
Abstract
The rapid proliferation of internet data, particularly through social media, has amplified the need for effective sentiment analysis, including the complex task of sarcasm detection. This paper presents a novel multi-modal sarcasm detection model leveraging cue learning techniques to address the challenges posed by data scarcity, especially in low-resource languages. The proposed model builds upon the CLIP architecture, integrating text and image modalities to co-learn sarcasm cues. The methodology encompasses discrete prompt generation, learnable continuous vectors, and multi-modal fusion to enhance detection accuracy. The multi-modal fusion process demonstrates a symmetric integration of text and image data, leading to improved performance. Experimental results on the Twitter Multi-modal Sarcasm Detection Dataset (MSD) demonstrate significant performance improvements over traditional models, highlighting the model’s robustness and adaptability in small-sample scenarios. This research contributes a practical solution for nuanced sentiment analysis, paving the way for advanced applications in public opinion monitoring and AI-driven decision-making processes.
Similar content being viewed by others

Introduction
The rapid development of the Internet has ushered in an era of information explosion, with social media platforms like Weibo, Douyin, and WeChat public accounts significantly enriching our entertainment lives and contributing vast amounts of data to the digital landscape. This surge in data, coupled with advancements in computer technology and hardware capabilities, has facilitated the transition of artificial intelligence (AI) technology from theoretical exploration to practical industrial applications. AI and big data are now deeply integrated into various facets of daily life, influencing everything from basic needs to complex decision-making processes. Extracting valuable insights from this massive data influx has become essential, highlighting the critical importance of effective data mining and utilization techniques.
Amidst the myriad of information available online, ensuring the security and integrity of network content has become a focus for cybersecurity practitioners. Public opinion detection technology, in particular, plays a crucial role by monitoring and predicting public comments and views on the Internet, enabling a quick grasp of public opinion dynamics on hot events. Sentiment analysis, a core component of public opinion detection, infers emotional tendencies from public comments, providing valuable insights for public opinion analysis. However, the complexity of satire-a literary and artistic form characterized by exaggeration, sarcasm, and humor-poses a significant challenge to sentiment analysis. Satirical content often disguises negative meanings behind seemingly positive expressions, leading to potential misjudgments in sentiment analysis and impacting the accuracy of public opinion assessments. This, in turn, can present risks for enterprises and governments.
Recognizing the need for accurate sarcasm detection, researchers have made strides in developing AI-based sarcasm detection technologies1. Early techniques focused on single sensory channels such as facial movements, voice, or text, overlooking the multidimensional nature of emotions and failing to leverage the combined benefits of multi-sensory data2. With the proliferation of social media networks and advancements in computing power, multimedia content on the Internet has expanded rapidly, offering diverse ways for individuals to express emotions. Consequently, integrating multi-modal data-including text, sound, image, and video-has become increasingly important for effective sarcasm recognition.
Despite progress in multi-modal sarcasm detection, challenges remain, particularly in effectively training models with limited samples, especially for languages such as Chinese3,4. Addressing these challenges, this paper focuses on the task of multi-modal sarcasm detection in small-sample scenarios. We propose leveraging cue learning methods and the powerful generalization capabilities of pre-trained models to develop a robust multi-modal sarcasm detection model. This model aims to provide a practical solution for accurately identifying ironic content under conditions of data scarcity, thereby enhancing the reliability of sentiment analysis and public opinion detection in diverse linguistic and cultural contexts.
The symmetry in our approach is evident through the balanced integration of multiple modalities-text and image-each contributing equally to the detection process. This symmetric co-learning of sarcasm cues enhances the model’s performance, ensuring that neither modality dominates, and both are harmoniously utilized to achieve accurate sarcasm detection. The main contributions of this work are summarized as follows:
-
We introduce a multi-modal sarcasm detection model that combines text and image modalities within the CLIP architecture to improve accuracy in detecting sarcasm.
-
We propose a discrete prompt generation method to expand sarcastic and non-sarcastic prompt lexicons, addressing data scarcity in low-resource languages.
-
Experiments show significant performance improvements, validating the model’s effectiveness in low-resource scenarios and across diverse linguistic and cultural contexts.
Related work
This section will introduce the development of uni-modal and multi-modal sarcasm detection respectively, and finally introduce the research content of this paper by analyzing the current situation of sarcasm detection data set.
Single-modal sarcasm detection
For the study of uni-modal sarcasm detection, researchers mainly proposed various methods to detect text sarcasm on the text sarcasm detection dataset. Earlier methods extracted elaborate discrete features5,6,7 from text, including n-gram (n-gram) overlaps, punctuation of words, part-of-speech labels, emotions, emoticons, etc.
With the development of artificial intelligence technology, researchers have begun to use deep learning techniques to obtain more precise semantics in satirical texts. A deep learning model8 was first proposed, which employs a CNN to model the relationship between adjacent semantics. Then, multi-layer RNN is used to model the temporal information of the text, in addition to modeling the historical behavior of the author and the audience and other contextual features as supplements.
In addition, Artificially designed author, audience, and response characteristics are employed to enhance sarcasm detection1. After obtaining the embeddings of the text, contextual features were also derived through the design of a series of rules, and multiple features were connected using the Bidirectional Gated Recurrent Unit (Bi-GRU)9. This extra feature improves the performance compared to the model that relies entirely on text embedding. User information was focused on learning, generating trainable user embeddings, and employing CNN to model user characteristics, thereby enhancing the model’s sarcasm detection ability10.
Further, the previous idea of classifying data by various features was expanded upon through the modeling of syntactic and emotional features in addition to text embedding. These various features were then integrated into a Long Short Term Memory (LSTM) for multi-task learning11,12. In terms of a more diversified model design, a new multidimensional attention mechanism was proposed to explicitly model inconsistencies in text content2. Two bi-directional LSTMs were used to model text features with different granularity of words and characters, thereby further revealing the complex syntactic and semantic relationships in satirical detection texts13.
