
Abstract
Social media platforms provide valuable insights into mental health trends by capturing user-generated discussions on conditions such as depression, anxiety, and suicidal ideation. Machine learning (ML) and deep learning (DL) models have been increasingly applied to classify mental health conditions from textual data, but selecting the most effective model involves trade-offs in accuracy, interpretability, and computational efficiency. This study evaluates multiple ML models, including logistic regression, random forest, and LightGBM, alongside DL architectures such as ALBERT and Gated Recurrent Units (GRUs), for both binary and multi-class classification of mental health conditions. Our findings indicate that ML and DL models achieve comparable classification performance on medium-sized datasets, with ML models offering greater interpretability through variable importance scores, while DL models are more robust to complex linguistic patterns. Additionally, ML models require explicit feature engineering, whereas DL models learn hierarchical representations directly from text. Logistic regression provides the advantage of capturing both positive and negative associations between features and mental health conditions, whereas tree-based models prioritize decision-making power through split-based feature selection. This study offers empirical insights into the advantages and limitations of different modeling approaches and provides recommendations for selecting appropriate methods based on dataset size, interpretability needs, and computational constraints.
Similar content being viewed by others

Introduction
Social media platforms have become critical tools for understanding mental health trends. It provides researchers with large-scale, real-time textual data that reflects users’ emotional states and psychological well-being. Platforms such as Twitter, Reddit, and Facebook provide valuable insights into conditions like depression, anxiety, and suicidal ideation, motivating the development of automated systems for early detection. This study aims to provide a systematic and reproducible comparison of representative machine learning (ML) and deep learning (DL) models for mental health classification, focusing on trade-offs in accuracy, interpretability, and computational efficiency. Rather than introducing new architectures, our goal is to benchmark commonly used pipelines using a real-world dataset, to inform model selection in practical mental health applications.
The major contributions of this work are as follows: (1) We conduct a comprehensive, side-by-side evaluation of traditional ML and DL models for mental health detection using social media text, covering both binary and multiclass tasks; (2) We assess trade-offs across predictive performance, interpretability, and computational efficiency, providing practical insights for model selection; (3) We utilize a diverse, real-world dataset and publicly available tools, ensuring reproducibility and applicability in real-world settings.
Mental illnesses affect approximately one in eight individuals globally, with depression alone impacting over 280 million people1. Early detection of these conditions is crucial for timely intervention, yet traditional diagnostic methods, such as clinical assessments and self-reported surveys, are resource-intensive and lack real-time insights2. In this context, analyzing social media data presents an alternative, data-driven approach for mental health monitoring, enabling scalable detection of distress signals and behavioral patterns3,4. Advances in artificial intelligence (AI) and natural language processing (NLP) have facilitated the application of ML and DL techniques for mental health classification, demonstrating promising results in various studies5.
ML and DL approaches, particularly those involving NLP, have emerged as valuable tools in early diagnosis. ML models, such as logistic regression, random forests, and LightGBM, rely on explicit feature engineering. For instance, they use Term Frequency-Inverse Document Frequency (TF-IDF) representations to capture key linguistic markers. This approach also provides interpretability through feature importance scores. In contrast, DL models automatically learn hierarchical representations from raw text. For example, transformer-based architectures like Bidirectional Encoder Representations from Transformers (BERT) and recurrent neural networks such as Gated Recurrent Units (GRUs) capture subtle linguistic patterns. However, this advantage comes at the cost of reduced transparency.
Recent studies have further demonstrated the efficacy of advanced ML and DL techniques in biomedical diagnosis. For example, Elkenawy et al.6 proposed a Greylag goose optimization approach combined with a multilayer perceptron for enhancing lung cancer classification, while Alkhammash et al.7 developed an optimized BPSO model to predict COVID-19 spread. Similarly, Tarek et al.8 introduced a snake optimization-based feature selection framework for rapid detection of cardiovascular disease, and Elshewey et al.9 presented the hyOPTGB framework for optimizing HCV disease prediction in Egypt. In addition, Alzakari et al.10 applied an enhanced CNN-LSTM model for early detection of potato disease, and Dalal et al.11,12 have advanced explainability techniques for depression detection. These contributions underscore the rapid progress in applying optimization and DL.
Despite these advancements, several challenges remain. ML and DL models are often hindered by several challenges. These include dataset biases, inconsistencies in preprocessing techniques, and reliance on imbalanced training data. Each of these issues affects model generalizability13,14,15. Linguistic complexities, such as informal language, sarcasm, and context-dependent meanings, further complicate the accurate detection of mental health conditions in social media text16. Another critical issue is the trade-off between model performance and interpretability. ML models, such as logistic regression and random forests, provide interpretability through feature importance scores but may struggle with nuanced language understanding. In contrast, DL models, including transformer-based architectures (e.g., Bidirectional Encoder Representations from Transformers, BERT) and recurrent neural networks (e.g., Gated Recurrent Units, GRUs), excel at capturing linguistic patterns but function as black-box models, limiting transparency in decision-making. It is also important to acknowledge that the use of social media data raises ethical concerns regarding privacy and data representation; these issues are further discussed in the Discussion section.
While prior systematic reviews have explored ML and DL applications in mental health detection13,17,18, there remains a need for an empirical evaluation that systematically compares model performance and interpretability across different classification tasks. This study addresses this gap by assessing ML and DL models in both binary and multiclass mental health classification settings using a publicly available dataset from Kaggle. The dataset includes various mental health conditions, such as depression, anxiety, stress, suicidal ideation, bipolar disorder, and personality disorders. Model performance is evaluated using weighted F1 score and area under the receiver operating characteristic curve (AUROC, or AUC) to account for class imbalance. Additionally, we assess model interpretability through feature importance measures, including logistic regression coefficients, random forest Gini impurity reduction, and LightGBM gain-based ranking.
This study examines the trade-offs between model accuracy, interpretability, and computational efficiency. Our findings provide empirical insights that can guide the selection of appropriate models for mental health classification on social media. The remainder of this paper is organized as follows. Section “Methods” describes the methodological framework, including data preparation, model development, and evaluation metrics. Section “Methods” presents findings on dataset characteristics, model performance evaluation, and interpretability assessments. Finally, the Discussion and Conclusion sections summarize key insights, implications for mental health research, and directions for future work.
Methods
This section outlines the methodological framework of our study, covering data collection, preprocessing, model construction, and evaluation metrics. All experiments were conducted using Python 3. We leveraged key libraries such as pandas for data processing, scikit-learn and lightgbm for ML, PyTorch for DL, and Transformers for pre-trained language models. These tools facilitated efficient data handling, systematic hyperparameter tuning, and rigorous performance evaluation. All models were trained on Google Colab, utilizing a high-RAM configuration powered by an NVIDIA T4 GPU, which provided the computational efficiency required for computational tasks, especially DL models. Complete code, including preprocessing scripts, dataset splits, hyperparameter settings, and reproducibility instructions (e.g., Colab notebooks), is available on GitHub. The following sections detail each stage of our approach.
