
Abstract
Real-time semantic segmentation is one of the most researched areas in the field of computer vision, and research on dual-branch networks has gradually become a popular direction in network architecture research. In this paper, a dual-branch automatic driving image segmentation network integrating spatial and channel attention mechanisms is proposed with named as “BiAttentionNet”. The network aims to balance network accuracy and real-time performance by processing high-level semantic information and low-level detail information separately. BiAttentionNet consists of three main parts: the detail branch, the semantic branch, and the proposed attention-guided fusion layer. The detail branch extracts local and surrounding context features using the designed PCSD convolution module to process wide-channel low-level feature information. The semantic branch utilizes an improved lightweight Unet network to extract semantic information from deep narrow channels. Finally, the proposed attention-guided fusion layer fuses the features of the dual branches using detail attention and channel attention mechanisms to achieve image segmentation tasks in road scenes. Comparative experiments with recent mainstream networks such as BiseNet v2, Fast-SCNN, ConvNeXt, SegNeXt, Segformer, CGNet, etc., on the Cityscapes dataset show that BiAttentionNet achieves a highest accuracy of 65.89% in the mIoU metric for the backbone network. This validates the effectiveness of the proposed BiAttentionNet.
Similar content being viewed by others
Introduction
As deep learning image segmentation gradually finds applications in real-life scenarios, the effectiveness and efficiency of dual-branch network architectures in real-time semantic segmentation tasks have been demonstrated1. In common fields such as automatic driving, the challenge of building a lightweight yet high-precision image segmentation network for environmental perception has become crucial due to hardware constraints. The exploration of dual-branch networks, achieved by adjusting the weights of different branches has emerged as a promising solution, has emerged as a new direction to address this challenge.
In recent years, several innovative image segmentation algorithms have further advanced the field by addressing various challenges associated with real-time performance and accuracy. These algorithms often integrate novel architectural components and attention mechanisms to enhance their capabilities. DeepLabV3+2 builds on the DeepLab series by incorporating an encoder-decoder structure that refines the segmented output. It employs atrous spatial pyramid pooling (ASPP) to capture multiscale contextual information and improves the segmentation boundaries through the decoder path. HRNet3 maintains high-resolution representations throughout the entire network by continuously fusing multi-resolution subnetworks. This approach preserves detailed spatial information, crucial for high-quality segmentation. OCRNet4, or Object-Contextual Representations, proposes using object-contextual representations to capture rich semantic context from the objects within the scene. This method refines the feature representations, leading to more accurate segmentation outputs. FANet5, or the feature aggregation network, uses a feature aggregation strategy to integrate multi-scale features effectively. This network achieves a balance between computational efficiency and segmentation accuracy, making it suitable for real-time applications. ANNNet6 introduces an attention neural network that combines spatial and channel attention mechanisms to enhance feature representation for segmentation tasks. This network effectively focuses on important regions and features, leading to improved accuracy, especially in complex scenes. PointRend7 proposes a high-resolution segmentation approach by iteratively refining selected points. This method focuses on rendering fine details in the segmentation boundaries, achieving state-of-the-art performance in accuracy while maintaining efficiency. To further extract image features. ALPD-Net8 addresses the inherent differences between RGB and thermal images, as well as the challenges of multi-modal feature interaction and fusion, by introducing an asymmetric light perception interaction module, a channel-space fusion module, and a staged progressive encoding strategy. ADSFNet9,10 employs a Siamese encoder-decoder structure with dilated neighborhood attention and SFE feature enhancement to improve feature extraction and small object detection. FFAGRNet11 proposes a UAV image object detection method based on full-scale feature aggregation (FFA) and grouped feature reconstruction (GFR) to enhance detection of small and ambiguous targets. CFANet designs a novel cross-layer feature aggregation (CFA) module introduces a Layered Associative Spatial Pyramid Pooling (LASPP) module to improve the extraction of small and dense objects. A dual-stream framework12 leveraging global context and local features is proposed to enhance recognition. The global stream captures high-level features and relationships throughout the entire scene, improving the representation of complex indoor environments. DSMSA-NET13 extracts multi-scale and contextual information by incorporating SAAU (Scale Attention Attention Unit) and SPAU (Spatial Attention Unit). A vehicle detection method based on disparity segmentation is proposed. This method uses disparity map segmentation technology to extract vehicle targets, addressing the issue of reduced detection accuracy in complex traffic scenes caused by occlusion or lighting changes, and enhancing detection robustness in dynamic environments14. An algorithm for joint scene flow estimation and moving object segmentation is proposed, which leverages the spatiotemporal characteristics of rotational LiDAR point clouds. By integrating graph neural networks (GNN) and self-attention mechanisms, the algorithm achieves efficient segmentation of dynamic objects and predicts their motion trajectories15. A cascade attention-modulation fusion mechanism is proposed, which enhances the extraction of key features of traffic signs through multi-stage attention modules16. A trajectory prediction model based on lane crossing and endpoint generation is proposed, which incorporates driving style classification. By leveraging Long Short-Term Memory (LSTM) networks and Generative Adversarial Networks (GANs), the model generates multimodal trajectories, addressing the prediction uncertainty caused by the diversity of driving behaviors in vehicle trajectory prediction17.
