
Abstract
Wildfires have emerged as a significant environmental concern in the Himalayan region, particularly in the Upper Ravi sub-basin of Himachal Pradesh, India. This study aims to map wildfire susceptibility by integrating Geographic Information Systems (GIS), remote sensing data, and advanced ensemble machine learning techniques. A total of sixteen biophysical and anthropogenic conditioning factors, including topography, climatic variables, vegetation indices, and human activity indicators, were used to develop wildfire susceptibility models. Five machine learning algorithms were evaluated, including Random Forest, XGBoost, LightGBM, CatBoost, and a stacking ensemble model. Among these, the stacking model demonstrated the best predictive performance with an AUC of 0.95.To enhance model interpretability and robustness, explainability, uncertainty, and sensitivity analyses were conducted on the best-performing stacking model using SHapley Additive exPlanations (SHAP), Monte Carlo uncertainty analysis, and Sobol global sensitivity analysis. SHAP results identified temperature, soil moisture, distance to villages, and relative humidity as the most influential wildfire conditioning factors. Monte Carlo simulations (1000 iterations) yielded a mean AUC of 0.847, indicating stable model performance under input perturbations. Sobol sensitivity analysis further confirmed soil moisture and temperature as the most influential variables, with total-order sensitivity indices of 0.45 and 0.21, respectively. Spatial analysis revealed that approximately 20.75% of the study area falls within high to very high wildfire susceptibility zones, primarily associated with regions characterized by steep terrain, low soil moisture conditions, and significant anthropogenic influence. Overall, the study presents an interpretable and uncertainty-aware GeoAI framework that integrates ensemble learning with explainable artificial intelligence and sensitivity analysis, providing a reproducible approach for wildfire susceptibility assessment in complex mountainous environments.
Similar content being viewed by others
Introduction
Forests are one of the most important natural resources and gene banks on the earth because they function as the reservoir of carbon, water and energy, along with maintaining the ecological balance of the ecosystem1. However, the demand for forest resources has been increasing in recent years due to population growth and industrial development2. Wildfires are among the most catastrophic events that destroy forest ecosystems and contribute to environmental degradation and biodiversity loss3. In recent decades, the frequency and intensity of wildfires have increased worldwide, driven by the combined influence of climatic factors such as rising temperatures, reduced precipitation, and dry winds, along with anthropogenic pressures including land use/land cover (LULC) changes and expanding tourism activities4. Globally, nearly 30% of the land surface is affected by forest fires caused by both natural and human-induced factors5, and an average of about 422.5 million hectares (Mha) of forest area burned annually between 2002 and 2016, exceeding the size of a country like India6. In early January 2025, a series of destructive wildfires erupted across the greater Los Angeles region, resulting in at least 30 fatalities, the evacuation of more than 200,000 residents, the destruction of over 18,000 homes and structures, and the burning of more than 57,000 acres of land7,8. India is one of the world’s most forest-rich countries, with covering 80.9 million hectares, accounting for 24.62 per cent of the country’s geographical area9.
According to the India State of Forest Report (ISFR, 2019) published by the Forest Survey of India, nearly 36% of India’s forested areas are susceptible to wildfires10. Among South Asian countries, India ranks as the second most vulnerable nation to wildfires, with approximately 32% of its forests exposed to fire risk11. Over the past two decades, the country has experienced a substantial increase in intense wildfire events, with studies reporting a 52% rise in severe fire incidents12. These increasing wildfire occurrences significantly contribute to black carbon emissions, which can alter surface albedo and accelerate snowmelt in the higher Himalayan regions13. Himachal Pradesh (HP), located within the Himalayan Biodiversity Hotspot, is highly susceptible to wildfires due to its dry pre-monsoon season (March–June) and the accumulation of highly combustible Chir pine needles, which significantly increase the forest fuel load. Studies have shown that the accumulation of pine needles on the forest floor enhances flammability and facilitates the rapid spread of fires in Himalayan pine forests14. In addition, wildfires in the western Himalayan region generally occur during the dry season from February to June, when low moisture conditions and wind facilitate fire ignition and spread15. During this period, even minor human negligence can trigger rapidly spreading fires, particularly in Chir pine-dominated landscapes. According to the Himachal Pradesh Forest Department, the state recorded 10,136 wildfire incidents between November 2023 and June 2024, representing the highest number of wildfire cases in India. The northern and central regions, particularly Uttarakhand, Himachal Pradesh, Madhya Pradesh, Chhattisgarh, Odisha and the northeastern states, are most severely affected15,16.
The use of satellite-based remote sensing (RS) data and new machine learning (ML) and artificial intelligence (AI) has made it easier to estimate wildfire susceptibility16,17. Machine learning (ML) models work really well because they can quickly process vast amounts of data and handle complicated connections between climate and geo-environmental elements18,19. Various studies have used ML approaches such as Random Forest (RF), Support Vector Machines (SVM), Xtreme Gradient Boosting (XGB) models for wildfire prediction17,20. For instance, Mishra et al. (2024) demonstrated the effectiveness of machine learning models such as Random Forest and Support Vector Machine in identifying wildfire susceptibility zones using multiple geospatial predictors16. Similarly, other recent research has emphasized the integration of ensemble learning algorithms and explainable artificial intelligence techniques to better interpret the contribution of environmental variables in wildfire prediction models21,22. Ensemble learning approaches have shown improved predictive capability by integrating multiple base models to capture complex environmental interactions22. However, most wildfire susceptibility studies in the Himalayan region have primarily relied on individual machine learning algorithms and have rarely incorporated explainable artificial intelligence or uncertainty analysis frameworks. Therefore, integrating ensemble learning with interpretability and uncertainty assessment remains an important research direction for improving wildfire susceptibility modelling in complex mountainous environments23,24. Despite these advances, most previous studies primarily focus on prediction accuracy, with limited attention given to the combined evaluation of model interpretability, uncertainty, and sensitivity of environmental drivers.
The novelty of this study lies in the development of an integrated GeoAI framework that combines stacking ensemble learning with explainable artificial intelligence and uncertainty analysis techniques for wildfire susceptibility assessment. Specifically, the proposed approach integrates SHAP-based explainability with Monte Carlo uncertainty analysis and Sobol global sensitivity analysis to evaluate the contribution, interaction, and uncertainty of wildfire conditioning factors within a unified modelling framework. While previous studies have applied ensemble machine learning or explainable AI techniques individually, their combined implementation with uncertainty and sensitivity analysis in wildfire susceptibility modelling remains limited. In addition, the framework is applied at a regional scale to the Upper Ravi sub-basin in the Indian Himalayan region, a complex mountainous environment where wildfire susceptibility studies remain relatively scarce. This regional application provides new insights into the spatial drivers of wildfire occurrence and demonstrates the applicability of integrated GeoAI approaches for wildfire susceptibility assessment in Himalayan landscapes. Based on the above research gaps, the following objectives were formulated: (i) to produce the wildfire susceptibility maps by comparing Random Forest (RF), XGBoost, LightGBM, CatBoost tree-based ensemble and Stacking models to build a spatial machine learning framework in relation to the wildfire susceptibility mapping, (ii) to examine how the best-performing model (the stacking model) is influenced by the conditioning factors using SHAP outputs, (iii) to obtain overall contributions of each factor to predictions and SHAP dependence plots for evaluating the isolated effect of factors on model predictions and (iv) to apply Monte Carlo technique and Sobol Sensitivity methods to perform sensitivity and uncertainty analyses of the best-performing ML model. This study provides reproducible framework for wildfire risk mitigation in the Upper Ravi sub-basin and contributes a novel methodological framework that can be adapted for susceptibility assessments in other regions.
