
Abstract
Spatio-temporal graph modeling is an important task in analyzing the spatio-temporal correlation of traffic flow prediction models, and although many existing methods optimize traffic flow modeling by constructing adaptive graphs, these methods use adaptive graphs in the training phase and do not effectively learn the traffic flow data used in the testing phase. To address the above problems, the Progressive Graph Convolutional Network Traffic Flow Prediction Model based on Spatio-Temporal Self-Attention (PGCN-STSA) is proposed. Specifically, the spatio-temporal self-attention mechanism layer is constructed to perceive the local context information and extract the nonlinear temporal features together with the dilated convolution module, which is favorable for long-term prediction. The PGCN-STSA model constructs an asymptotic adjacency matrix by learning the trend similarity between graph nodes and builds an asymptotic static graph convolution module based on it, which is combined with a graph convolution network to fully capture the dynamic spatial features of the traffic flow. In addition, multiple spatio-temporal layers are stacked to increase the extraction capability of spatio-temporal features of the model for prediction through the output layer. The experimental results show that, compared with the existing optimal baseline method ST-MetaNet, the MAE and RMSE of PGCN-STSA model on METR-LA data set are improved by 0.74%, 0.77%, 2.58% and 2.87% respectively in the 15-min and 30-min predictions.
Similar content being viewed by others

Introduction
Traffic flow forecasting is a cornerstone of Intelligent Transportation Systems (ITS), aiming to infer future traffic states from historical observations to support congestion mitigation, route planning, and fine-grained traffic control1. However, real-world traffic dynamics exhibit strong nonlinearity, complex periodicity (e.g., daily/weekly patterns), and time-varying spatial correlations driven by recurrent commuting behavior and non-recurrent disruptions. These properties make accurate multi-step forecasting particularly challenging, since prediction errors may accumulate quickly as the horizon increases.
Early studies mainly relied on statistical models such as ARIMA2 and Kalman filtering3, which are often limited by linear assumptions and struggle to capture nonlinear spatiotemporal dependencies. Subsequently, conventional machine learning approaches (e.g., SVR4 and random forest5) improved flexibility but typically require heavy feature engineering and still model temporal and spatial correlations in a fragmented manner. With the advancement of deep learning, recurrent models (RNN/GRU/LSTM) were introduced to capture temporal evolution6,7, while CNN-based architectures exploited local patterns in traffic sequences8. Nevertheless, purely temporal models ignore explicit spatial interactions among sensors, and recurrent architectures may suffer from long-range dependency degradation and error propagation, especially for long-horizon forecasting.
To better encode spatial dependencies in road networks, Graph Neural Networks (GNNs) have become a dominant paradigm by modeling sensors as nodes and road connections as edges. Representative methods, such as OGCRNN9, learn graph structures in a data-driven manner and combine them with temporal modeling to improve forecasting accuracy. Attention-enhanced spatiotemporal GNNs (e.g., ASTGCN) further introduce attention mechanisms to emphasize informative temporal segments and spatial neighbors, enabling more adaptive dependency modeling10. More recently, Transformer-based spatiotemporal models have been explored to jointly model long-range interactions11. However, two practical issues remain: (1) extracting temporal dependence from long traffic sequences is still non-trivial-pure attention models may be sensitive to temporal decomposition and may overlook latent interactions among decomposed components; (2) spatial correlations in traffic networks are not stationary-dependencies change over time due to evolving traffic demand and external conditions, which calls for dynamic spatial modeling.
A critical limitation of many adaptive-graph approaches is that they primarily learn graph structures during training and then apply the learned graph (or its parameterization) to the test phase. This can lead to a train-test mismatch when traffic relationships evolve over time: the spatial graph that is optimal for the training distribution may no longer be optimal under test-time patterns. In addition, many existing frameworks either emphasize spatial modeling (graph learning) or temporal modeling (recurrent/attention/convolution) separately, making it difficult to simultaneously achieve (i) robust time-varying spatial adaptation and (ii) effective long-horizon temporal feature extraction with controlled computational complexity.
To address these challenges, this paper proposes a Progressive Graph Convolutional Network based on a Spatio-Temporal Self-Attention mechanism (PGCN-STSA) for traffic forecasting. The core idea is to progressively update node relationships using online traffic signals, so that the spatial dependency structure can evolve together with real-time patterns, thereby alleviating the train-test graph mismatch. Meanwhile, we design a spatio-temporal self-attention layer to capture local contextual interactions, and combine it with a dilated (hole) temporal convolution module to enlarge the temporal receptive field, which is beneficial for medium- and long-horizon forecasting. By stacking multiple spatiotemporal layers, the model jointly learns dynamic spatial correlations and complex temporal dependencies in a unified framework.
The main contributions of this work are summarized as follows:
-
(1)
Progressive graph construction. We propose an asymptotic/progressive adjacency update mechanism based on trend similarity between node signals, enabling test-time spatial dependency adaptation using online observations.
-
(2)
Spatio-temporal representation learning. We design a spatio-temporal self-attention module coupled with dilated temporal convolution to capture contextual dependencies and long-range temporal patterns for multi-step forecasting.
-
(3)
Unified spatiotemporal architecture. We integrate progressive spatial adaptation with graph convolution and stacked spatiotemporal layers to enhance forecasting robustness under time-varying traffic patterns.
