
Abstract
Intraoperative frozen section analysis is critical for evaluating tumor malignancy, assessing surgical margins, and informing real-time clinical decisions. However, limitations such as inconsistent slide quality, diagnostic variability, and time constraints challenge its reliability in routine workflows. To address these issues, we collected a real-world dataset of 4,667 hematoxylin and eosin-stained whole slide images (WSIs) from intraoperative consultations spanning diverse organ types. A Vision Transformer (ViT)-based model enhanced with a Soft Mixture of Experts (Soft MoE) module was developed to perform binary classification (benign vs. malignant) under weak supervision using only slide-level labels. The proposed model achieved excellent performance on the test set (AUC = 0.957, sensitivity = 0.817, specificity = 0.961), and demonstrated consistent diagnostic utility across common and rare tissue types. Instance-level heatmap visualizations revealed consistent visual alignment with diagnostic tumor regions, supporting model interpretability. Importantly, the model enables local inference on standard clinical hardware (e.g., GPU with 24 GB memory), making it feasible for real-world deployment. These findings suggest that Soft MoE-ViT offers a practical and interpretable solution for AI-assisted intraoperative pathology.
Similar content being viewed by others

Introduction
Intraoperative frozen section examination plays a crucial role in real-time evaluation of tumor malignancy and surgical margins1,2. Despite its clinical utility, frozen sections are often compromised by lower slide quality, staining inconsistency3, and preparation artifacts when compared to formalin-fixed paraffin-embedded (FFPE) slides4. Combined with the time constraints and variability between pathologists, this diagnostic approach remains challenging and dependent on experienced personnel.
Recent advances in computer vision, particularly the Vision Transformer (ViT), have demonstrated excellent performance in image-based tasks by leveraging global attention mechanisms5,6. ViT has been adapted for histopathology image analysis and has outperformed convolutional neural networks (CNNs) in large-scale image classification settings7. However, the standard feed-forward network (FFN) layers in ViT limit its ability to capture diverse semantic patterns, especially in weakly supervised scenarios where only image-level labels are available8. This restricts the model’s ability to localize diagnostic features and generalize across tissue types.
To address these challenges, we propose a Soft Mixture of Experts-enhanced Vision Transformer (Soft MoE-ViT), which replaces FFNs with a differentiable multi-expert routing module9. Unlike sparse MoE mechanisms that selectively activate only a few experts, the Soft MoE framework softly aggregates outputs from all experts using learnable weights10. This design not only improves training stability and expert utilization, but also enhances the model’s ability to focus on subtle diagnostic cues in pathology images. The architecture is optimized for medium-scale datasets and weak supervision settings, where pixel-level annotations are unavailable8.
In addition, our model is designed for real-world deployment, which is particularly important for enabling adoption in smaller or resource-limited hospitals. It runs efficiently on accessible hardware with 24 GB of GPU memory (e.g., NVIDIA RTX 3090TI), supporting on-site inference without reliance on cloud infrastructure. This property is crucial for advancing digital pathology capacity in primary care settings and promoting equitable access to AI-assisted diagnostics in under-resourced regions11.
In this study, we constructed a real-world pan-cancer frozen section dataset comprising 4,667 WSIs. The cohort covers a broad spectrum of anatomical sites, which were categorized into major organ groups (Lung, Breast, Thyroid, Lymph Node, and Female Adnexal Tumors) and a consolidated “Others” group for robust statistical evaluation. Using only slide-level benign vs. malignant labels, our Soft MoE-ViT model achieved robust classification performance (AUC = 0.957), and remarkable adaptability to rare tissue types without organ-specific input. Heatmap visualizations confirmed precise tumor localization and diagnostic relevance, suggesting that our approach holds substantial promise for AI-assisted intraoperative pathology.
Materials and methods
Data collection and annotation
We retrospectively collected intraoperative frozen section whole slide images (WSIs) from the Department of Pathology at China-Japan Friendship Hospital, spanning from March 26, 2023, to January 23, 2025. A total of 4,754 WSIs from 2,640 patients were initially retrieved, representing a wide spectrum of tumor types commonly encountered during intraoperative consultations.
