
Abstract
This research examines the significance of privacy of synthetic data in healthcare and biomedicine by an analysis of actual data. The significance of authentic health care data necessitates the secure transmission of such data exclusively to authorized users. Therefore, to minimise the reliance on actual data, synthetic data is developed by incorporating diverse biometric pattern representations, necessitating a distinct setup with adversarial scenarios. Furthermore, to improve the quality of synthetic data, a deep convolutional adversarial network is examined under several operational modes. Furthermore, a distinct conditional metric is employed in this instance to avert the loss of synthetic data, so ensuring consistent transmissions. The system model is developed by examining numerous parameters associated with matching, classification losses, biometric privacy, information leakage, data relocations, and deformations, which are merged with a corresponding adversarial framework. To validate the results of the integrated system model, four scenarios and two case studies are examined, demonstrating that successful data creation can be achieved artificially with minimal losses of 5%.
Similar content being viewed by others


Introduction
The data management strategy is crucial in healthcare applications, utilizing diverse technological methods for authentication to safeguard real data from varied uses. An essential technological method for preventing unauthorized data consumption is the implementation of biometric patterns that only analyze the physiological characteristics of diverse users. However, the compromise of critical information must often be averted by substituting real-time data with artificially generated alternatives that may be utilized by users in all situations1. Accessing synthetic data with biometric patterns ensures a high level of security and enables the attainment of fully scalable solutions through appropriate training, testing, and validation of data. In addition to these conversions, all statistical features are diminished, enabling the processing of large-scale data across end users, with any unstructured data being transformed into structured representations2. In many instances, actual data is unnecessary for individual identification; thus, synthetic data can be utilized for such identifications without the risk of data leaking. Furthermore, the issues of data inadequacy can be addressed by the development of synthetic data, which incorporates relevant information without disrupting real-time data, so achieving a comprehensive set of balanced solutions3. In cost-effective analysis, synthetic data is crucial as it eliminates complex processing pathways by generating simply conditional outputs based on the applicable input patterns. The aforementioned cost-effective solution favored for healthcare applications utilizing synthetic data offers multi-layered security in identifying complex patterns through distinctive identification methods.
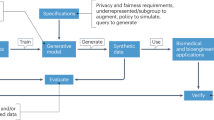
Figure 1 depicts the essential representations of biometric patterns utilizing synthetic data for healthcare purposes. Figure 1 illustrates that diverse input patterns containing information on biometric units can be considered inside each metadata unit. After the input circumstances are recorded, requisite transformations can be executed by artificially producing each data point; hence, at this juncture, all authentic data is altered and stays in a protected state. Consequently, a structured data representation of the synthetic data is created and processed into normalized units, ensuring that comprehensive synthetic data measurements are preserved under minimal risk. Subsequent to transformations, diverse data modalities are generated, resulting in all synthetic data being aligned with transformational channels, hence enhancing classification privacy while minimizing loss.

Connectivity representations of biometric and synthetic data.
Background and related works
This section outlines the suggested method’s framework by examining numerous issue statements associated with different sorts of biometric units utilized for obtaining synthetic data, thereby revealing significant distinctions. The background and associated studies offer insights into various types of healthcare data, enabling the identification of all critical concepts and ensuring that data utility patterns remain managed. In addition to data analysis and management, the significance of all underlying data-related issues can be elucidated by examining the foundational processes. The analysis in1 examines the efficacy of synthetic data in healthcare to mitigate hazards linked to connected networks, where re-identification incidents frequently occur. A distinct digital data security is implemented for this low-risk process, effectively addressing all substantial problems through adherence to regularization parameters. Nonetheless, in healthcare operations, the potential bias inherent in the development of sensitive medical data must be transformed into a standard metric format, which is quite challenging with optimization units. In addition to the identification process conducted with various power units, synthetic data can be generated using certain tools, hence allowing for the successful definition of the program technique2. Predictive analysis will be conducted using the specified tools, and hybrid optimizations incorporating additional validation methods will be incorporated in the generating process. This form of predictive analysis necessitates more real-time data, and the complexity of testing scenarios remains significant, compelling users to generate only synthetic representations with low precision, which subsequently results in elevated error levels.
In3, open-source tools are recommended, specifying the necessary sample size while minimizing the number of samples in this instance. A synthetic data workflow is established independently with the specified sample size, and necessary authorization must be obtained for further evaluation procedures. However, with restricted sample data, it is exceedingly challenging to segregate real-time measurements, as tabular and imaging data must be consistently differentiated across all time intervals, hence causing time series data to fluctuate in accordance with conditional models. Furthermore, the data collection technique continues to be challenging, prompting the selection of an alternative method utilizing wireless devices that handle larger volumes of real-time data created in a comparable manner to synthetic representations4. Real-time data collection enables the generation of synthetic data without external complications, as the fundamental traits of persons may be distinctly delineated. To analyze the causal effects of numerous treatments, synthetic data is generated, hence ensuring adequate privacy safeguards for analogous predictions5. Given the increasing demand for this type of numerous treatments, it is essential to deliver a unified solution by exerting considerable effort to generate a single set of synthetic data. The primary disadvantage of the multiple production method is that real-time distributions are determined only based on joint probability causes, which therefore diminishes the uniqueness of real-time data utilized across many conditional patterns. This type of joint distribution necessitates the processing of data through the amalgamation of diverse patterns, resulting in unstructured data distributions that cannot be transformed into structured data representations.
