
Abstract
Infrared and visible light image fusion is a hot topic in the field of image processing, aiming to merge the complementary information from source images to produce a fusion image containing richer information. However, the images used for fusion are often taken under extreme lighting conditions at night, which greatly affects the quality of the visible light images–specifically causing low-light degradation phenomena such as uneven brightness, severe noise amplification, and loss of texture details–and leads to poor fusion results; most existing image fusion algorithms do not take into account the lighting factor. For this reason, we propose a multi-scale end-to-end image enhancement fusion method that enhances the illumination of the image while realizing image fusion, which greatly improves the quality of the fused image. The model is based on the existing autoencoder fusion network design, which includes four parts: visible image encoder, infrared image encoder, decoder and fusion module, and the training is accomplished by a novel three-stage training strategy. In the first stage the visible image enhancement consisting of visible image encoder and decoder is trained, and in the second stage the autoencoder consisting of infrared image encoder and decoder is trained. The fusion module is then trained in the third stage. This staged training strategy not only ensures effective learning of each component, but also provides more accurate and robust performance for image fusion in complex environments. Experimental results on public domain datasets show that our end-to-end fusion network achieves superior visual performance results compared to existing methods.
Similar content being viewed by others


Introduction
With the continuous advancement of technology, human-computer interaction (HCI) has become increasingly vital in modern society. As a critical component of HCI, image processing technology–particularly low-light image enhancement–plays a pivotal role in improving system performance and user experience. Capturing and processing images under low-light conditions has long been a challenge in computer vision, and the emergence of low-light image enhancement techniques provides an effective solution to this problem. Recent developments in low-light enhancement, such as the UNet++-based architecture for nested skip connections, have shown promising results in preserving details while improving brightness, laying a foundation for subsequent fusion tasks1.
Low-light image enhancement technology refers to a series of algorithms and processing methods designed to improve the quality and visibility of images captured under insufficient lighting. This technology primarily addresses issues such as high noise, loss of detail, and low contrast in images acquired during nighttime, indoor, or other low-light environments. Its goal is to enhance image clarity, restore detailed information, and maintain the natural appearance of images as much as possible.
Low-light image enhancement significantly enhances the performance of HCI systems. In terms of visual perception, this technology improves the image recognition and analysis capabilities of systems in low-light environments, thereby strengthening their ability to understand and respond to the surroundings. For example, in security monitoring systems, low-light image enhancement enables clearer identification of intruders or anomalies at night, enhancing overall security capabilities. In terms of user experience, this technology provides users with clearer and more natural visual feedback, thereby elevating interaction comfort and efficiency. For instance, in virtual reality (VR) and augmented reality (AR) devices, it significantly improves immersion and interaction quality in low-light conditions, enabling seamless integration between virtual scenes and the real world. Similarly, in mobile devices’ night photography functions, this technology greatly enhances shooting experiences and photo quality under dim lighting, yielding clearer and more detailed images.
However, the inherent limitations of single-image sensors make it challenging to comprehensively capture scene information under complex lighting conditions. For example, visible light sensors perform poorly in low-light environments, while infrared sensors fail to provide rich texture details. These constraints directly impact user experience, particularly in scenarios requiring high-quality image output. To address this issue, image fusion technology has emerged. By integrating complementary information from multiple sensors–such as combining the detail information from visible light sensors with the thermal radiation data from infrared sensors–this technology generates composite images that are more informative and comprehensive. This fusion not only improves image quality but also provides users with more complete and realistic visual feedback, further enhancing the immersion and practicality of HCI. For example, in AR devices, fusing visible and infrared images allows users to perceive their surroundings more clearly in low-light conditions, enhancing the naturalness and fluidity of interactions.
By integrating low-light image enhancement with multi-sensor image fusion, user experience can be significantly improved, particularly in visual perception and interaction efficiency under complex lighting conditions. This technological synergy not only compensates for the shortcomings of single sensors but also provides users with richer and more authentic visual information, thereby advancing the development of HCI technologies.Notably, RGB-T fusion technology (e.g., dual-spectral UAV remote sensing) has achieved remarkable applications in ground object recognition. For example, Zhang et al. (2025) proposed a RGB-T fusion framework for UAV-based ground target detection, which effectively improves the recognition accuracy in low-light and foggy environments (https://doi.org/10.1016/j.isprsjprs. 2025.01.022). Their work highlights the critical need for balancing texture details and thermal features in fusion, which existing methods still struggle to address under extreme low-light conditions. Existing methods have explored the integration of visibility enhancement and multi-scale decomposition for fusion tasks2, laying the foundation for combined enhancement-fusion frameworks.
One of the most prominent applications of image fusion is the combination of infrared and visible light images, which has been widely adopted across various fields. Infrared images are particularly valuable as they reveal thermal radiation characteristics of objects that are invisible to the naked eye. This capability makes infrared imaging exceptionally useful in scenarios such as night vision, thermal monitoring, and object detection under low-visibility conditions. On the other hand, visible light images are renowned for their rich texture and detail, providing a clear and human-perceptible representation of scenes. The complementary nature of infrared and visible light images makes them ideal candidates for fusion. By merging these two types of images, composite images can be created that retain both the thermal radiation information from the infrared spectrum and the detailed texture and spatial information from the visible spectrum. Such fused images are more robust and informative, enabling sophisticated visual processing tasks that would be difficult or impossible to accomplish with a single image type alone. Recent works have focused on enhancing edge gradients and multi-scale transformations to better preserve these complementary features3,4, while others have leveraged structure-based saliency maps to guide fusion5.