After consecutive collection starting in 2023, a total of 4,754 WSIs were obtained. After quality screening and eligibility filtering, 4,667 WSIs were retained for model development. Inclusion criteria were: (1) WSIs prepared after January 1, 2023; (2) concordant frozen and FFPE diagnoses, clearly defined as benign or malignant; and (3) acceptable image quality without major artifacts (e.g., folds, bubbles, tissue overlap, or staining errors). Exclusion criteria included: (1) borderline or ambiguous diagnostic labels; (2) discordant results between frozen and FFPE diagnoses for the same tissue block; and (3) poor-quality slides unsuitable for analysis.
An additional set of 156 WSIs labeled as borderline or uncertain were excluded from training and evaluation but preserved as a separate “gray zone” dataset for future exploratory use.
All slides were stained with hematoxylin and eosin (H&E) and scanned at 40× magnification using the Slide Scan Imaging System SQS-600P (Shenzhen Shengqiang Technology, China). Scanning was performed either on the day of surgery or the following morning, ensuring image freshness and minimizing risks of staining degradation or color fading. WSIs were converted to SDPC format for downstream processing.
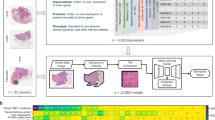
Slide-level annotations were manually assigned by expert pathologists based on integrated frozen and FFPE pathology reports. A three-level classification scheme was adopted: benign (label 0), borderline/uncertain (label 1), and malignant (label 2). For model development, only cases with definitive benign or malignant diagnoses were included. Although inspired by the ICD-O behavioral coding system, our annotations were determined based on actual clinical report semantics and diagnostic certainty. The overall case selection, data filtering, and downstream utilization workflow is summarized in Fig. 1.

Workflow of frozen-section WSI selection and dataset processing. A total of 4,754 WSIs were consecutively collected from routine clinical practice. After applying quality, diagnostic clarity, and consistency criteria, 4,667 frozen-section WSIs with definitive binary labels were retained. The dataset was partitioned into training, validation, and testing sets for model development and evaluation. Validation data were used for hyperparameter tuning, while 98 WSIs were randomly selected from the independent test set for heatmap visualization.
Dataset splitting
The final dataset of 4,667 WSIs was randomly partitioned at the slide level into three independent cohorts: training, validation, and testing, with an approximate ratio of 7:1.5:1.5. Specifically, the training set consisted of 3,328 WSIs, while the validation set—designated for hyperparameter tuning and automatic cutoff optimization—contained 670 WSIs. The remaining 669 WSIs (261 malignant and 408 benign) served as the independent test set. To prevent data leakage, strict patient-level isolation was enforced; no slides from the same patient or surgical case were shared across the three subsets.
While the data were consecutively collected in their natural chronological order of clinical acquisition, the partitioning was performed randomly to ensure unbiased group assignment. Tumor types and organ sites were not artificially balanced, as our primary objective was to preserve the inherent characteristics of real-world data rather than enforcing class uniformity. This design maintains the heterogeneity of routine clinical practice and enables ecologically valid model evaluation.
Model architecture
This study adopts the Vision Transformer (ViT) as the backbone architecture. ViT is well-suited for whole slide images (WSIs) due to its ability to model long-range contextual dependencies across large and heterogeneous histopathological structures12. In the standard ViT design, each Transformer block contains a feedforward network (FFN) for nonlinear transformation of token embeddings.
To enhance the model’s ability to focus on diagnostically meaningful regions under weak supervision, we replace the FFN modules in the final three Transformer blocks with a Soft Mixture-of-Experts (Soft MoE) mechanism10.
Unlike sparse-gated MoE architectures, which rely on discrete top-k routing and frequently suffer from expert imbalance, routing collapse, and unstable convergence on medium-scale datasets17, Soft MoE employs continuous, differentiable gating that allows all experts to contribute proportionally. This design improves optimization stability and parameter utilization in medical imaging tasks.
Each Soft MoE module consists of multiple parallel sub-networks (“experts”) with independent parameters. A differentiable gating function assigns tokens to experts using learned continuous weights. Each expert has a fixed slot capacity representing the maximum number of tokens it can process. When assignments exceed this limit, surplus tokens are smoothly redistributed to less-loaded experts according to the gating weights. This slot-based routing prevents expert overload, improves load balancing, and enhances training stability and computational efficiency.
From a clinical perspective, the Soft MoE module resembles a multidisciplinary team (MDT) review, where multiple subspecialist pathologists contribute complementary expertise. A schematic illustration of the expert routing and multi-expert aggregation process is provided in Supplementary Fig. S1.