Furthermore, the risk prediction processes implemented downstream, which remain in an underdeveloped form, are examined by using synthetic versions of generated data6. Downstream applications can access eventual data processing units, and issues arise from including multiple types of data conveyance. As the downstream process is conducted for synthetic data, hyper parameter tweaking is essential, and the latent dimensions generated from real data cannot be eliminated. The exploration of real data through modifications of minor property representations is facilitated by synthetic data sets, thereby circumventing all challenges associated with external sharing7. If the potential for unit sharing is eliminated, both utility and availability remain unregulated operations, resulting in a decreased retention rate of individual data. To regularize the data flow, it is essential to implement lower baselines instead of directly augmenting availability rates, as a distinct order may be adhered to in this scenario. Nonetheless, these types of orders are adhered to, resulting in the sharing units often remaining undistributed in the context of new baseline principles. A cross-sectional study is conducted in alignment with individual order representations, effectively saving data, which immediately enhances health processing units. It is also noted that during the same timeframe, it is considerably more challenging to identify alterations in actual data due to the imposition of additional constraints on various scaling operations for synthetic data units. In8, the fairness rate among various generated units is examined, ensuring that both privacy and regulations are upheld prior to the creation of individual data sets. Table 1 presents a comparison of the existing and proposed methods, including type and optimization units.
Research gap and motivation
Although a majority of health care data is accessible, the method of accessing these datasets is crucial in contemporary systems due to the heightened utilization of various resources. Furthermore, the techniques employed to integrate biometrics with synthetic data enhance health monitoring3,7,11,13,16 yet, the challenge of managing real datasets leads to issues such as data scarcity. Conversely, the utility and sensitivity patterns of the data remain unchanged in current methodologies, resulting in data imbalance due to inadequate data structures, which prevents the collection of complex patterns, even with artificially generated synthetic data. Moreover, regarding generalized and scalable solutions, the following research gaps have been identified.
RG1: Can both matching and classification losses be minimized by attaining balancing functions through adversarial networks?
RG2: Is it possible to enhance biometric privacy while minimizing information leakage in the presence of real-time data samples?
RG3: Can conditional inputs be utilized to transfer real-time data in healthcare to a synthetic dataset?
Major contributions
To address the stated research gap, adversarial networks incorporating both convolutional and conditional processes are employed through the integration of biometric features. Therefore, the primary contributions of the suggested method are as follows.
-
To achieve balanced functionality with synthetic data by minimising both matching and classification losses.
-
To mitigate actual data leakage by offering identical conversions in a reduced format alongside corresponding synthetic data.
-
To implement conditional input patterns with appropriate data relocations and deformations while preserving data quality in healthcare.
Proposed system model
The proposed system model is developed to handle all issues associated with real-time data processing systems by utilizing synthetic data. The system model is constructed using analytical representations, ensuring that all data is acquired through privacy-preserving procedures. The system model is integrated into the suggested approach to enhance all generalization patterns, allowing for the uninterrupted simulation of all edge patterns by external users. The analytical model incorporates multiple diversity limitations in data predictions, hence enhancing equality rates.
Biometric matching loss
As each real data is transformed into synthetic forms, feature extraction functions are employed to assess the extent of matching losses in the integrated biometric system. Consequently, the corresponding losses in this instance must be mitigated (as specified in Eq. (1)) by maintaining all real-time data, thereby facilitating the accurate detection of certain syndromes.
Equation (1) stipulates that the matching periods for n data representations must be minimized, and in numerous instances, if the matching losses are substantial, the total number of samples may be regarded with separation. Consequently, if the data is segregated, it becomes feasible to enhance the preservation of patterns, resulting in augmented variety aspects in healthcare and biomedicine applications.
Preliminary 1
Let us examine the learning parameters for biometric pattern recognition denoted as \(\:{\omega\:}_{i}\), with real and synthetic data represented as \(\:{\mathfrak{A}}_{1}+.+{\mathfrak{A}}_{i}\), \(\:\widehat{{\mathfrak{A}}_{1}}+.+\widehat{{\mathfrak{A}}_{i}}\). Therefore, it is essential to map the input features to the complete feature space utilising cosine similarity representations, adhering to the limitations specified in Eq. (2).
Lemma 1
To substantiate the aforementioned situation, the privacy preservation rule can be adhered to by evaluating two distinct data pieces that must fulfill the matching losses. Therefore, in this technique, the complete feature distance between two data points must equal zero; otherwise, the likelihood of inverse mapping must be minimized, as indicated in Eq. (3).
Biometric privacy
During the generation of synthetic data, it is imperative that real identities are never substituted, so enhancing the privacy of each data unit. In instances of heightened biometric privacy, the disparity between authentic and synthetic data is inherently diminished, as demonstrated in Eq. (4).
