
Abstract
Rapid post-event assessment of earthquake damage is essential for resilient emergency response and risk mitigation. We present a multi-scenario deep learning framework that uses stacked LSTM and a hybrid LSTM–RNN to (i) forecast structural response variables (displacement \(u\), velocity \(v\), acceleration \(a\), and Damage Index \(DI\)), (ii) classify damage status, (iii) conditionally estimate the weight factor \(w\) for damaged cases (\(DI\ge 1\)), and (iv) identify features most associated with negligible damage via GridSearchCV. In addition, we benchmark a quantum-inspired Activation-based Probabilistic Machine (APM) classifier head attached to the shared sequence encoder to probe whether compact state encodings and Hadamard-style interactions can improve damage discriminability under the same leakage-safe pipeline. Models were trained on 40-step windows for 100 epochs with Adam, using linear heads for regression and Softmax for classification (APM and standard heads share the global training schedule). Across sequence-regression tasks, the LSTM–RNN consistently outperformed stacked LSTM: \({R}^{2}\) improved from 98.37 to 99.42% for \(u\), 89.57 to 97.58% for \(v\), 97.69 to 99.8% for \(a\), and 99.68 to 99.97% for \(DI\). For \(DI\), error metrics were markedly lower with LSTM–RNN (MAE 0.0031 vs. 0.0132, RMSE 0.0047 vs. 0.0163, MAPE 1.51 vs. 5.25, MedAE 0.0022 vs. 0.0118), indicating tighter tracking of the damage signal. The conditional \(w\) estimation and feature-ranking scenario offers practical levers for risk-informed prioritization, while the APM head provides a compact, quantum-inspired alternative for damage classification within the same framework. Overall, the results support sequence models, particularly LSTM-RNNs, as an effective basis for rapid, data-driven earthquake damage modeling and decision support, with quantum-inspired heads as a complementary option.
Similar content being viewed by others
Introduction
Earthquakes play a significant role in the social and physical effects of natural disasters, though they may not happen often. The average yearly cost of earthquake-related damages from 1990 to 2017 was almost US$34.7 billion. Decision makers, emergency planners, insurers, and reinsurers need to know the approximate magnitude and geographic distribution of probable seismic damage inside a constructed environment1. Damage from earthquakes to buildings and infrastructure results in loss of functionality, monetary losses, casualties, and fatalities. The degree of damage to both structural and non-structural components primarily determines losses, deaths, and injuries. To ensure effective post-disaster rescue, relief, and recovery efforts following large earthquakes, it is critical to evaluate the severity and the geographical distribution of structures and infrastructure2. Therefore, doing a rapid evaluation of losses in the aftermath of a severe disaster is particularly crucial for societal resilience. Conducting a rapid and comprehensive loss assessment requires significant time and resources3.
One of the most devastating natural catastrophes is an earthquake, mainly because there is rarely any prior notice and little opportunity for preparation. Because of this, earthquake prediction is of great significance to humankind’s security. The scientific community is still interested in this subject, though there is disagreement over whether the answer can be determined accurately enough. However, the effective use of machine learning techniques across several academic disciplines suggests that they can be applied to produce more precise short-term projections4. One of the most well-known subfields of seismology is known as earthquake forecasting. This subfield evaluates the size and frequency of earthquakes in a particular region over periods ranging from years to decades, and then uses this information to determine the overall degree of earthquake seismic hazard probabilistically. The purpose of earthquake forecasting is to make an accurate evaluation of three fundamental criteria, namely, the time of the projected earthquake, its location, and its magnitude. Earthquake prediction is frequently distinguished from earthquake forecasting. The topic of earthquake prediction is exceedingly challenging and is entangled with a variety of other socio-economic issues5.
A prediction is only helpful if it is precise in terms of both location and time. At the same time, the prediction program is still in its early stages of refinement. Several precursory factors, such as unusual animal behavior, hydrochemical precursors, temperature changes, and others, have been found to correlate strongly with the likelihood of an approaching earthquake5. There are at least two primary types of earthquake forecasts: short-term and long-term. Predictions of earthquakes made hours or days in advance are considered short-term, whereas forecasts are made months to years in advance. The vast majority of research focuses on forecasting, using past earthquake occurrences in certain nations and regions6. The capacity to accurately forecast earthquakes is one of the most pressing challenges facing geology today. In the geosciences, machine learning can play a vital role in earthquake prediction5.
There is a scarcity of research on applying machine learning techniques to earthquake damage classification. To adequately address the growing use of machine learning in earthquake and seismological engineering applications, alongside the expanding availability of open-source data, it is imperative to conduct independent investigations using distinct datasets and diverse machine learning techniques. Such endeavors are crucial to advancing scientific knowledge in this emerging domain7. Numerous algorithms have been proposed in earthquake prediction, employing expert systems (ES) to facilitate comparisons of methodologies, models, frameworks, and instruments used to forecast seismic events across diverse criteria. The majority of the presented models have aimed to provide long-term forecasts of the temporal, magnitude, and spatial aspects of forthcoming earthquakes. The discussion focused on several iterations of expert systems used for earthquake prediction, including rule-based, fuzzy, and machine-learning approaches8. There are some comprehensive overviews of the current state of earthquake engineering regarding the use of Artificial Intelligence and machine learning techniques. The authors concluded that the integration of machine learning methodologies in earthquake engineering is still in its nascent phase and requires further investigation for future advancement9,10,11.
Within this context, our primary goal is to develop a unified, leakage-safe sequence-learning pipeline that can rapidly forecast structural response variables and assess damage states, providing asset-level information that can feed into regional resilience and restoration-scheduling frameworks. Recent studies on resilience-based post-earthquake restoration and retrofit focus on optimizing repair sequences and system-level recovery for transportation networks, power grids, and interdependent infrastructures, typically assuming that damage states are known or pre-classified. In contrast, this work concentrates on the upstream problem of data-driven damage assessment at the structural level. The quantum-inspired Autonomous Perceptron Model (APM) head is included as an exploratory, compact classification module attached to the shared sequence encoder, allowing us to investigate whether a low-dimensional operator-based representation can provide competitive discrimination capabilities for discretized damage states under the same leakage-safe training protocol.
The novelty of this study lies not in proposing yet another deep neural architecture, but in developing a unified, leakage-safe multi-task pipeline for rapid structural response forecasting and seismic damage assessment. Unlike prior works that treat displacement/velocity/acceleration prediction, damage classification, DI estimation, and prioritization as independent tasks, this work integrates all four into a single, coherent framework with strict data-leakage control.
Specifically, the core contributions are:
-
1.
A unified multi-task sequence-learning pipeline that jointly handles:
-
Forecasting \(\text{u}(\text{t})\), \(\text{v}(\text{t})\), \(\text{a}(\text{t})\)
-
Damage-state classification.
