
Abstract
Differentiating epileptic from functional seizures is a clinical challenge; while smartphone videos can aid diagnosis, they often require expert review, causing delays. We evaluated the accuracy of four successive multimodal large language models (LLMs), Gemini 1.5 Pro, 2.0 Flash, 2.5 Flash, and 2.5 Pro, in differentiating seizure types from smartphone videos without clinical context. In this prospective diagnostic study at a tertiary epilepsy center, 24 videos from 15 patients were analyzed, with video-electroencephalography monitoring as the gold standard. Of the 24 events (19 epileptic, 5 functional), diagnostic accuracy improved with successive models: Gemini 1.5 Pro (33.3%), Gemini 2.0 Flash (25.0%), and both Gemini 2.5 Flash and Pro (54.2%). In exploratory pairwise comparisons, Gemini 2.5 pro showed higher accuracy than Gemini 1.5 Pro (p = 0.01) and Gemini 2.0 Flash (p = 0.003). Performance was influenced by video features; for example, diagnosis was more accurate for the Gemini 2.5 models when videos focused on the upper body/face (80.0%-90.0%) compared to a whole-body view (28.6%-35.7%). All models reported high confidence scores (median 8.0–9.0) that were poorly aligned and did not correlate with correctness. Successive LLMs show improved yet modest accuracy for seizure classification from video alone, highlighting the need for domain-specific fine-tuning before clinical implementation.
Similar content being viewed by others
Introduction
Differentiating epileptic seizures from a wide array of functional seizures is a clinical challenge. The diagnostic process, traditionally reliant on patient history and witness accounts, is often confounded by the transient nature of the events and the variable quality of subjective descriptions. Review of a video recording of the event is more likely to lead to correct diagnosis than description of the event itself1. Bystander-recorded smartphone videos have thus emerged as a powerful diagnostic tool, providing objective visual data that enables accurate diagnosis particularly when reviewed by epilepsy experts2,3. However, reliance on expert review creates a significant bottleneck, contributing to diagnostic delays due to the need for consultation with a specialist, that can potentially expose patients to morbidity4,5.
Artificial intelligence (AI) offers a potential solution to the problem of delayed diagnosis and intervention6,7. To date, AI applications in neurology have largely focused on structured data from sources such as neuroimaging, EEG, and clinical history8,9. Video-based AI analysis has been explored, though typically with specialized deep learning models, such as 3-dimensional convolutional neural networks (3D-CNNs), designed for specific tasks like detecting tonic-clonic seizures in controlled settings such as the epilepsy monitoring unit (EMU)10,11. The use of video-based algorithms in evaluating neurological disorders has been limited to diagnosing stroke12, seizures, cognitive impairment, and developmental delays in children13,14, and assessing neurodegenerative causes of gait dysfunction and movement disorders15,16,17,18.
More recently, a new class of general-purpose, multimodal large language models (LLMs) have demonstrated the ability to process and reason across different data types, including video, audio, and text by leveraging advanced computer vision and natural language processing capabilities6,19,20. These models have shown potential to perform diagnostic tasks at a level comparable to human experts in some medical domains with improvement following each iteration21,22,23. These generalist models have shown diagnostic potential, primarily through their ability to process and analyze textual content from patient histories and medical literature24. While these models excel with textual input, their multimodal capabilities for video-based medical diagnosis remain largely unexplored24,25. This gap in knowledge raises a key applied question: can a general-purpose multimodal LLM accurately differentiate epileptic from functional seizures in real-world smartphone videos without domain-specific training?
In this study, we aimed to prospectively evaluate the diagnostic performance of four successive iterations of the Gemini series of multimodal LLMs in differentiating epileptic from functional seizures in smartphone videos recorded by bystanders, thereby establishing a preliminary benchmark for this emerging technology.
