
Abstract
Tuberculosis (TB), a contagious disease, significantly affects lungs functioning. Amongst multiple detection methodologies, Chest X-ray analysis is considered the most effective methodology. Traditional Deep Learning methodologies have shown good results for TB detection; however, model’s huge number of parameters, size, and compute requirements making it unsuitable for its practical deployment. Owing to scarce annotated datasets in medical domain augmented datasets are generated which is not a recommended technique in medical domain. This study presents TB-FSNet consisting of Few Shot Learning - Prototypical Network (FSL-PT) with a modified MobileNet-V2 backbone, incorporating a Self-Attention layer. The significant contribution of this study is to effectively train TB-FSNet in FSL-PT paradigm with six different backbones. The dataset utilised for this study consists of Montgomery County, and Shenzhen Chest X-ray Dataset combined. The proposed method attains highest accuracy of 93.6% with mere 2.21M parameters and 8.67 MB size, while maintaining high performance metrics such as precision, specificity, and sensitivity. Moreover, TB-FSNet is designed for seamless integration into embedded devices, making it suitable for deployment on edge devises. The model processes Chest X-ray images in real-time, providing immediate confidence scores for disease detection. This capability ensures that users can receive accurate diagnostic insights without needing to wait for medical professionals, enhancing the accessibility and efficiency of TB detection.
Similar content being viewed by others
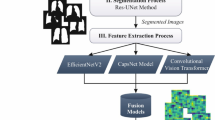
Introduction
Tuberculosis, commonly known as TB, is a contagious disease. It can affect various significant parts of the human body such as the brain, kidneys, or spine. However, the organs that are affected at elated levels are lungs. According to World Health Organization1 in the year 2021, 1.6 million individuals died of TB alone, making it the 13th largest fatal disease worldwide. Several methodologies are employed for the TB detection such as Sputum Test involving examination of mucus, Molecular Tests involving DNA matching of bacteria, and Chest X-ray (CXR) analysis, however the latter is preferred choice being the cost effective.
Amongst aforementioned techniques CXR image analysis is recommended as first choice for TB detection by WHO. Contagious diseases spread rapidly in underdeveloped countries due to inadequate safety and sanitation standards among the affected population. This dilemma further increases due to shortage of quality health facilities including trained health professionals in such locations. Artificial Intelligence (AI) has provided efficient, fast, and cost-effective solution for the automated detection of tuberculosis. This automation can help detection at an initial screening stage without dependency of trained radiologist and to limit its spread to a significant level.
The application of deep learning models in medical diagnostics has shown significant potential due to their capacity to analyze and interpret medical images with high precision. These models are built using advanced neural network architectures, which enable them to identify subtle patterns of disease that might be overlooked during manual examinations. By using multiple layers of computational nodes that mimic human neural activities, these models can learn from large datasets, thereby becoming more accurate and efficient over time, especially when there is plenty of data available. Considering the limited labeled medical datasets, techniques like data augmentation and synthetic data generation using algorithms like Generative Adversarial Networks (GANs) are used to generate realistic medical images. Such extended dataset are utilized to avoid risk of over-fitting where the model becomes too trained to the training data and performs poorly on new, and unseen data. Despite having huge computation cost, and model size, when trained on such extended datasets these dense models yields poor diversity & generalization, and bias.
Training these dense models from scratch produced reasonable results. However, to address the issue of huge compute cost and limited dataset size, an approach to focus on only relevant features using segmentation was adapted2, and3. This approach provides classifier with only most relevant set of features also known as the region of interest (ROI). Likewise, a similar approaches such as computation of attention coordinates and attention mechanism were found to be effective in terms of handling noise, and better generalization. Moreover, considering the healthcare environments, the consistency in the quality of dataset can be difficult to ensure, that include varying color, contrasts, and image quality. Such variations in the training datasets can adversely effect the model’s training, however, applied image enhancements techniques on dataset can help address such issues prior to classification4.
Data scarcity in medical domain is quite a challenge, approaches such as data augmentation, and synthetic data generation are being used for its redressal. Nevertheless, such techniques fulfill the dataset needs for deep learning models, but adversely affects model’s prediction by introducing challenges such as bias, poor generalization & diversity making them extremely unsuitable for medical datasets. A survey5 on the use of data augmentation techniques in medical imaging concluded that “Data augmentation techniques are not universally applicable to medical imaging as they may inadvertently distort clinically significant features.” Furthermore, it lacks appropriate variation of patient populations, such as age, ethnicity, and the variety of underlying conditions that could also influence model performance as well. One such method that solves this challenge as opportunity is Few Shot Learning (FSL). FSL is mainly targeted for domains where the annotated data is truly limited, and is of the type that works by computing prototype of each class using few training samples. Such trait reduces large dataset requirement and can be trained in shorter duration with limited compute resources.