-
Conditional estimation of the priority weight \(\text{w}\)
-
-
2.
A leakage-safe training and data-handling protocol, ensuring that forecasting, classification, DI estimation, and \(\text{w}\)-Priority scoring is trained on disjoint and non-overlapping samples—addressing a common but rarely discussed flaw in existing time-series studies.
-
3.
Use of an LSTM–RNN hybrid backbone as an efficient shared encoder, not as the novelty itself, but as a practical and lightweight architecture enabling stable training across all tasks.
-
4.
Exploratory evaluation of a quantum-inspired APM classifier as an optional classification head. Its role is secondary and included only to test whether compact operator-based classifiers can be integrated into the same multi-task pipeline.
In combination, these contributions advance beyond existing literature by providing a practical and cohesive structure that produces action-ready outputs (forecasts, DI, damage label, and priority score) suitable for direct integration into regional resilience analytics and post-earthquake restoration scheduling frameworks.
Related works
One of the natural calamities that significantly affects civilization is earthquakes. There are several research projects on earthquake detection at the moment. Significant advancements have been made in machine learning techniques and their applications across several fields in the last ten years. The effectiveness of applying machine learning approaches in seismic-risk engineering to address time and resource constraints has been demonstrated in recent research. Muhammad Murti et al. presented an earthquake multi-classification detection method that uses acceleration seismic waves to identify vandalism vibration and machine learning methods to discriminate between earthquakes and non-earthquakes. The best machine learning approach for earthquake multi-classification detection was developed by combining several techniques, including Support Vector Machine (SVM), Decision Tree (DT), Random Forest (RF), and Artificial Neural Network (ANN). According to the study’s findings, the ANN algorithm was the most effective method for distinguishing between earthquakes and non-earthquakes. Moreover, it has been demonstrated that adding velocity and displacement as extra features improves each model’s performance1.
Ji-Gang Xu et al. examined the use of machine learning (ML) to predict the seismic failure mode and the maximum bearing capacity of corroded reinforced concrete (RC) columns. The authors highlighted that the corrosion of steel reinforcements significantly impacts the seismic performance of RC columns. A total of six machine learning techniques were selected for developing the prediction model. These algorithms consisted of three single learning approaches, namely k-Nearest neighbors, Decision tree, and Artificial neural network, as well as three ensemble learning methods, namely Random Forest, AdaBoost, and CatBoost. The findings indicated that the Random Forest and CatBoost models had superior performance in predicting seismic failure modes, with an accuracy rate of 89%. The CatBoost model, with an R2 value of 0.92, was considered the most effective for predicting bearing capacity compared with classic mechanism-based coding models12.
To finally obtain prediction results for laboratory earthquake occurrence, Fan Yang et al. proposed an automated machine-learning-based regression model, the Automated Regression Pipeline (Auto-REP), as an automated regression approach. The computerized pipeline included steps for feature extraction, feature selection, modeling, and optimization. As part of the computerized process, the model’s hyperparameters were fine-tuned using a Bayesian optimization approach. The experimental findings revealed that the MAE and MSE of their model in the training and testing datasets were, respectively, 1.48, 1.51, and 1.52, and 1.59. The findings showed that the Auto-REP approach could correctly and effectively predict laboratory earthquakes13. The authors Rui Li et al. developed a deep learning model, DLEP, to fuse explicit and implicit data and accurately forecast earthquakes. In DLEP, authors employed a convolutional neural network (CNN) to extract implicit features and adopted eight precursory pattern-based indications as the explicit features. After that, an attention-based technique was proposed in order to successfully combine these two types of characteristics. Additionally, a dynamic loss function was developed in order to address the category imbalance that was present in the seismic data. In conclusion, the results of the experiments indicated that the proposed DLEP is successful for earthquake prediction in comparison to many baselines that are considered to be state-of-the-art14.
Papiya Debnath et al. conducted a study to predict different types of earthquakes and enhance disaster management strategies. The researchers analyzed to determine the optimal classification method for predicting earthquake types in the region of India. Three distinct categories have been established to classify earthquakes: deadly, moderate, and mild. To differentiate between these categories, seven different machine learning classifiers were employed to construct the model. To train the model, six distinct datasets covering India and its neighboring areas were used. The datasets were subjected to several algorithms, including Bayes Net, Random Tree, Random Forest, Simple Logistic, ZeroR, Logistic Model Tree (LMT), and Logistic Regression. Based on the analysis of earthquake type predictions and model performance verification, it can be inferred that the Logistic Model Tree and Simple Logistic classifier algorithms exhibit superior performance in detecting earthquake effects in India5.
Ratiranjan Jena et al. devised a Convolutional Neural Network (CNN) model to evaluate the likelihood of earthquakes in Northeast India. Subsequently, the classification outcomes were used for probability mapping, while intensity variation was used for hazard mapping. The production of an earthquake risk map was achieved by multiplying hazard, vulnerability, and coping capacity factors. The vulnerability was assessed by considering six elements that contribute to vulnerability. At the same time, coping capacity was evaluated by examining the number of hospitals and related variables, such as funding allocated to disaster management. The findings indicated that the Convolutional Neural Network (CNN) outperformed the other algorithms in accurately forecasting classifications. Specifically, the CNN achieved an accuracy of 0.94, a precision of 0.98, a recall of 0.85, and an F1 score of 0.91. The indications above were used in the probability mapping process, resulting in estimates of the total hazard area (21,412.94 km2), vulnerability (480.98 km2), and risk (34,586.10 km2)15.
Sajan K C et al. evaluated four widely used machine learning algorithms to predict damage grade and rehabilitation intervention. The XGBoost method achieved the highest accuracy of 58%, surpassing that of the decision tree, random forest, and logistic regression algorithms. The study revealed that the accuracy of repair solutions’ predictions is deemed adequate, with an 82% success rate achieved using XGBoost. This information has potential utility in developing a more sophisticated taxonomy for vulnerability classification. Additionally, its use extended to developing recommendations for the design and construction of buildings, conducting vulnerability assessments, and establishing policies to reduce seismic risk3. Murwantara et al. established a methodology for forecasting earthquake parameters, including location, depth, and magnitude, tailored explicitly for the Indonesian area. The researchers employed several machine learning algorithms, including multinomial logistic regression, support vector machine, and Naïve Bayes, to accomplish this task. The researchers compared the results of the root mean square error computation. The multinomial logistic regression yielded 0.777, Naïve Bayes yielded 0.922, and the support vector machine yielded 0.751. The Naïve Bayes approach showed little efficacy in predicting outcomes for a single-year grouping data set, but has greater applicability when applied to multi-year grouping data. The support vector machine exhibited superior performance compared to other algorithms when using Magnitude data as a reference, yielding better outcomes than when using Depth data16.