In the realm of multi-branch network research, significant progress has been made in addressing real-time semantic segmentation challenges. One notable contribution is ICNet18, an image cascade network designed to minimize computational overhead. This network employs three different resolutions of the same input image, each of which is processed by a distinct branch. By extracting features at multiple resolutions and subsequently merging them, ICNet achieves effective multi-scale feature fusion. This approach not only enhances segmentation accuracy but also maintains computational efficiency. In parallel, ContextNet19 proposed an innovative dual-branch framework in the same year. ContextNet utilizes both low-resolution and high-resolution versions of the same image to capture global contextual information and fine details, respectively. The integration of these features enables robust image segmentation. To optimize performance and reduce computational complexity, ContextNet incorporates depth-wise separable convolutions and inverted bottleneck residual modules within its detail and context branches. This strategic use of efficient convolutional operations significantly decreases the model’s computational demands, making it suitable for deployment on resource-constrained embedded devices.
In addition to leveraging images at varying resolutions as input, subsequent research has explored schemes where feature maps, processed by specific convolutions, are fed into distinct branches. PSPNet20 exemplifies this approach by proposing a method in which features, after being processed by regular convolutional layers, are combined into four separate feature maps of different scales. The feature map is encoded through four different branches, and ultimately, fusion is achieved through upsampling and channel concatenation, effectively integrating multi-scale contextual information. Similarly, Fast-SCNN21 introduces a dual-branch network architecture that uses downsampled feature maps to extract both high-resolution spatial details and low-resolution deep semantic features. The subsequent fusion of these dual-branch features improves the overall semantic segmentation performance. BiseNet v221 explicitly delineates the task of dual-branch image segmentation by separately handling spatial detail information in high-resolution wide channels and semantic information in low-resolution narrow channels. These are designated as the “detail branch” and the “semantic branch,” respectively. BiseNet v2 achieves dual-branch feature fusion through the innovative Bilateral Guided Aggregation (BGA) layer, demonstrating superior results on the Cityscapes22 dataset. DANet23 employs a dual-branch feature encoding strategy by applying spatial and channel attention mechanisms separately to feature maps generated by the ResNet-5024 backbone network. The final feature fusion leverages these attention mechanisms to improve segmentation accuracy. PIDNet1 solves a key challenge in dual-branch network architectures by preventing the overshadowing of high-resolution detail features with low-resolution contextual representations during direct feature fusion. To mitigate this, PIDNet establishes a connection between convolutional neural networks and proportional-integral-derivative controllers, incorporating a detail branch, context branch, and boundary branch. The use of boundary attention guides the effective fusion of detail and context branches, preserving the integrity of detail features. These advancements demonstrate the progression of dual-branch architectures through diversified approaches that balance spatial detail extraction with semantic context integration, advancing real-time semantic segmentation capabilities.
This paper introduces a novel dual-branch network designed for image segmentation tasks in road scenes for autonomous driving, drawing on the design philosophy of BiseNet v2. The proposed network comprises three primary components: the detail branch, the semantic branch, and the aggregation layer. The detail branch employs a sophisticated convolutional module that integrates dilated convolutions and strip convolutions, termed the PCSD (parallel concatenated strip and dilated convolution) module25. This module is instrumental in effectively extracting both spatial local and surrounding contextual information within the detail branch. Our previous work has been verified for its effectiveness and reliability through ablation and comparison experiments. In the semantic branch, we adapt the Unet network, widely utilized in medical image segmentation by reducing the number of channels at each stage. This modification significantly reduces computational complexity, making the network more lightweight and efficient. The combination of these innovative components within our dual-branch architecture aims to balance high segmentation accuracy with real-time performance, making it highly suitable for the computational constraints inherent in autonomous driving applications. The structure of Unet26, with its five encoders and four decoders, efficiently fuses features at different scales through “skip connections,” which enable superior extraction of deep semantic information. This design principle has been adapted in the semantic branch of our proposed BiAttentionNet. The aggregation layer of BiAttentionNet innovatively proposes fusion through dual attention mechanisms. Spatial attention is applied to the feature maps outputted by the detail branch to further enhance spatial detail information. Currently, channel attention processes the feature information produced by the semantic branch. This dual-attention strategy ensures that both spatial details and semantic features are optimally preserved and integrated. The final stage involves concatenating the features from both branches, achieving a comprehensive fusion of the dual-branch architecture. This meticulous combination of features enhances the network’s ability to perform accurate and efficient image segmentation in road scenes. The experimental results validate the efficacy of BiAttentionNet24. When evaluated in the Cityscapes dataset, the BiAttentionNet backbone network outperforms previous algorithms with accuracy of 64%. This demonstrates the superior performance and effectiveness of our proposed dual-branch network in real-world autonomous driving applications.
