
Abstract
Residual strength assessment of corroded pipelines is essential for ensuring the structural integrity and safe operation of gas transportation infrastructure. Traditional empirical formulas and finite element analyses, while widely used, often lack adaptability, interpretability, or computational efficiency. Recent advances in machine learning have improved prediction accuracy; however, many models remain opaque, limiting their utility in safety-critical structural health monitoring (SHM) applications where transparency and physical insight are imperative. This study introduces a novel framework, Symbolic Bayesian Networks (SyBN), for physically interpretable residual strength prediction of corroded pipelines. SyBN combines a Bayesian Feature-Weighted Neural Network (BFW-NN) for high-accuracy prediction and uncertainty quantification with a Deep Symbolic Regression (DSR) component that generates explicit mathematical expressions representing the relationship between pipeline parameters and failure pressure. A key innovation lies in an adaptive gating mechanism that dynamically balances prediction accuracy and symbolic consistency based on sample complexity. Extensive experiments were conducted on a public benchmark dataset comprising both experimental and simulation-based measurements of pipeline burst pressure. SyBN achieved state-of-the-art performance, with an \(R^2\) of 0.966, RMSE of 1.304 MPa, and MAE of 0.968 MPa, outperforming several classical and ensemble learning baselines. Feature importance analysis confirmed high consistency between Bayesian-derived feature weights and SHAP values, while ablation studies validated the necessity of each framework component. The SyBN framework provides an effective and interpretable solution for residual strength prediction in corroded pipelines, offering engineers explicit symbolic models that enhance transparency and support informed decision-making. This approach aligns well with the growing demand for explainable and trustworthy machine learning in SHM tasks, particularly in critical infrastructure systems.
Similar content being viewed by others
Introduction
Structural health monitoring (SHM) plays a critical role in ensuring the long-term safety and reliability of infrastructure systems, particularly those operating under harsh environmental conditions1,2,3,4. Among them, pressurized metallic pipelines are widely used in gas and oil transportation and are often referred to as the lifeline of modern energy infrastructure5,6,7. With increasing service time, corrosion becomes one of the predominant forms of pipeline degradation, leading to wall thinning, loss of mechanical strength, and eventual failure8,9. Catastrophic events such as leakage and rupture can result in significant economic loss, environmental damage, and safety hazards10,11,12. Thus, accurately assessing the residual strength of corroded pipelines is essential for proactive maintenance, safety evaluation, and risk-informed decision-making in SHM.
Traditionally, residual strength assessment relies on three main categories of methods: empirical formulas, finite element analysis, and data-driven approaches13,14. Empirical models, often derived from fracture mechanics, offer quick estimation but are typically conservative and poorly generalizable across different geometries or material conditions15. FEA improves accuracy by simulating physical behavior numerically, yet it requires substantial computational effort and re-modeling when pipeline configurations or loading conditions vary16,17,18.
In recent years, machine learning has emerged as a promising tool in SHM for modeling complex, nonlinear relationships between structural parameters and damage indicators19,20,21,22,23. Algorithms such as artificial neural networks, support vector machines, random forests, and gradient boosting have shown superior predictive accuracy in estimating failure pressure or residual strength from experimental and simulated datasets24,25. Despite their accuracy, these models generally function as “black boxes”—they offer little insight into the physical reasoning behind their predictions26,27,28, which limits their utility in high-stakes SHM tasks where transparency and interpretability are critical.
In safety-critical scenarios such as pipeline integrity assessment, engineers require models that are not only accurate but also interpretable–providing human-readable, physically meaningful relationships between input features and structural performance metrics29,30. Several strategies have been developed to address this challenge. A posteriori interpretability tools, such as SHAP and LIME, can explain black-box models but do not generate self-contained physical insight31,32,33. On the other hand, intrinsically interpretable models, including decision trees and linear regression, often lack the capacity to model complex nonlinearities. Physically informed neural networks embed physics-based constraints but require predefined governing equations, which may not exist for data-driven tasks34,35,36.
Symbolic regression has thus gained attention as a method to discover closed-form mathematical expressions that fit the data while offering inherent interpretability37,38. By searching the function space rather than fitting predefined model forms, symbolic regression enables extraction of concise, human-understandable equations that reflect underlying physical patterns39. However, symbolic methods often suffer from instability and poor generalization when applied to high-dimensional, noisy data–frequent in SHM applications–and typically lag behind deep learning in prediction performance40,41,42.
To bridge the gap between interpretability and accuracy, we propose a novel Symbolic Bayesian Network (SyBN) framework tailored for residual strength prediction of corroded pipelines. SyBN integrates a Bayesian Feature-Weighted Neural Network (BFW-NN) for robust prediction and uncertainty quantification, with a Deep Symbolic Regression (DSR) module that generates explicit mathematical formulas capturing relationships among pipeline geometry, material properties, and failure pressure. An adaptive gating mechanism is introduced to dynamically balance symbolic fidelity and predictive accuracy based on sample complexity.
The key contributions of this paper are summarized as follows:
-
1.
We construct a physically interpretable prediction framework by embedding a DSR component that simulates symbolic computation within a neural architecture, yielding explicit analytical expressions for residual strength estimation.
-
2.
We enable synergistic optimization of accuracy and interpretability through the joint training of BFW-NN and DSR, allowing the symbolic expressions to benefit from high-performance learning while maintaining transparency.
-
3.
We design a metacognitive gating mechanism that adaptively adjusts symbolic consistency constraints based on sample characteristics, improving model generalization and adaptability to complex data.