Data preparation
An extensive and varied dataset is fundamental for effective mental health detection via ML. We employed the ‘Sentiment Analysis for Mental Health’ dataset available on Kaggle, chosen for its comprehensive coverage of mental health conditions including depression, anxiety, stress, bipolar disorder, personality disorders, and suicidal ideation. This dataset was selected because it aggregates data from multiple social media platforms (e.g., Reddit, Twitter, and Facebook), thereby capturing a wide range of linguistic styles and demographic variations that closely reflect real-world scenarios. Data were primarily obtained from these platforms where individuals discuss personal experiences and mental health challenges. The data acquisition process involved using platform-specific APIs and web scraping, followed by removing duplicates, filtering out spam or irrelevant content, and standardizing mental health labels. Personal identifiers were also removed to adhere to ethical standards, resulting in a well-structured CSV file with unique identifiers for each entry.
The dataset was compiled and cleaned by the original authors on Kaggle, who aggregated data from multiple sources, removed duplicates and personal identifiers, and standardized mental health labels. Data were primarily obtained from these platforms where individuals discuss personal experiences and mental health challenges. After acquiring the dataset, we applied an automated preprocessing pipeline using Python to further clean the text by removing HTML tags, URLs, special characters, converting text to lowercase, and lemmatizing tokens. These steps were fully automated using established NLP tools (e.g., NLTK), with no manual relabeling or filtering applied.
Despite its diversity, the dataset presents challenges for natural language processing due to its varying demographics and language styles (e.g., slang and colloquialisms), which our preprocessing pipeline was specifically designed to address. These preprocessing steps-including normalization, lemmatization, and stopword removal-help reduce lexical variation and standardize informal and colloquial language across user-generated text. However, we acknowledge that such preprocessing cannot fully address deeper linguistic nuances such as sarcasm, irony, or contextually implied meaning, which remain challenging for both traditional and deep learning models. Overall, the dataset’s extensive coverage and inherent real-world diversity not only present a rigorous challenge for both ML and DL methods but also make it an ideal benchmark for systematically comparing these approaches. The variability in language and demographic factors allows us to assess the strengths and limitations of explicit feature engineering in ML as well as the hierarchical representation capabilities of DL, thereby enhancing the robustness and generalizability of our performance evaluations.
We applied a consistent preprocessing pipeline to prepare the dataset for both ML and DL models. Initially, we cleaned the text by removing extraneous elements such as URLs, HTML tags, mentions, hashtags, special characters, and extra whitespace. The text was then converted to lowercase to maintain consistency. Next, we removed common stopwords using the NLTK stopword list19 to eliminate non-informative words. Finally, lemmatization was used to reduce words to their base forms, ensuring that different forms of a word are treated uniformly. The processed dataset was randomly split into training, validation, and test sets, with 20% allocated for testing. The remaining data was further divided into training (75%) and validation (25%) sets to ensure reproducibility and optimize model tuning.
For classification, the dataset labels were structured in two distinct ways. In the multi-class scenario, the original labels in the Kaggle dataset were directly used, consisting of six categories: Normal, Depression, Suicidal, Anxiety, Stress, and Personality Disorder. For binary classification, all non-Normal categories were grouped under a single ‘Abnormal’ label.
In natural language processing, feature extraction depends on the model type. ML models require structured numerical representations, while DL models can process raw text sequences or dense vector embeddings.
For ML models, text is commonly converted into numerical features using techniques such as the bag-of-words (BoW) model20, which represents documents as token count vectors but treats all words equally. To address this limitation, Term Frequency-Inverse Document Frequency (TF-IDF)21 enhances BoW by weighting words based on their importance-emphasizing informative terms while downplaying common ones. In this study, we employed TF-IDF vectorization to extract numerical features, incorporating unigrams and bigrams and limiting the feature space to 1,000 features to optimize computational efficiency and mitigate overfitting.
Model development
A variety of ML and DL models were developed to analyze and classify mental health statuses based on textual input. Each model was selected to capture different aspects of the data, ranging from simple linear classifiers to complex non-linear relationships. For ML models, we used TF-IDF-based feature engineering, which is commonly employed in text classification tasks for its interpretability and computational efficiency. For DL models, we adopted raw text inputs with embedded representations, allowing these architectures to learn contextual features directly from the data. We did not incorporate hybrid approaches (e.g., using pre-trained embeddings with ML classifiers) because our primary aim was to benchmark standard, widely adopted ML and DL pipelines without introducing additional architectural complexity. This decision allowed us to maintain a clean and interpretable comparison between the two modeling paradigms.
Within the DL category, we selected ALBERT and GRU to represent two distinct neural architectures. ALBERT, a lightweight and efficient variant of BERT, was chosen for its strong performance and lower computational cost, making it well-suited for our Colab-based experimental environment. GRU was selected over LSTM due to its simpler gating mechanism and faster training time, while still being effective at capturing sequential dependencies in text. Although alternative models such as standard BERT or transformer-based models like T5 offer powerful capabilities, our selected models reflect a practical trade-off between performance, interpretability, and resource efficiency within the context of this comparative study. The following subsections outline the methodology of each model and its performance in binary and multiclass classification.
Logistic regression
Logistic regression is a fundamental classification technique widely used in social science and biomedical research22. It models the probability of a categorical outcome based on a weighted linear combination of input features. Despite its simplicity, logistic regression is still effective when applied to high-dimensional data, such as term frequency-based representations in natural language processing.
In this study, logistic regression served as an interpretable model that integrated various predictors (e.g., term frequencies) to estimate the probability of different mental health outcomes. The binary model predicts the likelihood of a positive case, while the multi-class extension accommodates multiple categories.
To prevent overfitting, model parameters were optimized using cross-entropy loss with regularization. A grid search was employed to fine-tune hyperparameters, including regularization strength, solver selection, and class weights, with the weighted F1 score guiding the selection process. The logistic regression models were implemented using the LogisticRegression class from scikit-learn.
Support vector machine (SVM)
Support Vector Machines (SVMs) are effective classifiers that identify an optimal decision boundary (hyperplane) to maximize the margin between classes23. Unlike probabilistic models such as logistic regression, SVMs utilize kernel functions to map input data into higher-dimensional spaces, allowing them to model both linear and non-linear relationships. Due to the high-dimensional and sparse nature of text-based features, we evaluated both linear SVMs and non-linear SVMs with a radial basis function (RBF) kernel. Model selection was based on the weighted F1 score. Hyperparameter optimization was conducted via grid search, including regularization strength, class weighting, and \(\gamma\) for RBF kernelsFootnote 1.
