
Abstract
Ensuring food security to meet the demands of a growing population remains a key challenge, especially for developing countries like Ethiopia. There are various policies and strategies designed by the government and stakeholders to confront the challenge. One of the strategies is using technology solutions to increase crop productivity. Precision agriculture using advanced technology has been utilized to increase crop yield. Identifying suitable land for a crop is one of the important factors that will affect the crop’s yield. The existing approach to land suitability identification for a crop is time-consuming, expensive, and inaccurate. In this study, land suitability has been predicted for the two widely grown cereal crops in Ethiopia—wheat and barley—using machine learning techniques. The dataset was obtained from the Engineering Corporation of Oromia (ECO). To make it suitable for modelling, we have pre-processed it. Features have been selected with univariate feature selection (UFS), recursive feature elimination with cross validation (RFECV), and sequential forward selection (SFS). Then, random forest (RF), gradient boosting (GB), and K-nearest neighbour (KNN) were used to predict the land suitability of the two selected crops. To optimize the performance of the models, hyperparameters were tuned with cross-validated randomized searches. The performance of the models has been evaluated using stratified tenfold cross-validation with performance metrics such as accuracy, precision, recall, and F1-score. GB with the SFS has better performance than the other models, with accuracy of 99.41%, precision of 99.37%, recall of 99.34%, and an F1-score of 99.35%. We believe that predicting land suitability accurately using machine learning techniques for the two commonly cultivated cereal crops in Ethiopia will be helpful in increasing the crops’ productivity. The developed model is very accurate. It can be used to develop a decision support system to identify the land suitable for the two crops.
Similar content being viewed by others
Introduction
Agriculture constitutes about 33.3% of the global gross domestic product (GDP), and its growth enhances shared prosperity1. Agricultural growth alleviates extreme poverty by minimizing food shortages. According to recent estimates, 68.7% of the population is multidimensionally poor in Ethiopia2. Despite efforts to diversify the country’s economy, agriculture is still the main source of income, and 80–85% of people’s livelihoods depend on it. Agricultural land is a limited resource that needs necessary protection and has to be used wisely. Growth in population leads to increasing demand and puts pressure on the availability of land3. Land use and land cover increases lead to a shortage of agricultural land availability, which results in food shortages4. Hence, there is a need for innovative ways to meet the food demand of the growing population5.
Agricultural land in Ethiopia is facing various problems such as erosion, landslides, deforestation, and groundwater depletion. The country’s farm size on average is less than one hectare per household6. Even if the livestock are considerable and are above the capacity of grazing land, it is still inadequate. Hence, optimal use of the available land is vital. Land evaluation is an important step in the process of optimal land use planning. Identifying land suitability for a specific crop can support decision-making in land-use planning and improve crop yield3,6. However, lack of knowledge to identify features that best characterize the land and match crops suitable for a particular land is a challenge that affects productivity. In Ethiopia, agricultural experts perform land suitability evaluations. They use geographical information systems (GIS) and AHP to classify land into suitability classes for a particular crop. According to the Food and Agricultural Organization (FAO) guidelines, effective land suitability classification requires a huge process to map attributes of land with crop nutrients requirements, which consumes a lot of time, requires a lot of effort, and is expensive3. The mismatch between the actual requirements and what is implemented on land affects crop yield4. Hence, land suitability assessment to determine the suitable land unit for a particular crop is an important process to enhance crop yield.
Since machine learning approach has been used in agriculture to improve productivity in several areas, such as species recognition, soil management, land suitability prediction, species breeding, water management, crop management, yield prediction, crop quality management, crop disease detection, weed recognition, and livestock management. This approach can be used for this study which is land suitability prediction5.
In this study, we predicted the land suitability of the two commonly cultivated cereal crops in Ethiopia, wheat and barley6, using machine learning techniques. Features of soil, climate, topography, and crops’ nutrient have been used to predict land suitability. We believe that effective land suitability classification can be helpful to farmers in identifying appropriate crops for their land and improving crop yield7.
Related works
Determining the suitable land unit for a particular crop is a crucial process to enhance crop yield. Many studies have been conducted on land suitability identification using machine learning techniques. The major related works have been discussed as follows:
Komolafe et al. proposed a land suitability predictive model for cassava8. Support vector machine (SVM) and decision tree have been used to predict land suitability. The data was collected from the Institute of Agriculture, Research, and Training (IART), Ibadan. It is a major agricultural research institute in Nigeria. The datasets contain features such as chemical properties, physical properties, climate, and topography as independent, and land suitability as dependent. There were total of 252 records. The accuracy of the model was 87.5%, and 12.7% of the instances were misclassified. The dataset is small for machine learning-based modelling. In this study, land attributes with crop needs were not also mapped.
Kennedy et al. predicted land suitability for sorghum using a parallel random forest classifier9. The dataset consisted of eight features: drainage, annual rainfall, rooting depth, salinity hazard (ECE), sodicity hazard (ESP), moisture-holding capacity (MHC), slope, and mean annual temperature. They trained different machine learning models such as Random Forest (RF), Logistic Regression (LR), Latent Dirichlet Allocation (LDA), K-Nearest Neighbour (KNN), Gaussian Naïve Bayes (GNB), and SVM. The performance of the models was evaluated. RF outperformed the other models with an accuracy of 90% under tenfold cross-validation. In this study, the best determinant features for land suitability, such as pH, N, and P, were not considered.
Fereydoon et al. predicted land suitability for wheat in the Kouhin region of Iran using SVM10. The dataset consists of 32 representative soil profiles and 10 land features. Features include climatic factors like precipitation and temperature, topography like relief and slope, and soil-related factors like soil texture, CaCO3, OC, coarse fragments, pH, and gypsum parameters. They implemented a two-class SVM model on a non-linear class boundary. They have used MATLAB 8.2 to train and test the model. In performance evaluation metrics, they got a root mean square error (RMSE) of 3.72 and a coefficient of determination (R square) of 0.84. The RMSE value in this study is larger than the optimum RMSE value, which is in the range between 0.2 and 0.5. The model tuning or hyperparameter tuning with different kernel values has not been explicitly stated.
