
Abstract
Heart disease is becoming more and more common in modern society because of factors like stress, inadequate diets, etc. Early identification of heart disease risk factors is essential as it allows for treatment plans that may reduce the risk of severe consequences and enhance patient outcomes. Predictive methods have been used to estimate the risk factor, but they often have drawbacks such as improper feature selection, overfitting, etc. To overcome this, a novel Deep Red Fox belief prediction system (DRFBPS) has been introduced and implemented in Python software. Initially, the data was collected and preprocessed to enhance its quality, and the relevant features were selected using red fox optimization. The selected features analyze the risk factors, and DRFBPS makes the prediction. The effectiveness of the DRFBPS model is validated using Accuracy, F score, Precision, AUC, Recall, and error rate. The findings demonstrate the use of DRFBPS as a practical tool in healthcare analytics by showing the rate at which it produces accurate and reliable predictions. Additionally, its application in healthcare systems, including clinical decisions and remote patient monitoring, proves its real-world applicability in enhancing early diagnosis and preventive care measures. The results prove DRFBPS to be a potential tool in healthcare analytics, providing a strong framework for predictive modeling in heart disease risk prediction.
Similar content being viewed by others

Introduction
The healthcare system (HCS) is one of the biggest in emerging nations, with yearly growth in both employment and income1. The essence of the HCS is collaboration2. This is because many stakeholders work together to achieve common goals of reducing medical expenses and mistakes, including nurses, radiologists, laboratory techs, physicians with various specialties, and pathologists, delivering high-quality, improved healthcare services3. In the past, diagnosing uncommon illnesses required a thorough physical and analytical examination performed in hospitals4. These days, a smartwatch may assist us in determining the cause of any health anomaly5. In the event an epidemic illness like Ebola strikes, technology is crucial in preventing its fast spread and notifying people about the necessary precautions to adopt6. Technology advancements are causing a transition in healthcare services from hospital-centric care to individualized, personalized treatment7. Numerous clinical tasks, including blood tests, diabetes monitoring, and pressure monitoring, may be completed in real-time and at a distance8. The development of data services and connectivity in developing nations has made remote healthcare system monitoring practical and valuable9. As the HCS grows, it requires big data technology to gather, analyze, manage, and store massive amounts of data10. Big Data analytics is becoming a common way to manage vast volumes of data and improve decision-making11.
Big data signifies the quantity of the data utilized and analyzed and includes the potential for data to provide essential insights through various features12. It is categorized into a few terms. i.e.13, volume is the quantity of information developed; velocity is the rate of data transmission, and Variety is used to describe the range of data types that may be contained in plain text files, including database, excel, and CSV14, value indicates the worth of the data. However, it’s essential to realize that not all data are helpful; veracity indicates the comprehension of data15, validity assures the correctness and Precision of data for future uses, variability is the reliability and significance of data, Viscosity denotes delay or time lag in data transfer between the source and destination16, viability denotes the speed with which data is transferred and received from multiple sources. Visualization represents the complexity of extensive data and helps organizations acknowledge its relevance17. It is essential to pay close attention to the increasing demands for improved technologies that can handle problems with processing large data sets without affecting security and privacy18,19. Healthcare organizations employ tools for extensive data analysis that guarantee the availability20, confidentiality21, and integrity of protected health information22. The World Health Organization’s estimates show that cardiac disease is the world’s most significant cause of demise, which accounts for 17.9 million fatalities every year23. The most common behaviors drinking alcohol is a contributing factor to the risk of stroke and heart disease, smoking, poor dietary habits, and not exercising24. Deep learning (DL) has become a necessary tool in the healthcare industry to help diagnose patients.
The key contribution of the proposed work is;
-
Initially, the IoT healthcare dataset was gathered and trained using the Python system.
-
A novel Deep Red Fox Belief Prediction System (DRFBPS) is introduced as a predictive method with the necessary features for prediction.
-
The collected data is preprocessed to remove noise, and feature analysis is performed using Red Fox optimization to select the required features from the vast data.
-
Using these selected features, the DRFBPS analyzes and predicts heart disease risk factors.
-
The model’s effectiveness is assessed using measures including accuracy, F-score, Precision, AUC, Recall, error rate, p-value, and confidence intervals.
This paper contains recent related works in the second portion, the model issue is described in the third portion, the obstacles are developed in the fourth portion, and the case study and performance validation for the developed Framework are discussed in the fifth. In the sixth portion, the work is finally concluded.
Related work
A few of the most current studies in this area include;
Alizadehsani et al.25 have examined the majority of COVID-19 cases that had flu-like symptoms, according to the investigation carried out in Iran from March to April 2020. 319 individuals participated in the research. The primary indications and manifestations were advanced age, fever, sweating, dyspnea, disorientation, weakness, ageusia, shivering, anosmia, anorexia, exhaustion, and dry cough. There was no discernible association between COVID-19 and the following variables: sputum-producing cough, eczema, conjunctivitis, travel, asthma, corticosteroids, liver illness, rheumatological diseases, and chest discomfort. The limitation is the extremely little (2-month) follow-up period may not have captured the disease’s long-term effects on death.
Dritsas and Trigka26 have assessed many models to provide an efficient basis for predicting long-term stroke risk incidence using ML. The primary contribution of this work is a stacking technique that produces excellent results. The experiment’s findings demonstrated that with an accuracy of 98%, the stacking classification works better than the other approaches. This study’s dependence on a publicly accessible dataset raises certain limitations. Data gathering techniques may not be standardized, and public datasets may not undergo strict quality control processes.