Although unimodal methods have contributed to some degree of improvement in sarcasm detection, they are inherently limited by the reliance on a single modality. Sarcasm, however, is a highly nuanced and multidimensional phenomenon, often encompassing various elements such as linguistic cues, sentiment, contextual information, and non-verbal cues, which cannot be fully captured by a single modality alone14. This complexity makes it difficult for unimodal approaches to accurately identify sarcasm in all its forms, as they may overlook crucial cues present in other modalities. Consequently, there has been a growing shift in the research community towards multimodal sarcasm detection. By integrating data from multiple modalities, including text, images, and audio, multimodal approaches offer the potential to improve detection accuracy and robustness, as they enable a more holistic understanding of the sarcasm expression and its contextual subtleties15,16.
Multi-modal sarcasm detection
Since researchers found that multi-modal data can effectively enhance the accuracy of sarcasm detection, various methods of multi-modal sarcasm detection have been proposed. In 2019, a Twitter-based Multi-modal Sarcasm Detection Dataset (MSD) was first created, and a Hierarchical Fusion Model (HFN) was proposed to address this issue17. The model initially obtains image features and image attribute features. Subsequently, attribute features and a bidirectional LSTM network are used to extract text features. Finally, the features of the three modes are reconstructed and fused into a feature vector for prediction.
Subsequently, it was found that modeling the inconsistency between multi-modal data is key to the task of multi-modal ironic detection, leading to the proposal of the Attribute BERT (Attr-BERT) model18. Intermodal attention, designed to capture inconsistencies between modes, applies the common attention mechanism to model contradictions in text. The results indicate that this model can effectively improve the performance of multi-modal sarcasm detection. Decomposition and relational networks were built to model cross-modal contrast and semantic association19. The decomposition network represented the commonality and difference between images and texts, while the relational network modeled the semantic association in a cross-modal context.
Multi-modal ironic detection was studied from a new perspective, leading to the proposal of in-modal and cross-modal graphs (InCrossMGS)20. By constructing heterogeneous internal modal and cross-modal graphs for each multi-modal example to achieve specific modal and cross-modal feature learning and exploring an interactive graph convolution network structure, we jointly and interactively learn the inconsistencies between internal modal graphs and cross-modal graphs to identify important clues in ironic detection. The experimental results show that the model achieves the most advanced performance in multi-modal sarcasm detection.
A deep learning model using a hierarchical fusion method was proposed to address the problem of missing emotion knowledge and sparse feature distribution across different modes in multi-modal ironic detection4. This method introduced Sentiment Analysis Network21. SenticNet (SenticNet) marks the emotion polarity of the input and simulates the inter-modal dependence by using cross-modal interaction. Experimental results show that the model can significantly improve the performance of sarcasm detection by effectively utilizing multi-modal information. Further, A lightweight multi-perspective interaction model based on deep learning was proposed to enrich the semantic information of image and text modes by integrating visual common sense knowledge, targeting the issue of a large number of parameters in ironic detection models on the Internet of Things22. The experimental results show that the performance of the model is the same as that of the multi-modal baseline in the multi-modal ironic detection task with fewer parameters.
Farabi et al.23 provides a comprehensive review of the field, summarizing the latest advancements, technical challenges, and future research directions, thus offering valuable insights for researchers. This work not only consolidates existing achievements but also outlines key directions for future studies. In the domain of deep learning and multimodal data processing, Lu et al.24 introduces a novel approach by constructing a combination network that captures the incongruity between facts and sentiment, effectively addressing the complexity of sarcasm through deep fusion of text and image information. Li et al.25 further enhances sarcasm detection by utilizing inter-modality inconsistency and leveraging attention mechanisms to improve context sensitivity, resulting in higher detection accuracy. This method emphasizes the critical role of context in identifying sarcasm in multimodal data. In the area of knowledge-enhanced detection, Yue et al.26 integrates knowledge graphs with neural networks, enriching semantic understanding and improving the model’s ability to detect subtle sarcasm. Similarly, Ren et al.27 applies knowledge augmentation to neural networks, significantly enhancing sarcasm recognition by incorporating domain-specific knowledge. Finally, Kei et al.28 focuses on social media sarcasm detection using attention-based neural networks, providing detailed analysis of sarcastic language structure and offering a powerful tool for automatic detection. Together, these studies highlight key developments in multimodal sarcasm detection and propose new methods using advanced machine learning techniques, knowledge fusion, and attention mechanisms, paving the way for more accurate and robust sarcasm recognition systems.
Limitations of existing methods
Limitations of single-modal solutions
For unimodal solutions such as CNN, RNN, and Bi-GRU, inherent limitations emerge when handling sarcasm detection tasks. CNN primarily focuses on local feature extraction, which limits its ability to capture the global semantics and contextual information crucial for identifying sarcasm in text. Although RNNs can process sequential data and capture temporal dependencies, they are prone to issues such as vanishing or exploding gradients, which restrict their capacity to learn long-term dependencies. Bi-GRU, by combining both forward and backward information, enhances contextual understanding; however, these models remain constrained by unimodal data, failing to leverage complementary information from other modalities such as images or audio. This is particularly problematic in sarcasm detection, where cross-modal interactions are often central to identifying sarcastic content.
Limitations of multi-modal solutions
Regarding multimodal solutions, while they offer a more comprehensive perspective by integrating data from multiple modalities, they also face several challenges. One significant issue is the alignment of multimodal data, as discrepancies may exist in time or space between different modalities, complicating the model’s ability to effectively process them. Additionally, multimodal models tend to have higher computational complexity, as they must process and fuse data from multiple sources, increasing both the training and computational costs. The interpretability of multimodal models is also a concern, as their decision-making processes often lack transparency, making it difficult to understand the underlying mechanisms driving their predictions. Moreover, the scarcity of high-quality multimodal data and the high cost of manual annotation pose significant barriers to the widespread development and application of such models.