Figure 2 presents the overall Soft MoE-ViT architecture. Each WSI is divided into non-overlapping 2048 × 2048 tiles (bags), which are subdivided into 256 × 256 instances. Instances are tokenized into 16 × 16 patches and embedded into 1024-dimensional vectors before entering a 24-layer ViT encoder. The final three layers adopt Soft MoE modules containing 64 experts each. Up to four experts are selected per token under slot constraints. GELU is used as the activation function, LayerNorm is applied for normalization, the MLP expansion ratio is 4.0, and qkv projections are computed without bias (qkv_bias=False). This configuration balances modeling capacity and computational feasibility for WSI-scale input.
Despite its modular complexity, the model remains computationally efficient: whole-slide inference requires ~ 4.83 TFLOPs and < 5 GB GPU memory, enabling deployment on standard clinical GPUs (e.g., NVIDIA RTX 3090Ti).

Overview of the preprocessing and Soft MoE-ViT architecture. Each frozen section WSI is divided into non-overlapping 2048 × 2048-pixel tiles, treated as MIL bags. Each tile is further subdivided into 64 non-overlapping 256 × 256-pixel instances. Each instance is tokenized into 16 × 16 patches and appended with a [CLS] token. Tokens are embedded into 1024-dimensional vectors and processed by a 24-layer Vision Transformer. The final three blocks adopt a Soft Mixture of Experts (Soft MoE) mechanism, in which 64 experts per block are assigned a limited number of token slots through a soft gating function. The [CLS] token output is used for binary classification via a softmax layer.
Training strategy and interpretability
We employ a weakly supervised learning strategy using only slide-level benign/malignant labels, consistent with real-world frozen-section workflows. Each WSI is partitioned into 2048 × 2048 tiles (bags), and each bag is subdivided into 256 × 256 instances. Instance-level embeddings are generated independently and processed by the ViT backbone.
To improve label granularity and localize tumor regions, we adopt the CAMEL2 framework8, which converts slide-level labels into confidence-guided pseudo labels for top-ranked instances. This enables fine-grained supervision without requiring pixel-level annotations, which are unavailable for routine frozen-section practice.
During each training iteration, one positive and one negative bag were randomly sampled to form a mini-batch. For negative bags, all instances were labeled negative. For positive bags, we assumed that at least 10% of instances correspond to tumor regions. Instances were ranked by predicted probability, and the highest-scoring 10% were selected as positive samples for loss computation, following the high-confidence MIL strategy proposed in CAMEL2.
Only slide-level labels were used during training, constituting a standard weakly supervised setup. Binary cross-entropy loss supervised selected positives and all negatives, while the AdamW optimizer and cosine-annealing scheduler stabilized convergence.
For interpretability, instance-level malignancy probabilities were visualized as heatmaps. High-probability regions highlight diagnostically relevant tissue areas, following established weakly supervised computational pathology practices13,14.
Model evaluation and threshold selection
All primary test-set results were obtained using a single global cutoff–threshold pair determined exclusively from the validation set. The cutoff controls patch-level instance selection during MIL aggregation, whereas the final threshold determines slide-level classification. These two parameters serve distinct roles and cannot be collapsed into a single operating point.
For organ-wise subgroup analyses, the same global cutoff–threshold pair was applied uniformly to all test-set samples. No organ-specific threshold optimization was performed. Organ-wise sensitivity, specificity, accuracy, and AUC therefore reflect the model’s true generalization performance under a fixed operating point, rather than post-hoc tuning within each organ. Specifically, for the Sparse MoE baseline, the routing parameters and top-k selection were also pre-determined during the validation phase and remained frozen during testing to ensure a fair comparison across all architectures.
Results
Overall classification performance
The model achieved excellent binary classification performance on the test set.
The proposed model demonstrated strong binary classification performance on the test set. A total of 669 intraoperative frozen-section whole slide images (WSIs) were evaluated, including 408 benign cases and 261 malignant cases. Under weakly supervised learning at the slide level, the model achieved excellent diagnostic performance, with an AUC of 0.957 (95% CI: 0.940–0.971), an accuracy of 0.904, a sensitivity of 0.817, and a specificity of 0.961. The cutoff threshold of 0.9985 was determined based on the Youden index derived from the ROC curve, optimizing the trade-off between sensitivity and specificity. These results confirm the model’s robust generalizability and discriminative power across diverse tumor types.