The final models were implemented using the SVC class from scikit-learn. For multi-class classification, the One-vs-One (OvO) strategy was employed, the default approach in SVC, which constructs pairwise binary classifiers for each class combination, with the final label determined through majority voting.
Tree-based models
Classification and Regression Trees (CART) are widely used for categorical outcome prediction in classification tasks. The algorithm constructs a binary decision tree by recursively partitioning the dataset based on predictor variables, selecting splits that optimize a predefined criterion. Common impurity measures, such as Gini impurity and entropy, assess split quality, with lower values indicating greater homogeneity within a node24. The tree expands iteratively until stopping conditions, such as a minimum node size, maximum depth, or impurity reduction threshold, are met.
To prevent overfitting, pruning techniques25 reduce tree complexity by removing splits with minimal predictive value, enhancing generalizability. However, standalone CART models often overfit, making them less suitable for complex classification tasks. Instead, this study employed ensemble methods, such as Random Forests and Gradient Boosted Trees, to improve robustness and predictive performance.
Random Forests Random Forests aggregate multiple decision trees to enhance classification performance. Each tree is trained on a bootstrap sample, ensuring diversity, while a random subset of features is considered at each split to reduce correlation and improve generalization26. Unlike individual trees, Random Forests do not require pruning, with complexity managed through hyperparameters such as the number of trees, tree depth, and minimum sample requirements.
Hyperparameter tuning via grid search optimized the number of estimators, tree depth, and minimum split criteria, using the weighted F1 score as the primary evaluation metric to address class imbalance. The best-performing binary classification model effectively distinguished between Normal and Abnormal mental health statuses. For multi-class classification, the same hyperparameter grid was used with a refined search scope for efficiency, ensuring balanced classification performance across mental health categories.
Beyond predictive accuracy, feature importance analysis provided insights into key variables influencing classification decisions, enhancing model interpretability. Random Forest models were implemented using RandomForestClassifier from scikit-learn, with hyperparameter tuning via grid search on the validation set.
Light Gradient Boosting Machine (LightGBM) LightGBM is an optimized gradient-boosting framework designed for efficiency and scalability, particularly in high-dimensional datasets. Unlike traditional Gradient Boosting Machines (GBMs), which sequentially refine predictions by correcting errors from prior models, LightGBM employs a leaf-wise tree growth strategy, enabling deeper splits in dense regions for improved performance27. Additionally, histogram-based feature binning reduces memory usage and accelerates training, making LightGBM faster and more resource-efficient than standard GBMs28.
Grid search was used to optimize hyperparameters, including the number of boosting iterations, learning rate, tree depth, number of leaves, and minimum child samples. To address class imbalance, the class weighting parameter was tested with both ‘balanced‘ and ‘None‘ options. Model selection was guided by the weighted F1 score, ensuring balanced classification performance.
For binary classification, LightGBM effectively distinguished between Normal and Abnormal statuses. For multi-class classification, it predicted categories including Normal, Depression, Anxiety, and Personality Disorder. Evaluation metrics included precision, recall, F1 scores, confusion matrices, and one-vs-rest ROC curves. LightGBM’s built-in feature importance analysis further enhanced interpretability by identifying key predictors. The models were implemented using lightGBMClassifier from the lightgbm library, with hyperparameter tuning via grid search on the validation set.
A lite version of bidirectional encoder representations from transformers (ALBERT)
ALBERT29 is an optimized variant of BERT30 designed to enhance computational efficiency while preserving strong NLP performance. It achieves this by employing parameter sharing across layers and factorized embedding parameterization, significantly reducing the total number of model parameters. Additionally, ALBERT introduces Sentence Order Prediction (SOP) as an auxiliary pretraining task to improve sentence-level coherence. These architectural refinements make ALBERT a computationally efficient alternative to BERT, particularly well-suited for large-scale text classification applications such as mental health assessment.
In this study, ALBERT was fine-tuned for both binary and multi-class classification. The binary model was trained to differentiate between Normal and Abnormal mental health statuses, while the multi-class model classified inputs into categories such as Normal, Depression, Anxiety, and Personality Disorder. The pretrained Albert-base-v2 model was utilized, and hyperparameter optimization was conducted using random search over 10 iterations, tuning learning rates, dropout rates, and training epochs. Model performance was evaluated using the weighted F1 score as the primary metric. For the multi-class task, the classification objective was adjusted to predict seven categories, with weighted cross-entropy loss applied to address class imbalances.
ALBERT’s architecture effectively captures long-range dependencies in text while offering substantial computational advantages. Performance optimization was conducted using random hyperparameter tuning within the Hugging Face Transformers framework, leveraging AlbertTokenizer and AlbertForSequenceClassification for implementation.
Gated recurrent units (GRUs)
Gated Recurrent Units (GRUs) are a variant of recurrent neural networks (RNNs) designed to model sequential dependencies, making them well-suited for natural language processing tasks such as text classification31. Compared to Long Short-Term Memory networks (LSTMs), GRUs provide greater computational efficiency by simplifying the gating mechanism. Specifically, they merge the forget and input gates into a single update gate, reducing the number of parameters while effectively capturing long-range dependencies.
In this study, GRUs were employed for both binary and multi-class mental health classification. The binary model differentiated between Normal and Abnormal mental health statuses, while the multi-class model predicted categories such as Normal, Depression, Anxiety, and Personality Disorder.
The GRU architecture consisted of three primary components:
-
Embedding Layer: Maps token indices to dense vector representations of a fixed size.
-
GRU Layer: Processes sequential inputs, preserving contextual dependencies, with the final hidden state serving as the input to the classifier.
-
Fully Connected Layer: Transforms the hidden state into output logits corresponding to the classification categories.
To mitigate overfitting, dropout regularization was applied, and weighted cross-entropy loss was used to address class imbalance.
Hyperparameter tuning was conducted via random search, optimizing key parameters such as embedding dimensions, hidden dimensions, learning rates, and training epochs. The weighted F1 score was used for model selection, ensuring robust performance on both validation and test data.
Overall, GRUs effectively captured sequential patterns in text, enabling the extraction of linguistic features relevant to mental health classification. While less interpretable than tree-based models, their efficiency and ability to model long-range dependencies make them well-suited for text classification. The models were implemented using PyTorch’s torch.nn module, incorporating nn.Embedding, nn.GRU, and nn.Linear layers. Optimization was performed using torch.optim.Adam, with class imbalances handled through nn.CrossEntropyLoss.