This work contributes to the advancement of interpretable machine learning within SHM, particularly for residual strength evaluation in corroded pipeline systems. The proposed SyBN framework supports both high-accuracy estimation and engineering interpretability, helping bridge the gap between data-driven intelligence and domain-trusted decision-making.
Methodology
Overall framework of SyBN for SHM applications
To address the challenge of balancing accuracy and interpretability in the residual strength assessment of corroded pipelines, this paper proposes the SyBN framework. This framework integrates two core components: a BFW-NN and DSR, achieving cooperative optimization through an adaptive gating mechanism.
Given an input vector \(\textbf{x} = [D, t, \sigma _y, \sigma _u, E, d, l, w]^T \in \mathbb {R}^8\), comprising pipe geometric parameters, material properties, and defect features, SyBN predicts the residual strength of the corroded pipe, \(P_b\). The BFW-NN component captures the complex nonlinear relationship between the input features and residual strengths through its Bayesian feature-weighting mechanism, while simultaneously quantifying prediction uncertainty. The DSR component constructs explicit mathematical expressions relating the input variables to the residual strengths, thereby providing a physical interpretation of the predicted results. The adaptive gating mechanism dynamically adjusts the contribution weights of the two components based on the sample features, aiming to achieve an optimal balance between prediction accuracy and interpretability. We strategically integrate BFW-NN and DSR to leverage their complementary strengths: BFW-NN effectively mitigates data noise via probabilistic weighting, while DSR–unlike traditional evolutionary algorithms–enables seamless joint gradient optimization with the predictive network. This specific configuration allows the framework to achieve high-precision nonlinear modeling while simultaneously generating interpretable physical expressions.
To clearly illustrate the internal mechanism, Fig. 1 depicts the detailed network architecture of SyBN. It demonstrates how the input vector is processed in parallel by the probabilistic BFW-NN branch and the symbolic DSR branch, with their outputs fused via the adaptive gating module to compute the total loss.

The detailed network architecture of the SyBN framework.
BFW-NN: Bayesian feature-weighted neural network for robust prediction
In SHM applications, robustness and uncertainty quantification are crucial for trustworthy prediction, particularly when dealing with limited or noisy data. To this end, we design BFW-NN that models feature importance as distributions and captures predictive uncertainty. In the context of data-driven SHM, predictive uncertainty is generally categorized into aleatoric uncertainty, which arises from inherent data noise, and epistemic uncertainty, which stems from a lack of knowledge or limited training data43. The proposed BFW-NN primarily addresses epistemic uncertainty by treating feature attention weights not as deterministic values but as probability distributions. This allows the model to express higher confidence in regions with dense data and lower confidence in extrapolation regimes.
The distribution parameters are dynamically generated from the input features:
where \(\textbf{W}_{\mu }, \textbf{W}_{\rho } \in \mathbb {R}^{8 \times 8}\) are weight matrices, \(\textbf{b}_{\mu }, \textbf{b}_{\rho } \in \mathbb {R}^8\) are bias vectors, and the softplus function ensures positive variance.
During training, to allow for gradient backpropagation through stochastic nodes, attention weights are sampled using the reparameterization trick44:
During inference, the mean values are used for deterministic output:
Attention weights are applied to the original features after softmax normalization:
The weighted feature vector \(\textbf{x}^{\prime}\) is input to the multilayer perceptron for feature extraction and prediction:
where \(f_{\text {MLP}}\) is a three-layer fully connected network and \(\varvec{\theta }_{\text {BFW}}\) is a network parameter.
DSR: Deep symbolic regression for interpretable modeling
Interpretable modeling is essential in safety-critical domains such as pipeline integrity assessment, where transparent reasoning supports engineering decisions. DSR module aims to generate human-readable mathematical expressions reflecting the underlying physics of failure. The DSR component employs an encoder-decoder architecture, adapted from the Deep Symbolic Regression framework45, to simulate the symbolic computation process within a neural network framework, thereby learning the structured mathematical relationship between input features and residual strengths.
The encoder maps the input features to the hidden space:
where \(f_{\text {enc}}\) is a two-layer fully connected network. The symbol generator extracts symbol features from the encoded representation:
DSR simulates mathematical operations through an operation weight matrix \(\textbf{W}_{\text {op}} \in \mathbb {R}^{4 \times H}\), where the four rows correspond to addition, subtraction, multiplication, and division operations, and H denotes the symbolic feature dimension. Each operation result is computed as:
where \(\textbf{w}_i\) represents the i-th row of \(\textbf{W}_{\text {op}}\). The symbolic output aggregates all operation results:
The decoder maps the symbolic features back into the target space and combines them with the symbolic output to form the final prediction:
DSR employs L1 sparsity regularization to promote concise symbolic expressions:
where \(\lambda _s\) denotes the sparsity penalty coefficient.
Adaptive gating mechanism and joint loss design
SyBN achieves joint optimization through an adaptive gating mechanism. The gating unit generates dynamic constraint weights based on BFW-NN’s intermediate representation \(\textbf{h}_{\text {fc3}} \in \mathbb {R}^{16}\):
where \(\textbf{W}_{\text {gate}} \in \mathbb {R}^{1 \times 16}\) and \(b_{\text {gate}} \in \mathbb {R}\) are gating parameters, and \(\sigma (\cdot )\) denotes the sigmoid activation.
