
Abstract
Load balancing (LB) is a critical aspect of Cloud Computing (CC), enabling efficient access to virtualized resources over the internet. It ensures optimal resource utilization and smooth system operation by distributing workloads across multiple servers, preventing any server from being overburdened or underutilized. This process enhances system reliability, resource efficiency, and overall performance. As cloud computing expands, effective resource management becomes increasingly important, particularly in distributed environments. This study proposes a novel approach to resource prediction for cloud network load balancing, incorporating federated learning within a blockchain framework for secure and distributed management. The model leverages Dilated and Attention-based 1-Dimensional Convolutional Neural Networks with bidirectional long short-term memory (DA-DBL) to predict resource needs based on factors such as processing time, reaction time, and resource availability. The integration of the Random Opposition Coati Optimization Algorithm (RO-COA) enables flexible and efficient load distribution in response to real-time network changes. The proposed method is evaluated on various metrics, including active servers, makespan, Quality of Service (QoS), resource utilization, and power consumption, outperforming existing approaches. The results demonstrate that the combination of federated learning and the RO-COA-based load balancing method offers a robust solution for enhancing cloud resource management.
Similar content being viewed by others

Introduction
Cloud computing (CC) has transformed the way computing resources and services are provided, offering flexibility, scalability, and cost-efficiency. It allows users to access software, hardware, and network resources via the internet without the need for owning physical infrastructure. The core idea behind CC is that “everything can be served” online, enabling businesses and individuals to use resources on-demand through models such as Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and software as a service (SaaS)1. Among these, IaaS has become prominent as it provides essential computing infrastructure like data storage, computing power, and networking. Virtualization technology plays a critical role in IaaS by enabling the deployment of applications on Virtual Machines (VMs), which allows users to run their applications without needing to manage physical hardware, reducing costs significantly2. Additionally, the pay-as-you-go model offered by CC makes it an appealing solution for scaling operations while controlling costs.
As the adoption of CC has grown, so too have the challenges associated with managing its resources. One of the most critical challenges is load balancing (LB), a technique that ensures workloads are distributed evenly across cloud resources to prevent any single node from becoming overwhelmed while others remain underutilized3. Effective LB is crucial for maintaining high performance, reducing latency, and ensuring optimal resource utilization in cloud networks. Traditional LB methods, which often rely on static resource allocation, are increasingly becoming insufficient in handling the dynamic and fluctuating nature of cloud workloads. Modern CC systems require adaptive LB solutions capable of real-time resource management to meet the performance demands of today’s internet-driven services4. In addition to virtualization, blockchain technology has emerged as a complementary solution within cloud computing, addressing some of the key challenges related to data integrity and security. The decentralized nature of blockchain, with its immutable data structure and hashing mechanisms, ensures that each block of data is securely linked to the previous one, forming a chain that can be easily verified for accuracy5. This ability to ensure the integrity of stored data makes blockchain a powerful tool in enhancing cloud storage and computing services.
The growth of CC has been driven by the massive increase in internet usage and the diverse range of users with various needs, from individuals to large enterprises. This widespread adoption necessitates the provision of scalable resources—whether software, hardware, or network-based—via the internet. With increased demand, CC structures must not only provide resources efficiently but also control costs while avoiding overloading of data centers6. Data centers play a crucial role in managing cloud resources, and resource utilization is vital for ensuring optimal LB, which, in turn, enables smooth operation across servers and networks. Various LB techniques have been developed over the years to address these challenges. For instance, Saxena et al.7 proposed an Online Prediction-Based Multi-Objective LB (OP-MLB) model that utilizes multi-objective optimization to reduce power consumption and increase resource utilization. However, the model is limited in terms of reliability-based allocation. Kishor et al.8 introduced a system called Latency and Energy-Aware Load Balancing Scheme (LEWIS), which efficiently manages computation resources but faces challenges with optimization objectives. Other methods, such as the two-stage genetic approach by Hung et al.9 for Virtual Machine Hosts (VMH), offer improved decision-making for resource allocation but are limited by the applicability of diverse algorithm models.