Materials and methods
Study design and dataset
This study was reviewed and approved by the Mayo Clinic Florida Institutional Review Board (IRB 25–006380). We prospectively collected 24 smartphone videos of distinct paroxysmal events from 15 patients referred to our center for evaluation of seizure events. The reference standard was the final diagnosis from Video-EEG monitoring during EMU admission, categorized as epileptic or functional based on habitual event semiology and EEG correlates. To ensure diagnostic linkage, two board-certified epileptologists (B.E.F., W.O.T.) independently reviewed all smartphone videos using a structured assessment of ictal and peri-ictal features, including motor manifestations, responsiveness, and post-event behavior26. This semiology review was used to confirm that the smartphone recording was concordant with the event category established on EMU video-EEG. Discrepancies in semiology characterization were resolved by consensus adjudication.
Analyses also included technical features (video quality, lighting, interpretability, duration) and clinical characteristics of the patient’s seizures or events (preictal, ictal, or postictal state). All data were fully anonymized prior to analysis. The video dataset included both portrait and landscape videos to reflect the spontaneous nature of bystander recordings. We omitted manual cropping or re-orientation to preserve the ecological validity of the diagnostic task. Video quality was determined as acceptable or unacceptable and required visibility of the whole body, or upper body/face. These videos were then uploaded to the LLMs to obtain results. This study adheres to the Standards for Reporting of Diagnostic Accuracy Studies (STARD) guidelines27. All participants provided written informed consent prior to participation. All methods were carried out in accordance with the relevant guidelines and regulations, including the Declaration of Helsinki and institutional research policies.
LLM evaluation Protocol
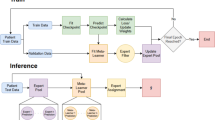
Four successive multimodal LLMs from the Google Gemini series were evaluated: Gemini 1.5 Pro, Gemini 2.0 Flash, Gemini 2.5 Flash, and Gemini 2.5 Pro. All models were accessed via a secure, HIPAA-compliant Google Cloud (Vertex AI) platform. Each video was analyzed using the same standardized prompt for every case and every model (Fig. 1). No additional clinical information was provided. Each video–model evaluation was performed as a single-turn query in a new session, with conversation history cleared between runs to prevent carryover effects. To assess the models’ internal certainty, the standardized prompt explicitly required each LLM to provide a self-reported confidence score on a 10-point Likert scale (1 = very uncertain, 10 = very confident) alongside its diagnostic classification. These scores represent a qualitative self-assessment by the model rather than a frequentist probability of correctness.
To minimize analytic degrees of freedom, decoding parameters were pre-specified and held constant across models (temperature = 1.0; top-p = 0.95; maximum output tokens = 8192). These parameters were not tuned to the dataset; they were kept identical across model versions to avoid confounding model comparisons with parameter optimization. Model responses were converted to a binary outcome (“epileptic seizure” vs. “functional seizures”) using a predefined, rule-based mapping based on the model’s explicit final classification statement. If a response did not provide a clear final classification, it was flagged as indeterminate. We did not score or validate the clinical fidelity of the model-generated rationales to the visible semiology in the videos. Detailed results are presented in Supplemental Table 1.

Example demonstration of the workflow. Figure illustrates the standardized workflow on the Google Cloud Vertex AI platform. A smartphone video was uploaded, and a consistent prompt instructed the selected Gemini model to provide a classification (epileptic vs. non-epileptic), a justification based on visual evidence, and a confidence score.