The joint optimization employs a multi-objective loss function:
This loss comprises three terms: the prediction accuracy term \(\mathcal {L}_{\text {MSE}}(y, \hat{y}_{\text {BFW}})\) ensures accurate BFW-NN predictions; the consistency term \({\beta } \cdot \mathcal {L}_{\text {MSE}}(\hat{y}_{\text {BFW}}, \hat{y}_{\text {DSR}})\) aligns DSR outputs with BFW-NN; and the sparsity term \(\lambda _s \Vert \textbf{h}_{\text {sym}}\Vert _1\) promotes concise symbolic expressions.
The adaptive weight \({\beta }\) dynamically adjusts symbolic consistency constraints based on sample complexity. This mechanism acts as a dynamic controller: it calculates the optimal weight \(\beta\) to balance the flexibility of the neural network with the structural rigor of the symbolic regression. By doing so, it determines when to rely on data-driven fitting and when to enforce physical consistency.This self-regulating behavior embodies a metacognitive process, where the model evaluates its own prediction difficulty to adjust its strategy.
Experimental setup and results
Data acquisition and preprocessing
Data acquisition
This study utilizes a publicly available dataset20 sourced from existing literature for model training and validation. The dataset comprises 453 samples, encompassing 102 experimental measurements and 351 finite element analysis results. The reliability of this dataset is ensured through a rigorous validation process established in the source study. Specifically, the experimental data were obtained from full-scale burst tests conducted in compliance with industrial testing standards, while the FEA data were generated using high-fidelity numerical models explicitly calibrated against these experimental results to ensure physical consistency. Furthermore, prior to modeling, we conducted a data quality assessment to verify that all geometric and material parameters fall within physically meaningful ranges consistent with engineering practice. The input features include eight key parameters characterizing the pipe geometry, material properties, and defect characteristics: pipe diameter (D/mm), wall thickness (t/mm), yield strength (\(\sigma _y\)/MPa), ultimate tensile strength (\(\sigma _u\)/MPa), elastic modulus (E/MPa), defect depth (d/mm), defect length (l/mm), and defect width (w/mm). The target variable is the burst pressure (\({P_b}\)/MPa), which represents the critical pressure at which pipe damage occurs.
Dataset descriptive statistics and feature distributions
The dataset employed for this study consists of 453 samples, each defined by eight input features and a single target variable, the burst pressure (\(P_b\)). These features characterize the pipe’s geometry (diameter D, wall thickness t), material properties (yield strength \(\sigma _y\), ultimate tensile strength \(\sigma _u\), elastic modulus E), and defect dimensions (depth d, length l, width w). Table 1 provides a summary of the descriptive statistics. The variables exhibit wide-ranging values, such as a pipe diameter (D) spanning from 41.92 mm to 2286.00 mm, reflecting diverse real-world engineering scenarios. A key challenge is presented by the target variable, burst pressure (\(P_b\)), which shows a high coefficient of variation (40.6%), indicating significant inter-sample heterogeneity. Further analysis of the variable distributions, as shown in Fig. 2, reveals their complex nature. For instance, the pipe diameter (D) follows a bimodal distribution, while several features, including material strengths and defect geometries, are characterized by pronounced right-skewness. This heterogeneity demands a modeling approach capable of handling non-Gaussian data distributions effectively.

Probability density distributions of eight input variables for corroded pipeline burst pressure prediction: (a) pipe diameter D (mm), (b) wall thickness t (mm), (c) yield strength \(\sigma\)y (MPa), (d) ultimate tensile strength \(\sigma\)u (MPa), (e) elastic modulus E (MPa), (f) defect depth d (mm), (g) defect length l (mm), and (h) defect width w (mm).
Dataset correlation and interaction analysis
To understand the relationships within the dataset, we analyzed both input-target correlations and inter-variable interactions. Figure 3 illustrates the complex, often nonlinear relationships between input features and the burst pressure (\(P_b\)). Material strength parameters (\(\sigma _y\), \(\sigma _u\)) and defect depth (d) show the strongest correlations with the target, exhibiting clear positive and negative trends, respectively. However, their relationships are nonlinear, with variance increasing at higher strength levels. Other geometric parameters display weaker or non-monotonic correlations, suggesting that simple linear models would be insufficient. To quantitatively assess inter-variable dependencies, Fig. 4 presents the Pearson correlation heatmap. The matrix explicitly reveals significant multicollinearity among input features, most notably between yield strength and ultimate tensile strength (\(\rho =0.92\)), as well as between pipe diameter and wall thickness (\(\rho =0.74\)). Regarding the target variable \(P_b\), wall thickness exhibits the strongest positive correlation, whereas defect length and depth show negative correlations. These statistical observations are consistent with physical failure mechanisms, where material hardening and geometric reinforcement increase load-bearing capacity, while defect expansion degrades it.

Scatter plots illustrating the relationships between input variables and burst pressure Pb for corroded pipeline strength assessment: (a) pipe diameter D (mm), (b) wall thickness t (mm), (c) yield strength \(\sigma\)y (MPa), (d) ultimate tensile strength \(\sigma\)u (MPa), (e) elastic modulus E (MPa), (f) defect depth d (mm), (g) defect length l (mm), and (h) defect width w (mm).

Pearson correlation heatmap quantifying the linear dependencies between input features and burst pressure.
Data-driven modeling challenges
The comprehensive data analysis highlights three principal challenges for predictive modeling. First, the high heterogeneity of the data, evidenced by bimodal and heavily skewed variable distributions, requires a robust and flexible model architecture. Second, the complex nonlinearity in the relationships between features and the target variable necessitates a model that can capture intricate, non-monotonic trends beyond the capacity of traditional linear methods. Third, the coupled interactions among variables, characterized by an asymmetric correlation network, demand a model that can effectively learn from interdependent features without being compromised by issues like multicollinearity. These data-driven challenges collectively underscore the necessity for an advanced machine learning framework, like the proposed SyBN, which is specifically designed to address such complexities while providing interpretable insights.
