
Abstract
Large scale data repositories like the All of Us Research Program are spurring new understanding of health and disease. All of Us aims to create a database of all Americans, addressing patterns of understudy of some groups in biomedical research. We study the representativeness (similarity to the U.S. population) and coverage (equality of proportion across U.S. Census demographic categories) of All of Us from 2017 to 2022, finding that All of Us recruited almost every understudied group at or above the group’s Census proportion. Building on the program’s successes, we propose a computational strategic recruitment method that optimizes multiple recruitment goals by allocating recruitment resources to sites and evaluate this method in recruitment simulation. We find that our methodology is indeed able to improve both cohort representativeness and coverage. Moreover, improvements in representativeness and coverage hold across numerous simulation conditions, supporting the promise of our recruitment techniques in real-world application.
Similar content being viewed by others


Introduction
Large biomedical datasets allow the discovery of groundbreaking new insights into health and disease. The need for, and utility of, these datasets will only increase with advances in artificial intelligence (AI). Yet, these datasets often do not adequately exemplify all groups in the population they are trying to study1. This understudying or underrepresentation occurs across many areas of biomedicine2,3,4,5,6,7,8,9, and can lead to several problems. For example, the results of scientific studies may not generalize to groups that are understudied or underrepresented in biomedical research (UBR), leading to an estimated economic cost of hundreds of billions of dollars in the United States from 2020 through 205010. While many examples from that report concerned clinical trials and research into pharmaceutical efficacy, computational tools and techniques are similarly vulnerable to issues induced by lack of representation. Classifiers, a common type of AI tool, have sometimes been observed to be less accurate for groups underrepresented in their training data11,12. Unrepresentative datasets can skew statistical association measures leading to irreproducible results13. Lack of representation across studies may also impact the perception of research more broadly, leading to decreased trust and legitimacy10,14. Thus, ensuring adequate representation is critical.
Representation and coverage are abstract concepts, so assessing and improving them requires concrete measures. We follow common convention and define representation as a measure of similarity between a study cohort and some target population based on a set of attributes15. For this analysis, we measure the similarity of a cohort’s distribution of demographics (age, gender, race, and ethnicity) to the U.S. population’s true distribution of those same demographics, as determined by the Census Bureau. This approach has been used by others to assess the cohort representativeness of clinical trials16,17,18. Another important concept, dataset coverage, assesses whether there are a sufficient number of data points for all relevant combinations of attributes of interest15,19,20. Because the notion of “sufficient” depends on the downstream uses of data and our aim is to build a desirable cohort independent of specific downstream uses, we adapt the definition of coverage. Thus, we define coverage as the number of data points in the smallest group. The uniform distribution maximizes coverage because it contains equal proportions of all groups, so we measure coverage as the similarity between a cohort’s distribution of attributes and the uniform distribution over the same attributes. The uniform distribution also maximizes entropy, which has been used to assess coverage and improve algorithmic fairness21,22. Moreover, the uniform distribution may be considered a baseline target by which to assess representation when a target population is not known, as each group makes up an equal proportion of the dataset.
We formulate representation and coverage as similarities to distinct target distributions. Thus, we may measure both representation and coverage using the same technique. This similarity yields results that may be compared with each other and offer desirable properties for dual objective optimization. We use Kullback-Leibler divergence (KLD) to measure the similarity of a recruited cohort to either the U.S. Census population (when assessing representation) or the uniform distribution (when assessing coverage). KLD is easily related to distributional entropy and does not require distance to be defined within the probability space, in contrast to earth mover’s distance. In an illustrative example, let a target population (Q in KLD(P∣∣Q)) be 40% ‘Young’ and 60% ‘Old’. A cohort (P in KLD(P∣∣Q)) that is 40% ‘Young’ and 60% ‘Old’ is optimally representative, with KLD of 0 to the target and KLD of 0.02 to the uniform. Likewise, a cohort that is 50% ‘Young’ and 50% ‘Old’ is optimally covering, with KLD of 0.02 to the target and KLD of 0 to the uniform. Finally, a cohort that is 45% ‘Young’ and 55% ‘Old’ would be somewhere in between, with KLD of 0.005 to both the target and uniform. Thus, KLD enables a unified framework for assessing representation and coverage. Having a unified framework promotes concrete recruitment goals, which can improve recruitment of UBR groups23. As stated in their core values, the All of Us Research Program aims to “reflect the rich diversity of the United States”, specifically including UBR groups24. To this end, All of Us has set recruitment targets of 45% of participants from racial and ethnic minorities and 75% from UBR groups more generally25,26. Notably, All of Us does not claim to be perfectly representative of the U.S. population. For comparison, a perfectly Census-representative cohort would have 37.28% of participants identifying as a racial and/or ethnic minority and 54.63% from UBR groups as as determined by race, ethnicity, and age. A perfectly covering cohort, which is more of a mathematical construct than a realistic recruitment goal for the vast majority of studies, would have 90% of participants from racial/ethnic minorities and 93% from underrepresented groups. Thus, All of Us’s recruitment goals aim to strike a balance between representativeness and coverage.
Several recent efforts have been made to improve representation and coverage, with specific emphasis on large biomedical data repositories. Strategies such as training patient navigators can help address barriers to participation27,28 in biomedical research studies. Involving participants in the design and execution of research projects has been shown to improve representation, coverage, study design, and communication between researchers and participants29,30,31. Conducting recruitment at multiple types of locations (e.g., academic hospitals and community centers) can also improve representativeness32,33. All of Us employs many of these efforts, as well as participant-centric enrollment processes, at scale25,34. Computational methods have been proposed to improve representation and coverage in sampling or recruitment. Nargesian et al. develop a method for achieving a target data distribution from multiple sources but may require discarding data, which may be undesirable (due to costs) in a study that recruits participants35. Selecting a representative cohort under competing objectives has also been explored: Flaginan et al. propose a method for selecting citizen’s assemblies that balances representativeness with equality of selection probability for individual members36. However, prospective recruitment fundamentally differs from selection, and the expected improvements in representativeness may differ by an order of magnitude or more37,38. The outside work most similar to ours is by Theodorou et al.22, who prioritize clinical trial recruitment sites through a reinforcement learning model which uses a reward function encoding enrollment numbers and participant diversity. Their definition of participant diversity is entropy, which is directly and negatively proportional to our formulation of coverage as KLD to the uniform distribution. However, Theodorou et al. assess diversity only by race and do not optimize for population representativeness. Representativeness, alongside coverage, may be of interest for large-scale biomedical datasets like All of Us because the distribution of attributes within the cohort should approximate that of the general population. Our recruitment model also assumes that recruitment resources can be re-allocated to different sites, so we do not optimize for enrollment numbers.
We situate this work to build upon the successes of All of Us. Although there are numerous participatory biomedical datasets and initiatives39,40,41, All of Us stands out due to its nationwide reach, broad range of participants, and its commitment to representing all Americans42,43. As a result, All of Us successfully includes most UBR groups near or above their Census proportions. In a study at one All of Us site, individuals from UBR groups had a higher chance of joining the program when approached for recruitment than their overrepresented counterparts44. This inclusion means that All of Us is substantially more covering and representative than many similarly sized and scoped biomedical datasets26. What remains unknown – and is the focus of this paper – is whether All of Us’s final cohort was as representative and covering as it could have been, given the recruitment sites available and their demographics over the course of the program. In a sense, this counterfactual question is unknowable: had the program pursued a different recruitment strategy, we do not know the precise impact that strategy would have had on the final cohort. Yet, through simulation, we approximate an answer to this question. We study how a hypothetical All of Us cohort would have looked if recruitment resources could be reallocated freely between sites. We also study the inherent competition between Census representativeness and coverage and discuss how to balance these two goals.