Bhimanpallewar and Narasinagrao determined land suitability for the Jowar using a decision tree11. Features including climatic (temperature and rainfall), topography (slope), soil (pH, EC, N, K, P, and soil moisture), and Jowar crop requirement ranges have been used. The class labels were suitability: highly suitable, moderately suitable, marginally suitable, currently suitable, and permanently not suitable. They have used FAO methods to map land attributes to crop requirements and calculate land suitability. The dataset was real-time data collected using aggregated reports. The accuracy of the model is 98.9%. In this study, the details of real-time data were not explored in detail. The performance evaluation was not comprehensive, and adequate validation has not been shown to show the model has not overfit.
Ogunde and Olanbo proposed a web-based decision support system for evaluating soil suitability for the cassava crop12. They acquired secondary data from reviewed articles on soil suitability for cassava plantations. The dataset contains attributes of soil such as pH, NPK, and organic matter as independent features and land suitability as a dependent feature. The accuracy of the suitability prediction model was 76.5%. The classification was carried out using the J48 decision tree algorithm. In this study, only five features of soil attributes have been used to determine land suitability. Climate and topographic data, which are crucial in determining land suitability, were not considered. The performance is also not very good, with about 23% misclassification.
Schmidt et al.carried out land suitability assessments for irrigated wheat and barley crops using machine learning techniques in Kurdistan, Iran41. The main objective of this study was to conduct a land suitability evaluation and map it for both rain-fed crops using parametric and machine learning algorithms such as RF and SVM. The outcome was compared to traditional approaches. They concluded that the machine-learning-based approach outperformed traditional land suitability mapping in terms of accuracy. In this study, comparisons with other machine learning models were not carried out.
We may see shortcomings in related works, including a significant amount of misclassification and small datasets that are prone to overfitting. Consequently, they are less generalizable to real-world applications. Only one or two of the related works are on wheat and barley. The models may not also be applicable due to variations in the context of the crop and area. The summary of related works including the methods used and gaps have been shown in Table 1. We therefore conducted this research in an effort to address those flaws. We thought that by using appropriate machine learning techniques and hyperparameter optimization, performance could be enhanced.
Materials and methods
Study area
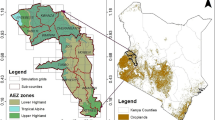
The total land area on which soil laboratory test is done including climate, and topographic data for wheat, and barley crops is about 1,086,436.84 hectares of Weyib Sub-Basin according to a soil survey staff report taken from the Engineering Corporation of Oromia, Akaki quality, Addis Ababa, Ethiopia. Weyib Sub-basin is located totally in Bale zone, Oromia region, and covers Districts such as Dinsho, and partial covers Districts of Agarfa, Goba, Sinana, Gasera, Gineer, Goro, Dawe Kachen, Dawe Sarar, and Rayitu. Its location extent from West to East is 39.59 to 41.68° East and South to North is 5.73 to 7.43° North. From the geological structure of the study area, the Weyib subbasin consists of three geological formations: Mesozoic sedimentary rocks, tertiary volcanic and sedimentary rocks, and quaternary volcanic and sedimentary rocks. Mesozoic sedimentary rocks include the main gypsum unit, representing the lowermost part of the cretaceous succession in the study area. The study area has a diverse landscape that causes varied microclimates. This allows for the possibility of producing a variety of crops. Figure 1 below illustrate the map of the Weyib Sub-Basin. Moreover, soil type, soil texture, climate, and topographic of the study area is explained in14.

Location map of the Weyib Subbasin.
Data source
The land suitability dataset of wheat and barley crops used for this study was obtained from the Engineering Corporation of Oromia (ECO), Ethiopia. The institute, formerly known as the Oromia Water Works Design and Supervision Enterprise, provides engineering consultation, community service, and land use planning15. Wheat and barley are among the major cereal crops that are commonly cultivated in the study area. The climate and topographic datasets have been collected from soil laboratory test result obtained from study area in the Weyib subbasin, Bale Zone, Oromia Region, Ethiopia.
The original dataset for land suitability modelling for the two crops comprises data on the soil’s physical and chemical properties, climatic features including temperature and rainfall, and topographic features like slope. The dataset has been mapped with wheat and barley crops’ soil, climatic, and topographic requirements’, in which ranges are set by the FAO Framework16 as used in the soil survey report14 taken from ECO. Then, labelling was carried out with land suitability classes identified in the FAO Framework16 such as S1 (highly suitable), S2 (moderately suitable), S3 (marginally suitable), N1 (currently suitable), and N2 (permanently not suitable), which are the class labels of this study. The dataset was reviewed by agricultural experts. Tables 2 and 3 shows the criteria for mapping the land attributes with their suitability classes for wheat and barley crops based on FAO guidelines14,16,17,18.
Pre-processing
The dataset obtained from ECO comprises missing values, noises, inaccurate values, inconsistencies, and irrelevant instances. Pre-processing such as data cleaning, handling missing values using mean imputation strategies, handling categorical data using a label encoder, and feature scaling using min–max feature normalization have been carried out to make the dataset ready for machine learning model building. In this study, three machine learning algorithms, such as RF, GB, and KNN, have been selected for modelling. Since KNN exploits distance or similarity in the form of scalar products between data points, it is sensitive to feature scaling. Hence, scaling of features was done for KNN. On the other hand, RF and GB are insensitive to feature scaling19. The normalization has been based on Eq. 1.
where x’ is newly transformed feature, Xmax, and Xmin are the maximum and the minimum feature values respectively.