Materials and methods
Study area
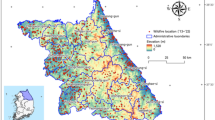
The Upper Ravi sub-basin is located in the northern region of Himachal Pradesh (HP), Punjab and the Southwestern region of Jammu & Kashmir, India, encompassing parts of Chamba, Kangra districts (HP) and some parts of Pathankot ( Punjab ) and Kathua district of Jammu & Kashmir (Fig. 1). The region covers an area of 5759 km2. Geographically, it lies between 32°46′34″– 33°01′5″N latitudes and 75°39′– 77°45′E longitude. Ravi River originates from Bara Banghal at an elevation of 4229 m above mean sea level (MSL) and flows through steep hills in a meandering and circling rhythm. This region is characterized by continuous mountainous topography with elevations ranging from 395 m to 6095 m above MSL and slopes reaching up to 70 degrees (Fig. 1).

Geographical location of Upper Ravi sub-basin in India.
The total population is approximately 442,650, found up to an elevation of 3000 m. The annual rainfall ranges from 696 mm to 1480 mm. The highest recorded temperature in July is 39 °C, and the lowest recorded temperature in winter is − 1°C25. Climatically, the lower part of the basin has a semi-tropical climate, while the central and northern sections experience a semi-arctic climate.
Material
For the susceptibility of wildfire, we used 16 conditioning factors from the various data portals (Table 1). For topographical factors, 12.5-meter resolution ALOS PALSAR DEM has been used to generate the elevation, aspect and slope, TWI, and Curvature factorial maps. Land use and land cover (LULC) and Normalized Differentiated Vegetation Index (NDVI) maps were created from Sentinel 2 imagery. Moreover, village location, religious place and tourist sites datasets were downloaded from Open Street Map (OSM). The annual mean temperature and annual mean rainfall data were downloaded from the WorldClim v.2.1 Database (~ 1 km). Annual mean evapotranspiration and soil moisture data were obtained from Giovanni and Copernicus Climate Data Store, respectively. The annual mean relative humidity data is downloaded from the NASA Power Access Hub, whereas wind speed data was taken from the portal of Global Wind Atlas. The road network data was retrieved from the Bhukosh website (Table 1). The NDVI was calculated using the standard formula based on the red and near-infrared bands. Sentinel-2 Level-2 A (L2A) Bottom-of-Atmosphere (BOA) reflectance imagery, which includes terrain, radiometric, and atmospheric corrections, was used, and cloud-free scenes were selected to minimize atmospheric contamination. The LULC layer was derived from Sentinel-2 imagery using a supervised classification approach followed by recoding in ERDAS Imagine generating the final land-use classes. In addition, proximity-based variables such as distance from roads, villages, tourist sites, and religious places were prepared using the euclidean distance tool in ArcGIS 10.8. All spatial datasets were projected to WGS84 / UTM Zone 43 N to ensure the spatial consistency, while climatic variables obtained from WorldClim, Giovanni, Global Wind Atlas were resampled to 12.5 m using bilinear interpolation to maintain spatial compatibility with the DEM-derived topographic layers.
Methods
Wildfire inventory map
Wildfire susceptibility models examine the relationships between past wildfire occurrences and their influencing factors26. Therefore, the initial step involves creating an inventory map of wildfires in the area, operating under the premise that analysing comprehensive historical data can help predict potential future fire events in the same locations27.

Schematic flowchart illustrating the overall methodology adopted for wildfire susceptibility mapping using machine learning (ML) models.
Wildfire inventories are essential for predictive modelling, but official records are often incomplete or inaccessible, particularly in rural and sparsely populated regions. To address this, we developed a historical inventory using NASA FIRMS MODIS C6.1 data (2002–2024) (https://firms.modaps.eosdis.nasa.gov/download/). To ensure reliability, only fire events with ≥ 80% confidence and Fire Radiative Power (FRP) ≥ 30 MW were considered28. FRP represents the rate at which radiative energy is emitted from an actively burning fire and is widely used as a proxy for fire intensity and combustion strength. Applying an FRP ≥ 30 MW threshold helps retain significant wildfire events while excluding low-intensity or uncertain detections28. Pseudo-absence samples representing non-wildfire locations were generated to construct a balanced dataset for machine learning modelling. Random points were created using the Create Random Points tool in ArcMap (ArcGIS 10.8). To prevent pseudo-absence samples from being located near known wildfire events, a 2 km buffer was applied around wildfire points and excluded from the sampling area. A minimum allowed distance of 1 km was also specified to ensure spatially well-distributed absence samples and reduce clustering. The number of pseudo-absence samples was set equal to the number of wildfire occurrences, resulting in 863 presence and 863 pseudo-absence points, thereby maintaining a balanced dataset for model training and validation16,19.The wildfire presence and pseudo-absence samples were randomly divided into training and testing datasets, with 70% of the samples used for model training and 30% reserved for validation16,20. However, spatial datasets may exhibit spatial autocorrelation, which can influence model evaluation. Although spatial cross-validation approaches can further minimize spatial dependence, the present study incorporated Monte Carlo uncertainty analysis and Sobol global sensitivity analysis to evaluate model robustness under varying input conditions a detailed methodological framework is shown in Fig. 2.
Conditioning factors
The probability of a wildfire arising in a specific area given the environmental conditions is known as the spatial probability of wildfire occurrence. These conditions may be topographical, hydrological, meteorological, anthropological, or geomorphological. These variables, which are chosen for their applicability to the research field, are referred to as conditioning factors and have the potential to significantly impact the final susceptibility mapping. Standardising the hazard’s conditioning factors is essential when getting ready for any kind of mapping of natural hazard susceptibility29.In the current analysis, we have used sixteen wildfire conditioning factors, namely slope, aspect, wind speed, curvature, temperature, distance from road, distance from village, distance from Tourist, Distance from Religious places, LULC, rainfall, relative humidity topographic wetness index (TWI), Soil Moisture, evapotranspiration and normalized difference vegetation index (NDVI). All spatial layers were prepared using ArcGIS 10.8 with the raster size of 12.5 × 12.5 m Fig. 3a–p. The wildfire inventory dataset covers the period 2002–2024, while the predictor variables represent long-term environmental and climatic conditions influencing wildfire susceptibility in the study area.
Topographic and climatic factors are playing vital role in assessing wildfire susceptibility. Slope affects the fire diffusion speed and intensity, while aspect decides the exposure to solar radiation and wind, accordingly, determining the dryness of the fuel30. The TWI demonstrates surface runoff and accumulation of water, which significantly impacts burned area in high-elevation terrain regions16. Curvature further influences the distribution of vegetation and surface processes that shape fire behaviour. Some of the key drivers of fire occurrence include meteorological variables like temperature, wind speed, rainfall, and humidity31,32. Temperature controls fuel moisture and thus, when it is hot and dry, the ignition may be favoured31. Wind leads to the spread of a fire by supplying oxygen and drying vegetation33. Rainfall and soil moisture maintain fuel humidity and act as natural suppressants, showing an inverse relationship with fire events34. Likewise, relative humidity reduces the probability of ignition by retaining moisture in air and vegetation32. This vegetation status, quantified using the Normalized Difference Vegetation Index (NDVI), is usually used as an indicator of live fuel moisture. According to Chuvieco et al., low NDVI values correspond to sparse or stressed vegetation, whereas high NDVI denotes healthy, moisture-rich vegetation35.
where NIR represents near-infrared reflectance and Red represents red band reflectance.
