
Abstract
Deepfake technology has enabled the widespread distribution of manipulated facial content online, raising serious societal concerns. In recent years, deepfake detection has emerged as a critical research focus. However, existing methods frequently overlook the connection between local details and overall image features, while also failing to address the problem of implicit identity leakage. Consequently, their performance is suboptimal, particularly in cross-dataset evaluations. Specifically, the proposed multi-attention deepfake detection model consists of the following three parts: (1) Texture Feature Enhancement: We employ CondenseNet to enhance texture features efficiently, preserving subtle details and ensuring feature integrity; (2) Multi-Scale Artifact Detection: We introduce an artifact detection module that identifies potentially manipulated regions, enabling localized detection and minimizing the impact of identity information. (3) Multi-Attention Mechanism: By generating multiple attention maps, our model prioritizes different regions of the input image, fusing both texture and local features to improve classification performance. Our method is evaluated on the FaceForensics++ and DFDC benchmarks for facial manipulation detection. Additionally, we assess its cross-dataset performance on Celeb-DF-v2, achieving state-of-the-art results.
Similar content being viewed by others

Introduction
In December 2017, a Reddit user known as “DeepFakes” released the first forged adult video featuring Hollywood actress Gal Gadot, generated using deep neural networks. This event marked the official emergence of deepfake technology for facial video manipulation. The term “deepfake” is derived from the combination of “deep learning” and “fake,” and it has since become a catch all phrase for various deep learning based video manipulation methods. These techniques encompass face swapping, expression editing, and other forms of manipulation, with applications ranging from evading detection and spreading misinformation to entertainment and other purposes.
While these technologies hold significant promise for the entertainment and media sectors, they are often exploited to generate counterfeit facial imagery, such as mimicking political leaders and celebrities, swaying public sentiment, and enabling deceitful actions. For instance, in 2022, a fabricated video surfaced online showing Ukrainian President Volodymyr Zelenskyy urging Ukrainian troops to surrender and lay down their arms. The video disseminated quickly across social media platforms, exacerbating the tensions between Russia and Ukraine1. In the 2023 U.S. presidential election, the Republican National Committee unveiled a deepfake campaign advertisement, leveraging deepfake technology to simulate political figures. This action had a detrimental impact on the electoral process and undermined political trust2. In 2024, criminals utilized deepfake technology to fabricate the images and voices of the Chief Financial Officer (CFO) and the executive team of the British headquarters of the multinational company Arup. Through video conferencing, they deceived employees at the company’s Hong Kong branch, causing a financial loss of nearly 200 million HKD3. Such misuse has amplified public concerns about personal image theft, identity fraud, and the dissemination of disinformation on social platforms, leading to serious issues of trust and security. In the political realm, deepfake technology poses significant risks, especially in election manipulation, potentially triggering severe crises of trust. As a result, the development of effective deepfake detection technologies has become an urgent necessity.
Previous approaches to deepfake detection primarily relied on binary classifiers. Although these methods often performed well on the training dataset, their effectiveness significantly decreased in cross-dataset scenarios. Generally, these techniques utilize a primary network to extract overall image features, which are subsequently input into a classification system to distinguish between authentic and manipulated content. However, as deepfake techniques evolve, the distinctions between forged and authentic images have become increasingly subtle, rendering global feature based classification methods less effective. The current image processing technology faces multi-dimensional challenges: the performance degradation of object recognition in low-light environments4, the lack of global information in super-resolution reconstruction5,6, and the ethical and fairness issues in face recognition7. These challenges have driven the demand for multi-modal feature fusion and lightweight model design.
To tackle this challenge, Zhao et al. reframed the deepfake detection task as a specialized fine grained binary classification problem8. They introduced a multi-attention mechanism emphasizing subtle local features, thereby improving the model’s generalization ability. Moreover, Dong et al. demonstrated that the limited generalization performance of binary classifiers in deepfake detection arises from the unintentional learning of identity information within images, a phenomenon known as “Implicit Identity Leakage”9. A straightforward approach to address this issue is to direct the model’s attention toward local image features for forgery detection. By prioritizing local features over global information often containing identity related cues the model reduces its reliance on identity information, thus improving its generalization ability. Similarly, Gao et al. emphasized that extracting local features and understanding their relationships are crucial and effective strategies for detecting deepfake facial manipulations10. This underscores the importance of localized analysis in enhancing detection performance.
Therefore, our goal is to achieve high quality deepfake detection while improving generalization performance. To facilitate its implementation on end devices, it is essential that the model be as lightweight as possible. We propose a multi-attentional based deepfake detection method that mitigates Implicit Identity Leakage, while also leveraging global features to capture the relationships between local features. Specifically, we introduce a multi-attentional detection approach that prevents the misuse of identity information. First, we introduce a multi-attentional mechanism to leverage deep semantic information for generating multiple spatial attention maps, allowing the model to focus on different regions where forgeries may occur. Second, to prevent subtle differences from being lost in deeper layers, we incorporate CondenseNet to enhance texture features. Additionally, we design a forgery trace detection module to identify potential textures and local regions indicative of forgeries. Finally, the feature representations from each component are independently pooled using Bilinear Attention Pooling, and these pooled features are fused to create a comprehensive representation of the entire image, which is then passed to the classifier. To verify the effectiveness of the proposed method, we performed extensive experiments on several existing datasets. The results indicate that our method achieves better performance on these datasets, surpassing current state-of-the-art methods.
The main contributions of this paper are listed as follows:
-
We propose a novel multi-attention detection method that captures local facial features from multiple regions to extract detailed local information. This approach not only mitigates the misuse of identity information but also enhances subtle texture features, utilizing various components to improve the model’s understanding of both fine grained local and global features.
-
We introduce a forgery trace detection module to identify manipulated regions, integrating global and texture features. This design lets the model focus on local features while minimizing reliance on identity information.
-
We conducted extensive experiments and comprehensive analyses on several benchmark datasets, including FaceForensics++, Celeb-DF, and DFDC, achieving superior performance compared to existing methods.
The remainder of this paper is organized as follows. “Related Work” Section reviews the related work, identifies the limitations of existing methods, and articulates the motivation for this study. “Proposed Method” Section provides a comprehensive description of the proposed detection model and the design of its core components. “Experiment” Section presents the experimental design and result analysis to validate the efficacy of the proposed method. Finally, “Conclusion” Section summarizes the main contributions of this research and discusses potential avenues for future work.