Through a case study of All of Us, we show how computational modeling could guide recruitment and further improve cohort representativeness and coverage. We treat participant recruitment, namely the efforts of recruitment staff, as a resource budget that may be distributed across recruitment sites. By strategically allocating recruitment resources over time, a study team may be able to recruit a more representative and covering cohort than a static or non-informed approach. In our prior work, we have shown this approach to be more effective than random or heuristic resource allocation methods, in a simplified setting, at recruiting simulated cohorts from a network of medical centers38.
However, those simulations distributed resources among only nine sites, compared to fifty in All of Us, which likely will make it more challenging for the algorithm to find the optimal solution in All of Us. That study also could not assess the distribution of participants who were willing to join a study (i.e., the response distribution), which may differ from the overall patient demographics at a medical center and is directly measurable in All of Us. Most saliently, the recruitment process in our prior study was purely hypothetical, meaning there was no real recruitment baseline to compare against. In this study, we use the actual recruitments of All of Us as its own baseline to demonstrate the potential further benefits of adaptive recruitment resource allocation.
To summarize, this study makes two primary contributions: first, we operationalize the goals of coverage and representation as a dual-objective optimization; second, we demonstrate, through simulation, how this optimization could be used to adapt recruitment strategies and achieve these goals. Using historical participant recruitment data from All of Us, we present counterfactual simulations of how the cohort could have been recruited using our strategic recruitment methodology. Moreover, we assess how our methodology aligns with All of Us’s stated recruitment goals to improve representation from UBR groups. Finally, we show how our recruitment methodology is robust to varied simulation parameters, representing a wide range of realistic scenarios.
Results
Current state of All of Us
Throughout our results, we focus on the subset of All of Us participants who have a defined 3-digit electronic health record (EHR) site code, obtained from variable src_id45. This subset of participants originates from EHR recruiting sites, so it is the subset that is theoretically modifiable through resource allocation. We find that this subset of participants is qualitatively similar to the overall All of Us cohort (Table 1 and Supplementary Table 3). This constraint is relaxed to include participants without a defined EHR site in Supplementary Section 1.
We begin our case study into All of Us recruitment by approximating the program’s goals through its recruitment patterns. Throughout the results, C refers to a cohort’s demographic distribution by age, gender, race and ethnicity, while P refers to the Census distribution over those attributes and U refers to the uniform distribution. KLD(C∣∣P), the Kullback-Leibler divergence from the cohort distribution to the Census, assess representativeness while KLD(C∣∣U), the divergence from the cohort distribution to the uniform, assess coverage. Lower divergence values are considered to be more representative and covering, respectively. In the first seven months (up to January 2018) of recruitment, All of Us substantially improved representativeness, coverage, and recruitment of UBR populations (Fig. 1a, b). These improvements may be attributed to almost all UBR subgroups (by age, race, or ethnicity) being recruited at levels matching or exceeding their Census levels of representation. The following two years of recruitment (January 2018–2020) continue this prioritization of UBR groups, especially for Black and Hispanic/Latino participants. As expected, this recruitment strategy improved cohort coverage at the cost of Census representativeness. Presumably due to the COVID-19 pandemic, recruitment substantially slowed from March 2020–2021, and then resumed from April 2021 onward.

In panels (a, b), we show the Kullback-Leibler divergence to the Census (KLD(C∣∣P)) and uniform (KLD(C∣∣U)) distributions, highlighting our measures of representativeness and coverage, respectively. Panel (c) tracks the progress of All of Us towards its goal of 75% participants from underrepresented in biomedical research (UBR) groups (of attributes we can measure) while panel (d) shows the number of recruited participants over time. Panels (e–j) detail the proportions of the UBR groups which we can measure in this analysis, along with each group’s Census proportion. NH/PI refers to Native Hawaiian/Pacific Islander race while H/L refers to Hispanic/Latino ethnicity.
Interestingly, the post-pandemic recruitment strategy appeared to reverse course. The proportion of Black and Hispanic/Latino participants decreased somewhat from respective 2020 maxima of 26.40% and 20.37% to respective final cohort percentages of 23.84% and 19.75%. Concomitantly, coverage (KLD(C∣∣U)) and proportion of UBR groups decreased while Census-representativeness improved (Fig. 1a–c, g, j). Another notable result is that the proportion of Asian participants appeared to follow an opposite trend compared to other UBR races and ethnicities. Except for an early uptick in late 2017, the proportion of Asian participants in the All of Us cohort monotonically decreased throughout most of the recruitment process, with the group’s final representation substantially below its Census level. This decreasing representation of Asian participants in the All of Us cohort highlights an opportunity the program may wish to consider. Sites with substantial underrepresentation of Asian participants contribute more cumulative participants to All of Us over time (Supplementary Section 2), so counteracting this effect through strategic recruitment may improve both representation and coverage.
The demographics of the final All of Us cohort generally align with the program’s goals. In All of Us’s total final cohort, 66.58% of the participants come from groups who are UBR as determined by age, race, or ethnicity, including 43.61% from racial and/or ethnic minorities. When we limit the dataset to participants with a defined EHR site, like we do for most of our analyses, the proportion of participants from underrepresented groups increases to 69.42% total and 45.15% from racial/ethnic minorities. These proportions approach or exceed All of Us’s recruitment goals of 75% UBR participants and 45% from racial/ethnic minorities. Notably, some attributes that define UBR groups in All of Us’s definition (e.g., income, sexual orientation, or access to healthcare) are not studied in this analysis because they are not available in the Census dataset studied. Moreover, participants who self-identify as a race that aligns with the Census category of American Indian or Alaska Native are not included in this version of All of Us data.
The demographics of the final All of Us cohort align with our formulated goals of representativeness and coverage. Because our combined objective function in Equation (5) balances representation and coverage, the ideal cohort proportion for each demographic group will lie somewhere between its Census and uniform proportions. Thus, we compare the proportion of each fully defined demographic group (e.g., 20–44 year old Asian Hispanic/Latino women) in the All of Us cohort to that group’s proportion in the Census and to the uniform distribution (Fig. 2). Of the 60 combined demographic groups studied, 35 (58%) were represented somewhere between their Census and uniform levels, and several more were only slightly outside these bounds. This subgroup representation appears to indicate that All of Us prioritized representativeness and coverage as we have defined it. Certain UBR groups (e.g., Black, Hispanic/Latino, or older participants) are intentionally overrepresented above their Census proportions in this cohort (Table 1 and Fig. 2). However, a few demographic groups remain consistently underrepresented in the All of Us cohort, particularly non-Hispanic/Latino Asian or Native Hawaiian / Pacific Islander participants. Younger and male participants also tended to be less represented in the cohort compared to older and female participants. Underrepresentation compounds across demographic factors: within the underrepresented Non-Hispanic/Latino Asian and Native Hawaiian / Pacific Islander subgroups, men are consistently represented less than women. Strategic recruitment strategies may also improve the representation of these groups, in addition to the hypothesized improvement in the representation of Asian participants discussed earlier.

Absolute proportions of each combined demographic group are shown as black dots and compared to a uniform distribution (black dashed line) and each group’s proportion in the U.S. Census (black solid line). Target group proportions are between the uniform and Census proportions (purple shaded area), while proportions above both lines are considered overrepresented and proportions below both lines are underrepresented. F refers to female, M refers to male, (N)H/L refers to (non-)Hispanic/Latino, and NH/PI refers to Native Hawaiian / Pacific Islander.