Anthropogenic factors are also one of the major causes for fire ignition. Land use and land cover, proximity to roads, villages, tourist, and religious sites enhance the possibility of fire due to human accessibility and activities16,36. Roads facilitate human intrusion into the interior part of the forested areas, enhancing the possibility of ignition. LULC types such as agricultural and degraded forest lands are more prone to fire incidents because of the availability of dry biomass and human activities16.


Conditioning factors employed for wildfire susceptibility mapping (a) slope, (b) aspect, (c) curvature, (d) TWI, (e) distance from religious places, (f) distance from tourist places, (g) distance from villages, (h) distance from roads (i) wind speed, (j) evapotranspiration, (k) NDVI, (l) LULC, (m) rainfall, (n) temperature, (o) relative humidity, (p) soil moisture.
Feature importance employing PCA and Pearson correlation matrix
Principal Component Analysis (PCA) is a common multivariate approach used to reduce the dimensionality of large datasets while retaining most of their variability37. In this study, the data were first standardised to eliminate the influence of differing units and scales across variables. PCA was then applied through eigenvalue decomposition, which transformed the original variables into new, uncorrelated components. The first ten principal components together explained nearly 98% of the total variance, with the first three alone accounting for around 37%, 12%, and 8%, respectively. Examination of the vector plots (Fig. 4a) showed that Soil Moisture and Relative Humidity had the strongest influence on the components, while the orientation of the vectors highlighted relationships between variables such as, distance to roads and villages were strongly positively correlated, whereas Soil Moisture and Slope, and Relative Humidity and Slope, displayed strong negative correlations38.However It should be noted that PCA was applied only for exploratory analysis and visualization of relationships among the conditioning factors, and it was not used directly for feature selection or model training in the machine learning models. To assess redundancy among predictors, a Pearson correlation matrix was also constructed (Fig. 4b). This analysis revealed very high correlations, such as between Elevation and Temperature (− 0.91). To avoid multicollinearity and improve model performance, highly correlated variable. such as elevation was excluded from the final modelling dataset due to its strong negative correlation with temperature (r = − 0.91). Since temperature directly influences vegetation dryness, fuel moisture content, and wildfire ignition probability, it was considered a more physically meaningful variable for wildfire susceptibility modelling. Retaining temperature while removing elevation helped reduce redundancy among predictors and improved the interpretability of the machine learning models37.

Principal component analysis (PCA) biplot illustrating the loadings of conditioning variables, where class 0 represents non-wildfire samples and class 1 denotes wildfire occurrences (a). Pearson correlation matrix showing relationships among the conditioning factors (b).
Multi-collinearity analysis
In natural sciences, multicollinearity tests are often applied to assess the influence of correlated variables on predictive models39. In this study, the Variance Inflation Factor (VIF) and tolerance values were used to evaluate sixteen parameters related to wildfire susceptibility. VIF quantifies how much the variance of regression coefficients is inflated due to collinearity, while tolerance indicates the proportion of variance unexplained by other predictors40. Thresholds of VIF > 9 and tolerance < 0.1 are generally considered problematic41. The analysis (Table 2) showed that all factors had tolerance values above 0.1 and VIF scores below 9, with values ranging from 0.12 to 0.95 for tolerance and a maximum VIF of 8.21 for temperature. These results confirm that multicollinearity was not a problem, which means that the modelling procedure was reliable.
where Rj2 is the coefficient of determination of the j-th independent variable to all other independent variables, and the TOL value is the reciprocal of the VIF value.
Model descriptions
Random forest (RF)
RF, which was first presented by Breiman, which causes the decision trees to be more accurate and is usually applicable to regression and classification tasks due to the robustness present42. RF uses a bootstrapped form of bagging, with Decision trees constructed of sets of variables and predictions via a majority vote. Key hyper parameters are the number of trees (NT), tree depth (d) and minimum sampling number to split (NS), which jointly control accuracy, complexity, and risk of overfitting. In order to achieve a good RF model that provides classifications through Eq. (4), striking a balance between hyper parameters is necessary.
where \(\:\widehat{y}\)is the final predicted output, \(\:{h}_{k}\) (X) is the prediction from the kth decision tree, and NT is the total number of trees in the R.F.
eXtreme gradient boosting machines (XGBoost)
XGBoost is a gradient boosting algorithm that builds decision trees sequentially, with each new tree correcting the errors of the previous ones43. It employs regularisation to reduce overfitting and uses a second-order Taylor expansion to make optimisation more accurate. Designed for speed and scalability, XGBoost performs well on big datasets by balancing predictive accuracy with model complexity. To minimize the regularized objective function, which is given in Eq. (5), is the aim of the XGBoost algorithm.
In Eq. (5), the first term represents the loss function, \(\:l\left({\widehat{y}}_{i},{y}_{i}\right)\), which measures the difference between the predicted value(\(\:{\widehat{\:y}}_{i})\) and the observed or true value (\(\:{y}_{i}\)) for the ith sample. The second term,\(\:\sum\:_{k}\varOmega\:\left({f}_{k}\right)\), is the regularization term, which penalizes model complexity and helps prevent overfitting by constraining the structure of the individual functions (or trees) fk. Together, these terms ensure that the model maintains both accuracy and generalization ability.
Here, in Eq. (6), T represents the number of leaves in the tree, w represents the score of each leaf, and γ and λ are regularisation parameters. With regard to minimising the objective function during each step T, XGBoost employs an iterative approach, as demonstrated in Eq. (7)
In Eq. (6), Lt denotes the objective function at iteration t. The first term quantifies the prediction error between the observed value yi and the cumulative prediction ŷi (t − 1) + ft(xi), while the second term Ω(ft) penalizes model complexity. XGBoost minimizes this function iteratively by fitting a new tree ft to the residual errors derived from the gradients of the loss function, ensuring both accuracy and regularization across boosting iterations.
Light gradient boosting machine (LightGBM)
LightGBM is a gradient boosting framework created for high efficiency on large datasets44. It uses gradient-based one-sided sampling to deal with sparse features well and a leaf-wise tree growth technique that concentrates on nodes with the greatest loss reduction, this makes faster training and better performance on complex interactions compared to XGBoost. The following is the LightGBM algorithm’s workflow:
In Eq. (8), the classifier starts with n decision trees. Each training sample is initially given a weight of 1/n. The strength α of the weak classifier f(x) is determined through training. With each training cycle, the classifier iteratively modifies these weights until it converges to the final classifier Fn(x).
Categorical boosting (CatBoost)
CatBoost is an ML ensemble algorithm based on Gradient Boosting Decision Trees (GBDT) and is particularly suitable for heterogeneous and categorical data45. The CatBoost algorithm inherently incorporates a mechanism to efficiently convert non-numerical data values into numerical ones without the need for parametric tuning and yields good results in a single execution46. It employs a random sorting technique to arrange the data and subsequently assigns a numerical value to each attribute inside the categorical variables. The utilization of priority factors and weight coefficients restricts the impact of low-frequency and noise data56.
In Eq. (9), where \(\:{{x}}_{{\gamma\:}}^{{i}}\)is the encoded value for the i-th categorical feature in sample γ, Yj is the target value for the j-th observation, \(\:\left\{{x}_{j}^{i}={x}_{k}^{i}\right\}\) is an indicator function equal to 1 when the category values are identical and 0 otherwise, a is a smoothing (regularization) parameter to avoid over fitting, p is the prior mean of the target variable (i.e., the global mean of all Yj), and n is the total number of samples.
