
Abstract
This research introduces a novel approach to enhance energy efficiency in Mobile-Edge Computing (MEC) systems by integrating Non-Orthogonal Multiple Access (NOMA) with energy harvesting in a full-duplex (FD) environment. The primary objective is to optimize edge computing performance while minimizing energy consumption. A comprehensive resource allocation strategy is proposed, considering CPU frequency, power control for both uplink and downlink, time scheduling, and data offloading. Mobile users can offload computationally demanding tasks to MEC servers via NOMA, promoting efficient data exchange. Full-duplex base stations simultaneously manage task offloading and energy transmission, improving resource utilization. A Block Coordinate Descent (BCD)-based algorithm addresses the non-convex optimization challenge, offering an optimal solution. Simulation results demonstrate that the NOMA-assisted FD-MEC system significantly outperforms traditional Orthogonal Multiple Access and Half-Duplex approaches, leading to improved energy efficiency and reduced energy consumption. This study highlights the potential of integrating NOMA, energy harvesting, and full-duplex technologies to create more energy-efficient MEC systems.
Similar content being viewed by others
Introduction
Energy efficiency in NOMA- assisted MEC system is a critical due to the rising demand for sustainable communication technologies1. With the rapid development of computationally intensive mobile applications, such as augmented reality, smart driving, and online gaming, the need for efficient, low-latency computing has grown significantly2. However, the concurrent rise in computational demands and energy consumption presents a considerable challenge3,4. Existing solutions primarily focus on optimizing resource allocation for Eh to sustain wireless networks5. However, many of these approaches need to sufficiently address the critical trade-offs between task offloading and energy transmission, limiting their effectiveness in real-world applications. This paper proposes a novel solution that seeks to enhance energy efficiency in MEC-NOMA systems by integrating a full-duplex base station with a sophisticated resource allocation strategy6,7. This strategy minimizes energy consumption while balancing task offloading and energy transmission, marking a significant advancement in the field.
MEC has gained widespread attention in recent years as a potential solution for enhancing the computing capabilities of user devices8. MEC servers, deployed close to users at the network‘s edge, allow for the offloading of computational tasks, significantly reducing latency and enhancing service quality9,10,11. Despite these advancements, the limited battery life of mobile devices remains a major obstacle. While Energy Harvesting (EH) technology has helped alleviate some of these concerns by providing an alternative energy source, the integration of EH with MEC systems still faces challenges in maximizing energy efficiency and extending system lifetime12. Additionally, NOMAtechnology, which offers improved spectral efficiency in 5G networks, is an emerging solution for enhancing multi-user MEC systems13 Unlike traditional orthogonal transmission systems, NOMA deliberately introduces interference at the transmitter and utilizes Successive Interference Cancellation (SCI) at the receiver to effectively manage and reduce interference. The integration of NOMA with wireless energy-carrying communication systems has been shown to improve further spectral efficiency, energy efficiency, and overall system performance14. However, the performance of NOMA-based MEC systems, particularly in terms of energy efficiency, remains suboptimal, and the interaction between task offloading and energy harvesting has yet to be fully explored.
To address the critical challenge of energy efficiency in MEC systems, this paper presents a novel integration of NOMA, full-duplextechnology, and energy harvesting. Unlike conventional approaches, the proposed framework enables simultaneous task offloading and energy transmission, significantly improving spectral efficiency and sustainability. Existing work focuses on either EH or NOMA separately, while our approach uniquely combines these technologies with FD to optimize resource utilization. Motivated by the need for green communication in 5 g/6 g networks, this solution enhances energy-efficient MEC systems for low-latency, high-throughput applications.
This study addresses these gaps by proposing a joint offloading and resource allocation technique for a full-duplex MEC system based on NOMA and EH. In this system, mobile users are grouped into several categories, and each group offloads computational tasks to an MEC server through NOMA. The base station simultaneously receives offloading tasks and energy from users using full-duplex operations. This innovative combination of NOMA and full-duplex energy harvesting significantly improves the energy efficiency and lifespan of the system’s while maintaining high performance in task offloading.
The main contributions of this paper are as follows:
-
1.
Energy constraint Solution: we propose a novel approach to addressing the energy constraint problem in MEC task offloading by developing a full-duplex MEC system model that combines NOMA and Eh. Unlike prior models, our approach divides users into different groups, each with a specific number of users, allowing for more efficient resource management. The base station operates in full-duplex mode, sending energy to some user groups while receiving offloading tasks from others. This dual functionality, combined with NOMA, enables more efficient task offloading and energy transmission.
-
2.
Optimization Framework: A comprehensive mathematical framework is developed to minimize energy consumption while satisfying computational delay and energy collection constraints. We optimize joint resource allocation across CPU frequency for local computing, power control for both uplink and downlink transmissions, time scheduling, and offload data allocation.
-
3.
Block Coordinates Descent (BCD) Technique: To solve the non-convex joint optimization problem, we introduce the BCD technique, which simultaneously optimizes both communication and processing resources. This method finds the optimal solution to the non-convex problem while minimizing computational complexity.
-
4.
Performance Validation: We demonstrate the effectiveness of the proposed algorithm through experimental analysis and comparisons with existing benchmark algorithms. The algorithm’s convergence and efficiency are verified through extensive simulations.
Through these contributions, our work not only addresses the critical challenge of energy efficiency in MEC-NOMA systems but also provides a novel solution by integrating full-duplex operations with resource allocation techniques. This approach significantly improves system performance and is a step forward in the development of sustainable, high-performance communication networks.
Related works
A cutting-edge method called Mobile Edge Computing enables data caching and computational offloading at the network’s edge, enabling mobile users to store and transmit data efficiently15. Recent research has focused on improving energy efficiency in MEC systems, especially through NOMA and energy harvesting techniques. For example, in16,17, the authors investigate energy-efficient strategies in NOMA-assisted wireless networks, highlighting its potential to reduce energy consumption. Similarly,18,19 explores energy harvesting in MEC systems, demonstrating its effectiveness in prolonging battery life and optimizing system performance. Our work builds upon these approaches by integrating both NOMA and energy harvesting in a full-duplex environment, offering a more comprehensive solution to energy optimization.Energy harvesting and MEC have been combined in many research with the goal of increasing computational power, extending battery life, and improving spectral efficiency while ensuring the completion of computational activities. For example,20,21 proposal for wireless-powered multi-user MEC systems included a wireless energy transfer-based MEC design method. A multi-antenna access point and a MEC server are combined in this design to enable the broadcast of wireless energy to numerous users for charging reasons. Each user node then employs the newly gained energy to carry out computing operations. Using the time division multiple access protocol, these duties can be carried out locally or offloaded partially or completely to the multi-antenna access point22. Proposed a full-duplex relay MEC system based on numerous inputs and multiple outputs in a different study. In this system, user devices can choose to run computational activities locally on their batteries or offload some or all of the work to an access point linked to the MEC server. The system uses the frequency division multiple access (FDMA) protocol, which not only receives computing results but also charges the battery during computation. The main goal of this system is to reduce system energy consumption over a predetermined period, hence solving the challenge of energy conservation.
