
Abstract
Atrial fibrillation (AF) is the most common sustained arrhythmia and a leading cause of ischemic stroke. Existing risk scores, such as CHA₂DS₂-VASc, offer limited predictive accuracy and fail to capture complex clinical patterns. To improve generalizability and clinical utility, we developed and externally validated clinically interpretable machine learning models using only age, comorbidities, and medication use to predict 1-year stroke risk in patients with newly diagnosed AF. Both logistic regression (LR) and Platt-calibrated extreme gradient boosting (XGB) models achieved high discrimination in internal (AUCs = 0.915 and 0.914) and external validation cohorts (AUCs = 0.877–0.886), significantly outperforming CHA₂DS₂-VASc (AUCs = 0.614–0.621; p < 0.001). Calibration curves and decision curve analysis confirmed strong clinical utility. Long-term follow-up demonstrated superior risk stratification and treatment responsiveness in LR-defined high-risk groups. These models provide accurate, individualized stroke risk estimates to guide direct oral anticoagulant (DOAC) initiation in real-world hospital settings.
Similar content being viewed by others

Introduction
Atrial fibrillation (AF) is the most common arrhythmia, affecting over 58 million people globally1, and is associated with a substantially increased risk of ischemic stroke and mortality2,3,4. Although the introduction of direct oral anticoagulants (DOACs) has improved safety profiles and simplified anticoagulation management5,6,7, residual stroke risk remains a major clinical concern8,9. Given the dynamic nature of thromboembolic and bleeding risks, short-term stroke risk assessment is essential for timely and personalized treatment decisions10.
The CHA₂DS₂-VASc score is widely used for stroke risk stratification in patients with AF11,12. However, its predictive performance is limited, particularly over mid- and long-term follow-up, with reported C-statistics of 0.67 (95% confidence interval [CI], 0.65–0.69) and 0.66 (95% CI, 0.63–0.69), respectively13. Its rule-based structure may also overlook complex interactions among clinical features. Recently, data from the Finnish Anticoagulation in Atrial Fibrillation (FinACAF) long-term follow-up cohort showed that the apparent increased stroke risk in women declines over time and that a modified CHA₂DS₂-VA score (omitting the female-sex point) performs marginally better14, underscoring the importance of examining sex-based differences in model performance.
Recent studies have explored machine learning (ML) approaches to improve stroke prediction in patients with AF¹⁵. For example, a recent meta-analysis by Goh et al. reviewed ML-based models and found that ensemble methods such as extreme gradient boosting (XGB) often achieved superior performance. However, many of these models lacked external validation, offered limited interpretability, and did not evaluate clinical utility15. Other studies, including work by Xiong et al., demonstrated the feasibility of using real-world EHR data to predict left atrial thrombus in patients with paroxysmal AF16. Bernardini et al. applied a deep learning-based Multi-gate Mixture-of-Experts (MMoE) model to predict composite outcomes of thromboembolism and bleeding in anticoagulated AF patients17. Although features such as renal function, platelet count, and hemoglobin levels are frequently used in risk models, these laboratory values are often missing at the time of AF diagnosis in clinical practice. Developing models based only on patients with complete laboratory data, without assessing differences from those without such data, may introduce selection bias. In addition, prior models often require extensive input features, including laboratory and imaging data18,19 and frequently target already treated populations17,20. These limitations restrict their practical use in routine care.
In this study, we aimed to develop and externally validate clinically interpretable ML models using only age, medication use, and clinical history to predict 1-year stroke risk in patients with newly diagnosed AF. We compared logistic regression (LR) and XGB models with the CHA₂DS₂-VASc score, conducted post-hoc sex-stratified analyses to ensure equitable performance, and evaluated their long-term predictive utility at 3 and 5 years. These models are intended to support clinicians in making individualized decisions about DOAC initiation based on patient-specific stroke risk at the time of AF diagnosis.
Results
Baseline characteristics
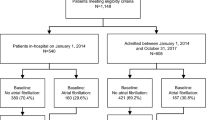
The study design, including cohort construction, feature selection, model training, validation, and clinical utility assessment, is summarized in Fig. 1. Among the 9511 patients in the derivation cohort, 5043 (53.0%) had laboratory data available within 6 months prior to initial AF diagnosis. Patients with laboratory data were significantly older and had higher CHA₂DS₂-VASc scores (both p < 0.001; standardized mean differences [SMDs] = 0.359 and 0.462, respectively), suggesting potential selection bias. To preserve generalizability, laboratory data were excluded from model development. After this exclusion, no missing data remained in any of the derivation or external validation cohorts. Within the derivation cohort, 1448 patients (15.2%) experienced ischemic stroke within 1 year. Compared to non-stroke patients, those with stroke were older and had higher prevalence of comorbidities such as diabetes (DM), hyperlipidemia, hypertension (HTN), peptic ulcer disease excluding bleeding (PUDB), peripheral vascular disease (PVD), and prior ischemic stroke (all p < 0.05), but lower rates of congestive heart failure (p = 0.031). Stroke patients were more frequently prescribed warfarin, antiplatelets (APA), oral hypoglycemic agents (OHA), and cardiovascular medications, but fewer antiarrhythmic drugs (AAD) (all p < 0.05; Supplementary Table 1).

This flowchart outlines the pipeline for developing and validating machine learning models to predict 1-year stroke risk after atrial fibrillation (AF) diagnosis. The derivation cohort (N = 9511) was obtained from National Taiwan University Hospital (NTUH). Patients were initially grouped based on the availability of laboratory data; due to significant differences in age and CHA₂DS₂-VASc scores (p < 0.001), laboratory variables were excluded to minimize potential selection bias. For logistic regression (LR), 9 features were selected via Bayesian Information Criterion (BIC); for extreme gradient boosting (XGB), 11 features were ranked by model importance. The dataset was split into 80% training and 20% internal validation subsets, with 5-fold cross-validation used for hyperparameter tuning. Class imbalance was addressed using model-based weighting, and Platt scaling was applied for XGB probability calibration. External validation was performed using two regional NTUH branches (cohort 1: N = 1300; cohort 2: N = 1242), with baseline differences assessed. Model performance was evaluated using discrimination (ROC AUC), calibration (Brier score, calibration curves), and confusion matrix metrics. To ensure fairness and robustness, we conducted sensitivity and subgroup analyses, including early event sensitivity analysis, sex-based fairness analysis, and prior stroke subgroup analysis. Clinical utility was assessed using decision curve analysis (DCA), net reclassification improvement (NRI), and evaluation of mid-term (3-year) and long-term (5-year) predictive utility. A web-based interactive prototype was developed to support future clinical deployment.
