
Abstract
Model compression is a technique for transforming large neural network models into smaller ones. Knowledge distillation (KD) is a crucial model compression technique that involves transferring knowledge from a large teacher model to a lightweight student model. Existing knowledge distillation methods typically facilitate the knowledge transfer from teacher to student models in one or two stages. This paper introduces a novel approach called counterclockwise block-wise knowledge distillation (CBKD) to optimize the knowledge distillation process. The core idea of CBKD aims to mitigate the generation gap between teacher and student models, facilitating the transmission of intermediate-layer knowledge from the teacher model. It divides both teacher and student models into multiple sub-network blocks, and in each stage of knowledge distillation, only the knowledge from one teacher sub-block is transferred to the corresponding position of a student sub-block. Additionally, in the CBKD process, deeper teacher sub-network blocks are assigned higher compression rates. Extensive experiments on tiny-imagenet-200 and CIFAR-10 demonstrate that the proposed CBKD method can enhance the distillation performance of various mainstream knowledge distillation approaches.
Similar content being viewed by others


Introduction
Deep learning stands as a pivotal direction in the realm of artificial intelligence1, revolutionizing the field and successfully driving the progress of various real-world applications, such as image classification2,3, object detection4,5, text classification6,7, and machine translation8,9. The powerful capabilities of deep learning models often stem from their vast number of parameters. However, most models are too computationally expensive to run on mobile or embedded devices. Therefore, in many industrial sectors, there is a demand for lightweight deep learning models, as these smaller models are suitable for deployment on end-user devices. Consequently, the current research focus lies in effectively reducing the size and computational requirements of deep learning models without compromising their performance. Currently, there are five primary strategies to achieve efficient and lightweight neural network models: the direct design of lightweight neural network models10,11,12, pruning13, quantization14,15, network automation design leveraging neural architecture search16,17, and knowledge distillation.
Due to its ability to effectively address the contradiction between the complexity of deep learning models and limited computational resources, as well as its strong model generalization capability, knowledge distillation has garnered significant attention from researchers in recent years. Knowledge distillation aims to transfer knowledge from a robust and large model (known as the teacher model) to a more lightweight model (known as the student model). The concept of knowledge distillation is attributed to the contributions made by Hinton in their groundbreaking work18. The proposed knowledge distillation method transfers knowledge from the teacher model to the student model by making the output of the student model closer to the soft target outputs generated by the teacher model. However, the significant capacity difference between the teacher and student models results in a “generation gap.” To address this issue, the research by Gotmare et al. theoretically demonstrates that complex teacher models and simple student models exhibit significant capacity differences in their intermediate hidden layers, leading to different feature representation abilities19. Therefore, merely acquiring the teacher’s output feature knowledge is insufficient. By transferring the intermediate layer knowledge of the teacher model, it helps to bridge this gap. Based on the above analysis, various novel knowledge distillation techniques have been proposed, including Progressive Block-wise Knowledge Distillation (PBKD) by Wang20. PBKD gradually replaces teacher subnet blocks with corresponding student subnet blocks, proceeding from shallow to deep layers. During each stage of the block replacement process, the other subnet blocks within the teacher network remain unchanged, enabling the student model to acquire intermediate layer feature knowledge from the teacher model. At each stage, the structural similarity between the teacher and student models narrows the generational gap. Furthermore, PBKD introduces a set of design principles for student subnet blocks, stipulating that the channel dimensions of student subnet blocks should be reduced from their corresponding teacher subnet blocks to ensure that both subnet blocks have the same receptive field and depth. Additionally, Blakeney et al. proposed a parallel block-level distillation method that identifies all compressible layers in the teacher model and creates individual tasks for their replacement21. Once all layers are successfully replaced, the main MPI process aggregates the weights from all processes and combines them into a new compressed model. Although this method further reduces training time, it primarily relies on the intermediate layer losses of the teacher and student subnet blocks, and therefore cannot transfer knowledge related to high-level semantic features such as logistic regression values. Meanwhile, both of the aforementioned block-level knowledge distillation methods apply the same channel reduction ratio to all subnet blocks of the teacher model, ignoring the inherent characteristic differences between subnet blocks at different locations, which may lead to a decrease in the overall accuracy or efficiency of the compressed model.