Stack model
Stacking constitutes a novel ensemble learning algorithm that combines a series of base models in order to achieve a better predictive accuracy47. Under this approach, individual base classifiers are trained on the dataset, and their prediction outputs are provided to a meta-classifier, which learns the optimal way to combine these predictions48. A meta-classifier is a higher-level learning model that combines the predictions of multiple base classifiers to produce a final, more accurate prediction. Overfitting was mitigated through the application of cross-validation, while Logistic Regression was employed as the meta-classifier, utilizing the predictive outputs of four established models—Random Forest (RF), XGBoost, LightGBM, and CatBoost—for wildfire susceptibility modelling.
Hyperparameter optimization
Hyperparameter tuning was conducted to improve model predictive performance and reduce overfitting. The optimization process was implemented using GridSearchCV with 10-fold cross-validation, where multiple combinations of model parameters were evaluated to identify the best-performing configuration49,50,51. For each algorithm, a predefined parameter grid was explored. The Random Forest model was optimized by tuning the number of trees and the number of features considered during node splitting. For the XGBoost and LightGBM algorithms, parameters controlling tree depth, learning rate, number of boosting rounds, feature sampling ratio, and regularization coefficients were evaluated. In the CatBoost model, hyperparameters such as the number of iterations, tree depth, learning rate, L2 regularization, bagging temperature, and random strength were optimized. For the stacking ensemble model, the optimized base learners were combined using Logistic Regression as the meta-learner. Logistic Regression was selected due to its robustness, simplicity, and ability to effectively integrate probabilistic outputs from heterogeneous machine learning models while minimizing the risk of overfitting22,52. Unlike complex meta-learners, Logistic Regression provides a stable linear combination of base model predictions and has been widely adopted in ensemble stacking frameworks. The optimal model configurations obtained through grid search were subsequently used to train the final models. This tuning strategy improves model generalization ability and has been widely used in environmental hazard susceptibility modelling studies. Optimized hyperparameters of different machine learning models used in this study has been shown in Table 3.
Validation
During the model validation phase, the predictive performance of the susceptibility models was assessed using an independent testing dataset. Various statistical indicators based on the Receiver Operating Characteristic (ROC) were employed to measure the performance of the models, including sensitivity (recall), specificity, accuracy, Kappa, and F1-scoring53. A Receiver Operating Characteristic (ROC) curve is a graphical approach used to evaluate the predictive performance of a model54. The model’s prediction accuracy is assessed using the Area Under the Curve (AUC), which ranges from 0.5 to 1. Higher AUC values indicate a stronger model fit and better discriminatory capability. It shows the relationship between the True Positive Rate (sensitivity) and the False Positive Rate (1 − specificity) by plotting the latter on the x-axis and sensitivity on the y-axis55. Sensitivity determines the number of actual fire events that the model correctly predicted, and specificity is the ability to identify places where non-fire events occurred. A kappa value approaching 1 signifies a highly reliable model. In contrast, the F1-score integrates sensitivity and precision into a single metric by calculating their harmonic mean, thereby providing a balanced assessment of both measures56.
A false positive (FP) refers to a non-wildfire pixel that the model incorrectly classifies as fire-prone, whereas a false negative (FN) represents an actual wildfire pixel that is misclassified as non-fire. Correct identification of these cases is essential for improving model reliability and minimizing misclassification errors. The FP (false positives) represents the non-wildfire pixel as a point of a false positive. The measure of precision is a ratio of TP to the summation of TP and FP. PC represents the proportion of pixels correctly classified by the model (i.e., true positives and true negatives), while Pexp denotes the proportion of agreement expected by chance. The Kappa coefficient (κ) quantifies the level of agreement between predicted and observed wildfire occurrences after accounting for random chance.
One of the most widely used methods to assess the usefulness of a wildfire susceptibility model is called the receiver operating characteristic (ROC) curve. The false positive rate is indicated on the x-axis and the sensitivity (true positive rate) on the y-axis of this curve. This simplifies the comparison of sensitivity with 1-specificity, also referred to as the false positive rate56.
Shapley additive explanations (SHAP) method
SHAP (Shapley Additive exPlanations) is a method based on game theory that helps explain how machine learning models make predictions57. The main idea behind SHAP is to measure how much each feature contributes to the model’s output. This allows researchers to understand complex “black box” models at both the overall (global) and individual (local) levels. For every data sample used in training or testing, the model produces a prediction, and SHAP assigns a specific value to each feature showing its influence on that prediction. These assigned values, known as Shapley values, are calculated using Eq. (16).
where Φi denotes the contribution of the ith feature, N denotes the set of all features, S denotes the subset of the given predicted features, \(\:f(S\:\cup\:\:\{i\left\}\right)\:\) denote the model results with or without the ith feature, respectively58.
Monte Carlo uncertainty analysis
Monte Carlo method Monte Carlo is a very common statistical uncertainty analysis tool that uses random samples of probability distributions in determining how the model would work under varying conditions, and that is able to tell whether the model is robust or not59. The Monte Carlo methods are widely applied in various fields such as nuclear techniques that show the great significance about the model output reliability60. In this study, a ± 10% perturbation range was applied to the conditioning factors during Monte Carlo simulations to represent moderate uncertainty in environmental predictor variables. Such uncertainty may arise from measurement errors, spatial interpolation processes, and temporal variability in climatic datasets. The purpose of introducing this perturbation was to evaluate the robustness and stability of the stacking model under plausible variations in the input variables. Similar perturbation ranges have been adopted in environmental modelling studies to assess model sensitivity and prediction uncertainty.
Sobol sensitivity analysis
The Sobol Global Sensitivity (SGS) is a method used to quantify how variations in input variables influence the overall output of a model. It helps identify which input factors have the most significant impact on model predictions across their entire range. The Sobol global sensitivity analysis was implemented in Python using the SALib library. Quasi-random input samples were generated using the Saltelli sampling scheme, which provides an efficient approach for estimating variance-based sensitivity indices. In this study, 10,000 model evaluations were performed to ensure stable and reliable estimation of the sensitivity indices. The trained stacking ensemble model was used as the evaluation function, where the generated input samples were propagated through the model to obtain wildfire susceptibility predictions. The Sobol method then decomposed the total variance of the model outputs into contributions from individual input variables and their interactions, allowing the computation of first-order, second-order, and total-order sensitivity indices. This approach enables the relative contribution of each conditioning factor to the overall prediction uncertainty to be quantified. It estimates both individual and interactive impacts of factors over the entire input space61. The tagline sensitises the uncertain factors which have a great impact on the output of the models62. This makes the Sobol analysis especially useful for complex models where variable interactions play a key role in influencing predictions that mathematically represents by:
where Y is the model output (e.g., susceptibility index), Xi are independent input variables (e.g., temperature, slope, rainfall, etc.), n is the total number of input variables.
where Vi = variance caused by the individual input Xi (main effect), while Vij = variance due to the interaction between Xi and Xj, and so on.
First-order sensitivity index
Where Si is the first-order Sobol sensitivity index of i-th input variable, representing the proportion of total output variance (Var(Y)) explained by that variable alone. Vi denotes the partial variance attributed to Xi, and the ratio Vi/Var(Y) expresses how much of the model output variance is driven solely by changes in Xi, independent of its interactions with other parameters.