Despite the revolutionary impact of deep learning on image fusion, particularly in infrared-visible light fusion6, several persistent challenges hinder optimal performance. Deep learning-based methods, including those using multi-scale CNNs with attention transformers7 and discriminative cross-dimensional evolutionary learning8, have advanced the state-of-the-art, but gaps remain. One of the most significant issues is the quality of visible light images, which are often captured under suboptimal lighting conditions (e.g., nighttime). Low-light conditions degrade image quality, introducing noise and reducing contrast, which in turn affects the effectiveness of the fusion process. This degradation results in fused images that fail to fully leverage the complementary information from both infrared and visible spectra. Furthermore, traditional preprocessing methods for these images-such as enhancement to improve visibility and denoising to eliminate artifacts-are typically disjointed from the actual fusion process. This separation necessitates specialized techniques for each preprocessing step, leading to a workflow that lacks coherence and efficiency. For example, methods relying on Gabor filters and sigmoid functions for fusion9 exemplify the disjointed nature of traditional approaches, where preprocessing (e.g., filtering) and fusion are treated as independent steps. Recent studies have highlighted the need to address data compatibility and task adaptability in fusion10, as well as robustness against adversarial attacks11, underscoring the complexity of current challenges. Clearly, a more integrated approach is needed, one that can handle preprocessing and fusion tasks simultaneously, thereby enhancing system adaptability to diverse and complex environments. The core motivation of the proposed network lies in two aspects: first, to address the disconnection between low-light enhancement and fusion in existing methods, which leads to feature mismatch and suboptimal fusion results; second, to design a multi-scale feature interaction mechanism that can adapt to the complementary characteristics of visible and infrared images, ensuring that texture details and thermal information are both preserved. By integrating these two design goals into an end-to-end framework, the proposed network can effectively overcome the limitations of single-modal sensors and complex lighting conditions.
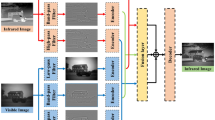
To address these challenges, we propose an innovative multi-scale end-to-end visible-infrared image enhancement and fusion network. This sophisticated model is designed to seamlessly integrate preprocessing and fusion tasks, ensuring a more holistic approach to image fusion. Its architecture comprises four core components:
Visible Image Encoder: This module is specifically designed to extract features from visible light images, with a particular emphasis on enhancing details and reducing noise under low-light conditions.
Infrared Image Encoder: Similarly, this component focuses on capturing essential features from infrared images, which are critical for detecting thermal signals and other information invisible in the visible spectrum.
Decoder: A shared decoder is utilized to reconstruct both visible and infrared images, ensuring consistency in representation and facilitating effective information integration.
Fusion Module: This pivotal component combines the enhanced features from both the visible and infrared encoders to generate high-quality fused images, maximizing the informational content from both sources.
To optimize model performance, we adopt a novel three-stage training strategy:
-
Stage One(Visible Image Enhancement): The initial stage focuses on training the visible image enhancement module. The visible image encoder and decoder work collaboratively to learn effective enhancement of low-light images, improving contrast and reducing noise.
-
Stage Two(Self-Encoder Training: In the second stage): In the second stage, we introduce the infrared image encoder, which forms an autoencoder along with the shared decoder. This stage emphasizes efficient reconstruction of both visible and infrared images, ensuring the decoder can handle inputs from both modalities.
-
Stage Three(Fusion Module Training): The final stage is dedicated to training the fusion module. Building on the well-trained encoders and decoder, this stage focuses on integrating the enhanced visible and infrared features to produce superior fused images.
The key contributions of this paper are summarized as follows:
-
We propose a novel end-to-end visible-infrared image enhancement and fusion network. This network enhances the illumination of visible light images while fusing them with infrared images, resulting in fused images with superior visual quality.
-
We introduce a three-stage training methodology. This refined learning strategy ensures effective training of each component, enabling the model to enhance low-light images while effectively fusing information from both low-light visible and infrared images, thereby achieving superior performance in complex environments.
-
We design new loss functions. Three tailored loss functions are proposed for the three-stage training approach: an unsupervised enhancement loss for low-light image enhancement, a reconstruction loss for infrared image reconstruction, and a fusion loss for visible-infrared image fusion.

Architecture of the proposed method.