Datasets
As shown in Table 1, these data sets are usually derived from different social media and online platforms, such as Amazon, Twitter, Reddit, etc., on the one hand, because the users of these platforms tend to express their emotions using sarcasm, and on the other hand, there are usually some hashtags in these platforms to facilitate the collection of data and provide rich examples for sarcasm detection. However, research has faced some limitations. First of all, the current data set is mainly in English and lacks samples from other languages, and the use and understanding of sarcasm in different cultural backgrounds may be different, so the direct translation method cannot be well applied to other language environments, which limits the generalization ability of the model and the application effect in other languages such as Chinese. Second, existing datasets focus on textual information, while satirical expressions tend to rely on more modal information. To sum up, the existing research work mainly focuses on models designed for data of more than 1,000 orders. Due to the high complexity of the models, a large amount of data is often needed to effectively learn, and good results cannot be trained under the condition of data limitation. Therefore, it is necessary to study methods that can effectively learn multi-modal ironic detection tasks under a small number of samples. Secondly, sarcasm detection is closely related to the task of emotion analysis, but most of the previous work did not involve the application of emotion knowledge. Although Liu et al.4 introduced emotion knowledge into their model, the actual effect was not optimal due to the limitation of the emotion analysis performance of the external emotion analysis model. Therefore, it is necessary to study how to use emotion data directly without relying on external models to assist sarcasm detection.
Table 2 summarize single - and multimodal methods to the related work section to more clearly show the different methods, the data sets used, and their limitations.
Model
Overview

Cue learning method model based on CLIP model.
Aiming at the problem of limited sarcasm detection data in some languages, this paper designs a prompt learning method based on a multi-modal pre-training model for the unique input format of multi-modal sarcasm detection data. This method can effectively mine sarcasm knowledge in the multi-modal pre-training model by co-learning cues from image and text data. Therefore, a model with high sarcasm detection performance can be trained with effective data.
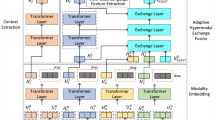
The whole model is divided into four main parts: text prompt vector generation, image prompt vector generation, sarcasm and non-ironic prompt vector generation, and multi-modal prompt vector fusion. From the perspective of model reasoning, firstly, a discrete prompt generation module is used to construct the input of sarcasm and non-satirical prompt vectors, and then the prompt vector generation method is used to generate graphics, sarcasm, and non-satirical prompt vector methods. Finally, the multi-modal prompt vector fusion module is used to fuse the graphic modes to generate multi-modal prompt vectors37. The sarcasm probability is calculated together with the sarcasm and non-irony cue vectors. The model diagram of the prompt learning method based on the CLIP (Contrastive Language-Image Pre-training) model is shown in Fig. 1. Typically, the CLIP model serves as the backbone for multi-modal feature extraction and alignment. By leveraging a shared embedding space for text and images, it facilitates the effective fusion of sarcasm-related features from both modalities.
Generation of discrete prompts
In general, the construction of sarcasm and non-satirical prompt vectors usually directly input “This is a satirical tweet” and “This is not a satirical tweet” into the CLIP pre-training model to get the sarcasm and non-satirical prompt vectors38, but this method over-relies on the sensitivity of the pre-training model to the input text, resulting in the model performance is often not optimal. To improve the model effect, more sophisticated methods need to be explored. Therefore, this paper proposes a discrete prompt generation method to make the sarcasm and non-ironic input texts more robust. Specifically, three sets are first created to construct ironic and non-ironic discrete prompts, including ironic discrete prompt templates, non-ironic discrete prompt templates, and ironic word sets. The collection of ironic words contains some synonyms of the word sarcasm, such as ridicule, mockery, teasing, etc. These words can show their characteristics of sarcasm in different contexts39,40. Finally, a large number of satirical discrete inputs and non-satirical discrete inputs can be generated by inputting any words in the satirical set into the satirical discrete prompt template and the non-satirical discrete template. The schematic diagram of the generation method is shown in Fig. 2.

Discrete prompt generation method.
Assume that the ironic discrete prompt template, non-ironic discrete template, and ironic word set are named sets A, B, and C, and the ironic discrete input and non-ironic discrete input sets D and E, respectively, and \(|A| = n_A, |B| = n_B, |C| = n_C\). It can be calculated as \(|D| = n_A \cdot n_C, |E| = n_B \cdot n_C\).
According to Fig. 2, although the discrete prompt generation method can generate enough input statements, not every statement has a positive effect on sarcasm detection, and some statements may contain irrelevant or misleading information, which affects the judgment accuracy of the model. How to select good enough prompt statements is a problem faced by prompt learning at present. Therefore, this paper proposes a prompt filtering strategy, which can select the appropriate prompt to a certain extent through the posterior distribution of the prompt in the data. The specific operation is shown in Fig. 3.

Discrete prompt screening method.
Suppose that the ironic discrete input set D contains discrete words \(\{D_1, D_2, \ldots \}\), and the non-ironic discrete input set E contains discrete words \(\{E_1, E_2, \ldots \}\). Initially, the discrete language is input into the CLIP text encoder to generate discrete language features \(\{\text {Emb}_{D_1}, \text {Emb}_{D_2}, \ldots \}\). Then, the data in the training set to be trained are divided into four groups, including:
-
The satirical picture set \(\{\text {Img}_{s_1}, \text {Img}_{s_2}, \ldots \}\),
-
Non-satirical pictures \(\{\text {Img}_{n_1}, \text {Img}_{n_2}, \ldots \}\),
-
Satirical text set \(\{\text {Text}_{s_1}, \text {Text}_{s_2}, \ldots \}\),
-
Set of non-satirical texts \(\{\text {Text}_{n_1}, \text {Text}_{n_2}, \ldots \}\).
Input the two groups of picture sets into the image encoder to obtain image features, and input the two groups of text sets into the text encoder to obtain text features. Specific calculations are shown in the formula.
After obtaining these six features, in order to accurately evaluate the applicability of discrete words, it is necessary to set specific score calculation rules to measure the quality of discrete words, so as to screen out the appropriate discrete prompt subset from the candidate discrete words.
