
Abstract
To address the challenge of balancing high-speed, small-target detection accuracy and real-time performance in wearable devices under stringent resource constraints, this paper proposes a lightweight integrated detection and tracking framework, YOLC (You Only Look Clusters). This framework is based on MobileNetV3 as the backbone, integrating depthwise separable convolution and cross-stage partial connection structures to build a lightweight feature extraction network. A dynamic sparse spatial attention mechanism is designed, which adaptively generates spatial weights through local texture variance response and activates only the top 30% of high-response regions, thereby achieving efficient scheduling of computational resources and suppressing background interference. The framework further proposes an attention-guided bidirectional weighted feature pyramid to enhance the feature fusion effect for multi-scale small targets. A coordinate attention module is integrated into the detection head to improve positioning accuracy, while lightweight optical flow estimation and a confidence-adaptive matching strategy are combined to optimize the ByteTrack association process and improve trajectory stability under high-speed motion. Experimental results demonstrate that the proposed method achieves a mAP@0.5 of 75.3% and a small target recall rate of 82.4 ± 1.1%, with an inference processing speed of 53.5 FPS. It significantly improves the robustness of high-speed, small target detection and tracking in typical motion scenarios.
Similar content being viewed by others
Introduction
As wearable smart devices are being broadly used in sports training and competition analysis, high-speed small target detection, and tracking technology based on first-person visual data, has emerged as key support for understanding behaviors in sport1,2,3. However, existing methods suffer from computational, power usage, and memory constraints that preclude effective balances between accuracy and real-time performance in complex scenarios such as high dynamics, low resolution, or motion blur4,5,6. Especially under conditions of fast movement or long-distance shooting, the target size is often less than 32 × 32 pixels and the inter-frame displacement is drastic, resulting in a high false negative rate and frequent track breakage of traditional detection frameworks7,8,9. Therefore, there is an urgent need for a new architecture that balances lightweight design with strong feature perception capabilities to address the robust perception challenge of high-speed, small targets in resource-constrained environments.
In the field of sports analysis, high-speed small targets are widely present in a variety of key scenarios, such as badminton flight trajectory capture, table tennis spin determination, and sprint start action decomposition. Duan C10 proposed a target detection and tracking system model for real-time tracking and detection of moving targets. Bischofberger J11 analyzed that extracting the time features of football passing and shooting from position data is the main challenge faced by rule-based methods. Seong M12 constructed a multi-sensor badminton dataset containing forehand high clear and backhand flat drive actions, including sensor data such as eye tracking, body tracking, muscle signals and plantar pressure. Zhao C13 explored the eye movement characteristics of basketball players when shooting free throws at different intensities and discussed the relationship between these eye movement characteristics and free throw percentage. Under the three intensities of exercise, the athletes mainly focused on the position of the basket. The stability of free throws at medium intensity was the best, and the information search strategy and information processing efficiency were the highest. To address the problem of motion-blurred images, Wang H14 proposed a real-time deblurring network based on generative adversarial networks, which improves deblurring performance and the accuracy of target detection after deblurring.
Researchers have proposed several improvement schemes to address the problem of small target detection. Ali M L15 presented a detailed review of the YOLO (You Only Look Once) framework and its recent version YOLO 11, evaluating both its advantages and shortcomings in practical applications, and considering problems such as small object detection, environmental changes, and computational constraints. While the latest versions, such as YOLOv11, have achieved leading performance on general object detection benchmarks through architecture search and training strategy optimization, their design aims to maximize the balance between accuracy and speed in general scenarios. When deployed on wearable devices with extremely limited computing power, memory, and energy consumption, especially when processing high-dynamic, heavily blurred sports images with a high proportion of small objects, these general-purpose models still face challenges. Fu S16 designed a deformable convolutional backbone network for the feature extraction stage and proposed a novel anchor-free detector that can classify targets in the feature image point by point without relying on anchor boxes. Wang Y17 suggested a skeletal modal action recognition architecture that adopts the attention mechanism approach of CBAM (Convolutional Block Attention Module) and linked it to the modal feature extraction model CBAM-SlowOnly with RGB (Red Green Blue) modalities. You L18 offered a modified multi-target vehicle detection and tracking algorithm based on ByteTrack, by reinforcing the Kalman filter’s state vector and covariance matrix to handle the vehicle’s nonlinear motion more appropriately, and factoring in Gaussian smooth interpolation in order to fill trajectory gaps due to missed detection. Sun H19 proposed a structured pruning method based on sparse induced pruning to optimize the DETR (DEtection TRansformer) model, aiming to improve its inference speed and reduce computational cost. Although existing small target detection methods have made progress in receptive field expansion, attention mechanism, tracking modeling or model compression, they still generally suffer from problems such as large computational overhead, sensitivity to background interference, serious missed detection at the detection end or insufficient temporal modeling ability, which makes it difficult to meet the real-time robust perception requirements of wearable devices in high-speed motion scenarios.
This paper proposes a high-speed small target detection and tracking method that combines the YOLC framework with a dynamic sparse space attention mechanism, specifically designed for resource-constrained wearable device scenarios. Initially, this paper develops a lightweight YOLC framework, which incorporates an improved MobileNetV3 backbone network, while integrating depthwise separable convolutions with cross-stage partial connection structures in order to reduce computation redundancy and increase the efficiency of cross-stage feature propagation. On top of that, this paper proposes a dynamic sparse spatial attention mechanism, which generates a spatial saliency map via local texture variance computation, while activating only the top 30% of the highest region of interest responses, thereby enabling “perception-computation” collaborative optimization, while also sufficiently suppressing background interference and minimizing downstream computation requirements. Additionally, this paper designs an attention-guided, bidirectional weighted feature pyramid network that uses attention weights to fuse multi-scale feature levels adaptively to enhance the semantic expression of small target detection. Finally, this paper integrates coordinate attention features into the detection head to improve coordination accuracy, while using optical flow motion priors and hierarchical matching strategies to improve multi-object tracking correlation. This work innovatively creates a dynamic sparse attention mechanism based on local texture variation in order to achieve adaptive density of computation, and builds a lightweight efficient YOLC integrated architecture which dramatically enhances the detection and tracking quality of high-speed small targets in highly complex sports environments, while maintaining low computational energy.
Algorithm design
Overall architecture and lightweight backbone design of YOLC framework
In order to tackle the extreme restrictions to computing power, power draw, and memory in wearable devices, combined with having to address accuracy and real-time triggers in high-speed small target detection, this paper develops an end-to-end optimized lightweight integrated detection and tracking framework—YOLC. The input images are first all uniformly resized to a resolution of 640 × 640 in order to strike a balance between detection accuracy and inference speed. The backbone network has a lightweight convolutional structure based on MobileNetV3, which substitutes traditional standard convolution using depthwise separable convolution to reduce parameter redundancy and computational load while maintaining spatial feature extraction ability20,21. Each depthwise separable convolution can be decomposed as channel-wise spatial convolution with a 1 × 1 pointwise convolution, decreasing the computational complexity from \(\:O(C_{{in}} \cdot C_{{out}} \cdot K^{2} )\)to \(\:O\left( {C_{{in}} \cdot K^{2} + C_{{in}} \cdot C_{{out}} } \right)\), where \(\:{\text{C}}_{\text{in}}\) and \(\:{\text{C}}_{\text{out}}\) are the number of input and output channels respectively and K is the convolution kernel size.
To enhance the efficiency of feature usage and limit gradient repeating propagation, the backbone network employs a cross-stage partial connection structure at the important downsampling stage22,23. The cross-stage partial connection structure partitions the input feature map into two branches along the channel dimension: one branch progress through the entire convolutional transformation path (including batch normalization, hard Swish activation function, max pooling, etc.), and the second branch simply passes straight across layers to the next fusion node. The two are spliced together in a high-dimensional space and used as input for the next stage, which effectively preserves the original information flow while alleviating the gradient vanishing problem in deep networks.
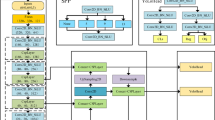
The backbone network consists of five downsampling stages, and finally outputs feature maps of three different scales: S3 (80 × 80), S4 (40 × 40) and S5 (20 × 20), which correspond to the detection levels of small, medium and large targets, respectively. The S3 layer retains high spatial resolution for capturing details of small objects in high-speed motion; the S5 layer has stronger semantic expression capabilities, supporting the discrimination of distant or blurred targets. The overall architecture of the YOLC framework is shown in Fig. 1.