Equation (4) indicates that preservations must be conducted concerning both actual and synthetic data; thus, if dissimilarities are to be minimized, the mapping technique must be eschewed in all critical instances. Consequently, by circumventing the mapping of real and synthetic data, the privacy distance for all original entities in healthcare can be optimized.
Preliminary 2
Let us examine the patterns of similarity and dissimilarity between real and synthetic data, denoted as \(\:{\mathfrak{C}}_{1}+.+{\mathfrak{C}}_{i}\) and \(\:{\mathfrak{D}}_{1}+.+{\mathfrak{D}}_{i}\), where elevated values are assigned to representations of dissimilar patterns. Therefore, with elevated values, the privacy loss functions must be diminished in accordance with the limitation specified in Eq. (5)
Lemma 2
In instances of heightened privacy concerning data functions, a non-linear mapping function may be employed, necessitating that two distribution types adhere to divergence measures by allocating data in alignment with likely variations. Therefore, the discrepancies between original and synthetic data must adhere to the threshold levels specified in Eq. (6).
Biometric classification loss
Understanding the distinction between real data and artificially generated data is essential, as it enables the effective reduction of classification-related losses. Given the significance of real-time data in healthcare, it is imperative to train synthetic data, as the original data cannot be recovered, as mentioned in Eq. (7).
Equation (7) establishes that low separation probabilities enhance predictive capability, so facilitating real-time diagnosis at early stages, while also processing bio molecular pattern signals in the presence of accurate labels. Consequently, with minimal separation, each user is unable to distinguish between the original and synthetic data as the training periods are extended in this scenario.
Preliminary 3
To ascertain classification errors, it is essential to identify the binary decision variables; thus, let us define \(\:{\mathfrak{U}}_{1}+.+{\mathfrak{U}}_{i}\) as the classification error. During the training process, it is imperative to minimise total error by establishing comprehensive balance functions, as delineated in Eq. (8)
Lemma 3
To demonstrate the balance constraint in this instance, it is essential to examine synthetic label techniques, wherein each decision boundary must correspond with the trained data. Therefore, the appropriate label prediction approach must be adhered to in this instance, ensuring optimal balance as specified in Eq. (9).
Information leakage
In real-time data authentication for healthcare applications, it is essential to avoid data leakage where reconstruction occurs. In healthcare-related data, the substantial volume of stored information results in the creation of synthetic data samples that correspond to the actual data, hence mitigating the risk of information leakage, as illustrated by Eq. (10) below.
Equation (10) indicates that an increased number of reconstructions will significantly elevate the losses, thereby directly impeding the safeguarding of healthcare data. Nevertheless, based on the supplied information, it is feasible to allocate the data according to requisite time intervals.
Preliminary 4
Let us denote \(\:{g}_{1}+.+{g}_{i}\) as the aggregate quantity of recovered data mapped throughout the entire underlying data space. Therefore, the initial disparity in this instance must be assessed to avert the total feasibility of encoding by examining the input feature vectors in accordance with the limitation in Eq. (11)
Lemma 4
To demonstrate the feasibility of minimizing information leakage, optimal techniques can be implemented wherein an identity mapping function is built at appropriate data units. Consequently, the pair construction process can independently learn the identity mapping units by adhering to the constraint in Eq. (12).
Synthetic data clusters
To enhance classification performance between actual healthcare data and artificially generated synthetic data, it is essential to establish distinct clusters, allowing for the extraction of individual features at requisite time intervals. Furthermore, these defined data clusters exert a direct influence on the quantity of synthetic data classes, as indicated in Eq. (13).
Equation (13) indicates that an increased number of data points allows for a greater number of cluster points, hence enhancing categorization with notable improvements in performance outcomes. Therefore, the synthetic feature spectrum generated for healthcare and biomedicine for individuals cannot be deciphered.
Data relocations
A data relocation path must be established for all stated models to enhance the correctness of stored data contents. The synthetic data generated for healthcare applications is critical, and since no comparable decisions can be made, the accuracy must be enhanced as specified in Eq. (14).
Equation (14) demonstrates that diverse training across the depicted data units allows for the definition of distinct tasks. The increased number of assigned tasks will compromise the correctness of real data, necessitating generalization, which can be effectively accomplished through transferability methods.
Geometric deformation
The generated synthetic data for healthcare is vulnerable to inversion assaults and therefore requires a geometric solution to mitigate these threats. Therefore, a deformation mechanism is developed that explicitly indicates the adversarial robustness of the proposed method using unique latent representations as follows.
Equation (15) demonstrates that a significant disparity between robust data units (actual and synthetic) will diminish the occurrence of inversion assaults. Therefore, even if a greater number of synthetic data samples are produced, the likelihood of resilient attacks can be diminished by deformation principles.
Composite objective functions
The suggested method analyses several objectives using min-max criteria, hence representing multi-objective functions to attain optimal results. Furthermore, to produce a trade-off in the examined healthcare data and biomedicine, individual parametric representations can be formulated as delineated in Equations (16) to (22).
All the above mentioned equations can be converted to simple representations by combining in a flexible objective unit as indicated in Eq. (23).
