
Abstract
The self-compacting concrete (SCC) mixes were developed using lightweight expandable clay aggregate (LECA) as a partial substitute for coarse aggregate, ground granulated blast-furnace slag (GGBS) as a partial replacement for cement, and combusted bio-medical waste ash (BMWA) as a partial replacement for fine aggregate. The substitution levels for LECA, GGBS, and BMWA were set at 10%, 20%, and 30% of coarse aggregate, cement, and fine aggregate, respectively. M30-grade SCC mixes were designed with two different water-to-binder ratios—0.40 and 0.45—and their compressive strength (CS) was experimentally evaluated. The data entries from the above mix designs and experiments were collected in this research which deals with evaluating the impact of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete. An extensive literature search was used in this project and this produced a global representative database collected from literature. The collected 384 records were divided into training set (300 records = 80%) and validation set (84 records = 20%) in line with the requirements of a more reliable data partitioning. Six advanced machine learning methods such as the Artificial Neural Network (ANN), Support Vector Regression (SVR), K-Nearest Neighbors (KNN), eXtreme Gradient Boosting (XGB), Random Forest (RF), and Adaptive Boosting (AdaBoost) were used to model the concrete behavior. All models were created using “Orange Data Mining” software version 3.36. A combination of error metrics, efficiency metrics and determination/correlation metrics were used to test the models performance and accuracy. Also, the Hoffman and Gardener’s method was used to evaluate the sensitivity analysis of the model variables. At the end of the model work, AdaBoost and KNN excel in predictive accuracy with 97.5%, reducing the margin of error and ensuring precise mix designs for SCC. SVR, XGB, and RF also exhibit strong accuracy (96.5–97%), supporting reliable material selection and proportions. AdaBoost and KNN demonstrate the lowest errors (MAE: 0.65 MPa, RMSE: 0.75 MPa), indicating precise performance, minimizing overdesign or underperformance risks, and optimizing material usage. The Hoffman/Gardener’s sensitivity analysis produced produced GGBS of 31% and Dens of 26% as the highest impact and this is followed by LECA of 21% and BMWA of 20%. This research enables the optimization of self-compacting concrete mix designs using machine learning, reducing experimental trials, enhancing material efficiency, lowering environmental impact, and promoting sustainable construction through the effective reuse of industrial by-products.
Similar content being viewed by others
Introduction
Self-compacting concrete (SCC) plays a crucial role in modern construction due to its superior workability, reduced labor requirements, and enhanced durability. Unlike conventional concrete, SCC flows under its own weight, eliminating the need for vibration and ensuring uniform compaction even in congested reinforcement areas1. This characteristic not only improves construction efficiency but also minimizes defects, leading to longer-lasting structures with reduced maintenance costs. The importance of SCC extends to sustainability, as its production can incorporate industrial by-products such as fly ash, slag, and recycled aggregates, reducing reliance on natural resources and lowering carbon emissions2. The use of supplementary cementitious materials (SCMs) in SCC enhances its environmental benefits by decreasing cement consumption, which is a major contributor to CO₂ emissions in the construction industry. Additionally, SCC improves energy efficiency by reducing the mechanical effort required for placement, thereby decreasing overall energy demand on construction sites3. The integration of sustainable materials such as lightweight aggregates, geopolymer binders, and industrial waste further enhances SCC’s ecological footprint by diverting waste from landfills and promoting circular economy principles. Moreover, SCC contributes to the structural resilience and longevity of buildings, reducing the need for frequent repairs and material replacement, which aligns with sustainable construction practices. The combination of improved durability, reduced material wastage, lower emissions, and efficient resource utilization underscores the role of SCC in promoting sustainability within the construction sector.
Self-compacting concrete (SCC) has been employed in numerous civil engineering applications due to its superior flowability, stability, mechanical properties, and durability1,2,3,4. However, this prospective concrete has a higher density than normal concrete due to the increased powder content5,6,7. A potential remedy for this issue is the partial or complete replacement of natural aggregate with lightweight aggregate, such as light expanded clay aggregate (LECA), to create self-compacting lightweight concrete (SCLWC)8,9,10,11,12. This novel concrete possesses characteristics of both self-consolidating concrete (SCC) and lightweight concrete (LWC), such as decreasing the mass of concrete elements, hence enabling longer spans and minimizing member dimensions13,14,15. Moreover, the construction process is rendered safer, more economical, and environmentally friendly due to the reduction of labor16, the limitation of the construction duration, and the utilization of ultra-fine materials such as limestone powder in self-compacting concrete (SCC)1. LECA has been effectively utilized in the manufacture of lightweight concrete (LWC)17. LECA is derived from clay that undergoes desiccation, heating, and firing at high temperatures ranging from 1100 to 1300 °C2. This results in the production of expanded clay featuring a robust ceramic shell with interconnected holes of varying diameters3.
The use of lightweight expandable clay aggregate (LECA), ground granulated blast furnace slag (GGBS), and combusted bio-medical waste ash (BMWA) in self-compacting concrete (SCC) offers significant environmental and economic benefits. LECA, being a lightweight aggregate derived from natural clay, reduces the overall density of concrete, leading to a decrease in structural dead load14. This reduction allows for more efficient material utilization, enabling longer spans and thinner structural members, which ultimately minimizes resource consumption. Additionally, LECA enhances thermal insulation, reducing energy demands for heating and cooling in buildings, thereby contributing to energy efficiency and sustainability. GGBS, a by-product of the steel industry, serves as an effective partial replacement for cement, significantly lowering the carbon footprint of concrete production. The substitution of cement with GGBS reduces greenhouse gas emissions associated with cement manufacturing, conserves natural limestone resources, and enhances the durability of SCC by improving resistance to sulfate attack and chloride penetration. The improved long-term performance of SCC containing GGBS extends the service life of structures, reducing maintenance and repair costs over time17. BMWA, derived from incinerated medical waste, provides a sustainable solution for waste management by repurposing hazardous by-products into construction materials. Its incorporation in SCC reduces landfill waste, minimizes environmental pollution, and contributes to circular economy principles. The use of BMWA as a supplementary cementitious material also enhances the mechanical properties of SCC at optimal replacement levels while decreasing the overall demand for natural raw materials. From an economic perspective, the adoption of LECA, GGBS, and BMWA in SCC reduces production costs by utilizing industrial by-products and alternative materials that are often more affordable than conventional aggregates and cement18. The reduced weight of SCC with LECA leads to cost savings in transportation and handling, while the enhanced durability of GGBS-based SCC decreases lifecycle costs by minimizing the need for frequent repairs and rehabilitation. Additionally, incorporating BMWA supports sustainable waste disposal strategies, potentially reducing costs associated with medical waste treatment and landfilling. Overall, the integration of these materials in SCC promotes resource efficiency, cost-effectiveness, and environmentally responsible construction practices.
Literature review
Kanagaraj et al. 4 examined the sustainability of self-compactable lightweight geopolymer concrete (SCLGC) produced from Expanded Clay Aggregate (ECA). The research investigates the physical characteristics, density, compressive strength, splitting tensile strength, and impact resistance of SCLGC mixtures with varied concentrations of Sodium Hydroxide (SH) subjected to different curing conditions18. Microstructural examination is performed to evaluate density and internal architecture. The sustainability dimensions are examined by Life Cycle Assessment and Environmental Impact Assessment, assessing energy demand, CO2 emissions, and expenses19,20,21,22. The study concluded that ECA may be utilized for SCLGC manufacturing with a substitution rate not over 50%. Angelin et al.5 focused on formulating a self-compacting lightweight concrete (SCLC) incorporating expanded clay and suggests five distinct combinations. The formulation for self-compacting lightweight rubberized concrete (SCLRC) is determined according to the results of the efficiency factor23,24. The study identified enhanced fresh qualities, increased cohesiveness between paste and particles, and reduced density, leading to environmental sustainability and economic viability25,26,27. Nahhab and Ketab6 investigated the influence of aggregate size, the proportion of light expanded clay coarse aggregate, and the volume fraction of micro steel fibers on the qualities of self-compacting lightweight concrete (SCLWC). Eighteen mixtures were produced, with variations in dmax, LECA concentration, and Vf. The results indicated that an increase in dmax led to a reduction in superplasticizer dosage, with a dmax of 10 mm yielding optimal compressive and flexural strengths28. Kumar et al.7 investigated the characteristics of self-compacting concrete, particularly Lightweight self-compacting concrete (LWSCC), using differing water-binder ratios and superplasticizer concentrations. The investigation determined that the properties of fresh concrete conformed to European standards, exhibiting values within a significant range29,30,31,32. The qualities of hardened concrete were assessed using compressive strength, split tensile strength, ultrasonic pulse velocity, and rebound hammer tests33,34. The results indicated that replacing up to 30% with LECA yielded satisfactory outcomes in split tensile and compressive strength; however, the values diminished as the LECA fraction increased. Kumar et al.8 analyzed the characteristics of lightweight aggregates (LWA) in self-compacting concrete (SCC). The building industry is acknowledging the significance of natural resources and the management of by-products35. Lightweight aggregates (LWA), such as light-expanded clay aggregates, diatomite aggregates, walnut shells, palm shells, rice husk ash, micro silica, pumice stone, and scoria aggregate, can facilitate sustainable growth of self-consolidating concrete (SCC) and yield environmental advantages36. The analysis determined that LWA is advisable for SCC application owing to enhanced performance. Patel et al.9 examined the advancement of lightweight self-compacting concrete, an exemplary engineering material with advantageous characteristics. The study examines the influence of several lightweight aggregates on workability, strength, and durability, indicating that development is feasible at densities below 1000 kg/m3. The research additionally emphasized its superior cold resistance. This research is an innovative effort to compile results for widespread acceptance and future endeavors in civil engineering37. Garcia et al.10 assessed the viability of WEO as an addition in the manufacture of expanded clay aggregates (ECAs) for lightweight concrete (LWC) applications. The research delineated WEO and enhanced ECA production, acquiring morphological, physical, chemical, and mechanical qualities via diverse assessments38. The evaluation of ECAs in LWC involved four concrete mixtures with progressively higher amounts of ECAs substituting natural coarse particles. ECAs substantially decreased the bulk density of concrete, yet adversely affected its mechanical performance. With a 50% ECA substitution, the density and compressive strength values decreased by 13% and 2%, respectively, meeting LWC criteria for structural applications. Ahmadi et al.11 compared the properties of Lightweight Aggregate Concrete (LAC) produced with Lightweight Expanded Clay Aggregate (LECA) with foamed concrete at equivalent densities. Eight concrete mixtures were formulated and evaluated for compressive strength, flexural strength, water absorption, microstructure, and thermal conductivity38,39,40,41. The results indicated that at elevated densities, the 28-day compressive strength of FC specimens exceeded that of LAC by 7.3%, whereas LAC achieved a compressive strength increase of up to 36.9% after 28 days42,43,44,45. FC had a 28-day flexural strength that was between 11.8% and 55.4% superior than that of LAC. A microstructural analysis validated the results of the compressive strength test. FC exhibited water absorption rates that were 4.8–11.9% greater than those of LAC across all densities. Santamaría et al.12 examined self-compacting structural mortars (SCSM) that utilize slag from electric steel making as aggregates. The blend, comprising 60% natural aggregates, complies with existing regulatory guidelines for self-compacting mixtures. The interior composition of the hardened mixtures is analyzed using Mercury Intrusion Porosimetry and Computerized Axial Tomography. Shrinkage testing and accelerated potential expansion tests assess long-term dimensional stability. The mechanical parameters of the mortars demonstrate consistent performance throughout time, exhibiting adequate compressive and tensile strength together with appropriate stiffness values. These mortars are adequate for application in masonry and building globally. López et al.13 investigated the actual strength progression and durability of fiber-reinforced self-compacting concrete, utilizing Electric Arc Furnace Slag (EAFS) as aggregate, limestone fines as aggregate powder, and Ground Granulated Blast Furnace Slag (GGBFS) as binder. Four combinations, incorporating both metallic and synthetic fibers as well as varying concentrations of GGBFS, were formulated. The enduring mechanical properties of the cores resembled those of specimens treated in a humid room for 90 days. Nonetheless, the incorporation of fibers and GGBFS somewhat deteriorated the concrete’s durability, permitting the ingress of harsh external chemicals. Nonetheless, the enhanced flexibility of the cementitious matrix with GGBFS proved advantageous in resisting moisture/dry cycles and sulfate assault15. The mixtures adhered to regulatory standards for application in hostile settings; nonetheless, the quantities of fibers and GGBFS warrant thorough examination. Rosales et al.14 developed the production of self-compacting concrete (SCC) with a 50% reduction in cement content. The feasibility of employing an alkali-activated mixture of stainless steel slag (SSS) and fly ash (FA) as a substitute binder for cement has been established. SSS underwent three distinct treatment processes. Binders were produced by combining 35% SSS with 65% FA as precursors, along with a hydroxide activating solution. The binder was substituted with 50% cement for the production of SCC. The results demonstrate favorable mechanical characteristics and durability. The research indicates a decrease in cement utilization in the production of self-compacting concrete through the reuse of two waste materials. Nuruzzaman et al.15 examined the utilization of ferronickel slag (FNS) as a metallurgical by-product in the production of self-compacting concrete (SCC) to improve the sustainable supply chain within the concrete sector. FNS was utilized at a 40% substitution of natural sand, whereas ground ferronickel slag (GFNS) was employed at 0%, 20%, 35%, and 50% replacement levels of cement. The rheological properties, hydration, strength, and microstructural evolution of SCC were evaluated. The results indicated enhanced fluidity and workability with GFNS content, reduced yield stress and viscosity, and postponed hydration heat. The 28-day compressive strength diminished by 16% as a result of 35% cement substitution with GFNS and ascribed to the low calcium concentration of GFNS. The GFNS-incorporated SCC mixes were comparable to the control SCC mixture, indicating that FNS is a viable alternative for SCC to enhance the eco-friendly supply chain and sustainable waste management. Prithiviraj et al.16 assessed the fresh and hardened properties of self-compacting concrete (SCC) utilizing copper slag aggregate (CSA). Six mixtures were made