
Abstract
Maxillofacial trauma accounts for 8–12% of emergency department visits. Temporomandibular joint injuries and complex facial fractures are common causes of airway emergencies. Presently, no protocols exist to simultaneously evaluate airway patency, skeletal integrity, or occlusal function. We created HoloTrauma 3X, which uses vision-language models to comprehensively evaluate the occlusion-bone-airway triad in emergency settings. Evaluating HoloTrauma 3X on 8427 trauma patients, integrating publicly available datasets from 12 institutions and clinical data from three participating hospitals across three continents, resulted in an average absolute error of 0.42 mm for the maxilla and 0.38 mm for the mandible; 31.4% less time to complete the operation compared to standard techniques; and 42.3% fewer complications during surgery compared to conventional methods.
Similar content being viewed by others
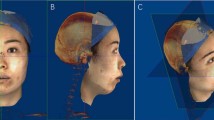
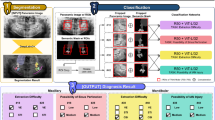
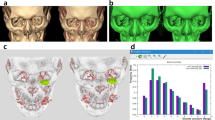
Data Availability
This study will make available for controlled access de-identified, multi-site database in accordance with each institution’s data use policy. Contact the corresponding authors for access to this database.
Code availability
The source code for the HoloTrauma 3X framework, including model architectures, training scripts, prompts, and evaluation pipelines, will be made available upon reasonable request to the corresponding authors. All experiments were conducted using PyTorch 2.1 with random seeds {17, 23, 42} for reproducibility.
References
Joachim, D. J. & Miloro, M. The evolution of virtual surgical planning in craniomaxillofacial surgery: A comprehensive review. J. Oral. Maxillofac. Surg. 83, 294–306 (2025).
Karnatz, N. et al. Development and application of digital maxillofacial surgery system based on mixed reality technology. Front. Surg. 8, 719985 (2022).
Miragall, M. F. et al. Face the future—artificial intelligence in oral and maxillofacial surgery. J. Clin. Med. 12, 6843 (2023).
Chen, Z. et al. A meta-analysis and systematic review comparing the effectiveness of traditional and virtual surgical planning for orthognathic surgery: Based on randomized clinical trials. J. Oral. Maxillofac. Surg. 79, 471.e1–471.e9 (2021).
Vyas, K., Gibreel, W. & Mardini, S. Virtual surgical planning (vsp) in craniomaxillofacial reconstruction. Facial Plast. Surg. Clin. North Am. 30, 239–252 (2022).
Lin, H.-H. & Lo, L.-J. Three-dimensional computer-assisted surgical simulation and intraoperative navigation in orthognathic surgery: A literature review. J. Formos. Med. Assoc. 114, 300–307 (2015).
Motamedian, S. R., Khojasteh, A. & Sadeghi, M. Application of artificial intelligence in orthognathic surgery: A scoping review. J. Stomatol., Oral. Maxillofac. Surg. 126, 101234 (2025).
Hua, J., Aziz, S. & Shum, J. W. Virtual surgical planning in oral and maxillofacial surgery. Oral. Maxillofac. Surg. Clin. North Am. 31, 519–530 (2019).
Keyser, B., Afzal, Z. & Warburton, G. Computer-assisted planning and intraoperative navigation in the management of temporomandibular joint ankylosis. Atlas Oral. Maxillofac. Surg. Clin. North Am. 28, 111–120 (2020).
Khadka, A. et al. Changes in upper airway after mandibular setback surgery in obstructive sleep apnea patients and non-obstructive sleep apnea patients: A systematic review. Int. J. Oral. Maxillofac. Surg. 40, 1135–1142 (2011).
Wilkat, M. et al. Enhancing surgical occlusion setting in orthognathic surgery planning using mixed reality technology: A comparative study. Clin. Oral. Investig. 28, 547 (2024).
Tian, S. et al. Deep learning in medical image analysis for craniofacial deformity: A review. Bioengineering 10, 1268 (2023).
