
Abstract
Accurate permeability characterization is essential for evaluating shale oil reservoirs quality. Chang 7 shale oil reservoirs, with diverse lithologies, low porosities and permeabilities, complex pore structures, and strong heterogeneity, pose challenges for traditional permeability prediction methods. This paper proposes an improved method that integrates lithology and hydraulic flow units (HFUs) with conventional logs for enhanced permeability prediction. The reservoir characteristics of the Chang 7 member in the Sai 392 area were analyzed, investigating relationships among lithology, porosity, pore structure parameters, and permeability. Lithology was identified by combining imaging logging and lithologic reconstruction curves (Ilith), with Ilith value boundaries of − 0.5, 1.5, and 3 for fine sandstone, argillaceous siltstone, silty mudstone, and mudstone, respectively. A back-propagation neural network predicted the flow zone index using lithological evaluation parameters and logging data, enabling HFU dentification and permeability model establishment. In this case study, the improved method was successfully implemented to accurately predict the permeability of the Chang 7 member shale oil reservoirs. Almost all data in the crossplot of the predicted versus measured permeability are within ± 0.17 uncertainty boundaries, with a root mean square error lower than 0.051. The results demonstrate that the improved method can effectively and accurately predict the permeability of the Chang 7 member shale oil reservoirs in the Sai 392 area.
Similar content being viewed by others
Introduction
The exploration and development of shale oil in China have recently achieved remarkable progress, particularly in the Ordos Basin. In 2019, the Qingcheng oilfield, with reserves exceeding 10 × 10⁸ t of shale oil, was discovered in the Chang 7 member of the Mesozoic Yanchang Formation in this basin1. Permeability is a crucial petrophysical parameter in reservoir evaluation as it directly influences the fluid output capacity of the reservoir. Therefore, accurate permeability prediction plays a vital role in reservoir assessment2,3,4,5,6. Permeability is controlled by porosity, lithology, and pore structure characteristics7,8,9,10,11. Shale oil reservoirs exhibit highly complex pore structures, a wide range of pore sizes, and high heterogeneity12,13. Traditional methods for predicting reservoir permeability have shown low accuracy, making the effective prediction of shale oil reservoir permeability a challenging issue that requires immediate attention.
For highly heterogeneous reservoirs, there are currently three primary types of models used to evaluate permeability: physical evaluation models, electrical evaluation models, and statistical classification models14,15,16,17,18,19,20,21. Physical evaluation models center on factors like porosity, bound water saturation, particle sorting, particle size, mineral composition, and specific surface area, which influence permeability. Electrical evaluation models consider conductivity, pore connectivity coefficient, and cementation index as key factors. Statistical classification models analyze the relationship between porosity and permeability through techniques like lithologic identification, physical phase constraints, structural classification, and flow unit division. Although physical and electrical evaluation models account for physical factors such as area and surface, they often have complex structures and numerous parameters, making it challenging to obtain accurate model parameters, especially in highly heterogeneity reservoirs. In contrast, statistical classification models can more directly reflect physical changes in reservoirs and are more practical.
The flow unit classification method is the most widely used quantitative classification method for reservoirs in statistical classification models, especially when only core physical property data are available22. A hydraulic flow unit (HFU) is a reservoir genesis unit that resulting from the interaction of geological processes such as sedimentation, diagenesis, and tectonic movement. It enables the quantitative description and characterization of reservoir heterogeneity, revealing the heterogeneity and fluid seepage characteristics of the reservoir23. Chen et al. used nuclear magnetic resonance (NMR) logging data to calculate the continuous flow unit index FZI and predict the permeability of a tight sandstone gas reservoir based on the classification24. Zhou et al. classified the HFU of sandstone reservoirs based on well logging data and analyzed the physical characteristics of each flow unit. They also established a model for evaluating permeability in shale gas reservoirs25. Lu et al. conducted a flow unit division of shale oil using well logging data and predicted the permeability of pure mud shale reservoirs26. However, previous researchers have only quantitatively divided reservoirs based on the FZI from a physical perspective, which fails to reflect the reservoir permeability determined by the complex depositional environment and exhibits obvious limitations27,28,29,30. In recent years, machine learning algorithms have been increasingly employed in permeability prediction31,32,33. Some of the commonly used algorithms include support vector machines (SVMs), random forests (RFs), decision trees (DTs), extreme learning machines (ELMs), and artificial neural networks (ANNs).ANNs are known for their ability to model complex nonlinear relationships and have been widely applied in various fields, including reservoir engineering34,35. ANN is inspired by the capabilities of the brain to process information, consisting of a number of neurons (nodes) linked by a special architecture. The ANN can minimize the errors between target outputs (in training dataset) and computed outputs (from the output nodes) through adjusting the weights of links and bias of nodes on the basis of a certain training algorithm. A Back Propagation (BP) neural network is a multilayer feed-forward ANN that uses an error back propagation algorithm for training36. In contrast to the complex processes and high requirements of traditional permeability prediction methods, which involve intricate mathematical derivations, parameter adjustments, iterative computations, factor correlations, and a need for complete data, BP neural network with its flexible model structure, formidable nonlinear mapping capabilities, and robust self-adaptation and self-learning abilities, demonstrate remarkable advantages in terms of efficiency and applicability37.
In order to overcome the limitations of traditional methods and enhance the accuracy of permeability prediction, this paper investigates the fundamental characteristics of the shale oil reservoir of the Chang 7 member in the Sai 392 area. By analyzing well logs, core samples, physical property data, and experimental techniques such as casting thin section (CTS) observation and scanning electron microscopy (SEM). The correlations among lithology, porosity, pore structure parameters, and permeability are thoroughly explored and discussed. An improved method is established by combining lithology and hydraulic flow units (HFUs) to predict permeability using conventional logs. This method improves the accuracy of permeability predictions and offers a reliable foundation for identifying high-quality reservoirs and achieving efficient reservoir development.
Regional geological background
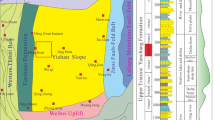
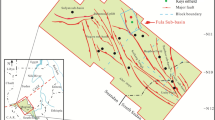
The Sai 392 area is situated in the central region of the Yishan slope within the Ordos Basin. It is between Zhidan and Jingbian counties in Shaanxi Province. The region has a flat tectonic structure, with several rows of low-amplitude nose structure belts locally developed against the background of a low-angle west-dipping monocline38 (Fig. 1a). The thickness of the Chang 7 layer in the Ordos Basin ranges from approximately 80–120 m. These lithofacies are distributed along the margin of the lake basin in a ring belt, with various types of deltaic facies near the shoreline. The lake depth increased toward the center of the basin39. During the sedimentary period of the Chang 7 member in the basin, the material sources were mostly oriented in the northeast‒southwest directions. The sand bodies at the delta front and the turbidite sand bodies formed in the semideep to deep lake were relatively widespread40. The source material of the Yanchang Formation in the study area originated primarily from the northeast. The Chang 7 member is primarily composed of delta front sediments, which can be further subdivided into four sedimentary microfacies: the underwater distributary channel, estuary dam, underwater natural levee, and interdistributary bay. The reservoir lithology varies significantly, primarily consisting of fine sandstone, siltstone, and mudstone. The reservoir sand bodies are oriented northwest‒southeast and are arranged in a flower-like shape (Fig. 1b).