Understanding the recruitment sites available
To propose strategies for improving All of Us cohort representativeness and coverage, we must first understand the recruitment sites available, which we term the policy space. As detailed in Section “Defining recruitment sites and prior knowledge”, we identify 50 EHR sites to constitute our policy space. Each site has its own response distribution that captures the demographics of participants potentially willing to join All of Us. We generate these response distributions using historical recruitment data from each site in All of Us. Although site response distributions varied somewhat over time, the vast majority of this variation is random. Only 0.233% of site demographic combinations had a statistically significant (α = 0.05, multiple hypothesis correction not supported) trend over time when assessed with a Kwiatkowski-Philips-Schmidt-Shin (KPSS) test with null hypothesis of stationary data around a constant46. Thus, we utilize each site’s cumulative historical recruitments up to the simulated date (e.g., recruitment data through January 2019 if the simulated recruitment step is in January 2019) to mitigate random distribution variation over time.
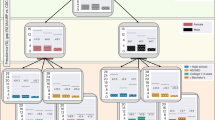
Figure 3 shows the final response distributions at each site, relative to the U.S. Census proportions of each demographic group. Few sites represent non-Hispanic/Latino Asian or Native Hawaiian / Pacific Islander participants at or above their Census levels, and several sites lack Native Hawaiian / Pacific Islander participants entirely. The Census proportions of these demographic groups are also far below the uniform distribution, so their underrepresentation would negatively impact both Census representativeness and coverage. Some sites differ from these overall trends. Sites 783, 195, 481, and 267 all represent non-Hispanic/Latino Asian participants near or above their Census levels, while sites 321, 195, and 199 have substantially better representation of Native Hawaiian / Pacific Islander participants than other sites (Fig. 3a). Thus, trends of underrepresentation may potentially be overcome by strategically prioritizing recruitment at certain sites. In Table 2, we summarize the geographical information about each EHR site, including the most common 3-digit ZIP codes (ZIP3s) of participants from the site and the major cities in the region. Eleven major cities have multiple EHR sites: Atlanta, GA (2); Birmingham, AL (2); Boston, MA (2); Chicago, IL (7); Jackson, MS (2), Los Angeles, CA (2); Milwaukee, WI (2); New Orleans, LA (2); New York, NY (3); Phoenix, AZ (2); and San Diego, CA (2). Even within the same geographic area, recruitment sites may have substantially different response distributions. New York City’s three sites have notable differences: site 752 is the only site which represents Native Hawaiian / Pacific Islander participants at all while site 783 is the only site to represent Asian participants at or above their Census levels (Fig. 4). Other cities with multiple EHR sites also show differences in their participant response distributions.

Six selected sites are shown in (a) while all 50 EHR sites are shown in (b). Each row corresponds to one site, sorted by descending number of participants, while each column corresponds to a fully defined demographic group. Blue colors indicate a group is overrepresented (relative to its Census proportion) at a site while red colors indicate a group is underrepresented. The deepest red color indicates there are no participants from that demographic group at that site. F refers to female, M refers to male, (N)H/L refers to (non-)Hispanic/Latino, and NH/PI refers to Native Hawaiian / Pacific Islander.

Blue colors indicate a group is overrepresented (relative to its Census proportion) at a site while red colors indicate a group is underrepresented. The deepest red color indicates there are no participants from that demographic group at that site. F refers to female, M refers to male, (N)H/L refers to (non-)Hispanic/Latino, and NH/PI refers to Native Hawaiian / Pacific Islander.
Identifying a representation and coverage goal
We operationalize the goals of cohort representativeness and coverage as a dual objective optimization detailed in Section “Balancing representation and coverage”. As a result, there are infinitely many optimal combinations of representativeness and coverage that arise from differentially weighting these two objectives. Thus, two optimal cohorts may have starkly different demographic distributions, and identifying a specific recruitment goal is critical. We specify a recruitment goal that balances representativeness and coverage such that both measures may be improved relative to the historical final All of Us recruited cohort. By doing so, our recruitment goal aligns with the apparent balance of representativeness and coverage that All of Us desires; it does not represent a major shift towards prioritizing either Census-representativeness or coverage. To empirically identify this recruitment goal, we run our recruitment algorithm with 40 different target combinations of representativeness and coverage. Under the constraints of our simulation, the final cohorts that could be recruited by strategically allocating resources to EHR-based sites are more representative and/or covering than the historic All of Us cohort, but they do not reach the theoretic Pareto frontier (Fig. 5). These results are expected because of the practical limitations of recruiting from a finite number of sites with unique response distributions. Eleven of our 40 simulated final cohorts exceed both the representativeness and coverage of the All of Us historical cohort, shown in the area below and to the right of the dashed black lines in Fig. 5. We empirically select the sixth (of eleven) target point in this region, corresponding to \({\rm{KLD}}\left(\right.C\,| | \,P{\left)\right.}_{T}=0.04\ {\rm{and}}\ {\rm{KLD}}\left(\right.C\,| | \,U{\left)\right.}_{T}=0.909\), as the target balance of representativeness and coverage in subsequent experiments.

The All of Us final cohort is shown as a black dot, with black dashed lines extending its KLD(C∣∣P) and KLD(C∣∣U) values outwards. Cyan lines show the relationship between a cohort’s final representativeness, coverage, and target point. The pink line and pink-outlined point indicate the final selected target point of (0.04, 0.909).
Recruiting a more representative and covering cohort through strategic resource allocation
Recognizing the numerous successes of All of Us in recruiting UBR populations, we aimed to evaluate whether strategic resource allocation could further improve the representativeness and coverage of All of Us. We present a counterfactual simulation of how recruitment could have unfolded from the inception of All of Us until June 2022; the same total number of participants are recruited in simulation, but their recruitment sites – and, thus, demographics – differ. In our simulation, we assume that All of Us has the ability to update their recruitment policy on a quarterly basis, for a total of 21 3-month recruitment iterations from 2017 to 2022. We repeat each simulation 40 times and report the mean and 95% Bayesian credible interval (CI) for all results of interest.
Despite starting without any knowledge of site response distributions, our model improves the coverage of All of Us as early as the first quarter of recruitment and improves upon representativeness after the fourth quarter (Fig. 6). These improvements are maintained throughout the recruitment process, producing a final cohort that is significantly more representative and covering than All of Us’s final cohort with mean final simulation KLD(C∣∣P) = 0.1508 [95% CI 0.1496–0.1520] and KLD(C∣∣U) = 0.9557 [95% CI 0.9550–0.9564] compared to All of Us KLD(C∣∣P) = 0.1834 and KLD(C∣∣U) = 1.0450. Two-sided Wilcoxon signed-rank tests comparing the mean final cohort representativeness and coverage to the null hypothesis of the All of Us baseline yield M = −20 (all 40 replicates less than the null hypothesis) and p-values of 1.819 × 10−12 for each measure.

Representativeness (KLD(C∣∣P), (a) and coverage (KLD(C∣∣U), (b) for simulated All of Us cohorts are compared to historical recruitment. The solid red line depicts simulated cohort representativeness over time with the shaded region indicating the 95% Bayesian credible interval while the dashed red line depicts All of Us's historical representativeness. The solid blue line depicts simulated cohort coverage over time with the shaded region indicating the 95% Bayesian credible interval while the dashed blue line depicts All of Us's historical coverage.
We further confirm these results by studying subgroup-specific proportions in the final mean simulated cohort compared to the actual All of Us cohort. Although All of Us historical recruitment produced a cohort in which 35 of 60 (58%) demographic groups were represented between their Census and uniform levels (i.e., the target zone), our strategic allocation of resources produced a cohort in which 41 of 60 (68%) groups had proportions in the target zone (Fig. 7). Even when strategic recruitment could not push a group into target zone levels of representation, the simulated cohort was typically closer to the target zone than the historical final All of Us cohort. This effect is particularly noticeable within the non-Hispanic/Latino Asian, Native Hawaiian / Pacific Islander, and multiracial subgroups, who are more represented under strategic recruitment.

