
Abstract
Patients with diabetes are at increased risk of comorbid depression or anxiety, complicating their management. This study evaluated the performance of large language models (LLMs) in detecting these symptoms from secure patient messages. We applied multiple approaches, including engineered prompts, systemic persona, temperature adjustments, and zero-shot and few-shot learning, to identify the best-performing model and enhance performance. Three out of five LLMs demonstrated excellent performance (over 90% of F-1 and accuracy), with Llama 3.1 405B achieving 93% in both F-1 and accuracy using a zero-shot approach. While LLMs showed promise in binary classification and handling complex metrics like Patient Health Questionnaire-4, inconsistencies in challenging cases warrant further real-life assessment. The findings highlight the potential of LLMs to assist in timely screening and referrals, providing valuable empirical knowledge for real-world triage systems that could improve mental health care for patients with chronic diseases.
Similar content being viewed by others
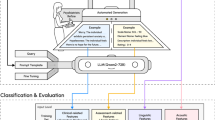
Main
Patients with diabetes are more than twice as likely to suffer from comorbid depression or anxiety1,2, increasing their risk of hospitalization, functional disability, complications, and mortality3. The bi-directional relationship between diabetes and comorbid depression can exacerbate both conditions4. Detecting symptoms of comorbid depression or anxiety is challenging due to patient unawareness or reluctance to report symptoms, clinicians’ limited time and expertise, and overlapping symptoms. Additionally, a shortage of trained psychiatrists and collaborative care teams further complicates timely diagnosis5,6. Addressing these issues is crucial to prevent disease progression and manage both physiological and psychiatric aspects effectively.
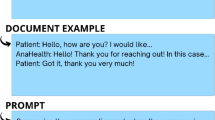
Patient-centered care, which includes addressing concerns, providing guidance, and involving patients in decision-making, is crucial for patients with depression or anxiety7. A patient-centered digital health platform enhances engagement, self-management, and treatment adherence8. Secure messaging via patient portals allows patients to communicate directly with clinicians, aiding medical management9. Patients with diabetes are among the most engaged user groups with the patient portal8. Therefore, secure patient messages are an important resource for improving patient-centered care beyond traditional clinical notes10.
Large language models (LLMs) have shown clinician-comparable levels of medical knowledge and competitive diagnostic performance in various medical specialties11,12. In psychiatry, LLMs outperformed mental health professionals in detecting obsessive-compulsive disorder13. Similarly, LLMs were promising in predicting the clinical prognosis of schizophrenia, assisting in triage recommendations for mental health referrals, and detecting the risk of depression through user-generated text data14,15,16. Though machine learning models have shown good performance, translating patients’ self-reported history into specific psychiatric symptoms and ultimately diagnoses has been challenging17,18. Currently, there is a critical knowledge gap in the performance of LLMs in detecting depressive or anxious symptoms, specifically in the context of secure patient messages, despite the importance and the potential promise of LLMs.
Thus, we aim to comprehensively evaluate the performance of LLMs in detecting symptoms of comorbid depression or anxiety from secure patient messages. To identify the best-performing model in this context and to specify the effective strategies to enhance the models’ performance, we applied multiple approaches, including engineered prompts for multi-level tasks, systemic persona, temperature adjustments, and zero-shot and few-shot learning. These findings could serve as empirical evidence of LLMs’ use for detecting symptoms of comorbid depression or anxiety from secure patient messages, highlighting the key factors to consider for optimal performance.
Results
Performance of LLMs: zero-shot vs. few-shot
The performance of LLMs in detecting depressive or anxious symptoms from patient messages differed by model and approaches (Fig. 1). In zero-shot settings, Llama 3.1 405B showed the highest performance in F-1 (0.93 [95% CI 0.91–0.95]), recall (0.95 [0.93–0.97]), and accuracy (0.93 [0.91–0.95]), and Llama 3.1 8B and DeepSeek R1 also showed excellent F-1 (0.91 [0.88–0.93] and 0.90 [0.88–0.93]) and accuracy (0.90 [0.88–0.93] and 0.91 [0.89–0.93]), respectively (Fig. 1. a). Two reasoning models showed nearly perfect precision (OpenAI o1: 1.00 [0.99–1.00]; DeepSeek R1: 0.99 [0.97–1.00]) yet presented much different recalls (OpenAI o1: 0.68 [0.62–0.73]; DeepSeek R1: 0.84 [0.79–0.88]).