Moreover, this study is used several development tools and packages to implement the proposed solution to address problems raised and to fill the gap identified on land suitability prediction to enhance wheat, and barley crop production using machine learning approach accurately as expected. Therefore, a python programming language is used for implementing and experimenting with each proposed solution starting from preprocessing phase to model building. It is also used to evaluate the implemented classifiers to identify the best model. Hence python is the programming language of choice for developers, researchers, and data scientists who need to develop machine learning models.
Feature selection
Feature selection methods such as univariate from the filter method, recursive feature elimination, and sequential forward selection from the wrapper method are better and easier to use20. Therefore, they have been used in this study to select relevant features from the original dataset. Univariate feature selection is a feature selection method that examines each feature individually to identify its relationship with the target feature. Recursive Feature Elimination (RFE) is a very common feature selection algorithm because it is easy to configure and use and very effective at selecting features in a training dataset that are most relevant in predicting the target variable20. It can be used with cross-validation. Before applying these feature selection techniques, categorical data like soil texture and crop name had been encoded using label encoding.
Univariate feature selection (UFS)
The univariate feature selection method, also known as the analysis of variance (ANOVA), chooses the best set of features based on univariate statistical tests that apply the Scikit-Learn feature selection package, which selects the K best routine, which eliminates all other features but keeps the top k-scoring features. This method ranks each feature independently, ignoring any interdependencies across features21.
Recursive feature elimination with cross-validation (RFECV)
It is the backward feature selection method of the predictors. It builds a model on the whole set of features, calculating an importance score for each feature. After removing the predictor(s) with the smallest important scores, the model is retrained, and importance scores are once again computed. The number of feature subsets needed to estimate the size of each subset is then determined. The subset size is adjusted as a parameter for RFE. The best feature(s) are selected based on the important score rankings of the feature and the size of the feature subset that improves the criteria. The last machine-learning predictive model is trained using the most effective subgroup. Cross-validated RFE is used to extract the best set of features from the initial feature set (Table 4).
Sequential forward selection (SFS)
This feature selection approach begins with an empty set and successively adds features selected by an evaluation function. The feature to be added to the feature set at each iteration is selected from the remaining available features in the feature set that have not been added to the set. So, compared to the addition of any other feature, the new extended feature set should result in the minimum classification error. This process is repeated until a predetermined number of features are chosen23. SFS is widely used for its ease of use and speed. Due to this reason, it has been used in this study. It has been applied to the selected machine learning models. Its accuracy is calculated at each iteration. The best feature subsets are then selected based on the model’s performance.
Machine learning model building
This study is intended to predict land suitability using machine learning techniques to enhance wheat and barley crop productivity using an already prepared and labelled land suitability dataset. Therefore, three supervised machine learning algorithms such as Random Forest, Gradient boosting, and K-nearest neighbor algorithms are selected for this study due to their successful applications in previous studies, and their relatively good accuracy, robustness, and ease of use3,10,13, and their capability to fit into imbalanced class distribution.
Random forest (RF)
RF is a combination of decision tree predictors proposed by Breiman in 200131. It is widely used for both regression and classification problems. It is ensemble learning that consists of decision trees that depend on the values of a random vector. The random vector is sampled independently with the same distribution for all trees in the forest. It is a supervised machine learning algorithm that generates multiple trees of randomly subsampled features3. There are different reasons why we have selected RF as one of the machine learning techniques in this study. The risk of overfitting is low because the model variance is reduced with the averaging of results from the ensemble of decision trees32. It is effective in capturing non-linear patterns in data. It provides improved accuracy on individual decision trees. It is also fast and noise-resistant. Due to these reasons, it has been used in various application areas, including for comparisons with deep learning techniques33. The RF pseudocode is shown in Figs. 2 and 3.

Random forest pseudocode34.

Random forest prediction pseudocode34.
K-nearest neighbour (KNN)
In KNN, a specified number (k) of data records in a dataset that are nearest in terms of their input variable values to each data record in the dataset to be predicted are identified35. Then, the identified k data records are used to calculate the class variable values for the test dataset. Values that are near each other are assumed to be similar. The new data points are classified based on distance-based similarity measures. Euclidean and Manhattan are the most commonly used distance metrics, which calculate the distance between the k nearest data points24. KNN has been successfully used in many classification tasks35,36,37,38,39. The KNN pseudocode is shown in Fig. 4.

K-nearest neighbour pseudocode34.
Gradient boosting (GB)
It is the method of ensemble learning that groups weak predictive models, typically a decision tree, and the resulting algorithms, which are known as gradient-boosted trees25. Boosting algorithms combine weak learner algorithms into a strong learner iteratively. The family of gradient-boosting algorithms has been recently explored widely. It is successful at classification tasks. Different attributes are tested for gradient-boosting. These attributes include learning rate, maximum depth of the tree, subsampling rate, number of features to consider when looking for the best split, and minimum number of samples required to split an internal node. The iterative process needs to be properly regularized to avoid overfitting.
The proposed architecture is shown in Fig. 5. The dataset was initially raw data. Hence, preprocessing, including cleaning, handling missing values, and handling categorical values, was performed to make it suitable for machine learning algorithms. Then, feature selection was implemented to identify relevant features. Univariate feature selection, recursive feature elimination with cross-validation, and sequential forward feature selection have been used for feature selection. RF, GB, and KNN were used to build predictive models. These models are selected to automate multiclass land suitability. Their predictive performance was assessed with and without feature selection methods using stratified k-fold cross-validation with k = 10. Stratified k-fold cross-validation is a modified version of k-fold cross-validation that does stratified sampling instead of random sampling so that it ensures each fold of the dataset with a given label has the same proportion of instances26.

Architecture of proposed models.