Second-order sensitivity index
where Sij is the second-order Sobol sensitivity index, representing the proportion of total output variance (Var(Y) explained by the interaction effect between the input variables Xi and Xj. Vij denotes the partial variance arising from their combined influence after removing their individual (first-order) effects. A higher Sij value indicates a stronger synergistic or interaction contribution of Xi and Xjto the overall model variance.
Total-order sensitivity index
where \(\:{S}_{{T}_{i}}\) is the total-order Sobol sensitivity index, representing the overall contribution of the input variable Xi to the total output variance (Var(Y)), including both its individual (first order) effects and all possible interaction effects with other variables. The term \(\:Var{X}_{i\:}\left({E}_{{X}_{i}}\left[Y|{X}_{i}\right]\right)\) represents the variance of the model output when Xi is fixed. A higher \(\:{S}_{{T}_{i}}\) value indicates that Xi has a greater total influence on the model output variance, directly or through interactions.
Results and discussion
Wildfire susceptibility mapping
Five machine learning techniques were used to make the wildfire susceptibility maps: Random Forest (RF), XGBoost, CatBoost, LightGBM, and Stacking models. These maps illustrate the cumulative impact of multiple wildfire conditioning factors, indicating the likelihood of wildfire incidence for each pixel. The susceptibility values were classified into five categories: Very Low (VL), Low (L), Moderate (M), High (H), and Very High (VH) using the natural breaks classification method63. Natural breaks (Jenks) classification method in ArcGIS 10.8 is a statistical approach that divides data into classes by identifying natural groupings inherent in the dataset63. It minimizes the variation within each class and maximizes the variation between different classes. All the models display a similar spatial pattern, with areas of High and Very High susceptibility mainly located in the central and southern regions. This is likely due to factors such as proximity to roads, dense vegetation, tourist spots, and built-up areas, supporting the accuracy of the maps. On the other hand, regions in the northern and north-eastern parts show Low and Very Low susceptibility, which can be attributed to snow cover, sparse vegetation, limited accessibility, and lower temperatures. The most wildfire-prone zones are identified around Chamba, Dalhousie, Kuther, Ghrau, Bhalai, and Langera. Nevertheless, the proportion of land area in each susceptibility class differs among the models, as illustrated in Fig. 5.

Wildfire susceptibility maps of the Upper Ravi sub-basin generated using five machine learning models: (a) Random forest (RF), (b) XGBoost, (c) CatBoost, (d) LightGBM, and (e) stacking model, (f) presents the percentage distribution of area under each susceptibility class for the corresponding models.
Validation
The predictive performance of the machine learning models was evaluated using several statistical metrics, including AUC-ROC, accuracy, sensitivity, specificity, precision, F1-score, and the kappa coefficient. These metrics were calculated using the testing dataset representing 30% of the wildfire inventory, and the detailed results are presented in Table 4. Overall, the stacking ensemble model demonstrated the best predictive performance among the evaluated models, achieving the highest accuracy (86%) and AUC value (0.95). The Random Forest model also showed strong performance with an AUC of 0.92, followed by XGBoost (0.91), CatBoost (0.90), and LightGBM (0.88). These results indicate that ensemble-based approaches can effectively capture complex relationships among wildfire conditioning factors and improve prediction accuracy. The ROC curves for all models are presented in Fig. 6. Since all models achieved AUC values above 0.85, they demonstrate strong predictive capability for wildfire susceptibility mapping in the Upper Ravi sub-basin (Table 4). Similar findings have been reported in previous studies highlighting the advantages of ensemble learning models for wildfire prediction64,65.

Receiver operating characteristic (ROC) curves illustrating the predictive performance of the five machine learning models LightGBM, Random Forest (RF), CatBoost, XGBoost and stacking model.
Feature Importance of the SHAP-based explainable stacking model
In the environmental and natural sciences, the explainability of machine learning models is equally important as prediction accuracy. The explainability of artificial intelligence (AI) models can be approached at two levels: global and local. Global explainability methods such as information gain, mean decrease impurity, and permutation feature importance that help to identify which features are most influential across the entire dataset. In contrast, local explainability focuses on individual (sample-specific) predictions, allowing researchers to understand which conditioning factors most strongly affect particular outcomes21,66. The importance of these factors has been widely documented in various global studies67,68,69,70. Hang et al. used SHAP analysis in a forest fire susceptibility study and found rainfall and evapotranspiration among the dominant controls23. We assessed whether a feature’s inclusion or exclusion from the model affected the algorithm’s performance on the validation set in order to ascertain its global importance. In this research, we employed SHAP-value analysis to gain insights into the key features that have the most impact on the Stacking model (Fig. 7).
The SHAP summary plot illustrates (Fig. 7a) how each variable affects the wildfire susceptibility stacking model’s output, which also takes into consideration both feature importance and the direction of the relationship. The features names are shown on the Y axis, and the Shapley value is shown on X axis. The colour denotes each feature’s value, which ranges from low to high. The horizontal axis plots the distribution of SHAP values, where positive SHAP values signify a factor’s positive influence on the probability of wildfire occurrences. In contrast, negative values indicate a detractive influence. The features are vertically ordered by their average importance on the predictions64. Temperature is the most significant feature, followed by Soil moisture, Distance from Village, Relative humidity, and Aspect, which are arranged from Top to Bottom. The colour ramp represents the feature values, with red colour signifying higher values and blue signifying lower values. For example, lower temperature tends to push predictions toward lesser susceptibility (negative SHAP value), whereas high temperature correlates with increasing fire susceptibility. Soil moisture is another crucial factor; higher soil moisture tends to show higher SHAP values. These findings indicate that higher temperatures and reduced soil moisture substantially elevate wildfire susceptibility, consistent with the physical processes that dry vegetation and reduce fuel moisture. Similar results were observed in previous studies where temperature and soil moisture were identified as dominant controls on wildfire activity using SHAP-based frameworks70,71. At the same time, the Distance from villages indicates that places closer to villages are generally associated with high susceptibility. Furthermore, the proximity to villages and tourist areas was found to increase fire likelihood, reflecting anthropogenic ignition sources paralleling observations by Iban & Aksu in Türkiye, where human-related variables such as distance to settlements and roads played a strong role in local fire ignition patterns21. The SHAP summary map is a helpful tool for understanding the complex relationships affecting wildfire susceptibility.
The bar diagram of mean absolute SHAP (Fig. 7b) values ranks each feature based on its average contribution to the model’s output, demonstrating the relative importance of each feature in predicting wildfire susceptibility. Temperature (0.081) is the most significant parameter, suggesting that variations in temperature have the most impact on wildfire susceptibility in the study area, which aligns with the findings of previous studies69,72. Soil Moisture (0.074) follows closely, showing that changes in soil moisture content significantly influence fire risk. The third rank, suggesting that proximity to human settlements affects fire occurrence, possibly due to human activities. Other important factors that have a big influence on the model’s outcome include Relative Humidity (0.058), Aspect (0.055), and Distance to Village (0.049). Comparing feature importance is made simple by this graphic, which shows the absolute average SHAP value for every factor. The graph’s conclusions show that environmental (such as Temperature and Soil Moisture) and anthropogenic (such as Distance from Villages and LULC) factors significantly influence wildfire susceptibility. In this study, temperature had the greatest influence on the occurrence of wildfires, these findings are consistent with previous wildfire susceptibility studies, which also identified temperature as a key driver of wildfire occurrence21,69,72.

SHAP summary plot of the Stacking model showing the contribution of each conditioning factor (a) Each dot represents a feature value’s impact on the model output (b) Mean absolute SHAP values indicating the overall importance of each conditioning factor.
