps should conform to a simple Gaussian distribution:
In Ref.31, it is proved that the model cannot well restore the true distribution when βt is too small. Therefore, a new probabilistic model \({p_\theta }\) is constructed to for the model prediction:
For the Gaussian noise m between diffusion steps, the posterior estimated distribution is:
According to Eq. (5), by combining the nature of the Markov chain, the inverse process of the diffusion model can be computationally inferred from the forward process.
Order noise perception
In the process of inverse noise reduction, it is known that the Gaussian noise distribution been different steps can be deduced from the initial sampling information. Therefore, the relationship between steps can be considered valuable for the instance segmentation tasks, and if the information between steps at different stages is utilized, it is meaningful for improving the accuracy of the segmentation model. On the basis of the above equations, it can be deduced from the Bayes’ theorem:
It can be seen that there is a controllable relation k between steps, and this controllable relation is defined as the order noise perception. In the section introducing the calculation of segmentation masks, further in-depth calculations will be implemented by combining this theory.
Calculation of segmentation masks

Instance segmentation network structure based on diffusion model.
In the actual training process, for the instance segmentation task, different diffusion noise filters are constructed for different instances. As shown in Fig. 1, tests on the COCO dataset, which is the public dataset for the MS COCO challenge that is available at https://cocodataset.org, assume that baseball, people, and other objects are distinguished with different bounding boxes. For the image I to be trained, its instance mask is N, so it needs to be segmented N times.
In the above Equation, in denotes the instance segmentation task, and mask is the mask. According to Eq. (7), by adding noise to the instance task, for any time t, there is a relation t ~ β for the associated noise, and it is assumed that there must be some relation between them.
Here, the change during the model diffusion process is balanced with the following loss:
In addition, the diffusion process can be regarded as a process of adding noise labels, which has been demonstrated in Ref.33. The addition of noise labels during the training process is helpful in improving the generalization of model training for the samples, so we have:
where, \({L_{gt}}\) and \({L_{noisy}}\) represent the losses from the true value during the step noisy perception in the calculation of the instance task; \(\alpha ,\,\beta ,\, \lambda\) are the weight values, respectively. In the case of this paper, weight allocation is matched according to the importance of weight. The core pseudocode for all of the above processes is described in detail in Algorithm 1. Refer to Sect. 4 for the relevant SNP performance section.

Segment instance.
Experimental details and discussion
Dataset
To evaluate the effectiveness of our approach, experimental validation was implemented on the publicly available dataset COCO38. This dataset is by far the largest dataset for semantic segmentation tasks, containing a labeled set annotated with instances of 80 classes and more than 330,000 images, of which 200,000 are labeled. This dataset consist of more than 1.5 million individual items, including the training, validation, and test sets. COCO has not only improved the resolution of images, but also contains many small objects and crowded scenes, which reveals most of the problems that could be encountered in the generic object detection tasks.
In addition, we further validate the generalization ability of our model on the LVIS (Large Vocabulary Instance Segmentation) dataset39. The LVIS dataset, developed by Facebook AI Research, is a large-scale image instance segmentation and object detection dataset that covers over 1,000 categories and millions of object instances. It particularly focuses on long-tail distribution problems, providing high-quality precise contour annotations and aiming to enhance model performance on rare categories.
Evaluation indicators
In some previous challenging datasets, the average precision with a specific threshold (e.g., 0.5 (standard) or 0.7 (strict)) is generally used as the indicator to evaluate the segmentation performance of the detected instance, such as the PASCAL VOC dataset. However, because the detection quality cannot be fully analyzed from all perspectives in the correlation metric scale, the COCO evaluation metric is currently used for evaluation of instance segmentation in most experimental procedures. Therefore, this paper follows this evaluation metric, and adopts the evaluation indicators as shown in Table 1. In the table, AP (Average Precision) denotes the precision for all classes, which is the most important standard data for evaluating instance segmentation. AP is defined as the intersection over union (IoU) ratio of the mask overlap between real instances and actual instances.
Implementation environment
Our algorithm was implemented in the deep learning framework PyTorch 1.7. The experimental environment is Ubuntu 20.04 operating system, and four NVIDIA 1080Ti×4 graphic processors are used to accelerate the computation in parallel.
Implementation details
The experiments were conducted on the ResNet-101 backbone network using the method proposed in this paper, and the weights pre-trained on ImageNet were utilized to initialize the network parameters. During the experiments, the stochastic gradient descent method was used for iterative training optimization. The initial learning rate was 0.0002, the weight decay was 0.0001, and batch size was set to 4. In addition, the dataset was also subjected to random cropping, rotation, and other operations.
