
Abstract
Many microorganisms swim by performing larger non-reciprocal shape deformations that are initiated locally by molecular motors. However, it remains unclear how decentralized shape control determines the movement of the entire organism. Here, we investigate how efficient locomotion emerges from coordinated yet simple and decentralized decision-making of the body parts using neuroevolution techniques. Our approach allows us to investigate optimal locomotion policies for increasingly large microswimmer bodies, with emerging long-wavelength body shape deformations corresponding to surprisingly efficient swimming gaits. The obtained decentralized policies are robust and tolerant concerning morphological changes or defects and can be applied to artificial microswimmers for cargo transport or drug delivery applications without further optimization “out of the box”. Our work is of relevance to understanding and developing robust navigation strategies of biological and artificial microswimmers and, in a broader context, for understanding emergent levels of individuality and the role of collective intelligence in Artificial Life.
Similar content being viewed by others
Introduction
Microorganisms are ubiquitous in nature and play an essential role in many biological phenomena, ranging from pathogenic bacteria affecting our health to phytoplankton as a key player in the marine ecosystem on a global scale. A large variety of microorganisms live in viscous environments, and their motion is governed by the physics of low Reynolds number hydrodynamics, where viscous forces dominate over inertia1,2,3,4. As a consequence, a common strategy is to periodically deform their body shape in a non-reciprocal fashion to swim. To thrive in the environment, they have developed different tailored strategies to exploit their swimming capabilities, such as actively navigating toward a nutrient-rich source, hunting down prey, escaping predators, or reproducing5,6. Besides being of direct biological relevance, understanding the corresponding navigation strategies of microorganisms bears potential for biomedical or technical applications, potentially utilized by synthetic microswimmers deployed as targeted drug delivery systems7,8,9,10.
Nature has evolved many different strategies and control mechanisms for microswimmers to swim fast, efficiently, and adaptive to environmental conditions5: For example, swimming algae cells or sperm cells move with the help of waving cilia or flagella11, respectively, or amoebae such as Dictyostelium12 and unicellular protists such as Euglenia13 by deforming their entire cell body. The associated deformation amplitudes and wavelengths can be on the order of the entire size of the organism.
In the last years, Reinforcement Learning14 (RL) has been applied to understand navigation strategies of microswimmers15,16, for example under external fluid flow17 or external fields18, or to perform chemotaxis in the presence of chemical gradients19,20,21,22,23. So far, most of these studies treat microswimmers as rigid agents, i.e., explicitly omitting body deformations or other internal degrees of freedom, and simply manipulate their ad hoc swimming speed and rotation rates for control purposes to perform well in a particular environment. Only very recent contributions19,24,25,26,27,28,29 consider the constraints of physically force-free shape-deforming locomotion of plastic model microswimmers in an effort to identify swimming gaits that explicitly utilize the hydrodynamic interactions between different body parts in a viscous environment. Modeling such a body-brain-environment offers explicit and more realistic behavior of the response of an organism to environmental conditions30,31.
The locomotion of microswimmers and microrobots moving in viscous fluids at low Reynolds numbers can be modeled with various numerical methods of different accuracy. Examples for actively deforming slender filaments as they occur in biological systems or in soft robotics are slender body theory (e.g., ref. 32), or Cosserat rod models (e.g., refs. 33,34). Yet the simplest models, which usually outperform the aforementioned methods in terms of computation time, discretize a filament or a microswimmer by interconnected beads where hydrodynamic interactions are captured in the far-field limit, such as in the Oseen or Faxén approximation1. These models are particularly useful for Evolutionary Algorithms (EAs) in RL, which rely on the efficient simultaneous simulation of a whole population of microswimmers19.
A prominent and very simple and efficient model that has frequently been investigated with RL techniques is the (generalized) Najafi-Golestanian (NG) microswimmer35,36,37, typically consisting of N = 3 (or more) concentrically aligned beads immersed into a viscous environment. Such a composite N-bead NG microswimmer can self-propel via nonreciprocal periodic shape deformations that are induced by coordinated time-dependent periodic forces applied to every bead, which sum up to zero for force-free microswimmers. Conventional strategies to describe the autonomous locomotion of a microswimmer consisting of hydrodynamically interacting beads utilize a centralized controller that integrates all the information about the current state of the microswimmer in its environment (comprising internal degrees of freedom and potential environmental cues such as chemical field concentrations). As such, it proposes control instructions for every actuator in the system, thereby inducing dynamics, i.e., body deformations, that are most optimal for a specific situation given a particular task19,24,28. To substitute and mimic the complex and adaptable decision-making machinery of biological microswimmers, such controllers are often realized by trainable Artificial Neural Networks (ANNs).