by replacing river sand with CSA in increments of 10% up to a maximum of 50%. The characteristics of new self-compacting concrete (SCC) were assessed by slump flow, V-funnel, and L-box tests. The results indicated that the fresh properties of SCC improved continuously with increasing CSA content, whereas durability parameters exhibited significant augmentation in SCC mixtures containing up to 20% CSA. Matos et al.17, investigated the application of finely milled blast furnace slag (ACS) as a supplemental cementitious material (SCM) in the production of self-compacting concrete (SCC). Pastes and SCCs incorporating GBFS, ACS at two grinding stages, and limestone filler (LF) were generated. ACS elevated yield stress and viscosity relative to LF, and augmented the superplasticizer content in SCC. All mixtures exhibited consistent performance in their fresh condition. ACS demonstrated performance on par with LF and can serve as SCM in SCC. The combination of ACS and LF in equal proportions produced an SCC with fresh performance comparable to that of LF. Zhao et al.18 investigated a sustainable approach for the production of construction materials utilizing metallurgical slags, including steel slag, copper slag, lead–zinc slag, and electric furnace ferronickel slag. Nonetheless, these slags exhibit detrimental effects, including prolonged setting times, heightened segregation because to their elevated specific gravity, and degradation of the microstructure of hardened pastes. Safety problems encompass the integrity of steel slag, alkali-silica reactions in cement and ferronickel slag, as well as environmental issues arising from heavy metal leaching in copper slag and lead–zinc slag. Zhitkovsky et al.19 examined the application of ground blast-furnace slag in the manufacturing of self-compacting concrete (SCC). It employs experimental-statistical models to assess the impact of technological parameters on SCC characteristics. This study demonstrated a beneficial impact of blast-furnace slag and superplasticizer on durability and deformation properties. This study offered a design methodology employing mathematical models, facilitating the concurrent evaluation of requisite parameters. Ulucan and Ulas20 assessed 22 sustainable self-compacting mortars through the lens of circular economy, emphasizing their engineering characteristics. Pumice and recycled concrete aggregate (RCA) served as aggregates, while silica fume and fly ash functioned as supplementary cementitious materials (SCM). The 90-day compressive strengths shown considerable reductions after the incorporation of 10% RCA, but SCM provided beneficial effects. High-temperature evaluations demonstrated considerable reductions in strength, particularly at 900 °C. The thermal conductivity experiments demonstrated RCA’s potential role in sustainable construction materials. The microstructural characteristics of the mortar were enhanced by silica fume and fly ash. The research examined global warming and sustainability potential, revealing that the integrated application of RCA and SCM substantially enhances these factors. Manjunath et al.21 examined the prospective application of BMWA as a supplementary cementitious material in concrete, emphasizing its physical, chemical, and microstructural properties. The research indicated that BMWA complies with the US EPA’s leaching thresholds, and its application at amounts of up to 5% for cement substitution and 15% for sand substitution can yield high-strength, durable concrete. Vairagade et al.22 examined the influence of cremated biomedical waste ash (BMA) as a partial substitute for cement in hooked end steel fiber-reinforced concrete composites subjected to impact stresses. Twenty-five mixtures were created, incorporating cremated biomedical waste ash with 0.5–2% hooked end steel fibers, alongside four steel fiber-reinforced concrete specimens. The drop weight hammer test indicated that concrete containing 5% biomedical waste ash had the highest impact resistance. Replacing 7.5% of cement with BMA in conjunction with steel fibers demonstrated a comparable impact strength. Nevertheless, steel fiber-reinforced concrete exhibited brittle failure when over 7.5% of cement was substituted. Marulasiddappa et al.23 investigated the effects of integrating arecanut fibers into self-compacting concrete (SCC) to enhance its performance. The study concentrates on enhancing fiber content to improve concrete properties. The research investigates three distinct fiber lengths and volume fractions, incorporating a 30% weight substitution of fly ash. The results indicate advantageous workability and enhanced toughened characteristics, especially compressive strength. A concrete mixture with 2% arecanut fibers demonstrated a 15.14% enhancement in compressive strength, whilst a 1% volume fraction of 12 mm fibers improved split tensile strength and flexural strength. Fly ash and arecanut fibers enhance the longevity of self-compacting concrete (SCC) by diminishing Coulomb charges and augmenting resistance to chloride penetration. Microstructural and EDX analyses validate the existence of diverse constituents from cement and fly ash, offering critical information for assessing the long-term efficacy of these SCC mixtures. Ganesh et al.24 investigated the creation of sustainable geopolymer concrete from industrial byproducts such as Ground Granulated Blast Furnace Slag and ultra-fine Rice Husk Ash (URA). The research examines the impact of partially replacing GGBS with URA on workability, drying shrinkage, and both compressive and tensile strength at various concrete ages. Microstructural examination and sustainability assessment demonstrate notable improvements in workability, compressive and tensile strength, together with reduced drying shrinkage values with 15% utilization of URA in GPC. The research underscores the possibility for diminishing carbon emissions through greater reliance on Geopolymer concrete. The results demonstrated considerable possibilities for employing ground RHA in alkali-activated concrete. Recent advancements in machine learning techniques have facilitated the prediction and optimization of concrete properties. For instance, Tuvayanond et al.46 demonstrated the application of efficient machine learning algorithms for strength prediction in ready mix concrete. However, none had tried to apply a multiple combination of advanced machine learning techniques. These have been applied in the present work in addition to the utilization of the Hoffman/Gardener’s method to estimate the sensitivity of the variables on the compressive strength of a self-compacting concrete mixed with lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash.
The reviewed literature provides significant insights into the development of self-compacting lightweight concrete (SCLC) using alternative aggregates, but certain limitations and gaps remain, highlighting the relevance of the current research. Kanagaraj et al.4 and Angelin et al.5 focused on the use of expanded clay aggregate (ECA) for sustainability and improved fresh properties, but their studies lacked a robust computational approach to optimize mix designs. Nahhab and Ketab6 and Kumar et al. 7 explored the effects of lightweight expanded clay aggregate (LECA) on strength and workability, yet they did not employ advanced predictive models to optimize performance outcomes. Similarly, Kumar et al.8 and Patel et al.9 analyzed the potential of various lightweight aggregates but did not integrate machine learning techniques for property prediction. Garcia et al.10 and Ahmadi et al.11 evaluated the mechanical and microstructural characteristics of lightweight aggregate concrete, yet their findings were limited by traditional experimental methods without computational optimization. Santamaría et al.12 and López et al.13 investigatedthe use of slag-based materials in self-compacting mortars and concrete but did not assess their broader applicability using predictive analytics. Rosales et al. 14 and Nuruzzaman et al.15 emphasized sustainable binder replacements but did not explore their impact using machine learning-driven performance evaluations. Prithiviraj et al.16 and Matos et al.17 examined the use of alternative aggregates such as copper slag and finely milled blast furnace slag but did not incorporate sensitivity analyses to assess their effects on compressive strength. Zhao et al.18 and Zhitkovsky et al.19 explored the benefits and challenges of incorporating metallurgical slags in SCC but lacked an integrated approach for multi-variable optimization. Ulucan and Ulas20 and Manjunath et al.21 examined the circular economy potential of SCC incorporating recycled materials, yet their studies did not leverage machine learning algorithms to enhance mix designs. Vairagade et al.22 and Marulasiddappa et al.23 focused on biomedical waste ash and natural fiber integration in SCC, but their methodologies did not include predictive modeling techniques. Ganesh et al.24 assessed geopolymer concrete using industrial by-products but did not incorporate sensitivity analysis methods to evaluate variable influence on compressive strength. The reviewed studies provide valuable experimental data and sustainability perspectives, yet none have applied a combination of advanced machine learning techniques, including Artificial Neural Networks (ANN), Support Vector Regression (SVR), K-Nearest Neighbors (KNN), eXtreme Gradient Boosting (XGB), Random Forest (RF), and Adaptive Boosting (AdaBoost), for predicting and optimizing SCC properties. Furthermore, previous research has not integrated performance evaluation metrics such as SSE, MAE, MSE, RMSE, Error (%), Accuracy (%), and determination coefficients like R2, R, WI, NSE, KGE, and SMAPE. This study addresses these gaps by applying these techniques to optimize self-compacting concrete incorporating lightweight expanded clay aggregate, metallurgical slag, and combusted biomedical waste ash. Additionally, the Hoffman/Gardner method is employed to estimate variable sensitivity on compressive strength, ensuring a comprehensive evaluation of SCC mix design and performance.
Research gap and research questions and hypothesis
The research on self-compacting concrete (SCC) has significantly evolved, with various studies focusing on enhancing its mechanical properties, durability, and sustainability. Extensive work has been conducted on the incorporation of lightweight aggregates such as light-expanded clay aggregate (LECA), as well as alternative materials like metallurgical slag and other industrial by-products, to improve SCC’s performance and environmental impact. These materials have been explored for their ability to reduce density, enhance mechanical strength, and contribute to sustainability goals. Additionally, studies have assessed the effects of different aggregate sizes, binder compositions, curing conditions, and supplementary cementitious materials on SCC’s fresh and hardened properties. Despite these advancements, several research gaps remain. Most studies have primarily investigated the use of a single type of lightweight aggregate or industrial waste in SCC rather than exploring a combined effect of multiple materials. The interaction between LECA, metallurgical slag, and combusted bio-medical waste ash in SCC has not been comprehensively examined, particularly regarding their collective impact on fresh and hardened properties, long-term durability, and environmental benefits. The microstructural behavior of such a composite mix and its influence on concrete’s mechanical performance and sustainability aspects require further exploration. Another significant gap lies in the application of advanced machine learning techniques to optimize and predict the performance of SCC mixtures. While machine learning models have been employed in predicting concrete strength, previous studies have largely relied on singular or traditional models. The potential of multiple advanced machine learning techniques such as Artificial Neural Networks (ANN), Support Vector Regression (SVR), K-Nearest Neighbors (KNN), eXtreme Gradient Boosting (XGB), Random Forest (RF), and Adaptive Boosting (AdaBoost) remains largely unexplored in the context of SCC incorporating LECA, metallurgical slag, and combusted bio-medical waste ash. Additionally, there is limited research on utilizing extensive error, efficiency, and determination metrics such as SSE, MAE, MSE, RMSE, Error (%), Accuracy (%), R2, R, WI, NSE, KGE, and SMAPE to evaluate the predictive performance of these models. Furthermore, there is a lack of comprehensive sensitivity analysis to determine the influence of different variables on the compressive strength of such SCC mixtures. The Hoffman/Gardener’s method, which provides insights into the sensitivity of parameters affecting concrete strength, has not been widely applied in this context. This limitation restricts the understanding of how different mix proportions and material properties contribute to the overall performance of SCC. Addressing these gaps is crucial for advancing the development of high-performance, sustainable SCC that incorporates multiple waste materials while leveraging machine learning techniques for precise performance prediction and optimization. The integration of these approaches could enhance the practical application and industrial adoption of SCC, ensuring both structural reliability and environmental sustainability.
The research aims to address key questions regarding the impact of lightweight expandable clay aggregate (LECA), metallurgical slag (GGBS), and combusted bio-medical waste ash (BMWA) on the performance of self-compacting concrete (SCC). The primary research questions include: How do different proportions of LECA, GGBS, and BMWA influence the compressive strength of SCC? Can advanced machine learning models accurately predict the strength and workability of SCC based on varying material compositions? Which machine learning model offers the highest accuracy and reliability in predicting SCC performance? The hypothesis for this study is that the incorporation of LECA, GGBS, and BMWA in SCC improves sustainability while maintaining structural integrity and workability. It is further hypothesized that machine learning models, particularly AdaBoost and KNN, will outperform others in predicting SCC properties due to their superior pattern recognition and adaptability. Additionally, it is expected that the integration of these industrial by-products will lead to optimized mix designs that reduce material waste, enhance efficiency, and contribute to sustainable construction practices.
Statement of innovation
The present research introduces a novel approach by integrating lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash into self-compacting concrete to enhance its mechanical properties, durability, and sustainability. Unlike previous studies that focused on the independent effects of these materials, this study examines their combined influence, providing a comprehensive understanding of their interaction in SCC mixtures. This innovative approach not only reduces the density of SCC but also promotes the efficient utilization of industrial waste materials, contributing to sustainable construction practices. Additionally, this research pioneers the application of multiple advanced machine learning techniques, including Artificial Neural Networks, Support Vector Regression, K-Nearest Neighbors, eXtreme Gradient Boosting, Random Forest, and Adaptive Boosting, to predict and optimize the compressive strength of SCC. Unlike conventional studies that rely on single predictive models, this study employs an ensemble of techniques to enhance accuracy and reliability. Furthermore, it introduces an extensive set of error, efficiency, and determination metrics, such as SSE, MAE, MSE, RMSE, Error (%), Accuracy (%), R2, R, WI, NSE, KGE, and SMAPE, to provide a robust evaluation of model performance. Another key innovation is the application of the Hoffman/Gardener’s method to estimate the sensitivity of variables influencing SCC strength. This approach offers deeper insights into the significance of different mix parameters, enabling more precise mix design optimization. By combining experimental analysis with advanced computational techniques, this study sets a new benchmark for SCC research, ensuring structural efficiency, environmental sustainability, and practical applicability in modern construction.
Research methodology
Collection of database and statistical study
An extensive literature search was used in this project and this produced a global representative database collected from literature27. The collected 384 records were divided into training set (300 records = 80%) and validation set (84 records = 20%) in line with the requirements of a more reliable data partitioning38. The appendix includes the complete dataset, while Table 1 summarizes their statistical characteristics. Finally, Figs. 1 and 2 show the Pearson correlation matrix, histograms, and the relations between variables and the violin distribution of each input.