Evaluation metrics
Classifying mental health conditions, such as depression or suicidal ideation, often involves imbalanced class distributions, where the ‘positive’ class (e.g., individuals experiencing a mental health condition) is significantly underrepresented compared to the ‘negative’ class (e.g., no reported issues). In such cases, traditional metrics like accuracy can be misleading, as a model predicting only the majority class may still achieve high accuracy despite failing to detect minority-class cases. To provide a more comprehensive assessment of classification performance, the following evaluation metrics were used:
-
Recall (Sensitivity): Captures the proportion of actual positive cases correctly identified. High recall is crucial in mental health detection to minimize false negatives and ensure individuals in need receive appropriate intervention32. However, excessive focus on recall may increase false positives, leading to potential misclassifications.
-
Precision: Measures the proportion of predicted positive cases that are actually positive. High precision is critical in mental health classification, as false positives can lead to unnecessary concern, stigma, and unwarranted interventions32. However, optimizing for precision alone may cause the model to miss true positive cases, limiting its usefulness.
-
F1 Score: Represents the harmonic mean of precision and recall, offering a balanced performance measure33. This metric is particularly useful for imbalanced datasets, ensuring that neither precision nor recall is disproportionately optimized at the expense of the other.
-
AUC: Assesses the model’s ability to distinguish between positive and negative cases across various classification thresholds. Although AUC provides an overall measure of discrimination performance, it may be less informative in severely imbalanced datasets, where the majority class dominates34.
Results
This section presents the findings from the analysis of the dataset and the evaluation of ML and DL models for mental health classification. First, we provide an Overview of Mental Health Distribution, highlighting the inherent class imbalances within the dataset and their implications for model development. Next, the Hyperparameter Optimization subsection details the parameter tuning process, which ensures that each model performs at its best configuration for both binary and multi-class classification tasks. Finally, the Model Performance Evaluation subsection compares the models’ performance based on key metrics, including F1 scores and AUC. Additionally, nuanced observations, such as the challenges associated with underrepresented classes, are discussed to provide deeper insights into the modeling outcomes.
Distribution of mental health status
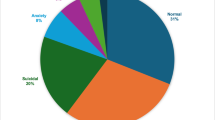
The dataset contains a total of 52,681 unique textual statements, each annotated with a corresponding mental health status label. The labels represent various mental health categories, reflecting the distribution of conditions within the dataset.
The dataset is heavily imbalanced, with certain categories having significantly higher representation than others. Specifically:
-
Normal: 16,343 statements (31.02%)
-
Depression: 15,404 statements (29.24%)
-
Suicidal: 10,652 statements (20.22%)
-
Anxiety: 3,841 statements (7.29%)
-
Bipolar: 2,777 statements (5.27%)
-
Stress: 2,587 statements (4.91%)
-
Personality Disorder: 1,077 statements (2.04%)
For the binary classification task, all mental health conditions (Depression, Suicidal, Anxiety, Bipolar, Stress, and Personality Disorder) were combined into a single category labeled as Abnormal, while the Normal category remained unchanged. This transformation resulted in:
-
Normal: 16,343 statements (31.02%)
-
Abnormal: 36,338 statements (68.98%)
Such imbalance feature in both multi-class and binary classification tasks highlights the importance of evaluation metrics that account for disparities, such as the weighted F1 score.
Computational efficiency
The computational time for training the models varied significantly based on the algorithm type and classification task. Among ML models, SVM required an exceptionally long training time, far exceeding other ML approaches like Logistic Regression, Random Forest, and Light GBM, for both binary and multi-class tasks. In contrast, DL models such as ALBERT and GRU consistently required more time compared to ML models, reflecting their higher computational complexity.
For ML models, training times for multi-class classification were longer than for binary classification, likely due to the increased complexity of predicting multiple categories. However, for DL models, there was no notable difference in training times between binary and multi-class tasks, indicating that their computational cost was primarily driven by model architecture rather than the number of classes.
A detailed information of training times is presented in Table 1.
Performance metrics
Table 2 presents the weighted F1 scores and AUC values, along with their 95% confidence intervals (CIs) that were calculated using a bootstrapping approach with 1000 samples, for all models evaluated on binary classification tasks. Across all models, there were minimal numerical differences in performance, with all achieving strong results in both metrics. The F1 scores ranged from 0.9347 (95% CI: 0.9299, 0.9397) for Random Forest to 0.9650 (95% CI: 0.9613, 0.9685) for ALBERT. Similarly, AUC values were consistently high, spanning from 0.9764 (95% CI: 0.9736, 0.9791) for Random Forest to 0.9928 (95% CI: 0.9916, 0.9941) for ALBERT. These results indicate that all models effectively distinguished between Normal and Abnormal mental health statuses.
Despite the close performance across models, a general trend emerged where DL models, such as ALBERT and GRU, outperformed ML models. For instance, ALBERT achieved the highest F1 score (0.9650, 95% CI: 0.9613, 0.9685) and AUC (0.9928, 95% CI: 0.9916, 0.9941), while GRU closely followed with an F1 score of 0.9520 (95% CI: 0.9478, 0.9558) and an AUC of 0.9879 (95% CI: 0.9863, 0.9896). In contrast, ML models such as Logistic Regression, Random Forest, and LightGBM showed slightly lower, albeit still competitive, performance.
Table 3 summarizes the weighted F1 scores and micro-average AUC values with their 95% CIs for multi-class classification tasks. Similar to binary classification, the differences in performance across models were small, with DL models generally outperforming ML models. ALBERT achieved the highest F1 score (0.7917, 95% CI: 0.7842, 0.7992) and shared the top AUC value (0.9676, 95% CI: 0.9655, 0.9698) with LightGBM and GRU. ML models such as Logistic Regression and Random Forest exhibited slightly lower F1 scores, at 0.7474 (95% CI: 0.7388, 0.7554) and 0.7454 (95% CI: 0.7369, 0.7544), respectively, but still demonstrated strong AUC values.
Notably, a consistent pattern was observed where multi-class classification yielded lower F1 scores compared to binary classification across all models. The lower F1 scores for multi-class classification reflect the increased complexity of predicting seven distinct mental health categories. Binary classification requires only a single decision boundary between Normal and all other classes (combined into Abnormal), whereas multi-class classification must learn multiple boundaries between overlapping categories like Depression, Anxiety, and Stress. This added complexity introduces more opportunities for misclassification, further lowering F1 scores. On the contrary, the AUC values remained consistently high for both binary and multi-class tasks, indicating robust discrimination between classes despite the added complexity.
