
Abstract
Existing geographic atrophy (GA) segmentation tasks can only use 3D data, ignoring the fact that a large number of B-scan images contain lesion information. In this work, we proposed a multistage dual-branch image projection network (DIPN) to learn feature information in B-scan images to assist GA segmentation. Considering that segmenting 3D data slices using a 2D network architecture ignores the neighboring information between volume data slices, we introduced ConvLSTM. In addition, to make the network focus on the attention in the projection direction to capture the contextual relationships, we proposed the projection attention module. Meanwhile, considering that the current projection network uses a unidirectional pooling operation to achieve feature projection, multi-scale features and channel information are ignored in the projection process. Therefore, we proposed an adaptive pooling module that aims to adaptively reduce feature dimensions when grasping multi-scale features and channel information. Finally, to mitigate the effect of image contrast on the network segmentation performance, we proposed a contrastive learning enhancement module (CLE). To validate the effectiveness of our proposed method, we conducted experiments on two different datasets. The segmentation results show that our method is more effective than other methods in the GA segmentation task and the foveal avascular zone (FAZ) segmentation task.
Similar content being viewed by others

Introduction
Geographic Atrophy (GA) is an advanced progressive lesion of non-exudative age-related macular degeneration, also referred to as complete retinal pigment epithelium and outer retinal atrophy1. It is estimated that approximately five million people worldwide suffer from GA, with its prevalence increasing exponentially with age2. GA is typically bilateral3, and the development and enlargement of the lesions result in irreversible loss of visual function. Therefore, accurate segmentation of the lesion area is of paramount importance for preventing progression and guiding subsequent treatment4. Optical coherence tomography (OCT) is a non-invasive and rapid biomedical imaging technology5. It can image biological tissues at the micron level and generate high-resolution three-dimensional cross-sectional images, which are widely used in clinical ophthalmology quantitative analysis6,7. Its high-resolution feature enables clear observation of various retinal diseases8, such as macular degeneration and macular holes9, pigment epithelial detachment10, choroidal neovascularization11 and GA1. OCT plays a vital role in the diagnosis and monitoring of retinal diseases12,13,14,15,16. Figure 1 demonstrates OCT projection and B-scan with GA lesions and the corresponding B-scan GT.

Example of retinal OCT GA. (a) GA lesion in projection image, (b) GA lesion in B-scan, (c) GT corresponding to the lesion in (b).
Previous work has made great efforts in exploring traditional methods for GA segmentation, including geometric active contours17, level set methods18. Niu et al.19 proposed a Chan-Vese model method based on local similarity factors for reducing computational effort. However, which cannot fully explore the advanced features and semantic information in the image and limits the segmentation performance. Most of the recent GA segmentation methods are deep learning networks20,21,22. Wu et al.20 proposed a method to creates OCT projection images by applying constrained sub-volume projection to 3D OCT data. Patil et al.21 used U-Net to automatically segment geographical atrophic lesions. Spaide et al.22 used two multimodal deep learning networks (U-Net and Y-Net) to automatically segment GA lesions on FAF. However, all of the above methods utilize only the features of the Enface image and ignore the spatial information in the volumetric data. To alleviate this problem, our methods used a 2D network framework while incorporating ConvLSTM to capture the neighboring information between slices of volumetric data. In addition, these methods may suffer from the problem of possible mis-segmentation when segmenting GA edges (low contrast of edge pixels), and it is difficult for the network to classify such hard samples. To alleviate this problem, we proposed a contrastive learning enhancement module (CLE) and select an appropriate sampling strategy to improve the classification ability of the network for difficult samples.
Compared with projection images, OCT volume data can provide detailed information on retinal structure. Li et al.23 proposed an image projection network (IPN) to achieve three-dimensional to two-dimensional retinal Foveal Avascular Zone(FAZ) segmentation through unidirectional pooling along the volume projection direction. In addition, the IPN V224 was also proposed to enhance horizontal direction perception capabilities. Morano et al.25 proposed a convolutional neural network (CNN) and self-supervised learning (SSL) method for 3D to 2D segmentation. However, the above methods are only suitable for certain lesion segmentation, ignoring the fact that clinics generally use single line scans and radial scans for B-scan data, which results in little 3D data. In the GA segmentation task, if the network relies only on a small amount of volume data, it may lead poor generalization ability. Meanwhile, they used unidirectional pooling to project the image, ignoring multi-scale features and channel information, and the network is unable to capture spatial relationships at different scales, limiting the ability of the model to understand the overall structure of the image. To address the above issues, we proposed a novel two-stage image projection segmentation method. While using volumetric data, we used a large number of B-scan images for pre-training in the first stage, which alleviates the problems of overfitting and poor generalization ability caused by the over-reliance of the network on a small amount of data. To address the limitation of the 2D network framework in overlooking neighboring information between slices of volumetric data, we introduced ConvLSTM in the second stage. This inclusion ensures that spatial information within the volumetric data is effectively leveraged during the segmentation process. At the meantime, we proposed Adaptive Pooling Module (APM) for capturing multi-scale features and channel information while adaptively reducing the feature dimensions. Furthermore, to enhance the network’s focus on features along the projection direction during the dimensionality reduction process, we proposed a Projection Attention Module (PAM) that calculates the affinity between pixels in the projection direction, thereby establishing long-range dependencies.
Specifically, we proposed a multi-stage Dual-branch Image Projection Network that can obtain pre-training weights using many B-scan images during the pre-training stage. In addition, inspired by Liu et al.26, we propose a Projective Attention Module (PAM) to integrate long-range dependencies by calculating the affinity between two different pixels on each projection column in the B-scan. An Adaptive Pooling Module (APM) is also proposed, which focuses on the channels while extracting and fusing multi-scale features, thus effectively improving the feature utilization. Finally, to ensure that the spatial information in the volumetric data is fully utilized during the segmentation process, we incorporated ConvLSTM to capture the neighborhood information between images in the fine-tuning stage. Utilizing a contrastive learning module to enhance the network’s ability to distinguish boundary features.