Jain et al. constructed a seismic forecasting model that leverages machine learning and deep learning techniques to predict earthquakes, focusing on the variables of position and depth. The methods employed in this study encompassed Multi-Layer Perceptron (MLP) regression, Random Forest (RF) Regression, and Support Vector Regression (SVR). The methodology was implemented across several radii around the designated target. The comparative analysis of algorithm efficiency involved calculating the discrepancy between actual and predicted results using error metrics. The results were evaluated using the Root Mean Square Error (RMSE) statistic. When assessing the boundary values, it was observed that the RMSE for RF Regression was 1.731, for MLP Regression was 1.647, and for SVR was 1.720. These values were obtained when the minimum radius value was set to 100. Similarly, when the maximum radius was set to 5000, the RMSE values for the respective algorithms were 0.436, 0.428, and 0.449. The findings indicated that the MLP Regressor performed better than other algorithms, as evidenced by its lower error rate in this scenario17. Abebe et al. employed a deep learning approach, particularly a transformer-based method, to predict earthquake magnitudes. Data from the Horn of Africa region were used for this purpose. A comparative analysis was conducted on the outcomes derived from the long short-term memory (LSTM), bidirectional long short-term memory (BILSTM), and bidirectional long short-term memory with attention (BILSTM-AT) models. The study found that the transformer model outperformed the other three in predicting earthquake magnitudes in the Horn of Africa. The transformer model achieved mean absolute error (MAE), mean squared error (MSE), root mean squared error (RMSE), and mean absolute percentage error (MAPE) values of 0.276, 0.147, 0.383, and 28.868% respectively18.
Harun Artuner and Rayan Abri suggested a prediction model to find earthquakes that occurred in the days prior. By examining the values of the Total Electron Content (TEC) parameter over the last days, the suggested LSTM deep learning models classified earthquake days. To assess the proposed earthquake prediction models, the LSTM-based models were evaluated against the Random Forest, LDA, and SVM classifiers. The findings showed that the proposed models were more accurate at identifying earthquakes, achieving an accuracy of around 0.8219. To quickly determine the location and size of an earthquake, Mohamed S. Abdalzaher et al. developed a deep learning model that combined an autoencoder (AE) and a convolutional neural network (CNN) after 3 s of the P-wave onset. 0.000028, 0.0000033, and 0.0001 in terms of magnitude, latitude, and longitude were observed in the suggested model’s predictions for the location and magnitude of EQ. A comparison between the 3S-AE-CNN and the benchmark approach revealed improved performance for both position and magnitude determination20.
Beyond prediction of seismic parameters or local damage states, a growing body of research investigates regional resilience and post-earthquake restoration scheduling. Recent works have proposed resilience-based restoration schemes for urban road networks, in which damage-informed repair ordering is optimized to enhance connectivity and emergency access21. Other studies consider interdependent infrastructure systems, integrating power, water, and transportation networks within simulation–optimization frameworks to quantify resilience and design repair or retrofit strategies under limited resources22. Our work complements these studies: instead of optimizing system-level repair sequences, we provide a fast, data-driven mechanism to forecast structural responses and classify damage, yielding inputs—such as damage labels and priority weights—that can be integrated into higher-level resilience and restoration models.
Methodology
Seismic dataset description
The primary dataset used to train and evaluate the LSTM and RNN models consists of numerically simulated time histories of seismic response for a reinforced concrete structural component modeled as a nonlinear Single-Degree-of-Freedom (SDOF) system. Due to the lack of publicly available labeled strong-motion datasets that include ground-truth displacement, velocity, acceleration, and Damage Index (DI) values simultaneously, high-fidelity simulations were used—a well-established practice in structural dynamics.
The structural model was subjected to N = 200 synthetic ground-motion records generated using a modulated Kanai–Tajimi filter. Each record spans 30 s at a sampling frequency of 100 Hz, producing 3000 time steps per signal. For each input excitation, the dynamic equilibrium equation was solved using the Newmark-β integration scheme, yielding displacement \(u(t)\), velocity \(v(t)\), and acceleration \(a(t)\).
Damage Index values \(DI(t)\) were computed using an energy-based formulation that captures cumulative inelasticity. The resulting dataset consists of approximately 600,000 labeled time steps across all variables.
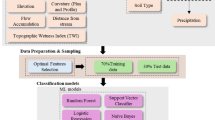
We develop a unified sequence learning pipeline that converts raw structural response signals into four actionable outputs: (i) next–step forecasting of displacement \(u\), velocity \(v\), acceleration \(a\), and Damage Index \(\text{DI}\); (ii) damage status classification; (iii) conditional estimation of a weight factor \(w\) for damaged cases; and (iv) feature attribution that highlights inputs associated with negligible damage23,24,25,26. The core design frames all tasks as supervised learning over fixed–length temporal windows, and benchmarks two recurrent backbones under an identical training and evaluation protocol: a stacked LSTM and a hybrid LSTM–RNN. Figure 1 displays the proposed approach for earthquake damage assessment.

The proposed approach for earthquake damage assessment.
Data preparation and leakage control
Let \({\text{x}}_{t}\in {\mathbb{R}}^{d}\) denote the multivariate signal at time \(t\), where channels include \(u,v,a,\text{DI}\) and any exogenous variables. Signals are inspected for missing values and spurious spikes; short gaps are forward–filled, and obvious non–physical outliers are clipped. We perform standardization using training set statistics only,
to avoid leakage. Temporal splits (train, validation, test) are created before any normalization, and sliding windows are generated within each split so that no window crosses split boundaries.
It should be explicitly noted that the seismic response variables used in the forecasting and classification tasks (displacement \(u\), velocity \(v\), acceleration \(a\), and Damage Index \(DI\)) are generated through a numerical structural dynamics model rather than collected by physical sensors. This is a common and well-established approach in earthquake engineering when high-resolution sensor data with corresponding ground-truth damage labels are unavailable. The simulated responses ensure complete control over system parameters and provide physically meaningful time-history patterns that are suitable for benchmarking sequence-learning models. No assumption is made that these signals originate from actual sensors; instead, they represent deterministic outputs of a validated dynamic formulation.
Windowed supervision
We construct a look–back window of length \(L=40\) at each index \(t\):
For multi–output regression, the target vector is
For damage classification, we define the label
For conditional \(w\) estimation, we retain only indices \({\mathcal{I}} = \left\{ {t:{\text{DI}}_{t + 1} \ge 1} \right\}\) and set the scalar target \(w_{t + 1}\) on \({\mathcal{I}}\). Unless otherwise noted, windows advance with unit stride.
