
Abstract
To address the non-stationarity of rolling bearing vibration signals and the interference under complex working conditions, this paper proposes a fault diagnosis method based on the fusion of short-time Fourier transform (STFT) and time-domain statistical features, optimized by an adaptive Lévy–seagull optimization algorithm (AL-SOA) for Bagging Tree (denoted as STSF-AL-SOA-BT). To simultaneously capture both the frequency-domain impulsive components and the time-domain waveform structure while controlling the input dimensionality, a lightweight dual-channel attention fusion module (AFF) is designed. The module adaptively weights and concatenates a 256-dimensional STFT spectrum with six time-domain statistical features, followed by dimensionality reduction via PCA to mitigate redundancy and overfitting. For optimizing the key structural parameters of the Bagging Tree, an AL-SOA strategy is developed, integrating Lévy flight and linear inertia weighting while maintaining an external elite archive to preserve the Pareto optimal set. This approach achieves a multi-objective balance among accuracy, model complexity, and training efficiency. The proposed method is systematically validated on the CWRU, SEU, and self-built SUT test rigs, achieving average accuracies of 98.88%, 98.50%, and 97.53%, respectively. Ablation studies demonstrate that both the attention mechanism and AL-SOA make significant contributions; the introduction of attention improves accuracy by 0.6–1.2% (p < 0.01), while the Pareto front analysis confirms an effective trade-off between accuracy and complexity. Overall, the proposed method balances discriminative capability, interpretability, and engineering deployability, providing a feasible solution for lightweight bearing fault diagnosis under variable operating conditions and strong noise interference.
Similar content being viewed by others
Introduction
Rolling bearings, as the core supporting components of rotating machinery, are widely applied in equipment such as wind turbines, rail transportation, and aircraft engines. Liang et al. 1 highlighted that their health directly impacts system safety and stability. Prolonged operation under complex conditions makes bearings susceptible to damage. Wang et al. 2 noted that approximately 42% of rotating machinery shutdown incidents are caused by bearing failures, with the amplitude of fault impact components under varying speed and load conditions decreasing by over 30%. Conducting efficient and accurate fault diagnosis research is crucial for enhancing equipment reliability and safety. The complex structure and harsh working environment of rolling bearings pose significant challenges to fault feature extraction. Sun et al. 3 pointed out that feature extraction methods struggle with complex noise interference and variable working conditions, thus making the development of intelligent fault diagnosis methods key to addressing this issue.
In the field of mechanical fault diagnosis, feature extraction and processing are pivotal for high-precision recognition. Early on, Nawab et al. 4 proposed the Short-Time Fourier Transform (STFT), which became widely used for time–frequency analysis of vibration signals due to its efficiency and simplicity. However, due to the limitations of fixed window functions, STFT struggles to capture sudden or transient features when processing non-stationary signals. Subsequently, Daubechies et al. 5 introduced Wavelet Transform (WT), which adapts time–frequency resolution to better describe the local features of signals, although its performance is highly influenced by the choice of wavelet basis and denoising strategies. Huang et al. 6 proposed Empirical Mode Decomposition (EMD) and its improved methods, such as Wu et al.’s 7 Ensemble Empirical Mode Decomposition (EEMD) and Torres et al.’s 8 Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN), which are advantageous for processing nonlinear and non-stationary signals but still face issues such as endpoint effects and mode mixing. To address this, Dragomiretskiy et al. 9 proposed Variational Mode Decomposition (VMD), which effectively mitigates mode mixing and enhances decomposition stability. In recent years, Daubechies et al. 10 proposed Synchronized Squeezed Transform (SST) and its subsequent methods, which enhance time–frequency focus by phase redistribution, making them particularly suitable for frequency-modulated and transient signals. Overall, feature extraction methods have evolved from linear methods to adaptive decomposition. Although traditional methods offer advantages in interpretability and engineering feasibility, they often face challenges such as high feature dimensionality, noise sensitivity, and strong dependence on parameters in complex operating conditions. Consequently, fusion strategies have become mainstream in recent years. By combining features from STFT, wavelet transforms, VMD, and time-domain statistics, fault mode discrimination ability has been enhanced. However, composite features often lead to high-dimensional redundancy, making feature selection and model optimization critical research directions.
In the area of feature selection and model optimization, intelligent optimization algorithms are widely applied. Holland et al. 11 proposed Genetic Algorithms (GA), which simulate natural selection and genetic mechanisms, showing strong global search ability but with slow convergence and a tendency to get trapped in local optima. Kennedy et al. 12 introduced Particle Swarm Optimization (PSO), which incorporates a population cooperation mechanism to simplify parameter settings but is prone to premature convergence. Storn et al. 13 proposed Differential Evolution (DE), which exhibits strong global search capabilities but suffers from performance degradation in high-dimensional optimization. Mirjalili et al. 14 introduced the Grey Wolf Optimizer (GWO), which enhances local search ability through social hierarchy, but issues with parameter sensitivity remain. In recent years, evolutionary learning and intelligent optimization methods have achieved significant progress in fields such as wind energy, transportation, and healthcare. For example, Wang et al. 15 applied the evolutionary variational YOLOv8 network in wind turbine fault detection, demonstrating the advantages of evolutionary learning under complex conditions. Zhang et al. 16 proposed a Particle Swarm Optimization-driven automatic prompt design strategy that performed excellently in medical text extraction, showcasing the power of swarm intelligence optimization in high-dimensional decision spaces. Guo et al. 17 applied the transfer optimization-enhanced parallel algorithm in the transportation field, further confirming the broad adaptability of evolutionary computation methods18. In recent years, new heuristic algorithms19, such as Whale Optimization 20, Lion Pride Algorithm 21, Sparrow Search 22, and Bat Algorithm 23, have also demonstrated good solving abilities, but they generally suffer from slow convergence and the tendency to get stuck in local extrema. Dhiman et al. 24 proposed the Seagull Optimization Algorithm (SOA), which simulates seagull migration and hunting behaviors, combining global exploration and local exploitation, demonstrating its potential in feature selection and model tuning.
At the classifier level, machine learning methods have evolved from single models to ensemble learning. Suthahar et al. 25 proposed Support Vector Machines (SVM), which perform well in small sample and high-dimensional feature scenarios but have high training complexity. De Ville et al. 26 introduced decision trees and ensemble methods such as Breiman et al.’s 27 Random Forest (RF) and Friedman’s 28 Gradient Boosting (XGBoost), which show strong advantages in handling multi-dimensional features. In recent years, the rapid development of deep learning has pushed fault diagnosis methods toward automatic feature learning29. Bai et al. 30 proposed a 1D Convolutional Neural Network (1D-CNN), and Li et al. 31 introduced a CNN-LSTM network, demonstrating superior performance in end-to-end feature extraction32. Despite its advantages, deep learning is limited by its high cost and low interpretability, restricting its application in industrial settings33. Additionally, it lacks robustness to operating condition changes and noise34. Despite advancements in self-supervised learning, transfer learning, and lightweight networks, deep learning still faces challenges related to data dependency and computational burdens35. Therefore, there is an urgent need for a unified framework that can enhance feature extraction, model optimization, and classification under non-stationary, small-sample, and noise-interference36. This paper proposes an intelligent diagnostic method that integrates Short-Time Fourier Transform (STFT) and time-domain statistical features, optimized by the adaptive Lévy Seagull Algorithm (AL-SOA) to optimize Bagging Tree. This method combines the advantages of STFT frequency-domain features and time-domain statistical features, significantly improving fault diagnosis accuracy and robustness, overcoming the limitations of traditional methods, and solving the problem of high-dimensional feature redundancy.
Problem statement. Practical rolling bearing fault diagnosis under variable operating conditions is challenged by the non-stationarity of vibration signals and noise interference, while engineering deployment further requires a compact and interpretable model with controllable computational cost. Despite recent progress, three gaps remain. (i) Many end-to-end deep models may improve accuracy, yet they often incur high computational cost and may generalize unstably when the data distribution shifts across rigs or loads, limiting edge deployment. (ii) Existing feature-fusion strategies are often implemented as direct concatenation or fixed-weight aggregation, which cannot adaptively re-balance heterogeneous features when their contributions drift under changing conditions. (iii) The structural hyperparameters of ensemble classifiers are typically tuned heuristically or with single-objective criteria, leaving the trade-off among accuracy, model complexity, and training efficiency insufficiently explored.
Design rationale of each stage. To directly address the above gaps, the proposed framework is organized as a modular pipeline, where each stage is designed to mitigate a specific limitation:
-
(1)
Data preprocessing and two-level windowing enhance fault-sensitive components and generate reproducible samples from non-stationary raw signals, improving robustness before learning. The complete preprocessing workflow (bandpass filtering + wavelet multi-scale denoising + overlapping sliding window + Z-score normalization) yields a marked accuracy gain and reduced fluctuation compared with raw signals, thereby strengthening stability under noise and operating-condition variations and alleviating the generalization risk described in gap-(i).
-
(2)
Dual-domain feature construction represents complementary information: the STFT spectrum captures fault-related frequency patterns, while six time-domain statistical indicators describe waveform characteristics, jointly enhancing discriminability under varying conditions. Ablation results show that using only STFT or only statistical features leads to a clear performance drop, whereas their fusion improves overall robustness, providing redundancy against distribution shift in gap-(i).
-
(3)
Dual-channel attention-based fusion (AFF) adaptively re-weights STFT and statistical features to mitigate contribution drift, thereby overcoming fixed-weight or direct-concatenation fusion. Empirically, removing AFF causes a measurable accuracy decrease, and attention-weight visualization exhibits distinct peaks aligned with bearing characteristic frequencies, supporting both discriminability and interpretability while addressing gap-(ii).
-
(4)
PCA-based compression reduces redundancy in the fused 262-dimensional representation to control input dimensionality and computational burden, facilitating lightweight deployment. With a 95% explained-variance threshold, PCA achieves efficient compression with only a marginal accuracy decrease (no more than 0.2%) and about an 18% reduction in training time, satisfying the complexity constraint implied by gap-(iii) without sacrificing diagnostic performance.
-
(5)
Bagging Tree classification with AL-SOA multi-objective tuning preserves interpretability and low inference cost, while AL-SOA explicitly balances diagnostic accuracy, model complexity, and training time via Pareto-based optimization rather than heuristic single-objective selection. AL-SOA incorporates Lévy flight and adaptive inertia weight to enhance global optimization in a discrete, non-convex search space; its convergence stabilizes around the 30–35th generation, and the resulting non-dominated solutions provide an explicit performance–complexity–time trade-off curve required by gap-(iii).
To clarify the originality of the proposed framework, we explicitly position our method with respect to several closely related research paradigms and representative frameworks. First, adaptive feedback systems in other data-driven applications highlight the value of closing the loop between model outputs and subsequent adjustments, but their problem setting and data modality differ substantially from mechanical condition monitoring37. Second, acoustic emission (AE) signal-based imaging for pipeline condition diagnosis provides an effective way to transform complex multivariate AE measurements into learnable representations, yet such imaging pipelines typically target AE sensing and pipeline scenarios rather than vibration-based bearing diagnosis38. Third, graph neural network (GNN) frameworks for multivariate AE under variable pressure conditions further demonstrate the benefit of modeling inter-sensor relationships, whereas they rely on multi-sensor topologies and graph construction that are not directly available in lightweight single-sensor bearing vibration monitoring39. Fourth, classical pattern-recognition pipelines developed for iris detection and recognition emphasize modular processing (segmentation–feature extraction–classification) with clear interpretability, but they operate on image data and do not address non-stationary vibration signals with operating-condition variations40. Fifth, burst-informed AE diagnostic frameworks for explainable failure analysis explicitly preserve transient burst events and integrate interpretable learning components, but they are tailored to burst-dominated AE signals in machining processes rather than bearing vibration characteristics41. Sixth, multi-sensor observer-based residual learning with Auto-Permutation Feature Importance (Auto-PFI) improves interpretability through residual modeling and feature-importance ranking under varying conditions, yet it depends on multi-sensor residual construction and observer design that are beyond the scope of a compact vibration-feature fusion setting42. Seventh, hybrid deep learning frameworks that combine logarithmic time–frequency imaging with CNN/ViT-style feature learning offer strong representation capability, but their heavy backbones and training demands may complicate deployment under limited computational budgets and distribution shifts across rigs or loads43. In addition, recent studies have further advanced feature extraction by transforming vibration or acoustic-emission signals into CWT-based time–frequency scalograms and applying attention-enhanced spatiotemporal extraction or vision-transformer-style representation learning. For example, Siddique et al. developed a hybrid bearing-diagnosis framework that combines CWT scalograms with attention-enhanced spatiotemporal feature extraction44, while another recent work employed vision transformers with semi-supervised learning and uncertainty quantification for advanced fault diagnosis in machining scenarios45. These studies highlight the strong representational capacity of CWT-to-image feature learning; however, they typically rely on heavier backbones and additional training strategies, which may increase implementation complexity when targeting edge deployment under variable operating conditions. To provide a fair and quantitative reference to this paradigm, we include a representative CWT + Transformer baseline in the comparative study, and the proposed framework achieves a more favorable and balanced performance profile on the evaluated datasets, especially in terms of Recall and F1-score.
In contrast to the above paradigms, this work focuses on deployment-oriented bearing diagnosis under noise and operating-condition variations by (1) using a compact fusion of the STFT spectrum and time-domain statistical features, and (2) introducing a dual-channel attention-based fusion module to adaptively re-weight heterogeneous features rather than relying on direct concatenation or fixed-weight aggregation. Moreover, instead of heuristic or single-objective tuning, we formulate hyperparameter selection of the ensemble classifier as a multi-objective problem and employ AL-SOA to jointly balance diagnostic accuracy, model complexity, and training time, thereby providing a practical and interpretable alternative for engineering applications.
The main contributions are summarized as follows:
-
(1)
We propose a lightweight STFT–statistical feature representation with a dual-channel attention-based fusion module (AFF) to adaptively re-weight heterogeneous features, overcoming the limitations of direct concatenation and improving interpretability.
-
(2)
We develop an Adaptive Lévy-based Seagull Optimization Algorithm (AL-SOA) to perform multi-objective tuning of Bagging Tree hyperparameters by jointly balancing accuracy, training time, and model complexity.
-
(3)
We establish a modular evaluation protocol including ablation, sensitivity analysis, and statistical significance tests to quantify the contribution of each module.
-
(4)
We validate the proposed framework on three rigs (CWRU, SEU, and a self-built test bench) and provide attention-weight visualization linked to bearing characteristic frequencies for explainable diagnosis.
The remainder of this paper is organized as follows. Sect. “Rolling Bearing Fault Diagnosis Method Based on STSF-AL-SOA-BT” describes the proposed STSF-AL-SOA-BT framework, including preprocessing, feature construction, fusion, and optimization. Sect. “Experimental Validation and Analysis” presents experimental settings and comparative results, followed by ablation and robustness analyses. Sect. “Conclusions and Future Work” concludes the paper and discusses limitations and future work.
Fundamental principle
Short-time Fourier transform
The Short-Time Fourier Transform (STFT) is an important tool for processing non-stationary signals. Unlike the traditional Fourier Transform, which reveals the overall frequency components of a signal, STFT introduces a local window function that enables the signal to be analyzed in sliding time segments. This provides a local spectral representation in the time–frequency joint domain 46.
Its mathematical expression is as follows:
where:
\(x\left( \tau \right)\) denotes the original time − domain signal,\(\omega \left( {\tau - t} \right)\) represents the window function, \(\tau\) is the time − shift variable, and \(\omega\) is the angular frequency. The STFT result characterizes the spectral distribution of the signal at frequency \(\omega\) corresponding to the time instant \(\tau\). The associated energy distribution is given by:
Due to the incorporation of the window function, the STFT inherently faces a trade-off between time and frequency resolution. Its essence is fundamentally constrained by the Heisenberg uncertainty principle:
The STFT is particularly suitable for capturing typical fault characteristics such as transient impulses and frequency drifts. It exhibits remarkable advantages in the time–frequency representation of mechanical vibration signals, thereby providing time-varying spectral information to support subsequent feature extraction and pattern recognition.
Fundamental principles of dimensionality reduction and feature selection
Principal Component Analysis (PCA) is a linear dimensionality reduction method aimed at reducing the dimensionality of features by maximizing the variance of the data. PCA computes the covariance matrix of the data and performs eigenvalue decomposition to identify the principal components that most effectively explain the data’s variance. In this study, PCA is applied to perform dimensionality reduction on the 262-dimensional feature vector obtained by combining the 256-dimensional STFT features and the 6-dimensional time-domain statistical features. By retaining the primary components, PCA effectively reduces redundant information and enhances the discriminative power of the features 47.
Let the centralized sample matrix be:
The covariance matrix is given by
By performing eigenvalue decomposition (or singular value decomposition, SVD), we obtain
where,\(U = \left[ {u_{1} ,u_{2} , \ldots ,u_{d} } \right]\) denotes the eigenvector matrix, and \({\Lambda } = {\text{diag}}\left( {\lambda_{1} ,\lambda_{2} , \ldots ,\lambda_{d} } \right)\) is the corresponding eigenvalue matrix, satisfying \(\lambda_{1} \ge \lambda_{2} \ge \cdots \ge \lambda_{d}\).
The original features are projected onto the first \(k\) principal components as follows:
The cumulative variance contribution ratio is defined as:
When the Explained Variance Ratio (EVR) for the first \(k\) principal components reaches a set threshold (95% in this study), it is considered that the first \(k\) components adequately represent the main information of the original features. The advantage of PCA lies in its ability to compress high-dimensional features and eliminate correlations without supervision. However, its projection direction is solely based on the sample variance and does not consider class information, potentially leading to a loss of discriminative power.
Feature selection is a critical step in optimizing machine learning models, aiming to select the most discriminative features to improve model performance while reducing computational overhead. In rolling bearing fault diagnosis, feature selection helps eliminate redundant information and noise, thereby enhancing the model’s generalization ability.
In this study, feature selection is performed on the features obtained after PCA dimensionality reduction. During the feature selection process, various statistical methods are employed to assess the correlation and contribution of each feature to fault classification, retaining the most representative features. This approach preserves the key features of fault modes while effectively avoiding overfitting issues that may arise from high-dimensional data.
In this research, the original 262-dimensional feature vector consists of the STFT spectrum (256 dimensions) and 6 time-domain statistical features. Since high-dimensional features tend to cause overfitting when the sample size is limited, dimensionality reduction methods such as PCA are introduced to improve the model’s generalization ability by reducing the feature dimensions. Moreover, the feature selection step further filters the most valuable features for classification to ensure the simplicity and efficiency of the model.
Seagull optimization algorithm principles and improvements
To automatically search for key hyperparameters of the Bagging Tree (such as the maximum number of leaf nodes, minimum leaf sample size, etc.) under multi-objective constraints, this study adopts the Seagull Optimization Algorithm (SOA), a swarm intelligence-based global optimization method. Building upon this, we propose the Adaptive Lévy-SOA (AL-SOA) to enhance the robustness and convergence performance of the search.
Standard SOA algorithm principles
The SOA simulates the migration and predation behaviors of seagulls, achieving global exploration and local exploitation through the coordinated movement of individuals in the search space. The algorithm typically consists of three components:
Population Initialization: The positions of the population are randomly initialized within the given search boundaries.
Migration Stage: During migration, each individual in the population moves toward the current global best position, completing a broad search.
Attacking Stage: In the final stage, local exploitation is refined by simulating the spiral predatory behavior of seagulls through local perturbations.
This framework is simple to implement and requires relatively few parameters, making it suitable for optimizing Bagging Tree hyperparameters, which involve “continuous intervals + non-convex performance surfaces.” However, the standard SOA tends to prematurely converge in later iterations on complex multi-modal problems, and lacks sufficient ability to escape local optima.
Adaptive Lévy-SOA (AL-SOA) improvements
To address these limitations, this study introduces Lévy flight and adaptive inertia weight to improve the standard SOA, resulting in the AL-SOA algorithm. Firstly, the Lévy flight is incorporated to generate random step sizes with heavy-tailed distributions, allowing individuals to make occasional long-distance jumps during local searches. This enhances the algorithm’s ability to escape local optima. Secondly, an adaptive inertia weight \(\omega \left( t \right)\) that linearly decreases with iterations is introduced. This maintains a larger inertia early in the search process to promote global exploration and gradually reduces it to emphasize local exploitation in the later stages. The updated velocity of an individual is expressed as:
where, \({\text{x}}_{{{\text{best}}}}^{\left( t \right)}\) s the current global best position, \({\text{L}}\left( \lambda \right)\) is the random step size generated by the Lévy flight, and \(\alpha\) and \(\beta\) are learning and disturbance coefficients.
In this study, AL-SOA is used as a multi-objective optimization algorithm to find a set of Pareto-optimal hyperparameters for the Bagging Tree, balancing classification accuracy, model complexity, and training time. Through this multi-objective optimization process, AL-SOA adapts to balance different objectives, thus enhancing the Bagging Tree’s performance on complex datasets. The primary task of AL-SOA is to optimize the hyperparameters of a single Bagging Tree model, rather than integrating the outputs of multiple models. By adjusting the hyperparameters, AL-SOA focuses on improving the internal structure of the model to achieve the best balance between classification accuracy and computational efficiency.
The selection of the AL-SOA algorithm is not arbitrary but based on its effectiveness in addressing the non-convexity and discreteness issues in Bagging Tree hyperparameter optimization. Traditional optimization methods, such as Particle Swarm Optimization (PSO), often struggle with the high-dimensional and discrete search space of Bagging Tree hyperparameters. AL-SOA, with its adaptive search mechanism and Lévy flight, effectively balances global exploration and local exploitation, enabling multi-objective optimization for accuracy, complexity, and training time.
Bagging tree classifier principles
Bagging (Bootstrap Aggregating) 48 is a typical parallel ensemble learning strategy that trains multiple base learners on different bootstrap sampling subsets and integrates their predictions to reduce model variance. Bagging Trees, where decision trees serve as base learners, exhibit robust performance and generalization capabilities when handling high variance and non-linear vibration signal classification problems.
Let the training dataset be:
where, \(x_{i} \in {\text{R}}^{d}\) denotes the d-dimensional feature vector of the \(i\)-th sample, and \(y_{i} \in y\) represents the corresponding class label. The basic process of Bagging includes:
Bootstrap Sampling: Perform \(T\) bootstrap resamples from \(D\) with replacement to generate training subsets \(\left\{ {D^{\left( 1 \right)} ,D^{\left( 2 \right)} ,...,D^{\left( T \right)} } \right\}\);
Base Learner Training: Independently train \(T\) decision tree models \(h^{\left( t \right)} \left( x \right)\) on the corresponding subsets;
Majority Voting Output:
where, \({\mathbb{I}}\left( \cdot \right)\) is the indicator function, which equals 1 if the condition inside the parentheses is true, and 0 otherwise, and \({\mathcal{Y}}\) denotes the set of class labels.
Each decision tree evaluates the quality of node splits using the Gini Index:
where, \(p_{k}\) denotes the proportion of samples belonging to class \(k\) in the dataset \(D\), and \(K\) is the total number of classes. For a splitting feature \(A\) and its resulting subsets \(\left\{ {D_{1} ,D_{2} } \right\}\), the overall impurity is defined as:
The decision tree recursively splits the nodes by choosing the split that minimizes \(Gini_{A} \left( D \right)\) , until the stopping criteria are met.
Bagging reduces model variance by integrating multiple base learners, thereby improving prediction accuracy. The expected squared error (MSE) can be decomposed into bias, variance, and noise terms:
Bagging primarily reduces the variance of base learners to improve the overall model performance, making it particularly suitable for classification tasks with high variance and low bias.
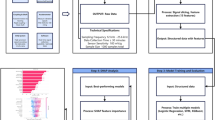
To provide an overall understanding of the method proposed in this paper, Fig. 1 presents the flowchart of the STSF–AL–SOA–BT rolling bearing fault diagnosis framework. The framework proceeds in the following order: “data preprocessing-feature construction-feature dimensionality reduction-hyperparameter optimization—model training and performance evaluation.” Initially, the raw vibration signals undergo preprocessing, including bias removal, bandpass filtering, and wavelet denoising. Then, multi-domain fusion features are constructed using STFT and time-domain statistical features, forming a 262-dimensional STSF feature vector through an attention-guided fusion module. PCA is then applied for dimensionality reduction. Finally, the improved AL-SOA algorithm performs multi-objective optimization on the key hyperparameters of the Bagging Tree, ultimately resulting in a lightweight fault diagnosis model that balances diagnostic accuracy and model complexity.