Uncertainty analysis using Monte Carlo technique
This study utilized the Monte Carlo technique to estimate the AUC score and evaluate the uncertainty of the Stacking model, identified as the best-performing model for wildfire susceptibility mapping. Figure 8a shows the distribution of AUC scores derived from 1,000 Monte Carlo simulations in which each feature was perturbed within a ± 10% range. The model’s robustness to input variations is reflected in a mean AUC value of approximately 0.847, with most values falling between 0.83 and 0.87, indicating high stability under variable conditions, consistent with findings from prior research73,74. The model’s robustness to input variations is reflected in a mean AUC value of approximately 0.847. The reduction in AUC observed during Monte Carlo perturbation analysis reflects the model’s performance under simulated input uncertainty and should therefore be interpreted as an indicator of model robustness rather than instability. Such perturbation-based testing evaluates how sensitive model predictions are to variations in conditioning factors.The near-normal distribution of AUC scores demonstrates consistent model behaviour, even in the presence of input uncertainty, similar to the uncertainty-aware wildfire modelling approach described by Kondylatos et al. (2025), who reported stable prediction ranges when epistemic and aleatoric uncertainties were integrated into deep learning frameworks75.
Figure 8b illustrates the AUC distributions for the six most influential features in the stacking model. The width of each frequency distribution represents the variability in AUC scores caused by perturbations in the corresponding feature. Narrower distributions indicate higher model stability, while broader ones reflect greater uncertainty. For example, soil moisture displayed a narrow distribution with small confidence intervals, confirming its robust and consistent contribution to model performance. In contrast, features such as distance from tourist areas (“Dist_Tourist”) exhibited wider distributions, implying higher variability. This feature-level sensitivity aligns with another study conducted by Ott et al. (2020), who highlighted that spatial heterogeneity and human-induced factors contribute disproportionately to predictive uncertainty in wildfire susceptibility forecasting76.

Monte Carlo uncertainty analysis of the model performance. Distribution of the Area Under the Curve (AUC) values obtained from 1,000 Monte Carlo simulations (a) and AUC distributions corresponding to the six most influential conditioning factors (b).
Sobol sensitivity analysis (global)
The first-order Sobol sensitivity index quantifies the direct contribution of each input variable to the model output variance, assuming other parameters remain constant. In other words, it measures how much each factor alone influences wildfire susceptibility77. The first-order Sobol sensitivity analysis (Fig. 9) identifies soil moisture, temperature, and relative humidity as the dominant factors on wildfire susceptibility. Soil moisture (0.26) emerged as the most influential variable, acting as a natural suppressant of wildfire risk by maintaining vegetation and soil moisture levels78. Rainfall (0.09) was the next most significant factor, as it enhances soil and vegetation moisture; however, its influence varies with the frequency and intensity of precipitation. Temperature (0.08) and relative humidity (0.04) also exert strong effects higher temperatures increase fire likelihood through vegetation aridness, while elevated humidity suppresses ignition by sustaining atmospheric moisture79. Factors such as distance from tourist areas, evapotranspiration (0.03), and wind speed showed moderate influence, whereas TWI, LULC, curvature, and proximity to roads and villages exhibited minimal first-order effects, implying limited direct influence but potential indirect interactions.

First-order Sobol sensitivity index of conditioning factors for wildfire susceptibility modelling using the stacking ensemble model.
The total-order Sobol sensitivity index accounts for both direct and interaction effects of each variable, reflecting its overall influence within the model. It thus represents the total contribution of a variable, including all possible synergies with other parameters. The total-order sensitivity index (Fig. 10), which captures both direct and interaction effects, highlights soil moisture (0.45), temperature (0.21), rainfall (0.20), and relative humidity (0.17) as the most critical contributors to wildfire susceptibility. These variables exhibit strong synergistic behaviour — for instance, the impact of soil moisture is magnified under high temperature and low humidity conditions. Similarly, temperature not only drives vegetation drying but also interacts with wind and humidity to intensify fire spread potential80. Moderate total sensitivity values for distance from tourist areas (0.12), evapotranspiration (0.11), and wind speed (0.08) indicate secondary but relevant influences. Overall, these findings confirm that climatic moisture balance and thermal stress are the dominant controls on wildfire occurrence.

Total-order Sobol sensitivity index of conditioning factors influencing wildfire susceptibility.
The second-order Sobol sensitivity index measures the interaction effect between pairs of variables, showing how two factors jointly contribute to output variance beyond their individual effects. This helps identify synergistic relationships that are otherwise hidden in first-order analyses. The second-order sensitivity index (Fig. 11) reveals key pairwise interactions, particularly soil moisture–curvature (0.040), soil moisture–wind speed (0.035), and soil moisture–slope (0.033) indicating that terrain shape and airflow dynamics amplify the effect of moisture deficiency on wildfire risk (e.g. terrain × moisture interactions). These results emphasize that wildfire susceptibility arises from nonlinear interactions among climatic and topographic variables, underscoring the need to consider both individual and combined effects for accurate fire risk modelling.

Second-order Sobol sensitivity indices for the conditioning factors influencing wildfire susceptibility illustrate the interactive effects between pairs of variables on the model output variance.
Conclusion
The results demonstrate that ensemble machine learning approaches provide strong predictive capability for wildfire susceptibility modelling in complex mountainous environments. Among the evaluated models, the stacking ensemble model achieved the best performance, indicating its effectiveness in capturing nonlinear relationships among wildfire conditioning factors. The integration of SHapley Additive exPlanations (SHAP), Monte Carlo uncertainty analysis, and Sobol global sensitivity analysis enabled a comprehensive interpretation of model predictions and provided insights into the relative importance and uncertainty associated with the conditioning variables. The wildfire susceptibility map indicates that approximately 20.75% of the Upper Ravi sub-basin falls within high to very high susceptibility zones, primarily located in areas characterized by steep terrain, lower soil moisture conditions, and significant anthropogenic influence. The spatial distribution of wildfire susceptibility reflects the combined influence of climatic, topographic, and human-related factors that govern fire occurrence in mountainous landscapes. The SHAP analysis improved the interpretability of the stacking model by identifying the most influential conditioning factors affecting wildfire susceptibility, while Monte Carlo simulations and Sobol sensitivity analysis provided additional assessment of model robustness and variable sensitivity. Together, these approaches enhance the transparency and reliability of the modelling framework.
Overall, this study presents an integrated GeoAI-based wildfire susceptibility modelling framework that combines stacking ensemble learning with explainable artificial intelligence and uncertainty–sensitivity analysis. The proposed approach offers a reproducible methodology for identifying wildfire-prone areas and improves understanding of wildfire susceptibility patterns in complex Himalayan environments. Future research may further extend this framework by incorporating dynamic climate projections and socio-environmental scenarios to assess potential changes in wildfire susceptibility under evolving environmental conditions.
Data availability
The data that support the findings of this study are available on request from the corresponding author.
References
Feng, J. G. et al. Case-based evaluation of forest ecosystem service function in China. Ying Yong Sheng Tai Xue Bao 27, 1375–1382 (2016).
Jaafari, A., Termeh, S. V. R. & Bui, D. T. Optimized neuro-fuzzy prediction of wildfire probability using genetic and firefly algorithms. J. Environ. Manag. 243, 358–369 (2019).
Zhang, G., Wang, M. & Liu, K. Forest fire susceptibility modeling using convolutional neural networks in China. Int. J. Disaster Risk Sci. 10, 386–403 (2019).