Model architectures
Stacked LSTM
This backbone stacks four LSTM layers with hidden sizes \(300,\hspace{0.17em}128,\hspace{0.17em}64,\hspace{0.17em}32\). Dropout is applied between layers. The regression head is a linear layer that maps the final hidden state to \({\mathbb{R}}^{4}\); the classification head is a linear layer followed by Softmax for binary damage status.
Quantum-inspired classifier (Autonomous Perceptron Model (APM))
Before presenting the formal operator formulation, we provide an intuitive explanation of the Autonomous Perceptron Model (APM). The APM is termed ‘quantum-inspired’ because it represents features as 2D complex-like vectors and processes them through small operator matrices that mimic interference patterns—similar to how amplitudes interact in quantum systems. Conceptually, APM replaces the conventional dense-layer-plus-Softmax classifier with a compact module that encodes the input vector into a normalized 2D state, transforms it using operator-valued weights, and computes a class probability via an operator activation rule.
This design is attractive for discriminating structural damage because the interactions between features (e.g., peaks, oscillation patterns, nonlinearities) can be captured through interference-like transformations rather than with large, fully connected layers. The goal here is not to claim superiority over classical classifiers but to test whether such compact operator-based mechanisms can plug into the unified pipeline.
In addition to standard linear–Softmax heads attached to the sequence encoder, we explore a quantum-inspired Autonomous Perceptron Model (APM) classifier as an alternative damage-status head. The motivation for including APM is twofold. First, it provides a compact parametrization in which inputs are mapped to qubit-like vectors and processed through 2 × 2 operator-valued weights and activation operators, enabling interference-like interactions between feature components in a low-dimensional space. Second, this structure has shown competitive performance on other pattern-classification tasks while maintaining an interpretable operator-based formulation. In this study, the APM head is treated as an exploratory add-on: it shares the same leakage-safe pipeline and encoded sequence features as the standard head, allowing us to assess whether such compact operator representations can support accurate discrimination among discretized damage states.
A machine learning classifier inspired by quantum computing concepts, termed the Autonomous Perceptron Model (APM), was proposed in27.
The structure of this classifier is depicted in Fig. 1, which illustrates a directed graph from the pattern inputs to the class label output and comprises various components. Algorithm 1 outlines the detailed steps for training the APM classification model. Initially, it includes a single neuron that receives inputs. Firstly, the features of a dataset, whose domains are bound by the interval [0,1], are encoded such that each input is the normalized vector (see Fig. 2). These input vectors are formulated in resemblance to qubit vectors, represented as follows:

The schematic diagram for training the APM classifier from a dataset.
Here, \(e_{i} = \sqrt {1 - \left| {f_{i} } \right|^{2} } ,\) and \(f_{i}\) represents the scaled value of the feature at the input index \(i\).
Second: a set of \(2 \times 2\) operators which are used as weights, each weight \(w_{i}\) scales the input \(\left| {x_{i} } \right\rangle\) to produce a set of n weighted sum vectors according to the following formula:
where \(O_{1k}\), and \(O_{2k}\) are the coefficients of the weighted sum vector \(y_{k}\) for the training pattern that has the index \(k\), \(k = 1, 2, \ldots ,N\), and N is the number of the training patterns and that is the third component. The fourth component is for each weighted sum \(y_{k}\) which is calculated from.
Equation (1), the APM classifier creates an activation operator in the form:
where \(\theta_{1}\), \(\theta_{2}\), \(\theta_{3}\), and \(\theta_{4}\) are hyperparameters tuned according to the dataset at hand. The estimated output of the classifier is calculated according to Eq. (2).
where the target class label \(\:{d}_{k}={\left[{d}_{{f}_{k}},{d}_{{e}_{k}}\right]}^{T}\) for the kth training pattern. Where the target class label \(\left| {{\text{d}}_{{\text{k}}} } \right\rangle = \left[ {{\text{d}}_{{{\text{f}}_{{\text{k}}} }} ,{\text{d}}_{{{\text{e}}_{{\text{k}}} }} } \right]^{{\text{T}}}\) for the kth training pattern. Consequently, Eq. (12) can be written as two equations as follows:
The weight operators of the APM classifier are updated according to Eq. (3):
The final component is the class label C, produced by the APM classifier for a test pattern and calculated from Eqs. (4–5).
where Z is a vector of size \(2{ } \times 2\) such that Z = \(\left[ {1,1,{ } \ldots ,1} \right]^{{\text{T}}}\), and the operation “\({\text{o}}\)” is the Hadamard product operation between two vectors. Algorithm 1 displays the APM classifier’s learning algorithm.

The APM classifier’s learning algorithm.
Hybrid LSTM–RNN
This backbone uses three LSTM layers with sizes \(200,\hspace{0.17em}100,\hspace{0.17em}50\) followed by a simple RNN layer with \(32\) units. The additional simple RNN encourages short–horizon smoothing while keeping parameter count moderate. Heads mirror those of the stacked LSTM.
Both backbones are trained for \(100\) epochs with Adam. The stacked LSTM uses a batch size \(64\) and learning rate \(10^{ - 4}\), and the LSTM–RNN uses batch size \(128\) and learning rate \(10^{ - 3}\). The regression loss is mean squared error (MSE),
And the classification loss is binary cross–entropy
Gradients are clipped to a fixed norm to mitigate rare exploding updates. We monitor validation loss each epoch and retain the checkpoint with the best validation criterion (early stopping). Algorithm 2 displays the Methodology of LSTM-RNN.

Methodology of LSTM-RNN.
Unified multi-task pipeline design
The unified pipeline uses a shared sequence encoder (an LSTM–RNN backbone) to simultaneously support four tasks: forecasting displacement/velocity/acceleration, multi-class damage-state classification, computation of the Damage Index (DI), and conditional estimation of the priority weight \(\text{w}\).
Training integration
All tasks operate on the same input sequence \((\text{u},\text{v},\text{a})\), but each task has its own task-specific head. To prevent information leakage, the dataset is split into four mutually exclusive partitions—one for each task. Each training batch activates only one task head:
-
The forecasting head.
-
The damage-classification head.
-
The DI-regression head.
-
The priority-weight head.
Thus, the shared encoder learns a generalizable representation of the structural response, while each task head learns independently from its designated subset.
Inference integration
During inference, a single input sequence passes through the shared encoder only once, then all four heads are activated:
-
Forecasting head → \({\hat{\text{u}}}\left( {\text{t}} \right),{\hat{\text{v}}}\left( {\text{t}} \right),{\hat{\text{a}}}\left( {\text{t}} \right)\)
-
DI head → \(\:\widehat{\text{D}\text{I}}\)
-
Classification head → predicted damage label
-
Priority head → \(\:\widehat{\text{w}}\), interpreting urgency or inspection priority
This design enables real-time, multi-output decision support in a single forward pass without retraining or reprocessing the input.
