
Abstract
The rapid expansion of online social networks has led to explosive growth of information cascades, necessitating effective prediction methods for both research and industry. While deep learning approaches prevail in this domain, existing methods face several critical challenges in capturing the dynamic nature of cascades and integrating temporal and structural information effectively. This paper presents CasSubTS, a novel subgraph-based information cascade prediction model to address these limitations. CasSubTS samples subgraphs from the cascade graph at different time steps to capture dynamic node changes. It enhances node representation by integrating in-degree and out-degree as structural features and uses a multi-head graph attention network to learn multi-scale structural information. The model employs an attention mechanism to aggregate important temporal information of nodes, providing richer temporal data for the subsequent Bi-GRU model. Additionally, channel attention is used to prioritize the fusion of spatiotemporal features, improving the focus on key features and reducing noise interference. Integrated features are fed into a multilayer perceptron for incremental prediction. Extensive experiments on two real-world datasets and a synthetic dataset compared with six other classic and recent prediction models demonstrate the superior effectiveness of CasSubTS in accurately predicting information cascades.
Similar content being viewed by others
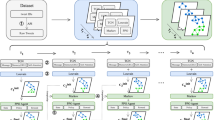

Introduction
In the contemporary digital landscape, social networks have emerged as pivotal platforms for the public to acquire and disseminate information. Information in social networks is usually diffused in a cascading manner, for example, users join in the reposts of a specific post on Weibo or Twitter1,2. As shown in Fig. 1, information cascades characterize the dynamic process of information diffusion in social networks, and they generally consist of the trajectory and structure of information diffusion, as well as participants in information dissemination3. Information cascades exhibit significant complexity and uncertainty, hence understanding their dynamics is of great significance for comprehending the actual mechanisms of information dissemination and predicting the future popularity of information. Predicting information cascades in social networks helps to grasp the mechanisms and rules of information dissemination and evolution within the network, providing support for platform operators in advertising marketing2 and content recommendation4.

An illustration of the propagation of information cascade. Nodes represent people, groups, or other entities engaged in social behavior. Arrows between nodes represent a sequence in which information is disseminated amongst nodes. Solid lines represent the direct connection between nodes. Dashed lines represent the indirect connection between nodes.
Information cascade prediction research commonly delineates into two levels of predictive tasks: micro (next user prediction)5 and macro (popularity prediction)2. In this paper, we focus on macro prediction and aim to predict the overall trend of information evolution. Previous research on information cascade modeling typically employed engineering-based approaches6 and point process methodologies7. However, with the development of artificial intelligence and the enhancement of computational resources, utilizing deep learning for modeling and forecasting has become the mainstream in this field. Deep learning-based methods perform feature learning in an end-to-end manner, avoiding explicit assumptions and heuristic feature extraction processes. Although these methods have achieved outstanding performance in specific tasks8,9, they still have some limitations:
Ignoring the node variation dynamics in cascade graphs. In practical forecasting, nodes continually join or exit the information dissemination process due to internal and external factors, leading to dynamic changes in node status and distribution. Overlooking these dynamics results in deviations between model predictions and actual outcomes. Although various methods have been proposed to sample subgraph sequences, they fail to fundamentally capture the local and global change states of nodes. Moreover, the quality of sequences obtained from such sampling is often poor, severely impacting model training and forecasting. Therefore, effectively learning the dynamics of nodes in cascade graphs remains an urgent issue to address.
Inadequate learning and integration of temporal and structural features. Temporal and structural features reflect the temporal trends and evolutionary paths of information diffusion, serving as dominant factors in information cascade prediction. However, existing models typically employ separate single models to learn these features independently, followed by feature fusion through concatenation or weighted attention mechanisms. Recent advances in semi-supervised learning have shown potential in addressing these limitations. For instance, hypergraph Laplacian-based methods10 utilize sparse regularization to select discriminative features while capturing high-order relationships, while dual autoencoder frameworks11 integrate structural and attribute information through co-regularized views. These approaches highlight the importance of combining topology-aware learning with adaptive feature fusion, which motivates our design of a unified model to jointly optimize temporal and structural representations. This approach may fail to yield efficient feature representations and could result in the loss of crucial information.
To address these challenges, we propose a novel subgraph-sampling-based model named CasSubTS (Subgraph-based Information Cascades Prediction Combining Temporal and Structural Features). In response to the insufficient learning of temporal and structural features in previous studies, this model employs a time-step-based subgraph sampling strategy. The CasSubTS model takes into account the state changes of nodes across different time periods and effectively learns and integrates temporal and structural features. The main contributions of this paper are as follows:
The CasSubTS model presents a novel approach to learn structural features, which incorporates multi-scale structural information and integrates the out-degree and in-degree of nodes as directional information into the structural features, aiming for a more comprehensive understanding of the cascade graph’s structure.
In the process of temporal feature learning, the CasSubTS model employs a node attention mechanism, which accounts for the differences in temporal information embedded in nodes across various time intervals. After aggregating nodes with more significant information, it then utilizes a Bidirectional Gated Recurrent Unit (BI-GRU) for learning temporal dependencies.
In order to fuse structural and temporal features, the CasSubTS model employs a channel attention mechanism that is more capable of focusing on the weighted fusion of features. The introduction of a multi-head attention mechanism also strikes a balance between the model’s robustness and flexibility.