Hyperparameter tuning
Grid search and random search are the two most commonly used algorithms for hyperparameter optimization. Grid search is a traditional method that makes a complete search over a given subset of the hyperparameter space of the training algorithm and exhaustively generates candidates from a specified grid of parameter values. One of the downsides of the method is that it suffers from high-dimensional spaces. However, it can often be easily parallelized since the hyperparameter values that it works with are usually independent of each other27. Random search overrides the complete selection of all combinations by their random selection. It outperforms a grid search, particularly if only a few hyperparameters affect the performance of the machine learning algorithm27. As a result, we have used a random search for this study.
Models’ performance evaluation
Different performance evaluation methods have been used to measure the performance of the three machine learning techniques in predicting land suitability for the two common cereal crops in Ethiopia, with and without feature selection. The aim is to be sure that the models fit the dataset and perform well on unseen data. The performance evaluation provides a comprehensive, objective assessment of the machine learning techniques and checks the models’ generalizability. Optimal splitting of the dataset into training and testing is vital. The performance of the model can sometimes be affected by the random selection of the training and testing datasets40. Cross-validation is a solution for this problem. Still, each fold of the k-fold cross-validation may not contain the same proportion of observations with each label. Hence, stratified k-fold cross-validation with k = 10 has been used to split the dataset into training and testing. The folds are stratified to make the class distribution of the values in each fold approximately the same as the initial data. Accuracy, precision, recall, F1-score, sensitivity, and specificity have been used to measure the performance of the models. The metrics for performance evaluation have been discussed below.
Accuracy is widely used to evaluate the performance of machine learning classifiers. It is a percentage of correctly classified values in the test dataset, as shown in Eq. 2.
where TP is true positive, TN is true negative, FP is false positive, and FN is false negative.
Precision is the proportion of true positive values classified as positive, as shown in equation 3.
Recall is a positive recognition rate. It is a proportion of correctly classified positives, as shown in Eq. 4.
F1-score shows the performance of the model in terms of both precision and recall. It is the harmonic mean of precision and recall, as shown in equation 5.
Results and discussion
Dataset feature description
The dataset used for this study is collected from the Engineering Corporation of Oromia (ECO) located in Akaki Kality, Addis Ababa, Ethiopia. ECO is a committed company that gives a knowledge base of a sustainable engineering solution that boosts the development of our nation, and international communities at large. Doing research, and giving training in the area of agriculture, Irrigation, Water resource study and supply, land use study and planning, and laboratory services such as water quality testing, soil fertility testing, geotechnical testing, and material testing are among core community services delivered by ECO15. Accordingly, soil laboratory test result which was done for Oromia rural land Administration, and use Bureau on Weyib Sub-Basin in 2016 is taken from ECO along with soil survey report that is used as a dataset for this study. The report helps the researcher for a detailed understanding of each parameter and dataset labelling. Therefore, Weyib Sub-Basin is used as the study area for this study. Data was collected by targeting to identify the level of suitability class for wheat, and barley crops in the study area which is a five-class classification. Hence soil data, topographic, and climatic data were collected, and contain 2024 rows with 16 columns including one target class.
The columns of the dataset are Soil texture, Soil sodicity, Mean-min temp, Mean-max temp, Annual rainfall, Soil depth, Slope, PH, EC, K, CEC, T_N, O_M, AV_P, Crop name, and Suitability classes (Table 5).
Dataset class distributions
To label the dataset into its suitability classes such as S1, S2, S3, N1, and N2, direct communication was held with the agricultural experts and soil survey report of the study area. The labelled dataset was again reviewed by agricultural professionals and finally, it contains 2024 rows with 16 columns including target class as shown on Table 5 above. Among the features of the collected dataset rainfall, Min_mean Temp, Max_mean Temp, soil depth, min and max slope contains small percentages of missing values which can be handled by mean imputation strategies (Table 6).
The total wheat and barley crop soil characteristics, climatic parameter such as annual rainfall, maximum and minimum temperature including topographic data which is slope was collected from study area of 1,086,436.84 hectares, Weyib Sub-Basin. Of the total instances collected, 1016 are instances of barley, and 1008 are instances of wheat. As shown in Fig. 6, the class distribution of 1008 instances of wheat is 139 classified as highly or S1 with 6.23% total study area, 161 as moderately or S2 with 13.15% of total study area, 233 as marginally suitable or S3 with 5.41% of total study area, 236 as currently or N1 with 16.63% of total study area, and 239 as permanently not suitable or N2 with 58.58% of total study area. Similarly, the class distribution of 1016 instances of barley is 132 as highly or S1 with 10.5% of total study area, 201 as moderately or S2 with 14.05% of total study area, 197 as marginally suitable or S3 with 11.37% of the total study area, 240 as currently or N1 with 11.35% of total study area, and 246 as permanently not suitable or N2 with 52.73% of total study area.

Class distribution for wheat and barley.
Feature selection result
Feature selection methods were applied for this study to select an appropriate feature set. UFS, RFECV, and SFS techniques have been used to select relevant feature sets. The original feature set contains 16 features. In Table 7, the selected features by each feature selection technique out of 16 features for each selected model have been shown. In the table, the features selected by different feature selection methods with different models from the original features have been shown. RFECV can only be applied to a model that exposes either a coeff_ or feature_importance_attribute, and therefore machine learning algorithms such as KNN could not be used in this case30. Hence, RFECV cannot be used with KNN.

Outlier detection and removal from our dataset.
Models’ performance and evaluation results
The performance of the selected models is stated and evaluated with each feature selection method and compared with the performance of the models on the original features. The performance of the selected models has been evaluated with and without feature selection. This has been useful to identify the most performing model with the corresponding feature selection method.
Performance of models with original features
The first experiment of modeling for land suitability prediction of wheat and barley has been carried out with the selected three machine learning models, such as RF, GB, and KNN, with original features. None of the feature selection techniques have been applied for this experiment. Stratified tenfold cross-validation has been used for the experiments for each of the three models. The dataset has been divided into ten folds, where one-fold was used as the test set and the remaining folds were used iteratively as the training set. The classification models were built on the dataset with five class classifications. The trained models were evaluated using stratified tenfold cross-validation, and the result of each evaluation in terms of all performance metrics has been discussed.