-
(4)
Empirical validation. Extensive experiments on METR-LA and PEMS-BAY demonstrate that PGCN-STSA achieves competitive or superior performance compared with strong baselines across multiple horizons.
Related work
Due to the complex spatial correlation between different roads and the dynamic trend of time patterns, traffic flow prediction has become a challenging task. As time series data, traffic flow data shows specific periodicity and trend, such as early and late peaks. These complex time correlations make it difficult to predict traffic flow for a long time. In recent years, the prediction model based on deep learning has made great progress, but it still has some limitations in the following aspects:
First of all, for time-dependent modeling, most methods, such as diffusion recursive neural network (DCRNN)12, spatio-temporal graph convolutional network, STGCN)13 and ASTGCN14 directly use RNN, Temporal Convolutional Network (TCN) and temporal attention to capture time dependence. However, these methods ignore the potential complex time patterns in the time series, that is, the traffic time series is composed of weekly patterns and daily patterns, and each part is independent of each other but also related. Although the methods based on TCN15 can extract multiple time patterns from time series with different down-sampling frequencies or convolution kernels of different sizes, they use pre-fixed kernels to model time patterns, which has the defect of information loss.
Secondly, for the medium-and long-term traffic flow prediction, multiple sensors on the road network have direct or indirect spatial correlation. The method based on Graph Neural Network (GNN)16 can capture spatial dependence and achieve better prediction performance in traffic prediction tasks. STGCN uses CNN with gating to obtain time features and GCN to obtain spatial features. Temporal graph convolutional network (T-GCN)17 uses Gated Recurrent Unit (GRU) to obtain time features and GCN to obtain space features. However, the method based on GNN still has some limitations: 1) The spatial dependence between traffic flows in the road network changes significantly with the passage of time. On the one hand, traffic flow forecasting will be influenced by external factors such as weather conditions, sudden accidents and rush hours. For example, Li et al.13 put forward the spatiotemporal attention-based graph convolution network (AST-GAT) method to predict the sectional traffic flow, which takes into account the additional information such as speed, flow and weather information to further improve the prediction performance. Jin et al.18 used heterogeneous graph attention network for expressway traffic speed prediction, considering other related factors, such as equivalent lane number, accident occurrence and toll data. On the other hand, the sensors are directly or indirectly adjacent to each other geographically, and the traffic flow information contained may be irrelevant, such as two opposite traffic flows on adjacent highways. Therefore, it is an arduous task to dynamically select sensor data to predict traffic conditions in a specific time range. 2) The complexity of different forecasting tasks is unbalanced in space (such as suburbs and downtown) and time (such as peak hours and off-peak hours). At the same time, for a specific road, the peak-hour traffic is more difficult to predict than the off-peak traffic. Therefore, the imbalance of task complexity brings great challenges to accurate traffic prediction. However, the existing methods are difficult to capture the complex spatial correlation and assign the same computational load to all tasks at the same time. Complex tasks ignore important details because of limited computational load, while simple tasks waste too much computational load.
The emergence of dynamic computing provides a better solution to the above problems. For example, Hong et al.19 constructed an efficient calculation method of large-area dynamic traffic noise map based on hybrid modeling method to further improve the calculation efficiency. Yang et al.20 applied the multi-task learning method to traffic speed prediction and effectively captured the characteristics of multi-traffic patterns. Wen et al.21 proposed the RPCnovformer prediction method, which further considered the local correlation of traffic state, and extended multiple sequential Transformer layers through dynamic calculation, and dynamically controlled the layers according to the complexity of the task. However, this method is inefficient when the calculation load is heavy or dynamic, and the deeper layer receives less training data than the shallower layer.
In addition to the aforementioned studies, recent works have advanced spatiotemporal traffic forecasting through dynamic graph learning, multi-scale temporal modeling, and structural disentanglement. To cope with large-scale urban data, Transformer-based architectures have been optimized for efficiency and scalability via improved spatial data management and attention computation22, while spatiotemporal foundation models promote unified frameworks integrating representation learning, preprocessing, and task adaptation for enhanced generalization23. SSGCRTN24 combines graph convolutional, recurrent, and Transformer components to capture localized and global dependencies, and MSTDFGRN25 adopts multi-view dynamic fusion to model heterogeneous spatial relationships. Structurally, PSTCGCN26 incorporates causal priors through principal spatiotemporal graph construction, whereas TIIDGCN27 leverages temporal-identity interaction to stabilize periodic variations. In the temporal domain, SDSINet28 and MTEGCRN29 enhance fine-grained and multi-scale temporal modeling, respectively, while GDGCRN30 and DMFGCRN31 employ decoupled architectures to disentangle spatial and temporal dependencies for improved robustness and interpretability. Despite these advances, challenges remain in modeling ultra-long dependencies, ensuring computational efficiency, and achieving unified dynamic structural reasoning.
Table 1 provides a comprehensive comparison of representative spatiotemporal traffic forecasting models. The Structure column categorizes spatiotemporal coupling strategies as In Series, In Embedded, or In Parallel, while the Relationship between layers describes how spatial, temporal, and feature representations interact—denoted as Interactive (IT), Shared (S), or Independent (I). The Relationship type indicates whether dependencies are modeled as pre-defined (P), adaptive (A), or dynamic (D). Compared with existing methods, DSTGA-Mamba achieves fully interactive parameter sharing across spatial, temporal, and feature dimensions and integrates pre-defined, adaptive, and dynamic graph structures, demonstrating a more systematic and innovative modeling framework.