Reddy et al.27 have developed 10 ML classifications for predicting heart disease risk by utilizing the Cleveland heart dataset and the best attributes determined by attribute assessors. With the whole collection of attributes, the sequential minimum algorithm classifier produced 85%ccuracy; with the optimum characteristics, the classifier produced 86% accuracy. The best ROC area of 0.91 was obtained. The limitation is that it performs with a small dataset, which may cause overfitting.
Mahmud et al.28 investigated Veterans’ Results and Costs Related to Liver Disease (VOCAL) data used in a retrospective cohort analysis and found 4712 surgical operations in 3785 cirrhosis patients. The research classified procedures and utilized multivariable logistic regression to estimate postoperative mortality using the models. The models showed good discrimination and higher performance, but the limitation is they face misclassifications with the large dataset.
Yang et al.29 have developed a computational technique to predict people with diabetes by merging multiple forms of physical assessed data. Data on physical tests of both healthy persons and diabetic patients were gathered between 2011 and 2017 in Luzhou City, China. An eXtreme Gradient Boosting (XGBoost)-based model was created to distinguish between diabetic patients and healthy people. Additionally, a diabetes risk scorecard was developed to assess people’s health. Based on this information, an online diabetes risk evaluation approach was created to improve personal lifestyle management and diabetes cascade screening to offer recommendations for managing human health. It demonstrates poor performance in feature analysis.
Alqammash et al.30 have developed an advanced model to predict COVID-19 cases in high-altitude and low-sea-level regions of Saudi Arabia. In addition to three machine learning methods—random forest, gradient boosting, and naive Bayes—this model integrates binary particle swarm optimization. The results show that the gradient boosting model outperforms both the random forest and naive Bayes models. However, it has problems with computational complexity.
Elshewey et al.31 have developed a novel method for accurately classifying potato late blight disease. This approach employs pre-trained models such as ResNet-50, GoogLeNet, AlexNet, and VGG19Net. Specifically, the AlexNet model is utilized to extract features, which are subsequently optimized using ten different algorithms. The most accurate is the Binary Waterwheel Plant Algorithm Sine Cosine (WWPASC). Five machine learning models train the specified features. With high classification accuracy, it outperforms the previous four optimization methods. However, it has limitations due to the risk of overfitting.
Elshewey et al.32 have introduced a model that uses an optimized gradient-boosting classifier to predict HCV disease in Egypt. The model’s accuracy is improved by optimizing hyperparameters with the OPTUNA framework. The model uses a 1385-instance dataset and a forward selection-wrapped method to identify essential features. The study compares the performance of five machine learning models, achieving a 95.3% accuracy rate. However, it faces challenges in computationally expensive and requires high processing time.
Alqammash et al.33 have developed an improved linear regression model using multivariate adaptive regression splines (LR-MARS) to forecast crude oil demand in Saudi Arabia using the social spider optimization (SSO) algorithm. The performance of this model was higher than other models, as demonstrated by the ANOVA results. However, this study did not compare it with other commonly used optimization algorithms.
A Convolutional neural network with long short-term memory (CNN-LSTM) model for potato disease detection was proposed by Alsakhari et al.34, which was evaluated on a Z-score-standardized dataset. The model was tested against five classic machine learning algorithms: Random Forest, Extra Trees, K-Nearest Neighbors, Adaptive Boosting, and Support Vector Machine. The CNN-LSTM model has the highest accuracy of 97.1%, outperforming other models in terms of Precision, sensitivity, specificity, F-score, and AUC. However, the uneven distribution of disease groups in the dataset is a major drawback.
Research gap
Despite significant advances in predictive models for heart disease risk assessment, several challenges persist. Many existing models suffer from issues like overfitting, inadequate feature selection, and limited scalability when applied to diverse and large datasets. Traditional machine learning approaches often fail to incorporate the complex interactions among multiple risk factors, which can lead to inaccurate predictions. Moreover, while Deep Learning (DL) techniques have shown promise in handling such complexities, they often require substantial computational resources and are prone to overfitting, especially when trained on imbalanced datasets.
Furthermore, the current literature lacks comprehensive solutions that integrate effective feature selection methods with robust predictive models to enhance accuracy and reliability. The potential of optimization techniques, such as Red Fox Optimization, in selecting relevant features for improving prediction performance remains underexplored. Additionally, there is a need for models that can efficiently process large-scale healthcare data while maintaining the confidentiality and integrity of patient information.
The introduction of a novel Deep Red Fox Belief Prediction System (DRFBPS) aims to address these gaps by integrating advanced feature selection with deep learning for improved prediction accuracy and reliability. By focusing on these under-researched areas, this study seeks to contribute to the development of more effective heart disease risk prediction models, ultimately enhancing patient outcomes through early intervention and personalized treatment strategies.
System model with problem
Big data is necessary in the healthcare system to enable smooth communication between patients and healthcare professionals, to boost patient involvement in the treatment process, to provide evidence-based care, and to aid in the early identification of disease and security concerns. Heart disease continues to be a concern to world health. To avoid problems and enhance patient outcomes, early identification, and risk factor prediction are essential. Traditional risk assessment techniques have certain limitations in prediction due to the missing data and the inability of the methods to handle large datasets. The challenges faced by the existing techniques are shown in Fig. 1.