The discrepancy between the F1 score and AUC observed in the multi-class classification results can be attributed to the fundamental differences in what these metrics measure. The F1 score, which balances precision and recall, is sensitive to class imbalance and specific misclassifications. In Table 4, generated for the LightGBM multi-class model and included here for illustration purposes, certain classes such as Suicidal (Class 6) and Depression (Class 2) show notable misclassifications, including frequent overlaps with Stress (Class 5) and Normal (Class 3). This directly impacts the F1 score by lowering the precision and recall for these specific classes.
In contrast, AUC measures the model’s ability to rank predictions correctly across thresholds, and it remains robust to class imbalances and individual misclassification errors. The AUC (see Table 4), also from the LightGBM multi-class model and included for illustrative purposes, demonstrate strong separability for most classes, with areas under the curve (AUC) exceeding 0.95 for all but Class 2 (Depression) and Class 6 (Suicidal). The micro-average AUC of 0.9566 (95% CI: 0.9534, 0.9594) indicates that the model can effectively rank instances across all classes, even when specific misclassifications reduce the F1 score.
Statistical test for model comparison
To assess whether the observed differences in model performance were statistically significant, we conducted formal hypothesis testing using appropriate statistical methods for binary and multi-class classification tasks.
For binary classification tasks, we applied McNemar’s test, a non-parametric method designed to compare the paired classification errors of two models on the same test dataset. McNemar’s test is particularly suited for classification tasks where the outcome is categorical and predictions are paired. Given that multiple pairwise comparisons were conducted among models, we adjusted the resulting p-values using the Holm method to control the family-wise error rate.
For multi-class classification tasks, we employed the Wilcoxon signed-rank test to compare model performance scores (e.g., F1 scores) across different cross-validation runs. This non-parametric test evaluates whether the median difference between paired samples is zero and is appropriate for comparing model performances on the same datasets. To account for multiple testing in the multi-class setting, we applied the Bonferroni correction to the p-values obtained from the Wilcoxon signed-rank tests.
The results of the statistical tests, along with corrected p-values and significance levels, are presented in Tables 5 and 6. These statistical analyses provide robust evidence for the performance differences observed in our evaluation metrics.
Interestingly, although ALBERT achieved a slightly higher average F1 score compared to GRU in both binary and multi-class classification tasks, the statistical tests (McNemar’s test and Wilcoxon signed-rank test) indicated that GRU significantly outperformed ALBERT in pairwise comparisons. This result suggests that GRU provided more consistent and stable performance across different evaluation runs, whereas ALBERT’s performance, although strong on average, exhibited higher variability. This finding highlights the importance of complementing point estimate metrics (such as F1 scores) with statistical testing to capture performance consistency and robustness across different data splits.
Error analyses
The confusion matrix reveals specific patterns of misclassification that contribute to the lower F1 scores for some classes in the multi-class classification task. Key observations include:
-
Overlap Between Emotionally Similar Classes: As indicated in Table 4, Depression (Class 2) and Personality Disorder (Class 6) show significant overlap, with many instances of Depression misclassified as Personality Disorder or vice versa. Similarly, Suicidal (Class 3) was frequently misclassified as Depression, likely due to overlapping linguistic patterns. Another possible explanation lies in the nature of the dataset itself, which was constructed by combining data from multiple sources. While these labels may have been well-defined and effective for their original studies, they may lack consistency when integrated into a unified dataset, leading to ambiguity in class boundaries.
-
Poor Discrimination for Depression: The AUC summary (in Table 4 highlights that Depression (Class 2) has the lowest AUC (0.90) among all classes in the LightGBM model. For other models, the AUC for Class 2 drops even further, indicating consistent difficulty in distinguishing Depression from other classes. This is likely due to semantic overlap with related classes such as Stress (Class 4), Suicidal (Class 3), and Personality Disorder (Class 6). Additionally, inconsistencies in labeling across data sources may further exacerbate the challenge of identifying Depression accurately.
-
Underrepresented Classes and Data Imbalance: Bipolar (Class 5) and Personality Disorder (Class 6) were underrepresented in the dataset, which exacerbated misclassification issues.
Quantitative Breakdown of Per-Class Performance: To further support the error analysis, we provide a per-class breakdown of precision, recall, F1-score, and AUC in Table 4. This breakdown highlights that Normal (Class 3) achieved the highest F1-score (0.9140), while Stress (Class 5) and Suicidal (Class 6) exhibited relatively lower F1-scores (0.6155 and 0.6806, respectively).
Model interpretability
In ML models, variable importance can be quantified to understand how individual features contribute to predictions. This interpretability allows researchers to identify key linguistic and behavioral markers associated with mental health conditions. However, DL models operate differently. Rather than relying on explicit features, DL models extract representations from raw text, making them inherently black-box models. Since these models learn hierarchical patterns across entire sentences and contexts, they do not produce traditional variable importance scores, making direct interpretability more challenging. In this project, we assessed variable importance for three out of four ML models: logistic regression, random forest, and LightGBM. Support Vector Machine (SVM) was excluded from this analysis because Radial Basis Function (RBF) kernel was selected during model construction, which is a nonlinear kernel. In such cases, variable importance is not directly interpretable due to the transformation of the input space, making it difficult to quantify individual feature contributions meaningfully35. Unlike linear models, where coefficients provide a direct measure of feature importance, nonlinear SVMs construct decision boundaries in high-dimensional spaces, where the contribution of each feature depends on complex interactions36.
For logistic regression, variable importance is derived from model coefficients, where positive coefficients indicate a higher likelihood of the outcome (e.g., mental health condition), while negative coefficients suggest a protective effect. To enhance interpretability, we adopted a color scheme in our visualizations: dark gray for positive coefficients and light gray for negative coefficients. For Random Forest, variable importance is computed using the Gini impurity reduction criterion26. This metric quantifies how much each feature contributes to reducing class impurity across the decision trees by assessing the decrease in Gini impurity at each node split. Features with higher importance scores have a greater impact on classification performance. For LightGBM, variable importance is measured using information gain, which quantifies the total improvement in the model’s objective function when a feature is used for node splitting across all trees in the boosting process. Information gain reflects how much a feature contributes to minimizing the loss function during training and is commonly used in gradient boosting frameworks27. Features with higher gain values contribute more to optimizing the model’s predictive accuracy.