Methodology
Problem definition
-
(1)
Traffic network diagram: Traffic flow refers to the collection of vehicles (such as cars, trains, etc.) passing through a specific traffic network (such as roads, railways, etc.) in a given period of time, which describes the flow of vehicles in space and time and is an important attribute to characterize the traffic state. In this paper, directed graph \(G = \left( {V,E} \right)\) is utilized to represent the traffic network graph, where \(V\) is a set of \(N\) nodes, and each node represents the observation sensor in the road network. \(E\) is a set of edges between nodes, and its weight is represented by the distance between nodes. \(A{ = }\left( {A_{ij} } \right) \in {\mathbb{R}}^{N \times N}\) represents the initial adjacency matrix generated by graph \({G}\), in which the element \(A_{ij}\) represents the weight of an edge \(\left( {v_{i} ,v_{j} } \right) \in E\). If \(v_{i}\), \(v_{j} \in V\) and \(\left( {v_{i} ,v_{j} } \right) \in E\), \(A_{ij}\) is 1, otherwise it is 0.
-
(2)
Graph signal: The signal of node \(v_{i}\) at time \(t\) is expressed as \(x_{t}^{i} \in {\mathbb{R}}^{C}\), where \(C\) is the characteristic number of the node. The graph signal of \(N\) nodes is \(X_{t} { = }\left[ {x_{t}^{1} ,x_{t}^{2} , \ldots ,x_{t}^{N} } \right] \in {\mathbb{R}}^{N \times C}\). In addition, the signal of node \(v_{i}\) observed in the last time step of \(T\) from time \(t\) is denoted as \(x_{t}^{i(T)} \in {\mathbb{R}}^{T \times C}\), and the historical graph signal of the whole past \(T\) period is denoted as \(X_{t - T + 1:t} \in {\mathbb{R}}^{T \times N \times C}\). Similarly, the graph signal of the future \(T^{\prime}\) period can be expressed as \(\hat{Y}_{{t + 1:t + T^{\prime}}} \in {\mathbb{R}}^{{T^{\prime} \times N \times C}}\).
-
(3)
As-Graph: With the evolution of the relationship between nodes, it is very intuitive to use online traffic data to gradually update the relationship between nodes. Asymptotic graph is a set of graphs of \(G_{As}^{t} = \left( {V,A_{\alpha }^{t} } \right)\), where \(A_{\alpha }^{t}\) is an asymptotic adjacency matrix at time \(t\), which contains pairwise weights learned from node signal similarity.
-
(4)
Traffic flow prediction: The purpose of traffic flow prediction is to predict the traffic flow in the future \(T^{\prime}\) period: \(\hat{Y}_{{t + 1:t + T^{\prime}}} = \ell \left( {X_{t - T + 1:t} ;G} \right)\) through the given historical space–time traffic data of the past \(T\) period.
To clearly illustrate the dimensional consistency across different components of the proposed framework, Table 2 summarizes the input and output dimensions of each module in PGCN-STSA.
Construction of PGCN-STSA model
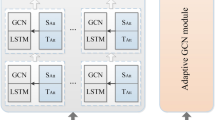
Figure 1 shows the overall framework of PGCN-STSA model, which is mainly composed of spatio-temporal attention layer, progressive graph construction module, hole convolution module, graph convolution network and output layer.

PGCN-STSA model.
As shown in Fig. 2, this paper constructs a spatio-temporal attention layer to perceive local context information, which is mainly composed of spatio-temporal self-attention mechanism, normalization and full connection layer. The spatio-temporal self-attention layer and hole convolution module are used to extract nonlinear time features, which is beneficial to long-term prediction at the same time, the ability to extract the spatio-temporal features of the model is increased by stacking multiple spatio-temporal layers, and the parameters of the asymptotic graph constructor are shared among the layers. Finally, the output layer consists of one hop connection and two complete connections in each layer to prevent the information of the initial layer from being lost.

Spatio-temporal attention layer.
Progressive graph construction
The similarity between the signals of two nodes changes with time. For example, the morning peak of a school is similar to that of a nearby office building, but the evening peak may be quite different. Modeling this kind of correlation based on static characteristics (such as POI category or speed limit) is intuitive, but considering the scale and complexity involved, this method is effective. On the contrary, the method proposed in this paper learns the hidden traffic data itself by evaluating the similarity between nodes rather than simply spatial adjacency.
Firstly, this paper defines the trend similarity between node signals by using parameterized cosine similarity, and proposes a progressive graph which can gradually adapt to traffic flow changes according to the trend similarity, with the goal of giving higher weight to nodes with similar signals, regardless of their spatial proximity. At the same time, the trend similarity between graph nodes is measured by cosine similarity of their signals.
Assume that the node signal \(x_{t}^{i}\) has an input characteristic. The cosine similarity \(s_{ij}\) between \(v_{i}\) and \(v_{j}\) of two nodes is defined as:
where \(\tilde{x}_{t}^{i\left( T \right)} = \overline{x}_{t}^{i\left( T \right)} /\left\| {\overline{x}_{t}^{i\left( T \right)} } \right\|\) is the unit vector, and \(\overline{x}_{t}^{i\left( T \right)}\) is the minimum and maximum normalized signal of the node \(v_{i}\) at time \(t\). In this paper, node signals are normalized to consider the similarity in trend rather than absolute value, because two nodes may have similar trends with different values.