Evaluation and model selection
For sequence regression, we report MAE, MSE, RMSE, MedAE, MAPE, and \({R}^{2}\). For classification, we report accuracy, precision, recall, and F1. Model selection uses a combined view of validation metrics and the generalization gap between train and test. Qualitative inspection of actual versus predicted traces and learning curves is used to confirm stable convergence and to diagnose underfitting or overfitting.
For variables such as velocity and acceleration that can take values close to zero or change sign, MAPE may become numerically unstable because the denominator \(\mid y\mid\) can be extremely small. Consequently, MAPE may report huge percentage errors even when the absolute prediction error is minimal. For this reason, RMSE, MAE, MedAE, and \({R}^{2}\) are treated as the primary indicators of model performance for these signals.
Conditional estimation of \(\mathbf{w}\)
The \(w\) regressor is trained only on \(\mathcal{I}\) where \({\text{DI}}_{t+1}\ge 1\). At inference time, the pipeline first predicts damage status; when positive, the conditional regressor is invoked to estimate \({w}_{t+1}\). This design restricts the learning problem to the relevant sub–manifold associated with damaged cases and prevents dilution by the majority of non–damaged windows.
Feature attribution for negligible damage
To expose drivers of low–damage outcomes, we train a lightweight supervised model on samples with negligible damage (for example, \(\text{DI}<1\)) and tune hyperparameters via grid search. We then compute feature importance using model–appropriate measures (for instance, mean decrease in impurity for tree ensembles or absolute standardized coefficients for linear models). The resulting ranking provides interpretable levers that complement the sequence models and support risk–aware decision making.
Reproducibility and implementation
Experiments are implemented in Python. Random seeds are fixed, and preprocessing parameters and model configurations are logged for exact replay. The final system outputs next–step forecasts for \((u,v,a,\text{DI})\), a damage label, a conditional estimate of \(w\) for damaged cases, and a ranked list of features associated with negligible damage. These outputs can be integrated into dashboards that support rapid triage and resource prioritization.
Experimental results and discussion
Before presenting the APM classifier experiment, it is essential to clarify that this TNT-explosion dataset is not used for training, validating, or benchmarking the earthquake-damage forecasting tasks. The unified LSTM–RNN pipeline for predicting displacement \(u\), velocity \(v\), acceleration \(a\), and Damage Index (DI), as well as the conditional \(w\)-estimation and the low-damage feature attribution modules are developed and evaluated exclusively using seismic-response time series. The TNT dataset serves only as a controlled, auxiliary benchmark for testing the expressiveness of the quantum-inspired APM classifier, whose mathematical structure requires discrete class boundaries and normalized inputs.
The displacement, velocity, and acceleration values in this section are generated by a mathematical model for verifying the APM classifier and are not obtained from physical structural sensors. Their purpose is strictly experimental and serves to evaluate the classifier’s capability under controlled, physically consistent conditions.
Here, we will use the APM classifier to classify the state of exploding buildings by TNT explosives. In this experiment, we generated for the first time a novel dataset for exploding buildings by TNT explosives28. This dataset consists of 1170 patterns with 9 attributes. The nine attributes are: TNT weight, Stand-off distance, time \({\text{T}}_{\text{n}},\) building weight, building type, type of soil, the displacement u, velocity, and the acceleration a. Here, it must be noted that although in this paper the displacement u, the velocity v, and the acceleration a are assumed to be received from sensors fixed on the smart building. However, in our generated dataset, we generate them from the mathematical model explained in Sec Quantum-Inspired Classifier for verification purposes. To explore the standalone classification behavior of the Autonomous Perceptron Model (APM) in a controlled setting with discretized structural damage states, a secondary dataset was generated using blast-induced response simulations. TNT loads produce impulse-like structural excitations that yield clear, separable damage classes, making this dataset suitable for benchmarking APM’s operator-based classification mechanism. This dataset is not used in the seismic damage pipeline and does not influence the earthquake assessment results.
Figure 3 reveals a random sample of the generated dataset. The dataset is labeled into four classes. The first class label is “insignificant damage” for patterns with \(DI<0.2\). The second class label is “repairable damage” for patterns with \(0.2\le DI<0.5\). The third class label is “damaged beyond repair” for patterns with \(0.5\le DI<1.0\). The fourth class label is “total damage” for patterns with \(DI\ge 1.0\). In these experiments, we used a tenfold cross-validation technique to train the APM classifier, with a learning rate \({\upalpha } = 0.01,\) with 71 epochs. The classifier reported a classification accuracy of 92.1%. Overall, we can conclude that machine learning can be used to predict the state of the smart buildings that are attacked via explosives.

Sample of the dataset generated for exploding buildings by TNT explosives.
In this work, the TNT-based experiment should be interpreted as a controlled feasibility test for the APM classifier rather than as the primary vehicle for our earthquake-damage conclusions. The four discrete damage labels (insignificant, repairable, beyond repair, total) mirror commonly used seismic damage states and thus form an analogue classification task in which APM operates on normalized structural response attributes. This setting allows us to examine whether the operator-based activation mechanism of APM can achieve high accuracy on damage-like categories while sharing the same pre-processing and leakage-safe training principles adopted for earthquake response modeling.
Dataset representativeness and limitations
The TNT-explosion dataset used in this subsection is not intended to represent real seismic ground-motion characteristics. Blast loads generate short-duration, high-impulse responses that differ from earthquake excitations, which typically exhibit frequency-rich, long-duration motion. Therefore, this dataset is used solely to benchmark the classification capability of the APM model under controlled conditions. It does not influence the training or validation of the earthquake-damage prediction models, nor are any earthquake-related conclusions derived from it. The core results and scientific claims of this paper rely entirely on the seismic time-series dataset introduced in the Methodology section.
Results analysis
The experimental results were generated using Jupyter Notebook 6.4.6, a popular Python-based platform for data analysis and visualization. Jupyter Notebook provides an integrated environment that facilitates code composition, execution, visualization, and result documentation. It is web-based and supports multiple programming languages, including Python 3.8. These experiments were carried out on a computer with an Intel Core i5 processor and 16 GB of RAM, running Microsoft Windows 10. This robust hardware setup ensured efficient execution and in-depth analysis of the experimental processes. In this research, we applied four scenarios.