Statistical analysis
Baseline characteristics of participants and videos were summarized using descriptive statistics. The primary performance of each LLM was assessed by calculating diagnostic accuracy, sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), and the F1-score against the video-EEG ground truth28. Corresponding 95% confidence intervals (CIs) for accuracy, sensitivity, and specificity were calculated using the exact binomial (Clopper-Pearson) method. Pairwise comparisons of diagnostic accuracy between models were performed using McNemar’s test. To evaluate the impact of data dependency from participants with multiple recordings, a patient-level sensitivity analysis was performed using only the first chronologically captured video for each of the 15 participants. Each smartphone video was otherwise treated as an independent index test, as each captured a distinct paroxysmal event occurring at a different time and clinical context. Exploratory subgroup analyses were performed to assess how model accuracy varied according to pre-specified technical (video quality, video focus on whole body or upper body/face, lighting, interpretability and duration) and clinical subgroups (ictal status, semiology, and bystander behavior) characteristics, using the Chi-square or Fisher’s exact test as appropriate. A two-tailed P-value < 0.05 was considered statistically significant. All analyses were performed using Python (version 3.9) and IBM SPSS Statistics (version 29).
Results
Participant and video characteristics
The study included 24 videos from 15 participants (9 female, 6 males; mean age, 38.8 years). Nineteen videos (79.2%) captured epileptic seizures and 5 (20.8%) captured functional seizures. Six participants submitted multiple videos; of these, three participants showed semiological diversity between recordings of the same event type. Each submitted smartphone video was treated as an individual index test and linked to the EMU reference diagnosis.
Diagnostic performance
A progressive improvement in diagnostic accuracy was observed with successive model iterations (Table 1). Overall accuracy increased from 33.3% for Gemini 1.5 Pro to 54.2% for both Gemini 2.5 Flash and Gemini 2.5 Pro. Exploratory pairwise comparisons using McNemar’s test suggested higher accuracy for Gemini 2.5 Pro than for Gemini 1.5 Pro (54.2% vs 33.3%; p = 0.012) and Gemini 2.0 Flash (54.2% vs 25.0%; p = 0.003) (Table 2). Gemini 2.5 Flash also showed higher accuracy than Gemini 2.0 Flash (54.2% vs 25.0%; p = 0.016). Accuracy was similar between Gemini 2.5 Flash and Gemini 2.5 Pro (p = 0.219). Given the pilot sample size, repeated videos from some participants, and multiple comparisons, these p-values are presented as exploratory. Overall, the results are consistent with improved performance in later Gemini versions within this dataset.
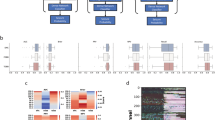
As illustrated in Fig. 2A, the models exhibited distinct performance profiles that evolved over time. The first three models (Gemini 1.5 Pro, 2.0 Flash, and 2.5 Flash) were highly conservative, achieving perfect specificity (100%) and PPV (100%) but low sensitivity, ranging from 5.3% to 42.1%. This suggests an early classification strategy biased toward avoiding false positives. In contrast, Gemini 2.5 Pro demonstrated a more balanced profile, achieving the highest sensitivity (52.6%) and the highest F1-score (64.5%), though with moderate specificity (60.0%). However, these estimates should be interpreted cautiously because only five functional seizure videos were included, resulting in wide confidence intervals (e.g., specificity of 100% yields an exact 95% CI of 47.8–100.0%).
Given the class imbalance in the dataset, we also evaluated a trivial majority-class baseline for interpretability. A classifier that labels every event as epileptic would achieve an apparent accuracy of 79.2% (19/24), which is higher than the observed accuracy of all evaluated models. However, this baseline has 0% specificity for functional seizures and therefore does not provide meaningful differentiation between epileptic and functional events. In contrast, the evaluated models were assessed for differential performance, and interpretation was based on sensitivity, specificity, PPV, NPV, and F1-score in addition to accuracy.

Diagnostic performance and confidence score of gemini models for seizure classification. Panel A displays diagnostic performance metrics (sensitivity, specificity, positive predictive value [PPV], negative predictive value [NPV], accuracy, and F1-score) for each Gemini model when classifying clinical seizure videos. Each bar represents one metric, color-coded by model. Panel B presents box plots of the self-reported confidence scores for the same models, using real confidence data for each case (scale: 1 = very uncertain, 10= very confident). Box plots display the median (black line), interquartile range (box), and outliers (colored circles). All results are based on the prospective evaluation of 24 de-identified smartphone videos.