While ML models offer explicit feature importance scores, DL models such as ALBERT and GRU do not provide direct interpretability outputs. To explore the potential for explaining DL model predictions, we attempted to apply SHAP (SHapley Additive exPlanations) to both ALBERT and GRU models. However, the computation of SHAP values for deep learning models, particularly in text classification tasks, is known to be computationally intensive and resource-demanding. In our setting, even with the computational resources introduced in section “Methods” (Google Colab with high-RAM configuration and NVIDIA T4 GPU), SHAP analysis did not produce results within a reasonable time frame. Specifically, after running for more than 72 hours, we were unable to generate complete interpretability outputs for a single model. This limitation aligns with recent studies that have highlighted challenges in applying SHAP to complex deep learning models mosca2022shap, questioning its scalability and interpretability value in certain contexts. Given these constraints, we did not include SHAP-based interpretability results in this study but acknowledge this as a limitation and an important direction for future work.
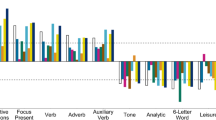
The variable importance for both binary and multiclass models using logistic regression, random forest, and LightGBM is presented in Figure 1. To ensure comparability across models, we rescaled the variable importance scores for random forest and LightGBM by normalizing them to a maximum value of 100. For logistic regression, variable importance is represented by model coefficients, retaining both their relative scale and sign. Among ML models that provide feature importance, logistic regression offers a more interpretable framework since its importance scores are derived directly from model coefficients. Unlike tree-based methods, which rely on splitting criteria (such as Gini impurity for Random Forest or Gain for LightGBM), logistic regression coefficients retain their sign, allowing researchers to distinguish positive and negative associations with the target outcome. This property is particularly valuable in mental health detection, where it is critical to understand whether a term increases or decreases the likelihood of classification (e.g., identifying depressive symptoms).

Comparison of Feature Importance Across Different Models.
Despite variations in ranking, the top features identified across ML models share strong overlap, reinforcing their relevance in mental health classification. However, different importance criteria lead to model-specific variations: logistic regression ranks features based on coefficient magnitude (allowing both positive and negative values), random forest uses Gini impurity reduction, and LightGBM employs gain-based ranking. While these models prioritize features differently, they consistently highlight depression-related language as the strongest predictor of mental health conditions on social media.
For binary classification models, ‘depression’ emerges as the most predictive feature across all methods, reinforcing its centrality in identifying mental health status. Beyond this, words associated with emotional distress-such as ‘feel,’ ‘want,’ and ‘anxiety’-consistently appear in the top ranks, though their order varies. Logistic regression assigns strong positive coefficients to ‘restless’ and ‘suicidal,’ suggesting their direct correlation with depressive states. Meanwhile, tree-based models (random forest and LightGBM) highlight terms like ‘die,’ ‘kill,’ and ‘suicide’ more prominently, likely due to their effectiveness in decision splits. These differences reflect how each model processes textual features, with logistic regression providing interpretability through sign-based coefficients, while tree-based models prioritize decision-making power through split-based feature selection.
In the multiclass setting, feature importance rankings shift to reflect the distinctions between different mental health conditions. While ‘depression’ remains a dominant predictor, terms like ‘bipolar’ and ‘anxiety’ gain prominence, particularly in tree-based models (random forest and LightGBM), suggesting their utility in distinguishing among multiple mental health states. Logistic regression, on the other hand, highlights ‘restless’ and ‘nervous’ more strongly, aligning with its emphasis on anxiety-related symptoms. The presence of ‘kill’ and ‘suicidal’ in tree-based models underscores their role in severe mental health classifications. Despite these ranking differences, the core predictive features remain largely consistent, validating their role in mental health detection on social media.
Among models capable of generating variable importance, logistic regression stands out for its interpretability. Unlike tree-based methods, which assign importance based on split-based metrics, logistic regression allows for direct interpretation of feature coefficients, capturing both positive and negative associations. This provides a clearer understanding of which terms contribute most strongly to classification and in what direction. In contrast, while random forest and LightGBM effectively rank important features, their criteria for feature selection make direct interpretability more challenging.
Discussion
This study provides an empirical evaluation of ML and DL models for mental health classification on social media, focusing on their predictability, interpretability, and computational efficiency. The findings highlight key trade-offs that researchers should consider when selecting models for mental health detection tasks. While DL models, such as ALBERT and GRU, have gained popularity for their ability to extract hierarchical representations from raw text, their advantages in small-to-medium datasets remain limited. The results indicate that in cases where dataset size is moderate, ML models, such as logistic regression, random forests, and LightGBM, perform comparably to DL models while offering additional benefits in terms of interpretability and computational efficiency.
The size of the dataset plays a crucial role in determining the most suitable modeling approach. When working with small to medium-sized datasets, ML models remain an effective choice. Their reliance on structured feature engineering, while requiring additional preprocessing efforts, allows for a more controlled and interpretable learning process. In contrast, DL models require large-scale training data to leverage their full potential. Although DL architectures can automatically extract complex linguistic patterns without extensive feature engineering, this advantage is less pronounced in settings with limited training samples. For researchers with small datasets, the use of feature engineering and careful selection of input variables is critical to optimizing model performance. The results suggest that DL models are more suitable for large-scale mental health detection tasks, where the volume of data is sufficient to justify their increased computational demands.
In addition to dataset size, computational efficiency remains a practical consideration in model selection. ML models consistently required less computational time than DL models, making them preferable when efficiency is a priority. Although DL models demonstrated competitive performance, their longer training times pose challenges for researchers with limited computing resources. Given that many mental health detection applications require scalable solutions, this finding suggests that ML models provide a more efficient and accessible alternative for researchers seeking to deploy classification models without extensive computational infrastructure.
Interpretability remains critical for real-world applications. Among the methods evaluated, logistic regression provides the clearest interpretability through direct coefficient estimates along with confidence interval, providing insights into the influence of individual features. Although tree-based models and DL architectures also yield competitive performance, their inherent complexity often limits transparency. In particular, while ML models allow for explicit feature importance evaluation, DL models such as ALBERT and GRU require additional explainability frameworks (e.g., SHAP) to generate local or global interpretations. We attempted to apply SHAP to our DL models to enhance interpretability, but the computational cost was prohibitive as indicated in the recent research37. These findings highlight the trade-offs that researchers must consider when selecting models, balancing performance, resource availability, and the need for understandable and actionable insights. While these preprocessing steps help reduce surface-level variability in social media language, they are not sufficient to capture deeper semantic challenges such as sarcasm, irony, or implied emotional meaning. These nuances often influence the interpretation of mental health signals and remain difficult for both ML and DL models to handle effectively. Future work should explore incorporating context-aware embeddings, sentiment-enhanced representations, or task-specific fine-tuning strategies to better address these complexities in user-generated text.