Recent advancements include Shen and Chen’s Resource Intensity Aware LB (RIAL) model10, which improves communication cost and minimizes performance degradation. However, scalability and effectiveness trade-offs remain challenges in this model. Meanwhile, ensemble techniques like the Pigeon Inspired Optimization (PIO) and Harries Hawks Optimization (HHO) proposed by Poornima et al.11 have shown significant improvements in latency, computational time, and cost, but complexity issues arise with these methods. Other models, such as the Fractional Dragonfly Based LB Algorithm (FDLA) developed by Kumar et al.12, leverage VM and task selection probabilities to optimize task reallocation, but they still face challenges in task migration and real-time performance optimization. Additionally, research has explored metaheuristic approaches to optimize LB. For example, Kaur et al.13 implemented heuristics and metaheuristics to improve task migration, while Wu et al.14 developed a cloud-edge-end architecture to optimize load distribution in electric load management. Other innovative approaches, like Kaviarasan et al.’s Improved Lion Optimization Meta-Heuristic Approach (ILOMHA)15, improve exploration and exploitation capabilities but lack fault tolerance in cloud networks. Given the advancements and challenges in classical LB approaches, there is a clear need for innovative methods that can address these limitations. As cloud networks grow more complex, the introduction of predictive models for LB becomes essential for improving system efficiency. In this paper, a novel framework is proposed to enhance LB and resource prediction in cloud networks using federated learning, which enables distributed machine learning without compromising data privacy. This approach aims to improve resource utilization, system reliability, and scalability in cloud environments. Table 1 highlights some of the major advancements and restrictions in classical LB models, providing a comparison of their features and challenges.
The key objectives of the proposed study are as follows:
-
To develop a novel framework for effective resource prediction and LB in cloud networks using federated learning, improving network stability and reliability.
-
To design a DA-DBL model that combines dilated and attention-based 1D-CNN with Bi-LSTM for accurate resource prediction in cloud networks.
-
To propose the RO-COA method, which modifies traditional Cuckoo Optimization Algorithm (COA) for optimal load balancing, ensuring that predicted resources meet required constraints.
-
To evaluate the efficiency of the introduced system by comparing it with existing optimization methods in terms of performance metrics like resource utilization, scalability, and response time.
The remainder of this paper is organized as follows. Sect “Novel framework of resource prediction and load balancing in cloud sector: heuristic-based federated learning” outlines the proposed framework for resource prediction and load balancing in cloud networks. Sect “Federated learning: dilated and attention-based 1DCNN with Bi-LSTM layer for predicting the resources used in cloud” describes the DA-DBL resource prediction model, and Sect “Load balancing mechanism using proposed RO-COA in cloud and objective function” details the LB mechanism using the developed RO-COA approach. The results and analysis of the proposed model are presented in Sect “Results and discussions”, followed by a summary of the findings in Sect “Conclusion”.
Novel framework of resource prediction and load balancing in cloud sector: heuristic-based federated learning
Proposed system of resource prediction and load balancing
In recent years, cloud computing (CC) has gained significant popularity due to its ability to provide greater availability and flexibility of computing resources at a low cost. CC offers on-demand delivery of services and resources over the internet. A major factor contributing to the operational cost of the CC network is energy consumption. Effective load balancing is crucial for minimizing energy consumption and ensuring quality of service (QoS). Various types of cloud environments, such as public, private, and hybrid clouds, have been developed, with scalability being one of CC’s most important features. With the rapid growth in cloud services, cloud LB has emerged as a critical research area. Additionally, the physical distance between the cloud server and the user introduces challenges such as limited security, uncertainty in service reliability, high latency, and privacy concerns. Tasks executed on the cloud server may also struggle to meet latency requirements. Methods such as Particle Swarm Optimization (PSO), hash methods, genetic algorithms (GAs), and scheduling-based algorithms have been developed to address these challenges. Although CC offers many attractive features, it also faces challenges related to traditional security methods and controls. One of the main issues in resource management is handling the heterogeneity that arises in hardware, data, software, and communication technologies, as well as addressing fault tolerance. The developed RO-COA approach aims to overcome these issues, and the system’s structure is shown in Fig. 1.

Graphical representation of developed effective LB and resource prediction in cloud network.
In cloud optimization, the federated learning scheme introduces effective LB. Resource prediction is the major desire of the model based on the processing time, resource availability and reaction time using the federated learning. Between the result of transaction level for the presented scheme in the effective protection, the deep trust created by the distributed blockchain simultaneously. For resource prediction, the developed DA-DBL is used as the federated learning. In CC, the RO-COA performs for tuning the parameters for the LB aspect. For further examination, the effectiveness of the suggested model is considered by the diverse constraints like makespan, resource utilization, active server, power consumption and QoS. The diverse parameters validate the model’s performance and are compared against the managed methodologies. The result demonstrates that the suggested model attains better cloud optimization outcomes for efficient LB with a federated learning model.
Details of input attributes
The proposed model is built on multiple resource attributes that vary depending on demand. These attributes serve as input for LB and resource prediction. Key inputs include the available memory and CPU, processing time, reaction time, and CPU clock speed. Additionally, the model considers the memory and CPU requirements for all tasks, as well as the completion time of each task. These attributes together provide a comprehensive view of the system’s resources, enabling more accurate predictions and efficient load balancing.