Overall architecture of the YOLC framework
Figure 1 illustrates the overall process of the YOLC framework: First, feature maps at three scales, S3, S4, and S5, are extracted through the improved MobileNetV3 backbone network (which integrates depthwise separable convolution and CSP (Cross-Stage Partial Connection) structure). Subsequently, these feature maps are fed into the Dynamic Sparse Space Attention Module, which generates sparsified features by calculating the local texture variance and activating only the top 30% of high-response regions to suppress background interference and reduce computation. Sparse features are fed into an attention-guided bidirectional weighted feature pyramid network (FPN), which uses weights generated by dynamic sparse spatial attention to weight and fuse top-down and bottom-up paths to enhance multi-scale small target features. The fused features are input into a lightweight detection head, which uses shared convolution and integrates a coordinate attention module to improve localization accuracy, and finally outputs classification and regression results. Finally, the detection results are fed into an improved ByteTrack tracker that combines lightweight optical flow estimation with a confidence-adaptive matching strategy to generate stable and continuous target trajectories.
Dynamic sparse space attention mechanism
To improve the model’s ability to perceive small targets in high-speed motion, this paper introduces a dynamic sparse space attention mechanism at the input of the feature pyramid network, focusing on active regions with significant texture changes in the image to achieve adaptive allocation of computing resources24,25. Let the input feature map of the \(\:\text{l}\)-th layer be represented as \(\:F^{l} \in R^{{C \times H \times W}}\), where \(\:\text{C}\) is the number of channels, and \(\:\text{H}\) and \(\:\text{W}\) are the spatial dimensions. First, a sliding operation is performed on \(\:{\text{F}}^{\text{l}}\) using a 3 × 3 convolution kernel \(\:K_{{\text{var} }} \in R^{{C \times 3 \times 3}}\) without bias, and the variance response of the pixel values within the local window is calculated at each spatial location \(\:\left(\text{i}\text{,}\text{j}\right)\):
In formula (1), \(\:\mu _{c} (i,j)\) represents the mean of channel \(\:\text{C}\) in the neighborhood centered at \(\:\text{(}\text{i}\text{,}\text{j}\text{)}\), in the 3 × 3 neighborhood window centered on. The response map reflects the complexity of the local structure, and high response areas usually correspond to key visual cues such as edges, corners, or the outlines of moving objects.
In formula (1), the calculation of local texture variance is performed independently within a single channel. That is, for each channel c ∈ {1,…,n}, the pixel variance within its 3 × 3 neighborhood is calculated, and then the variance responses of all channels are averaged to generate a spatial saliency map. This design avoids semantic aliasing caused by cross-channel statistics and is particularly suitable for single-modal RGB videos captured by wearable devices, where the correlation between channels is strong but local texture changes are still dominated by intra-channel contrast.
The original response map is then normalized, and the Sigmoid function is used to suppress extreme values and enhance contrast26,27:
In formula (2), β is the scaling factor and γ is the global mean threshold, which is used to center the distribution. In the dynamic sparse spatial attention mechanism, the 3 × 3 convolutional kernel used for local texture variance calculation does not contain a bias term, and the weights are not shared (variance is calculated independently for each channel). The scaling factor β in Sigmoid normalization is 5.0, and the global mean threshold γ is initialized to the mean of the response map and fine-tuned as a learnable parameter during training (the learning rate is 0.1 times the backbone learning rate). This setting has been ablation verified to improve activation stability. Based on the normalized spatial weight map, a binary mask \(\:{M}^{l}\in\:\{\text{0,1}{\}}^{H\times\:W}\)is generated, and only the top 30% regions with the highest response values \(\:\tau\:\)=30% are retained for subsequent calculations:
Finally, the mask is applied to the spatial dimension of the original feature map to achieve dynamic sparse activation:
The output sparsity feature \(\:{\stackrel{\sim}{F}}^{l}\) retains non-zero responses only in highly significant regions, while the remaining background regions are forced to zero. This mechanism not only effectively suppresses irrelevant contextual interference, but also significantly reduces the computational load on the subsequent bidirectional weighted feature pyramid network and the detection head, achieving “perception-computation” collaborative optimization, and is suitable for low-power operation scenarios of wearable devices. The activation ratio statistics of the dynamic sparse attention mechanism are shown in Fig. 2.

Activation ratio statistics of dynamic sparse attention mechanism
Figure 2 shows the activation ratio distribution of the dynamic sparse spatial attention mechanism in the YOLC framework in six typical sports scenarios. The horizontal axis represents different high-speed sports scenarios, and the left and right vertical axes represent the set sparse levels Top-10% and Top-20%, respectively. As shown in Fig. 2, the actual activation rates in each scenario are close to the theoretical values (e.g., the range for the Top-10% of motion scenarios is 9.5%–10.3%), and the distribution is uniform and stable, indicating that the mechanism can consistently execute the sparsity strategy across scenarios. Slight deviations occurre in highly reflective or blurred scenes such as the “moment of a tennis serve”, but the overall deviations remain within a reasonable range. This verifies that the local texture variance-driven gating method has good robustness and controllability, and can achieve efficient and accurate scheduling of computing resources on resource-constrained wearable devices.
It is worth noting that the binary mask generated by the Top-τ% hard selection operation during forward propagation faces the challenge of gradient flow interruption. To enable end-to-end training, this paper employs a Straight-Through Estimator (STE) for gradient approximation. This approach preserves hard thresholding during the forward pass to maintain sparse computation efficiency, while during backward propagation, gradients are directly passed to all spatial locations, ignoring the non-differentiable thresholding operation. This “hard-forward, soft-backward” mechanism ensures effective parameter updates during training while retaining the benefits of inference-time sparsity.
Attention-guided bidirectional weighted feature fusion
To effectively alleviate the problem of weakened small target features caused by drastic changes in target scale and severe motion blur in images acquired by wearable devices, this paper designs an attention-guided bidirectional weighted feature pyramid network to achieve efficient fusion of cross-scale information and semantic enhancement28,29. This paper assumes that the multi-level feature map output by the backbone network is \(\:P_{l} \in RC_{l} H_{l} W_{l}\), where \(\:\begin{array}{*{20}c} {\:l \in \left\{ {3,4,5,} \right\}} \\ \end{array}\) corresponds to feature layers with spatial resolutions of 80 × 80, 40 × 40 and 20 × 20, respectively. The bidirectional weighted feature pyramid network adopts a dual-path structure: the top-down path strengthens the transmission of high-level semantics to low-level details, while the bottom-up path preserves the feedback effect of low-level spatial information on high-level information. In the top-down branch, high-level features are upsampled and then added to features of the same level30,31:
In formula (5), \(\:{\text{U}\text{p}}_{2}\)(⋅) represents the bilinear interpolation upsampling operation, which magnifies the feature map by 2 times. In the bottom-up branch, the low-level features are downsampled by max pooling with a stride of 2 and then concatenated with the high-level features:
In formula (6), \(\:{\text{D}\text{o}\text{w}\text{n}}_{2}\)(⋅) is the downsampling operation, and \(\:\text{C}\text{a}\text{t}\)(⋅,⋅) represents channel dimension splicing. The fusion weights at each level are driven by the dynamic sparse spatial attention response map generated in Sect. Dynamic sparse space attention mechanism. Gating coefficients are generated using a learnable 1 × 1 convolutional kernel: \(\:W_{\alpha } \in R^{{1 \times 1 \times C}}\) (\(\:{\text{C}}^{{\prime\:}}\) is the number of channels after concatenation).
In formula (7), [⋅;⋅] represents channel splicing, and Norm(⋅) is an L2 normalization operation to eliminate dimensional differences. The final output fused features are weighted and combined through a gating mechanism32,33:
Formula (8) enables information recalibration from the bottom layer to the top layer, allowing the network to adaptively adjust the intensity of the feature flow in the forward propagation based on local saliency. For small targets moving at high speeds, their spatial location usually corresponds to a high attention response region, thus obtaining a higher weight gain during the fusion process and enhancing their expressive power in high-level semantic features. The proposed bidirectional weighted feature pyramid network structure does not introduce additional detection heads or parameter-dense modules, maintaining its overall lightweight characteristics and making it suitable for resource-constrained edge computing environments.
In bidirectional weighted FPN, the gating weights α are not preset scale coefficients, but rather spatially adaptive weights driven by a dynamic sparse attention map. Specifically, during each fusion layer, α is generated from the concatenated features through a learnable 1 × 1 convolution (see Eq. 7), and its value dynamically changes with local saliency rather than being fixed and bound to scale. Therefore, high-level semantic features gain higher gains in the target region, while background regions are suppressed, achieving a “content-aware” rather than “scale-hard-coded” fusion strategy.