Methods
Framework of the proposed method
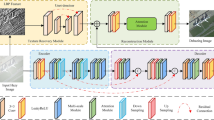
Figure 2 demonstrates the segmentation of retinal GA by our proposed DIPN network through three stages: pre-training, fine-tuning and inference. We have defined the retinal GA segmentation task. In the pre-training phase, training is conducted using the data set \({D}_{train}^{1}={\left\{\left({X}_{n}^{1},{S}_{n}^{1}\right)\right\}}_{n=1}^{N}\), where \({S}_{n}^{1}\) is the corresponding label. The sizes of \({X}_{n}^{1}\in {R}^{C\times H\times W}\) and \({S}_{n}^{1}\in {\left\{\text{0,1}\right\}}^{1\times 1\times W}\) are different, because our method involves dimensionality reduction along the projection direction, finally obtains a line segment. In the fine-tuning phase, the training dataset \({D}_{train}^{2}={\left\{\left({X}_{n}^{2},{S}_{n}^{2}\right)\right\}}_{n=1}^{N}\), where \({X}_{n}^{2}\in {R}^{C\times L\times H\times W}\) denotes the set of 3D images, and \({S}_{n}^{2}\in {\left\{\text{0,1}\right\}}^{1\times L\times 1\times W}\) is the labels corresponding to \({X}_{n}^{2}\). We use the test dataset \({D}_{test}={\{\{{X}_{m},{S}_{m}\}\}}_{m=1}^{N}\)(\({X}_{m}\in {R}^{C\times L\times H\times W},{S}_{m}\in {\left\{\text{0,1}\right\}}^{1\times L\times 1\times W}\)) for testing.

Flowchart of our proposed method. The data used at different stages are shown in the figure. The first stage uses a single B-scan image for pre-training to enable the network to learn the feature representation. The second stage uses the complete volume data for training to enable the network to fully learn and utilize the proximity information between slices. Finally, testing is performed.
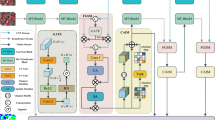
The pre-training stage model is shown in Fig. 3. It consists of an image projection branch (IPB) and a feature complementary branch (FCB), each containing five stages. Each stage is connected to each other and the feature complementary branch passes the extracted feature \({f}_{i}^{APM}(i\in \text{1,2},\text{3,4},5)\) of each stage to the feature projection branch. It is connected to the stage feature \({f}_{i}^{IPB}(i\in \text{1,2},\text{3,4},5)\). The two branch features \({f}^{FB}\) and \({f}^{SB}\) are concatenated and then the contrast loss \({L}^{CLE}\) and the segmentation loss \({L}^{SEG}\) are computed by the projection and segmentation headers.

Pre-training network architecture. The first branch is the image projection branch (IPB), which incorporates the Projection Attention Module (PAM) that focuses on attention in the projection direction when reducing dimensions. The second branch is our proposed Feature Complement Branch (FCB), which contains the proposed Adaptive Pooling Module (APM) to ensure feature retention and feature fusion during the projection process. When using multiple convolutions for a feature, we use the residual structure.
Projective attention module (PAM)
For retinal OCT B-scan images containing GA lesions, the lesions are usually located near the RPE and exhibit significant translucency (as shown in Fig. 1b), so many previous GA segmentation methods use projection maps or 3D volume data segmentation rather than 2D network segmentation slices. In addition, we observe that the degree of pixel contribution varies from region to region when determining pixel labels in a deep learning-based approach. Therefore, it is crucial to distinguish these feature representations. In order to build rich contextual relationships on local features, we proposed the PAM inspired26,27,28. The PAM encodes broader contextual information into local features, thus enhancing the representation of local features. Next, we describe in detail how the PAM works.
As shown in Fig. 4 PAM, our proposed PAM is capable of processing features of different scales at different stages. ⨂ denotes the batch matrix multiplication with batch size W. For easy understanding, we take the first PAM in the image projection branch as an example. Given a feature \({\mathbb{R}}^{64\times H\times W}\), we first feed it into a convolutional layer to obtain a new feature \(F\in {\mathbb{R}}^{64\times H\times W}\). Then, we feed the feature F into a 1 × 1 convolutional layer to obtain two new feature mappings Q and K, where \(\{Q,K\}\in {\mathbb{R}}^{32\times H\times W}\), and arrange them as \({\mathbb{R}}^{W\times H\times 32}\), \({\mathbb{R}}^{W\times 32\times H}\). Then reshape them as \({\mathbb{R}}^{W\times (H\times 32)}\), \({\mathbb{R}}^{W\times (32\times H)}\). We then perform matrix multiplication on Q and K and apply a Sigmoid to compute the space-attentive mapping \(Atts\in {\mathbb{R}}^{W\times H\times H}\).
where \(\{k,i,j,c|1\le k\le W,1\le i,j\le H,1\le c\le 32\}\), \({Atts}_{kij}\) denotes the influence of position \(i\) on position \(j\). The closer the feature representations of two positions are, the greater is their correlation. \({Q}_{kic}\) denotes the \(i\)-th pixel on the \(k\)-th column in the \(c\)-th feature map. \(\cdot\) represents the element multiplication. At the meantime, we input the feature \(F\) into the convolutional layer to generate a new feature mapping \(V\in {\mathbb{R}}^{32\times H\times W}\) and reshape it into \({\mathbb{R}}^{W\times (H\times 32)}\). We then perform a matrix multiplication between \(V\) and \(Atts\) and arrange the result as \({\mathbb{R}}^{W\times H\times 32}\). The result is then fed into the convolutional layer to recover the number of channels, and the result is arranged as \({\mathbb{R}}^{64\times H\times W}\). Finally, we perform an element-wise summation operation between it and the feature \(F\) to obtain the final output \(E\in {\mathbb{R}}^{64\times H\times W}\) as follows.
where \(pReLU\) represents the activation function, \(Conv\) and \(Perm\) represent 1 × 1 convolution and permutation operations respectively, and \(\otimes\) represents matrix multiplication. \(F\) represents the input feature. From Eq. (2), it can be inferred that the obtained feature E for each location is a weighted sum of the features of all locations and the original feature. Thus, it has a global context view and selectively aggregates contexts based on spatial attention. Similar semantic features gain from each other, thus improving intra-class compactness and semantic consistency.