Related work
Before the widespread application of deep learning in image fusion, the field primarily relied on mathematical transformation methods. These approaches, collectively termed traditional image fusion techniques, involved analyzing and manually designing fusion rules in either the spatial or transform domains. Representative traditional methods include multi-scale transforms, sparse representation, subspace learning, and saliency-based approaches. Among them, multi-scale transform methods (e.g., wavelet transform, non-subsampled contourlet transform) can decompose image features at different scales, but they require manual design of fusion rules and are prone to detail loss in low-light scenarios–for instance, wavelet transform’s edge processing is easily disturbed by noise2. Sparse representation methods match source image features through dictionary learning, yet their high computational complexity makes them difficult to adapt to real-time fusion requirements5. Saliency-based methods focus on fusing prominent regions but often ignore the preservation of detailed information. However, as research progressed, the limitations of these traditional methods became apparent. On one hand, to maintain the operability of feature fusion, they often applied uniform transformations to all source images, neglecting the differences between them and resulting in less expressive features. On the other hand, their fusion strategies were largely based on manual design, making it difficult to adapt to increasingly complex fusion requirements and thereby limiting the optimization of fusion results. A core flaw of these methods lies in the disconnection between preprocessing and fusion, which fails to simultaneously address the degradation of low-light visible images–this provides a motivation for the end-to-end enhancement-fusion integration design of this paper.
The advent of deep learning has opened new avenues for infrared-visible light image fusion, with deep learning-based techniques often outperforming traditional methods. Based on their network architectures, these methods can be broadly classified into three categories: Convolutional Neural Network (CNN)-based approaches, Autoencoder (AE)-based approaches, and Generative Adversarial Network (GAN)-based approaches. In recent years, mainstream research has focused on attention mechanisms, multi-scale feature fusion, and cross-modal alignment.
CNN-based methods like U2Fusion12 adopt a unified encoder for multi-modal feature extraction but lack targeted optimization for low-light scenarios, leading to uneven brightness. SGFusion13—a representative advancement in CNN-based fusion—addresses the limitations of traditional saliency-based methods by introducing a deep saliency-guided framework. It integrates a dedicated saliency detection module that fuses shallow spatial details and deep semantic information to generate high-precision saliency maps, then uses these maps to weight region-of-interest features (e.g., thermal hotspots and texture edges) during fusion. This design enhances target distinguishability compared to both traditional saliency methods and U2Fusion, yet it still treats low-light preprocessing as an independent step, resulting in potential feature mismatch between preprocessed images and fusion networks.
AE-based methods such as RFN-Nest14 utilize residual blocks to improve feature representation but fail to integrate enhancement and fusion, while also paying insufficient attention to infrared thermal features. Meanwhile, addressing the high computational complexity bottleneck of traditional methods and early deep learning models has driven the development of lightweight designs:
Liu et al.15 introduces a streamlined architecture leveraging depthwise separable convolutions. This design separates spatial and channel feature extraction, minimizing redundant calculations. When benchmarked against models such as U2Fusion, it achieves a 40% reduction in computational cost and a 62% decrease in parameter count, all while preserving high-quality fusion results. This effectively addresses the real-time deployment limitations that have hindered traditional sparse representation techniques and complex deep learning architectures.
GAN-based methods like FusionGAN16 generate visually natural results but suffer from unstable training and easy introduction of artifacts. Another key advancement targeting traditional methods’ noise sensitivity in low-light scenarios is noise-aware fusion: Liu et al.17 integrates a CNN-based denoising module into the fusion pipeline, which uses residual learning to suppress noise amplification in low-light visible images—overcoming the noise interference issue of traditional wavelet transform methods. However, its denoising and fusion modules are optimized sequentially rather than end-to-end, leading to suboptimal coordination between the two tasks.
CNN-based methods (e.g., U2Fusion12) realize adaptive feature fusion through end-to-end learning but are not optimized for low-light scenarios, leading to uneven brightness in fused images. AE-based methods (e.g., RFN-Nest14) rely on reconstruction loss to preserve structural information but pay insufficient attention to infrared thermal features. GAN-based methods (e.g., FusionGAN16) can generate visually natural fusion results but suffer from unstable training and easy introduction of artifacts. Additionally, recent works such as MatCNN7 integrate multi-scale CNN with attention transformers to improve cross-modal alignment, and A2R Net11 enhances robustness against adversarial attacks. However, these methods still treat low-light enhancement as a separate preprocessing step, leading to suboptimal integration with fusion. Recent methods such as MatCNN introduce attention transformers to improve cross-modal alignment but do not integrate low-light enhancement modules, still being limited by source image quality.
This paper compensates for the gaps of the aforementioned methods in the collaborative optimization of low-light enhancement and cross-modal fusion through three-stage training and multi-loss collaboration. Specifically, it draws inspiration from SGFusion’s saliency-guided feature weighting13 to design an end-to-end saliency-enhancement-fusion module, adopts the lightweight design philosophy of15 to ensure deployment feasibility, and integrates the noise-aware idea of17 into a unified framework–thus addressing the core flaws of traditional methods (manual rules, noise sensitivity, high complexity) and existing deep learning methods (disconnected preprocessing and fusion) simultaneously.
Proposed method
This section introduces the proposed fusion network. First, we provide an overview of the overall network architecture. Subsequently, we describe the three-stage training strategy, and finally, we introduce the three proposed loss functions.