This rule implies the assumption that the more similar the sarcasm discrete language features are to the sarcasm data features and the less similar they are to the non-ironic data features, the more appropriate the sarcasm discrete language will be, while the less similar the non-ironic discrete language features are to the sarcasm data features and the more similar they are to the non-ironic data features, the more appropriate the non-ironic discrete language will be. Among them, the F function is used to measure the similarity of two features, which a variety of functions in practical applications, such as Euclidean distance, cosine similarity, and information entropy can measure. Consider two sets of inputs \(A = \{a_0, a_1, \ldots , a_n\}\) and \(B = \{b_0, b_1, \ldots , b_n\}\). The following metrics are calculated:
-
Euclidean Distance \(d(A, B)\):
$$\begin{aligned} d(A, B) = \sqrt{\sum _{i=0}^n (a_i - b_i)^2} \end{aligned}$$(5) -
Cosine Similarity \(\text {sim}(A, B)\):
$$\begin{aligned} \text {sim}(A, B) = \frac{\sum _{i=0}^n a_i b_i}{\sqrt{\sum _{i=0}^n a_i^2} \sqrt{\sum _{i=0}^n b_i^2}} \end{aligned}$$(6) -
Pearson Correlation Coefficient \(r(A, B)\):
$$\begin{aligned} r(A, B) = \frac{n \sum a_i b_i - \sum a_i \sum b_i}{\sqrt{(n \sum a_i^2 - (\sum a_i)^2)(n \sum b_i^2 - (\sum b_i)^2)}} \end{aligned}$$(7)
The scores of ironic and non-ironic discrete words can be obtained by selecting a suitable scoring function. Let \(\text {Score}_D = \{\text {Score}_{D_1}, \text {Score}_{D_2}, \ldots \}\) and \(\text {Score}_E = \{\text {Score}_{E_1}, \text {Score}_{E_2}, \ldots \}\). By sorting these sets, the top best sarcastic and non-ironic discrete words can be selected:
This ranking and selection process ensures that the model accurately extracts the most representative sarcasm and non-ironic expressions from a large number of candidates. The effectiveness of this method depends on accurate preliminary scores and a reasonable ranking mechanism, providing a certain level of interpretability to facilitate researchers’ exploration.
Finally, the selected discrete words are encoded by the word vector of the text encoder to obtain their word embedding vectors. An average pooling operation is then carried out on these word embedding vectors to combine the characteristics of different discrete words, thereby obtaining more robust sarcasm and non-ironic word vectors \(W_s\) and \(W_n\):
In the subsequent training, appropriate cue learning methods can be used to generate sarcasm and non-ironic cue vectors that are easy to train for the model by using sarcasm and non-ironic word vectors \(W_s\) and \(W_n\).
Prompt vector generation
Although discrete word vectors possess inherent capabilities for sarcasm detection, their performance in prediction tasks is limited due to their static nature and lack of training adaptability. To address this, we introduce learnable continuous vectors into the representation. Specifically, we prepend a learnable continuous vector \(\textbf{P} = \{ p_i \in \mathbb {R}^d \}\) to both the sarcastic and non-ironic word vectors to form the prompted inputs \(W_s^\prime\) and \(W_n^\prime\) as shown in Eq. (12):
These enhanced vectors are then fed into the multi-layer Transformer architecture of the CLIP text encoder. Each layer \(L_i\) transforms its input to obtain a richer vector representation, as delineated in Eq. (13):
The final output of this series of transformations, specifically from the last layer( K-th layer ) for both sarcastic and non-ironic inputs, is projected into a common latent semantic space via the text mapping layer \(\text {TextProj}\), resulting in the vectors \(Z_s\) and \(Z_n\):
Unlike the sarcasm and non-satirical prompt vectors, text prompt vectors are generated without discrete language integration and screening. Instead, learnable continuous vectors \(\textbf{P}_i^t\) are generated at each layer of the text encoder and concatenated with the output of the respective layer. The operation at the i-th layer layer is described in Eq. (15):
The final text prompt vector \(Z_t\) is computed as:
Unlike text prompt vectors, image prompt vectors are constructed using a collaborative multi-modal prompt method. This approach allows for the optimization of both text and image prompt vectors simultaneously by sharing some parameters between them. Specifically, the image prompt vector \(\textbf{P}_i^I\) is encoded using the text prompt vector \(\textbf{P}_i^t\) through a multi-layer perceptron (MLP), as outlined in Eq. (17):
The encoded image prompt vectors are further processed through a series of transformation layers. Each layer \(L_i^I\) in the image encoder updates the vector representations by incorporating both the prompt vector and the previous layer’s output, as shown in Eq. (18):
The final output from the last layer of this transformation process is projected into a common semantic space through the image projection layer \(\text {IMGProj}\), resulting in the final image prompt vector \(\textbf{Z}_I\):
Sarcasm probability generation
The pre-training task of the CLIP model involves comparative learning, aiming to converge the representations of positive samples while diverging those of negative samples into a unified representation space41. While in simple image classification tasks, the similarity between images and category-specific texts can be directly computed, the multi-modal sarcasm detection task involves more complexity due to dual text modes that may both express sarcasm. Therefore, direct similarity calculations between these text inputs are not sufficient for classification.
To address this, multi-modal prompt vectors are constructed specifically for the sarcasm detection task. These vectors combine the contributions of both text and image modalities. The multi-modal prompt vector \(Z_M\) is generated through two projection functions \(F_t(\cdot )\) and \(F_I(\cdot )\), as shown in Equation (3.12):
Finally, the sarcasm probability \(\hat{y}\) is computed using the cosine similarity function \(\text {sim}(\cdot )\) among the multi-modal prompt vector \(Z_M\) and the sarcastic and non-ironic prompt vectors \(Z_s\) and \(Z_n\), respectively. This computation is encapsulated in Equation (3.13):
Experiment
Setup
Dataset
This paper conducted the experiment using the Twitter Multi-modal sarcasm detection Dataset (MSD), which was published by Cai17 in 2019. The data set first collects English tweets containing a picture and some special hashtags (e.g., #sarcasm, etc.) from Twitter as an example of sarcasm, and English tweets with pictures, takes the data without sarcasm related hashtags as non-sarcasm data, and finally does some data cleaning. Tweets containing sarcasm, sarcastic, irony and ironic in the text and tweets containing urls were dropped to avoid introducing additional information. It also dropped words that often appeared alongside sarcasm tweets, such as jokes, humor and exgag. All data is divided into training set, verification set and test set, the ratio is 80% : 10% : 10%. Finally, in order to evaluate the model more accurately, Cai et al.17 manually checked the validation set and the test set to ensure the accuracy of the labels, and some statistics of the MSD dataset are shown in Table 3.