Key components in the framework. Projection Attention Module (PAM) is to make the network focus on the attention in the projection direction to model the dependencies in the projection direction. Adaptive Pooling Module (APM) aims to grasp multi-scale features and channel information while adaptively reducing the feature dimensions. Contrast Learning Enhancement Module (CLE) aims to improve feature differentiation between lesions and their contexts.
Adaptive Pooling Module (APM)
Because GA lesions are translucent, the upper and lower boundaries of the lesion cannot be accurately defined in OCT B-scan images, thus most current GA segmentation methods use Enface image and 3D volume data instead of volume slices. However, segmentation using enface image ignores a large amount of spatial information and also requires a large amount of volume data. Whereas in image projection networks, the feature dimension decreases with increasing depth and a large number of important features may be lost in the dimensionality reduction process. The loss of these important information may cause the model to be unable to effectively capture the subtle features in the image, thus reducing the segmentation performance. Therefor it is very important to effectively reduce feature dimensions and retain important information to the greatest extent. Therefore, we propose the Adaptive Pooling Module (APM) to achieve the above purpose, and the APM structure is shown in Fig. 4. APM performs dimensionality reduction on the features in the feature complementation branch and inputs these features into the image projection branch to complement the features that were lost during the dimensionality reduction process. As shown in Fig. 4, input feature \(I\in {\mathbb{R}}^{C\times H\times W}\) to APM and then output feature \(O\in {\mathbb{R}}^{C\times P\times W}\). \(P\) is the output feature height (the P of the first APM is 256). First, in order to extract multiscale features, we split the input feature \(I\) into two parts (in the channel dimension). Splitting the input data into two groups on the channel and processing it through different branching paths. Specifically, each branch is characterized by \({I}_{i}\in {\mathbb{R}}^{\frac{C}{2}\times H\times W}\), \(i=1,2\). \(C1\) and \(C2\) denote 3 × 3 size convolution and 5 × 5 size convolution, respectively. Then, to obtain the multiscale feature map, the multiscale features obtained from the two branches are concatenated in the channel dimension to obtain the whole multiscale feature map M. The process is shown in the following equation.
where \(M\in {\mathbb{R}}^{C\times H\times W}\), M contains rich deep semantic information. In order to focus on spatial information while also focusing on information between channels. Channel descriptions are obtained using global average pooling in the spatial information of the multiscale feature M. Then, the channel correlation terms are captured by convolution. The correlations between features are captured by these operations. The channel attention \(S\) is defined as follows.
where \(S\in {\mathbb{R}}^{C\times 1\times 1}\), \(\sigma\) represent the sigmoid function, δ represents the ReLU function, and \({Conv}_{1}\) and \({Conv}_{2}\) represent the 1 × 1 convolution. To facilitate the later feature fusion, we reconstruct the multiscale feature \(M\) as \({M}{\prime}\in {\mathbb{R}}^{C\times (H/P)\times W}\). In addition, some features may be lost during the extraction of multi-scale features, thus, a reconstruction operation is performed on the input \(I\) to obtain \({I}{\prime}\in {\mathbb{R}}^{C\times (H/P)\times W}\). \({I}{\prime}\) is then reweighted and summed along the projection direction of the features to achieve feature fusion. The final output of the APM can be written in the following form.
where \(Softmax\) is used to obtain attentional weights in the projection direction and channel dimension. \(\odot\) denotes broadcast element-by-element multiplication and \(\cdot\) represents element-by-element multiplication. \(U\) denotes unidirectional pooling of size \(H/P\), and then concatenates P features of size \(C\times 1\times W\) along the projection direction. The O obtained through the above steps fuses multi-scale information and channel information, which alleviates the information loss caused by simple unidirectional pooling to some extent. The feature representation thus obtained is richer and more comprehensive and can better reflect the complex structure and semantic information of the input data.
Contrastive learning enhancement (CLE)
We can see in Fig. 1b that the contrast between the GA and the noise and between the borders on both sides of the GA is low. When dealing with regions that are similar to GA features, with insufficiently distinctive features, the network may have difficulty in distinguishing these regions leading to incorrect segmentation. To increase the differentiation of features between GA and its context, we proposed a contrastive learning strategy29.
The CLE module is shown in Fig. 4. We use the projection head for contrast learning after concatenating two branching features. The final output feature of the network is \({f}^{out}\in {\mathbb{R}}^{C\times 12\times W}\)(\(C=32\)) . To calculate the contrast loss, the projection head maps each pixel in the feature map to 128 dimensions. The contrast learning head consists of a multi-layer perceptron with two 1 × 1 convolutional layers. In supervised contrast learning, computing contrast loss on a single image would lack category diversity, this is because our OCT images contain only one category. To solve this problem, inspired by30,31, we propose a pathology samples library, consisting of two parts: one pixel library and one region library. We maintain a queue for every class in the pixel library. We select \(V=24\) pixels (random) from each category in each image based on GT labels, these pixels are then arranged into a queue of size \(Q=V\times N\) (\(N\): Number of images in a batch). This produces a library of samples of size \(2\times Q\times D\) (2 is the number of categories, \(D\) is a 128-dimensional feature embedding). We also incorporate a region library to trap global semantic information. During training, we calculate the mean and combine it with the pixel embedding of the categories in the image, to obtain a D-dimensional global feature vector. The size of the region library is \(2\times N\times D\). Therefore, our sample library size is \(2\times (Q+N)\times D\). Note that the pathology sample library only takes effect during the training process.
