
Abstract
Panoramic images, with their wide field of view and abundant information, have become essential visual materials in digital art creation and virtual reality. However, existing panoramic image restoration and quality enhancement methods lack high-level semantic understanding and global feature control, which often leads to structural disorder in complex scenes. They also struggle to balance semantic comprehension, real-time performance, and restoration quality. To address these issues, this paper raises a panoramic image restoration and visual quality enhancement model for digital art creation. The model uses a Multi Scale Residual Network, a Coordinate Space Attention mechanism, and super resolution reconstruction to construct a visual quality enhancement algorithm, which accurately captures both local details and global structural features. Based on this algorithm, an optimized Generative Adversarial Network and a Vision Transformer are integrated to model the spatial correlation and semantic logic between damaged and undamaged regions, achieving high-quality completion. Experimental results show that the model achieves a Structural Similarity Index of 0.975 and 0.971, a Peak Signal to Noise Ratio of 53.82 dB and 53.75 dB, a maximum memory usage of 394 MB, and a response time of 3.12 s with a data volume of 2000 in DIV2K and SUN360 datasets. The model outperforms comparison models in all metrics, enhances both detail clarity and global consistency, and maintains efficient processing performance. It provides high-quality visual materials for digital art creation and shows significant advantages across various performance indicators.
Similar content being viewed by others

Introduction
Research background
Amid the rapid growth of digital art creation, panoramic images, due to their wide field of view and abundant information, have become core visual materials in fields such as virtual reality, augmented reality, and digital museums1. In virtual exhibitions, the exhibits often have rich details and complex lighting, while existing restoration methods often result in blurred textures and inaccurate color reproduction. In interactive narrative works, traditional methods cannot effectively handle dynamic blur and occlusion. Although some methods using deep learning have achieved certain progress, they still face problems such as unnatural style transfer and conflicts between restoration results and overall artistic style. Under this background, this paper aims to develop a panoramic image restoration and visual quality enhancement method suitable for digital art creation. Through innovative algorithms, it improves the visual quality of digital artworks, accurately restores various defects, ensures a high consistency with artistic styles, and supports the continuous innovation of the digital art industry.
Research status
Many scholars have explored image restoration and visual quality enhancement. M. E. Celik et al. improved the resolution of panoramic radiographic images using super resolution technology, achieving a Structural Similarity Index (SSIM) of 0.82–0.98 and a Peak Signal to Noise Ratio (PSNR) of 28.7–40.2 dB in three datasets. However, the performance of their model significantly decreased as the scaling factor increased2. H. Jindal et al. adopted an integrated stitching fusion ridgelet transform to address the visual quality degradation of underwater panoramic images, achieving a PSNR of 26.8–31.2 dB and an SSIM of 0.79–0.88. However, their model produced edge artifacts in highly turbid water or strong motion blur scenes and had long processing times, making it unsuitable for real-time underwater detection3. Traditional panoramic image restoration applied seam optimization, exposure correction, and local texture synthesis to address stitching defects, but lacked high-level semantic understanding and global feature control, which often caused structural disorder in complex semantic scenes4,5. With the development of artificial intelligence, intelligent algorithms have gradually been applied to panoramic image restoration and visual quality enhancement. J. Wu et al. put forward a Generative Adversarial Network (GAN)-based tripod removal model for panoramic images, achieving an SSIM of 0.82–0.91 and a PSNR of 27.3–32.5 dB. However, their model produced artifacts in complex low-light scenes and still required further optimization of generalization ability6. Y. Hong et al. proposed a deep learning framework to tackle reflection interference in panoramic medical images, achieving SSIM values between 0.85 and 0.97. However, its high computational complexity resulted in a processing time of about 2.3 s per image, which could not meet the requirements of real-time diagnosis7. M. Yurttas used a YOLO network to extract features of panoramic X-ray images and combined it with a region proposal network to generate candidate regions for restoration of dental panoramic images. However, the model had positioning errors for overlapping structures and produced artifacts in the generated images8. To present the advantages and disadvantages of the existing research more clearly, the study summarizes the contents of the aforementioned research, and the summary is shown in Table 1.
Research content
The main goal of panoramic image restoration and quality enhancement is to solve problems such as stitching defects, noise interference, and insufficient resolution while maintaining scene semantics and visual coherence, thus providing high-quality materials for digital art creation9,10. A Multi Scale Residual Network (MSRN) is effective in capturing hierarchical features and can adaptively extract both local details and global structural features of panoramic images11. A Coordinate Space Attention (CSA) mechanism enhances the perception of spatial position dependencies by normalizing pixel coordinates as additional channels in the feature map, thereby avoiding the loss of useful features12. Super-Resolution (SR) reconstruction technology gradually increases the resolution of feature maps and integrates multi scale high frequency detail features, providing fine-grained enhancement for panoramic image quality improvement13. A GAN, through adversarial training of a generator and a discriminator, adaptively completes missing regions in panoramic images, improving structural and semantic consistency14. A Vision Transformer (ViT) models long-range dependencies among pixels, improving the model’s capacity to capture cross-regional structural relationships in large scenes and thereby maintaining global structural consistency in the restoration outcomes15. Therefore, this paper combines MSRN, CSA, and SR to construct a visual quality enhancement algorithm, and based on this algorithm, uses GAN and ViT to precisely model the spatial correlation and semantic logic between damaged and undamaged regions, providing technical support for restoring panoramic materials in digital art creation. The innovation of this research lies in the construction of an efficient model that simultaneously enhances visual quality and repairs complex scenes through cross-technology integration and optimization strategies. The study optimizes the multi-branch structure of MSRN and incorporates the context modeling capability of CSA to improve the model’s accuracy in capturing high-frequency details of images and the efficiency of multi-scale feature fusion. In the field of image restoration, the research utilizes the self-attention mechanism of ViT to capture long-range dependencies in images, solving the structural disorder problem in large-sized damaged area restoration by traditional convolutional networks. At the same time, the research optimizes the output of the generator through the adversarial training strategy of GAN and combines multi-stage feature matching loss to enhance the structural integrity and visual authenticity of the restored images.
Paper structure
This paper is divided into five sections. The first section presents the research background and relevant literature, examines the current status and limitations of panoramic image restoration and quality enhancement methods, and defines the research objectives. The second part details the design principles of the visual quality enhancement algorithm and the image restoration model, and explains the overall process of the model. The third part verifies the proposed method through comparative experiments in terms of visual quality, restoration accuracy, and processing efficiency. The fourth section presents a detailed analysis of the experimental results and discusses them in relation to relevant studies. The fifth part summarizes the research findings and discusses future directions in cross-scene generalization and real-time processing.
Materials and methods
Panoramic image visual quality enhancement algorithm for digital Art creation
Panoramic images have a wide field of view and contain both abundant local texture details and complex global spatial structures. Existing visual quality enhancement methods have limitations in precise extraction and coordinated expression of multi scale features, which makes it difficult to meet the requirements of detail enhancement and structural consistency simultaneously16. This section provides a detailed description of the construction process of the algorithm for enhancing the visual quality of panoramic images. The main process is shown in Fig. 1.