Overall workflow of the STSF-AL-SOA-BT method.
In this study, Adaptive Lévy-Seagull Optimization (AL-SOA) is introduced at the classifier level, not as a mere addition of algorithms, but as an inevitable choice based on the problem structure. The key hyperparameters of the Bagging Tree (MaxNumSplits, MinLeafSize, NumLearningCycles) form a discrete, non-convex, non-differentiable, and coupled search space under cross-validation objectives. Simultaneously, accuracy, model complexity (average number of leaf nodes), and training time are jointly considered for optimization, resulting in a typical multi-objective trade-off. In this context, AL-SOA takes on the role of structural search within the overall pipeline of “feature construction → dimensionality reduction → structural optimization → training and evaluation.” It utilizes Lévy flight to leap across platforms and local optima, adaptive inertia weight to balance exploration and exploitation, and an external elite archive to maintain Pareto non-dominated solutions. As a result, AL-SOA automates the structural optimization process, replacing manual hyperparameter tuning.
Rolling bearing fault diagnosis method based on STSF-AL-SOA-BT
Data processing
The raw signal is processed through zero-mean normalization to eliminate DC bias. Next, a fourth-order Butterworth bandpass filter is applied with a passband of 500–3000 Hz to suppress interference from irrelevant frequency bands. To enhance local pattern resolution and generate sufficient training samples while avoiding excessive redundancy, the vibration signal is segmented using a sliding window with a length of 1024 samples and a segmentation overlap ratio of 50%, i.e., 512 samples overlap and a hop size of 512 samples. Within each 1024-sample segment, time–frequency characterization is performed by STFT using a 256-point Hamming window with an STFT overlap ratio of 50%, i.e., 128 samples overlap and a hop size of 128 samples. This two-level windowing/overlap design decouples sample generation (segmentation-level overlap) from time–frequency resolution control (STFT-level overlap), thereby improving reproducibility and interpretability of the preprocessing and feature construction pipeline. The specific lengths of the two windows were selected to balance representational adequacy, time–frequency resolution, and computational cost under the adopted sampling frequency (fs = 5120 Hz). The segmentation length of 1024 samples corresponds to 0.2 s, which is sufficiently long to capture a stable local vibration pattern while still short enough to avoid excessive non-stationarity within a single sample under variable operating conditions. Meanwhile, using a 50% overlap at the segmentation level (hop size = 512) increases the effective sample count without introducing excessive redundancy. For the STFT stage, a 256-point Hamming window provides a frequency resolution of fs/256 = 20 Hz, which is adequate to describe the spectral distribution within the fault-sensitive band (500–3000 Hz) while keeping the spectrum representation compact (256 dimensions) for subsequent fusion and lightweight classification. In addition, the choice of a 256-point STFT window with 50% overlap is supported by the sensitivity analysis reported in Sect. “Contribution of Feature Fusion to Classification Performance”, where this configuration exhibits the most stable accuracy and the highest computational efficiency compared with 128- or 512-point windows. The process is shown in Fig. 2.