After establishing the pathology sample library, we need to design a sampling strategy to select more reliable anchors \(\mathcal{p}\). In previous work30, it was found that when both positive and negative samples are close to the anchor \(\mathcal{p}\) (the reference point that defines the relative relationship between positive and negative samples), it is difficult to distinguish negative samples from them, especially negative samples that are similar to the anchor. Similarly, when both positive and negative samples are far from the anchor \(\mathcal{p}\), it is difficult to distinguish the positive samples from them. The specific matching probability formula is as follows.
where \(\mathcal{p}\) denotes an anchor in the sample library, and \({\mathcal{p}}^{+/-}\) represents the positive samples (for a pixel \(\mathcal{p}\) with its GT labeling class, the positive sample belongs to other pixels in the same class) similar to the \(\mathcal{p}\) category or dissimilar negative samples in the sample library. \(\rho \in (\text{0,1})\) is the matching probability. \(\uptau (\uptau >0)\) represents the temperature hyperparameter. \({Z}_{\mathcal{p}}\) represents the set of pixel embeddings for positive samples and \({N}_{\mathcal{p}}\) represents the set of pixel embeddings for negative samples. It can be seen from the Eq. (6), the anchor \(\mathcal{p}\) obtained from different sampling strategies will affect the discriminative power in the training samples. A reasonable sampling strategy will improve the distinction between positive and negative samples and help train a more accurate model. We designed a mixed sampling strategy in which we sampled a total of 240 anchor pixels (120 per class) in the maintained sample library. During the collection of positive samples, the first 30% of the hardest samples (negative samples that are close to 1 when the multiplication with the anchor point \(\mathcal{p}\) is done, and conversely, positive samples that are close to -1 when the multiplication with the anchor point \(\mathcal{p}\) is done) are collected. Then 40% of projection boundary points were randomly sampled, and the remaining 30% are randomly collected from the entire sample library. Negative samples are sampled in the same way as positive samples. After the above is done, we calculate the supervised contrast loss.
where N is the number of anchors in the training dataset. \({L}_{\mathcal{p}}^{CLE}\) is the contrastive loss for individual anchors. \({L}^{CLE}\) is the total contrast loss.
ConvLSTM-based fine-tuning stage
In the pre-training stage, the network (e.g., Fig. 2) learns the GA lesion features using a large number of B-scan images. After obtaining the pre-training weights, in order to exploit the large amount of spatial information contained in the volumetric data. we propose the fine-tuning stage.
As shown in Fig. 5, the network structure before the fine-tuning stage ConvLSTM32 is the same as the pre-training network structure. After using the pre-training weights obtained in the pre-training stage, 3D volume data is input for training. Unlike conventional LSTM methods, convolutional LSTM uses the convolution operator * instead of matrix multiplication to preserve the spatial information of long-term sequences. The entire definition is as follows.
where \(\sigma\) is the sigmoid function, \(*\) denotes the convolution operation, and \(\text{tanh}\) is the hyperbolic tangent function. Input gate \({i}_{t}\), forget gate \({f}_{t}\) and output gate \({o}_{t}\) are the three gates that make up the entire network. \({b}_{i}\), \({b}_{f}\), \({b}_{c}\) and \({b}_{o}\) are the bias terms, while \({X}_{t}\), \({c}_{t}\), and \({h}_{t}\) are the input, active, and hidden states at moment \(t\). W represents the weight matrix, e.g., \({W}_{hi}\) is responsible for controlling how the input gate gets its value from the hidden state. \(\circ\) denotes Hadamard product.

Flowchart of the fine-tuning phase. Input volumetric data, segmentation of data slices, and utilization of ConvLSTM to grasp the adjacency between slices.
Loss function
Because GA segmentation is a pixel-level binary segmentation task, we use Dice loss \({L}^{Dice}\) and binary cross-entropy loss \({L}^{BCE}\) to guide model training. Our segmentation loss is calculated as follows.
where \({\lambda }_{Dice}\) is set to 0.5 and \({\lambda }_{BCE}\) is set to 0.5, \(P\) and \(S\) represent the predicated segmentation results and the corresponding ground truth, and 1 and \(w\) represents the coordinates of the pixel on \(P\) and \(S\). As shown in Eq. (16), Dice loss is used to evaluate the spatial overlap ratio between the ground truth and the predicted GA area. While binary cross-entropy loss is used to optimize the model at the pixel level.
Finally, the total loss of the proposed DIPN is defined as.
where \({\lambda }_{CLE}\) is set to 1, \({L}^{CLE}\) is defined as the contrastive learning enhanced loss in the inference stage, excluding the L2 norm.
Experimental and results
Data sets and processing
The proposed method is experimented on two datasets. The first dataset was the retinal geographic atrophy dataset (RGA dataset for short) obtained at Wuhan Aier Eye Hospital. It contains 44 OCT volumes and individual 2823 GA B-scan images. Each OCT volume contains 512 B-scans with a resolution of 1024 × 512. All lesions were manually labeled. In our experiments, we used all the individual 2823 GA B-scan images for the pre-training phase and performed fivefold cross-validation on 34 volume data in the fine-tuning stage (among these 5 parts, one part contains 6 volume data, and the remaining four parts contain 7 volume data each.). We resized the individual B-scan images to 512 \(\times\) 512. For the volumes in the dataset, we resized them to 512 \(\times\) 512 \(\times 512\).
To explore the cross-domain generalizability of our method33, the second data set is the public data set OCTA50023,24. It is a multimodal dataset containing two different morphology types (OCT and OCTA), with subsets of two different field of view types, namely OCTA_6M (No.10001-10300) and OCTA_3M (No.10301-10500). The OCTA500 dataset includes 3D FAZ segmentation labels and retinal vessel (RV) segmentation labels. In our experiments, we choose to segment the FAZ region and RV in OCTA-500. For the selection of the two modalities, we do the same as previous work34, select the FAZ data and RV data in OCTA_6M to evaluate our method. This dataset contains 300 subjects and has a volume size of 400 × 400 × 640. For the fairness of the experiment, we based on the previous work34, the data set is divided into training set (No.10001-10180), verification set (No.10181-10200), and test set (No.10200-10300). For more details on the OCTA500 dataset, see24. We resized the dataset to a uniform size of 400 \(\times\) 512 \(\times\) 512. Due to the lack of separate B-scan images, we skipped the pre-training phase and started training from the fine-tuning phase.