a Messages from those with diabetes and co-morbid depression or anxiety; b Symptomatic keywords grouped with depression or anxiety were extracted; c a health researcher reviewed, and a psychiatrist confirmed applying predefined criteria. Only the concordant messages between two reviewers were included as the benchmark.
Across three knowledge models (Llama 3.1 8B and 405B, and Gemini Pro 1.5), few-shot learning increased precision while decreasing recall (Fig. 1b, c). Few-shot learning increased the performance of Gemini Pro 1.5 compared to zero-shot, including F-1 (0.87→0.89, n = 12), yet it did not effectively enhance other models’ accuracy and F-1 score. All results of zero-shot vs. few-shot are available in Supplementary Data 2.
Performance of LLM: PHQ-4 vs. binary classification
While the performance of binary classification was superior in all tested LLMs, three knowledge models showed overall competitive F-1 scores and accuracy (over 0.8) when using PHQ-4 compared to using binary classification in zero-shot settings in detecting depressive or anxious symptoms from patient messages: F-1 (0.82 [0.78–0.85] Llama 3.1 8B; 0.87 [0.84–0.89] Llama 3.1 405B; 0.83 [0.80–0.86] Gemini Pro 1.5) (Fig. 2). However, two reasoning models’ F-1 scores and accuracy were significantly poorer when PHQ-4 was used compared to binary-based symptom detection [PHQ-4 vs. binary]: OpenAI o1, F-1 [0.61 vs. 0.81], P < 0.0001; DeepSeek R1, F-1 [0.51 vs. 0.90], P < 0.0001.

 All results (F-1, precision, recall, and accuracy for N = 606) of zero-shot vs few-shot by model are available in Supplementary Data 2.
All results (F-1, precision, recall, and accuracy for N = 606) of zero-shot vs few-shot by model are available in Supplementary Data 2.
Effect of systemic persona
Effect of persona on few-shot learning
In zero-shot, F-1 and accuracy decreased with systemic persona compared to baseline in Llama 3.1 8B (F-1: 0.91→ 0.88), Llama 3.1 405B (F-1: 0.93→0.87), and DeepSeek R1 (F-1: 0.90→0.87), yet those increased with persona in Gemini Pro 1.5 (F-1: 0.87→0.90, accuracy: 0.88→ 0.90) (Fig. 3). However, in few-shot settings, the systemic persona mostly enhanced F-1 and accuracy consistently across models up to 0.09 (e.g. F-1: 0.73→0.82, Gemini Pro 1.5). All results of the effect of systemic persona are available in Supplementary Data 3.

* Statistically different by z-test (P < 0.05); Binary: Yes [1] vs. No [0];PHQ-4: i) assess each message for four categories (little interest, hopelessness, nervousness, worrying), ii) rate the message for four levels using a 4-point Likert scale (0=not at all; 3=most likely) in each category, iii) calculate the sum of all the ratings, iv) categorize it into No [0] if sum < 6, or Yes [1] if sum ≥ 6.
Effect of persona on mental health measurement metric
Applying systemic persona increased precision of LLMs; however, it decreased F-1, recall, and accuracy in PHQ-4 based classification, widening the gap with binary classification.
Performance of LLMs in challenging cases
In challenging cases, DeepSeek R1 showed a competitive F-1 score (0.84 [0.67–0.97]) and accuracy (0.87 [0.74–0.97]) (Fig. 4). The remaining five models—including two knowledge models (Llama 3.1 8B and 405B) that showed the highest F-1 and accuracy in our initial assessments and the three latest reasoning models (OpenAI o3-mini, OpenAI o1 and Gemini Pro 2.0 Thinking) —performed much worse (F-1 scores of 0.52–0.70). Unlike the results of our initial assessments, LLMs showed high recall (over 0.9 in four LLMs) but low precision (0.43–0.58 in four LLMs) in challenging cases. Two psychiatrists agreed that the LLM reasoning was logical, and the explanations were thorough.

 With systemic persona N = 606; All results (F-1, precision, recall, and accuracy) of the effect of systemic persona by model are available in Supplementary Data 3.
With systemic persona N = 606; All results (F-1, precision, recall, and accuracy) of the effect of systemic persona by model are available in Supplementary Data 3.