Dropout is a regularization technique designed to prevent overfitting in deep neural networks by randomly shutting down a portion of neurons during the training process, thereby enhancing the model’s generalization ability22. This concept provides inspiration for our research. In each stage of Progressive Blockwise Knowledge Distillation (PBKD), an attempt is made to replace the teacher subnet block with a student subnet block from a subnetwork. However, due to the generation gap between the teacher and the student, each replacement process incurs information loss, similar to the impact of randomly discarding subnodes. Neural networks that utilize dropout typically employ a lower dropout rate at shallow layers to avoid losing too much input data, while using a higher dropout rate at deeper layers. This prompts us to consider whether a similar approach can be adopted in PBKD.
In summary, this paper proposes a counterclockwise block-wise knowledge distillation method for neural network compression, with the main contributions outlined as follows:
-
(1)
Based on Progressive Blockwise Knowledge Distillation, an innovative method for adjusting the compression rate according to the depth of the network is proposed, enabling a higher channel reduction ratio to be achieved in deeper subnet blocks. This strategy not only enhances distillation efficiency but also allows the generated academic subnet blocks to achieve higher classification accuracy with similar computational resource consumption.
-
(2)
By introducing the concept of compressed block-wise distillation, a novel multi-stage knowledge distillation method named CBKD (Compressed Blockwise Knowledge Distillation) has been developed. This method can more effectively utilize the knowledge from the teacher network and transfer it to the student network, demonstrating superior distillation performance among various mainstream knowledge distillation techniques.
The remainder of this paper is organized as follows. Section 2 introduces the concept of knowledge distillation and the existing problems. Section 3 presents the design process of a new knowledge distillation method, CBKD. Section 4 provides the experimental results of the proposed method. Finally, Section 5 concludes the paper.
Related work
Knowledge distillation The core concept of knowledge distillation involves transferring “knowledge” from a teacher model, which is typically a large and high-performance model, to a student model, which is typically a smaller and lightweight model. This transfer aims to enable the student model to acquire the reasoning and generalization capabilities of the teacher model. At present, knowledge distillation can be divided into four main types based on the type of knowledge transferred: (i) output feature knowledge23: output feature knowledge usually refers to the final layer features of the teacher model, mainly including logical unit knowledge and soft target knowledge. The basic idea of output feature knowledge distillation is to enable the student model to learn the final prediction of the teacher model, thereby achieving the same prediction ability as the teacher model. Although the original knowledge distillation was proposed for classification tasks and only included inter-class similarity as soft target knowledge, in other tasks such as object detection, the final layer feature output of the network may also contain information related to object localization. (ii) Transfer intermediate feature knowledge24,25: This method focuses on extracting features from the network layer of the teacher model to provide guidance for the intermediate layer of the student model. (iii) Knowledge of relational features26,27: This approach considers that the essence of learning is not in the output of features, but in the relationships between layers and sample data. It mainly emphasizes providing consistent identity mapping, enabling the student model to better grasp the relational knowledge of the teacher model. (iv) Structural Feature Knowledge28,29: This strategy involves conveying the comprehensive knowledge system of the teacher model, encompassing not only the output layer knowledge, intermediate feature knowledge, and relational feature knowledge but also the spatial feature distribution and other aspects of the teacher model knowledge.