Implementation details
The proposed method is implemented in PyTorch framework, and all experiments are conducted on a single NVIDIA 3090 GPU. Each dataset is independently trained and tested on the model. We train the model using the Adam optimizer with an initial learning rate of 1e-5 and momentum parameters of \({\beta }_{1}=0.9\) and \({\beta }_{2}=0.999\). 250 epochs are trained in the pre-training phase with a batch size of 4. The best weights are migrated to the fine-tuning phase, where 100 epochs are trained in the fine-tuning phase. The test set and the training set are independent during the experiments.
Evaluation metrics
In order to evaluate the segmentation performance in different methods. We quantitatively analyze the experimental results using five metrics as in recent methods23: the Jaccard index (Jac), the Dice similarity coefficient (DSC), the balanced accuracy (BACC), precision (PRE) and the recall (REC), where Jac and DSC are widely used in evaluating segmentation performance35,36,37. Using accuracy to evaluate the results may lead to overestimation or loss of significance. To evaluate the accuracy when positive and negative samples are not balanced, we use balanced accuracy instead of general accuracy to evaluate the results. The evaluation metric formula is shown below.
where TP is true positive, TN is true negative, FP is false positive and FN is false negative, TPR is true positive rate, and TNR is true negative rate.
Results and analysis
Performance comparison and analysis
In this section, to evaluate the performance of our proposed method for GA segmentation, we compare it with several other best methods on the RGA dataset. In addition, to verify the significance of our method with the method of others. We performed a two-tailed paired t-test on the results of the above networks, which is significant at P < 0.05 (the smaller the p-value the greater the significance).
In Table 1, compared to UNet++, DoubleUNet helps the network to better focus on both global and local information and utilize multi-scale information to improve the model performance. Therefore, it achieves better results. For the geographic atrophy (GA) segmentation task, limited volume data hinders the performance of 3D segmentation, but this can be alleviated by 2D networks by using a large number of B-scan images. However, 2D networks for volumetric data slice segmentation ignore the spatial information in the volumetric data, leading to jagged edges in the final segmentation results. Unlike the above methods, IPN uses a projection learning module that focus on feature extraction in the projection direction rather than downscaling the features each direction. The feature information is preserved to some extent and better results are achieved. We can see that IPN improves the mean Dice and mean PRE by 2.32% and 2.23%. IPN-V2 uses a planar perceptron on top of IPN, the approach of Lachinov et al. and ResensNet introduced projected skip connections. All three approaches aim to make the network utilize more information. Compared to these methods, PAENet proposes a two-path segmentation framework and incorporates an attention mechanism to enhance the focus of model on lesion regions. PAENet improved segmentation performance of the network, with Dice and JAC reaching 83.74% and 76.63%, respectively. Morano et al. proposed a self-supervised method for modal reconstruction, introducing 3D to 2D projection block connections, resulting in a final Dice score of 84.86% (1.12% improvement over PAENet). In contrast, the proposed DIPN exhibits better performance than all compared methods with an average Dice score of 87.03%. It can be seen that with the multistage two-branch model, our method can utilize a large number of individual B-scans to fully learn the lesion features without neglecting the neighboring information between images in the volumetric data. In addition, our module ensures that the sampling process retains more feature information and utilizes multi-scale features. Finally, we also provide a qualitative comparison in Fig. 6. When segmenting slices of volume data under ConvLSTM, the adjacency information between slices is grasped to fully utilize the spatial information in volume data. In addition, the introduced contrast learning enhancement module strengthens the ability of the network to classify hard samples and improves the segmentation performance of the network. In addition, PAM enables the network to model the long-range dependencies between every two pixels in the projection direction, thus enhancing the representation of important features to reduce the loss of more rich feature information during the projection process. Finally, APM enables the network to focus on spatial information and capture inter-channel correlations to reduce feature loss during projection. Through the synergy of these modules, the network obtains a good segmentation performance.

Examples of GA segmentation results for the ten methods on the RGA dataset. The red line represents the ground truth; the green line represents the segmentation result. The content in the white box represents the corresponding Dice score for the image.
Experiments on the OCTA-500 dataset
In this section, we will evaluate the segmentation performance of our method on the OCTA-500 dataset. Quantitative analysis is shown in Table 2, where our methods achieve the best performance in FAZ segmentation. It also achieves good performance in the retinal vessel segmentation task.
With sufficient 3D data, all these methods can achieve better performance. However, as 3D data decreases and B-scan images increase, our network effectively utilizes B-scan data to learn features and improve segmentation performance. Results from paired t-tests show that the segmentation performance improvement of our method is significant compared to most methods. The segmentation results are shown in Fig. 7.

Examples of central foveal avascular zone and retinal vessel segmentation results of the six methods on the OCTA-500 dataset. The first to third columns show the segmentation results of different methods on FAZ dataset, with the red line indicating the ground truth and the green line indicating the segmentation results. The figure in the bottom right corner yellow box in each image is an enlarged figure of the segmentation. The fourth to sixth columns are the segmentation results of different methods on the RV dataset, and the red dashed box indicates significant differences in segmentation results of different methods in this area. The content in the white box represents the corresponding Dice score for the image.
Ablation experiments
In this section, we performed a series of ablation experiments on the RGA dataset. The aim is to investigate the role played by different modules of our method (DIPN) during segmentation, and the ablation experiments are set up as follows.