The first scenario is predicting the values of u, v, a, and DI. In the second scenario, we performed classification on the target feature related to damage. In the third scenario, our objective is to predict the weight (w) when the Damage Index (DI) ≥ 1. The fourth scenario uses GridSearchCV to identify the critical features that render the damage insignificant. In the four scenarios, two significant Deep Learning (DL) models were applied. The two DL models are stacked Long Short-Term Memory (stacked_LSTM) and LSTM with Recurrent Neural Networks (LSTM_RNN). In the stacked_LSTM model, we employ four layers with varying numbers of hidden units. The first layer comprises 300 hidden units, the second layer includes 128 hidden units, the third layer contains 64 hidden units, and the fourth layer comprises 32 hidden units. During training, a batch size of 64 is used, with a learning rate set at 0.0001. The training process iterates for 100 epochs. We opt for the Adam optimizer as our optimization algorithm. The input data is organized into time steps of 40, and the choice of activation functions varies depending on the task. For regression, we use a linear activation function, whereas for classification, we use the SoftMax activation function. In the LSTM_RNN model, we employ three LSTM layers and one RNN layer with varying numbers of hidden units. The first layer in LSTM comprises 200 hidden units, the second layer in LSTM consists of 100 hidden units, and the third layer in LSTM includes 50 hidden units. The RNN layer consists of 32 hidden units. During training, a batch size of 128 is used, with a learning rate set at 0.001. The training process iterates for 100 epochs. We opt for the Adam optimizer as our optimization algorithm. The input data is organized into time steps of 40, and the choice of activation functions varies depending on the task. For regression, we use a linear activation function, whereas for classification, we use the SoftMax activation function. In regression, six regression evaluation metrics, specifically Mean Absolute Error (MAE), Mean Squared Error (MSE), Median Absolute Error (MedAE), Root Mean Squared Error (RMSE), Mean Absolute Percentage Error (MAPE), and the Coefficient of Determination (R2), have been calculated for two models: the stacked_LSTM and LSTM_RNN models. In classification, four classification evaluation metrics, specifically accuracy, F score, recall, and precision, have been calculated for two models: the stacked_LSTM model and LSTM_RNN. In the first scenario, we predicted the values of u, v, a, and DI using stacked_LSTM and LSTM_RNN models. Tables 1, 2, 3 and 4 demonstrate the performance of the two models, stacked_LSTM and LSTM_RNN, while predicting the values of u, v, a, and DI.
It is important to note that the MAPE value for acceleration (a) in Table 3 becomes huge because several ground-truth acceleration values are close to zero. Since MAPE involves division by \(\mid y\mid\), even minor absolute errors lead to disproportionately large percentage errors when \(\mid y\mid\) approaches zero. Therefore, MAPE should not be interpreted as an indicator of poor model performance in this context. The other metrics (RMSE, MAE, MedAE, and \({R}^{2}\)) and the prediction plots provide a more faithful assessment of model accuracy.
As indicated in Tables 1, 2, 3 and 4, the LSTM_RNN model outperforms the stacked_LSTM model when it comes to predicting the values of u, v, a, and DI, respectively. In the Tables 1, 2, 3 and 4, the stacked_LSTM model has an MSE of approximately 1.09 \(\times {10}^{-5}\), 0.0001, 0.0001, and 0.00026, while predicting the values of u, v, a, and DI, respectively. The LSTM_RNN model has an MSE of approximately 6.29 \(\times {10}^{-6}\), \(2.6\times {10}^{-5}\), \(4.9\times {10}^{-6}\), and \(2.24\times {10}^{-5}\) while predicting the values of u, v, a, and DI, respectively. A lower MSE indicates better model performance; thus, the LSTM_RNN model is better. The stacked_LSTM model has MAEs of approximately 0.0027, 0.0102, 0.0089, and 0.0132 when predicting u, v, a, and DI, respectively. The LSTM_RNN model has MAEs of roughly 0.0018, 0.0043, 0.0013, and 0.0031 when predicting u, v, a, and DI, respectively. Like MSE, a lower MAE is desirable; thus, the LSTM_RNN model is better. The stacked_LSTM model has an RMSE of approximately 0.0033, 0.0106, 0.01038, and 0.01630. The LSTM_RNN model has RMSEs of roughly 0.0025, 0.0051, 0.0022, and 0.0047 when predicting u, v, a, and DI, respectively, which are lower than those of stacked_LSTM, indicating better model performance. The stacked_LSTM model has MAPEs of 147.9, 492.91, 12,270.9, and 5.25 when predicting u, v, a, and DI, respectively. The LSTM_RNN model has MAPEs of 78.83, 191.81, 823.57, and 1.51 when predicting u, v, a, and DI, respectively. The lower value is preferred; thus, the LSTM_RNN model is better than the stacked_LSTM. The stacked_LSTM model has MedAEs of approximately 0.0025, 0.0104, 0.0082, and 0.0118 when predicting u, v, a, and DI, respectively. The LSTM_RNN model has MedAEs of roughly 0.0016, 0.0040, 0.0006, and 0.0022 when predicting u, v, a, and DI, respectively. The lower value is preferred; thus, the LSTM_RNN model is better than the stacked_LSTM. R2 quantifies the proportion of the target variable’s variance explained by the model. It ranges from 0 to 100%, with higher values indicating a better fit. An R2 close to 100% suggests a good model fit. The stacked_LSTM model achieves R2 scores of 98.37%, 89.57%, 97.69%, and 99.68% when predicting u, v, a, and DI, respectively. The LSTM_RNN model achieves R2 scores of 99.42%, 97.58%, 99.8%, and 99.97% when predicting u, v, a, and DI, respectively, which are better than those of stacked_LSTM.
For clarity and consistency, all regression metrics in Tables 1, 2, 3 and 4 have been rounded to a uniform number of decimal places. Mean-based error measures (MSE, MAE, RMSE, MedAE, MAPE) are reported with four decimal places, while \({R}^{2}\) values are presented as percentages with two decimal places (e.g., 99.80%). In addition, units are now stated explicitly in the table captions for displacement \(u\)(m), velocity \(v\)(m/s), acceleration \(a\)(m/s2), and Damage Index \(DI\)(dimensionless).
Although the stacked_LSTM model exhibits extremely high MAPE values for acceleration, this should not be interpreted as a degradation of predictive accuracy. The instability of MAPE in this variable results from near-zero acceleration values in the dataset, not from model failure. The \({R}^{2}\) value, RMSE, and the visual alignment in Figs. 4 and 5 confirm that the model accurately tracks the acceleration waveform.



Training and testing mean absolute error, along with mean squared error, for the LSTM_RNN model and the stacked_LSTM model while predicting the values of u, v, a, and DI, respectively.

Actual values vs. predicted values for LSTM_RNN model and stacked_LSTM model while predicting the values of u, v, a, and DI, respectively.