Jain, P. et al. Machine learning applications in wildfire science and management: A review. Environ. Rev. 28, 478–505 (2020).
Pechony, O. & Shindell, D. T. Driving forces of global wildfires over the past millennium and the forthcoming century. Proc. Natl. Acad. Sci. USA 107, 19167–19170 (2010).
Giglio, L. et al. Collection 6 MODIS burned area mapping algorithm and product. Remote Sens. Environ. 217, 72–85 (2018).
Collins, B. et al. The rising threats of wildland-urban interface fires in the era of climate change: The Los Angeles 2025 fires. Innovation 6, 100835 (2025).
Michailidis, K., Pseftogkas, A., Koukouli, M. E., Biskas, C. & Balis, D. Los Angeles wildfires 2025: Satellite-based emissions monitoring and air-quality impacts. Atmosphere 17, 50 (2025).
Sagar, N. et al. Forest fire dynamics in India (2005–2022): Unveiling climatic impacts, spatial patterns, and interface with anthrax incidence. Ecol. Indic. 166, 112454 (2024).
Sarkar, M. S. et al. Ensembling machine learning models to identify forest fire-susceptible zones in Northeast India. Ecol. Inf. 81, 102598 (2024).
Reddy, C. S. et al. Identification and characterization of spatio-temporal hotspots of forest fires in South Asia. Environ. Monit. Assess. 191, 1–17 (2019).
Mohanty, A. & Mithal, V. Managing forest fires in a changing climate. Council on Energy, Environment and Water Report 1–23 (2022).
Murthy, K. K., Sinha, S. K., Kaul, R. & Vaidyanathan, S. A fine-scale state-space model to understand drivers of forest fires in the Himalayan foothills. Ecol. Manag. 432, 902–911. https://doi.org/10.1016/j.foreco.2018.10.009 (2019).
Bargali, H., Calderon, L. P. P., Sundriyal, R. C. & Bhatt, D. Impact of forest fire frequency on floristic diversity in the forests of Uttarakhand, western Himalaya. Trees People 9, 100300 (2022).
Kumar, M., Sheikh, M. A., Bhat, J. A. & Bussmann, R. W. Effect of fire on soil nutrients and understory vegetation in chir pine forest in Garhwal Himalaya, India. Acta Ecol. Sin. 33, 59–63 (2013).
Mishra, M. et al. Spatial analysis and machine learning prediction of forest fire susceptibility: A comprehensive approach for effective management and mitigation. Sci. Total Environ. 926, 171713 (2024).
Guria, R. et al. Predicting forest fire probability in Similipal Biosphere Reserve (India) using Sentinel-2 MSI data and machine learning. Remote Sens. Appl. Soc. Environ. 36, 101311 (2024).
Mabdeh, A. N. et al. Forest fire susceptibility assessment using support vector regression and ANFIS-based evolutionary algorithms. Sustainability 14, 9446 (2022).
Rihan, M. et al. Forest fire susceptibility mapping with sensitivity and uncertainty analysis using machine learning and deep learning algorithms. Adv. Space Res. 72, 426–443 (2023).
Guria, R., Mishra, M., Mohanta, S. & Paul, S. Forest fire probability zonation using dNBR and machine learning models: A case study at the Similipal Biosphere Reserve, Odisha, India. Environ. Sci. Pollut Res. 32, 1–22 (2025).
Iban, M. C. & Aksu, O. SHAP-driven explainable AI framework for wildfire susceptibility mapping using MODIS active fire pixels in Izmir, Türkiye. Remote Sens. 16, 2842 (2024).
Nguyen Van, L. & Lee, G. Optimizing stacked ensemble machine learning models for accurate wildfire severity mapping. Remote Sens. 17(5), 854 (2025).
Hang, H. T. et al. Exploring forest fire susceptibility and management strategies in Western Himalaya: Integrating ensemble machine learning and explainable AI for accurate prediction and comprehensive analysis. Environ. Technol. Innov. 35, 103655 (2024).
Moumane, A. et al. Advancing wildfire susceptibility mapping through machine learning and SHAP-integrated geospatial analysis in Northern Morocco’s Mediterranean region. Front. Glob Change. 8, 1705341 (2025).
Sharma, N. Physical and Social Analysis of Ravi River Basin in Himachal Pradesh (Rating Academy, 2020).
Higuera, P. E. et al. Changing strength and nature of fire–climate relationships in the northern Rocky Mountains, USA (1902–2008). PLoS One. 10, e0127563 (2015).
Tehrany, M. S., Kumar, L. & &Drielsma, M. J. Review of native vegetation condition assessment concepts and methods. J. Nat. Conserv. 40, 12–23 (2017).
Durlević, U., Ilić, V. & Aleksova, B. Wildfire probability mapping in Southeastern Europe using deep learning and machine learning models based on open satellite data. AI 7, 21 (2026).
Rahmati, O., Pourghasemi, H. R. & &Zeinivand, H. Flood susceptibility mapping using frequency ratio and weights-of-evidence models in Golestan Province, Iran. Geocarto Int. 31, 42–70 (2016).
Sannigrahi, S. et al. Effects of forest fire on terrestrial carbon emission and ecosystem production in India using remote sensing. Sci. Total Environ. 725, 138331 (2020).
Tran, T. T. K. et al. Improving wildfire susceptibility prediction using explainable hybrid machine learning. J. Environ. Manag. 351, 119724 (2024).
Guo, M. et al. Importance degree of weather elements in driving wildfire occurrence in mainland China. Ecol. Indic. 148, 110152 (2023).
Bilucan, F., Teke, A. & &Kavzoglu, T. Susceptibility mapping of wildfires using XGBoost, random forest and AdaBoost: A Mediterranean case study. in Proc. Int. Conf. Mediterranean Geosciences Union 99–101 (2022).
Sazib, N., Bolten, J. D. & &Mladenova, I. E. Assessing fire susceptibility using NASA SMAP over Australia and California. IEEE J. Sel. Top. Appl. Earth Obs Remote Sens. 15, 779–787 (2021).
Chuvieco, E. et al. Combining NDVI and surface temperature for estimation of live fuel moisture content. Remote Sens. Environ. 92, 322–331 (2004).
Da Silva, S. S. et al. Dynamics of forest fires in the southwestern Amazon. Ecol. Manag. 424, 312–322 (2018).
Kuhn, M. & Johnson, K. Applied Predictive Modeling (Springer, 2013).
Ageenko, A. et al. Landslide susceptibility mapping using machine learning: A Danish case study. ISPRS Int. J. Geo-Inf. 11, 324 (2022).
Naikoo, M. W. et al. Peri-urban land use/land cover change and drivers using geospatial techniques and GWR. Environ. Sci. Pollut Res. 30, 116421–116439 (2023).
Gigović, L. et al. Testing a new ensemble model based on SVM and random forest in forest fire susceptibility assessment and its mapping in Serbia’s Tara National Park. Forests 10, 408 (2019).
Chen, W. et al. Spatial prediction of landslide susceptibility using data mining-based kernel logistic regression, naive Bayes and RBFNetwork models for the Long County area (China). Bull. Eng. Geol. Environ. 78, 247–266 (2019).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Chen, T. & &Guestrin, C. XGBoost: A scalable tree boosting system. in Proc. 22nd ACM SIGKDD Int. Conf. Knowledge Discovery and Data Mining 785–794 (2016).
Ke, G. et al. LightGBM: A highly efficient gradient boosting decision tree. Adv Neural Inf. Process. Syst 30 (2017).