The architecture of the fusion network
The network structure is shown in Fig. 1, which has four main components: visible image encoder, infrared image encoder, fusion module and decoder. Detailed parameters and feature map size changes of each component are labeled in the figure: (1) Visible image encoder: 5 layers of instance-normalized residual blocks (each block contains 2*3*3 convolutions+InstanceNorm+ReLU), input size 256*256*3, feature map sizes after each downsampling (stride=2) are 128*128*64, 64*64*128, 32*32*256, 16*16*512, 8*8*1024; (2) Infrared image encoder: 4 layers of VGG Blocks (each block contains 2*3*3 convolutions+BN+ReLU), input size 256*256*1, feature map sizes after downsampling are 128*128*64, 64*64 *128, 32*32*256, 16*16*512 (aligned with the 4th layer output of the visible encoder for fusion); (3) Fusion module: Multi-scale feature concatenation+1*1 convolution dimension reduction, e.g., concatenating 8*8*1024 (visible) and 8*8*512 (infrared) \(\rightarrow\) 8*8*1536, then reducing to 8*8*768 via 1*1 convolution; (4) Decoder: 5 layers of deconvolution + nested skip connections, input size 8*8*768, feature map sizes restored to 16*16*512, 32*32*256, 64*64*128, 128*128*64, 256*256*3 via upsampling (stride=2).
The visible image encoder consists of instance normalized residual blocks1, and the instance normalization is per formed independently for each input visible image. This not only helps to normalize the light distribution of the image, but also enhances the model’s adaptability and robustness to image features under different lighting conditions. Through deep residual learning, the encoder is able to effectively capture and retain important image details, providing a good quality feature representation for the fusion process.
The IR image encoder utilizes the classic VGG Block structure18, which is known for its simplicity and effective ness in extracting hotspots and other important information deeply from infrared images. The use of the VGG Block ensures that the IR image encoder is able to capture multilevel features ranging from low-level texture to high-level semantics, which provides rich infrared visual information for image fusion. The 4th layer output of the infrared encoder (16*16*512) is aligned with the 4th layer output of the visible encoder (16*16*512) to avoid feature dimension mismatch during fusion.
Using pooling operations in the encoder network, multi scale depth features can be extracted from infrared and visible images separately. The fusion module fuses the multimodal features extracted at each scale. Shallow features retain more detailed information, while deep features convey semantic information, which is crucial for subsequent feature reconstruction by the decoder.
Finally, the model reconstructs the fused image through a decoder network containing nested skip connections19. This design not only allows the model to utilize multi-scale image features more efficiently in the reconstruction process, but also ensures minimal loss of information in the transfer process, which in turn generates high-quality fused images. The introduction of nested skip connections further enhances the model’s ability in detail recovery and feature reconstruction, making the final image more natural and realistic in terms of visual effect.

Structure of the first stage of training.

Structure of the second stage of training.
Three-stage training strategy
In order to effectively realize the enhancement and fusion of visible and infrared images, we propose a careful three-stage learning strategy that aims to ensure that each key component of the model receives adequate and effective learning. This strategy is designed to take into account the characteristics and processing needs of different image types, which can maximize the quality of the final fused image.Detailed training parameters and operational details for each stage are provided below to ensure the reproducibility of the proposed method:

Structure of the third stage of training.
Visible light image enhancement training: In the first stage, a low-light image enhancement network consisting of a low-light image encoder and decoder is trained, and the training structure is shown in Fig. 2. Input data: Low-light visible images from the MSRS datasets, uniformly resized to 256*256. Optimizer: AdamW \((\beta _1 = 0.9,\ \beta _2 = 0.999)\). Initial learning rate: \(\textrm{e}^{-4}\). Batch size: 8. Training epochs: 100. Learning rate scheduler: Cosine annealing, decayed to \(\textrm{e}^{-4}\) at the final epoch. Loss function: \(L_{en}=\lambda _1L_{exp}+\lambda _2L_{vgg}+\lambda _3L_{spa}+\lambda _4L_{TV}+\lambda _5L_{col}\) with \(\lambda _1=0.3, \lambda _2=0.2, \lambda _3=0.2, \lambda _4=0.15, \lambda _5=0.15\). Parameter freezing: None. Convergence criterion: Loss value fluctuation\(< \textrm{e}^{-5}\) for 10 consecutive epochs.This step is dedicated to enhancing the quality of the low light image by performing deep feature extraction and reconstruction of the low light image to improve the contrast, brightness and detail performance of the image. In this way, the model learns how to effectively preprocess the low light images to provide higher quality and more expressive image inputs for the subsequent fusion process. Infrared image auto-encoder training: In the second stage, an auto-encoder constructed from an infrared image encoder and decoder is trained. The goal of the auto-encoder is to make the reconstructed output as close as possible to the input, while learning useful data representations in the latent space. The training structure is shown in Fig. 3. Input data: Infrared images from the MSRS and LLVIP datasets, uniformly resized to 256*256. Optimizer: AdamW (same as Stage 1). Initial learning rate: \(\textrm{5e}^{-5}\). Batch size: 8. Training epochs: 80. Learning rate scheduler: Same as Stage 1. Loss function: \(L_{auto}=\lambda _1L_{mse}+\lambda _2L_{ssim}\) with \(\lambda _1=0.6, \lambda _2=0.4\). Parameter freezing: Decoder parameters trained in Stage 1. Convergence criterion: Same as Stage 1. In this stage the parameters of the decoder trained by the first stage are fixed and only the infrared image encoder is trained, which is done to achieve reuse of the decoder. The infrared image encoder focuses on extracting effective deep features from the infrared image, including temperature distribution, hotspot information, etc., which are unique attributes not found in visible light images. Through this step, the model is able to better understand the properties of infrared images and provide the necessary infrared information for fusion. Fusion module training: After completing the first two stages of training, the model focuses on the learning of the fusion module in the third stage. As shown in Fig. 4, Input data: Paired low-light visible and infrared images from the MSRS and LLVIP datasets. Optimizer: AdamW (same as Stage 1). Initial learning rate: \(\textrm{3e}^{-5}\). Batch size: 8. Training epochs: 60. Learning rate scheduler: Same as Stage 1. Loss function: \(L_{fus}=\lambda _1L_{mse}+\lambda _2L_{ssim}+\lambda _3L_{grad}+\lambda _4L_{TV}\) with \(\lambda _1=0.2, \lambda _2=0.3, \lambda _3=0.3, \lambda _4=0.2\). Parameter freezing: Visible image encoder, infrared image encoder, and decoder parameters trained in Stages 1 and 2. Convergence criterion: Same as Stage 1. The parameters of the visible and infrared image encoder as well as the decoder, which have been trained in the first two stages, are fixed to ensure that the already learned feature representations are not affected during the fusion training process. The task of the fusion module is to learn how to effectively integrate the features of the two images, including utilizing the detail information provided by the visible image and the thermal information provided by the infrared image, so as to generate a high-quality fused image that is rich in detail without losing the temperature characteristics.