Figure 4 presents the training and test mean absolute errors, along with the mean squared errors, for the LSTM_RNN and stacked_LSTM models when predicting u, v, a, and DI, respectively.
Figure 5 presents the actual vs. predicted values for the LSTM_RNN and stacked_LSTM models when predicting u, v, a, and DI, respectively.
Conclusions and recommendations
This work presented a unified sequence-learning pipeline for rapid earthquake damage analysis that integrates four complementary tasks: next-step forecasting of structural responses (displacement \(u\), velocity \(v\), acceleration \(a\), and Damage Index \(\text{DI}\)), damage status classification, and conditional estimation of a prioritization weight \(w\) for damaged cases, and feature attribution for negligible-damage regimes. Across regression targets, the hybrid LSTM–RNN consistently outperformed the deeper stacked LSTM, yielding tighter tracking and lower error. Representative gains included improvements in \({R}^{2}\) from \(98.37\text{\%}\) to \(99.42\text{\%}\) for \(u\), from \(89.57\text{\%}\) to \(97.58\text{\%}\) for \(v\), from \(97.69\text{\%}\) to \(99.80\text{\%}\) for \(a\), and from \(99.68\text{\%}\) to \(99.97\text{\%}\) for \(\text{DI}\). For \(\text{DI}\) specifically, the hybrid model reduced MAE and RMSE by several fold relative to the stacked LSTM, indicating that the architecture better captures both long-range memory and short-horizon dynamics in seismic response signals.
The conditional \(w\) estimator adds actionable value beyond detection by quantifying relative urgency among damaged cases. Coupled with the classifier, it enables a two-stage triage in which resources are directed first where both the probability of damage and the implied impact are high. The feature-attribution analysis complements the sequence models by highlighting inputs associated with negligible damage, offering interpretable levers for mitigation policies and design choices.
Overall, the findings demonstrate that lightweight hybrid recurrent models can deliver high accuracy with stable convergence while remaining practical for deployment. By unifying forecasting, classification, conditional prioritization, and interpretability in a single pipeline, the approach shortens the path from raw time-series sensing to early decisions in the first hours after an event.
For operational adoption, establish a rolling, leakage-safe data pipeline with automated monitoring of input distributions and performance drift. Calibrate the conditional \(w\) estimates against historical loss or repair-cost proxies so that rankings align with agency priorities and budget constraints. Select damage-alert thresholds via cost-sensitive analysis that balances missed detections against false alarms under realistic resource limits.
For technical enhancement, broaden external validity by training and testing on multi-region, multi-typology datasets that include soil class, structural system, and ground-motion descriptors. Report uncertainty alongside point estimates using Monte-Carlo dropout, deep ensembles, or conformal prediction to support risk-aware decision making. Explore physics-informed or gray-box variants that encode structural dynamics (for example, constraints from single-degree-of-freedom response or modal properties) to improve generalization and robustness under distribution shift.
For model diagnostics, perform systematic ablation to quantify the contribution of each architectural block and input channel, and evaluate calibration quality for the classifier using reliability curves and expected calibration error. Extend explainability beyond global rankings to local post-hoc analyses (for example, SHAP on window embeddings) to reveal why specific windows are flagged as damaged.
For deployment at scale, prioritize lightweight inference paths suitable for edge devices and intermittent connectivity, with resilience to missing or delayed sensors through imputation and gating of unreliable channels. Integration with early-warning systems can enable pre-emptive staging, while multi-step forecasting can inform evolving risk over the next minutes to hours. Maintain an MLOps loop with versioned data, reproducible training, and automated retraining triggers to ensure that performance remains stable as new earthquakes and structures enter the data stream. A key limitation of the present study is the use of numerically simulated structural response data rather than field-recorded sensor measurements. While simulation-based datasets are widely accepted and allow full control over structural parameters and damage states, real sensors introduce noise, temperature effects, and hardware uncertainties that are not captured here. Therefore, deployment of the proposed models requires additional validation using instrumented building datasets or strong-motion records to confirm applicability in real monitoring environments. The primary novelty of the paper lies in the formulation of a unified, leakage-safe multi-task pipeline that consolidates structural response forecasting, damage classification, DI determination, and priority scoring. This distinguishes the work from prior studies that address these tasks separately and do not enforce strict anti-leakage measures. The LSTM–RNN backbone and optional APM head serve as supporting components within this larger contribution.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Code availability
The code used in this study is available from the corresponding author upon reasonable request.
Abbreviations
- LSTM:
-
Long short-term memory
- RNN:
-
Recurrent neural network
- DI:
-
Damage index
- APM:
-
Autonomous Perceptron Model (quantum-inspired classifier)
- RMSE:
-
Root mean square error
- MSE:
-
Mean square error
- MAE:
-
Mean absolute error
- MAPE:
-
Mean absolute percentage error
- MedAE:
-
Median absolute error
- (\({R}^{2}\)):
-
Coefficient of determination
- NN:
-
Neural network
- ANN:
-
Artificial neural network
- ML:
-
Machine learning
- (t):
-
Time index
- (u(t)):
-
Displacement at time (t) (m)
- (v(t)):
-
Velocity at time (t) (m/s)
- (a(t)):
-
Acceleration at time (t) (m/s2)
- (DI(t)):
-
Damage index (dimensionless)
- (w):
-
Conditional prioritization weight
- \(\left( {x_{t} } \right)\) :
-
Input feature vector at time (t)
- \(\left( {h_{t} } \right)\) :
-
Hidden state of LSTM/RNN at time (t)
- (\(\:\widehat{{y}_{t}}\)):
-
Predicted output at time (t)
- \(\left( {\epsilon_{t} } \right)\) :
-
Forecasting residual
- \(\left( {{\upsigma }\left( \cdot \right)} \right)\) :
-
Activation function
- \(\left( {\mathcal{L}} \right)\) :
-
Loss function
- \(\left( {\uptheta } \right)\) :
-
Model parameters
- \(\left( O \right)\) :
-
APM operator-valued weight matrix (2 × 2)
- \(\left( u \right)\) :
-
Qubit-like encoded input vector
- (\(A\)):
-
APM activation operator
- (\(T_{n}\)):
-
Wave arrival time (s)
- (\(W\)):
-
TNT weight (kg)
- (\(S_{t}\)):
-
Stand-off distance (m)
References
Murti, M. A., Junior, R., Ahmed, A. N. & Elshafie, A. Earthquake multi-classification detection based velocity and displacement data filtering using machine learning algorithms. Sci. Rep. 12(1), 21200 (2022).
Mangalathu, S. & Jeon, J.-S. Regional seismic risk assessment of infrastructure systems through machine learning: Active learning approach. J. Struct. Eng. 146(12), 4020269 (2020).