System model with problem.
As the healthcare system contains a vast amount of data, the predictive model should possess the capacity to manage big data for prediction. Specifically for large data healthcare systems, this paper proposes an efficient deep learning technique. The goal of this strategy is to create a more precise and effective model for predicting heart disease risk factors by using an enormous quantity of patient data.
Proposed methodology
Heart disease risk factor prediction is the identification of people with an increased chance of heart disease. This information helps healthcare professionals implement early interventions and preventive measures to reduce risk and improve cardiovascular health. Hence, a novel Deep red fox belief prediction system (DRFBPS) has been introduced as a predictive model. Initially, the datasets from the health care system are collected and preprocessed to eliminate errors and handle missing values. The red fox optimization is used to select the required features, and based on these selected features, the DRFBPS predicts the risk factors. Finally, the performance is evaluated.
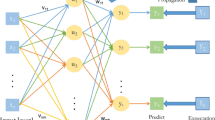
The proposed model architecture is displayed in Fig. 2. A few measures are used to assess the predictive model’s performance and efficiency. Here is a description of the demonstrated model process.

Proposed DRFBPS architecture.
Process of proposed DRFBPS
The recommended Framework functions with deep belief network (DBN)35 and red fox optimization (RFO)36. Red Fox Fitness selects the required features to predict risk factors. The deep brief network is a DL technique; it can handle complex data and efficiently learn complex relationships among features for the best prediction. The DRFBPS layer diagram is provided in Fig. 3

DRFBPS layer.
The DRFBPS has three layers. Input layer, hidden layer, and output layer. The Input Layer takes healthcare data in the form of multiple health parameters. The Hidden Layer comprises three Restricted Boltzmann Machines (RBMs). The RBM 1 is employed for the preprocessing, the RBM 2 conducts feature selection with Red Fox Optimization, and the RBM 3 performs prediction. The RBMs used the sigmoid activation function for probabilistic feature learning and ReLU in the prediction layer to add non-linearity. The Cross-Entropy Loss function is utilized for classification. Training is done with the hyperparameters learning rate of 0.001, batch size of 32, and a dropout of 0.2 to avoid overfitting. Lastly, the Output Layer utilizes a Softmax activation function for binary prediction and classifies the heart disease risk as High Risk or Low Risk. Initially, the datasets have been gathered and trained. It is executed in Eq. (1)
here, \(T\) denotes the training variable, \(H_{d}\) denotes the health care data, and \(\{ 1,2,3,...,n\}\) denotes the \(n\) amount of data.
Preprocessing
Preprocessing is a critical initial step in leveraging IoT healthcare data to forecast heart disease risk using DRFBPS. It entails cleaning and handling missing values, identifying and eliminating outliers, and deleting extraneous information. The RFO Worst function handles preprocessing. It detects the worst-performing features that cause redundancy and eliminates them. It initiates by checking each feature statistically and heuristically, i.e., variance, correlation with the target variable, and the contribution of the feature. The RFO makes a dynamic ranking of features and eliminates the least optimal ones. Thus, it minimizes dimensionality and improves the data quality. By using this method, the system produces more precise and efficient results and performs better at filtering than a traditional filter. By using this method, the system produces more accurate and efficient results and performs better at filtering than a traditional filter37. The preprocessing is done in Eq. (2)
here, \(P\) signifies the preprocessing variable, \(\lambda\) signifies the noise filtering function of the RFO, and \(e\) denotes the error constraints. It enhances data quality, and these strategies increase model performance, eventually leading to more accurate forecasts.
Feature selection
Feature selection is the technique of selecting pertinent traits from a large quantity of data. The Fitness function of the red fox fitness is used in the feature selection process. It enhances the model’s effectiveness and accuracy for predicting the risk of heart disease by selecting the most relevant features that differentiate the heart as a risk factor. Feature selection is executed in Eq. (3)
here, \(F\) denotes the feature extraction variable, \(P(H_{d} )\) denotes preprocessed data, \(t\) denotes the iteration, \(\alpha\) denotes the red fox fitness function, \(P\left( {H_{d}^{best} } \right)\) is the best feature that is randomly selected for each iteration. RFO imitates the wise hunting and escape behavior of red foxes. The Algorithm selects optimal feature subsets by iteratively improving candidate solutions based on exploration and exploitation rules. RFO adaptively modifies the search process in terms of balancing exploitation that optimizes promising subsets and exploration for searching new feature combinations. So that local optima may be avoided and an optimal feature subset identified. This method of reduction in dimension, improved model performance, and prevention of overfitting occurs.
Prediction
Heart disease risk factor prediction determines and evaluates the variables that influence a person’s risk of heart disease. With several features, such as heart rate, cholesterol level, age, gender, etc., that are analyzed in the feature selection process, the predictive model determines the risk of heart disease. It is shown in Eq. (4)
\(D\) denotes the disease risk prediction variable, \(F(H_{d} )\) denotes selected features, \(R,H\) denotes the heart at risk and health, respectively, and \(E\) denotes the Established standard score. Based on the prediction, the disease is classified, and it is executed in Eq. (5)
here, \(C\) implies the classification variable. The classification is based on the high and low-risk condition of the heart. Hence, the proposed DRFBPS performs better in predicting and classifying the disease.