To simulate a data shortage scenario, this paper outlines the experimental conditions specifically designed for small sample classification. From the original dataset, a specified number \(k\) of sarcastic and non-ironic samples are randomly selected from the training and validation sets. These samples are then used to construct a balanced training set \(|D_{\text {train}}|\) and a validation set \(|D_{\text {dev}}|\), ensuring that \(|D_{\text {train}}| = |D_{\text {dev}}|\). This approach aims to mimic a realistic small-sample learning environment.
Additionally, the original test set is utilized as the test set \(|D_{\text {test}}|\). Thus, the specific experimental configuration maintains equal sizes for the training and validation sets, represented as \(|D_{\text {test}}|, |D_{\text {train}}| = |D_{\text {dev}}|\).
This setup ensures that the challenges of small-sample learning are realistically represented, providing a robust framework for assessing the model’s performance under constrained data conditions. In addition, All experiments were conducted on a server with an NVIDIA Tesla V100 GPU (32GB), 128GB RAM, and an Intel Xeon processor.
To evaluate the models, Accuracy and F1-Score were selected as the primary metrics. Accuracy provides a high-level measure of the model’s ability to correctly classify samples, making it suitable for comparing overall performance across different models. In contrast, F1-Score balances precision and recall, offering deeper insights into the model’s effectiveness in detecting sarcasm, especially when class distributions are slightly imbalanced. The combination of these two metrics ensures a comprehensive assessment of the model’s overall performance and its ability to handle the nuances of sarcasm detection.
Parameter
In terms of the selection of the pre-training model, this paper uses the openai/clip-vit-large-patch14 (hereinafter referred to as CLIP-large) model downloaded from huggingface official website as the pre-training model. During training, CLIP-large parameters are frozen and only the parameters of the cue vector are trained. The parameters of the model are shown in Table 4.
In the process of prompt learning training, various kinds of hyperparameter settings are shown in Table 5.
Baselines
Since the scheme in this paper is mainly aimed at multi-modal sarcasm detection tasks in small-sample scenarios, it is necessary to compare model performance against multiple baselines on MSD datasets. In the selection of baseline, in addition to several classic multi-modal sarcasm detection models, a method based on CLIP model and a number of small sample classification methods are also added for testing, including:
P-Tuning v242: A prompt learning method that adds and optimizes continuous prompt information in each layer of the pre-trained model to improve the model’s adaptability and performance for specific tasks, and is more flexible and efficient than the traditional method of injecting prompts only in the input layer. During reproduction, CLIP-large text encoder is used for training.
BBT v243: A prompt learning method designed to optimize continuous prompts before input text through derivatively-free optimization methods, thereby improving the performance of large pre-trained language models in black box scenarios where internal parameters of the model are not accessible. During reproduction, CLIP-large text encoder is used for training.
BERT44: a text classification method, a deep learning model based on the Transformer architecture, specifically for natural language processing tasks. During reproduction, CLIP-large text encoder is used for training.
ViT45: An image classification method, a deep learning model based on the Transformer architecture, specifically for computer vision tasks. It splits images into patches of fixed size and transforms them into linear embedding vectors that capture global context information and long-term dependencies through self-attention mechanisms. During reproduction, CLIP-large image encoder is used for training.
HFN17: A multi-modal sarcasm detection algorithm that uses GloVe46 and ResNet47 as feature extractors to fuse multi-modal features using a hierarchical fusion network with a single attention layer. During reproduction, the GloVe and ResNet feature extractors were converted into CLIP-large graphic encoders for training.
Attr-BERT18, a multi-modal sarcasm detection algorithm, proposed a method to capture modal inconsistencies in multi-modal sarcasm detection using a collaborative attention mechanism to improve model performance. On reproduction, replace the encoder from ResNet and BERT with a CLIP-large encoder.
InCrossMGS20: a multi-modal sarcasm detection algorithm, which constructs text modal graph and image modal graph respectively based on graphic features, and then adopts a cross-modal interaction graph to integrate these two features. On reproduction, replace the encoder from ResNet and BERT with a CLIP-large encoder.
SAHFN-BERT4: A multi-modal sarcasm detection algorithm that extracts emotion data from each mode and uses cross-modal transformations to describe modal inconsistencies. In addition, an emotion-sensing image-text contrast loss mechanism is introduced to better synchronize the semantics of images and text. In reproduction, the encoders were replaced from DenseNet48 and RoBERT with CLIP-large encoders.
MVK22: a multi-modal sarcasm detection algorithm, proposes a lightweight multi-modal interaction model based on deep learning, which integrates visual common sense knowledge to enrich the modal representation of images and text in the sarcasm detection model. During reproduction, the encoder is replaced by DenseNet and BERT to CLIP-large encoder.
CLIP-MLP49: a multi-modal classification method based on CLIP model, which extracts graphic features through CLIP-large model, splices the graphic features, and then gets the prediction result after multi-layer perceptron classification.
Overall performance
We implemented the baseline models alongside our proposed model, and the experimental results are presented in Table 6. The baseline models were trained using the Adam optimizer, except for BBT v2, which does not require optimization. The training setup included a batch size of 16, 100 training epochs, and a learning rate selected from 2e-3, 2e-4, 2e-5 based on validation performance. The comparison experiments were conducted under a 16-shot classification scenario (16 training samples), and the reported results are the mean and standard deviation of performance across five different random seeds.
Here, “seeds” refer to the random seeds used to initialize the random number generator during the training process. By varying the seeds, the experiments account for different sources of randomness, such as weight initialization, data shuffling, and other stochastic processes. This ensures a more robust evaluation by minimizing the impact of any specific random initialization on the results.