Related work
Previous studies have approached the deepfake detection problem from various perspectives11,12,13,14,15,16,17,18,19. To address this challenge, researchers have attempted to enhance deepfake detection methods from various perspectives20,21,22. These efforts include designing diverse loss functions23, extracting richer features24,25, and analyzing the continuity between consecutive frames26,27. The majority of these deepfake detection methods can be broadly categorized into two main groups.
Binary classifiers
Initial approaches often structured the problem as a binary classification task, with the objective of differentiating between authentic and manipulated content. While this approach was straightforward, it often led to poor generalization performance, particularly when applied to deepfakes generated using techniques that were not represented in the training data15,28. This limitation highlighted the need for more sophisticated and adaptable detection strategies.
The core idea behind binary classification is to employ traditional deep neural networks (DNNs), such as XceptionNet and EfficientNet, to extract global features from an image via successive convolutional layers3,29. This frequently leads to the oversight of shallow texture and local features. These approaches generally employ a backbone encoder to extract high-level features, which are then fed into a classifier to ascertain whether the input image has been manipulated. Durall et al.30 were the first to propose a frequency domain analysis model for detecting face forgeries. Masi et al.31 employed a dual branch recursive network to simultaneously extract high level semantic information from both the original RGB image and its frequency domain, achieving strong performance across multiple public datasets. Li et al.28 put forward a single-center loss function that narrows the classification space for genuine samples, thereby boosting the detection rate for forged ones.
Binary classifiers demonstrate robust performance in terms of detection accuracy when applied to the same dataset. However, they struggle to maintain strong performance when confronted with unseen forgery techniques or high quality fake images. Moreover, as the quality of forged images improves, the distinction between authentic and fake images becomes increasingly subtle, resulting in decreased detection performance when dealing with high quality forgeries. Therefore, developing more effective localization mechanisms to capture local information is essential.
Handcrafted classifiers
More recent approaches have focused on designing handcrafted classifiers that leverage domain specific knowledge and feature engineering to improve detection accuracy. These methods aim to create robust models that can generalize better across different types of deepfake forgeries. However, despite these advancements, handcrafted classifiers still face significant challenges when dealing with novel forgery techniques that differ from those encountered during the training phase. This persistent challenge highlights the necessity of creating more adaptable and robust detection frameworks that can keep pace with the swiftly changing realm of deepfake technology.
Numerous studies have attempted to enhance the generalization capacity of deepfake detectors by identifying specific artifacts linked to diverse facial manipulation techniques. Li et al.32 proposed that certain physical characteristics of real humans cannot be easily manipulated in fake videos. They developed a blinking detector that assesses the authenticity of a video based on the frequency of blinking. Since 3D data cannot be directly generated from fake images, Yang et al.33 approached the face forgery detection task from the perspective of generating samples using non-3D projections. Sun et al.34 and Li et al.13 focused on detecting forgeries by emphasizing precise geometric features, such as facial landmarks, and blended artifacts. Liu et al.35 incorporated frequency domain information into their model, as the frequency domain is particularly sensitive to upsampling operations, which are commonly used in deepfake generation. Additionally, they employed shallow networks to extract rich local texture information, thereby improving the model’s generalization and robustness.
In summary, handcrafted deepfake detectors guide models to capture specific artifact features and use the responses to these features as indicators of manipulated images or videos. However, these approaches frequently encounter difficulties when the forged content lacks the particular artifacts that were introduced during the training phase.
Proposed method
Motivation
Current research has demonstrated that the suboptimal performance of deepfake detection can be primarily attributed to implicit identity leakage, where overlapping identity feature information between authentic and forged images leads to erroneous predictions by classifiers. It is widely held that employing local features can effectively prevent models from learning identity related information. Therefore, we should not only consider how to effectively collect richer local features but also prioritize the focused enhancement of shallow layer textural features. This comprehensive integration of both aspects constitutes a critical dimension that has been overlooked by current state-of-the-art detection methodologies. It has been posited that the challenge of deepfake detection is analogous to fine grained image classification8. The authors conceptualize deepfake detection as a fine grained classification problem with two categories (authentic and forged), where discrimination is achieved through localized subtle discrepancies rather than relying solely on global image characteristics. A prevalent approach to addressing fine grained image classification involves part based models, which systematically analyze region specific discriminative patterns. This approach is characterized by decomposing target objects into constituent parts, performing independent detection on each localized component, and subsequently synthesizing their spatial interrelationships to determine the categorical identity of the target object.
Inspired by the part based models in fine grained problem solving approaches, our framework also consists of three key components. Our framework eschews the prevalent use of global features in current deepfake detection methodologies and instead employs localized feature aggregation to accomplish the task. Concurrently, given that forgery artifacts are inherently subtle and often imperceptible, meticulous analysis of fine grained textural features becomes imperative in our investigative framework. The textural information, which represents high frequency components in shallow layer features, is consequently represented through residual information derived from RGB images in our methodology.
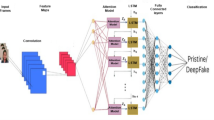
As shown in Fig. 1, the id-intensive multi-attention deepfake detection model framework proposed in this paper is based on the aforementioned observations.

Schematic diagram of the id-intensive multi-attention deepfake detection model framework.
This system is made up of three key parts. The multi-scale artifact detection module gets a multi-level grasp of the input features, considering both the local details and the overall context of the image being detected. The texture information enhancement module can amplify shallow texture feature information, keeping and boosting complete subtle features. The attention map generation module can produce several attention maps, directing the focus to various local areas of the detection object.
Framework
For the proposed framework, as shown in Fig. 1, we first convert video frames into images, and then employ RetinaFace for face detection and cropping, using the obtained facial images as input. Following the initial processing by the backbone network, the resulting shallow features are channeled into the texture feature enhancement module. This module performs texture feature extraction and enhancement, ultimately producing a refined texture feature map. The shallow features are then processed through another layer of the backbone network, after which we utilize the attention map generation module to obtain multiple attention maps, which are used to guide the subsequent feature fusion process. Finally, we input the backbone features into the multi-scale artifact detection module and fuse them with the backbone features after average pooling, further enriching the learned deepfake features.