While this study focused on representative ML and DL models, we acknowledge the growing body of research exploring advanced transformer-based architectures-such as BERT, T5, and other large language models (LLMs)-for mental health detection. Recent studies, including Dalal et al.11,12, demonstrate how such models can improve predictive performance and diagnostic explainability, particularly in specialized clinical applications. However, many of these approaches rely on proprietary datasets or require substantial computational resources, limiting their reproducibility and accessibility. By contrast, our study benchmarks widely adopted and computationally efficient models using a publicly available, real-world dataset to support scalable and reproducible research. We have expanded our literature review to incorporate recent state-of-the-art (SOTA) efforts and recognize the importance of evaluating these newer architectures in future work to further advance the field.
In addition to model selection, dataset composition and label consistency present challenges in mental health classification. The dataset used in this study was compiled from multiple publicly available sources, which, while beneficial for enhancing linguistic diversity, also introduced inconsistencies in class labels. Since each dataset was originally created for different research purposes, class boundaries may not be clearly defined when combined. This issue likely contributed to increased misclassification rates in the multi-class setting, particularly in categories with overlapping linguistic features such as depression, stress, and suicidal ideation.
Beyond label inconsistency, we also acknowledge that while the dataset draws from multiple social media platforms and reflects a range of linguistic styles and user experiences, certain demographic or platform-specific biases may persist. Future work should consider incorporating a broader set of data sources and populations to improve fairness and generalizability across diverse user groups. The presence of ambiguous class definitions suggests that future studies should consider collecting data directly from social media platforms using standardized labeling criteria. By ensuring greater consistency in data annotation, researchers can improve model generalizability and reduce classification errors.
Class imbalance was another practical consideration during model development. Although we initially experimented with resampling techniques such as SMOTE and random oversampling, we found that these methods often degraded model performance-particularly for LightGBM, which is sensitive to synthetic inputs due to its leaf-wise growth strategy. Furthermore, the selected dataset exhibited a moderate imbalance ratio of approximately 1:2 between normal and combined abnormal classes, which did not warrant aggressive rebalancing strategies. As a result, we excluded oversampling-based results from the final analysis and instead relied on class weighting and metric-based evaluation (e.g., weighted F1 score and AUC) to ensure robustness across models.
Another limitation relates to annotation quality. Given the subjective nature of mental health expressions, the reliability of pre-existing labels in publicly available datasets can be uncertain. Manual verification of labels by domain experts could improve classification accuracy, but such an approach is time-consuming and resource-intensive. As an alternative, future work could explore Artificial Intelligence-assisted annotation strategies to enhance labeling consistency. Advances in natural language processing, particularly in large language models, offer opportunities for developing semi-automated annotation systems that incorporate human-in-the-loop validation. By combining automated text classification with expert oversight, researchers could create more comprehensive and reliable datasets for mental health detection.
The ethical implications of using social media data for mental health research warrant careful consideration. While such datasets offer valuable insights into psychological well-being, they often contain sensitive information and may include mislabeled content, potentially leading to misinterpretation of users’ mental states. Privacy-preserving techniques, such as anonymization and differential privacy, should be explored to protect user identities while retaining essential linguistic information. Although the dataset used in this study is publicly available and aggregated from multiple online sources, it was not originally collected with explicit user consent for clinical or research purposes. This raises broader ethical questions regarding the secondary use of user-generated content in sensitive domains. Additionally, the risk of model misclassifications-such as false positives that may cause undue concern, or false negatives that may delay necessary intervention-underscores the importance of responsible deployment and human oversight. Future research should prioritize the development of ethical frameworks addressing privacy, consent, and model transparency to support the socially responsible application of AI in mental health detection.
The findings from this study also have implications for real-world deployment of mental health detection tools. Models with high interpretability and low computational demands, such as logistic regression and random forests, may be especially valuable in resource-constrained settings, such as non-profit organizations or educational institutions, where transparency and efficiency are critical. These models can be integrated into digital platforms to assist with early detection of psychological distress, support triage in online mental health services, or flag high-risk content for further review by trained professionals. While deep learning models may be more suitable for large-scale deployments or embedded systems with greater computational resources, their limited transparency may hinder clinical integration without additional explainability layers. It is important to emphasize that such models should not be used for diagnosis, but rather as supportive tools to augment human decision-making and facilitate timely intervention. Future work should explore stakeholder needs and system-level integration pathways to ensure these technologies are ethically and effectively deployed.
This study is also limited in its ability to capture temporal and contextual variations in social media language use. Patterns of communication, terminology, and expressions evolve rapidly in online environments, influenced by cultural trends, emerging slang, or platform-specific behaviors. Our analysis was based on a static, cross-sectional dataset aggregated from multiple sources, without time-stamped annotations or consideration of temporal dynamics. As a result, we could not assess how model performance might change in response to evolving language use over time. Future research would also benefit from longitudinal studies or continuous learning frameworks that monitor model stability, track linguistic shifts, and adapt classification systems to maintain effectiveness in real-world mental health detection as language and social context evolve.
In summary, this study provides a comparative analysis of ML and DL models for mental health classification on social media, highlighting key considerations in accuracy, interpretability, and computational efficiency. The findings suggest that ML models remain a practical and interpretable choice for small to medium-sized datasets, while DL models may offer advantages when working with larger data volumes. Among ML models, logistic regression is particularly useful for its ability to distinguish between positive and negative feature importance, offering valuable insights into linguistic markers associated with mental health conditions. However, researchers should remain mindful of model assumptions and dataset inconsistencies, which can impact classification performance. Moving forward, efforts to improve data collection, annotation quality, and ethical considerations will be essential for advancing AI-driven mental health detection and ensuring that these models contribute to more effective, transparent, and responsible research practices.
Data availability
This study utilized the Sentiment Analysis for Mental Health dataset, available on Kaggle. Link: https://www.kaggle.com/datasets/suchintikasarkar/sentiment-analysis-for-mental-health/data.
Code availability
The programming code of this manuscript is hosted on GitHub. Link: https://github.com/VVVVVOID/Tutorial-on-Using-Machine-Learning-and-Deep-Learning-Models-for-Mental-Illness-Detection.
Change history
20 June 2025
The original online version of this Article was revised: In the original version of this Article Yuchen Cao & Xiaorui Shen were incorrectly affiliated with ‘Department of EECS, University of California, Berkeley, Berkeley, USA’, Yexin Tian was incorrectly affiliated with ‘Khoury College of Computer Science, Northeastern University, Boston, USA’ and Jianglai Dai was incorrectly affiliated with ‘College of Computing, Georgia Institute of Technology, Atlanta, USA’. The affiliation list in the original article has been corrected.
Notes
The gamma parameter determines the influence of individual training samples, where higher values result in more localized decision boundaries, while lower values promote broader generalization.
References
WHO. Mental disorders (2023). Retrieved February 9, 2025.