Demographic groups in the final All of Us historical cohort are represented by black circles while groups in the mean simulated final cohort for strategic recruitment are depicted with green violin plots. The caps of each violin plot indicate the maximum and minimum proportion of a group across the 40 experimental replicates, while the middle line indicates the group’s mean proportion and the shaded region shows the distribution of the group’s proportion across experimental replicates. A subgroup is considered to be within target levels of representativeness and coverage if its proportion is between its Census and uniform levels. F refers to female, M refers to male, (N)H/L refers to (non-)Hispanic/Latino, and NH/PI refers to Native Hawaiian / Pacific Islander.
As an additional measure of representation, we study the proportions of our simulated cohorts that are considered underrepresented in biomedical research, and the subsets which are underrepresented by race and ethnicity. These are measures that All of Us has used for its recruitment goal setting, aiming to have 75% of the cohort UBR and 45% underrepresented by race or ethnicity. We find our simulated cohort to, on average, include 68.20% [95% CI 68.10%–68.31%] UBR populations, of which 46.71% [95% CI 46.65%–46.77%] are racial and/or ethnic minorities. Although the total proportion of UBR populations is slightly lower than the historical All of Us final cohort (at 69.42%), the simulated cohort has a higher proportion of participants identifying with racial/ethnic minorities than All of Us (at 45.15%). Given that our assessment of underrepresentation is limited to age, race, and ethnicity, the total percentage of participants from underrepresented groups in our final simulated cohort would likely be higher.
To study how our model for strategic recruitment improves cohort representativeness and coverage, we analyze how it allocates resources among available recruitment sites. In particular, we study the EHR sites (each src_id) that are prioritized or de-prioritized for recruitment compared to All of Us’s historical baseline. We show a violin plot of each site’s recruitment resource allocation (measured in number of participants recruited) in simulation and compare these allocations to the historical number of participants recruited from each site in All of Us (Fig. 8). Patterns of resource allocation to certain sites vary greatly across experimental replicates. For instance, the resources allocated to site 195 are roughly uniformly distributed from recruitment counts of 1000 to almost 30,000. This likely reflects the adaptive response of our recruitment strategy to stochasticity in recruitment simulation, prioritizing or de-prioritizing sites as needed.

Blue violin plots show the distribution of simulated resources allocated while historical allotments in All of Us recruitment are denoted by red dots. The caps on each blue line indicate the minimum and maximum recruitments at that site across 40 simulations, while the middle cross-line indicates the median recruitment number, and the shaded region indicates the distribution of recruitments at each site.
Overall, most sites have similar recruitment numbers in our simulation as they did historically in All of Us: 29 of 50 sites (58%) have an experimental resource allocation range that encompasses the site’s historical recruitment number (Fig. 8). Yet, the 42% of sites that would receive substantially different amounts of resources highlight where adaptive recruitment can improve representativeness and coverage. Some sites (e.g., 703, 267, 412, and 944) are recruited from substantially more often in simulation than they were historically. By referencing Fig. 3, we can gain insight into this prioritization. Sites 703, 412, and 944 all represent non-Hispanic/Latino Black participants at a greater rate than the Census, which addresses a limitation of the most highly prioritized site (both historically and in simulation), 321. Likewise, site 267 has some of the highest representation of non-Hispanic/Latino participants identifying as Asian or with multiple races, who are not as highly represented at other sites. Other sites (e.g., 699, 305, 250, and 638) are recruited from substantially less often in simulation than historically. While site 699 generates the second highest number of recruitments in All of Us historically, its response distribution has relatively low levels of UBR groups. Sites 305 and 250 generally follow similar demographic trends to the highly-prioritized site 321 but lack some of site 321’s unique benefits like high representation of Native Hawaiian / Pacific Islander participants. Finally, site 638 shows uniquely pronounced differences in representation by age, with older individuals being more highly represented at the site across all race, ethnicity, and gender groups. While this may align with All of Us’s goals to recruit individuals aged 65 and up, older adults are generally well-represented at other sites, so the benefit of the site is somewhat blunted.
Interestingly, some geographic regions have at least one site that is prioritized while another is de-prioritized, compared to the historical All of Us baseline. For instance, site 703 is prioritized while site 305 is de-prioritized, despite both sites covering similar ZIP3s in the Boston, MA area. The distributions at these two sites are broadly similar, with one exception: site 703 has a greater proportion of non-Hispanic/Latino Black participants (relative to the Census) while site 305 has a lower proportion. Relatively limited differences in response distributions have magnified impact on cohort representativeness and coverage, and our recruitment strategy is able to identify and leverage these differences.
Varying simulation parameters
For clarity and brevity, we presented results for one policy space and set of simulation parameters that balanced realism with experimental simplicity. To validate that our results hold under a variety of recruitment conditions, we systematically modified several key simulation components. We tabulate some summary results of these analyses in Supplementary Table 1 and provide further cohort details in the Supplementary Information. Briefly, including participants who do not have a defined EHR site modifies final cohort characteristics but does not invalidate improvements in representation and coverage from adaptive recruitment. Constraining the model to be less flexible in resource allocation or only allowing annual (instead of quarterly) policy updates hampers, but does not eliminate, the model’s adaptive recruitment ability. Modifying the recruitment goal to only prioritize representativeness or coverage achieves the desired effect at the cost of the other objective. Models prioritizing coverage yield final cohorts with the highest proportion of UBR populations of any experiment we ran, as expected. When compared to a uniform resource allocation policy baseline, our methodology yielded significantly more representative and covering final cohorts. Lastly, we considered the stochastic effects of varying demographic imputations in Supplementary Table 2, which had little discernible impact on results.
Discussion
Significant efforts and funding have been employed to ensure biomedical research adequately generalizes to everyone. One facet of these efforts has been improving the representation of understudied (i.e., UBR) populations in biomedical datasets. All of Us exemplifies these efforts, aiming to “build one of the most diverse health databases in history”24. To this end, All of Us has stated recruitment goals as 75% of participants from UBR groups and 45% from racial and ethnic minorities25,26. These proportion goals provide a straightforward assessment of All of Us’s cohort and can evaluate progress over time. However, aggregate proportion goals lack the specificity to determine which groups are under- or overrepresented in detail. Thus, these measures have limited utility for planning recruitment strategies. More detailed statistical distance measures derived from entropy have been used to assess cohort representativeness to a target population and guide recruitment efforts in simulation22,38,47. In this paper, we extended this methodology to a dual objective problem, prioritizing both Census-representativeness and coverage. By doing so, we address a key limitation of Census-representative datasets: a perfectly Census representative cohort may only have a few individuals from particularly small groups. For example, a perfectly Census representative 1000-person cohort would only contain 18 participants aged 85 or over (U.S. Census Table S0101). Such numbers may be insufficient for statistical power or to train a fair machine learning algorithm11. The insufficiency of proportionate representation can further magnify when smaller groups are differentially impacted by disease48. When we recruited a cohort using only representativeness as the objective, the proportion of UBR individuals was substantially lower than any other experiments (Supplementary Table 1). By including coverage as a second objective, we balance out the blind spots of proportional representation.
The main finding of this work is that a different allocation of recruitment resources among All of Us’s recruitment sites may yield a final cohort that is more representative and covering than the program’s current composition. There are several potential reasons why we observe these improvements. A straightforward reason might be that All of Us did not allocate recruitment resources to optimize what we defined as representativeness and coverage. While we believe this reason is partly responsible for our observed improvements in simulation, other factors also play a role. It is possible and likely that All of Us used a different objective function for determining where to prioritize recruitment or open new sites. Because we do not know this objective function, we proposed the goals of representativeness and coverage and mathematically measured these through Kullback-Leibler divergence.