Multi-scale artifact detection module
Although we believe that the traditional method of extracting global features from the input image and feeding them into a classifier is impractical, this does not mean that we will completely abandon global information. On the contrary, we hold the view that global information remains highly useful in the task of deepfake detection. Given that recent research has demonstrated the significant value of local information in overcoming existing limitations, we argue that the model should not only focus on global features but also pay close attention to local features. Therefore, we introduced a multi-scale artifact detection module9. This module accepts the features extracted by the backbone network as input and locates artifact regions using multi-scale anchors. Precisely, after the backbone processing, four additional layers with varying scales have been included. The feature map sizes gradually reduce by the dimensions specified by the tuple (7 × 7, 5 × 5, 3 × 3, 1 × 1). During the training phase, the multi-scale detection module was placed after the first three additional layers, utilizing multi-scale default anchors on the image to detect artifact regions in fake images. Consistent with20,36,37, each grid in the feature map corresponds to multiple default anchors of varying scales on the input image. The multi-scale detection module appends detectors and classifiers to each added layer, outputting position offsets (N × 4) and class confidence scores (N × 2, indicating fake or real anchors) for every default anchor. When the IoU between an anchor box and the ground truth of an artifact region surpasses a threshold, the anchor is labeled as fake. Additionally, the final 1 × 1 feature map of the Artifact Perception Module (APM) forms a shortcut connection with the end of the backbone, enriching the artifact features learned by the APM. The output is subsequently fed into a fully connected layer to generate the final prediction. In essence, the APM assesses whether artifact regions exist within multi-scale anchors. This architecture diverts the model’s focus away from global identity features in the image, thereby diminishing the impact of implicit identity leakage.
Texture enhancement module
A notable oversight in the frameworks of most previous deepfake detection methods is that, regardless of the forgery technique employed, the shallow texture features of the manipulated regions in the forged images are prominent. It makes sense that the manipulated regions in an image typically exhibit contours, such as those around the eyes, nose, and mouth. The edges of these contours represent the high frequency components of the image, which correspond to its texture details. These texture features are easily overlooked by the model when we extract deeper features. However, the differences between forged and real images are often very subtle. In the RGB representation, residuals can also express texture information. Therefore, we designed a texture enhancement module, as shown in Fig. 2. We take the shallow feature (SF) as input, down sample it, and perform average pooling to obtain the feature map D. By performing residual processing on SF and D, we can obtain the desired texture information, which we refer to as the texture feature map (TF). This TF contains the rich texture information from the shallow feature SF. Then, we use CondenseNet to enhance the obtained texture feature map. CondenseNet is a lightweight version of DenseNet that mainly implements a pruning of connections during the training process to eliminate redundant connections in DenseNet. We denote the output as the texture enhanced feature map (THF), and then input THF into a multi-scale artifact detection module to fuse the local and global texture features, resulting in the final enriched texture-enhanced feature map (DTHF). This further enriches the model’s learning of texture features.

Texture enhancement module.
Attention map generation module
The attention module is utilized to produce multiple attention maps. This module is lightweight, comprising a 1 × 1 convolutional layer, a batch normalization layer, and a ReLU activation layer. The 1 × 1 convolutional layer primarily serves to adjust the channel count of the input feature map or to recombine features. It carries out a linear combination of all channels at each pixel location. To guide the attention maps to focus on differing regions of the input image, derivation from high level semantic features is needed. Therefore, it is necessary to leverage the deep features extracted by the backbone network. The deep features are fed into the attention module, generating M attention maps, denoted by \(A^{k} \in R^{{\{ H_{t} \times W_{t} \} }}\). Each attention map has the same size, with a dimension of \(H_{t} \times W_{t}\).
Drawing from the component model, the model is designed to automatically pinpoint the differences between real and fake images. It uses shallow features to extract texture details and deep semantic features to create multiple spatial attention maps for each image. These texture and semantic features are then merged to form a comprehensive representation of each local area. Finally, these local feature representations are independently fed into a module called the "Bilinear Attention Pooling" layer for pooling, and the pooled results are fused to serve as the representation for the entire image. This enables the model to concurrently comprehend the image’s fine details and its overall context, thereby better distinguishing between real and fake images that are similar in appearance but different in details. Upon acquiring the attention maps and texture feature maps, it is necessary to extract both the global and local features of the image. These two sets of features are then input into the classifier to perform fine grained image classification.
The local features of the original input image are often too large in size. Directly feeding them into a fully connected neural network classifier would result in an excessive number of parameters, leading to overfitting and thereby compromising the model’s generalization ability. A common approach to address this issue is to pass the features through global pooling (which reduces each two dimensional matrix to a scalar, representing the value for each channel) before inputting them into the classifier. Global average pooling achieves this by averaging the values of all pixels in each channel’s feature map, resulting in a scalar. This means that for each channel of the input feature map, the output is computed as follows:
After global average pooling, each channel of the feature map is condensed into a single value, resulting in a one-dimensional vector whose length matches the number of channels. However, given the varying strengths of attention maps across different local regions, traditional global average pooling may lead to scalars from different regions being affected by the strength of the corresponding regional attention maps. This may lead to the attenuation of some originally distinct textures or the enhancement of some originally indistinct textures. Such a situation results in a loss of distinguishability, which contradicts the purpose of focusing on texture information. To address this issue, we employ a regularized average pooling, which will be discussed in the next section.
Loss function
In the proposed model, a composite loss function is designed, comprising three distinct loss components: cross-entropy loss for classification (\(L_{cross}\)), regional independence loss (\(L_{{{\text{multi}}}}\)), and detection loss (\(L_{test}\))8,9,38. It is worth noting that the detection loss is further divided into confidence loss (\(L_{conf}\)) and location loss (\(L_{loc}\))9.
Cross-entropy loss
We use the classification loss to evaluate the accuracy of the model in determining whether the input image is real or fake38. This loss is implemented through the cross-entropy loss function, which measures the difference between the model’s predicted probability distribution and the actual label distribution to gauge performance. The cross-entropy loss is defined as:
where \(y_{i}\) represents the true label and \(\hat{y}_{i}\) represents the probability predicted by the model. The model’s accuracy assessment in final predictions, which centers on image authenticity judgment (authentic versus fake), is a crucial process aimed at ensuring the model’s reliability and effectiveness in practical applications.