The core innovation of this study includes: (1) Multi-scale structural feature learning. The in-degree and out-degree of nodes are integrated as explicit structural features with the original node features, which enhances the expressive power of node representation. Subsequently, a multi-head graph attention network (MH-GAT) is adopted to learn multi-scale structural features. (2) Attention mechanism for temporal information aggregation. An attention mechanism is used to aggregate the important temporal information of nodes. After obtaining the adaptive weights of each node, all nodes are weighted and aggregated to provide data input with richer temporal information for the subsequent Bi-GRU model. (3) Channel attention for spatiotemporal feature fusion. Channel attention (SENet) is utilized for priority fusion of spatiotemporal features to enhance the ability to focus on important features and reduce interference from noise and redundancy.
Related work
Research on information cascade prediction can be primarily categorized into three approaches, feature engineering-based methods, point process-based methods, and deep learning-based methods for cascade forecasting.
Feature engineering-based methods
These methods utilize statistical machine learning techniques to manually extract features closely related to the dynamics of information cascades, which are then input into classifiers or regression models for final prediction. The quality of manually extracted features is a decisive factor for model performance, including temporal features12, structural features13, content features14, and user features15.
Temporal features are crucial for comprehending intricate cascade dynamics and play an important role in information cascade prediction. Gao et al.16 demonstrated that using temporal features alone in a microblog popularity prediction experiment achieved accuracy comparable to that of utilizing the complete feature set. Zhou et al.17 incorporated sophisticated temporal features, such as the average arrival time of participants, average reaction time, propagation rate of change, and retweet dormancy period, all of which significantly influence the dynamics of information cascades.
The number of nodes, edge density, and depth in the cascade graph are pivotal structural features. Weng et al.18 discovered that community structure within networks is a crucial predictive feature, with the popularity of information in the network increasing as more community groups participate in the information spread.
Content features refer to the characteristics embedded in the information posted by users on social networks, encompassing various modalities, commonly including text, images, and videos. Ugale et al.14 leveraged content features in conjunction with topic modeling, using Support Vector Machines (SVMs) to predict the popularity of information. Arora et al.19 extracted meta-features, content features, and image features from information and utilized ensemble learning techniques to predict the popularity of online news.
User features pertain to the intrinsic attributes of the individuals involved in the cascade. Suh et al.20 found that in addition to the number of followers, user characteristics such as age, number of followings, and account tenure also influence the retweet rate to some extent. Lee et al.21 further investigated the impact of retweeters’ historical behavior on their participation in information dissemination, considering features such as the average daily retweet count and retweet timing.
Nonnegative Matrix Factorization (NMF) has also been widely applied in feature engineering as a dimensionality reduction technique, capturing latent structures in high-dimensional data while preserving interpretability22. By decomposing data into non-negative components, NMF enhances feature selection by identifying parts-based representations, which could complement traditional feature engineering approaches in capturing complex user interaction patterns.
Point process-based methods
The evolution of information cascades can be regarded as a sequence of events across consecutive time intervals, with point processes treating these events as discrete points in time or space. This approach forecasts future events by modeling the probabilities and interactions of event occurrences, along with the causal influences among them. Typical point process models include the Poisson process and the Hawkes process.
The Poisson process is a mathematical model that describes the occurrence of independent random events over continuous time. Lin et al.23 proposed a dynamic activity model based on the Poisson process to capture three key characteristics of social network dynamics: reach, duration, and intensity. Shen et al.24 employed an enhanced Poisson process (RPP) framework to precisely simulate and predict the dynamics of information popularity.
The Hawkes process is a self-exciting point process model in which the occurrence of new events is influenced by both their intrinsic characteristics and historical events. Cao et al.25 were the first to integrate the Hawkes process with deep learning, developing the DeepHawkes model, which retained the high interpretability of the Hawkes process in information diffusion and possesses end-to-end learning capabilities for implicit feature representation. Li et al.26 employed a pattern-aware self-exciting point process (PSEISMIC) to generate time series, enhancing the performance of popularity prediction models.
Deep learning-based methods
Deep learning methods have become mainstream in information cascade prediction, utilizing end-to-end learning of features, thereby eliminating the need for explicit assumptions and heuristic feature extraction. Current deep learning prediction methods can be divided into two categories: deep representation learning and deep fusion methods.
Deep representation learning leverages the composition and representation power of deep networks to learn more powerful feature representations from data. Researchers commonly use techniques such as graph neural networks and recurrent neural networks (RNN) to extract temporal and structural information from cascade graphs for information cascade prediction. Li et al.27 presented an end-to-end deep learning architecture named DeepCas, which first represented a cascade graph as a set of cascade paths sampled through multiple random walk processes. Chen et al.28 employed graph neural networks to directly model the local structure of cascade subgraphs, proposing a semi-supervised recursive cascade convolutional network that enhanced the accuracy of cascade prediction. Sun et al.2 developed a cascade Transformer, which utilized global spatiotemporal position encoding and relative relation bias matrices within self-attention mechanisms to capture multi-scale cascade relationships, achieving superior prediction results.