The generation gap between teacher and student models In the context of knowledge impartation and educational processes, disparities in understanding, experience, and language between educators or experts and students can hinder effective information transmission, leading to learning obstacles or misunderstandings. During the process of knowledge distillation, structural differences (i.e., the generation gap) between teacher and student models can result in information loss. FitNets30 mitigates this generation gap by aligning the outputs of the student model’s hidden layers with those of the teacher model’s hidden layers to transfer intermediate-level knowledge. Cho et al.31 and Mirzadeh et al.32 have identified several potential reasons for the mismatch in teacher and student capabilities. For instance, excessively strong teacher capabilities may impede the student model’s ability to emulate similar behaviors. Additionally, increased certainty in the teacher’s predictions leads to less “soft” logits (soft targets). To validate their hypotheses, they conducted a series of experiments and proposed solutions to address this issue. Cho et al. recommended optimizing the knowledge distillation process by strategically halting it in advance. Meanwhile, Mirzadeh et al. sought to assist students in model learning by incorporating assistant models.
Our approach
CBKD
To better understand our instructions, we provide a detailed explanation of the symbols used in this article in Table 1.
A teacher network T can be represented as a composite function of its k subnet blocks (as is shown in Formula 2), while a student network S as a composite function of its k student subnet blocks (Formula 1), where the circles represent the connections between different network modules.

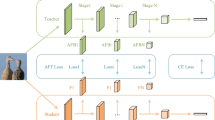
Overview of CBKD.
The comprehensive process of CBKD is vividly depicted in Fig. 1. The red dotted box indicates the subnet block trained for the current stage. Specifically, the shallowest segment of the teacher network is directly preserved within the corresponding shallow layer of the student model, reflecting a direct inheritance of foundational knowledge. The remainder of the teacher network is meticulously structured into N subnet blocks, each encapsulating unique layers of depth and complexity. CBKD is strategically segmented into N+1 phases, each playing a crucial role in the transfer of knowledge. During the initial N phases, the distillation loss serves as the guiding beacon, facilitating the transfer of knowledge from the teacher model to the student model. This transfer occurs progressively, moving from the shallowest teacher subnet blocks to the deepest, with each student subnet block mirroring its teacher counterpart in terms of knowledge acquisition. This layered approach ensures a gradual and thorough assimilation of knowledge. An intriguing aspect of CBKD lies in its phased training methodology. In the first N-1 phases, a meticulous focus is placed on the sequential training of each student subnet block. During these phases, only one student subnet block is actively trained, while the remaining networks within the student model remain in a frozen state. This isolated training environment allows for a detailed examination and refinement of each subnet block, ensuring optimal performance before integrating it into the larger student model. At the pivotal N-th phase, a transformation occurs. All parameters within the student model are unfrozen, marking the commencement of a comprehensive training session. This comprehensive training is designed to fine-tune the entire student model, reducing its reliance on the teacher model and fostering the discovery of a more suitable parameter distribution. This final phase serves as the culmination of the CBKD process, preparing the student model for independent operation with enhanced performance and reduced complexity.
Progressive Block Knowledge Distillation (PBKD) leverages a dual-pronged approach in defining its distillation loss for each stage. Specifically, it employs both the intermediate layer loss, as clearly delineated in Formula 3, and the output layer loss, comparing the outputs of the teacher and student models. This holistic consideration of losses at multiple levels ensures a comprehensive transfer of knowledge from the teacher to the student model. In stark contrast, Cross-layer Block Knowledge Distillation (CBKD) adopts a more streamlined approach. It solely focuses on the output layer loss between the student and teacher models, consciously omitting the losses calculated between corresponding student and teacher subnet blocks. This decision stems from the recognition that teacher and student subnet blocks often possess vastly different structures and capacities, making a direct comparison of their outputs impractical and potentially misleading. Instead of enforcing a rigid alignment between these subnet blocks, CBKD respects their inherent differences and focuses on aligning their final outputs. Furthermore, by adopting a single loss function, CBKD minimizes the number of hyperparameters that need to be fine-tuned during the distillation process. This simplification not only reduces the computational overhead but also streamlines the optimization process, making it more efficient and less prone to overfitting. Experimental results have consistently demonstrated the effectiveness of CBKD’s loss function scheme. By focusing on the output layer loss and respecting the differences between teacher and student subnet blocks, CBKD is able to produce a superior student model that maintains high performance while being more compact and efficient. These results validate the robustness and practicality of CBKD’s approach in knowledge distillation.
where I is the input of the network (e.g., image). In this context, ’n’ represents the area of output feature maps for both teacher and student subnet blocks, with ’T’ and ’S’ denoting the value matrices of the output feature maps for teacher and student subnet blocks, respectively.