DRFBPS.

The Algorithm for the proposed DRFBPS is displayed. The Python system executes the entire computing process employing a pseudo-code pattern. Figure 4 shows the process diagram for the designed Framework.

Flowchart for the proposed DRFBPS.
The workflow for the designed Framework is displayed in Fig. 4. It presents the working methodology for the suggested DRFBPS sequentially. Algorithm 1 shows some mathematical operators. Some criteria are used to compute the proposed DRFBPS model successfully.
Results and discussion
The Windows 10 Python Environment is used to validate the proposed DRFBPS model. The datasets have been collected, and they undergo preprocessing to remove errors and feature selection to select the needed features for accurate prediction. The Red Fox Fitness function selects this feature. Based on the selected features, the disease has been predicted. The computational time of the suggested DRFBPS is also a major concern for healthcare applications. Here, the training took an efficient time of 150 s. Furthermore, memory usage was measured at 209.87 MB, which reflects effective resource usage. For inference, the DRFBPS model is optimized to run with optimal feature selection to achieve quicker prediction times with little computational overhead. The necessary metrics for the proposed DRFBPS are depicted in Table 1.
Case study
Initially, the healthcare dataset was gathered and loaded from the Kaggle standard site. It is the heart attack risk prediction (HARP) dataset. The dataset contains 88,414 records with a size of 18.43 MB. The dataset has 46,944 low-risk samples and 41,470 high-risk samples. Of that data, it is split into 70% for training as 32,861 low-risk and 29,029 high-risk instances. Similarly, the data is split into 30% for testing as 14,083 low-risk and 12,441 high-risk instances. The key information gathered from the health care data includes age, gender, blood pressure readings (systolic and diastolic), body temperature, and cholesterol rates (low, high, and total). Table 2 illustrates the risk characteristics and the embedded value consideration for each.
Table 2 demonstrates the risk features for heart disease with its labeled code for two stages: low and high risk 0 and 1, which are the two states in which the model is intended to establish high and low levels of characteristics.
The Shapley Additive Explanations (SHAP) plot in Fig. 5 provides an insight into the impact of different features on the model output. The top bar plot shows the SHAP values on average, and the features Heart, LDL Cholesterol (LDL Chol), and Age have the highest impact on model predictions. The bottom summary plot shows the direction and magnitude of feature contributions, where each point represents an instance in the data, with color coding (blue for low values and pink for high values). Features like Heart and LDL Cholesterol have high impacts on predictions, with high values (pink) contributing positively to the model output. Features like HDL Cholesterol and Body Temperature have relatively lower impacts. The SHAP values also show feature interactions and their impact on prediction variability, and hence, it is an appropriate tool for explainable AI in medicine and medical diagnostics.

SHAP feature impact.
The feature importance heat map in Fig. 6 displays the correlation matrix of different features, and color intensity shows the strength and direction of associations. A value close to 1 (red) shows a strong positive correlation, and a value close to − 1 (blue) shows a strong negative correlation. Features such as heart rate (Hea) and systolic BP (Sys) are strongly and positively related, indicating that rising systolic pressure is related to heart conditions. Similarly, diastolic BP (Dia) and age are strongly and positively related, implying that pressure rises with age. Gender (Gen) and age are strongly and negatively related, implying gender-based patterns. LDL Cholesterol (LDL) and HDL Cholesterol (HDL) are weakly negatively correlated. The heatmap is useful in interpreting feature interactions, is important in predictive modeling, and demonstrates the greater influence of features on results. Figures 7 and 8 show the accuracy and loss curves, respectively, that were acquired throughout the training and testing phases. An accuracy and loss curve visually represents the model’s accuracy and loss throughout training and testing epochs. It shows the capacity of the model to distinguish heart disease between normal and risky.

Feature importance heat map.

Training and testing accuracy curve.

Training and testing loss curve.
The loss curve represents the model’s error throughout training and testing epochs. A loss curve that starts high and gradually falls throughout testing indicates higher performance, whereas a loss curve that continuously drops during training indicates more accurate predictions.
Figure 9 shows the confusion matrix of a classification model’s performance. The matrix displays true labels against the predicted labels. The model correctly classified 14,081 instances as class 0 low risk and 12,441 instances as class 1 high risk. There are merely two instances of misclassification. This implies that the model acts exceptionally well with very few errors. To verify the importance of the red fox optimizations, feature selection, the results are evaluated and compared before and after feature selection. The results are displayed in Fig. 10

Confusion matrix.