Centralized decision-making relies on the (sensory) input of all individual body parts of a composite microswimmer, i.e., quantities such as the relative positions, velocities, or other degrees of freedom for all N beads, and the corresponding control actions target all system actuators, i.e., what forces to apply to every one of the N beads. While the number of trainable parameters of a controller ANN scales at least quadratically with the number of beads N, the number of possible perceivable states and controlling actions scales in a combinatorial way with the number of degrees of freedom of the sensory input and the action output. This not only immensely complicates deep-learning procedures14 but essentially renders exhaustive approaches infeasible given the vast combinatorial space of possible input-output mappings for large N. Thus, while generalized NG swimmers with N ≥ 3 have been successfully trained to perform locomotion or chemotaxis tasks19,24,28, they have been limited to a relatively small number of body parts, i.e., a small number of degrees of freedom, N ≲ 10, so far.
However, even unicellular organisms are fundamentally made of (many) different parts, which (co-)operate in a seamlessly coordinated way: in biological microswimmers, for example, collective large body deformations are typically achieved through orchestrated and cooperative action of molecular motors and other involved proteins, inducing, e.g., the local deformation of the cilia-forming axoneme via localized contractions and extensions5,38. Consequently, such organisms—without an apparent centralized controller—cooperatively utilize their body components in a fully self-orchestrated way in order to swim by collectively deforming and reconfiguring their body shape. For example, the periodically deforming shapes of eukaryotic flagella are not designed or pre-defined by cellular signals, but are an emerging property of the specific local forces applied by the molecular motors on the filament6,39. Moreover, such decentralized navigation policies tend to be robust and failure-tolerant with respect to changing morphological or environmental conditions, e.g., if parts of the locomotive components are disabled or missing, or unforeseeable situations are encountered. Strong signs of such generalizing problem-solving skills are observed, for example, in cells40, slime molds41, and swarms42,43, and, as recently suggested44, this fundamental ability of biological systems to self-organize via collective decision-making might be the unifying organizational principle for integrating biology across scales and substrates. Thus, the plastic and functional robustness and the innate drive for adaptability found in biological systems might not only further robotics45,46,47,48,49,50 but facilitate unconventional forms of computation based on collective intelligence51,52,53.
So far, it remains unclear how decentralized decision-making in a deformable microswimmer can lead to efficient collective locomotion of its body parts. We thus investigate biologically motivated decentralized yet collective decision-making strategies of the swimming behavior of a generalized NG swimmer, serving as a simple model system for, e.g., a unicellular organism, or a controllable swimming microrobot. Optimizing collective tasks in systems of artificial agents, such as collectively moving composite (micro)-robots54, can be addressed with Multi-Agent Reinforcement Learning (MARL). Typically employed concepts such as Centralized Training with Decentralized Execution (CTDE) often rely on the usage of overparameterized deep neural networks and complex information sharing across agents during training55,56,57. In contrast to conventional MARL we employ here a recently developed method58,59 which utilizes EAs to optimize lean decentralized control policies based on collective performance quantified by a global fitness signal (i.e., without the need for local credit assignment). Such collective agents have a topology reminiscent of Neural Cellular Automata60,61 (NCAs), where all distributed agents share the same ANN architecture while exchanging low-bandwidth information between neighbors on the grid of a cellular automaton to update their states and hence the collective behavior in the problem domain; here, the beads of a generalized NG swimmer will be treated as the cells of an NCA which will learn to coordinate locally to exert non-reciprocal bead-specific forces to propagate the collective microswimmer body. Furthermore, in our approach, we are able to overcome earlier limitations by extending our swimmers to much larger N than previously feasible, allowing us to identify locomotion strategies in the limit N→∞. To this end, we interpret each bead of the microswimmer’s body as an agent that can only perceive information about its adjacent beads and whose actions induce contractions or extensions of its adjacent muscles. We substitute the internal decision-making machinery of such single-bead agents with ANNs and employ genetic algorithms and neuroevolution to machine learn optimal policies for such single-bead decision-making centers, such that the entire N-bead swimmer can efficiently self-propel collectively, i.e., in a decentralized way. We show that the evolved policies are robust and failure-tolerant concerning morphological changes of the collective microswimmer and that such decentralized control—trained for microswimmers with a specific number of beads—generalizes well to vastly different morphologies.