To account for potential data dependency arising from multiple videos per participant, a sensitivity analysis was performed at the patient level (N = 15) by evaluating only the first chronologically recorded video for each participant (Supplemental file-2). In this independent subset, diagnostic accuracy followed an evolutionary trend consistent with the primary analysis: Gemini 1.5 Pro (20.0%), Gemini 2.0 Flash (26.7%), Gemini 2.5 Flash (53.3%), and Gemini 2.5 Pro (46.7%). While the reduced sample size led to slight fluctuations in absolute accuracy, the substantial improvement in the Gemini 2.5 series compared to the 1.5 and 2.0 generations remained evident. These findings suggest that the models’ diagnostic performance was driven by event-specific semiological features rather than a visual familiarity with individual participants.
Analysis of model-reported confidence and calibration
All models reported high confidence in their classifications, regardless of accuracy (Fig. 2B), with median confidence scores between 8.0 and 9.0 on a 10-point scale (Table 3). Because these values are self-reported ordinal ratings rather than probabilistic outputs, they should not be interpreted as formal likelihood estimates. Empirically, confidence showed poor alignment with correctness. For Gemini 2.5 Pro, mean confidence for incorrect classifications was nearly identical to that for correct classifications (8.45 vs. 8.46), indicating that the model often assigned similarly high confidence to both correct and incorrect predictions (“confidently wrong” behavior).
Factors associated with accuracy
Exploratory subgroup analyses were performed to identify technical and clinical features associated with diagnostic accuracy (Table 4). Model performance was highly dependent on video quality. For “Good” quality videos (n = 21), Gemini 2.5 models achieved 57.1% accuracy, whereas for “Poor” quality videos (n = 3), accuracy was substantially lower, with some models failing to correctly classify any videos. Similarly, for videos with low light and those deemed poor quality limiting interpretation by experts, all models performed at or near 0% accuracy. This reflects a significant deficiency of the models when recording conditions were suboptimal.
Accuracy was also associated with the video’s focal point. In subgroup comparisons, Gemini 2.5 Flash and Gemini 2.5 Pro showed higher accuracy when the focus was on the upper body or face compared to the whole body (p = 0.004 and p = 0.047, respectively). Finally, performance varied by seizure semiology. The initial models (Gemini 1.5 Pro and 2.0 Flash) failed to correctly classify any non-motor seizures (0.0% accuracy; p = 0.002 and p = 0.016 vs. motor seizures, respectively). The Gemini 2.5 models showed improved and more balanced performance across non-motor (63.6% for Pro) and motor events (46.2% for Pro). This suggests early models were biased toward detecting overt motor events, whereas later iterations could analyze a broader range of semiologies. These findings should be interpreted as hypothesis-generating trends rather than established statistical certainties.
Discussion
This pilot study provides a preliminary evaluation of general-purpose improvement with successive Gemini models focused on video-based seizure classification. We found that while the diagnostic accuracy of these models improved with newer iterations, overall performance was modest. This behavior, coupled with performance that is dependent on video quality and seizure semiology, indicates that these models are not yet suitable for autonomous clinical use26.
Despite these limitations, we observed a promising qualitative shift in analytical capability. The most advanced model, Gemini 2.5 Pro, progressed beyond simple pattern recognition toward a form of clinical inference, such as correctly identifying a post-ictal state as a sign of recovery from a preceding seizure. This ability to interpret behavioral patterns in a clinical context represents a crucial step toward developing a clinically useful “gestalt,” aligning with broader trends in AI development for a more nuanced interpretation29. However, we must exercise caution in labeling this as “clinical inference.” While these outputs align with experts, they likely represent advanced pattern matching visual tokens rather than a true understanding of pathophysiology. There remains a significant risk that such models may “hallucinate” clinically sound justifications for a classification reached through unrelated data biases. Consequently, these models should be viewed as sophisticated pattern-recognition tools rather than autonomous clinical reasoner.