Federated learning-based resource prediction and load balancing
Federated learning is the new insertion to split machine learning16, which focuses on training across multiple local datasets in the servers with local data samples without sharing the data. Therefore, critical issues were addressed, such as data security, privacy and access. This developed federated learning is opposite to the classical centralized process. Here the data are sent to a centralized server and the local samples are distributed identically for resource prediction. The basic design of federated learning in resource prediction contains exchanging parameters and local data samples, which trains the local to generate the global method17. The centralized server that federated learning uses adapts the different steps and acts as a reference without a centralized server. The process of federated learning is split into different rounds. Here the local training, the parameters are computed by the local network and then moved to the inner network. In recent aggregating, the secure aggregation was performed by the central server of the uploaded parameter without local information. In parameter broadcasting, the aggregated parameters are broadcast by the central network to the local network. The respective models updated by the local server with received parameters and the updated model performance were examined for resource prediction in the model updating18,19.
The major benefit of using federated learning is, the participating domine guaranteed by the federated learning and it directly learns from the separated domain data and updates the model only with participants20. Also, federated learning has the quality such as differential privacy and secure aggregation for data encryption to protect the information. Federated learning also minimizes the bandwidth network, because during the training process the model parameters are sent to the centralized aggregator. For resource prediction with the given demand attributes, two techniques 1 DCNN and Bi-LSTM are adopted which are explained below. Figure 2 shows diagrammatic view of the federated learning where all devices train their models independently using their own data, with the only data shared being updates to the models. This decentralised approach allows for more flexibility and efficiency. Since raw data is never transferred outside of the device, this method improves privacy and security. After collecting all of the changes, the central server creates a global model. Then, it redistributes it to the devices so they can continue training. When it comes to load balancing and resource prediction, federated learning makes it possible to efficiently use local training data to forecast resource needs. The system is able to do dynamic load balancing by anticipating the resource needs of each device. This prevents any one device from being overloaded, which improves overall performance and makes better use of resources.

Diagrammetic view of federated learning for resource prediction and load balancing.
Federated learning: dilated and attention-based 1DCNN with Bi-LSTM layer for predicting the resources used in cloud
One-dimensional CNN
The basic Convolutional Neural Network (CNN)21 is the convolution operation sustained out in the place of convolutional layers. 1DCNN is employed here to predict the resources in the cloud network, where the data attributes act as input. The 1DCNN22 method runs on the identical policy; the main change is the input and filter size. 1DCNN contain 5 × 1 input vector acted upon by another 1DCNN 3 × 1 weight vector. The 3 × 1 vectors work on a 3 × 1 section of input as it progresses to produce a 3 × 1 output vector.
Accordingly, the weight vector is mentioned as \(\mathop X\limits^{ \to }\) of the dimension \(s \times 1\) behaves on the input vector \(\mathop U\limits^{ \to }\) and the convolution output \(a\) is explained in Eq. (1)
Here \(q\) is the present place of the weight vector to provide the output value vector. \(*\) Denotes the weight vector; element-wise multiplication with the input comes after obtained value total. The implementation of the operation described in Eq. (2)
The value \(a\) is the filter moving over the input from the input to the reference layer. Each weight vector is responsive after the parameters training to specify the binary feature. These accessible fields are determined by the factors of sequence command taken from the binaries out to work instruction sub-sequence detectors. The weight vector conventional layer with the dimension 3 × 1 is used as a tri-gram sensor.
The activation layer conventionally works with the previous convolutional layer by appealing a certain function to the output vector. Rectified Linear Unit (ReLU) is utilized by the detector as an activation function. At the end of the architecture, the dense layer is placed, and input is received from the previous layers. In terms of functionality, these layers are identical to traditional multi-layer perception. In the 1DCNN, the dense layer serves as the last phase for the parametric procedure in advance of the class chances being developed. The architectural view of the IDCNN is shown in Fig. 3.

Architectural view of 1DCNN.
Bi-directional LSTM
In the Bi-directional LSTM, one LSTM model is taken for the further direction, and the other for the reverse direction which forms Bi-LSTM. The data fed from beginning to end and end to start helps the Bi-LSTM to recall information, which helps in better prediction. The three gates in the LSTM blocks are input, output and forget gate, which help to read, write and reset the operation. To predict an element, Bi-LSTM23 carries information from the past and future. The mathematical model for the Bi-LSTM is defined in Eqs. (3), (4)
Here \(c\) is each hidden layer with bias, \(y\) the input value, the weight added on each hidden layer, and each neuron output value. \(Activation1\) represent the “input and hidden layer” and \(Activation2\) indicates the output layer. Figure 4 shows the Bi-LSTM view.

Diagrammatic view of Bi-LSTM.
DA-DBL for prediction
To increase resource prediction and LB, the DA-DBL is proposed, which is formed by the 1DCNN and Bi-LSTM. The classification operation and feature extraction are merged in a single process optimized to improve the classification performance.