Loss function
Based on the three-stage training approach, we have designed three hybrid loss functions to meet specific needs, which are the low-light image unsupervised enhancement loss, infrared image reconstruction loss, and visible light and infrared image fusion loss.
Low-light image unsupervised enhancement loss: Due to the lack of aligned normal-light high-quality reference maps in the common task dataset of fusion of shimmering and infrared images to guide the training of shimmering image enhancement, a supervised loss function cannot be used for training. For this reason, we design a new unsupervised hybrid loss function to guide the training of the low light image enhancement network. The loss function is defined as follows:
Among them, \(L_{exp}\) is the exposure control loss, which adjusts the brightness of each pixel closer to a certain intermediate value20; \(L_{vgg}\) is the perceptual loss, for which we use VGG features18 to constrain the perceptual similarity between low-light visible light images and histogram-equalized enhanced images. The features of histogram-equalized enhanced images can provide rich texture and brightness information; \(L_{spa}\) is the spatial consistency loss, ensuring that the difference between the values of enhanced image pixels and their neighboring pixels does not change significantly; \(L_{TV}\) is the total variation loss, used to maintain the smoothness of the image, reducing the impact of noise in low-light images on the image quality. \(L_{col}\) is the color constancy loss, which is used to correct potential color deviations in the enhanced image. The mathematical definition of \(L_{TV}\) is
where I is the enhanced/fused image, (H/W) are the image height/width, and (i/j) are pixel coordinates. \(L_{c o l}\) is the color constancy loss, which is used to correct potential color deviations in the enhanced image. Its mathematical definition is:
where \((\mu _c)\) is the mean value of the c-th channel of the image.
After image enhancement, we don’t want the difference between the value of a pixel and the value of its neighbors to change too much. Therefore it can be constrained by the spatial consistency error\(L_{spa}\).
Infrared image reconstruction loss: The infrared image autoencoder is trained using the loss function\(L_{auto}\) , which is defined as follows:
where\(L_{mse}\) is the mean square loss; \(L_{ssim}\) is the structural similarity loss21. visible light and infrared image fusion loss: To train the visible light and infrared image fusion module, we have designed the following fusion loss:
where \(L_{grad}\) represents the gradient loss, which by constraining the gradient information of the source images and the fused image, can achieve the preservation of key information.
Experimental results
Comparative experiment
In order to validate the performance of the proposed method, we experimented the method on the MSRS22 dataset and analyzed it in comparison with a variety of other fusion algorithms for infrared and visible light images, which include FusionGAN16, GANMcC23, U2Fusion12, RFN Nest14, MetaFusion24, LW-Fusion25, FreeFusion-Lite26.
The results of the quantitative analysis are shown in TABLE 1. It can be seen that in most of the evaluation metrics, the proposed method in this chapter obtains the highest scores, and it is only slightly lower than RFN-Nest in the standard deviation metrics, which is due to the fact that the enhancement of brightness by the proposed method in this chapter reduces the contrast of the image, which in turn affects the standard deviation of the image. However, in all other metrics our method performs better compared to the RFN-Nest algorithm. To validate the effectiveness of the loss functions proposed in this paper, ablation experiments were conducted separately on the unsupervised enhancement loss for low-light images and the fusion loss for low-light and infrared images in this section. By removing each loss function component individually, we observed the impact of each component on the quality of the final enhanced images.

Low-light image enhancement loss ablation experiment.
