
Abstract
Large Language Models (LLMs) hold promise for medical applications but often lack domain-specific expertise. Retrieval Augmented Generation (RAG) enables customization by integrating specialized knowledge. This study assessed the accuracy, consistency, and safety of LLM-RAG models in determining surgical fitness and delivering preoperative instructions using 35 local and 23 international guidelines. Ten LLMs (e.g., GPT3.5, GPT4, GPT4o, Gemini, Llama2, and Llama3, Claude) were tested across 14 clinical scenarios. A total of 3234 responses were generated and compared to 448 human-generated answers. The GPT4 LLM-RAG model with international guidelines generated answers within 20 s and achieved the highest accuracy, which was significantly better than human-generated responses (96.4% vs. 86.6%, p = 0.016). Additionally, the model exhibited an absence of hallucinations and produced more consistent output than humans. This study underscores the potential of GPT-4-based LLM-RAG models to deliver highly accurate, efficient, and consistent preoperative assessments.
Similar content being viewed by others
Introduction
Large Language Models (LLMs) have gained significant attention for their clinical applications potential1, and have been demonstrated to match human performance in basic clinical tasks such as rating a patient’s American Society of Anesthesiologists (ASA) physical status2. However, where complex tasks, such as clinical assessment and management are given, the response only relies on pre-train knowledge and is not grounded on institutional practicing guidelines. Most importantly, hallucinations from LLMs pose significant safety and ethical concerns3.
Surgery cancellations on the day of surgery due to medical unfitness4, incorrect physician instructions5, and non-compliance to preoperative instructions6 pose a significant economic impact7, with operating room expenses estimated between USD 1400 to 1700 per hour8. Thorough preoperative evaluations can minimize these cancellations9, but traditional preoperative evaluations are inherently labor-intensive and costly. The utilization of domain-specific LLM for delivering preoperative instructions presents substantial potential for personalized preoperative medicine.
In the rapidly evolving field of LLMs, the challenge of optimizing performance to meet specific needs is a key focus. While out-of-the-box LLMs offer impressive capabilities, techniques like fine-tuning and RAG present promising avenues for further enhancing their accuracy and relevance.
The primary challenges in fine-tuning LLMs stem from various factors including the need for extensive retraining datasets, particularly for complex fields like healthcare; and technical hurdles such as limitations in context tokens and the computational demands typically quantified in petaflops for Graphics Processing Unit (GPU) memory10.
Retrieval Augmented Generation (RAG) is an innovative approach for tailoring LLMs to specific tasks, and a scalable solution agnostic to various LLM-based healthcare applications. It offers an easier solution without the need for extensive training examples or time as required by fine-tuning, and accessibility to updated customized knowledge without significant time in creating up-to-date ground truth and retraining required by fine-tuning. Unlike traditional LLMs, RAG functions similarly to a search engine, retrieving relevant, customized text data in response to queries. This capability effectively turns RAG into a tool that integrates specialized knowledge into LLMs, enhancing their baseline capabilities. In healthcare, for instance, LLMs equipped with RAG and embedded with extensive clinical guidelines (LLM-RAG) can yield more accurate outputs11. Currently, two primary open-source frameworks for RAG exist - LangChain12 and Llamaindex13. Although the retrieval process of RAG can be technically challenging, RAG’s utility in contexts with smaller, more focused knowledge corpora remains significant.
This study aims to develop and evaluate an LLM-RAG pipeline for preoperative medicine using various LLMs and perioperative guidelines. The primary objective is to assess the pipeline’s accuracy in determining patients’ fitness for surgery. The secondary objective is to evaluate the LLM-RAG’s ability to provide accurate, consistent, and safe preoperative instructions, including fasting guidelines, pre-operative medication management, and whether the patient should be seen by a nurse or a doctor in the pre-operative clinic.
Results
A total of 3682 components were evaluated (448 human-generated and 3234 LLM-generated). The LLM-RAG models took on average 1 s for retrieval and 15–20 s for results generation, while the human evaluators took an average of 10 min to generate the full preoperative instructions. The Generative Pre-training Transformer (GPT)4_international model emerged as the most accurate model with the highest accuracy in predicting medical fitness for surgery (96.4%) compared to answers given by human evaluators (86.6%), as well as its non-RAG counterpart (92.9%) and RAG counterpart with local guidelines (92.9%) (Fig. 1 and Supplementary Table 2). A detailed example of the prompt, clinical scenario and the GPT4-international response (response 1) can be found in Table 1. The GPT4_international model performed better than humans in evaluations of patient’s fitness for surgery (Odds Ratio (OR) = 4.84, p = 0.016).

The figure illustrates the percentage of accurate assessments for medical fitness for surgery made by various LLMs and human evaluators. Each bar represents the accuracy of a specific model or human-generated response. The overall accuracy of GPT4_international models was 93.0%, which was significantly higher than human evaluators (86.0%).