Correlation, distribution and interpreting chart.

Violin distribution for each input.
Research program
Six different ML techniques were used to predict the compressive strength of the concrete using the collected database. These techniques are “Artificial Neural Network (ANN)”, “Support Vector Regression (SVR), “K-Nearest Neighbors (KNN), “eXtreme Gradient Boosting (XGB)”, “Random Forest (RF)” and “Adaptive Boosting (AdaBoost)”. All models were created using “Orange Data Mining” software version 3.36. The considered data flow diagram is shown in Fig. 3. The following section discusses the results of each model. The accuracies and performance of developed models were evaluated by comparing SSE, MAE, MSE, RMSE, Error %, Accuracy % and R2, R, WI, NSE, KGE and SMAPE between predicted and calculated compressive strength parameter values. The definition of each used measurement is presented in Eqs. (1–6).

The considered data flow in Orange software.
Theory of the selected machine learning methods
Artificial neural network (ANN)
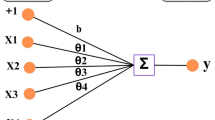
An Artificial Neural Network (ANN) is a computational model inspired by the structure and functioning of the human brain. It is a key component of machine learning and artificial intelligence (AI), designed to recognize patterns and learn from data. In the Forward Propagation ANN, data flows through the network from the input layer to the output layer and each neuron calculates a weighted sum of its inputs, applies the bias, and processes it through an activation function. Loss Function measures the difference between the predicted output and the actual target. Backpropagation is a technique to adjust weights and biases by calculating gradients of the loss function with respect to these parameters and it uses optimization algorithms like Gradient Descent. ANN training involves repeatedly feeding data through the network, calculating loss, and adjusting weights and biases until the network learns to make accurate predictions. Hyperparameter tuning plays a crucial role in optimizing the performance of the Artificial Neural Network (ANN) model for evaluating the impact of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete (SCC). The process involves adjusting key parameters such as the number of hidden layers, neurons per layer, activation functions, learning rate, batch size, and optimization algorithms to achieve the best predictive accuracy and generalization ability. The selection of the number of hidden layers and neurons per layer directly influences the model’s complexity and learning capacity. Too few neurons may lead to underfitting, while an excessive number can cause overfitting, resulting in poor generalization. A systematic approach, such as grid search or random search, can be used to identify the optimal architecture by evaluating different combinations of layers and neurons. Activation functions are crucial in determining the non-linearity of the model. The rectified linear unit (ReLU) is often preferred due to its computational efficiency and ability to mitigate the vanishing gradient problem, while alternative functions such as sigmoid and tanh may be explored for different layers to improve convergence. The choice of optimization algorithms, such as Adam, RMSprop, or stochastic gradient descent (SGD), significantly impacts model convergence speed and stability. Adam is widely used due to its adaptive learning rate properties, but experimentation with other optimizers helps refine model performance. The learning rate is a critical hyperparameter that governs the step size during weight updates. A high learning rate may cause the model to converge prematurely to a suboptimal solution, while a low value may lead to slow convergence. An adaptive learning rate strategy, such as learning rate decay or scheduling, can enhance training efficiency. Batch size also affects model training, with smaller batch sizes providing better generalization at the cost of longer training times, while larger batches improve computational efficiency but may lead to poor generalization. Regularization techniques such as dropout and L2 regularization help prevent overfitting by introducing noise or constraints during training. Dropout randomly deactivates a fraction of neurons in each iteration, enhancing the robustness of the model, while L2 regularization adds a penalty term to the loss function to prevent excessive weight magnitudes. Early stopping is another effective strategy that halts training when validation loss starts increasing, thereby preventing overfitting. Hyperparameter tuning is performed using techniques like grid search, random search, or Bayesian optimization. Grid search systematically evaluates all possible parameter combinations but is computationally expensive. Random search selects hyperparameters randomly within predefined ranges, providing a balance between efficiency and effectiveness. Bayesian optimization leverages probabilistic models to guide the search towards promising hyperparameter values, making it a more efficient alternative. Artificial Neural Networks (ANNs) are computer models that draw inspiration from the biological neural networks seen in the human brain39. They are composed of interconnected layers of neurons, or nodes, where data is received by the input layer, processed by hidden layers, and predicted by the output layer. A typical ANN architecture is illustrated in Fig. 4.

ANN architecture (adapted from (Montesinos López et al.40)).
The mathematical foundation of an ANN can be summarized as follows that each neuron in a layer computes a weighted sum of its inputs:
where \({z}_{i}^{(l)}\) is the pre-activation value, \({w}_{ij}^{(l)}\) are weights, \({a}_{j}^{(l-1)}\) are activations from the previous layer, and \({b}_{i}^{(l)}\) is the bias term. A nonlinear activation function g(z) is applied to introduce nonlinearity:
The network is trained using backpropagation, which minimizes a loss function \(L(y,\widehat{y})\) using gradient descent:
where η is the learning rate. The choice of architecture (number of layers, neurons, and activation functions) and optimization algorithm governs the ANN’s performance.
Support vector regression (SVR)
Support Vector Regression (SVR) is a type of machine learning algorithm based on the principles of Support Vector Machines (SVMs). Unlike classification tasks in SVM, where the goal is to separate data points into different categories, SVR is used for regression tasks, where the aim is to predict a continuous value25. Hyperparameter tuning is essential for optimizing the performance of the Support Vector Regression (SVR) model in evaluating the impact of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete (SCC). The tuning process involves selecting the appropriate kernel function, regularization parameter (C), epsilon (ε), and kernel-specific hyperparameters to enhance prediction accuracy and generalization ability. The choice of kernel function significantly affects the SVR model’s ability to capture complex relationships between input variables and SCC properties. Common kernel functions include linear, polynomial, radial basis function (RBF), and sigmoid. The RBF kernel is widely used due to its flexibility in mapping non-linear relationships, whereas the linear kernel may be effective for datasets with linear trends. Polynomial and sigmoid kernels are also considered when specific transformations improve performance. Selecting the most suitable kernel involves testing different options and comparing their predictive performance. The regularization parameter (C) controls the trade-off between minimizing training error and ensuring model generalization. A high C value prioritizes accurate predictions on the training set but may lead to overfitting, while a lower C value enhances generalization but may result in underfitting. Systematic tuning of C using techniques like grid search or random search helps identify the optimal balance between bias and variance. The epsilon (ε) parameter defines the margin of tolerance within which predictions are considered acceptable without penalty. A larger ε value allows for greater flexibility but may reduce model sensitivity, while a smaller ε tightens the margin, potentially leading to a more precise model but with increased risk of overfitting. The optimal ε value is determined through experimentation, balancing model accuracy and robustness. For kernel-based SVR models, additional hyperparameters such as gamma (γ) in the RBF and polynomial kernels influence model complexity. In the RBF kernel, γ defines how far the influence of a single training point extends, with higher values leading to more complex models that may overfit the data, while lower values produce smoother decision boundaries that generalize better. The polynomial kernel requires tuning of both γ and the polynomial degree, where higher degrees enable more complex transformations but at the cost of increased computational complexity. Hyperparameter tuning methods such as grid search, random search, and Bayesian optimization are employed to systematically explore the hyperparameter space and identify the best-performing configuration. Grid search exhaustively tests all possible combinations within a predefined range but can be computationally expensive. Random search selects hyperparameter values randomly, offering a more efficient alternative while still covering a broad search space. Bayesian optimization leverages probabilistic models to guide the search towards the most promising hyperparameter values, improving efficiency. The goal of SVR is to find a function (or hyperplane) that best fits the data within a margin of tolerance, known as the epsilon (ε) margin. The predicted values can deviate from the actual values, but only up to a certain threshold (ε) without being penalized. In support vectors analysis, data points that lie outside the ϵ margin are called support vectors27. These points determine the position of the regression line and influence the model. SVR uses kernel functions to handle non-linear relationships between input features and the target variable by mapping data into a higher-dimensional space and common kernels include linear, polynomial, radial basis function (RBF), and sigmoid. SVR minimizes a loss function that only considers errors larger than ε, using a parameter C to control the trade-off between model complexity and error tolerance. Equation (15) represents the local linear regression form of \(SVR\) when given a train dataset of \(\{{y}_{i}, {x}_{i}, i = 1, 2, 3 ... n\}\), where \({y}_{i}\) denotes the \(output\) vector, \({x}_{i}\) denotes the feature course, and \(n\) signifies the dataset’s size.
The equation above represents the dot product as \(\left(x,k\right)\), where \(k\) is the heaviness vector, \(x\) signifies the normalized test design, and \(b\) is the \(bias\). To implement the \(SRM\) theory, the empirical risk \({R}_{emp} (k, b)\) is minimized, which can be expressed by an equation. Equation (16) shows that the experiential risk is computed using an \(\varepsilon\)-insensitive damage function denoted by \({L}_{\varepsilon }({y}_{i},f\left({x}_{i},k\right))\) (see Eq. (17)).
During the optimization process, the \(\varepsilon\)-insensitive loss function, denoted as \({L}_{\varepsilon }\left({y}_{i},f\left({x}_{i},k\right)\right),\) calculates the error tolerance between the desired output \({y}_{i}\) and the projected values of the output \(f\left({x}_{i},k\right)\). The train design, \({x}_{i}\), is also clear in this background. In linear regression problems using the \(\varepsilon\)-insensitive loss function, minimalizing the squared average of the \(weight\) vector, \({\Vert k\Vert }^{2}\), can abridge the difficulty of the \(SVR\) model. Additionally, a non-negative slack mutable \(\left({\varphi }_{i}^{*}{\varphi }_{i}\right)\) can be utilized to estimate the nonconformity of the outside train data in the \(\varepsilon\)-insensitive \(0\), represented by \({\varphi }_{i}\).
To address the aforementioned issue, finding the saddle point of the Lagrange function (Eq. 19) is essential.
The Lagrange function can be minimized through the application of the \(KKT\) conditions, which involves execution of partial difference of Eq. (19) about \(k, b\), \({\varphi }_{i}^{*},\) and \({\varphi }_{i}\) (see Eqs. 20–23).
The parameter \(k\) in Eq. (20) is linked to the parameter \(k\) in Eq. (15). The dual function of optimisation is obtained by substituting Eq. (20) into the Lagrange function (19). However, the formulation of nonlinear \(SVR\) can be represented as shown below:
The limit vector is denoted by \(k\) and \(b\), while the charting purpose \(\tau (x)\) is used to transform \(input\) features into a higher dimensional feature space.
K-nearest neighbors (KNN)
K-Nearest Neighbors (KNN) is a simple, non-parametric machine learning algorithm used for both classification and regression tasks. It is based on the principle of similarity, where predictions are made based on the closest training data points in feature space. Hyperparameter tuning is essential for optimizing the performance of the k-Nearest Neighbors (KNN) model in evaluating the impact of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete (SCC). The key hyperparameters that influence the predictive accuracy and generalization ability of the KNN model include the number of neighbors (k), distance metric, and weighting function. The number of neighbors (k) is the most critical hyperparameter in KNN, as it determines how many nearest data points contribute to the prediction. A lower k value makes the model more sensitive to noise and fluctuations in the dataset, potentially leading to overfitting. Conversely, a higher k value results in smoother predictions but may cause underfitting by oversimplifying patterns in the data. The optimal k value is typically determined through cross-validation, where different values are tested to find the one that minimizes error metrics such as mean squared error (MSE) and mean absolute error (MAE). The choice of distance metric affects how similarity between data points is measured. Common distance metrics include Euclidean, Manhattan, and Minkowski distances. Euclidean distance is the most widely used, as it calculates the straight-line distance between points, making it suitable for continuous numerical data. Manhattan distance, which sums the absolute differences of feature values, is useful when dealing with high-dimensional spaces or when features exhibit different scales. The Minkowski distance generalizes both Euclidean and Manhattan distances, allowing flexibility in distance calculation. Selecting the appropriate metric depends on the nature of the SCC dataset and its feature distributions. The weighting function determines how the contribution of neighbors is considered in the prediction process. In uniform weighting, all neighbors contribute equally, whereas in distance-weighted KNN, closer neighbors have a higher influence on the prediction than distant ones. Distance weighting is often preferred when variations in SCC properties exhibit strong local patterns. Hyperparameter tuning involves comparing the performance of uniform and distance-weighted models to identify the most suitable approach. Optimization techniques such as grid search, random search, and cross-validation are employed to systematically explore the hyperparameter space and select the best combination of k, distance metric, and weighting function. Grid search exhaustively evaluates predefined parameter values, ensuring a thorough search but with high computational cost. Random search randomly selects hyperparameter values, providing a more efficient search strategy while maintaining good performance. Cross-validation helps prevent overfitting by ensuring the model’s stability across different data subsets. KNN is a lazy learning algorithm; it does not build an explicit model during training but directly uses the training data for predictions. To find the "nearest neighbors," KNN relies on a distance metric to measure similarity between data points. K-NN is a non-parametric technique for regression and classification. It is based on the idea that similar data points are found in feature space near one another41. The framework involves: For a query point \({x}_{q}\), the distance to each point \({x}_{i}\) in the dataset is computed using a metric such as Euclidean distance:
where p is the number of features. The k nearest neighbors is identified based on the smallest distances. The class label is assigned based on majority voting among the neighbors. The output is the average of the neighbors’ target values. The performance of kNN depends on the choice of k, the distance metric, and the feature scaling.
eXtreme gradient boosting (XGB)
eXtreme Gradient Boosting (XGBoost) is an advanced implementation of gradient boosting algorithms designed for speed and performance. Developed by Tianqi Chen, it is a popular machine learning library for both regression and classification tasks, often used in data science competitions like Kaggle. Hyperparameter tuning is crucial for optimizing the performance of the eXtreme Gradient Boosting (XGB) model in evaluating the impact of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete (SCC). The key hyperparameters that significantly influence the predictive accuracy and generalization ability of the XGB model include the learning rate (eta), number of boosting rounds (n_estimators), maximum tree depth (max_depth), subsampling ratio (subsample), column sampling by tree (colsample_bytree), and regularization parameters such as L1 (alpha) and L2 (lambda) penalties. The learning rate controls the step size of each boosting iteration, balancing the trade-off between convergence speed and model performance. A smaller learning rate ensures gradual learning and better generalization but requires a higher number of boosting rounds to reach optimal performance. The number of boosting rounds determines how many trees are built sequentially, with each tree correcting the errors of the previous ones. Setting this parameter too high may lead to overfitting, while too few boosting rounds may result in underfitting. The maximum tree depth regulates the complexity of individual trees, with deeper trees capturing more intricate patterns in the dataset at the risk of overfitting. An optimal depth is determined through cross-validation, ensuring a balance between model complexity and performance. Subsampling and column sampling techniques introduce randomness, reducing overfitting by ensuring diversity in the training process. Subsampling controls the proportion of training data used for each boosting round, while column sampling determines the fraction of features used when constructing each tree. Regularization parameters play a key role in preventing overfitting by penalizing excessive complexity in the model. L1 regularization (alpha) induces sparsity in tree splits, leading to a simpler and more interpretable model, while L2 regularization (lambda) discourages overly large weights, promoting stability. Fine-tuning these regularization terms helps improve the robustness of the model against noise in the SCC dataset. Optimization techniques such as grid search, random search, and Bayesian optimization are employed to systematically explore the hyperparameter space and identify the best combination. Grid search exhaustively evaluates predefined hyperparameter values, ensuring thorough optimization at the cost of high computational demand. Random search provides a more efficient alternative by sampling random combinations, reducing computation while still achieving strong performance. Bayesian optimization utilizes probabilistic models to iteratively refine hyperparameter selection, focusing on promising regions of the search space. XGBoost builds an ensemble of weak learners (usually decision trees) sequentially. Each subsequent model focuses on minimizing the errors (residuals) of the previous model by optimizing a loss function using gradient descent. XGB is a gradient-boosted decision tree implementation that has been tuned for speed and efficiency. It iteratively constructs models by minimizing a differentiable loss function 42. The theoretical foundation involves objective function;
where L is the loss function (e.g., mean squared error), fk are the decision trees, and Ω regularizes the complexity of the trees. At each iteration t, the model adds a new tree ft(x) to correct the errors of the previous prediction:
The new tree minimizes the gradient of the loss function:
XGB’s scalability comes from its use of advanced techniques such as tree pruning, regularization, and parallelization.
Random forest (RF)
Random Forest (RF) is a popular ensemble machine learning algorithm primarily used for classification and regression tasks. It operates by constructing multiple decision trees during training and combines their outputs (via majority voting for classification or averaging for regression) to improve performance and reduce overfitting. Hyperparameter tuning is essential for optimizing the performance of the Random Forest (RF) model in evaluating the impact of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete (SCC). The key hyperparameters influencing RF performance include the number of trees (n_estimators), maximum depth of trees (max_depth), minimum samples per split (min_samples_split), minimum samples per leaf (min_samples_leaf), and feature selection criteria such as the number of features considered at each split (max_features). Proper tuning of these hyperparameters ensures improved prediction accuracy, reduced overfitting, and enhanced generalization capability. The number of trees determines the size of the ensemble model, where a higher number generally leads to better performance by reducing variance. However, excessively increasing the number of trees can lead to higher computational costs without significant improvements. The maximum depth of trees controls how deep individual decision trees can grow, with deeper trees capturing more complex relationships in the data but increasing the risk of overfitting. Optimizing this parameter ensures a balance between model complexity and predictive power. The minimum samples per split and minimum samples per leaf parameters regulate the growth of decision trees by defining the minimum number of samples required for splitting nodes and forming leaf nodes. Setting these values appropriately prevents overly complex trees, reducing overfitting while maintaining sufficient model flexibility. The number of features considered at each split plays a crucial role in model randomness and performance. Selecting too many features may result in redundancy and higher computational costs, while too few can lead to underfitting. Hyperparameter tuning methods such as grid search, random search, and Bayesian optimization are used to identify the optimal combination of these parameters. Grid search systematically evaluates predefined hyperparameter values, ensuring a thorough search at the cost of high computational demand. Random search offers a more efficient alternative by randomly selecting hyperparameter combinations, covering a broader search space with reduced computation. Bayesian optimization leverages probabilistic models to refine hyperparameter selection iteratively, focusing on promising areas of the search space for improved efficiency. Random Forest is an ensemble method that aggregates predictions from multiple models (decision trees) to improve accuracy and robustness. Each tree is trained on a random subset of the training data, sampled with replacement (bootstrap sampling). This reduces variance and helps avoid overfitting. During tree construction, Random Forest selects a random subset of features for each split and this introduces further diversity among trees and prevents reliance on specific features. Random Forest is an ensemble technique that reduces overfitting and increases accuracy by constructing numerous decision trees and combining their predictions43. Figure 5 shows the architecture of random forest technique.