A multi-user mobile edge computing resource allocation model based on the frequency division multiple access protocol was put forth23,24 and merges MEC with energy harvesting technologies for compute offloading. In cellular communication systems that enable multiple-input, multiple-output frequency division multiplexing, this paradigm is especially helpful. It aims to reduce energy consumption in multi-user FDMA-based MEC cellular networks and ease the strain of user-intensive computational operations. Within a multiuser frequency division multiple access system based on MEC, another research effort25 produced a MEC design framework that jointly optimizes the central processor frequency, uplink transmit power, uplink rate, and computing jobs.
Although MEC systems with energy harvesting have been investigated in this research, the offloading techniques used are based on OMA, which only partially utilizes the potential capacity between numerous users and the base station. Furthermore, it is unable to meet future needs for mobile communication, such as those for multi-access channel capacity and spectrum resources26. Examined NOMA-assisted MEC systems to overcome these constraints, optimizing power and time allocations reduce energy consumption during computational offloading. In order to identify the circumstances in which MEC offloading should make use of traditional OMA, pure NOMA, or hybrid NOMA techniques, the study developed closed-form expressions for the best power and time allocation solutions. In multi-user computational offloading scenarios,27,28 optimized the offloading decision, communication, and resource allocation by utilizing the superior spectral efficiency of NOMA technology. The study was effective in increasing the MEC system’s access capacity while lowering the overall computational overhead for all users by implementing the results of resource allocation.
Another noteworthy strategy suggested29 was a system using two edge servers, one located closer to and one further from the edge users, to enable cooperative communication. Edge users could use NOMA to distribute some of their computational workload between the closer and further MEC servers. The near server then established a full-duplex relay by decoding and sending task data from the far server. The study developed an optimization problem seeking to reduce overall system energy consumption by concurrently optimizing local CPU frequency, power allocation, system time allocation, and job division. In their proposal for a combination of multi-site multitasking computational offloading, NOMA transfer, and computational resource allocation optimization,30,31 used NOMA for computational offloading. The goal was to reduce the overall energy consumption of IoT devices while still accomplishing operations within a given time frame. The study developed an online deep reinforcement learning algorithm to choose the most effectiveoffloading option quickly. A literature review32 that focused on energy-efficient MEC designs also took binary and partial offloading situations into account individually. The study aimed to reduce the overall energy consumption of all users by optimizing the allocation of communication and processing resources.
Additionally, it focused on optimizing the decoding order of following interference cancellations by the base station, while still meeting the users’ computational delay limits. To find the globally optimal solution for partial offloading, an effective approach based on the Lagrangian pair wise method was suggested. For binary offloading, the branch-and-bound technique was used first to identify the global best solution. Next, two low-complexity algorithms based on the greedy method and the convex relaxation method, respectively, were designed to find suboptimal solutions. As a result, the multi-user MEC system’s energy efficiency significantly increased. The issues of energy harvesting have yet to be taken into account, despite the fact that previous literature has offered MEC systems combining NOMA technology for computational offloading, offering workable technical solutions for optimizing energy use. Given the environmentally friendly needs of 5G networks, it is crucial to improve energy and spectral efficiency while extending node life cycles, lowering conventional energy use, and shortening system delays. As a result, this research examines a full-duplex MEC system based on NOMA and energy harvesting, allowing users to use NOMA to offload computational tasks to the base station while the base station makes use of full-duplex to receive offloading tasks and transfer energy to other users simultaneously.. The suggested system offers promising ways to improve the functionality of MEC networks by addressing these important issues. The Symbol/Acronym section provided in the Supplementary Material outlines the key terminologies and mathematical notations used throughout the manuscript, facilitating a clearer understanding of the proposed methodologies and results.
Methodology
This section present the system model and optimization framework for the proposed NOMA-assisted FD-MEC system. First, we describe the system architecture, including the key components of the NOMA-assisted FD-MEC system. Then, we present the mathematical formulation of the optimization problem.
System model
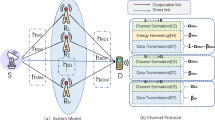
Figure 1 shows that this work analyzes multi-user energy harvesting full-duplex mobile edge computing system comprised of a Base Station (BS) and K = {1, 2, …,K} users. The BS has N antennas, and each user has a single antenna; the BS is combined with a Radio Frequency (RF) energy transmitter and a MEC server, and each user device has energy harvesting circuitry and a rechargeable battery. All users are divided into M = {1,2,…,M} groups in order to employ the NOMA approach. Let \({\mathcal{J}}_{{\text{i}}} = \left\{ {{\text{J}}_{{{\text{i}} - 1}} + 1, \ldots ,{\text{J}}_{{\text{i}}} } \right\}\) signify the user in groupi,where \({\text{J}}_{0} = 0,\;{\text{J}}_{{\text{M}}} = {\text{K,J}}_{{\text{i}}} = \sum\nolimits_{{{\text{z}} = 1}}^{{\text{i}}} {\left| {{\mathcal{J}}_{{\text{z}}} } \right|} \cup_{{{\text{i}} \in {\text{K}}}} {\mathcal{J}}_{{\text{i}}} = {\text{M}}\).

Multi-user mobile-edge computation system.