Regional independence loss
To mitigate feature region overlap caused by multiple attention mechanisms, this study introduces a regional independence loss to ensure that the attention heads in the model focus on distinct local regions8. This loss function is implemented by measuring the distance between feature vectors and feature centers, and it consists of two components: inter class loss and intra class loss. The intra class loss seeks to bring together the feature vectors of the same class, thereby enhancing the consistency of within class features. Conversely, the inter class loss pushes the feature centers of different classes apart, increasing the distance between them to improve the distinguishability of between class features. Its expression is:
where \(V_{ij}\) stands for the feature vector, \(C_{j}\) for the feature center, and \(m_{in}\) and \(m_{out}\) for the intra class and inter class boundaries, respectively. In the absence of fine—grained labels, training a multi—attention network tends to result in network degeneration. This is characterized by different attention maps focusing on the same image region, which impedes the network’s ability to capture diverse and rich information from the input data. To address this, we aim for each attention map to concentrate on fixed semantic areas across various input images. For example, attention map A1 should focus on eyes in all images, and A2 on mouths. To realize this goal, we introduce a regional independence loss. This loss function serves to minimize the overlap between attention maps and maintain consistency in their focus across different inputs, thereby reducing the randomness of the information each attention map captures and enhancing the network’s performance.
Detection loss
To minimize the impact of implicit identity leakage on the model’s performance and encourage the model to learn general features of forged images, rather than over-relying on identity information from specific datasets, we employ the detection loss to guide the APM module in identifying local forged regions within the image9. The detection loss consists of two components: confidence loss and location loss. Together, these components offer a comprehensive evaluation of the model’s performance in object detection tasks, ensuring that the model not only accurately predicts the presence of objects but also precisely locates their positions. The location loss measures the discrepancy between the position offset of the anchor box and the true annotation. The expression for the detection loss is:
In the equation, N represents the number of positive samples, \(L_{conf}\) denotes the confidence loss, \(L_{loc}\) signifies the location loss, and \(\alpha\) stands for the weight. The confidence loss is used to measure the classification result of each anchor box. The expression for \(L_{conf}\) is:
In the equation, N denotes the number of positive samples, \(y_{i}\) represents the true label (where 1 signifies the presence of an object and 0 signifies its absence), and \(\hat{y}_{i}\) indicates the model’s predicted confidence. The location loss is employed to measure the difference between the position offset of the anchor box and the true annotation. The expression for \(L_{loc}\) is:
In the equation, N denotes the number of positive samples, \(x_{ij}\) represents the coordinates of the ground truth box, and \(\hat{x}_{ij}\) represents the coordinates predicted by the model. The term \(SmoothL1\) is defined as follows:
This loss function guides the learning of the APM and is composed of two components: confidence loss (Lconf) and location loss (Lloc). Lconf leverages binary cross—entropy loss to evaluate the prediction accuracy of each anchor, determining whether it represents a real or fake object. Lloc, utilizing smooth L1 loss36, measures the positional discrepancy between the ADM’s predicted artifact area and the corresponding ground—truth.
Composite loss function
The final loss function is a combination of the three aforementioned loss functions, each weighted by a specific coefficient:
where \(\lambda_{1}\), \(\lambda_{2}\) are the weight coefficients used to balance the different parts of the loss. This combination enables the model to simultaneously focus on global features for classification, concentrate on local forged features through the APM module, and ensure the effectiveness of the attention mechanism via the regional independence loss. In the experiments, the default values for these two coefficients are set to 0.5 each.
Experiment
In this section, we first detail the experimental setup, including the dataset, data preprocessing steps, model parameter selection, and the metrics used to evaluate performance. Subsequently, the experimental outcomes are introduced and scrutinized to highlight the strengths of the proposed approach. Finally, ablation experiments are conducted to assess the impact of each model component and verify the model’s overall efficacy.
Experimental setup
Description of the dataset and data preprocessing
To evaluate the performance of our model, experiments were conducted using the FF++, DFDC, and Celeb-DF-v2 datasets39,40,41. The FF++ and DFDC datasets were utilized for training and validation, while the Celeb-DF-v2 dataset was employ- ed to assess cross-dataset generalization.
FF++: FaceForensics++ is widely used in deepfake detection methods39. It comprises 1000 original YouTube videos, each paired with corresponding forged versions created using four distinct forgery techniques: Deepfakes, NeuralTextures, FaceSwap, and Face2Face42,43,44. For each technique, there are 1,000 forged videos. To evaluate the model’s sensitivity to compression rates, experiments were conducted at two compression levels: HQ (c23) and LQ (c40). Figure 3 provides a visual illustration of the five face forgery techniques and their effects on the FF++ dataset.

This illustration showcases the five face forgery techniques and their effects on the FF++ dataset. It presents two sets of randomly selected face images, each consisting of the original image (Origin) and its processed counterpart using different forgery techniques. These techniques include DF (DeepFakes), F2F (Face2Face), FS (FaceShifter), FSwap (FaceSwap), and NT (NeuralTextures). In each set, the facial features of the two individuals are swapped during the forgery process, highlighting the ability of these techniques to perform facial feature replacement.
DFDC: As a benchmark for synthetic media forensics, the DFDC dataset represents a comprehensive open access repository specifically developed to advance research in digital media authenticity verification. This corpus aggregates 100,000+ annotated video segments derived from 3426 professionally contracted subjects, encompassing methodological pluralism in synthetic content creation spanning both contemporary GAN based architectures and conventional manipulation approaches. A key feature of the DFDC dataset is its ethical consideration: all individuals involved in the video production have consented to the use of their likeness for modifications within the dataset. In addition to videos produced in controlled environments, the dataset also includes deepfake videos generated under “wild” conditions, making it particularly valuable for evaluating the generalization capabilities of detection models.
Celeb-DF-v2: The Celeb-DF-v2 dataset is a large-scale and highly challenging deepfake forensic dataset, consisting of 590 original videos sourced from YouTube and 5,639 deepfake synthetic videos, amounting to over 2 million frames in total. The original videos feature celebrity interview clips, exhibiting diverse characteristics, including variations in gender, age, ethnicity, lighting conditions, backgrounds, and facial orientations. The deepfake videos are generated using an enhanced algorithm that significantly improves resolution and minimizes common forgery artifacts, such as color mismatches and synthesis glitches, making them comparable in quality to real deepfake content found online. As such, Celeb-DF-v2 serves as a critical benchmark for evaluating the robustness of deepfake detection models, offering valuable resources for assessing the generalization capability and performance of detection algorithms.