However, the models struggled particularly with non-motor seizures, underscoring the challenge of applying generalist AI to specialized medical domains. It is essential to contextualize these results within the broader framework of clinical neurology; differentiating non-motor epileptic seizures from functional mimics based solely on video recordings is a complex task that frequently challenges even experienced epilepsy experts. Without the benefit of a detailed patient history or EEG data, the behavioral cues in non-motor events are often too subtle or non-specific for a definitive visual diagnosis. This limitation likely reflects a training data bias toward the more visually obvious convulsive/motor semiologies common in public internet sources and more accurately diagnosed, as opposed to subtler, non-motor events2,30. This contrasts with the high accuracy reported for specialized deep learning models that are trained on curated, expert-labeled medical datasets, such as detecting tonic-clonic seizures in an epilepsy monitoring unit8,10,11.
Our findings also suggest that high-quality video acquisition is a critical prerequisite for reliable AI-based classification, as technical factors fundamentally determine the reliability of any video-based assessment2,4,31. Further, more focus on a specific body part as opposed to the whole body itself appeared to provide a more suitable environment for accurate diagnosis, and the environment in which videos are taken may impact the interpretation from the LLM32. Taken together, this indicates a clear need to improve existing algorithms, with domain-specific training on diverse, high-quality medical video datasets for clinically acceptable performance8.
Interestingly, the most recent iteration demonstrated lower diagnostic confidence, mirroring observations from human expert reviews. For instance, less experienced resident physicians exhibit higher confidence yet lower diagnostic accuracy when interpreting smartphone-recorded seizure videos2. Effective integration of AI into neurology depends critically on physician trust and model interpretability, yet our findings reveal that all models frequently exhibited “confidently wrong” behavior, assigning high confidence scores to incorrect diagnoses33,34. This misalignment poses a significant safety risk, as it could mislead clinicians or patients. This issue is compounded by the proprietary “black box” nature of these models, which prevents analysis of their failure modes35. Moving forward, it will be crucial to address the broader ethical challenges associated with integrating such complex, opaque AI systems into clinical medicine, including issues of accountability, bias, and patient privacy36. The increasing use of smartphone videos in diagnosis provides an environment in which AI systems could be highly useful37. However, until models are better calibrated and more interpretable, they cannot be considered trustworthy to augment clinical practice.
Strengths of this study include its prospective design, use of video-EEG as a gold-standard for diagnosis, and direct head-to-head comparison of successive model versions. However, our study has several limitations. First, the small sample size from a single center limits the generalizability and the statistical power of subgroup analyses. Second, a class imbalance in the dataset may have affected performance metrics. With only five functional seizures events included in the dataset, metrics such as specificity and positive predictive value are inherently unstable. Because of the class imbalance, accuracy alone can be misleading and may favor trivial prediction strategies (e.g., always predicting the majority class). We therefore added an explicit majority-class baseline and emphasized differential performance metrics (especially sensitivity and specificity) when interpreting model utility. Third, the task was constrained to video-only analysis to isolate the models’ visual capabilities, which does not reflect multimodal real-world diagnosis integrating clinical history but does mirror how clinicians often review videos independently and simulate non-expert analysis. Finally, the proprietary nature of these commercial models prevented any analysis of their architecture or training data, a persistent challenge in the evaluation of closed-source LLM systems.
Conclusion
This study presents data on seizure diagnosis through analysis of video-recorded events by general-purpose multimodal LLMs, showing moderate accuracy and suggesting that they are not yet ready for autonomous diagnostic use in diagnosing epilepsy. However, the iterative improvement with each version and the rapidity with which newer versions are becoming available is promising. Future work should focus on fine-tuning models with large, diverse, and expert-annotated medical video datasets. Further, it would be important to determine how clinical data inputs could assist in improving diagnostic accuracy. It is also critical to develop and validate methods that improve the alignment between model-reported confidence and diagnostic correctness (ideally with clinically interpretable confidence outputs) to support safety and reliability. Finally, conducting larger, multicenter studies is necessary to validate model performance across diverse populations and settings. Ultimately, the goal should be to integrate these tools into a human-centered, multimodal diagnostic framework that augments standard clinical evaluations led by trained experts.