In addition, a learnable parameter \(W_{adj} \in {\mathbb{R}}^{T \times T}\) is applied to cosine similarity to adapt to the pattern and randomness of noise in real data sets. Use \(W_{adj}\) to define each element of progressive adjacency matrix \(A_{{\alpha_{ij} }}^{t}\):
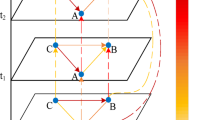
In the formula, the progressive adjacency matrix is normalized by \(softmax\) function, and the negative connection is eliminated by activating \(ReLu\). Parameter \(W_{adj}\) learns the relationship between the two signals \(\tilde{x}_{t}^{i\left( T \right)}\) and \(\tilde{x}_{t}^{j\left( T \right)}\), and encodes the linear transformation of the signals to obtain the final similarity value. For signals with multiple features, the similarity of each feature is calculated. If the signal has three characteristics, three different progressive adjacency matrices will be defined. It is worth noting that the parameter \(W_{adj}\) is learned in the training stage, and the on-line node signals \(\tilde{x}_{t}^{i\left( T \right)}\) and \(\tilde{x}_{t}^{j\left( T \right)}\) are used to update the graph gradually. The progressive diagram is shown in Fig. 3. Given four nodes \(\left\{ {v_{1} ,v_{2} ,v_{3} ,v_{4} } \right\}\), each row in the matrix represents a single characteristic node signal observed in the last \(T = 5\) time steps. Given two matrices of time \(t\) and \(t + h\), the strong similarity between \(v_{1}\) and \(v_{4}\) can be observed at \(t\), while \(v_{1}\) and \(v_{2}\) are the most similar at time \(t + h\). Each row in the asymptotic graph matrix of Fig. 3 is a given node signal of the last 5-time steps. At \(t\), \(v_{1}\) and \(v_{4}\) show the highest similarity, but this connection disappears at \(t + h\).

Progressive graph.
Hole convolution network
The main component of the traditional causal convolution is the convolution layer, which makes the model more concise without recursive calculation. This operation can be carried out as shown in Fig. 4a. However, causal convolution has the limitation that many layers are needed to increase the size of receptive field. In contrast, extended causal convolution can overcome the limitation of causal convolution (Fig. 4b). Extended causal convolution network obtains a larger receptive field by stacking convolution layers. In addition, extended causal convolution slides the input with a specific step size, and non-recursive parallel computing is used to deal with long time series, so as to improve the learning speed and alleviate the problem of gradient disappearance.

Causal Convolution and Hole Causal Convolution Diagram.
Using hole causal convolution with kernel size of 2 and hole factor of \(k\), the input is selected every \(k\) step, and the standard 1D convolution is used for the selected input. Given a one-dimensional sequence input \(x \in {\mathbb{R}}^{H}\) and filter \(f \in {\mathbb{R}}^{K}\), the expression of hole causal convolution operation between \(x\) and \(f\) at step \(t\) is as shown in Formula (3):
where \(d\) is the hole factor that controls the jump step size. By stacking hole causal convolution layers with hole factors in increasing order, the receptive field of time convolution network layer increases exponentially. Therefore, PGCN-STSA’s hole convolution network can capture longer sequences with fewer layers, saving computational resources and improving the accuracy of long-term prediction.
Given the input \(X \in {\mathbb{R}}^{T \times N \times F}\), the form of gated TCN is:
where \(\zeta_{1}\), \(\zeta_{2}\), \(b\) and \(c\) are model parameters, \(\odot\) is the product of elements, \(g\left( \cdot \right)\) is the activation function of output, and \(\sigma \left( \cdot \right)\) is the Sigmoid function, which determines the ratio of information transmitted to the next layer.
Graph convolution network
GCN smooth the signals of nodes by aggregating and transforming neighborhood information, and supports multi-dimensional input. Let \(X_{S} \in {\mathbb{R}}^{N \times F}\) represent the input signal, \(Z \in {\mathbb{R}}^{N \times H}\) represents the output, \(W \in {\mathbb{R}}^{D \times H}\) represents the model parameter matrix, \(\tilde{A} \in {\mathbb{R}}^{N \times N}\) represents the normalized adjacency matrix with self-circulation ability, and the graph convolution network is defined as:
PGCN-STSA combines diffusion convolution network with graph convolution network, and obtains the extended form of formula (5) as follows:
where \(P^{k}\) represents the power series of the transfer matrix. In an undirected graph, \(P = {A \mathord{\left/ {\vphantom {A {rowsum\left( A \right)}}} \right. \kern-0pt} {rowsum\left( A \right)}}\). In the directed graph, the diffusion process is divided into forward and backward, in which the forward transfer matrix \(P_{f} = {A \mathord{\left/ {\vphantom {A {rowsum\left( A \right)}}} \right. \kern-0pt} {rowsum\left( A \right)}}\) and the backward transfer matrix \(P_{b} = {{A^{T} } \mathord{\left/ {\vphantom {{A^{T} } {rowsum\left( {A^{T} } \right)}}} \right. \kern-0pt} {rowsum\left( {A^{T} } \right)}}\). Combining the forward and backward transfer matrices, the convolution network of diffusion graph is obtained:
At the same time, diffusion convolution is regarded as the basic graph convolution module. In this paper, the multiplication of progressive adjacency matrix, graph signal matrix and additional weight parameters is added to diffusion convolution, and the graph convolution is proposed by combining the predefined spatial dependence and the dynamic spatial characteristics of self-learning hiding:
Loss function
Huber Loss36 is a commonly used loss function, which combines the linear terms of mean square error (MSE) and absolute error. When it is close to the true value, it is closer to the square loss, and when it is far from the true value, it is closer to the absolute loss, which can reduce the influence of outliers and maintain good stability in the process of model training. Therefore, this paper uses Huber Loss as the loss function in the optimization process:
where \(\delta\) is the super parameter of the balanced square error, and \(\hat{x}\) and \(x\) are the predicted value and the real value respectively.