Performance before and after feature selection.
The p-value attained before feature selection is 0.07, and after feature selection is 0.001. Moreover, the error rate attained before feature selection is 0.1369, and after feature selection is 0.014. Feature selection with the RFO technique improves the model’s performance by selecting the most relevant features and removing noisy and redundant information. This leads to improved generalization, reduced error rates, and improved statistical significance, as indicated by the decrease in p-value. Feature selection also improves computational efficiency to the largest possible degree, such that the model can make faster and better predictions. Overall, feature selection improves the model’s learning by improving predictive performance and accuracy. The ablation study is provided in Table 3
Performance analysis
The Python environment is used to verify the developed model’s efficacy. To analyze the model’s abilities in prediction, it is compared with metrics such as Accuracy, F score, Precision, AUC, Recall, and error rate. To assess the proposed DRFBPS model performance with other techniques, it is compared with a few existing approaches such as ML Voting Classifier (MLVC)38, ML stacking classifier MLSC39, Light Gradient Boosting Classifier (LGBC)40, Extreme Gradient Boosting with Random Forest (EGBRF)40, CNN Sparse Autoencoder (CNNSA)41 and Linear SVM (LSVM)42.
Accuracy
Accuracy is a significant performance measure used to predict heart disease risk factors. It demonstrates that the percentage of the model correctly predicts whether heart disease risk variables are present or absent. Accuracy is evaluated by Eq. (6)
here, \(CP\) denotes the correctly predicted risk present, \(CA\) denotes correctly predicted absence of risk, \(IP\) denotes incorrectly predicted the risk present, and \(IA\) denotes the incorrectly predicted absent of risk. The accuracy is compared with the existing approaches and is shown in Fig. 11

Accuracy comparison.
The accuracy rate achieved by the existing MLVC is 80.1%, MLSC is 90.9%, LGBC is 77.84%, EGBRF is 75.63%, CNNSA is 83.56% and LSVM is 86.43%. The developed DRFBPS achieved an accuracy of 98.6%, and with a high attained accuracy rate, the proposed model shows better performance.
Precision
Precision, also known as optimistic prediction, is a measurement used to validate the accuracy of a predictive model, especially in classification tasks like recognizing heart disease risk factors. Precision measures the proportion of correct risk forecasts among all risk forecasts. It is computed by Eq. (7)
The precision metric is assessed and compared with existing techniques displayed in Fig. 12. High Precision indicates that the model has high accuracy in its optimistic predictions, implying that most of the occurrences it predicts as having the heart disease risk factor are correct.

Precision comparison.
The existing techniques MLVC, MLSC, LGBC, EGBRF, CNNSA, and LSVM attained a precision rate of 80.4%, 96.7%, 74.6%, 73.13%, 85.2%, and 87.5% respectively. The proposed DRFBPS model attained 94.7%, which performs better than the existing approaches.
Recall
Recall is an important metric to assess the model’s efficiency. It measures the predicted risk instances to the total actual risk. It assesses the model’s capacity to detect every risk instance accurately. It is evaluated by Eq. (8)
High Recall ensures that most patients with heart disease are appropriately recognized. It is assessed, and the abovementioned techniques are compared in Fig. 13.

Recall comparison.
The Existing MLVC gained a recall rate of 80.1%, MLSC gained 87.6%, LGBC gained 73.26%, EGBRF gained 68.25%, CNNSA gained 82.9% and LSVM gained 85.9%. The proposed model DRFBPS gained a recall rate of 97.9%. In comparison to the other methods, DRFBPS achieved a relatively greater recall rate.
F score
Precision and Recall are combined in a statistic called the F score. It combines the Precision and recall measures and assesses the Framework’s ability to correctly predict the risk factors by avoiding errors. It is equated in Eq. (9)
here, \(x\) denotes the precision rate and \(y\) denotes the recall rate. The F score value for the DRFBPS model is assessed, and its comparison is shown in Fig. 14.

F-score comparison.
The F score for the existing MLVC is 80.1%, MLSC is 92.15%, LGBC is 73.93%, EGBRF is 70.61%, CNNSA is 84.05%, LVSM is 86.7% and the proposed technique attained a 97.7% F score value. The attained higher F score demonstrates better performance of the model in predicting.
Error rate
Error rate represents the proportion of incorrect predictions to the total prediction number. It is evaluated to determine the negative predictions done by the model. It describes the overall performance of the model. It is evaluated by Eq. (10)
Figure 15 displays the error rate comparison. The error rate achieved by the existing MLVC is 0.199, MLSC is 0.091, LGBC is 0.2216, EGBRF is 0.2437, CNNSA is 0.1644, and LSVM is 0.1375. The designed model DRFBPS has an error rate of 0.014. The error rate obtained by the developed technique is lower, so it performs better.

Error rate comparison.
AUC
The AUC is the performance indicator for classification models that is significant in evaluating the model’s capacity to differentiate. In performance categorization, a high AUC value is more effective. Its comparison is shown in Fig. 16.