Deep fusion-based forecasting methods encompass multi-feature and multi-model integration. Distinct from the straightforward concatenation of feature vectors, these methods achieve comprehensive feature integration through various mechanisms. Liao et al.29 proposed an attention mechanism-based multi-feature fusion approach, realizing a weighted integration of multiple features by assigning different weights to each type of feature. On the other hand, multi-model fusion methods can complement the strengths between models. To achieve the interaction of two models, Wu et al.30 developed a multi-model fusion framework based on generative adversarial learning.
Preliminary work
Information cascade
In social networks, an information cascade is a diffusion sequence constituted by the information-posting users and the timing of their posts. Assuming user u posted an initial message m at time t0, within the observation period, a total of n other users \({v}_{i}\) interact with this information, then the information cascade Ck is defined as:
Information cascade graph
The information cascade graph G for an information cascade Ck of message m is defined as follows:
where \({\text{v}}_{\text{i}}\) represents the node (a user) and \({\text{e}}_{\text{i}}\) represents an edge (interaction between users) in the information cascade graph.
In addition to nodes and edges, an information cascade graph usually includes timestamps ti, which can be represented in a triplet form as:
Cascade subgraph
A subgraph \({\text{G}}_{\text{i}}\left({\text{t}}_{\text{n}}\right)\) of an information cascade graph \({\text{G}}_{i}\)={\({v}_{i}\),\({e}_{i}\)} can be represented as:
where \(G_{i} \left( {t_{n} } \right)\) is the observed information cascade subgraph at the time \(t_{n}\) , n \(\in \left[ {1,N} \right]\) is time node, \(v^{{t_{n} }} \in v_{i}\) is the node set, and \(e^{{t_{n} }} \in e_{i}\) is the edge set.
Information cascade prediction
As shown in Fig. 2, for the information cascade graph \({\text{G}}_{\text{T}}\), observed within the time interval [0, T], the information cascade prediction task of the next time period Tp is defined as follows:
where \({\text{R}}_{\text{t}}\) is the retweet volume within T, \({\text{R}}_{\text{tp}}\) is the retweet volume within the next time period Tp.

Based on the evolutionary trend of the cascade observed within a predefined time period, the task is to predict the specific magnitude of the cascade at a future point in time.
Model design
Model architecture
CasSubTS is an end-to-end deep learning model for information cascade prediction. It begins by sampling subgraphs from the input information cascade graph based on time steps. Then, it employs a Multi-headed Graph Attention Network (MH-GAT) and Bi-GRU to embed expressions of structural and temporal information. Subsequently, a channel attention mechanism is introduced for feature fusion. Finally, a Multilayer Perceptron (MLP) is utilized for macroscopic incremental prediction of information cascades.
The overall architecture of the CasSubTS model contains five parts, as shown in Fig. 3. (1) Input layer. The input data for the CasSubTS is the observed information cascade graph \({\text{G}}_{\text{i}}\left({\text{t}}_{0}\right)=(v,e)\), which is typically represented in the form of an adjacency matrix. (2) Subgraph sampling layer. To characterize the dynamic process and uncertainty of cascade evolution, the model samples subgraphs from the input cascade graph. By setting different time step sizes, the cascade graph is segmented into multiple cascade subgraphs, which are then fed as a sequence into the feature learning layer. (3) Feature learning layer. The model learns the embedded representations of the structural and temporal features of the cascade graph in parallel. For structural features, a GAT with a multi-head attention mechanism is employed to obtain a node representation matrix that preserves topological information. For temporal features, node aggregation is performed using an adaptive node attention mechanism, and then a Bi-GRU is introduced to model the temporal features. (4) Feature fusion layer. The model employs a channel attention mechanism to enhance responsiveness to critical features and obtain an integrated representation of the feature vectors. (5) Prediction Layer. An MLP is selected as the predictor, which takes the final vector representation obtained from the subgraph sampling layer, feature learning layer, and feature fusion layer to predict the increment of the information cascade. The following sections will provide detailed introductions to key steps.

The overall architecture of the CasSubTS model consists of five parts: (1) Input Layer, (2) Subgraph Sampling Layer, (3) Feature Learning Layer, (4) Feature Fusion Layer, and (5) Prediction Layer.
Subgraph sampling layer
The temporal factor profoundly influences the scale and propagation path of information cascades. As initial information m spreads over time, it may generate large-scale cascades, which increases the difficulty of data processing. Concurrently, existing methods represent cascades by aggregating node sequences, neglecting the dynamic temporal ordering of nodes, leading to models that inaccurately depict actual propagation processes and result in fitting errors.
To fully account for the temporal evolution of cascades during subgraph sampling, we propose a time-step-based sampling method to produce cascade subgraphs. This method samples subgraphs based on the temporal information of nodes in the observed cascade graph, thereby capturing the temporal dynamics of the cascade. To enhance training efficiency, a partial sampling strategy is employed, where different time step sizes T are set to decompose the cascade into multiple subgraphs and obtain their sequences. The total number of sampled subgraphs N can be calculated using the following formula:
where \({S}_{i}\) is the size of the subgraph sequence and t is the set time step. During the sampling process, considering the uniformity and representativeness of the sampling, a small value of \(t\) is set to ensure that the subgraph sequence can cover different stages of the cascade evolution.