Even if we perfectly operationalized All of Us’s recruitment goals, our observed improvements in simulation may not manifest in reality. Our simulation necessarily simplifies real-world factors that affect recruitment, which could translate to a simulation-reality gap. For instance, 3- or 12-month cycles may be too short for resource re-allocation in practice and not reflect the realities of recruitment site staffing. To prevent massive disparities in resource allocation between sites, we constrain the ratio of maximum and minimum resource allocation to sites. Tightening this constraint has a noticeable impact on cohort representativeness and coverage (Supplementary Table 1). We also consider recruitments to be interchangeable between sites, which may not reflect differences in recruitable populations at different EHR sites. A site in a sparsely populated region may not support as many recruitments as one in a major urban center. Despite these caveats, the recruitment strategies empirically identified by our model often align with each site’s historical resource allocation. Experimentally-derived resource allocations overlap with sites’ historical recruitment counts in more than half of the EHR recruitment sites, including seven of the ten sites most heavily prioritized by our methodology. Nevertheless, sites such as 412, 148, and 640 would need to recruit about an order of magnitude more participants in simulation than reality, which may not be feasible. Even if such recruitment volume were feasible, it may change the response distribution at the site. This effect would be particularly pronounced at recruitment sites employing highly specialized recruitment strategies that may not scale easily. Likely, the improvements we observe over historical All of Us representativeness and coverage can be attributed to a combination of all three of these factors: a more optimized experimental methodology, a slightly different objective function, and a somewhat optimistic simulation of real-world recruitment.
In addition to the differences between our simulations and All of Us noted above, our work has some dataset limitations. Our assessments of representativeness and coverage are limited by data availability and harmonization between All of Us and the U.S. Census (Section “Datasets and harmonization”). This leads to imperfect matches like “sex” in Census data with “gender” in All of Us and the exclusion of individuals identifying as American Indian / Alaska Native (because they are not included in the All of Us dataset used) or Middle Eastern / North African (because they are not reported in Census data). We matched values as closely as possible given the dataset limitations we faced but note that these limitations reduce our ability to assess representation and coverage over these groups and lead to a consistent underestimate of UBR proportions. Likewise, a large number of participants who identify as Hispanic/Latino in both All of Us and the Census list “Other” (or some variation thereof) as their race. The Census Bureau imputes a race for individuals listing “Some Other Race” in the dataset we used, so we applied a similar imputation methodology to best approximate their data; however, we acknowledge that this imputation process will shift our data from the ground truth. Because our Census dataset was limited to age, sex, race, and ethnicity, other measures which define UBR groups could not be compared in this study, as discussed in Section “Current state of All of Us”. Thus, all total UBR proportions in this study are underestimates of the true UBR proportions. We mitigate this limitation by comparing UBR proportions within our experiments, such that the underestimation effect is consistent. A relative change in UBR proportions, then, would still be expected to yield an absolute change when a more comprehensive definition is applied.
Despite the aforementioned limitations, this work has several promising applications and future directions. Using data available to the program right now, All of Us can evaluate which existing sites are worth investing additional recruitment resources in to achieve their desired recruitment goals. The same methodology can also be used to determine where to open new recruitment sites as long as the program has some prior knowledge about the response demographics at the potential new site. Beyond All of Us, other data repositories and collectors may utilize our methodology to guide recruitment efforts for representativeness and coverage. Our methodology may be applied to multi-site studies at any scale. Another promising avenue for research could be to measure participant retention rates and adapt the recruitment strategy accordingly, which may be of particular relevance for longitudinal studies and interventional trials. Further research could analyze the impacts – expected and unforeseen – of these modified recruitment strategies. For example, studies may analyze whether more representative and covering datasets do, in fact, yield more accurate or generalizable artificial intelligence models. Other future studies may analyze the impact of strategic recruitment on data quality or define representation across additional study-relevant variables. A notable strength of our proposed methodology is that study designers may choose which variables they want to prioritize for representation and coverage, provided they have a ground truth or target value available. We opted to use broad demographic variables (age, gender, race, and ethnicity) because of their availability for comparison against Census data, but clinical or geographic variables may also be used.
In conclusion, we showed the utility of computational strategic recruitment to guide site selection and improve representation and coverage of recruited cohorts. We extended previous work in adaptive recruitment resource allocation38 in three notable ways: to dual-objective constrained optimization that balances representation and coverage, to actual participant response distributions using historical data from a nationwide program, and to the larger and more complex recruitment policy space in All of Us. With these contributions, we further bridge the gap between methodological theory and practice and provide an actionable pathway for data-collecting programs to achieve several simultaneous recruitment goals.
Methods
All research activities described in this article were conducted in accordance with the All of Us Data User Code of Conduct and Data and Statistics Dissemination Policy and only authorized authors who completed All of Us Responsible Conduct of Research training accessed data. Per the All of Us Institutional Review Board, research in the Controlled Tier uses a data passport model and does not constitute research involving human subjects (Protocol 2021-02-TN-001), so IRB approval was not required for this study.
Balancing representation and coverage
While representation and coverage are both desirable properties of a cohort, there is no cohort that can be perfectly representative of the U.S. population and perfectly covering. This impossibility stems from the fact that the U.S. population is not uniformly distributed among all demographic groups. For example, assume a cohort demographic distribution (C) is perfectly reflective of the demographic distribution of the U.S. population (P). We show that such a cohort cannot be perfectly reflective of the uniform distribution (U) in Equation (1), which also holds in reverse.
Nevertheless, this tension between the representation and coverage terms gives way to a set of possible solutions that optimize some combination of the two objectives. Because Kullback-Leibler divergence is a convex function, we know that the Pareto frontier of our two KLD terms would admit the form of a superellipse49. Moreover, we know two endpoints of the superellipse must be KLD(U∣∣P) and KLD(P∣∣U), because these values each minimize one term of the dual objective function. Then, following Li et al.49, we empirically determine the superellipse power n by fitting a curve to other points on the Pareto frontier. We use the SciPy minimize function to empirically generate demographics distributions approximating combinations of KLD(C∣∣P) and KLD(C∣∣U) as shown in Equation (2).
We use α = 0, 0.01, . . . , 0.99, 1 to generate the Pareto frontier of optimal solutions and find an approximate value for n through SciPy’s curve_fit function, yielding n = 0.522 (Fig. 9) and Equation (3).

Optimal cohorts (C) balance KLD to the Census population (P) and uniform distribution (U). Each black circle indicates a theoretic cohort with an optimal combination of the two objectives, while the blue best-fit line plots the resultant superellipse. The superellipse power n and mean squared error (MSE) of the best fit line are also reported.
We summarize the left-hand side of the equation as “distance to optimal” (DistOpt), a measure of how close a cohort is to the set of optimal solutions. It would be mathematically impossible to create a cohort with DistOpt < 1 and recruiting a cohort with an optimal DistOpt of 1 may be extremely challenging in practice. However, we may still use DistOpt as a general measure of cohort optimality that naturally balances representation and coverage. Other weightings of the two objective terms may be used by recruitment coordinators to yield cohorts that prioritize representativeness over coverage, or vice versa.
Datasets and harmonization
U.S. Census Bureau data were obtained from July 2022 population estimates in Table “CC-EST-2022-ALL”50. This dataset details the United States population by the joint distribution of federal information processing standard (FIPS) code location, age (in 5-year bins), sex, race, and Hispanic origin (i.e., ethnicity) for the fifty states. We used this table because it was closest in time to All of Us data and provided the most granular level of population attribute detail we could find. Data from All of Us were obtained from the most recent snapshot available at the time of writing, Controlled Tier dataset C2022-Q4-R9. This dataset includes 413,448 unique participants with intake survey dates. We harmonized these datasets as closely as possible, but the attributes measured or options that could be selected in these datasets often differed (Table 3). Because sex is self-identified in Census data (document D-OP-GP-EN-450), we harmonized it with All of Us gender.