The performance of such light weight models can be further complemented by utilization of segmentation techniques to focus on most relevant features6,7 and to look for the targeted features or feed pixel location for specific feature extraction. The use of explainable AI (XAI) has further improved the model’s performance, which works by complementing the model’s prediction by embedding the semantic features extracted using Long short-term memory (LSTM)8. Creating a blend of various techniques has also proven to be helpful. For instance, combining meta-learning with transfer-learning along with self attention has yielded promising results9.
On contrary, to address the challenges of scarce labeled data techniques Ye et al.10 such as self-training are also being used. In such techniques a Proxy-based pseudo-label generator project features into embedding space, and generate pseudo-labels according to distance, mean dice similarity coefficient (DSC) scores are computed for data sets.
Considering, performance limitations on unseen data, real world generalization, and bias of such computationally expensive models trained on large augmented dataset. In this work, we present a computationally inexpensive solution for Tuberculosis classification using scarce non-augmented dataset. Main contributions of this study are as follows:
-
A U-Net segmentation model was trained on a part of dataset for which lungs masks were available to predict lungs masks for the rest of dataset.
-
Light weight feature extractor having mere 2.2M parameters for the proposed Few-Shot Learning model.
-
Introduction of self-attention mechanism to extract only relevant features under the supervision of predicted lungs masks to reduce compute requirements.
-
Producing optimal key performance metrics by training, validating and testing on solely un-augmented limited size Chest X-Ray images to evaluate real world generalization ability and bias.
Previous work
The primary diagnostic method for the detection of TB has always been entrusted with CXR images. From decades analysis of the CXR images by the radiologists is the primary TB screening methodology. CXR images are considered least expensive in terms of cost, and quickest in terms of turnaround time. Ever since the use of machine learning models for medical diagnostics, several detection methodologies have used for the detection of the disease that too with significantly accurate results. This related work covers methodologies that produced reasonable results for the detection of the disease.
In the recent past, work was focused on the disease detection using traditional deep learning methodologies that involve training a dense architecture from scratch which pose huge computation cost. For instance, Showkatian et al.11 using CXR images from12 trained a CNN model from scratch having achieved 87% accuracy and compared the results with five other pretrained models. With a slight variation in 2022, Nafisah et al.3 utilised segmentation to extract the Region of Interest (ROI) from CXR images12 dataset and resultantly achieved 98.7%. Likewise in 2023, an Xception DL model was trained by Sharma et al.2 from scratch on NIAID TB portal program dataset13, however, this study adopted segmentation prior to classification and yielded promising results of 99% accuracy.
Some researchers have adopted a slightly different methodology for targeted focus on relevant features. Coordinate Attention module was introduced by Xu et al.14 to help accurate identification of interested targets. The proposed model was trained on Shenzhen Hospital CXR Set12 and achieved an accuracy of 93.18%. Similarly, CBAMWDnet by Huy et al.15 provide attention mechanism that allows focus on certain parts of image that captures detailed features by better focusing on the targeted task. Moreover, Dense Blocks make sure the information propagates from the entire block and more abstract features are learnt and finally reached an accuracy of 98.8%. Study combined Shenzhen Hositpical CXR9, and Tuberculosis (TB) chest X-ray dataset7 for training and evaluation purpose.
Some studies focused on image processing methods for better feature extraction, such as Munadi et al.4 used image enhancement methods such as Unsharp Masking (UM), High-Frequency Emphasis Filtering (HEF) to enhance the CXR images quality of dataset Shenzhen Hospital CXR Set12. After improving its quality it ultimately highlighted the important feature that were not prominent earlier attaining an accuracy of 89%.
Despite variations in detection methodologies, Commonality in the referred studies were dense model architectures with higher computation cost, data scarcity, and approach to address the data scarcity challenge, that is various data augmentation techniques. Such methods can mitigate the dataset size but introduce challenges such as reduced diversity, and elated bias than the original dataset. However, computation overhead remained a challenge.