Data preprocessing flowchart.
Feature extraction
For each 1024-point segment of the sample, a 256-dimensional one-dimensional frequency spectrum vector is first constructed using STFT. Then, six statistical features (mean, standard deviation, skewness, kurtosis, RMS, and peak-to-peak value) are extracted from the time domain and concatenated with the frequency spectrum vector to form a 262-dimensional fused feature vector. Two-step normalization is applied to ensure comparability. Subsequently, the data enters the attention-weighted fusion and dimensionality reduction stage.
Time–frequency feature extraction
To characterize the energy evolution patterns of non-stationary vibration signals in both time and frequency domains, time–frequency features are extracted based on Short-Time Fourier Transform (STFT). For each 1024-point segment of the sample, a 256-point Hamming window is applied with an STFT overlap ratio of 50% (128-point overlap, hop size of 128) for sliding calculation, resulting in a two-dimensional power spectral matrix. The power spectrum is then compressed and resampled along the frequency axis to extract the energy distribution of the dominant frequency band, constructing a 256-dimensional one-dimensional frequency spectrum feature vector to represent the energy patterns in the fault-related frequency bands.
To mitigate the impact of overall energy level differences between samples on feature distribution, a two-step normalization strategy is introduced during the spectrum feature construction process. First, energy normalization is performed on the power spectrum of each sample along the frequency dimension, ensuring that the total energy is 1, thus emphasizing the relative energy distribution. Then, Z-score standardization is applied based on the sample’s statistical properties, mapping the frequency spectrum features to a zero-mean, unit-variance space. This process ensures the comparability of different samples in terms of scale and distribution, which improves the convergence stability and discriminative power of the model during training 49.
The 256-dimensional frequency spectrum vector obtained through the above process can effectively reflect the energy concentration characteristics caused by local bearing defects in specific frequency bands, as well as their harmonic distribution, thereby enhancing the separability between different fault types. Figure 3 shows the time–frequency spectrogram of a typical sample, highlighting the energy concentration in the fault-related frequency bands. Figure 4 presents the averaged power spectrum of the same sample, revealing its main fault frequency band information. Further, Fig. 5 compares the time–frequency spectrograms of three typical fault conditions: inner race fault, outer race fault, and rolling element fault. It can be observed that there are distinct differences in the energy distribution patterns across low, medium, and high frequencies for different fault types, providing an intuitive basis for the classifier to distinguish between various fault modes. The above time–frequency features and normalization process provide stable and discriminative input representations for subsequent feature fusion and classifier optimization.

Time–frequency spectrogram of a raw segment.

Averaged power spectrum of the segment.

Spectrogram comparison of three fault types.
Time-domain statistical feature extraction
To complement the frequency features in waveform structure characterization, this study extracts six commonly used time-domain statistical features from each segment of the vibration signal, including Mean, Standard Deviation, Skewness, Kurtosis, Root Mean Square (RMS), and Peak-to-Peak value. These statistics reflect the fault impact characteristics from different perspectives, such as central tendency, dispersion, distribution symmetry, sharpness, and energy levels, and have been widely applied in rolling bearing fault diagnosis. To avoid excessive length, only the mathematical formulations for Kurtosis, which is most sensitive to impact signals, and RMS, which represents energy levels, are provided here, while the other statistics are defined by their standard forms.
RMS:
Kurtosis:
Feature fusion strategy
To achieve the adaptive integration of frequency-domain and time-domain features, this study proposes a lightweight dual-channel attention-based feature fusion module (Attention-based Feature Fusion, AFF). Its core structure is shown in Fig. 6, and the specific process is as follows., and the specific process is as follows.

Structure of the feature fusion module.
To enhance the relevance and adaptiveness of the STFT and time-domain statistical features during the fusion stage, a lightweight attention-weighted module (AFF) is introduced before feature concatenation to dynamically adjust the weights of the spectral and statistical features. Let the spectral feature vector obtained through Short-Time Fourier Transform (STFT) be:
The time-domain statistical features obtained through feature extraction are:
To adaptively highlight the importance of different feature dimensions, a dual-channel attention mechanism is employed, comprising spectral attention \(A_{f}\) and statistical feature attention \(A_{s}\).
(1) Spectral attention.
Global average pooling is used to extract overall spectral information, followed by a two-layer lightweight fully connected network to implement weight mapping:
where, \(pool\left( \cdot \right)\) denotes the global average pooling operation, and \(\sigma \left( \cdot \right)\) represents the Sigmoid activation function. The weighted spectral features are then obtained as:
(2) Statistical attention.
Softmax normalization is employed to highlight the relative importance of the statistical features:
The weighted statistical features are then obtained as:
The final fused feature vector is given by:
where \(\alpha\) is a balancing coefficient used to globally rescale the statistical-feature branch before concatenation. In this study, α is set to 0.5 and kept constant across all datasets (CWRU, SEU, and SUT) to provide a stable magnitude alignment between the 256-dimensional STFT spectrum and the 6-dimensional statistical indicators, which facilitates subsequent Z-score standardization and PCA-based compression. Note that the relative contribution of the two branches is still adaptively adjusted by the learned attention weights; α only serves as a fixed global scaling term for numerical stability and reproducibility. This module contains only a small number of parameters (r = 16) and has very low computational complexity, yet it can significantly enhance feature representation capability. The fused features are subsequently normalized using Z-score standardization before being input into the Bagging Tree classifier.
Feature selection and dimensionality reduction
To address potential overfitting and low computational efficiency caused by high-dimensional feature vectors (262 dimensions), this study employs three strategies—Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA), and Tree-Based Feature Importance (TBFI)—to optimize the feature space based on the mathematical principles described above. All experiments are conducted using a consistent training/testing split (70:30 ratio, random seed 42) and repeated 10 times to report the mean performance ± standard deviation. Paired t-tests (p < 0.05) are used to ensure the statistical significance of the results.
-
(1)
PCA implementation details.
First, the 262-dimensional fused feature matrix is column-wise mean-centered, and the principal components are subsequently obtained via Singular Value Decomposition (SVD). To determine the optimal projection dimensionality, a dual-strategy evaluation is employed: (i) selecting the number of principal components \(k\) automatically when the explained variance ratio (EVR) ≥ 95%; and (ii) performing a parameter scan over k = 10:10:200 to systematically assess the impact of dimensionality on classification performance. Each configuration is evaluated using 10 repetitions of tenfold cross-validation, with mean accuracy, standard deviation, and training time recorded.
-
(2)
LDA implementation details50.
Considering that the maximum effective projection dimension of LDA is C-1 = 9 and that high-dimensional small-sample scenarios can render the within-class scatter matrix \(S_{W}\) ill − conditioned, a two − stage dimensionality reduction approach is adopted. First, PCA is used to pre − reduce the feature dimension to \(m = min\left( {120,N - C} \right)\) to eliminate singularity, followed by LDA projection into a 9-dimensional discriminant subspace. The resulting low-dimensional features are directly input into the Bagging Tree classifier for performance evaluation.
-
(3)
TBFI implementation details51.
A single CART decision tree (parameters: MaxNumSplits = 30, MinLeafSize = 1) is used to compute the Gini importance scores of features. To mitigate the influence of the randomness inherent in a single tree, the importance evaluation is repeated 10 times and averaged for ranking. Finally, feature subsets of Top-{120, 80, 60, 40, 20} are selected to train Bagging Tree classifiers, and their cross-validation performance is compared.
The above experiments aim to identify an optimal feature subset that balances performance and computational efficiency for subsequent model training. As shown in Fig. 14, the model performance stabilizes when the number of PCA components reaches approximately 120, providing a critical reference for feature compression.
Model construction and optimization
Multi-objective parameter optimization based on adaptive seagull algorithm
The Bagging Tree hyperparameter configuration is modeled as a non-gradient, discrete, non-convex multi-objective structural search problem (objectives: ten-fold accuracy, average number of leaf nodes, and training time). Therefore, the AL-SOA with Lévy flight and adaptive inertia mechanisms is employed as the structural search strategy, and the external elite archive is used to output the Pareto optimal set.
To balance classification accuracy, model complexity, and training time, a multi-objective weighted fitness function is used to drive the parameter optimization of the Seagull Optimization Algorithm. The three evaluation metrics for each individual are: (1) Ten-fold cross-validation average accuracy; (2) Model complexity (measured by the average number of leaf nodes); (3) Training time. To eliminate dimensional differences, the objectives are normalized first, as shown in Eq. (26).
The comprehensive fitness function is defined in Eq. (27), where \(\lambda 1, \lambda 2\), and \(\lambda 3\) are the weights for accuracy, complexity, and time, respectively. In this study, \(\lambda 1:\lambda 2:\lambda 3\) is initially set as 0.6 : 0.25 : 0.15 to emphasize diagnostic accuracy as the primary objective while explicitly penalizing model complexity and training time to encourage lightweight solutions. Notably, AL-SOA employs an external elite archive to maintain the Pareto non-dominated solution set; therefore, the optimization is not restricted to a single scalarized optimum. Following the Pareto-based optimization, the final optimal solution is selected from the Pareto front as the individual with the minimum model complexity under the condition that the accuracy does not decrease by more than 0.3%, yielding a balanced parameter combination between performance and deployment cost.
Sensitivity to weight coefficients. To evaluate the impact of the multi-objective weighting coefficients, the weight vector (\(\lambda 1, \lambda 2,{ }\lambda 3{ }\)) was scanned over combinations within [0.5,0.7], [0.2,0.3] and [0.1,0.2] , respectively, corresponding to different emphases on accuracy, complexity, and training time. The experimental results show that when \(\lambda 1:\lambda 2:\lambda 3 = 0.6{ }:{ }0.25{ }:{ }0.15\), the optimization effectively reduces model complexity and controls training time while maintaining high accuracy across the CWRU, SEU, and self-built SUT datasets. Under the adopted setting, the representative non-dominated solutions on the Pareto front on the CWRU dataset (Table 13) further indicate that the trade-off region is compact, with accuracy ranging from 98.73 to 98.92%, average leaf nodes from 42 to 68, and training time from 15.8 s to 17.4 s.
The core process of AL-SOA includes two stages: migration behavior and attacking behavior. In each generation, the algorithm computes the multi-objective fitness based on the updated population positions and updates the Pareto front using the external elite archive. The population size is set to 30, and the maximum number of iterations is set to 50, considering both optimization accuracy and computational overhead. The algorithm parameters are shown in Table 1. The main computational load of AL-SOA comes from the accuracy evaluation based on tenfold cross-validation, with an overall time complexity of approximately Eq. (28), where C_BT represents the complexity of a single Bagging Tree training.
The comprehensive fitness function is defined as:
where \(\lambda_{1} ,\lambda_{2} ,\lambda_{3}\) are the weights for accuracy, complexity, and time, initially set as 0.6: 0.25: 0.15.
-
(1)
Multi-objective solving mechanism.
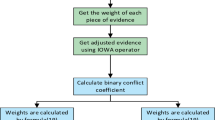
AL-SOA employs an external elite archive to store the non-dominated solution set and maintains the uniformity of the Pareto front using non-dominated sorting and crowding distance criteria. The final optimal solution is selected as the individual with the minimum model complexity, under the condition that the accuracy does not decrease by more than 0.3%, to obtain a more balanced parameter combination between performance and complexity.
-
(2)
Algorithm flowchart and pseudocode.
The overall optimization process of AL-SOA is shown in Fig. 7, which includes key steps such as population initialization, multi-objective fitness evaluation, elite archive update, migration and attacking position updates, and termination criteria. The corresponding pseudocode is described in Algorithm 1, which formalizes the input–output and iterative logic of each stage, making it easier to implement and replicate in different programming environments.