Discussion
We comprehensively assessed LLMs’ performance in detecting symptoms of depression or anxiety from secure patient messages of those with diabetes. We found that three out of five LLMs showed excellent performance with over 90% in both F-1 and accuracy. Llama 3.1 405B was the highest performing model (both F-1 and accuracy of 93%) with a zero-shot approach. Moreover, the two reasoning models (OpenAI o1 and DeepSeek R1) presented nearly perfect precision, highlighting their potential usefulness even in the resource-constrained health system. The LLMs not only showed a promising capacity to detect anxiety and depression symptoms in a binary classification but could also handle a complex screening metric (PHQ-4). Finally, for the challenging cases, only one reasoning model (DeepSeek R1) presented a competitive F-1 score (84%) and accuracy (87%). The findings from our comprehensive LLM evaluations of clinical messages from patients highlight the significant potential of LLMs in detecting symptoms of comorbid depression and anxiety, which could be considered as assistance for timely screening and referrals.
The excellent F-1 score and accuracy with a zero-shot approach highlight the efficiency of the application of LLM in detecting symptoms of comorbid depression or anxiety without fine-tuning or further tailored approaches. Previously, LLMs with zero-shot classification showed limited capacity in mental health prediction tasks, suggesting recent improvements of these models19. Given that those tailoring efforts could increase the cost of LLM use in healthcare and frequently require significant expertise that is not always widely available, the superlative performance of the zero-shot approach was particularly encouraging20. Moreover, while previous studies using AI/LLMs heavily focused on vignette-based diagnostic performance, our findings are applicable to real-world screening scenarios21,22. The LLMs’ ability to assist in screening depression or anxiety through text-based communications could open novel opportunities for timely detection of symptoms of comorbid depression or anxiety among those with various chronic diseases.
However, despite the LLMs’ excellent performance, immediate clinical applications require caution due to the observed inconsistencies in challenging cases. As challenging cases were defined as messages that contained words that expressed negative emotions but were not determined as depressive or anxious by two highly experienced psychiatrists, these cases may be prevalent in actual clinical settings. Hence, further assessment is warranted to see how LLMs perform in real-life settings. In the current study, LLMs’ reasoning in challenging cases was comprehensive, which aligned with previous findings23, offering cautious optimism about the potential for LLMs to augment clinicians’ workflow. Piloting text-based mental health screening in clinical settings is a suggested next step to evaluate the practical impact of this approach, including symptom detection rate, operational cost, care efficiency, clinicians’ acceptance, and patients’ perspectives. Additionally, the process for handling high-risk messages, such as those indicating suicidal thoughts, should be thoroughly discussed to ensure they can be integrated effectively into the current workflow and receive urgent attention. Exploring potential applications for longitudinal assessment of seasonal variation of symptoms would also be beneficial for tailored mental health care in the future. These rigorous evaluations will help guide the use of LLMs as an automated screening agent to assist clinicians at the front line for enhanced mental health care.
We observed robust zero-shot accuracy (85% and higher in three LLMs) using multi-class and multi-level symptom detection for depression or anxiety (PHQ-4), unlike previously reported poor performance (39.6–65.6%) in four-level classification using social media data19. Our findings of LLMs’ capacity to process the complex mental health measurement tool at a promising level highlight the enhanced explainability of LLMs’ performance in text-based symptom detection for comorbid depression or anxiety. By successfully classifying each message into four different domains (e.g. worrying, little interest, hopeless, and nervous) and rating the severity level for each domain as directed, LLMs demonstrated that they had the ability of comprehensive assessment, and the multi-step process was interpretable. Notably, all knowledge models (F-1 and accuracy) outperformed reasoning models with the PHQ-4-based assessment, suggesting that the knowledge models are more suitable for this type of symptom detection task. In this study, the performance of binary classification was better than PHQ-4-based assessments. The use of binary classification in preparing the reference data may have influenced the outcomes, warranting further investigation in the future.
Proper diagnosis is especially challenging because comorbid depression or anxiety shares similar symptomatic issues with some chronic conditions, including diabetes (e.g. loss of energy, trouble sleeping). Unnecessary false positive alerts may discourage the adoption of LLM use among clinicians due to anticipated burden24. Hence, models with high precision could be optimal. While two reasoning models showed perfect precision in zero-shot (99–100%), all three knowledge models (including Llama 3.1 8B) also easily achieved 99% precision with 2–4 few-shot learning. While not applicable in this case, high precision is sometimes the result of model overfitting and will be important to keep in mind in the future if fine-tuning or task-specific training strategies are applied. As cost is an important factor for LLMs in healthcare, the ability to achieve comparable precision when necessary using small, open-source local models is critical for widespread adoption. Cost and inference speed information of the models assessed is available in Supplementary Table 1.