Construction process of the algorithm for improving the visual quality of panoramic images.
As shown in Fig. 1, the algorithm for improving the visual quality of panoramic images mainly consists of three parts. Firstly, the dual-output MSRN extracts the shallow texture and deep structure. Then, through the CSA mechanism, it strengthens the pixel spatial positional dependency. Finally, the SR reconstruction module enhances the resolution of the foot and fuses multi-scale details, ultimately outputting a high-definition and coherent feature map. The technical details will be explained step by step according to the flowchart modules below. MSRN, with its adaptive learning ability for hierarchical features, effectively captures image information at different scales and provides precise multi scale feature support for detail enhancement and quality optimization17. To extract image features more efficiently, this paper introduces a dual output MSRN to process panoramic images and combines it with a residual network framework to improve feature extraction efficiency. The structure of the dual-output MSRN is illustrated in Fig. 2.

Dual-output MSRN structure diagram.
As shown in Fig. 2, features processed by multi layer multi scale residual blocks are converted into two feature tensors through a dual output convolution layer. The shallow feature tensor retains more spatial details, while the deep feature tensor contains stronger semantic information. These two features are independently optimized through parallel convolution branches and enhanced with cross branch residual connections to improve feature complementarity. The dual output features are integrated through hierarchical feature fusion to adaptively extract key information. A convolution layer then reduces computational complexity while preserving multi scale feature correlation. The final fused feature map is combined with the input features of the initial convolution layer through residual connection to form a closed loop feature enhancement path, which further improves the edge clarity and structural consistency of panoramic images. The preliminary feature map is expressed in Eq. (1).
In Eq. (1),
p1 represents the output feature map, \({P_1}\) represents the feature map of the first layer, C represents the input convolution layer. Features extracted through multiple residual blocks are then fused with the input image to generate the network output, as shown in Eq. (2).
In Eq. (2), \({B_1}\) and \({B_2}\) represent the outputs of the first and second layers, \({C^{\prime}_1}\) and \({C^{\prime}_2}\) represent the output convolution layers of the first and second layers, \({F^{\prime}_1}\) and \({F^{\prime}_2}\) represent the feature maps extracted by multiple residual blocks, and \({P_2}\) represents the feature map of the second layer. Residual connections then fuse the multi scale features to generate the output, as expressed in Eq. (3).
In Eq. (3), \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{F}\) is the output of the residual block, and \(\tilde {F}\) is the input of the residual block. The output of the residual block is subsequently combined with a weight matrix, and the final loss function is represented in Eq. (4).
In Eq. (4), K is the hierarchical sum, k is the variable index, \(\varepsilon\) represents the scaling coefficient, \(\lambda\) represents the weight coefficient, and λ represents the extracted feature tensor. Although the dual output MSRN effectively captures information of panoramic images at different scales18, it still has limitations in precise extraction and coordinated expression of multi scale features, and it cannot fully perceive spatial position dependencies between pixels. CSA enhances spatial dependency perception by normalizing pixel coordinates as additional channels in the feature map and generating attention weights, which helps to avoid the loss of useful features. Therefore, this paper optimizes the MSRN with CSA to obtain the CSA-MSRN algorithm, as shown in Fig. 3.

Operation flow chart of the CSA-MSRN algorithm.
As shown in Fig. 3, the original image is first processed by an initial convolution layer to generate a preliminary feature map. Multiple residual blocks then capture local details and global structure features at different scales step by step. Residual connections fuse the multi scale features and form a dual output feature tensor to provide multi dimensional feature support for subsequent processing. Pixel coordinate information is then embedded into the feature map generated by the dual output MSRN. The attention weight generation module models spatial position dependencies of the fused feature map to strengthen key region features and avoid useful feature loss during transmission. Finally, the optimized feature map integrates multi scale high frequency details and spatial correlation information through an integration layer, outputting high quality features with both detail clarity and structural consistency. During this process, CSA encodes the horizontal and vertical coordinates of the pixels as position features and concatenates them as two additional channels with the feature maps of the dual-output MSRN. This enhances the network’s ability to perceive spatial positions, and the coordinate information is embedded in the expression as shown in Eq. (5).
In Eq. (5), \(P^{\prime}\) denotes the pixel values of the feature map after spatial position enhancement, and \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{P}\) denotes those of the original feature map. a b and represent the horizontal and vertical coordinates of pixels in the feature map. Channel attention weights and spatial attention masks are then generated to weight and fuse the multi scale features extracted by MSRN to strengthen the feature representation of key regions, as expressed in Eq. (6).
In Eq. (6), \(\omega\) represents the attention weight, and \(\sigma\) represents the Sigmoid function, which strengthens the feature weights of key regions. By integrating CSA, the dual output MSRN effectively captures both local details and global structure features of panoramic images while strengthening spatial position dependency perception. However, although it improves feature extraction efficiency and spatial perception ability, it lacks the ability to actively enhance feature map resolution and deeply integrate multi scale high frequency details. SR reconstruction technology gradually increases feature map resolution and precisely integrates multi scale high frequency details, effectively compensating for the limitations of CSA-MSRN in resolution improvement and detail fusion. In SR reconstruction, external factors such as ambient optics and motion blur are considered, and the reconstruction process is expressed in Eq. (7).
In Eq. (7), I represents the high-resolution image before reconstruction, and \(I^{\prime}\) represents the low-resolution image after reconstruction. k represents the blur kernel, h and \(\varphi\) represent the blur factor and noise interference, and \(\downarrow s\) represents the downsampling method with scaling factor s. Based on the above, this study integrates the CSA-MSRN algorithm with the SR algorithm to develop a panoramic image quality enhancement algorithm, named SMC. This algorithm improves the visual quality of panoramic images. The specific process of SMC is shown in Fig. 4.