Performances in the experiment
The specific instance segmentation performances and accuracies on the COCO dataset by using different methods are shown in Table 2. As shown in the table, our method is compared with a total of eight different classical instance segmentation methods developed in recent years. According to the data results, the diffusion model can provide significantly better segmentation precisions than other methods for medium and small object samples in the instance segmentation tasks. For example, the APM and APS of our method are 2.1% and 4.6% higher than those of the UniInst method. However, we also find that for the large object samples, our precision is 1.3% lower than that of SOLO V2, which indicates that the filtering and noise addition processes of the diffusion model is not ideal for model training of large object samples, which is also an area that needs to be focused on for improvement in our future works.
Experimental visualization
Figure 2 shows the actual segmentation effect of our method on COCO dataset, and selectively presents the effects in different actual scenes, including a single object, complex background, small object, large object, multi-class, single-class and other scenes. The segmentation results in the figure demonstrate that our can achieve great results in some scenarios, such as the indoor scenes containing a computer, mouse, mouse pad, and keyboard, and other complex scenes, which is still able to obtain good segmentation results. Moreover, our method can accomplish normal detection of the skiing scene and the distant objects, and for scenes where the object is partially obscured, such as the person riding a motorcycle in the figure, the object detection can also be accomplished.

Visualization of instance segmentation performance of our method on diffusion model.
Ablation experiment
Generation of attention maps is an important research subject in the field of image segmentation, especially in weakly supervised learning8. Therefore, in order to evaluate the effectiveness of our method based on diffusion model. As shown in Table 4, this paper adopts the generation of attention maps in the publicly available VOC 2012 dataset to demonstrate the semantic segmentation performance and results of images. It should be especially noted that in the table, SNP denotes the step noisy perception coding.
Furthermore, we also conducted ablation experiments on the COCO dataset in the instance segmentation tasks, as shown in Table 5, so as to verify the research value of the diffusion model-based approach. According to the experimental results in Table 5, the SNP method can well improve the diffusion model.
The number of parameters is an important index to evaluate the complexity and performance of deep learning models. In practical applications, reasonable control of the number of parameters can help design efficient models while avoiding overfitting and high computational costs. Therefore, in Table 6, several representative methods are selected to analyze the model parameter information.
Conclusion
This paper presents new insights into an instance segmentation model that demonstrates the feasibility of using a diffusion model based on step noisy perception in the image instance segmentation tasks. To achieve this approach, we combine the instance segmentation task with an improved diffusion model for training. In addition, the step noisy perception is used to improve the quality of the generated pseudo-masks of the model during the training process. At the same time, satisfactory results are obtained on open COCO and LVIS data sets. However, in the process of experiment, it is found that the diffusion model needs constant iteration to generate the diffusion graph in the case segmentation task, resulting in unnecessary model overhead. Therefore, in the future work, we plan to further study the inverse process of diffusion model to optimize the model cost, so as to improve the generation performance of diffusion model.
Data availability
The datasets generated and analysed during the current study are not publicly available due restrictions apply to the availability of these data, but are available from the corresponding author on reasonable request.
References
Minaee, S. et al. Image Segmentation Using deep Learning: A Survey. (2021).
Jumiawi, W. A. H. & El-Zaart, A. A Boosted Minimum Cross Entropy Thresholding for Medical Images Segmentation Based on Heterogeneous mean Filters Approaches. (2022).
Li, C. H. & Lee, C. Minimum Cross Entropy Thresholding. (1993).
Jumiawi, W. A. H. & El-Zaart, A. Gumbel (EVI)-based Minimum cross-entropy Thresholding for the Segmentation of Images with Skewed Histograms. (2023).
Kittaneh, O. A. The Variance Entropy multi-level Thresholding Method. (2023).
Bai, M. & Urtasun, R. Deep watershed transform for instance segmentation. In: Proc. IEEE conference on computer vision and pattern recognition. 5221–5229. (2017).
He, K., Gkioxari, G., Dollár, P. & Girshick, R. Mask r-cnn. In: Proc. IEEE international conference on computer vision. 2961–2969. (2017).
Wang, X., Kong, T., Shen, C., Jiang, Y. & Li, L. Solo: Segmenting objects by locations. In: Computer Vision–ECCV : 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVIII 16. 649–665. (Springer, 2020).
Chen, B., He, S. & Liu, J. Weld structured light image segmentation based on lightweight DeepLab v3 + network, Publisher, City. (2023).
Graham-Knight, J. B., Bond, C., Najjaran, H., Lucet, Y. & Lasserre, P. Predicting and Explaining Performance and Diversity of Neural Network Architecture for Semantic Segmentation. (2023).
Bi, X., Chen, D., Huang, H., Wang, S. & Zhang, H. Combining pixel-level and structure-level Adaptation for Semantic Segmentation. (2023).
Xu, G. et al. Lightweight real-time Semantic Segmentation Network with Efficient Transformer and CNN. (2023).
Wang, C. et al. Channel Correlation Distillation for Compact Semantic Segmentation. (2023).
Palanivel, D. A., Natarajan, S. & Gopalakrishnan, S. Retinal Vessel Segmentation Using Multifractal Characterization. (2020).