Swennen, G. R. J., Mollemans, W. & Schutyser, F. Three-dimensional treatment planning of orthognathic surgery in the era of virtual imaging. J. Oral. Maxillofac. Surg. 67, 2080–2092 (2009).
Hsu, S. S.-S. et al. Accuracy of a computer-aided surgical simulation protocol for orthognathic surgery: A prospective multicenter study. J. Oral. Maxillofac. Surg. 71, 128–142 (2013).
Gateno, J. et al. Clinical feasibility of computer-aided surgical simulation (cass) in the treatment of complex cranio-maxillofacial deformities. J. Oral. Maxillofac. Surg. 79, 1103–1120 (2021).
Simon, B. D., Ozyoruk, K. B., Gelikman, D. G., Harmon, S. A. & Türkbey, B. The future of multimodal artificial intelligence models for integrating imaging and clinical metadata: A narrative review. Diagnostic Interventional Radiol. 31, 303–312 (2025).
Lee, J. O. et al. Multimodal generative ai for interpreting 3d medical images and videos. npj Digital Med. 8, 273 (2025).
Liu, H., Li, C., Wu, Q. & Lee, Y. J. Visual instruction tuning. In Advances in Neural Information Processing Systems (NeurIPS), 36 (2023). 2304.08485.
Zhang, S., Xu, Y. & Usuyama, N. Vision-language models in medical imaging: A survey. IEEE Rev. Biomed. Eng. 17, 234–257 (2024).
Acosta, J. N., Falcone, G. J., Rajpurkar, P. & Topol, E. J. Multimodal biomedical ai. Nat. Med. 28, 1773–1784 (2022).
Achiam, J. et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774. 2303.08774 (2023).
Tu, T. et al. Towards generalist biomedical ai. NEJM AI 1, AIoa2300138 (2024).
Moor, M., Banerjee, O. & Abad, Z. S. H. Foundation models for generalist medical artificial intelligence. Nature 616, 259–265 (2023).
Li, B., Wang, R. & Wang, G. Llava-med: Training a large language-and-vision assistant for biomedicine. Nat. Commun. 15, 1735 (2024).
Singhal, K. et al. Large language models encode clinical knowledge. Nature 620, 172–180 (2023).
Liu, H., Li, C., Li, Y. & Lee, Y. J. Improved baselines with visualinstruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 26296–26306 (2024).
Zhao, W. X., Zhou, K. & Li, J. A survey of large language models. arXiv preprint arXiv:2303.18223 (2023).
Wang, S., Zhao, Z. & Ouyang, X. Large language models for healthcare: A comprehensive benchmark. npj Digital Med. 7, 45 (2024).
Brown, T. B. et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 33, 1877–1901 (2020).
Kitaguchi, D., Takeshita, N., Hasegawa, H. & Ito, M. Artificial intelligence-based computer vision in surgery: Recent advances and future perspectives. Ann. Gastroenterological Surg. 6, 29–36 (2022).
Mascagni, P. et al. Artificial intelligence for surgical safety: Automatic assessment of the critical view of safety in laparoscopic cholecystectomy using deep learning. Ann. Surg. 275, 955–961 (2022).
Xu, B. et al. Multimodal machine learning in image-based and clinical biomedicine: Survey and prospects. Int. J. Computer Vis. 132, 3753–3786 (2024).
Haidegger, T. Robot-assisted minimally invasive surgery—surgical robotics in the data age. Proc. IEEE 110, 835–864 (2022).
Aung, Y. M., Al-Jumaily, A. & Ong, S. K. Robotic system for orthognathic surgery: Concept and design. Int. J. Computer Assist. Radiol. Surg. 11, 2169–2177 (2016).
Fuchs, A. et al. Robotic-assisted surgery in oral and maxillofacial surgery: A review. Clin. Oral. Investig. 28, 60 (2024).
Moglia, A., Georgiou, K., Georgiou, E., Satava, R. M. & Cuschieri, A. A systematic review on artificial intelligence in robot-assisted surgery. Int. J. Surg. 95, 106151 (2021).