The stratified tenfold cross-validation accuracy of each fold for RF, GB, and KNN models has been shown in Table 8. GB has the highest accuracy. The other performance metrics of the three algorithms are shown in Table 9. GB outperformed the other models.
Performance of models with feature selection
The next experiment was modelling with feature selection. Three feature selection techniques, such as UFS, RFECV, and SFS, have been used to select the best feature subset. The performances of the models have been computed under stratified tenfold cross-validation with each feature selection method. The performance is then compared with the previous experiment using the original feature set. The first feature selection experiment was implemented using UFS with tenfold cross-validation. The resulting performance evaluation metrics have been shown in Table 10.
The other performance metrics, such as precision, recall, and F1-score, of the three models with univariate feature selection have been shown in Table 11.
As it can be seen from the previous results in Tables 8, 9, 10 and 11, the performances of RF, GB, and KNN models with original feature sets are better than those of UFS. Therefore, the UFS feature selection method with RF, GB, and KNN models has inferior performance compared to the performance of RF, GB, and KNN models with original feature sets.
RFECV is the second feature selection technique used in this study. RFECV cannot be applied to models that do not show feature importance. Hence, machine learning algorithms such as KNN and SVM, other than linear kernels, cannot be used with this feature selection technique28. Therefore, RFECV has been used only with RF and GB models to select the relevant set of features in this study. Performance evaluation results of RF and GB models with the RFECV under stratified tenfold cross-validation have been shown in Table 12. Selected features with cross-validation of RF and GB have been shown in Fig. 8.

Selected features with cross-validation of RF and GB.
The performance metrics such as precision, recall, and F1-score of RF and GB with RFECV have been shown in Table 13.
As it can be seen in Table 13, RF and GB with RFECV perform better as compared to RF and GB with the original feature set in all performance metrics. Even though RF with RFECV performs better, it is still less than GB with the original feature set in all performance metrics under stratified tenfold cross-validation.
SFS is the third feature selection technique used under stratified tenfold cross-validation in this study. The performance metrics of the three models with the SFS feature selection have been discussed. The classification performance evaluation results of the three models with the SFS are shown in Table 14.
The performance metrics such as precision, recall, and F1-score of RF and GB with SFS have been shown in Table 15.
Generally, the performance of RF, GB, and KNN with SFS has superior performance compared to other feature selection methods such as UFS and RFECV and with original feature sets. The performance of GB with SFS has the highest performance.
In order to explore the best-performing model’s performance with the best feature selection method, we have discussed the confusion matrix. The performance of GB with SFS has been shown in the confusion matrix in Fig. 9. GB correctly classified 474 instances out of 476, 484 instances out of 485, 268 instances out of 271, 358 instances out of 362, and 428 instances out of 430 as N1, N2, S1, S2, and S3, respectively. It wrongly classified 1, 1 instance of N1 as N2 and S3, respectively, 1 instance of N2 as N1, 3 instances of S1 as S2, 1, 2, 1 instance of S2 as N1, S1, and S3, respectively, and 2 instances of S3 as S2. The normalized confusion matrix for GB has been shown on the right side of Fig. 9. It is the same as the left, except it indicates correctly classified instances in percentage.

Confusion matrix of GB with SFS without and with normalization.
The performance summary results of the three models with and without feature selection are shown in Table 16. In the table, the number of selected features by each feature selection method and the performance of the models with each feature selection method are shown.
Result of KNN based on feature scaling
KNN is a distance-based learning algorithm that is based on the calculated distance between two data samples. Which means it can be affected by feature scaling. Therefore, min–max feature scaling has been applied to the dataset to build the KNN model. The result has been compared with the KNN model built on the dataset without feature normalization, as shown in Table 17. The result of the comparison showed that KNN with min–max feature scaling has inferior performance to KNN built on a dataset without applying feature scaling. Therefore, normalizing the features of the dataset to ranges between zero and one has no improvement on the accuracy of the KNN model.
Hyperparameter tuning
Cross-validated randomized search hyperparameter tuning has been used in this study. Both grid search and randomized search cross-validation have been experimented with in this study. Randomized search cross-validation has better performance than grid search. The list of selected parameters used in RF and the values of parameters recommended by randomized search cross-validation are shown in Table 18. For the rest of the parameters, default values have been used.
The list of selected parameters used in GB and the values of parameters recommended by randomized search cross-validation are shown in Table 19. For parameters not listed in Table 19, default values have been used.
The list of selected parameters used in KNN and the values of parameters recommended by randomized search cross-validation are shown in Table 20. For the rest of the parameters, default values have been used.