Generative adversarial networks
The proposed system architecture requires enhancement with rigorous criteria for distinguishing between genuine and synthetic data in healthcare applications; thus, it is essential to incorporate generative adversarial networks to mitigate complete data inadequacy, even when artificial data is produced. When data sets are limited, generative adversarial networks are employed while adhering to privacy limits found in real-time data, so ensuring that the integrity of available data in healthcare applications is maintained17,18. The primary benefit of generative adversarial networks is that they mitigate the risk of unauthorized use of sensitive information while creating synthetic data, hence allowing for the unrestricted use of various biometric patterns. Furthermore, generative adversarial networks employ two distinct phases: one for generation and the other for distinction. During data generation, all authentic data will be produced, and in the presence of random noise, it is essential to enhance the generated data, which can be achieved through augmented dataset features. Data privacy is guaranteed in data generation, since sensitive information is safeguarded by not sharing raw data in these processing units, resulting in enhanced accuracy. Moreover, the majority of healthcare midpoints can facilitate translations about diverse image patterns; hence, each synthetic pattern is reorganized without any exterior perturbations. In addition to this form of translation, it is feasible to enhance training models with minimal reconstruction losses, wherein border-sharing techniques can be automatically integrated with created synthetic data. In contrast, the suggested method examines two varieties of generative adversarial networks to enhance data stability, with the descriptions of both types provided below.
Deep convolutional adversarial networks
The likelihood of direct data generation in generative adversarial networks has inherent limitations with synthetic data, necessitating replacement with equivalent types of generation. Consequently, each data instance is produced in convolutional layers utilizing deep convolutional adversarial networks. In deep convolutional adversarial networks, data patterns are formed by considering both spatial and hierarchical contexts, incorporating both image and signal data. Moreover, as the majority of realistic data fluctuates about various types of health care observations, it is imperative to integrate the complete layer without disruptions to attain optimal accuracy. Most layers are interconnected, allowing for the sharing of synthetic data with users in a non-identical manner; nonetheless, in the case of similar data requests, distinct biometric patterns will be verified. Furthermore, in healthcare applications, the scarcity of labelled data necessitates the consideration of reconstruction situations without further training units, hence enabling the processing of huge samples. The technique of inception scores is integrated after distinguishing between actual and synthetic data, so minimizing total diversity losses in the projected approach, which enhances the accuracy of healthcare and biomedicine data. In real-time, several data collaborations can be formed and distinguished, enabling the creation of structured data at no additional expense. In contrast to previous forms of generative adversarial networks, the convolutional processes utilize input filters, hence ensuring a superior level of data generalization in the suggested method. The mathematical formulations of deep convolutional adversarial networks are as follows.
Adversarial setup
The establishment of an adversarial setup aims to accurately assess all losses associated with generation and discrimination. Therefore, during the generating phase, the total loss must be minimized, whilst in contrast, the losses must be maximized about the distance in the measurement stage, as illustrated in Eq. (24).
Equation (24) indicates the necessity of establishing prior distributions on the available dataset, hence enabling all forms of predictions following the generation of requisite samples. However, in the case of a greater number of samples, the difference must be specified for each categorization unit present.
Entropy loss
The data operations used in the suggested method must mitigate complete mode collapse between real and synthetic data, hence resulting in diminished loss concerning entropy functions. The aforementioned instance shall be processed alone if numerous data distributions are encompassed as specified in Eq. (25).
Equation (25) indicates that an increased number of modes allows for the error-free distribution of synthetic data. However, in instances of low data distributions, a constant mode may be employed, resulting in relatively little alterations in healthcare data units.
Quality maintenance
In deep convolutional adversarial networks, quality maintenance can be attained by evaluating three distinct types of metrics: reconstruction, privacy, and accuracy, with a greater number of biometric images exhibiting identical quality metrics as delineated in Eq. (26).
Equation (26) indicates that privacy preservation can only be achieved by appropriate identifications, hence introducing the potential for modifications with weight factors. The block representations and flow graph of deep convolutional adversarial networks are illustrated in Figs. 2 and 3, with the following step indications.

Convolutional adversarial networks.

Block representations of deep convolutions adversarial networks.

Flow chart of deep convolutional adversarial networks.
Conditional adversarial networks
Conditional adversarial networks are employed to apply certain conditions in the synthetic data creation process following a comprehensive analysis of data inside healthcare systems, where all input criteria pertain to a collection of labeled units. Conditional adversarial networks differ from other classes by enabling the specification of critical tasks that are very beneficial for real-time applications in healthcare and biology. When the potential for real-time data generation is diminished, conditional tasks are supplied at the input unit together with descriptions and image sets, thereby enabling the alignment of each data set with structured scenarios. The primary benefit of a conditional adversarial network is the significant enhancement in classification performance attributable to the input circumstances, hence diminishing the likelihood of data collapse with minimal risk assessment. Additionally, all sensitive information is safeguarded owing to input conditions, thereby ensuring consistent output during the data creation process, which is executed using multi-label connection. In contrast, conditional adversarial networks facilitate the rapid identification of missing data, so enabling a complete dataset for improved decision-making without the necessity for complex information units. Personalised learning methodologies are employed only under specific input conditions and during designated time periods, which subsequently enhances the input conditions and ensures the protection of data privacy at all times. Moreover, conditional adversarial networks facilitate the translation of input images, hence eliminating the necessity for distinct style-based connection inside the system, where imbalanced data sets are excluded. The analytical framework of conditional adversarial networks is as follows.