The GPT-4 RAG model, when using local guidelines, accurately predicted whether a patient should be seen by a nurse or a doctor 93.0% of the time (Supplementary Table 3). This performance is notably higher compared to its non-RAG counterpart, which achieved an accuracy of 86.0%. Furthermore, the GPT4 models also had the highest accuracy when assessing for fitness for operation in sicker, ASA 3 patients. The comparison, the Gemini and Large Language Model Meta AI (LLAMA)2-13b models had less than 50% accuracy when assessing ASA 3 patients (Supplementary Fig 1).
The secondary outcomes show that the GPT4_international model was better than humans at generating what medical optimization was required by the scenario (71.0% vs 55.0%, p = 0.026), but the human-generated answers were better than the GPT4_international model at generation of medication instructions order (91.0% vs 98.0%, p = 0.035) (Supplementary Table 4 and 5). Overall, there were no significant differences between GPT4_international and human responses in terms of accuracy across all secondary outcomes combined (83.0% vs. 81.0%, p = 0.710), and this was not changed at 65% sensitivity analysis (p = 0.688) and 85% sensitivity analysis (p = 0.710) (Supplementary Table 6).
The S.C.O.R.E (Safety, Consensus, Objectivity, Reproducibility, Explainability) evaluation showed that the GPT4 RAG model was able to have high reproducibility of results (4.86 out of 5) and provided safe instructions (4.93 out of 5) (Supplementary Table 7). The false negative rate, which reflects instances where medically unfit patients were incorrectly identified as fit for surgery, was 62.5% among human evaluators compared to 25% in the GPT4_international model (Supplementary Table 8).
The Inter-rater reliability (IRR) for human-generated answers was consistently lower than that for GPT-4 International across all categories (Supplementary Table 9). The IRR for GPT-4_International in predicting medical fitness was 0.93. Additionally, GPT-4_International demonstrated high consistency in providing instructions for healthcare workers (IRR = 0.96) and identifying types of optimization requirements (IRR = 0.92).
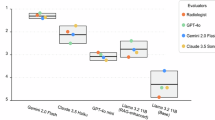
The evaluation revealed low hallucination rates across several LLM systems, including GPT3.5, GPT4, GPT4o, LLAMA3, Gemini, and Claude, with hallucination rates ranging from 0% to 2.9%. In contrast, LLAMA2 exhibited significantly higher hallucination rates (Supplementary Fig 2). Notably, the RAG-enhanced versions of the LLAMA2-7b model demonstrated substantially higher hallucination rates compared to their native counterparts, with rates of 48.6% and 32.9% versus 12.8%, respectively (Supplementary Table 4). The distinct n-gram analysis revealed that GPT-3.5, GPT-4, GPT-4-turbo, LLAMA3-80b, Gemini, and Claude models achieved high average distinct scores for both 2-gram and 3-gram metrics (Fig. 2), indicating strong language diversity across these models.

The figure shows the average distinct 1-gram (Yellow line), 2-gram (Orange line), and 3-gram (Red line) scores for each LLM-RAG model. N-gram scores are a measure of linguistic diversity, with higher scores indicating greater originality and creativity in the generated text. 1-grams represents individual words, 2-grams represents pairs of consecutive words, and 3-grams represents triplets of successive words. The bot shows that the Llama3 models have little variations in their linguistic variability.
Discussion
This study highlights the potential of integrating LLM-RAG models into healthcare workflows, such as preoperative medicine. Our findings indicate that the LLM-RAG system can outperform doctors in assessing a patient’s fitness for surgery and deliver comparably accurate, yet more consistent evaluations for other preoperative assessments. These results suggest that LLM-RAG models could complement and assist clinicians, improving efficiency and reducing workload in specific preoperative tasks.
The emergence of fine-tuned models with Unified Language Model for Biomedical Sciences14 and Biomedical Language Model (BioMedLM) developed by the Stanford Center for Research on Foundation Models (Stanford-CRFM)15 exemplifies the trend toward specialization in LLM applications. These domain-specific models are tailored to understand and process medical information, offering enhanced accuracy and relevance in clinical settings16. The capability of LLM-RAG models to process vast amounts of data and generate responses based on comprehensive, updated guidelines positions them as potentially valuable tools in standardizing preoperative assessments.
This study also highlights a key advantage of the LLM-RAG—its ability to incorporate local healthcare practices and adapt international recommendations to the specific context. This is evident in the GPT responses, where generic referrals to “medicine colleagues” were transformed into the specific “Optimize diabetes control with the Internal Medicine Perioperative Team (IMPT)” within the local context (Scenario 1, GPT4 response). This ability to reproduce guidelines tailored to local requirements not only demonstrates the system’s adaptability but also provides specific, actionable information that supports potential automation.