Marked heterogeneity was observed between the derivation and external validation cohorts (Table 1). External cohort patients were older, had higher CHA₂DS₂-VASc scores, and greater incidence of stroke and mortality at all follow-up intervals (all Holm-adjusted p < 0.05). Differences in comorbidities and all medication variables were also significant. Notably, DOAC use was higher in the external cohorts, reflecting broader adoption following its introduction in 2011. These findings underscore the importance of external validation across temporally and clinically diverse populations.
Model development and internal validation
Both the LR and XGB models were developed using readily available clinical features, including medication use, age, and clinical history. For the LR model, 9 predictors were selected via Bayesian Information Criterion (BIC)-based feature selection: age, use of warfarin, APA, AAD, OHA, and the presence of chronic lung disease (CLD), HTN, DM, and prior stroke. Feature coefficients are shown in Supplementary Fig. 1. Univariate analysis identified AAD as a protective factor, while the other predictors were associated with increased stroke risk. In multivariable analysis, the associations of OHA, HTN, and DM were attenuated, suggesting possible non-linear effects (Table 2). For the XGB model, 11 predictors were selected based on gain-based importance: prior stroke, age, AAD, HTN, APA, warfarin, DM, mild liver disease (MLD), PVD, PUDB, and valvular heart disease (VHD) (Fig. 2). 7 predictors overlapped with those in the LR model. The SHapley Additive exPlanations (SHAP) summary plot highlighted the XGB model’s capacity to capture non-linear effects and feature interactions. For instance, age exhibited bidirectional SHAP values, reflecting context-dependent influence such as protective effects in younger individuals and increased risk in older ones (Fig. 2).

The SHAP (SHapley Additive exPlanations) summary plot illustrates the relative contribution of each predictor to the 1-year stroke risk prediction in the XGB model. Each dot represents a patient; color indicates the feature value (red = high, blue = low), and horizontal position reflects the SHAP value (positive values increase stroke risk, negative values decrease it). Prior ischemic stroke was the most influential predictor, consistently increasing stroke risk, followed by age, atrial arrhythmia drugs (AAD), and hypertension (HTN). Some features (e.g., age) exhibited bidirectional effects, highlighting context-dependent interactions captured by the XGB model. This interpretability enables clinicians to understand individualized risk profiles, supporting precision decision-making. AGE age at diagnosis, AAD anti-arrhythmic drugs, HTN hypertension, APA antiplatelet agents, DM diabetes mellitus, MLD mild liver disease, PVD peripheral vascular disease, PUDB peptic ulcer disease (excluding bleeding), VHD valvular heart disease, XGB extreme gradient boosting.
Using 5-fold cross-validation on the training set (80%) of the derivation cohort, optimal hyperparameters were identified for both LR and XGB models (Supplementary Table 2). Internal validation on the hold-out test set (20%) demonstrated that both LR (area under the receiver operating characteristic curve [AUROC]: 0.91; 95% CI: 0.89–0.93) and XGB (AUROC: 0.91; 95% CI: 0.89–0.93) significantly outperformed the CHA₂DS₂-VASc score (AUROC: 0.67; 95% CI: 0.65–0.69; DeLong p < 0.001) (Fig. 3a). Both models also achieved substantially higher area under the precision–recall curve (AUPRC) values compared to the CHA₂DS₂-VASc score: LR (AUPRC: 0.74; 95% CI: 0.68–0.79), XGB (AUPRC: 0.74; 95% CI: 0.68–0.80), and CHA₂DS₂-VASc (AUPRC: 0.22; 95% CI: 0.19–0.24). Additional performance metrics, including accuracy, sensitivity, specificity, precision, and F1 score, are provided in Supplementary Table 3.

Receiver operating characteristic (ROC) curves comparing logistic regression (LR), Platt-calibrated extreme gradient boosting (XGB), and the CHA₂DS₂-VASc score in (a) internal validation, (b) external cohort 1, and (c) external cohort 2. The LR model achieved an AUC of 0.915 internally, and 0.877 (DeLong p = 0.08) and 0.882 (p = 0.14) in cohorts 1 and 2, respectively. The XGB model yielded an internal AUC of 0.914, with external AUCs of 0.886 (p = 0.22) and 0.879 (p = 0.11). Both models substantially outperformed the CHA₂DS₂-VASc score and showed no signs of overfitting. d XGB calibration curve before and after Platt scaling, showing improved calibration (Brier score decreased from 0.0920 to 0.0540). Calibration curves for (e) LR and (f) Platt-calibrated XGB models across internal and external cohorts. LR showed better alignment with the derivation cohort (stroke incidence 15.2%), while the XGB model calibrated more effectively in external cohorts with higher stroke incidence (18.8% and 20.4%), suggesting superior robustness across varying baseline risk profiles. AUC area under the receiver operating characteristic curve, LR logistic regression, XGB extreme gradient boosting, ROC receiver operating characteristic.
Probability prediction performance was assessed using the Brier score, with lower values indicating better calibration. The LR model demonstrated strong calibration, with a Brier score of 0.054, and its predictions closely aligned with observed outcomes across the probability range (Fig. 3e), without requiring post-hoc adjustment. In contrast, the XGB model initially exhibited a higher Brier score of 0.091 and tended to overpredict risk at thresholds below 0.6 (Fig. 3d). To improve probability alignment, Platt scaling was applied, reducing the XGB model’s Brier score from 0.092 to 0.054 and improving its calibration curve fit to the diagonal reference line (Fig. 3d). The CHA₂DS₂-VASc score showed poor probabilistic calibration, with a Brier score of 0.486.
External validation
Both the LR and XGB models demonstrated strong generalizability in external validation without evidence of overfitting. The LR model yielded an AUC of 0.915 in internal validation (Fig. 3a), with comparable performance in external cohort 1 (n = 1300; AUC = 0.877, p = 0.08) and cohort 2 (n = 1242; AUC = 0.882, p = 0.14). The XGB model similarly achieved an internal AUC of 0.914, with external AUCs of 0.886 (p = 0.22) and 0.879 (p = 0.11), respectively. Both models significantly outperformed the CHA₂DS₂-VASc score in external validation (AUC = 0.614 and 0.621, DeLong p < 0.001) (Fig. 3b, c). Calibration remained strong across datasets: LR Brier scores ranged from 0.0542 (internal) to 0.0654 (cohort 2) (Fig. 3e), while Platt-calibrated XGB models achieved Brier scores of 0.0540, 0.0609, and 0.0636 (Fig. 3f), with predicted probabilities closely aligned to the ideal calibration line. All additional performance metrics from the external validation are provided in Supplementary Table 3.