Heatmap visualization based on positive probability ranking
Heatmaps demonstrated that the model effectively identified regions morphologically consistent with tumor areas across various cancer types.
To assess model interpretability, we randomly selected 98 representative WSIs from the test set (N = 669) and generated heatmaps using instance-level positive probability ranking. All heatmaps were independently reviewed by senior pathologists.
The results showed highly interpretable attention to diagnostically relevant areas, with effective suppression of irrelevant structures, aligning qualitatively with pathological findings. For example, in lung specimens, the model correctly highlighted regions of adenocarcinoma in situ, minimally invasive adenocarcinoma, and invasive adenocarcinoma while avoiding vessels and fibrous tissue. In breast samples, heatmaps focused precisely on invasive carcinoma. In thyroid slides, the model accurately identified papillary thyroid carcinoma while showing minimal activation in nodular goiter.
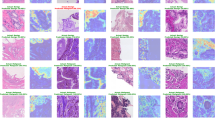
As illustrated in Fig. 3A–D, the model accurately highlighted tumor regions across four representative pathological scenarios: adenocarcinoma in situ (AIS), invasive adenocarcinoma, metastatic lymph node involvement, and papillary thyroid carcinoma. These visualizations provide qualitative evidence of the model’s spatial attention and interpretability.
Expert-based qualitative grading further confirmed these findings: 41 cases (41.8%) showed high consistency between heatmaps and ground truth lesions, with precise coverage of tumor areas and no activation in nonspecific structures. Another 36 cases (36.7%) exhibited moderate alignment, typically involving slight shifts in tumor boundary coverage or partial overlap with non-tumor tissue. The remaining 21 cases (21.4%) showed limited agreement, mainly due to: (i) tissue compression or pleural thickening (5 cases), (ii) staining artifacts or air bubbles (4 cases), and (iii) absence of visible lesions in benign or normal tissue (12 cases), where some activation was noted in fibrous regions without causing diagnostic confusion.
These results indicate that the model, even under weak supervision, can achieve accurate spatial focus on tumor regions and demonstrates clear advantages in clinically critical settings such as margin assessment. Misalignment in a subset of cases suggests future improvements may be achieved through enhanced data quality and increased training diversity.

Heatmaps overlaid on H&E-stained WSIs from four representative cases. (A) Lung adenocarcinoma in situ (AIS), with the heatmap precisely covering the neoplastic area.(B) Invasive adenocarcinoma, where the heatmap avoids internal stromal regions and highlights tumor periphery.(C) Lymph node with metastatic adenocarcinoma, showing clear model focus on the metastatic cluster.(D) Papillary thyroid carcinoma, with heatmap attention accurately localized within the malignant area.
All heatmaps were generated under weak supervision, demonstrating strong interpretability and spatial alignment with expert-recognized tumor regions. Because frozen-section workflows lack region-level annotations, heatmaps are evaluated qualitatively rather than using overlap-based quantitative metrics.
Performance across cancer types
To evaluate the model’s robustness across various anatomical sites, we conducted an extensive subgroup analysis on the test set (n = 669). Given the pan-cancer nature of our cohort, the Soft MoE-ViT demonstrated consistent diagnostic utility across diverse organ systems without requiring organ-specific fine-tuning.
As detailed in Table 2, the model achieved reliable classification performance across major organ categories. In breast specimens (n = 173), it achieved a sensitivity of 100% (35/35) and a specificity of 92.8% (128/138), with an AUC of 0.9986. For female adnexal tumors (n = 50), the model successfully identified 91.7% (11/12) of malignant cases (AUC = 0.9930). In lung specimens, which constituted the largest subgroup (n = 207), the model reached a sensitivity of 100% (153/153). While the specificity in the lung subgroup was lower due to the prioritization of diagnostic sensitivity at the global operating point, this ensures clinical safety by minimizing missed diagnoses during critical intraoperative windows. For thyroid tissues (n = 42) and lymph nodes (n = 121), the model maintained stable performance with sensitivities of 73.9% (17/23) and 68.8% (11/16), respectively.
The “Other organs” category (n = 76, representing 11.4% of the test set) reflects the distribution of a consecutive, real-world intraoperative workflow. This group includes the gastrointestinal tract (stomach, colon, and esophagus; n = 32), the hepatobiliary system (liver and gallbladder; n = 21), and specialized sites such as the larynx, skin, and soft tissues (n = 23). In routine clinical practice, these organs are less frequently subjected to intraoperative frozen section analysis compared to standard paraffin-embedded sections. By consolidating these rare categories, we ensured statistical stability while evaluating the model’s versatility.