AL-SOA optimization flowchart.

Adaptive Lévy–Seagull Optimization (AL-SOA)
-
(3)
Termination criteria and fitness design.
To ensure that AL-SOA effectively improves the performance of the Bagging Tree classifier, it is essential to define the optimization objectives and the construction of the fitness function. In this study, the average classification accuracy under ten-fold cross-validation is used as the core evaluation metric, with model complexity and training time incorporated to form a weighted multi-objective fitness function, as shown in Eq. (29). The termination criteria are based on a “maximum iterations + convergence stagnation” dual criterion. Specifically, the algorithm terminates early if the number of iterations reaches the preset maximum or if there is no significant improvement in the optimal fitness over several consecutive generations (Eq. (30)), thus avoiding unnecessary iterations while ensuring the solution quality.
where, \({\text{x}} = \left\{ {n_{{{\text{trees}}}} ,{\text{MinLeafSize}}} \right\}\) represents the parameter vector to be optimized, \(K = 10\) denotes the number of folds in cross-validation, and \({\text{Acc}}^{\left( k \right)} \left( {\text{x}} \right)\) represents the classification accuracy for parameter configuration \(x\) in the \(k\)-th fold.
This fitness function comprehensively evaluates the generalization capability of a given parameter configuration across the entire dataset, effectively mitigating overfitting and ensuring robustness and transferability.
The termination criteria for the AL-SOA optimization are designed to ensure that sufficiently good solutions are obtained within a controllable computational budget. Therefore, a dual stopping mechanism is adopted:
Maximum Iteration Threshold (\(T_{max}\)): the algorithm terminates when the maximum number of iterations is reached, with no further improvement in fitness;
Stagnation Threshold (\(T_{s}\)): the algorithm terminates prematurely if the best fitness does not improve over \(T_{s}\) consecutive generations, preventing entrapment in local optima.
The specific expressions are as follows:
where, \(t\) denotes the current iteration number, \(\in\) is the convergence tolerance, typically set to \(10^{ - 4}\), and \(T_{s}\) denotes the number of consecutive generations without improvement.
The selection of AL-SOA is based on two structural considerations: First, the key hyperparameters of Bagging Tree (MaxNumSplits, NumLearningCycles, MinLeafSize) form a discrete, non-convex, and coupled search space under cross-validation objectives. Traditional gradient-based or single-objective searches are prone to converge to local optima. Second, in industrial engineering scenarios, it is often necessary to balance accuracy with model complexity/training time. Therefore, combining multi-objective search with an external elite archive allows for a set of solutions that not only guarantee accuracy but also offer lower complexity. Compared to the standard SOA, AL-SOA can escape local extrema earlier and obtain a better Pareto front within the same computational budget.
Bagging tree model design
In this study, a Bagging ensemble model with decision trees as base learners (Bootstrap Aggregating) is employed to construct a rolling bearing fault diagnosis classifier. The model generates multiple subsets by performing bootstrap sampling with replacement on the original training set, with each subset used to train a base learner (decision tree). The final classification decision is made through a majority voting mechanism, which reduces the variance of a single decision tree and enhances the generalization ability of the model. The model construction is based on the MATLAB fitcensemble function, using the templateTree template to define the structure of the base learner. The core hyperparameters include:
Maximum Split Depth (MaxNumSplits): Controls the maximum depth of a single decision tree. A value that is too large may lead to overfitting, while a value that is too small restricts the model’s expressive power.
Minimum Leaf Node Sample Size (MinLeafSize): Restricts the minimum number of samples in a leaf node to prevent overfitting to a small number of outlier samples.
Number of Learners (NumLearningCycles): Represents the number of base learners (subtrees). Increasing this number can improve the stability of the ensemble model but also increases the training overhead.
For ease of subsequent optimization using AL-SOA, the three key hyperparameters are denoted as \(\uptheta = (\text{MaxNumSplits},\text{NumLearningCycles},\text{MinLeafSize})\), and their search ranges and initial configurations are constrained to reasonable engineering intervals. The overall construction process of the Bagging Tree model is shown in Fig. 8, which illustrates the relationship between feature input, model training, prediction output, and parameter optimization modules. The search range and initial values for the three hyperparameters are provided in Table 2.

Workflow of bagging tree model construction.
Model training and testing
Before inputting the feature vector formed by the fusion of STFT and time-domain statistical features into the Bagging Tree model, PCA is first applied to reduce the 262-dimensional feature vector. This step helps to reduce model complexity and mitigate the risk of overfitting in the case of limited samples. Afterward, fault type predictions are made for each sample. The dataset is split into training and testing sets with a 7:3 ratio, and the random seed is fixed at 42 to ensure the reproducibility of the experimental results. After the model is trained, batch predictions are made on the test set, and diagnostic performance is evaluated based on the confusion matrix and various evaluation metrics.
The experiment is conducted on an AMD Ryzen 9950X CPU and an NVIDIA RTX A6000 GPU platform. The complete training time is approximately 22 s, and the single prediction delay during the testing phase is less than 50 ms, indicating that the constructed model has a certain potential for online inference. Considering the sampling frequency fs = 5120 Hz, the raw-signal sampling interval is 1/fs ≈ 0.195 ms. Since each inference corresponds to one segmented sample (1024 points, i.e., 0.2 s) and the segmentation hop size is 512 points (i.e., 0.1 s under 50% overlap), the reported latency (< 50 ms) is lower than the update interval of the sliding-window stream, supporting near-real-time deployment under the studied sampling setting. Further, the model’s memory usage is approximately 300 MB, primarily determined by the tree structure of the Bagging Tree model and the number of leaf nodes per tree. The computational complexity of each epoch during training is \(O(N\times T\times {C}_{BT})\), where \(N\) is the population size, \(T\) is the number of iterations, and \({C}_{BT}\) represents the complexity of a single Bagging Tree training. Memory usage is mainly determined by the tree structure of the Bagging Tree model and the number of leaf nodes per tree, increasing linearly with the number of leaf nodes. For example, on the CWRU dataset, the average memory usage per tree is approximately 300 MB. To quantify the computational cost, the FLOPs for each training iteration are estimated. As the tree depth and the number of leaf nodes increase, the FLOPs increase from approximately 109 to 1010 computations. The average training time per epoch is 16.5 s, and for the SUT dataset, it is 18 s, demonstrating that the model’s training time exhibits good scalability on large datasets. Further analysis shows that the training time is related to the population size \(N\), the number of iterations T, and the tree depth (MaxNumSplits). Hyperparameter adjustment is crucial for controlling the training time.
To ensure fairness in comparison with other baseline models, all traditional machine learning and deep learning baselines (SVM, RF, XGB, CNN, Trans-CNN, SOA-BT) are trained under identical data preprocessing, feature construction, and training/testing split settings as the STSF-AL-SOA-BT model. All baseline models are tuned using the same grid search and tenfold cross-validation strategy to ensure a consistent hyperparameter tuning process and parameter space across models. Specifically, the hyperparameter tuning process for SVM, RF, and XGB includes tenfold cross-validation on the training set, adjusting key hyperparameters such as penalty factors, kernel function types, number of trees, and maximum depth. For the CNN and Trans-CNN models, the network structures are maintained according to recommendations in the literature, but hyperparameters such as learning rate, batch size, and number of training epochs are optimized through grid search with tenfold cross-validation to ensure fairness in the tuning process. To ensure fairness in comparison with other baseline models, all traditional machine learning and deep learning baselines (SVM, RF, XGB, CNN, Trans-CNN, SOA-BT) are trained under identical data preprocessing, feature construction, and training/testing split settings as the STSF-AL-SOA-BT model. All baselines are tuned using the same grid search and tenfold cross-validation strategy to ensure a consistent hyperparameter tuning process and parameter space across models. Specifically, for SVM, RF, and XGB, key hyperparameters (e.g., penalty factors, kernel types, number of trees, and maximum depth) are adjusted via tenfold cross-validation on the training set. For CNN and Trans-CNN, the network structures follow the recommended configurations in the literature, while training-related hyperparameters (e.g., learning rate, batch size, and number of epochs) are optimized using the same grid search and tenfold cross-validation procedure. The best-performing configurations from the validation phase are reported in Table 12 and Table 13, ensuring that all models operate at reasonable working points and avoiding performance underestimation due to inconsistent tuning.
To facilitate an overall understanding of the STSF-AL-SOA-BT diagnostic framework, the entire rolling bearing fault diagnosis system is abstracted into six stages: “Data Preprocessing-Feature Construction-Feature Dimensionality Reduction-Hyperparameter Optimization-Model Training-Performance Evaluation,” with each stage handling signal enhancement, feature representation, sample construction, structural optimization, and classification decision-making. Algorithm 2 provides a pseudocode summary of the training–testing process, outlining the key steps from raw vibration signals to the final diagnostic model.