Take into account a system with duration \({\text{ T}}\), as shown in Fig. 2. There are \({\text{M}}\) phases in the time \({\text{T}}\), each with a time slot \({\text{t}}_{{\text{i}}} \left( {{\text{i}} = \left\{ {1,2, \ldots ,{\text{M}}} \right\}} \right)\), where \(0 \le {\text{t}}_{{\text{i}}} \le {\text{T}}\). Assume for the moment that a user’s computing task can be broken down into two components, each of which can be finished in \({\text{ti}}\). The total amount of computing data for a user is represented by the symbol \({\text{R}}_{{\text{j}}}\) bits, where \(\left( {{\text{R}}_{{\text{j}}} - {\text{l}}_{{\text{j}}} } \right)\) bits are reserved for base station offloading, and \({\text{l}}_{{\text{j}}}\) bits are set aside for local computing.User \({\text{j}}\) from group \({\text{i}}\) uses NOMA during the uplink phase to offload \(\left( {{\text{R}}_{{\text{j}}} - {\text{l}}_{{\text{j}}} } \right)\) bits to the base station. The compute task is delivered to the MEC server attached to the base station, which then starts processing it. The computational delay is ignored because the MEC server has strong computational capabilities31.The base station sends user \({\text{j}}\) the computed result, represented as \({\text{R}}_{{\text{j}}}^{{\text{s}}}\) bits, during the downlink phase. The user receives energy from the RF source while simultaneously getting the computing result. It is crucial to understand that, unlike the user, who has a reliable energy source and depends on the base station for energy, the base station is continuously fueled by a stable energy source throughout the communication. As a result, the base station keeps sending energy to the user.

FD-MEC system time slot process.
In conclusion, the system works in phases that allow users to divide their computing duties into different parts and offload some of them to the base station utilizing NOMA in the uplink. The MEC server handles the tasks and then, using a downlink, returns the results to the users. To compensate for the users’ erratic energy supply, the base station provides energy to them during the communication process.
Up-link model
In the uplink phase, each user offloads its computational task to the BS using NOMA. The uplink transmission rate \({\text{r}}_{{{\text{ij}}}}^{{\text{u}}}\) is given by the following equation. Equitation (1) for the uplink transmission rate.
The user delegated their computing job to the base station (BS) during the uplink phase. User \({\text{j}}\) and the base station’s uplink channel gain are shown as \({\text{h}}_{{\text{j}}}\). The uplink channels between group \({\text{i}}\) users and the base station are organized in decreasing order as \({\text{h}}_{{{\text{J}} - 1}} + 1 \ge \cdots \ge {\text{h}}_{{\uppi }}\) without losing generality. Succeeding interference cancellation (SIC) is a technique used by the BS to decode the computing workload from the user device. According to the SIC principle, the BS first decodes the user data with the maximum channel gain and then purges it of further sources of interference. The user \({\text{i }}\) in group \({\text{ jj}} \in {\mathcal{J}}_{{\text{i}}}\) may obtain an uplink rate of \({\text{r}}^{{{\text{u}}_{{{\text{ij}}}} }}\) by using NOMA and full-duplex approaches.
In this case, B stands for the system bandwidth, \({\text{P}}_{{\text{j}}}\) for user \({\text{j }}\) transmit power, and \({\upsigma }_{{\text{u}}}^{2}\) for noise power. The following restriction must be met in order for user \({\text{j }}\) to successfully dump \(\left( {{\text{R}}_{{\text{j}}} - {\text{l}}_{{\text{j}}} } \right)\) bits of data to the base station:
The offload transmission delay for user \({\text{j }}\) in group \({\text{i }}\) is represented by \({\text{t}}^{{\text{u}}} {\text{i }}\) in this instance. Being that the user is sending energy in the uplink, it is important to note that the energy used by user \({\text{j}} \in {\mathcal{J}}_{{\text{i}}}\) throughout the offloading procedure is provided by:
Downlink model
Once the BS receives the task, the MEC server processes it and returns the results for the downlink phase. The BS also transmits energy to the users during this phase to sustain their operations. Equation (4) to models the energy received by the users.
Think of \({\text{q}}_{{\text{i}}}\) as the downlink power that is being transmitted from the (BS) base station to the user. Based on the findings in the literature33,34, the energy received by user \({\text{j}}\) in group \({\text{i }}\) may be designated as follows since the base station has been continually transmitting energy to the user:
The energy-collecting mechanism used by the user \({\text{j}}\) has an energy efficiency of \(0 \le {\text{u}}_{{\text{j}}} \le 1\). Additionally, \({\text{t}}^{{\text{d}}} {\text{i}}\) stands for the downlink transmission time delay of the ith group of users \({\text{ j}}\), and \({\text{g}}_{{\text{j}}}\) denotes the channel gain between the base station and user \({\text{j}}\). These values may be attained rather easily.
Let the weighting factor be \(0 \le {\upgamma } \le 1\). Due to the tiny amount of downlink data and the rapid transmission rate, Eq. (5) is seen as fair. Furthermore, it is frequently noted that the computation results supplied by the user are generally lower in size than the jobs that the base station is capable of performing. Consequently, we may say that.
Given the restricted processing capability of the edge cloud, we designate \({\text{F}}\) as the maximum number of CPU cycles permitted to calculate the offloaded data within the complete time period. The following prerequisite must be satisfied for the edge cloud in order to guarantee minimal computational latency:
Additionally, the base station’s total energy consumption, or \({\text{E}}^{{{\text{BS}}}}\), includes both the energy used for broadcasting and the energy used for calculations. Consequently, the base station’s overall energy usage may be stated as follows:
Let \({\text{P}}_{0}\) stand for the base station’s cycle-by-cycle energy usage. Equation (8) illustrates the right side of the equation, where the first term is the energy used for broadcasting, and the second term is the energy used for calculations.
Local computational model
User \({\text{j }}\) uses \({\text{lj }}\) bits for the local computing process according to the local computing paradigm. \({\text{C}}_{{\text{j}}}\) stands for the number of CPU cycles needed to compute one input value at user \({\text{j}}\), and \({\text{f}}_{{\text{j}}}^{{\text{n}}}\) stands for the required CPU frequency for the \({\text{n}}\) th CPU cycle. These CPU frequencies should adhere to the following limitations: \(0 \le {\text{f}}_{{\text{j}}}^{{\text{n}}} \le {\text{f}}_{{\text{j}}}^{{{\text{max}}}} ,{\text{n}} \in \left\{ {1, \ldots ,{\text{l}}_{{\text{j}}} {\text{C}}_{{\text{j}}} } \right\}\) where \({\text{f}}_{{\text{j}}}^{{{\text{max}}}}\) stands for user \({\text{j}}\) maximum CPU frequency. The formula \(1/{\text{f}}_{{\text{j}}}^{{\text{n}}}\) gives the length of a CPU cycle, \({\text{n}}\). It is assumed that the local computation delay, abbreviated as \({\text{f}}^{{ \circ {\text{oc}}_{{\text{i}}} }}\), is less than the offload transmission delay, abbreviated as \({\text{t}}^{{{\text{loc}}}} {\text{i}}\). The CPU frequencies \(\left\{ {{\text{f}}_{{\text{j}}}^{{\text{n}}} } \right\}\) must meet the following computational latency restrictions to ensure that the local calculation is finished in the allotted time \({\text{T}}\): For every \({\text{t}}^{{{\text{loc}}}} {\text{i}} \le {\text{t}}^{4}\).