Despite the significant morphological heterogeneity among these rare types, the model achieved a specificity of 94.4% (51/54) and an accuracy of 86.8% (66/76) in this category (AUC = 0.8242). Specifically, it correctly identified 68.2% (15/22) of malignant cases. These results suggest that the Soft MoE-ViT effectively captures fundamental histopathological features of malignancy—such as nuclear atypia and architectural loss—that are conserved across different tissue origins.
Importantly, all organ-specific metrics were obtained using the same fixed global threshold determined exclusively from the validation set. The raw counts (TP, FP, TN, and FN) for each subgroup are provided in Table 2, and the corresponding ROC curves are presented in Fig. 4. This comprehensive evaluation confirms that our model successfully captures transferable histological features, enabling effective pan-cancer diagnostics in a unified clinical setting.

ROC curves for organ-specific classification tasks. ROC curves for organ-specific classification tasks. Subgroup analysis demonstrates the model’s performance across: (A) Lung (n = 207), (B) Breast (n = 173), (C) Lymph node (n = 121), (D) Female adnexal tumors (n = 50), (E) Thyroid (n = 42), and (F) Other organs (n = 76). All curves were generated using the fixed global operating point determined from the validation cohort.
Model comparison and ablation studies
To comprehensively evaluate the effectiveness of the proposed Soft MoE-ViT, we compared it with two representative baseline architectures: ResNet50 (CNN-based model) and Standard ViT (Transformer without Mixture-of-Experts). All models were trained under identical weakly supervised conditions, and their operating points (cutoff + threshold) were selected on a held-out validation set and then fixed for evaluation on the test set to avoid optimistic bias.
Table 3 summarizes the overall diagnostic performance. Soft MoE-ViT achieved the highest discriminative ability, with an AUC of 0.957 (95% CI: 0.940–0.971), outperforming both Standard ViT (AUC = 0.934) and ResNet50 (AUC = 0.921). Soft MoE-ViT also demonstrated the highest PR-AUC (0.949), indicating superior performance under class imbalance. Correspondingly, its specificity (96.1%) was markedly improved while maintaining competitive sensitivity (81.7%).
To visualize these differences, we present the ROC curves of all three models in Fig. 5 and the Precision–Recall curves in Fig. 6, both showing consistent superiority of Soft MoE-ViT across probability thresholds.
Soft MoE-ViT also achieved the lowest Brier Score (0.167), reflecting more reliable probability calibration than Standard ViT (0.171) and ResNet50 (0.174). This finding aligns with the improved calibration curve presented in Fig. 7, further confirming that the Soft MoE design enhances both discriminative performance and the trustworthiness of predicted malignancy probabilities.

Receiver Operating Characteristic (ROC) curves of three baseline models on the test set. ROC curves comparing the performance of (A) Soft MoE-ViT, (B) Standard ViT, and (C) ResNet50 for binary classification of frozen-section WSIs. Soft MoE-ViT achieved the highest AUC (0.957), followed by Standard ViT (0.934) and ResNet50 (0.921). The optimal operating points selected from the validation set are indicated on each curve.

Precision–Recall curves of three baseline models on the test set. Precision–Recall (PR) curves illustrating the performance of (A) Soft MoE-ViT, (B) Standard ViT, and (C) ResNet50 under class-imbalanced conditions. The Soft MoE-ViT achieved the highest PR-AUC (0.949), followed by Standard ViT (0.907) and ResNet50 (0.830), indicating superior ability to maintain high precision across varying recall levels. The PR curves further demonstrate the robustness of the Soft MoE-ViT in distinguishing malignant from benign slides in a real-world imbalanced dataset.
Ablation of the soft MoE module
The comparison between Standard ViT and Soft MoE-ViT serves as an explicit ablation study isolating the contribution of the Soft MoE module. Replacing the feedforward networks in the final three Transformer blocks with Soft MoE improved AUC from 0.934 to 0.957 (+ 2.3%), increased PR-AUC from 0.907 to 0.949, and substantially reduced calibration error. These results demonstrate that the Soft MoE module enhances feature expressiveness, improves token-level specialization, and stabilizes optimization under weak supervision—collectively leading to stronger and more reliable WSI classification.
