
Abstract
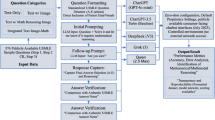
Large language models (LLMs) are increasingly incorporated into medical education and clinical learning environments. While prior studies have focused on model accuracy on licensing-style examinations, less attention has been paid to the stability and reproducibility of LLM clinical reasoning under varying input structures—an issue central to safe educational and clinical deployment. To examine how question delivery structure influences performance stability, inter-model variability, and reproducibility of clinical reasoning across multiple contemporary LLMs using pediatric residency–level multiple-choice questions (MCQs). A standardized, evidence-based prompt was used to generate advanced-level pediatric USMLE Step 2/3–style MCQs emphasizing diagnostic reasoning, management decisions, and ethical judgment. One hundred draft MCQs generated using a standardized LLM prompt were randomly selected and independently reviewed by three pediatric physicians for medical accuracy, clinical realism, subspecialty relevance, and adherence to USMLE formatting. Twenty three questions were excluded by unanimous consensus, yielding a validated set of 77 MCQs. Six publicly available LLMs (ChatGPT, DeepSeek AI, Gemini, Microsoft Copilot, Perplexity AI, and OpenEvidence; October–December 2025 versions) were evaluated under two delivery conditions: (1) simultaneous presentation of all questions and (2) sequential delivery in batches of ten. Accuracy and inter-model variability were compared using paired t-tests and one-way ANOVA. When all questions were presented simultaneously, model accuracy varied widely (38%–90%), with significant inter-model differences, indicating poor reproducibility. In contrast, batch delivery resulted in marked convergence of performance across models (83%–88%), with no statistically significant inter-model differences. Sequential delivery in batches of ten substantially reduced performance dispersion and instability across all evaluated systems. LLM clinical reasoning performance is highly sensitive to input structure. Reducing contextual load through structured batch delivery improves reproducibility and minimizes inter-model variability, independent of model architecture. These findings suggest that prompt structure—rather than model selection alone—is a critical determinant of reliable LLM behavior and should be explicitly considered in the design of AI-supported medical education and assessment systems. This should be explicitly considered in the design of AI-supported medical education and assessment systems, particularly when LLMs are used as formative learning tools or clinical reasoning aids. Clinical Trial Number. The protocol was reviewed by the Office of the IRB at Good Samaritan University Hospital and determined to be exempt.
Similar content being viewed by others

Data availability
The datasets generated and analyzed during the current study are available from the corresponding author upon reasonable request. No patient-level or identifiable data were used in this study.
Code availability
Custom scripts used for statistical analysis are available from the corresponding author upon reasonable request. No proprietary or restricted software was developed or modified for this study.
References
DiDonna, N., Shetty, P. N., Khan, K. & Damitz, L. Unveiling the Potential of AI in Plastic Surgery Education: A Comparative Study of Leading AI Platforms’ Performance on In-training Examinations. Plast. Reconstr. Surg. Glob Open. 12 (6), e5929 (2024).
Luke, W. A. N. V. et al. Is ChatGPT ‘ready’ to be a learning tool for medical undergraduates and will it perform equally in different subjects? Comparative study of ChatGPT performance in tutorial and case-based learning questions in physiology and biochemistry. Med. Teach. 46 (11), 1441–1447 (2024).
Puga-Tejada, M. et al. Artificial intelligence-enabled histology exhibits comparable accuracy to pathologists in assessing histological remission in ulcerative colitis: a systematic review, meta-analysis, and meta-regression. J. Crohns Colitis. 19 (1), jjae198 (2025).
Suen, K., Zhang, R. & Kutaiba, N. Accuracy of wrist fracture detection on radiographs by artificial intelligence compared to human clinicians. A systematic review and meta-analysis. Eur. J. Radiol. 178, 111593 (2024).
Bang, Y. et al. A systematic study of prompt sensitivity in large language models. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 4567–4585. (2023).
Ji, Z. et al. Survey of hallucination in natural language generation. ACM Comput. Surv. 55 (12), 1–38 (2023).
Anthropic Interpretability in Claude models [Large Language Model]. (2024). Available from: https://www.anthropic.com/news/claude-interpretability
Bubeck, S. et al. Sparks of artificial general intelligence: Early experiments with GPT-4. (2023). arXiv:2303.12712 [Preprint].
Liu, N. Lost in the middle: How language models use long contexts. Trans. Assoc. Comput. Linguist. 12, 157–173. https://doi.org/10.1162/tacl_a_00638 (2024).
Bordage, G. Conceptual frameworks to illuminate and magnify. Med. Educ. 43 (4), 312–319. https://doi.org/10.1111/j.1365-2923.2009.03295.x (2009).
Sweller, J. Cognitive load during problem solving: Effects on learning. Cogn. Sci. 12 (2), 257–285. https://doi.org/10.1207/s15516709cog1202_4 (1988).
Sweller, J., Ayres, P. & Kalyuga, S. Cognitive Load Theory (Springer, 2011). https://doi.org/10.1007/978-1-4419-8126-4.