Sensitivity and subgroup analyses
To test temporal robustness and rule out early misclassification, we performed a sensitivity analysis excluding stroke events within 3 days after AF diagnosis. Model performance remained stable (LR AUROCs: 0.87 in both external validation cohorts; XGB AUROCs: 0.88 and 0.87), supporting the validity of our temporal separation strategy and indicating no evidence of data leakage. Moreover, despite differences in baseline characteristics across sites, performance was consistent across sexes. In a pooled, sex-stratified analysis of the two external cohorts (female n = 1138; male n = 1404), the LR model achieved AUCs of 0.893 versus 0.868 (z = 1.207, DeLong p = 0.23) and Brier scores of 0.0645 versus 0.0633, and the Platt-calibrated XGB model achieved AUCs of 0.892 versus 0.875 (z = 0.805, p = 0.42) and Brier scores of 0.0630 versus 0.0620. These non-significant differences confirm equitable discrimination and calibration by sex. We also examined model performance stratified by prior ischemic stroke history. In the stroke-naïve subgroup (n = 2136), both models showed lower discrimination as expected (AUROCs of 0.57 for LR and 0.58 for XGB), but remained comparable to the CHA₂DS₂-VASc score (0.53; DeLong p-values non-significant). These results suggest that our models retained discriminative ability by leveraging additional clinical features.
Clinical interpretability and utility
To evaluate the clinical utility of the ML models, decision curve analysis (DCA) and net reclassification improvement (NRI) were conducted. As shown in Fig. 4, both the LR and Platt-calibrated XGB models demonstrated greater net benefit across a broad range of threshold probabilities compared with the CHA₂DS₂-VASc rule, with Platt-calibrated XGB providing the highest benefit, particularly within the clinically relevant range of 0.1–0.7. For instance, in External Cohort 1, at a threshold of 0.2, the LR and XGB models achieved net benefits of ~135 per 1000 patients, while CHA₂DS₂-VASc achieved 33 per 1000. This corresponds to an additional 102 high-risk patients correctly identified per 1000 individuals without increasing overtreatment (Fig. 4a). NRI analysis at a 0.1 risk threshold confirmed significant improvements in risk classification: in external cohort 1, NRIs were 0.489 for LR and 0.485 for Platt-calibrated XGB; in cohort 2, 0.489 for LR and 0.487 for Platt-calibrated XGB (all Z-test p < 0.001). At the 0.7 threshold, NRIs remained positive and statistically significant, further supporting the models’ clinical utility across the full range of DCA-informed decision thresholds. Both LR and Platt-calibrated XGB models offered marked improvement in stroke risk stratification compared to the CHA₂DS₂-VASc score.

a Net benefit across a range of threshold probabilities for external cohort 1. b Net benefit for external cohort 2. Both the logistic regression (LR) and Platt-calibrated extreme gradient boosting (XGB) models demonstrated superior clinical utility compared to the CHA₂DS₂-VASc rule and the “treat-none” strategy. The net benefit curves for LR and XGB remained consistently higher, particularly within the clinically relevant threshold range of 0.1–0.7. In contrast, the CHA₂DS₂-VASc rule, being rule-based with a fixed threshold, yields a constant net benefit across all probability thresholds, illustrated by a flat dashed line. Higher net benefit indicates more patients appropriately treated per 1000 individuals, accounting for the trade-off between true-positive and false-positive classifications at each decision threshold.
To further evaluate the mid-term and long-term predictive utility of the models, patients from both external validation cohorts (N = 2542) were stratified into high- and low-risk groups based on the 1-year stroke risk estimated by the LR model or CHA₂DS₂-VASc score, and cumulative incidence of stroke was plotted over 3- and 5-year follow-ups, stratified by DOAC usage (Fig. 5). In the LR-defined high-risk group, DOAC use was associated with significantly lower stroke incidence at both 3 years (log-rank p = 0.0042) and 5 years (p = 0.011) (Fig. 5a, b), whereas no significant benefit was observed in the LR-defined low-risk group (p = 0.42 and 0.34) (Fig. 5a, b). In contrast, CHA₂DS₂-VASc-defined risk groups showed inconsistent patterns. Although statistically significant differences were observed in the low-risk group at 3 years (p = 0.02) and 5 years (p = 0.04), the DOAC group paradoxically exhibited higher stroke incidence (Fig. 5c, d), suggesting potential misclassification of stroke risk under the CHA₂DS₂-VASc rule. Gray’s test accounting for the competing risk of death further supported these findings: in the LR-defined high-risk group, stroke incidence remained significantly lower in DOAC users at 3 years (p = 0.022), with borderline significance at 5 years (p = 0.055), despite the limited number of death events (n = 3 at 3 years; n = 5 at 5 years). These results reinforce the LR model’s superior accuracy in long-term risk stratification and treatment decision-making.

Kaplan–Meier curves showing 3-year (a) and 5-year (b) cumulative stroke incidence among high- and low-risk groups defined by the logistic regression (LR) model, using a 1-year stroke risk threshold of 0.2. Panels (c) and (d) present corresponding 3-year and 5-year curves for risk groups defined by the CHA₂DS₂-VASc score. Each curve is further stratified by direct oral anticoagulant (DOAC) use. Analyses were conducted using pooled data from external cohort 1 and external cohort 2. Log-rank tests were used to assess differences in stroke incidence between DOAC users and non-users within each risk stratum. Shaded bands represent 95% confidence intervals. DOAC indicates direct oral anticoagulant.
Discussion
In this study, we developed and externally validated clinically interpretable ML models for short-term stroke risk prediction in patients with newly diagnosed AF. Both the LR and Platt-calibrated XGB models demonstrated excellent discrimination (internal AUCs >0.91) and strong generalizability across external cohorts without evidence of overfitting. Calibration was well maintained across datasets, and both models significantly outperformed the CHA₂DS₂-VASc score in discrimination, calibration, and net clinical benefit. A pooled sex-stratified analysis confirmed no significant differences in discrimination or calibration between women and men, indicating absence of sex-based algorithmic bias. As expected, model performance declined in the subgroup without prior stroke (n = 2136), reflecting the lower event rate and absence of this dominant predictor, but remained comparable to the CHA₂DS₂-VASc score. DCA showed consistently higher net benefit for LR and Platt-calibrated XGB models across a wide range of thresholds, while NRI analysis confirmed improved patient risk classification over CHA₂DS₂-VASc at clinically relevant thresholds (between 0.1 and 0.7). At a threshold of 0.2, our ML models identified over 100 more high-risk patients per 1000 than the CHA₂DS₂-VASc score, without increasing harm from false positives, demonstrating substantial added value for individualized anticoagulation decisions. Because the CHA₂DS₂-VASc score assigns a fixed point for female sex, it may lead to overtreatment of lower-risk women; by contrast, our ML models estimate risk in a context-dependent manner, which is particularly appropriate for older patients with comorbidities such as peptic ulcer disease and aligns with evidence that apparent sex differences in stroke risk are largely driven by age and disparities in cardiovascular care21,22. In long-term follow-up, the LR-defined high-risk group more accurately identified patients who benefited from DOACs, while the CHA₂DS₂-VASc score demonstrated paradoxical associations, suggesting potential misclassification. However, the higher stroke incidence observed among DOAC users in the CHA₂DS₂-VASc low-risk group may also reflect confounding by indication (Fig. 5c, d), wherein clinicians prescribe anticoagulants based on unmeasured clinical concerns not captured by the score. Notably, LR-based stratification showed clearer separation between high- and low-risk groups, as reflected by distinct absolute stroke incidence under a unified y-axis scale in cumulative incidence plots (Fig. 5). These findings support the use of interpretable ML models to enhance risk stratification and guide individualized stroke prevention strategies in AF.