Of the All of Us participants, we excluded almost 90,000 because of demographics that could not be harmonized, most often missing or unknown values (Fig. 10). Upon examination of the filtered participant counts, we discovered that nearly 85% of participants who identified with Hispanic or Latino ethnicity selected a non-harmonizable race value (i.e., not Asian, Black, Native Hawaiian / Pacific Islander, Two or more races, or White). The separation of race and ethnicity questions on surveys is a known source of confusion, and the majority of Census respondents who select “Some Other Race” are of Hispanic / Latino ethnicity51. In the Census dataset we used, respondents who listed “Some Other Race” were assigned an imputed race value by the Census Bureau to align with the race categories shown in Table 352. To align our All of Us data with Census counts, we applied a similar imputation strategy: participants who self-identified with Hispanic/Latino ethnicity and did not have a defined race value were assigned a random race value following the age- and gender-specific distribution of Hispanic/Latino participants who did indicate a defined race value. This imputation returned almost 64,000 participants back into the dataset (Fig. 10). Supplementary Section 1 assesses the impacts of imputation. Our final dataset restriction steps ensures that recruitment sites could be determined: a participant had to either have an available EHR site (269,862 total) for EHR site based analyses or a ZIP3 within the 50 states (387,583 total) for geographic analyses.

Starting amounts and processing of missing information are shown in green boxes, the blue box indicates participants with available electronic health record (EHR) site code, and the yellow box indicates participants with available 3-digit ZIP code (ZIP3). Red arrows indicate exclusions and purple arrows indicate re-inclusion through imputation.
Simulation methodology
To evaluate our recruitment resource allocation methodology, we created a realistic yet focused simulation to mirror recruitment over time in All of Us. Our goal is to show how the All of Us cohort could have looked if our recruitment methodology had been applied, either from the cohort’s inception or from some intermediate stage of recruitment. To determine recruitment resource policies, we adapt our previously described methodology to All of Us38. Briefly, recruitment is formalized as an iterative process where resources may be allocated among sites to recruit a cohort that has some desirable characteristics like representativeness and coverage (Fig. 11). Following our prior work, iterations are defined using the maximum possible frequency of updating resource allocation. We default to quarterly resource allocation updates, equating to 21 recruitment iterations of 3 months over the span of All of Us recruitment from 2017 to 2022. Quarterly reporting is one of the shortest intervals used by the U.S. National Institutes of Health (NIH) in its Other Transactions53, so we use it as the maximum frequency of updating resource allocation. In Supplementary Section 1, we also assess our recruitment methodology using 6 annual resource allocation updates instead of 21 quarterly updates, which represents the much more common annual reporting frequency used by the NIH. Due to stochasticity, simulations are repeated 40 times for each analysis. Because some of our simulation results do not follow a normal distribution, we report 95% Bayesian credible intervals from the bayes_mvs function in SciPy54,55. For the same reason, we use non-parametric Wilcoxon signed-rank tests to compare simulation results to the All of Us historic baseline.

First, prior knowledge about response distributions at each recruitment site is initialized (a). Then, after defining a target population and uniform distribution (b), the optimizer (c) determines the optimal recruitment resource allocation policy (d) among available sites. Recruitment is then simulated (e), yielding participants for the cohort (f) and updated knowledge about site distributions (a). This process is iterated until some goal is reached, such as participant count or number of steps.
Defining recruitment sites and prior knowledge
First, we determine the set of potential recruitment sites. In our experiments, we use two formulations for recruitment sites: 1) Three-digit codes for EHR sites (src_id variable), which correspond to hospital systems or 2) Three-digit ZIP codes (ZIP3), which are sometimes aggregated with nearby ZIP3s to ensure sufficient participant counts to obtain a reliable demographics distribution. There are 50 unique three-digit EHR site codes in the All of Us dataset compared to 386 aggregated ZIP3 sites, which were generated from 863 total ZIP3s (details in Supplementary Section 3). We restricted the All of Us cohort to the subset which could be recruited under a particular policy: for EHR site-based policies, this is the 269,862 participants with a defined 3-digit EHR site; for ZIP3-based policies, this is the 387,583 participants with a defined ZIP3 code in the 50 United States. To ensure our simulated cohorts are comparable to the All of Us cohort, our simulation recruits the same number of participants at each timestep that All of Us recruited, after the previous filtering step.
Next, we derive initial estimates for each site’s response distribution, the demographics of respondents who are willing to participate in the program. Knowledge about each site’s response distribution is represented through a Dirichlet distribution, which is the conjugate prior for the categorical demographics distribution. This encoding of prior knowledge allows us to ‘draw’ an estimated response distribution for each site as we update our knowledge of the sites. For EHR site-based policies, we use a non-informative Jeffreys prior with αi = 0.5 ∀ i56. This choice represents a worst-case scenario where no prior knowledge of demographics at recruitment sites is available, and such information must be obtained through the recruitment process. For ZIP3-based policies, we default to the natural prior of the U.S. Census population distribution within the region.
Adaptive recruitment resource allocation
Once prior knowledge of all sites’ response distributions has been generated, estimated categorical demographics distributions are drawn from each site’s Dirichlet. Based on these estimates, our algorithm determines the optimal allocation of resources among sites to minimize the objective function f, a process highlighted in Equation (4).
where ρ is a vector of fractional resource allocations at each site, f is an objective function, C is the currently recruited cohort, and \(\hat{D}\) are the estimated site response distributions.
The choice of objective function f operationalizes recruitment goals mathematically. For instance, \(f={\rm{KLD}}\left(\right.C\,| | \,P\left)\right.\) will allocate recruitment resources to minimize distance from the Census population, thereby optimizing representativeness. A combined objective like \(f={\rm{KLD}}\left(\right.C\,| | \,P\left)\right.+{\rm{KLD}}\left(\right.C\,| | \,U\left)\right.\) or f = DistOpt from Equation (3) will optimize for a combination of both representation and coverage. To precisely control our desired combination of representativeness and coverage, we define target values for representativeness and coverage, respectively labeled KLD(C∣∣P)T and KLD(C∣∣U)T. Then, we may optimize the recruitment policy to a cohort with the target values of representativeness and coverage by using the L2 objective function defined in Equation (5). We identify target values of representativeness and coverage by selecting a tuple on the optimal superellipse: values of KLD(C∣∣P) and KLD(C∣∣U) that satisfy Equation (3).
Guided by this objective function, our algorithm identifies an optimal resource allocation among the available sites. To improve realism, we impose a constraint on the resource allocation, which limits the maximum ratio between the amount of resources allocated to the sites with the highest and lowest allocations. In our default parameter settings, we empirically set this minmax constraint to e5 ≈ 148.41, a lower ratio than is seen in reality. Such a constraint better reflects real-world recruitment at multi-site projects that typically cannot concentrate all recruitments at one site. As an added benefit, this constraint forces the algorithm to explore all sites at each recruitment step and prevents it, for instance, from missing an optimal site that joined All of Us later. Because the number of iterations in our simulations is often fewer than the number of sites, this method allows for efficient exploration.
Simulated recruitment and knowledge updating
After a resource allocation is determined, we simulate participant recruitment for the iteration in a manner similar to our previous work38, with notable modifications to leverage the depth of historical recruitment knowledge available from All of Us. Most significantly, we have access to the true response distributions of recruitment sites over time because only individuals who agreed to join the program are included in our dataset. Thus, the response distribution at each site is calculated from its cumulative participant demographic distribution at the simulated timepoint in recruitment. For example, the response distribution at a site for simulated recruitment in July 2019 will be the demographics of All of Us participants at that site from program inception through July 2019.