The energy consumed by user \({\text{j}}\) for local computation can be represented as follows:
The equation includes the chip architecture’s effective capacitance factor at user \({\text{j}}\), represented by \({\upkappa } > 0\)35.
Energy causality constraint
The energy gathered must be enough to cover the energy spent by user \({\text{j}}\), including the energy used for offloading computing and local computation, according to the energy causality constraint in the energy harvesting system. Thus,
By considering Eqs. (3), (4), (8) and (10), the total energy consumption of the entire system can be represented as follows:
Problem description
This section formulates the energy minimization problem for the system, defining the objective function, constraints, and key variables, followed by a Block Coordinate Decent based framework to solve the non-convex optimization problem.
Optimization objectives and constraints
The optimization problem is formulated to minimize the total energy consumption \({\text{E}}^{\text{Sum}}\) which includes both the energy consumed by users for offloading and local computation, as well as the energy used by the BS for communication and computation. Equation (12) for total energy consumption.
The major goal of this research is to ensure that all computational tasks are completed and that system services are maintained while at the same time optimizing the system’s total processing capability. This is accomplished through synchronized uplink power control optimization, temporal regulation, system service quality assurance, data allocation for offloading, and CPU frequency manipulation for local computing users. Keeping the system’s overall energy usage as low as possible is the main goal. Consequently, the system’s intrinsic optimization problem may be clearly stated as follows:
Ensure the minimum data rate requirement for reliable communication.
Energy consumed by each user does not exceed the energy harvested.
Limits the total computational resources allocated to tasks.
Time allocated for uplink/downlink transmission and computation does not exceed the scheduling window.
Local CPU frequency to maximum allowable level.
Uplink/downlink transmission times do not exceed the total time slot length.
Local computation allocated uplink transmission time.
Ensure a minimum downlink data rate.
Restricts the transmission power of user.
Joint resource allocation framework
To solve this non-convex problem, we used a block coordinate Decent (BCD) based algorithm. The BCD framework decomposes the problem into sub problems:
-
1.
Uplink/Downlink Power control (\(\text{p}\)) (\(\text{q}\))
-
2.
Computational offloading (\(\text{l}\))
-
3.
Time Allocation (\({\text{t}}\))
The algorithm iteratively optimizes each variable block while fixing others, ensuring convergence to a locally optimal solution. The detailed steps are presented in Sect. "Optimization approach".
We define numerous vectors in the system under consideration: The transmission power vector of the users is represented as \(p = \left[ {p_{1} , \ldots ,p_{M} } \right]^{T}\), where each member pi stands for the transmission power of user i. Similar to this, \(q = \left[ {q_{{1, \ldots ,q_{N} }} } \right]^{T}\) stands for the base station’s transmit power vector, with each element qi standing for the base station’s transmit power in the respective link. The transmission time slot vector, represented by \(t = \left[ {t_{1} , \ldots ,t_{N} } \right]^{T}\), also shows the allocated time slots for each connection. Additionally, the local computation distribution vector is denoted by the notation \(l = \left[ {l_{l} , \ldots ,l_{M} } \right]^{T}\), where each member li specifies the percentage of local computation carried out by user \(i\). To describe the distribution of CPU frequencies for locally computed users, we introduce the vector \({\varvec{f}} = \left[ {f_{1}^{n} , \ldots ,f_{N}^{n} } \right]^{T}\), where F stands for the CPU frequency. P stands for the maximum transmit power for the base station, whereas Q represents the maximum transmit power for each user.
The objective function (12a) seeks to reduce the system’s overall energy consumption, which includes both the energy used by users and the base station. The uplink’s minimum transmission data need is satisfied thanks to constraint (13b), ensuring a trustworthy communication link. The energy received by each user from the energy harvesting process must equal the energy spent by that user, accounting for both offloading and local computing energy consumption, according to constraint (13c). Additionally, restriction (13d) places a limit on the maximum CPU frequency for the edge clouds, ensuring effective use of the computing resources. To ensure that calculations are finished on time, constraint (13e) states that the entire time slot length, \({\text{T}}\), shall not be exceeded by the base station’s downlink transmission time and the waiting times for offloading by each user. Additionally, limitation (13f.) limits each user’s CPU frequency to not go beyond the maximum permitted level. The user’s offload delay and the base station’s downlink transmission delay cannot be longer than the entire time slot length, \({\text{T}}\), thanks to constraint (13g). The local calculation time is guaranteed to stay inside the allotted uplink transmission time by constraint (13 h).
Additionally, restriction (13i) sets a minimum downlink transmission data requirement, providing enough data flow from the base station to the consumers. Last but not least, restriction (13j) regulates the transmission power such that neither the base station nor the users go above their corresponding maximum transmission power limitations. It is clear that the optimization issue (13)'s objective function and constraints are not convex, making a direct solution impossible. As a result, creative strategies are attempted to develop fresh solutions to this challenging optimization issue.
Optimization approach
The Block Coordinate Descent (BCD) approach is employed to solve the optimization problem due to its ability to decompose the problem into simpler sub problems. The complexity of each sub problem is linear in terms of the number of users, with an overall complexity of \({\text{O}}_{{\text{j}}}^{{\left( {\text{n}} \right)}}\), where \({\text{n}}\) is the number of users in the system. In this section, the BCD approach is implemented to sequentially tackle the three sub-issues of downlink power allocation, computational offloading optimization, and time allocation. The algorithm converges efficiently and guarantees an optimal solution after a few iterations.
Local computation \(f\) optimization
This section’s goal is to identify the ideal CPU frequency, designated using the method suggested in the literature36,37. Finding the CPU frequency that maximizes system performance is the essential concept. To do this, each time slot has to meet the requirements listed below:
Maintaining the same CPU frequency during each cycle, designated as \({\text{f}}_{{\text{j}}}\), is important to minimize both the goal function and the value of \({\text{f}}_{{\text{j}}}\). It can be inferred from the results of the literature38 and taking into account the restriction \(0 \le {\text{C}}_{{\text{j}}} {\text{l}}_{{\text{j}}} /{\text{f}}_{{\text{j}}} \le {\text{t}}_{{\text{i}}}^{{\text{u}}}\) that the best answer for the local CPU frequency, \({\text{f}}_{{\text{j}}}\), is provided by:
Therefore, it can be concluded that
The ideal locally calculated energy consumption for user \({\text{j}} \in {\mathcal{J}}\) at the specified location indicated as \({\text{E}}_{{{\text{ij}}}}^{{{\text{Loc}}}}\) is obtained by substituting expression (16) into Eq. (10).