Numerous stroke risk prediction models have been developed in recent years. The ABC stroke risk score incorporates biomarkers such as troponin and NT-proBNP and achieves moderate discrimination (C-indices 0.65–0.68 in the derivation cohort and 0.63–0.66 in the validation cohort)23,24, but requires blood testing, which limits real-time clinical use. Recent ML models using large-scale datasets, such as the Korean National Health Insurance Database and UK Biobank, achieved AUROC values of 0.727 and 0.631 for stroke prediction in AF patients, respectively, outperforming the CHA₂DS₂-VASc score but requiring 48 or more features, including numerous laboratory biomarkers25,26. While such variables often show statistical associations with stroke risk27,28, their inclusion does not consistently improve ML model performance and may limit clinical scalability29. Imaging-based models, such as AI-enabled CT analysis, achieve high accuracy but are resource-intensive30. Deep learning models using 12-lead ECGs, such as one published in Circulation (2022), show potential but lack interpretability and require specialized infrastructure31. In contrast, our interpretable ML models rely only on medications, age, and clinical history, features readily available at AF diagnosis, and demonstrated strong discrimination (AUROC 0.88–0.91) with external validation. Moreover, class imbalance was addressed using model-based weighting32 rather than synthetic resampling such as SMOTE or over-sampling33,34, preserving real-world distributions. These characteristics support practical and scalable implementation of our models for individualized stroke prevention and DOAC initiation in patients with newly diagnosed AF.
Beyond predictive performance, interpretability is essential for clinical adoption. The case-level interpretability shown in Fig. 6 underscores the clinical utility of our ML models relative to the rule-based CHA₂DS₂-VASc score. The LR model applies additive risk contributions with fixed effect directions: predictors such as AAD and CLD consistently reduce stroke risk, while others increase it. In contrast, the XGB model captures context-dependent interactions, as reflected in the SHAP values35 (Fig. 2). For example, AAD and DM increased stroke risk in patient 994 (Fig. 6d) but had protective effects in patient 19 (Fig. 6b), illustrating non-linear relationships that LR cannot account for. In borderline-risk cases such as patient 994, advanced age appeared to shift multiple predictors toward a risk-increasing effect in the XGB model (Fig. 6d). CLD was identified as a protective factor in the LR model (Fig. 6c), potentially due to the use of phosphodiesterase-4 (PDE4) inhibitors like roflumilast, which have been associated with reduced cardiovascular risk36.

Individual-level risk contribution plots from the logistic regression (LR) model and SHAP (SHapley Additive exPlanations) plots from the Platt-calibrated XGB model are shown for 3 example patients. Panels (a) and (b): a 68-year-old male without stroke within 1 year, classified as low-risk. Panels (c) and (d): an 82-year-old male who experienced stroke within 1 year, representing a borderline-risk case. Panels (e) and (f): a 70-year-old female with stroke within 1 year, predicted as high-risk. In the LR model, feature effects are additive and directionally fixed, whereas the XGB model captures context-dependent, non-linear interactions. Notably, features such as AAD and DM exhibited opposite contributions between patients 19 and 994 in the XGB model, highlighting individualized risk interpretation. The calibrated probabilities from the XGB model are shown alongside the raw risk estimates. LR logistic regression, XGB extreme gradient boosting, SHAP SHapley Additive exPlanations, AAD anti-arrhythmic drugs, HTN hypertension, APA antiplatelet agents, DM diabetes mellitus, CLD chronic lung disease, OHA oral hypoglycemic agents, MLD mild liver disease, PVD peripheral vascular disease, PUDB peptic ulcer disease (excluding bleeding), VHD valvular heart disease.
Importantly, raw predicted probabilities from the XGB model (Fig. 3d) revealed substantial heterogeneity among stroke-positive patients. Those with prior stroke were assigned higher predicted risks, while stroke-naïve patients who experienced events often received lower predicted probabilities. This highlights the well-recognized difficulty of risk prediction in lower-risk subgroups. At the same time, it illustrates a key strength of probabilistic models such as XGB: they allow for individualized threshold adjustment. For instance, in older patients with accumulating risk factors, such as the 82-year-old male without prior stroke (Fig. 6d), the XGB model assigned a raw predicted risk of 39.07%. In such cases, clinicians may choose to apply a lower intervention threshold to prompt preventive action. This adjustment can be made on an individual basis rather than applied to the entire population, thereby preserving specificity for other patients. Although AUROC is insensitive to threshold shifts, this adaptability improves the model’s clinical utility by supporting personalized, risk-guided decision-making.
The clinically relevant threshold range of 0.1–0.7 used in our DCA further reflects this flexibility. This range (0.1–0.7) reflects a realistic spectrum of clinical risk tolerance and treatment strategies observed across diverse patient populations and care settings, as the DCA formula inherently adjusts the relative weighting of false positives based on the chosen threshold. Lower thresholds reflect greater clinical tolerance for overtreatment, while higher thresholds emphasize specificity and conservative intervention. Lower thresholds (e.g., 0.1) may be appropriate for frail or high-risk individuals, while higher thresholds (e.g., 0.7) can help avoid overtreatment in lower-risk patients. Although thresholds as high as 0.7 are less likely to be used in routine anticoagulation decisions, evaluating model performance across this wide spectrum helps demonstrate robustness. Our ML models maintained a consistent net benefit advantage across these thresholds, supporting their potential utility in risk-adapted, individualized decision-making compared to the fixed thresholds of CHA₂DS₂-VASc. Provided the net benefit remains positive, as shown in our DCA (Fig. 4), probabilistic predictions may assist clinicians in tailoring anticoagulation strategies to patient-specific risk profiles.