Baseline models and evaluation metrics
Baseline methods and comparative analysis
In order to comprehensively evaluate the performance of the proposed SyBN framework, this study compares it against a range of established machine learning methods. These baseline methods span various modeling paradigms, including linear regression techniques, instance-based algorithms, kernel-based approaches, and ensemble learning models.
-
Linear regression Fits a linear mapping between input features and target variables using the least squares criterion.
-
Ridge regression Enhances linear regression by incorporating an L2 regularization term, which improves model robustness and addresses multicollinearity.
-
K nearest neighbors (KNN) A non-parametric method that makes predictions based on the characteristics of the closest training samples in feature space.
-
Support vector regression (SVR) Utilizes kernel functions to capture nonlinear relationships within high-dimensional feature spaces, providing flexibility and precision.
-
Random forest (RF) An ensemble learning technique that improves stability and generalization by aggregating predictions from multiple decision trees constructed on different data subsets.
-
Gradient boosted decision tree (GBDT) Builds an additive model in a forward stage-wise fashion, where each new learner focuses on correcting the residuals of the previous ensemble.
-
Extreme gradient boosting (XGBoost) A highly efficient implementation of GBDT that introduces regularization and parallel processing, leading to improved performance and scalability.
The key parameter configurations used in the experiments for each comparison method are summarized in Table.2.
Evaluation metrics and statistical analysis
To ensure the robustness and statistical reliability of the results, each experiment was independently repeated ten times. The reported performance metrics represent the mean and standard deviation across these repeated runs. The evaluation of SyBN, along with all baseline methods, was conducted using three widely accepted metrics46:
The Coefficient of Determination (\(R^2\)) quantifies the proportion of variance in the target variable that is predictable from the independent variables. It is formally defined as:
The Root Mean Square Error (RMSE) measures the standard deviation of the residuals, reflecting how concentrated the data are around the line of best fit:
The Mean Absolute Error (MAE) provides a linear score of the average magnitude of the prediction errors, offering an interpretable measure of predictive accuracy:
In these equations, \(y_i\) denotes the true value, \(\hat{y}_i\) the predicted value, and \(\bar{y}\) the mean of the true values. Together, these metrics offer a comprehensive evaluation of the model’s predictive performance across multiple dimensions.
Implementation details
Experiments were conducted on a computing platform equipped with an Intel Core i9-13980HX processor, NVIDIA GeForce RTX 4060 Laptop GPU, and 64GB memory. The PyTorch 2.0.1 deep learning framework was employed with Python version 3.9.18 and CUDA version 11.8. Key dependency libraries include numpy 1.24.3 for numerical computation and scikit-learn 1.3.0 for evaluation metric calculation. Under this configuration, the total computation time for training and evaluating the SyBN model was approximately 60 seconds. The average inference latency was negligible, satisfying the requirements for real-time SHM applications.It is worth noting that this high computational efficiency is primarily attributed to the end-to-end differentiable architecture of the proposed DSR module, which enables rapid gradient-based optimization and effectively avoids the high computational overhead associated with traditional evolutionary search strategies typically used in symbolic regression.
To strictly ensure the reproducibility of the proposed model, the detailed architectural design and training hyperparameters are summarized in Table 3. The BFW-NN consists of a three-layer multilayer perceptron with ReLU activation, while the DSR module employs a symmetric encoder-decoder structure. The sparsity regularization coefficient \(\lambda _s\) was tuned to balance expression complexity and accuracy.
Comparative performance
This section evaluates the performance of SyBN on the task of corrosive pipe burst pressure prediction by comparing it with several existing machine learning methods.
Table 4 presents the average performance metrics computed from 10 independent experiments. SyBN demonstrates superior performance across all evaluated metrics: its MSE, RMSE, and MAE values are 1.700, 1.304, and 0.968, respectively, representing the lowest recorded values. Furthermore, its \(R^2\) value of 0.966 is notably higher than that of other models. In contrast, integrated methods such as XGBoost and GBDT achieved higher accuracy than other baselines, but their performance was still inferior to that of SyBN. The relatively low performance of traditional linear and kernel-based methods further confirms the nonlinear characteristics inherent in this prediction task.
Figure 5 further elucidates the differences in model stability. As illustrated by the boxplot of the \(R^2\) distribution, SyBN not only exhibits the highest median performance but also the smallest interquartile range, indicative of its excellent stability and consistency in prediction results. In contrast, the other models display greater performance fluctuations, particularly the traditional linear methods, which exhibit larger distribution dispersion, reflecting their inherent instability when addressing complex nonlinear relationships.

Boxplot comparison of \(R^2\) performance stability across different models.
The high stability of SyBN originates from two protective mechanisms. The Bayesian component reduces variance by smoothing out random data noise through probabilistic weighting. Simultaneously, the symbolic component restricts the model to learn only simple and smooth mathematical forms. This prevents the network from memorizing random fluctuations and ensures consistent performance across different data samples.
Uncertainty quantification analysis
A key advantage of the SyBN framework over traditional black-box models is its ability to quantify predictive uncertainty, encompassing both aleatoric and epistemic components. To validate this, we constructed 95% prediction intervals via 300 Monte Carlo stochastic forward passes.