Substituting Eq. (18) into Eq. (13), problem (13) can be transformed into
Uplink power control p
Problem (19) analysis can lead to the following Lemma:
Lemma 1. The following requirements must be met by the best solutions \({\text{p}}^{{\text{opt }}} ,{\text{q}}^{{\text{opt }}} ,{\text{t}}^{{\text{opt }}} ,{\text{l}}^{{\text{opt }}}\) to problem (19).
The method of contradiction can be used to demonstrate Lemma 1. If all limitations are met, decreasing \({\text{p}}_{{\text{j}}}\) will minimize the system’s energy usage if \({\text{r}}_{{{\text{ij}}}}^{{\text{u}}} {\text{t}}_{{\text{i}}}^{{\text{u}}} > \left( {{\text{R}}_{{\text{j}}} - {\text{l}}_{{\text{j}}} } \right)\). This, however, runs counter to the best course of action. Lemma 1 demonstrates that it is always more energy efficient to send with fewer resources by demonstrating that when fewer data bits are communicated, the impact is likewise demonstrated.
According to Lemma 1 and Eq. (18), we can obtain
where \({\text{j}} = {\text{J}}_{{{\text{i}} - 1}} + 1, \cdots ,{\text{J}}_{{\text{i}}}\), defined in this paper
where, according to Eqs. (21) and (22) \({\text{u}}_{{\text{j}}}\) represents the transmit power from user \({\text{j}}\) of group i to user \({\text{J}}_{{\text{i}}}\) Ji multiplied by the total of channel gain.
From \(\sum _{{z = J_{{i + 1}} }}^{{J_{t} }} h_{z} p_{z} = 0\) obtains
On the basis of Eq. (24), solving (23) by recursive method yields
From Eqs. (22) and (24), the transmit power of user \({\text{j}}\) is
Thus, the optimal solution for \({\text{p}}_{{\text{j}}}\) is
Equation (27) will be included in Eq. (19) to transform the original problem into the following optimization challenge:
Because the optimization variables are so tightly connected, solving the issue (28) is still difficult. In this section, the block coordinate descent (BCD) approach is implemented to sequentially tackle the three sub-issues of downlink power allocation, computational offloading optimization, and time allocation. Subsequently, a closed-form solution is constructed for each sub-problem, yielding the optimal outcome. For the \(n\) th iteration, let \(\left( {\left\{ {q_{{\text{i}}}^{\left( n \right)} } \right\},\left\{ {l_{j}^{\left( n \right)} } \right\},\left\{ {t_{i}^{\left( n \right)} } \right\}} \right)\) signify the ideal distribution of communication and computing resources.
Downlink power control q
Firstly, this paper uses \(\left( {\left\{ {l_{j}^{{\left( {n - 1} \right)}} } \right\},\left\{ {t_{i}^{{\left( {n - 1} \right)}} } \right\}} \right)\) in the nth iteration more \(\left\{ {q_{{\text{i}}}^{\left( n \right)} } \right\}\) uplink power control can be rewritten as
The optimal downlink power in closed form is found as
Computational offloading optimization
Second, for a fixed \(\left( {\left\{ {{\text{q}}^{{\left( {\text{n}} \right)}} } \right\},\left\{ {{\text{t}}^{{\left( {{\text{n}} - 1} \right)}} {\text{i}}} \right\}} \right)\), the optimal computational offloading strategy is obtained by solving the following equation
The ideal offloading strategy is solved at the nth iteration as follows. The ideal solution to issue (31) is either at the stationary point of the objective function or at the edge point.
where \({\text{O}}_{{\text{j}}}^{{\left( {\text{n}} \right)}}\) is the number of task offloading, and in addition
Time allocation
The final optimal allocation time slot is founded by closed form as shown below:
Algorithm 1 outlines the joint communication and computational offloading optimization method for the problem (13). It iteratively computes the optimal CPU frequency, uplink power, downlink power, offloading strategy, and computational time allocation. The algorithm ensures convergence to an optimal solution by updating the relevant parameters at each step until the stopping criterion is met.

joint communication and computational offloading optimization.
Simulation experiments and performance analysis
This part conducts a thorough evaluation and analysis of the system performance and the suggested method described in this study through the use of 1000 Monte Carlo simulation runs. The experiments are divided into two separate sections, each with a particular function. First, the proposed Non-Orthogonal Multiple Access algorithm for Full-Duplex Mobile Edge Computing (referred to as NOMA FD) is evaluated for convergence and viability. The second goal is to demonstrate this algorithm’s usefulness by contrasting it with other methods.
The system parameters in the experimental setup are defined as follows. Table 1 presents the key simulation parameters used in this study to model and evaluate the system’s performance.
The system parameters in the experimental setup are defined as follows. In the experiments, the system parameters are set as follows: the mobile edge computing system is assumed to consist of M = 10 users uniformly distributed in a circle with a radius of 10 m centered at the base station, the number of antennas at the base station is N = 4, the system bandwidth is B = 5 MHz, the noise power \(\sigma_{u}^{2} = \sigma_{d}^{2} = - 104{\text{dBm}}\), path loss model is 128.01 + \(37.6{\text{log}}_{10} d\), where unit of \(d\) is km, and the shadow fading’s standard deviation is 4 dB, the computational task size \(R_{j}\) is \(10^{5} {\text{bit}},C_{i}\) is \(10^{3} {\text{cycles}}/{\text{bit}}\), the maximum CPU computing power per user \(f^{i} {\text{max}} = 1{\text{GHz}}\) and all \(j \in M\) and \(j = 0{ }\) users or BS per cycle. The local computational energy consumption is \(P_{J} = 10^{ - 10} {\text{J}}\)/cycle, and the maximum transmit power of each user and base station is set to \(P = 37{\text{dBm}}\) and \(Q = 44{\text{dBm}}\), respectively. In addition, the effective capacitance factor of the chip architecture at user \(j\) is \(k = 10^{ - 28}\), the energy efficiency of each user in the energy harvesting process is \(u_{j} = 0.8\), the system duration \(T\) is \(0.2\) seconds, and the edge computing capability is \(F = 6 \times 10^{9}\) cycles/slot.