Dataset Preprocessing: We utilized the RetinaFace detector to extract facial imag- es1. RetinaFace is a powerful single stage face detection tool that simultaneously carries out face detection and facial landmark localization via multi-task learning. The model leverages a feature pyramid network (FPN) and a context module to improve detection accuracy, particularly in challenging scenarios such as occlusions, low resolution, and complex lighting conditions. The model’s input consists of facial images resized to 380 × 380 pixels.
Model parameter settings
For the model training parameters, we set the value of \(m_{out}\) in Eq. (3) to 0.2. The minimum edge values for all images are set to 0.05 and 0.1, respectively. EfficientNet-B4 is used as the backbone network of the model3. EfficientNet consists of seven primary layers, labeled L1 through L7. We observed that subtle artifacts introduced by the forgery method are typically preserved in the texture features of the network’s shallow layers. Concurrently, to direct the attention maps toward different regions of the input, guidance from high level semantic information is necessary. Thus, for the feature layer (SLa) used to extract texture features and the attention layer (SLt) responsible for generating multiple attention maps, we select SL2 and the deeper layer SL5, respectively. Our model employs the Adam optimizer with a learning rate of 0.001 and weight decay of 1e−6. In AGDA, we set the resizing factor to 0.3 and the Gaussian blur parameter to σ = 72. Training is performed on four RTX 2080 Ti GPUs with a batch size of 48. Meanwhile, TensorBoard was utilized to monitor and analyze the training process, allowing real—time viewing of loss curves, accuracy changes, and feature map visualizations, which enhanced our understanding of model behavior and facilitated timely training strategy adjustments. Moreover, to visually demonstrate the model’s classification performance, t—SNE was adopted to reduce the dimensionality of high—dimensional features and visualize the classification results, mapping complex data structures to 2D or 3D spaces, which enabled clear observation of the distribution of different—class samples and further verified the model’s ability to distinguish various deep—fake images.
The learning rate was set at 0.001, a value determined through extensive experimentation. We explored various learning rates (0.0001, 0.001, 0.01) and monitored the model’s performance on both the training and validation sets. The choice of 0.001 was motivated by its ability to promote stable convergence of the model without unduly prolonging the training process. A higher learning rate may destabilize training and cause divergence, whereas an excessively low rate can slow down training, thus reducing efficiency.
To prevent model overfitting, the weight decay was set to 1e−6. It introduces a regularization term to the loss function, constraining the model parameter size. This enables the model to emphasize important features and enhances its generalization ability. Verified through experiments, this value ensures model performance without adversely impacting the training process.
Evaluation metrics
To benchmark our model against state-of-the-art techniques, we employ two evaluation metrics: AUC (Area Under the Receiver Operating Characteristic Curve) and ACC (Accuracy). AUC measures the model’s ability to differentiate between positive and negative samples across various classification thresholds, with values closer to 1 signifying superior performance. ACC measures the proportion of correctly classified samples, reflecting the overall accuracy of the model’s predictions. These metrics are utilized in this experiment to offer a thorough evaluation of the model’s detection capabilities.
Comparative experiments
In this section, we benchmark our model against the present day top tier deepfake detection approaches. The model’s performance is evaluated not only on the FF++ and DFDC datasets but also through cross-dataset validation experiments using Celeb-DF-v2. As depicted in Fig. 4, we have presented a detailed visualization of various facial manipulation techniques.

This schematic diagram illustrates the application of various facial manipulation techniques in image processing. It includes the following techniques: Origin (original image) from the FF++ dataset, as well as NeuralTextures, FaceShifter, DeepFakes, Face2Face, and FaceSwap. Additionally, it features FSGAN from the Celeb-DF-v2 dataset and X2Face from the DFDC dataset. Each technique is presented across three dimensions: Picture, which displays the processed facial images; Global, which reveals the overall structural information of the image; and Texture, which highlights the fine details and local variations within the image.
Performance of different models on FaceForensics++
The FF++ dataset comprises 1000 real videos and 4000 forged videos generated using four different methods: Deepfakes, NeuralTextures, FaceSwap, and Face2Face. To balance the real and forged labels, we increased the number of real images by four times during training. We conducted experiments on both LQ and HQ versions, first pretraining the model on HQ with initialized parameters, and then training on LQ to accelerate convergence. The comparison results are presented in Table 1.
Table 1 demonstrates that the proposed model achieves superior performance on both LQ and HQ datasets. Specifically, compared to existing models, our model achieves a significant enhancement on the LQ dataset, with an average increase of 2 percentage points in ACC and 4 percentage points in AUC. This enhancement is attributed to the APM module, which ensures that fine grained local information is preserved through multi-scale detection, while CondenseNet’s efficient feature extraction enables high precision forgery detection even with limited resources, addressing the sensitivity of existing models to high compression rates. Although the proposed method outperforms the original model in several aspects, these results warrant further validation across a broader range of application scenarios.
We visualized the detection result distributions extracted by the LD-CNN model and the proposed method (Ours) on the FF++ (c23) dataset using t-SNE45. For each method, we reduced the feature dimensions after the classifier to 2D and visualized them in Fig. 5. As shown, the feature distributions of different categories (i.e., Real and Fake) generated by Ours exhibit clear distinctions, whereas the feature distribution obtained by LD-CNN shows less separation. This further confirms that the proposed method is more discriminative during detection compared to competing methods.

Visualization of detection results within the dataset.
Performance of different models on DFDC
The DeepFake Detection Challenge (DFDC) dataset, being one of the largest publicly accessible face-swapping video datasets, is designed to enhance the performance of deepfake detection models. Capitalizing on the dataset’s strengths, we selected 3293 videos to evaluate our model’s performance and compared it with other state-of-the-art models. The experimental results, as shown in Table 2, indicate that our proposed model achieves state-of-the-art performance on the DFDC dataset.
