
Abstract
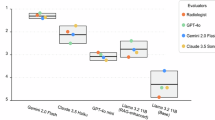
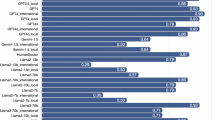
To evaluate the clinical reasoning ability of large language models (LLMs) and retrieval-augmented generation (RAG) systems in pediatric myopia management using a real-world, expert-annotated case set covering diverse refractive, pathological, and high-risk scenarios. Six models were tested: baseline LLMs (GPT Base, Gemini Base, Grok Base) and their RAG variants (GPT-RAG, Gemini-RAG, Grok-RAG). RAG was augmented with 41 authoritative guidelines, including IMI white papers and the LAMP study. Performance was evaluated through automated scoring by Claude 4 Opus and blinded adjudication by three senior ophthalmologists, focusing on Accuracy, Utility, and Safety. RAG-enhanced models significantly outperformed baseline models across all metrics. Notably, GPT-RAG achieved the highest weighted automated score (7.46), surpassing GPT Base (7.37). Human adjudication revealed that RAG models achieved 90–94% consensus alignment compared to 68–82% for baselines. Crucially, the probability of high-risk recommendations—those capable of causing severe vision loss—was eliminated (0%) in all RAG models, whereas baseline models exhibited high-risk error rates of 6–14%. LLM + RAG integration boosts reliability and safety in pediatric myopia care, particularly for high-risk decisions. RAG’s domain knowledge incorporation advances AI clinical tools in ophthalmology, though ophthalmologist-in-the-loop refinement is essential pre-deployment.
Similar content being viewed by others
Funding
This work was financially supported by the Natural Science Foundation of China (grant number 82201195), and was financially supported by the AI For Education series empirical teaching research project at Zhejiang University.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Kang, D., Zhao, K., Cheng, D. et al. Evaluation of large language models and retrieval-augmented generation for clinical reasoning in pediatric myopia: a 50-case real-world study. Sci Rep (2026). https://doi.org/10.1038/s41598-026-51205-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-026-51205-7