Meta Learning, a cutting-edge approach in machine learning, revolves around designing algorithms that can learn how to learn. These systems are initially trained on extensive datasets like ImageNet, equipping them with a broad knowledge base, and then they can rapidly adapt to new tasks or data with minimal additional training, showcasing remarkable flexibility and efficiency in learning from small datasets. Singh et al.16 presented Meta-Med that outperforms transfer learning for 3, 5 10 shot tasks in both 2 way and 3 way classification for the ISIC 2018 dataset. Algorithm performance was varied with augmentation technique, for instance, MixUp for lower shot at different zoom levels and Reptile with CutMix consistently outperforms transfer learning for few-shot task with 91.12% accurarcy. Jiang et al.17 has combined meta-learning with transfer-learning and metric-learning. This approach consists of multiple components, an auto-encoder maps high dimension to low and vice versa for decoder, a metric-learner explain similarity amongst images based on distance, and task-learner for better feature extraction in FSL. Gaussian Disturbance Soft Label (GDSL) reduce the risk of overfitting by adding a random variable to the label space, and increases the learning efficiency by real-time data augmentation. Study utilizes diverse datasets BLOOD, PATHOLOGY, CHEST (frontal-view X-Ray images).
Few Shot Learning (FSL) is an innovative approach in machine learning that involves features extraction, and subsequent calculation of similarity amongst them with minimal amount of data. This technique is particularly beneficial in scenarios where data is scarce, allowing models to rapidly adapt and make accurate predictions based on just a few examples. Cores et al.6 proposed an FSL based architecture for COVID-19 detection; in order to retain focus on requisite features only, segmentation techniques were utilised to extract Regions of Interest. Earth Mover Distance (EMD) is calculated amongst extracted feature using ResNet-12 to establish similarity amongst them with an accuracy of 87.40%. Meanwhile, Shuai et al.7 presented a similar approach with slight variation, Single-Key Global Spatial Attention Module fetches and feeds pixel location into Feature Extractor to only look for specific features, and subsequently nearest class mean is computed for classification. Another approach Wang et al.8 made use of radiology reports via LSTM network to extract semantic features and subsequently establish a joint feature representation with morphological features. Subsequently, FSL model was trained episodically using these joint features and similarity with accuracy of 98.89% was computed. Pramana et al.18 applied FSL techniques for the TB detection with reported accuracies of 98.93% for ResNet-18, 98.60% for ResNet-50, and 33.33% for VGG16, however, details that can validate the claim were not provided, such as Training, validation and test accuracies, key performance metrics (specificity, sensitivity), handling class imbalance of dataset, detailed dataset description. Shome et al.19 trained FSL for TB detection on an augmented version of the Chest X-ray TB dataset, whereas the 700 images from TB class were augmented fivefold to match the 3500 images from Normal class. The authors reported training and validation results based on the heavily augmented dataset, producing inflated performance metrics, and degraded generalization to real-world clinical scenarios. Image augmentation is discouraged due to its potential to introduce bias and distort clinically significant features Litjens et al.5.
Siamese architecture refers to a unique neural network structure designed for tasks like image comparison or object tracking. This innovative setup involves two or more identical subnetworks, which share the same parameters and weights, allowing the network to efficiently learn to distinguish between similar sets of data. Xiao et al.9 has introduced similar approach that combines Siamese architecture with few-shot learning. Proposed grid attention (GA) module combines channel and spatial information as it binds attention weights with local context information, to increase focus on semantic information. The model has achieved better segmentation results without compromising on memory or computation requirements. The Triplet Siamese Network (TSN) is an advanced variation of the Siamese architecture consisting of three identical neural networks, specifically engineered for fine-grained similarity learning, refining the model’s ability to differentiate and relate distinct data points with 88.9% but at the cost of computation complexity of 42M parameters . Ornob et al.20 proposes Triplet Siamese Network (TSN) architecture blended with few-shot learning and an ensemble of pre-trained convolutional neural network. Embeddings by each of 6 model are concatenated and fed into a neural network to reduce generalization error. Such setting have achieved an accuracy of 99.53%, however, huge computation cost to obtain the results was taken into account.
Material and methods
Datasets
Datasets utilized for this study, including two publicly available datasets maintained by the National Institutes of Health, which are from Montgomery County, Maryland, and Shenzhen, China12. Table 1 shows the summary of TB CXR image datasets.
Montgomery county chest X-ray dataset
This dataset is gathered with the help of the Department of Health and Human Services, Montgomery County, Maryland, USA. It consists 138 CXR PNG images belonging to two classes: 80 normal and 58 TB. For each CXR image in the dataset, there is a corresponding mask available; sample images belonging to each category and their corresponding masks are shown in Fig. 1. Under the supervision of trained radiologist, the author performed segmentation, marking landmarks for vital organs and following the diaphragm. The segmented masks of each corresponding CXR images were stored in respective directories with the same file name as of CXR image.