Discussions
Around 80–85% of Ethiopia’s population rely on agriculture as their primary source of livelihood2. It is the source of livelihood for many people, particularly those who live in rural areas. As a result, the agricultural sector is the priority focus area of policies and initiatives by stakeholders. There are many agricultural research centers in the country with the aim of improving food security and farmers’ living standards. They carry out research in various areas to achieve these objectives. One of the areas of their research is land suitability evaluation to identify which land unit is best suited to which crop. For instance, an assessment of land suitability for wheat and barley was carried out using a GIS-based multi-criteria approach17. They have used topographic, soil, and climatic data and mapped it with wheat and barley crop requirements to identify land suitability classes in the study area as set by FAO guidelines. There are also similar works that have aimed to evaluate land suitability for various crops based on the FAO framework4,29, and30. These research works performed land evaluation by taking a given land unit in a given area along with data associated with that area and dividing the area into its suitability classes using GIS and AHP software based on FAO criteria. However, the existing land suitability estimation methods have shortcomings. They have limitations in predicting the level of land suitability for various crops automatically and accurately. Mapping crop nutrient requirements to their suitability classes takes a long time. We believe that these shortcomings can be overcome with the current study. Hence, we aim to predict the land suitability of wheat and barley using machine learning techniques in this study. We believe this will enhance crop productivity by improving land suitability prediction accuracy and saving time. The study was carried out using machine learning techniques such as RF, GB, and KNN with and without feature selection under stratified cross-validation. The dataset consisting of soil, topographic, and climate data with soil survey reports from the ECO has been used. According to the FAO framework16, to perform land suitability evaluation, soil data such as soil physical and chemical parameters, climate data such as temperature regime and rainfall parameters, and topographic data such as slope in percentage are mandatory features and should be included in the dataset. Therefore, data were collected by considering those features individually. GB with SFS has the best performance. Hence, GB with SFS is recommended for land suitability prediction due to its high accuracy, precision, recall, and F1-score of 99.41%, 99.37%, 99.34%, and 99.35%, respectively, under stratified tenfold cross-validation31. The relevant features selected by SFS are 10 such as soil texture, mean minimum temperature, mean maximum temperature, annual rainfall, soil depth, maximum slope in percentage, soil electronic conductivity, soil potassium, available phosphorus, and crop name.
Many studies were carried out using the machine learning approach in the agricultural domain to improve productivity and quality of the crop, combat poverty, enhance food security, and improve countries’ economies in general and farmers’ lifestyles in particular. A way to evaluate land suitability for crop productivity using soil, climate, and topographic data has been carried out based on guidelines set by FAO to identify whether the particular land unit is highly, moderately, marginally suitable, currently, or permanently not suitable for a specific crop to enhance its productivity. In this study, machine learning techniques for predicting land suitability to enhance wheat and barley productivity have been proposed. It was aimed at increasing agricultural wheat and barley crop yields. The results of the study have been compared with previous studies on land suitability classification.
Komolafe et al. predicted suitable land using SVM and the DT model for the cassava crop. They have used a dataset of 252 total instances and got an accuracy of 87.5% using a tenfold cross-validation12. The dataset was small. Cassava crop nutrients required range mapping with soil, climatic, and topographic data to label the dataset, which was not stated. The performance can also be said to be inferior when it is compared with this study.
A parallel RF classifier for predicting land suitability for sorghum crop production was studied13. In this paper, RF, LR, LDA, KNN, GNB, and SVM models have been used. The maximum accuracy is 96% with the RF classifier and is evaluated using tenfold cross-validation. It has four target classes: highly, moderately, marginally, and unsuitable. No feature selection technique has been applied, and the performance can also be said to be inferior when compared with this study.
Sarmadian et al. proposed SVM-based land suitability analysis for rainfed agriculture to predict land suitability for wheat production based on the FAO land evaluation framework10,14. It is a binary class classification to identify whether the study area was moderately or marginally suitable for wheat production, and feature selection techniques were not applied, which may improve the model performance. They used a train-test split and got an RMSE of 3.72 and an R square of 0.84.
Bhimanpallewar et al. have proposed to assess crop-specific suitability for small or marginal-scale crop lands for Jowar crop productivity using a machine learning approach11,15. They have used 74,737 total datasets, which were collected in real-time, and the DT model with a holdout method was applied to evaluate the model, which has an accuracy of 98.9%. Our proposed study outperforms this study by applying different feature selection methods and hyperparameter tuning algorithms. Accordingly, GB with SFS feature selection has 99.41% accuracy under stratified tenfold cross-validation.
Ogunde et al. proposed soil suitability evaluation for cassava crop cultivation using web-based decision support using the DT model12,16. It has four land suitability classes as a target class. The accuracy is 76.5%. According to FAO guidelines, to assess land suitability, climatic, topographic, and soil data must be considered16. Climate and topographic datasets were not included in this work. The comparison of this study with previous studies is shown in Table 21.
We believe that this study can have an important contribution. It automates the conventional methods of land suitability evaluations. It can help farmers identify the suitability level of their land if they get soil, climate, and topographic data on their land unit from experts. The performance is superior to the previous studies. Additional features have been included and cover more areas with more data compared to previous studies.
Conclusion
Meeting the demands of food for growing population is a long-lasting challenge, particularly in developing countries like Ethiopia. The government and stakeholders have implemented policies and strategies to address this problem. Land suitability identification is part of agricultural activities aimed at increasing crop yield. Current methods are time-consuming, expensive, and less accurate. Hence, this study was carried out to predict land suitability for the two widely grown cereal crops in Ethiopia—wheat and barley—using machine learning techniques. RF, GB, and KNN were used with three feature selection methods, such as UFS, RFECV, and SFS. These machine learning approach have been selected because they are appropriate to the study. The reasons to select them include their success in previous classification tasks, low risk of overfitting, and effectiveness in capturing non-linear patterns in data. The selection of the models has been justified by their performances. A dataset of soil (soil physical and chemical properties), climate (temperature and rainfall), and topography (slope) was used that has been obtained from ECO. Different experiments have been carried out with the original feature set and with the three feature selection methods. From the modelling experiment with the original feature set, GB has the best performance and KNN has the worst performance. Performances of RF, GB, and KNN models with UFS are inferior performances with the original feature set in all performance metrics. The performance of RF with RFECV is better than that of RF with the original feature set, but it is inferior to that of GB with the original feature set. GB with RFECV has the same performance as GB in the original feature set. The performance of RF, GB, and KNN has been improved with SFS in all performance metrics. GB with the SFS and 10 relevant feature sets exhibits highest performance with performance metrics such as accuracy of 99.41%, precision of 99.37%, recall of 99.34%, and F1-score of 99.35% under stratified tenfold cross-validation. Comparisons of the results have been made with related works in previous research. The proposed model of GB with SFS has superior performance. Therefore, GB with SFS has been the best-performing model in all performance metrics for predicting wheat and barley. We believe that a very accurate decision support system for the land suitability identification of the two crops can be developed based on the results of this study. This can be helpful to agricultural experts, land evaluators, and farmers to accurately and timely classifying suitable lands for the two crops. In the future, the work can be extended to the other relevant crop’s land suitability prediction.