The results in Table 6 show that our proposed model achieves superior performance in the 16-shot scenario, with an accuracy of 72.22% and an F1-score of 72.57%. Compared to the sub-optimal CLIP-MLP model, our method achieves a 2.6% improvement in accuracy and a 3.1% improvement in F1-score. These results highlight the effectiveness of prompt-based learning in low-data scenarios. From the comparisons between P-Tuning v2, BBT v2, and BERT, it is evident that prompt learning significantly outperforms traditional fine-tuning approaches under small-sample conditions. In particular, models based on traditional fine-tuning exhibit higher performance variance across different seeds (with standard deviations exceeding 4), while prompt-learning-based methods consistently maintain lower deviations (mostly within 2.5). This observation aligns with findings in existing literature that prompt learning is more stable and reliable in limited data scenarios. In contrast, models with large numbers of parameters, such as SAHNF-BERT, tend to overfit in low-sample settings, resulting in poorer performance stability. This further underscores the advantages of our lightweight prompt-based framework in achieving robust performance while avoiding overfitting.
To evaluate the scalability of our proposed method, we extended the experiments to include 128-shot, 512-shot, 1024-shot, and full-data scenarios. The accuracy and F1-score results are shown in Figs. 4 and 5. As data volume increases, the performance of baseline models such as SAHNF-BERT and InCrossMGs improves significantly, eventually surpassing our model in the 512-shot scenario and beyond. This is expected, as these models have larger parameter capacities that allow them to better leverage larger datasets. However, under small-sample conditions (16-shot and 128-shot), our method consistently achieves the best performance, demonstrating its superior ability to generalize with limited data. This trend reflects the inherent characteristics of prompt learning, which excels in efficiently utilizing small datasets but faces limitations in scaling to larger ones due to fewer learnable parameters. Despite this, our model maintains competitive performance even in larger data settings, highlighting its flexibility and adaptability.

Performance acc value of each model under different data amounts.
We further conducted parameter sensitivity analysis to evaluate the impact of prompt length, discrete prompt filtering, and the number of discrete prompts on model performance. The F1-score results for different prompt lengths are shown in Fig. 6. The results indicate that prompt length plays a critical role in model performance. For sarcasm, text, and image inputs, the optimal prompt lengths align with the average lexeme lengths of the respective inputs after encoding: 11.8 for sarcasm, 19.3 for text, and 196 for image (due to a fixed embedding size of \(224 \times 224\) with a patch size of 16). Prompts that are too short fail to capture sufficient contextual information, while excessively long prompts lead to feature convergence and poor sample differentiation. Therefore, choosing an appropriate prompt length is crucial to optimizing the model’s ability to detect sarcasm effectively. In addition, the discrete prompt filtering method proposed in our scheme significantly improves model performance compared to using no filtering or no discrete prompts, as shown in Table 7. Cosine similarity achieves the best results, which is consistent with the CLIP model’s pretraining mechanism based on contrastive learning. This demonstrates that cosine similarity effectively measures the alignment between discrete prompts and sarcasm-related features, leading to better detection results.

F1-score value of each model under different data amounts.
Parameter sensitivity analysis
In addition, this paper also makes several parameter sensitivity analysis experiments on sarcasm, image and text prompt length, discrete prompt calculation, and the number of discrete prompts to show the superiority of this scheme in selecting parameters and methods. The model performance F1 values for different prompt length Settings are shown in Fig. 6.

Model performance F1 value under different prompt length settings.
It can be seen that the length of the prompt vector basically presents a trend from small to large, rising to a vertex and then decreasing. Due to the different lengths of sarcasm input, text input, and image input, the length of the prompt vector to achieve the best performance is also different. The average lexical length of sarcasm input after word vector encoding is 11.8. The average lexical length of text input after word vector encoding is 19.3. When the input resolution is 224*224 and the value of the image block is 16, the lexical length of image input after image embedding encoding is fixed at 196. Therefore, it can be concluded that inputs with longer lexeme lengths usually require longer prompt vector lengths so as to introduce enough prompt information to stimulate the model’s perception of irony, while inputs with relatively short lexeme lengths are not suitable for longer prompt lengths because the excessively long prompt length will lead to feature convergence after word vector encoding. The output after encoding by the multi-layer encoder will tend to be consistent, resulting in poor differentiation of different samples.
In addition, for the generation of sarcasm and non-ironic prompt vectors, this scheme will first use a discrete prompt generation method to generate enough discrete prompts, but the quality of discrete prompts is different, and not all of them have a positive effect on sarcasm detection. Therefore, this scheme proposes a discrete prompt filtering method, in which Euclidean distance can be used. Cosine similarity and Pearson correlation coefficient were used as feature similarity functions to calculate the quality score of the discrete prompt. The experimental results are shown in Table 7.
It can be seen that the discrete prompt filtering method in this scheme has better performance than no filter function and no discrete prompt. On the one hand, this verifies the validity of the discrete prompt generation method in this scheme; on the other hand, it also verifies the conjecture in this paper that not every discrete prompt is effective. In addition, the cosine similarity in the filtering function has the best performance, which may be due to the fact that the comparative learning pre-training method adopted by CLIP model during pre-training is realized based on cosine similarity. Therefore, the discrete prompt filtering method in this scheme adopts cosine similarity to better reflect the similarity of discrete prompt to sarcasm and nonironic data, so as to achieve a better sarcasm detection effect.
In addition, different numbers of discrete prompts have significant effects on model performance. In the early stage of the experiment, as the number of discrete prompts increases, the performance of the model can be observed to gradually improve. This trend indicates that increasing the number of prompts helps to enhance the robustness of the model and make the learning process more stable. Specifically, the standard deviation of model performance decreases significantly with the increase of the number of prompts, which further indicates that adding more discrete prompts can effectively improve the adaptability of the model to different data changes. However, when the number of discrete prompts exceeds 20, the performance of the model begins to decline. This phenomenon suggests that only 20 to 50 of the generated discrete cues may be valid and have a positive impact on model training. When the number of prompts is too large, noise or redundant information may be introduced, which will affect the learning efficiency and performance of the model. Therefore, it is very important to properly control the quantity of discrete prompts to ensure their quality and efficiency to optimize the model performance. The model performance under different discrete prompt quantity settings is shown in Table 8. The term Top-N in the table refers to the N highest-ranked discrete prompts based on their quality scores, which reflect the relevance of the number and quality of discrete prompts to sarcasm detection performance.