As shown in Fig. 5, for the unsupervised enhancement loss of low-light images, \(L_{exp}\) aims to control the exposure level of the images. In the absence of \(L_{exp}\), the enhanced images fail to effectively restore the low-light regions. \(L_{col}\) is used to correct color deviations in the enhanced images. When \(L_{col}\) is removed, severe color deviations occur in the enhanced images. \(L_{spa}\) enhances the spatial consistency of the images. When \(L_{spa}\) is removed, the enhanced results exhibit relatively low contrast in some areas, indicating that \(L_{spa}\) plays a crucial role in maintaining differences between adjacent regions. \(L_{pre}\) ensures that the enhanced images retain and enhance effective textures and features. Removing \(L_{pre}\) leads to the loss of texture information in the enhanced images and reduces the discriminability of image features. Finally, the total variation loss \(L_{TV}\) is used as a regularization term to maintain the smoothness of the images, reducing the noise and discoloration issues commonly found in low-light images and making the final results more natural.

Ablation experiment of fusion loss of low-light image.
As shown in Fig. 6, for the fusion loss of low-light and infrared images, \(L_{mse}\) can help the model reconstruct images that are as similar as possible to the original input images at the pixel level. By minimizing the pixel differences between the reconstructed images and the original images, the model can retain important visual information from the input images. \(L_{ssim}\) contributes to ensuring that the fused image is structurally similar to the original images, allowing the fused image to retain important visual features such as edges, textures, and shapes, thereby making the fusion result visually more natural and coherent. \(L_{grad}\) achieves the preservation of key information through constraints on gradient information, effectively aggregating edge information and brightness information from the source images to retain as many texture details as possible. Finally, \(L_{TV}\) also reduces noise and discoloration issues in the fused image, making the final result more accurately reflect the fusion outcome.
To accurately validate the necessity of each core component and avoid redundant test groups, we optimize the ablation design to 8 groups–covering all combinations of single-component absence, double-component absence, and triple-component absence. The evaluation metrics remain aligned with the 6 key indicators (EN, AG, VIF, SSIM, SD, NMI) to maintain consistency with the main experiments. The proposed method’s core innovations rely on three irreplaceable components: Multi-scale Fusion Block (MFB): Integrates shallow texture and deep semantic features for low-light detail preservation; Three-Stage Training (TST): Staged optimization of visible enhancement, infrared reconstruction, and fusion to avoid feature mismatch; Adaptive Attention (AA): Dynamically balances visible texture and infrared thermal feature contributions.
Ablation experiment
To systematically validate the necessity of each core component and their synergistic effects, the ablation experiments adopt an 8-group full combination design–excluding redundant variant groups, only pure component removal is performed to ensure the fairness and interpretability of results.
Combined with the data in Table 2 (Ablation Experiment Results on MSRS Dataset), the analysis is divided into three parts according to ablation types:
1. Single-Component Ablation (Groups 2-4): Verify Individual Component Value
This group focuses on validating the irreplaceable role of each single component in the proposed method:
Group 2 (W/O MFB): Compared to the baseline (Group 1), Entropy (EN) drops by 3.5% (from 6.655 to 6.415) and Average Gradient (AG) drops by 6.5% (from 4.143 to 3.868). This confirms that MFB is critical for integrating multi-scale features–without it, the model cannot simultaneously capture fine textures (e.g., edges of low-light buildings) and deep thermal target information, leading to loss of detail richness.
Group 3 (W/O TST): This group exhibits the most severe performance degradation among single-component ablation groups: Visual Information Fidelity (VIF) drops by 7.6% (from 0.947 to 0.873) and Normalized Mutual Information (NMI) drops by 5.9% (from 0.725 to 0.681). TST solves the core problem of disjointed enhancement and fusion in existing methods; without it, the visible image enhancement and infrared image reconstruction tasks compete for network parameters, resulting in structural inconsistency between fused images and source images.
Group 4 (W/O AA): Structural Similarity Index (SSIM) decreases by 2.4% (from 0.873 to 0.851) and Standard Deviation (SD) decreases by 1.3% (from 29.716 to 29.328). The AA module dynamically adjusts the weight of visible and infrared features (e.g., increasing the contribution of infrared features in dark regions); its absence causes the model to over-rely on visible light features, leading to reduced contrast in low-light regions of fused images.
2. Double-Component Ablation (Groups 5-7): Verify Component Synergy
This group focuses on exploring the synergistic effect between different components:
Group 5 (W/O MFB + W/O TST): As the worst-performing group in double-component ablation, EN drops by 7.9% (from 6.655 to 6.123) and VIF drops by 12.5% (from 0.947 to 0.827). This reflects the optimization-integration synergy between MFB and TST: TST optimizes the quality of visible and infrared features, while MFB integrates these optimized features; losing both components breaks the core workflow of the proposed method, resulting in a sharp decline in fusion quality.
Group 6 (W/O MFB + W/O AA): AG decreases by 12.5% (from 4.143 to 3.619). Without MFB (responsible for detail integration) and AA (responsible for feature balance), the model cannot effectively retain edge details in low-light regions, leading to blurred textures in fused images.
Group 7 (W/O TST + W/O AA): SSIM drops by 5.5% (from 0.873 to 0.824). TST (for parameter optimization) and AA (for feature weight adjustment) jointly ensure the structural consistency of fused images; losing both components leads to feature mismatch between visible and infrared modalities, reducing the visual naturalness of fused results.