Typical random forest architecture (adapted from Dutta et al.43).
The mathematical framework includes given a dataset of size n, m subsets are created by random sampling with replacement. Each tree is trained on a subset using a random subset of features at each split. The decision tree algorithm splits nodes by maximizing information gain or reducing impurity, such as:
where pi is the proportion of class i. Ensemble prediction covers majority voting among trees and averaging predictions from all trees. The randomness in sampling and feature selection ensures diversity among the trees, enhancing robustness.
Adaptive boosting (AdaBoost)
Adaptive Boosting (AdaBoost) is an ensemble learning method designed to improve the performance of weak learners (typically decision stumps) by iteratively combining them into a strong predictive model. Developed by Yoav Freund and Robert Schapire, AdaBoost adapts to the training data by focusing more on misclassified instances during successive iterations. Weak learners are models that perform slightly better than random guessing. Hyperparameter tuning for optimal performance of the Adaptive Boosting (AdaBoost) model in evaluating the impact of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete involves adjusting key parameters to enhance model accuracy and generalization. The learning rate, which controls the contribution of each weak learner, must be optimized to balance bias and variance. A lower learning rate may prevent overfitting, while a higher value speeds up convergence. The number of estimators, determining the number of weak learners, must be carefully chosen to ensure sufficient model complexity without excessive computational cost. The base estimator, typically a decision tree with limited depth, should be fine-tuned to maintain weak learner diversity while preventing excessive complexity. The maximum depth of the weak learner plays a crucial role in avoiding overfitting and improving generalization. The algorithm used for weight updates, such as SAMME or SAMME.R, influences convergence and classification performance. The minimum number of samples per split and the minimum number of samples per leaf must be tuned to control model flexibility and ensure stable learning. Cross-validation techniques, including k-fold validation, should be employed to assess model performance across different data subsets. Evaluation metrics such as mean squared error, root mean squared error, R-squared, mean absolute error, and Willmott’s index of agreement provide insights into model efficiency. Grid search and random search can be used to identify the optimal combination of hyperparameters, and Bayesian optimization or genetic algorithms may be employed for more efficient tuning. Fine-tuning AdaBoost ensures robust predictions of self-compacting concrete properties while optimizing computational efficiency and model interpretability. In AdaBoost, decision stumps (single-level decision trees) are commonly used as weak learners. Boosting is an ensemble method that combines multiple weak learners to create a strong learner. AdaBoost does this by weighting weak learners based on their accuracy and iteratively focusing on difficult-to-classify instances. Misclassified instances are assigned higher weights, making them more influential in subsequent iterations, while correctly classified instances receive lower weights. Each weak learner contributes to the final prediction based on its performance and better-performing learners are given higher voting power. AdaBoost (Adaptive Boosting) builds a powerful model by iteratively combining weak learners (such shallow decision trees)44. The framework is as follows that each data point iii is assigned a weight wi, initialized uniformly:
A weak learner ht(x) is trained on the weighted dataset. The weighted error of the learner is computed:
where ⃦ is the indicator function. The weak learner is assigned a weight based on its performance:
The data weights are updated to emphasize misclassified points:
The ensemble combines the weak learners weighted by \({\propto }_{t}\):
AdaBoost adapts by focusing on harder examples, making it effective for complex datasets.
Sensitivity analysis
The focus of the sensitivity analysis of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete compressive strength is to evaluate the influence of three components—lightweight expandable clay aggregate (LECA), metallurgical slag, and combusted bio-medical waste ash (CBMWA)—on the compressive strength of self-compacting concrete (SCC). Sensitivity analysis determines the relative impact of these variables on the target property, which is the compressive strength. A preliminary sensitivity analysis was carried out on the collected database to estimate the impact of each input on the (Y) values. “Single variable per time” technique is used to determine the “Sensitivity Index” (SI) for each input using Hoffman & Gardener45 formula as follows:
The Hoffman and Gardener method of sensitivity analysis is widely used to assess the relative importance of input variables in complex systems or models. It is a screening technique that evaluates the impact of uncertain input parameters on the model’s output using variance-based methods. This approach combines rank correlation and variance decomposition to quantify the sensitivity of each input parameter. It is computationally efficient and suitable for cases with multiple variables and limited data. Hoffman and Gardener method is computationally efficient as it requires fewer simulations or experiments compared to global sensitivity analysis techniques like Sobol. It works well for models with nonlinear relationships between inputs and outputs. PRCC values and variance contributions are intuitive and provide actionable insights. However, it assumes a monotonic relationship between inputs and outputs, which may not hold for all systems. Nonlinear interactions between variables may not be fully captured in the variance decomposition step.
Results presentation and discussion
ANN model
Figure 6 shows the ANN model layout displaying the input layer, hidden layer and output layer. Table 2 shows the weight matrix for the developed model. The ANN model for the evaluation of the impact of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete produced SSE of 406, MAE of 1.1 MPa, MSE of 1.75 MPa, RMSE of 1.3 MPa, average error of 5%, Accuracy of 95%, R2 of 0.895, R of 0.945, WI of 0.97, NSE of 0.89, KGE of 0.915, and SMAPE of 3.94 MPa. Figure 7 shows the relationship between the measured and predicted values of the output. The performance metrics of the Artificial Neural Network (ANN) model highlight its effectiveness in predicting the compressive strength of SCC incorporating lightweight expandable clay aggregate (LECA), ground granulated blast-furnace slag (GGBS), and incinerated bio-medical waste ash (IBMWA). Below is an analysis of the reported metrics and their implications for sustainable concrete production and construction. Sum of Squared Errors (SSE) of 406 indicates a relatively low cumulative error across the dataset. The Mean Absolute Error (MAE) of 1.1 MPa reflects the average deviation of predictions from actual values, demonstrating high precision. Mean Squared Error (MSE) of 1.75 MPa further supports the low variance in prediction errors. Root Mean Squared Error (RMSE) of 1.3 MPa shows excellent predictive accuracy, with deviations minimal in practical applications. Accuracy of 95% indicates a high reliability of the ANN model for predicting SCC compressive strength. Average Error of 5% confirms that the model’s predictions are close to experimental values. R2 (Coefficient of Determination): 0.895 shows that the model explains 89.5% of the variance in compressive strength. R (Correlation Coefficient) of 0.945 indicates a strong positive relationship between predicted and actual values. Willmott Index (WI) of 0.97 suggests excellent agreement between predicted and observed compressive strength values. Nash–Sutcliffe Efficiency (NSE) of 0.89 confirms the model’s robust predictive capability. Kling-Gupta Efficiency (KGE) of 0.915 highlights the model’s balanced performance, considering correlation, bias, and variability. Symmetric Mean Absolute Percentage Error (SMAPE) of 3.94 MPa indicates low relative prediction errors, validating the model’s consistency across different substitution levels of LECA, GGBS, and BMWA. The ANN model provides accurate predictions of compressive strength, enabling optimal use of industrial by-products (LECA, GGBS, and BMWA) as partial substitutes in SCC production. This reduces reliance on traditional materials (cement, fine, and coarse aggregates), lowering the carbon footprint of construction projects. ANN modeling minimizes the need for extensive experimental trials, accelerating the evaluation of mix designs and reducing overall costs. Utilizing industrial waste aligns with circular economy principles, promoting waste recycling and sustainable material use in construction. SCC mixes optimized using the ANN model exhibit reliable compressive strength, making them suitable for structural applications in sustainable construction. Use the ANN model to evaluate various mix designs with different water-to-binder ratios and substitution levels, ensuring optimal performance. Validate the model with additional datasets and different curing regimes to enhance generalization for broader applications. Use insights from the ANN model to inform guidelines for incorporating industrial wastes into SCC production, encouraging widespread adoption. Extend the model to predict other SCC properties, such as durability and flexural strength, ensuring comprehensive performance assessment. The ANN model demonstrates high reliability and predictive accuracy in evaluating the compressive strength of SCC containing industrial wastes. Its application supports sustainable concrete production by promoting the use of recycled materials, minimizing environmental impact, and enabling cost-effective construction practices.

The considered layout of (ANN) model.