STSF-AL-SOA-BT Diagnostic Procedure
Performance evaluation metrics
To comprehensively evaluate the performance of the proposed model in fault recognition tasks, this study uses four common classification metrics: Accuracy, Precision, Recall, and F1-score. Additionally, confusion matrices are employed to analyze the recognition performance for each fault category. The definitions of these four metrics are standard in classification problems, and are not elaborated here. It is emphasized that the F1-score provides a balanced trade-off between false positives and false negatives, making it particularly suitable for conditions where the class distribution may not be entirely balanced.
To ensure the statistical reliability of the experimental conclusions, each dataset undergoes 10 independent repeated experiments (with different random seeds), and the results for Accuracy, Recall, F1-score, and training time are reported as “mean ± standard deviation.” For performance differences between different methods, the Shapiro–Wilk test is first used to check for normality. If the normality assumption is satisfied, paired t-tests are used to compare differences between models. Otherwise, the Wilcoxon signed-rank test is employed. For the overall comparison of multiple models, the Friedman test is used, followed by Nemenyi post-hoc analysis to assess significant differences between multiple methods. Additionally, Cohen’s d effect size and the 95% confidence interval are provided as supplementary information. The significance threshold is set uniformly at \(p<0.05\) (significant) and \(p<0.01\) (highly significant). The relevant statistical test results are noted in the subsequent comparison and ablation experiment tables.
Experimental validation and analysis
Experimental data and experimental environment
In this study, the proposed STSF-AL-SOA-BT method is systematically validated on three types of datasets: the publicly available Case Western Reserve University (CWRU) dataset, the Southeast University (SEU) experimental platform dataset, and data from a self-built rolling bearing test rig (SUT). The sampling methods and operating conditions for the first two publicly available datasets are described in the respective sections. To ensure the completeness of the experimental system, the mechanical structure, sensor arrangement, and data acquisition system of the self-built experimental platform are introduced in this section.
The self-built experimental platform uses the deep groove ball bearing SKF 6207 as the test object. The fault types include inner race fault, outer race fault, and rolling element fault. The damages are created using laser engraving, with fault diameters of 0.3 mm and 0.6 mm, respectively. Additionally, the normal condition is undamaged. The sampling frequency is set to 5120 Hz, with experimental speeds of 2000 r/min and 4000 r/min to cover typical medium- and high-speed operating conditions in industrial scenarios. The platform structure is shown in Fig. 9, the sensor arrangement is shown in Fig. 10, and the signal acquisition platform is shown in Fig. 11.

Rolling bearing test rig.

Signal acquisition sensors.

Signal acquisition platform.
To expand the dataset size and enhance the robustness of model training, the collected time-series data is segmented using a sliding window with 50% overlap. This data is then combined with Z-score normalization, STFT, and statistical feature construction to form the training samples for subsequent model training. The data labels and operating condition information for the self-built experimental rig are shown in Table 3.
Performance verification of individual method modules
This section aims to validate the independent effectiveness of each key module in the proposed fault diagnosis method, analyzing the specific contribution of each component to the final performance. Three systematic experiments are designed to quantitatively assess the impact of data preprocessing, feature fusion, feature dimensionality reduction, and the AL-SOA optimization and parameter tuning process.
Impact of data preprocessing on diagnostic performance
To assess the impact of the data preprocessing module on fault recognition performance, four different input schemes (A-D) are designed on the CWRU dataset, with only the preprocessing process altered, while the feature extraction and classifier structure remain consistent. The specific configurations are shown in Table 4, where scheme A uses the raw vibration signal, scheme B performs bandpass filtering, scheme C adds wavelet denoising on top of the bandpass filtering, and scheme D corresponds to the complete preprocessing process proposed in this study (filtering + wavelet denoising + Z-score normalization).
For each preprocessing configuration, 256-dimensional STFT frequency spectrum features are used as input, with the hyperparameters of the Bagging Tree classifier fixed as NumLearningCycles = 150 MaxNumSplits = 15 MinLeafSize = 5.Independent repeated experiments are conducted for each scheme, and the average classification accuracy and standard deviation are summarized in Table 5. The visual comparison results based on Accuracy and F1-score are shown in Fig. 12.

Comparison of classification performance under different data preprocessing workflows.
From Table 5 and Fig. 12, it can be observed that Scheme A (raw signal) has the lowest recognition performance (86.4%), indicating that noise and trend components significantly interfere with feature extraction and classification decisions when no filtering or denoising is applied. Scheme B, after bandpass filtering to suppress irrelevant frequency bands, improves the accuracy to 91.2%, suggesting that frequency-domain constraints targeting fault-related frequency bands are essential. Building on this, Scheme C further incorporates wavelet multi-scale denoising, increasing the accuracy to 95.8%, while the standard deviation decreases, indicating that wavelet denoising helps to enhance the model’s robustness. Finally, Scheme D (complete preprocessing process) achieves the highest accuracy of 97.6% and the smallest standard deviation of 0.4% among the four schemes, demonstrating that the combination of “bandpass filtering + wavelet multi-scale denoising + overlapping sliding window + Z-score normalization” not only significantly improves diagnostic accuracy but also effectively reduces result fluctuations, positively impacting subsequent feature construction and classification modeling.
Contribution of feature fusion to classification performance
Before conducting the feature fusion experiments, a sensitivity analysis of hyperparameter selection was performed to verify the impact of STFT window length, overlap ratio, and PCA variance threshold on model performance. To further validate the reasonableness of the hyperparameters selected during the feature extraction phase, different STFT window lengths, overlap ratios, and PCA variance thresholds were tested, and their effects on classification performance were analyzed. The specific experimental settings are as follows:
STFT Window Length and Overlap Ratio: Different window lengths (128, 256, 512) and overlap ratios (50%, 75%) were selected to analyze their impact on classification accuracy, computational complexity, and training time.
PCA Variance Threshold: Experiments were conducted with variance contributions set to 90%, 95%, and 98% to compare their effects on the features after dimensionality reduction. Table 6 summarizes the classification accuracy, training time, and computational cost under different hyperparameter settings.
The classification performance is most stable and computational efficiency is highest when the STFT window length is 256 and the STFT overlap ratio is 50% (i.e., a 128-point overlap with a hop size of 128). Accordingly, this configuration was adopted as the default STFT setting in Sect. “Data Processing” for all datasets to ensure reproducibility and computational efficiency. Regarding PCA, setting the explained-variance threshold to 95% effectively reduces redundant features while maintaining high classification performance; a higher threshold retains more information but increases computational cost and may increase the risk of overfitting.
To evaluate the role of fused features in fault characterization, three feature input configurations were compared: using only STFT frequency features (256 dimensions), using only 6-dimensional time-domain statistical features, and the fusion of STFT and statistical features (262 dimensions). Furthermore, to further validate the effectiveness of the proposed attention-weighted fusion module (Attention-based Fusion), comparisons were made between STSF + BT (no attention), STSF + Attention + BT, and Attention + PCA + BT on the three datasets, with CNN and ResNet1D as references.
To further analyze the role of attention in the frequency domain, Fig. 13 illustrates the average attention weight distribution corresponding to the STFT frequency bands. It is evident that attention peaks at several frequency bands, which correspond to the bearing’s inherent frequencies (BPFO, BPF, etc.), indicating that the model can autonomously focus on spectral components related to fault patterns, reflecting good interpretability.

Spectral attention weight distribution and its correspondence with bearing characteristic frequencies.
To quantify the contribution of attention-weighted feature fusion to classification performance, comparisons were made between STSF + BT (no attention), STSF + Attention + BT, and several alternative schemes (such as Attention + PCA + BT, CNN) on the three datasets. The main performance metrics were accuracy (Accuracy), training time, and model complexity (average number of leaf nodes). The results are shown in Table 7 (mean ± standard deviation, 10 repetitions of tenfold cross-validation).
Table 7 shows the performance of models with and without the attention module on the CWRU, SEU, and SUT datasets (mean ± standard deviation, 10 repetitions). As seen, the STSF + Attention + BT model, with the attention mechanism, achieves an average accuracy of 98.9% (± 0.3), 98.5% (± 0.4), and 97.53% (± 0.5) on the three datasets, which is significantly better than the baseline without attention (p < 0.01). To demonstrate the interpretability of the attention module, the attention weights from the trained model were averaged on the test set and the frequency spectrum weight distribution was plotted. As shown in Fig. 13, the attention mechanism exhibits distinct peaks in several frequency bands, which correspond to the theoretical fault frequencies of the bearings, indicating that the attention mechanism has learned to focus on the spectral components related to faults.
The core goal of the AFF module is to adaptively assign weights to STFT spectral features and time-domain statistical features during the feature fusion stage, thereby highlighting frequency components related to fault patterns while suppressing redundant information. Table 8 shows the input and output tensor shapes for the module.
Where \(N\) is the batch size (238 during training, any positive integer during inference).
The AFF module includes a dual-channel attention mechanism: Spectral Attention and Statistical Attention. Its pseudocode is shown in Algorithm 3.

Spectral Attention: Through global average pooling, the STFT spectral features are compressed into a single scalar. The weights of the spectral features are then computed through fully connected layers followed by a ReLU activation. After applying a Sigmoid activation function, the final attention weights are obtained, which are then used to weight the spectral features.
Statistical feature attention: The time-domain statistical features undergo a Softmax activation function to compute their corresponding attention weights, which are then applied for weighting.
Weighted fusion: The weighted spectral features and the rescaled statistical features (α = 0.5) are concatenated to obtain the final fused feature vector, with a dimension of (N, 262).
Through the attention mechanism, the model can adaptively focus on spectral components related to faults while effectively suppressing redundant information. This plays a significant role in improving fault diagnosis performance.
Feature selection and dimensionality reduction experimental results
To validate the stability and effectiveness of the 262-dimensional feature fusion under different dimensionality reduction strategies, this study compares the performance of PCA, LDA, and Tree-based Feature Importance (TBFI) methods on the CWRU, SEU, and self-built test rig (SUT) datasets. All experiments were conducted with the same data partition and parameter settings, repeated 10 times independently. The average accuracy ± standard deviation (%) is reported. Table 9 summarizes the results of the comparison of dimensionality reduction methods (mean ± standard deviation).
The accuracy drop for each dimensionality reduction method across different datasets is less than 0.4%, validating that the redundancy in the STFT-statistical feature fusion vector is relatively low. The PCA (95%) model reduces the training time by approximately 18% compared to the original model, with an accuracy drop of no more than 0.2%. Thus, PCA can be considered as a potential option for lightweight deployment. Figure 14 shows the relationship curve between the number of PCA components and classification accuracy.