This study has limitations. First, the message samples were from a single academic medical center, which could limit the generalizability of findings. However, the message data included messages from 22 affiliated centers in California, and patient demographics reflect the general population (Supplementary Table 2). Moreover, the benchmark patient messages are more than 600, which may have included a diverse range of conversational topics, such as messages sent by the caretakers. Despite the limitations, the findings from this comprehensive evaluation of various LLMs contribute valuable insights to the field. By utilizing secure patient messages, we demonstrated the performance of LLMs in real-world applications relying on our patients’ own words. Moreover, we evaluated multiple new state-of-the-art reasoning models, which have not yet been assessed in the healthcare domain.
Given that only 5% of LLMs have been tested with patient data25, our findings on LLM performance in detecting symptoms of comorbid depression or anxiety through secure messages from individuals with diabetes offer significant empirical knowledge. The novel knowledge could serve as a foundation for implementing real-world triage and screening systems, which could initiate timely treatment and care, eventually enhancing the health outcomes in millions of patients.
Methods
Data source and study design
We obtained secure patient messages received from individuals with diabetes (ICD-10 codes: E08, E09, E10, E11, E13) as well as depression (ICD-10 code: F32, F33) or anxiety (ICD-10 code: F41) through the secure patient portal of a large academic medical center (Stanford Health Care, [SHC]) and 22 affiliated centers in California in 2013–2024. We included clinical issues labeled as patient medical advice requests (PMAR) routed to internal medicine, family medicine, and primary care clinics. The Stanford Institutional Review Board approved this study.
Preparation of benchmark data
The secure patient messages were deidentified using the Safe Harbor method. Before inputting messages into the LLM, two researchers (JK and CIR) reviewed each message to ensure that no protected health information was included in our data set. We collected the most recent six-month messages (10/2023-04/2024) and randomly ordered them.
For positive benchmark (Yes [1], depression or anxiety symptoms are present), we used messages from patients with diabetes and comorbid depression or anxiety (Fig. 5). The first researcher (JK) labeled messages containing at least one depression or anxiety-related keyword, and negative sentiment as “Yes [1]preliminary”. An experienced psychiatrist (CIR) reviewed and confirmed these as “Yes [1]confirmed” if the patient seemed to need further assessment for depression or anxiety. For negative benchmark (No [0], depression or anxiety symptoms are not present), we used messages from patients with diabetes but no comorbid depression or anxiety. JK labeled messages without a depression or anxiety-related keyword and with neutral or positive sentiment as “No [0]preliminary”. CIR confirmed these as “No [0]confirmed” if no further assessment was needed. A total of 606 reference messages were prepared (No [0], n = 300; Yes [1], n = 306).

Challenging cases (N = 39); The Challenging benchmark can be found in Supplementary Data 1 along with LLMs’ reasoning and classification.
Identification of patients’ language for depression or anxiety
To identify patients’ language that they used to describe their depression or anxiety symptoms via secure messaging, we analyzed the messages from those with diabetes and comorbid depression or anxiety (Fig. 5). By leveraging Bidirectional Encoder Representations from Transformers (BERT) and Balanced Iterative Reducing and Clustering (BIRCH) algorithms, we developed a 2-staged natural language processing (NLP) topic model26,27. In the first topic model, similar messages were clustered by cosine similarity score, which we set as 0.82, and key topic groups were created. In the second topic model, the generated topic groups were clustered once again by similarity, keeping the essential topics. The topic model assigned representative keywords of each topic. Through the topic modeling, we obtained keywords that were grouped together with depression or anxiety (e.g. mood, worry, panic, stress), which were used for benchmark data preparation. A full list of keywords is in Supplementary Note 1.
Evaluation of LLMs
The primary outcome was the F-1 score, precision, recall, and accuracy computed by the binary classification of depression or anxiety symptoms (Yes [1] vs. No [0]) using the benchmark data. Using a bootstrapping method (n = 1000), we computed 95% confidence intervals of each primary outcome. Given that the patient messages offered limited information about the patient’s history, we did not precisely separate depression and anxiety symptoms, instead combining the symptoms as one outcome.