BiAttentionNet network introduction
The construction and functionality of BiAttentionNet are described in detail in this section. It examines the structural designs of the detail branch, semantic branch, and aggregation layer, demonstrating their distinct roles in enhancing segmentation accuracy and computational efficiency.
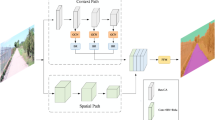
The BiAttentionNet backbone architecture as shown in Fig. 1 comprises: the detail branch, the semantic branch, and the dual attention aggregation layer. Each module is meticulously designed to optimize the network’s performance in handling real-time image segmentation tasks for autonomous driving. Detail Branch: This branch features a shallow network with wide channels specifically tailored to capture and process spatial detailed features. The wide channel architecture ensures that fine-grained spatial information is effectively retained, which is crucial for accurate segmentation in complex road scenes. Semantic Branch: In contrast, the semantic branch employs a deep network with narrow channels. This configuration is designed to process high-level semantic features, facilitating the extraction of contextual information that is essential to understand the broader scene. To ensure both real-time performance and accuracy, the detail branch is designed to capture shallow detailed information. Performance in real time is improved by PCSD with replacing traditional convolution modules with strip convolution and contextual dilated convolution, while using fewer channels to extract detailed information. On the other hand, the semantic branch aims to extract deep semantic information and ensures accuracy by using a U-Net network with higher resolution and more channels to capture feature information effectively. Dual Attention Aggregation Layer: The integration of features from both branches is achieved through the dual attention aggregation layer. This layer employs spatial attention to enhance the detail branch’s spatial features and channel attention to refine the semantic branch’s high-level features. The fusion of these features ensures a comprehensive and cohesive representation to balance detailed spatial information with a deep semantic context.

BiAttentionNet network framework.
BiAttentionNet feature
Before the batch of standardized images enters the main network for feature extraction in the network, it undergoes a series of pre-processing steps, as illustrated in Fig. 2. These pre-processing operations are crucial for enhancing the network’s performance and ensuring robust feature extraction. Batch Standardization: Initially, the images are subjected to batch standardization. This step is essential to ensure that the input images are uniformly scaled to stabilize the training process and improve convergence. Resizing: Following standardization, the images are resized to dimensions of 1024\(\times\)512\(\times\)3. This resizing ensures that all input images are sized in a consistent way, which facilitates receive efficient processing by the network. Random Cropping: To introduce variability and improve the generalization ability of the mode, a random cropping operation is performed with a probability of 0.75.

Data preprocessing.
This step crops the images to a uniform size of 512 × 512 × 3. Random cropping helps the network learn to recognize features from different parts of the images to enhance its robustness. Random Flip: Subsequently, a random flip operation is applied with a probability of 0.5. This operation involves flipping the images in four possible directions: up, down, left, and right. Random flipping further augments the dataset, allowing the network to learn invariant features in different orientations. Normalization: The final pre-processing step involves normalizing the batch of images. Normalization is critical for accelerating image convergence and mitigating issues such as gradient vanishing or explosion during training. By scaling the pixel values to a standard range, normalization ensures that the input data is well suited for the subsequent feature extraction process. Once these pre-processing steps are completed, the batch of images is passed into the BiAttentionNet main network for feature extraction. The pre-processing operation enhances the network’s ability to effectively and efficiently extract meaningful features from the input images, contributing to better performance in image segmentation tasks.