Figure 6 visualizes the calibrated results sorted by burst pressure. The shaded regions represent the total predictive uncertainty. It is observed that the confidence intervals effectively bracket the true values for the majority of samples. Crucially, the intervals exhibit significant widening in regions with sparse training data, correctly reflecting high epistemic uncertainty where the model lacks knowledge. Conversely, in dense data regions, the intervals narrow but maintain a baseline width, capturing the irreducible aleatoric uncertainty inherent in the stochastic nature of pipeline corrosion and material properties. This distinction allows engineers to identify whether prediction risks stem from data quality or data scarcity.

Uncertainty quantification on the test set where samples are sorted by true burst pressure. The blue line represents the true values, and the shaded area indicates the calibrated 95% prediction interval.
To quantitatively assess the reliability of these estimates, we calculated the Prediction Interval Coverage Probability (PICP). For a nominal 95% confidence level, the SyBN model achieved an observed PICP of 94.5%, indicating that the quantified uncertainty is well-calibrated and trustworthy for risk-informed decision-making.
Gating mechanism analysis
To understand the decision-making of the adaptive gating unit, we analyzed the gating weight \(\beta\) distribution and its relationship with prediction error.
Figure 7 reveals two key insights into the model’s behavior. First, the overall magnitude of \(\beta\) remains extremely low and stays below \(5 \times 10^{-4}\). This confirms that the SyBN framework relies primarily on the high-precision BFW-NN for prediction, while the symbolic component serves as a soft auxiliary constraint rather than a dominant factor.
Second, despite these small values, Fig. 7b shows a clear positive correlation between prediction error and \(\beta\). This indicates a corrective mechanism where the model automatically increases \(\beta\) to enforce stricter symbolic constraints when the neural network produces large errors on difficult samples. Conversely, for easy samples where the network predicts accurately, \(\beta\) drops to near zero to allow the network to fit the data flexibly without unnecessary interference.

Analysis of the adaptive gating mechanism. (a) Density distribution of gating weight \(\beta\). (b) Relationship between gating weight and absolute prediction error.
Ablation study
To validate the architectural design of the SyBN framework and to quantify the contribution of its principal components, a systematic ablation study was conducted. This study methodically deconstructs the model to isolate the functional significance of each module. The investigation began with the complete SyBN model (SyBN-Full), which integrates the BFW-NN, DSR, and the Adaptive Gating mechanism.
Subsequently, a series of variant models were configured to probe the necessity of each component. To ascertain the impact of symbolic regression, a variant termed SyBN w/o DSR was established by removing the DSR module and its associated symbolic consistency constraints. The role of Bayesian feature weighting was examined in the SyBN w/o BFW model, where this mechanism was substituted with a standard attention layer. To evaluate the adaptive gating, the SyBN w/o Gate model was formulated with the gating weight \(\alpha\) fixed at a constant of 0.5, thereby disabling its dynamic adjustment. The influence of model parsimony on symbolic representation was assessed through the SyBN w/o Sparse configuration, from which the \(L_1\) sparsity regularization in the DSR component was omitted. Finally, a Standard Neural Network (Standard NN), possessing an identical network architecture but devoid of all specialized SyBN components, served as a performance baseline.
The empirical results of the ablation experiments are presented in Table 5. The complete SyBN-Full model achieved the highest performance with a coefficient of determination (\(R^2\)) of 0.966. The removal of the DSR module (SyBN w/o DSR) led to a significant performance degradation of 11.6 % (\(R^2=0.854\)), underscoring the critical role of DSR in not only enhancing model interpretability but also imposing a structured learning paradigm that improves predictive accuracy. A comparable degradation of 12.2% was observed upon removing the Bayesian feature weighting (SyBN w/o BFW), with the \(R^2\) value dropping to 0.848. This result highlights the necessity of the BFW-NN’s adaptive feature weighting for modeling complex nonlinear relationships effectively. Disabling the adaptive gating mechanism (SyBN w/o Gate) resulted in a 5.1% decrease in performance (\(R^2=0.917\)), confirming the importance of dynamically balancing predictive accuracy with symbolic fidelity based on sample-specific characteristics. Furthermore, the exclusion of the sparsity constraint (SyBN w/o Sparse) caused an 8.8% reduction in \(R^2\) to 0.881, indicating that \(L_1\) regularization is vital for learning concise and generalizable symbolic expressions. In comparison to the SyBN-Full model, the Standard NN baseline exhibited a 15.9% lower performance, which quantitatively demonstrates the synergistic advantage conferred by the integration of Bayesian modeling, deep symbolic regression, and adaptive mechanisms within the SyBN framework.
Hyperparameter sensitivity
This section investigates the sensitivity of the SyBN model to critical hyperparameters, including learning rates and optimizers, to identify the optimal training configuration. The experiments evaluated three learning rates (0.001, 0.005, and 0.01) in combination with six optimizers (Adagrad, RMSprop, Adam, SGD, Adamax, and NAdam), resulting in 18 unique configurations. Model performance was assessed using the coefficient of determination (\(R^2\), with the mean calculated from five training runs for each configuration. The results are presented in Table 6.
Table 6 indicates that the model’s performance exhibits significant sensitivity to both the learning rate and the choice of optimizer. Across all tested combinations, the model achieved its highest \(R^2\) value of 0.965 when the learning rate was 0.001 and the NAdam optimizer was employed. The Adam optimizer also performed commendably at learning rates of 0.001 and 0.005, with \(R^2\) values exceeding 0.959 in both instances. RMSprop and Adamax demonstrated relatively consistent performance across the different learning rates, with \(R^2\) values exceeding 0.959 in most cases. In contrast, Adagrad performed significantly worse than the other optimizers at all learning rates, which may be attributed to its gradient accumulation method being unsuitable for the current task. The SGD optimizer’s performance varied considerably with the learning rate, and its overall performance was inferior to that of optimizers based on adaptive gradients.