This study presents externally validated, clinically interpretable ML models for 1-year stroke risk prediction in patients with newly diagnosed AF, using only readily accessible clinical features. To support future implementation, we developed a prototype web-based interface to facilitate clinician engagement and prospective validation (Fig. 7) with built-in input validation. Unanswered yes/no fields prompt users until completed, and continuous entries (for example, age) are constrained to plausible ranges (≥20 years) before any risk calculation. No programming expertise is required to use the tool, although clinical training is assumed for interpreting the outputs.

This video shows how to enter patient data (e.g., an 87-year-old male with diabetes and mild liver disease) and view 1-year stroke risk estimates from both logistic regression and Platt-calibrated XGB models alongside a SHAP feature-interaction plot. It then illustrates the Decision Curve Analysis page using a local cohort where net benefit and risk classification update in real time via a threshold slider, and Net Reclassification Improvement quantifies gains over the CHA₂DS₂-VASc score. A second example (69-year-old female with hypertension, diabetes, peripheral vascular disease, peptic ulcer disease, and APA/OHA use) highlights how our models avoid misclassification that could lead to unnecessary anticoagulation. In the PDF version of this article, please click anywhere on the figure or caption to play the video in a separate window.
Although our work is retrospective and limited to a single health system, validation in two geographically and temporally distinct external cohorts supports broad generalizability. While all data were drawn from NTUH-affiliated hospitals, the cohorts represent different levels of care and regional populations, ranging from an urban center in northern Taiwan to a rural county in the south. This introduces meaningful variation in demographics and clinical practices. However, similarities in coding and workflows within a unified system may still exist. Validation in entirely independent health systems is needed to further support broad applicability. Moreover, because all derivation and validation cohorts were drawn from Taiwanese populations, additional validation in non-Asian populations is warranted to assess generalizability across diverse ethnic and healthcare contexts.
The relatively high 1-year stroke rates observed in our cohorts likely reflect the hospital-based nature of the study and real-world diagnostic patterns, wherein many patients were diagnosed with AF during or shortly after a stroke hospitalization (Supplementary Fig. 2). This phenomenon aligns with findings from large population-based studies in Taiwan, Sweden, and Korea, which reported that stroke incidence peaks within the first 30–90 days following an AF diagnosis37,38. Prior ischemic stroke also emerged as the most influential predictor in both the LR and XGB models, consistent with the weighting in the CHA₂DS₂-VASc score. In a subgroup of stroke-naïve patients, model performance declined due to the absence of this dominant predictor and lower event rates but remained comparable to the CHA₂DS₂-VASc score. However, the limited number of stroke events (310 among 8099 patients without prior ischemic stroke) constrained the statistical power for independent model development. Based on the events-per-variable principle, which recommends at least 10–20 outcome events per predictor variable, developing a dedicated model for this subgroup remains statistically challenging. Moreover, although we intentionally selected validation cohorts from a later period than the derivation cohort to assess the model’s temporal generalizability across different treatment eras, the continuous evolution in AF management strategies, such as the shift from warfarin to DOAC use, highlights the need for periodic model revalidation and recalibration. This process will help ensure the model remains clinically relevant as practice patterns and treatment guidelines change over time. Additional limitations remain. For example, the observed protective association of CLD warrants further investigation to clarify potential pharmacologic or population-specific effects. Future research should prioritize prospective or community-based data and consider developing tailored models for stroke-naïve AF patients to improve early risk detection and guide personalized prevention strategies.
Methods
This study was conducted in accordance with the Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis extended for Artificial Intelligence (TRIPOD + AI) guidelines to ensure rigorous development and validation of AI-based prediction models39. The overall study workflow is illustrated in Fig. 1.
Study population and data source
This study utilized data from the National Taiwan University Hospital Integrated Medical Database (NTUH-iMD), a comprehensive electronic health record system that spans multiple branches of the National Taiwan University Hospital (NTUH) healthcare system. The derivation cohort (n = 9511) for model development was assembled from NTUH, a tertiary medical center located in Taipei. Two external validation cohorts were constructed from regional branches: the NTUH Hsin-Chu Branch (external cohort 1; n = 1300) and the NTUH Yun-Lin Branch (external cohort 2; n = 1242). These hospitals are located in distinct geographic regions outside of Taipei, allowing evaluation of model performance in diverse care settings and patient population. The NTUH-iMD includes clinical data from NTUH since January 2007, from the Yun-Lin Branch since February 2014, and from the Hsin-Chu Branch since November 2014. External validation cohorts were collected during different time periods than the derivation cohort, allowing for temporal validation. Disease diagnoses were coded using the International Classification of Diseases, Ninth Revision, Clinical Modification (ICD-9-CM) prior to 2016, and the International Classification of Diseases, Tenth Revision (ICD-10) from 2016 onward. Eligible patients were adults aged ≥20 years who received a new diagnosis of AF, identified from both outpatient and inpatient encounters. The index date was defined as the date of the initial AF diagnosis, either the date of the outpatient visit or the admission date of the index hospitalization, and marked the start of the follow-up period.
All personally identifiable information within NTUH-iMD was encrypted in accordance with Taiwanese data protection regulations. Data analyses were conducted using de-identified datasets. Given the retrospective nature of the study and the absence of direct patient involvement or influence on clinical care, informed consent was waived. The study protocol was reviewed and approved by the Research Ethics Committee of NTUH (No. 202010027RINA). To ensure fairness and generalizability, it is notable that AF management, including anticoagulation therapy and stroke-related care, is fully covered under Taiwan’s National Health Insurance program, which has a population coverage rate of approximately 99%. This universal coverage reduces access-related disparities in care, thereby enhancing fairness in outcome assessment and generalizability of the prediction models.
Predictors and outcomes
Demographic and clinical information, including age, sex, comorbidities, and medication use within six months prior to the index date, was extracted from the NTUH-iMD. All predictor variables were derived strictly from data recorded on or before the index date, using a 180-day look-back window to identify baseline characteristics. Laboratory values, such as complete blood cell counts and renal function indicators, were also collected when available. Comorbid conditions were identified using the Elixhauser comorbidity definitions40. To ensure model stability and clinical relevance, only comorbidities and medications with a prevalence greater than 2.5% were included in the final analysis. Features with prevalence between 1 and 2.5% were retained if their distribution suggested disproportionate enrichment in the outcome group. The CHA₂DS₂-VASc score was calculated for each patient on the index date. In addition to baseline predictors, DOAC use was recorded during the specified follow-up period or prior to the occurrence of stroke or death, and was used in subsequent stratified subgroup analyses. Patients were followed from the index date, defined as the date of initial AF diagnosis, until death or the end of the observation period (December 31, 2021), whichever occurred first. The primary outcome was the occurrence of ischemic stroke within 1 year after the index date. Only stroke events that occurred after the index date were included as outcomes. Events recorded on the same day as, or prior to, the index date were considered part of the patient’s clinical history and not counted as outcome events. Secondary outcomes included all-cause mortality within 1 year, as well as ischemic stroke and all-cause mortality within 3 and 5 years following the index date. Outcome and predictor data were extracted algorithmically from the NTUH-iMD, and blinding was not feasible. To reduce bias, definitions were standardized and applied uniformly across cohorts.