BiAttentionNet detail branch
High-resolution images encompass a wealth of details, including textures, colors and shapes, which represent specific low-level features. Although these images may contain less semantic information, the targets are often clearly discernible and can be advantageous for segmenting small objects. The detail branch is designed to handle these shallow low-level semantic features through a limited number of convolution modules and wider feature channels. Although the traditional 3 × 3 convolution is commonly used in networks for visual image feature extraction, it has limitations in capturing spatial detail information effectively. For instance, substituting 3 × 3 convolutions with 1 × 3 and 3 × 1 Non-bottleneck-1D strip convolutions can enhance computational efficiency by 33% in road image segmentation tasks. This substitution not only reduces computational load, but also maintains a high level of detail extraction. Moreover, the 7 × 7 convolution modules and inverted bottleneck structures employed in ConvNeXt27 have demonstrated significant accuracy improvements over conventional 3 × 3 convolutions in image classification tasks. The advance indicates the potential benefits by using larger and more sophisticated convolutional kernels to extract meaningful features. However, these types of convolutions primarily focus on local feature information and often neglect surrounding contextual feature content. To address the problem, the detail branch in our proposed BiAttentionNet employs a convolutional module that combines both dilated convolutions and strip convolutions, specifically the PCSD module. This module effectively captures both local spatial details and surrounding contextual information, enhancing the network’s ability to perform precise segmentation. By integrating these advanced convolutional techniques, the detail branch not only improves computational efficiency, but also ensures complete representation of spatial details, which is critical for accurate segmentation in complex road scenes.

Schematic diagram of the PCSD convolution module.
In our previous work, we introduced the PCSD convolution module, as depicted in Fig. 3. This module leverages Non-bottleneck-1D convolutions as the local feature extraction branch and integrates three additional branches for surrounding context feature extraction using dilated convolutions. These branches capture a range of contextual information at different scales, essential for complete feature representation. The process begins with the Non-bottleneck-1D branch extracting local features. Simultaneously, the three surrounding context branches, each employing dilated convolutions with varying dilation rates, extract broader contextual features. These branches are subsequently fused through concatenation followed by a convolution operation. This fused output is then combined with the local feature branch via pointwise addition, ensuring that both local and contextual features are effectively integrated. Our experiments have demonstrated that the PCSD convolution module significantly improves segmentation accuracy. Specifically, it improves accuracy by over 8% compared to traditional 3 × 3 and Non-bottleneck-1D convolutions. Furthermore, the PCSD module outperforms other advanced convolutional modules such as MSCA, CCA, and CG in the context of road image segmentation.
This performance gain underscores the efficacy of the PCSD module in capturing and integrating both local and contextual features, making it a superior choice for real-time semantic segmentation tasks, particularly in autonomous driving applications. By balancing computational efficiency and feature richness, the PCSD convolution module represents a significant advancement in the design of convolutional architectures for image segmentation. BiAttentionNet’s detail branch consists of three network layers. At the beginning of each network layer, convolutional downsampling is performed to reduce the image size to half of the previous layer, while sequentially transforming the number of channels to (64, 64, 128). Leveraging the high performance of the PCSD convolution module, BiAttentionNet employs it as the convolutional module for feature extraction in the detail branch. Following the downsampling operation, each layer’s PCSD module has a depth of 3. Ultimately, the input image of size 512 × 512 × 3 is encoded into feature maps of size 64 × 64 × 128, rich in spatial detail features, thus completing the construction of BiAttentionNet’s detail branch.
BiAttentionNet semantic branch introduction
The Semantic Branch of BiAttentionNet is designed to extract deep, high-level semantic information. Deep networks are capable of capturing rich semantic features and possess a larger receptive field, advantageous for extracting features of larger objects. The Unet network, known for its exceptional performance in the field of medical imaging, particularly excels in tasks such as organ and cell segmentation. Its encoder-decoder structure allows the network to effectively fuse semantic information from different scales and receptive fields. This ability to integrate multi-scale features makes Unet highly suitable for complex segmentation tasks. In this work, we adapt the Unet network as the Semantic Branch of BiAttentionNet, leveraging its strengths to enhance road scene image segmentation. By integrating Unet into our architecture, we leverage its ability to capture and fuse semantic information across different scales. This integration is particularly beneficial for road scene segmentation, where accurate detection of objects at different sizes and distances is crucial. The Unet-based Semantic Branch enhances the overall performance of BiAttentionNet by ensuring that high-level semantic features are robustly extracted and integrated. This approach not only improves the accuracy of segmentation, but also ensuring computational efficiency for real-time autonomous driving applications.

Schematic diagram of the semantic branch.
As illustrated in Fig. 4, the Semantic Branch of BiAttentionNet comprises five stages, each including five encoder stages and four decoder stages. The encoders are responsible for extracting feature representations at five distinct scales. At each stage, max-pooling downsampling is applied, halving the image size and progressively capturing more abstract and high-level semantic features. The decoders then map these features back to the original spatial resolution, enabling dense predictions. This upsampling process ensures that the detailed spatial information is restored, crucial for precise segmentation tasks28. The network incorporates skip connections that link corresponding encoder and decoder stages. These connections facilitate the preservation of fine-grained details and enhance the learning of subsequent convolutional features by combining low-level spatial information with high-level semantic context. To optimize the model for real-time applications and reduce computational load, we have made significant channel adjustments. Specifically, the number of channels is reduced to one-quarter of the original Unet network. This reduction not only decreases the model size, but also enhances its computational efficiency without compromising the quality of feature extraction. By effectively fusing semantic information from different scales and depths, the Unet architecture within the Semantic Branch ensures robust feature integration29. This comprehensive approach enhances the network’s ability to accurately segment road scenes, accommodating various object sizes and complexities. With these modifications and optimizations, the construction of the Semantic Branch in BiAttentionNet is completed. This branch, leveraging the proven capabilities of Unet, plays a pivotal role in enhancing the overall performance of BiAttentionNet for autonomous driving applications.