Sajan, K. C., Bhusal, A., Gautam, D. & Rupakhety, R. Earthquake damage and rehabilitation intervention prediction using machine learning. Eng. Fail. Anal. 144, 106949 (2023).
Galkina, A. & Grafeeva, N. Machine learning methods for earthquake prediction: A survey. In Proc. of the Fourth Conference on Software Engineering and Information Management (SEIM-2019) 25 (Saint Petersburg, Russia, 2019).
Debnath, P. et al. Analysis of earthquake forecasting in India using supervised machine learning classifiers. Sustainability 13(2), 971 (2021).
Mallouhy, R., Abou Jaoude, C., Guyeux, C. & Makhoul, A. Major earthquake event prediction using various machine learning algorithms. In 2019 International Conference on Information and Communication Technologies for Disaster Management (ICT-DM). 1–7 (IEEE, 2019).
Ghimire, S., Guéguen, P., Giffard-Roisin, S. & Schorlemmer, D. Testing machine learning models for seismic damage prediction at a regional scale using building-damage dataset compiled after the 2015 Gorkha Nepal earthquake. Earthq. Spectra 38(4), 2970–2993 (2022).
Tehseen, R., Farooq, M. S. & Abid, A. Earthquake prediction using expert systems: a systematic mapping study. Sustainability 12(6), 2420 (2020).
Xie, Y., Ebad Sichani, M., Padgett, J. E. & DesRoches, R. The promise of implementing machine learning in earthquake engineering: A state-of-the-art review. Earthq. Spectra 36(4), 1769–1801 (2020).
Ridzwan, N. S. M. & Yusoff, S. H. M. Machine learning for earthquake prediction: A review (2017–2021). Earth Sci. Inf. 16(2), 1133–1149 (2023).
Al Banna, M. H. et al. Application of artificial intelligence in predicting earthquakes: state-of-the-art and future challenges. IEEE Access 8, 192880–192923 (2020).
Xu, J.-G., Hong, W., Zhang, J., Hou, S.-T. & Wu, G. Seismic performance assessment of corroded RC columns based on data-driven machine-learning approach. Eng. Struct. 255, 113936 (2022).
Yang, F., Kefalas, M., Koch, M., Kononova, A. V., Qiao, Y. & Bäck, T. Auto-REP: an automated regression pipeline approach for high-efficiency earthquake prediction using LANL data. In 2022 14th International Conference on Computer and Automation Engineering (ICCAE). 127–134 (IEEE, 2022).
Li, R., Lu, X., Li, S., Yang, H., Qiu, J. & Zhang, L. DLEP: A deep learning model for earthquake prediction. In 2020 International Joint Conference on Neural Networks (IJCNN). 1–8 (IEEE, 2020).
Jena, R., Pradhan, B., Naik, S. P. & Alamri, A. M. Earthquake risk assessment in NE India using deep learning and geospatial analysis. Geosci. Front. 12(3), 101110 (2021).
Murwantara, I. M., Yugopuspito, P. & Hermawan, R. Comparison of machine learning performance for earthquake prediction in Indonesia using 30 years historical data. TELKOMNIKA Telecommun. Comput. Electron. Control. 18(3), 1331–1342 (2020).
Jain, R., Nayyar, A., Arora, S. & Gupta, A. A comprehensive analysis and prediction of earthquake magnitude based on position and depth parameters using machine and deep learning models. Multimed. Tools Appl. 80(18), 28419–28438 (2021).
Abebe, E., Kebede, H., Kevin, M. & Demissie, Z. Earthquakes magnitude prediction using deep learning for the Horn of Africa. Soil Dyn. Earthq. Eng. 170, 107913 (2023).
Rayan, A. & Artuner, H. LSTM-based deep learning methods for prediction of earthquakes using ionospheric data. Gazi Univ. J. Sci. 35(4), 1417–1431 (2022).
Abdalzaher, M. S., Soliman, M. S., El-Hady, S. M., Benslimane, A. & Elwekeil, M. A deep learning model for earthquake parameters observation in IoT system-based earthquake early warning. IEEE Internet Things J. 9(11), 8412–8424 (2021).
Wang, H. et al. Resilience assessment and optimization method of city road network in the post-earthquake emergency period. Earthq. Eng. Eng. Vib. 23, 765–779. https://doi.org/10.1007/s11803-024-2254-8 (2024).
Liu, C., Xu, M., Hu, S. & Ouyang, M. Resilience-based seismic retrofit of urban infrastructure systems. Dis. Prev. Res. 2, 10. https://doi.org/10.20517/dpr.2023.07 (2023).
Kaushal, A. et al. Earthquake prediction optimization using deep learning hybrid RNN-LSTM model for seismicity analysis. Soil Dyn. Earthq. Eng. 195, 109432. https://doi.org/10.1016/j.soildyn.2025.109432 (2025).
Mekaoui, N. & Saito, T. A deep learning-based integration method for hybrid seismic analysis of building structures: Numerical validation. Appl. Sci. 12(7), 3266. https://doi.org/10.3390/app12073266 (2022).
Bilal, M. A. et al. Earthquake detection using stacked normalized recurrent neural network (SNRNN). Appl. Sci. 13(14), 8121. https://doi.org/10.3390/app13148121 (2023).
Hong, Z. et al. Enhancing 3D reconstruction model by deep learning and its application in building damage assessment after earthquake. Appl. Sci. 12(19), 9790. https://doi.org/10.3390/app12199790 (2022).
Sagheer, A., Zidan, M. & Abdelsamea, M. M. A novel Autonomous Perceptron Model for pattern classification applications. Entropy 21(8), 763 (2019).
Abd-Elhamed, A., Alkhatib, S. & Abdelfattah, A. M. H. Prediction of blast-induced structural response and associated damage using machine learning. Buildings 12, 2093 (2022).
Acknowledgements
The authors extend their appreciation to Prince Sattam bin Abdulaziz University for funding this research work through the project number (PSAU/2024/01/29770).
Funding
The authors extend their appreciation to Prince Sattam bin Abdulaziz University for funding this research work through the project number (PSAU/2024/01/29770).
Author information
Authors and Affiliations
Contributions
Abdulaziz Alotaibi prepared figures, recorded tables results and draft of the main manuscript. Sattam Alharbi wrote the main manuscript, prepared the methodology and software. Ahmed M. Elshewey prepared figures, recorded tables results, software and draft of the main manuscript. All authors reviewed and approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Alotaibi, A., Alharbi, S. & Elshewey, A.M. Rapid earthquake damage assessment via hybrid LSTM-RNN with a quantum-inspired classification head based on Autonomous Perceptron Model APM. Sci Rep 16, 9686 (2026). https://doi.org/10.1038/s41598-026-38982-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-38982-x