Relationship between PCA principal components and classification accuracy.
The experimental results of different dimensionality reduction strategies show that the classification accuracy achieved by PCA (with cumulative variance contribution ≥ 95%) and TBFI (Top-60 features) is almost identical to that obtained using the full 262-dimensional features (with a difference of less than 0.4%). This fully demonstrates that the STFT-statistical feature fusion vector contains significant redundancy, with the main discriminative information being highly concentrated in the first few principal components or high-importance features.
Although both methods performed similarly in terms of accuracy, PCA was ultimately selected as the unified dimensionality reduction solution, based on the following three considerations:
Unsupervised nature and generalization capability: PCA is an unsupervised method, with its projection direction determined by the data variance and independent of sample labels. This makes it more robust to unknown fault categories or new states, whereas the supervised TBFI needs to re-evaluate feature importance when categories change.
Feature stability and orthogonality: PCA generates orthogonal principal components through linear transformation, which are linear combinations of the original features. This approach retains the physical context while effectively eliminating multicollinearity. The feature subsets selected by TBFI may fluctuate due to random sampling of the training set.
Ease of engineering deployment: Once the projection matrix for PCA dimensionality reduction is determined, a single matrix multiplication is required during the online diagnostic phase, making it computationally efficient and stable in process. On the other hand, the feature selection logic of TBFI is relatively more complex for deployment.
Therefore, under the premise that the accuracy loss is acceptable, PCA is considered a superior choice due to its excellent generalization capability, stability, and engineering convenience. However, in applications requiring extreme interpretability and the identification of key original features, TBFI remains a valuable alternative.
Impact of the improved seagull optimization algorithm on model performance
To validate the effectiveness of the Adaptive Lévy-Seagull Algorithm (AL-SOA) in hyperparameter optimization, the average accuracy change of the Bagging Tree model before and after optimization using ten-fold cross-validation was compared. Figure 15 presents the comparison of accuracy between the baseline model and the AL-SOA optimized model on the CWRU dataset, where it is evident that the overall recognition performance is significantly improved after introducing multi-objective optimization.

Comparison of ten-fold cross-validation average accuracy between baseline and AL-SOA optimized models.
To further assess the performance of the improved algorithm on different datasets, Table 10 summarizes the average accuracy, training time, and average number of leaf nodes (mean ± std) for AL-SOA-BT and SOA-BT across the CWRU, SEU, and SUT datasets. From Fig. 15 and Table 10, it can be observed that AL-SOA achieved steady improvements in accuracy across all three datasets, while also reducing both training time and model complexity. This indicates that the proposed multi-objective optimization mechanism significantly improves the quality of hyperparameter configurations without increasing model size.
To further verify the convergence characteristics and generalization performance of AL-SOA compared to the standard SOA, independent comparative experiments were conducted on the CWRU, SEU, and self-built SUT datasets. The two algorithms maintained consistency in parameter search space, population size, maximum iterations, and fitness function design, with differences only in the migration and attack update mechanisms. Table 10 presents the results of 10 independent experiments (mean ± standard deviation) on the three datasets for both standard SOA and the improved AL-SOA. Figure 16 shows the convergence curves for the two algorithms on the CWRU dataset.

Comparison of convergence curves between AL-SOA and SOA.
As shown in Fig. 16, the improved AL-SOA maintains strong global search ability in the early iterations and enters a fast convergence phase after approximately the 20th generation, stabilizing around the 30–35th generation. In contrast, the standard SOA converges more slowly and exhibits greater fluctuation in the early stages. From the statistical results of the three datasets, AL-SOA outperforms the standard SOA in both average accuracy and result stability. Further statistics reveal that, with the introduction of mechanisms such as Lévy flight, external elite archives, and adaptive inertia weight, AL-SOA incurs only about an 8.6% increase in training time compared to the standard SOA. However, it reduces the effective number of iterations by approximately 17% to reach the same accuracy, indicating a better cost-performance ratio in terms of convergence efficiency and global optimization capability.
To analyze the search results of both algorithms from the complexity perspective, Fig. 17 shows the distribution of the non-dominated solution set based on AL-SOA, with model complexity (leaf nodes) on the x-axis and accuracy on the y-axis. It can be observed that the optimized non-dominated solutions are mainly concentrated in the region with an accuracy of 98.7–98.88% and a relatively low number of leaf nodes, indicating that AL-SOA is capable of maintaining high accuracy while effectively controlling model complexity.

Pareto front distribution of AL-SOA.
To analyze the impact of each hyperparameter on the performance of the Bagging Tree model, univariate sensitivity analysis was conducted on MaxNumSplits, NumLearningCycles, and MinLeafSize using the CWRU dataset. Specifically, two hyperparameters were fixed at a time, and the third parameter was uniformly sampled within the search range. The model’s classification accuracy variation was recorded under the same training/test partition. Figure 18 presents the sensitivity curves of the three hyperparameters. The model is most sensitive to MaxNumSplits, where both too small or too large values lead to accuracy degradation. The variation of MinLeafSize has the next highest impact, where too small values tend to cause overfitting, while appropriately increasing it helps enhance model robustness. In comparison, NumLearningCycles has a relatively mild impact on accuracy within the given range, primarily affecting result stability. Based on the above analysis, AL-SOA was used to jointly optimize these three hyperparameters, ultimately converging to the optimal combination of (MaxNumSplits, NumLearningCycles, MinLeafSize) = (16, 80, 4).

Parameter sensitivity analysis Plot.
Additionally, to evaluate the statistical significance of the advantages of the improved algorithm, Table 11 presents the significance test and effect size analysis based on the results of 10 independent experiments on the three datasets. The results show that in most cases, AL-SOA significantly outperforms SOA, with an effect size of medium or higher, further confirming that the proposed improvement mechanism effectively enhances global search capability and optimization stability, significantly improving fault diagnosis performance without excessively increasing model complexity and computational overhead.
Ablation study of model components
To analyze the contribution of each module to the overall model performance, an ablation study was designed, progressively removing or replacing the STFT frequency features, time-domain statistical features, attention module, AL-SOA optimization, and dimensionality reduction process, while keeping other parameters consistent. In particular, to further isolate the impact of the feature fusion method, three scenarios were constructed: only retaining STFT frequency features (STFT-only), only retaining time-domain statistical features (Statistics-only), and removing the AFF attention fusion module while keeping both feature types (Fusion without AFF), for comparison with the full model. The experiments were conducted using the same tenfold cross-validation with 10 repetitions, and the results are reported as the average accuracy (mean ± std) and relative decrease (Δ), as shown in Table 12.
From Table 12, it can be seen that the full model (STSF + Attention + AL-SOA + BT) achieved the highest accuracy (98.9%). When the STFT features were removed, the accuracy dropped by approximately 2.5%, indicating the critical role of spectral features in representing fault patterns. The removal of the Attention module led to a 0.8% decrease in accuracy, suggesting that the weighted fusion mechanism effectively enhances feature discriminability. When AL-SOA was replaced with random parameters, accuracy decreased by 1.7%, indicating that multi-objective optimization contributes to improving the generalization performance of the classifier. Removing dimensionality reduction resulted in a slight 0.6% decrease, suggesting that PCA primarily plays a role in feature compression and computational efficiency.
The model using only STFT features (STFT-only) achieved an accuracy of 94.7%, with a decrease of 4.2%, indicating that using only frequency-domain features has limitations when dealing with complex signals. The model using only statistical features (Statistics-only) achieved an accuracy of 92.3%, with a decrease of 6.6%, further confirming the inadequacy of time-domain statistical features in diagnostic tasks. After removing the AFF module, although the model still performed well (97.1%), the accuracy was slightly lower than the full model (98.9%), with a decrease of 1.8%, highlighting the important role of the AFF module in enhancing model performance.
Overall, STFT, lightweight attention weighting, and AL-SOA are the core modules contributing to the performance improvement, validating the rationality of the proposed design and the synergistic effect of each component.
Multi-objective optimization results and trade-off analysis
The improved AL-SOA jointly optimizes the hyperparameters of the Bagging Tree model under three objectives: classification accuracy, model complexity, and training time. Figure 19 shows the Pareto front obtained on the CWRU dataset, where the x-axis represents model complexity (average number of leaf nodes), the y-axis represents the average accuracy from ten-fold cross-validation, and the color scale indicates the corresponding average training time. It can be observed that the front-end solutions display a typical trade-off distribution: as complexity decreases, accuracy slightly declines, and as the model size increases, training time moderately increases. Overall, most of the non-dominated solutions are concentrated in the accuracy range of 98.7%–98.9% and a moderate number of leaf nodes, suggesting that AL-SOA can provide multiple performance-complexity combinations within a large solution space.

Pareto front of multi-objective optimization obtained by AL-SOA.
To avoid merely providing qualitative impressions through scatter plots, three representative non-dominated solutions were selected in Table 10, corresponding to the strategies of “low complexity priority” (S1), “performance-complexity trade-off” (S2), and “high accuracy priority” (S3). As seen, the extremely low-complexity solution S1 maintains a relatively low number of leaf nodes and training time, but with a slight decrease in accuracy. The extremely high-accuracy solution S3 performs slightly better in terms of performance but leads to a significant increase in model size and computational cost. The trade-off solution S2, indicated in Fig. 19, achieves a more balanced configuration across the three metrics, maintaining approximately 54 leaf nodes and a training time of about 16.5 s, with only a marginal sacrifice in accuracy, which is consistent with the statistical results of AL-SOA-BT on the CWRU dataset in Table 7.
To further evaluate the impact of the multi-objective weighting coefficients on the optimization results, the weight vector λ₁, λ₂, λ₃ was scanned over combinations within the intervals [0.5, 0.7], [0.2, 0.3], and [0.1, 0.2], respectively, corresponding to different emphases on accuracy, complexity, and training time. The experimental results show that when λ₁:λ₂:λ₃ = 0.6:0.25:0.15, the optimization is able to effectively reduce model complexity and control training time while maintaining high accuracy on the CWRU, SEU, and self-built SUT datasets. Compared with other weight combinations, this configuration shows the most stable performance in the performance-complexity trade-off, thus it was uniformly adopted as the default setting in all experiments.
By combining Fig. 19 and Table 13, it can be concluded that the proposed AL-SOA framework not only provides a clear Pareto front trade-off between accuracy, complexity, and computation time, but also allows the selection of appropriate trade-off solutions based on real-time and resource constraints for different application scenarios, balancing fault diagnosis performance with engineering deployability.
Generalization experiments
Comparative analysis with different methods
To validate the superior performance of the proposed method on conventional rolling bearing fault data, the CWRU public dataset was selected as the standard testing platform, and five comparative models were designed. All methods were based on the same data partitioning ratio (training/testing = 7:3), ensuring a balanced distribution of each class of samples to eliminate the influence of class imbalance. The evaluation metrics include four standard classification metrics: Accuracy, Precision, Recall, and F1-score. The comparison results are shown in Table 14:
From the table, it can be observed that the AL-SOA-BT model proposed in this study achieved the optimal results across all metrics, with an overall accuracy of 98.88%, significantly higher than other deep learning models. Compared to the best-performing Parallel 1D-CNN, the proposed method improves Precision and Recall by approximately 0.8%, with a simultaneous increase in F1-score. These results indicate that the proposed feature fusion strategy and AL-SOA optimization mechanism effectively enhance the model’s ability to differentiate complex fault patterns and improve generalization performance.
To further verify the stability and generalization ability of the proposed method across different operating conditions and signal feature distributions, multiple representative baseline algorithms were compared on the CWRU, SEU, and self-built SUT datasets, including traditional machine learning models such as SVM, RF, XGB, deep networks based on one-dimensional convolution such as CNN and Trans-CNN, as well as SOA-BT and AL-SOA-BT without AL-SOA optimization. All baseline models were trained using the STFT-statistical feature fusion representation, with the same 7:3 training/testing partition and 10 repetitions of independent experiments to ensure fair and reproducible results. The experimental results are shown in Table 15.
From the table, it is evident that AL-SOA-BT outperforms the baseline model SOA-BT on all three datasets, with an average accuracy improvement of approximately 0.6% and a reduction in standard deviation by around 0.04%. This demonstrates the robustness of the proposed method across different operating conditions. Notably, on the SEU and self-built SUT datasets, the model maintains high classification accuracy under background interference and varying load conditions present in the datasets, highlighting its strong generalization ability.
To assess the statistical significance of performance differences, paired significance tests were performed on the four evaluation metrics between the six comparison methods and the proposed method. Each method was repeated 10 times on the same data partition, and the difference sequence was first tested for normality using the Shapiro–Wilk test (α = 0.05). If the differences followed a normal distribution, a paired t-test was applied; otherwise, the Wilcoxon signed-rank test was used. To control the Type I error rate for multiple comparisons, Holm-Bonferroni correction was applied (α’ = 0.05/m, where m is the number of comparisons). The paired effect size Cohen’s d was also calculated to assess the strength of the differences. The test results are shown in Table 16.
From the table, it can be observed that the p-values for Accuracy, Recall, and F1-score are all less than 0.01, indicating that the differences between the proposed method and other models are statistically significant (p < 0.01). The p-value for Precision falls between 0.01 and 0.05, indicating that the difference is also statistically significant but relatively weaker. Cohen’s d values are all greater than 1.2, indicating a strong effect, further confirming that the proposed method significantly outperforms other methods in classification performance.
To provide a more intuitive view of the overall performance across the four metrics, radar plots of the performance of the six methods on the CWRU dataset are shown in Fig. 20. Each vertex corresponds to a metric, with the radius representing the average value and the shaded area representing the standard deviation range.