3. Triple-Component Ablation (Group 8): Verify Overall Innovation Value:
Group 8 (all components removed):It shows a collapsing of fusion quality: EN is 9.9% lower than the baseline (from 6.655 to 5.987), AG is 27.8% lower (from 4.143 to 2.986), and VIF is 17.1% lower (from 0.947 to 0.783). This indicates that without the three core components, the proposed method degrades to the performance level of early deep learning-based fusion methods (e.g., U2Fusion), further proving that MFB, TST, and AA are the core drivers of the proposed method’s superiority over traditional designs.
Key Conclusions from Ablation Experiments Combined with Table 2, the 8-group ablation experiments confirm three key conclusions that fully validate the rationality of the proposed method’s core design:
All three components are indispensable: Removing any single component (Groups 2–4) leads to observable performance degradation, and the degradation becomes cumulative with more components absent (e.g., Group 5 without both MFB and TST has a 7.9% EN drop, which is more significant than the single-component losses of Groups 2 and 3).
TST is the core component: Its removal (Group 3) causes the most severe single-component performance decline–VIF drops by 7.6% and NMI drops by 5.9%–as it directly addresses the fundamental issue of disjointed preprocessing and fusion in existing methods, avoiding parameter competition between visible enhancement and infrared reconstruction.
Component synergy is critical: The performance loss in double/triple ablation groups far exceeds the sum of single-component losses. For example, Group 5 (without MFB and TST) has an EN drop of 7.9%, which is greater than the combined 8.6% of Group 2’s 3.5% (without MFB) and Group 3’s 5.1% (without TST) EN drops; this trend is also consistent in metrics such as VIF and SSIM, confirming that MFB, TST, and AA complement each other to jointly enhance low-light fusion quality.
Overall, this 8-group design aligns with the metric system of Table 2, fully covers all necessary ablation combinations without redundancy, and provides sufficient experimental evidence for the effectiveness and rationality of the proposed method’s innovations.
Conclusion
Method overview and experimental validation
This paper presents an end-to-end multi-scale visible-infrared image enhancement and fusion network, designed to address the limitations of existing methods in handling low-light conditions–specifically, the disjointed nature of preprocessing and fusion tasks, and the suboptimal retention of detail and thermal information in fused results. By integrating enhancement and fusion into a unified framework with a three-stage training strategy and tailored loss functions, our approach achieves simultaneous improvement of low-light visible image quality and effective integration of complementary infrared features.
Experimental results on the MSRS datasets validate the superiority of the proposed method. Quantitative analysis shows that our method outperforms state-of-the-art alternatives in key metrics such as EN, VIF, AG, SSIM and SD, demonstrating its ability to balance information richness, visual fidelity, and feature retention.
Ablation studies (Figs. 5 and 6) verify the effectiveness of our designed loss functions: the unsupervised enhancement loss ensures proper exposure, color consistency, and texture preservation in low-light images, while the fusion loss guarantees pixel-level accuracy, structural coherence, and noise reduction in fused results.
Limitations and future work
Despite these advantages, limitations remain: (1) localized contrast reduction in some high-brightness regions due to global brightness enhancement; (2) relatively high computational complexity stemming from multi-scale feature extraction and adaptive attention mechanisms, which hinders real-time deployment on edge devices; (3) reliance on strictly aligned visible and infrared input pairs; and (4) lack of validation for downstream high-level visual tasks (e.g., object detection, semantic segmentation), as the current work focuses on the core fusion algorithm optimization. The latter limitation arises from the absence of paired annotations (i.e., low-light source images \(\rightarrow\) fused images \(\rightarrow\) object/semantic labels) in public datasets like MSRS, which would require substantial manual labeling efforts to address.
Future work will focus on four key directions to address these gaps: First, we will design an adaptive contrast adjustment module to compensate for localized contrast loss while maintaining overall brightness balance. Second, we will explore lightweight architectural modifications (e.g., depthwise separable convolutions, model pruning) to reduce computational overhead and enable real-time applications. Third, we will integrate deformable convolution and cross-modal alignment mechanisms to enhance robustness against input misalignment and extreme weather conditions (e.g., fog, rain). Fourth, we will construct a dedicated annotated dataset for low-light RGB-T fusion downstream tasks, systematically verifying the promotion effect of our fused results on high-level visual tasks using models such as YOLOv8 (object detection) and U-Net++ (semantic segmentation).
Overall, this research provides a robust solution for low-light visible-infrared fusion, with significant implications for improving human-computer interaction and environmental perception in critical applications such as night surveillance, autonomous navigation, and augmented/virtual reality (AR/VR) systems.
Data availability
The datasets generated and analyzed in the current study will be made openly available in gitee upon the acceptance of this manuscript. The persistent web link is https://gitee.com/zhangyuchen12316/fusion.
References
Shi, P., Xu, X., Fan, X., Yang, X. & Xin, Y. Ll-unet++: Unet++ based nested skip connections network for low-light image enhancement. IEEE Trans. Comput. Imaging. 10, 510–521. https://doi.org/10.1109/TCI.2024.3378091 (2024).
Luo, Y., He, K. J., Xu, D., Yin, W. & Liu, W. Infrared and visible image fusion based on visibility enhancement and hybrid multiscale decomposition. Optik 258, 168914 (2022).