Statistical analysis
Baseline characteristics were reported as means with standard deviations (SD) for continuous variables and as counts with corresponding percentages for categorical variables. To assess potential selection bias related to missing laboratory data, comparisons between patients with and without available laboratory test results were performed using independent two-sample t-tests for continuous variables and Chi-square tests for categorical variables. SMDs were also calculated to quantify the magnitude of between-group differences. In the derivation cohort, the normality of the continuous variable was assessed using Kolmogorov–Smirnov test in the non-stroke group (N = 8063) and the Shapiro–Wilk test in the stroke group (N = 1448). As the only continuous variable, age was not normally distributed, differences between groups were compared using the Mann-Whitney U-test. Categorical variables were analyzed using the Chi-square test. Comparisons of baseline characteristics across the derivation and external validation cohorts were conducted using the Kruskal–Wallis test for continuous variables and the Chi-square test for categorical variables. When pairwise post hoc comparisons were necessary, Holm-adjusted p-values were applied to correct for multiple testing.
To evaluate whether the trained LR or XGB model exhibited overfitting, a bootstrap test with Bonferroni correction was used to compare the AUROC between 2 independent samples: the hold-out test set (20% of the derivation cohort) and each external validation cohort. This comparison was conducted separately for the LR and XGB models. DeLong’s test was applied to evaluate differences in the AUROC between models within each external validation cohort. Bonferroni correction was used to adjust for multiple comparisons across LR, XGB, and CHA₂DS₂-VASc models. This approach allowed formal evaluation of heterogeneity in model discrimination across derivation and external validation datasets. To assess long-term predictive utility and clinical interpretability, patients were stratified into high- and low-risk groups based on 1-year stroke risk predicted by either the LR model or the CHA₂DS₂-VASc score. Within each group, cumulative stroke incidence over 3 and 5 years was plotted by DOAC usage. Kaplan–Meier estimates were used, with stroke as the event of interest and censoring for competing risks. Differences between DOAC users and non-users were evaluated using the log-rank test. As this test does not account for competing risks (e.g., death), Gray’s test was additionally performed and reported in the Results section. All statistical analyses were conducted using R (version 4.4.0) with RStudio.
Model development and validation
Model development was conducted using the derivation cohort from NTUH in Taipei. Two supervised ML algorithms were employed: LR, selected for its strong clinical interpretability, and XGB, chosen for its ability to model complex non-linear relationships. Both models were developed using structured clinical variables, including age, sex, clinical history, and medication use, to ensure generalizability and ease of clinical integration.
For the LR model, feature selection was performed using a stepwise strategy based on the BIC41. The process was repeated across multiple randomized subsets of predictors, with all possible feature combinations (up to 12 features per subset) evaluated using logistic regression. The combination with the lowest BIC in each iteration was selected. Features that appeared in at least 3 iterations were retained in the final model to balance model parsimony and performance. Continuous variables were standardized using z-score transformation to ensure comparability of coefficient estimates in the LR model. For the XGB model, predictors were ranked according to gain-based feature importance. To determine the optimal number of features, models were iteratively trained using an increasing number of top-ranked predictors, and the configuration yielding the highest cross-validated AUROC was selected. Hyperparameter tuning for both models was performed using grid search with 5-fold cross-validation. Class imbalance was addressed using built-in parameters specific to each algorithm. A complete list of hyperparameters is provided in Supplementary Table 2.
Internal validation was performed using a hold-out test set (20% of the derivation cohort), and external validation was conducted using two independent cohorts from the NTUH Hsin-Chu Branch (external cohort 1; n = 1300) and the NTUH Yun-Lin Branch (external cohort 2; n = 1242). Model predictions were generated using the predict_proba() method from the scikit-learn LogisticRegression model and the XGBClassifier in the xgboost library. For both models, the predicted probabilities of 1-year stroke occurrence (i.e., positive class) were used as the primary output. To compute classification metrics (e.g., accuracy, sensitivity, specificity), a probability threshold of 0.5 was applied. This threshold was chosen as a conventional default to reflect clinical decision points and allow comparison across models.
Primary model performance was assessed using the AUROC, while the AUPRC was used to evaluate the trade-off between precision and recall in the context of class imbalance. 95% CIs were calculated via bootstrapping. Additional discrimination metrics at a threshold of 0.5, including accuracy, sensitivity, specificity, precision, and F1 score, were reported (Supplementary Table 3). Model calibration was evaluated using Brier scores and calibration curves. The Brier score quantified the overall accuracy of probabilistic predictions, while calibration curves visually assessed the agreement between predicted probabilities and observed outcomes across risk strata. For the LR model, no post-hoc calibration (e.g., slope or intercept adjustment) was performed, as it demonstrated adequate calibration during internal validation. In contrast, to improve probability calibration, Platt scaling (sigmoid calibration) was applied to the final XGB model using the calibration subset42. The CHA₂DS₂-VASc score served as the benchmark for comparison across all cohorts, with its scoring criteria detailed in Supplementary Table 4.
Sensitivity and subgroup analyses
Since ischemic stroke plays a role as both a predictor (prior stroke history) and an outcome (post-AF stroke event), a sensitivity analysis was conducted to further reduce the risk of reverse causality or early misclassification by excluding outcome events that occurred within the first 3 days after AF diagnosis. To assess model fairness, we pooled the two external cohorts (n = 2542), stratified patients by sex (female n = 1138; male n = 1404), and compared discrimination (AUROC) and calibration (Brier score) between subgroups. An unpaired DeLong test was used to evaluate whether observed AUROC differences were statistically significant. Additionally, we conducted a subgroup analysis by stratifying the validation cohort based on the presence (n = 406) or absence (n = 2136) of prior ischemic stroke at baseline. This analysis evaluated model performance in stroke-naïve versus stroke-experienced patients and assessed whether prior stroke history significantly influenced discrimination metrics.