Modified generations
To align conditional deviations, it is essential to create altered input unit patterns where penalty functions are standardized in this context. Consequently, both labels and penalties are incorporated in this instance by aligning all input units without specifying any loss functions, as seen in Eq. (27) as follows.
Equation (27) indicates that the changed generations are based on two labels included in the generated loops (i, n). Consequently, for this category of labels, only variations in input weight may be regarded for alignment with certain conditional scenarios, thereby enhancing the system’s accuracy.
Stability loss
To enhance the likelihood of each training class inside the specified synthetic datasets, it is essential to augment stability by adhering to specific regularization measures. The loss of stability guarantees that only constant data is produced by implementing certain substitutions associated with unstructured data, as seen in Eq. (28).
Equation (28) indicates that to attain consistent stability, a collective of individual data must be generated, wherein the aggregate difference remains below the threshold values established by foundational principles. Furthermore, in instances of such losses, if stable outcomes are not attained, the entire synthetic data will persist in a disrupted state.
Synthetic representations
In establishing specific conditions for each input unit, a class-consistent representation must be generated, ensuring that only relevant conditions are attained. Consequently, each synthetic representation maintains consistency about all applicable inputs by selecting adaptable data loads in healthcare and biomedicine.
Equation (29) indicates that a greater quantity of output data units is required to provide regularized synthetic data points in this instance. Consequently, reliable synthetic data can yield high-quality outputs that directly produce multi-class results. The block representations and flow graph of conditional adversarial networks are illustrated in Figs. 4 and 5, with the following step indications. Table 2 indicates the types of variables and corresponding significance.

Conditional adversarial networks.

Block representations of conditional adversarial networks.

Flow chart for conditional networks with maximized accuracy.
Results
This part evaluates the real-time outcomes of each biometric pattern, utilizing synthetic data equalizations matched to actual healthcare data. To ensure equalized data distributions, it is essential to examine all information available for each patient, hence considering the distributive character. Initially, biometric data is extracted from accessible sources that preserve comprehensive health records through the interconnection of multiple health units. The analysis of currently accessible data sets includes the potential for integration with synthetic data, followed by successful time series forecasts that yield comprehensive characteristic answers. Although the dataset is sourced from open repositories, the classification likelihood and distribution are verified using both text and picture characteristics, ensuring that each user can only access the requested synthetic data, hence rendering the decoding of additional data impossible in the proposed method. In contrast, an effective analysis necessitates the consideration of roughly 50,000 biometric patterns in diverse formats, thereby enabling their distinctive data diversity characteristics. Data augmentation approaches, including scaling concepts, are employed to transform unstructured data into structured formats across many datasets. Upon data augmentation, mirror data is generated from MDclone, ensuring the secrecy of data production and verification, hence maintaining the integrity of all medical data. In addition to data augmentation, the mapping of data set sources is evaluated using two types of adversarial networks to assure quality and prevent data loss. To validate the results of biometric patterns through concurrent data representation in healthcare, the following scenarios are examined, along with the significance of each scenario that is provided in Table 3.
Scenario 1: Data matching and classification loss
Scenario 2: Prevention of information leakage
Scenario 3: Probability of data clusters
Scenario 4: Maximization of relocations and deformations
Discussions
A real-time experimental environment is offered for all circumstances by directly accessing each biometric pattern with secure input indications, where genuine data is transformed into synthetic form. The suggested method converts the complete dataset, structured in form, into an input signal encompassing all physiological representations using MATLAB, hence facilitating dynamic simulations. The input signals are collected using a synthetic dataset, resulting in the representation of only high-fidelity data, hence eliminating similarity indices in each signal that support both hidden structures and input variables. Furthermore, this form of conversion and data set integration reduces total reliance on existing real data; hence, in instances of data imbalance, the simulation unit exhibits heightened error patterns. The gap between real and synthetic data is entirely diminished, hence enhancing generalization capability without establishing any direct connections to the data.
Table 4 presents information regarding simulation environments, wherein Simulink is utilised for data production and distribution, employing an augmentation scale measure of 100x for each available healthcare dataset. The learning rate is decreased in this instance, as both the training and testing phases are conducted in a 70:30 ratio, hence maintaining a controlled batch size. Furthermore, the noise levels are diminished within the range of 0 to 1, resulting in output channels being displayed in a time series fashion, with the total number of samples varying for each time period. Nevertheless, the intricacy of input patterns diminishes due to the limited sample size, as each time series representation processes 10,000 data points, so allowing for an extended training period. The concise summary of the enumerated circumstances along with comparative outcomes is as follows.
Scenario 1: Data matching and classification loss.
This scenario examines the potential for aligning synthetic input data with real datasets sourced from multiple repositories, as well as evaluating the classification of artificially generated patterns. In the standard method of representation, following the generation of synthetic data, the correlation of individual data across different forms must be minimized, hence facilitating an increase in the disparity between actual and synthetic data. The suggested method utilizes n sample representations to produce and supply low-matching data, hence establishing the setup by considering both prediction distributions. Given that the configuration is standardized in the conversion process, an accurate label set is supplied across different operating modes, hence enabling the reduction of classifications among various data units. Furthermore, for classifications, the individual weight of each data point is taken into account to maximize the original distance between two categories of data, even when expressed in different ways.