The simulation uses a few users per resource multiplexing to take the complexity of decoding and error propagation into consideration. To ascertain the impact of user pairing techniques, two users are matched within each group. The matching strategies Strong–Weak (SW), Strong-Middle (SM), and Strong-Strong (SS) are all taken into consideration. In SW pairing, users are paired based on the order of their channel strength, with the user having the strongest channel condition being paired with the user having the weakest channel condition. The user with the highest channel condition is paired with the user with the next highest channel condition for spatial multiplexing (SM) pairing, and this process continues with the remaining users. In the SS pairing scheme, those with the second-highest channel condition are matched with those who have the highest channel condition, and this pattern continues for subsequent pairs.
The initial stages of the experimental research primarily focus on discussing the viability and convergence of the NOMA FD algorithm. Figure 3 displays the total energy consumption of the NOMA FD technique, which varies based on the duration of the time slot. Based on the testing findings, the SM pairing strategy demonstrates a lower overall energy consumption compared to the other two methods. The advantage stems from the substantial discrepancies in channel gain across individual users within each SM-paired group, leading to less energy loss in the system as a whole. The benefits of the SM technique are elaborated in subsequent iterations of the trials, which are conducted utilizing SM pair selection.

Effect of user pairing on NOMA FD Algorithm overall power consumption.
The convergence of the NOMA FD method with various cloud computing capacities is shown in Fig. 4. According to the experimental findings, the system’s overall energy is low as the number of repetitions rises. It only requires three iterations to converge fully, demonstrating the viability and efficiency of the NOMA FD technique presented in this study.

The suggested algorithm’s convergence behavior across various cloud computing capacities.
The NOMA FD algorithm put forth in this work is contrasted with other algorithms in the study that follow to demonstrate its usefulness and superiority. A comparison is made between the OMA algorithms used in a full-duplex mobile edge computing system30,31 (referred to as OMA FD) and the OMA algorithm used in a half-duplex mobile edge computing system (referred to as OMA HD), in addition to the NOMA FD algorithm. The goal is to assess the overall energy performance and show how effective the method suggested in this study is.
The link between the total energy used and the magnitude of the computing workloads in the NOMA-MEC system for various time slots is shown in Fig. 5. Energy usage in the computing and communication domains both rises, as does the number of computational user jobs. Consequently, with an increase in computing activities, the curves for various periods show an upward tendency. The chart also shows that overall energy usage increases when time slot duration decreases. This results in higher energy consumption in the communication domain because transmission within shorter time windows forces user devices to offload computing work to the base station.

Comparison of overall energy usage in relation to the duration of time slot.
Additionally, when compared to the other three comparable experimental methods, the suggested NOMA FD algorithm performs better. This is due to the benefits of full-duplex mode, in which a transmitter and a receiver are present at both ends of the communication system. As a result, the base station may receive data from the uplink user while also transferring energy to the user equipment, controlling data transmission in both the uplink and downlink directions. As a consequence, the suggested approach uses less energy than NOMA HD. Additionally; using NOMA technology lowers the system’s overall energy usage as compared to OMA FD. The base station’s computing complexity has increased due to the use of Successive Interference Cancellation (SIC) technology, which is vital to mention. The testing findings unmistakably reveal that the suggested NOMA FD algorithm works better than the other algorithms taken into consideration, demonstrating its efficiency and superiority in terms of overall energy consumption and system performance.
Figure 6 illustrates the correlation between the total energy consumption and the user count for different computing tasks. The image illustrates a positive correlation between the number of users and the total energy consumption of all algorithmic systems. This phenomenon occurs due to the correlation between the increase in the number of users and the subsequent rise in data offloading, resulting in an amplified energy consumption of the system. The recommended NOMA FD algorithm outperforms the NOMA HD, OMA FD, and OMA HD algorithms, showcasing the effectiveness of the proposed method and its suitability for multi-user applications. Furthermore, the OMA approach consumes a greater amount of energy, regardless of whether it is functioning in full-duplex or half-duplex mode. Operating in full or half-duplex mode results in increased energy consumption. These findings demonstrate that NOMA exhibits outstanding performance enhancements and effectively reduces system energy consumption.

Under different user counts (k), the total energy consumption of the system as a function of compute task size (R).
Figure 7 compares the proposed algorithm’s overall energy usage to that of the other three benchmark methods for various levels of cloud computing power. The graph shows that the overall energy usage of all scenarios lowers as cloud computing capacity rises. This is due to the fact that more powerful cloud computing enables customers to offload more data to the base station, hence consuming less energy. According to the findings of the experiments, the suggested NOMA-assisted full-duplex mobile Among the three experimental algorithms, the NOMA FD system uses the least energy. The NOMA FD method in this work performs best when compared to the other three experimental algorithms, demonstrating the efficiency of our technique. This experimental result aligns with the literature’s observation that the overall energy usage of all schemes remains relatively constant when the cloud computing capacity is beyond the threshold. Furthermore, when the cloud computing capacity is above the threshold, the overall energy consumption of all schemes remains rather stable.

Total energy consumption versus cloud computation capacity.
Figure 8 illustrates the relationship between the overall energy consumption for Non-Orthogonal Multiple Access and Orthogonal Multiple Access in both full and half duplex modes, as well as the power transmitted by different Base Stations (BSs). The comparative experimental results in Fig. 8 clearly demonstrate that an increase in the transmission power of the base station leads to a decrease in the energy consumption of the four algorithms. This phenomenon occurs because users are able to gather more energy when the gearbox powers of the BS are higher. As a result, the amount of energy needed to offload user tasks is reduced. In summary, the full-duplex technique consumes less energy compared to half-duplex. On the other hand, NOMA utilizes significantly less energy and achieves superior performance compared to OMA. Consequently, out of the three approaches outlined in this study, the NOMA FD algorithm consumes the least amount of energy.

Total Energy Consumption versus power of the transmitting Bs.
Performance comparison with existing algorithms
In this section, we present a comparative analysis of the key performance metrics of the NOMA FD algorithm, including convergence speed, energy consumption, scalability, and computational efficiency. The comparison is made against conventional methods and existing algorithms, highlighting the advantages of NOMA FD in various operational scenarios.
Figure 9a illustrates the rapid convergence of the NOMA FD algorithm, demonstrating its ability to reach the optimal solution faster than traditional methods, which is essential for efficient resource management in the MEC system. (b) Compares energy consumption across different time slot durations, showing that NOMA FD consistently outperforms other methods by achieving lower energy consumption as the time slot duration increases. (c) Demonstrates the scalability of NOMA FD, maintaining energy efficiency even as the number of users increases, making it well-suited for large–scale MEC systems. Finally, (d) compares the convergence time of NOMA FD with a convex-based optimization algorithm, revealing that NOMA FD converges more quickly, providing significant advantages in terms of computational efficiency and real-time decision-making.