Student subnet block design methodology
Dropout serves as a widely employed regularization technique in deep learning. It operates by stochastically “dropping out” certain neurons of a neural network during the training process, effectively setting their outputs to zero, thereby mitigating overfitting. Given the substantial presence of input feature information in shallow networks, where each layer’s features make a relatively significant contribution to the final output, it is advisable to apply a lower dropout rate in the shallow layers of a neural network.Through experimentation, we have further observed that retaining certain network layers from the bottom of the teacher network directly leads to improved knowledge distillation performance.
In our approach, we utilize the downsampling layer as a strategic demarcation to segment the teacher network into subnet blocks, preserving the shallowest teacher subnet block as it often contains critical information for subsequent layers. To derive the student subnet block, we systematically reduce the number of channels within the corresponding teacher subnet block. This reduction is critical for achieving model compression without compromising too much on performance. To facilitate the seamless integration of the student subnet block into the overall network architecture, we employ a 1\(\times\)1 convolutional layer. This layer serves a dual purpose: it adjusts the input channel number of the student subnet block to ensure compatibility with the surrounding layers, and it helps in maintaining dimensional consistency throughout the substitution process, as vividly illustrated in Fig. 2. C_i, C_o and \(\lambda\) represent the input channels, output channels and compression ratio of the teacher subnet block. This design choice ensures that the student subnet block can seamlessly replace its teacher counterpart without disrupting the overall flow of information within the network. The ratio of the number of channels in the student subnet block to that in the teacher subnet block serves as a quantifiable metric of the compression applied. A lower ratio indicates a higher degree of compression, potentially leading to a more compact and efficient student model. By tuning this ratio, we can balance the trade-off between model compression and performance. Furthermore, we conducted a comparative analysis to assess the effectiveness of CBKD in different scenarios where the teacher and student subnet blocks are of varying types. This analysis was crucial for understanding the versatility and robustness of CBKD across diverse network architectures. Our findings revealed that CBKD consistently delivered impressive results, highlighting its potential as a powerful tool for model compression and knowledge distillation.

Illustration of the student subnetwork block design.
Experiments
Experimental details
Datasets :We ran our experiment on two datasets. CIFAR-1033 is a labeled subset of the 80 million small image dataset for object recognition, which contains 60,000 32 \(\times\) 32RGB images in 10 categories, 5000 images per class for training and 1000 images per class for testing.Tiny-imagenet-20034 is a subset of Imagenet35, which contains 200 categories of 64 \(\times\) 64RGB images, each with 500 training samples and 50 validation samples.
DNN Models :In this paper we use the widely used VGG-1636, Resnet1837 as the teacher module. It should be noted that adding a normalization layer after one or more convolutional layers is a popular practice, so we added a batch normalization layer after each convolutional layer in VGG-16.
Data Preprocessing:When experimenting on CIFAR-10 using the VGG-16 model, we simply subtract the RGB mean on the training data from each image on the dataset. For the rest of the experiments,we used the same data augmentation, that is, random cropping (crop ratio (0.6, 1.0), crop area aspect ratio (3.0/4.0, 4.0/3.0)), random horizontal and vertical flipping (probability = 0.5), normalization and random adjustment of the four attributes of brightness, contrast, saturation and hue of the image (the variation range is 0.4, 0.4, 0.4 and 0.1 in order).
Training Details:We implemented our architecture via PyTorch, we trained the network with Tesla P100 16GB GPUs on CIFAR-10 , RTX3080ti GPUs on Tiny-imagenet-200, Pytorch’s default AdamW as the optimizer, and we set up training epoches to make each distillation stage close to convergence. More training details are shown in Tables 2 and 3.