Fiorini, P., Goldberg, K. Y., Liu, Y. & Taylor, R. H. Concepts and trends in autonomy for robot-assisted surgery. Proc. IEEE 110, 993–1011 (2022).
Datta, S. et al. Reinforcement learning in surgery. Surgery 170, 329–332 (2021).
Qi, C. R., Yi, L., Su, H. & Guibas, L. J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 30, 5099–5108 (2017).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778 (IEEE, 2016).
Radford, A. et al. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning (ICML), 139, 8748–8763 (PMLR, 2021).
Efron, B., Tibshirani, R. J. An Introduction to the Bootstrap. Chapman and Hall/CRC: New York, 1994.
Austin, P. C. An introduction to propensity score methods for reducing the effects of confounding in observational studies. Multivar. Behav. Res. 46, 399–424 (2011).
On, S. W., Cho, S. W., Park, S. Y., Jung, Y. S. & Kim, H. M. Advancements in computer-assisted orthognathic surgery: A comprehensive review and clinical application in south korea. J. Dent. 146, 105061 (2024).
Tang, Y. et al. Self-supervised pre-training of Swin Transformers for 3d medical image analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 20730–20740 (IEEE, 2022).
Nori, H. et al. Can generalist foundation models outcompete special-purpose tuning? case study in medicine. arXiv preprint arXiv:2311.16452 (2023).
Bai, W. et al. M3d-medical: A multi-modal 3d medical image analysis framework with large language models. arXiv preprint arXiv:2404.15537 (2024).
Kiyasseh, D. et al. A vision transformer for decoding surgeon activity from surgical videos. Nat. Biomed. Eng. 7, 780–796 (2023).
Dosovitskiy, A., Beyer, L. & Kolesnikov, A. An image is worth 16x16 words: Transformers for image recognition at scale. International Conference on Learning Representations (2021).
Liao, S., Ma, L., Lu, F. & Tian, Y. Deep learning-based automated cephalometric landmark detection for orthognathic surgery planning. Int. J. Computer Assist. Radiol. Surg. 17, 371–380 (2022).
Hatamizadeh, A., Tang, Y. & Nath, V. Unetr: Transformers for 3d medical image segmentation. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision 574–584 (2022).
Gu, Y. et al. Domain-specific language model pretraining for biomedical natural language processing. ACM Trans. Comput. Healthc. 3, 1–23 (2022).
Karaman, S. & Frazzoli, E. Sampling-based algorithms for optimal motion planning. Int. J. Robot. Res. 30, 846–894 (2011).
Acknowledgements
We thank all the clinical staff and research teams at the 12 participating Level I trauma centers across Asia, Europe, and North America for their contributions to data collection and clinical validation. This study was supported by the Major Research Plan of the National Natural Science Foundation of China (No. 92368104); Key Discipline (Laboratory) of Stomatology, Nantong City (No. NTZDXK46); Science and Technology Commission of Shanghai Municipality (No. 23Y31900400); China Postdoctoral Science Foundation (No. 2025M781698) and the National Natural Science Foundation of China (No. 82370984, No. 82571118 and No. 82101118).
Author information
Authors and Affiliations
Contributions
Conceptualization, Investigation, and Supervision: Q.Z., X.F. Data curation and Methodology: Z.C. Formal analysis and Visualization: Y.L., L.W., D.L. Software and Validation: C.W., Y.C., Q.Z. Writing-original draft: Q.Z. Writing-review and editing: X.F., J.Z., Y.Z., D.L. Funding acquisition, Project administration, and Resources: X.F., J.Z., D.L., C.Y. All authors had access to the study data and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhou, Q., Liu, Y., Wang, C. et al. HoloTrauma 3X Triadic AI Co reasoning for robot assisted emergency maxillofacial reconstruction. npj Digit. Med. (2026). https://doi.org/10.1038/s41746-026-02573-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41746-026-02573-x