Comparison with optimization Algorithms.
Comparison with existing literature
This work present key advancement in MEC systems, such as combining Full-Duplex (FD) with NIOMA, introducing a joint resource optimization framework, and proposing a scalable multi-user offloading strategy. These innovations significantly improve energy efficiency and scalability compared to existing methods. Detailed comparisons with existing methods are analyzed in Table 2.
Conclusions
In conclusion, this work proposes a unique solution that combines full-duplex technology, NOMA, and energy harvesting to overcome the issues presented by energy-constrained MEC devices. All users are divided into M groups in the proposed system design, which uses NOMA to offload computational activities to the base station while concurrently supplying energy to the user groups during each time slot. A hybrid communication and computation optimization technique for full-duplex MEC systems based on NOMA and energy harvesting is provided in order to achieve green communication and improve system performance. This strategy’s goal is to reduce the system’s overall energy use while meeting energy and computation latency restrictions. By breaking down the original non-convex issue into smaller problems, the suggested joint optimization technique tackles the highly linked character of the optimization variables. Local computation CPU frequency, upstream and downstream connection power control, time scheduling, and offload data allocation are some of these sub-problems. These sub-problems are resolved using the block coordinate descent approach to get closed-form ideal solutions. The NOMA-assisted full-duplex MEC system suggested in this research outperforms competing benchmark methods like orthogonal multiple access (OMA) and half-duplex systems, as shown by numerical simulations. Lower energy usage and greater performance advantages are achieved by the resource allocation technique described in this study. The suggested network system can be further improved in future research areas. For better system performance and optimal relay selection, the optimization framework can be expanded to incorporate one or more relay nodes. Relay nodes allow the system to take use of cooperative communication to reduce channel fading and increase overall network capacity. To assess the scalability and resilience of the suggested technique in realistic deployment settings, the influence of various network topologies and user distributions may also be examined.
Overall, mobile edge computing systems show enormous promise for establishing energy-efficient and high-performance wireless communication because they integrate full-duplex technology, NOMA, and energy harvesting. This study’s findings open the door for future developments in resource allocation tactics and system architecture, assisting in the creation of resilient and effective wireless networks.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request.
References
Banafa, A. Secure and Smart Internet of Things (IoT) (River Publishers, 2018).
Akyildiz, I. F., Kak, A. & Nie, S. 6G and beyond: The future of wireless communications systems. IEEE Access 8, 133995–134030. https://doi.org/10.1109/access.2020.3010896 (2020).
Wang, Y., Zhao, J. Mobile edge computing, metaverse, 6G wireless communications, artificial intelligence, and blockchain: Survey and their convergence. In: Proceedings of the 2022 IEEE 8th World Forum on Internet of Things (WF-IoT), 2022; pp. 1–8. https://doi.org/10.1109/WF-IoT54382.2022.10152245
Lin, L., Liao, X., Jin, H. & Li, P. Computation offloading toward edge computing. Proc. IEEE 107, 1584–1607. https://doi.org/10.1109/JPROC.2019.2922285 (2019).
Alsamhi, S. H. et al. Computing in the sky: A survey on intelligent ubiquitous computing for uav-assisted 6g networks and industry 4.0/5.0. Drones 6, 177. https://doi.org/10.3390/drones6070177 (2022).
Hu, Y. C., Patel, M., Sabella, D., Sprecher, N. & Young, V. Mobile edge computing—A key technology towards 5G. ETSI White Paper 11, 1–16. https://doi.org/10.1017/9781316771655.005 (2015).
Matin, M. A. & Islam, M. Overview of wireless sensor network. Wireless Sensor Netw. Technol. Protocols https://doi.org/10.5772/49376 (2012).
Wei, Z., Zhao, B., Su, J. & Lu, X. Dynamic edge computation offloading for Internet of Things with energy harvesting: A learning method. IEEE Internet Things J. 6, 4436–4447. https://doi.org/10.1109/jiot.2018.2882783 (2018).
Mao, Y., Zhang, J. & Letaief, K. B. Dynamic computation offloading for mobile-edge computing with energy harvesting devices. IEEE J. Sel. Areas Commun. 34, 3590–3605. https://doi.org/10.1109/JSAC.2016.2611964 (2016).
Liaqat, M., Noordin, K. A., Abdul Latef, T. & Dimyati, K. Power-domain non orthogonal multiple access (PD-NOMA) in cooperative networks: An overview. Wireless Netw. 26, 181–203. https://doi.org/10.1007/s11276-018-1807-z (2020).
Islam, S., Zeng, M., Dobre, O.A., Kwak, K.-S. Non-orthogonal multiple access (NOMA): How it meets 5G and beyond. arXiv preprint arXiv:1907.10001 2019. https://doi.org/10.1002/9781119471509.w5GRef032
Shin, W. et al. Non-orthogonal multiple access in multi-cell networks: Theory, performance, and practical challenges. IEEE Commun. Mag. 55, 176–183. https://doi.org/10.1109/MCOM.2017.1601065 (2017).
Hamamreh, J. M., Abewa, M. & Lemayian, J. P. New non-orthogonal transmission schemes for achieving highly efficient, reliable, and secure multi-user communications. RS Open J. Innov. Commun. Technol. https://doi.org/10.4640/03d8ffbd.324cc0fb (2020).
Mahady, I. A., Bedeer, E., Ikki, S. & Yanikomeroglu, H. Sum-rate maximization of NOMA systems under imperfect successive interference cancellation. IEEE Commun. Lett. 23, 474–477. https://doi.org/10.1109/LCOMM.2019.2893195 (2019).
Pokhrel, S. R., Ding, J., Park, J., Park, O.-S. & Choi, J. Towards enabling critical mMTC: A review of URLLC within mMTC. IEEE access 8, 131796–131813. https://doi.org/10.1109/access.2020.3010271 (2020).
Albataineh, Z., Andrawes, A., Abdullah, N. F. & Nordin, R. Energy-efficient beyond 5G multiple access technique with simultaneous wireless information and power transfer for the factory of the future. Energies 15(16), 6059. https://doi.org/10.3390/en15166059 (2022).
Jawad, H. M. et al. Accurate empirical path-loss model based on particle swarm optimization for wireless sensor networks in smart agriculture. IEEE Sens. J. 20(1), 552–561. https://doi.org/10.1109/JSEN.2019.2940186 (2019).