Dilated and attention 1DCNN: The dilated 1DCNN is also called expended convolution, it replaces the traditional 1DCNN operation by initiating the expansion ratio, which can retain completely the information from the feature in the original signal so that the 1DCNN of similar size can be obtained larger in the respective field. 1DCNN utilizes the attention layer to process the features respectively. The attention layer summarizes the input from various modalities into embeddings. Instead of organizing and selecting features manually, the 1DCNN with an attention mechanism can learn the important characteristics of the sentenced input. The dilated 1DCNN model is merged with Bi-LSTM for the result, in which the FC layer of 1DCNN is replaced with the Bi-LSTM formation. Finally, the output layer of Bi-LSTM provides the resource-predicted results.
The major advantages are low computational complexity and the application where the labeled data for training is “scarce and low-cost”; all-time implementation is needed. Bi-LSTM extracts the long-distance dependant features, connecting all the hidden layers to the same output layers. Likewise, both technique has their limitations, such as; for the computation, it requires special hardware for training purposes. To conquer the restrictions and to increase the performance, DA-DBL is suggested, and the effectiveness is improved by introducing the parameters as shown in Eq. (5)
RMSE often uses elements of the changes between the determined ranges by the calculator and the observed values24, which being derived in Eq. (6)
MAE is mentioned as the evaluation of errors between the true value and the evaluated observation25, and it is computed in Eq. (7)
Here, the observed and predicted values are explained as \(z\,\) and \(y\) accordingly. The overall dimension and the fitted points are pointed as \(p\) and \(q\) respectively.
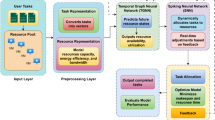
The DA-DBL system enhances prediction accuracy by integrating data augmentation approaches with dynamic Bayesian learning as shown in below Fig. 5. Preprocessing involves gathering data from multiple sources, cleaning it up, and adding missing or inaccurate values to the dataset. The Bayesian learning model receives the preprocessed data as input, and it uses feature extraction to adapt to incoming data by dynamically updating its parameters. To better distribute resources and balance network loads, the trained model makes predictions about future situations.

Structural representation of developed DA-DBL for prediction.
Load balancing mechanism using proposed RO-COA in cloud and objective function
Random opposition of Coati Optimization algorithm
From the traditional COA procedure, RO-COA is derived. Regular coat is behavior is enabled by the COA algorithm. The coati’s design was inspired by hunting iguanas and running away from predators. No standard algorithm parameter is one benefit of the general COA. It handles optimization issues better and balances search process research. The COA outperforms ISWO26 and BIQIO27 in computational efficiency. ISWO and BIQIO cannot improve energy efficiency in cloud networks or tackle multi-dimensional problems. This research utilizes the Cuckoo Optimization Algorithm (COA) for cloud load balancing to address the aforementioned issues. However, challenges remain, such as reducing the search method complexity and computational overhead. The article Forest Optimization Algorithm from Expert Systems with Applications28 was inspired by the natural growth of forest trees and is widely recognized for solving complex optimization problems. Similarly, in Cuckoo Search Optimization29, the authors demonstrate the adaptability and effectiveness of the algorithm in addressing engineering challenges by modeling the reproductive behavior of cuckoo birds. Additionally, the comprehensive analysis of Convolutional Neural Networks (CNN)30,31 highlights their importance in image and pattern recognition. The model’s performance with noisy data shows that attention mechanisms can significantly improve load detection systems. These studies present innovative models and techniques for solving real-world problems, ranging from machine learning applications to optimization challenges. Their findings underscore the need for ongoing research and development to enhance the reliability and performance of various computing systems and applications. To overcome the limitations of COA, such as its randomness in number generation, we propose a new algorithm, RO-COA, which aims to improve the objective function value, as formulated in Eq. (8).
Term CF represent the current fitness, BF is the best fitness and WF is the worst fitness. The functionality of the classical COA technique is explained below.
COA32: Coatis are omnivores from the Procyonidae family group called Nasuella and Nasua. It has a lean head with an extended flexible upward, turned nose. Coatis is the size of a big house cat, and the weight ranges between 2 and 8 kgs. Male coatis are double the size of females. They eat invertebrates, small vertebrate prey. One of their favorite foods is green iguana found on trees; coats hunt them in groups. Some of the coati climb on the tree and attack the iguanas; when they fall down the group of coatis attack them immediately. Predators like foxes, dogs, wolves, jaguars and anacondas also attack coatis. The behaviour of the coatis while hunting the iguanas and escaping from the predators is an intelligent process and serves as COA’s inspiration.
It is the population-based metaheuristic algorithm in which the coatis are known for population members. In the search space, every coati position demonstrates the decision variable values. Hence the candidate solution indicated by the coatis to the problem in the COA. The position of the coatis is randomly initialized at the beginning of the COA using Eq. (9).