The results of our study are particularly relevant in the context of the evolving landscape of elective surgical services, which have increasingly shifted towards day surgery models, reduced hospital stays, and preoperative assessments conducted in outpatient clinics17. By employing a simple vanilla RAG framework, Langchain, and Pinecone retrieval agent, we observed significant improvements and improved clinical alignment for pre-operation assessment in LLM healthcare applications. For complex clinical use cases, such as clinical decision tools for medication-related queries, advanced RAG frameworks such as Llamaindex and improved chunking, embedding, and retrieval are expected. The potential role of LLM-RAG in this setting as a clinical adjunct is, therefore, of considerable interest because manpower constraints are common within healthcare.
Furthermore, the inherent subjectivity in clinical decisions, driven by variations in individual judgment and risk tolerance, underscores the value of LLM-RAG systems in promoting consistency. For example, GPT models have demonstrated more uniform responses than anesthesiologists in tasks such as ASA scoring2. This consistency offers a critical advantage in perioperative medicine, where standardized evaluations can prevent miscommunication and reduce conflicts among the care team. In our study, the lower agreement between human responses and “ground truth” reflects variability among eight clinicians, whereas the ground truth was established by an expert panel. Differences in guideline familiarity highlight how LLM-RAG can offer consistent, guideline-based support and reduce subjective variation. By providing standardized recommendations, LLM-RAG systems foster a more cohesive approach to patient care.
A qualitative analysis of LLM-RAG model responses compared to human-generated answers revealed potential discrepancies in information completeness. In Scenario 4, for example, the GPT4 models included specific instructions for all the medications (Keppra, Paracetamol, and Tramadol) on the surgical day. Conversely, the majority of the human evaluators did not give instructions for the analgesics. This observed difference could be attributed to a lack of universally accepted guidelines for continuing certain medications (e.g., analgesics) on the surgical day. These findings suggest that LLM-RAG models, by comprehensively incorporating available information, may be less susceptible to such variability (with higher IRR), potentially leading to more consistent and improved preoperative instructions for current clinical workflows.
A valuable application of this LLM-RAG pipeline is to augment the preoperative workflow while ensuring safety through a “human-in-the-loop” framework. In many pre-op clinics, including ours, patients are initially screened to determine whether they require evaluation by a nurse or a doctor, or if they should be seen in advance versus on the day of surgery, particularly for low-risk, healthy patients. By safely triaging these decisions, the pipeline has the potential to save significant time and reduce costs. Additionally, this approach could support clinicians by drafting patient instructions, which may help alleviate some of the administrative burden and reduce clinician burnout. Importantly, the LLM-RAG model would be deployed as a support tool rather than an autonomous decision-maker, ensuring that a qualified clinician reviews all recommendations.
While the RAG system demonstrated versatility, we observed that the international guidelines often led to more accurate outputs compared to local guidelines. This difference may stem from the fact that international guidelines tend to be more comprehensive, with text-based explanations accompanying diagrams and tables, facilitating easier extraction and interpretation by the RAG system. In contrast, local guidelines may be less detailed, limiting the model’s ability to fully leverage the information. To further optimize this application, future improvements could focus on enhancing the completeness of local guideline texts or manually converting diagrams into text, supporting the seamless integration of LLM-RAG systems in diverse clinical environments.
A key consideration for LLM-RAG models is their computational overhead, particularly the added latency and resource demands of combining retrieval with generation. RAG models require embedding, indexing, and retrieval steps, which can increase processing time, especially in real-time applications. Scalability is also a challenge, as larger retrieval pools can enhance accuracy but require more memory and computational power. Future adaptations, such as dynamic retrieval mechanisms, could help optimize retrieval depth based on system load and query complexity, improving efficiency across different settings.
While RAG models still require significant resources, they offer a more sustainable alternative to traditional fine-tuning, reducing the need for extensive retraining cycles10,18. Solutions like GPT-4 Turbo, with a 128k-token context, could further decrease resource use by allowing access to larger document sets in a single pass, enhancing overall efficiency for real-world applications.
The study’s findings are based on simulated clinical scenarios, which may limit their generalizability to real-world settings. Additionally, variations in individual hospital protocols can lead to different thresholds for assessing surgical fitness. Although efforts were made to standardize the clinical scenarios following both local and international guidelines to minimize ambiguities regarding fitness for surgery, these standardizations may not account for all possible variables in actual clinical practice.
Fine-tuning, as another attractive LLM technique, was not explored for assessing its performance in patients’ pre-operation assessment in the current study. This is mainly attributed to the limitation of training dataset numbers less than traditionally recommended amounts (at least 50 examples are suggested by OpenAI documentation). Further experimentation on finetuning LLMs would be necessary to compare their performance with the current LLM-RAG framework.