Results and discussion
Reservoir characterization
Lithological characteristics
To elucidate the properties of the reservoir, we first analyzed the lithological characteristics of the Chang 7 member in the study area. The dominant lithologies consist of lithic arkose and arkose, and the sandstone grains are mostly extremely fine-grained to fine-grained, with moderate to good sorting. The grain shapes are mostly subangular, and the rock debris is primarily composed of metamorphic rocks and mica. The average content of the matrix is 5.1%, with hydromica and chlorite serving as the primary interstitial materials. The cement content ranges from 0.5 to 30% (average of 7.5%). The primary cement is ferroan calcite, with smaller amounts of calcite, siliceous cement, and dolomite cement (Fig. 2).

Ternary diagram of the sandstone composition of the Chang 7 shale oil reservoirs. Q: Quartz, F: Feldspar, R: Rock debris.
The lithological data of the shale oil reservoirs within the Chang 7 member in the study area reveal a composition primarily consisting of fine sandstone, argillaceous siltstone, silty mudstone, and mudstone. These lithologies exhibit varying thicknesses. Fine sandstone is the most prevalent, accounting for 48.29%, followed by mudstone at 19.73% (Fig. 3b). An analysis of permeability distribution across these lithologies reveals that the permeability of the fine sandstone ranges from 0.052 to 0.14 mD, that of the argillaceous siltstone ranges from 0.035 to 0.094 mD, that of the silty mudstone ranges from 0.009 to 0.06 mD, and that of the mudstone is less than 0.048 mD (Fig. 3a). The permeability decreases progressively from the fine sandstone to the mudstone, indicating that lithology is the key factor influencing permeability. Therefore, incorporating lithological parameters is crucial for accurate permeability predictions.

Different lithological characteristics of the Chang 7 shale oil reservoirs. (a) Range of permeability distribution. (b) Thickness ratios.
Physical characteristics
The analysis of the porosity–permeability data reveals that the porosities primarily range between 4 and 9%, while the permeabilities are mainly distributed between 0.01 and 0.2 mD (Fig. 4a and b). These findings suggest that the reservoirs in this region have ultralow porosity and permeability. Additionally, a weak correlation between porosity and permeability was observed (Fig. 4c), likely due to late diagenesis of the reservoirs. The Chang 7 reservoirs have experienced significant compaction, resulting in the loss of numerous pores and a decrease in porosity (Fig. 5g). Conversely, the dissolution of feldspar has generated dissolution pores, enhancing pore connectivity and improving the reservoir storage capacity (Fig. 5a, b, and e). However, the presence of ferric calcite and clay as cementing materials led to more developed cementation processes, leading to reduced pore space and pore throat sizes, ultimately diminishing the reservoir seepage capacity (Fig. 5d and h).

Reservoir quality of the Chang 7 shale oil reservoirs. (a) The distribution of reservoir porosity. (b) The distribution of reservoir permeability. (c) The relationship between porosity and permeability from the reservoir test data.