First, the optimized resource allocation to each site is rounded using a floor function and the remaining sum of all fractional recruitments is assigned to the site with the highest recruitment density. Then, recruitment proceeds as a series of ‘draws’ from each site’s categorical response distribution, where the number of draws is equal to the site’s resource allocation. Each site’s recruitments constitute a new categorical likelihood distribution, which we use to update the site’s Dirichlet prior knowledge distribution, yielding a Dirichlet posterior. For ZIP3-based sites using a Census prior, this prior is overwritten and the Dirichlet demographic distribution is set to the actual recruitments from the site. Groups which were not recruited within the first iteration (i.e., count of 0) have their α values set to a small positive number of 1 × 10−10. This process is repeated for every recruitment iteration, with response distribution knowledge improving at each step.
Data availability
All of Us Research Program data (dataset C2022-Q4-R9) are available through a data use agreement in the Researcher Workbench. All of Us Registered Tier and Controlled Tier data are available to researchers affiliated with a participating institution, pursuant to the program's policies. EHR site based results can be reproduced with Registered Tier data, while ZIP3 based results require Controlled Tier access. All of Us notes that participant counts may differ between data tiers due to different curation processes. Under the program's Data User Code of Conduct, these data cannot be published or redistributed.
Code availability
The underlying code for data collection and analysis is available on GitHub and can be accessed at https://github.com/vaborza/aourp_paper. The GitHub page also includes instructions for replication analyses, provided that the user can set up an appropriate validation workspace in All of Us.
References
Bozkurt, S. et al. Reporting of demographic data and representativeness in machine learning models using electronic health records. J. Am. Med. Inform. Assoc. 27, 1878–1884 (2020).
Melloni, C. et al. Representation of women in randomized clinical trials of cardiovascular disease prevention. Circulation: Cardiovasc. Qual. Outcomes 3, 135–142 (2010).
Kwiatkowski, K., Coe, K., Bailar, J. C. & Swanson, G. M. Inclusion of minorities and women in cancer clinical trials, a decade later: Have we improved? Cancer 119, 2956–2963 (2013).
Weng, C. Optimizing Clinical Research Participant Selection with Informatics. Trends Pharmacol. Sci. 36, 706–709 (2015).
Pathiyil, M. M. et al. Representation and reporting of diverse groups in randomised controlled trials of pharmacological agents in inflammatory bowel disease: a systematic review. Lancet Gastroenterol. Hepatol. 8, 1143–1151 (2023).
Li, F. et al. Evaluating and Mitigating Bias in Machine Learning Models for Cardiovascular Disease Prediction. J. Biomed. Informat. 104294 https://www.sciencedirect.com/science/article/pii/S1532046423000151 (2023).
Ng, M. Y., Olgin, J. E., Marcus, G. M., Lyles, C. R. & Pletcher, M. J. Email-Based Recruitment Into the Health eHeart Study: Cohort Analysis of Invited Eligible Patients. J. Med. Internet Res. 25, e51238 (2023).
Abel, K. M. et al. Representativeness in health research studies: an audit of Greater Manchester Clinical Research Network studies between 2016 and 2021. BMC Med. 21, 1–11 (2023).
Tsiouris, A. et al. Recruitment of Patients With Cancer for a Clinical Trial Evaluating a Web-Based Psycho-Oncological Intervention: Secondary Analysis of a Diversified Recruitment Strategy in a Randomized Controlled Trial. JMIR Cancer 9, e42123 (2023).
National Academies of Sciences, Engineering, and Medicine, Policy and Global Affairs, Committee on Women in Science & Committee on Improving the Representation of Women and Underrepresented Minorities in Clinical Trials and Research. Why Diverse Representation in Clinical Research Matters and the Current State of Representation within the Clinical Research Ecosystem. In Bibbins-Domingo, K. & Helman, A. (eds.) Improving Representation in Clinical Trials and Research: Building Research Equity for Women and Underrepresented Groups https://www.ncbi.nlm.nih.gov/books/NBK584396/ (National Academies Press (US), 2022).
Chen, I., Johansson, F. D. & Sontag, D. Why Is My Classifier Discriminatory? In Advances in Neural Information Processing Systems, vol. 31 https://proceedings.neurips.cc/paper/2018/hash/1f1baa5b8edac74eb4eaa329f14a0361-Abstract.html (Curran Associates, Inc., 2018).
Bentley, A. R., Callier, S. L. & Rotimi, C. N. Evaluating the promise of inclusion of African ancestry populations in genomics. npj Genom. Med. 5, 5 (2020).
Schoeler, T. et al. Participation bias in the UK Biobank distorts genetic associations and downstream analyses. Nat. Hum. Behav. 1–12 https://www.nature.com/articles/s41562-023-01579-9 (2023).
Arnesen, S. & Peters, Y. The legitimacy of representation: how descriptive, formal, and responsiveness representation affect the acceptability of political decisions. Comp. Political Stud. 51, 868–899 (2018).
Shahbazi, N., Lin, Y., Asudeh, A. & Jagadish, H. V. Representation bias in data: a survey on identification and resolution techniques. ACM Computing Surveys 3588433 https://doi.org/10.1145/3588433 (2023).
He, Z. et al. Multivariate analysis of the population representativeness of related clinical studies. J. Biomed. Inform. 60, 66 (2016).
Qi, M. et al. Quantifying representativeness in randomized clinical trials using machine learning fairness metrics. JAMIA Open 4, https://doi.org/10.1093/jamiaopen/ooab077 (2021).
Sen, A. et al. GIST 2.0: A scalable multi-trait metric for quantifying population representativeness of individual clinical studies. J. Biomed. Inform. 63, 325–336 (2016).
Asudeh, A., Jin, Z. & Jagadish, H. V. Assessing and remedying coverage for a given dataset. In 2019 IEEE 35th International Conference on Data Engineering (ICDE), vol. 35, 554–565 https://ieeexplore.ieee.org/document/8731614/ (IEEE, Macao, Macao, 2019).
Jin, Z., Xu, M., Sun, C., Asudeh, A. & Jagadish, H. V. MithraCoverage: A System for Investigating Population Bias for Intersectional Fairness. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, 2721–2724 https://doi.org/10.1145/3318464.3384689 (ACM, Portland OR USA, 2020).
Celis, L. E., Keswani, V. & Vishnoi, N. Data preprocessing to mitigate bias: A maximum entropy based approach. In Proceedings of the 37th International Conference on Machine Learning, 1349–1359 https://proceedings.mlr.press/v119/celis20a.html (PMLR, 2020).
Theodorou, B., Glass, L., Xiao, C. & Sun, J. FRAMM: Fair ranking with missing modalities for clinical trial site selection. Patterns 5, https://www.cell.com/patterns/abstract/S2666-3899(24)00043-6 (2024).
Javid, S. H. et al. A prospective analysis of the influence of older age on physician and patient decision-making when considering enrollment in breast cancer clinical trials (SWOG S0316). Oncologist 17, 1180–1190 (2012).
All of Us Research Program. Core Values https://allofus.nih.gov/about/core-values (2020).
Denny, J. C. et al. The “All of Us” Research Program. N. Engl. J. Med. 381, 668–676 (2019).
Mapes, B. M. et al. Diversity and inclusion for the All of Us research program: A scoping review. PLOS ONE 15, e0234962 (2020).
Clark, L. T. et al. Increasing Diversity in Clinical Trials: Overcoming Critical Barriers. Curr. Probl. Cardiol. 44, 148–172 (2019).