Clinical utility and interpretability
To assess the clinical utility of the prediction models, DCA was performed to quantify the net benefit of model-guided decisions across a range of threshold probabilities, expressed per 1000 patients43. The net benefits of the LR and XGB models were compared with those of the CHA₂DS₂-VASc score and with default strategies of treating all or no patients44. Net benefit reflects the number of additional patients correctly identified for treatment per 1000, accounting for the trade-off between true positives and the harm of false positives at each threshold. Additionally, NRI was calculated to evaluate whether the ML-based models improved individual risk stratification compared to the CHA₂DS₂-VASc score45. All model development, validation, and clinical utility analyses were conducted using Python (version 3.12) within Jupyter Notebook.
To assess longer-term predictive utility and clinical interpretability, patients were stratified into high- and low-risk groups based on the predicted 1-year stroke risk generated by either the LR model using a threshold of 0.2, or the CHA₂DS₂-VASc score. The 0.2 cutoff was selected based on supporting evidence from both the NRI and DCA. NRI values remained robust between thresholds of 0.2 and 0.6 across external validation cohorts, while higher thresholds showed diminished or even negative reclassification performance (Supplementary Table 5). Similarly, DCA plots demonstrated that a threshold near 0.2 yielded the highest net clinical benefit per 1000 patients (Fig. 4). Within each risk stratum, cumulative incidence curves of ischemic stroke were plotted over 3-year and 5-year follow-up periods, further stratified by DOAC usage. These visualizations were used to examine whether model-derived risk classifications aligned with clinical outcomes and anticoagulant prescribing patterns over time.
Finally, to support clinical integration and user-centered interpretability, individual-level risk predictions were incorporated into a prototype decision support tool. A web-based interactive interface was developed using Python Streamlit, allowing clinicians to visualize patient-specific stroke risk estimates and risk strata. A demonstration video of the interface is provided in the Supplementary Material to illustrate potential clinical deployment and shared decision-making scenarios.
Data availability
Access to the NTUH-iMD is managed by the Integrative Medical Data Center at National Taiwan University Hospital (NTUH) and requires approval from the NTUH Research Ethics Committee. Due to the sensitive nature of the database, data sharing is not permitted under current regulations.
Code availability
The primary Python code used for model development, validation, and clinical utility assessment is available in Jupyter Notebook format and maintained in the GitHub repository Stroke-Prediction-in-AF, accessible at: https://github.com/Jesse-cwl/Stroke-Prediction-in-AF.git.
References
Linz, D. et al. Atrial fibrillation: epidemiology, screening and digital health. Lancet Reg. Health Eur. 37, 100786 (2024).
Lippi, G., Sanchis-Gomar, F. & Cervellin, G. Global epidemiology of atrial fibrillation: an increasing epidemic and public health challenge. Int. J. Stroke 16, 217–221 (2021).
Escudero-Martinez, I., Morales-Caba, L. & Segura, T. Atrial fibrillation and stroke: a review and new insights. Trends Cardiovasc. Med. 33, 23–29 (2023).
Kornej, J., Borschel, C. S., Benjamin, E. J. & Schnabel, R. B. Epidemiology of atrial fibrillation in the 21st century: novel methods and new insights. Circ. Res. 127, 4–20 (2020).
Alberts, M. et al. Risks of stroke and mortality in atrial fibrillation patients treated with rivaroxaban and warfarin. Stroke 51, 549–555 (2020).
Garcia, D. A. et al. Apixaban versus warfarin in patients with atrial fibrillation according to prior warfarin use: results from the Apixaban for Reduction in Stroke and Other Thromboembolic Events in Atrial Fibrillation trial. Am. Heart J. 166, 549–558 (2013).
Bai, Y., Shantsila, A. & Lip, G. Y. H. Response by Bai et al to letter regarding article, “rivaroxaban versus dabigatran or warfarin in real-world studies of stroke prevention in atrial fibrillation: systematic review and meta-analysis. Stroke 48, e149 (2017).
Ding, W. Y. et al. Incidence and risk factors for residual adverse events despite anticoagulation in atrial fibrillation: results from phase II/III of the GLORIA-AF registry. J. Am. Heart Assoc. 11, e026410 (2022).
Almutairi, A. R. et al. Effectiveness and safety of non-vitamin k antagonist oral anticoagulants for atrial fibrillation and venous thromboembolism: a systematic review and meta-analyses. Clin. Ther. 39, 1456–1478.e1436 (2017).
Chao, T.-F., Potpara, T. S. & Lip, G. Y. H. Atrial fibrillation: stroke prevention. Lancet Reg. Health Eur. 37, 100797 (2024).
Chao, T. F. et al. Comparisons of CHADS2 and CHA2DS2-VASc scores for stroke risk stratification in atrial fibrillation: which scoring system should be used for Asians? Heart Rhythm 13, 46–53 (2016).
Joglar, J. A. et al. 2023 ACC/AHA/ACCP/HRS guideline for the diagnosis and management of atrial fibrillation: a report of the american college of cardiology/american heart association joint committee on clinical practice guidelines. Circulation 149, e1–e156 (2024).
Siddiqi, T. J. et al. Utility of the CHA2DS2-VASc score for predicting ischaemic stroke in patients with or without atrial fibrillation: a systematic review and meta-analysis. Eur. J. Prev. Cardiol. 29, 625–631 (2022).
Teppo, K. et al. Comparing CHA2DS2-VA and CHA2DS2-VASc scores for stroke risk stratification in patients with atrial fibrillation: a temporal trends analysis from the retrospective Finnish AntiCoagulation in Atrial Fibrillation (FinACAF) cohort. Lancet Reg. Health Eur. 43, 100967 (2024).
Goh, B. & Bhaskar, S. M. Evaluating machine learning models for stroke prognosis and prediction in atrial fibrillation patients: a comprehensive meta-analysis. Diagnostics 14, 2391 (2024).
Xiong, W. et al. Machine-learning model for predicting left atrial thrombus in patients with paroxysmal atrial fibrillation. BMC Cardiovasc Disord. 25, 429 (2025).
Bernardini, A. et al. Machine learning approach for prediction of outcomes in anticoagulated patients with atrial fibrillation. Int. J. Cardiol. 407, 132088 (2024).
Lu, J. et al. Performance of multilabel machine learning models and risk stratification schemas for predicting stroke and bleeding risk in patients with non-valvular atrial fibrillation. Comput. Biol. Med. 150, 106126 (2022).
Daidone, M., Ferrantelli, S. & Tuttolomondo, A. Machine learning applications in stroke medicine: advancements, challenges, and future prospectives. Neural Regen. Res. 19, 769–773 (2024).