Module ablation experiments
Table 3 shows the segmentation performance of the five modules in our method under different settings. We designed 7 sets of ablation experiments, the first 6 sets of experiments did not use B-scan images for pre-training, and directly input 3D volume data for training in the fine-tuning phase. The experimental design is as follows: (1) The baseline is defined as a segmentation model similar to IPN without our proposed modules. (2) ConvLSTM is added to (1). (3) PAM is added to (2). (4) FCB is added to (3). (5) APM is added to (4). (6) All modules are co-integrated into the baseline architecture. (7) Pre-training based on (6) using B-scan images to obtain pre-training weights, migrating pre-training weights to the fine-tuning stage. Training segmentation of volumetric data is performed in the fine-tuning stage. The results of the ablation experiments are schematically shown in Fig. 8. Pre-train using B-scan images to obtain pre-training weights, migrate the pre-training weights to the fine-tuning stage. Training segmentation of the volume data is performed in the fine-tuning stages. A schematic of the results of the ablation experiment is given in Fig. 8.

Qualitative results of ablation experiments of the proposed module on GA dataset. (a) GA Enface. (b) Baseline. (c) Baseline + ConvLSTM. (d) Baseline + ConvLSTM + PAM. (e) Baseline + ConvLSTM + PAM + FCB (APM replaced with unidirectional pooling). (f) Baseline + ConvLSTM + PAM + FCB + APM. (g) The fine-tuning stage of our proposed method (Baseline + ConvLSTM + PAM + FCB + APM + CLE) trained without using the pre-training weights of the individual B-scan images. (h) Pre-training weights obtained from the pre-training stage are loaded in the fine-tuning stage. (i) ground truth. The content in the white box represents the corresponding Dice score for the image.
In the second set of experiments (the second row of Table 3), we observed that incorporating ConvLSTM into the network improved the performance by 2.47%(DICE) compared to the baseline. This improvement is attributed to the fact that the baseline segmented volume data slices individually, ignoring the neighboring information between images in the volume data. As a result, the spatial information within the complete 3D volume data was lost, leading to subpar segmentation performance. The ConvLSTM module effectively leverages the information from adjacent slices in the volume data, enabling the network to better utilize the 3D spatial information and enhance the segmentation performance. In the third set of experiments (the third row of Table 3), integrating PAM on top of (2) resulted in a performance increase of 3.69%(DICE). This enhancement is due to the fact that (2) solely relies on convolution operations for feature extraction, lacking explicit attention and utilization of directional information. By calculating the affinities between different pixels along the projection directions, PAM constructs dependencies to emphasize crucial feature information, thereby improving the network’s segmentation performance. In the fourth set of experiments (the fourth row of Table 3), introducing FCB led to a 2.59%(DICE) performance improvement compared to the network without FCB. This indicates that the additional feature information provided by FCB enhances the network’s feature utilization, mitigates feature loss, and enhances segmentation accuracy, demonstrating the necessity of the dual-branch network.
In the fifth set of experiments (the fifth row of Table 3), we observed a 0.23%(DICE) improvement by using APM compared to unidirectional pooling. This validates that APM facilitates multi-scale feature fusion and channel-wise information utilization, thereby increasing feature utilization and enhancing the network’s segmentation performance. Introducing the CLE module in the sixth set of experiments (the sixth row of Table 3) resulted in a 1.04%(DICE) improvement, demonstrating that CLE enhances the network’s ability to differentiate foreground and background, improving boundary distinction and ultimately boosting segmentation performance. In the final set of experiments, we observed a significant improvement in network performance by utilizing a large number of independent B-scan images, with an average Dice increase of 2.32% (from 84.71 to 87.03%). We believe that, compared to networks that only use volume data slices, the network can learn richer and more diverse feature representations from a large number of independent B-scan images. This, in turn, enhances the network’s ability to discriminate GA features, alleviates the issues of poor generalization and overfitting caused by excessive reliance on a small amount of data, and improves segmentation performance.
Figure 8 shows the segmentation results under the influence of each module. As depicted in the Fig. 8b,c, incorporating ConvLSTM in the baseline greatly improves the segmentation performance compared to the baseline network, making the boundaries coherent, which is due to the fact that ConvLSTM utilization of spatial information in the volume data. As can be seen in column (d) of Fig. 8, the problem of segmentation error is alleviated by fusing PAM to increase the attention of the network to the features in the projection direction. We can see from column (e) of Fig. 8 that by using an additional branch to capture features by sending the captured features to various stages of the projection branch. This mitigates the feature loss problem, allowing the network to utilize more semantic information and improve network segmentation. Compared with the segmentation results in column (e), the segmentation results in column (f) are better. This is because FCB can only capture a small number of features as well, while feature dimensionality reduction and multi-scale information fusion can be better performed using APM. As shown in column (g) of Fig. 8, our proposed contrast learning enhancement strategy utilizes the correlation between pixels in an image to cluster pixels of the same category and separate pixels of different categories, which enhances the capability of the model to distinguish between different categories. In column (h) of Fig. 8, the network is pretrained using a large number of individual B-scan images to enable the network to learn more feature representations for subsequent localization and segmentation tasks.
Contrastive learning analysis
In our segmentation task, the low contrast between the GA foreground and background makes it difficult to segment this part of the region correctly. Especially image edges, GA and background and uncertain regions such as noise, noise can greatly affect the segmentation results. To focus the network on indistinguishable foreground and background pixels, we proposed a contrast learning enhancement strategy. Ablation experiments were conducted in order to select suitable contrastive learning strategies. The performance corresponding to different strategies is shown in Table 4.
To better investigate the effect of different anchor sampling strategies in contrast learning on segmentation performance, we performed experiments on the RGA dataset (Table 4.). Hardest anchor sampling31 collects more meaningful pixels and improves the network more significantly than random sampling. By mixing the two sampling methods (random and hardest), the overfitting problem is effectively avoided while improving the robustness of the training set and the training efficiency. Finally, we add a projected boundary anchor sampling strategy because only the projected boundaries are preserved during the dimensionality reduction process, and when the boundaries are misclassified, this can make the edges of the final projected segmentation map not smooth. In order to avoid this problem and accurately categorize the projection boundary anchors, a mixed sampling method of hard anchors, random anchors and projection boundary anchors is proposed.