Figure 6 illustrates the simulation results for both matching and classification losses in the context of planned and existing methodologies16. Figure 6 illustrates that both matching and classification losses are diminished in the suggested strategy relative to the existing model. The potential for reductions is achieved by supplying individual biometrics to identify diverse patterns in the context of synthetic data, hence minimizing data matching discrepancies. To validate the results of matching and classification losses, a variety of real and synthetic datasets are examined, specifically {151,203,222,279,291} and {87,95,102,109,113}. The legitimate label representation with verified biometric patterns is maintained at {80, 92, 100, 103, 110}, hence minimizing the wastage of synthetic data. Therefore, for the aforementioned dataset The proposed strategy, utilizing an adversarial setup, reduces the matching and classification losses to 9% and 5%, respectively, whereas the present methodology achieves reductions of 21% and 27%.

Representation of matching and classification losses for synthetic data.
Scenario 2: Prevention of information leakage.
This example demonstrates the potential to avoid information leaking while preserving data privacy. In healthcare, it is crucial that when data is given in a synthetic fashion, many users may attempt to exploit specific biometric patterns to illicitly acquire information. In the proposed method, several statistical patterns are employed to avert information leakage by monitoring the overall number of sample losses in interconnected data units. Furthermore, in each instance, data privacy is preserved by safeguarding original data representations, so ensuring quality is upheld at every stage without the inclusion of any individual’s additional data. In addition to this form of privacy in the suggested method, users are permitted to share data inside an adversarial framework that is entirely reliant on time series, hence ensuring complete prevention of output leakage.
Figure 7 illustrates the simulation of information leakage prevention and its comparison with the existing approach16. Figure 7 demonstrates that the suggested strategy effectively reduces information leakage and preserves the privacy of synthetic data in healthcare compared to previous approaches. The potential for statistical data preservation and time series representations of data sharing methods is regarded as a primary factor in upholding privacy across various data types. The consequences regarding information leakage and data privacy are verified by observing the statistical data shared across specific time intervals: 51, 69, 76, 85, and 92, with total losses over these intervals recorded as 4, 7, 11, 14, and 16, respectively. Consequently, the suggested strategy reduces overall information leakage to 2%, whereas the conventional model maintains a leakage rate of 16% due to the variable configuration that produces low-quality data.

Information leakage in accordance with total loss at framing time periods.
Scenario 3: Probability of data clusters.
This scenario demonstrates the optimal potential for data separation during artificial generation, as each biometric pattern can be independently acquired, hence enhancing data privacy. Given that individual attributes confer additional advantages on data clusters, it is essential to segregate the data by adhering to specific requirements that incorporate penalty functions. Furthermore, the integrated data, presented in a structured format, must have a high degree of stability; hence, even when more than two data groups are established, it becomes significantly easier to delineate several clusters in a brief timeframe. In this instance, authorized users receive flexible data measures, as only a portion of the desired data is generated without reference to the underlying data. Moreover, when data is available without any references, it is considerably easier to uphold its integrity, and essential enhancements can be implemented.
Figure 8 illustrates the potential data clusters present in synthetic data for both the proposed and existing approaches16. Figure 8 demonstrates that the stability of data clusters is enhanced in the projected model relative to existing methodologies. As loss factors diminish in prior observation scenarios, the segregation of created data is executed with more ease. To validate the results for data clusters under consistent processing, the total number of data points corresponding to synthetic data is noted to be 5%, 10%, 15%, 20%, and 25%. The total number of accommodated clusters for the occupied data is established at 15, 24, 36, 49, and 54, with the flexibility percentages maximized at 87%, 91%, 93%, 95%, and 97% for the proposed method. In contrast, the present methodology maintains flexibility at 55%, 61%, 64%, 67%, and 70%, respectively. Therefore, with heightened likelihood, it is feasible to delineate distinct data clusters where data consistency can be preserved.

Flexible data operating points for accommodated clusters.
Scenario 4: Maximization of relocations and deformations.
This scenario examines the potential for moving the converted data by taking into account the overall amount of training delivered during the mapping time periods. As the number of tasks provided during training increases, the level of generalization correspondingly rises. Furthermore, during relocations, erroneous mapping values in healthcare data are entirely eliminated, and only the newly requested parameters are taken into account, resulting in modifications being executed with minimal error rates. This method defines more responsibilities, resulting in increased relocations with enhanced privacy. Furthermore, during the relocation process, the volume of robust data will correspondingly rise in relation to the total number of samples. Conversely, due to deformation, inversion assaults are diminished, resulting in a greater original distance between real and synthetic data, hence enhancing the effective utilization of data sources in healthcare.