One of RAG’s notable advantages is its adaptability, allowing it to incorporate the latest medical guidelines and best practices—an especially critical feature in the rapidly evolving field of perioperative medicine. However, the model’s performance remains contingent on both the quality of retrieved information and ongoing expert oversight. Physicians play a crucial role in monitoring the model’s input and output to identify and correct any inaccurate or outdated information. It is vital to develop adaptive retrieval mechanisms that prioritize up-to-date, high-quality sources, and maintain vigilant human supervision to ensure patient safety and optimal care.
The use of LLM-RAG models also raises several ethical considerations, particularly around the potential for biases to influence model outputs. Since these models are trained on large datasets and guided by institutional protocols, any inherent biases within the source material can inadvertently affect clinical recommendations. For instance, biases related to race, gender, socioeconomic status, or regional healthcare practices could impact the model’s decision-making process, potentially reinforcing existing healthcare disparities. This is particularly concerning in high-stakes environments where equitable patient access to care is essential.
In this study, the chosen clinical scenarios were structured to yield clear decisions about delaying surgeries for medical optimization. However, real-world clinical situations often involve nuanced decisions, particularly in critical areas like cancer treatment, where the choice to postpone surgery exists in a realm of ethical ambiguity. Users of LLM-RAG models must recognize that in complex ethical landscapes where nuanced recommendations are needed, the model might lean towards certain decisions influenced by its training data. These models are best utilized as supportive tools that complement but do not replace, the expert judgment of medical professionals.
Future research on LLM-RAG could address several key areas to enhance model performance and adaptability. One promising direction is the development of adaptive retrieval mechanisms that dynamically prioritize relevant documents based on query specificity and real-time filtering, potentially improving response relevance while reducing computational demands. Additionally, domain-specific retrieval augmentation could be explored to fine-tune RAG for specialized fields such as cardiology or oncology. Future studies could also investigate optimal inference parameters to determine the most effective settings for balancing response diversity, accuracy, and relevance across different clinical applications. Moreover, establishing standardized evaluation metrics specific to healthcare, particularly for assessing factual accuracy and contextual relevance, would support rigorous testing and model comparison, laying the groundwork for broader clinical deployment.
LLM-RAG models hold significant promise for real-world applications that demand precise, context-rich information retrieval and response generation. In healthcare, RAG can streamline workflows by retrieving up-to-date guidelines for decision support and assisting in comprehensive medical documentation, all while significantly reducing the time required to process patient information. For example, at our local institution, we have implemented a SecureGPT-enabled RAG system in our anesthesia clinical practice that supports real-time and secure information retrieval. Notably, this system can process a patient chart in around 10 s, thereby enabling faster decision-making, potential cost savings, and increased productivity.
In conclusion, this study shows that the LLM-RAG model with GPT-4 can achieve high accuracy, consistency, and safety in assessing patient fitness for surgery. The model performed as well as, and in some cases better than, clinicians in generating detailed instructions for a variety of clinical scenarios, while keeping hallucination rates low. These results suggest that the model could be a valuable support tool in healthcare, helping to improve consistency and reduce clinician workload. Its adaptability and scalability make it promising for use in preoperative care and other healthcare applications.
Methods
The LLM-RAG pipeline framework is composed of multiple distinct components:
Retrieval augmented generation pipeline
To utilize clinical documents effectively within RAG frameworks, they must first be converted into a structured text format. Conventional RAG models, such as vanilla RAG, often rely on tools like Langchain, which provide loaders to extract text while preserving essential metadata for retrieval. However, this automated process may retrieve extraneous content19 and can have difficulty interpreting visual elements (like diagrams) or structured data (such as tables). In our study, the clinical documents—particularly the international perioperative guidelines—already included textual explanations for key diagrams and tables within the main document. After text conversion, the content is segmented into chunks for embedding and retrieval. The optimal chunk size for capturing semantic information in healthcare contexts remains a focus of ongoing research.
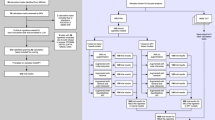
In our study, we utilized an advanced LLM-RAG framework developed with Python 3.11, employing Llamaindex for its streamlined pipeline and enhanced retrieval capabilities (see Fig. 3). Specifically, we implemented the Auto-Merging Retrieval feature in Llamaindex, which is designed to improve retrieval quality by organizing chunks in a hierarchical, tree-like structure. During retrieval, parent chunks accumulate relevant sub-chunks based on a predefined threshold, creating a merged representation that enhances contextual flow and continuity.

This figure illustrates the architecture of a RAG model. Unlike traditional LLM-based search models, RAG models incorporate a retrieval module that searches a pre-indexed database of domain-specific knowledge. This enables the model to access and utilize external information, such as medical guidelines or research papers, to generate more accurate and informative responses. The retrieved information is then fed into a language model to produce a final response that is grounded in factual knowledge. This approach significantly reduces the risk of generating hallucinations or misleading information, making RAG models particularly well-suited for tasks that require accurate and reliable information.