Microscopic characteristics of the Chang 7 shale oil reservoirs. CTS observations: (a) Feldspar dissolution pore, well X538, 1970.71 m. (b) Intergrain pores, feldspar dissolution pores, well S544, 2142.38 m. (c) Micropores, well X538, 1972.81 m. (d) Ferroan calcite, well X538, 1972.2I. SEM observations: (e) Feldspar dissolution pore, well X538, 1990.91 m. (f) Clay micropores, well X538, 1990.91 m. (g) Mica compressive deformation, well X538, 1972.81 m. (h) Ferroan dolomite, chlorite, illite, well S246 1973.6 m. InterG: intergranular. F-disso: feldspar dissolution.
Pore structure characteristics
The Chang 7 shale oil reservoirs in the study area exhibit poor pore development. As observed in the CTSs, the total surface porosity of only 1.93%. Dissolution pores are the predominant type of pores in this rock, accounting for 1.34% of the surface porosity. Some samples also contain intergranular pores and a small number of clastic dissolution pores, with surface porosities of 0.52% and 0.07%, respectively (Fig. 5a–c). SEM images (Fig. 5e and f) demonstrate the presence of numerous dissolution pores and clay micropores. The pore types are mainly composed of dissolution pores and micropores, intergranular pores and dissolution pores, and micropores.
The analysis of the Hg pressure data revealed that the median radii of the reservoir ranged from 0 to 0.17 µm (average of 0.09 µm). The outlet pressures were mainly distributed between 1.09 and 41.41 MPa (average of 7.36 MPa). The maximum pore throat radii were primarily distributed between 0.02 and 0.68 µm (average of 0.039 µm), falling within the fine pore throat, micro- to fine pore throat, and micropore throat categories, with the latter two being the most common. The maximum mercury saturation values primarily ranged between 42.05 and 89.27% (average of 72.75%). The mercury removal efficiency values were mainly distributed between 23.14 and 36.06% (average of 28.79%). The pore throat connectivity in the reservoir was weak (Table 1), with pore throat combinations mainly characterized as mesopores and micro- to fine pore throats, small pores and micro- to fine pore throats, and micropores and micropore throats. The complex pore structure of the reservoir reflects its strong heterogeneity.
Pore structure parameters, such as the maximum pore throat radius and the average pore throat radius, directly reflect the distribution, sorting, and connectivity of rock samples41,42. The crossplots of permeability and these parameters reveal strong positive correlations (correlation coefficients R2 > 0.73) (Fig. 6a and b). This indicates that the pore structure of the Chang 7 reservoirs in the study area directly affects their permeability.

Correlations between the permeability and pore structure parameters of the Chang 7 shale oil reservoirs. (a) Relationship between permeability and maximum pore throat radius. (b) Relationship between permeability and average pore throat radius.
Lithology identification and classification
Reservoir physical properties are largely determined by lithology, and the impact of lithology must be considered when predicting reservoir physical properties43. The complexity of lithology of the shale oil reservoirs within the study area is notable. While the lithologic profile along the longitudinal direction of a single well was established during logging, errors in lithology interpretation due to artificial factors during logging are significant. Thus, there is an urgent need to enhance the accuracy of lithologic profile interpretation in the study area. Relying solely on a single logging curve is insufficient for effective lithology identification. Imaging logging enables direct qualitative identification of different lithologies and reflects changes in rock grain size44,45. However, this method is prone to artifacts, resulting in inaccuracies in lithologic classification and low identification efficiency. By reconstructing a logging curve to amplify the logging response, the accuracy of identifying reservoir lithology can be improved, enabling quantitative classification of different lithologies. The use of the BP neural network method is effective in correcting the entire logging-based lithological profile, ultimately enhancing the accuracy of lithological interpretation.
The BP neural network model employed to predict the properties of the reservoir is contingent upon a set of input features, namely natural gamma ray (GR), acoustic (AC), density (DEN), neutron (CNL), and true formation resistivity (RT). These features are pivotal in capturing the various characteristics of the reservoir, as they offer distinct and complementary details about the reservoir’s physical and geological properties46. DEN, which quantifies the density of the rock, is associated with the composition and texture, facilitating the differentiation of different rock types and indicating the presence of minerals such as calcite or dolomite. AC measures the acoustic properties, which are affected by the pore structure and fluid content, thus providing valuable insights into the porosity and permeability of the reservoir. CNL measures the neutron porosity, which is a significant parameter for characterising the fluid-bearing capacity of the reservoir. GR is sensitive to radioactive elements and can be used to determine the lithology and mineralogy of the reservoir. RT provides information regarding the electrical resistivity, which is related to the salinity and fluid conductivity of the reservoir47.
The performance and accuracy of the model are greatly influenced by the selection and quality of these input features. The combination of DEN, AC, CNL, GR, and RT has been found to improve the model’s ability to accurately predict the reservoir properties48,49. Studies have demonstrated that including these features leads to enhanced correlations between the predicted and measured values of porosity and permeability. This enable the model to better capture the complex relationships between these parameters and the geological and physical properties of the reservoir28.
In this study, we first consolidated, categorized, and arranged the lithologies observed in the core samples, and then correlated the imaging logging data with the core observation data. Image features were utilized to determine the lithology throughout the entire wellbore interval, resulting in the classification of target formations into four primary lithologies: fine sandstone, argillaceous siltstone, silty mudstone, and mudstone (Fig. 7). The sensitivity curves for lithology, derived from GR, AC, DEN, and CNL data, were screened through sensitivity analysis. These results were used to construct the lithologic reconstruction curve Ilith (Eq. 1). The Ilith values for different lithologies exhibited notable distinctions (Fig. 8), leading to the establishment of lithology identification and classification criteria for shale oil reservoirs in the specific study area (Table 2).

Lithologic characteristics interpreted from conventional logging and imaging logging of the Chang 7 shale oil reservoirs. (a) Mudstone. (b) Silty mudstone. (c) Argillaceous siltsAtone. (d) Fine sandstone.