For each subgraph \({G}_{k}\), its time window is \(\left[{t}_{k},{t}_{k}+T\right]\), where \({t}_{k}={t}_{start}+\left(k-1\right)\cdot T,k=\text{1,2},\dots ,n\).
The node set \({V}_{k}\) and edge set \({E}_{k}\) of subgraph \({G}_{k}\) are defined as follows:
The final set of subgraph sequences obtained after subgraph sampling can be represented as:
where \({\text{g}}_{\text{t}}\) denotes a subgraph sequence sampled at different time steps.
Subsequently, after representing the final subgraph sequences in a cascade, the corresponding adjacency matrix can be expressed as:
where \({\text{a}}_{\text{t}}\) is the adjacency matrix representation of a single subgraph sequence.
Feature learning layer
As previously mentioned, structural and temporal features are crucial for information cascade prediction. The CasSubTS model employs parallel feature learning, utilizing MH-GAT and Bi-GRU to simultaneously extract structural and temporal features from cascade graphs, thereby enhancing data processing efficiency and the model’s generalization capability.
Structural feature learning
We employ the MH-GAT model to perform spatial convolution on the adjacency and feature representation matrices of the input cascade graph, dynamically assigning attention weights to achieve weighted aggregation of node features, resulting in a vector representation containing structural information. To comprehensively learn the cascade graph structure and enhance predictive performance, we integrated node directionality information, represented by node degree, into the structural features, reflecting the node’s pivotal role in information propagation.
The model integrates multi-scale structural information across three levels: node-level (in-degree and out-degree for directional influence), subgraph-level (local community density and path length via time-step sampling), and global-level (graph diameter and clustering coefficient through hierarchical graph convolutions), with multi-head graph attention (MH-GAT) dynamically aggregating micro-neighbor and macro-path dependencies.
In a given cascade graph, the number of edges with node vi as an endpoint is referred to as the degree of vi, which can be expressed by the following formula:
the in-degree \({d}_{i}^{in}\) and out-degree \({d}_{i}^{out}\) of nodes are respectively mapped to a low-dimensional space that matches the original feature dimension through a nonlinear transformation:
where \({f}_{{\theta }_{in}}\) and \({f}_{{\theta }_{out}}\) are parameterized mapping functions, \(d_{i}^{in} , d_{i}^{out} \in {\mathbb{R}}^{k}\), and \(k\) is the dimension after mapping.
Concatenate the mapped in-degree and out-degree features with the original node features to obtain an enhanced node feature representation:
where \(\oplus\) denotes the vector concatenation operation. Through this method, the local structural information of nodes is explicitly encoded into the node features, thereby providing richer input for subsequent graph neural network layers. The concatenated features \(X\) can be further processed by graph neural networks for information aggregation and feature learning. Since the in-degree and out-degree information has been integrated into the node features, the model can simultaneously consider the topological properties and original features of nodes during the information propagation process, thus more accurately capturing the structural roles and global context information of nodes in social graphs.
The initial node features are mapped to various representation spaces during the MH-GAT training process, after which the node features are linearly transformed using a linear transformation matrix to produce the query vectors \({\text{Q}}_{\text{W}}\), key vectors \({\text{K}}_{\text{W}}\), and value vectors \({\text{V}}_{\text{W}}\) for each attention header:
where X is the node feature vector and H is the linear transformation matrix.
Subsequently, for each attention head k, the attention score eij of node vi with its neighbor node vj is computed using the attention mechanism to determine the relevance and importance between node vi and its neighbor node vj:
where \({\text{LeakyReLU}}\left( \cdot \right)\) is a linear function, and \(\vec{a}^{T}\) is the parameter vector of the attention head k, and \(||\) denotes the vector splicing operation.
After obtaining the relationship coefficient eij between node vi and its neighbor node vj through the attention score, the next step is to calculate the attention weight between them. This can be achieved through normalization as follows:
where \({\text{N}}_{\text{i}}\) is the set of neighbor nodes of node i, and \({\text{e}}_{\text{ij}}\) represents the correlation coefficient between any neighbor node and vi.
Next, the features of each node’s neighbors are aggregated using attention weights, dynamically adjusting the aggregation representation for each node. The calculation process is as follows:
Finally, to address interference from noisy data, prevent overfitting, and enhance the robustness of the training process, a multi-head attention mechanism is incorporated into the GAT to construct the MH-GAT model. The MH-GAT model independently learns the feature representations of each node through k attention heads, and the final output feature representation is obtained by summing and averaging the k sets of learned node representations:
In brief, in the structural features learning, the CasSubTS model utilizes a GAT enhanced with a multi-head attention mechanism to achieve feature extraction of the complex cascade graph structure, obtaining node feature representations that encapsulate the topological information of the cascade.
Temporal feature learning
After processing the sampled subgraphs, a temporal feature sequence for each subgraph can be obtained, denoted as \(S_{t} = \left\{ {S_{0} ,S_{1} ,S_{2} \ldots ,S_{n} } \right\}\). To enhance the capacity to learn implicit temporal information in the cascade graph and minimize information loss during the process of learning temporal features, the CasSubTS model first employs a designed node attention mechanism to adaptively adjust node weights and aggregate node representations. Next, the temporal relationships in the information propagation process are modeled using the Bi-GRU, a variant of RNN.