To address computational efficiency in our RAG framework, we set the “similarity_top_k” parameter (the maximum number of retrievable information pieces) to 30. This threshold was chosen to balance two primary objectives: maximizing the retrieval of essential clinical information while minimizing the inclusion of irrelevant content that could introduce noise. By limiting the number of retrieved documents, we reduce unnecessary computational load, which helps to control resource consumption and latency. Additionally, this configuration aligns with the requirements of long-context LLMs, allowing them to access an optimal amount of information without compromising the logical flow in complex clinical scenarios. This approach effectively reduces computational overhead, supporting cost-effectiveness and efficiency, especially for real-time healthcare applications where quick response times are critical.
Prompt engineering
Prompt engineering followed the guidance by Bertalan et al.20. Key principles we emphasized included specificity, contextualization, and open-endedness to elicit comprehensive responses from the LLM. In this context, “role-playing” refers to structuring prompts so that the LLM assumes the perspective of a specific clinical role, such as a preoperative clinician, to generate responses that align with that professional viewpoint. Our approach involved an iterative process of prompt refinement and sample response generation, continuing until we achieved satisfactory output from the LLM.
Large language model and response generation
A list of pre-trained foundational LLMs is selected for this case study, including Generative Pre-trained Transformer (GPT) 3.521, GPT 422, GPT4o23, Large Language Model Meta AI (LLaMA) 2-7B24, LLAMA2-13B24, LLAMA2-70B25, LLAMA3-8B26, LLAMA3-70B27, Gemini-1.5-Pro28, and Claude-3-Opus29. Current LLM selections were based on evaluating the best-performing cloud-based models, including the GPT family and Gemini, as well as the top-performing local models, such as the LLaMA family and Claude. Cloud-based LLMs offer the advantages of flexible scaling and continuous updates but also depend on the ongoing viability of the external provider. By contrast, local LLMs necessitate substantial institutional investments in hardware and energy consumption, while granting enhanced data privacy and more direct control over system performance. Both approaches are important considerations for future LLM integration into clinical workflows. Detailed characteristics of these LLMs are provided in Table 2. In each scenario, the same knowledge corpus extracted from clinical guidelines was used as user prompts, and clinical questions were input as system prompts for consistency across all models. The complete codebase used in this study is publicly available on GitHub: https://github.com/Liyuan1Y/RAG-LLM-Demo.
To ensure consistency in responses generated by the various LLMs, we standardized key inference parameters. The “temperature” was set to 0.1 to reduce randomness and make outputs more deterministic, enhancing consistency. The “maximum output token length” was fixed at 2048 to limit response length and prevent overly lengthy outputs. The “Top-P value” was set at 0.90, enabling the model to sample from the smallest group of words whose cumulative probability exceeds this threshold, balancing response creativity and relevance. This configuration aimed to minimize hallucinations and produce responses that were both meaningful and reproducible. We utilized the cloud-based OpenAI playground platform to conduct our experiments.
Inference for LLaMA models was performed on the Google Cloud Platform (GCP™) using two NVIDIA® A100 (80GB) GPUs through Vertex AI™. We obtained the models from Meta’s official Hugging Face® repository for LLM-RAG inferences. However, for LLaMA2 models, we refined the process by selecting the top 10 relevant information pieces to feed into the LLM for inference. Additionally, the maximum tokens generated were reduced to 1,024 due to LLaMA2’s 4k context length limitation.
For the Gemini-1.5-Pro responses, we employed GCP Vertex AI’s language generation playground. On the other hand, the Claude-3 Opus model was implemented via GCP’s notebooks and through API calls. Detailed in Fig. 4 is the operational framework of the LLM-RAG model, providing a schematic representation of the interplay of the algorithmic workflow integral to the system’s functionality.

This figure illustrates the operational framework of the LLM-RAG model, which leverages both local and international preoperative guidelines to provide accurate and reliable medical advice. The model first processes a user query to extract relevant keywords and semantic information. It then searches a pre-indexed database containing local and international guidelines to identify relevant information. The retrieved information is analyzed to understand the context of the query, and a language model is used to generate a comprehensive response.
Nomenclature of LLM systems
Three distinct answer sets were generated for this study using the GPT-4 model. The first, denoted as “GPT-4,” utilized the base language model without additional context. The second, “GPT-4-local,” was the LLM-RAG system using the GPT-4 base model with a knowledge base derived from 35 local preoperative guidelines. The third, “GPT-4_international,” utilized a knowledge base derived from 23 international preoperative guidelines. Similar configurations were also generated using other LLMs in this study.