Radar plots of diagnostic performance on the CWRU dataset.
From the figure, it can be seen that the proposed method forms the outermost polygon boundary across the four dimensions of Accuracy, Precision, Recall, and F1-score, demonstrating the most balanced and optimal overall performance. Parallel 1D-CNN and CWT + Swin Transformer are close to the proposed method in some metrics, but still show significant gaps in Recall and F1-score, validating the effectiveness of the proposed feature fusion strategy and AL-SOA optimization mechanism. The CWT + Swin Transformer baseline represents the mainstream “CWT-based time–frequency imaging + attention/Transformer feature learning” paradigm adopted in recent feature-extraction studies; the quantitative comparison in Fig. 20 therefore provides direct evidence that the proposed framework achieves a more favorable and balanced performance profile on this paradigm, particularly in terms of Recall and F1-score.
Validation of model generalization across different datasets
To further verify the generalization performance of the proposed STSF-AL-SOA-BT model under multi-source conditions and cross-platform environments, two external transfer validation experiments were designed in this section: One involves transferring the trained model to the Southeast University bearing dataset (SEU) for validation, and the other uses the measured vibration signals from the self-built experimental platform to assess the model’s robustness and adaptability under real-world conditions. The structural composition, sensor arrangement, and acquisition system of the self-built experimental platform were introduced earlier in the “Experimental Data and Experimental Environment” section of this chapter.
-
(1)
SEU dataset transfer validation experiment.
The SEU dataset, collected from the Southeast University experimental platform, includes normal, inner race fault, outer race fault, and rolling element fault signals for rolling bearings at various speeds. The data sampling environment significantly differs from the CWRU public dataset, making it an effective test for the model’s adaptability in practical deployment scenarios.
Training set source: CWRU public bearing dataset.
Test Set Source: SEU experimental data, with samples evenly balanced across categories.
Model structure and parameters: The model structure and parameters are consistent with the previous training process. The SOA-optimized Bagging Tree model was used, with the following hyperparameter settings: MaxNumSplits = 16, NumLearningCycles = 80, MinLeafSize = 4.
Preprocessing and Feature Extraction: The preprocessing and feature extraction methods remain consistent, including denoising, STFT, statistical feature fusion (262-dimensional features), and PCA for dimensionality reduction.
The model achieved an accuracy of 98.50% on the SEU dataset, with Recall for rolling element and outer race faults decreasing by less than 2%. Figure 21 shows the confusion matrix comparison of the model’s performance on the SEU dataset, validating the model’s strong cross-platform transferability and robustness.

Confusion matrix on the SEU dataset.
-
(2)
Experimental platform measured signal validation.
This section evaluates the classification performance of the self-built SUT dataset based on the previously described preprocessing process and STFT-statistical feature fusion strategy. The raw vibration signals were subjected to sliding window segmentation (50% overlap), Z-score normalization, and STSF feature fusion before being input into the AL-SOA-optimized Bagging Tree model for training and testing. Figure 22 illustrates the sliding resampling mechanism.

Sliding window resampling mechanism.
On the test set of the SUT dataset, the model achieved an accuracy of 97.53%, with the confusion matrix shown in Fig. 23. It is evident that all fault types were identified with high accuracy, with the rolling element fault recognition accuracy remaining above 98%, demonstrating the model’s effectiveness and stability in practical engineering applications.

Confusion matrix on the self-built dataset.
To visually demonstrate the model’s convergence characteristics on different data sources, Fig. 24 shows the change in the fitness function across iterations for both the SEU and SUT datasets. It can be observed that the model stabilizes around the 28th iteration in both datasets.

Convergence curves of the fitness function across different datasets.
Figure 25 compares the final accuracy of the three datasets. The accuracy achieved on the CWRU, SEU, and SUT datasets were 98.90%, 98.50%, and 97.53%, respectively, further proving the good generalization performance of the proposed method under multi-source conditions.