Future work
Even though this study shows a significant improvement over the existing study on land suitability prediction to enhance wheat and barley crop productivity using machine learning approach and using collected and prepared dataset that helps agricultural experts, land evaluators, and hence farmers who perform agricultural land suitability assessments, it is better to extend this study into Internet of Things based system to get real-time soil, climate, and topographic data, where sensors are installed in the farming to detect soil nutrients, temperature, and rainfall data directly, that is used as input to the model for prediction. So that farmers can get an informed decision regarding how much their land unit is suitable for their respective crop via a message sent into their mobile phone.
Data availability
The data related with this study will be available based on reasonable request through corresponding author.
Abbreviations
- ACC:
-
Accuracy
- AHP:
-
Analytic hierarchy process
- AI:
-
Artificial intelligence
- CaCO3 :
-
Calcium carbonate
- CSV:
-
Common separated value
- CV:
-
Cross validation
- DT:
-
Decision tree
- EC:
-
Electronic conductivity
- ECE:
-
Salinity hazard
- ECO:
-
Engineering Corporation of Oromia
- ESP:
-
Sodicity hazard
- FAO:
-
Food and Agricultural Organization
- FS:
-
Feature selection
- GB:
-
Gradient boosting
- GDP:
-
Gross domestic product
- GIS:
-
Geographic information system
- GNB:
-
Gaussian Naïve Bayes
- GPS:
-
Global positioning system
- KNN:
-
K-nearest neighbour
- LDA:
-
Latent Dirichlet allocation
- LR:
-
Logistic regression
- MHC:
-
Moisture holding capacity
- NPK:
-
Nitrogen, phosphorous, potassium
- OM:
-
Organic matter
- pH:
-
Potential of hydrogen
- RF:
-
Random forest
- RMSE:
-
Root mean square error
- RFE:
-
Recursive feature elimination
- RFECV:
-
Recursive feature elimination with cross validation
- SFS:
-
Sequential forward selection
- UFS:
-
Univariate feature selection
References
MT Knudsen N Halberg JE Olesen J Byrne V Iyer N Toly 2006 Global trends in agriculture and food systems Danish Res. Centre Organ. Food Farming (DARCOF) https://doi.org/10.1079/9781845930783.0001
E Gotor M Kozicka T Pagnani M Occelli F Caracciolo 2021 Understanding the link between the productive safety net program and agrobiodiversity cultivation in Ethiopia CIAT 51 1 10
R Taghizadeh-Mehrjardi K Nabiollahi L Rasoli R Kerry T Scholten 2020 Land suitability assessment and agricultural production sustainability using machine learning models Agronomy 10 4 1 20 https://doi.org/10.3390/agronomy10040573
A Kahsay M Haile G Gebresamuel M Mohammed 2018 Land suitability analysis for sorghum crop production in northern semi-arid Ethiopia: Application of GIS-based fuzzy AHP approach Cogent Food Agric. 4 1 1 4 https://doi.org/10.1080/23311932.2018.1507184
KG Liakos P Busato D Moshou S Pearson D Bochtis 2018 Machine learning in agriculture: A review Sensors 18 8 1 29 https://doi.org/10.3390/s18082674
IS Arvanitoyannis P Tserkezou 2008 Cereal waste management: Treatment methods and potential uses of treated waste Waste Manag. Food Indus. 1 629 702
LO Fresco H Huizing H Keulen van H Luning R Schipper 1994 Land evaluation and farming systems analysis for land use planning FAO Work. Doc. FAO Rome 13 4 20 21
EO Komolafe IO Awoyelu JO Ojetade 2019 Predictive modeling for land suitability assessment for cassava cultivation Comput. Electron. Agric. 9 21 31 https://doi.org/10.5923/j.ac.20190901.02
K Senagi N Jouandeau P Kamoni 2017 Using parallel random forest classifier in predicting land suitability for crop production J. Agric. Inform. 8 3 23 32
F Sarmadian A Keshavarzi A Rooien G Zahedi H Javadikia 2014 Support vector machines based-modeling of land suitability analysis for rainfed agriculture J. Geosci. Geomatics 2 4 2 3 https://doi.org/10.12691/jgg-2-4-4
R Bhimanpallewar MR Narasinagrao 2017 A machine learning approach to assess crop specific suitability for small/marginal scale croplands Int. J. Appl. Eng. Res. 12 23 2 4
AO Ogunde AR Olanbo 2017 A web-based decision support system for evaluating soil suitability for cassava cultivation Adv. Sci. Technol. Eng. Syst. 2 1 42 50 https://doi.org/10.25046/aj020105
K Senagi N Jouandeau P Kamoni 2017 Using parallel random forest classifier in predicting land suitability for crop production J. Agric. Inform. 8 3 23 32 https://doi.org/10.17700/jai.2017.8.3.390
Staff Soil Survey 2016 Weyib Sub Basin Land Evaluation Addis Ababa 104 113
ECO, “Eco Research Training And Laboratory,” 2021. https://ecoet.org/research-training-and-laboratory/ (Accessed 17 May 2021).