Evaluation of LLM with the S.C.O.R.E. evaluation framework
In this study, we are employing a novel qualitative evaluation framework S.C.O.R.E30. It provides a nuanced analysis of medical context based LLM responses, addressing several limitations in existing quantitative and qualitative methodologies. This framework offers unique assessments that align with our research objectives in qualitatively assessing LLM responses based on its safety, clinical consensus, objectivity, reproducibility, explainability which are essential for our study to clinically validate our LLM-RAG pipeline. Initial assessments indicate robust performance, promising significant contributions upon release. Additionally, a distinct n-gram analysis was conducted to assess language diversity.
To assess the reproducibility and reliability of the LLM framework, we conducted a primary analysis to identify the best-performing system for the primary outcome. The GPT-4 international model emerged as the top performer (accuracy rate of 93%). Subsequently, the GPT-4 international LLM-RAG system underwent four additional iterative evaluations to further test its robustness.
The performance of the GPT4-international LLM-RAG system in generating preoperative instructions was evaluated by two attending anesthesiologists (more than 5 years and 15 years of anesthesiology experiences, respectively) using the S.C.O.R.E. Evaluation Framework framework (Table 2). Each scenario was scored based on the 4x repeats generated. The average score was taken and represented. This assessment encompassed (1) safety, ensuring non-hallucinated responses with no misleading information; (2) consensus, gauging agreement with existing medical literature; (3) objectivity, verifying the absence of bias or personal opinions; (4) reproducibility, confirming consistent performance across multiple iterations; and (5) explainability, evaluating the clarity and rationale behind generated instructions. In addition, a Distinct n-gram analysis was conducted to evaluate the linguistic diversity of the generated responses.
Evaluation framework
This study utilized two distinct sets of preoperative guidelines, reflecting both local and international perspectives. The first comprised 35 local protocols from a major tertiary hospital in Singapore, adapted from established international perioperative standards; these protocols represent the full set of anesthesia guidelines currently in use at our institution. The second set consisted of 23 internationally recognized guidelines from various anesthesia societies (e.g., the American Society of Anesthesiologists, European Society of Anaesthesiology, and relevant specialty organizations) and UpToDate articles (Supplementary Table 1). UpToDate was included for its high-quality, consensus-based recommendations grounded in current evidence and its ability to synthesize information when guidelines differ among societies. All guidelines—complete with diagrams and figures—were extracted in their native PDF format and loaded into separate LLM-RAG systems. This selection process provides a comprehensive framework covering patient assessment, medication management, and specific surgical procedures, ensuring relevance across both local and global contexts.
Clinical scenarios
This study assessed the performance of the LLM-RAG system on 14 de-identified clinical scenarios, carefully selected to represent a range of ASA classifications (ASA 1–3), medical conditions, and surgical complexities (Table 3). The scenarios were formatted to reflect real preoperative clinic notes, retaining clinical acronyms commonly used in practice, such as DM for diabetes mellitus and HTN for hypertension. Each scenario was fully de-identified, with modifications to age, sex, and past medical history, as well as adjustments to surgical dates and types of procedures. Due to the anonymized nature of the data and the minimal risk associated with this study, ethics approval was not required (Reviewed by Singapore General Hospital Research and Innovation Office).
Six key aspects of preoperative instructions were assessed, with the primary outcome being the assessment of the patient’s fitness for surgery. This was complemented by five additional parameters: (1) fasting guidelines, (2) suitability for preoperative carbohydrate loading, (3) medication instructions, (4) instructions to healthcare workers (perioperative instructions), and (5) types of preoperative optimizations required. These aspects were selected due to their established significance in the current medical literature and their potential impact on surgical outcomes31.
Output
Four junior doctors (1–7 years of anesthesia experience) and four attending anesthesiologists (1 from Singapore General Hospital, Singapore, 1 from Harvard Medical School, United states, 2 from Chang Gung Memorial Hospital, Taiwan) independently responded to the primary outcome assessment as human evaluators. This selection reflects the typical global practice in which preoperative assessments are often conducted by junior doctors or anesthetic nurses32, while senior consultants provide the final, individualized clinical decisions. Additionally, the junior doctors provided responses for parameters related to secondary outcomes. To maintain the integrity of the study and ensure unbiased responses, the participants were blinded to the study’s objectives. The human-generated answers were then collated and aggregated for comparison with the LLM-generated answers.
The ‘correct’ answers in the study were based on established preoperative guidelines and reviewed by an expert panel made up of two board-certified perioperative anesthesiologists. Where there were disagreements, discussions were made between the two panelists to come to a final decision. In ambiguous cases, like the suspension of ACE inhibitors before surgery, both potential answers were considered correct33. This was to reflect the real-world complexities of preoperative decision-making, especially where evidence for one choice over another was scarce. The study focused on scenarios with clear directives regarding the postponement of operations for additional optimizations.