To better illustrate the sensitivity of hyperparameters, Fig. 8 presents the model’s \(R^2\) values across various learning rates and optimizer combinations, accompanied by error bars.

Visualization of \(R^2\) values and errors of the SyBN model under different learning rate and optimizer combinations.
Figure 8 illustrates the effect of various learning rates and optimizer combinations on the performance (mean \(R^2\) value) of the SyBN model using 3D bar charts. The height of each bar represents the average \(R^2\) value for a given combination, while the error bar above each bar indicates the range of fluctuation, i.e., the error value, based on five training results for that combination. The length of the error bar reflects the stability of the model’s performance under each hyperparameter configuration: shorter error bars indicate more stable and repeatable performance, while longer error bars suggest greater fluctuation and higher uncertainty in the results. The figure provides the following insights:
Among the tested optimizers, NAdam exhibited superior performance at a learning rate of 0.001, achieving a high coefficient of determination (\(R^2\)) of 0.965 and a minimal error of 0.005425. This combination indicates that the model configuration is both highly accurate and stable. In contrast, the Adagrad optimizer consistently yielded low \(R^2\) values across all tested learning rates. Although it demonstrated some stability at a lower rate of 0.001 with an error of 0.014825, its overall predictive performance remained suboptimal.
The performance of the Stochastic Gradient Descent (SGD) optimizer fluctuated significantly, particularly at learning rates of 0.005 and 0.01, which produced large error bars of 0.03855 and 0.064, respectively, indicating instability. Conversely, the Adam and RMSprop optimizers showed robust performance, exhibiting high \(R^2\) values and relatively small error bars across most learning rates. For instance, at learning rates of 0.001 and 0.005, Adam achieved an \(R^2\) value of approximately 0.959 with low corresponding errors of 0.011175 and 0.010975, respectivel, reflecting its strong and reliable performance.
From the perspective of the learning rate, better-performing optimizers typically exhibit improved or comparable performance with lower learning rates. In contrast, some optimizers experience a slight reduction in performance when the learning rate is increased to 0.01. This observation suggests that, for training the SyBN model, adopting a smaller learning rate facilitates model convergence and enhances performance.
In conclusion, the NAdam and Adam optimizers demonstrated the best performance during SyBN model training, particularly at lower learning rates. Based on the sensitivity analysis results, NAdam is selected as the default optimizer for SyBN model training in this study, with a learning rate of 0.001. The optimal configuration must balance computational efficiency with model performance, and this analysis provides a critical foundation for the hyperparameter tuning of the SyBN model.
Interpretability analysis
The principle of SHAP
This study introduces the SHAP (SHapley Additive exPlanations) method47 to validate the reliability of the SyBN model’s feature importance assessment. SHAP is based on game-theoretic Shapley value theory, which quantifies the marginal contribution of each feature to the model’s prediction.
For sample \(\textbf{x}\) and model f, the SHAP value \(\phi _j(\textbf{x})\) quantifies feature \(x_j\)’s contribution:
where \(\phi _0\) denotes the baseline value and p represents feature dimensionality.
The Shapley value considers feature j’s marginal contribution across all possible feature subsets:
where \(N = \{1, 2, \ldots , p\}\) denotes the feature index set and S represents feature subsets excluding j.
Global feature importance averages absolute SHAP values across all samples:
Feature importance analysis
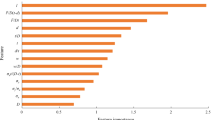
The purpose of this section is to assess the relative importance of each input feature of the SyBN model in predicting the burst pressure of corroded pipelines. Accurate identification of key influences is essential for model validation and to guide engineering practice. The SyBN framework quantifies feature contributions through a Bayesian feature-weighting mechanism integrated into its BFW-NN component. To validate the reasonableness of the Bayesian weight assignment, this study employs the model-independent SHAP interpretation method. SHAP evaluates the average impact of each feature on the overall model output by calculating the Shapley value. Comparing the Bayesian feature weights with the SHAP values allows for cross-validation of the reliability of feature importance determination within the model from different perspectives.

Bayesian feature weights and SHAP values of input features.
Figure 9 presents the Bayesian average feature weights alongside SHAP global importance values. The results indicate that wall thickness (t) exhibits the highest importance across both metrics, followed by the modulus of elasticity (E) and defect length (l). This finding aligns well with the engineering common sense regarding pipeline structural integrity and the impact of defects. In contrast, ultimate tensile strength (\(\sigma _u\)) and defect width (w) demonstrate relatively lower importance. Notably, the Bayesian weights and SHAP values show significant agreement in the relative ordering of feature importance. This mutual corroboration from independent interpretive methods strongly supports the rationality and effectiveness of the Bayesian feature-weighting mechanism within the SyBN model for identifying key predictor variables. By combining Bayesian probabilistic modeling with SHAP a posteriori analysis, this study enhances the credibility of feature importance analysis.
Conclusion and future work
This study presents a novel SyBN framework for interpretable and accurate prediction of the residual strength of corroded pipelines. By integrating a BFW-NN with a DSR module, and coordinating them through an adaptive gating mechanism, SyBN achieves a balanced fusion of predictive accuracy and model transparency. Experimental validation on a benchmark dataset demonstrates that SyBN significantly outperforms traditional machine learning methods and ensemble models, achieving an R2 of 0.966, while providing concise symbolic expressions that reveal underlying relationships between pipeline parameters and failure pressure.