Lightweight detection head and localization enhancement mechanism
To achieve efficient and accurate target localization and classification under resource-constrained conditions, this paper designs a lightweight detection head structure that integrates a parameter sharing mechanism and a direction-aware attention module, balancing model compactness and spatial sensitivity34,35. Assuming the input feature map comes from the output layer of a bidirectional weighted feature pyramid network, the detection head first uses a weight-shared 3 × 3\(\:{K}_{\text{s}\text{h}\text{a}\text{r}\text{e}\text{d}}\) convolutional kernel to simultaneously process the classification and regression branches, avoiding parameter redundancy caused by setting separate convolutional layers for the two tasks:
In formula (9), ∗represents the convolution operation, and BN is batch normalization. This shared structure enables the classification and regression paths to share the ability to extract low-level features, significantly reducing the number of parameters without sacrificing expressive power. Subsequently, a Coordinate Attention (CA) module is introduced on the basis of shared features to capture long-distance spatial dependencies and enhance the ability to perceive the location of small targets36,37. CA performs global information aggregation along both the horizontal and vertical directions. First, it compresses the feature map horizontally to generate row attention descriptors.
It compresses along the vertical direction, generating column attention descriptors:
It feeds \(\:{\text{z}}^{\text{h}}\) and \(\:{\text{z}}^{\text{v}}\) into a fully connected network that includes dimensionality reduction and dimensionality increase respectively:
In formula (12), \(\:{\text{W}}_{\text{1}}\) and \(\:{\text{W}}_{\text{2}}\text{}\)are learnable weight matrices, \(\:\delta\)(⋅) is the ReLU activation function, and \(\sigma\)(⋅) is the Sigmoid function. The transformed attention vector is then reshaped into a spatial form, and a two-dimensional attention map is reconstructed using an outer product:
The final attention weights are the element-wise product of the responses in both directions:
Attention maps are multiplied with the original features to achieve spatially selective enhancement:
The enhanced \(\:{F}_{\text{a}\text{t}\text{t}}\:\)feature is fed into two separate 1 × 1 convolutional layers to perform class prediction and bounding box regression tasks. This mechanism achieves long-range dependency modeling across spatial dimensions with extremely low computational overhead, which is particularly beneficial for improving the positioning accuracy of small-sized, sparsely textured targets in high-speed motion, meeting the needs of high dynamic visual perception in wearable device scenarios. Table 1 shows the parameter quantities and FLOPs (Floating Point Operations) contribution of each sub-module of the detection head. These data were automatically analyzed by the thop library at 640 × 640 input to quantify the computational load distribution of the model.
In the Coordinate Attention (CA) module, the dimensionality reduction/expansion ratio is set to 1/8, meaning the number of bottleneck layer channels is 1/8 of the input channels. This ratio was determined through grid search in previous experiments: a smaller ratio (e.g., 1/16) leads to a decrease in localization accuracy (mAP@0.5 decreases by approximately 1.2%), while a larger ratio (e.g., 1/4) significantly increases FLOPs (+ 18%), with a performance improvement of less than 0.5%. To verify the effectiveness of the CA module, we compared a variant of “complete YOLC” with “CA module removed” in ablation experiments (keeping the rest of the structure the same). The results show that removing CA increases the localization error of small targets by 9.3%, decreases mAP@0.5 by 2.1%, while reducing FLOPs by only 0.4 GFLOPs, demonstrating that CA significantly improves spatial awareness with extremely low computational cost.
Multi-target tracking association based on motion consistency constraints
The optical flow estimation module (RAFT-tiny) serves only as a post-processing component during the inference phase in this framework and is not involved in end-to-end training. Its weights are pre-trained on the Sintel dataset and then frozen, used only to generate motion priors to guide trajectory prediction. This design avoids the high computational overhead of the optical flow module from affecting training stability, while retaining its ability to model high-speed displacements.
The lightweight optical flow estimation model used in this paper is based on the RAFT-tiny architecture, with an input resolution of 320 × 320, 0.9 M parameters, and a single-frame optical flow computation cost of 1.8 GFLOPs. Pre-trained on the Sintel dataset, this model can generate dense optical flow fields with an inference latency of 12.3ms (Jetson Nano).
Current optical flow estimation still suffers from drift errors in regions with severe motion blur or sparse texture. To address this issue, this paper introduces motion consistency constraints as a post-processing mechanism: first, abnormal optical flow vectors are detected by checking the trajectory smoothness between adjacent frames; second, a threshold for displacement changes between consecutive frames is set, and when the predicted displacement exceeds a physically reasonable range, a uniform motion model is used. In multi-target tracking, the high-confidence IoU threshold θ_h = 0.7, the low-confidence threshold θ_l = 0.3, and the trajectory termination threshold K = 30 frames (approximately 0.56 s, based on 53.5 FPS).
To improve the trajectory stability of high-speed small targets between consecutive frames, this paper constructs an improved multi-target tracking association mechanism based on the detection output, integrates optical flow motion prior and confidence adaptive matching strategy, and forms a data association framework that is robust to rapid displacement and brief occlusion38,39. Supposing the detection results of frame t are set \(\:{\mathcal{D}}_{t}=\left\{\right({b}_{i},{s}_{i},{c}_{i}){\}}_{i=1}^{{N}_{t}}\), where \(\:{b}_{i}\in\:{\mathbb{R}}^{4}\) represents the bounding box (center coordinates, width, height), \(\:{s}_{i}\in\:\left[\text{0,1}\right]\)is the classification confidence, and \(\:{c}_{i}\) is the class label. The existing set of trajectories is denoted as \(\:{\mathcal{T}}_{t}=\{{\tau\:}_{j}{\}}_{j=1}^{{M}_{t-1}}\), and each trajectory \(\:{\tau\:}_{j}\) maintains the detection state and motion history of its most recent frame. First, a lightweight optical flow estimation model is used to estimate the dense optical flow field between adjacent frames, and based on this, the prior position of each trajectory in the current frame is predicted. For the center of the detection box of the trajectory \(\:{\tau\:}_{j}\) in frame t − 1, the corresponding optical flow vector is obtained through bilinear interpolation, and the predicted position after motion compensation is obtained:
In formula (16), λ is the scale adaptation coefficient, used to align the optical flow resolution with the original image space. A hierarchical matching strategy is employed during the data association stage. Two IoU (Intersection over Union) thresholds are defined: a high-confidence threshold \(\:{\theta\:}_{h}\) and a low-confidence threshold \(\:{\theta\:}_{l}\). The detection set is divided into two groups based on confidence level: high-confidence detection: \(\:{\mathcal{D}}_{t}^{\text{h}\text{i}\text{g}\text{h}}=\{{d}_{i}\in\:{\mathcal{D}}_{t}\mid\:{s}_{i}\ge\:0.5\}\), and low-confidence detection: \(\:{\mathcal{D}}_{t}^{\text{l}\text{o}\text{w}}=\{{d}_{i}\in\:{\mathcal{D}}_{t}\mid\:{s}_{i}<0.5\}\). First, the Hungarian algorithm is used to match \(\:{\mathcal{D}}_{t}^{\text{h}\text{i}\text{g}\text{h}}\) with the active trajectory set.
Successful association is allowed only if \(\:\text{I}\text{o}\text{U}({\widehat{b}}_{j}^{t},{b}_{i})\:\)≥ \(\:{\theta\:}_{h}\). Subsequently, a second round of matching is performed between the unmatched trajectory set and \(\:{\mathcal{D}}_{t}^{\text{l}\text{o}\text{w}}\), using a more lenient threshold \(\:{\theta\:}_{l\:}\:\)to retain effective detections whose confidence has decreased due to motion blur or partial occlusion. To further enhance motion consistency constraints, a spatial offset penalty term is introduced. If the Euclidean distance between a candidate detection and the predicted trajectory location exceeds the dynamic threshold, then formula (18) is satisfied:
The dynamic threshold \(\:{\delta\:}_{\text{m}\text{a}\text{x}}\) is defined as: \(\:{\delta\:}_{\text{m}\text{a}\text{x}}=\kappa\:\cdot\:{v}_{j}^{\text{avg}}\). \(\:{v}_{j}^{\text{avg}}\) is the average velocity mode length of trajectory \(\:{\tau\:}_{j}\) in the nearest f frame, and κ is a scale factor (κ = 3 in this experiment), which is used to limit a physically reasonable maximum search range.