BiAttentionNet dual-branch attention aggregation layer introduction
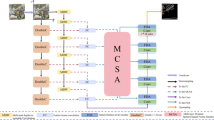
BiAttentionNet proposes a novel dual-branch attention aggregation layer, where the semantic branch is responsible for extracting spatial detail information of shallow-level low-level semantics. As shown in Fig. 5, the left branch is the detailed branch input. The detailed branch future map is processed by a 3 × 3 convolutional module to extract shallow spatial detail features using the spatial attention mechanism in CBAM30, and the image size is transformed into 512 × 512 × 128 to align with the size of the semantic branch feature map by upsampling.

BiAttentionNet dual-branch attention aggregation layer.
The semantic branch is responsible for extracting deep semantic information for a wide channel. Therefore, the output feature map of the semantic branch is processed by a 3 × 3 convolutional module to perform channel feature extraction using the ECA31 attention mechanism. The spatial attention mechanism takes the feature map output by the channel attention module as the input feature map of this module. Firstly, pooling (AvgPool) operations are performed to obtain two H × W × 1 feature maps; then, the two feature maps are concatenated based on the channel dimension, i.e., Contact operation; then, a 7 × 7 convolutional kernel is used to reduce the dimensionality along the channel dimension to a single-channel feature map, i.e., H × W × 1; finally, the dependency relationship between spatial elements is learned through Sigmoid to generate spatial dimension weights, the formula of which is as follows:
The ECA channel attention mechanism achieves channel attention through global average pooling, transforming the feature map from a matrix of [h,w,c] into a vector of [1,1,c]. It then utilizes 1D convolution to obtain weights for each channel, learns the dependencies between channels using the Sigmoid activation function, and finally generates channel-dimensional weights, which are multiplied channel-wise with the input feature map. This completes the construction of the BiAttentionNet dual-branch attention aggregation layer.
BiAttentionNet FCN head introduction
The output layer employed in the BiAttentionNet network is FCNHead, a crucial component for semantic segmentation tasks. The FCNHead, part of the Fully Convolutional Network (FCN) architecture, extends traditional Convolutional Neural Networks (CNNs) to generate pixel-level prediction results from deep feature maps, making it highly effective for dense prediction tasks.

FCN head introduction.
As depicted in Fig. 6, the FCNHead is responsible for the final per-pixel prediction task on the feature maps. The backbone network of BiAttentionNet, comprising the semantic branch, detail branch, and aggregation layer, generates a feature map of dimensions 512 × 512 × 256. This feature map encapsulates the integrated spatial and semantic features necessary for accurate segmentation. To prepare the feature map for final predictions, it is first expanded to a size of 1024 through regular convolution operations. Following this, normalization stabilizes data distribution, and ReLU introduces non-linearity, enhancing the network’s ability to model complex patterns. Additionally, dropout operations are implemented to prevent over fitting by randomly deactivating a fraction of the neurons during training. The channel size of the feature map is then compressed back to match the number of target categories, which is typically 19 for the Cityscapes dataset. This compression ensures that each pixel in the feature map corresponds to a class prediction. Finally, the FCNHead performs predictions for each pixel’s class. The prediction loss is computed using the cross-entropy loss function, a standard choice for classification tasks due to its effectiveness in measuring the difference between the predicted and true class distributions. The per-pixel loss calculation, which guides the backpropagation and parameter updates, can be expressed as follows:
Experimentation research
In this section, we introduce the dataset and implementation details, and report the final accuracy compared to other algorithms to validate the advancement of BiAttentionNet proposed in this paper.