MC CXR image dataset.
Shenzhen chest X-ray dataset
This chest X-rays (CXR) dataset was gathered from Shenzhen No.3 People’s Hospital, Guangdong Medical College, Shenzhen, China. Collected from outpatient department (OPD) patients, the dataset consists of 662 CXR images in PNG format containing images belonging to two classes: 326 normal and 336 TB. This repository does not contain corresponding lung masks for each image; sample images belonging to each category are shown in Fig. 2.

Shenzhen CXR image dataset.
Dataset split for FSL model: train, validation, and test sets
A combined dataset includes CXR images from the Montgomery and Shenzhen Dataset, consisting of 800 chest X-ray images. The dataset is divided two equal sets of 350 images for training and validation, meanwhile remaining part was reserved for testing for an unbiased evaluation of the model’s performance after training and validation. When training a few-shot learning (FSL) model, the distribution of data between training and validation sets is critical, particularly for training with a limited amount of data. Having a substantial validation set (equal to the size of the training set) ensures that you have enough data to effectively validate and tune the model. This helps in reliably assessing the model’s generalization capabilities, and is robust and performs consistently across different sets of data. Table 2 shows the dataset distribution for training, validation and test set.
Dataset split for U-Net segmentation
The segmentation model was trained on Montgomery dataset which consisted of 138 images along with corresponding masks, partitioned into 80, and 20 percent for training and validation respectively. The model’s performance was tested on Shenzhen Dataset for which binary lungs masks were unavailable. Table 3 shows the dataset split of training and validation set for the U-Net segmentation.
Methods
Segmentation model: U-Net
Segmentation model is of significant role in overall architecture of the system due to distinct composition of dataset utilised for the study. The combined dataset for this study consists of two datasets: the Montgomery and Shenzhen chest X-ray (CXR) datasets. The former includes CXR images and their corresponding masks, while the latter lacks the lung masks, crucial for the proposed attention module. In order to address this issue, as illustrated in Fig. 3, the CXR images and their corresponding masks were be used to train U-Net segmentation model; the trained U-Net model predicts the lungs masks for Shenzhen, ensuring consistency for complete dataset.
U-Net is known for its effectiveness in handling such tasks due to its robust architecture. The symmetric encoder-decoder captures the contextual details and allows to capture precise features, which is crucial for accurate segmentation, this focused segmentation is the key behind its accurate predictions of lungs masks.
Encoder
Downsampling paths of U-Net model are equipped with ResNet-34 encoder which is pretrained on ImageNet dataset. Considering the medical imaging requirement of in-depth analysis of features, deeper architecture was chosen which was pretrained on large and diverse set of images like ImageNet, which is crucial for the detailed analysis required in medical imaging.
Dice loss function
Dice Loss is known for its effectiveness in handling the imbalanced nature of dataset. Likewise, in lungs CXR images, the areas of interest such as lung pathologies are typically much smaller compared to the overall image area. Dice Loss focuses on increasing the overlap between the predicted masks and the ground truth, thereby directly enhancing the precision of the segmentation. The Dice Loss function, used in the training of the U-Net model for image segmentation tasks, is defined as:
Where \(X\) is predicted set of pixels and \(Y\) being the ground truth. The Dice coefficient measures the overlap between the prediction and the ground truth, with a value of 1 indicating perfect overlap and 0 indicating no overlap. Thus, Dice Loss, being \(1\) minus this coefficient, penalizes the model proportionally to the lack of overlap.