Here \(Z_{k}\) is the \(k^{th}\) place of the coati in the search space. \(z_{k,l}\) is the \(l^{th}\) decision range variable. \(P\) is the quantity of coatis, \(o\) the number of decision variable, and the real random number in the range [0, 1]. \(nd_{l}\) and \(wd_{l}\) are the \(l^{th}\) decision value variables lower and upper bound. The coati’s COA population is mathematically represented using Eq. (10).
The evaluation of the different values leads by the candidate solution in decision variables for the objective function problem. These values are equated in Eq. (11)
Here \(H\) is the objective function vector, \(H_{k}\) is the range of the objective function based on the \(k^{th}\) coati. The quality of the candidate solution is measured from the proposed COA. The evaluation led by the member of the population is the best value for the objective function. The applicant solution is updated during the algorithm iteration, and the population’s best member is updated in each iteration.
Exploration phase: For attacking the iguanas, each search space of the coati’s population is modelled based on the strategy of updating the first phase. A group of coatis climbs the tree while others are waiting under the tree to attack and hunt the fallen iguanas. The position of the iguana is assumed by the position of the great member of the population in the COA framework. The coatis which climb the tree are simulated mathematically using Eq. (12)
To find the choice variable’s value, the "random real number" is optimized here. Once the iguana has fallen, it will be somewhere in the search space at random. Equations (13) and (14) are equivalent for ground-dwelling coatis that migrate to the search space based on the random position.
The new position is calculated for each coati, and the update procedure increases the range of the objective function, or else, the coati endures in the same position. This new condition for \(k = 1,2, \ldots ,P\) simulated in Eq. (15)
Here \(Z_{k}^{R1}\) is the calculated coati’s new position \(z_{k,l}^{R1}\) is the \(l^{th}\) dimension of \(H_{k}^{R1}\). \(Iguana\) indicates the position of the iguana in the search space”, it also shows as best member position.
Exploitation phase: Escaping from predators and updating position is a coati’s trait. When an animal attacks on coatis, it moves to the nearest safe place as soon as possible. The random position is generated near each coati’s position is simulated in Eq. (16) and (17).
If the newly calculated position improves the objective function, then the condition is simulated using Eq. (18)
Here \(Z_{k}^{R2}\) is the \(k^{th}\) coati’s new position, based on the COA, \(Z_{k,l}^{R2}\) is the \(l^{th}\) dimension, \(H_{k}^{R2}\) is the objective function value, respectively.
Load balancing using RO-COA
LB promotes network and resources by providing the highest throughput with less response time. Users could experience delays and long response times in the system without LB. Separating the traffic between the server helps the data timing without delay in sending and receiving. Load-balancing solutions generally apply redundant servers to better distribute the communication traffic. The cloud network depends on automatic LB services, in which entities increase the quantity of CPU or memory of the resource with the increased demand. The traditional data center implementation depends on powerful computing hardware and network architecture, which tends to cause regular issues associated with physical devices, such as network interruptions, resource limitations and hardware failure. The major intention is to provide regular service in case of any service failure component. However, it has challenges in implementation and operations. There are more complex in designing the LB and cause negative performance issues. In the proposed method, LB is optimized by the RO-COA for the effective analysis of the implemented technique. Here multiple constraints like active server, makespan, Quality of Service (QoS), resource utilization, and power consumption are examined when the predicted resource equals the demand. Or else a penalty is added to the objectives. The constraints were demonstrated in the below section.
Constraint specification
Active Server: To manage the extra workload, the number of active servers has to be reduced and referred to a host which makes power reduction simpler.
Makespan: This metric determines the high completion time. Compared with other metrics, makespan pays more attention to time constraints, which helps in calculating the real-time scheduling LB.
QoS: The QoS refers to the capacity to counter with quality for the user needs to impart a service as per necessary in terms of “response time, bandwidth, availability”, etc.
Resource Utilization: It determines resource utilization and optimizes for effective LB, and also assesses if a host is underutilized or overloaded. Resource utilization plays a crucial role in achieving optimal LB in Cloud operation.
Power Consumption: It determines the energy used by every node. LB assists in evading “overheating and minimizing energy consumption” by balancing the load.
Results and discussions
Experimental setup
The recommended efficient LB in cloud optimization with a federated learning technique was evaluated in Python, and the performance examination will be carried out. The designed model has four chromosome lengths, 50 maximum iterations and 10 population count. Multiple models were used, and the existing models, such as Tuna Swarm Optimization (TSO)23, Coati Optimization Algorithm (COA)32, Forest Optimization Algorithm (FOA)28, Cuckoo Search Algorithm (CSA)29 were utilized. Also, architectures such as CNN30, 1DCNN22, Bi-LSTM33 and DA-DBL34 were adopted.
Performance measures
The measurement applied for the assessment of system performance is explained below24. RMSE value is demonstrated in Eq. (6) and MAE in Eq. (7).