AUC comparison.
The AUC for MLVC, MLSC, LGBC, EGBRF, CNNSA, and LVSM is 88.4%, 96.1%, 72.27%, 74.71%, 90.3% and 92.1% respectively, and the proposed DRFBPS obtained 98.2%.
P-vale and confidentiality interval
The p-value and confidence interval (CI) are important statistical validation metrics to evaluate the robustness of predictive models. P-value aids in identifying the significance of correlations between risk factors. The CI gives an interval of values. The CI is narrow for greater precision and wide for greater variability of the estimates. Both these measures combined increase the statistical validity of heart attack risk prediction, so predictive models should be accurate and generalizable to larger populations. The results of the statistical validation p-value and confidence intervals are described in the Table 4
Moreover, the overall effectiveness of the designed Framework demonstrates a better predictive technique. The entire functionality of the planned DRFBPS with current techniques is depicted in Table 4.
DRFBPS’s higher performance compared to existing models is due to its capability of capturing intricate, non-linear interactions in the data more efficiently. The model delivers a remarkable accuracy rate, which greatly surpasses existing approaches. This enhancement is seen in all the evaluation metrics, with DRFBPS having a very low error percentage among all other models, which reflects its low misclassification rate. Its high Precision and Recall also reflect its strength in true positive detection while keeping false positives and false negatives to a minimum. Its high F-score verifies its equitable performance in Precision and recall, further establishing its dependability. In addition, DRFBPS has the best AUC value, demonstrating its best discriminant ability in classifying. The low p-value indicates a statistically significant relationship. While so, the CI gives an interval of values in which the actual effect size will probably fall, generally at a 97% confidence level. The wide gap in performance implies that DRFBPS has optimized feature selection processes that maximize its predictability, generality, and resilience to intricacies in the data structure to make it the best-performing model among the compared methods.
Additionally, to verify the selection of RFO, other optimization algorithms such as the genetic Algorithm (GA), Particle swarm (PS), and Bayesian optimization (BO) are hybrid with DBN, and the results are shown in Table 5
Table 5 shows that the proposed DBN + RFO model performs the best with accuracy, which signifies an excellent selection of RFO. It also possesses the lowest error rate and highest AUC, indicating superior discrimination ability. The lowest p-value, indicating statistical significance and a high confidence interval, supports its credibility. These findings demonstrate the efficiency of the proposed DBN + RFO method in enhancing prediction accuracy.
Discussion
The proposed DRFBPS demonstrates better performance in predicting risk factors. It leverages a novel strategy, Red Fox Optimisation, and a Deep belief neural network that uses the capabilities of both approaches as the data for the current research were obtained from Kaggle, which might expose the model to potential biases and make generalization a challenge. The RFO was used to address the biases in the Kaggle data during successful processing. This approach served as a tool for preprocessing and feature selection by filtering noise and retaining only the most informative features, reducing the impact of data that is either overrepresented or underrepresented. The red fox fitness function ensures the most predictive and useful variables are included, minimizing dimensionality and boosting model performance. It ensures that the DRFBPS makes accurate and reliable predictions in a wide range of patient populations, enhancing its generalizability and clinical utility. This robust Framework accurately identifies individuals at risk of heart disease, potentially assisting in early diagnosis and intervention efforts. Additionally, to prove the generalizability, the developed model is validated with the Cleveland dataset, and the results are displayed in Table 6.
Evaluations were performed on the Cleveland and the HARP datasets to validate the robustness of the proposed model. The results are uniformly high performance on both datasets, exhibiting the reliability of the model in the prediction of heart disease risk. The small differences in performance metrics illustrate the strength of the model. These findings provide evidence that the approach illustrates the model’s ability to perform well on diverse datasets.
-
The study proves that DRFBPS outperforms the prediction of heart disease risk by overcoming difficulties of inappropriate feature selection and overfitting.
-
Applying Red Fox Optimization, the model efficiently chooses applicable features, thereby improving predictive Precision.
-
The model is extensively evaluated using Accuracy, F-score, Precision, AUC, Recall, error rate, P value, and confidence intervals, depicting consistent and higher performance than existing approaches.
-
The findings verify that DRFBPS makes accurate and stable disease risk predictions with probable applications in early diagnosis, personal treatment planning, and enhanced patient outcomes in practical healthcare environments.
Implications: The DRFBPS can be integrated into hospital procedures by incorporating it in clinical decision support systems and electronic health records. The model can run based on real-time patient data like lab reports, history, and so on to aid healthcare providers in making diagnosis and treatment decisions. It can be interoperable with hospital information systems using secure APIs, facilitating working with the available infrastructure and fulfilling regulatory requirements such as HIPAA and GDPR. It can even be applied in predictive resource planning analysis, prioritization of the patient, and treatment plans based on the patient, and makes it more efficient.
The pipeline in Fig. 17 shows the real-time deployment architecture of the DRFBPS for disease prediction and healthcare monitoring. The workflow begins with patient data gathering, where raw health information is collected and assembled into reports. The collected dataset is fed into the DRFBPS model, where it is preprocessed to eliminate noise and select the feature to evaluate the risks associated with the disease. Additionally, it transfers patient health data to cloud storage for scalable and convenient access. Subsequently, Edge computing is introduced to improve efficiency and minimize latency by processing the data in real-time near the source of data. This promotes quicker decision-making and minimizes the reliance on centralized cloud servers. Finally, the information is implemented across various healthcare platforms.