U-Net model flow diagram.
Classification model: few shot learning - prototypical network
In this study our focus is to perform classification using a model which is computationally inexpensive, and which can be trained on limited number of samples without relying on the need of augmentation being the not recommended practice for medical datasets.
In this context one of the most popular methodologies is Few-shot learning (FSL). Proposed by Jake Snell21, utilised the concept of prototypes, to represent each class by a prototype, typically the mean feature vector of its support examples. Samples are classified based on their distance from learned feature space. FSL aims to classify new samples using only a fewer support sample. Traditional machine learning models needs huge amount of labelled data to be effectively trained. However, its collection is a very costly and time-consuming task specifically in medical domain.
To effectively train a FSL model following key parameters needs calculated based on size of dataset and nature of problem
-
N_WAY (Number of Classes): 2, in our case representing TB and normal lung conditions.
-
N_SHOT (Number of training examples per class): Indicating the number of images per class the model will learn from during each evaluation task.
-
N_QUERY (Number of validation images per class): Representing the number of images used for validation of the model’s predictions per class during each evaluation task.
-
N_EVALUATION_TASKS: Denoting the number of unique tasks the model will be evaluated on.

FSL architecture.
Figure 4 illustrates the flow of activities for classification. In the first step, an CXR image, along with its corresponding mask, is fed into to the feature extractor. The extracted features are then processed for prototype computation, here a prototype for each sample is computed. Subsequently, distance is computed between prototypes to assign the sample to a particular class based on a predefined threshold.
Prototype calculation
For each class \(k\) in the support set, the prototype \(c_k\) is calculated as the average of the feature vectors \(z_i\) from all support samples \((x_i, y_i) \in S_k\) belonging to class \(k\). Mathematically, it is given by:
where:
-
\(S_k\) is the set of support samples belonging to class \(k\),
-
\(z_i\) is the feature vector (representation) of the sample \(x_i\),
-
\(|S_k|\) is the number of samples in class \(k\).
This prototype \(c_k\) represents the central or average feature of class \(k\) in the feature space.
Distance calculation
Euclidean distance between a query sample’s feature vector \(z_{\text {query}, i}\) and the prototype \(c_k\) for each class \(k\) is computed as follows:
where:
-
\(z_{\text {query}, i}\) is the feature representation of the query sample \(x_i\),
-
\(c_k\) is the prototype of class \(k\),
-
\(\Vert \cdot \Vert\) denotes the Euclidean distance.
This distance measures the similarity of query sample to the prototype
Classification scores
The computed distances \(d_{i,k}\) are utilized to compute the classification scores (logits) for each class \(k\). The score is computed as:
where:
-
\(d_{i,k}\) is the distance between the query sample and the prototype of class \(k\),
-
\(\text {Classifier}(\cdot )\) is a function that converts the distance into a classification score (logit).
Based on value of these scores query sample is assigned to each class based on threshold.
FSL models caters the issue by generalizing to new tasks using available data of related tasks. They have two components, a backbone which helps extract features from input data followed by classifier which make predictions.
FSL models are computationally inexpensive due to following factors:
-
Fewer Parameters: FSL model learns from fewer samples, making the model smaller in size and consequently posing a reduced computational cost.
-
Transfer Learning: FSL uses a transfer learning approach, which reduces the amount of training required, making the overall training faster and computationally inexpensive.
-
Feature Reuse: FSL’s ability to reuse learned features of related tasks eliminates the need for learning from scratch, thus reducing the computational cost of training and inference.
Feature extractor
Feature extractor is a component that extracts a set of features from raw data. These features serves as a basic building blocks for alot applications such as segmentation, classification, etc by providing a representation of key characteristics while significantly reducing the data dimensionality. Detailed structure of proposed feature extractor and its constituent components is shown in Fig. 5
The architecture of MobileNet-V2 as shown in Fig. 5a is primarily composed of series of inverted residual blocks, Fig. 5b represents the structure of a single inverted residual block. These blocks ensures reduced computational demand using depth wise separable convolutions. This performance is achieved by performing three majors steps: first, a point-wise convolution (1x1) is used to expand the channel dimensions of the input feature map, allowing temporary representation of features at higher dimension. Subsequently, a 3x3 convolution is applied that performs single convolution per input channel. This capability enables learning spatial features efficiently. Lastly, point-wise convolution compresses the channels back down to reduce dimensionality and aggregate the learned features, followed by batch normalization and ReLU activation to quick training.

Key components of inverted residual block of proposed MobileNet-V2.
The proposed modified MobileNetV2 architecture in Fig. 5a also introduces a self-attention mechanism embedded at the end of fifth inverted residual block to elate the network’s capability and to look only for specific features with in input image. This modification not only reduces the computational requirements but also the time complexity significantly.
Figure 5c illustrates self attention layer, which effectively manages the contextual information within an image by generating three distinct sets of feature maps queries as (Q), keys as (K), and values as (V) through separate convolutional layers. A dot product of Query and key is processed through a soft-max to produce attention scores. These scores represents the importance of each feature with respect to others in the map. These modification dynamically prioritize regions within the feature map, making it versatile and robust in handling diverse and challenging visual data.
The addition of self-attention allows MobileNetV2 to be more adaptive in its processing, enhancing its ability to capture pertinent features and suppress less informative ones. This can lead to improvements in accuracy and robustness, especially in complex visual tasks where context and detail are crucial. The modification aims to achieve these benefits while still maintaining the lightweight and efficient nature of the base MobileNetV2 architecture.
For the support set:
For the query set:
Binary cross-entropy (BCE) loss function
Binary Cross-Entropy (BCE) loss function is widely used for binary classification tasks. It works by computing negative log of predicted probability as penalty if actual class label was 1 and negative log of (1 - Predicted probability) if class label was 0. In case of significant deflection from actual label it will result in higher loss, thus pushing model for accurate predictions.
The Binary Cross-Entropy (BCE) loss for the predicted probabilities \({\hat{y}}\) and true labels \(y\):
Evaluation metrics
Evaluation of results in medical domain is very crucial. In medical domain performance of a model is not just limited to certain parameters, it must provide detailed insights of its ability for all classes under examination. Few metrics such as false positives and negatives are paramount in medical applications. In this study we have evaluated our model’s performance in term of Accuracy, Specificity, Sensitivity, Precision, Recall, and F1-Score. Each metric has a unique perspective on the model’s effectiveness and reliability in clinical settings and provide a validation of diagnosis.
Accuracy
It provides the overall correctness of model for all classifications. In other words, it is the ratio of true results to the number of cases examined.
Specificity
It is the ratio of correctly predicted negatives to the true negatives label.
Sensitivity
Sensitivity, also known as recall or true positive rate, measures the proportion of actual positives that are correctly identified as such (e.g., the percentage of diseased patients correctly identified).
Precision
Precision assesses the accuracy of positive predictions made by the model. It is the proportion of positive identifications that were actually correct.
Recall
Recall (which is synonymous with Sensitivity in binary classification) measures the model’s ability to detect positive samples. The higher the recall, the more positives are correctly identified.
F1-score
F1-Score is the harmonic mean of precision and recall. It is a better measure than accuracy for the cases where there are imbalanced classes or when false negatives and false positives are crucial.
Results and discussions
Training performance and classification results
U-Net: training
The U-Net Model was trained using ResNet-34. Initially, the U-Net model was initialized with a ResNet-34 backbone pretrained on ImageNet and is configured to process grayscale images. In order to reduce overfitting, dropout is manually integrated into the convolutional layers of the model’s decoder. Table 4 shows the parameters used in the U-Net training.
U-Net: analysis
The U-Net Model was trained separately using ResNet-34, the training, and validation loss results obtained consequent to both training were plotted separately. The Fig. 6 represents the training vs. validation loss of ResNet-34 model. The Best model check point ensured that the most effective version of the model was retained and ResNet-34 was the best performing model selected for further processing i.e., lungs masks generation.