Mean of Percentage Errors (MEP) is equated by the variation between the estimated and actual values in Eq. (19)
Symmetric Mean Absolute Percentage Error (SMAPE) is a calculation of accuracy based on relative errors given in Eq. (20)
Mean Absolute Scaled Error (MASE) measures forecast correctness as shown in Eq. (21)
L1-Norm is determined by the total vector magnitude in the place is formulated in Eq. (22).
L2-Norm is defined as the optimal distance to move from one region to another is computed in Eq. (23).
L-Inf-Norm is estimated by the vector length that can be evaluated using the maximum Norm is determined in Eq. (24)
Here the term \(H\) is represented the matrix value.
Convergence analysis for the proposed optimization algorithm over distinct algorithms for resource prediction
Figure 6 compares the developed method’s cost function estimation to those of other techniques. In this case, the range of possible iterations is zero to fifty. The suggested approach reduces TSO by 91%, FOA by 88.5%, CSA by 92.5%, and COA by 90.5% when the cost function iteration value is 20. For this reason, we advocated a higher model convergence rate in order to achieve superior outcomes.

The cost function analysis of the proposed resource prediction model in a cloud network compared with other existing algorithms. TSO-DA-DBL tunicate swarm optimization with double adaptive deep belief network, FOA-DA-DBL fruit fly optimization algorithm with double adaptive deep belief network, CSA-DA-DBL crow search algorithm with double adaptive deep belief network, COA-DA-DBL cuckoo optimization algorithm with double adaptive deep belief network, RO-COA-DA-DBL random optimization-based cuckoo optimization algorithm with double adaptive deep belief network.
Comparing the suggested model statistically to other optimisation models
The statistical evaluation of the proposed DA-DBL has been done over different algorithms in Table 2. Taking the best measures improved the suggested model by 6.9% of TSO, 7% of FOA, 9.1% of CSA and 3.9% of COA. The analysis shows the efficient performance of the proposed model.
Evaluating the suggested model in comparison to other optimised models and classifiers for resource prediction
Figures 7 and 8 present a comparative analysis of the proposed model against various algorithms and classifiers. Figure 7 illustrates the results of comparing the developed model for resource prediction with other traditional models, evaluated using several performance metrics: Mean Error Percentage (MEP), which measures the average prediction error as a percentage; Symmetric Mean Absolute Percentage Error (SMAPE), assessing accuracy while accounting for the scale of values; Mean Absolute Scaled Error (MASE), providing a relative measure of errors; Mean Absolute Error (MAE), indicating the average absolute differences between predicted and actual values; Root Mean Square Error (RMSE), highlighting the model’s predictive accuracy by penalizing larger errors; L1-Norm, summing the absolute differences to measure prediction deviation; L2-Norm, summing the squares of differences to emphasize larger deviations; and L-Infinity Norm (L-Inf-Norm), focusing on the maximum absolute error to assess worst-case performance. The developed model demonstrated superior accuracy, reliability, and robustness in predicting future resource needs compared to conventional models across all these measures. Figure 7 specifically illustrates the RMSE measurement, showing that, when using the ReLU activation function, the proposed method achieved reductions of 1.8% over TSO, 1.4% over FOA, 1.6% over CSA, and 1.9% over COA. The introduced model exhibited lower values than other existing algorithms. In Fig. 8, the performance of the proposed model for load balancing and resource prediction is compared against other classifiers using various metrics. These results show that the proposed model is more accurate and efficient than traditional classifiers across these measures.

Comparative evaluation of developed model for resource prediction compared with multiple traditional models in terms of MEP, SMAPE, MASE, MAE, RMSE, L1-Norm, L2-Norm and L-Inf-Norm.

Comparative evaluation of a proposed model for resource prediction and load balancing compared with multiple classifiers in terms of MEP, SMAPE, MASE, MAE, RMSE, L1-Norm, L2-Norm and L-Inf-Norm.
Figure 9 demonstrates the cost function analysis of the suggested method in contrast with various algorithms. Here the number of iterations varies from 0 to 50. When the iteration value is 10 for the cost function, the developed method decreases by 75% of TSO, 76% of FOA, 75% of CSA and 80% of COA. Hence the implemented method has a convergence rate increased to impart better results.

The cost function analysis of proposed load balancing in cloud network compared with other existing algorithms.