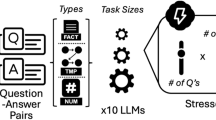
We carefully selected five LLMs for evaluation—three knowledge models by size: 1) small: Llama 3.1 8B (Meta Inc., July 2024), 2) medium: Gemini Pro 1.5 (Google LLC., September 2024), 3) large: Llama 3.1 405B (Meta Inc., July 2024); and two reasoning models: 1) OpenAI o1 (OpenAI Inc., September 2024), 2) DeepSeek R1 (January 2025)—to comprehensively compare the performance and the changes of the performance by approach. Applying various strategies, we intended to identify the optimal approaches by model: 1) zero-shot vs. few-shot (n = 2, 4, 6, 8,10, and 12); 2) binary classification vs. Patient Health Questionnaire (PHQ)-4 based classification; 3) with vs. without systemic persona; and 4) temperature of the test environment (0.6 vs. 0.3). We performed all of the assessments in secure analytics environments provided by SHC that ensure data privacy and security through private API endpoints and end-to-end encryption28. All analytic codes and prompts used in this study are available in Supplementary Note 2.
Zero-shot vs. few-shot learning
We applied a few-shot learning with reference examples of how to diagnose the message annotated with a highly experienced psychiatrist’s (CIR) reasoning (n = 2, 4, 6, 8, 10, and 12). Each set of reference examples included a balanced sample of positive (Yes [1]) and negative (No [0]) references.
Binary classification vs. PHQ-4-based classification
While the primary outcome measurement was binary classification (Yes [1] vs. No [0]), we explored if LLMs could apply more complex measurement metrics and how this approach might differ from using binary classification. We applied the PHQ-4, a simplified yet validated diagnostic tool for depression and anxiety29. Employing systemic persona and zero-shot learning, we directed LLMs to do multiple tasks, involving multi-class and multi-level classification to: 1) assess each message for four categories (little interest, hopelessness, nervousness, worrying); 2) rate the message for four levels using a 4-point Likert scale (0=not at all; 3=most likely) in each category; 3) calculate the sum of all the ratings; and 4) categorize it into No [0] if sum < 6, or Yes [1] if sum ≥ 6, applying the original scoring standard of PHQ-4. We performed z tests to compare the performance of binary and PHQ-4 based classifications by model. The statistical significance was determined at P < 0.05.
With vs. without systemic persona
To enhance LLMs’ performance, we meticulously crafted a systemic persona using multiple prompting strategies30,31: 1) role prompting (e.g. as Dr. GPT, a professional psychiatrist, your role is~), 2) directive commanding (e.g. evaluate the message~, be sure to offer~), 3) expertise emulation (e.g. I myself am a psychiatrist in the hospital), 4) zero-shot chain of thought (e.g. take time to think deeply and step-by-step to be sure). The full-engineered prompts are in Supplementary Note 3.
Exploration of LLMs using challenging cases
We further assessed the performance of LLMs using challenging cases (N = 39). Challenging positive benchmark (Yes [1]challenges, n = 14) comprised the messages with symptoms that required further discussion by two experienced psychiatrists (CIR and PJR), because they involved differential diagnosis and proxy symptoms (e.g. demoralization, anticipatory anxiety). If two psychiatrists agreed that they would flag the patient for further assessment, it was labeled as positive benchmark. Challenging negative benchmark (No [0]challenges, n = 25) comprised the messages that contained at least one mental health keyword, but were determined as not depressive or anxious by the two psychiatrists.
We aimed to see if LLMs could understand the overall context, not relying heavily on the appearance of the signaling words to detect symptoms. In this post hoc assessment, we additionally explored the performance of two of the latest reasoning models (OpenAI o3-mini [OpenAI Inc., January 31, 2025] and Gemini Pro 2.0 Thinking model [Google LLC., January 21, 2025]), hypothesizing that the reasoning models may have higher performance in challenging cases. We assessed the performance of binary classification of six LLMs regarding F-1 score, precision, recall, and accuracy in zero-shot settings. At this time, LLMs were required to provide their reasoning along with classification. Two experienced psychiatrists (CIR and PJR) reviewed the LLMs’ classification reasoning to detect any unreasonable rationale or hallucinations. Challenging benchmarks and LLMs’ reasoning and classification are in Supplementary Data 1.
Data availability
The extended data, which were the further results of our analyses from the current study, are available from the Supplementary Information. The original message data (Challenging Benchmark) also can be found from the Supplementary Data 1. Additionally, all the original benchmarks will be made available online (https://github.com/JK0902/MH_LLM) upon publication.