Lithologic identification chart of the Chang 7 shale oil reservoirs.
The lithologic reconstruction curves are shown below:
where GR’, AC’, CNL,' and DEN’ are the normalized values of the logging curves GR, AC, CNL, and DEN, respectively (Eqs. 2–4).
We employed the BP neural network method to correct the lithological profiles of individual wells. The four lithological categories (fine sandstone, argillaceous siltstone, silty mudstone, and mudstone) identified in the previous section were digitized and replaced by 1–4 as parameters for lithological evaluation (Table 2). A BP neural network model for lithology was established by using the GR, AC, DEN, CNL, and lithologic evaluation parameters as input layers and lithology as the output layer. The network training results showed that the predicted lithologic profile was more detailed and accurate than the log-based lithologic profile (Fig. 9, Tracks 6 and 7). This enhanced lithologic profile can serve as a basis for permeability prediction50.

Comparison between the log-based lithologic profile and the predicted lithologic profile of the Xin488 well. Track 1 shows the Chang 7 member; Track 2 shows the depth; Tracks 3, 4, and 5 are the main logging curves; Track 6 is the log-based lithologic profile; and Track 7 is the predicted lithologic profile.
HFU identification and permeability estimation
HFU identification and classification
Porosity and permeability are crucial parameters for evaluating hydrocarbon reservoirs because they reflect the storage and flow capacity of a medium46. Porosity is typically determined using three types of logging data (AC, DEN, and CNL). The effective porosity can be measured in the laboratory. The total porosity is determined by well logging data and impacted by the clay content of the shale reservoir. GR data can be used to determine the clay content of shale reservoirs effectively. Therefore, this study utilized three types of porosity logs and GR logs as input layers to predict porosity using a BP neural network model based on the multilayer perceptron (MLP) architecture in SPSS Modeler 14.1 software.
Taking the Xin488 well as a case study, the MLP architecture was optimal when it has 70 and 30 data points in the training and test subsets, respectively. The crossplot between the predicted and measured porosities shows a strong correlation (R2 = 0.84) (Fig. 10).

Relationship between the measured porosity and predicted porosity of the Xin488 well.
By substituting the measured porosity and permeability data into Eqs. (7) and (8), the reservoir quality index (RQI) and the normalized porosity index (PMR) can be calculated. Equation (9) was applied to determine the FZI, which can be classified to identify HFUs in the shale oil reservoirs. The distribution of log(FZI) from the Xin488 well data suggests that the reservoir can be categorized into five HFUs (Fig. 11a), with varying FZI distribution ranges across each HFU type. The value of log(FZI) decreases from HFU I to HFU V (Table 3).

Identification of the five HFUs and associated data in the Xin488 well. (a) Cumulative frequency plot of log(FZI) data. (b) Porosity–permeability relationship.
The permeability‒porosity crossplots of the different HFUs reveal a strong correlation between the porosity and permeability within the same HFU type (R2 > 0.82). (Fig. 11b). Therefore, based on the evaluation of porosity, the permeability of shale oil reservoirs can be predicted by the correlation between the porosity and permeability of each HFU.
Model validation and permeability prediction of the uncored well
The HFUs are classified in the cored interval based on FZI values calculated from the measured porosity and permeability data of the samples. These FZI values typically align with the corresponding well logging data, aiding in the continuous identification of HFUs in both cored and uncored intervals. Therefore, for uncored intervals without measured porosity and permeability data, it becomes essential to model the relationship between the FZI and well logging response using readily available well logging data. Initially, the FZI is calculated for the uncored intervals and then used to classify the HFU types. The correlations between the FZI and well logging curves are more complex than the correlations between the porosity and logging curves51. Therefore, this paper selects an enhanced accuracy model for predicting permeability. A BP neural network model is established using a substantial amount of logging data strongly correlated with FZI (DEN, AC, CNL, GR, and RT) and with lithological evaluation parameters to calculate FZI, following a similar approach to that used for predicting porosity.
Due to the complex diversity of lithologies and pore structures in the Chang 7 member of the study area, the shale oil reservoirs exhibit significant differences in terms of the reservoir FZI and well logging response. As a result, establishing a unified model for predicting permeability based on well logging is challenging, requiring separate modeling and evaluation efforts for each well. Using the Xin488 well as a case study, the network training results showed a strong positive correlation (R2 = 0.85) between the predicted and measured FZI values (Fig. 12). This suggests that the model is effective for identifying HFUs continuously in both cored and uncored intervals of a well. Based on the five types of HFUs classified by FZI identification (Fig. 11b), we established a permeability prediction index model for each HFU type, specifically the porosity–permeability relationship equation (Table 4).

Relationship between the measured FZI and predicted FZI of the Xin488 well.
In this study, the permeability of shale reservoirs was predicted in 10 un-cored wells within the Sai 392 area. Figures 13 and 14 show predicted permeability values for 2 wells (the Xin488 and Xin485 wells). The predicted permeability values correspond well to measured values, indicating that the improved model can accurately predict the permeability of shale reservoirs.

Prediction results of the porosity and permeability profiles for the Xin488 well. Track 1: Chang 7 member; Track 2: depth; Tracks 3, 4, and 5: well logging curves; Track 6: log-based lithologic profile; Track 7: predicted lithologic profile; Track 8: predicted porosity results; Track 9: predicted permeability results.