Real-time deployment pipeline of DRFBPS.
Conclusion
In summary, the Proposed DRFBPS model for identifying heart disease risk factors that combine Red Fox Optimisation and deep belief neural network shows a reliable and effective method for managing IoT healthcare data. To ensure data integrity, the gathered dataset is first trained and preprocessed to remove noise. The novel DRFBPS approach uses the Red Fox fitness function to perform a thorough feature analysis, selecting the most relevant characteristics from the large dataset to improve prediction accuracy and lower computing complexity. The proposed DRFBPS accurately assesses and predicts the risk factor for heart disease using these features. The developed model performance is thoroughly examined, and the findings show that the DRFBPS model provides greater prediction performance by attaining a high accuracy of 98.6%, 97.7% F score, 97.4% precision, 98.2% AUC, 97.9% recall, and low error rate of 0.014. It demonstrates its potential as an essential early identification and risk assessment tool. Though the model displays high predictive performance in predicting heart disease risk, it has severe security issues. The model processes large-scale medical data, privacy, confidentiality, and potential breaches become severe issues, particularly when sensitive patient information is involved. However, security is crucial in big data healthcare systems to protect patients’ sensitive information. Hence, future work will focus on implementing robust security measures for handling big data. It includes federated learning to facilitate decentralized care among multiple healthcare institutions and keeps sensitive patient information localized while permitting collaborative learning to enhance the risk prediction of diseases. By keeping data local and preventing data movement between institutions, FL minimizes data breaches and unauthorized access. Besides that, homomorphic encryption will also be investigated in order to reinforce the protection of data.
Data availability
The data that support the findings of this study are available upon reasonable request from the corresponding author.
References
Tadesse, T., Abuye, H. & Tilahun, G. Availability and affordability of children essential medicines in health facilities of southern nations, nationalities, and people region, Ethiopia: Key determinants for access. BMC Public Health 21, 1–2 (2021).
Ros, F., Kush, R., Friedman, C., Gil Zorzo, E., Rivero Corte, P., Rubin, J.C., Sanchez, B., Stocco, P., Van Houweling, D. Addressing the COVID‐19 pandemic and future public health challenges through global collaboration and a data‐driven systems approach. (2021).
Aminizadeh, S. et al. Opportunities and challenges of artificial intelligence and distributed systems to improve the quality of healthcare service. Artif. Intell. Med. 1(149), 102779 (2024).
Cusi, K. et al. American Association of Clinical Endocrinology clinical practice guideline for the diagnosis and management of nonalcoholic fatty liver disease in primary care and endocrinology clinical settings: Co-sponsored by the American Association for the Study of Liver Diseases (AASLD). Endocr. Pract. 28(5), 528–562 (2022).
Masoumian Hosseini, M., Masoumian Hosseini, S. T., Qayumi, K., Hosseinzadeh, S. & Sajadi Tabar, S. S. Smartwatches in healthcare medicine: Assistance and monitoring; a scoping review. BMC Med. Inform. Decis. Mak. 23(1), 248 (2023).
Mbunge, E. et al. Framework for ethical and acceptable use of social distancing tools and smart devices during COVID-19 pandemic in Zimbabwe. Sustain. Operations Comput. 1(2), 190–199 (2021).
Palozzi, G., Ranalli, F. Telemedicine implementation between innovation and sustainability: An operating model for designing patient-centered healthcare. in Human-Centered Service Design for Healthcare Transformation: Development, Innovation, Change, pp. 375–399. (Springer International Publishing, 2023).
Chatrati, S. P. et al. Smart home health monitoring system for predicting type 2 diabetes and hypertension. J. King Saud Univ.-Comput. Inform. Sci. 34(3), 862–870 (2022).
Philip, N. Y., Rodrigues, J. J., Wang, H., Fong, S. J. & Chen, J. Internet of Things for in-home health monitoring systems: Current advances, challenges and future directions. IEEE J. Sel. Areas Commun. 39(2), 300–310 (2021).
Ye, Y. et al. Management of medical and health big data based on integrated learning-based health care system: A review and comparative analysis. Comput. Methods Programs Biomed. 1(209), 106293 (2021).
Niu, Y., Ying, L., Yang, J., Bao, M. & Sivaparthipan, C. B. Organizational business intelligence and decision making using big data analytics. Inf. Process. Manage. 58(6), 102725 (2021).
Rehman, A., Naz, S. & Razzak, I. Leveraging big data analytics in healthcare enhancement: Trends, challenges and opportunities. Multimed. Syst. 28(4), 1339–1371 (2022).
Cappa, F., Oriani, R., Peruffo, E. & McCarthy, I. Big data for creating and capturing Value in the digitalized environment: Unpacking the effects of volume, Variety, and Veracity on firm performance. J. Prod. Innov. Manag. 38(1), 49–67 (2021).
Sandhu, A. K. Big data with cloud computing: Discussions and challenges. Big Data Mining Analytics. 5(1), 32–40 (2021).
Attaallah, A., Alsuhabi, H., Shukla, S., Kumar, R., Gupta, B.K., Khan, R.A. Analyzing the big data security through a unified decision-making approach. Intell. Automat. Soft Comput. 32(2) (2022).