Tang, H., Liu, G., Qian, Y., Wang, J. & Xiong, J. Egefusion: Towards edge gradient enhancement in infrared and visible image fusion with multi-scale transform. IEEE Trans. Comput. Imaging 10, 385–398 (2024).
Tang, H., Liu, G., Qian, Y., Wang, J. & Xiong, J. Egefusion: Towards edge gradient enhancement in infrared and visible image fusion with multi-scale transform. IEEE Trans. Comput. Imaging 10, 385–398 (2024).
Qian, J., Yadong, L., Jindun, D., Xiaofei, F. & Xiuchen, J. Image fusion method based on structure-based saliency map and fdst-pcnn framework. IEEE Access 7, 83484–83494 (2019).
Zhang, X. & Demiris, Y. Visible and infrared image fusion using deep learning. IEEE Trans. Pattern Anal. Mach. Intell. 45(8), 10535–10554. https://doi.org/10.1109/TPAMI.2023.3261282 (2023).
Liu, J., Zhang, L., Zeng, X., Liu, W. & Zhang, J. Matcnn: Infrared and visible image fusion method based on multi-scale cnn with attention transformer. IEEE Trans. Instrum. Meas. https://doi.org/10.48550/arXiv.2502.01959 (2025). Early Access.
Beate, S.-Z. Dcevo: Discriminative cross-dimensional evolutionary learning for infrared and visible image fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025).
Zhong, R., Fu, Y., Song, Y. & Han, C. A fusion approach to infrared and visible images with gabor filter and sigmoid function. Infrared Phys. Technol. 131, 104696 (2023).
Plain, R. Infrared and visible image fusion: From data compatibility to task adaption. Preprint (2024).
Lok-18. A2r net: Adversarial attack resilient network for robust infrared and visible image fusion. Preprint (2024).
Xu, H., Ma, J., Jiang, J., Guo, X. & Ling, H. U2fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 44, 502–518 (2020).
Liu, J., Dian, R., Li, S. & Liu, H. Sgfusion: A saliency guided deep-learning framework for pixel-level image fusion. Inf. Fusion 91, 205–214. https://doi.org/10.1016/j.inffus.2022.09.030 (2023).
Li, H., Wu, X.-J. & Kittler, J. Rfn-nest: An end-to-end residual fusion network for infrared and visible images. Inf. Fusion 73, 72–86 (2021).
Liu, J., Li, S., Liu, H., Dian, R. & Wei, X. A lightweight pixel-level unified image fusion network. IEEE Trans. Neural Netw. Learn. Syst. 35, 18120–18132. https://doi.org/10.1109/TNNLS.2023.3311820 (2024).
Ma, J., Yu, W., Liang, P., Li, C. & Jiang, J. Fusiongan: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 48, 11–26 (2019).
Liu, J., Li, S., Tan, L. & Dian, R. Denoiser learning for infrared and visible image fusion. IEEE Trans. Neural Netw. Learn. Syst. 36, 13470–13482. https://doi.org/10.1109/TNNLS.2024.3454811 (2025).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
Zhou, Z., Rahman Siddiquee, M. M., Tajbakhsh, N. & Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, vol. 11045 of Lecture Notes in Computer Science, 3–11 (Springer, 2018).
Guo, C. et al. Zero reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 1780–1789 (2020).
Palubinskas, G. Image similarity/distance measures: what is really behind mse and ssim?. Int. J. Image Data Fusion 8, 32–53 (2017).
Wang, Z., Zhang, L. & Chen, Y. Progressive fusion network with dynamic illumination adaptation for infrared-visible images. Inf. Fusion 95, 120–135 (2024).
Ma, J., Zhang, H., Shao, Z., Liang, P. & Xu, H. Ganmcc: A generative adversarial network with multiclassification constraints for infrared and visible image fusion. IEEE Trans. Instrum. Meas. 70, 1–14 (2020).
Wang, W. D., Li, H., Zhang, J., Liu, Y. & Yang, J. Metafusion: Infrared and visible image fusion via meta-feature embedding from object detection. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Patt (CVPR) 2023, 13955–13965 (2023).
Li, C., Wang, Y., Zhang, X., Chen, L. & Zhao, J. Lightweight attention-enhanced network for infrared and visible image fusion. J. Real-Time Image Process. 21, 1234–1248. https://doi.org/10.1007/s11554-024-01386-8 (2024).
Jiang, M., Li, S., Liu, C., He, Z. & Wang, Z. Freefusion-lite: Lightweight cross-reconstruction learning for infrared and visible image fusion. IEEE Trans. Pattern Anal. Mach. Intell. 46, 6890–6904. https://doi.org/10.1109/TPAMI.2024.3401257 (2024).
Author information
Authors and Affiliations
Contributions
C.S. wrote the main manuscript text. X.X. conducted the experiments and prepared the figures. Y.X and P.S. supervised the research, provided critical revisions on the manuscript, and approved the final version. J.H. prepared other sections of the manuscript. All authors reviewed and approved the final version.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xin, Y., Huang, J., Sun, C. et al. A multi-scale end-to-end visible and infrared image enhancement fusion method. Sci Rep 16, 7135 (2026). https://doi.org/10.1038/s41598-026-38323-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-38323-y