The structure of the node attention mechanism is shown in Fig. 4. Specifically, it begins by employing a fully connected layer to obtain the adaptive weights for each node, followed by the normalization of these weights. To enhance the efficiency of node aggregation, the learned weights are then allocated to the corresponding node feature vectors. Ultimately, the aggregation of nodes is achieved by summing the feature vectors of all nodes and calculating their average.

Node attention mechanism.
The node attention mechanism automatically adjusts node weights based on their significance, directing the model to focus on features of nodes with higher weights. This provides a more precise and temporally informative data input for the subsequent Bi-GRU model, enhancing the Bi-GRU’s expressive power for temporal features from both micro and global perspectives. The computation is as follows:
where \({\text{W}}_{\text{v}}\) is the node weights learnt by the fully connected layer, and \({\text{X}}_{\text{v}}\) is the node feature vector.
To address the limitations of traditional RNNs in sequence learning, a Bi-GRU is employed to capture both forward and backward information in sequence data. Specifically, the node representations aggregated by the node attention mechanism are used as input of the Bi-GRU. These representations are processed sequentially through its forward and backward gating units, resulting in the final hidden output that encodes temporal information, as represented by the following formula:
where \(\overrightarrow{{h}_{p-1}}\) indicates the forward hidden state output vector at instant t−1, and \(\overleftarrow{{h}_{p-1}}\) indicates the inverse hidden state output vector at time t−1. GRU(∙) is the nonlinear transformation function, and \({x}_{p}\) is the current input.
Feature fusion layer
CasSubTS model incorporates a channel attention mechanism named Squeeze-and-Excitation Networks (SENet) to perform a weighted fusion of features, as illustrated in Fig. 5. The core idea of SENet is to interject Squeeze and Excitation operations between the layers of the neural network. The Squeeze operation employs global average pooling, effectively transforming each channel’s feature map into a scalar representation, capturing the global information of channel features. The Excitation operation, through a fully connected layer and an activation function, converts the global feature vector into a channel attention vector. This attention vector is then applied to the original feature map to enhance the feature responses of important channels.

Diagram of SENet structure.
SENet’s squeeze-excitation operation ensures that high-weight channels correspond to global trends (e.g., bursty retweets), while low-weight channels capture local interactions. Formally, the attention vector \(s\) satisfies:
where \({W}_{1},{W}_{2}\) project features into global–local subspaces.
SENet adaptively adjusts the importance of each channel, focusing the network on channel features with higher information content while reducing reliance on redundant and irrelevant features during feature fusion, thereby enhancing feature representation and model prediction performance. The computational process is as follows:
where \(\sigma\) is the Sigmoid function, MLP(\(\cdot\)) is a fully connected neural network, and \({\text{W}}_{0}\) and \({\text{W}}_{{1}}\) represent the MLP weights.
Prediction layer
The prediction layer employs a MLP as the predictor, where the feature representation \({h}_{e}\) fused by SENet is inputted to predict the final cascade increment, expressed by the formula:
The loss function applied to model training is defined as:
where \(L_{R}\) is the L2 regularization paradigm, N is the total number of information cascades, and \(\Delta R_{tp}\) indicates the genuine cascade increment and \(\Delta \overline{R}_{tp}\) denotes the predicted cascade increment.
Experiments
In this section, we initially present the experimental datasets, benchmark models, and experimental setup, followed by comparative and ablation studies to validate the performance of the CasSubTS model.
Datasets
The experiments are based on two large-scale social network dataset and a small-scale graph dataset, namely, the Weibo dataset31, the DBLP dataset32 and the Synthetic dataset33, both of which are publicly available. During the experiment, the training, validation, and test sets were divided in a ratio of 70%, 10%, and 20%, respectively. The relevant statistical information of the two datasets is presented in Table 1.
Weibo dataset
This dataset originates from Sina Weibo, China’s largest social media platform, encompassing all original microblogs posted on June 1, 2016, and their retweets within 24 h, totaling 119,313 entries. It includes desensitized user data, retweet paths, and timestamps. The observation window T is set to 1, 2, and 3 h for our experiments, and microblogs posted before 8 AM and after 6 PM are excluded based on the growth of information cascades.
DBLP dataset
This dataset originates from DBLP, a computer science bibliography website, including over 3 million nodes and over 8 million links. The cascade sequence here corresponds to a source paper and the subsequent papers that cite the source paper. The cascade graph corresponds to the co-citation relationship among papers in the cascade sequence. The cascades with the length fewer than 10 and the cascades if a paper does not get any new citation for 3 years are filtered out.
Synthetic dataset
This dataset is used to validate the transferability and adaptability of the CasSubTS model on graphs of varying sizes. It is a scale-free network constructed using the Barabasi-Albert model with 880 nodes and 1992 edges. Initial nodes are selected randomly, and information spread paths are simulated using the independent cascade and linear threshold models. In data processing, noise nodes with fewer than 10 cascades are removed, and the growth of information cascades at step 2 is predicted.
Evaluation metrics
The experiment adopts the commonly used metric MSLE for macro information cascade prediction tasks as the evaluation criterion. A smaller MSLE value indicates a more accurate prediction by the model. Specifically, the calculation of MSLE is as follows:
where \(\Delta R_{tp}\) represents the actual cascade increment and \(\Delta \overline{R}_{tp}\) denotes the predicted cascade increment, and N is the total number of information cascades.