Cross dataset performance evaluation on celeb-DF-v2
In this section, we assess the generalization capability of the proposed model using the Celeb-DF dataset. We initially trained the model on the FF++ dataset and subsequently tested it on Celeb-DF, sampling 30 frames per video to calculate the frame level AUC scores. The results are displayed in Table 3. The experimental outcomes indicate that the proposed method outperforms most existing methods in terms of generalization. Notably, the Two Branch method slightly outperforms the proposed approach in terms of cross-dataset generalization. This can be attributed to its unique dual branch architecture and feature extraction approach, which effectively handles global and local features separately, allowing for stronger adaptability across different datasets. However, despite its advantage in generalization, the Two Branch method’s AUC scores within the dataset are significantly lower than those of the proposed model.
We visualized the result distributions of the DSP-FWA model and the proposed method (Ours) using t-SNE, trained on the FF++ dataset and validated on the DFDC dataset. For each method, we reduced the feature dimensions after the classifier to 2D and visualized the results in Fig. 6. As shown, the feature distributions of different categories (Real and Fake) generated by Ours exhibit clear distinctions, while the feature distribution obtained by DSP-FWA shows less separation. This further confirms that the proposed method is more discriminative during detection compared to competing methods.

Visualization of cross-dataset results.
Ablation study
In the ablation study, we separately evaluate the APM and CondenseNet to demonstr- ate the rationale and effectiveness of our approach.
Effectiveness of the artifact perception module
To demonstrate the effectiveness of the APM module, we conducted additional experiments. APM is specifically designed to detect locally forged regions in deepfake images. Unlike traditional global feature extraction methods, APM effectively identifies forged areas through multi-scale anchor detection, particularly for subtle facial feature alterations. This module reduces the model’s reliance on global identity features when processing across datasets, thereby improving generalization performance. For instance, prior research has indicated that deepfake detection models are frequently constrained by implicit identity leakage, where the model erroneously links identity features to forged images. The implementation of the APM module steers the model to concentrate more on local forged features instead of depending on global identity information, thereby boosting both detection robustness and generalization capacity. Since the model without APM already achieved optimal performance on FF++ HQ, we conducted experiments on FF++ LQ. The experimental results, presented in Table 4, show that APM compensates for the accuracy drop caused by the loss of certain features due to high compression rates.
Effectiveness of condense block
To further validate the effectiveness of the Condense Block module, we carried out extra experiments58. We assessed CondenseNet in terms of training time and memory usage, revealing its superior computational efficiency compared to DenseNet. This efficiency stems from CondenseNet’s employment of channel compression and aggregation techniques, which considerably cut down the number of parameters while preserving model accuracy. In deepfake detection tasks, this compact architecture not only lowers computational costs but also enables the network to focus on more effective feature extraction. When combined with the APM module, the features extracted by CondenseNet align more effectively with local forged regions, further enhancing the model’s performance across different datasets. The experimental results are presented in Tables 5 and 6.
The efficiency of the proposed model
To evaluate the inference efficiency of the proposed model, we conducted the experiments with several classic models on the DFDC dataset, and reported the results in Table 7. It can be observed that compared with these methods the proposed model can not only achieve higher accuracy but also reduce the reference time. This is primarily attributed to the channel compression and aggregation techniques employed by CondenseNet, which significantly reduce the number of parameters while maintaining model accuracy.
Limitations and future work
Although the multi-attention mechanism deepfake detection model proposed in this paper has achieved significant performance improvements across multiple datasets, there are still some limitations in the current approach. First, while the model demonstrates good generalization ability in cross-dataset testing, its detection performance may still be affected when handling images with extreme compression rates or complex backgrounds. Second, the model’s reliance on predefined anchor scales for locating forged traces during the training phase may limit its adaptability to unknown forgery patterns. In future research endeavors, we are committed to further enhancing the performance of the multi-attention mechanism deepfake detection model. Initially, to address the challenges posed by images with extreme compression rates and complex backgrounds, we will explore novel feature extraction methods and background-aware modules to bolster the model’s robustness under these complex conditions. Subsequently, aiming to resolve the model’s limited adaptability to unknown forgery patterns, we will investigate dynamic anchor scale adjustment mechanisms and multimodal forgery trace detection approaches, enabling the model to more flexibly identify a variety of forgery patterns. Moreover, to further improve the model’s generalizability and adaptability to emerging challenges, we will employ a broader range of data augmentation strategies, cross-dataset validation methods, and maintain a vigilant watch on novel forgery techniques. Simultaneously, in order to enhance the model’s detection efficiency and fairness, we will seek out efficient feature extraction and classification methods and introduce fairness constraints to optimize the model’s performance across different demographics and scenarios. Through these optimization measures, we anticipate a significant enhancement in the model’s robustness under extreme conditions, adaptability to diverse forgery patterns, and overall detection performance and generalizability, thereby better equipping it to tackle the increasingly complex tasks of deepfake detection.
Conclusion
We propose a novel multi-attention detection method that decomposes the target object into multiple local parts, detects these parts individually, and combines their relative positional relationships to determine the category of the target object. This approach not only minimizes the misuse of identity information but also enhances the model’s ability to focus on subtle texture features. We employ a forgery trace detection module to locate forged regions and fuse global and texture features, enabling the model to prioritize local features while reducing reliance on identity information. Comprehensive experiments and detailed analysis performed on the FaceForensics++, Celeb-DF, and DFDC datasets reveal that our approach yields outstanding results. At the same time, we have also successfully demonstrated that addressing the generalization issue in the field of deepfake detection through various artifacts is the right approach.
Data availability
The datasets generated and/or analysed during the current study are available in the FaceForensics++, DFDC , Celeb-DF repository, https://github.com/ondyari/FaceForensi-cs, https://ai.meta.com/datasets/dfdc/, and https://github.com/yuezunli/celeb-deepfakeforensics.
References
Deng, J., Guo, J., Zhou, Y., Yu, J., Kotsia, I. & Zafeiriou, S. Retinaface: Single-stage dense face localisation in the wild. http://arxiv.org/abs/1905.00641 (2019).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9, 2015, Conference Track Proceedings (eds Bengio, Y. & LeCun, Y.) (2015).
Tan, M. & Le, Q. V. Efficientnet: Rethinking model scaling for convolutional neural networks. in Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9–15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research (eds Chaudhuri, K. & Salakhutdinov, R.) 6105–6114 (PMLR, 2019).