Downing, S. M. Construct-irrelevant variance and flawed test questions: Do multiple-choice item-writing principles make any difference?. Acad. Med. 77(10), S103–S104. https://doi.org/10.1097/00001888-200210001-00032 (2002).
Case, S. M. & Swanson, D. B. Constructing Written Test Questions for the Basic and Clinical Sciences 3rd ed. (National Board of Medical Examiners, 2001).
Liu, N. F. et al. Lost in the middle: How language models use long contexts. Trans. Association Comput. Linguistics. 11, 117–132. https://doi.org/10.1162/tacl_a_00520 (2023).
Zhang, Y. et al. Hallucinations in large language models: A survey. ACM Comput. Surveys. 56 (2), 1–38. https://doi.org/10.1145/3626237 (2024).
Singhal, K. et al. Large language models encode clinical knowledge. Nature 620 (7972), 172–180 (2023).
Jason Wei, X., Wang, D. & Schuurmans et. al. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems (NIPS 2022). Curran Associates Inc., Red Hook, NY, USA, Article 1800, 24824–24837.
Ban, T., Chen, L., Lyu, D., Wang, X. & Chen, H. Causal structure learning supervised by large language model. arXiv preprint arXiv:2311.11689. Nov 20. (2023).
Gierl, M., Changjiang, W. & Jiawen, Z. Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees’ Cognitive Skills in Algebra on the SAT©. The Journal of Technology, Learning, and Assessment. 6. (2008).
Lewis, P. et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. Adv. Neural Inf. Process. Syst. 33, 9459–9474 (2020).
Chen, Y. et al. Model editing can hurt general abilities of large language models. arXiv:2401.11439 [Preprint] (2024).
Wang, X. et al. Self-consistency improves chain of thought reasoning in language models. In: The Eleventh International Conference on Learning Representations (ICLR 2023). (2023).
Thirunavukarasu, A. J. et al. Large language models in medicine. Nat. Med. 29(8), 1930–1940 (2023).
Greenblatt, R. et al. Alignment faking in large language models. arXiv preprint arXiv:2412.14093. 2024 Dec 18.
Farquhar, S. et al. Detecting hallucinations in large language models using semantic entropy. Nature 630, 625–630. https://doi.org/10.1038/s41586-024-07421-0 (2024).
Case, S. & Swanson, D. Constructing Written Test Questions For the Basic and Clinical Sciences (National Board of Examiners, 2002).
Kadavath, S. et al. Language models (mostly) know what they know. arXiv:2207.05221 [Preprint]. (2022).
Ayers, J. W. et al. Physician versus artificial intelligence chatbot responses to patient questions posted to a public social media forum. JAMA Intern. Med. 183 (6), 589–596 (2023).
Hang, C. N., Yu, P. D., Chen, S., Tan, C. W. & Chen, G. MEGA: Machine Learning-Enhanced Graph Analytics for Infodemic Risk Management. IEEE J Biomed Health Inform 27(12), 6100–6111. https://doi.org/10.1109/JBHI.2023.3314632 (2023).
Hang, C., Yu, P. D. & Tan, C. TrumorGPT: Graph-Based Retrieval-Augmented Large Language Model for Fact-Checking. (2025). https://doi.org/10.48550/arXiv.2505.07891
Hang, C., Tan, C. & Yu, P.-D. MCQGen: A large language model-driven MCQ generator for personalized learning. IEEE Access https://doi.org/10.1109/ACCESS.2024.3420709 (2024).
OpenAI. ChatGPT (April 2025 version) [Large Language Model]. (2025). Available from: https://openai.com/chatgpt
DeepSeek. DeepSeek model documentation [Large Language Model]. (2025). Available from: https://platform.deepseek.com/api-docs/
Google Gemini model system documentation [Large Language Model]. (2025). Available from: https://ai.google.dev/gemini-api/docs
GitHub. Copilot model platform documentation [Large Language Model]. (2025). Available from: https://docs.github.com/en/copilot
Perplexity, A. I. Perplexity model documentation [Large Language Model]. (2025). Available from: https://docs.perplexity.ai/
Author information
Authors and Affiliations
Contributions
V.J. conceived and designed the study, generated and curated the dataset, performed statistical analyses, interpreted the results, and drafted the manuscript.C.C. reviewed the manuscript and critically revised it for intellectual content.R.S. supervised the study, contributed to methodological refinement, and provided critical review and editing of the manuscript.All authors approved the final manuscript and agree to be accountable for all aspects of the work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval and informed consent
This study did not involve patients, patient data, biological samples, or identifiable personal information. Human participation was limited to voluntary expert review of multiple-choice questions and scoring of model outputs by qualified physicians. All participating reviewers provided informed consent for study participation. No identifying information was collected or reported. The study met criteria for institutional review board (IRB) exemption as minimal-risk educational research. All methods performed in this study were carried out in accordance with relevant guidelines and regulations. The study was approved by the Institutional Review Board of Good Samaritan University Hospital.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
James, V., Caronia, C. & Savargaonkar, R. Input structure–driven instability and convergence in large language model clinical reasoning: a formative study using pediatric residency–level MCQs. Sci Rep (2026). https://doi.org/10.1038/s41598-026-48326-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-026-48326-4