Experiments
Datasets
METR-LA data set and PEMS-BAY data set are used in this paper33. To verify the prediction performance of the PGCN-STSA model proposed in this paper. The details of these two experimental datasets are shown in Table 3.
PEMS-BAY dataset is the expressway speed data collected by California Transportation Bureau (CalTrans) Performance Measurement System (PEMS) for traffic flow prediction. This data set contains the traffic speed information of 325 sensors for six months. The sensor summarizes the traffic flow speed every 5 min.
METR-LA data set is an expressway traffic flow data set. The data collected from 207 loop detectors in Los Angeles includes the traffic flow speed information of 207 sensors for 4 months, and the sensors summarize the traffic flow speed every 5 min.
There are some missing data in METR-LA data set. In this paper, the missing values are filled by linear interpolation, and the data are normalized by Min–Max, which is limited to [0,1]. The normalization formula is as follows:
where \(x_{i}\) represents the \(i\) original data, \(x_{max}\) represents the maximum value of the original data, \(x_{min}\) represents the minimum value of the original data, and \(x_{i}^{norm}\) represents the normalized input data.
Settings
In this paper, the spatio-temporal network layer of PGCN-STSA model is set to 8 layers, the hidden dimension is set to 32, the expansion factor sequence used in the hole convolutional network is 1, 2, 1, 2, 1, 2, and the kernel size is set to 2. At the same time, Adam optimizer is used to train the model, and the initial learning rate is 0.001.
All experiments were carried out in an environment equipped with CPU: Intel (R) Core (TM) i7-1065G7 CPU @ 1.30 GHz 1.50 GHz, 16GBRAM, GPU: Nvidia GeForce RTX 2080 T I. Based on Pytorch deep learning framework, the construction and training of PGCN-STSA prediction model are completed in PyCharm development environment.
In order to better analyze the experimental results and evaluate the prediction performance of PGCN-STSA model, this paper selects mean absolute error (MAE), root mean square error (RMSE) and mean absolute percentage error (MAPE) to evaluate the error between the actual traffic flow speed and the prediction results:
Baseline methods
In this paper, PGCN-STSA model is compared with other 20 widely used traffic flow forecasting models, such as statistical analysis-based forecasting model, traditional model considering only time dimension and classical time series forecasting method considering only space dimension, HA37, VAR35, SVR38 and ARIMA39. Spatio-temporal prediction model considering temporal and spatial correlation, FC-LSTM40, DCRNN33, STGCN32, ASTGCN35, STGCN41, TGC-GRU42, DMSTGCN43, AGCRN44, ST-MetaNet45, Graph WaveNet34. The latest spatio-temporal models, MRes-RGNN46, Z-GCNETs47, DSTAGNN48, Trafformer49, FedAGAT50 and LEISN-ED51.
Experimental results
As shown in Tables 4 and 5, the comparison between the proposed PGCN- STSA model and other baseline models on METR-LA and PEMS-BAY data sets for 15, 30 and 60 min is shown. It can be seen that statistical methods (HA, VAR, ARIMA) and traditional machine learning method SVR are not effective in dealing with nonlinear traffic flow data, indicating that this method has limited forecasting ability for long-term complex time series data.
In contrast, the model based on GCN can deal with non-Euclidean traffic data and capture the hidden relationship between road network nodes more effectively. The spatio-temporal GCN model represented by STGCN and STGCN performs better in capturing time correlation and predicting traffic flow data. Compared with other spatio-temporal models, FC-LSTM and TGC-GRU show poor performance in the 15-min prediction, while Graph WaveNet has better performance in the 15-min and 30-min prediction. The reason is that Graph WaveNet embeds GCN into TCN and integrates time information through TCN, but this model does not combine the self-attention mechanism to further capture the hidden spatio-temporal features, so the prediction performance of Graph WaveNet has declined in the 60-min prediction. ST-MetaNet uses Meta graph information to generate graph attention mechanism and RNN weight, which improves the accuracy without greatly increasing parameters. DMSTGCN takes additional features as auxiliary information, and shows good prediction performance on data sets. Compared with traditional methods and classical spatio-temporal models, the latest spatio-temporal prediction models, MRes-RGNN and Z-GCNETs, almost all achieved better prediction performance.