Interpretability of PAM module
To better understand the PAM module, we visualized the attention map in the second PAM to understand the effect of the PAM module. We choose the attention maps in the second PAM module because the low-level attention maps do not show the region of interest clearly. In addition, the high-level attention map will be smaller because our network gradually reduces the feature dimensions during the projection process. Choosing these two attention maps does not visualize the region of interest.
We can observe from Fig. 9d that when the model predicts GA, it focuses mainly on its own position in the OCT image and less on the whole B-scan, which is consistent to translucency that GA demonstrates in the OCT B-scan image, where the borders on both sides of the lesion are more easily distinguishable. In addition, we can see that the horizontal direction of the GA lesion region also received a small amount of attention laterally. We believe that this is related to the characteristics of the GA lesion, as the GA lesion is in the vicinity of the RPE layer, so the two parts have similar characteristics, which makes the APM give a small amount of attention to this part of the layer region.

Attention maps in PAM. (a) OCT B-scan with GA lesions. (b) GA regions labeled by the physician. (c) Column labeling of regions obtained by processing (b). (d) Attention maps for GA lesions in (a).
Effects of weighting parameters on loss function
The segmentation network is optimized by a joint loss function consisting of three components (e.g., Eqs. (16, 17)), which influence the learning of the network through different weighting parameters. Theoretically, different loss terms have different value ranges, where \({L}^{Dice}\) and \({L}^{BCE}\) are in [0, 1] and \({L}^{CLE}\) is in [\(-\infty\), \(+\infty\)]. In network training, we observe that the values of these loss terms are in similar ranges. To facilitate our experiments, the range of values of the weights parameter is set to [0.2,0.5,1,2], and the results are listed in Table 5. When \({\lambda }_{Dice}\), \({\lambda }_{BCE}\) and \({\lambda }_{CLE}\) are 0.5, 0.5 and 1, respectively, the segmentation model obtains the highest dice score.
Conclusion
In this study, we propose a novel OCT retinal geographic atrophy segmentation method using a multistage two-branch network structure. A large number of individual B-scan images are utilized for pre-training in the pre-training stage, followed by 3D volumetric data in the fine-tuning stage to address the current lack of a large amount of volumetric data for GA segmentation. Then, we capture the inter-pixel dependencies through the projection attention module to improve the segmentation precision and accuracy, and extract multi-scale features and channel information through the adaptive pooling module to alleviate the feature loss problem. In addition, we propose a contrast learning enhancement module to mitigate the contrast problem and improve the ability of the model to distinguish features. Finally, we incorporate the ConvLSTM module to utilize the information between neighboring slices, which helps mitigate the problem of volumetric data slice segmentation ignoring the spatial information of volumetric data. Our network effectively combines these components, using a large number of individual B-scans images to pre-train the network, and experimental validation on two datasets demonstrates the soundness and effectiveness of our approach.
However, it is worth noting that our approach is fully supervised, and all labels are obtained by processing pixel-level markers, and obtaining pixel-level markers is labor-intensive. This is one of the reasons why many researchers continue to explore weakly supervised and semi-supervised approaches. In future research, we will continue to explore weakly supervised and semi-supervised GA segmentation. We hope to reduce the labeling time while ensuring the quality of segmentation. At the same time, we will continue to collect larger retinal OCT datasets.
Data availability
Publicly available dataset used in this study can be found at https://ieee-dataport.org/open-access/octa-500. Private datasets cannot be shared publicly available and authors do not have permission to share data but are available from lxmspace@gmail.com upon reasonable request.
Change history
01 April 2025
A Correction to this paper has been published: https://doi.org/10.1038/s41598-025-95219-z
References
Sadda, S. R. et al. Consensus definition for atrophy associated with age-related macular degeneration on OCT: classification of atrophy report 3. Ophthalmology 125, 537–548 (2018).
Wong, W. L. et al. Global prevalence of age-related macular degeneration and disease burden projection for 2020 and 2040: a systematic review and meta-analysis. Lancet Glob. Health 2, e106–e116 (2014).
Group, A. R. Change in area of geographic atrophy in the Age-Related Eye Disease Study: AREDS report number 26. Arch. Ophthalmol. 127, 1168 (2009).
Holz, F. G. et al. Imaging protocols in clinical studies in advanced age-related macular degeneration: recommendations from classification of atrophy consensus meetings. Ophthalmology 124, 464–478 (2017).
Fazekas, B. et al. Segmentation of Bruch’s membrane in retinal OCT with AMD using anatomical priors and uncertainty quantification. IEEE J. Biomed. Health. Inf. 27, 41–52. https://doi.org/10.1109/JBHI.2022.3217962 (2023).
Tajmirriahi, M. et al. In 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC) 3866–3869 (2022).
Liu, X., Zhu, X., Zhang, Y. & Wang, M. Point based weakly semi-supervised biomarker detection with cross-scale and label assignment in retinal OCT images. Comput. Methods Programs Biomed. 251, 108229. https://doi.org/10.1016/j.cmpb.2024.108229 (2024).
He, J., Zhu, Q., Zhang, K., Yu, P. & Tang, J. An evolvable adversarial network with gradient penalty for COVID-19 infection segmentation. Appl. Soft Comput. 113, 107947. https://doi.org/10.1016/j.asoc.2021.107947 (2021).
Ye, L., Zhu, W., Bao, D., Feng, S. & Chen, X. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part V 23. 735–744 (Springer).
Sun, Z. et al. An automated framework for 3D serous pigment epithelium detachment segmentation in SD-OCT images. Sci. Rep. 6, 21739 (2016).
Zhu, S. et al. Choroid neovascularization growth prediction with treatment based on reaction-diffusion model in 3-D OCT images. IEEE J. Biomedical Health Inform. 21, 1667–1674 (2017).