Prediction result profile of the porosity and permeability for the Xin485 well. Track 1: Chang 7 member; Track 2: depth; Tracks 3, 4, and 5: well logging curves; Track 6: log-based lithologic profile; Track 7: predicted lithologic profile; Track 8: predicted porosity results; Track 9: predicted permeability results.
In order to quantitatively assess the performance of the model, crossplots of predicted and measured values were generated. Most of the data in the crossplot of the measured permeability versus the lithologic-control-based predicted permeability fall within the ± 0.17 uncertainty boundaries, and show a strong positive correlation, the R2 value is 0.803 for the Xin488 well and 0.801 for the Xin485 well. Analysis of the linear fitting error reveals that the predictions with a low root mean square error (RMSE ≤ 0.037) (Fig. 15a and b). Furthermore, R2 and RMSE of 8 un-cored wells within the Sai 392 area and 2 un-cored wells within the Longdong area of the Ordos Basin (the Chen96 and Li357 wells) were statistically analyzed. The results indicating a strong overall correlation between the measured and predicted permeabilities (R2 > 0.72), and a low RMSE of predictions (RMSE ≤ 0.051). Among them, the R2 value is 0.826 for Chen96 well and 0.797 for Li357 well, and RMSE values are 0.031 for Chen96 well and 0.046 for Li357 well (Fig. 16). Therefore, the improved method can be considered to be generally applicable.

Relationships between the measured permeability and predicted permeability of the improved method. (a) Xin488 well. (b) Xin485 well.

The R2 and RMSE for different single wells.
In addition, the traditional multiple regression method was employed to predict permeability of the Xin488 well and the Xin485 well, respectively. It is evident that the correlations between the measured and predicted permeabilities of the 2 wells are relatively poor, the R2 value is 0.318 for the Xin488 well and 0.245 for the Xin485 well (Fig. 17a and b). Conversely, the correlations between the predicted permeabilities and the measured permeabilities are significantly enhanced, with all R2 value greater than 0.8(Fig. 15a and b). This further confirms the assumption that this method has strong performance in accurately predicting permeability. Moreover, the predicted permeability curves effectively revealed favorable shale oil/gas seepage layers37.

Relationships between the measured permeability and predicted permeability of the traditional method. (a) Xin488 well. (b) Xin485 well.
Conclusions
The Sai 392 Chang 7 member shale reservoirs in the Ordos Basin have a low surface porosity and are primarily composed of lithic arkose and arkose. The Chang 7 member shale reservoir porosity mainly ranges from 4 to 9%, and the corresponding permeability mainly ranges from 0.01 to 0.2 mD. These characteristics are indicative of typical ultralow-porosity, ultralow-permeability reservoirs. The relationship between porosity and permeability is weak, with a variety of pore throat structures present, including mesopores and micro- to fine pore throats, small pores and micro- to fine pore throats, and micropores and micropore throats, indicating strong heterogeneity.
-
1)
The lithology of the shale oil reservoirs in the Chang 7 member in the study area consists mainly of fine sandstone, argillaceous siltstone, silty mudstones, and mudstones. Each lithology exhibits a distinct range of permeabilities, with fine sandstone exhibiting the highest permeability, followed by argillaceous siltstone. The permeability of a reservoir is strongly correlated with both the maximum and average pore throat radii. Therefore, the permeability of the studied reservoirs is influenced primarily by the lithology and pore structure.
-
2)
Lithology identification criteria are established based on lithologic reconstruction curves, with Ilith value boundaries of −0.5, 1.5, and 3. Additionally, the BP neural network is used to correct single-well logging-based lithologic profiles, enhancing the accuracy of lithologic interpretation.
-
3)
A reservoir permeability log prediction model is established using the lithology–flow unit–BP neural network permeability evaluation method to estimate the permeability of the entire studied well interval. The predicted permeability values closely align with the measured values, with nearly all the data falling within the uncertainty boundary of ± 0.17. The prediction results reveal a strong positive correlation (R2 > 0.72) and a low root mean square error (RMSE ≤ 0.051), indicating that the proposed model can effectively and accurately predict the permeability of the whole well interval of the Chang 7 member.
The proposed method may be more applicable to shale reservoirs. However, due to the unique geological characteristics and fluid behaviors exhibited by different reservoirs, it is imperative to develop a novel method with extensive applicability, high accuracy, and robustness. In future studies, we should incorporate a more diverse array of data, covering seismic, core, production, and various geological data. Integrating these data sources can provide a more comprehensive understanding of the reservoir. It is essential to deeply explore the potential of leveraging machine learning algorithms and data mining techniques to extract valuable information from multi-source data. Additionally, it is recommended to contemplate the concurrent application of multiple modeling approaches. By capitalizing on their individual fortes, we can enhance the accuracy of reservoir property prediction, which is instrumental for more accurate reservoir assessment and more effective identification of favourable shale oil/gas seepage layers.