Data availability
All data supporting the findings of this study are available within the paper and its Supplementary Information. The analyzed datasets generated during the current study, including performance metrics and model classifications (presented in Supplemental Table 1), are available within this published article and its supplementary information files. The raw video data analyzed in this study are not publicly available due to their nature as protected health information and the potential for patient identification, which contravenes the terms of our IRB approval and participant consent.
References
Beniczky, S. A. et al. Seizure semiology inferred from clinical descriptions and from video recordings. How accurate are they?. Epilepsy Behav 24, 213–215. https://doi.org/10.1016/j.yebeh.2012.03.036 (2012).
Tatum, W. O. et al. Assessment of the Predictive Value of Outpatient Smartphone Videos for Diagnosis of Epileptic Seizures. JAMA Neurol 77, 593–600. https://doi.org/10.1001/jamaneurol.2019.4785 (2020).
Amin, U. et al. Value of smartphone videos for diagnosis of seizures: Everyone owns half an epilepsy monitoring unit. Epilepsia 62, e135–e139. https://doi.org/10.1111/epi.17001 (2021).
Freund, B. E. & Feyissa, A. M. EEG as an indispensable tool during and after the COVID-19 pandemic: A review of tribulations and successes. Front Neurol 13, 1087969. https://doi.org/10.3389/fneur.2022.1087969 (2022).
Konomatsu, K. et al. Referral odyssey plot to visualize causes of surgical delay in mesial temporal lobe epilepsy with hippocampal sclerosis. Epilepsy Behav 147, 109434. https://doi.org/10.1016/j.yebeh.2023.109434 (2023).
Thirunavukarasu, A. J. et al. Large language models in medicine. Nat. Med. 29, 1930–1940. https://doi.org/10.1038/s41591-023-02448-8 (2023).
Kline, A. et al. Multimodal machine learning in precision health: A scoping review. NPJ Digit. Med. 5, 171. https://doi.org/10.1038/s41746-022-00712-8 (2022).
Zhou, S. et al. Large language models for disease diagnosis: a scoping review. NPJ Artif. Intell. 1, 9. https://doi.org/10.1038/s44387-025-00011-z (2025).
Zhang, Y., Yu, L., Lv, Y., Yang, T. & Guo, Q. Artificial intelligence in neurodegenerative diseases research: a bibliometric analysis since 2000. Front Neurol 16, 1607924. https://doi.org/10.3389/fneur.2025.1607924 (2025).
Boyne, A. et al. Video-based detection of tonic-clonic seizures using a three-dimensional convolutional neural network. Epilepsia 66, 2495–2506. https://doi.org/10.1111/epi.18381 (2025).
Rai, P. et al. Automated analysis and detection of epileptic seizures in video recordings using artificial intelligence. Front Neuroinform 18, 1324981. https://doi.org/10.3389/fninf.2024.1324981 (2024).
Degerli, A., Jäkälä, P., Pajula, J., Immonen, M. & López, M. B. MAMAF-Net: Motion-aware and multi-attention fusion network for stroke diagnosis. Biomed. Signal Proc. and Control 95, 106381. https://doi.org/10.1016/j.bspc.2024.106381 (2024).
Elliott, C. et al. Early Moves: a protocol for a population-based prospective cohort study to establish general movements as an early biomarker of cognitive impairment in infants. BMJ Open 11, e041695. https://doi.org/10.1136/bmjopen-2020-041695 (2021).
Karayiannis, N. B. et al. Automated detection of videotaped neonatal seizures based on motion segmentation methods. Clin Neurophysiol 117, 1585–1594. https://doi.org/10.1016/j.clinph.2005.12.030 (2006).