Liu, J., Zhang, F., Zhou, Z. & Wang, J. Bilateral Feature Fusion Network with multi-scale Context Aggregation for real-time Semantic Segmentation. (2023).
Hui, G., Xiaodong, Y., Heng, Z., Yiting, N. & Jiaqi, W. Multi-scale sea-land Segmentation Method for Remote Sensing Images Based on Res2Net. (2022).
Xu, C., Zhou, Y. & Luo, C. Visual SLAM Method Based on Optical flow and Instance Segmentation for Dynamic Scenes. (2022).
Wang, H., Ma, S. & Min, L. Lung CT Image Enhancement Based on Image Segmentation and Total Variation. (2022).
Zhu, L., Peng, L., Ding, S. & Liu, Z. An encoder-decoder Framework with Dynamic Convolution for Weakly Supervised Instance Segmentation. (2023).
Tian, Z., Zhang, B., Chen, H. & Shen, C. Instance and Panoptic Segmentation Using Conditional Convolutions. (2022).
Zhou, S. et al. Semantic Instance Segmentation with Discriminative deep Supervision for Medical Images. (2022).
Yu, J., Yang, X., Zhou, S., Wang, S. & Hu, S. BRefine: Achieving High-Quality Instance Segmentation. (2022).
Zhao, X., Xiao, J., Zhang, B., Zhang, Q. & Waleed, A. N. Weight-guided loss for long-tailed Object Detection and Instance Segmentation. (2023).
Zhao, K., Wang, X., Chen, X., Zhang, R. & Shen, W. Rethinking mask Heads for Partially Supervised Instance Segmentation. (2022).
Li, X., Zhu, L., Wang, W. & Yang, K. Refine-FPN: Instance Segmentation Based on a Non-local Multi-feature Aggregation Mechanism. (2023).
Rossi, L., Karimi, A. & Prati, A. Self-Balanced R-CNN for instance segmentation. (2022).
Huang, Z., Pan, D. & Wu, G. Weakly Supervised Instance Segmentation via peak Mining and Filtering. (2024).
Rombach, R., Blattmann, A., Lorenz, D., Esser, P. & Ommer, B. High-resolution image synthesis with latent diffusion models. In: Proc. IEEE/CVF conference on computer vision and pattern recognition. 10684–10695. (2022).
Preechakul, K., Chatthee, N., Wizadwongsa, S. & Suwajanakorn, S. Diffusion autoencoders: Toward a meaningful and decodable representation. In: Proc. IEEE/CVF conference on computer vision and pattern recognition. 10619–10629. (2022).
Baranchuk, D., Rubachev, I., Voynov, A., Khrulkov, V. & Babenko, A. Label-efficient Semantic Segmentation with Diffusion Models. (2021).
Ho, J., Jain, A. & Abbeel, P. Denoising Diffusion Probabilistic Models. (2020).
Amit, T., Shaharbany, T., Nachmani, E. & Wolf, L. Segdiff: Image segmentation with diffusion probabilistic models. (2021).
Gu, Z., Chen, H. & Xu, Z. Diffusioninst: Diffusion model for instance segmentation. In: ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2730–2734. (IEEE, 2024).
Wu, J. et al. Medical Image Segmentation with Diffusion Probabilistic Model. 1623–1639 (Medical Imaging with Deep Learning, PMLR, 2024).
Shao, S. et al. Expanding Dataset for 2D Medical Image Segmentation Using Diffusion Models. (2023).
Chen, T., Wang, C. & Shan, H. Berdiff: Conditional bernoulli diffusion model for medical image segmentation. In: International conference on medical image computing and computer-assisted intervention. 491–501. (Springer, 2023).
Guo, X. et al. Accelerating diffusion models via pre-segmentation diffusion sampling for medical image segmentation. In: 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI). 1–5. (IEEE, 2023).
Puri, D. COCO dataset stuff segmentation challenge. In: 2019 5th international conference on computing, communication, control and automation (ICCUBEA). 1–5. (IEEE, 2019).
Gupta, A., Dollar, P. & Girshick, R. Lvis: A dataset for large vocabulary instance segmentation. In: Proc. IEEE/CVF conference on computer vision and pattern recognition. 5356–5364. (2019).
Acknowledgements
This work is supported by the Anhui Province natural science research key funding project (No. KJ2021A1471), In 2022, the cultivation of outstanding talents in colleges and universities- Domestic general visiting program (No. gxgnfx2022180), Research on depression recognition of adolescents with microexpression based on deep learning(NO.SYS2024A04).
Author information
Authors and Affiliations
Contributions
Wanchun Sun and Hui ma designed the experiments, Shujia Li conducted the experiments. Hui Ma and Jianjun Zhang wrote the manuscript. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ma, H., Sun, W., Li, S. et al. Image instance segmentation based on diffusion model improved by step noisy. Sci Rep 15, 7408 (2025). https://doi.org/10.1038/s41598-025-90631-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-90631-x