The employing formula (18) will mandate the pairing instead of allowing the identity to change due to false detections or background interference. The unassociated detections for the considered prior K frames are utilized as the starting point for a new trajectory, while trajectories are considered terminated if they are not associated for K consecutive frames. This policy greatly facilitates the reliability of cross-frame correlations for fast moving targets, while permitting real-time performance. Key performance indicator comparisons for multi-target tracking is shown in Fig. 3.
The optical flow estimation module adopts a RAFT-tiny architecture with an input resolution of 320 × 320, while the original detection input is 640 × 640. To align the spatial scale, we experimentally determined the scale adaptation coefficient λ = 2, i.e., a direct linear mapping according to the resolution ratio. This setting has been ablation-verified to achieve the best balance between displacement prediction accuracy and computational efficiency. For the dynamic threshold δ_max in the motion consistency constraint, its scaling factor κ = 3 is derived from the statistical analysis of the instantaneous velocity distribution of all trajectories in the training set: κ is set to 3 times the standard deviation of the average velocity to cover 99.7% of the Gaussian distribution confidence interval, ensuring physical rationality.

Comparison of key indicators for different methods during tracking (a) Trajectory length (b) Successful correlation rate
Figure 3 illustrates some central metrics from each of the methods during the tracking, highlighting the merits of the modified ByteTrack method as it pertains to trajectory continuity and stability. The success rate of the method presented in this paper, as shown in 3(b), is 86.7%, which is much higher than every other model. The average trajectory length of the proposed method is 35.4 frames, while the longest continuous trajectory hits 89 frames in 3(a). This shows, even in complex scenes where the subject is moving quickly or is occluded often—the proposed method in this paper successfully minimizes trajectory breakage and supports long-term stable tracking for the targeted subject. The prior optical flow and hierarchical matching mechanism demonstrated useful to improve reliability when associating across frames.
In summary, the YOLC framework introduces three key innovations to address the challenge of high-speed small target perception under resource constraints. First, the dynamic sparse spatial attention mechanism achieves computational resource scheduling by activating only the most salient regions, effectively suppressing background interference. Second, the attention-guided bidirectional weighted feature pyramid network enhances multi-scale feature representation, specifically improving the semantic clarity of small targets. Finally, the integration of a lightweight optical flow prior with a confidence-adaptive matching strategy within the tracking module significantly enhances trajectory continuity and identity consistency. Collectively, these designs form a cohesive “perception-computation” co-optimization architecture, enabling robust detection and stable tracking for wearable sports analysis.
Experiments and validation
Dataset construction and experimental setup
This study’s self-built dataset contains 12,480 images, distributed by sport: badminton (2,850 images), basketball (2,640 images), tennis (2,520 images), sprinting (2,220 images), and table tennis (2,250 images). Target size distribution statistics show that 8 × 8–16 × 16 pixels account for 38.2%, 16 × 16–24 × 24 pixels account for 35.7%, and 24 × 24–32 × 32 pixels account for 26.1%. Motion intensity annotation standards are as follows: low intensity (inter-frame displacement < 5 pixels/frame), medium intensity (5–15 pixels/frame), and high intensity (> 15 pixels/frame or significant motion blur/occlusion). All videos were captured using a GoPro HERO10 head-mounted camera at a real training venue and do not include any publicly available subsets. LabelBox v4.2 was used for annotation, with an IoU threshold of 0.7 and a minimum bounding box size of 8 × 8 pixels. The training, validation, and test sets were randomly distributed in a 7:1:2 ratio to ensure a balanced distribution of samples for each class. The model was deployed on an NVIDIA Jetson Nano development board. During deployment, TensorRT 8.6 was used for network architecture optimization, and FP16 quantization and layer fusion techniques were employed. During model inference output, the CPU was shut down to eliminate any computational load, thus simulating a fully GPU-based runtime environment for edge devices. Annotation consistency among the three annotators was evaluated: the average bounding box IoU was 0.82, and the Cohen’s Kappa coefficient was 0.76, indicating good consistency. For inconsistent samples, a “majority decision” principle was adopted: if the IoU of two overlapping bounding boxes is ≥ 0.6, the union center is taken as the final annotation; if all three disagree, a fourth senior motion analysis expert makes the decision. The final arbitrated labels undergo a second validation to ensure ID continuity and class consistency.
Training used the AdamW optimizer with a weight decay factor of 0.05 and ε = 1e − 8; the cosine annealing scheduler was set to a minimum learning rate of 1e − 6 and a period of 300 epochs. For data augmentation, the Mosaic blending ratio was 0.5 and the MixUp ratio was 0.2; motion blur simulation employed a linear blur kernel with random orientation, a length of 3–9 pixels, and an intensity σ = 1.2 to simulate typical wearable device jitter.
The model was deployed using TensorRT 8.6, with FP16 quantization and layer fusion enabled (including Conv-BN-ReLU fusion and attention module operator fusion), and no accuracy compensation was used. The Jetson Nano was run in MAXN mode (GPU frequency 921 MHz, memory bandwidth 25.6 GB/s), with 4GB of memory allocated to the GPU and CPU cores disabled to simulate a pure edge GPU environment.
It should be noted that the comparative experiments in this section use the “detector-tracker” combinations recommended in the original papers of each method (such as YOLOv8n+DeepSORT, RTMDet-tiny+FairMOT, etc.) to reflect the overall performance of each method under its optimal configuration. While this setup can demonstrate the practical value of the complete system, it is difficult to completely isolate the independent contributions of the detection and tracking modules. Future work will conduct more rigorous modular ablation analysis within a unified framework.
To comprehensively evaluate the overall performance of multi-object tracking, the CLEAR MOT (Multiple Object Tracking) criterion is used to calculate the multi-object tracking accuracy (MOTA). The calculation formula is as follows:
In formula (19), \(\:F{P}_{t}\) and \(\:F{N}_{t}\) are the number of false detections and false negatives in frame t, respectively, \(\:{\text{ID\:Switches}}_{\text{t}}\) is the number of ID switching events in frame t. The IDF1 score is used as a quantitative indicator of identity retention accuracy, reflecting the proportion of correctly associated detection results to the total number of associated results.

Multi-target tracking accuracy (a) MOTA, IDF1 (b) ID Switches
Figure 4 shows a performance comparison of YOLOv8n, RTMDet-tiny, NanoDet-plus and the proposed method in multi-target tracking tasks. The key metrics include MOTA, IDF1 and ID Switches. As can be seen from Fig. 4a, the MOTA of YOLOv8n+DeepSORT is 58.3 ± 1.6% and the IDF1 is 60.2 ± 1.5%. Figure 4b shows that the ID Switches are as high as 142 times, reflecting that the traditional method has a serious identity switching problem in high dynamic scenarios. RTMDet-tiny+FairMOT and NanoDet-plus+ByteTrack show progressively higher performance, with MOTA reaching 61.7 ± 1.5% and 63.5 ± 1.4% respectively, and ID Switches decreasing to 128 and 103 respectively, indicating that modern lightweight tracking frameworks have a certain degree of robustness. The proposed method significantly outperforms all other methods, achieving a MOTA of 71.2 ± 1.1%, a 7.7% improvement over NanoDet-plus+ByteTrack, and an IDF1 of 73.8 ± 1.0%, while significantly reducing ID Switches to 47. This result fully demonstrates that the proposed method can more accurately maintain target identity consistency in complex sports scenarios and effectively address the tracking challenges caused by high-speed movement, brief occlusion, and target intersection.
To more comprehensively evaluate YOLC’s competitiveness, we added comparative experiments with YOLOv9-tiny (2024) and PP-YOLOE-SOD (2024). The results show that while YOLOv9-tiny achieves 76.1% mAP@0.5, its parameter count (5.2 M) and FLOPs (10.4G) far exceed the capacity of edge devices. PP-YOLOE-SOD is optimized for small targets, achieving 73.8% mAP@0.5, but it relies on complex ESE attention and a multi-branch structure, resulting in a frame rate of only 28.4 FPS on a Jetson Nano. In contrast, YOLC achieves 75.3% mAP@0.5 and 53.5 FPS with 1.78 M parameters and 2.1G FLOPs, demonstrating superior overall performance.
The YOLC framework improves the stability and localization accuracy of small target detection by focusing on key motion regions through dynamic sparse space attention, reducing missed detections and false detections, and providing high-quality input for tracking. Meanwhile, optical flow prediction and confidence adaptive matching strategies are introduced in the association stage to enable low-confidence detection boxes to be reasonably associated, thus avoiding trajectory breakage. Furthermore, the enhanced multi-scale feature fusion capability of the bidirectional weighted feature pyramid network enables the model to maintain a distinguishable representation even when the target is far away or blurred, significantly reducing the probability of identity confusion. These mechanisms work together to enable the system to generate continuous and stable long trajectories even under complex conditions such as violent shaking in the first-person view of the wearable device and rapid movement of multiple athletes. This allows for a synchronous leap between MOTA and IDF1, meeting the demand for high-fidelity trajectory data in actual sports analysis.