Data and methods
Samples and experimental section
In this study, we collected physical property data from 69 wells, Hg pressure data from 10 wells, imaging logging data from 8 wells, CTS data from 36 wells, and SEM data from 20 wells in the Sai 392 area of the Changqing Oilfield Corporation. Additionally, we extracted the oil from 11 samples from the study area using a solvent mixture of dichloromethane and methanol (9:1 ratio) for 72 h. The extracted samples were then dried at 110 °C to eliminate residual oil and water. Subsequently, CTS and SEM experiments were conducted with the samples.
The CTS experiments were completed on a CIAS-2007 rock casting image analyzer. The CTS was resin-impregnated with blue epoxy; therefore, the blue color in the micrographs of the casts represents pores.
The SEM experiments were first performed by polishing the observation surface of the samples with an Ilion+ II 697C argon-ion polisher produced by the Gatan Company in the United States; then, the samples were observed with a Quanta 450 field emission SEM produced by the FEI in the United States.
Data preprocessing
Data preprocessing refers to standardizing data so that different variables have the same scale, The standardization process is performed to make the data comparable. Data standardization methods are as follows52:
Standard deviation standardization:
xij is expressed as the raw data of the jth index of the ith sample; x'ij is the standardized data of the jth index of the ith sample.
Min–Max normalization:
Hydraulic flow units
A HFU refers to a collection of reservoirs that share similar lithologic and seepage characteristics, both vertically and laterally53,54 These reservoirs exhibit uniform fluid flow properties due to their similar pore throat characteristics55,56 By classifying reservoirs into different categories based on HFUs, the heterogeneity of the reservoir can be mitigated to some extent. The RQI and flow zone index (FZI) effectively reflect the differences in the microscopic pore structure. The FZI can be used to quantitatively identify and classify HFUs, with each HFU being characterized by its FZI. This allows for the establishment of a strong correlation between permeability and porosity. Estimating porosity from logging curves is a simpler approach than directly predicting permeability. Therefore, based on the porosity–permeability relationship for each HFU, it is possible to predict the permeability of samples within each HFU57,58,59,60.
According to the Kozeny–Carman Eq.61, permeability and porosity satisfy the following relationship:
where K is the permeability in µm2, Φ is the effective porosity (fraction), and Hc is a structural property constant that is formed by the product of the pore tortuosity, shape factor, and square of the specific surface area.
Dividing both sides of Eq. (5) by Φ and taking the square root results in the following form:
The parameters that can be defined when permeability (K) is expressed in mD are:
The RQI:
The normalized porosity index (PMR):
The FZI:
Equation (9) illustrates that the FZI is a parameter that reflects the characteristics of the pore structure of the rock; hence, its value accurately reflects the heterogeneity of the reservoir seepage characteristics.
By taking the logarithm of Eq. (9), the following relationship is derived:
Equation (10) shows that there is a linear relationship between the RQI and the PMR. This means that data points with similar FZI values are distributed on the same straight line, while data points with different FZI values are distributed on a set of parallel straight lines.
Back-propagation (BP) neural network
The BP network comprises an input layer, an output layer, and multiple hidden layers and operates in two stages: forward propagation and BP. In the forward propagation stage, the input signal is transmitted to the hidden layer, and after applying the activation function, the output information of the hidden layer is forwarded to the output layer for the final output result. If the output layer fails to reach the desired output value, the network proceeds to the BP error stage, where the connection weights of each layer are adjusted based on the back-propagated error signals to determine the optimal set of weights for the correct output (Fig. 18). As there are feedback connections between neurons within each layer, information is transmitted only from the input layer to the output layer. The architecture of the network includes feedback connections between neurons within layers, ensuring that information flows from the input to the output layer only, with no direct connections between neurons within the same layer. Therefore, the BP neural network algorithm is effective in solving the relationship between the input and output and addressing complex nonlinear problems. BP neural networks have been successfully applied in predicting the porosity, reservoir sedimentary microfacies, and lithology of heterogeneous reservoirs62, FZI can be evaluated using a BP neural network.