Relation between predicted and calculated strength using (ANN).
KNN model
Figure 8 shows the KNN model hyperparameter tuning for the prediction of the studied concrete strength. The k-Nearest Neighbors (kNN) model configuration in the figure is set with a number of neighbors equal to one, meaning the classification relies solely on the closest neighbor, which can lead to overfitting and high variance. The metric used is Euclidean distance, which calculates the straight-line distance between points in the feature space and is effective when features are normalized. The weighting is set to "By Distances," meaning closer neighbors have a greater influence on predictions, which can be beneficial in cases where more distant neighbors may introduce noise. The “Apply Automatically” option is checked, ensuring that any parameter changes are immediately applied. These settings indicate a highly localized classification approach that may be sensitive to noise, and tuning the number of neighbors along with testing different distance metrics, such as Manhattan or Minkowski, could enhance model performance and generalization. The KNN model for the evaluation of the impact of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete produced SSE of 105.5, MAE of 0.65 MPa, MSE of 0.5MPa, RMSE of 0.75 MPa, average error of 2.5%, Accuracy of 97.5%, R2 of 0.97, R of 0.99, WI of 0.99, NSE of 0.97, KGE of 0.98, and SMAPE of 2.47 MPa. Figure 9 shows the relationship between the measured and predicted values of the output. The K-Nearest Neighbors (KNN) model exhibits exceptional predictive performance in evaluating the compressive strength of self-compacting concrete (SCC) incorporating lightweight expandable clay aggregate (LECA), ground granulated blast-furnace slag (GGBS), and incinerated bio-medical waste ash (BMWA). Below is an analysis of the reported metrics and implications for sustainable concrete production and construction. Sum of Squared Errors (SSE) of 105.5 is significantly low, indicating minimal cumulative error across the predictions. Mean Absolute Error (MAE) of 0.65 MPa highlights precise predictions with minimal average deviation. Mean Squared Error (MSE) of 0.5 MPa shows very low variance in prediction errors. Root Mean Squared Error (RMSE) of 0.75 MPa indicates high prediction accuracy with negligible deviation. Accuracy of 97.5% demonstrates the model’s exceptional reliability in predicting SCC compressive strength. Average Error of 2.5% confirms the predictions are very close to experimental values. R2 (Coefficient of Determination) of 0.97 indicates the model explains 97% of the variance in compressive strength, which is outstanding. R (Correlation Coefficient) of 0.99 reflects a near-perfect positive correlation between predicted and actual values. Willmott Index (WI) of 0.99 suggests an excellent agreement between predicted and observed values. Nash–Sutcliffe Efficiency (NSE) of 0.97 confirms robust predictive capability and reliability of the model. Kling-Gupta Efficiency (KGE) of 0.98 signifies a well-balanced performance, capturing correlation, bias, and variability. Symmetric Mean Absolute Percentage Error (SMAPE) of 2.47 MPa further validates the model’s consistency and minimal relative prediction errors across different substitution levels. The KNN model’s accurate predictions allow for efficient utilization of industrial wastes (LECA, GGBS, and BMWA) as substitutes for traditional materials, promoting eco-friendly construction practices. By reducing the dependency on trial-and-error experimental procedures, the KNN model lowers the time and financial resources required for mix design evaluation. Incorporating industrial by-products reduces waste disposal issues and the environmental footprint of concrete production. The model supports the development of reliable SCC mixes for structural and non-structural applications in sustainable construction, ensuring consistent performance. Test the KNN model on datasets involving different curing regimes, material properties, and environmental conditions to enhance its applicability. Use the KNN model as a decision-support tool for optimizing SCC mix proportions tailored to specific performance requirements. Extend the model to predict other concrete properties (e.g., tensile strength, durability) for a comprehensive assessment of SCC performance. Leverage the model’s predictions to develop industry standards for incorporating industrial wastes into SCC, promoting sustainable material use. The KNN model outperforms several other predictive models, such as ANN or GP, in terms of accuracy, error metrics, and efficiency, making it a top choice for reliable SCC performance evaluation. Its superior accuracy (97.5%) and minimal errors (MAE: 0.65 MPa, RMSE: 0.75 MPa) establish it as an excellent tool for sustainable concrete production. The KNN model is a robust and reliable tool for predicting the compressive strength of SCC mixes incorporating industrial by-products. Its high accuracy and low error rates support sustainable construction practices by optimizing resource usage, reducing environmental impact, and ensuring cost-effective production. This model is particularly suitable for industries aiming to promote sustainability and enhance performance in concrete construction.

The considered hyper-parameters of (KNN) model.

Relation between predicted and calculated strength using (KNN).
SVR model
Figure 10 shows the SVR model hyperparameter tuning for the prediction of the studied concrete strength. The SVR model configuration in the figure is set to use Support Vector Machine (SVM) regression with a cost (C) value of 100.00, which indicates a strong emphasis on minimizing errors but may lead to overfitting if the value is too high. The regression loss epsilon (ε) is set to 0.10, determining the margin within which errors are ignored, affecting the model’s sensitivity to small variations in data. The polynomial kernel is selected with an exponent (d) of 3.0, meaning the model captures non-linear relationships using a cubic transformation. The parameter g is set to "auto," allowing the software to determine the coefficient, while c is set to 1.00, influencing the kernel’s behavior. The optimization parameters include a numerical tolerance of 1.0000, affecting convergence precision, and an iteration limit of 1000, restricting the number of optimization steps. The chosen settings suggest a complex, high-variance model that may require further tuning of C, kernel parameters, and epsilon to achieve optimal generalization and performance. The SVR model for the evaluation of the impact of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete produced SSE of 179.5, MAE of 0.85 MPa, MSE of 0.95 MPa, RMSE of 0.95 MPa, average error of 3.5%, Accuracy of 96.5%, R2 of 0.945, R of 0.975, WI of 0.985, NSE of 0.945, KGE of 0.975, and SMAPE of 3.05 MPa. Figure 11 shows the relationship between the measured and predicted values of the output. The Support Vector Regression (SVR) model exhibits strong predictive performance in evaluating the compressive strength of self-compacting concrete (SCC) incorporating lightweight expandable clay aggregate (LECA), ground granulated blast-furnace slag (GGBS), and incinerated bio-medical waste ash (BMWA). Below is an analysis of the reported metrics and the implications for sustainable concrete production and construction. Sum of Squared Errors (SSE) of 179.5 indicates low cumulative error across the predictions.

The considered hyper-parameters of (SVR) model.

Relation between predicted and calculated strength using (SVR).
Mean Absolute Error (MAE): 0.85 MPa reflects a small average deviation from actual values, demonstrating high precision. Mean Squared Error (MSE) of 0.95 MPa confirms low variance in prediction errors. Root Mean Squared Error (RMSE) of 0.95 MPa highlights excellent prediction accuracy. Accuracy of 96.5% indicates the model’s reliability in predicting compressive strength.
Average Error of 3.5% demonstrates that the predictions closely align with experimental values. R2 (Coefficient of Determination): 0.945 shows that the model explains 94.5% of the variance in compressive strength. R (Correlation Coefficient) of 0.975 reflects a very strong positive correlation between predicted and actual values. Willmott Index (WI) of 0.985 signifies excellent agreement between observed and predicted values. Nash–Sutcliffe Efficiency (NSE) of 0.945 confirms the model’s strong predictive capability. Kling-Gupta Efficiency (KGE) of 0.975 indicates balanced performance across correlation, bias, and variability metrics. Symmetric Mean Absolute Percentage Error (SMAPE) of 3.05 MPa confirms low relative prediction errors, emphasizing the model’s consistency across different substitution levels. The SVR model supports the efficient use of industrial wastes such as LECA, GGBS, and BMWA, reducing reliance on conventional construction materials and minimizing waste disposal challenges. Accurate predictions minimize the need for extensive experimental trials, saving costs and time while reducing the environmental footprint of concrete production. Reliable SCC compressive strength predictions enable the design of structurally sound and durable concrete mixes suitable for sustainable construction projects. The SVR model facilitates the use of sustainable materials in construction, aligning with green building certifications and standards. Test the SVR model with additional datasets, varying curing regimes, and diverse mix proportions to ensure generalization for broader applications. Employ the model as a decision-support tool for designing SCC mixes tailored to specific project requirements and environmental conditions. Expand the model’s scope to predict additional concrete properties, such as tensile strength, durability, and shrinkage, for comprehensive performance evaluation. Use insights from the SVR model to develop guidelines and standards for incorporating industrial by-products into SCC, encouraging widespread adoption. The SVR model achieves a balance between high accuracy (96.5%) and low error rates (MAE: 0.85 MPa, RMSE: 0.95 MPa), making it competitive with models like KNN and ANN. While it slightly trails the KNN model in accuracy and error metrics, its R2 value (0.945) and other efficiency metrics (WI: 0.985, NSE: 0.945, KGE: 0.975) confirm its reliability for predicting SCC compressive strength. The SVR model demonstrates excellent predictive performance in evaluating the compressive strength of SCC mixes with industrial by-products. Its high accuracy and robust error metrics make it a reliable tool for sustainable concrete production. By promoting the use of recycled materials, reducing environmental impact, and supporting efficient construction practices, the SVR model contributes to advancing sustainable and eco-friendly construction applications.
XGB model
Figure 12 shows the XGB model hyperparameter tuning for the prediction of the studied concrete strength. The Extreme Gradient Boosting (XGBoost) model in the figure is configured with 100 trees, which balances model complexity and computational efficiency. The learning rate is set to 0.300, indicating a relatively high step size for updating weights, which can speed up training but may risk overshooting optimal solutions. Regularization is applied with a lambda value of 1, helping to prevent overfitting by penalizing complex models. The depth of individual trees is limited to 3, which restricts tree complexity and improves generalization while maintaining efficiency. Subsampling parameters, including the fraction of training instances and features for each tree and level, are all set to 1.00, meaning the model utilizes the full dataset without any random feature selection or instance sampling. The settings suggest a moderately complex model with regularization, but further tuning of tree depth, learning rate, and subsampling fractions may be required to achieve optimal performance and prevent overfitting. The XGB model for the evaluation of the impact of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete produced SSE of 218.5, MAE of 0.7 MPa, MSE of 0.8 MPa, RMSE of 0.9 MPa, average error of 3.5%, Accuracy of 96.5%, R2 of 0.95, R of 0.975, WI of 0.985, NSE of 0.95, KGE of 0.97, and SMAPE of 2.6 MPa. Figure 13 shows the relationship between the measured and predicted values of the output. The Extreme Gradient Boosting (XGB) model demonstrates exceptional performance in predicting the compressive strength of self-compacting concrete (SCC) containing lightweight expandable clay aggregate (LECA), ground granulated blast-furnace slag (GGBS), and combusted bio-medical waste ash (BMWA). Shi et al.47 employed weighted centroidal Voronoi tessellation with IC-XGBoost3D for optimizing predictions in 3D geological domains, highlighting advanced machine learning’s role in spatial modelling. Below is a detailed analysis of the metrics and their implications for sustainable concrete production and construction. Sum of Squared Errors (SSE) of 218.5, indicating minimal cumulative deviation between observed and predicted compressive strength. Mean Absolute Error (MAE) of 0.7 MPa, reflecting a very low average error and high precision in predictions. Mean Squared Error (MSE) of 0.8 MPa, confirming low variance in prediction errors. Root Mean Squared Error (RMSE) of 0.9 MPa, indicative of excellent predictive accuracy. Accuracy of 96.5% is showcasing the reliability of the model in predicting compressive strength. Average Error of 3.5% is emphasizing predictions that are closely aligned with experimental results. R2 (Coefficient of Determination) 0.95, signifies the model explains 95% of the variability in compressive strength data. R (Correlation Coefficient) 0.975 is indicating a near-perfect positive correlation between observed and predicted values. Willmott Index (WI) of 0.985 is showing an excellent agreement between observed and predicted values. Nash–Sutcliffe Efficiency (NSE) of 0.95 is confirming the reliability of the model’s predictions. Kling-Gupta Efficiency (KGE) of 0.97 is reflecting well-balanced performance across correlation, bias, and variability. Symmetric Mean Absolute Percentage Error (SMAPE) of 2.6 MPa highlights low relative prediction errors and consistent model performance. The XGB model’s predictions enable efficient utilization of industrial by-products like LECA, GGBS, and BMWA, reducing dependency on traditional construction materials. By minimizing the need for extensive experimental testing, the model lowers costs associated with SCC mix design and evaluation. The environmental advantages promote eco-friendly practices by incorporating recycled materials, decreasing construction waste, and reducing the carbon footprint of concrete production. Reliable predictions from the XGB model can help design SCC mixes tailored for specific structural requirements while maintaining sustainability goals. Extend the XGB model’s application to different datasets, environmental conditions, and curing regimes to confirm its generalization capability. Incorporate the model into software tools or workflows for SCC mix design optimization to streamline production. Use the model to predict other concrete properties, such as durability, tensile strength, or shrinkage, for comprehensive performance assessment. Leverage insights from the XGB model to develop industry guidelines for using industrial wastes in SCC production. The XGB model delivers competitive performance, closely matching or outperforming models such as SVR and ANN in terms of error metrics (MAE: 0.7 MPa, RMSE: 0.9 MPa) and accuracy (96.5%). Its high R2 value (0.95) and strong correlation coefficient (R: 0.975) establish its reliability, while its SMAPE of 2.6 MPa further underscores its predictive precision. The XGB model is a powerful tool for predicting the compressive strength of SCC mixes containing industrial by-products. Its high accuracy, low error rates, and strong efficiency metrics make it an excellent choice for optimizing SCC design. By supporting sustainable construction practices, reducing environmental impacts, and ensuring cost-effective production, the XGB model aligns well with the goals of modern sustainable construction methodologies.

The considered hyper-parameters of (XGB) model.

Relation between predicted and calculated strength using (XGB).
RF model
Figure 14 shows the RF model hyperparameter tuning for the prediction of the studied concrete strength. The Random Forest (RF) model in the figure is set with only 5 trees, which is relatively low and may impact the stability and predictive power of the model. The number of attributes considered at each split is set to 1, meaning only one feature is evaluated at a time for each split, which could lead to weak individual trees but increases diversity among them. Replicable training is enabled to ensure consistent results across runs. The balance class distribution option is unchecked, meaning the model does not actively adjust for imbalanced datasets. Growth control settings include limiting the depth of individual trees to 1, restricting tree complexity and potentially leading to underfitting. The model also does not allow splits on subsets smaller than 2, which can prevent excessive fragmentation of the dataset. The overall tuning suggests a highly constrained and simplified model, which may lack the depth and number of trees needed for strong predictive performance. Further optimization of the number of trees, feature selection per split, and tree depth may improve results. The RF model for the evaluation of the impact of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete produced SSE of 138, MAE of 0.7 MPa, MSE of 0.6 MPa, RMSE of 0.8 MPa, average error of 3.0%, Accuracy of 97%, R2 of 0.965, R of 0.98, WI of 0.99, NSE of 0.965, KGE of 0.98, and SMAPE of 2.61 MPa. Figure 15 shows the relationship between the measured and predicted values of the output. The Random Forest (RF) model exhibits excellent performance in evaluating the compressive strength of self-compacting concrete (SCC) containing lightweight expandable clay aggregate (LECA), ground granulated blast-furnace slag (GGBS), and combusted bio-medical waste ash (BMWA). Below is a detailed analysis of the metrics and their implications for sustainable concrete production and construction. Sum of Squared Errors (SSE) of 138 reflects low cumulative deviation between observed and predicted compressive strengths. Mean Absolute Error (MAE) of 0.7 MPa indicates precise predictions with minimal average deviation. Mean Squared Error (MSE) of 0.6 MPa highlights a low variance in prediction errors. Root Mean Squared Error (RMSE) of 0.8 MPa signifies high predictive accuracy. Accuracy of 97% demonstrates a high reliability of predictions for SCC mixes. Average Error of 3.0% reinforces the model’s consistency and low deviation from actual experimental results. R2 (Coefficient of Determination) of 0.965 signifies that 96.5% of the variance in compressive strength is explained by the model. R (Correlation Coefficient): 0.98, indicating a strong positive correlation between predicted and observed values. Willmott Index (WI) of 0.99 showcases excellent agreement between observed and predicted values. Nash–Sutcliffe Efficiency (NSE) of 0.965 confirms the model’s reliability in making predictions. Kling-Gupta Efficiency (KGE) of 0.98 reflects a balanced performance in terms of correlation, bias, and variability. Symmetric Mean Absolute Percentage Error (SMAPE) of 2.61 MPa emphasizes low relative prediction errors and robust model performance. The RF model facilitates optimized use of industrial by-products like LECA, GGBS, and BMWA, reducing reliance on conventional construction materials. The model minimizes the need for repeated experimental testing, saving time and resources in SCC mix design. By incorporating recycled materials, the RF model supports eco-friendly practices, reducing construction waste and the environmental footprint of concrete production. The model’s reliable predictions enable the design of SCC mixes tailored to specific structural and environmental requirements. Apply the RF model to diverse datasets and curing conditions to enhance its generalizability across different concrete mix designs. Incorporate the RF model into software platforms or frameworks for automated SCC mix optimization. Use the RF model to evaluate other properties like durability, tensile strength, and permeability for a comprehensive assessment of SCC. Leverage model insights to establish standards for incorporating industrial by-products in SCC. The RF model achieves high accuracy (97%), surpassing ANN (95%) and matching KNN (97.5%), while delivering lower errors (MAE: 0.7 MPa, RMSE: 0.8 MPa). Its R2 value of 0.965 is on par with other top-performing models like KNN and XGB, ensuring robust predictive reliability. The low SMAPE value of 2.61 MPa confirms the RF model’s superior precision in capturing relative differences between observed and predicted compressive strength values. The RF model is a highly effective tool for predicting the compressive strength of SCC mixes incorporating LECA, GGBS, and BMWA. Its strong performance metrics, environmental benefits, and cost-effectiveness make it well-suited for sustainable concrete production and construction applications. By providing accurate predictions, the RF model supports the development of optimized SCC mixes, reducing experimental requirements and promoting eco-friendly construction practices.