Additionally, we conducted experiments on the Weibo 1-h dataset using more evaluation metrics to further validate the effectiveness of our model. Specifically, an R2 value closer to 1 indicates stronger model fitting ability, while a smaller MAPE value signifies a lower relative prediction error.
Experiments setting
The CasSubTS model is implemented based on PyTorch 2.0, the detailed parameters of each module in CasSubTS are shown in Table 2.
Baseline models
To evaluate the performance of the proposed model, a total of six classic and recent models in the field of information cascade prediction are selected as baseline methods.
Feature-linear
The input features of the model include the structural and temporal characteristics of the cascade graph, with predictions made using a linear regression model with L2 regularization.
Feature-deep
Its input features are the same as Feature-Linear, with predictions conducted using a two-layer fully connected neural network.
DeepCas
The first end-to-end model that applies deep learning techniques to cascade prediction problems27. It samples the graph by generating multiple paths through random walks and uses GRU combined with an attention mechanism to learn the representation of the cascade graph.
DeepHawkes
A classic model that combines deep learning with point processes34. This model obtains node sequences based on the paths of information diffusion and feeds the node vectors into a GRU to obtain sequence representations. After weighted and pooling operations, a neural network is used to obtain the prediction results. The contribution of these representation vectors to retweets is calculated through a Hawkes process considering user influence, self-excitation, and time decay.
CasCN
This model is based on Graph Convolutional Neural Networks (GCNNs)31. By leveraging timestamps, the cascade graph is decomposed into a series of subgraphs, yielding a sequence of subgraphs, each containing the structure and temporal information of the cascade. For this information, CasCN employs dynamic multi-directional graph convolution to encode the features of the subgraphs, followed by the use of Long Short-Term Memory (LSTM) to learn the temporal dependencies of the cascade.
CasSeqGCN
The model processes each subgraph independently using a Graph Convolutional Neural Network (GCNN)35, allowing parameter sharing across different subgraphs. It then employs LSTM to learn the temporal characteristics of the subgraph sequence and aggregates vectors based on a dynamic routing algorithm. Finally, an MLP is used as the predictor.
Experimental results
The comparative experimental results are presented in Tables 3 and 4. Compared to the best-performing baseline method, the CasSubTS model achieved MSLE improvements of approximately 3.4%, 3.7%, and 2.8% on the Weibo dataset for the 1-h, 2-h, and 3-h prediction tasks, respectively. On the DBLP dataset, CasSubTS achieved the best performance for the 2-year and 3-year prediction tasks, with MSLE improvements of about 17.9% and 5.0%, respectively. On the Synthetic dataset, the MSLE of the CasSubTS model improved by approximately 19.1%, 30.3%, and 9.6% for the 1-step, 2-step, and 3-step prediction tasks, respectively. As shown in Table 4, on the 1-h Weibo dataset, the CasSubTS model outperforms the previous baseline method across all metrics, with MSLE, R2, and MAPE improvements of 3.4%, 1.2%, and 4.8%, respectively. The results demonstrate that the CasSubTS model outperforms most other baseline methods, particularly on the Weibo and Synthetic datasets, highlighting its superior predictive performance.
Table 3 reveals that models based on manual feature engineering generally underperform compared to deep learning models. This may be attributed to the inability of manually constructed features to capture the underlying nonlinear relationships in cascade graphs and a lack of capacity to model features at various levels. Moreover, these models heavily rely on human prior knowledge, which can more significantly limit their generalization ability in large-scale cascade graph prediction tasks. Notably, although prediction models based on feature processes have a simpler structural design, their performance surpasses the Feature-Deep model when predicting a 1-h time window on the Weibo dataset. This indicates that in certain cases, high-quality feature engineering can still contribute to improving the predictive performance of models.
The DeepCas model learns node representations through random walks, but this approach may overlook key nodes or paths and suffer from sampling bias, leading to an imbalance in the node sequence, which affects predictive performance. The DeepHawkes model integrates deep learning with the Hawkes process, considering user influence, self-excitation, and time decay in information diffusion, but it performs poorly on the Synthetic dataset, possibly due to insufficient consideration of other relevant features.
CasCN samples subgraphs based on node activation states, creating cascade snapshots upon the activation of new nodes. This approach models temporal changes and refines prediction tasks but may overlook the global structural information of the cascade graph. The CasSeqGCN model combines temporal and structural information, enhancing predictive performance, but there is room for improvement in the design of node aggregation. The CasSubTS model, while employing a multi-head attention mechanism-based graph attention network and Bi-GRU to extract structural and temporal features, adopts a more effective node attention mechanism and feature fusion strategy, significantly improving predictive performance.
Ablation study
To investigate the effectiveness of each module in the CasSubTS and evaluate their contribution to the predictive accuracy, we conducted a series of ablation studies. The results of the ablation experiments and comparison graphs are shown in Table 5 and Fig. 6, with MSLE as the evaluation metric. Introductions to the models are as follows:

Comparison of ablation study results.