The interpretable nature of SyBN offers substantial benefits for SHM applications, where engineers often require not only accurate estimations but also explicit, physically meaningful models to support risk-informed maintenance, inspection planning, and failure prevention. Specifically, regarding the engineering problem of pipeline integrity assessment, SyBN resolves the conflict between high-precision requirements and the need for transparent decision-making. Its symbolic outputs facilitate rapid onsite verification, while its uncertainty quantification aids in optimizing maintenance schedules under data scarcity. The agreement between Bayesian-derived feature weights and SHAP-based post hoc explanations further strengthens the credibility of the model’s reasoning process, making it a practical tool for field deployment in safety-critical infrastructure systems.
Despite these advancements, this study remains limited by its reliance on static geometric data, which precludes the modeling of time-dependent corrosion growth rates. Additionally, the current dataset does not encompass environmental variables such as soil chemistry and temperature that significantly influence degradation kinetics. Future work will focus on extending the framework to handle real-time data from in-situ monitoring systems, incorporating multi-source sensor data (e.g., acoustic emission, vibration), and expanding symbolic modeling to encompass time-dependent degradation patterns. Furthermore, integration with digital twin platforms may enable adaptive, interpretable diagnostics for pipeline networks operating under variable loading and environmental conditions. The proposed SyBN framework lays a promising foundation for advancing explainable AI methods in the SHM domain.
Data availability
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request and will be upload to GitHub after acceptance.
References
Lu, Y. et al. Acoustic emission-based graph learning for internal valve leakage localisation in offshore pipelines. Nondestruct. Test. Eval. 1–29 (2025).
Zhang, Y., Pullin, R., Oelmann, B. & Bader, S. On-device fault diagnosis with augmented acoustic emission data: A case study on carbon fiber panels. IEEE Trans. Instrum. Meas. 74, 1–12 (2025).
Muthumala, U., Zhang, Y., Martinez-Rau, L. S. & Bader, S. Comparison of tiny machine learning techniques for embedded acoustic emission analysis. In 2024 IEEE 10th World Forum on Internet of Things (WF-IoT), 444–449 (2024).
Zhang, Y., Martinez-Rau, L. S., Vu, Q. N. P., Oelmann, B. & Bader, S. Survey of quantization techniques for on-device vision-based crack detection. In 2025 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), 1–6 (2025).
Farh, H. M. H., Seghier, M. E. A. B. & Zayed, T. A comprehensive review of corrosion protection and control techniques for metallic pipelines. Eng. Fail. Anal. 143, 106885 (2023).
Hussein Farh, H. M., Ben Seghier, M. E. A., Taiwo, R. & Zayed, T. Analysis and ranking of corrosion causes for water pipelines: A critical review. NPJ Clean Water 6, 65 (2023).
Lu, Y. et al. End-to-end graph neural network framework for precise localization of internal leakage valves in marine pipelines based on intelligent graphs. Adv. Eng. Inf. 68, 103716 (2025b).
Vanaei, H., Eslami, A. & Egbewande, A. A review on pipeline corrosion, in-line inspection (ili), and corrosion growth rate models. Int. J. Press. Vess. Piping 149, 43–54 (2017).
Ossai, C. I., Boswell, B. & Davies, I. J. Pipeline failures in corrosive environments-a conceptual analysis of trends and effects. Eng. Fail. Anal. 53, 36–58 (2015).
Cheng, Y. F. Stress corrosion cracking of pipelines (John Wiley & Sons, 2013).
Wasim, M. & Djukic, M. B. External corrosion of oil and gas pipelines: A review of failure mechanisms and predictive preventions. J. Nat. Gas Sci. Eng. 100, 104467 (2022).
Ilman, M. et al. Analysis of internal corrosion in subsea oil pipeline. Case Stud. Eng. Fail. Anal. 2, 1–8 (2014).
Miao, X. & Zhao, H. Novel method for residual strength prediction of defective pipelines based on htlbo-delm model. Reliab. Eng. Safety 237, 109369 (2023).
Li, S., Yang, Y., Huang, B. & Jia, Y. Residual strength hybrid prediction of hydrogen-blended natural gas pipelines based on FEM-FC-BP model. Energy 321, 135463 (2025).
Stephens, D. R. & Leis, B. N. Development of an alternative criterion for residual strength of corrosion defects in moderate-to high-toughness pipe. In international Pipeline Conference Vol 40252, V002T06A012 (American Society of Mechanical Engineers, 2000).
Zhou, R., Gu, X. & Luo, X. Residual strength prediction of x80 steel pipelines containing group corrosion defects. Ocean Eng. 274, 114077 (2023).
Larin, O., Potopalska, K. & Mygushchenko, R. Statistical estimation of residual strength and reliability of corroded pipeline elbow part based on a direct fe-simulations. J. Serbian Soc. Comput. Mech. 12, 80–95 (2018).
Wang, Z., Long, M., Duan, W., Wang, A. & Li, X. Predicting the residual strength of oil and gas pipelines using the GA-BP neural network. Recent Innov. Chem. Eng. 17, 233–254 (2024).
Li, G., Chen, M., Lu, Y. & Zhang, Y. Rolling bearing fault diagnosis in noisy environments using channel-time parallel attention networks. Sci. Rep. 15, 35034 (2025).
Wang, Q. & Lu, H. A novel stacking ensemble learner for predicting residual strength of corroded pipelines. NPJ Mater. Degrad. 8, 87 (2024).