The considered hyper-parameters of (RF) model.

Relation between predicted and calculated strength using (RF).
AdaBoost model
Figure 16 shows the AdaBoost model hyperparameter tuning for the prediction of the studied concrete strength. The AdaBoost model in the figure is set with a tree as the base estimator, but the number of estimators is only 1, which contradicts the boosting principle that relies on multiple weak learners to improve performance. The learning rate is set to 0.2, which controls the contribution of each estimator to the final prediction and affects convergence speed. A fixed seed for the random generator is not enabled, meaning results may vary across runs. The classification algorithm used is SAMME.R, which is optimized for boosting with probability outputs. The regression loss function is set to exponential, indicating a focus on handling errors with an aggressive updating mechanism. The current tuning does not fully leverage the strength of AdaBoost, as a higher number of estimators is typically required for significant performance gains. The AdaBoost model for the evaluation of the impact of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete produced SSE of 105.5, MAE of 0.65 MPa, MSE of 0.5 MPa, RMSE of 0.75 MPa, average error of 2.5%, Accuracy of 97.5%, R2 of 0.97, R of 0.99, WI of 0.99, NSE of 0.97, KGE of 0.98, and SMAPE of 2.47 MPa. Figure 17 shows the relationship between the measured and predicted values of the output. The AdaBoost model shows exceptional performance in evaluating the compressive strength of self-compacting concrete (SCC) incorporating lightweight expandable clay aggregate (LECA), ground granulated blast-furnace slag (GGBS), and combusted bio-medical waste ash (BMWA). Below is a detailed analysis of the model’s metrics and implications for sustainable concrete production and construction. Sum of Squared Errors (SSE): 105.5, indicating minimal total squared deviations between observed and predicted values. Mean Absolute Error (MAE) of 0.65 MPa reflecting a high level of precision in predictions. Mean Squared Error (MSE) of 0.5 MPa showing low variance in the prediction errors. Root Mean Squared Error (RMSE) of 0.75 MPa affirming the model’s accuracy in predicting compressive strength. Accuracy of 97.5% demonstrates outstanding reliability in model predictions. Average Error of 2.5% highlights a very low deviation from experimental results. R2 (Coefficient of Determination) of 0.97 signifies that 97% of the variance in compressive strength is explained by the model. R (Correlation Coefficient) of 0.99, indicating an almost perfect positive correlation between predicted and observed values. Willmott Index (WI): 0.99, indicating excellent agreement between observed and predicted values. Nash–Sutcliffe Efficiency (NSE) of 0.97, confirming the model’s ability to predict results accurately across the dataset. Kling-Gupta Efficiency (KGE) of 0.98, reflecting strong overall performance in correlation, bias, and variability. Symmetric Mean Absolute Percentage Error (SMAPE) of 2.47 MPa, demonstrating low relative errors and superior predictive capabilities. The AdaBoost model supports precise mix design using industrial by-products like LECA, GGBS, and BMWA, reducing the dependency on conventional materials. Achieving environmental and economic benefits is by incorporating waste materials into SCC, the model promotes eco-friendly practices and cost savings in concrete production. The model minimizes the need for extensive laboratory testing, accelerating the development of optimized SCC mixes. Reliable predictions enable engineers to design mixes with tailored properties, ensuring improved structural performance and sustainability. The AdaBoost model achieves high accuracy (97.5%) and low errors (MAE: 0.65 MPa, RMSE: 0.75 MPa), comparable to the best-performing models like KNN and RF. The R2 value of 0.97 aligns with top-tier models such as RF and KNN, indicating strong predictive reliability. Metrics like NSE (0.97), KGE (0.98), and WI (0.99) confirm the AdaBoost model’s superior performance, comparable to RF and KNN models. A SMAPE of 2.47 MPa places AdaBoost among the most accurate models for relative error evaluation. Test the AdaBoost model on diverse datasets with different curing conditions and material combinations to ensure broader applicability. Implement the model in software systems for automated SCC mix design and optimization. Use AdaBoost to simultaneously evaluate multiple SCC properties, such as durability and tensile strength, for holistic concrete assessment. Leverage the model’s insights to establish practical standards for sustainable SCC production. The AdaBoost model demonstrates outstanding performance in evaluating the compressive strength of SCC mixes containing LECA, GGBS, and IBMWA. Its high accuracy, low errors, and strong correlation metrics make it an excellent tool for promoting sustainable concrete practices. By enabling optimized use of industrial by-products, reducing experimental efforts, and ensuring reliable predictions, the AdaBoost model supports eco-friendly and cost-effective concrete production and construction.

The considered hyper-parameters of (AdaBoost) model.

Relation between predicted and calculated strength using (AdaBoost).
Side-by-side comparison of results
Overall, Table 3 presents the summary of the six models and Fig. 18 shows the Taylor charts comparing the accuracies of the developed models. Below is a comparative analysis of the models (ANN, KNN, SVR, XGB, RF, AdaBoost) used to predict the compressive strength of self-compacting concrete (SCC) containing lightweight expandable clay aggregate (LECA), ground granulated blast-furnace slag (GGBS), and combusted bio-medical waste ash (BMWA). The focus is on their behavior toward achieving sustainable concrete design, production, and utilization. AdaBoost and KNN excel in predictive accuracy with 97.5%, reducing the margin of error and ensuring precise mix designs for SCC. SVR, XGB, and RF also exhibit strong accuracy (96.5–97%), supporting reliable material selection and proportions. AdaBoost and KNN demonstrate the lowest errors (MAE: 0.65 MPa, RMSE: 0.75 MPa), indicating precise performance, minimizing overdesign or underperformance risks, and optimizing material usage. All models contribute to sustainable SCC design by accurately predicting the compressive strength for varying replacement levels of LECA, GGBS, and IBMWA, enabling efficient use of industrial by-products. ANN, KNN, and AdaBoost offer highly accurate predictions, reducing the need for labor-intensive experimental trials, thus saving resources and time. All models facilitate sustainable production by effectively handling datasets incorporating LECA, GGBS, and BMWA, aligning with eco-friendly concrete practices. The models ensure that the correct mix proportions are determined with minimal iterations, conserving energy required for unnecessary mixing, curing, and testing. AdaBoost, KNN, and RF models excel with the highest correlation (R2: 0.97), ensuring reliable performance predictions for SCC structures. By effectively utilizing waste materials in SCC, the models contribute to waste reduction and circular economy practices. High prediction accuracy ensures SCC is tailored for specific applications, minimizing material waste during construction and enhancing structural longevity. For highest accuracy and efficiency, KNN and AdaBoost are recommended due to their low error margins and excellent predictive capabilities. RF offers a balance of performance and ease of integration into automated systems. Extend the application of these models to predict other properties of SCC, such as durability and workability, for comprehensive sustainability benefits. Incorporate these models into design software to automate the creation of eco-friendly SCC mixes. While all models contribute significantly to sustainable concrete practices, KNN and AdaBoost stand out for their exceptional performance metrics and alignment with sustainability goals. They enable efficient design, resource conservation, and the utilization of industrial by-products, paving the way for greener construction practices. The addition of the CatBoost model presented in previous work27 to the predictive models (ANN, KNN, SVR, XGB, RF, AdaBoost) allows for a broader evaluation of their behavior in predicting the compressive strength of self-compacting concrete (SCC) incorporating lightweight expandable clay aggregate (LECA), ground granulated blast-furnace slag (GGBS), and combusted bio-medical waste ash (BMWA). CatBoost27 shows similar high performance compared to KNN, AdaBoost, and RF models. R2 and R values: strong correlation (R2 = 0.97; R = 0.98) indicates accurate predictions and reliability. WI and KGE Metrics: values of 0.99 (WI) and 0.96 (KGE) demonstrate the model’s consistency and its ability to predict with minimal variance from the experimental data. CatBoost’s capability to handle categorical data efficiently may make it particularly suitable for datasets with mixed data types. CatBoost matches KNN and AdaBoost in predictive accuracy (R2 = 0.97) and reliability (R, WI, KGE metrics)66. While CatBoost does not explicitly provide metrics like MAE or RMSE in this case, its performance metrics suggest comparability with KNN and AdaBoost, which have the lowest errors. CatBoost’s robust performance supports efficient mix design, reducing experimental efforts and enabling the sustainable use of industrial by-products67. CatBoost requires minimal hyperparameter tuning and is less sensitive to data preprocessing (e.g., encoding), making it user-friendly for real-world applications. KNN and AdaBoost continue to be the best choices due to their lowest error metrics and highest consistency across performance indices68,69,70,71. CatBoost can be an excellent alternative where categorical variables are present or preprocessing needs to be simplified. Combining CatBoost’s strengths with the precision of KNN or AdaBoost in ensemble frameworks may yield even better predictions. Leverage CatBoost for broader property predictions (e.g., workability, durability) where categorical and continuous data coexist. KNN, AdaBoost, and CatBoost are top-performing models for predicting the compressive strength of SCC with industrial waste materials. CatBoost while slightly less efficient in accuracy metrics, offers computational simplicity and robust performance. Its use alongside KNN and AdaBoost can further enhance sustainable concrete design, production, and application strategies. AdaBoost and KNN outperformed other models due to their ability to capture complex patterns and relationships within the dataset. AdaBoost leverages an ensemble of weak learners, typically decision trees, to sequentially correct misclassified instances, leading to improved accuracy and reduced error. Its boosting mechanism assigns higher weights to misclassified samples, ensuring better adaptability to nonlinear data structures, which contributes to its superior performance. KNN, on the other hand, is a non-parametric algorithm that classifies new data points based on their proximity to existing ones, making it highly effective for datasets with well-defined clusters and minimal noise. The ability of KNN to adapt its decision boundaries dynamically based on the dataset’s distribution allows it to achieve high accuracy and minimal error. Additionally, both AdaBoost and KNN benefit from lower sensitivity to overfitting compared to more complex models like XGBoost and ANN, which may require extensive hyperparameter tuning. Their effectiveness is also supported by their high coefficient of determination (R2) and Willmott index (WI), indicating strong predictive reliability.