Dataset and experimental environment
The Cityscapes dataset captures urban street scenes from the perspective of a car and comprises high resolution images from 50 European cities. This dataset is widely used for benchmarking semantic segmentation algorithms, particularly in the context of autonomous driving. The 2975 training images and 500 validation images are used to achieve our experiments, covering 19 categories relevant to the semantic segmentation task. During training, we set the batch size to 2 and resized the image dimensions to 512 × 512 × 3 to balance computational efficiency and model performance. The training process involved selecting the best model after 400 iterations, ensuring that the network had sufficient opportunities to learn the underlying patterns in the data. We evaluated segmentation accuracy using the mean Intersection over Union (mIoU) metric, a standard measure for assessing the performance of segmentation models. Our experiments were conducted using Python, PyTorch 1.13, and the segmentation framework, which provided a robust environment for implementing and testing our network. For the inference stage, we utilized a single NVIDIA GeForce RTX 3060 GPU with 12GB of memory, operating under a CUDA 11.6 environment. This setup ensured that our model could perform real-time inference with high accuracy. The optimizer employed during training was AdamW32, chosen for its effective handling of weight decay and gradient updates. We set the weight decay to 0.05 to prevent over fitting and enhance generalization. Inspired by the MobileNet architecture33, BiAttentionNet employed a polynomial learning rate schedule, starting with an initial learning rate of 0.045. This learning rate schedule assists in gradually reducing the learning rate, allowing the model to converge more effectively. These settings ensured optimal BiAttentionNet training and evaluation, leading to robust and accurate semantic segmentation performance in the Cityscapes dataset.
Algorithm comparison experiment
This section aims to evaluate the performance of BiAttentionNet compared to other state-of-the-art multi-branch image segmentation algorithms, common pure convolutional image segmentation algorithms, and some Transformer-based image segmentation algorithms on the Cityscapes dataset. We conducted comparisons under the same experimental environment and parameter settings, analyzing the final accuracy of the backbone networks and the model parameter counts of different algorithms. According to the experimental results in Table 1, BiseNet v2 achieves an accuracy of \(59.36\%\) in urban road segmentation tasks, which is \(5.35\%\) higher than the similar dual-branch image segmentation network Fast-SCNN21. Although the ConvNeXt backbone network only achieves an accuracy of \(60.65\%\) in image segmentation tasks, it has a larger parameter count. SegNeXt achieves an accuracy of \(60.99\%\), Segformer achieves \(61.58\%\), and CGNet achieves \(63.05\%\). However, compared to common single-branch network algorithms such as ConvNeXt27, SegNeXt34, Segformer35, and CGNet36, typical representatives, BiseNet v2 and Fast-SCNN, are relatively weaker in urban road segmentation ability. However, the proposed BiAttentionNet, which is also a dual-branch image segmentation algorithm, achieves an accuracy of \(65.89\%\) with a slight increase in parameters. Compared to recent representative main image segmentation networks, BiAttentionNet, the proposed dual-branched image segmentation algorithm, demonstrates significantly higher precision and validates its effectiveness and advancement.

Visualization comparison with previous algorithms.
As shown in Fig. 7, the visualization of the comparative experiment employs the classic dual-branch network BiseNet v2 as the reference. In the first column of Fig. 7 are the original images captured by the dashcam, the second column shows the manually annotated ground truth, the third column displays the prediction results of the BiseNet v2 algorithm, and the fourth column presents the prediction results of the BiAttentionNet algorithm proposed in this paper. Here, the focus primarily lies on the portions marked with red circles and rectangles in the original images. Regarding the segmentation of the distant bus and its overhead traffic lights in the first row, the segmentation effect of the BiAttentionNet algorithm proposed in this paper is more pronounced compared to BiseNet v2. In the second row, BiseNet v2 fails to segment distant small pedestrians, whereas BiAttentionNet can clearly delineate the contours in pedestrians. In the third row, for the slender poles of the traffic lights, and in the fourth row, for the poles arranged on the right side of the road, BiAttentionNet also demonstrates superior performance. Thus, it can be observed that BiAttentionNet not only improves overall accuracy, but also exhibits stronger performance, especially in segmenting small and distant objects.
Conclusions
In this work, we introduced the BiAttentionNet real-time semantic segmentation model, which combines dual-branch attention fusion. The PCSD convolution module was utilized for the detail branch to encode spatial local details and surrounding contextual information of the image. Deep semantic information was then extracted using the Unet network. A novel dual-branch feature fusion module that combines spatial attention with channel attention has been proposed to enhance segmentation performance. Through experiments on the Cityscapes dataset, we demonstrated the effectiveness of the proposed BiAttentionNet algorithm in segmenting distant and small objects.While the results indicate promising performance, particularly in terms of segmentation accuracy, the model’s robustness and generalization capabilities require further validation across additional datasets in future work. Looking ahead, there are several promising directions for future research and development. One potential area of improvement lies in further optimizing the dual-branch fusion mechanism to enhance the model’s efficiency and performance on real-time hardware platforms, especially in the context of embedded systems and autonomous driving. Additionally, we aim to explore the integration of BiAttentionNet with other modalities, such as depth and radar data, to improve segmentation performance in challenging environments such as low-light, fog, and rain. Another exciting prospect is the expansion of BiAttentionNet to more complex and dynamic environments, including those involving moving objects or real-time scene changes. By incorporating temporal information and tracking algorithms, the model could evolve to support video-based semantic segmentation, offering enhanced real-time capabilities for applications such as robotics and surveillance. Lastly, we plan to open-source the algorithm and share the experimental parameters to encourage collaboration and further validation from the research community. With continued improvement, BiAttentionNet can become a valuable tool for real-time, high-accuracy segmentation.