Accuracies on three datasets.
Conclusions and future work
Conclusions
This study proposed a deployment-oriented rolling bearing fault diagnosis framework, namely STSF–AL–SOA–BT, to address non-stationary vibration characteristics and noise interference under variable operating conditions. The method integrates a compact STFT spectrum representation and six time-domain statistical indicators, and introduces a lightweight dual-channel attention-based feature fusion module (AFF) to adaptively re-weight heterogeneous features before concatenation. To reduce redundancy and mitigate overfitting in the fused 262-dimensional representation, PCA-based dimensionality reduction (95% explained variance) was adopted as a unified compression strategy. At the classifier level, an Adaptive Lévy–Seagull Optimization Algorithm (AL-SOA) was developed to perform multi-objective tuning of Bagging Tree hyperparameters, explicitly balancing diagnostic accuracy, model complexity, and training time through a Pareto-based optimization mechanism.
Extensive experiments on three bearing datasets (CWRU, SEU, and a self-built test bench) demonstrated that the proposed framework achieved high and stable diagnostic performance, with average accuracies of 98.88%, 98.50%, and 97.53%, respectively. The ablation studies further confirmed that both AFF-based fusion and AL-SOA contributed consistently to performance improvement. In particular, the attention mechanism improved accuracy by approximately 0.6–1.2% (p < 0.01), and the multi-objective optimization yielded an effective trade-off between performance and complexity by steering solutions toward a compact Pareto region. Overall, the proposed method provides an interpretable and practically feasible solution for lightweight bearing fault diagnosis under variable operating conditions and noise interference.
Limitations and practical deployment considerations
Despite the encouraging results, several limitations and practical considerations should be acknowledged to clarify the applicability boundary of the proposed framework and guide future extensions. For clarity, this section summarizes five limitation items, and each item is explicitly linked to a corresponding future research direction in Sect. Future work to form a limitations-driven roadmap.
-
(1)
Dependence on preprocessing frequency band and sampling conditions.
In this work, a fourth-order Butterworth bandpass filter with a passband of 500–3000 Hz was adopted to suppress irrelevant frequency interference and retain fault-sensitive components. While this setting performed effectively under the experimental sampling frequency and operating conditions, the optimal passband may vary with sampling rate, rotational speed, load, and machine structure. When these conditions change significantly, the retained frequency content may shift, which can weaken the discriminative quality of the extracted spectrum features. In practical deployment, it is recommended to re-check the passband selection using a small amount of representative data, or to incorporate adaptive band selection strategies to improve robustness across different machines and speeds. This limitation directly motivates the adaptive preprocessing direction outlined in Sect. Future work (1).
-
(2)
Transferability of windowing and overlap configurations at two processing levels.
The pipeline involves two windowing/overlap mechanisms: (i) sliding-window segmentation of raw signals (window length 1024 samples, 50% overlap, i.e., 512-sample overlap and a hop size of 512) for sample generation, and (ii) STFT computation within each segment using a 256-point Hamming window with a 50% overlap (i.e., 128-point overlap and a hop size of 128) for time–frequency feature construction. These two overlap settings operate at different stages and serve different purposes (sample augmentation vs. time–frequency resolution). However, their choices still introduce parameter dependence: window length and overlap affect time–frequency resolution, spectral smoothing, and computational cost. Although the sensitivity analysis in this study supports the stability of the selected configuration, practitioners should be aware that different speed/load regimes may favor different windowing trade-offs. A practical recommendation is to preserve the current configuration as a default and conduct a lightweight sensitivity check when transferring to new rigs or markedly different operating conditions. This limitation directly motivates the parameter self-tuning direction outlined in Sect. Future work (2).
-
(3)
Unsupervised PCA compression may sacrifice discriminative information.
PCA was chosen primarily for its deployment simplicity (a fixed projection matrix and efficient matrix multiplication during inference) and its stable behavior across datasets. Nevertheless, PCA does not leverage class information, and its variance-maximizing projection can potentially discard discriminative cues in certain scenarios, especially when fault signatures are subtle or class separation relies on low-variance directions. This limitation is partially mitigated by the observed small accuracy drop under PCA compression and the reduced training time, but applications requiring stronger class-aware compression may benefit from supervised alternatives (e.g., LDA) or feature-importance-based selection (e.g., TBFI), at the cost of additional re-training or re-selection when the label space changes. This limitation directly motivates the label-informed compression direction outlined in Sect. Future work (3).
-
(4)
Potential failure cases under distribution shift, severe noise interference, and similar fault signatures.
The proposed method was validated under multiple datasets and operating conditions, including cross-rig evaluations. Nevertheless, failure cases may still arise when the data distribution shifts further (e.g., different bearing types, mounting structures, severe background vibration) or when fault signatures are weak (early-stage defects with low impulsiveness). Moreover, fault modes with similar spectral energy distributions may be more easily confused, particularly when transient components are masked by strong background interference. In the present study, controlled noise-injection stress tests at predefined noise levels were not conducted; therefore, the exact failure threshold under severe interference remains to be systematically quantified in future work. The cross-domain results indicate that some class-wise recall can decrease under domain transfer conditions (e.g., slight degradation for certain fault categories). For safety–critical deployment, conservative decision policies (e.g., confidence-based rejection), periodic calibration with a small set of on-site data, or multi-sensor fusion can be considered to reduce the risk of misdiagnosis. This limitation directly motivates the domain-robust and uncertainty-aware direction outlined in Section Future work (4).
-
(5)
Computational footprint and engineering deployment boundary.
From a deployment standpoint, the framework is modular and compatible with edge inference: preprocessing (de-meaning, bandpass filtering, wavelet denoising, normalization)-feature extraction (STFT spectrum + statistical indicators)-AFF weighting-PCA projection-Bagging Tree inference. In the current implementation environment, the full training time is approximately 22 s, and the single-sample prediction latency during testing is below 50 ms, indicating the feasibility of near-real-time inference under the studied sampling frequency. The single-sample prediction latency during testing is below 50 ms, indicating the feasibility of near-real-time inference under the studied sampling frequency. With fs = 5120 Hz and a segmentation hop size of 512 samples (0.1 s under 50% overlap), this latency is below the sliding-window update interval, which further supports the feasibility of online inference in streaming settings. Memory usage is mainly determined by the Bagging Tree structure (leaf nodes and tree depth) and scales with model complexity. Therefore, in engineering scenarios with strict memory and latency constraints, it is recommended to select solutions from the Pareto front with reduced complexity under an acceptable accuracy-drop threshold (as adopted in this study), and to keep the preprocessing and projection parameters fixed for consistency during online operation. This limitation directly motivates the implementation-level optimization direction outlined in Sect. Future work (5).
Overall, these limitations do not invalidate the proposed method; instead, they clarify the conditions under which re-calibration or further enhancement may be necessary. To ensure a clear and verifiable linkage, the future work in Sect. Future work follows the same (1)–(5) numbering.
Research innovations
The main innovations of this work can be summarized as follows:
-
(1)
A compact dual-domain representation was constructed by fusing a 256-dimensional STFT spectrum and six time-domain statistical indicators, and a lightweight dual-channel attention fusion module (AFF) was designed to adaptively re-weight heterogeneous features for improved robustness and interpretability.
-
(2)
A multi-objective AL-SOA strategy was developed by integrating Lévy flight, adaptive inertia weighting, and an external elite archive to optimize Bagging Tree hyperparameters, explicitly balancing accuracy, model complexity, and training time.
-
(3)
A unified evaluation protocol including ablation studies, sensitivity analysis, and statistical significance tests was established to quantify the contributions of each module and verify robustness.
-
(4)
The proposed framework was validated on three datasets, and attention-weight visualization was provided to link discriminative frequency regions with bearing characteristic frequencies, supporting explainable diagnosis.
Future work
Future research will focus on extending the applicability and robustness of the proposed framework in broader industrial scenarios. To make the linkage explicit, the numbering of the following directions is aligned one-to-one with the limitation items summarized in Sect. “Limitations and Practical Deployment Considerations”.
-
(1)
Based on limitation (1) (dependence on a fixed preprocessing passband), adaptive preprocessing strategies will be explored to reduce sensitivity to sampling rate, speed/load variations, and machine-specific spectral characteristics, thereby improving transferability across different machines and operating regimes.
-
(2)
Based on limitation (2) (transferability of windowing/overlap configurations at two processing levels), parameter self-tuning mechanisms will be investigated to alleviate reliance on fixed windowing settings when transferring to different rigs, speeds, and bearing types, while maintaining a balanced trade-off between time–frequency resolution and computational cost.
-
(3)
Based on limitation (3) (unsupervised PCA compression may sacrifice discriminative information), more robust feature compression strategies that incorporate label information may be investigated to further enhance discrimination under subtle fault signatures, while retaining deployment feasibility.
-
(4)
Based on limitation (4) (potential failure cases under distribution shift, strong noise interference, and similar fault signatures), domain-robust modeling and uncertainty-aware decision policies will be considered to reduce misdiagnosis risk in safety–critical settings, and integrating multi-sensor information (e.g., vibration and acoustic emission) will be explored to strengthen fault evidence under weak or masked signatures.
-
(5)
Based on limitation (5) (computational footprint and engineering deployment boundary), implementation-level optimization and lightweight deployment (e.g., embedded acceleration and streamlined preprocessing) will be further studied to meet stricter real-time constraints in edge computing environments, while preserving consistency of online preprocessing and projection parameters.
Data availability
The data used to support the findings of this study are available from the corresponding author upon request.
References
Liang, M. & Zhou, K. A hierarchical deep learning framework for combined rolling bearing fault localization and identification with data fusion. J. Vib. Control 29, 3165–3174 (2022).
Wang, L., Zou, T., Cai, K. & Liu, Y. Rolling bearing fault diagnosis method based on improved residual shrinkage network. J. Braz. Soc. Mech. Sci. Eng. 46, 1–12 (2024).
Sun, L., Zhu, X., Xiao, J., Cai, W., Ma, Q., & Zhang, R. A hybrid fault diagnosis method for rolling bearings based on GGRU-1DCNN with AdaBN algorithm under multiple load conditions. Measurement Science and Technology, 35 (2024)
Nawab, S.H., Quatieri, T.F., & Lim, J.S. Signal reconstruction from the short-time Fourier transform magnitude. IEEE International Conference on Acoustics, Speech, and Signal Processing (1982)
Daubechies, I. The wavelet transform, time-frequency localization and signal analysis. IEEE Trans. Inf. Theory 36, 961–1005 (1990).
Huang, N., Shen, Z., Long, S.R., Wu, M.C., Shih, H.H., Zheng, Q., Yen, N., Tung, C., & Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proceedings of the Royal Society of London. Series A Math. Phys. Eng. Sci. 454, 903–995 (1998).
Wu, Z. & Huang, N. E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 1(01), 1–41 (2009).
Torres, M. E., Colominas, M. A., Schlotthauer, G., & Flandrin, P. (2011, May). A complete ensemble empirical mode decomposition with adaptive noise. In 2011 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 4144–4147). IEEE.
Dragomiretskiy, K. & Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 62(3), 531–544 (2013).
Daubechies, I., Lu, J. & Wu, H. T. Synchrosqueezed wavelet transforms: An empirical mode decomposition-like tool. Appl. Comput. Harmon. Anal. 30(2), 243–261 (2011).
Holland, J. H. Genetic algorithms. Scientific american 267(1), 66–73 (1992).
J Kennedy, R Eberhart. Particle swarm optimization, in: Proceedings of ICNN’95-International Conference on Neural Networks 4 1942–1948 (1995).
Storn, R. & Price, K. Differential evolution–a simple and efficient heuristic for global optimization over continuous spaces. J. Global Optim. 11(4), 341–359 (1997).
Mirjalili, S., Mirjalili, S. M. & Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61 (2014).
Wang, H., Shen, Q., Dai, Q., Gao, Y., Gao, J., & Zhang, T. Evolutionary variational YOLOv8 network for fault detection in wind turbines. Computers, Materials & Continua, 80(1) (2024).
Zhang, T. et al. Automatic prompt design via particle swarm optimization driven LLM for efficient medical information extraction. Swarm Evol. Comput. 95, 101922 (2025).
Guo, T., Mei, Y., Zhang, M., Tang, K., Cai, K., & Du, W. Enhanced evolution of parallel algorithm portfolio for vehicle routing problem via transfer optimization. IEEE Transac. Evolut. Comput.
Sun, Z. et al. Multi-tree genetic programming hyper-heuristic for dynamic flexible workflow scheduling in multi-clouds. IEEE Trans. Serv. Comput. 17(5), 2687–2703 (2024).
Bai, H., Tong, W., Wei, B., Duan, C. & Liu, Q. A sterna migration algorithm-based efficient bionic engineering optimization algorithm. Sci. Rep. 15(1), 38261 (2025).
Mirjalili, S. & Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 95, 51–67 (2016).
Yazdani, M. & Jolai, F. Lion optimization algorithm (LOA): A nature-inspired metaheuristic algorithm. J. Comput. Des. Eng. 3(1), 24–36 (2016).
Xue, J. & Shen, B. A novel swarm intelligence optimization approach: sparrow search algorithm. Syst. Sci. Control Eng. 8(1), 22–34 (2020).
Yang, X. S. & Hossein Gandomi, A. Bat algorithm: A novel approach for global engineering optimization. Eng. Comput. 29(5), 464–483 (2012).
Dhiman, G. & Kumar, V. Seagull optimization algorithm: Theory and its applications for large-scale industrial engineering problems. Knowl.-Based Syst. 165, 169–196 (2019).
Suthaharan, S. Support vector machine. In Machine learning models and algorithms for big data classification: thinking with examples for effective learning 207–235 (Springer, US, 2016).
De Ville, B. Decision trees. Wiley Interdisciplinary Reviews: Computational Statistics, 5(6), 448-455 (2013).
Breiman, L. Random Forests. Mach. Learn. 45, 5–32 (2001).
Friedman, J. H. (2001). Greedy function approximation: a gradient boosting machine. Annals of statistics, 1189–1232.
Cover, T. & Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 13(1), 21–27 (1967).
Bai, S., Kolter, J. Z., & Koltun, V. (2018). An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv preprint arXiv:1803.01271.
Li, Q., Wang, G., Wu, X., Gao, Z., & Dan, B. (2024). Arctic short-term wind speed forecasting based on CNN-LSTM model with CEEMDAN. Energy.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
Fan, H., Xiong, B., Mangalam, K., Li, Y., Yan, Z., Malik, J., & Feichtenhofer, C. Multiscale vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 6824–6835) (2021).
Bai, H., Tong, W., Geng, Z. & Gao, C. A rolling bearing fault diagnosis method based on an improved parallel one-dimensional convolutional neural network. PLoS ONE 20(8), e0327206 (2025).
Liu, Q., Tong, W., Bai, H. & Dong, S. SCBM-Net: A multimodal feature fusion-based dual-channel method for bearing fault diagnosis. Sci. Rep. 15(1), 37904 (2025).
Dong, S., Tong, W., Bai, H. & Liu, Q. Bearing fault diagnosis method based on WSST and ISSA-MCNN-BIGRU. Sci. Rep. 15(1), 41533 (2025).
Qadir, H. M. et al. An adaptive feedback system for the improvement of learners. Sci. Rep. 15(1), 17242 (2025).
Hasan, M. J., Noman, K., Navid, W. U., Li, Y., Haruna, A., & Ashfak, K. Intelligent diagnosis of gas pipeline condition through multivariate analysis of acoustic emission signal-based imaging. Nondestructive Testing and Evaluation, 1–20 (2025).
Hasan, M. J., Arifeen, M., Sohaib, M., Rohan, A., & Kannan, S. (2024, June). Enhancing Gas Pipeline Monitoring with Graph Neural Networks: A New Approach for Acoustic Emission Analysis under Variable Pressure Conditions. In Proceedings of the International Conference on Condition Monitoring and Asset Management 1, 10–19. The British Institute of Non-Destructive Testing.
Biswas, R., Uddin, J. & Hasan, M. J. A new approach of iris detection and recognition. Int. J. Electr. Comput. Eng. (IJECE) 7(5), 2530–2536 (2017).
Umar, M., Siddique, M. F., & Kim, J. M. (2025). Burst-informed acoustic emission framework for explainable failure diagnosis in milling machines. Eng. Failure Anal 110373.
Ullah, S., Siddique, M. F., & Kim, J. M. (2025). Multi-sensor observer-based residual learning with Auto-Permutation Feature Importance for fault diagnosis of multistage centrifugal pumps under variable pressures. Sci. Rep.
Siddique, M. F., Zaman, W., Umar, M., Kim, J. Y. & Kim, J. M. A hybrid deep learning framework for fault diagnosis in milling machines. Sensors 25(18), 5866 (2025).
Siddique, M. F., Saleem, F., Umar, M., Kim, C. H. & Kim, J. M. A hybrid deep learning approach for bearing fault diagnosis using continuous wavelet transform and attention-enhanced spatiotemporal feature extraction. Sensors 25(9), 2712 (2025).
Siddique, M. F., Umar, M., Ahmad, W. & Kim, J. M. Advanced fault diagnosis in milling cutting tools using vision transformers with semi-supervised learning and uncertainty quantification. Sci. Rep. 15(1), 42460 (2025).
Gabor, D. Theory of communication. J. Inst. Electr. Eng. Part I: Gen. 94, 58–58 (1946).
Maćkiewicz, A. & Ratajczak, W. Principal components analysis (PCA). Comput. Geosci. 19(3), 303–342 (1993).
Prasad, A. M., Iverson, L. R. & Liaw, A. Newer classification and regression tree techniques: Bagging and random forests for ecological prediction. Ecosystems 9(2), 181–199 (2006).
Chennana, A. et al. Vibration signal analysis for rolling bearings faults diagnosis based on deep-shallow features fusion. Sci. Rep. 15, 9270 (2025).
Izenman, A. J. (2013). Linear discriminant analysis. In Modern multivariate statistical techniques: regression, classification, and manifold learning New York, NY: Springer New York. 237–280.
Freeman, C., Kulić, D. & Basir, O. Feature-selected tree-based classification. IEEE Transac. Cybern. 43(6), 1990–2004 (2013).
Funding
This study was supported by Liaoning Provincial Science and Technology Program Joint Project (2024-BSLH-210) and the Basic Scientific Research Project of Liaoning Provincial Department of Education (LJ112510142017), China.
Author information
Authors and Affiliations
Contributions
Hongwei Bai conceived and designed the study, developed the methodology, implemented the model, conducted the experiments, and drafted the manuscript. Weiyan Tong supervised the research, provided critical revisions, and was responsible for overall project coordination and funding acquisition. Chongxi Duan assisted with data preprocessing and experimental setup. Yu Zhou contributed to the visualization and analysis of the results. Shien Dong assisted with the revision and refinement of the manuscript. All authors reviewed and approved the final manuscript.
All authors reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Bai, H., Tong, W., Duan, C. et al. Rolling bearing fault diagnosis method based on fusion of STFT-statistical features and AL-SOA optimized bagging tree. Sci Rep 16, 10314 (2026). https://doi.org/10.1038/s41598-026-37914-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-37914-z