Truong, B. et al. Development and validation of machine learning algorithms to predict 1-year ischemic stroke and bleeding events in patients with atrial fibrillation and cancer. Cardiovasc. Toxicol. 24, 365–374 (2024).
Nielsen, P. B., Brondum, R. F., Nohr, A. K., Overvad, T. F. & Lip, G. Y. H. Risk of stroke in male and female patients with atrial fibrillation in a nationwide cohort. Nat. Commun. 15, 6728 (2024).
Buhari, H. et al. Stroke risk in women with atrial fibrillation. Eur. Heart J. 45, 104–113 (2024).
Hijazi, Z. et al. The ABC (age, biomarkers, clinical history) stroke risk score: a biomarker-based risk score for predicting stroke in atrial fibrillation. Eur. Heart J. 37, 1582–1590 (2016).
Rivera-Caravaca, J. M. et al. Long-term stroke risk prediction in patients with atrial fibrillation: comparison of the ABC-Stroke and CHA2DS2-VASc scores. J. Am. Heart Assoc. 6, e006490 (2017).
Jung, S. et al. Predicting ischemic stroke in patients with atrial fibrillation using machine learning. Front. Biosci. 27, 80 (2022).
Papadopoulou, A., Harding, D., Slabaugh, G., Marouli, E. & Deloukas, P. Prediction of atrial fibrillation and stroke using machine learning models in UK Biobank. Heliyon 10, e28034 (2024).
Zhang, R. et al. Hemoglobin concentration and clinical outcomes after acute ischemic stroke or transient ischemic attack. J. Am. Heart Assoc. 10, e022547 (2021).
Abramson, J. L., Jurkovitz, C. T., Vaccarino, V., Weintraub, W. S. & McClellan, W. Chronic kidney disease, anemia, and incident stroke in a middle-aged, community-based population: the ARIC Study. Kidney Int 64, 610–615 (2003).
Guyon, I. & Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 3, 1157–1182 (2003).
Naghavi, M. et al. AI-Enabled CT cardiac chamber volumetry predicts atrial fibrillation and stroke comparable to MRI. JACC Adv. 3, 101300 (2024).
Khurshid, S. et al. ECG-Based deep learning and clinical risk factors to predict atrial fibrillation. Circulation 145, 122–133 (2022).
Wang, C., Deng, C. & Wang, S. Imbalance-XGBoost: leveraging weighted and focal losses for binary label-imbalanced classification with XGBoost. Pattern Recognit. Lett. 136, 190–197 (2020).
Vandewiele, G. et al. Overly optimistic prediction results on imbalanced data: a case study of flaws and benefits when applying over-sampling. Artif. Intell. Med. 111, 101987 (2021).
Van den Goorbergh, R., van Smeden, M., Timmerman, D. & Van Calster, B. The harm of class imbalance corrections for risk prediction models: illustration and simulation using logistic regression. J. Am. Med. Inf. Assoc. 29, 1525–1534 (2022).
Li, Z. Extracting spatial effects from machine learning model using local interpretation method: An example of SHAP and XGBoost. Comput. Environ. Urban Syst. 96, 101845 (2022).
Chong, J., Leung, B. & Poole, P. Phosphodiesterase 4 inhibitors for chronic obstructive pulmonary disease. Cochrane Database Syst. Rev. 9, CD002309 (2017).
Son, M. K., Lim, N.-K., Kim, H. W. & Park, H.-Y. Risk of ischemic stroke after atrial fibrillation diagnosis: a national sample cohort. PloS one 12, e0179687 (2017).
Putaala, J. et al. Ischemic stroke temporally associated with new-onset atrial fibrillation: a population-based registry-linkage study. Stroke 55, 122–130 (2024).
Collins, G. S. et al. TRIPOD+ AI statement: updated guidance for reporting clinical prediction models that use regression or machine learning methods. BMJ 385, q902 (2024).
Quan, H. et al. Coding algorithms for defining comorbidities in ICD-9-CM and ICD-10 administrative data. Med Care 43, 1130–1139 (2005).
Wah, Y. B., Ibrahim, N., Hamid, H. A., Abdul-Rahman, S. & Fong, S. Feature selection methods: Case of filter and wrapper approaches for maximising classification accuracy. Pertanika J. Sci. Technol. 26, 329–340 (2018).
Ojeda, F. M. et al. Calibrating machine learning approaches for probability estimation: A comprehensive comparison. Stat. Med. 42, 5451–5478 (2023).
Vickers, A. J., van Calster, B. & Steyerberg, E. W. A simple, step-by-step guide to interpreting decision curve analysis. Diagn. Progn. Res. 3, 18 (2019).
Vickers, A. J., Van Calster, B. & Steyerberg, E. W. Net benefit approaches to the evaluation of prediction models, molecular markers, and diagnostic tests. BMJ 352, i6 (2016).
Leening, M. J., Vedder, M. M., Witteman, J. C., Pencina, M. J. & Steyerberg, E. W. Net reclassification improvement: computation, interpretation, and controversies: a literature review and clinician’s guide. Ann. Intern Med. 160, 122–131 (2014).
Acknowledgements
We express our gratitude to the staff of the Department of Medical Research, NTUH, for their assistance and approval in utilizing the NTUH-iMD. We thank Dr. Chi-Sheng Hung at the Department of Internal Medicine, NTUH, and Dr. Zheng-Wei Chen at the Department of Internal Medicine, NTUH Yun-Lin Branch for their assistance in the application of the NTUH-iMD. This work was supported by NTUH Hsin-Chu Branch (Grant numbers [110-HCH023] and [111-HCH057]).
Author information
Authors and Affiliations
Contributions
J.C.W.L. and C.L.L. conceptualized the study. C.L.L. and Y.L.H. supervised the project. J.C.W.L. and H.Y.P. devised and created the cohort datasets. J.C.W.L. and C.L.L. devised the analytic methods. J.C.W.L. and C.M.C. carried out the analysis and produced the plots, graphics and supplementary video and developed the web-based interactive prototype. J.C.W.L., C.L.L. and Y.K.T. verifying the underlying data reported in the paper. J.C.W.L. wrote the first draft of the paper. C.L.L., C.M.C. and Y.K.T. made critical comments regarding the paper. C.L.L. contributed medical expertise regarding the medical interpretation of the findings. J.C.W.L., C.L.L., Y.K.T., C.M.C., H.Y.P., and Y.L.H. conducted reviewing and editing of the paper. All authors read and approved the final paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Lin, J.CW., Chang, CM., Pan, HY. et al. Interpretable machine learning models for stroke risk prediction in patients with newly diagnosed atrial fibrillation. npj Digit. Med. 9, 289 (2026). https://doi.org/10.1038/s41746-026-02470-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41746-026-02470-3