-
A1: The CasSubTS model eliminates the MH-GAT model, meaning that only temporal features are utilized to accomplish the prediction objective, and structural features are not considered.
-
A2: The Bi-GRU is not employed for learning temporal features, and predictions are made directly using structural features.
-
A3: The SENet for feature fusion is removed, and feature concatenation is used as a substitute.
-
A4: Removes the node attention mechanism module in CasSubTS.
The results in Table 5 and Fig. 6 indicate that, compared to other modules, the node attention mechanism contributes significantly to the performance of CasSubTS. This is likely because the node attention mechanism can more selectively allocate weights and aggregate operations on nodes within the cascade graph, enhancing the quality of node representations used in subsequent feature learning, and thereby improving the model’s performance.
After eliminating structural feature learning (i.e., the MH-GAT model), the performance of the CasSubTS model experienced a significant decline, thus fully validating the importance of structural features for cascaded macro prediction tasks. Additionally, the experiments demonstrate that temporal features are also indispensable for model prediction, jointly influencing the model’s performance with structural features. Lastly, regarding the channel attention mechanism and node attention mechanism in feature fusion, the ablation study results indicate that the node attention mechanism makes a greater contribution to the CasSubTS model. This may be attributed to the node attention mechanism’s enhanced ability to capture critical node information within the cascading graph, thereby enhancing the model’s overall predictive performance.
Discussion and future work
To address the issues of dynamic changes in node activation states, insufficient feature learning and feature fusion in information cascade prediction, this paper proposes the CasSubTS model. CasSubTS initially employs a time-step sampling strategy to partition subgraphs, capturing changes in node states and cascade structures. Subsequently, it utilizes GAT and a multi-head attention mechanism to learn structural features, enhancing node attention and training stability. The designed node attention mechanism combined with Bi-GRU, learns temporal features and captures temporal dependencies. Finally, a channel attention mechanism is adopted to improve feature utilization efficiency, achieving the fusion of temporal and structural features. Comparative experiments on three datasets of different scales demonstrate that the CasSubTS model excels baseline models in prediction performance, generalization, and transferability.
In future work, leveraging large language models could enhance the ability to learn from cascade graphs. The cascade graph learning methods proposed in this paper rely on explicit information as supervisory signals, such as node attributes and topological structures, which may lead to difficulties in handling noisy and sparse data. Large language models have already shown promise in various domains. Future research could focus on integrating large language models with cascade graph learning to better exploit the implicit information contained in nodes and edges, thus enhancing graph learning methods and potentially designing new frameworks for graph learning.
Data availability
The data sets used during the current study are available from the corresponding author on reasonable request.
References
Tan, C., Lee, L. & Pang, B. The effect of wording on message propagation: Topic-and author-controlled natural experiments on twitter. arXiv preprint arXiv:1405.1438 (2014).
Sun, X., Zhou, J., Liu, L. & Wei, W. Explicit time embedding based cascade attention network for information popularity prediction. Inf. Process. Manag. 60, 103278 (2023).
Islam, M. R., Muthiah, S., Adhikari, B., Prakash, B. A. & Ramakrishnan, N. Deepdiffuse: Predicting the ’who’ and ’when’ in cascades. In 2018 IEEE international conference on data mining (ICDM), 1055–1060 (IEEE, 2018).
Wu, Q., Gao, Y., Gao, X., Weng, P. & Chen, G. Dual sequential prediction models linking sequential recommendation and information dissemination. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery and data mining, 447–457 (2019).
Sankar, A., Zhang, X., Krishnan, A. & Han, J. Inf-vae: A variational autoencoder framework to integrate homophily and influence in diffusion prediction. In Proceedings of the 13th international conference on web search and data mining, 510–518 (2020).
Van Canneyt, S., Leroux, P., Dhoedt, B. & Demeester, T. Modeling and predicting the popularity of online news based on temporal and content-related features. Multimed. Tools Appl. 77, 1409–1436 (2018).
Kobayashi, R. & Lambiotte, R. Tideh: Time-dependent hawkes process for predicting retweet dynamics. In Proceedings of the international AAAI conference on web and social media, 10, 191–200 (2016).
Cao, Q., Shen, H., Gao, J., Wei, B. & Cheng, X. Popularity prediction on social platforms with coupled graph neural networks. In Proceedings of the 13th international conference on web search and data mining, 70–78 (2020).
Xu, X., Zhou, F., Zhang, K., Liu, S. & Trajcevski, G. Casflow: Exploring hierarchical structures and propagation uncertainty for cascade prediction. IEEE Trans. Knowl. Data Eng. 35, 3484–3499 (2021).
Sheikhpour, R., Berahmand, K., Mohammadi, M. & Khosravi, H. Sparse feature selection using hypergraph laplacian-based semi-supervised discriminant analysis. Pattern Recognit. 157, 110882 (2025).
Berahmand, K., Bahadori, S., Abadeh, M. N., Li, Y. & Xu, Y. Sdac-da: Semi-supervised deep attributed clustering using dual autoencoder. IEEE Trans. Knowl. Data Eng. (2024).
Alrajebah, N., Tiropanis, T. & Carr, L. Cascades on online social networks: A chronological account. In Internet Science: 4th International Conference, INSCI 2017, Thessaloniki, Greece, November 22–24, 2017, Proceedings 4, 393–411 (Springer, 2017).