Calibration analysis
We further evaluated the reliability of the model’s confidence scores using Calibration Curves and the Brier Score. As shown in Fig. 7 (Calibration Curve), the Soft MoE-ViT demonstrates a high degree of alignment between predicted probabilities and actual outcomes, with a low Brier Score of 0.167. This indicates that the model provides well-calibrated probability estimates, in addition to its strong discriminative performance. Reliable probability calibration is particularly important in intraoperative frozen-section workflows, where malignancy probability directly informs surgical decision-making.

Calibration curves of three baseline models on the test set. Calibration curves showing the relationship between predicted malignancy probability and the observed proportion of malignant cases for (A) Soft MoE-ViT, (B) Standard ViT, and (C) ResNet50. The dashed diagonal line represents perfect calibration. Among the three models, Soft MoE-ViT exhibits the closest alignment to the ideal calibration curve and achieves the lowest Brier Score (0.167), indicating more reliable probability estimates. These results highlight the importance of well-calibrated confidence outputs for intraoperative frozen-section decision-making.
Failure case analysis
To better understand the model’s limitations in real intraoperative frozen-section settings, we systematically reviewed representative false-negative (FN) and false-positive (FP) cases from the test set.
False-negative errors frequently occurred in slides where tumor cells were extremely scant, making malignant foci difficult to identify under weak supervision. In several cases, focal scanning blur further obscured nuclear detail and architectural cues, contributing to missed detections. Additionally, intense inflammatory or fibrotic reactions sometimes masked subtle malignant components, especially when tumor nests were small or embedded within reactive stroma.
False-positive predictions were commonly associated with benign proliferative or reactive lesions that mimicked malignant patterns. These included adenosis with ductal epithelial hyperplasia, dense fibroinflammatory changes, granulomatous inflammation, and tissue fragments showing reactive epithelial atypia. In some slides, crushed, distorted, or folded frozen tissue created irregular structures that triggered malignant-like activation. These findings illustrate the morphological complexity and artifact variability inherent to frozen sections and highlight potential areas for future improvement, such as artifact-aware preprocessing or multi-scale morphological refinement. Representative false-negative (FN) and false-positive (FP) cases are illustrated in Fig. 8.

Representative false-negative (FN) and false-positive (FP) cases from the test set. False-negative cases were mainly associated with scant tumor cells, focal scanning blur, and dense inflammatory or fibrotic reactions that obscured subtle malignant components. False-positive cases commonly arose from benign proliferative or reactive lesions (such as adenosis with ductal epithelial hyperplasia), fibroinflammatory or granulomatous tissue responses, reactive epithelial atypia, or crushed and folded frozen tissue fragments that mimicked malignant patterns. All images are shown at 20× magnification.
Discussion
In this study, we proposed the Soft Mixture of Experts Vision Transformer (Soft MoE-ViT) model for pan-cancer classification of intraoperative frozen sections, achieving excellent diagnostic performance (overall AUC = 0.957, accuracy = 90.4%). Compared with traditional histopathological workflows15, the weakly supervised AI-based approach significantly improves diagnostic consistency, reduces pathologist workload, and demonstrates promising translational value for intraoperative support.
The proposed Soft MoE-ViT architecture achieves a favorable balance between representational power and resource efficiency. While the standard Vision Transformer (ViT) exhibits strong global modeling capabilities16, its large feedforward network (FFN) layers often impede real-world deployment due to high computational demands5. Although sparse Mixture of Experts (MoE) modules reduce computation, they tend to suffer from training instability and poor generalization in small- to medium-scale datasets17. In contrast, our model integrates a differentiable soft gating mechanism, allowing all experts to contribute to token-level representation. This improves feature expressiveness, training stability, and parameter utilization. Importantly, the model supports local inference on commodity clinical hardware (e.g., GPU with 24 GB memory), enabling practical deployment in real-world pathology labs18. In addition, the model’s lightweight architecture enables whole-slide inference with only ~ 4.83 TFLOPs and less than 5 GB of GPU memory, reinforcing its feasibility for routine clinical deployment, especially in resource-constrained hospital settings.
Notably, the model demonstrated robust cross-organ performance. Despite the absence of organ-specific labels during training, it achieved high classification performance across multiple organ types (e.g., AUC = 0.9986 for breast, 0.9930 for adnexal tumors), indicating its ability to extract transferable histological features across diverse tissue types. This is particularly important for rare tumors or ambiguous intraoperative presentations13.