Kessler, R. C. et al. Trauma and ptsd in the who world mental health surveys. Eur. J. Psychotraumatol. 8, 1353383 (2017).
Guntuku, S. C., Yaden, D. B., Kern, M. L., Ungar, L. H. & Eichstaedt, J. C. Detecting depression and mental illness on social media: An integrative review. Curr. Opin. Psychol. 18, 43–49 (2017).
De Choudhury, M., Counts, S. & Horvitz, E. Social media as a measurement of depression in populations. In Proceedings of the ACM Annual Web Science Conference, 47–56 (New York, NY, USA, 2013).
Shatte, A., Hutchinson, D. M. & Teague, S. J. Machine learning in mental health: A scoping review of methods and applications. Psychol. Med. 49, 1426–1448 (2019).
Elkenawy, E. et al. Greylag goose optimization and multilayer perceptron for enhancing lung cancer classification. Sci. Rep. 14, 23784. https://doi.org/10.1038/s41598-024-72013-x (2024).
Alkhammash, E. H. et al. Application of machine learning to predict covid-19 spread via an optimized bpso model. Biomimetics 8, 457. https://doi.org/10.3390/biomimetics8060457 (2023).
Tarek, Z., Alhussan, A. A., Khafaga, D. S., El-Kenawy, E.-S.M. & Elshewey, A. M. A snake optimization algorithm-based feature selection framework for rapid detection of cardiovascular disease in its early stages. Biomed. Signal Process. Control 102, 107417. https://doi.org/10.1016/j.bspc.2024.107417 (2025).
Elshewey, A. M. et al. Optimizing hcv disease prediction in egypt: The hyoptgb framework. Diagnostics 13, 3439. https://doi.org/10.3390/diagnostics13223439 (2023).
Alzakari, S. A. et al. Early detection of potato disease using an enhanced convolutional neural network-long short-term memory deep learning model. Potato Res. https://doi.org/10.1007/s11540-024-09760-x (2024).
Dalal, S. et al. A cross attention approach to diagnostic explainability using clinical practice guidelines for depression. IEEE J. Biomed. Health Inf.. (2024).
Dalal, S., Jain, S. & Dave, M. Deep knowledge-infusion for explainable depression detection (2024). ArXiv preprint, arXiv:2409.02122.
Cao, Y. et al. Machine learning approaches for depression detection on social media: A systematic review of biases and methodological challenges. J. Behav. Data Sci. 5, 1–25. https://doi.org/10.35566/jbds/caoyc (2025).
Hargittai, E. Is bigger always better? potential biases of big data derived from social network sites. Ann. Am. Acad. Pol. Soc. Sci. 659, 63–76 (2015).
Helmy, A., Nassar, R. & Ramdan, N. Depression detection for twitter users using sentiment analysis in english and arabic tweets. Artif. Intell. Med. 147, 102716 (2024).
Calvo, R. A., Milne, D. N., Hussain, M. S. & Christensen, H. Natural language processing in mental health applications using non-clinical texts. Nat. Lang. Eng. 23, 649–685 (2017).
Liu, Y. et al. A systematic review of machine learning approaches for detecting deceptive activities on social media: Methods, challenges, and biases. arXiv, arXiv:2410.20293 (2024).
Chen, Y., Zhao, C., Xu, Y. & Nie, C. Year-over-year developments in financial fraud detection via deep learning: A systematic literature review (2025). arXiv:2502.00201.
Bird, S., Klein, E. & Loper, E. Natural Language Processing with Python (O’Reilly Media Inc., 2009).
Harris, Z. S. Distributional structure. In Word, vol. 10, 146–162 (Taylor & Francis, 1954).
Jones, K. S. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 28, 11–21. https://doi.org/10.1108/eb026526 (1972).
Hosmer, D. W. & Lemeshow, S. Applied Logistic Regression (John Wiley & Sons, Inc., New York, NY, 2000), second edition edn.
Cortes, C. & Vapnik, V. N. Support-Vector Networks, vol. 20 (Springer, 1995).
Bishop, C. M. Pattern Recognition and Machine Learning (Springer, 2006).
Breiman, L., Friedman, J. H., Olshen, R. A. & Stone, C. J. Classification and Regression Trees (Wadsworth & Brooks/Cole Advanced Books & Software, Monterey, CA, 1984).
Breiman, L. Random Forests, vol. 45 (Springer, 2001).
Ke, G. et al. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), 3149–3157 (2017).
Friedman, J. H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 29, 1189–1232 (2001).
Lan, Z. et al. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint, arXiv:1909.11942 (2020).
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint, arXiv:1810.04805 (2019).
Cho, K. et al. Learning phrase representations using rnn encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1724–1734 (2014).
Bradford, A., Meyer, A., Khan, S., Giardina, T. D. & Singh, H. Diagnostic error in mental health: a review. BMJ Qual. Saf. 33, 663–672 (2024).
Powers, D. M. Evaluation: From precision, recall and f-measure to roc, informedness, markedness and correlation. J. Mach. Learn. Technol. 2, 37–63 (2011).
Davis, J. & Goadrich, M. The relationship between precision-recall and roc curves. In Proceedings of the 23rd International Conference on Machine Learning, 233–240 (ACM, 2006).
Guyon, I., Weston, J., Barnhill, S. & Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 46, 389–422 (2002).
Chang, C.-C. & Lin, C.-J. Libsvm: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2, 1–27 (2011).
Mosca, E., Szigeti, F., Tragianni, S., Gallagher, D. & Groh, G. Shap-based explanation methods: A review for nlp interpretability. In Proceedings of the 29th International Conference on Computational Linguistics (COLING), 4593–4603 (International Committee on Computational Linguistics, Gyeongju, Republic of Korea, 2022).
Author information
Authors and Affiliations
Contributions
Y.Z., Z.D., Y.C., and Z.W. contributed to data cleaning and model training. Y.C., X.S., and Y.T. drafted the main manuscript text, while J.D. and Y.L. prepared all figures and tables. All authors reviewed and edited the manuscript. Additionally, Y.C. and Z.W. oversaw project administration, and Y.Z. and Z.D. contributed to the development of the methodology.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ding, Z., Wang, Z., Zhang, Y. et al. Trade-offs between machine learning and deep learning for mental illness detection on social media. Sci Rep 15, 14497 (2025). https://doi.org/10.1038/s41598-025-99167-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-99167-6
Keywords
This article is cited by
-
Personalized mental health interventions through ML-based depression and QoL assessment
International Journal of Information Technology (2026)
-
A systematic review of machine learning approaches for detecting deceptive activities on social media: methods, challenges, and biases
International Journal of Data Science and Analytics (2025)