Heller, C. et al. Strategies Addressing Barriers to Clinical Trial Enrollment of Underrepresented Populations: a Systematic Review. Contemp. Clin. trials 39, 169–182 (2014).
Larkey, L. K., Gonzalez, J. A., Mar, L. E. & Glantz, N. Latina recruitment for cancer prevention education via Community Based Participatory Research strategies. Contemp. Clin. Trials 30, 47–54 (2009).
Gluck, M. A., Shaw, A. & Hill, D. Recruiting Older African Americans to Brain Health and Aging Research Through Community Engagement. Gener. (San. Francisco, Calif.) 42, 78–82 (2018).
McCarron, T. L. et al. Patients as partners in health research: A scoping review. Health Expectations: Int. J. Public Participation Health Care Health Policy 24, 1378–1390 (2021).
Shaukat, A. et al. S557 Enhancing Diversity and Inclusion in the PREEMPT CRC Study Through Strategic Site Selection and Innovative Recruitment Tools. J. Am. Coll. Gastroenterol. ∣ ACG 119, S386 (2024).
Ruder, K. US Government Turns to Retail Pharmacies to Improve Representation in Clinical Trials. JAMA 333, 7–8 (2025).
Klein, D. et al. Building a Digital Health Research Platform to Enable Recruitment, Enrollment, Data Collection, and Follow-Up for a Highly Diverse Longitudinal US Cohort of 1 Million People in the All of Us Research Program: Design and Implementation Study. J. Med. Internet Res. 27, e60189 (2025).
Nargesian, F., Asudeh, A. & Jagadish, H. V. Tailoring data source distributions for fairness-aware data integration. Proc. VLDB Endow. 14, 2519–2532 (2021).
Flanigan, B., Gölz, P., Gupta, A., Hennig, B. & Procaccia, A. D. Fair algorithms for selecting citizens’ assemblies. Nature 596, 548–552 (2021).
Borza, V. A., Clayton, E. W., Kantarcioglu, M., Vorobeychik, Y. & Malin, B. A. A representativeness-informed model for research record selection from electronic medical record systems. AMIA Annu. Symp. Proc. 2022, 259–268 (2023).
Borza, V. A. et al. Adaptive Recruitment Resource Allocation to Improve Cohort Representativeness in Participatory Biomedical Datasets. AMIA Annu. Symp. Proc. 2024, 192–201 (2025).
Forrest, C. B. et al. PCORnet®2020: current state, accomplishments, and future directions. J. Clin. Epidemiol. 129, 60–67 (2021).
Bridge2AI Voice. The Consortium (Who We Are) - B2AI-Voice.org. https://www.b2ai-voice.org/consortium-who-are.php.
AI-READI. Artificial Intelligence Ready and Equitable Atlas for Diabetes Insights https://aireadi.org/ (2024).
Denny, J. C. & Collins, F. S. Precision medicine in 2030-seven ways to transform healthcare. Cell 184, 1415–1419 (2021).
Sankar, P. L. & Parker, L. S. The Precision Medicine Initiative’s All of Us Research Program: an agenda for research on its ethical, legal, and social issues. Genet. Med. 19, 743–750 (2017).
Beaton, M. et al. Using patient portals for large-scale recruitment of individuals underrepresented in biomedical research: an evaluation of engagement patterns throughout the patient portal recruitment process at a single site within the All of Us Research Program. J. Am. Med. Informat. Assoc. ocae135 https://doi.org/10.1093/jamia/ocae135 (2024).
All of Us Research Program. Data Dictionaries https://support.researchallofus.org/hc/en-us/articles/360033200232-Data-Dictionaries (2024).
Kwiatkowski, D., Phillips, P. C. B., Schmidt, P. & Shin, Y. Testing the null hypothesis of stationarity against the alternative of a unit root: How sure are we that economic time series have a unit root? J. Econ. 54, 159–178 (1992).
Whitney, H. M. et al. Longitudinal assessment of demographic representativeness in the Medical Imaging and Data Resource Center open data commons. J. Med. Imag. 10, https://www.spiedigitallibrary.org/journals/journal-of-medical-imaging/volume-10/issue-06/061105/Longitudinal-assessment-of-demographic-representativeness-in-the-Medical-Imaging-and/10.1117/1.JMI.10.6.061105.full (2023).
Gilmore-Bykovskyi, A., Jackson, J. D. & Wilkins, C. H. The Urgency of Justice in Research: Beyond COVID-19. Trends Mol. Med. 27, 97–100 (2021).
Li, Y., Fadel, G. M., Wiecek, M. & Blouin, V. Y. Minimum Effort Approximation of the Pareto Space of Convex Bi-Criteria Problems. Optim. Eng. 4, 231–261 (2003).
U.S. Census Bureau. Index of /programs-surveys/popest/datasets/2020-2022/counties/asrh https://www2.census.gov/programs-surveys/popest/datasets/2020-2022/counties/asrh/ (2023).
Strmic-Pawl, H. V., Jackson, B. A. & Garner, S. Race Counts: Racial and Ethnic Data on the U.S. Census and the Implications for Tracking Inequality. Sociol. Race Ethnicity 4, 1–13 (2018).
U.S. Census Bureau. Methodology for the United States population estimates: vintage 2022 https://www2.census.gov/programs-surveys/popest/technical-documentation/methodology/2020-2022/methods-statement-v2022.pdf (2022).
NIH Office of Acquisition Management and Policy. Standard Operating Procedures for Other Transactions. https://oamp.od.nih.gov/sites/default/files/OT%20SOP%20Final.pdf.
Oliphant, T. A Bayesian perspective on estimating mean, variance, and standard-deviation from data. Faculty Publi. 18 https://scholarsarchive.byu.edu/facpub/278 (2006).
Hespanhol, L., Vallio, C. S., Costa, L. M. & Saragiotto, B. T. Understanding and interpreting confidence and credible intervals around effect estimates. Braz. J. Phys. Ther. 23, 290–301 (2019).
Kelly, D. & Atwood, C. Finding a minimally informative Dirichlet prior distribution using least squares. Reliab. Eng. Syst. Saf. 96, 398–402 (2011).
United States Postal Service. L002 3-Digit ZIP Code Prefix Matrix https://fast.usps.com/fast/fastApp/resources/labelListFileDownloadFile.action?fileName=DMM_L002.pdf&effectiveDate=12/01/2024 (2024).
Acknowledgements
We acknowledge the feedback and contributions of the All of Us Data and Research Center to this work. We also acknowledge All of Us participants for their contributions, without whom this research would not have been possible. Additionally, we thank the National Institutes of Health’s All of Us Research Program for making available the participant cohort examined in this study. V.B. is supported by NIH/NHLBI grant F30HL168976. E.C. and B.M. are supported by NIH/NHGRI grant U54HG012510. B.M. is also supported by NIH/OD grant OT2OD035404. The funders played no role in study design, data collection, analysis and interpretation of data, or the writing of this manuscript.
Author information
Authors and Affiliations
Contributions
V.B. and B.M. conceptualized the ideas for this paper. V.B. collected the data and performed the analysis described with advising from Q.C., M.K., L.S., Y.V., E.C., and B.M. V.B., Q.C., M.K., L.S., Y.V., E.C., and BM. contributed to the evaluation and discussion of the results. V.B., Q.C., M.K., L.S., Y.V., E.C., and B.M. contributed to the writing and editing of this manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Borza, V.A., Chen, Q., Clayton, E.W. et al. Computational strategic recruitment for representation and coverage studied in the All of Us Research Program. npj Digit. Med. 8, 402 (2025). https://doi.org/10.1038/s41746-025-01804-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41746-025-01804-x