Ali, E., Ismail, M., Nordin, R. & Abdulah, N. F. Beamforming techniques for massive MIMO systems in 5G: overview, classification, and trends for future research. Front. Inform. Technol. Electron. Eng. 18, 753–772. https://doi.org/10.1631/FITEE.1601817 (2017).
Andrawes, A., Nordin, R. & Abdullah, N. F. Energy-efficient downlink for non-orthogonal multiple access with SWIPT under constrained throughput. Energies 13(1), 107. https://doi.org/10.3390/en13010107 (2019).
Bello, M., Yu, W., Pischella, M., Chorti, A., Fijalkow, I., Musavian, L. Flexible multiple access enabling low-latency communications: Introducing NOMA-R. arXiv preprint arXiv:2001.10637 2020. https://doi.org/10.48550/arXiv.2001.10637
Nath, S. & Wu, J. Deep reinforcement learning for dynamic computation offloading and resource allocation in cache-assisted mobile edge computing systems. Intell. Converged Netw. 1, 181–198. https://doi.org/10.23919/ICN.2020.0014 (2020).
Feng, J. et al. Cooperative computation offloading and resource allocation for blockchain-enabled mobile-edge computing: A deep reinforcement learning approach. IEEE Internet Things J. 7, 6214–6228. https://doi.org/10.1109/JIOT.2019.2961707 (2019).
Rehman, B. U. et al. Uplink non-orthogonal multiple access in heterogeneous networks: A review of recent advances and open research challenges. Int. J. Distrib. Sens. Netw. 18, 15501329221132496. https://doi.org/10.1177/15501329221132496 (2022).
Baig, M. B., Li, T. S. Parallel String Matching for Urdu Language Text. In Intelligent Technologies and Applications: First International Conference, INTAP 2018, Bahawalpur, Pakistan, October 23–25, 2018, Revised Selected Papers 1, pp. 369–378. Springer Singapore. (2019). https://doi.org/10.1007/978-981-13-6052-7_32
Li, T., Ning, Q. & Wang, Z. Optimization scheme for the SWIPT-NOMA opportunity cooperative system. J. Commun. 41, 141–154. https://doi.org/10.11959/j.issn.1000-436x.2020109 (2020).
Mao, Y., You, C., Zhang, J., Huang, K. & Letaief, K. B. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surveys Tutor. 19, 2322–2358. https://doi.org/10.1109/COMST.2017.2745201 (2017).
Xiao, Z. et al. Resource management in UAV-assisted MEC: State-of-the-art and open challenges. Wireless Netw. 28, 3305–3322. https://doi.org/10.1007/s11276-022-03051-4 (2022).
Attiah, M. L. et al. Adaptive multi-state millimeter wave cell selection scheme for 5G communications. Int. J. Electrical Comput. Eng. 8(5), 2088–8708. https://doi.org/10.1191/IJECE.V8I5.PP2967-2978 (2018).
You, C., Huang, K., Chae, H. & Kim, B.-H. Energy-efficient resource allocation for mobile-edge computation offloading. IEEE Trans. Wireless Commun. 16, 1397–1411. https://doi.org/10.1109/TWC.2016.2633522 (2016).
Wu, Y., Qian, L. P., Ni, K., Zhang, C. & Shen, X. Delay-minimization nonorthogonal multiple access enabled multi-user mobile edge computation offloading. IEEE J. Selected Topics Signal Process. 13, 392–407. https://doi.org/10.1109/JSTSP.2019.2893057 (2019).
Cao, X., Wang, F., Xu, J., Zhang, R. & Cui, S. Joint computation and communication cooperation for energy-efficient mobile edge computing. IEEE Internet Things J. 6, 4188–4200. https://doi.org/10.1109/JIOT.2018.2875246 (2018).
Liu, C.-F., Bennis, M., Debbah, M. & Poor, H. V. Dynamic task offloading and resource allocation for ultra-reliable low-latency edge computing. IEEE Trans. Commun. 67, 4132–4150. https://doi.org/10.1109/TCOMM.2019.2898573 (2019).
Wang, X., Yang, Y. & Sheng, J. Energy efficient power allocation for the uplink of distributed massive MIMO systems. Future Internet 9, 21. https://doi.org/10.3390/fi9020021 (2017).
Sun, Y., Ng, D. W. K., Ding, Z. & Schober, R. Optimal joint power and subcarrier allocation for full-duplex multicarrier non-orthogonal multiple access systems. IEEE Trans Commun 65(3), 1077–1091. https://doi.org/10.1109/TCOMM.2017.2650992 (2017).
Li, T., Baumberger, D., Koufaty, D.A., Hahn, S. Efficient operating system scheduling for performance-asymmetric multi-core architectures. In: Proceedings of the Proceedings of the 2007 ACM/IEEE Conference on Supercomputing, 2007; pp. 1–11. https://doi.org/10.1145/1362622.1362694
Ghani, B., Launay, F., Pousset, Y., Perrine, C. & Cances, J. P. Low-complexity hybrid interference cancellation for sparse code multiple access. EURASIP J. Wirel. Commun. Netw. 2022, 95. https://doi.org/10.1186/s13638-022-02162-y (2022).
Jadhav, M. M., Dongre, G. & Purandare, R. Resource allocation in 5G network using orthogonal frequency division multiplexing-hybrid automatic repeat request. Int. J. Commun. Syst. 35, e5343. https://doi.org/10.1002/dac.5343 (2022).
Singh, K. et al. Resource optimization in full duplex non-orthogonal multiple access systems. IEEE Trans. Wireless Commun. 18, 4312–4325. https://doi.org/10.1109/TWC.2019.2923172 (2019).
Author information
Authors and Affiliations
Contributions
Babar Mirza Baig, Muhammad Zain Yousaf: Conceptualization, Methodology, Software, Visualization, Investigation, Writing- Original draft preparation. Taoshen Li, Arvind R. Singh: Data curation, Validation, Supervision, Resources, Writing—Review & Editing. Mohit Bajaj, Milkias Berhanu Tuka: Project administration, Supervision, Resources, Writing—Review & Editing.
Corresponding authors
Ethics declarations
Competing interest
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Baig, M.B., Li, T., Yousaf, M.Z. et al. Synergizing NOMA and energy harvesting in full duplex mobile edge computing for optimized energy efficiency. Sci Rep 15, 13806 (2025). https://doi.org/10.1038/s41598-025-96272-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-96272-4