Conclusion
This paper introduces a novel cue learning method based on a multi-modal pre-training model to address the challenges of sarcasm detection in low-resource settings. The study began by selecting the CLIP model as the foundational pre-training model through comprehensive comparative experiments. Subsequently, a tailored prompt learning framework was designed specifically for the CLIP model. This framework encompasses several key components: discrete prompt generation, prompt vector generation, and multi-modal prompt vector fusion.
The discrete prompt generation method involves expanding the sarcastic and non-ironic prompt lexicons through a series of predefined rules. These prompts are then filtered to identify the most effective discrete prompts, enhancing the robustness and accuracy of the sarcasm detection model. The prompt vector generation method leverages learnable continuous cue vectors inserted into sarcastic and non-ironic text inputs. These vectors are encoded by the model to obtain distinct cue vectors. Specific projection functions are then utilized to facilitate interaction between multi-modal features, ultimately generating multi-modal cue vectors through a fusion layer.
The proposed approach was rigorously evaluated through comparative experiments and a series of parameter sensitivity analyzes. The results demonstrate the superior performance of this method in multi-modal sarcasm detection tasks, particularly under conditions of data scarcity. The discrete prompt filtering strategy, in particular, proved effective in refining the quality of prompts, thereby improving model performance. Furthermore, the integration of learnable continuous vectors and multimodal fusion techniques significantly improved the ability of the model to accurately detect sarcasm in different modalities.
In summary, the cue learning method based on the CLIP model offers a practical and effective solution for multi-modal sarcasm detection in low-resource scenarios. The symmetric integration of text and image data within this approach not only advances the state-of-the-art in sarcasm detection but also provides a robust framework for future research in multi-modal sentiment analysis and public opinion monitoring. The insights gained from this study can be extended to other domains where understanding nuanced human expressions is crucial, paving the way for more sophisticated and contextually aware AI systems. The symmetry in our method’s design ensures a balanced and effective utilization of diverse data sources, reinforcing the reliability and robustness of our sarcasm detection model. This symmetric approach underscores the importance of equal contribution from each modality, fostering a more holistic and accurate analysis of sarcasm in multi-modal data.
While the proposed method demonstrates strong performance on the Twitter Multi-modal Sarcasm Detection Dataset (MSD), its generalizability to other datasets or real-world scenarios has not been explored due to the lack of publicly available large-scale multi-modal sarcasm detection datasets. Future research will focus on evaluating the model on additional datasets, including domain-specific and cross-lingual sarcasm detection tasks. Furthermore, the versatility of the proposed framework suggests potential applications beyond sarcasm detection, such as multi-modal sentiment analysis and humor detection. Exploring these areas will not only validate the robustness of the model but also extend its applicability to broader domains. Additionally, further investigations into optimizing prompt design and multi-modal fusion strategies could lead to even greater improvements in performance and adaptability.
Data availability
The datasets analyzed during the current study are available in the data-of-multimodal-sarcasm-detection repository. This repository contains both text and image data used for multimodal sarcasm detection.
References
Bamman, D. & Smith, N. Contextualized sarcasm detection on twitter. In proceedings of the international AAAI conference on web and social media 9, 574–577 (2015).
Tay, Y., Luu, A. T., Hui, S. C. & Su, J. Reasoning with sarcasm by reading in-between. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1010–1020 (2018).
Zhang, Y. et al. Stance-level sarcasm detection with bert and stance-centered graph attention networks. ACM Transactions on Internet Technology 23, 1–21 (2023).
Liu, H. et al. Sarcasm driven by sentiment: A sentiment-aware hierarchical fusion network for multimodal sarcasm detection. Information Fusion 108, 102353 (2024).
Riloff, E. et al. Sarcasm as contrast between a positive sentiment and negative situation. In Proceedings of the 2013 conference on empirical methods in natural language processing, 704–714 (2013).
Davidov, D., Tsur, O. & Rappoport, A. Semi-supervised recognition of sarcastic sentences in twitter and amazon (pp. 15–16). Retrieved from Association for Computational Linguistics website: https://www.clweb.org/anthology/W10-2914.pdf (2010).
Bouazizi, M. & Ohtsuki, T. Sarcasm detection in twitter:“ all your products are incredibly amazing!!!”-are they really? In 2015 IEEE global communications conference (GLOBECOM), 1–6 (IEEE, 2015).
Ghosh, A. & Veale, T. Fracking sarcasm using neural network. In Proceedings of the 7th workshop on computational approaches to subjectivity, sentiment and social media analysis, 161–169 (2016).
Zhang, M., Zhang, Y. & Fu, G. Tweet sarcasm detection using deep neural network. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: technical papers, 2449–2460 (2016).
Amir, S., Wallace, B. C., Lyu, H., Carvalho, P. & Silva, M. J. Modelling context with user embeddings for sarcasm detection in social media. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, 167–177 (2016).
Wu, C. et al. Thu_ngn at semeval-2018 task 3: Tweet irony detection with densely connected lstm and multi-task learning. In Proceedings of The 12th International Workshop on Semantic Evaluation, 51–56 (2018).
Graves, A. & Graves, A. Long short-term memory. Supervised sequence labelling with recurrent neural networks 37–45 (2012).
Baziotis, C. et al. Ntua-slp at semeval-2018 task 3: Tracking ironic tweets using ensembles of word and character level attentive rnns. In Proceedings of The 12th International Workshop on Semantic Evaluation (Association for Computational Linguistics, 2018).
Chen, W., Lin, F., Li, G. & Liu, B. A survey of automatic sarcasm detection: Fundamental theories, formulation, datasets, detection methods, and opportunities. Neurocomputing 578, 127428 (2024).
Huang, J., Zhou, J., Tang, Z., Lin, J. & Chen, C.Y.-C. Tmbl: Transformer-based multimodal binding learning model for multimodal sentiment analysis. Knowledge-Based Systems 285, 111346 (2024).
Yu, B., Wang, H. & Xi, Z. Multifaceted and deep semantic alignment network for multimodal sarcasm detection. Knowledge-Based Systems 301, 112298 (2024).