Basic schematic of a BP neural network.
Data availability
The datasets generated and/or analyzed during the current study are not publicly available due to privacy issues. If someone wants to obtain data from this study, please get in touch with Heting Gao and Weichao Tian.
References
Fu, S. et al. Accumulation conditions and key exploration and development technologies in Qingcheng oilfield. Acta Petrolei Sinica 41(7), 777–795 (2020).
Zou, C. et al. Shale oil and gas revolution and its impact. Acta Petrol. Sinica 41(1), 1–12 (2020).
Zhao, P., Wang, Z., Sun, Z., Cai, J. & Wang, L. Investigation on the pore structure and multifractal characteristics of tight oil reservoirs using NMR measurements: Permian Lucaogou Formation in Jimusaer Sag, Junggar Basin. Marine Petrol. Geol. 86, 1067–1081 (2017).
Wang, S., Li, F., Guo, Q. & Wang, S.-Y. Tight oil resource assessment methods and key parameters. Nat. Gas. Geosci. 27(9), 1576–1582 (2016).
Jiang, Z., Zhang, W., Liang, C. & Wang, Y. Characteristics and evaluation elements of shale oil reservoir. Acta Petrolei Sinica 35(1), 184–196 (2020).
Chen, X. & Yao, G. An improved model for permeability estimation in low permeable porous media based on fractal geometry and modified Hagen-Poiseuille flow. Fuel 210, 748–757 (2017).
Ma, B., Fan, F. & Sun, Z. Experimental study on influencing factors of shale oil flow capacity in laminar shale in Jiyang depression. Petrol. Geol. Oilfield Dev. Daqing 41(5), 153–159 (2019).
Wang, X. et al. Experimental study on permeability anisotropy and stress sensibility of Shale of Longmaxi in East Sichuan. Sci. Technol. Eng. 19(26), 174–777 (2019).
Bourg, I. C. & Ajo-Franklin, J. B. Clay, water, and salt: Controls on the permeability of fine-grained sedimentary rocks. Account Chem. Res. 50(9), 2067–2074 (2017).
Yang, S., Zhang, K., Liu, S. & Zhao, X. Research progress on measurement methods and influencing factors of shale permeability. Petrol. Geol. Recovery Eff. 29(6), 1–10 (2022).
Wang, D. et al. Forming condition of high-quality reservoir and its relative problems in low porosity and permeability enrichment zone. Nat. Gas Geosci. 14(2), 87–91 (2003).
Wang, J., Xiao, D., Lu, S., Kong, X. & Fan, Q. Classification evaluation of shale oil reservoir physical properties in Lucaogou formation, Jimsar sag. J. China Univers. Min. Technol. 49(1), 172–183 (2020).
Gao, H. et al. Classification and evaluation of shale oil reservoirs of the chang 71–2 sub-member in the Longdong area. Energies 15(15), 5364 (2022).
Wang, L. et al. A new method for calculating fluid permeability of shaly sandstone. Chinese J. Geophys. 58(10), 3837–3844 (2015).
Liu, Y. et al. Permeability characterization and directional wells initial productivity prediction in the continental multilayer sandstone reservoirs: A case from Penglai 19–3 oil field, Bohai Bay Basin. Petrol. Explorat. Dev. 44(1), 97–104 (2017).
Yin, S. et al. Permeability calculation of fight sandstone reservoir by conductivity parameters. Lithol. Reserv. 28(6), 117–124 (2016).
Jiao, N., Ding, W., Yin, S., Wang, W. & Cao, X. Method of calculating tight sandstone reservoir permeability by creating dynamic permeability chart based on formation rock conductivity. Sci. Technol. Eng. 16(21), 20–26 (2016).
Lai, J. et al. A fine logging interpretation model of permeability confined by petrophysical facies of tight gas sandstone reservoirs. Progr. Geophys. 29(3), 1173–1182 (2014).
Meng, W., Lu, Z., Tang, Y. & Feng, M.-S. Reservoir permeability prediction based on sandstone texture classification. J. China Univer. Petrol. 37(2), 1–6 (2013).
Chen, K., Chen, X. & Zhang, J. Combined methods of permeability logging evaluate in glutenite reservoirs—a case study of Badaowan formation in Karamay oilfield. Adv. Earth Sci. 30(7), 773–779 (2015).
Zhang, C., Cheng, Y. & Zhang, C. An improved method for predicting permeability by combining electrical measurements and mercury injection capillary pressure data. J. Geophys. Eng. 14(1), 132–142 (2017).
Lu, M., Lin, C., Zhang, X. & Zhang, J. Evaluation and optimization of flow unit division methods. Lithol. Reserv. 27(1), 74–80 (2015).
Yue, D., Wu, S. & Lin, C. Research progress in flow unit of clastic reservoir. China Science paper 3(11), 810G817 (2008).
Chen, Z., Wu, S. & Bai, R. Logging evaluation for permeability of tight sandstone gas reservoirs based on flow unit classification: A case from Xujiahe Formation in Guang’an area, central Sichuan Basin. Lithol. Reserv. 29(6), 76–83 (2018).
Zhou, J., Li, Z., Gu, L. & Zhang, S. The method for the division and description of reservoir flow unit. Resour. Ind. 8(5), 88–91 (2006).
Lu, S. et al. Classification of microscopic pore-throats and the grading evaluation on shale oil reservoirs. Petrol. Expl. Devel. 45(3), 452–460 (2018).
Lu, Y., Xu, S., Liu, K. & Wang, Y. Quantitative characterization of reservoir flow units of basin floor-fan turbidite. J. China Univer. Petrol. 43(6), 1–10 (2020).
Zheng, X., Wu, J., He, S., Hu, X. & Liang, Y. Fine evaluation of permeability of conglomerate reservoir based on flow unit. J. Jilin Univer. (Earth Sci. Edn.) 46(1), 286–294 (2016).
Shi, L. et al. Multilevel division method of flow units for accurate permeability assessment of glutenite reservoirs: a case study of reservoir W53 of Paleogene Wenchang Formation in Lufeng oifield. Geophys. Geochem. Explorat. 46(1), 78–86 (2022).
Liu, Y., Liu, Y. & Li, C. Division of flow units in thick carbonate reservoirs: Taking MF reservoir in Middle East as an example. J. Xian Shiyou Univers. (Nat. Sci. Edn.) 34(1), 104–411 (2019).
Vapnik, V. N. The nature of statistical learning theory 314 (Springer, 2000).
Al-Mudhafar, J. W. Integrating lithofacies and well logging data into smooth generalized additive model for improved permeability estimation: Zubair formation, South Rumaila oil field. Marine Geophys. Res. 40, 315–332 (2019).
. Al-Mudhafar, W. Integrating bayesian model averaging for uncertainty reduction in permeability modeling. In offshore technology conference (pp. OTC-25646) (2015).
Wang, G., Cheng, G. & Carr, T. R. The application of improved NeuroEvolution of augmenting topologies neural network in marcellus shale lithofacies prediction. Comput. Geosci. 54, 50–65 (2013).