Figure 9 illustrates the potential for relocations and deformations in both the proposed and existing methodologies16. Figure 9 illustrates that data relocations and deformations are maximized in the projected model relative to the existing technique16. The primary rationale for this form of maximization is that a greater number of jobs are assigned based on the analyzed data samples, hence facilitating the successful identification of robust data. To validate the results about the simulation, a total of 81, 89, 94, 99, and 112 training models were investigated, with robust data seen at 51, 57, 68, 74, and 87. Therefore, in the aforementioned scenario, the likelihood of relocations with specified duties is 87% for the suggested method, while the existing methodology reduces this likelihood to 51%. The deformations were achieved at a rate of 89%, in contrast to the 63% attained by the previous method.

Possibility of data relocations for all training models.
Performance metrics
The performance metrics are utilized to evaluate the potential modifications in generic data representations, hence enabling the identification of precise points at which changes occur. The dependability and effectiveness of artificially generated synthetic data are assessed by performance metrics, and the typical application forms in the processing units are also examined. Furthermore, performance measures clearly indicate the potential of real-world distributions solely by evaluating data performance, which subsequently diminishes reconstruction mistakes. Two case studies are utilized in the suggested method to evaluate the performance measures as follows.
Case study 1: Data robustness
Case study 2: Data complexity
Case study 1: Data robustness.
This case study evaluates the potential of employing artificially generated synthetic data in the presence of noise and other adversarial threats. Given that the synthetic data is utilized at low resolutions and generated through edge cases, it is essential to assess the resilience of the data. When this type of data is utilized in real time, it may be instantly applied to multiple application platforms, hence enabling effective identification of the classification and behavior of each individual. As the distance increases, both real and synthetic data must be mapped, necessitating the adoption of various methodologies that enhance data synthesis. If data robustness diminishes, the reconstruction of synthetic data, expressed with original measurements, can be utilized reliably. Moreover, leakage information can be mitigated if the data is exposed to low robustness conditions. Figure 10 depicts the comparative results of data robustness for both the existing and proposed methodologies. Figure 10 indicates that the new strategy has diminished data robustness relative to the present methodology. The resilience of the data is enhanced by implementing suitable control levels and generations to eliminate undesirable disturbances in the development of synthetic data. To validate the results of the proposed methodology, a total of 10, 20, 30, 40, 50, 60, 70, 80, 90, and 100 iterations are examined, ensuring that the generated data conforms to the specified data characteristics. In all the aforementioned iterations, it is noted that robustness diminishes to 31%, 24%, 21%, 17%, and 13% for the present model [8]. The robustness of the suggested method is diminished to 23%, 16%, 11%, 8%, and 6%, thereby enabling the creation of a low-dimensional resilient space for synthetic data.

Percentage of robust data representations for all iterations.
Case study 2: Data complexity.
This case study assesses the intricate nature of data to minimize disruptions in the generation of synthetic data. In healthcare, it is evident that a majority of data is saved in an unstructured manner; therefore, it is essential to establish a certain structure prior to the creation process, so fully reducing complexity. Furthermore, if the losses associated with both classification and matching are elevated, the complexity of the overall generated data will increase. In each hostile scenario, the data patterns exhibit unique complexities that complicate the maintenance of data quality; nevertheless, these complexities are mitigated in the generation of synthetic data. Moreover, the suggested method generates data clusters that introduce additional complexity in generative patterns, which are subsequently diminished by the effective utilization of data points.
Figure 11 illustrates the results of data complexity for both the current and suggested methodologies. Figure 11 illustrates that data complexity are diminished in the projected model relative to the existing technique, even within data clusters. A potential cause of reduction is the limited amount of data samples, which amplifies the distance between real and synthetic data. To validate the results of data complexities, optimal epoch periods of 20, 40, 60, 80, and 100 are examined. In the existing approach16, the complexities diminish to 19%, 16%, 12%, 11%, and 9% respectively, while for the same generated data, the complexities decrease to 10%, 7%, 4%, 2%, and 1% correspondingly. Consequently, the suggested strategy utilising a conditional adversarial framework reduces data complexity at each level, thereby directly minimising losses associated with data stability.

Comparison of data complexities with best epoch periods.
Conclusions
The amalgamation of synthetic data with biometric systems in healthcare exhibits significant potential for improving data security, scalability, and functionality while safeguarding patient privacy. This study emphasizes the efficacy of utilizing sophisticated methodologies, including deep convolutional and conditional generative adversarial networks, to produce high-fidelity synthetic data. These techniques guarantee the precise replication of statistical traits and essential biometric patterns, such as face features, iris scans, and fingerprints, without revealing vital real-time data. The findings confirm that synthetic data substantially diminishes reliance on real-world data, successfully mitigating challenges like data shortage and imbalance. Synthetic data enhances accessibility and usability for healthcare and biomedical applications by transforming unstructured data into structured representations. Moreover, the suggested methodology reduces classification mistakes and matching losses, facilitating the efficient implementation of models in applications such as disease prediction, patient monitoring, and biometric authentication.