Ablation experiments
In this section, we have performed a total of 5 ablation experiments: (1) Comparison of loss function and optimization order selection approach; (2) Comparison of thawing training strategies; (3) Comparison of student subnet block design strategies; (4) Comparison of the number of training epoches; (5) Combined with other knowledge distillation methods. In Section 4.2.6, we compared the performance of CBKD with previous knowledge distillation methods based on PBKD.
Comparison of loss function and optimization order selection approach
Due to the structural differences between the teacher model and the student model, there is a generation gap in performance between them. In order to solve this problem, we hope that the student model can pay more attention to the higher-level knowledge of the teacher model, and we also hope to reduce the hyperparameters that need to be tuned by reducing the variety of loss functions, so we only select the final output of the intermediate model and the cross-entropy loss of the ground truth at each distillation stage as the loss function. Several combinations of optimization order and loss function have been compared in PBKD, and the final result is that the bottom-up optimization order and the loss function scheme of cls loss+local loss are optimal. In this section, we try two other combinations of optimization order and loss functions and compare them with the optimal scheme in PBKD. The comparison results are shown in Table 4, and the optimization order of Top-Down and the scheme of using only Lcls as the loss function are the best. Top-Down refers to distillation from the shallow layers of the teacher model to the deeper layers. Skipping-First refers to the replacement of subnet blocks in the order N-1, N-2, . . . . , 1, N.
Comparison of thawing training strategies
We try to reduce the dependence of the student model on the teacher model and make it find a more suitable parameter distribution by thawing the student model obtained in the last distillation stage of CBKD. In addition, we believe that when thawing training, the learning rate setting is also a hyperparameter that should be valued, because too small a learning rate setting will make the student model unable to get out of the previous local best position, and too large a learning rate setting may make the student model forget too much of the knowledge transmitted by the teacher model. The results in Table 5 show that it is most effective to increase the thawing training stage at the end of the counterclockwise progressive distillation phase and use a learning rate close to the distillation stage. “lr” uses the same learning rate settings as the distillation stage.
Comparison of student subnet block design strategies
Comparison of teacher subnet block compression policies:
We applied different channel compression ratios to different subblocks of the teacher model in CBKD and compared them. As is shown in Fig. 3, reducing the compression degree of shallow subnetwork blocks of the teacher model can improve the accuracy of the student model with only a small amount of parameters and GFLOPs, but increasing the compression degree of the deep subnetwork block can not only reduce a large number of parameters, but also reduce only a small amount and even improve the accuracy of the student model, so we believe that the compression degree of the teacher subnetwork block should be increased from shallow to deep. In the figure, the width of the bubble represents the parameter size of the model. The three channel compression ratios are: Policy 1 (0.5, 0.5, 0.5, 0.5, 0.5), Policy 2 (0.75, 0.5, 0.5, 0.5), and Policy 3 (0.75, 0.5, 0.375, 0.25).

Model results with different subnet block channel reduction policies.
For the student model structure that is heterogeneous with the teacher model, we also recommend increasing the compression degree of the teacher subnet block from shallow to deep. We replaced the conventional convolutional layers in the teacher model with depthwise separable convolutional layers to create the student model. This approach was employed to evaluate the knowledge distillation effects when there is a structural disparity between the teacher and student models. To support our idea, we controlled the degree of compression of the teacher subnet block by controlling the number of Depthwise Separable Convolution Layer’s channels in the heterogeneous student model, and the results in Fig. 4 confirm our opinion. In the figure, the width of the bubble represents the parameter size of the model. The three channel ratios for student subnet blocks and teacher replaceable subnet blocks are: P1 (1, 1, 1, 1), P2 (1.25, 1, 1, 1), and P3 (1.5, 1, 0.75, 0.5).

Effect of different subnetwork block channel compression strategies on heterogeneous student models.