Conclusion
The RO-COA paradigm enhances resource management in cloud networks by utilizing resource prediction and load balancing techniques. Federated learning alters the characteristics of demand in order to develop configurations for resource prediction. This approach safely and distributed collects data from numerous sources, ensuring privacy and model robustness. The resource prediction step use the characteristics. The optimization of specific features depends on the use of DA-DBL (Data Augmentation-Dynamic Bayesian Learning). In order to optimize the accuracy of predictions, hyperparameters are adjusted to decrease the root mean square error (RMSE) and mean absolute error (MAE). The Cuckoo Optimization Algorithm (COA) is employed for Resource Optimization (RO-COA) to enhance system efficiency by ensuring load balancing. This model verifies the anticipated distribution of resources in relation to predetermined constraints. In order to guarantee that the system acquires knowledge and adjusts itself for the best possible performance, any predictions that surpass these limitations are subject to penalties. Real-time adaptation is essential for achieving optimal performance and dependability in a cloud environment characterized by unpredictable demand. The enhanced accuracy of resource forecasting and workload balancing in the model is seen through the reduction in RMSE. This comprehensive investigation demonstrates that the suggested approach is superior in terms of efficiency compared to traditional solutions. The full solution for cloud network resource prediction and management includes federated learning for feature extraction, DA-DBL feature optimization, and strong RO-COA load balancing. This multifaceted approach enhances the precision of predictions, the efficiency of systems, the ability to adapt, and the scalability, so establishing it as a potent instrument for managing cloud resources.
Data availability
All data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Goyal A, Kanyal HS, Kaushik S, Khan R. IoT based cloud network for smart health care using optimization algorithm. Inform. Med. Unlocked 27, (2021).
Javadi, S. A. & Gandhi, A. User-centric interference-aware load balancing for cloud-deployed applications. IEEE Trans. Cloud Comput. 10, 736–748 (2022).
Nezami, Z., Zamanifar, K., Djemame, K. & Pournaras, E. Decentralized edge-to-cloud load balancing: Service placement for the internet of things. IEEE Access 9, 64983–65000 (2021).
Shafiq, D. A., Jhanjhi, N. Z., Abdullah, A. & Alzain, M. A. A load balancing algorithm for the data centres to optimize cloud computing applications. IEEE Access 9, 41731–41744 (2021).
Kathole, A. B. et al. Secure federated cloud storage protection strategy using hybrid heuristic attribute-based encryption with permissioned blockchain. IEEE Access https://doi.org/10.1109/ACCESS.2024.3447829 (2024).
Gamal, M., Rizk, R., Mahdi, H. & Elnaghi, B. E. Osmotic bio-inspired load balancing algorithm in cloud computing. IEEE Access 7, 42735–42744 (2019).
Saxena, D., Singh, A. K. & Buyya, R. OP-MLB: An online VM prediction-based multi-objective load balancing framework for resource management at cloud data center. IEEE Trans. Cloud Comput. 10, 2804–2816 (2022).
Kishor, A., Niyogi, R., Chronopoulos, A. T. & Zomaya, A. Y. Latency and energy-aware load balancing in cloud data centers: A bargaining game based approach. IEEE Trans. Cloud Comput. 11, 927–941 (2023).
Hung, L. H., Wu, C. H., Tsai, C. H. & Huang, H. C. Migration-based load balance of virtual machine servers in cloud computing by load prediction using genetic-based methods. IEEE Access 9, 49760–49773 (2021).
Shen, H. & Chen, L. A resource usage intensity aware load balancing method for virtual machine migration in cloud datacenters. IEEE Trans. Cloud Comput. 8, 17–31 (2020).
Princess, G. A. P. & Radhamani, A. S. A hybrid meta-heuristic for optimal load balancing in cloud computing. J. Grid Comput. https://doi.org/10.1007/s10723-021-09560-4 (2021).
Ashok Kumar, C., Vimala, R., Aravind Britto, K. R. & Sathya Devi, S. FDLA: Fractional dragonfly based load balancing algorithm in cluster cloud model. Cluster Comput. 22, 1401–1414 (2019).
Kaur, A., Kaur, B. & Singh, D. Meta-heuristic based framework for workflow load balancing in cloud environment. Int. J. Inf. Technol. 11, 119–125 (2019).
Wu, X., You, L., Wu, R., Zhang, Q. & Liang, K. Management and control of load clusters for ancillary services using internet of electric loads based on cloud-edge-end distributed computing. IEEE Internet Things J. 9, 18267–18279 (2022).
Kaviarasan, R., Balamurugan, G., Kalaiyarasan, R. & Reddy, Y. V. R. Effective load balancing approach in cloud computing using Inspired Lion Optimization Algorithm. ePrime Adv. Electr. Eng. Electron. Energy 6, 100326 (2023).
Jain, P., Islam, M. T. & Alshammari, A. S. Comparative analysis of machine learning techniques for metamaterial absorber performance in terahertz applications. Alex. Eng. J. 103, 51–59 (2024).
Ding, Z. et al. Identifying alternately poisoning attacks in federated learning online using trajectory anomaly detection method. Sci. Rep. 14, 20269 (2024).
Gures, E., Shayea, I., Ergen, M., Azmi, M. H. & El-Saleh, A. A. Machine learning-based load balancing algorithms in future heterogeneous networks: A survey. IEEE Access 10, 37689–37717. https://doi.org/10.1109/ACCESS.2022.3161511 (2022).