Anifowose, F., Abdulraheem, A. & Al-Shuhail, A. A parametric study of machine learning techniques in petroleum reservoir permeability prediction by integrating seismic attributes and wireline data. J. Petrol. Sci. Eng. 176, 762–774 (2019).
Wu, B., Han, S., Xiao, J., Hu, X. & Fan, J. Error compensation based on BP neural network for airborne laser ranging. Opt. Int. J. Light Electron Optics 127(8), 4083–4088 (2016).
Zhang, P. et al. Permeability evaluation on oil-window shale based on hydraulic flow unit: A new approach. Adv. Geo-Energy Res. 2(1), 1–13 (2018).
Fu, J., Li, S., Niu, X., Deng, X. & Zhou, X. Geological characteristics and exploration of shale oil in Chang 7 Member of Triassic Yanchang Formation, Ordos Basin, NW China. Petrol. Explorat. Devel. 47(05), 931–945 (2020).
Fu, J. et al. Discovery and resource potential of shale oil of Chang 7member, Triassic Yanchang formation, Ordos Basin. Petrol. Explorat. Dev. 26(5), 1–11 (2021).
Yang, H., Dou, W., Liu, X. & Zhang, C. Analysis on sedimentary facies of member 7 in Yanchang formation of triassic in Ordos Basin. Acta Sedimentol. Sinica 28(2), 254–263 (2010).
Xiao, Y., Lan, J. & Yao, W. Micropore structure and movable fluid distribution characteristics of tight sandstone reservoirs: Taking the He 8 reservoir in the Shenmu area of the eastern Ordos Basin as an example. Bull. Geol. Sci. Technol. 43(2), 41–51 (2024).
Tian, W. et al. The grading evaluation of physical properties of tight sandstone in Chang 7 member of Wujiao Area in Ordos Basin. J. Yangtze Univer. (Nat. Sci. Edn.) 18(4), 24–32 (2021).
Zhou, J., Gui, B., Li, M. & Lin, W. An application of the artificial neural net dominated by lithology to permeability prediction. Acta Petrolei Sinica 31(6), 985–988 (2013).
Wu, Y., Xie, Y. & Qiu, Y. Application of FMI imaging logging to interpretation of sedimentary facies in Lijin Sub-Sag. Xinjiang Petrol. Geol. 29(3), 765–767 (2008).
Chen, K. et al. Identification of thin interbedded sand and shale with electrical imaging logging in Ordos Basin. Well Logg. Technol. 44(6), 576–583 (2020).
Li, J. et al. Insights on the gas permeability change in porous shale. Adv. Geo-Energy Res. 1(2), 69–73 (2017).
Liu, M. et al. Permeability prediction from mercury injection capillary pressure curves by partial least squares regression method in tight sandstone reservoirs. J. Petrol. Sci. Eng. 169, 135–145 (2018).
Huang, Y. et al. Logging evaluation of pore structure and reservoir quality in shale oil reservoir: The Fengcheng Formation in Mahu Sag Junggar Basin, China. Marine Petrol Geol 156, 106454 (2023).
Jiang, Y. et al. Logging evaluation of favorable areas of a low porosity and permeability sandy conglomerate reservoir based on machine learning. Acta Geophys. 72(2), 711–725 (2023).
Li, X. et al. Permeability calculation model based on lithology identification. Logg. Technol. 46(01), 84–88 (2022).
Jin, Y., Lin, C., Zhao, L. & Zhao, L. J. Discussions on FZI methodology in flow unit identification and discrimination. Petrol. Explorat. Devel. 31(5), 130–132 (2004).
Yang, Z. et al. Cluster analysis of residents’ consumption levels in provinces and cities based on systematic clustering algorithm and elbow criterion. China Sci. Technol. Inf. 12, 121–122 (2021).
Al-Rbeawi, S. & Kadhim, F. The impact of hydraulic flow unit & reservoir quality index on pressure profile and productivity index in multi-segments reservoirs. Petroleum 3(4), 414–430 (2017).
Onuh, H. M., David, O. O. & Onuh, C. Y. Modified reservoir quality indicator methodology for improved hydraulic flow unit characterization using the normalized pore throat methodology (Niger Delta field as case study). J. Petrol. Explorat. Product. Technol. 7(2), 409–416 (2017).
Hearn, C. L., Ebanks, W. J., Tye, R. S. & Ranganathan, V. Geological factors influencing reservoir performance of the hartzog draw field Wyoming. J. Petrol. Technol. 36(8), 1335–1344 (1984).
Dou, Z. A Study on flow unit model and distribution of remaining oil in fluvial sandstone reservoirs of the Guantao formation in Gudong oil field. Petrol. Explorat. Dev. 27(6), 50–52 (2000).
Desouky, S. E. D. M. Predicting permeability in un-cored intervals/wells using hydraulic flow unit approach. J. Canad. Petrol. Technol. 44(7), 55–58 (2005).
Jiao, C. & Xu, C. An approach to permeability prediction based on flow zone index. Well Logg. Technol. 30(4), 317–319 (2009).
Bhattacharya, S., Byrnes, A. P., Watney, W. L. & Doveton, J. H. Flow unit modeling and fine-scale predicted permeability validation in Atokan sandstones: Norcan East field Kansas. AAPG Bullet. 92(6), 709–732 (2008).
Orodu, O. D., Tang, Z. & Fei, Q. Hydraulic (flow) unit determination and permeability prediction: A case study of block Shen-95, Liaohe oilfield North-East China. J. Appl. Sci. 9(10), 1801–1816 (2009).
Carman, P. C. Fluid flow through granular beds. Chem. Eng. Res. Design 75, S32–S34 (1997).
Ali, D. & Ebrahim, S. Physical properties modeling of reservoirs in Mansuri oil field, Zagros region, Iran. Petrol. Explorat. Dev. 43(4), 611–615 (2016).
Acknowledgements
The authors would like to thank the National Natural Science Foundation of China (Grant Nos. 42202187 and 42272160).
Funding
This research was financially supported by the National Natural Science Foundation of China (Grant Nos. 42202187 and 42272160).
Author information
Authors and Affiliations
Contributions
Conceptualization, project administration, and funding acquisition: Z.W.; methodology, supervision, writing—review & editing, and funding acquisition: W.T.; writing—original draft, data curation, and investigation: H.G.; resources: Y.S., H.Z., and F.Z.; data curation and algorithms: Y.F. and X.C. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Gao, H., Sun, Y., Zhao, H. et al. An improved method for predicting the permeability of Chang 7 shale oil reservoirs based on lithology and hydraulic flow units. Sci Rep 15, 9168 (2025). https://doi.org/10.1038/s41598-025-94294-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-94294-6
Keywords
This article is cited by
-
Quantifying and Predicting Heterogeneity in Marine Clastic Reservoirs Through Machine Learning: Methodology and Applications
Natural Resources Research (2025)