Comparison of the number of reserved subnet blocks:
We compared the CBKD effect of retaining the number of different teacher subnet blocks, and when the number of subnet blocks that are reserved=0, our compression ratio for the lowest subnet block of the teacher network is 0.75, and the training epoches in this stage is the same as in the previous stage. As shown in Table 6, the student model that retains the lowest subnetwork block of the teacher model tends to achieve the highest accuracy, while the student model that retains more subnetwork blocks of teachers achieves an accuracy improvement close to 0 or even negative values.
Combined with other knowledge distillation methods
We compared the CBKD method proposed in this paper with various advanced knowledge distillation approaches. Among the compared experimental methods, FitNets38 belong to intermediate feature distillation, which utilizes the intermediate layers of the teacher model to guide the training of the student network. RKD39 falls into the category of relational feature distillation, transferring the structural relationships among multiple output samples as knowledge to the student network. DKD40 and logit-standardization-KD41 belong to logits distillation. DKD divides classification predictions into two levels: (1) binary predictions for the target class and all non-target classes, and (2) multi-class predictions for each non-target class. Based on this, DKD adjusts the influence of these two levels on the final distillation effect separately. Logit-standardization-KD standardizes the logit outputs to enhance the effectiveness of knowledge distillation. The way CBKD integrates with these methods is as follows: FitNets take the fourth subnet blocks of the teacher model as hints, while for other methods, only the loss function of each distillation stage in CBKD is modified to correspond to the integrated method.
After subjecting the student model to training using Curriculum-based Knowledge Distillation (CBKD), we proceed with further training employing KD42, FitNets, and RKD. The three methods belong to logits distillation, intermediate feature distillation, and relational feature distillation, respectively, and the experimental results in Table 7 show that our CBKD can effectively improve the distillation effect of these three knowledge distillation methods. KD(temperature=2, soft_loss weighted 0.2),FitNets take the fourth subnet blocks of the teacher model as hints.
Algorithm comparison
We compare the proposed method with the previous method based on PBKD, and the results are shown in Table 8, under the close FLOPS compression ratio, the student model obtained by CBKD has higher accuracy and a much smaller number of parameters.
Conlusion
In this paper,we finds that teachers should be given a greater degree of compression at the deeper network layer of the network during the Progressive Blockwise Knowledge Distillation process, and proposes a new student subnet block design criterion based on this. Compared with the previous student subnet block design of Progressive Blockwise Knowledge Distillation, it can obtain several times the reduction rate of parameter quantities and higher accuracy of student models at similar GFLOPs compression ratio. In addition, we also propose a multi-stage knowledge distillation method called Counterclockwise Progressive Blockwise Knowledge Distillation(CBKD), which can obtain a better student model and is easier to implement than the previous Progressive Blockwise Knowledge Distillation(PBKD). And it can be effectively combined with a variety of mainstream knowledge distillation methods to obtain better performance. Subsequently, we will assess the efficacy of CBKD on a broader spectrum of neural network models and datasets.
Data Availability
The data used to support the findings of this study are available from the corresponding author upon request.
References
Sun, J., Zhai, Y., Liu, P. & Wang, Y. Memristor-based neural network circuit of associative memory with overshadowing and emotion congruent effect. IEEE Trans. Neural Netw. Learn. Syst.[SPACE]https://doi.org/10.1109/TNNLS.2023.3348553 (2024).
Wang, C., Guo, Y. & Fu, J. Dual-stream discriminative attention network for cross-scene hyperspectral image classification. IEEE Trans. Geosci. Remote Sensing 62, 5515512 (2024).
Gong, A. et al. Spectrum-image dual-modality fusion empowered accurate and efficient classification system for traditional chinese medicine. Inf. Fusion 101, 101981 (2024).
Yang, W., Zhang, H., Lim, J. B., Zhang, Y. & Meng, H. A new chiller fault diagnosis method under the imbalanced data environment via combining an improved generative adversarial network with an enhanced deep extreme learning machine. Eng. Appl. Artif. Intell. 137, 109218 (2024).