In contrast, compared with the baseline model, the PGCN-STSA model proposed in this paper has achieved the best prediction performance and improved the prediction accuracy obviously. On the METR-LA data set, compared with the most advanced model ST-MetaNet, in 15 min and 30 min, the PGCN-STSA model was improved by 0.74%, 0.77%, 2.58% and 2.87% in MAE and RMSE, respectively. Similarly, on PEMS-BAY data set, compared with the optimal baseline model Graph WaveNet, the MAE, RMSE and MAPE of PGCN-STSA model are increased by 1.54%, 1.46% and 0.02% and 1.84%, 0.81% and 0.06% respectively. Compared with other models with adaptive graphs, the adaptability of PGCN-STSA model to real-time data is helpful for the model to judge unexpected changes and irregularities in traffic flow more accurately, and then to achieve higher precision prediction. At the same time, it shows that the asymptotic chart constructed in this paper is very important to adapt to the test data, and the graph convolution module constructed by the asymptotic chart can significantly improve the prediction accuracy of the model. It is proved that the PGCN-STSA model proposed in this paper can effectively further integrate temporal and spatial characteristics and improve the continuous prediction ability of the model.
In order to better explain the proposed PGCN-STSA model, the experimental results of PGCN-STSA, Z-GCNETs, FC-LSTM, Graph WaveNet and STGCN are visualized on PEMS-BAY data set, as shown in Figs. 5, 6 and 7. It is obvious from the three diagrams that the performance of PGCN-STSA is far superior to other models, indicating that the proposed model can capture the dynamic spatio-temporal characteristics of traffic flow more fully. At the same time, with the increase of the forecast duration, the forecast error increases slightly. When the forecast duration is more than 15 min, the forecast error of PGCN-STSA is obviously lower than that of other comparative models, which shows that the model has better forecast performance in the long-term forecast.

visualization of MAE prediction results.

visualization of MAPE prediction results.

visualization of RMSE prediction results.
Further, Fig. 8 shows the visual comparison between the predicted results of PGCN-STSA model at the 15th and 60th minutes on the 300–1200th sample points on the PEMS-BAY data set and the real values. From the two figures, it can be found that the PGCN-STSA model in this paper shows better prediction accuracy and can predict the fluctuation of data more accurately. At the same time, it can be seen that the prediction result of PGCN-STSA model in 15 min is more accurate than that in 60 min, which is because the long-term prediction is better due to the complex dynamic spatio-temporal characteristics of traffic flow. However, it can still be seen that the prediction result of the proposed model in 60 min also accurately follows the real value of traffic flow, which proves the accuracy and effectiveness of the proposed PGCN-STSA model in traffic flow prediction.

visual comparison of the prediction performance of PGCN-STSA model on PEMS-BAY data set for 15 and 30 min.
As shown in Fig. 9, PGCN-STSA consistently outperforms the compared models in both accuracy and stability. In Fig. 9, the MAE boxplot indicates that PGCN-STSA achieves a lower median error and a more compact distribution than the best baseline, demonstrating reduced prediction error and stronger robustness. PGCN-STSA attains the lowest average rank among all models, further confirming its superior and consistent overall performance.

Statistical Testing and Average Ranking Visualization.
As shown in Fig. 10, the training loss decreases rapidly in the early epochs and gradually stabilizes as training progresses, indicating effective convergence of the PGCN-STSA model. Meanwhile, the validation loss exhibits a similar downward trend with only a small gap from the training curve, demonstrating strong generalization ability without evident overfitting.

Training and validation loss curves of PGCN-STSA on the METR-LA and PEMS-BAY datasets.
As shown in Fig. 11, PGCN-STSA achieves the lowest and most concentrated RMSE distribution on the METR-LA dataset, indicating both higher prediction accuracy and stronger robustness. In contrast, baselines such as HA and STGCN exhibit higher medians and wider spreads, reflecting larger errors and greater performance variability.

RMSE violin plots of different models on the METR-LA and PEMS-BAY dataset.
Conclusion
In this paper, we propose a Progressive Graph Convolutional Network with a Spatio-Temporal Self-Attention mechanism (PGCN-STSA) for network-scale traffic forecasting. By introducing a progressive graph construction strategy that dynamically updates node relationships based on real-time traffic signals, the proposed model alleviates the limitations of static adjacency matrices and enhances adaptability to time-varying spatial correlations. The spatio-temporal self-attention module, combined with dilated temporal convolution, effectively captures local contextual dependencies and long-range temporal patterns, which is particularly beneficial for medium- and long-horizon forecasting. Experimental results on METR-LA and PEMS-BAY demonstrate that PGCN-STSA consistently outperforms strong baselines across multiple prediction horizons. The performance gains indicate that progressive spatial adaptation reduces train–test structural mismatch and mitigates long-term error accumulation, while attention-based temporal modeling improves the tracking of rapid traffic fluctuations and complex nonlinear dynamics.
Despite these advantages, several limitations remain. The model has been validated mainly on speed datasets with fixed sensor layouts, and its generalization to other traffic variables and network configurations requires further investigation. The cosine-similarity-based progressive mechanism may also be sensitive to noise, missing data, or abrupt distribution shifts, and the current framework does not explicitly incorporate exogenous factors such as weather conditions, incidents, or holiday effects, which are critical for modeling non-recurrent congestion. Future work will therefore focus on integrating external features through dedicated encoders and cross-attention or gated fusion mechanisms, constructing event-aware heterogeneous graphs to model disruption propagation, enhancing robustness via uncertainty-aware similarity learning and continual adaptation strategies, and improving efficiency and interpretability through sparse progressive graphs and edge-importance analysis.