Code availability
The underlying code for this study is available through a public website (https://github.com/JK0902/MH_LLM) upon submission.
References
Norra, C., Skobel, E. C., Arndt, M. & Schauerte, P. High impact of depression in heart failure: Early diagnosis and treatment options. Int. J. Cardiol. 125, 220–231 (2008).
Pivato, C. A. et al. Depression and ischemic heart disease. Int J. Cardiol. 364, 9–15 (2022).
Khaledi M., Haghighatdoost F., Feizi A., Aminorroaya A. The prevalence of comorbid depression in patients with type 2 diabetes: an updated systematic review and meta-analysis on huge number of observational studies. Acta Diabetol. 56. https://doi.org/10.1007/S00592-019-01295-9 (2019).
Gold, S. M. et al. Comorbid depression in medical diseases. Nat. Rev. Dis. Prim. 6, 1–22 (2020).
Chen, K. Y., Evans, R. & Larkins, S. Why are hospital doctors not referring to Consultation-Liaison Psychiatry? - A systemic review. BMC Psychiatry 16, 390 (2016).
Beck A. J., Page C., Buche J., Rittman D., Gaiser M. Estimating the Distribution of the U.S. Psychiatry Subspecialist Workforce Project Team—Google Search. Accessed March 5, 2025. https://www.google.com/search?sca_esv=e51cbab9ee5c3981&rlz=1C5GCCM_en&q=Beck+AJ,+Page+C,+Buche+J,+Rittman+D,+Gaiser+M.+Estimating+the+Distribution+of+the+U.S.+Psychiatry+Subspecialist+Wor+kforce+Project+Team&sa=X&ved=2ahUKEwjuppfLmPOLAxUsFzQIHbiQKF0Q7xYoAHoECAoQAQ&biw=1102&bih=912&dpr=2.
de Pinho L. G. et al. Patient-centered care for patients with depression or anxiety disorder: an integrative review. J. Pers. Med. 11. https://doi.org/10.3390/JPM11080776 (2021).
Brands, M. R. et al. Patient-centered digital health records and their effects on health outcomes: systematic review. J. Med. Internet Res. 24, e43086 (2022).
Wade-Vuturo, A. E., Mayberry, L. S. & Osborn, C. Y. Secure messaging and diabetes management: experiences and perspectives of patient portal users. J. Am. Med Inf. Assoc. Jamia. 20, 519–525 (2013).
Sarraju, A. et al. Identifying reasons for statin nonuse in patients with diabetes using deep learning of electronic health records. J. Am. Heart Assoc. 12, e028120. https://doi.org/10.1161/JAHA.122.028120 (2023).
Beam, K. et al. Performance of a large language model on practice questions for the neonatal board examination. JAMA Pediatr. 177, 977–979 (2023).
Cai Z. R. et al. Assessment of correctness, content omission, and risk of harm in large language model responses to dermatology continuing medical education questions. J. Investig. Dermatol. Published online February 2, 2024:S0022-202X(24)00088-5. https://doi.org/10.1016/j.jid.2024.01.015.
Kim, J. et al. Large language models outperform mental and medical health care professionals in identifying obsessive-compulsive disorder. NPJ Digit. Med. 7, 193 (2024).
Elyoseph, Z. & Levkovich, I. Comparing the perspectives of generative AI, mental health experts, and the general public on schizophrenia recovery: case vignette study. JMIR Ment. Health 11, e53043 (2024).
Taylor, N. et al. Model development for bespoke large language models for digital triage assistance in mental health care. Artif. Intell. Med. 157, 102988. https://doi.org/10.1016/j.artmed.2024.102988 (2024).
Shin, D., Kim, H., Lee, S., Cho, Y. & Jung, W. Using large language models to detect depression from user-generated diary text data as a novel approach in digital mental health screening: instrument validation study. J. Med Internet Res. 26, e54617 (2024).
Madububambachu, U., Ukpebor, A. & Ihezue, U. Machine learning techniques to predict mental health diagnoses: a systematic literature review. Clin. Pr. Epidemiol. Ment. Health CP Emh. 20, e17450179315688. https://doi.org/10.2174/0117450179315688240607052117 (2024).
Guerreiro, J. et al. Transatlantic transferability and replicability of machine-learning algorithms to predict mental health crises. NPJ Digit. Med. 7, 227 (2024).
Xu, X. et al. Leveraging Large Language Models for Mental Health Prediction via Online Text Data. (2023).