Operation flow chart of the SMC algorithm.
In Fig. 4, a low resolution panoramic image is first processed by the dual output MSRN to generate a preliminary feature map. Multiple residual blocks then capture local texture details and global structure features at different scales step by step. Residual connections fuse the features and output a multi scale feature tensor, which provides multi dimensional feature support. Pixel coordinate information is then normalized and embedded into the feature map through CSA, and the attention weight generation module models spatial position dependencies to enhance the feature weight of key regions such as edges and textures. The optimized feature map is then sent to the SR reconstruction module, which increases the resolution by integrating multi scale high frequency details. Finally, the integration layer fuses multi scale information and outputs a high quality, high resolution panoramic image with both detail clarity and structural consistency.
Panoramic image restoration model based on SMC and improved GAN
The constructed SMC visual quality enhancement algorithm integrates the dual-output MSRN’s multi-scale feature extraction, CSA’s spatial position dependency perception, and SR reconstruction’s detail enhancement technique. It improves detail clarity, structural consistency, and resolution of panoramic images. However, panoramic images often contain occlusion, damage, and texture loss during acquisition, stitching, or transmission. Visual quality enhancement alone does not restore the semantic integrity and visual continuity of the scene. Therefore, in this section, the research will be based on the SMC algorithm and the improved GAN to construct a panoramic image restoration model. The construction process is shown in Fig. 5.

Construction process of panoramic image restoration model.
As shown in Fig. 5, the panoramic image restoration model is constructed based on the SMC algorithm and GAN. During this process, the variational autoencoder and ViT are introduced to optimize the GAN, thereby enhancing the stability of the model and the accuracy of the restoration. The technical details will be explained step by step according to the flowchart modules below. GAN models the contextual features of missing regions in panoramic images through the generator. It fills occluded and missing areas while the discriminator distinguishes between generated and real images. The discriminator drives the generator to optimize outputs and continuously improve the visual consistency between the restored region and the background19]– [20. The generator is expressed as shown in Eq. (8).
In Eq. (8), \({L_G}\) denotes the loss function of the generator, E is the mean structure of the noise sampling distribution, p is the prior probability distribution of the noise, G is the generated data. The discriminator seeks to maximize its capacity to differentiate between real and generated data, with its loss function expressed in Eq. (9)21.
In Eq. (9), \({L_D}\) denotes the loss function, LD is the input data, and \(Pdata\) represents the probability distribution of real data. The core of GAN is adversarial optimization between maximization and minimization. Its objective function is expressed in Eq. (10).
In Eq. (10), the maximization objective of the discriminator and the minimization objective of the generator are optimized. This process minimizes classification errors and aligns the distribution of generated data with that of the real data. Through alternating adversarial training, the generator and discriminator co-evolve and eventually reach a dynamic balance, completing the data generation task. The optimization process is shown in Eq. (11)22.
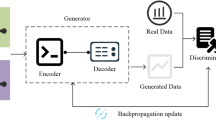
In Eq. (11), \(G^{\prime}\) denotes the optimal generator, and \({D^{\prime}_G}\) denotes the optimal discriminator under a given generator. Although GAN achieves a balance between generative capacity, diversity, and flexibility, it often suffers from gradient vanishing or mode collapse during training. The Variational Auto Encoder (VAE) improves training stability through variational inference and reconstruction loss, and enhances GAN in standard learning and feature extraction23. Thus, the study optimizes GAN with VAE to form a hybrid algorithm named VAE-GAN. Its feature extraction process is shown in Fig. 6.

Schematic diagram of the feature extraction process of VAE-GAN (Icon source from: iconpark.oceanengine.com).
As shown in Fig. 6, the panoramic image is first mapped to the latent space through multiple layers of convolution, generating mean and variance parameters to construct the probability distribution of the latent variables. Then, the decoder outputs the reconstruction loss, and the encoder restores the latent variables to generate the data. During the training process, the reconstruction loss is used to minimize the difference between the image and the original image. At the same time, the generated image and the real digital image are input into the discriminator, and through adversarial training, the output accuracy of the generator is optimized to ensure that the repaired content is consistent with the original work. In the VAE process, the reconstruction of the probability distribution and its alignment with the original distribution are evaluated using Eq. (12)24.
In Eq. (12), x represents the observed data, p represents the probability distribution, and z is the latent variables. To quantify the difference between the probability distribution and the original distribution, the relative entropy is computed as shown in Eq. (13).
In Eq. (13), d denotes the latent space dimension, \(\sigma\) is the standard deviation from the encoder, \(\mu\) represents the mean from the encoder, and i represents the index of the latent space dimension. After computing the KL divergence between the two distributions, the overall loss function of VAE is expressed in Eq. (14).
In Eq. (14), y represents the latent variables, t represents the generated distribution, h represents the variational posterior, and E is the expectation operator. By incorporating the probabilistic modeling of VAE, GAN alleviates mode collapse during training and balances generative quality and latent space interpretability. However, due to the wide field of view of panoramic images, the feature extraction of VAE-GAN mainly relies on convolution operations, whose receptive field is limited by kernel size. This often leads to deviations in global structural consistency. To address this, the study introduces ViT to further optimize VAE-GAN. ViT models long-range pixel dependencies across the image via self-attention, precisely capturing structural relations and semantic logic in large-scale scenes25. The ViT structure is shown in Fig. 7.

Schematic diagram of the structure of ViT.
As shown in Fig. 7, the input image is first divided into flattened patches, linearly projected, and embedded with positional encoding before entering the encoder. The encoder applies multi-head attention and multilayer perceptrons with residual connections for deep feature encoding. The encoded features are then passed to multilayer perception heads for classification. In this process, self-attention is the core of ViT, and its attention weight calculation is shown in Eq. (15).
In Eq. (15), X denotes the input matrix, and V, Q, and K represent the value, query, and key vectors, respectively. W is weight matrices. The input signal is multiplied by the attention weights to obtain the final output, as expressed in Eq. (16).
In Eq. (16), A is the output, \({d_K}\) is the dimension of the key vector, and \({K^T}\) is the transposed key matrix. After computing similarity, it is scaled by a factor and processed with residual connections to obtain intermediate output features, as shown in Eq. (17).
In Eq. (17), \(o\prime\) represents the intermediate output feature, O’ represents the output feature, \(LN\) represents normalization, \(MSA\) represents the multi-head attention, l represents the layer index, and \(MLP\) represents the multilayer perceptron. After multiple encoding layers, the final encoder output is expressed in Eq. (18).
In Eq. (18), y represents the final encoder output, and M denotes the total number of layers in the model. Based on this, the study combines VAE-GAN and ViT to form the hybrid algorithm VAE-GAN-ViT. Its process is shown in Fig. 8.