Munsif, M. et al. Optimized efficient attention-based network for facial expressions analysis in neurological health care. Comput. Biol. Med. 179, 108822. https://doi.org/10.1016/j.compbiomed.2024.108822 (2024).
Iseki, C. et al. Artificial Intelligence Distinguishes Pathological Gait: The Analysis of Markerless Motion Capture Gait Data Acquired by an iOS Application (TDPT-GT). Sensors (Basel) https://doi.org/10.3390/s23136217 (2023).
Zhao, P. et al. Computer Vision for Gait Assessment in Cerebral Palsy: Metric Learning and Confidence Estimation. IEEE Trans Neural Syst. Rehabil. Eng. 32, 2336–2345. https://doi.org/10.1109/tnsre.2024.3416159 (2024).
Williams, S. et al. The discerning eye of computer vision: Can it measure Parkinson’s finger tap bradykinesia?. J. Neurol Sci. 416, 117003. https://doi.org/10.1016/j.jns.2020.117003 (2020).
Lu, M.Y, Chen, B, Williamson, D.F.K, Chen, R.J, Zhao, M, Chow, A.K, Ikemura, K, Kim, A, Pouli, D, Patel, A. et al. A multimodal generative AI copilot for human pathology. Nature. 634, 466–473. https://doi.org/10.1038/s41586-024-07618-3 (2024).
Patel, A., Cheung, J. Artificial intelligence in sleep medicine: assessing the diagnostic precision of ChatGPT-4. J. Clin. Sleep Med. 21:1511–1517. https://doi.org/10.5664/jcsm.11732 (2025).
Kim, J., Leonte, K. G., Chen, M. L., Torous, J. B., Linos, E., Pinto, A., Rodriguez, C. I. Large language models outperform mental and medical health care professionals in identifying obsessive-compulsive disorder. NPJ Digit Med. 7, 193. https://doi.org/10.1038/s41746-024-01181-x (2024).
Patel, A., Ruoff, C., Helgeson, S. A., Carvalho, D. Z., Castillo, P. R., Cheung, J. Diagnostic performance of Large Language Models (LLMs) compared with physicians in sleep medicine. Sleep Med. 134, 106677. https://doi.org/10.1016/j.sleep.2025.106677 (2025).
Patel, A., Contractor, H., Heninger, H., Vallamchetla, S. K., Li, P., Tao, C., Cheung, J. Performance of successive generative pretrained transformers (GPT) models in medical cases and board style questions. Scientific Reports. https://doi.org/10.1038/s41598-025-34939-8 (2026)
AlSaad, R., Abd-Alrazaq, A., Boughorbel, S., Ahmed, A., Renault, M. A., Damseh, R., Sheikh, J. Multimodal Large Language Models in Health Care: Applications, Challenges, and Future Outlook. J. Med. Internet. Res. 26, e59505. https://doi.org/10.2196/59505 (2024).
Saab, K., Tu, T., Weng, W-H., Tanno, R., Stutz, D., Wulczyn, E., Zhang, F., Strother, T., Park, C., Vedadi, E. et al. Capabilities of Gemini Models in Medicine. In: arXiv (2024).
Tatum, W. O., Hirsch, L. J., Gelfand, M. A., Acton, E. K., LaFrance, W. C., Duckrow, R. B., Chen, D., Blum, A. S., Hixson, J., Drazkowski, J. et al. Video quality using outpatient smartphone videos in epilepsy: Results from the OSmartViE study. Eur. J. Neurol. 28, 1453–1462. https://doi.org/10.1111/ene.14744 (2021).
Bossuyt, P. M., Reitsma, J. B., Bruns, D.E., Gatsonis, C. A., Glasziou, P. P., Irwig, L., Lijmer, J. G., Moher, D., Rennie, D., de Vet H. C. et al. STARD 2015: An Updated List of Essential Items for Reporting Diagnostic Accuracy Studies. Clin. Chem. 61, 1446–1452. https://doi.org/10.1373/clinchem.2015.246280 (2015).