For the secondary objectives, which involved preoperative instructions with multiple components, a response was deemed “correct” if it aligned with at least 75% of the guidelines. This threshold acknowledges the inherent subjectivity in preoperative instructions, where the clinical significance of omissions can vary. For example, omitting a recommendation for continuous positive airway pressure (CPAP) use in a high-risk sleep apnea patient could be critical, whereas omitting a preference for morning surgery in a non-critical case might be less consequential (Supplementary, Scenario 1). Given the absence of established accuracy thresholds in this context, we conducted a sensitivity analysis by evaluating performance at both 65% and 85% accuracy cutoffs.
Only the LLMs were evaluated to determine whether a patient should be seen by a nurse anesthetist or a doctor. The assessment criteria were based on Singapore’s local guidelines, which state that ASA I or II patients over 21 years old, not undergoing high-risk surgery or facing a high risk of complications, and without any abnormal investigation results, can be evaluated by a nurse anesthetist. These guidelines are more conservative than those in other countries due to the heavily doctor-led nature of Singapore’s healthcare system, and they account for variations in thresholds across different institutions.
We assessed the LLM-RAG systems’ responses for accuracy, consistency, and safety. The comparison between the LLM-RAG responses and the correct answers was conducted manually, allowing minor differences in wording as long as the clinical meaning remained consistent. We prioritized the intent and medical implications of each recommendation over exact phrasing, ensuring a fair and meaningful assessment. To further safeguard patient welfare, any response containing a critical medical error (e.g., incorrect fasting instructions or medication dosages) was classified as a “Hallucination” and automatically deemed incorrect, regardless of whether other aspects of the response were accurate.
A comparative analysis is performed against the human-generated responses and the best-performing LLM-RAG model using Fisher’s exact test. Consistency within the human and LLM answers were analyzed using percentage agreement for interrater reliability (IRR). All statistical evaluations are performed in the Python 3.6 environment.
The study is not funded. All the authors had full access to the study data. The full raw data is available within the appendix and upon request. The manuscript was reviewed by all the other authors. YHK and DSWT were responsible for the decision to submit the manuscript for publication.
Research in context
Evidence before this study: Prior research suggests the potential of LLM-RAG models for generating context-specific information. However, their application, adaptability to both regional and international guidelines, and evaluation within realistic, simulated clinical scenarios in healthcare still need to be improved.
Added value of this study
We developed and evaluated 10 LLM-RAG models specifically tailored to the preoperative setting using 35 local perioperative guidelines and 23 international guidelines. The GPT4 LLM-RAG model with international guidelines demonstrated the best accuracy and consistency, and outperforms anesthesiologists in assessing surgical fitness, providing safe responses with a low hallucination rate.
Implications of all the available evidence
Our findings, combined with existing research, underscore the advantages of grounded knowledge, agnostic to various healthcare domains, upgradability, and scalability as essential factors for successfully deploying efficient RAG-enhanced LLMs in healthcare settings. This study provides strong support for considering these models as potential assistive companions in fields like perioperative medicine.
Data availability
Data is provided within the manuscript or supplementary information files.
Code availability
The complete codebase used in this study is publicly available on GitHub: https://github.com/Liyuan1Y/RAG-LLM-Demo.
References
Thirunavukarasu, A. J. et al. Large language models in medicine. Nat. Med. 29, 1930–1940 (2023).
Lim, D. Y. Z. et al. Large language models in anaesthesiology: use of ChatGPT for American Society of Anesthesiologists physical status classification. Br. J. Anaesth. https://doi.org/10.1016/j.bja.2023.06.052 (2023).
Lee, S.-W. & Choi, W.-J. Utilizing ChatGPT in clinical research related to anesthesiology: a comprehensive review of opportunities and limitations. Anesth. Pain. Med. 18, 244–251 (2023).
Garg, R., Bhalotra, A. R., Bhadoria, P., Gupta, N. & Anand, R. Reasons for cancellation of cases on the day of surgery-a prospective study. Indian J. Anaesth. 53, 35–39 (2009).
Pfeifer, K., Slawski, B., Manley, A. -M., Nelson, V. & Haines, M. Improving preoperative medication compliance with standardized instructions. Minerva Anestesiol. 82, 44–49 (2016).
Naderi-Boldaji, V. et al. Incidence and root causes of surgery cancellations at an academic medical center in Iran: a retrospective cohort study on 29,978 elective surgical cases. Patient Saf. Surg. 17, 24 (2023).
Koushan, M., Wood, L. C. & Greatbanks, R. Evaluating factors associated with the cancellation and delay of elective surgical procedures: a systematic review. Int. J. Qual. Health Care 33, mzab092 (2021).
Haana, V., Sethuraman, K., Stephens, L., Rosen, H. & Meara, J. G. Case cancellations on the day of surgery: an investigation in an Australian paediatric hospital. ANZ J. Surg. 79, 636–640 (2009).
Liu, S. et al. Preoperative assessment clinics and case cancellations: a prospective study from a large medical center in China. Ann. Transl. Med. 9, 1501 (2021).