VAE-GAN-ViT operation flow chart (Image source from: http://www.naturalearthdata.com/).
As shown in Fig. 8, the panoramic image first undergoes mapping of the input features to the latent space through VAE, generating mean and variance parameters and constructing a probability distribution. Subsequently, through reparameterization sampling, the latent variables are obtained and input into GAN to generate the content for repairing the damaged area. At the same time, using ViT, the output features are segmented into image blocks and embedded with position encoding to capture long-range dependencies of all image pixels. Then, the global features are output, further optimizing the semantic logic of the repaired content. Finally, through the joint optimization of three types of losses, a high-quality repaired panoramic image with both detailed authenticity and global coherence is output. However, the existing loss functions only focus on the single dimension of feature matching and style fidelity, failing to address the core contradiction of the collaborative optimization of structural integrity and style consistency in digital art restoration. Therefore, the research proposes a multi-dimensional loss collaborative constraint mechanism of structure, style, and semantics. The art structure prior is embedded in the feature matching loss, a style weight module is set for the style fidelity loss, and a new semantic adversarial loss layer is added to model the global semantic correlation. Through the fusion and weight optimization of the three-stage losses, a theoretical breakthrough from single-dimensional optimization to multi-dimensional collaborative constraint is achieved, solving the shortcomings of existing methods in balancing multiple objectives of digital art restoration. The first stage is the feature matching loss, whose expression is shown in Eq. (19).
In Eq. (19), \({L_f}\) represents the feature loss, L represents the total number of layers in the training network, l represents the index of the network layers, \({C_l}\), \({H_l}\) and \({W_l}\) respectively represent the number of channels, height and width of the feature map, \(\phi\) represents the feature extraction function, and \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{X}\) represents the real sample. The feature loss function ensures the structural consistency of the repaired area with the original image. Subsequently, through the style fidelity loss, the artistic style features are captured to ensure the style consistency of the repaired area with the original image. Its expression is shown in Eq. (20).
In Eq. (20), \({L_s}\) represents the style fidelity loss, and \({G_l}\) represents the Gram matrix of the features. Subsequently, through the adversarial training between the generator and the discriminator, the visual authenticity of the restored content is enhanced. The final joint loss is shown in Eq. (21).
In Eq. (21), \({L_{total}}\) represents the overall loss, while \(\alpha ^{\prime}\), \(\beta ^{\prime}\), and \(\gamma\) represent the weight coefficients, with their respective values being 0.4, 0.3, and 0.3. Based on this, the study integrates the SMC algorithm with VAE-GAN-ViT to construct a panoramic image visual enhancement and restoration model (SMC-VGV) for digital art creation. The process of the SMC-VGV model is shown in Fig. 9.

Operation flow chart of the SMC-VGV model.
As shown in Fig. 9, the panoramic image is first processed by the SMC enhancement module. The low-resolution image passes through the dual-output MSRN to generate initial features. Multi-layer residual blocks extract local textures and global structures, and the features are fused into a multi-scale feature tensor. The pixel coordinates are then normalized and embedded as additional channels. The attention module enhances key regions such as edges and textures. The optimized features are combined with multi-scale high-frequency details to gradually increase resolution. The integrated layer outputs a high-resolution feature map. The map is encoded by VAE to generate a probability distribution in the latent space. Reconstruction loss and KL divergence optimize the feature restoration accuracy. The global features captured by multi-head self-attention guide the filling of damaged regions. The generated result is refined by adversarial loss with the discriminator. The final output is a high-quality panoramic image with clear details, realistic local restoration, and global consistency. The pseudo-code is as follows.

SMC-VGV panoramic image restoration and visual quality enhancement.
Results and analysis
Performance analysis of SMC visual quality enhancement algorithm
To evaluate the performance of the SMC image quality enhancement algorithm, it was compared with the Hybrid Attention Transformer (HAT), the Laplacian Pyramid Super Resolution Network (LapSRN), and the Feature Pyramid Network-Spatial Attention (FPN-SA)26,27,28. The experimental system ran on Windows 10 with an AMD Ryzen 9 7950 × 3D@4.7 GHz CPU, an NVIDIA RTX 3090 GPU (24 GB), and 32 GB of memory. The Google Street View (GSV) and DIV2K panoramic datasets were used for testing. The dataset excluded samples with motion blur intensity ≥ 0.7 and occlusion area percentage ≥ 30%. At the same time, high-resolution images were cropped to 1024*2048, and low-resolution images were scaled to 512*512. Ultimately, 2,000 images were retained for the training set, 300 for the validation set, and 200 for the test set. During the training phase, random cropping was used with a cropping size of 512*512, a horizontal flip probability of 0.5, and a vertical flip probability of 0.3. The images were also enhanced by adjusting the brightness within the range of [0.8, 1.2] and the contrast within the range of [0.9, 1.1]. The experiment used the Adam optimizer (β1 = 0.9, β2 = 0.999), and the initial training learning rate was set at 0.0005, with a batch size of 4. The PSNR and SSIM of the four algorithms were tested, and the results are shown in Fig. 10.

Comparison of PSNR and SSIM test results.
As shown in Fig. 10a, the SSIM of the SMC algorithm reached 0.955, which was 0.032 higher than LapSRN and 0.027 higher than FPN-SA. As shown in Fig. 10b, the PSNR of the SMC algorithm reached 36.79 dB, which was 9.78% higher than FPN-SA. Overall, the SMC algorithm enhanced the richness of details, edge sharpness, and global visual quality more effectively than the compared models. To further analyze the performance of the SMC algorithm, a 10 × 10 grid was used to validate optimization in each algorithm. Each grid region was compared with a high-resolution image, and the results are shown in Fig. 11.