Furthermore, the incorporation of privacy-preserving techniques like differential privacy guarantees that the produced synthetic data does not jeopardize sensitive information. The prevention of information leakage and effective management of adversarial attacks enhance the dependability of synthetic data in essential healthcare contexts. Methods like as data augmentation, noise management, and simulation-driven transformations boost generalization and scalability, addressing the increasing requirements of practical applications. This study highlights the capacity of synthetic data to enable new solutions for healthcare issues while adhering to relevant regulatory standards. Further investigation is required to enhance model stability, minimize computational burden, and examine multimodal data integration. The results highlight that synthetic data, when integrated with strong biometric systems, serves as a transformative instrument for attaining safe, scalable, and efficient healthcare solutions.
Data availability
The datasets used and/or analysed during the current study are available from the corresponding author on request.
References
Hazra, D., Byun, Y. C. & Synsiggan Generative adversarial networks for synthetic biomedical signal generation. Biology (Basel) 9, 1–20 (2020).
Röglin, J. et al. Improving classification results on a small medical dataset using a GAN; an outlook for dealing with rare disease datasets. Front. Comput. Sci. 4, (2022).
Hamapa, A. M., Zulu, J. M., Khondowe, O. & Hangulu, L. Healthcare workers’ perceptions and user experiences of biometric technology in the selected healthcare facilities in Zambia. Discov Public. Heal 21, (2024).
Hernandez, M., Epelde, G., Alberdi, A., Cilla, R. & Rankin, D. Synthetic data generation for tabular health records: A systematic review. Neurocomputing 493, 28–45 (2022).
Kuo, N. I. H. et al. Enriching data science and health care education: Application and impact of synthetic data sets through the health gym project. JMIR Med. Educ. 10, 1–15 (2024).
Jahan, S., Chowdhury, M., Islam, R. & Chaudhry, J. Securing healthcare data using biometric authentication. Lect Notes Inst. Comput. Sci. Soc. Telecommun Eng. LNICST. 239, 123–132 (2018).
Falkenberg, M., Bensen Ottsen, A., Ibsen, M. & Rathgeb, C. Child face recognition at scale: Synthetic data generation and performance benchmark. Front. Signal. Process. 4, 1–17 (2024).
Wang, Z., Myles, P. & Tucker, A. Generating and evaluating cross-sectional synthetic electronic healthcare data: Preserving data utility and patient privacy. Comput. Intell. 37, 819–851 (2021).
Qian, Z. et al. Synthetic data for privacy-preserving clinical risk prediction. medRxiv 2023.05.18.23290114 (2023).
Shi, J., Wang, D., Tesei, G. & Norgeot, B. Generating high-fidelity privacy-conscious synthetic patient data for causal effect Estimation with multiple treatments. Front. Artif. Intell. 5, (2022).
Khan, S., Parkinson, S., Grant, L., Liu, N. & McGuire, S. Biometric systems utilising health data fromwearable devices: Applications and future challenges in computer security. ACM Comput. Surv. 53, (2020).
Pezoulas, V. C. et al. Synthetic data generation methods in healthcare: A review on open-source tools and methods. Comput. Struct. Biotechnol. J. 23, 2892–2910 (2024).
Gonzales, A., Guruswamy, G. & Smith, S. R. Synthetic data in health care: A narrative review. PLOS Digit. Heal 2, 1–16 (2023).
Giuffrè, M. & Shung, D. L. Harnessing the power of synthetic data in healthcare: Innovation, application, and privacy. Npj Digit. Med. 6, 1–8 (2023).
Blümel, F. E., Schulz, M., Breithaupt, R., Jung, N. & Lange, R. Enhancing resilience in biometric research: Generation of 3d synthetic face data using advanced 3d character creation techniques from high-fidelity video games and animation. Sensors 24, (2024).
Jacobsen, B. N. Machine learning and the politics of synthetic data. Big Data Soc. 10, (2023).
James, S., Harbron, C., Branson, J. & Sundler, M. Synthetic data use: Exploring use cases to optimise data utility. Discov Artif. Intell. 1, (2021).
Mittal, S. et al. On responsible machine learning datasets emphasizing fairness, privacy and regulatory norms with examples in biometrics and healthcare. Nat. Mach. Intell. 6, 936–949 (2024).
Author information
Authors and Affiliations
Contributions
Data curation: S.S. and H.M.; Writing original draft: A.O.K., S.S. and H.M.; Supervision: A.O.K.; A.O.K.; Project administration: A.O.K.; A.O.K.; Conceptualization: S.S. and H.M.; Methodology: S.S. and H.M.; Validation: S.S.; Visualization: S.S.; Resources: S.S.Overall Review & Editing: S.S., S.S. All authors reviewed the final manuscript. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Human and animal rights
We declare that no human or animal involvement is associated with this project.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Khadidos, A.O., Manoharan, H., Khadidos, A.O. et al. Synthetic healthcare data utility with biometric pattern recognition using adversarial networks. Sci Rep 15, 9753 (2025). https://doi.org/10.1038/s41598-025-94572-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-94572-3
Keywords
This article is cited by
-
Enhancing reliability and security in cloud-based telesurgery systems leveraging swarm-evoked distributed federated learning framework to mitigate multiple attacks
Scientific Reports (2025)
-
IoT-based bed and ventilator management system during the COVID-19 pandemic
Scientific Reports (2025)
-
Indoor navigation app of healthcare facilities using machine learning algorithms
Applied Geomatics (2025)