Hassan, B., Raja, G., Hassan, T. & Akram, M. U. Structure tensor based automated detection of macular edema and central serous retinopathy using optical coherence tomography images. JOSA A 33, 455–463 (2016).
Wang, M. et al. Semi-supervised capsule cGAN for speckle noise reduction in retinal OCT images. IEEE Trans. Med. Imaging 40, 1168–1183 (2021).
Fang, J., Zhang, Y., Xie, K., Yuan, S. & Chen, Q. in Ophthalmic Medical Image Analysis: 6th International Workshop, OMIA 2019, Held in Conjunction with MICCAI 2019, Shenzhen, China, October 17, Proceedings 6. 130–138 (Springer).
Yang, J. et al. RMPPNet: residual multiple pyramid pooling network for subretinal fluid segmentation in SD-OCT images. OSA Continuum 3, 1751–1769 (2020).
Shi, F. et al. Automated 3-D retinal layer segmentation of macular optical coherence tomography images with serous pigment epithelial detachments. IEEE Trans. Med. Imaging 34, 441–452 (2014).
Chen, Q. et al. Semi-automatic geographic atrophy segmentation for SD-OCT images. Biomedical Optics Express 4, 2729–2750 (2013).
Hu, Z. et al. Segmentation of the geographic atrophy in spectral-domain optical coherence tomography and fundus autofluorescence images. Investig. Ophthalmol. Vis. Sci. 54, 8375–8383 (2013).
Niu, S., de Sisternes, L., Chen, Q., Leng, T. & Rubin, D. L. Automated geographic atrophy segmentation for SD-OCT images using region-based CV model via local similarity factor. Biomedical Opt. Express 7, 581–600 (2016).
Wu, M. et al. Geographic atrophy segmentation in SD-OCT images using synthesized fundus autofluorescence imaging. Comput. Methods Programs Biomedicine 182, 105101 (2019).
Patil, J., Kawczynski, M., Gao, S. S. & Coimbra, A. F. Geographic atrophy lesion segmentation using a deep learning network (U-net). Investig. Ophthalmol. Vis. Sci. 60, 1459–1459 (2019).
Spaide, T. et al. Geographic atrophy segmentation using multimodal deep learning. Transl. Vis. Sci. Technol. 12, 10–10 (2023).
Li, M. et al. Image projection network: 3D to 2D image segmentation in OCTA images. IEEE Trans. Med. Imaging 39, 3343–3354. https://doi.org/10.1109/TMI.2020.2992244 (2020).
Li, M. et al. OCTA-500: A retinal dataset for optical coherence tomography angiography study. Med. Image Anal. 93, 103092. https://doi.org/10.1016/j.media.2024.103092 (2024).
Morano, J. et al. In International Conference on Medical Image Computing and Computer-Assisted Intervention. 589–599 (Springer).
Liu, X., Cao, J., Wang, S., Zhang, Y. & Wang, M. Confidence-guided topology-preserving layer segmentation for optical coherence tomography images with focus-column module. IEEE Trans. Instrum. Meas. 70, 1–12 (2020).
Shao, H.-C. et al. Keeping deep lithography simulators updated: Global–local shape-based novelty detection and active learning. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 42, 1000–1014 (2022).
Zhang, H., Goodfellow, I., Metaxas, D. & Odena, A. In International Conference on Machine Learning. 7354–7363 (PMLR).
Liu, X., Ding, Y., Zhang, Y. & Tang, J. Multi-scale local-global transformer with contrastive learning for biomarkers segmentation in retinal OCT images. Biocybern. Biomed. Eng. 44, 231–246 (2024).
Wang, W. et al. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 7303–7313.
Li, J., Tan, Z., Wan, J., Lei, Z. & Guo, G. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6949–6958.
Akilan, T., Wu, Q. J., Safaei, A., Huo, J. & Yang, Y. A 3D CNN-LSTM-based image-to-image foreground segmentation. IEEE Trans. Intell. Transp. Syst. 21, 959–971 (2019).
Shao, H.-C. et al. Retina-transnet: a gradient-guided few-shot retinal vessel segmentation net. IEEE J. Biomed. Health. Inf. (2023).
Wu, Z. et al. In 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). 1579–1584 (IEEE).
Zhao, H., Shi, J., Qi, X., Wang, X. & Jia, J. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2881–2890.
Chen, L.-C., Papandreou, G., Schroff, F. & Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587 (2017).
Fu, J. et al. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3146–3154.
Diakogiannis, F. I., Waldner, F., Caccetta, P. & Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 162, 94–114 (2020).
Zhou, Z., Rahman Siddiquee, M. M., Tajbakhsh, N. & Liang, J. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, September 20, 2018, Proceedings 4. 3–11 (Springer).
Jha, D., Riegler, M. A., Johansen, D., Halvorsen, P. & Johansen, H. D. In 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS). 558–564 (IEEE).
Lachinov, D. et al. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part I 24. 431–441 (Springer).
Seeböck, P. et al. Linking function and structure with ReSensNet: predicting retinal sensitivity from OCT using deep learning. Ophthalmol. Retina 6, 501–511 (2022).
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China under Grant 62176190.
Author information
Authors and Affiliations
Contributions
Conceptualization: X-ML, J-YL. Methodology: X-ML, J-YL. Data curation: All. Validation: X-ML, J-YL. Formal analysis: X-ML, J-YL, YZ and J-PY. Investigation: X-ML, J-YL. Writing-original draft: J-YL. Visualization: J-YL. Supervision: X-ML. Project administration: X-ML. Funding acquisition: X-ML. Writing-review and editing: All. Final approval: All.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this Article was revised: The original version of this Article contained errors in the Affiliations. Full information regarding the affiliations can be found in the correction article.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, X., Li, J., Zhang, Y. et al. Dual-branch image projection network for geographic atrophy segmentation in retinal OCT images. Sci Rep 15, 6535 (2025). https://doi.org/10.1038/s41598-025-90709-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-90709-6