Nishant, R., Kennedy, M. & Corbett, J. Artificial intelligence for sustainability: challenges, opportunities, and a research agenda. Int. J. Inf. Manag. 53, 102104 (2020).
Zakka, C. et al. Almanac: retrieval-augmented language models for clinical medicine. Res. Sq. https://doi.org/10.21203/rs.3.rs-2883198/v1 (2023).
LangChain. https://www.langchain.com/.
LlamaIndex—data framework for LLM applications. https://www.llamaindex.ai/.
Yang, R. et al. Integrating UMLS Knowledge into Large Language Models for Medical Question Answering. arXiv [cs.CL] (2023).
stanford-crfm/BioMedLM · Hugging Face. https://huggingface.co/stanford-crfm/BioMedLM.
Pal, S., Bhattacharya, M., Lee, S. -S. & Chakraborty, C. A domain-specific next-generation large language model (LLM) or ChatGPT is required for biomedical engineering and research. Ann. Biomed. Eng. https://doi.org/10.1007/s10439-023-03306-x (2023).
Nicholson, A., Coldwell, C. H., Lewis, S.R. & Smith, A. F. Nurse-led versus doctor-led preoperative assessment for elective surgical patients requiring regional or general anaesthesia. Cochrane Database Syst. Rev. https://doi.org/10.1002/14651858.CD010160.pub2 (2013).
Vinuesa, R. et al. The role of artificial intelligence in achieving the Sustainable Development Goals. Nat. Commun. 11, 233 (2020).
Hinton, G., Vinyals, O. & Dean, J. Distilling the knowledge in a neural network. arXiv [stat.ML] (2015).
Meskó, B. Prompt engineering as an important emerging skill for medical professionals: tutorial. J. Med. Internet Res. 25, e50638 (2023).
GPT-3.5 Turbo fine-tuning and API updates. https://openai.com/blog/gpt-3-5-turbo-fine-tuning-and-api-updates.
Hello GPT-4o. https://openai.com/index/hello-gpt-4o/.
Introducing LLaMA: a foundational, 65-billion-parameter language model. https://ai.meta.com/blog/large-language-model-llama-meta-ai/.
Meta-llama/llama-2-70b-chat-hf · hugging face. https://huggingface.co/meta-llama/Llama-2-70b-chat-hf.
meta-llama/Meta-Llama-3-8B · Hugging Face. https://huggingface.co/meta-llama/Meta-Llama-3-8B.
meta-llama/Meta-Llama-3-70B · Hugging Face. https://huggingface.co/meta-llama/Meta-Llama-3-70B.
Gemini Team et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv [cs.CL] (2024).
Claude. https://claude.ai/.
Tan, T. F. et al. A proposed S.c.o.r.e. evaluation framework for large language models : Safety, Consensus, Objectivity, Reproducibility and Explainability. arXiv [cs.CL] (2024).
Gagné, S. & McIsaac, D. I. Modifiable risk factors for patients undergoing lung cancer surgery and their optimization: a review. J. Thorac. Dis. 10, S3761–S3772 (2018).
Malley, A., Kenner, C., Kim, T. & Blakeney, B. The role of the nurse and the preoperative assessment in patient transitions. AORN J. 102, 181.e1–9 (2015).
Cohn, S. L., Grant, P. J. & Slawski, B. 2019 Update in perioperative cardiovascular medicine. Cleve. Clin. J. Med. 86, 677–683 (2019).
Acknowledgements
The authors sincerely thank Dr. Leong Yun Hao, Dr. Victoria Tay, Dr. Jasper Goh, and Dr. Taylor Lim from Singapore General Hospital for their invaluable contributions as human evaluators in this study. Their dedication and insightful input enriched the research. We also acknowledge the preoperative clinical guidelines provided by the hospital, which were pivotal in the successful execution of this project. The project is not funding by any funding agency in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Contributions
Conceptualization and guidance: Y.H. Ke, H.R. Abdullah, D.S.W. Ting. Grading models: H.R. Abdullah, Y.H. Ke, V.P. Kovacheva, C.F. Kuo, S.C. Wu. Coding and technical development: L. Jin, K. Elangovan. Data analysis: Y.H. Ke, L. Jin, J.Y.M. Tung, J.C.L. Ong, A.T.H. Sia, C.R. Soh, N. Liu. Manuscript preparation and proof-reading: All authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ke, Y.H., Jin, L., Elangovan, K. et al. Retrieval augmented generation for 10 large language models and its generalizability in assessing medical fitness. npj Digit. Med. 8, 187 (2025). https://doi.org/10.1038/s41746-025-01519-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41746-025-01519-z
This article is cited by
-
From blink to care: smartphone video–based functional analysis and personalized management in pediatric blepharoptosis
npj Digital Medicine (2026)
-
Artificial intelligence for autoimmune diseases
npj Digital Medicine (2025)