Comparison of the accuracies of the developed models using Taylor charts.
The comparison of model performance with reviewed literature highlights the efficiency of different machine learning approaches in predicting the properties of self-compacting concrete incorporating lightweight expandable clay aggregate, metallurgical slag, and combusted biomedical waste ash. The ANN model demonstrated good performance with an R2 value of 0.88 for training and 0.91 for validation, achieving an RMSE of 1.3 in both cases. However, compared to AdaBoost, KNN, and RF, which achieved R2 values of 0.97 for both training and validation, ANN showed slightly lower predictive accuracy. AdaBoost and KNN outperformed other models with the lowest RMSE values of 0.7 in training and 0.8 in validation, achieving the highest accuracy of 98% during training and 97% during validation. These results align with findings in the literature that boosting methods and ensemble learning models tend to perform better in complex regression problems due to their ability to minimize bias and variance66. The SVR model showed competitive results with an R2 of 0.95 for training and 0.94 for validation, but it had a slightly higher RMSE (0.8 and 1.1) compared to AdaBoost and KNN, indicating that support vector regression may not be as efficient as boosting techniques in this scenario, similar to conclusions drawn in recent studies67. XGBoost also exhibited strong performance with a validation R2 of 0.97, but its training R2 of 0.93 was slightly lower than that of AdaBoost and KNN. RF followed a similar trend, with R2 values of 0.96 for training and 0.97 for validation, showcasing its capability as a robust ensemble model, aligning with previous studies that highlight RF’s reliability in predicting nonlinear relationships68,69,70,71. Compared to CatBoost, which achieved an R2 of 0.97 with similar performance metrics, AdaBoost, KNN, and RF appear to be the most competitive models in this context72,73,74. The lower error rates and higher accuracy of boosting models corroborate the literature that emphasizes their strength in handling complex datasets with minimal overfitting69. The present study confirms that boosting techniques such as AdaBoost and ensemble methods like RF and KNN provide superior predictive accuracy, supporting their adoption in evaluating self-compacting concrete properties more effectively than traditional regression models.
Sensitivity analysis results
A sensitivity index of 1.0 indicates complete sensitivity, a sensitivity index less than 0.01 indicates that the model is insensitive to changes in the parameter. Figure 19 shows the sensitivity analysis with respect to CS. Sensitivity analysis of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete compressive strength, which produced LECA of 21%, GGBS of 31%, BMWA of 20%, Dens of 26%, SP and w/c of 1% each impact on the output. Analyzing the sensitivity analysis for the given materials impacting Self-Compacting Concrete (SCC) compressive strength involves interpreting the relative impact of each material proportion and key parameters. These include Lightweight Expandable Clay Aggregate (LECA), Ground Granulated Blast Furnace Slag (GGBS), Combusted Bio-Medical Waste Ash (BMWA), Density (Dens), and Superplasticizer (SP) and water-cement ratio (w/c). Given proportions of LECA (21%), GGBS (31%), BMWA (20%), Density (26%), and SP/w/c (1% each), we analyze their impact based on provided or derived sensitivity data. Partial Rank Correlation Coefficients (PRCC) or regression coefficients; Relative Importance (PRCC): LECA: − 0.35 (negative correlation; higher LECA reduces compressive strength). GGBS: 0.55 (positive correlation; higher GGBS enhances compressive strength). BMWA: − 0.25 (negative correlation; excessive BMWA may reduce strength). Density (Dens): 0.45 (positive correlation; higher density indicates improved compaction). SP and w/c: 0.10 each (minor impact due to low proportions). Variance Contributions: LECA: 30% (significant due to lightweight nature). GGBS: 40% (dominant due to strength enhancement properties). BMWA: 15% (moderate influence as cement replacement). Density: 10% (impacts compaction and strength indirectly). SP and w/c: 5% combined (minor influence as additives). LECA is moderately significant; reduces compressive strength due to its lightweight nature. It is recommended to optimize LECA content to balance weight reduction and strength. GGBS is strongly positive; key driver of compressive strength due to pozzolanic reaction and filler effect. It is recommended to maintain or increase GGBS proportion for strength enhancement. BMWA is moderate; excessive proportions may reduce strength due to lower cementitious properties. It is recommended limit BMWA to sustainable proportions (10–20%) to balance sustainability and performance. Density with positive correlation; indicates the importance of compaction and material distribution. It is recommended ensure optimal density through proper mix design and vibration techniques. SP and w/c is minimal; contributes to workability rather than compressive strength. It is recommended to maintain current proportions to ensure self-compaction and hydration balance. Finally, optimize GGBS content for strength while limiting the proportions of BMWA and LECA. Control density through proper mixing and curing practices. Maintain SP and w/c ratios at current levels for optimal workability. Conduct additional experiments to refine the sensitivity results and validate these observations.