Lu, H. et al. Uncertainty quantification for damage detection in 3d-printed auxetic structures using ultrasonic guided waves and a probabilistic neural network. Thin-Wall. Struct. 205, 112466 (2024).
Du, J. et al. Uncertainty quantification of compressive after impact strength in laminated composites using improved bayesian resnet deep learning model. Polym. Comp. 46, S787–S801 (2025).
Liu, H., Lu, Y., Cheng, W., Qiu, X. & Li, X. Marine pipeline corrosion rates prediction via adversarial cloud data synthesis and pipeline medium similarity graph neural networks. Ocean Eng. 342, 122832 (2025).
Liu, P., Han, Y. & Tian, Y. Residual strength prediction of pipeline with single defect based on svm algorithm. J. Phys.: Conf. Ser. 1944, 012019 (2021).
Mokhtari, M. & Melchers, R. E. A new approach to assess the remaining strength of corroded steel pipes. Eng. Fail. Anal. 93, 144–156 (2018).
Adın, V., Zhang, Y., Andò, B., Oelmann, B. & Bader, S. Tiny machine learning for real-time postural stability analysis. In 2023 IEEE Sensors Applications Symposium (SAS), 1–6 (2023).
Zhang, Y., Adin, V., Bader, S. & Oelmann, B. Leveraging acoustic emission and machine learning for concrete materials damage classification on embedded devices. IEEE Trans. Instrument. Measur. 72, 1–8 (2023).
Zhang, Y. et al. On-device crack segmentation for edge structural health monitoring. In 2025 IEEE Sensors Applications Symposium (SAS), 1–6 (2025).
Sun, C., Wang, Q., Li, Y., Li, Y. & Liu, Y. Numerical simulation and analytical prediction of residual strength for elbow pipes with erosion defects. Materials 15, 7479 (2022).
Netto, T., Ferraz, U. & Botto, A. Residual strength of corroded pipelines under external pressure: A simple assessment. Int. Pipeline Conf. 42622, 143–156 (2006).
Mosca, E., Szigeti, F., Tragianni, S., Gallagher, D. & Groh, G. Shap-based explanation methods: A review for nlp interpretability. In Proceedings of the 29th International Conference on Computational Linguistics, 4593–4603 (2022).
Van den Broeck, G., Lykov, A., Schleich, M. & Suciu, D. On the tractability of shap explanations. J. Artif. Intell. Res. 74, 851–886 (2022).
Li, Z. Extracting spatial effects from machine learning model using local interpretation method: An example of shap and xgboost. Comput. Environ. Urban Syst. 96, 101845 (2022).
Charbuty, B. & Abdulazeez, A. Classification based on decision tree algorithm for machine learning. J. Appl. Sci. Technol. Trends 2, 20–28 (2021).
Rana, K. K. et al. A survey on decision tree algorithm for classification. Int. J. Eng. Dev. Res. 2, 1–5 (2014).
Navada, A., Ansari, A. N., Patil, S. & Sonkamble, B. A. Overview of use of decision tree algorithms in machine learning. In 2011 IEEE Control and System Graduate Research Colloquium, 37–42 (IEEE, 2011).
Billard, L. & Diday, E. Symbolic regression analysis. In Classification, Clustering, and Data Analysis: Recent Advances and Applications, 281–288 (Springer, 2002).
Angelis, D., Sofos, F. & Karakasidis, T. E. Artificial intelligence in physical sciences: Symbolic regression trends and perspectives. Arch. Comput. Methods Eng. 30, 3845–3865 (2023).
Makke, N. & Chawla, S. Interpretable scientific discovery with symbolic regression: A review. Artif. Intell. Rev. 57, 2 (2024).
Biggio, L., Bendinelli, T., Neitz, A., Lucchi, A. & Parascandolo, G. Neural symbolic regression that scales. In International Conference on Machine Learning, 936–945 (PMLR, 2021).
Lu, H. et al. Uncertainty-quantified unsupervised transfer learning for ultrasonic-based corrosion detection in underwater steel pipes. Autom. Constr. 178, 106385 (2025).
Lu, H. et al. Damage identification using ultrasonic lamb waves with multi-scale adaptive attention transformer-based unsupervised domain adaptation. Mech. Syst. Signal Process. 234, 112772 (2025d).
Kendall, A. & Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision?. In Bayesian; Epistemic Uncertainties; Learning Frameworks; Learning Models; Learning Tool; Loss Functions; Modeling Uncertainties; Noisy Data; Semantic Segmentation; Uncertainty. (2017).
Kingma, D. P. & Welling, M. Auto-encoding variational Bayes. arXiv.org (2014).
Petersen, B. K. Deep symbolic regression: Recovering mathematical expressions from data via policy gradients. CoRR. arXiv:1912.04871 (2019).
Chicco, D., Warrens, M. J. & Jurman, G. The coefficient of determination R-squared is more informative than smape, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 7, 1–24 (2021).
Lundberg, S. M. & Lee, S.-I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems Vol 30 (2017).
Funding
Open access funding provided by Mid Sweden University.
Author information
Authors and Affiliations
Contributions
Menghan Chen: Methodology, Visualization, Software, Formal analysis, Writing—original draft. Yuxuan Zhang: Supervision, Writing—review and editing. Yanchen Ye: Data curation,Validation Yuchen Lu: Supervision, Funding, Writing—review and editing. All authors have approved the final version of this manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, M., Zhang, Y., Ye, Y. et al. physically interpretable residual strength prediction of corroded pipelines via symbolic Bayesian networks. Sci Rep 16, 8151 (2026). https://doi.org/10.1038/s41598-026-41914-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-41914-4