Training and Validation Loss Plot of U-Net with ResNet-34.
U-Net: results
The trained U-Net Model performed exceptionally well during training as well as testing, the same was utilized in predicting binary lungs masks for the Shenzhen Dataset, for which Lungs Masks were not available. Figure 7 illustrates the segmentation prediction for both labels along with the extracted region of interest

Segmentation predictions for different labels: (a) Normal and (b) TB.
Figure 7a presents an original image of Normal class, followed by its predicted binary lungs mask from our trained segmentation model, and extracted region of interest inline with the predicted mask. Furthermore, Fig. 7b presents an original image of TB class, followed by its predicted binary lungs mask from our trained segmentation model, and extracted region of interest inline with the predicted mask
The trained U-Net model was crucial in predicting masks of dataset for whom masks were not available. Efficacy of the model prediction is evident from the extracted ROI based on mask predicted by the segmentation model. The third column of Fig. 7a and 7b visually demonstrate the extracted ROI for both classes.
FSL: training
Prototypical Networks Few Shot Learning is a neural network designed for few-shot classification tasks. Network consist of a backbone feature extractor, a forward pass for computing embedding for both support and query sets, prototypes are computed for support images per class, and calculates distances between prototypes to generate class scores. An episodic Training loop works by iterating over support and query sets, loss is computed on their predictions using Binary Cross Entropy Loss. Training loop is followed by the validation loop to verify its performance using accuracy and loss metrics, and dynamically adjusts learning rates, best state of the model is retained and saved in case of any improvement in validation metrics. Model was trained using 6 other feature extractors other than the proposed feature extractor to compare its performance and the proposed model yielded superior performance in terms of all key performance metrics. Table 5 shows the parameters used for training the FSL model.
FSL: analysis
The line graph of training and validation loss and accuracy indicated successful model learning, with a consistent decrease in loss values as shown in Fig. 8 and consistent increase in accuracy values as shown in Fig. 9. Best model check point ensured that the most effective version of the model was preserved.

Training and validation loss plot for FSL MobileNet-V2 with SelfAttention.

Training and validation accuracy plot for FSL MobileNet-V2 with SelfAttention.
Comparative analysis of FSL
Performance of FSL with MobileNet-V2 Self-Attention
In this study, the performance of the Few-Shot Learning (FSL) Prototypical Model with a proposed feature extractor was studied alongside six other feature extractors. The FSL model integrating a MobileNetV2 with Self-Attention outperformed the rest in terms of the majority of key performance metrics.

Confusion matix, specificity and sensitivity values of FSL with proposed feature extractors.
The proposed approach achieved the highest accuracy of 93.6%, specificity of 91.8%, and sensitivity of 95.4%. Additionally, it attained an F1 Score of 93.7% due to its impressive precision and recall of 92.1% and 95.4%, respectively as shown in Fig. 10. Despite this excellent performance, it maintains a low computational overhead with only 2,210,348 trainable parameters, underscoring its suitability for applications requiring high accuracy, low-latency processing, and are short of computation resources.
Low-complexity feature extractors: assessing MobileNet-V2, EfficientNet-B0
The model performed reasonably well with the standard MobileNetV2 as well, achieving an accuracy of 91.3% and a balanced specificity and sensitivity of above 90% as illustrated in Fig. 11. This variant involves slightly more trainable parameters (2,223,875). The increase of about 13,000 more parameters and a decrease in its performance further validate our proposed approach.

Confusion matix, specificity and sensitivity of FSL with MobileNet-V2 feature extractors.
On contrary, from Fig. 12 it is evident that, EfficientNet-B0 despite having 4,010,113 trainable parameters, produced a comparatively similar performance having accuracy of 91% as of standard MobileNetV2 but with almost double the parameter count.

Confusion matix, specificity and sensitivity of FSL with EfficientNet-B0 feature extractors.
Medium-complexity feature extractors: assessing ResNet-18 and ResNet-34
ResNet18, having 11,176,515 parameters, showed a similar accuracy but distinguished itself with a higher specificity of 94.5% as shown in Fig. 13. Despite this superior specificity value, its deployment in resource-scarce environments is challenging due to the high parameter count.

Confusion Matix, Specificity and Sensitivity of FSL with ResNet-18 feature extractors.
ResNet34, with 21,284,675 trainable parameters, demonstrated a significant increase in model complexity. It achieved specificity and sensitivity of around 90% as highlighted in Fig. 14, which was comparatively lower than other models.