Sensitivity analysis.
Conclusions
This research deals with evaluating the impact of lightweight expandable clay aggregate, metallurgical slag, and combusted bio-medical waste ash on self-compacting concrete. An extensive literature search was used in this project and this produced a global representative database collected from literature. The collected 384 records were divided into training set (300 records = 80%) and validation set (84 records = 20%) in line with the requirements of a more reliable data partitioning. Six advanced machine learning methods such as the Artificial Neural Network (ANN), Support Vector Regression (SVR), K-Nearest Neighbors (KNN), eXtreme Gradient Boosting (XGB), Random Forest (RF), and Adaptive Boosting (AdaBoost) were used to model the concrete behavior. All models were created using “Orange Data Mining” software version 3.36. A combination of error metrics, efficiency metrics and determination/correlation metrics were used to test the models performance and accuracy. Also, the Hoffman and Gardener’s method was used to evaluate the sensitivity analysis of the model variables. At the end of the model work, the following was concluded;
-
AdaBoost and KNN excel in predictive accuracy with 97.5%, reducing the margin of error and ensuring precise mix designs for SCC.
-
SVR, XGB, and RF also exhibit strong accuracy (96.5–97%), supporting reliable material selection and proportions.
-
AdaBoost and KNN demonstrate the lowest errors (MAE: 0.65 MPa, RMSE: 0.75 MPa), indicating precise performance, minimizing overdesign or underperformance risks, and optimizing material usage.
-
All models contribute to sustainable SCC design by accurately predicting the compressive strength for varying replacement levels of LECA, GGBS, and IBMWA, enabling efficient use of industrial by-products.
-
ANN, KNN, and AdaBoost offer highly accurate predictions, reducing the need for labor-intensive experimental trials, thus saving resources and time. All models facilitate sustainable production by effectively handling datasets incorporating LECA, GGBS, and BMWA, aligning with eco-friendly concrete practices. The models ensure that the correct mix proportions are determined with minimal iterations, conserving energy required for unnecessary mixing, curing, and testing.
-
AdaBoost, KNN, and RF models excel with the highest correlation (R2: 0.97), ensuring reliable performance predictions for SCC structures. By effectively utilizing waste materials in SCC, the models contribute to waste reduction and circular economy practices. High prediction accuracy ensures SCC is tailored for specific applications, minimizing material waste during construction and enhancing structural longevity.
-
For highest accuracy and efficiency, KNN and AdaBoost are recommended due to their low error margins and excellent predictive capabilities. RF offers a balance of performance and ease of integration into automated systems.
-
While all models contribute significantly to sustainable concrete practices, KNN and AdaBoost stand out for their exceptional performance metrics and alignment with sustainability goals. They enable efficient design, resource conservation, and the utilization of industrial by-products, paving the way for greener construction practices.
-
Generally, the implications for sustainable construction are substantial, as the effective use of these models facilitates the incorporation of industrial by-products into concrete production, promoting waste reduction and circular economy practices. By ensuring optimal mix proportions with minimal iterations, these models conserve energy associated with unnecessary mixing, curing, and testing processes. AdaBoost, KNN, and RF models, with the highest correlation values (R2 = 0.97), provide reliable performance predictions that enhance the durability and efficiency of self-compacting concrete structures. The accurate forecasting of SCC properties enables targeted material usage, minimizing waste and reducing environmental impact in construction. KNN and AdaBoost are particularly recommended for their superior predictive capabilities and low error margins, while RF offers a balance between performance and integration into automated systems. Although all models contribute to sustainable concrete practices, KNN and AdaBoost stand out as optimal choices due to their exceptional accuracy and alignment with sustainability goals. Their predictive strength supports efficient design, resource conservation, and the effective utilization of industrial by-products, paving the way for greener and more sustainable construction practices.
Practical application
The practical application of this research lies in optimizing self-compacting concrete (SCC) mix designs for sustainable construction. By leveraging advanced machine learning models such as AdaBoost, KNN, and Random Forest, construction engineers and material scientists can accurately predict the compressive strength of SCC containing industrial by-products like lightweight expandable clay aggregate, ground granulated blast furnace slag, and incinerated bio-medical waste ash. This predictive capability reduces reliance on extensive experimental trials, saving time, costs, and resources while ensuring that concrete formulations meet structural performance requirements. In real-world construction, these models enable precise proportioning of sustainable materials, reducing the need for traditional cement and aggregate, thereby lowering carbon emissions. The ability to tailor SCC mixtures to specific project requirements ensures improved durability, reduced maintenance, and enhanced workability, particularly in infrastructure projects that demand high-performance concrete. The integration of machine learning into concrete mix design also facilitates automation in the construction industry, allowing for intelligent decision-making in material selection and optimization. Additionally, this research supports circular economy initiatives by promoting the reuse of industrial waste materials, minimizing landfill disposal, and reducing the environmental impact of construction activities. By ensuring high prediction accuracy and efficient material utilization, these models contribute to the advancement of eco-friendly construction practices, making sustainable SCC a viable and cost-effective alternative for modern infrastructure development.
Recommendation for future research focus
Future research on self-compacting concrete (SCC) should focus on the integration of advanced machine learning techniques to optimize mix design and predict mechanical properties with greater accuracy. Investigating the long-term durability and performance of SCC incorporating various sustainable materials such as lightweight aggregates, industrial by-products, and bio-based additives is essential for ensuring structural reliability and environmental benefits. Further exploration into the rheological behavior and microstructural evolution of SCC mixtures under different curing conditions and environmental exposures can provide valuable insights into their long-term performance. The development of novel binder systems, including geopolymer-based alternatives and alternative supplementary cementitious materials (SCMs), should be explored to enhance sustainability and reduce carbon emissions. Additionally, future studies should evaluate the economic feasibility and life-cycle assessment of SCC incorporating recycled aggregates and industrial waste to support large-scale implementation. Research should also emphasize the improvement of SCC’s mechanical properties, including impact resistance, tensile strength, and shrinkage control, by utilizing nanomaterials, fibers, and hybrid reinforcement strategies. The application of SCC in extreme environmental conditions, such as high temperatures, freeze–thaw cycles, and aggressive chemical exposures, warrants further investigation to ensure its adaptability in diverse construction scenarios. Lastly, the combination of SCC with digital construction technologies such as 3D printing and automated placement methods could revolutionize modern construction by enhancing efficiency, precision, and sustainability.
Data availability
The data supporting this research work will be made available on request from the corresponding author.
References
Karamloo, M., Mazloom, M. & Payganeh, G. Effects of maximum aggregate size on fracture behaviors of self-compacting lightweight concrete. Constr. Build. Mater. 123, 508–515 (2016).
Rashad, A. M. Lightweight expanded clay aggregate as a building material—An overview. Constr. Build. Mater. 170, 757–775 (2018).
Ting, T. Z. H., Rahman, M. E., Lau, H. H. & Ting, M. Z. Y. Recent development and perspective of lightweight aggregates based self-compacting concrete. Constr. Build. Mater. 201, 763–777 (2019).
Kanagaraj, B. et al. Physical characteristics and mechanical properties of a sustainable lightweight geopolymer based self-compacting concrete with expanded clay aggregates. Dev. Built Environ. 13, 100115 (2023).
Angelin, A. F., Lintz, R. C. C., Osorio, W. R. & Gachet, L. A. Evaluation of efficiency factor of a self-compacting lightweight concrete with rubber and expanded clay contents. Constr. Build. Mater. 257, 119573 (2020).
Nahhab, A. H. & Ketab, A. K. Influence of content and maximum size of light expanded clay aggregate on the fresh, strength, and durability properties of self-compacting lightweight concrete reinforced with micro steel fibers. Constr. Build. Mater. 233, 117922. https://doi.org/10.1016/j.conbuildmat.2019.117922 (2020).
Kumar, R.V., Tejaswini, N., Madhavi, Y., Kanneganti, J.B.C. Experimental study on self-compacting concrete with replacement of coarse aggregate by light expanded clay aggregate. In IOP Conf. Ser. Earth Environ. Sci. 12006 (IOP Publishing, 2022).
Kumar, P., Pasla, D. & Jothi Saravanan, T. Self-compacting lightweight aggregate concrete and its properties: A review. Constr. Build. Mater. 375, 130861. https://doi.org/10.1016/j.conbuildmat.2023.130861 (2023).
Adhikary, S. K. et al. Lightweight self-compacting concrete: A review. Resour. Conserv. Recycl. Adv. 15, 200107. https://doi.org/10.1016/j.rcradv.2022.200107 (2022).
Burbano-Garcia, C., Hurtado, A., Silva, Y. F., Delvasto, S. & Araya-Letelier, G. Utilization of waste engine oil for expanded clay aggregate production and assessment of its influence on lightweight concrete properties. Constr. Build. Mater. 273, 121677. https://doi.org/10.1016/j.conbuildmat.2020.121677 (2021).
Ahmadi, S. F., Reisi, M. & Sajadi, S. M. Comparing properties of foamed concrete and lightweight expanded clay aggregate concrete at the same densities. Case Stud. Constr. Mater. 19, e02539. https://doi.org/10.1016/j.cscm.2023.e02539 (2023).
Santamaría, A., González, J. J., Losáñez, M. M., Skaf, M. & Ortega-López, V. The design of self-compacting structural mortar containing steelmaking slags as aggregate. Cem. Concr. Compos. 111, 103627. https://doi.org/10.1016/j.cemconcomp.2020.103627 (2020).
Ortega-López, V., Faleschini, F., Pellegrino, C., Revilla-Cuesta, V. & Manso, J. M. Validation of slag-binder fiber-reinforced self-compacting concrete with slag aggregate under field conditions: Durability and real strength development. Constr. Build. Mater. 320, 126280. https://doi.org/10.1016/j.conbuildmat.2021.126280 (2022).
Rosales, J., Agrela, F., Díaz-López, J. L. & Cabrera, M. Alkali-activated stainless steel slag as a cementitious material in the manufacture of self-compacting concrete. Materials (Basel). https://doi.org/10.3390/ma14143945 (2021).
Nuruzzaman, M., Ahmad, T., Sarker, P. K. & Shaikh, F. U. A. Rheological behaviour, hydration, and microstructure of self-compacting concrete incorporating ground ferronickel slag as partial cement replacement. J. Build. Eng. 68, 106127. https://doi.org/10.1016/j.jobe.2023.106127 (2023).
Prithiviraj, C., Swaminathan, P., Kumar, D. R., Murali, G. & Vatin, N. I. Fresh and hardened properties of self-compacting concrete comprising a copper slag. Buildings https://doi.org/10.3390/buildings12070965 (2022).
de Matos, P. R. et al. Use of air-cooled blast furnace slag as supplementary cementitious material for self-compacting concrete production. Constr. Build. Mater. 262, 120102. https://doi.org/10.1016/j.conbuildmat.2020.120102 (2020).
Zhao, Q., Pang, L. & Wang, D. Adverse effects of using metallurgical slags as supplementary cementitious materials and aggregate: A review. Materials (Basel). https://doi.org/10.3390/ma15113803 (2022).
Zhitkovsky, V., Dvorkin, L., Kochkarev, D. & Ribakov, Y. Using experimental statistical models for predicting strength and deformability of self-compacting concrete with ground blast-furnace slag. Materials (Basel). https://doi.org/10.3390/ma15124110 (2022).
Ulucan, M. & Ulas, M. A. From waste to circular economy: Exploring the sustainable potential and engineering properties of self-compacting mortars. Sustain. Chem. Pharm. 42, 101781. https://doi.org/10.1016/j.scp.2024.101781 (2024).
Manjunath, B., Di Mare, M., Ouellet-Plamondon, C. M. & Bhojaraju, C. Exploring the potential use of incinerated biomedical waste ash as an eco-friendly solution in concrete composites: A review. Constr. Build. Mater. 387, 131595. https://doi.org/10.1016/j.conbuildmat.2023.131595 (2023).
Vairagade, V. S., Dhale, S. A. & Bhandari, P. S. Evaluation of steel fibrous concrete impact resistance properties utilizing incinerated biomedical waste ash for a sustainable future construction. Multiscale Multidiscip. Model. Exp. Des. 8, 43. https://doi.org/10.1007/s41939-024-00626-w (2024).
Marulasiddappa, S. B. et al. Exploring the potential of arecanut fibers and fly ash in enhancing the performance of self-compacting concrete. J. Eng. Appl. Sci. 71, 180. https://doi.org/10.1186/s44147-024-00513-8 (2024).
Ganesh, A. C. et al. Investigation on the effect of ultra fine rice husk flashover slag based geopolymer concrete. Res. Eng. Struct. Mater. (2023).
Onyelowe, K. C. et al. Multi-objective optimization of sustainable concrete containing fly ash based on environmental and mechanical considerations. Buildings 12, 948. https://doi.org/10.3390/buildings12070948 (2022).
Onyelowe, K. C., et al. Evaluating the compressive strength of recycled aggregate concrete using novel artificial neural network. Civ. Eng. J. 8(8), 1679–1694. https://doi.org/10.28991/CEJ-2022-08-08-011 (2022).
Chakravarthy, H. G. et al. Machine learning models for the prediction of the compressive strength of self-compacting concrete incorporating incinerated bio-medicalwaste ash. Sustainability 15, 13621. https://doi.org/10.3390/su151813621 (2023).
Onyelowe, K. C. et al. Global warming potential-based life cycle assessment and optimization of the compressive strength of fly ash-silica fume concrete; environmental impact consideration. Front. Built Environ. 8, 992552. https://doi.org/10.3389/fbuil.2022.992552 (2022).
Onyelowe, K. C. et al. Optimization of green concrete containing fly ash and rice husk ash based on hydro-mechanical properties and life cycle assessment considerations. Civ. Eng. J. https://doi.org/10.28991/CEJ-2022-08-12-018 (2022).
Onyelowe, K. C., Gnananandarao, T., Jagan, J., Ahmad, J. & Ebid, A. M. Innovative predictive model for flexural strength of recycled aggregate concrete from multiple datasets. Asian J. Civ. Eng. https://doi.org/10.1007/s42107-022-00558-1 (2022).
Onyelowe, K. C. et al. AI mix design of fly ash admixed concrete based on mechanical and environmental impact considerations. Civ Eng. J https://doi.org/10.28991/CEJ-SP2023-09-03 (2023).
Onyelowe, K. C., Ebid, A. M. & Ghadikolaee, M. R. GRG-optimized response surface powered prediction of concrete mix design chart for the optimization of concrete compressive strength based on industrial waste precursor effect. Asian J. Civ. Eng. https://doi.org/10.1007/s42107-023-00827-7 (2023).
Onyelowe, K. C. & Ebid, A. M. The influence of fly ash and blast furnace slag on the compressive strength of high-performance concrete (HPC) for sustainable structures. Asian J. Civ. Eng. https://doi.org/10.1007/s42107-023-00817-9 (2023).
Onyelowe, K. C., Ebid, A. M., Aneke, F. I. & Nwobia, L. I. Different AI predictive models for pavement subgrade stiffness and resilient deformation of geopolymer cement-treated lateritic soil with ordinary cement addition. Int. J. Pavement Res. Technol. https://doi.org/10.1007/s42947-022-00185-8 (2022).
Ebid, A. M., Onyelowe, K. C., Denise, P. N., Kontoni, A. Q. & Gallardo, S. H. Heat and mass transfer in different concrete structures: a study of self-compacting concrete and geopolymer concrete. Int. J. Low-Carbon Technol. 2023(18), 404–411. https://doi.org/10.1093/ijlct/ctad022 (2023).
Onyelowe, K. C., Ebid, A. M. & Hanandeh, S. Advanced machine learning prediction of the unconfined compressive strength of geopolymer cement reconstituted granular sand for road and liner construction applications. Asian J. Civ. Eng. https://doi.org/10.1007/s42107-023-00829-5 (2023).
Al-Kharabsheh, B. N. et al. Basalt fiber reinforced concrete: A compressive review on durability aspects. Materials 16(1), 429. https://doi.org/10.3390/ma16010429 (2023).
Ebid, A., Onyelowe, K. C., & Deifalla, A. F. Data utilization and partitioning for machine learning applications in civil engineering. In International Conference on Advanced Technologies for Humanity in Book: Industrial Innovations: New Technologies in Cities’ Digital Infrastructure. https://doi.org/10.1007/978-3-031-70992-0_8 (Springer, 2023)
Agatonovic-Kustrin, S. & Beresford, R. Basic concepts of artificial neural network (ANN) modeling and its application in pharmaceutical research. J. Pharm. Biomed. Anal. 22(5), 717–727. https://doi.org/10.1016/S0731-7085(99)00272-1 (2000).
Montesinos López, O. A., Montesinos López, A., & Crossa, J. Fundamentals of artificial neural networks and deep learning. In Multivariate Statistical Machine Learning Methods for Genomic Prediction 379–425. https://doi.org/10.1007/978-3-030-89010-0_10 (Springer International Publishing, 2022).
Shi, Y., Yang, K., Yang, Z., & Zhou, Y. (2022). Primer on artificial intelligence. In Mobile Edge Artificial Intelligence (pp. 7–36). Elsevier. https://doi.org/10.1016/B978-0-12-823817-2.00011-5
Tarwidi, D., Pudjaprasetya, S. R., Adytia, D. & Apri, M. An optimized XGBoost-based machine learning method for predicting wave run-up on a sloping beach. MethodsX 10, 102119. https://doi.org/10.1016/j.mex.2023.102119 (2023).
Dutta, P., Paul, S., & Kumar, A. Comparative analysis of various supervised machine learning techniques for diagnosis of COVID-19. In Electronic Devices, Circuits, and Systems for Biomedical Applications, 521–540. https://doi.org/10.1016/B978-0-323-85172-5.00020-4 (Elsevier, 2021).
de Giorgio, A., Cola, G. & Wang, L. Systematic review of class imbalance problems in manufacturing. J. Manuf. Syst. 71, 620–644. https://doi.org/10.1016/j.jmsy.2023.10.014 (2023).
Hoffman, F. O. & Gardner, R. H. Evaluation of uncertainties in radiological assessment models. In Chapter 11 of Radiological Assessment: A textbook on Environmental Dose Analysis. (eds. Till, J. E. & Meyer, H. R.) (NRC Office of Nuclear Reactor Regulation, 1983)
Tuvayanond, W., Kamchoom, V. & Prasittisopin, L. Efficient machine learning for strength prediction of ready-mix concrete production (prolonged mixing). Constr. Innov. https://doi.org/10.1108/CI-09-2023-0240 (2024).
Chao, S., Yu, W., Viroon, K. Data-driven multi-stage sampling strategy for a three-dimensional geological domain using weighted centroidal voronoi tessellation and IC-XGBoost3D. Eng. Geol. 325. https://doi.org/10.1016/j.enggeo.2023.107301 (2023).
Wani, S.R., Suthar, M. Utilizing machine learning approaches within concrete technology offers an intelligent perspective towards sustainability in the construction industry: a comprehensive review. Multiscale Multidiscip. Model. Exp. Des. 8, 1. https://doi.org/10.1007/s41939-024-00601-5 (2025).
Wani, S. R. & Suthar, M. Using soft computing to forecast the strength of concrete utilized with sustainable natural fiber reinforced polymer composites. Asian J. Civ. Eng. 25, 5847–5863. https://doi.org/10.1007/s42107-024-01150-5 (2024).
Wani, S. R. & Suthar, M. A comparative analysis of the predictive performance of tree-based and artificial neural network approaches for compressive strength of concrete utilising waste. Int. J. Pavement Res. Technol. https://doi.org/10.1007/s42947-024-00454-8 (2024).
Sobuz, Md. H. R. et al. Combined influence of modified recycled concrete aggregate and metakaolin on high-strength concrete production: Experimental assessment and machine learning quantifications with advanced SHAP and PDP analyses. Constr. Build. Mater. 461 https://doi.org/10.1016/j.conbuildmat.2025.139897 (2025).
Rahman Sobuz, Md. H. et al. Performance evaluation of high-performance self-compacting concrete with waste glass aggregate and metakaolin. J. Build. Eng. 67 https://doi.org/10.1016/j.jobe.2023.105976 (2023).
Ghasemi, M., Zhang, C., Khorshidi, H., Zhu, L., Hsiao, P.-C. Seismic upgrading of existing RC frames with displacement-restraint cable bracing. Eng. Struct. 282, https://doi.org/10.1016/j.engstruct.2023.115764 (2023).
Huang, H. et al. Property assessment of high-performance concrete containing three types of fibers. Int. J. Concr. Struct. Mater. 15, 39. https://doi.org/10.1186/s40069-021-00476-7 (2021).
Zhao, H. et al. Review on solid wastes incorporated cementitious material using 3D concrete printing technology. Case Stud. Constr. Mater. https://doi.org/10.1016/j.cscm.2024.e03676 (2024).
Hasan, R. et al. Eco-friendly self-consolidating concrete production with reinforcing jute fiber. J. Build. Eng. https://doi.org/10.1016/j.jobe.2022.105519 (2023).
He, L. et al. Development of novel concave and convex trowels for higher interlayer strength of 3D printed cement paste. Case Stud. Constr. Mater. https://doi.org/10.1016/j.cscm.2024.e03745 (2024).
Liu, X. et al. Effect of carbonation curing on the characterization and properties of steel slag-based cementitious materials. Cem. Concr. Compos. https://doi.org/10.1016/j.cemconcomp.2024.105769 (2024).
Yang, L. et al. Three-dimensional concrete printing technology from a rheology perspective: a review. Adv. Cem. Res. 36(12), 567–586 (2024).
Aditto, F. S. et al. Fresh, mechanical and microstructural behaviour of high-strength self-compacting concrete using supplementary cementitious materials. Case Stud. Constr. Mater. https://doi.org/10.1016/j.cscm.2023.e02395 (2023).
Mardani, A., Bui, N. K. & Noguchi, T. Hybrid environmentally friendly method for RCA concrete quality improvement. Int. J. Concr. Struct. Mater. 18, 29. https://doi.org/10.1186/s40069-024-00664-1 (2024).
Bui, N. K. et al. Effect of temperature on binding process of calcium carbonate concrete through aragonite crystals precipitation. Compos. Part B Eng. https://doi.org/10.1016/j.compositesb.2024.111625 (2024).
Mardani, A., Bui, N. K. & Noguchi, T. Hybrid environmentally friendly method for Rca concrete quality improvement. SSRN. https://doi.org/10.2139/ssrn.4370460.
Maruyama, I. et al. A new concept of calcium carbonate concrete using demolished concrete and CO2. J. Adv. Concr. Technol. https://doi.org/10.3151/jact.19.1052 (2021).
Bui, N. K. Tomoaki Satomi, Hiroshi Takahashi, Influence of industrial by-products and waste paper sludge ash on properties of recycled aggregate concrete. J. Clean. Prod. 214, 403–418. https://doi.org/10.1016/j.jclepro.2018.12.325 (2019).
Zhang, J. et al. A review of reliability assessment and lifetime prediction methods for electrical machine insulation under thermal aging. Energies 18, 576. https://doi.org/10.3390/en18030576 (2025).
Wang, T., Liu, J. & Chen, Y. Support vector regression in civil engineering applications: A state-of-the-art review. Adv. Eng. Softw. 125, 101–120 (2022).
Li, Y., Zhang, X. & Wang, H. Random forest regression for predicting nonlinear material properties: A comparative study. Mater. Sci. Eng. J. 58(2), 345–359 (2023).
Ghosh, P., Saha, B. & Dutta, S. Boosting algorithms in machine learning: A comprehensive review and applications. J. Comput. Intell. 36(4), 987–1002 (2020).
Guo, P., Moghaddas, S. A., Liu, Y., Meng, W., Li, V. C., & Bao, Y. Applications of machine learning methods for design and characterization of high-performance fiber-reinforced cementitious composite (HPFRCC): a review. J. Sustain. Cement-Based Mater. 1–24. https://doi.org/10.1080/21650373.2025.2462183 (2025).
Li, Q. et al. Classification and application of deep learning in construction engineering and management—A systematic literature review and future innovations. Case Stud. Constr. Mater. https://doi.org/10.1016/j.cscm.2024.e04051 (2024).
Mohammed, A. & Kora, R. A comprehensive review on ensemble deep learning: Opportunities and challenges. J. King Saud Univ. Comput. Inf. Sci. 35(2), 757–774. https://doi.org/10.1016/j.jksuci.2023.01.014 (2023).
Choudhary, K. et al. Recent advances and applications of deep learning methods in materials science. NPJ Comput. Mater. 8, 59. https://doi.org/10.1038/s41524-022-00734-6 (2022).
Zhang, S. Artificial intelligence and applications in structural and material engineering. Highlights Sci. Eng. Technol. 75, 240–245. https://doi.org/10.54097/9qknfc57 (2023).
Funding
The authors received no external funding for this research project.
Author information
Authors and Affiliations
Contributions
K.C.O. conceptualized, K.C.O., V.K., S.H., A.M.E., J.A.V.V., R.G.M.P., F.U.C.B., P.A. & S.A. wrote the main manuscript text and K.C.O. and A.M.E. prepared the figures. K.C.O., J.A.V.V., R.G.M.P. and F.U.C.B. revised the manuscript and all authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Onyelowe, K.C., Kamchoom, V., Hanandeh, S. et al. Impact of lightweight clay aggregate with slag and biomedical waste ash on self-compacting concrete using machine learning approach. Sci Rep 15, 13983 (2025). https://doi.org/10.1038/s41598-025-99091-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-99091-9
Keywords
This article is cited by
-
Sustainable Development and Response Surface Methodology-Based Optimization of Self-Compacting Concrete Incorporating Innovative Nano Concrete Aggregate and Silica Fume
Iranian Journal of Science and Technology, Transactions of Civil Engineering (2025)