Data availability
The data are available from the corresponding author on reasonable request. https://github.com/cll-max/PGCN-STSA.
References
Tedjopurnomo, D. A. et al. A survey on modern deep neural network for traffic prediction: Trends, methods and challenges. IEEE Trans. Knowl. Data Eng. 34(4), 1544–1561 (2020).
Chen, K. et al. Research on short-term traffic flow forecast based on ARIMA-SVM Model. J. Qingdao Univ. Technol. 43(5), 104–109 (2022).
Jiao, J. F. & Wang, H. H. Traffic behavior recognition from traffic videos under occlusion condition: A Kalman filter approach. Transp. Res. Rec. 2676, 55–65 (2022).
Cheng, S. H. A. N. Y. I. N. G. Construction of short-term traffic flow prediction model based on SVR. China Comput. Commun. 34(14), 18–20 (2022).
Xiujuan, X. U. et al. Traffic flow prediction based on random forest in severe weather conditions. J. Shaanxi Normal Univ. Nat. Sci. Ed. 48(2), 7 (2020).
Li, Z.H., Xu, H., Gao, H.L., et al. Fusion attention mechanism bidirectional LSTM for short-term traffic flow prediction. J. Intell. Transp. Syst. (2023).
Shu, W., Cai, K. & Xiong, N. N. A short-term traffic flow prediction model based on an improved gate recurrent unit neural network. IEEE Trans. Intell. Transp. Syst. 99, 1–12 (2021).
Zhang, W. et al. Short-term traffic flow prediction based on spatio-temporal analysis and CNN deep learning. Transportmetrica 15(2), 1688–1711 (2019).
Guo, K. et al. Optimized graph convolution recurrent neural network for traffic prediction. IEEE Trans. Intell. Transp. Syst. 22(2), 1138–1149 (2021).
Wang, Y. et al. Attention based spatiotemporal graph attention networks for traffic flow forecasting. Inf. Sci. 607, 869–883 (2022).
Huang, B. et al. Adaptive spatiotemporal transformer graph network for traffic flow forecasting by IoT loop detectors. IEEE Internet Things J. 10(2), 1642–1653 (2023).
Shao, Z., Zhang, Z., Wei, W., et al. Decoupled dynamic spatial-temporal graph neural network for traffic forecasting. Angela Bonifati. In Proceedings of the International Conference on Very Large Data Bases. Sydney: VLDB Endowment. 2733–2746 (2022).
Li, D. & Lasenby, J. Spatiotemporal attention- Based graph convolution network for segment level traffic prediction. IEEE Trans. Intell. Transp. Syst. 23(7), 8337–8345 (2022).
Qi, J. et al. A graph and attentive multi-path convolutional network for traffic prediction. IEEE Trans. Knowl. Data Eng. 35, 6548–6560 (2022).
Zhang, X., Xu, Y. & Shao, Y. Forecasting traffic flow with spatial-temporal convolutional graph attention networks. Neural Comput. Appl. 34, 15457–15479 (2022).
Zhang, Z. et al. Multiple dynamic graph-based traffic speed prediction method. Neurocomputing 461, 109–117 (2021).
Zhao, L. et al. T-GCN: a temporal graph convolutional network for traffic prediction. IEEE Trans. Intell. Transp. Syst. 21(9), 3848–3858 (2019).
Jin, C.H., Tao, R., Wu, D.X., et al. HETGAT: A heterogeneous graph attention network for freeway traffic speed prediction. J. Amb. Intell. Hum. Comput. 1–12 (2021).
Hong, X. D., Xia, D. & Zhu, W. Y. An efficient calculation method of large-region dynamic traffic noise maps based on hybrid modeling. Environ. Pollut. https://doi.org/10.1016/j.envpol.2023.121842 (2023).
Yang, Y. J. et al. Short-term passenger flow prediction for multi-traffic modes: A transformer and residual network based multi-task learning method. Inf. Sci. https://doi.org/10.1016/j.ins.2023.119144 (2023).
Wen, Y. J. et al. Rpconvformer: A novel transformer-based deep neural networks for traffic flow prediction. Expert Syst. Appl. 218, 119587 (2023).
Fang, Y., Liang, Y., Hui, B., et al. Efficient large-scale traffic forecasting with Transformers: A spatial data management perspective. KDD '25: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 307–317 (2024).
Fang, Y. et al. Unraveling spatio-temporal foundation models via the pipeline lens: A comprehensive review. Inf. Fusion 115, 102346 (2025).
Yang, S. et al. SSGCRTN: A space-specific graph convolutional recurrent transformer network for traffic prediction. Appl. Intell. 54(22), 11978–11994 (2024).
Yang, S. et al. MSTDFGRN: A multi-view spatio-temporal dynamic fusion graph recurrent network for traffic flow prediction. Comput. Electr. Eng. 123, 110046 (2025).
Yang, S., Wu, Q., Li, Z., et al. PSTCGCN: Principal spatio-temporal causal graph convolutional network for traffic flow prediction. Neural Comput. Appl. 1–14 (2024).
Yang, S. et al. Temporal identity interaction dynamic graph convolutional network for traffic forecasting. IEEE Internet Things J. 12(11), 15057–15072 (2025).
Yang, S. & Wu, Q. SDSINet: A spatiotemporal dual-scale interaction network for traffic prediction. Appl. Soft Comput. https://doi.org/10.1016/j.asoc.2025.112892 (2025).