Zhou, X., Du, X. & Ru, P. Dark light enhancement for dark scene urban object recognition. IET Image Proc. 17(7), 2043–2055 (2023).
Du, X., Jiang, S. & Liu, J. Augmented global attention network for image super-resolution. IET Image Proc. 16(2), 567–575 (2022).
Du, X., Liu, C. & Yang, X. region attention network for single image super-resolution. in 2021 International Joint Conference on Neural Networks (IJCNN) 1–6 (IEEE, 2021).
Du, X. et al. Ethics-aware face recognition aided by synthetic face images. Neurocomputing 600, 128129 (2024).
Zhao, H., Zhou, W., Chen, D., Wei, T., Zhang, W. & Yu, N. Multi-attentional deepfake detection. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2185–2194 (2021).
Shichao, D. et al. Implicit identity leakage: The stumbling block to improving deepfake detection generalization. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023).
Gao, Y. et al. Refining localized attention features with multi-scale relationships for enhanced deepfake detection in spatial-frequency domain. Electronics 13(9), 1749 (2024).
Afchar, D., Nozick, V., Yamagishi, J. & Echizen, I. Mesonet: a compact facial video forgery detection network. in 2018 IEEE International Workshop on Information Forensics and Security, WIFS 2018, Hong Kong, China, December 11–13, 2018, 1–7 (IEEE, 2018).
Matern, F., Riess, C. & Stamminger, M. Ex ploiting visual artifacts to expose deepfakes and face manip ulations. in 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW) 83–92 (2019).
Mejri, N., Papadopoulos, K. & Aouada, D. Leveraging high-frequency components for deep fake detection. in 2021 IEEE 23rd International Workshop on Multimedia Signal Processing (MMSP) 1–6 (2021).
Nguyen, H. H., Yamagishi, J. & Echizen, I. Capsule-forensics: Using capsule networks to detect forged images and videos. http://arxiv.org/abs/1810.11215 (2018).
Nguyen, T. T., Nguyen, C. M., Nguyen, D. T. & Nahavandi, S. Deeplearning for deepfakes creation and detection. http://arxiv.org/abs/1909.11573 (2019).
Singh, I. P., Mejri, N., van Nguyen, D., Ghorbel, E. & Aouada, D. Multi-label deepfake classification. in IEEE Workshop on Multimedia Signal Processing (2023).
Wang, R., Ma, L., Juefei-Xu, F., Xie, X., Wang, J. & Liu, Y. Fakespotter: A simple baseline for spotting ai-synthesized fake faces. CoRR, http://arxiv.org/abs/1909.06122 (2019).
Coccomini, D., Messina, N., Gennaro, C. & Falchi, F. Combining efficientnet and vi sion transformers for video deepfake detection. CoRR, http://arxiv.org/abs/2107.02612 (2021).
Xu, X. et al. A novel model compression method based on joint distillation for deepfake video detection. J. King Saud Univ.-Comput. Inf. Sci. 35(9), 101792 (2023).
Hsu, C.-C., Lee, C.-Y. & Zhuang, Y.-X. Learn ing to detect fake face images in the wild. in 2018 Inter national Symposium on Computer, Consumer and Control (IS3C) 388–391 (IEEE, 2018).
Mo, H., Chen, B. & Luo, W. Fake faces identi f ication via convolutional neural network. in Proceedings of the 6th ACM Workshop on Information Hiding and Multime dia Security 43–47 (2018).
Quan, W., Wang, K., Yan, D.-M. & Zhang, X. Distinguishing between natural and computer generated images using convolutional neural networks. IEEE Trans. Inf. Forens. Secur. 13(11), 2772–2787 (2018).
Bondi, L., Cannas, E. D., Bestagini, P. & Tubaro, S. Training strategies and data augmentations in cnn-based deepfake video detection. in 2020 IEEE In ternational Workshop on Information Forensics and Security (WIFS) 1–6 (IEEE, 2020).
Du, M., Pentyala, S., Li, Y. & Hu, X. To wards generalizable forgery detection with locality-aware autoencoder. arXiv e-prints, pages arXiv–1909 (2019).
Xuan, X., Peng, B., Wang, W. & Dong, J. On the generalization of gan image forensics. in Chinese Conference on Biometric Recognition 134–141 (Springer, 2019).
Hernandez-Ortega, J., Tolosana, R., Fierrez, J. & Morales, A. Deepfakeson-phys: Deepfakes de tection based on heart rate estimation. arXiv preprint http://arxiv.org/abs/2010.00400 (2020).
Nirkin, Y., Wolf, L., Keller, Y. & Hassner, T. Deepfake detection based on discrepancies between faces and their context. IEEE Trans. Patt. Anal. Mach. Intell. 44(10), 6111–6121 (2021).
Li, J., Xie, H., Li, J., Wang, Z. & Zhang, Y. Frequency-aware discriminative feature learning supervised by single-center loss for face forgery detection. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 6458–6467 (2021).
Chollet, F. Xception: Deep learning with depthwise separable convolutions. in 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21–26, 2017, 1800–1807 (IEEE Computer Society, 2017).
Durall, R., Keuper, M., Pfreundt, F.-J. & Keuper, J. Unmasking deepfakes with simple features. arXiv preprint http://arxiv.org/abs/1911.00686 (2019).
Masi, I., Killekar, A., Mascarenhas, R. M., Gurudatt, S. P. & AbdAlmageed, W. Two-branch recurrent network for isolating deepfakes in videos. arXiv preprint http://arxiv.org/abs/2008.03412 (2020).
Li, Y., Chang, M.-C. & Lyu, S. In ictu oculi: Exposing ai created fake videos by detecting eye blinking. in 2018 IEEE International Workshopon Information Forensics and Security (WIFS) 1–7 (IEEE, 2018).
Yang, X., Li, Y. & Lyu, S. Exposing deep fakes using inconsistent head poses. in ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 8261–8265 (IEEE, 2019).
Sun, Z., Han, Y., Hua, Z., Ruan, N. & Jia, W. Improving the efficiency and robustness of deepfakes detec tion through precise geometric features. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 3609–3618 (2021).
Liu, H., Li, X., Zhou, W., Chen, Y., He, Y., Xue, H., Zhang, W. & Yu, N. Spatial phase shallow learning: rethinking face forgery detection in frequency domain. in Proceedings of the IEEE/CVF Con ference on Computer Vision and Pattern Recognition 772–781 (2021).