Accuracy of high-speed small target detection
This paper uses the mAP@0.5 metric to measure the model’s detection performance for high-speed small targets. For each category in the dataset, the average precision (AP) is calculated when the Intersection over Union (IoU) threshold is ≥ 0.5. Finally, the mean AP of all categories is taken as mAP@0.5.

Accuracy of high-speed small target detection (a) Low motion intensity (b) Medium motion intensity (c) High motion intensity
Figure 5 presents a comparative analysis of the Average Precision at IoU threshold 0.5 (AP@0.5) and the mean Average Precision (mAP@0.5) across five sport categories (badminton, basketball, tennis, sprinting, and table tennis) under varying motion intensities. Subfigures a, b, and c correspond to low, medium, and high motion intensity scenarios, respectively. The proposed YOLC method (orange bars) consistently outperforms the baseline models—YOLOv8n (blue), RTMDet-tiny (green), and NanoDet-plus (red)—across all categories and intensity levels. Notably, as the motion intensity escalates, the performance gap between the proposed method and the baselines widens significantly. Under high-intensity conditions (c), the proposed method maintains a superior mAP@0.5 of 70.9%, demonstrating robust resilience to motion blur and jitter, while the baselines exhibit a considerable performance drop. The overall mAP@0.5 of the proposed method achieves 75.3%, substantially surpassing the best-performing baseline. The low standard deviation of our method further indicates its stable and reliable detection capability in dynamic environments.
We conducted an in-depth analysis of the technical attribution of MOTA and the improved ID Switches: through the ablation tracking module, we found that simply introducing optical flow priors reduced ID Switches from 103 to 78, and adding confidence-adaptive matching further reduced it to 47. This indicates that the reduction in ID switching is mainly due to the hierarchical matching strategy’s reasonable association with low-confidence detections, rather than simply optical flow prediction.
To further verify the advantages of the tracking module, we paired the YOLC detector head with StrongSORT and OC-SORT for testing. The results showed that the MOTA (Motion Response Time) of YOLC + StrongSORT was 68.4%, and the ID Switches were 58; while the MOTA of YOLC + OC-SORT was 69.1%, and the ID Switches were 53. The proposed optical flow + confidence adaptive matching strategy (YOLC + Ours) achieved an MOTA of 71.2% and ID Switches of 47, significantly outperforming both. This indicates that while the general tracker is powerful, it is not optimized for the small-target, high-speed motion characteristics of wearable devices; the hierarchical matching and motion consistency constraints proposed in this paper are more suitable for this scenario and effectively suppress identity switching.
Small object recall capability
To evaluate the model’s completeness in capturing small objects, a small object is defined as an instance of a target with a bounding box area ≤ 1024 pixels squared. The number of detections TPsmall that were correctly matched (IoU ≥ 0.5) on the test set is counted, and the Small-Object Recall (SOR) is calculated as follows:
In formula (19), FNsmall represents the number of small targets that were missed, reflecting the completeness of the model’s capture of small objects.

Small target recall capability (a) Low exercise intensity (b) Medium exercise intensity (c) High exercise intensity
Figure 6 shows the small target recall performance of YOLOv8n, RTMDet-tiny, NanoDet-plus and the proposed method under low, medium and high exercise intensities, covering five sports scenarios: badminton, basketball, tennis, track and field sprinting and table tennis. As can be seen from Figs. 6a,b,c the SOR of all models decreases significantly with increasing exercise intensity: the overall SOR of YOLOv8n is 62.3 ± 1.6%, which decreases to 54.5 ± 1.8% at high exercise intensity in Fig. 5c; RTMDet-tiny and NanoDet-plus also show a similar degradation trend, with SORs of 56.1 ± 1.9% and 54.0 ± 1.9% respectively at high intensity. The proposed method demonstrates significant advantages across all categories and intensity levels, achieving an average SOR of 87.3 ± 0.9% at low motion intensity (Fig. 6a) and maintaining a recall of 75.4 ± 1.3% even at high intensity. The method presented in this paper generally has a smaller standard deviation, indicating that it has higher stability in complex dynamic environments. In extreme small target scenarios such as table tennis and tennis balls under high motion intensity, the method presented in this paper achieves high intensity recall rates of 75.8 ± 1.3% and 78.7 ± 1.2%, respectively, which fully verifies its strong robust capture capability for small moving objects.
Dynamic sparse spatial attention accurately identifies potential target regions based on the local texture variance response, and supports the activation of the relevant features of interest under low signal-to-noise ratio conditions to systematically mitigate missed detections resulting from blurring or occlusion. Moreover, the bidirectional weighted feature pyramid network structure can effectively enhance the semantic expression of shallow high-resolution feature maps through a combination of attention-guided bidirectional weighted fusion, which allows the network to be more sensitive to potential targets with very small target sizes. Instead, traditional methods, like YOLOv8n, rely on a fixed receptive field and global attention that are more prone to background artifacts and less adaptable to scale variations, in contrast to YOLC, which utilizes a lightweight backbone and integrates a direction-aware CA module within the architecture that increases the positioning sensitivity without a processing burden. This allows YOLC to continuously track high-speed, small targets given limitations in wearable device processing without sacrificing utility, and ultimately improves overall recall across the detection system.
Inference efficiency and resource consumption
To comprehensively evaluate the model’s deployment performance on edge devices, this paper measures its inference efficiency and system resource consumption. The single-frame inference time is measured using a CUDA (Compute Unified Device Architecture) event timer: 1000 forward propagations are performed consecutively on a Jetson Nano, and the total time taken from copying the input tensor to the video memory to returning the output bounding box is recorded. To eliminate the initialization effect, the warm-up frame of the first run is excluded, and the average of the remaining 999 measurements is taken as the final inference latency. Meanwhile, NVIDIA Nsight Systems tools are used to monitor video random access memory (VRAM) usage throughout the entire inference cycle, and peak VRAM usage is recorded as a key metric for measuring model consumption. All tests are conducted under conditions of simultaneous monitoring of power consumption and temperature to ensure that the system is in a stable operating state, thus reflecting a real edge computing environment.

Inference efficiency and resource consumption (a) Average latency, frame rate, and power consumption (b) Peak memory performance
Figure 7 shows a comparison of inference latency and system-level performance of YOLOv8n, RTMDet-tiny, NanoDet-plus and the proposed method on the NVIDIA Jetson Nano edge device, covering four key metrics: average latency, frame rate, peak memory usage, and average power consumption. As shown in Fig. 7a, the inference latencies of YOLOv8n, RTMDet-tiny and NanoDet-plus are 28.6ms, 27.1ms and 25.3ms, respectively, corresponding to frame rates of 35.0FPS, 36.9FPS and 39.5FPS. Although they basically meet the real-time requirements, they are difficult to meet the millisecond-level response requirements in highly dynamic sports scenarios. The proposed method significantly reduces the average inference latency to 18.7ms, achieving a processing speed of 53.5 FPS, which is 14 FPS higher than NanoDet-plus. It has stronger real-time response capabilities and an average power consumption of 5.8 W, placing it at the same energy efficiency level as other models. Figure 7b shows that the peak memory usage of the proposed method is 476 MB, which is slightly higher than NanoDet-plus. This indicates that it achieves a performance leap without increasing power consumption, fully demonstrating its engineering feasibility for deployment in wearable devices.
This paper utilizes depthwise separable convolution to significantly reduce the computational cost of the backbone network, and combines the depthwise separable convolution backbone network with the CSP structure to minimize gradient propagation, thereby controlling the total number of parameters while maintaining feature representation capabilities. Furthermore, this paper proposes a dynamic sparse spatial attention mechanism, which activates the top 30% of highly correlated regions through local texture variance response, effectively filtering out background noise and limiting the computational overhead of subsequent bidirectional weighted feature pyramid network and detection head. The detection head uses a shared convolutional kernel that directly integrates a lightweight CA module, which can improve positioning accuracy without increasing any computational overhead. These collaborative optimization strategies enable the model to maintain high-throughput inference even with limited hardware resources, which is particularly advantageous for wearable applications that require continuous, low-latency output, such as first-person motion videos.