Zhang, H., Zhang, Y., Meng, H., Lim, J. B. & Yang, W. A novel global modelling strategy integrated dynamic kernel canonical variate analysis for the air handling unit fault detection via considering the two-directional dynamics. J. Build. Eng. 96, 110402 (2024).
Li, F., Zuo, Y., Lin, H. & Wu, J. Boostxml: Gradient boosting for extreme multilabel text classification with tail labels. IEEE Trans. Neural Netw. Learn. Syst.[SPACE]https://doi.org/10.1109/TNNLS.2023.3285294 (2023).
Taha, K., Yoo, P. D., Yeun, C., Homouz, D. & Taha, A. A comprehensive survey of text classification techniques and their research applications: Observational and experimental insights. Comput. Sci. Rev.54 (2024).
Yin, Y., Fu, B. L., Li, Y. & Zhang, Y. On compositional generalization of transformer-based neural machine translation. Inf. Fusion 111, 102491 (2024).
Guo, J., Su, R. & Ye, J. Multi-grained visual pivot-guided multi-modal neural machine translation with text-aware cross-modal contrastive disentangling. Neural Netw. 178, 106403 (2024).
Nahiduzzaman, M., Abdulrazak, L. F., Ayari, M. A., Khandakar, A. & Islam, S. M. R. A novel framework for lung cancer classification using lightweight convolutional neural networks and ridge extreme learning machine model with shapley additive explanations (shap). Expert Syst. Appl. 248, 123392 (2024).
Zhang, J. & He, M. Methodology for severe convective cloud identification using lightweight neural network model ensembling. Remote Sens. 16, 2070 (2024).
Tang, X. et al. A lightweight model combining convolutional neural network and transformer for driver distraction recognition. Eng. Appl. Artif. Intell. 132, 107910 (2024).
He, H. et al. Pruning self-attentions into convolutional layers in single path. IEEE Trans. Pattern Anal. Mach. Intell. 46, 3910–3922 (2024).
Wang, M., Zhou, W., Yao, X., Tian, Q. & Li, H. Towards codebook-free deep probabilistic quantization for image retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 46, 626–640 (2024).
Wang, L. et al. Non-serial quantization-aware deep optics for snapshot hyperspectral imaging. IEEE Trans. Pattern Anal. Mach. Intell. 46, 6993–7010 (2024).
Wang, Y. et al. Mednas: Multiscale training-free neural architecture search for medical image analysis. IEEE Trans. Evol. Comput. 28, 668–681 (2024).
Zhou, X. et al. Toward evolutionary multitask convolutional neural architecture search. IEEE Trans. Evol. Comput. 28, 682–695 (2024).
Hinton, G., Vinyals, O., Dean, J. et al. Distilling the knowledge in a neural network. arXiv preprint [SPACE]arXiv:1503.025312 (2015).
Langovoy, M., Gotmare, A. & Jaggi, M. Unsupervised robust nonparametric learning of hidden community properties. Math. Found. Comput. 2, 127–147 (2019).
Wang, H., Zhao, H., Li, X. & Tan, X. Progressive blockwise knowledge distillation for neural network acceleration. In IJCAI, 2769–2775 (2018).
Blakeney, C., Li, X., Yan, Y. & Zong, Z. Parallel blockwise knowledge distillation for deep neural network compression. IEEE Trans. Parallel Distrib. Syst. 32, 1765–1776 (2021).
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I. & Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15, 1929–1958 (2014).
Sun, T. et al. Uni-to-multi modal knowledge distillation for bidirectional lidar-camera semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 46, 11059–11072 (2024).
Wang, X., Wang, Y., Ke, G., Wang, Y. & Hong, X. Knowledge distillation-driven semi-supervised multi-view classification. Inf. Fusion 103, 102098 (2024).