SC Ng TA Bongso SL Liow R Edirisinghe V Tok SS Ratnam 1992 Framework for land evaluation J. Assist. Reprod. Genet. 9 3 186 189 https://doi.org/10.1007/BF01203810
H Yohannes T Soromessa 2018 Land suitability assessment for major crops by using GIS-based multi-criteria approach in Andit Tid watershed, Ethiopia Cogent Food Agric. 4 1 1 29 https://doi.org/10.1080/23311932.2018.1470481
E Fekadu A Negese 2020 GIS assisted suitability analysis for wheat and barley crops through AHP approach at Yikalo sub-watershed, Ethiopia Cogent Food Agric. 6 1 1 22 https://doi.org/10.1080/23311932.2020.1743623
J Brownlee 2020 “Data preparation for machine learning”, ambiguous childhoods peer social Sch. Agency a Zambian Village 1 1 232 246
R. Shaikh, “Feature Selection Techniques in Machine Learning with Python,” 2018. https://towardsdatascience.com/feature-selection-techniques-in-machine-learning-with-python-f24e7da3f36e (accessed 03 Apr 2021).
P Drotár J Gazda Z Smékal 2015 An experimental comparison of feature selection methods on two-class biomedical datasets Comput. Biol. Med. 66 1 10 https://doi.org/10.1016/j.compbiomed.2015.08.010
M Awad S Fraihat 2023 Recursive feature elimination with cross-validation with decision tree: Feature selection method for machine learning-based intrusion detection systems J. Sensor Actuat. Netw. 12 5 67 https://doi.org/10.3390/jsan12050067
M Awad S Fraihat 2023 Recursive feature elimination with cross-validation with decision tree: Feature selection method for machine learning-based intrusion detection systems J. Sensor Actuat. Netw. 12 5 67 https://doi.org/10.1109/IECON.2010.5675075
LY Hu MW Huang SW Ke CF Tsai 2016 The distance function effect on k-nearest neighbor classification for medical datasets Springerplus https://doi.org/10.1186/s40064-016-2941-7
C Bentéjac A Csörgő G Martínez-Muñoz 2021 A comparative analysis of gradient boosting algorithms Artif. Intell. Rev. 54 1937 1967 https://doi.org/10.1007/s10462-020-09896-5
MT Novaes OL Carvalho de PH Ferreira TL Tiraboschi CS Silva JC Zambrano CM Gomes ME Paula de OA Carvalho Júnior de JJ Bessa de 2021 Prediction of secondary testosterone deficiency using machine learning: A comparative analysis of ensemble and base classifiers, probability calibration, and sampling strategies in a slightly imbalanced dataset Inform. Med. Unlocked. 1 23 100538 https://doi.org/10.1016/j.imu.2021.100538
Liashchynskyi, P. “Grid Search, Random Search, Genetic Algorithm: A Big Comparison for NAS,” pp. 1–11, 2019, [Online]. Available: http://arxiv.org/abs/1912.06059
Gupta, C. “Feature Selection and Analysis for Standard Machine Learning Classification of Audio Beehive Samples,” Masters Thesis, Utah State Univ., pp. 68–70, 2019.
A Bozdağ F Yavuz AS Günay 2016 AHP and GIS based land suitability analysis for Cihanbeyli Turkey County Environ. Earth Sci. https://doi.org/10.1007/s12665-016-5558-9
B Tashayo A Honarbakhsh M Akbari M Eftekhari 2020 Land suitability assessment for maize farming using a GIS-AHP method for a semi- arid region, Iran J. Saudi Soc. Agric. Sci. 19 5 332 338 https://doi.org/10.1016/j.jssas.2020.03.003
L Breiman 2001 Random forests Mach. Learning 45 5 32
C Montes Z Kapelan J Saldarriaga 2021 Predicting non-deposition sediment transport in sewer pipes using Random forest Water Res. 189 116639
HS Barjouei H Ghorbani N Mohamadian DA Wood S Davoodi J Moghadasi H Saberi 2021 Prediction performance advantages of deep machine learning algorithms for two-phase flow rates through wellhead chokes J. Petrol. Explor. Prod. 11 1233 1261
V Kumar 2021 Evaluation of computationally intelligent techniques for breast cancer diagnosis Neural Comput. Appl. 33 8 3195 3208
M Farsi HS Barjouei DA Wood H Ghorbani N Mohamadian S Davoodi HR Nasriani MA Alvar 2021 Prediction of oil flow rate through orifice flow meters: Optimized machine-learning techniques Measurement 174 108943
X Luo D Li Y Yang S Zhang 2019 Spatiotemporal traffic flow prediction with KNN and LSTM J. Adv. Transp. 2019 1 4145353
D Li B Zhang Z Yao C Li 2015 A feature-scaling-based K-nearest neighbor algorithm for indoor positioning systems IEEE Internet Things J. 3 4 590 597 https://doi.org/10.1109/GLOCOM.2014.7036847
SA Dudani 1976 The distance-weighted k-nearest-neighbor rule IEEE Trans. Syst. Man Cybernet. 4 325 327
Taneja, S., Gupta, C., Goyal, K., Gureja, D. An enhanced K-nearest neighbor algorithm using information gain and clustering, in: 2014 Fourth International Conference on Advanced Computing & Communication Technologies, Rohtak, 2014, pp. 325–329. https://doi.org/10.1109/ACCT.2014.22.
S Prusty S Patnaik SK Dash 2022 SKCV: Stratified K-fold cross-validation on ML classifiers for predicting cervical cancer Front. Nanotechnol. 4 972421
Schmidt, K., Rasoli, L., Nabiollahi, K., and Scholten, T. “Machine Learning and Land Suitability Assessment for Irrigated Wheat and Barley Crops in Kurdistan, Iran pp. 2–3, 2019.
Funding
No funding for the research.
Author information
Authors and Affiliations
Contributions
The development of the basic research questions, identifying the problems and selecting appropriate machine learning algorithms, data collection, data analysis, and interpretation have been done by Bikila Abebe. The overall progress of the work, critical review , writing and edition of the manuscript have been carried out by Tilahun Melak. Both authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Consent for publication
All authors agreed to submit the manuscript .
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ganati, B.A., Sitote, T.M. Predicting land suitability for wheat and barley crops using machine learning techniques. Sci Rep 15, 15879 (2025). https://doi.org/10.1038/s41598-025-99070-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-99070-0