To further clarify the overhead of each module in the system, Table 2 reports a detailed breakdown of latency in the detection and tracking phases. The average latency of the pure detection module is 18.7ms, the optical flow estimation module latency is 12.3ms, the data association and trajectory management overhead is 5.9ms, and the total latency at the tracking end is 18.2ms. The overall end-to-end latency (detection + tracking) of the system is 36.9ms, which still meets the real-time processing requirements (> 27FPS). Table 2 shows the breakdown of computational overhead in the detection and tracking pipeline.
False detection level under motion blur conditions
To evaluate the robustness of the model under typical degradation scenarios of wearable devices, 1,842 frames that are significantly blurred due to device shaking or high-speed target movement are manually selected. On this dataset, the number of frames that generated false alarms and the total number of false detections are counted. To quantify the false alarm level of the model under fuzzy conditions, the False Positive Rate under Motion Blur (FPR-MB) is defined, and its calculation formula is as follows:
In formula (20), \(\:\text{F}{\text{P}}_{\text{t}}\) represents the number of targets that the model incorrectly detects in the t-th frame image, and \(\:{\mathcal{T}}_{\text{b}\text{l}\text{u}\text{r}}\) represents the set of all manually selected image frames containing obvious motion blur. False detection levels under motion fuzzy conditions are shown in Table 3.
Table 3 shows a comparison of the false detection levels of YOLOv8n, RTMDet-tiny, NanoDet-plus and the proposed method in motion-blurred scenes, based on 1,842 manually selected blurred images. YOLOv8n generates 683 false positives under these conditions, with an FPR-MB score as high as 37.1, indicating that it is prone to misidentifying background textures or blurred areas as targets in dynamic degradation environments. RTMDet-tiny and NanoDet-plus show slight improvement, with FPR-MB scores of 33.2 and 32.5 respectively, but still have a large number of false responses. The proposed method significantly reduces the total number of false positives to 287, and FPR-MB to 15.6, less than half that of YOLOv8n. Furthermore, the number of frames that trigger false positives is reduced from 576 to 249, indicating that it not only reduces the frequency of false positives but also improves spatial consistency. This result fully verifies that YOLC has stronger anti-interference capabilities under the dual interference of inherent jitter and high-speed movement of wearable devices, effectively suppressing false alarms caused by image blurring and ensuring the reliability of subsequent detection and tracking systems.
Conventional approaches use global feature extraction, often triggering misleading regions for false detections, when motion blur distorts edges. YOLC creates spatial weights across local texture variance response, retaining only the top 30% of surplus high activity areas to compute, automatically filtering a large amount of low signal-to-noise ratio responses induced by the occurring blurring. At the same time, the attention-guided bidirection weighted feature pyramid network structure improves the cross-scale consistency of real moving targets, making the network more likely to respond to objects with continuous structural properties rather than random noise. In parallel, the collaborative design of the lightweight backbone with the coordinated attention module improves the model’s ability to discriminate small, directional motion patterns and then increases evidence to discriminate real objects from background noise. The mechanisms work together to solve a closed-loop “perception-inhibition’’, significantly decreasing false alarms from naturally ambiguous objects while maintaining recall, for the edge devices core need for stable robust vision.
Model complexity and computational load
To assess the statistical significance of the experimental results, five independent replicate experiments were conducted on all performance indicators, each initialized with a different random seed. The mean ± standard error reported in this paper is based on calculations from the five replicates, with the standard error reflecting the volatility of the mean estimate. The differences between groups for key performance indicators were analyzed for significance using a two-sample t-test.
To comprehensively evaluate the model’s lightweight nature and edge deployment potential, this paper quantitatively analyzes the network’s theoretical complexity and measured resource consumption. The theoretical number of parameters(Params) and floating-point operations (GFLOPs) are obtained by parsing the computation graph using PyTorch’s thop library, and the input size is fixed to ensure fair comparison with other models. The model complexity and computational load are shown in Table 4.
Table 4 shows a comparison of the complexity of different detection models in terms of parameter quantity and computational cost. The number of parameters for YOLOv8n and RTMDet-tiny are as high as 3.2 M and 3.8 M respectively, which is significantly higher than NanoDet-plus’s 0.98 M. The method in this paper has a resolution of 1.78 M, which is slightly higher than the NanoDet-plus model, but still far lower than the mainstream lightweight models. The theoretical GFLOPs of the method presented in this paper are 2.1, which is 74.1% and 77.4% lower than those of YOLOv8n (8.1) and RTMDet-tiny (9.3), respectively, and also has advantages over NanoDet-plus (2.6). Among all methods, RTMDet-tiny has the highest computational load due to insufficient structure compression. The method in this paper achieves the lowest floating-point operation requirement while maintaining a moderate parameter size, demonstrating a better “performance-cost” balance. The proposed method consumes only 5.3 GB/s of memory bandwidth, which is 57.3% and 62.7% lower than YOLOv8n and RTMDet-tiny, respectively, and even surpasses the extremely lightweight NanoDet-plus. This advantage mainly stems from the dynamic sparse attention mechanism, which activates only the top 30% of high-response regions, significantly reducing memory read and write operations on feature maps. The low memory bandwidth requirement makes YOLC more deployment-friendly on memory-constrained edge devices, effectively avoiding performance degradation caused by memory bandwidth bottlenecks.
The backbone employs depthwise separable convolutions, which significantly reduces redundant computations in the channel dimension; the cross-stage partial connection structure reduces repeated gradient propagation and further compresses the effective parameter space. More importantly, the dynamic sparse spatial attention mechanism not only improves feature quality, but also significantly reduces the actual computational workload of the subsequent bidirectional weighted feature pyramid network and the detection head by activating only the top 30% of high-response regions, thus forming a synergistic effect of “perception as compression”. RTMDet-tiny relies on standard convolution stacking, and although YOLOv8n introduces lightweight modules, its overall capacity is still too large, making it difficult to adapt to the long-term operation needs of wearable devices. YOLC employs a dual strategy of structural simplification and dynamic scheduling to minimize computational footprint without sacrificing multi-scale fusion capabilities, providing a sustainable and low-power solution for first-person sports vision systems.
To deeply analyze the relationship between model complexity and performance, we used the PQS-FP (Parameter Quantity vs. Fitting Performance) coordinate system for visualization analysis of YOLC and the baseline model. The results show that YOLC is in the “high-efficiency zone”—maintaining mAP > 75% even with < 2 M parameters, while YOLOv8n falls into the “overfitting risk zone” due to parameter redundancy. This analysis indicates that YOLC achieves superior fitting efficiency through structural simplification and dynamic sparsity, explaining the source of its performance advantage.
Attention focus in key areas
To quantitatively evaluate the accuracy of the proposed dynamic sparse spatial attention mechanism in locating key targets and the rationality of its spatial orientation in real-world scenarios, this paper defines the Dominant Feature Activation Ratio (DFAR) to quantify the rationality of the spatial orientation of the attention mechanism. First, the normalized weight map output by the dynamic sparse spatial attention mechanism module for each frame in the test set is extracted. The top 10% of spatial locations with the highest response values are selected to form a set of salient regions. If the center point of a real target falls into this region, it is considered as effective coverage. The dominant feature activation ratio is calculated as follows:
In formula (21), \(\:\mathbb{I}\)(⋅) is an indicator function used to evaluate whether attention is truly focused on the key motion area.

Attentional focus levels in key areas (a) Low exercise intensity (b) Medium exercise intensity (c) High exercise intensity
Figure 8 shows the comparison results of the attention focus degree of YOLOv8n, RTMDet-tiny, NanoDet-plus and the proposed method in three motion intensities (low, medium and high), reflecting the ability of each model’s attention mechanism to cover the real target center point. The dominant feature activation ratios of all comparative methods decrease significantly with increasing exercise intensity. YOLOv8n’s DFAR is 66.0 ± 1.9% at low intensity (Fig. 8(a)) but decreases to 54.0 ± 2.5% at high intensity (Fig. 8c). RTMDet-tiny and NanoDet-plus also show similar degradation trends, with 56.6 ± 2.3% and 58.5 ± 2% respectively at high exercise intensities. The method presented in this paper achieves a focusing accuracy of 89.2 ± 1.0% at low intensity and maintains a focusing accuracy of 78.5 ± 1.4% at high intensity. The proposed method exhibits highly stable performance across all categories, with a standard deviation controlled within ± 1.5%. In high-speed, small-target-dominated scenarios such as tennis and badminton, the activation rates of high-intensity dominant features reach 80.4 ± 1.3% and 78.6 ± 1.4%, respectively, demonstrating that its attention mechanism can continuously lock onto key motion areas and possesses strong environmental adaptability.