Comparison of optimization results with high-resolution images.
As shown in Fig. 11a, the SMC algorithm produced 88 grids with good quality and 12 grids with medium quality. As shown in Figs. 11b and c, LapSRN and FPN-SA produced 78 and 75 high-quality grids, respectively, while FPN-SA contained 4 grids with poor optimization results. As shown in Fig. 11d, the HAT algorithm contained 6 grids with poor optimization results. These results indicated that the SMC algorithm achieved better optimization performance in multi-region panoramic image enhancement. To present the actual visual improvement effect of the SMC algorithm more intuitively, the research conducted a visual display of the improvement effects of four algorithms on blurred images. The results are shown in Fig. 12.

Comparison of actual visual improvement effects (Image source from: http://www.naturalearthdata.com/).
As shown in Fig. 12a, the image processed by the SMC algorithm performed best: textures appeared sharp and clear, local details were complete and refined, global structures were coherent and natural, and no significant blur or artifacts appeared. Compared with Fig. 12b, the image processed by LapSRN preserved some details in certain areas but showed slight blur locally. As shown in Fig. 12c, the image processed by FPN-SA lacked stability, with some regions suffering from detail loss or edge blur. As shown in Fig. 12d, the image processed by HAT did not show major defects but was weaker than SMC in texture sharpness and global structural consistency. This comparison directly confirmed the superiority of the SMC algorithm in enhancing the actual visual quality of panoramic images, as it more effectively improved edge sharpness and global structure coherence. To further analyze the performance of the SMC algorithm, the Gradient Magnitude Similarity Deviation (GMSD) and Variance Inflation Factor (VIF) of the four algorithms were tested, and the results are shown in Table 2.
As shown in Table 2, on the GSV dataset, the GMSD of the SMC algorithm was 0.035, which was 0.019 lower than LapSRN (0.054) and 0.047 lower than HAT (0.082). On the DIV2K dataset, the GMSD and VIF of the SMC algorithm were 0.035 and 0.92, respectively. Among the compared algorithms, LapSRN performed best with a GMSD of 0.055 and a VIF of 0.87, which was still inferior to the proposed algorithm. Overall, the SMC algorithm maintained gradient consistency and visual information fidelity more effectively in panoramic images.
Application analysis of SMC-VGV panoramic image restoration and visual quality enhancement model
After verifying the performance of the SMC algorithm, it is necessary to analyze the performance of the SMC-VGV panoramic image restoration and visual quality improvement model constructed based on SMC and improved GAN. To analyze the role of each module in the SMC-VGV model, the research first designed ablation experiments to verify the performance of each component of the model. The experiments were conducted using the DIV2K dataset for testing, and the test results are shown in Table 3.
As shown in Table 3, it can be seen that the complete SMC-VGV model integrates the SMC visual quality improvement module and the VAE-GAN-ViT restoration module, and has the best performance. The SSIM of the SR-MSRN-VGV model is 0.033 lower than that of the complete model, indicating that CSA’s perception ability of spatial position dependence can enhance feature utilization. When the dual-output MSRN is changed to a single output, the PSNR of the model is 2.94 dB lower than that of the complete model, suggesting that the complementary shallow and deep features of the dual-output structure can enhance the multi-scale feature capture effect. Meanwhile, after removing the ViT and VAE modules, the model performance decreases the most significantly. The SSIM and PSNR are 0.905 and 47.83 respectively, verifying the optimization of VAE for the stability of GAN training and the enhancement value of ViT for global semantic consistency. The study compared SMC-VGV model with three models: a GAN combined with Fast Fourier convolution (FFC) and Transformer (FFC-Trans-GAN), a Wasserstein GAN combined with Gated Convolution (GC) and Hierarchical Transformer (HT) (GC-HT-WGAN), and the Residual Gated Connection Generative Adversarial Network (ReGGAN). The DIV2K panoramic dataset and the SUN360 dataset were used for testing. First, the study conducted loss training tests on the four models, and the results are shown in Fig. 13.

Loss training test results comparison.
As shown in Fig. 13a, when the iteration count reached 50, the loss value of the SMC-VGV model was 0.029, which was significantly lower than that of the other models, and the loss curve gradually stabilized afterward. When the iteration count reached 80, the loss value of the SMC-VGV model was 0.026, while the loss value of the ReGGAN model was 0.057. As shown in Fig. 13b, when the iteration count reached 90, the loss value of the SMC-VGV model was 0.023, which was 0.038 lower than that of the ReGGAN model. The loss curve of the SMC-VGV model also converged the fastest when the number of iterations was less than 20. The results indicated that the loss curve of the SMC-VGV model converged faster than those of the other models and achieved the lowest loss value. Then, the study tested the Receiver Operating Characteristic (ROC) curve and Precision-Recall (PR) curve of the four models, and the results are shown in Fig. 14.

Comparison of ROC and PR curve results.
In Fig. 14a, the ROC curve of the SMC-VGV model was closest to the upper left corner, and its Area Under the Curve (AUC) value reached 0.923, which was closest to 1 and higher than those of the other models (0.899, 0.846, and 0.813), indicating better image restoration performance. As shown in Fig. 14b, the PR curve of the SMC-VGV model was closest to the upper right corner and was significantly better than those of the other models. This indicated that the model maintained high precision while achieving high recall, which further verified its superior restoration performance. Overall, the SMC-VGV model achieved better recall and precision in image restoration than the other models and demonstrated stronger robustness. To analyze the running efficiency and memory usage of the four models, the study tested their system memory usage and response time, and the results are shown in Fig. 15.