Data availability
All data generated or analysed during this study are included in the supplementary information files.
References
Xu, J., Xiong, Z. & Bhattacharyya, S. P. Pidnet: A real-time semantic segmentation network inspired by pid controllers. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 19529–19539. https://doi.org/10.1109/CVPR52729.2023.01871 (2023).
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, H. & Florianand, A. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Computer Vision—ECCV 2018 (eds Ferrari, V. et al.) 833–851 (Springer, Cham, 2018). https://doi.org/10.1007/978-3-030-01234-2_49.
Wang, J. et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 43, 3349–3364. https://doi.org/10.1109/TPAMI.2020.2983686 (2021).
Yuan, Y., Chen, X. & Wang, J. Object-contextual representations for semantic segmentation. In Computer Vision—ECCV 2020 (eds Vedaldi, A. et al.) 173–190 (Springer, Cham, 2020).
Singha, T., Pham, D.-S. & Krishna, A. Fanet: Feature aggregation network for semantic segmentation. In 2020 Digital Image Computing: Techniques and Applications (DICTA), 1–8. https://doi.org/10.1109/DICTA51227.2020.9363370 (2020).
Gu, R. et al. Ca-net: Comprehensive attention convolutional neural networks for explainable medical image segmentation. IEEE Trans. Med. Imaging 40, 699–711. https://doi.org/10.1109/TMI.2020.3035253 (2021).
Kirillov, A., Wu, Y., He, K. & Girshick, R. Pointrend: Image segmentation as rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 9799–9808 (2020).
Zhang, Y., Wang, S., Zhang, Y. & Yu, P. Asymmetric light-aware progressive decoding network for RGB-thermal salient object detection. J. Electron. Imaging 34, 013005. https://doi.org/10.1117/1.JEI.34.1.013005 (2025).
Zhang, Y., Zhen, J., Liu, T., Yang, Y. & Cheng, Y. Adaptive differentiation Siamese fusion network for remote sensing change detection. IEEE Geosci. Remote Sens. Lett. 22, 1–5. https://doi.org/10.1109/LGRS.2024.3516775 (2025).
Zhang, Y., Wu, C., Zhang, T. & Zheng, Y. Full-scale feature aggregation and grouping feature reconstruction-based UAV image target detection. IEEE Trans. Geosci. Remote Sens. 62, 1–11. https://doi.org/10.1109/TGRS.2024.3392794 (2024).
Zhang, Y., Wu, C., Guo, W., Zhang, T. & Li, W. CFANet: Efficient detection of UAV image based on cross-layer feature aggregation. IEEE Trans. Geosci. Remote Sens. 61, 1–11. https://doi.org/10.1109/TGRS.2023.3273314 (2023).
Khan, S. D. & Othman, K. M. Indoor scene classification through dual-stream deep learning: A framework for improved scene understanding in robotics. Computers 13, 121. https://doi.org/10.3390/computers13050121 (2024).
Khan, S., Alarabi, L. & Basalamah, S. DSMSA-Net: Deep spatial and multi-scale attention network for road extraction in high spatial resolution satellite images. Arab J. Sci. Eng. 48, 1907–1920. https://doi.org/10.1007/s13369-022-07082-z (2023).
Li, S., Chen, J., Peng, W., Shi, X. & Bu, W. A vehicle detection method based on disparity segmentation. Multimed. Tools Appl. 82, 19643–19655. https://doi.org/10.1007/s11042-023-14360-x (2023).
Chen, X. et al. Joint scene flow estimation and moving object segmentation on rotational LiDAR data. IEEE Trans. Intell. Transp. Syst. 25, 17733–17743. https://doi.org/10.1109/TITS.2024.3432755 (2024).
An, F., Wang, J. & Liu, R. Road traffic sign recognition algorithm based on cascade attention-modulation fusion mechanism. IEEE Trans. Intell. Transp. Syst. 25, 17841–17851. https://doi.org/10.1109/TITS.2024.3439699 (2024).
Liu, X. et al. Trajectory prediction of preceding target vehicles based on lane crossing and final points generation model considering driving styles. IEEE Trans. Veh. Technol. 70, 8720–8730. https://doi.org/10.1109/TVT.2021.3098429 (2021).