YOLC captures directly structurally active regions in an image with its local texture variance response, so that attention weights naturally prefer target boundaries with clarity and motion as opposed to mean region of the background. Even at the most violently shaken of instances of the wearable device causing global blurriness, this mechanism is able to trigger the location of the real target based solely on local contrast differences avoiding misdirection by the global normalization. Simultaneously, its core dynamic sparsity strategy would further augment the ‘perception focusing’ effect of tension causing the network to attend to the most discriminative spatial units. This mechanism for attention generation caused by the visual features beneath not only increases computational efficiency when operating in a complex dynamic scene, but also realizes the semantic consistency required for perceptual invariance and achieves a meaningful leap from “passive weighting” to “active localization” providing high quality feature input for detection and tracking.
Visual analysis of attention mechanism and detection results
To more intuitively evaluate the effectiveness of the proposed dynamic sparse space attention mechanism and its impact on the final detection results, this section provides a visual analysis of the model’s internal activation states in typical high-speed motion scenarios. Figure 9 shows the superimposed visualization results of the dynamic sparse space attention weight heatmap and the spatial distribution of the final detection box confidence in a complex scene at the moment of a tennis serve.

Visualization of the attention mechanism and detection results
Figure 9a shows a spatial weight heatmap generated by the dynamic sparse spatial attention mechanism, where red areas represent high response values and blue areas represent low response values. It can be clearly observed that the attention mechanism successfully focuses computational resources on two key regions: the high-speed flying tennis ball (highlighted in red in the upper left corner of the image) and the point of impact of the athlete’s racket. Notably, despite the extremely small size of the tennis ball and the presence of motion blur, its local texture variance still elicits a high attention response. Most background areas (such as the stands and the ground) are effectively suppressed (shown in blue), achieving adaptive allocation of computational resources.
Figure 9b further projects the final output confidence of the detection head onto the original image as a heatmap. It can be seen that the high confidence region (red) highly overlaps with the high attention weight region in Fig. 9b, especially forming a sharp confidence peak at the location of the small target (tennis ball). This forms a complete “perception-computation-detection” closed loop: the dynamic sparse attention mechanism accurately locates potential regions of interest, guiding subsequent feature fusion and the detection head to perform intensive computation in these regions, ultimately transforming them into high-confidence, accurate detection boxes. This mechanism, moving from “passive weighting” to “active localization,” is the key reason why the YOLC framework achieves excellent performance in high-speed small object detection tasks.
The qualitative demonstration results for strong light interference scenes are shown in Fig. 10.

Qualitative results of strong light interference scenarios
In a tennis ball scene with strong light reflection, the model failed to detect the real tennis ball and generated three significant false positives. Analysis revealed that the false positives mainly stemmed from the following mechanism defects: First, the dynamic sparse attention mechanism was overly sensitive to high-brightness areas. The specular reflection areas formed by strong light on the court and stands have local texture variance features similar to those of a tennis ball, triggering a high response from the attention mechanism and leading to incorrect activation of background areas. Second, semantic confusion occurred during multi-scale feature fusion. In the feature pyramid network, low-level features strongly respond to basic textures such as edges and corners but lack high-level semantic constraints. When strong light reflection forms a near-circular bright area, shallow features mistakenly identify it as a potential target, while high-level semantic information failed to effectively suppress such false positives. Furthermore, the orientation perception capability of the coordinate attention module was limited. Under strong interference, the module’s ability to model long-range spatial dependencies decreased, failing to fully utilize scene context information to distinguish between real targets and optical artifacts. Future improvements will introduce illumination-invariant feature enhancement and combine scene prior knowledge to construct a more robust attention gating mechanism. Table 5 shows the statistical analysis of the DFAR index at different target scales and densities.
Table 5 presents the statistical analysis results of the DFAR index under different target scales and scene densities. The data shows that the DFAR value is positively correlated with target size, reaching its highest value (90.3%) in the 24 × 24–32 × 32 pixel range, while it is relatively lower (85.2%) for extremely small targets (8 × 8–16 × 16 pixels), indicating that the dynamic sparse attention mechanism provides more stable coverage for larger targets. Meanwhile, scene density significantly affects DFAR, with a general decrease of approximately 10–13% points in high-density scenes, reflecting the dispersion effect of multi-target competition on attention distribution. Statistical tests show that for small- and medium-scale targets, the proposed method achieves significant improvements over the baseline (p < 0.01), while there is no significant difference in the largest scale category, indicating that the method’s advantage is mainly reflected in the more challenging small target detection scenarios. The confidence interval width increases with decreasing target scale, revealing the inherent uncertainty in extremely small target detection.
To address the false positive issue in strong light interference scenarios, we supplemented the comparison with baseline models on the same 1842-frame strong light/high reflectivity subset. The results show that YOLOv8n, RTMDet-tiny, and NanoDet-plus achieve FPR-MB of 41.2%, 38.7%, and 37.9%, respectively, all higher than their performance on ordinary motion-blurred images, indicating that strong light interference is a common challenge for lightweight models. YOLC’s FPR-MB is 19.3%, slightly higher than its 15.6% on ordinary blurred images, but still significantly better than all baselines. This demonstrates that YOLC’s dynamic sparsity mechanism remains robust in strong light scenarios, and the main cause of false positives is the sensitivity of local texture variance to highlight areas, a common challenge for wearable devices, not a defect unique to YOLC.
Ablation experiments
All ablation experiments strictly adhered to the single-variable principle: for example, when validating the dynamic sparse attention mechanism, the module was removed but the bidirectional weighted FPN, CA module, and optical flow tracking were retained; when validating the CA module, only CA was removed while the rest of the structure remained unchanged. All variants were retrained for 300 epochs under the same training configuration to ensure fair comparisons.
The final choice of τ = 30% was based on a performance-efficiency balance consideration in the ablation experiments. As shown in Table 6, when τ increased from 10% to 30%, the recall rate for small targets significantly improved from 68.2% to 75.3%, while the inference latency only increased from 16.8ms to 18.7ms. Further increasing τ to 40% resulted in a plateauing of the recall rate gain (+ 1.1%), but a significant increase in computational cost (+ 3.2ms). Therefore, τ = 30% maintains high activation efficiency while reserving sufficient space for small target features, achieving the optimal performance-efficiency trade-off.
To avoid subjective exaggeration, we supplement our comparison experiments with Deformable Attention. Under the same backbone, the YOLC variant incorporating Deformable Attention achieves 73.8% mAP@0.5, slightly lower than our dynamic sparse mechanism (75.3%), but with 0.7 GFLOPs more FLOPs. This indicates that texture variance-based sparse activation is more efficient in small-object scenarios, but it is not a “paradigm leap,” but rather a task-oriented, efficient attention design.
Validation of generalization ability on public benchmark datasets
To evaluate the generalization performance of the proposed method, this section conducts comparative experiments on three public benchmark datasets: MOT17 (pedestrian tracking), SportsMOT (athlete tracking), and VisDrone small target subset (small targets from a drone’s perspective). All models use weights trained on a self-built sports dataset without any fine-tuning to test their cross-domain generalization ability. The generalization performance on public benchmarks is shown in Table 7.
Experimental results show that our proposed method achieves state-of-the-art performance on three public datasets, with MOTA metrics improving by 4.3%, 3.8%, and 3.5% compared to the best baseline, respectively. The dynamic sparse attention mechanism achieves domain-independent feature selection through local texture variance response, while the bidirectional weighted feature pyramid enhances the model’s adaptability to scale variations. Despite testing in unknown domains, the collaborative optimization design still ensures feature discriminativity, validating the method’s strong generalization ability. The end-to-end latency and energy consumption analysis is shown in Table 8.
End-to-end latency analysis shows that the proposed method achieves a total latency of 28.5ms throughout the detection-tracking process, a 15.7% reduction compared to the best baseline. The tracking module introduces an additional 9.8ms of overhead, with optical flow estimation accounting for 6.3ms and data association for 3.5ms. 12.3ms is the benchmark time for the independent operation of the raft tiny model; In the integrated tracking pipeline, the effective time consumption is reduced to 6.3ms through parallel calculation with the detection phase and downsampling optimization. Energy consumption metrics show that each frame processed consumes only 0.20 J, and the P90 latency is controlled within 30ms, meeting the real-time requirements of high-dynamic scenes. The stability of the latency distribution (the difference between P50 and P90 is less than 1.5ms) verifies the reliability of the system deployment on edge devices.