Cai, Y., Cai, H. & Wan, X. Multi-modal sarcasm detection in twitter with hierarchical fusion model. In Proceedings of the 57th annual meeting of the association for computational linguistics, 2506–2515 (2019).
Pan, H., Lin, Z., Fu, P., Qi, Y. & Wang, W. Modeling intra and inter-modality incongruity for multi-modal sarcasm detection. In Findings of the Association for Computational Linguistics: EMNLP 2020, 1383–1392 (2020).
Xu, N., Zeng, Z. & Mao, W. Reasoning with multimodal sarcastic tweets via modeling cross-modality contrast and semantic association. In Proceedings of the 58th annual meeting of the association for computational linguistics, 3777–3786 (2020).
Liang, B. et al. Multi-modal sarcasm detection with interactive in-modal and cross-modal graphs. In Proceedings of the 29th ACM international conference on multimedia, 4707–4715 (2021).
Cambria, E., Li, Y., Xing, F. Z., Poria, S. & Kwok, K. Senticnet 6: Ensemble application of symbolic and subsymbolic ai for sentiment analysis. In Proceedings of the 29th ACM international conference on information & knowledge management, 105–114 (2020).
Liu, H., Yang, B. & Yu, Z. A multi-view interactive approach for multimodal sarcasm detection in social internet of things with knowledge enhancement. Applied Sciences 14, 2146 (2024).
Farabi, S., Ranasinghe, T., Kanojia, D., Kong, Y. & Zampieri, M. A survey of multimodal sarcasm detection. arXiv preprint arXiv:2410.18882 (2024).
Lu, Q., Long, Y., Sun, X., Feng, J. & Zhang, H. Fact-sentiment incongruity combination network for multimodal sarcasm detection. Information Fusion 104, 102203 (2024).
Li, Y. et al. An attention-based, context-aware multimodal fusion method for sarcasm detection using inter-modality inconsistency. Knowledge-Based Systems 287, 111457 (2024).
Yue, T., Mao, R., Wang, H., Hu, Z. & Cambria, E. Knowlenet: Knowledge fusion network for multimodal sarcasm detection. Information Fusion 100, 101921 (2023).
Ren, Y., Wang, Z., Peng, Q. & Ji, D. A knowledge-augmented neural network model for sarcasm detection. Information Processing & Management 60, 103521 (2023).
Keivanlou-Shahrestanaki, Z., Kahani, M. & Zarrinkalam, F. Interpreting sarcasm on social media using attention-based neural networks. Knowledge-Based Systems 258, 109977 (2022).
Filatova, E. Irony and sarcasm: Corpus generation and analysis using crowdsourcing. In Lrec, 392–398 (Citeseer, 2012).
Ling, J. & Klinger, R. An empirical, quantitative analysis of the differences between sarcasm and irony. In The Semantic Web: ESWC 2016 Satellite Events, Heraklion, Crete, Greece, May 29–June 2, 2016, Revised Selected Papers 13, 203–216 (Springer, 2016).
Khodak, M., Saunshi, N. & Vodrahalli, K. A large self-annotated corpus for sarcasm. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018) (2018).
Oraby, S. et al. Creating and characterizing a diverse corpus of sarcasm in dialogue. In Proceedings of the 17th Annual Meeting of the Special Interest Group on Discourse and Dialogue, 31–41 (2016).
Shrikhande, P., Setty, V. & Sahani, A. Sarcasm detection in newspaper headlines. In 2020 IEEE 15th international conference on industrial and information systems (ICIIS), 483–487 (IEEE, 2020).
Castro, S. et al. Towards multimodal sarcasm detection (an _obviously_ perfect paper). In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 4619–4629 (2019).
Tang, Y.-j. & Chen, H.-H. Chinese irony corpus construction and ironic structure analysis. In Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, 1269–1278 (2014).
Xiang, R. et al. Ciron: a new benchmark dataset for chinese irony detection. In Proceedings of the Twelfth Language Resources and Evaluation Conference, 5714–5720 (2020).
Zhang, L. et al. Mitigating social hazards: Early detection of fake news via diffusion-guided propagation path generation. In ACM Multimedia 2024.
Zhang, L. et al. Knowledge-aware multimodal pre-training for fake news detection. Information Fusion 114, 102715. https://doi.org/10.1016/j.inffus.2024.102715 (2025).
Zhang, L., Zhang, X., Zhou, Z., Huang, F. & Li, C. Reinforced adaptive knowledge learning for multimodal fake news detection. In Proceedings of the AAAI Conference on Artificial Intelligence 38, 16777–16785 (2024).
Zhang, L. et al. Early detection of multimodal fake news via reinforced propagation path generation. IEEE Transactions on Knowledge and Data Engineering (2024).
Zhang, L., Zhang, X. & Pan, J. Hierarchical cross-modality semantic correlation learning model for multimodal summarization. In Proceedings of the AAAI Conference on Artificial Intelligence 36, 11676–11684 (2022).
Liu, X. et al. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. arXiv preprint arXiv:2110.07602 (2021).
Sun, T. et al. Bbtv2: Towards a gradient-free future with large language models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 3916–3930 (2022).
Kenton, J. D. M.-W. C. & Toutanova, L. K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT, 4171–4186 (2019).
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations (2020).
Pennington, J., Socher, R. & Manning, C. D. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 1532–1543 (2014).
Deng, L. et al. Deep learning: methods and applications. Foundations and trends in signal processing 7, 197–387 (2014).
Huang, G., Liu, Z., Van Der Maaten, L. & Weinberger, K. Q. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4700–4708 (2017).
Radford, A. et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, 8748–8763 (PMLR, 2021).
Acknowledgements
The authors would like to thank the anonymous reviewers for their insightful comments.
Funding
This work was supported in part by the National Natural Science Foundation of China (No. 62272025 and No. U22B2021), and in part by Fund of the State Key Laboratory of Software Development Environment.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Lu, M., Dong, Z., Guo, Z. et al. A multi-modal sarcasm detection model based on cue learning. Sci Rep 15, 10261 (2025). https://doi.org/10.1038/s41598-025-94266-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-94266-w