Chang, V. An ethical framework for big data and smart cities. Technol. Forecast. Soc. Chang. 1(165), 120559 (2021).
Mathrani, S. & Lai, X. Big data analytic framework for organizational leverage. Appl. Sci. 11(5), 2340 (2021).
Chen, J., Ramanathan, L. & Alazab, M. Holistic big data integrated artificial intelligent modeling to improve privacy and security in data management of smart cities. Microprocess. Microsyst. 1(81), 103722 (2021).
Zarour, M. et al. Ensuring data integrity of healthcare information in the era of digital health. Healthc. Technol. Lett. 8(3), 66–77 (2021).
Upadhyay, R.K. Chronic non-communicable diseases: Risk factors, disease burden, mortalities and control. Acta Scientific MEDICAL SCIENCES (ISSN: 2582-0931). 6(4) (2022).
Teo, K. K. & Rafiq, T. Cardiovascular risk factors and prevention: A perspective from developing countries. Can. J. Cardiol. 37(5), 733–743 (2021).
Sekar, J., Aruchamy, P., Sulaima Lebbe Abdul, H., Mohammed, A. S. & Khamuruddeen, S. An efficient clinical support system for heart disease prediction using TANFIS classifier. Comput. Intell. 38(2), 610–640 (2022).
Kaul, D., Raju, H., Tripathy, B.K. Deep learning in healthcare. Deep learning in data analytics: Recent techniques, practices and applications. 97–115 (2022).
Khanna, A. et al. Internet of things and deep learning enabled healthcare disease diagnosis using biomedical electrocardiogram signals. Expert. Syst. 40(4), e12864 (2023).
Alizadehsani, R. et al. Risk factors prediction, clinical outcomes, and mortality in COVID-19 patients. J. Med. Virol. 93(4), 2307–2320 (2021).
Dritsas, E. & Trigka, M. Stroke risk prediction with machine learning techniques. Sensors. 22(13), 4670 (2022).
Reddy, K. V. et al. Heart disease risk prediction using machine learning classifiers with attribute evaluators. Appl. Sci. 11(18), 8352 (2021).
Mahmud, N. et al. Risk prediction models for postoperative mortality in patients with cirrhosis. Hepatology 73(1), 204–218 (2021).
Yang, H. et al. Risk prediction of diabetes: Big data mining with fusion of multifarious physical examination indicators. Inform. Fusion. 1(75), 140–149 (2021).
Alkhammash, E. H. et al. Application of machine learning to predict COVID-19 spread via an optimized BPSO model. Biomimetics. 8(6), 457 (2023).
Elshewey, A. M., Tawfeek, S. M., Alhussan, A. A., Radwan, M. & Abed, A. H. Optimized deep learning for potato blight detection using the waterwheel plant algorithm and sine cosine algorithm. Potato Res. 28, 1–25 (2024).
Elshewey, A. M. et al. Optimizing HCV disease prediction in Egypt: The hyOPTGB framework. Diagnostics. 13(22), 3439 (2023).
Alkhammash, E. H., Kamel, A. F., Al-Fattah, S. M. & Elshewey, A. M. Optimized multivariate adaptive regression splines for predicting crude oil demand in Saudi arabia. Discret. Dyn. Nat. Soc. 2022(1), 8412895 (2022).
Alzakari, S. A., Alhussan, A. A., Qenawy, A. S. & Elshewey, A. M. Early detection of Potato Disease using an enhanced convolutional neural network-long short-term memory Deep Learning Model. Potato Res. 8, 1–9 (2024).
Javeed, M., Gochoo, M., Jalal, A. & Kim, K. HF-SPHR: Hybrid features for sustainable physical healthcare pattern recognition using deep belief networks. Sustainability. 13(4), 1699 (2021).
Połap, D. & Woźniak, M. Red fox optimization algorithm. Expert Syst. Appl. 15(166), 114107 (2021).
Srikanth, B. et al. An optimized generalized adversarial system for predicting specific substructures in brainstem. Multimed. Tools Appl. 82(5), 7181–7205. https://doi.org/10.1007/s11042-022-13663-9 (2023).
Dritsas, E. & Trigka, M. Supervised machine learning models for liver disease risk prediction. Computers. 12(1), 19 (2023).
Trigka, M. & Dritsas, E. Long-term coronary artery disease risk prediction with machine learning models. Sensors. 23(3), 1193 (2023).
Guarneros-Nolasco, L. R., Cruz-Ramos, N. A., Alor-Hernández, G., Rodríguez-Mazahua, L. & Sánchez-Cervantes, J. L. Identifying the main risk factors for cardiovascular diseases prediction using machine learning algorithms. Mathematics. 9(20), 2537 (2021).
García-Ordás, M. T., Bayón-Gutiérrez, M., Benavides, C., Aveleira-Mata, J. & Benítez-Andrades, J. A. Heart disease risk prediction using deep learning techniques with feature augmentation. Multimed. Tools Appl. 82(20), 31759–31773 (2023).
Rojek, I., Kotlarz, P., Kozielski, M., Jagodziński, M. & Królikowski, Z. Development of AI-based prediction of heart attack risk as an element of preventive medicine. Electronics 13(2), 272 (2024).
Funding
The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
All authors contributed equally.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval
The submitted work is original and has not been published elsewhere in any form or language.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Thatha, V.N., Chalichalamala, S., Pamula, U. et al. Optimized machine learning mechanism for big data healthcare system to predict disease risk factor. Sci Rep 15, 14327 (2025). https://doi.org/10.1038/s41598-025-98721-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-98721-6
Keywords
This article is cited by
-
Validation of experimental and gradient boosting regressor model for predicting performance, combustion, emission, and biomedical implications of cerium oxide (CeO₂)-augmented B20 biodiesel blends derived from used temple oil
BMC Chemistry (2025)
-
Interpretable machine learning framework for detection of cardiovascular diseases from real-time ECG signals
Network Modeling Analysis in Health Informatics and Bioinformatics (2025)