Zhao, H., Qi, X., Shen, X., Shi, J. & Jia, J. Icnet for real-time semantic segmentation on high-resolution images. In Computer Vision—ECCV 2018 (eds Ferrari, V. et al.) 418–434 (Springer, Cham, 2018).
Poudel, R. P. K., Bonde, U. D., Liwicki, S. & Zach, C. Contextnet: Exploring context and detail for semantic segmentation in real-time. In British Machine Vision Conference (2018).
Zhao, H., Shi, J., Qi, X., Wang, X. & Jia, J. Pyramid scene parsing network. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 6230–6239 (2016).
Poudel, R. P. K., Liwicki, S. & Cipolla, R. Fast-scnn: Fast semantic segmentation network. ArXiv arXiv:1902.04502 (2019).
Zhang, Y., Zhang, T., Wang, S. & Yu, P. An efficient perceptual video compression scheme based on deep learning-assisted video saliency and just noticeable distortion. Eng. Appl. Artif. Intell. https://doi.org/10.1016/j.engappai.2024.109806 (2025).
Fu, J. et al. Dual attention network for scene segmentation. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 3141–3149. https://doi.org/10.1109/CVPR.2019.00326 (2019).
Wu, Z. & Zhu, Y. Swformer-vo: A monocular visual odometry model based on swin transformer. IEEE Robot. Autom. Lett. 9, 4766–4773. https://doi.org/10.1109/LRA.2024.3384911 (2024).
Wu Zhigang, Z. Y. Biconvnet: Integrating spatial details and deep semantic features in a bilateral-branch image segmentation network. IEICE Trans. Inf. Syst. E107.D, 1385–1395. https://doi.org/10.1587/transinf.2024EDP7025 (2024).
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015 (eds Navab, N. et al.) 234–241 (Springer, Cham, 2015).
Liu, Z. et al. A convnet for the 2020s. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11966–11976, https://doi.org/10.1109/CVPR52688.2022.01167 (2022).
Yunzuo, Z., Tian, Z., Cunyu, W. & Ran, T. Multi-scale spatiotemporal feature fusion network for video saliency prediction. IEEE Trans. Multimed. 26, 4183–4193. https://doi.org/10.1109/TMM.2023.3321394 (2024).
Zhang, Y., Liu, Y., Kang, W. & Tao, R. VSS-Net: Visual semantic self-mining network for video summarization. IEEE Trans. Circuits Syst. Video Technol. 34, 2775–2788. https://doi.org/10.1109/TCSVT.2023.3312325 (2024).
Woo, S., Park, J., Lee, J.-Y. & Kweon, I. S. Cbam: Convolutional block attention module. In Computer Vision—ECCV 2018 (eds Ferrari, V. et al.) 3–19 (Springer, Cham, 2018).
Wang, Q. et al. Eca-net: Efficient channel attention for deep convolutional neural networks. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11531–11539. https://doi.org/10.1109/CVPR42600.2020.01155 (2020).
Loshchilov, I. & Hutter, F. Decoupled weight decay regularization. In International Conference on Learning Representations (2017).
Howard, A. G. et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications. ArXiv arXiv:1704.04861 (2017).
Guo, M.-H. et al. Segnext: Rethinking convolutional attention design for semantic segmentation. ArXiv arXiv:2209.08575 (2022).
Xie, E. et al. Segformer: Simple and efficient design for semantic segmentation with transformers. In Neural Information Processing Systems (2021).
Wu, T., Tang, S., Zhang, R., Cao, J. & Zhang, Y. Cgnet: A light-weight context guided network for semantic segmentation. IEEE Trans. Image Process. 30, 1169–1179. https://doi.org/10.1109/TIP.2020.3042065 (2021).
Acknowledgements
This work was supported in part by Natural Science Foundation of Jiangxi Province (2023BAB204059), in part by Science and technology project of State Grid Corporation of China: Research on lightweight modular drilling equipment for hard rock formation in transmission line foundation construction in Mountainous Areas (5200-202321476A-3-2-ZN). in part by State grid Gansu electric power company construction branch(SGGSJS00JSJS2400177)
Author information
Authors and Affiliations
Contributions
R. J. L. and Z. G. W. conceived the experiment(s) and modified the writing, Y. J. Z. and J. Y. C. conducted the experiment(s), Y. H. Z. written the paper, J. L. and M. C. analysed the results. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, R., Zhang, Y., Chen, J. et al. BiAttentionNet: a dual-branch automatic driving image segmentation network integrating spatial and channel attention mechanisms. Sci Rep 15, 13193 (2025). https://doi.org/10.1038/s41598-025-95470-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-95470-4