Comparison of memory usage and response time test results.
As shown in Fig. 15a, the memory usage of the SMC-VGV model increased slowly, and its maximum memory usage was 394 MB. When the data volume reached 2000, its response time was 3.12 s. As shown in Fig. 15b, the maximum memory usage and highest response time of the GC-HT-WGAN model were 482 MB and 4.54 s, respectively. As shown in Figs. 15c and d, the maximum memory usage of the FFC-Trans-GAN and ReGGAN models was 560 MB and 598 MB, and their highest response times were 4.93 s and 5.21 s, respectively. Overall, the SMC-VGV model achieved more stable and efficient restoration performance than the other models. For the restoration of digital art creations, the preservation of artistic style consistency also holds significant importance. Therefore, the study tested the similarity of learned perceptual image patches (LPIPS) of four models using five different styles of artworks. The test results are shown in Table 4.
As shown in Table 4, the SMC-VGV model performed the best among all artistic styles, with its LPIPS values ranging from 0.10 to 0.14. Among them, the sketch style had the lowest value of 0.10, while the illustration style had the highest value of 0.14. The overall style consistency was prominent. The LPIPS values of the GC-HT-WGAN and FFC-Trans-GAN models were respectively in the range of 0.23–0.27 and 0.25–0.30, with moderate style fidelity effects. The ReGGAN model had the highest LPIPS value, and the difference between the restored result and the original artistic style was the most obvious. The experimental results show that the SMC-VGV model can accurately retain the style characteristics of digital art works and meet the style fidelity requirements of diversified digital art creation. During the restoration process of digital art works, there are often works with low light intensity (Light intensity ≤ 50 lx) or high dynamic range (Contrast ratio ≥ 100:1), which will significantly increase the difficulty of restoration29. Therefore, in order to further test the generalization performance of the model, the study tested the SSIM and PSNR of the four models in low-light and high dynamic range scenarios separately, and the results are shown in Table 5.
As shown in Table 5, the SMC-VGV model performed the best in both extreme scenarios. In the low-light scenario, the SSIM reached 0.925 and the PSNR reached 48.12 dB. In the high dynamic range scenario, the SSIM of the SMC-VGV model reached 0.931 and the PSNR reached 49.25 dB, demonstrating a significant advantage over the comparison models. The ReGGAN model performed the worst, with SSIM values of only 0.855 and 0.864 in the low-light and high dynamic range scenarios respectively, and the PSNR values were all below 43 dB. The GC-HT-WGAN and FFC-Trans-GAN models performed between the two, but still had a significant gap compared to SMC-VGV. The experimental results indicate that the SMC-VGV model has stronger adaptability to extreme scenarios and can meet the panoramic image restoration requirements for diverse and complex scenarios in digital art creation.
Discussion and interpretation
The raised SMC visual quality enhancement algorithm showed significant performance advantages in panoramic image quality optimization tasks. The SSIM on the GSV dataset reached 0.955, and the PSNR was 36.79 dB, with an improvement of 0.032 in SSIM and 9.78 dB in PSNR compared with the LapSRN algorithm. On the DIV2K dataset, the GMSD was as low as 0.038, and the VIF reached 0.92, which indicated its advantages in detail fidelity and global structure consistency. This performance was attributed to the hierarchical capture of multi-scale features by the dual-output MSRN and the cross-branch residual connections that achieved feature complementarity. Y. Cui also employed a cross-scale feature aggregation module with multi-scale convolution kernels30. However, it only achieved multi-scale fusion through the simple addition of features in a single dimension, failing to distinguish the differentiated requirements for texture details and semantic structures in digital art images. As a result, local texture fractures and structural disorder occurred. At the same time, the CSA mechanism enhanced the perception of pixel spatial position dependence through coordinate information embedding and attention weight modeling, which avoided the loss of key edge and texture features during transmission. The actual optimization comparison showed that the images processed by the SMC algorithm achieved 88% of superior areas in the 10 × 10 grid test, and the texture sharpness and structural coherence were significantly better than the compared algorithms, which verified its ability to enhance local details and maintain global consistency in complex scenes. Y. Liu also employed a hierarchical attention mechanism, but it relied on complex attention matrix calculations to achieve cross-scale feature correlation31. Moreover, it lacked coordinate information and was unable to precisely adapt to the aspect ratio characteristics of panoramic images, resulting in insufficient global consistency.
In panoramic image inpainting tasks, the SMC-VGV model also showed outstanding comprehensive performance. From the loss convergence curve, this model converged rapidly at the 20th iteration, and the final loss value dropped to 0.023, which was significantly lower than the 0.057 of the ReGGAN model, showing the effectiveness of VAE optimization and improving the generation stability. The ROC curve result showed that the AUC of the SMC-VGV model reached 0.923, and the PR curve was closer to the upper right corner, indicating that it maintained high precision under high recall, and the semantic rationality and visual authenticity of the restored results were better. This advantage came from the long-range dependency modeling capability of the ViT, which captured the associations among all pixels through the multi-head self-attention mechanism, making the restored content better match the global logic in cross-regional structural associations. J. Zhang employed the Transformer model for panoramic semantic segmentation32. However, the size of the image segmentation blocks was too large, and there was a lack of collaborative optimization of position encoding and attention, which prevented it from accurately capturing the fine-grained correlation between damaged and undamaged areas. This led to semantic logical errors. Additionally, no constraint mechanism for style features was constructed. It only focused on structural completion and ignored the consistency requirements of the style of digital art works, resulting in insufficient artistic coordination of the repair results. While SMC-VGV maintains the original image’s style tone through variational inference, and ViT uses small-sized image blocks for segmentation, combined with position encoding, it can precisely capture the association between