Yang, S. & Wu, Q. MTEGCRN: Multi-scale temporal enhanced graph convolutional recurrent network for traffic prediction. Neurocomputing https://doi.org/10.1016/j.neucom.2025.131064 (2025).
Yang, S. et al. General decoupled graph convolutional recurrent network for traffic prediction. IEEE Sens. J. https://doi.org/10.1109/jsen.2025.3580440 (2025).
Yang, S., Wu, Q. & Li, M. Decoupled multi-spatio-temporal fusion graph convolutional recurrent network for traffic prediction. Eng. Appl. Artif. Intell. 163, 112956 (2025).
Yu, B., Yin, H., Zhu, Z. Spatio-temporal graph convolutional networks: a deep learning framework for traffic forecasting. In Proceedings of the International Joint Conference on Artificial Intelligence. Bangkok, Thailand. 3634–3640 (2017).
Li, Y., Yu, R., Shahabi, C., et al. Diffusion convolutional recurrent neural network: data-driven traffic forecasting. In Proceedings of the International Conference on Learning Representations. Vancouver, Canada (2018).
Wu, Z. et al. Graph WaveNet for deep spatial-temporal graph modelling. Association for the Advancement of Artificial Intelligence 1907–1913 (Hawaii, 2019).
Guo, S. et al. Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. Association for the Advancement of Artificial Intelligence 922–929 (Hawaii, 2019).
Xie, J., Song, L. & Huang, H. Thermal radiation bias correction for infrared images using Huber function-based loss. IEEE Trans. Geosci. Remote Sens. 62, 1–15 (2024).
Liu, J. & Wei, G. A summary of traffic flow forecasting methods. J. Highw. Transp. Res. Dev. 21(3), 82–85 (2004).
Wu, C.H., Wei, C.C., Su, D.C., et al. Travel time prediction with support vector regression. In Proceedings of the Intelligent Transportation Systems. Shanghai, China (2003).
Williams, B. & Lester, A. Modeling and forecasting vehicular traffic flow as a seasonal ARIMA process: Theoretical basis and empirical results. J. Transp. Eng. 129(6), 664–672 (2003).
Sutskever, I., Vinyals, O. & Le, Q. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 27, 3140–3142 (2014).
Song, C., Lin, Y., Guo, S., et al. Spatial-temporal synchronous graph convolutional networks: A new framework for spatial-temporal network data forecasting. Association for the Advancement of Artificial Intelligence. New York USA. 914–921 (2020).
Cui, Z., Henrickson, K. & Ke, R. Traffic graph convolutional recurrent neural network: A deep learning framework for network-scale traffic learning and forecasting. IEEE Trans. Intell. Transp. Syst. 21(11), 4883–4894 (2020).
Han, L., Du, B., Sun, L., et al. Dynamic and multi-faceted spatio-temporal deep learning for traffic speed forecasting. In Proceedings of the Conference on Knowledge Discovery and Data Mining. Singapore. 547–555 (2021).
Bai, L. et al. Adaptive graph convolutional recurrent network for traffic forecasting. Adv. Neural. Inf. Process. Syst. 33, 17804–17815 (2020).
Pan, Z. et al. Spatio- temporal meta learning for urban traffic prediction. IEEE Trans. Knowledge Data Eng. 34(3), 1462–1476 (2022).
Chen, C. et al. Gated residual recurrent graph neural networks for traffic forecasting. Association for the Advancement of Artificial Intelligence 485–492 (Hawaii, 2019).
Chen, Y., Segovia, I., Gel, Y.R. Z-Gcnets: time zigzags at graph convolutional networks for time series forecasting. Proceedings of the International Conference on Machine Learning. Xiamen, China. 1684–1694 (2021).
Lan, S., Ma, Y., Huang, W., et al. DSTAGNN: Dynamic spatial-temporal aware graph neural network for traffic flow forecasting. In International Conference on Machine Learning, PMLR. 11906–11917 (2022).
Jin, D., Shi, J., Wang, R., Li, Y., et al. Trafformer: Unify time and space in traffic prediction. In Proceedings of the AAAI Conference on Artificial Intelligence. 37, 8114–8122 (2023).
Al-Huthaif, R. et al. FedAGAT: Real-time traffic flow prediction based on federated community and adaptive graph attention network. Inf. Sci. 667(2024), 120482 (2024).
Lai, Q. & Chen, P. LEISN: A long explicit-implicit spatio-temporal network for traffic flow forecasting. Expert Syst. Appl. 245(2024), 123139 (2024).
Funding
This work was supported by the research project Optimization Research on Decision-Making of Expressway Pavement Maintenance Schemes Based on Multi-Source Data (Project No.: 2025-22, Gansu Provincial Department of Transportation).
Author information
Authors and Affiliations
Contributions
The authors confirm contribution to the paper as follows: study conception and design: Chunya Liu; data collection: Yujiao Kou and Zilong Xie; analysis and interpretation of results: Shaohua Wang and Yuanqi Su. All authors reviewed the results and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, C., Kou, Y., Wang, S. et al. Research on traffic flow prediction of progressive graph convolutional networks based on spatio-temporal self-attention mechanism. Sci Rep 16, 14112 (2026). https://doi.org/10.1038/s41598-026-44004-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-44004-7