Girshick, R. Fast r-cnn. in Proceedings of The IEEE Inter-National Conference on Computer Vision 1440–1448 (2016)
He, K., Zhang, X., Ren, S. & Sun, J. Deep Residual Learning for Image Recognition. arXiv preprint http://arxiv.org/abs/1512.03385v1. Accessed 10 Dec 2015.
LeCun, Y., Bottou, L., Bengio, Y. & Haffner, P. Gradient-based learning applied to document recognition. in Proceedings of the IEEE vol. 86, 2278–2282 (1998).
Rossler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J. & Nießner, M. Faceforensics++: Learning to detect manipulated facial images. in Proceedings of the IEEE International Conference on Computer Vision 1–11 (2019).
Dolhansky, B., Bitton, J., Pflaum, B., Lu, J., Howes, R., Wang, M. & Ferrer, C. C. The deepfake detection challenge dataset. arXiv preprint http://arxiv.org/abs/2006.07397 (2020).
Li, Y., Yang, X., Sun, P., Qi, H. & Lyu, S. Celeb-df: A large-scale challenging dataset for deepfake forensics. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 3207–3216 (2020).
Thies, J., Zollhöfer, M. & Nießner, M. Deferred neural rendering: image synthesis using neural textures. Acm Trans. Graph. 38(4), 1–12 (2019).
Zhang, J., Zeng, X., Pan, Y., Liu, Y., Ding, Y. & Fan, C. Faceswapnet: Landmark guided many-to-many face reenactment. http://arxiv.org/abs/1905.11805 (2019).
Thies, J., Zollhofer, M., Stamminger, M., Theobalt, C. & Niebner, M. Face2face: Real-time face capture and reenactment of rgb videos 2387–2395 (2016).
van der Maaten, L. & Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 9(11), 2579–2605 (2008).
Fridrich, J. J. & Kodovsky, J. Rich models for steganalysis of digital images. IEEE Trans. Inf. Forens. Secur. 7(3), 868–882 (2012).
Cozzolino, D., Poggi, G. & Verdoliva, L. Recasting residual-based local descriptors as convolutional neural networks: an application to image forgery detection. in Proceedings of the 5th ACM Workshop on Information Hiding and Multimedia Security, IH&MMSec 2017, Philadelphia, PA, USA, June 20–22, 2017 (eds Stamm, M. C. Kirchner, M. & Voloshynovskiy, S.) 159–164 (ACM, 2017).
Li, L., Bao, J., Zhang, T., Yang, H., Chen, D., Wen, F. & Guo, B. Face x-ray for more general face forgery detection. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 5001–5010 (2020).
Gunawan, T. S. et al. Development of photo forensics algorithm by detecting photoshop manipulation using error level analysis. Indones. J. Electr. Eng. Comput. Sci. 7(1), 131–137 (2017).
Chen, M., Sedighi, V., Boroumand, M. & Fridrich, J. Jpegphase-aware convolutional neural network for steganalysis of jpeg images. in Proceedings of the 5th ACM Workshop on Information Hiding and Multimedia Security (2017).
Qian, Y., Yin, G., Sheng, L., Chen, Z. & Shao, J. Thinking in frequency: Face forgery detection by mining frequency-aware clues. in European Conference on Computer Vision 86–103 (Springer, 2020).
Nguyen, H. H., Yamagishi, J. & Echizen, I. Capsuleforensics: Using capsule networks to detect forged images and videos. in ICASSP 2019: 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2307–2311 (2019).
Zhou, P., Han, X., Morariu, V. & Davis, L. Two-stream neural networks for tampered face detection. in 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) 1831–1839 (2017).
Mallet, J., Krueger, N., Dave, R. & Vanamala, M. Hybrid deepfake detection utilizing MLP and LSTM. in Proceedings of the International Conference on Electrical, Computer, Communications and Mechatronics Engineering (ICECCME 2023), 19–21 July 2023, Tenerife, Canary Islands, Spain 979-8-3503-2297-2/23 (2023).
Li, Y. & Lyu, S. Exposing deepfake videos by detecting face warping artifacts. in CVPR Workshops (2019).
Coccomini, D.A., Messina, N., Gennaro, C. & Falchi, F. Combining EfficientNet and vision transformers for video deepfake detection. in Image Analysis and Processing: ICIAP 2022. ICIAP 2022. Lecture Notes in Computer Science (eds Sclaroff, S., Distante, C., Leo, M., Farinella, G. M. & Tombari, F.) vol 13233 (Springer, Cham, 2022). https://doi.org/10.1007/978-3-031-06433-3_19
Nguyen, H. H., Fang, F., Yamagishi, J. & Echizen, I. Multi-task learning for detecting and segmenting manipulated facial images and videos. in 2019 IEEE 10th International Conference on Biometrics Theory, Applications and Systems (BTAS) 1–8 (2019).
Huang, G., Liu, S., van der Maaten, L. & Weinberger, K. Q. CondenseNet: An Efficient DenseNet using Learned Group Convolutions. http://arxiv.org/abs/1711.09224v2 (2018).
Krizhevsky, A. One weird trick for parallelizing convolutional neural networks. arXiv preprint http://arxiv.org/abs/1404.5997v2. Accessed 26 Apr 2014.
Funding
This work was supported by the Joint Funds of National Natural Science Foundation of China (Grant No. U23A20304), the Fund of Laboratory for Advanced Computing and Intelligence Engineering (No. 2023-LYJJ-01-033), the Special Funds of Jiangsu Province Science and Technology Plan (Key R&D Program Industry Outlook and Core Technologies) (No: BE2023005-4), the Science Project of Hainan University (KYQD(ZR)-21075).
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation was performed by Yuncan Sheng, Zhengrui Zou, Zongxuan Yu, and Wei Ou. Data collection and analysis were performed by Yuncan Sheng, Mengxue Pang, Wei Ou and Wenbao Han. The first draft of the manuscript was written by Yuncan Sheng, Zhengrui Zou and Wei Ou. All authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Sheng, Y., Zou, Z., Yu, Z. et al. ID-insensitive deepfake detection model based on multi-attention mechanism. Sci Rep 15, 11168 (2025). https://doi.org/10.1038/s41598-025-96254-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-96254-6