damaged and undamaged areas, improving the restoration effect. Furthermore, M. Zhou employed a perception-oriented U-shaped Transformer network, relying on spherical coordinate mapping to preprocess and adapt panoramic images, which increased the model complexity and preprocessing costs33. Moreover, no explicit distribution constraint mechanism for digital art styles was designed, and style fidelity relied on implicit learning from training data, lacking the ability to personalize adaptation for different art styles. Additionally, the self-attention mechanism did not specifically optimize spatial position-dependent perception, and performed poorly in balancing global consistency and detail fidelity, making it difficult to meet the stability requirements of digital art creation. SMC-VGV can model digital art style features through VAE and ensure consistency between the generated content and the original style through KL divergence constraints. In terms of objective metrics, the model achieved an SSIM of 0.975 and a PSNR of 53.82 dB on the DIV2K dataset, which were improved by 0.023 and 3.13 dB compared with the GC-HT-WGAN model. On the SUN360 dataset, the SSIM improved by 0.055 compared with the ReGGAN model, which fully verified its adaptability to diverse scenes. This is because SMC-VGV, through adversarial training between the generator and the discriminator, can continuously enhance the sharpness of the generated lines. The blind image restoration model of Z. Yue based on deep variational networks still mainly relies on convolution operations for feature extraction34. It has not broken through the receptive field limitation of convolution operations and is unable to effectively model the long-distance pixel dependencies of panoramic images. Moreover, its hierarchical variational inference module is only optimized for fuzzy problems and does not construct feature constraints related to artistic styles, resulting in insufficient style consistency and global coherence of the restoration results. At the same time, it has not optimized the generalization mechanism of the model, and has limited ability to adapt to features in extreme scenarios, making it difficult to meet the complex scene requirements in digital art creation. The efficiency test showed that the maximum memory usage of the model was only 394 MB, and the response time was 3.12 s with a data volume of 2000, which was better than the 4.93 s of FFC-Trans-GAN. To more intuitively demonstrate the superiority of the model, the study compared the proposed method with the existing ones, and the comparison results are shown in Table 6.
As shown in Table 6, the proposed method in the study has significant advantages over the existing methods. It can more accurately and efficiently restore digital art panoramic images and improve their visual quality. The contribution of this study was mainly reflected in three aspects. First, the SMC algorithm combined the dual-output MSRN and CSA to achieve multi-scale feature complementarity and spatial attention modeling, which broke through the structural balance limitations of traditional super-resolution techniques. Second, the VAE-GAN-ViT inpainting module was constructed, where the VAE enhanced generation stability and the ViT captured long-range dependencies, effectively solving the structural disorder problem of GAN in complex scenes. Third, the end-to-end integration of the SMC and the inpainting module achieved a full-process optimization from quality enhancement to defect restoration, meeting the multiple requirements of digital art creation for material clarity, integrity, and semantic rationality.
Summary
The study put forward a panoramic image restoration and visual quality enhancement model for digital art creation to address the limitations of traditional panoramic restoration methods, which lacked high-level semantic understanding and global feature control, often causing structural disorder in complex semantic scenes. Existing intelligent algorithms also had obvious shortcomings in scene adaptability, restoration accuracy, processing efficiency, and generalization ability. The study integrated MSRN, CSA mechanism, and SR reconstruction to build the SMC visual quality enhancement algorithm. On this basis, the model combined GAN optimized by VAE with ViT to restore occluded and missing regions with high quality. Experimental results showed that the model effectively resolved the defects of traditional methods in complex scenes, including structural disorder and inconsistent restoration. It also improved detail authenticity and global coherence, significantly enhancing the quality and visual effect of panoramic image restoration. This study provided strong material support for digital art creation. Although the proposed model performed well, its performance under extremely complex scenes was not fully verified. Future work focuses on improving cross-scene generalization and real-time processing, while adjusting feature weights to meet the needs of digital art creation and enhance its applicability and accuracy in diverse scenarios.
Data availability
DATA AVAILABILITYThe datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Wang, G. et al. Panoramic neural radiance field from a single panorama. IEEE Trans. Pattern Anal. Mach. Intell. 46 (10), 6905–6918. https://doi.org/10.1109/TPAMI.2024.3387307 (2024).
Celik, M. E., Mikaeili, M. & Celik, B. Improving resolution of panoramic radiographs: Super-resolution concept. Dentomaxillofac Rad. 53 (4), 240–247. https://doi.org/10.1093/dmfr/twae009 (2024).
Jindal, H., Bharti, M., Kasana, S. S. & Saxena, S. An ensemble mosaicing and ridgelet based fusion technique for underwater panoramic image reconstruction and its refinement. Multimed Tools Appl. 82 (22), 33719–33771. https://doi.org/10.1007/s11042-023-14594-9 (2023).
Purohit, J. & Dave, R. Leveraging deep learning techniques to obtain efficacious segmentation results. Arch. Adv. Eng. Sci. 1 (1), 11–26. https://doi.org/10.47852/bonviewAAES32021220 (2023).
Wu, K. Creating panoramic images using ORB feature detection and RANSAC-based image alignment. Adv. Comput. Commun. 4 (4), 220–224. https://doi.org/10.26855/acc.2023.08.002 (2023).
[6], J., Wu, H., Deng, F., Cheng & Wang, H. Camera tripod removal model in panoramic images based on generative adversarial networks. J. Comput. 34 (3), 19–29. https://doi.org/10.53106/199115992023063403002 (2023).
Hong, Y. et al. PAR2Net: End-to-end panoramic image reflection removal. IEEE Trans. Pattern Anal. Mach. Intell. 45 (10), 12192–12205. https://doi.org/10.1109/TPAMI.2023.3286429 (2023).
Yurttas, M. et al. Aug., Detection of the fixed prostheses on panoramic images: an artificial intelligence based study, JCPSP, 34, 8, pp. 922–926, https://doi.org/10.29271/jcpsp.2024.08.922 (2024).