Vallamchetla, S. K. et al. Do it faster with PICOS: Generative AI-Assisted systematic review screening. J. Biomed. Inform. 168, 104860. https://doi.org/10.1016/j.jbi.2025.104860 (2025).
Bajwa, J., Munir, U., Nori, A. & Williams, B. Artificial intelligence in healthcare: transforming the practice of medicine. Future Healthc. J. 8, e188–e194. https://doi.org/10.7861/fhj.2021-0095 (2021).
Kerr, W. T. et al. Supervised machine learning compared to large language models for identifying functional seizures from medical records. Epilepsia 66, 1155–1164. https://doi.org/10.1111/epi.18272 (2025).
Freund, B. & Tatum, W. O. Pitfalls using smartphones videos in diagnosing functional seizures. Epilepsy Behav. Rep. 16, 100497. https://doi.org/10.1016/j.ebr.2021.100497 (2021).
Lee, J. O., Zhou, H. Y., Berzin, T. M., Sodickson, D. K. & Rajpurkar, P. Multimodal generative AI for interpreting 3D medical images and videos. NPJ Digit. Med. 8, 273. https://doi.org/10.1038/s41746-025-01649-4 (2025).
Omar, M., Agbareia, R., Glicksberg, B. S., Nadkarni, G. N. & Klang, E. Benchmarking the Confidence of Large Language Models in Answering Clinical Questions: Cross-Sectional Evaluation Study. JMIR Med. Inf. 13, e66917. https://doi.org/10.2196/66917 (2025).
Kim, J. et al. Limitations of large language models in clinical problem-solving arising from inflexible reasoning. Sci. Rep. 15, 39426. https://doi.org/10.1038/s41598-025-22940-0 (2025).
Quinn, T. P., Senadeera, M., Jacobs, S., Coghlan, S. & Le, V. Trust and medical AI: the challenges we face and the expertise needed to overcome them. J. Am. Med. Inform. Assoc. 28, 890–894. https://doi.org/10.1093/jamia/ocaa268 (2021).
Chen, Z. Ethics and discrimination in artificial intelligence-enabled recruitment practices. Human. Soc. Sci. Commun. 10, 567. https://doi.org/10.1057/s41599-023-02079-x (2023).
Tatum, W. O. et al. Smartphone use in Neurology: a bibliometric analysis and visualization of things to come. Front Neurol 14, 1237839. https://doi.org/10.3389/fneur.2023.1237839 (2023).
Acknowledgements
The authors have no acknowledgments to declare.
Funding
This study did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Contributions
Anshum Patel: Conceptualization, Data Curation, Formal Analysis, Writing – Original Draft, Writing – Review & Editing. Sai Krishna Vallamchetla: Data Curation, Formal Analysis, Investigation, Writing – Original Draft. Adrian Safa: Project Administration, Validation. Caroline Tatit: Investigation, Data Curation, Validation. Olivia Bestic: Data Curation. Alicia Kissinger Knox: Methodology, Data Curation, Formal Analysis. Mark Roberts: Methodology, Software, Validation, Formal Analysis. William O. Tatum: Conceptualization, Resources, Supervision, Writing – Review & Editing. Brin Freund: Conceptualization, Methodology, Supervision, Funding Acquisition, Writing – Original Draft, Writing – Review & Editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval and consent to participate
The study was approved by the Mayo Clinic Institutional Review Board (IRB 25-006380). Written informed consent was obtained from all participants.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Patel, A., Vallamchetla, S.K., Safa, A. et al. Diagnostic accuracy of multimodal large language models in differentiating epileptic from functional seizures in smartphone recorded videos. Sci Rep 16, 11719 (2026). https://doi.org/10.1038/s41598-026-46333-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-46333-z