Zhou, W., Cai, Y., Dong, X., Qiang, F. & Qiu, W. Adrnet-s*: Asymmetric depth registration network via contrastive knowledge distillation for rgb-d mirror segmentation. Inf. Fusion 108, 102392 (2024).
Han, J., Zheng, H. & Bi, C. Kd-inr: Time-varying volumetric data compression via knowledge distillation-based implicit neural representation. IEEE Trans. Visual. Comput. Gr. 30, 6826–6838 (2024).
Shao, J., Wu, F. & Zhang, J. Selective knowledge sharing for privacy-preserving federated distillation without a good teacher. Nat. Commun. 15, 349 (2024).
Liu, M. et al. Towards better unguided depth completion via cross-modality knowledge distillation in the frequency domain. IEEE Tran. Intell. Vehicles.[SPACE]https://doi.org/10.1109/TIV.2024.3396174 (2024).
Zhang, J., Liu, J., Pei, Y., Zhang, J. & Zhao, X. Learn from voxels: Knowledge distillation for pillar-based 3d object detection with lidar point clouds in autonomous driving. IEEE Trans. Intell. Vehicles. https://doi.org/10.1109/TIV.2024.3397617 (2024).
Romero, A. et al. Fitnets: Hints for thin deep nets. arXiv preprint[SPACE]arXiv:1412.6550 (2014).
Cho, J. H. & Hariharan, B. On the efficacy of knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 4794–4802 (2019).
Mirzadeh, S. I. et al. Improved knowledge distillation via teacher assistant. In Proceedings of the AAAI Conference on Artificial Intelligence, 5191–5198 (2020).
Krizhevsky, A. et al. Learning Multiple Layers of Features from Tiny Images (ON, Canada, Toronto, 2009).
Le, Y. & Yang, X. Tiny imagenet visual recognition challenge. CS 231N(7), 3 (2015).
Deng, J. et al. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–255 (IEEE, 2009).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint[SPACE]arXiv:1409.1556 (2014).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778 (2016).
Romero, A. et al. Fitnets: Hints for thin deep nets. arXiv preprint[SPACE]arXiv:1412.6550 (2014).
Park, W., Kim, D., Lu, Y. & Cho, M. Relational knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3967–3976 (2019).
Zhao, B., Cui, Q., Song, R., Qiu, Y. & Liang, J. Decoupled knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11953–11962 (2022).
Sun, S., Ren, W., Li, J., Wang, R. & Cao, X. Logit standardization in knowledge distillation. arXiv preprint [SPACE]arXiv:2403.01427v1 (2014).
Hinton, G., Vinyals, O., Dean, J. et al. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.025312 (2015).
Wang, H., Zhao, H., Li, X. & Tan, X. Progressive blockwise knowledge distillation for neural network acceleration. In IJCAI, 2769–2775 (2018).
Blakeney, C., Li, X., Yan, Y. & Zong, Z. Parallel blockwise knowledge distillation for deep neural network compression. IEEE Trans. Parallel Distrib. Syst. 32, 1765–1776 (2020).
Acknowledgements
This work is financially sponsored by Shandong Provincial Natural Science Foundation (ZR2023MF025), Shandong Provincial Technology Innovation Guidance Program (Central Guidance for Local Scientific and Technological Development Fund) (YDZX2023085), and Shandong Province Science and Technology Smes Innovation Ability Improvement Project (2022TSGC1248).
Author information
Authors and Affiliations
Contributions
XiaoWei Lan: Methodology, Formal analysis, Writing-original draft. Yalin Zeng: Software, Validation, Writing-original draft. Xiaoxia Wei: Writing-review and editing. Tian Zhang: investigation, Funding acquisition. Yiwen Wang: Validation. Chao Huang: Fire field certification. Weikai He: Conceptualization, Project administration.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lan, X., Zeng, Y., Wei, X. et al. Counterclockwise block-by-block knowledge distillation for neural network compression. Sci Rep 15, 11369 (2025). https://doi.org/10.1038/s41598-025-91152-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-91152-3