Haghanifar, A., Majdabadi, M. M., Haghanifar, S., Choi, Y. & Ko, S. B. PaXNet: tooth segmentation and dental caries detection in panoramic X-ray using ensemble transfer learning and capsule classifier. Multimed Tools Appl. 82 (18), 27659–27679. https://doi.org/10.1007/s11042-023-14435-9 (2023).
Nazir, S., Vaquero, L., Mucientes, M., Brea, V. M. & Coltuc, D. Depth Estimation and image restoration by deep learning from defocused images. IEEE Trans. Comput. Imag. 9, 607–619. https://doi.org/10.1109/TCI.2023.3288335 (2023).
Mao, J. et al. Multilevel Spatial refinement network for transmission line fastener defect detection. IEEE Trans. Ind. Inf. 20 (10), 11610–11621. https://doi.org/10.1109/TII.2024.3409448 (2024).
Li, X., Li, Y., Chen, H., Peng, Y. & Pan, P. CCAFusion: Cross-modal coordinate attention network for infrared and visible image fusion. IEEE Trans. Circ. Syst. Vid Technol. 34 (2), 866–881. https://doi.org/10.1109/TCSVT.2023.3293228 (2024).
[13], W. et al. Frequency generation for real-world image super-resolution. IEEE Trans. Circ. Syst. Vid Technol. 34 (8), 7029–7040. https://doi.org/10.1109/TCSVT.2024.3367876 (2024).
Zhu, J., Koh, V. K. Z., Lin, Z. & Wen, B. A transformer-based multi-modal generative adversarial network for guided depth image super-resolution. IEEE J. Emerg. Sel. Top. Circ. Syst. 14 (2), 261–274. https://doi.org/10.1109/JETCAS.2024.3394495 (2024).
Xie, T. et al. ViT-MVT: A unified vision transformer network for multiple vision tasks. IEEE Trans. Neural Netw. Learn. Syst. 36 (2), 3027–3041. https://doi.org/10.1109/TNNLS.2023.3342141 (2025).
Gao, T. et al. Frequency-oriented efficient transformer for all-in-one weather-degraded image restoration. IEEE Trans. Circ. Syst. Vid Technol. 34 (3), 1886–1899. https://doi.org/10.1109/TCSVT.2023.3299324 (2024).
Zhou, Z., Yuan, M., Zhao, M., Guo, J. & Yan, D. M. Multi-scale graph embedding network for residual mesh denoising. IEEE Trans. Vis. Comput. Graph. 31 (4), 2028–2044. https://doi.org/10.1109/TVCG.2024.3378309 (2025).
Han, S., Sun, S., Zhao, Z., Luan, Z. & Niu, P. Deep residual multiscale convolutional neural network with attention mechanism for bearing fault diagnosis under strong noise environment. IEEE Sens. J. 24 (6), 9073–9081. https://doi.org/10.1109/JSEN.2023.3345400 (2024).
Singh, M., Baranwal, N., Singh, K. N. & Singh, A. K. Using GAN-based encryption to secure digital images with reconstruction through customized super resolution network. IEEE Trans. Consum. Electron. 70 (1), 3977–3984. https://doi.org/10.1109/TCE.2023.3285626 (2024).
Zhu, L. et al. A feature-oriented enhanced GAN for enhancing thermal image super-resolution. IEEE Signal. Process. Lett. 31, 541–545. https://doi.org/10.1109/LSP.2024.3356751 (2024).
Liu, J. et al. Robust dual discriminator generative adversarial network for microscopy hyperspectral image super-resolution. IEEE Trans. Med. Imag. 43 (11), 4064–4074. https://doi.org/10.1109/TMI.2024.3412033 (2024).
Zhang, W. et al. Unpaired optical coherence tomography angiography image super-resolution via frequency-aware inverse-consistency GAN. IEEE J. Biomed. Health Inf. 29 (4), 2695–2705. https://doi.org/10.1109/JBHI.2024.3506575 (2025).
Pan, Z., Wang, Y., Cao, Y. & Gui, W. VAE-based interpretable latent variable model for process monitoring. IEEE Trans. Neural Netw. Learn. Syst. 35 (5), 6075–6088. https://doi.org/10.1109/TNNLS.2023.3282047 (2024).
Zhang, T., Chen, C., Wang, D., Guo, J. & Song, B. A VAE-based user preference learning and transfer framework for cross-domain recommendation. IEEE Trans. Knowl. Data Eng. 35 (10), 10383–10396. https://doi.org/10.1109/TKDE.2023.3253168 (2023).
Zhang, J. et al. Multimodal informative vit: information aggregation and distribution for hyperspectral and lidar classification. IEEE Trans. Circ. Syst. Vid Technol. 34 (8), 7643–7656. https://doi.org/10.1109/TCSVT.2024.3375511 (2024).
[26], V. et al. Human visual system based optimized mathematical morphology approach for enhancement of brain MR images. J. Amb Intel Hum. Comp. 15 (1), 799–807. https://doi.org/10.1007/s12652-019-01386-z (2024).
Yao, J., Zhao, Y., Bu, Y., Kong, S. G. & Chan, J. C. W. Laplacian Pyramid Fusion Network With Hierarchical Guidance for Infrared and Visible Image Fusion, IEEE T Circ. Syst. Vid., vol. 33, no. 9, pp. 4630–4644, https://doi.org/10.1109/TCSVT.2023.3245607. (2023).
Zhou, X. & Zhang, L. SA-FPN: An effective feature pyramid network for crowded human detection, Appl. Intell., 52(11): 12556–12568.vol. 52, no. 11, pp. 12556–12568, https://doi.org/10.1007/s10489-021-03121-8 (2022).
Pan, H., Gao, B., Wang, X., Jiang, C. & Chen, P. DICNet: achieve low-light image enhancement with image decomposition, illumination enhancement, and color restoration. Visual. Comput. 40 (10), 6779–6795. https://doi.org/10.1007/s00371-024-03262-0 (2024).
Cui, Y., Ren, W., Cao, X. & Knoll, A. Revitalizing convolutional network for image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 46 (12), 9423–9438. https://doi.org/10.1109/TPAMI.2024.3419007 (2024).
Liu, Y., Wu, Y. H., Sun, G., Zhang, L. & Chhatkuli, A. and G. L.Van, Vision transformers with hierarchical attention, Mach. Intell. Res., vol. 21, no. 4, pp. 670–683, https://doi.org/10.1007/s11633-024-1393-8.
Zhang, J. et al. Behind every domain there is a shift: adapting distortion-aware vision Transformers for panoramic semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 46 (12), 8549–8567. https://doi.org/10.1109/TPAMI.2024.3408642 (2024).
Zhou, M. et al. Perception-oriented U-shaped transformer network for 360-degree no-reference image quality assessment. IEEE Trans. Broadcast. 69 (2), 396–405. https://doi.org/10.1109/TBC.2022.3231101 (2023).
Yue, Z. et al. Deep variational network toward blind image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 46 (11), 7011–7026. https://doi.org/10.1109/TPAMI.2024.3365745 (2024).
Funding
The research is supported by Shaanxi Social Science Fund, Research on the Digital Preservation and Restoration Techniques and Dissemination Strategies of Red Woodblock Prints from the Yan’an Period, 2024J048.
Author information
Authors and Affiliations
Contributions
Z.X.Y. processed the numerical attribute linear programming of communication big data, and the mutual information feature quantity of communication big data numerical attribute was extracted by the cloud extended distributed feature fitting method. T.W. and P.T. Combined with fuzzy C-means clustering and linear regression analysis, the statistical analysis of big data numerical attribute feature information was carried out, and the associated attribute sample set of communication big data numerical attribute cloud grid distribution was constructed. Z.X.Y. and X.J.L. did the experiments, recorded data, and created manuscripts. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yu, Z., Wang, T., Tian, P. et al. Panoramic image restoration and visual quality enhancement methods for digital art creation. Sci Rep 16, 7140 (2026). https://doi.org/10.1038/s41598-026-37659-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-37659-9