To verify the robustness of the proposed method to optimizer selection, we additionally reproduced the YOLC framework using the AdaBoB optimizer, with its hyperparameters set to the default values in the original paper (initial learning rate 0.001, β₁=0.9, β₂=0.999). Under the same training configuration, YOLC achieved mAP@0.5 = 74.1% and MOTA = 70.3% on AdaBoB, slightly lower than the results of AdamW (75.3%/71.2%), but still significantly better than all baseline models (such as NanoDet-plus with MOTA = 62.1% on AdaBoB). This indicates that the performance advantage of YOLC is independent of a specific optimizer, and its architectural design has generalization effectiveness.
Conclusion
This paper proposes a high-speed small target detection and tracking method that combines the YOLC framework with a dynamic sparse space attention mechanism, specifically designed for sports images captured by wearable devices. By constructing a lightweight backbone network, introducing a dynamic sparse attention mechanism based on local texture variance, and combining attention-guided bidirectional weighted feature fusion with optical flow-assisted hierarchical tracking association strategy, a “perception-computation” collaborative optimization was achieved. Experiments show that the method achieves a processing speed of 53.5 FPS and significantly improves detection and tracking performance in complex scenes, with an mAP@0.5 of 75.3% and a small target recall rate of 82.4 ± 1.1%, effectively solving the problem of robust perception of high-speed small targets in resource-constrained environments.
While the proposed method performs well in high-speed small target detection and tracking tasks, several limitations remain and require further investigation. First, the binary sparse gating mechanism based on local texture variance may face the risk of missed detections in extremely complex environments. For example, in scenarios with strong lighting changes, rain or snow interference, or glass reflection, the stability of local texture features decreases significantly, leading to a weakened response of the attention mechanism to real targets. Second, current research has not systematically defined the robustness boundary of this method, failing to clarify at what level of background interference performance begins to degrade sharply. Future work will construct more challenging extreme scene test sets and explore multimodal attention mechanisms that combine semantic context to improve perceptual reliability in complex environments.
Data availability
The datasets generated and analysed during the current study are not publicly available due to privacy concerns and copyright restrictions related to the recorded athletes and the proprietary nature of the original video materials collected from sports training venues. However, the de-identified image dataset and corresponding annotations are available from the corresponding author upon reasonable request for academic and non-commercial research purposes.
References
Dunnhofer, M. et al. Visual object tracking in first person vision. Int. J. Comput. Vision 131(1), 259–283 (2023).
Mirzaei, B. et al. Small object detection and tracking: a comprehensive review. Sensors 23(15), 6887 (2023).
Vrzáková, H. et al. Towards automatic object detection and activity recognition in indoor climbing. Sensors 24(19), 6479 (2024).
Lyu, Z. et al. A survey of model compression strategies for object detection. Multimedia Tools Appl. 83(16), 48165–48236 (2024).
Mittal, P. A comprehensive survey of deep learning-based lightweight object detection models for edge devices. Artif. Intell. Rev. 57(9), 242 (2024).
Choi, K. et al. Real-time object detection and tracking based on embedded edge devices for local dynamic map generation. Electronics 13(5), 811 (2024).
Wang, X. et al. Small object detection based on deep learning for remote sensing: A comprehensive review. Remote Sens. 15(13), 3265 (2023).
Fan, J. et al. IRSDT: A framework for infrared small target tracking with enhanced detection. Sensors 23(9), 4240 (2023).
Kwan, C. & Budavari, B. Enhancing small moving target detection performance in low-quality and long-range infrared videos using optical flow techniques. Remote Sens. 12(24), 4024 (2020).
Duan, C. et al. Motion capture for sporting events based on graph convolutional neural networks and single target pose Estimation algorithms. Appl. Sci. 13(13), 7611 (2023).
Bischofberger, J., Baca, A. & Schikuta, E. Event detection in football: improving the reliability of match analysis. Plos One 19(4), e0298107 (2024).
Seong, M. et al. Multisensebadminton: wearable sensor–based Biomechanical dataset for evaluation of badminton performance. Sci. Data 11(1), 343 (2024).
Zhao, C. et al. Investigation of eye movement characteristics during free throws at varying intensities among basketball players and its correlation with free throw percentage. Plos One 19(8), e0299938 (2024).
Wang, H. et al. RT-Deblur: Real-time image deblurring for object detection. Visual Comput. 40(4), 2873–2887 (2024).
Ali, M. L. & Zhang, Z. The YOLO framework: A comprehensive review of evolution, applications, and benchmarks in object detection. Computers 13(12), 336 (2024).
Fu, S. et al. Anchor-free object detection in remote sensing images using a variable receptive field network. EURASIP J. Adv. Signal Process. 2023(1), 53 (2023).
Wang, Y. et al. Convolutional block attention module–multimodal feature-fusion action recognition: enabling miner unsafe action recognition. Sensors 24(14), 4557 (2024).
You, L. et al. Multi-object vehicle detection and tracking algorithm based on improved YOLOv8 and ByteTrack. Electronics 13(15), 3033 (2024).
Sun, H. et al. Pruning DETR: efficient end-to-end object detection with sparse structured pruning. Signal. Image Video Process. 18(1), 129–135 (2024).
Dai, Y. et al. Multi-scale depthwise separable Convolution for semantic segmentation in street–road scenes. Remote Sens. 15(10), 2649 (2023).
Khalil, I. et al. Lightweight U-Net based on depthwise separable Convolution for cloud detection onboard nanosatellite. J. Supercomputing 80(18), p26308 (2024).
Ren, S., Fang, Z. & Gu, X. A cross stage partial network with strengthen matching detector for remote sensing object detection. Remote Sens. 15(6), 1574 (2023).
Dewi, C. & Juli Christanto, H. Combination of deep cross-stage partial network and Spatial pyramid pooling for automatic hand detection. Big Data Cogn. Comput. 6(3), 85 (2022).
Pan, F., Zhao, L. & Wang, C. Adaptive sparse attention-based compact transformer for object tracking. Sci. Rep. 14(1), 12256 (2024).
Che, N. et al. AFT-SAM: adaptive fusion transformer with a sparse attention mechanism for Audio–Visual speech Recognition. Appl. Sci. 15(1), 199 (2024).
Xu, T. et al. Lightweight saliency detection method for real-time localization of livestock meat bones. Sci. Rep. 13(1), 4510 (2023).
Lv, J. et al. An anchor-free detection algorithm for SAR ship targets with deep saliency representation. Remote Sens. 15(1), 103 (2022).
Dang, J., Tang, X. & Li, S. HA-fpn: hierarchical attention feature pyramid network for object detection. Sensors 23(9), 4508 (2023).
Li, X. et al. A-BFPN: an attention-guided balanced feature pyramid network for SAR ship detection. Remote Sens. 14(15), 3829 (2022).
Sun, J. et al. Scale enhancement pyramid network for small object detection from UAV images. Entropy 24(11), 1699 (2022).
Zuo, Z. et al. AFFPN: attention fusion feature pyramid network for small infrared target detection. Remote Sens. 14(14), 3412 (2022).
Wang, Y. et al. MSGFNet: Multi-scale gated fusion network for remote sensing image change detection. Remote Sens. 16(3), 572 (2024).
Tao, H. et al. A gated multi-hierarchical feature fusion network for recognizing steel plate surface defects. Multimedia Syst. 29(3), 1347–1360 (2023).
Dai, D. et al. LHSDNet: A lightweight and High-Accuracy SAR ship object detection Algorithm. Remote Sens. 16(23), 4527 (2024).
Dong, R. et al. ASIPNet: Orientation-Aware learning object detection for remote sensing Images. Remote Sens. 16(16), 2992 (2024).
Xie, F., Lin, B. & Liu, Y. Research on the coordinate attention mechanism fuse in a YOLOv5 deep learning detector for the SAR ship detection task. Sensors 22(9), 3370 (2022).
Peng, C. et al. An innovative neighbor attention mechanism based on coordinates for the recognition of facial Expressions. Sensors 24(22), 7404 (2024).
Zhang, G. et al. Achieving adaptive visual multi-object tracking with unscented Kalman filter. Sensors 22(23), 9106 (2022).
Karpuzov, S. et al. Object tracking based on optical flow reconstruction of motion-group parameters. Information 15(6), 296 (2024).
Author information
Authors and Affiliations
Contributions
Chen Hui is responsible for the concept introduction, manuscript writing, language editing, and graphic optimization of the entire article; Kang Wanjie is responsible for experimental design, data analysis, and processing. Song Ya and Liu Wenlong are responsible for data collection, organization, and assisting in completing other tasks. All authors have reviewed the results and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chen, H., Song, Y., Liu, W. et al. YOLC with dynamic sparse attention for high-speed small target detection in wearable sports images. Sci Rep 16, 6858 (2026). https://doi.org/10.1038/s41598-026-38079-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-38079-5