Jain, S. S., Mello, M. M. & Shah, N. H. Avoiding financial toxicity for patients from clinicians’ use of AI. N. Engl. J. Med. 391, 1171–1173 (2024).
Perlis, R. H., Goldberg, J. F., Ostacher, M. J. & Schneck, C. D. Clinical decision support for bipolar depression using large language models. Neuropsychopharmacol. Publ. Am. Coll. Neuropsychopharmacol. 49, 1412–1416 (2024).
Levkovich, I. & Elyoseph, Z. Identifying depression and its determinants upon initiating treatment: ChatGPT versus primary care physicians. Fam. Med. Community Health 11, e002391 (2023).
Cabral, S. et al. Clinical reasoning of a generative artificial intelligence model compared with physicians. JAMA Intern. Med. 184, 581–583 (2024).
Rabbani, N. et al. Targeting repetitive laboratory testing with electronic health records-embedded predictive decision support: a pre-implementation study. Clin. Biochem. 113, 70–77 (2023).
Bedi, S. et al. Testing and evaluation of health care applications of large language models: a systematic review. JAMA 333, 319–328 (2025).
Devlin J., Chang M. W., Lee K., Toutanova K. BERT: Pre-training of deep bidirectional transformers for language understanding. Published online May 24, 2019. https://doi.org/10.48550/arXiv.1810.04805.
Grootendorst M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. Published online March 11, 2022. https://doi.org/10.48550/arXiv.2203.05794.
Ng, M. Y., Helzer, J., Pfeffer, M. A., Seto, T. & Hernandez-Boussard, T. Development of secure infrastructure for advancing generative artificial intelligence research in healthcare at an academic medical center. J. Am. Med. Inf. Assoc. 32, 586–588 (2025).
An ultra-brief screening scale for anxiety and depression: the PHQ-4—PubMed. Accessed March 1, 2025. https://pubmed.ncbi.nlm.nih.gov/19996233/.
Leypold, T., Schäfer, B., Boos, A. & Beier, J. P. Can AI Think Like a Plastic Surgeon? Evaluating GPT-4’s Clinical Judgment in Reconstructive Procedures of the Upper Extremity. Plast. Reconstr. Surg. Glob. Open. 11, e5471 (2023).
Kojima T., Gu S (Shane), Reid M., Matsuo Y., Iwasawa Y. Large Language Models are Zero-Shot Reasoners. Adv. Neural Inf. Process Syst. 2022;35:22199-22213. Accessed March 19, 2024. https://proceedings.neurips.cc/paper_files/paper/2022/hash/8bb0d291acd4acf06ef112099c16f326-Abstract-Conference.html.
Acknowledgements
J.K. is supported by the NIH (K01MH137386). E.L. is supported by the NIH (grants R01AR082109 and K24AR075060). The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH. The funding organizations had no role in the design and conduct of the study; collection, management, analysis, and interpretation of the data; preparation, review, or approval of the manuscript; and decision to submit the manuscript for publication.
Author information
Authors and Affiliations
Contributions
J.K. and E.L. had full access to all the data in this study and take responsibility for the integrity of the data and the accuracy of the data analysis. JK conceived and designed the study. J.K. and E.L. obtained the data, and J.K., S.P.M., M.L.C. developed the analytic codes for analysis. J.K., S.P.M., M.L.C., C.I.R. and J.H.C. analyzed and interpreted the results. I.R.G., P.J.R., and C.I.R. provided material supports. S.P.M., J.T., C.S., M.A.P. and C.I.R. provided clinical insights into the study, critically reviewed, and conducted several rounds of revisions. C.I.R., E.L. and J.H.C. supervised the study. All authors read and approved the final version of the manuscript and agreed to submit it for publication.
Corresponding author
Ethics declarations
Competing interests
In the last 3 years, C.I.R. has served as a consultant for Biohaven Pharmaceuticals, Osmind, and Biogen; and receives research grant support from Biohaven Pharmaceuticals, a stipend from American Psychiatric Association Publishing for her role as Deputy Editor at The American Journal of Psychiatry, and book royalties from American Psychiatric Association Publishing. The other authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kim, J., Ma, S.P., Chen, M.L. et al. Optimizing large language models for detecting symptoms of depression/anxiety in chronic diseases patient communications. npj Digit. Med. 8, 580 (2025). https://doi.org/10.1038/s41746-025-01969-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41746-025-01969-5