Hussine, U. U., Islam, M. T. & Misran, N. Analysis of microstrip patch antenna for L1 and L2 for global positioning system applications. J. Eng. 24, 29–33 (2012).
Subramanya, T. & Riggio, R. Centralized and federated learning for predictive VNF autoscaling in multi-domain 5G networks and beyond. IEEE Trans. Netw. Serv. Manag. 18, 63–78 (2021).
Sahoo, P. K. et al. An improved VGG-19 network induced enhanced feature pooling for precise moving object detection in complex video scenes. IEEE Access 12, 45847–45864 (2024).
Shaik, T. et al. FedStack: Personalized activity monitoring using stacked federated learning. Knowl. Based Syst. https://doi.org/10.1016/j.knosys.2022.109929 (2022).
Yan, Z., Yan, J., Wu, Y., Cai, S. & Wang, H. A novel reinforcement learning based tuna swarm optimization algorithm for autonomous underwater vehicle path planning. Math. Comput. Simul. 209, 55–86 (2023).
Jain, P. et al. Machine learning assisted hepta band THz metamaterial absorber for biomedical applications. Sci. Rep. 13, 1792 (2023).
Jain, P. et al. Machine learning techniques for predicting metamaterial microwave absorption performance: A comparison. IEEE Access 11, 128774–128783 (2023).
Saber, S. & Salem, S. High-performance technique for estimating the unknown parameters of photovoltaic cells and modules based on improved spider wasp optimizer. Sustain. Mach. Intell. J. https://doi.org/10.61185/SMIJ.2023.55102 (2023).
Salem, S. An improved binary quadratic interpolation optimization for 0–1 Knapsack problems. Sustain. Mach. Intell. J. https://doi.org/10.61185/SMIJ.2023.44101 (2023).
Ghaemi, M. & Feizi-Derakhshi, M. R. Forest optimization algorithm. Expert Syst. Appl. 41, 6676–6687 (2014).
Joshi, A. S., Kulkarni, O., Kakandikar, G. M. & Nandedkar, V. M. Cuckoo search optimization- A review. Mater. Today Proc. 4, 7262–7269 (2017).
Gu, J. et al. Recent advances in convolutional neural networks. Pattern Recognit. 77, 354–377 (2018).
Pattnaik, T. et al. An efficient low complex-functional link artificial neural network based framework for uneven light image thresholding. IEEE Access https://doi.org/10.1109/ACCESS.2024.3447716 (2024).
Dehghani, M., Montazeri, Z., Trojovská, E. & Trojovský, P. Coati optimization algorithm: A new bio-inspired metaheuristic algorithm for solving optimization problems. Knowl. Based Syst. 259, 110011 (2023).
Yin, X., Liu, Z., Liu, D. & Ren, X. A novel CNN-based Bi-LSTM parallel model with attention mechanism for human activity recognition with noisy data. Sci. Rep. https://doi.org/10.1038/s41598-022-11880-8 (2022).
He, W. et al. Random dynamic load identification with noise for aircraft via attention based 1D-CNN. Aerospace https://doi.org/10.3390/aerospace10010016 (2023).
Li, C., Min, Z. & Youlong, L. Efficient load-balancing aware cloud resource scheduling for mobile user. Comput. J. 60, 925–939 (2017).
Simaiya, S. et al. A hybrid cloud load balancing and host utilization prediction method using deep learning and optimization techniques. Sci. Rep. https://doi.org/10.1038/s41598-024-51466-0 (2024).
Mohapatra, S. et al. DPSO: A hybrid approach for load balancing using dragonfly and PSO algorithm in cloud computing environment. EAI Endorsed Trans. Internet Things https://doi.org/10.4108/eetiot.4826 (2024).
Funding
The authors want to acknowledge the Universiti Kebangsaan Malaysia Research Grant through the Dana Padanan Kolaborasi (DPK) under the grant number DPK-2023-022
Author information
Authors and Affiliations
Contributions
A.B.T.: Validation, Investigation, Formal analysis, Writing—Original Draft. V.K.S.: Software, Validation, Writing- Reviewing and Editing. A.G.: Methodology, Writing- Reviewing and Editing. S.K.: Resources, Visualization, Investigation. A.S.S.: Resources, Software, Validation. S.A.U.: Investigation, Formal analysis, Validation. P.J.: Resources, Visualization, Investigation. MTI: Supervision, Funding, Writing- Reviewing and Editing. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Kathole, A.B., Singh, V.K., Goyal, A. et al. Novel load balancing mechanism for cloud networks using dilated and attention-based federated learning with Coati Optimization. Sci Rep 15, 15268 (2025). https://doi.org/10.1038/s41598-025-99559-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-99559-8