Furthermore, instance-level heatmap visualizations across 98 slides, randomly selected from the test set, confirmed the model’s spatial attention and visual alignment with morphological features. The model effectively avoided false-positive activation in benign cases (e.g., non-metastatic lymph nodes, fibroadenoma), precisely delineated tumor margins in MIA and invasive adenocarcinomas, and showed consistent performance in critical tasks such as margin assessment for breast and biliary tumors.
Of particular interest, the model successfully localized metastatic foci in lymph node slides without using pixel-level annotations, suggesting that it implicitly learned generalizable features for metastasis detection from across tissue domains. Given the clinical importance of minimizing false negatives during intraoperative consultations, the model’s performance in lymph nodes highlights its potential utility in identifying metastatic clusters.
Limitations of quantitative interpretability assessment
Although expert-reviewed heatmaps demonstrated that the model consistently focused on histologically meaningful tumor regions, we were unable to perform quantitative interpretability evaluation such as overlap-based metrics (e.g., Dice, IoU or pixel-level recall). This limitation arises because routine intraoperative frozen-section workflows do not generate region-level or pixel-level tumor annotations, and creating such detailed masks would require substantial manual delineation by senior pathologists, which is not feasible at scale in real-world clinical practice.
We acknowledge this limitation and plan to incorporate region-level annotations or weakly supervised localization benchmarks in future studies to quantitatively assess and further validate the model’s spatial precision.
While this study provides broad coverage across cancer types, several organs (e.g., tongue, soft tissue) remain underrepresented. Future efforts should focus on expanding multi-center datasets and incorporating more diverse morphologies to enhance model robustness and generalizability.
To address the reviewer’s concern regarding potential optimistic bias, all test-set performance metrics—including organ-specific analyses—were computed using the same global cutoff–threshold pair determined exclusively on the validation set. No test-set or organ-level threshold tuning was performed, ensuring that all reported results reflect unbiased generalization under a fixed operating point.
Limitations related to sparse MoE baseline
Although a sparse Mixture-of-Experts (Sparse MoE) baseline was recommended by the reviewer, we were unable to include a fully trained Sparse MoE-ViT model due to its extremely high computational and memory requirements. Sparse MoE architectures require multi-expert parallelism and heavy all-to-all communication, resulting in substantial GPU bandwidth demands that exceeded the capacity of our available hardware. Prior studies have also reported that sparse-gated MoE frequently suffers from expert imbalance, routing instability, and convergence degradation, particularly when applied to vision transformers or trained on small- to medium-scale datasets19. These issues were further amplified in our high-resolution whole-slide image setting, leading to unstable optimization and poor performance during preliminary attempts.
Moreover, early Sparse MoE runs in our environment produced markedly inferior accuracy and unstable probability outputs compared with our Soft MoE design, which aligns with recent findings showing that dense or soft gating often offers more stable optimization and better downstream task performance than sparse routing20.
To ensure reproducibility under realistic clinical computational constraints, we therefore limited baseline comparisons to stable and resource-feasible architectures (ResNet50, Standard ViT, and Soft MoE-ViT). We acknowledge the exclusion of Sparse MoE as a limitation of the present study, and future work will explore its integration when adequate computational resources become available.
In conclusion, the proposed Soft MoE-ViT model demonstrates excellent weakly supervised classification performance, strong cross-organ generalization, interpretable heatmap outputs, and deployment feasibility. With further scaling of training data, stratified learning, and potential multi-modal integration, this model may serve as a valuable AI tool to support standardized, accurate, and efficient intraoperative pathology diagnostics. Finally, we acknowledge the emergence of large-scale pathology foundation models, such as UNI, Virchow, and H-optimus. While these models offer powerful feature extraction capabilities pre-trained on millions of paraffin-embedded slides, our study prioritized the end-to-end optimization of a specialized Soft MoE architecture to address the specific artifacts inherent to frozen sections (e.g., ice crystals and staining variability). Comparing our approach with frozen feature extraction from these foundation models is a highly promising direction, which we intend to incorporate in our next phase of research to further enhance diagnostic robustness.
Data availability
All datasets generated or analysed during the current study are available from the first author, Jingpeng Wu (email: 583934185@qq.com), upon reasonable request.