Confusion matix, specificity and sensitivity of FSL with ResNet-34 feature extractors.
High-complexity feature extractors: assessing ResNet50 and ViT
From Fig. 15, it is evident that, no significant improvement in performance of ResNet50 was observed despite having 23,508,035 parameters and produced a specificity of around 80.0%.

Confusion Matix, Specificity and Sensitivity of FSL with ResNet-50 feature extractors.
As shown in Fig. 16, the performance of Vision Transformer (ViT) is not consistent with its large parameter count of 85,798,659, achieving a sensitivity of about 81.8%.

Confusion matix, specificity and sensitivity of FSL with ViT feature extractors.
Comparative key performance metrics of FSL across feature extractors
The performance of FSL with various feature extractors, including the proposed feature extractor was evaluated using the evaluation criteria defined in Section 3.3.
The Fig. 17 presents the performance of FSL with various feature extractors including the proposed feature extractor. The results of the proposed model, along with the other feature extractors were illustrated using a heat map, it is evident that the proposed approach maintains its superiority in terms of performance in almost all key performance metrics necessary for medical diagnostics.

Performance metrics of various feature extractors.
The computational complexity of any model is directly proportional to the number of parameters it contains. Model with dense architecture has the capability and capacity to learn more features than the model with the fewer parameters. Figure 18 presents a visual comparison of the number of parameters of all the feature extractors utilised for the study. The figure clearly illustrates that, the proposed MobileNetV2 with Self-Attention has even less parameters than the standard MobileNetV2, which is the lowest amongst all with only 2,210,348 parameters. However, despite this low parameter count, it has maintained optimal performance metrics as shown in Fig. 17 indicating a highly efficient architecture.