Bao, P., Shen, H.-W., Huang, J. & Cheng, X.-Q. Popularity prediction in microblogging network: a case study on sina weibo. In Proceedings of the 22nd international conference on world wide web, 177–178 (2013).
Ugale, S. N., Sherekar, S. S. & Thakare, V. M. A popularity prediction model for detection of the trustable content over social media network by using feature selection. Int. J. Creat. Res. Thoughts 9, 12–18 (2021).
Kang, P. et al. Catboost-based framework with additional user information for social media popularity prediction. In Proceedings of the 27th ACM international conference on multimedia, 2677–2681 (2019).
Gao, X. et al. Taxonomy and evaluation for microblog popularity prediction. ACM Trans. Knowl. Discov. from Data (TKDD) 13, 1–40 (2019).
Zhou, F., Xu, X., Trajcevski, G. & Zhang, K. A survey of information cascade analysis: Models, predictions, and recent advances. ACM Comput. Surv. (CSUR) 54, 1–36 (2021).
Weng, L., Menczer, F. & Ahn, Y.-Y. Predicting successful memes using network and community structure. In Proceedings of the international AAAI conference on web and social media, vol. 8, 535–544 (2014).
Arora, A. et al. A novel multimodal online news popularity prediction model based on ensemble learning. Expert. Syst. 40, e13336 (2023).
Suh, B., Hong, L., Pirolli, P. & Chi, E. H. Want to be retweeted? Large scale analytics on factors impacting retweet in twitter network. In 2010 IEEE second international conference on social computing, 177–184 (IEEE, 2010).
Lee, K., Mahmud, J., Chen, J., Zhou, M. & Nichols, J. Who will retweet this? detecting strangers from twitter to retweet information. ACM Trans. Intell. Syst. Technol. 6, 1–25 (2015).
Saberi-Movahed, F., Berahman, K., Sheikhpour, R., Li, Y. & Pan, S. Nonnegative matrix factorization in dimensionality reduction: A survey. arXiv preprint arXiv:2405.03615 (2024).
Lin, S., Kong, X. & Yu, P. S. Predicting trends in social networks via dynamic activeness model. In Proceedings of the 22nd ACM international conference on information & knowledge management, 1661–1666 (2013).
Shen, H., Wang, D., Song, C. & Barabási, A.-L. Modeling and predicting popularity dynamics via reinforced poisson processes. In Proceedings of the AAAI conference on artificial intelligence, vol. 28 (2014).
Cao, Q., Shen, H., Cen, K., Ouyang, W. & Cheng, X. Deephawkes: Bridging the gap between prediction and understanding of information cascades. In Proceedings of the 2017 ACM on conference on information and knowledge management, 1149–1158 (2017).
Li, C.-T., Chen, H.-Y. & Zhang, Y. On exploring feature representation learning of items to forecast their rise and fall in social media. J. Intell. Inf. Syst. 56, 409–433 (2021).
Li, C., Ma, J., Guo, X. & Mei, Q. Deepcas. In Proceedings of the 26th international conference on world wide web (international world wide web conferences steering committee, 2017).
Chen, X. et al. Information diffusion prediction via recurrent cascades convolution. In 2019 IEEE 35th international conference on data engineering (ICDE), 770–781 (IEEE, 2019).
Liao, D. et al. Popularity prediction on online articles with deep fusion of temporal process and content features. In Proceedings of the AAAI conference on artificial intelligence, vol. 33, 200–207 (2019).
Wu, Y. et al. Content popularity prediction in fog radio access networks: A federated learning based approach. In ICC 2020–2020 IEEE international conference on communications (ICC), 1–6 (IEEE, 2020).
Wang, J., Zheng, V. W., Liu, Z. & Chang, K. C.-C. Topological recurrent neural network for diffusion prediction. In 2017 IEEE international conference on data mining (ICDM), 475–484 (IEEE, 2017).
DBLP: Computer Science Bibliography. https://dblp.org/. Accessed on March 2022 (2022).
Barabási, A.-L. & Albert, R. Emergence of scaling in random networks. Science 286, 509–512 (1999).
Wang, S., Zhou, L. & Kong, B. Information cascade prediction based on t-deephawkes model. In IOP Conference Series: Materials Science and Engineering, 715, 012042 (IOP Publishing, 2020).
Wang, Y., Wang, X., Ran, Y., Michalski, R. & Jia, T. Casseqgcn: Combining network structure and temporal sequence to predict information cascades. Expert. Syst. Appl. 206, 117693 (2022).
Acknowledgements
This work is supported by the National Natural Science Foundation of China (Grant No. 62172287, 62102273).
Author information
Authors and Affiliations
Contributions
J.W. and J.L. conceived the project, analyzed part of the data and wrote the initial draft of the paper. C.L. analyzed part of the data and wrote the manuscript. Y.P. provided detailed guidance on writing the manuscript, X.L. made meticulous revisions and polish to the manuscript. All authors reviewed and edited the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, J., Li, J., Liu, C. et al. Fusing temporal and structural information via subgraph sampling and multi-head attention for information cascade prediction. Sci Rep 15, 6801 (2025). https://doi.org/10.1038/s41598-025-91752-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-91752-z