References
Hamming, J. F. et al. Role of fine-needle aspiration biopsy and frozen section examination in determining the extent of thyroidectomy. World J. Surg. 22(6), 575–580. https://doi.org/10.1007/s002689900437 (1998).
Gakis, G. et al. Sequential resection of malignant ureteral margins at radical cystectomy: A critical assessment of the value of frozen section analysis. World J. Urol. 29(4), 451–456. https://doi.org/10.1007/s00345-010-0581-z (2011).
Laakman, J. M. et al. Frozen section quality assurance. Am. J. Clin. Pathol. 156(3), 461–470. https://doi.org/10.1093/ajcp/aqaa259 (2021).
Rodig, S. J. Preparing frozen tissue sections for staining. Cold Spring Harb. Protoc. 2021(3), pdb.prot099655 (2021).
Dosovitskiy, A., Beyer, L., Kolesnikov, A. et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proc Int Conf Learn Represent (2021).
Atabansi, C. C. et al. A survey of Transformer applications for histopathological image analysis: New developments and future directions. Biomed. Eng. Online 22, 96. https://doi.org/10.1186/s12938-023-01157-0 (2023).
Deininger, L., Stimpel, B., Yuce, A. et al. A comparative study between vision transformers and CNNs in digital pathology. arXiv preprint arXiv:2206.00389 (2022).
Li, Z. et al. Vision transformer-based weakly supervised histopathological image analysis of primary brain tumors. iScience 26(1), 105872. https://doi.org/10.1016/j.isci.2022.105872 (2023).
Lepikhin, D., Lee, H., Xu, Y. et al. GShard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668 (2020). https://doi.org/10.48550/arXiv.2006.16668
Puigcerver, J., Riquelme, C., Mustafa, B., Houlsby, N. From sparse to soft mixtures of experts. In ICLR (2024).
Lin, H. et al. Edge computing for AI in digital pathology: Opportunities and challenges. Front. Med. Technol. 3, 728502. https://doi.org/10.3389/fmedt.2021.728502 (2021).
Wang, X. et al. Transformer-based unsupervised contrastive learning for histopathological image classification. Med. Image Anal. 81, 102559 (2022).
Ilse, M., Tomczak, J. M. & Welling, M. Attention-based deep multiple instance learning. Proc. Mach. Learn. Res. 80, 2127–2136 (2018).
Lu, M. Y. et al. Data-efficient and weakly supervised computational pathology on whole-slide images. Nat. Biomed. Eng. 5(6), 555–570 (2021).
Pallua, J. D., Brunner, A., Zelger, B., Schirmer, M. & Haybaeck, J. The future of pathology is digital. Pathol. Res. Pract. 216(9), 153040. https://doi.org/10.1016/j.prp.2020.153040 (2020).
Fang, Y., Wang, X., Wu, R. & Liu, W. What makes for hierarchical vision transformer? IEEE Trans. Pattern Anal. Mach. Intell. 45(10), 12714–12720 (2023).
Fedus, W., Zoph, B., Shazeer, N. Switch Transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv preprint arXiv:2101.03961 (2021).
Schwen, L. O., Kiehl, T. R., Carvalho, R., Zerbe, N. & Homeyer, A. Digitization of pathology labs: A review of lessons learned. Lab. Invest. 103(11), 100244. https://doi.org/10.1016/j.labinv.2023.100244 (2023).
Han, X., Wei, L., Dou, Z. et al. ViMoE: An empirical study of designing vision mixture-of-experts. arXiv preprint arXiv:2410.15732 (2024).
Chen, T., Zhang, Z., Jaiswal, A., Liu, S., Wang, Z. Sparse MoE as the new dropout: Scaling dense and self-slimmable transformers. arXiv preprint arXiv:2303.01610 (2023).
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. 82473138).
Author information
Authors and Affiliations
Contributions
J.P. Wu designed and wrote the manuscript, coordinated the entire project, and was responsible for complete data organization and the creation of all statistical figures. M.X. Yang and J.C.L constructed the model. P.Y. Sun revised the figures and proofread the manuscript. X.Q. Zhi assisted in organizing a portion of the data. S.H. Wang conceived the idea for the manuscript. D.R. Zhong conceived the idea for the manuscript and supervised the project.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wu, J., Yang, M., Li, J. et al. Pan-cancer frozen section classification using a soft mixture of experts vision transformer under weak supervision. Sci Rep 16, 10297 (2026). https://doi.org/10.1038/s41598-026-40924-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-40924-6