Complexity in terms of Parameters of feature extractors employed for our experiments.
Additionally, the Vision Transformer (ViT), with 85,798,659 parameters was found to be the most costly in terms of complexity. Despite the reasonable performance achieved the large number of parameters renders it less efficient and computationally costly for real-world applications. Moreover, feature extractors such as ResNet34 and EfficientNetB0, with 21,284,675 and 4,010,113 parameters and ResNet34 reaching 21,284,675 parameters has shown a trade off between performance and complexity, but also highlights that the correlation of increase in number of parameters with higher computation demands not necessarily result in increase in performance. These results clearly underscores the need to strike a balance between efficiency and complexity in order to get the optimal outcomes.
Discussion and future work
The study started by successfully training a segmentation model on the Montgomery County TB dataset, containing CXR images and their corresponding masks, to predict binary lung masks for the Shenzhen Hospital TB dataset. Subsequently, a feature extractor was proposed equipped with self-attention. This feature extractor use binary lungs masks to focus only on the region of interest (ROI), significantly reducing the number of extracted features. This technique prioritizes the most relevant features for TB detection, enhancing the model’s overall performance. Afterwards, the research contributed with the use different feature extractors for detection of disease providing insights of the results and highlighted the areas which needs improvements.
The FSL prototypical model was used with six pre-trained feature extractors. Their performance and computation complexity in terms of parameters were compared. The proposed MobileNetV2 with self-attention mechanism has achieved a reasonable accuracy of 93.63% with 2.21 Million parameters, the lowest among all models used for comparison. Similarly, MobileNetV2 , EfficientNetB0, ResNet18, ResNet34, ResNet50, ViT reached maximum accuracies of 91.36%, 91.36%, 90.91%, 89.54%, 82.27%, and 83.18% with 2.22 M, 4 M, 11 M, 21 M, 23 M, and 85 M parameters, respectively.
FSL prototypical networks works effectively work by extracting features which are used to create prototypes and subsequently calculate distances among them. To improve the time and computation complexity, this study integrated segmentation techniques followed by self-attention mechanism, modifying the built-in MobileNetV2 model to enhance feature extraction while reducing the computational cost and enhancing the model’s performance. These results are highly relevant, as this study offers a feasible solution for implementing reliable medical diagnostics in environments where time, data, and computational resources are scarce. Equipping FSL models with targeted feature extraction techniques can help achieve higher accuracies with limited data and computational resources. In conclusion, TB-FSNet not only achieves high diagnostic accuracy but also excels in practical deployment. Its ability to operate on embedded and edge devices allows for real-time Chest X-ray analysis, making accurate diagnostic insights readily available without relying on medical professionals, thereby advancing the accessibility and efficiency of TB detection. Future work can expand this study by incorporating larger annotated original datasets to enhance the model’s performance and generalization.
Conclusion
This paper presents a lightweight solution for TB detection using dataset consisting of non synthetic, and unaugmented CXR images. In this study, a combined publicly available dataset consisting of Shenzhen and Montgomery Chest X-ray images, is used for training and evaluation. The solution consists of two parts, initially corresponding lungs masks for the Shenzhen CXR images were predicted with , subsequently, FSL-PT was trained using proposed lightweight feature extractor for classification. Model’s performance was evaluated on key performance metrics and produced an accuracy of 93.6%, F1-Score of 93.8%, specificity, and sensitivity of 91.8% and 95% along with 2.2 M number of parameters and model size 8 MB. Analysing the performance metrics of the proposed model with the traditional deep learning models with huge number of parameters, proposed model yielded results with a mere difference of maximum 6% against all metrics. The performance metrics of the proposed model are exceptionally better as compared to FSL approaches in previous work.
Data availibility
All data supporting the findings of this study are publicly available. The datasets used for the experiments are accessible from the National Institutes of Health (NIH) repository under the following DOI: https://doi.org/10.3978/j.issn.2223-4292.2014.11.20.
References
World Health Organization, Tuberculosis, https://www.who.int/health-topics/tuberculosis, Accessed: November 11, (2023).
Sharma, V. et al. Deep learning models for tuberculosis detection and infected region visualization in chest X-ray images. Intelligent Medicine 4(2), 104–113 (2023).
Nafisah, S.I, et al., Tuberculosis detection in chest radiograph using convolutional neural network architecture and explainable artificial intelligence, Neural Computing and Applications, 1–21 (2022).
Munadi, K. et al. Image enhancement for tuberculosis detection using deep learning. IEEE Access 8, 217897–217907 (2020).
Litjens, G. et al. A survey on deep learning in medical image analysis. Medical Image Analysis 42, 60–88 (2017).
Cores, D. et al., A few-shot approach for COVID-19 screening in standard and portable chest X-ray images, Scientific Reports, 12, 1, 21511 (2022)
Shuai, W. & Li, J. Few-shot learning with collateral location coding and single-key global spatial attention for medical image classification. Electronics 11(9), 1510 (2022).
Wang, Y. et al. Semantic-Powered Explainable Model-Free Few-Shot Learning Scheme of Diagnosing COVID-19 on Chest X-Ray. IEEE Journal of Biomedical and Health Informatics 26(12), 5870–5882 (2022).
Xiao, G. et al. Siamese few-shot network: a novel and efficient network for medical image segmentation. Applied Intelligence 53(14), 17952–17964 (2023).
Ye, Z. et al., A dynamic few-shot learning framework for medical image stream mining based on self-training, EURASIP Journal on Advances in Signal Processing, 2023, 1, 49 (2023).
Showkatian, E. et al. Deep learning-based automatic detection of tuberculosis disease in chest X-ray images. Polish journal of radiology 87, 118–124 (2022).
Jaeger, S. et al. Two public chest X-ray datasets for computer-aided screening of pulmonary diseases. Quantitative imaging in medicine and surgery 4(6), 475 (2014).
Rahman, T. et al. Reliable Tuberculosis Detection Using Chest X-Ray With Deep Learning, Segmentation and Visualization. IEEE Access 8, 191586–191601 (2020).
Xu, T. & Yuan, Z. Convolution Neural Network With Coordinate Attention for the Automatic Detection of Pulmonary Tuberculosis Images on Chest X-Rays. IEEE Access 10, 86710–86717 (2022).
Huy, V. T. Q. & Lin, C.-M. An Improved Densenet Deep Neural Network Model for Tuberculosis Detection Using Chest X-Ray Images. IEEE Access 11, 42839–42849 (2023).
Singh, R. et al. MetaMed: Few-shot medical image classification using gradient-based meta-learning. Pattern Recognition 120, 108–111 (2021).
Jiang, H. et al. Multi-Learner Based Deep Meta-Learning for Few-Shot Medical Image Classification. IEEE Journal of Biomedical and Health Informatics 27(1), 17–28 (2023).
Pramana, A.A.G. et al., Few-Shot Learning Approach on Tuberculosis Classification Based on Chest X-Ray Images, arXiv preprint arXiv:2409.11644 (2024).
Shome, N., Kashyap, R. & Laskar, R. H. Detection of tuberculosis using customized MobileNet and transfer learning from chest X-ray image. Image and Vision Computing 147, 105063 (2024).
Ornob, T. R. et al. CovidExpert: A Triplet Siamese Neural Network framework for the detection of COVID-19. Informatics in Medicine Unlocked 37, 101156 (2023).
Snell, J. et al., Prototypical networks for few-shot learning. Advances in neural information processing systems 30 (2017).
Acknowledgements
Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R136), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia
Author information
Authors and Affiliations
Contributions
Kamran Riasat: Conceptualization, Methodology, Writing-original draft & editing. Akhtar Jamil: Supervision. Shaha Al-Otaibi: investigation and reviewing, Sania Zeb: Methodology, Resources, & Writing-review. Saima Riasat: Investigation, Shamsa Kanwal: Reviewing and editing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Riasat, K., Jamil, A., Al-Otaibi, S. et al. Tuberculosis detection using few shot learning. Sci Rep 15, 13167 (2025). https://doi.org/10.1038/s41598-025-97803-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-97803-9