Zhang, Y., Zhao, Z. & Zheng, J. CatBoost for estimating daily reference crop evapotranspiration in arid regions. J. Hydrol. 588, 125087 (2020).
Prasanna Venkatesh, N. et al. CatBoost-based improved detection of P-wave changes in sinus rhythm and tachycardia conditions: A lead selection study. Phys. Eng. Sci. Med. 46, 925–944 (2023).
Wolpert, D. H. Stacked generalization. Neural Netw. 5, 241–259 (1992).
Dou, J. et al. Improved landslide assessment using SVM with ensemble learning in Japan. Landslides 17, 641–658 (2020).
Inan, M. S. K. & Rahman, I. Explainable AI integrated feature selection for landslide susceptibility mapping using TreeSHAP. SN Comput. Sci. 4, 482 (2023).
Muhammad, S. et al. Machine learning-based forest fire vulnerability assessment in subtropical chir pine forests of Pakistan. Fire Ecol. 21, 1–17 (2025).
Bouzeraa, Y. et al. Machine learning-based wildfire susceptibility mapping: A GIS-integrated predictive framework. Appl. Sci. 15, 12188 (2025).
Symeonidis, P., Vafeiadis, T., Ioannidis, D. & Tzovaras, D. Wildfire susceptibility mapping in Greece using ensemble machine learning. Earth 6, 75 (2025).
Ghasemian, B. et al. A robust deep-learning model for landslide susceptibility mapping. Sensors 22, 1573 (2022).
Naderpour, M., Rizeei, H. M., Khakzad, N. & Pradhan, B. Forest fire-induced Natech risk assessment: A geospatial technology survey. Reliab. Eng. Syst. Saf. 191, 106558 (2019).
Youssef, A. M. & &Pourghasemi, H. R. Landslide susceptibility mapping using machine learning in Saudi Arabia. Geosci. Front. 12, 639–655 (2021).
Agrawal, N. & Dixit, J. Assessment of landslide susceptibility for Meghalaya (India) using bivariate and multi-criteria decision analysis models. All Earth. 34, 179–201 (2022).
Lundberg, S. M. & Lee, S. I. A unified approach to interpreting model predictions. Adv Neural Inf. Process. Syst. 30 (2017).
Lundberg, S. M., Erion, G. G. & Lee, S. I. Consistent individualized feature attribution for tree ensembles. arXiv:1802.03888 (2018).
Rodriguez, M. A. & &Dabdub, D. Monte Carlo uncertainty and sensitivity analysis of the CACM chemical mechanism. J Geophys. Res. Atmos 108 (2003).
Didi, A. et al. Monte Carlo transport code for simulating the neutron yield of spallation targets for an accelerator based on high proton beam. in Proc. 4th Int. Conf. Optimization and Applications (ICOA), 1–7 (2018).
Sobol’, I. M. Sensitivity estimates for nonlinear mathematical models. Math. Model. Comput. Exp. 1, 407 (1993).
Saltelli, A., Chan, K. & Scott, E. M. (eds) Sensitivity Analysis: Gauging the Worth of Scientific Models (Wiley, 2000).
Tang, X. et al. Flood susceptibility assessment using a random naïve Bayes method. Catena 190, 104536 (2020).
Li, Y. et al. Forest fire risk prediction using stacking ensemble learning in Yunnan province, China. Fire 7, 13 (2023).
Shahzad, F. et al. Multi-layer stacking ensemble model for forest fire prediction. Earth Sci. Inf. 18, 270 (2025).
Lundberg, S. M. et al. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2, 56–67 (2020).
Suryabhagavan, K. V., Alemu, M. & Balakrishnan, M. GIS-based multi-criteria decision analysis for forest fire susceptibility mapping in Ethiopia. Trop. Ecol. 57, 33–43 (2016).
Tan, C. & Feng, Z. Mapping forest fire risk zones using machine learning in Hunan Province, China. Sustainability 15, 6292 (2023).
Pragya et al. Integrated spatial analysis of forest fire susceptibility using GIS-based fuzzy AHP in the western Himalayas. Remote Sens. 15, 4701 (2023).
Ribeiro, M. T., Singh, S. & &Guestrin, C. Explaining the predictions of any classifier. in Proc. 22nd ACM SIGKDD Int. Conf. Knowledge Discovery and Data Mining, 1135–1144 (2016).
Cilli, R. et al. Explainable artificial intelligence detects wildfire occurrence in Mediterranean countries of southern Europe. Sci. Rep. 12, 17560 (2022).
Sun, Y., Zhang, F., Lin, H. & Xu, S. Forest fire susceptibility modeling using the LightGBM algorithm. Remote Sens. 14, 4362 (2022).
Ambrose, G. P. Monte Carlo simulation in the evaluation of susceptibility breakpoints: Predicting the future. Pharmacotherapy 26, 129–134 (2006).
Dahri, N. & Abida, H. Monte Carlo simulation-aided AHP for flood susceptibility mapping in Gabes Basin, Tunisia. Environ. Earth Sci. 76, 302 (2017).
Kondylatos, S., Camps-Valls, G. & Papoutsis, I. Uncertainty-aware deep learning for wildfire danger forecasting. arXiv 2509–2517 (2025).
Ott, C. W. et al. Predicting fire propagation across heterogeneous landscapes using WyoFire: A Monte Carlo-driven wildfire model. Fire 3, 71 (2020).
Rihan, M. et al. Improving landslide susceptibility prediction in Uttarakhand through hyper-tuned artificial intelligence and global sensitivity analysis. Earth Syst. Environ. 9, 3405–3424 (2024).
Hou, X. & Orth, R. Observational evidence of wildfire-promoting soil moisture anomalies. Sci. Rep. 10, 1–8 (2020).
Yu, G. et al. Performance of fire danger indices and their utility in predicting future wildfire danger over the conterminous United States. Earth’s Future. 11, e2023EF003823 (2023).
Trucchia, A. et al. On the merits of sparse surrogates for global sensitivity analysis of multi-scale nonlinear problems: Application to turbulence and fire-spotting model in wildland fire simulators. Commun. Nonlinear Sci. Numer. Simul. 73, 120–145 (2019).
Acknowledgements
We highly acknowledge the European Space Agency (ESA) and the National Aeronautics and Space Administration (NASA) for the acquisition of satellite datasets that we employed for study. Authors are thankful to anonymous reviewers for their critical evaluation that helps to improve the quality of manuscript.
Author information
Authors and Affiliations
Contributions
Suheb: research framework, data curation, software, original draft review and editing; Md. Nawazuzzoha: Data curation, formal analysis, visualization; Md Shahid Ali: Data curation, formal analysis, visualization; Md. Mamoon Rashid: Data curation, software, visualization; Darakhsha Fatma Naqvi: Data curation, software, visualization; Honey Qaiser: visualization, review and editing Shankar Karuppannan: Formal analysis, Reviewing and Editing; Pierre Sicard: Formal analysis, Reviewing and Editing; Hasan Raja Naqvi: Formal analysis, supervision, resources, editing original draft-Reviewing and Editing. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Consent for publication
We have carefully reviewed all the images in our manuscript and confirm that no human faces are present.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Suheb, Nawazuzzoha, M., Ali, M.S. et al. An explainable GeoAI framework for spatial assessment of wildfire susceptibility in the Upper Ravi sub-basin, Indian Himalaya. Sci Rep 16, 11662 (2026). https://doi.org/10.1038/s41598-026-46924-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-46924-w