Results and discussion
The \(N\)-bead swimmer model
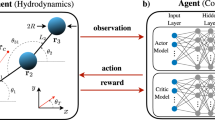
Here, we investigate swimming strategies optimized by RL and the corresponding physical implications of N-bead generalized NG35 swimmer models moving in a fluid of viscosity μ. A swimmer consists of N co-centrically aligned spheres of radius R located at positions xi(tk), i = 1…, N, at time tk. These beads are connected pairwise by massless arms of length li(tk) = xi+1(tk) − xi(tk), as illustrated in Fig. 1a. The swimmer deforms and moves by applying time-dependent forces \({F}_{i}({t}_{k})={F}_{i}^{a}({t}_{k})+{F}_{i}^{r}({t}_{k})\) on the beads. The active forces \({F}_{i}^{a}({t}_{k})\) are proposed by RL agents (see below), and passive restoring forces19\({F}_{i}^{r}({t}_{k})\) are applied when arm lengths li(tk) becomes smaller than 0.7L0 or lager than 1.3L0, where we choose L0 = 10R as the reference arm length. The swimmer is force-free, ∑iFi(tk) = 0, and the bead velocities vi(tk) are obtained in the Oseen approximation62, vi = Fi/(6πμR) + ∑j≠iFj/(4πμ∣xi − xj∣), (see the “Hydrodynamic interactions and numerical details for the N-bead swimmer model” subsection in the “Methods”).

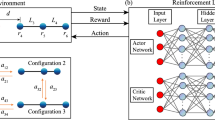
a Schematics of an N-bead microswimmer environment, with (b) functionally identical yet operationally independent Artificial Neural Networks (ANNs) acting as decentralized decision-making centers (or controllers) to update the respective internal states of the beads, si → si + Δsi (red arrows), and to apply bead-specific forces, Fi ∈ [−2F0, 2F0] (green arrows; ensuring ∑iFi = 0), such that the entire microswimmer self-propels purely based on local perception-action cycles of the constituting bead controllers. c The training progress of optimizing various N-bead microswimmer locomotion policies of type A (see the “Modeling system-level decision-making with decentralized controllers” subsection in the “Results and Discussion”), respectively identifying for predefined values of (N = 3 − 100) the parameters of the morphology-specific ANN controllers via evolutionary algorithms (EAs). The fitness score for different N, quantifying a specific N-bead center of mass velocity \(\bar{v}\) (see the “Modeling system-level decision-making with decentralized controllers” subsection in the “Results and Discussion”), is presented over 200 subsequent generations. Opaque-colored areas below the fitness trajectories indicate the corresponding STD of 10 independent EA searches per morphology and serve as a measure for convergence for the optimization process.
Modeling system-level decision-making with decentralized controllers
To identify the active forces \({F}_{i}^{a}({t}_{k})\) on the beads, we assign an ensemble of independent yet identical controllers to every bead which respectively can only perceive local information about adjacent beads (such as distances and velocities of their neighbors) and propose actions to update their respective states (such as proposing bead-specific forces to update their own positions). Yet, these bead-specific agents follow a shared objective to collectively self-propel the entire N-bead swimmer’s body. More specifically—as illustrated in Fig. 1 and detailed in the “Artificial neural network-based decentralized controllers” subsection in the “Methods”—for each time tk the controller associated with the bead i perceives its left- and right-neighbor distances, \({{{{{\mathcal{L}}}}}}_{i}({t}_{k})=\{{l}_{i}({t}_{k}),{l}_{i+1}({t}_{k})\}\), and its own- and the neighboring beads’ velocities \({{{{{\mathcal{V}}}}}}_{i}({t}_{k})=\{{v}_{i-1}({t}_{k}),{v}_{i}({t}_{k}),{v}_{i+1}({t}_{k})\}\). Moreover, each bead maintains an internal vector-valued state, si(tk). This state can be utilized by the respective controller to store, update, and actively share recurrent information with other beads that is not necessarily bound to the physical state of the swimmer but an emergent property of the collective RL system: Every controller thus perceives its neighboring states, \({{{{{\mathcal{S}}}}}}_{i}({t}_{k})=\{{{{{{\bf{s}}}}}}_{i-1}({t}_{k}),{{{{{\bf{s}}}}}}_{i}({t}_{k}),{{{{{\bf{s}}}}}}_{i+1}({t}_{k})\}\), which additionally guide the agent’s decision-making (see “Methods” and ref. 58 for details). In total, the perception of a single bead agent is given by \({{{{{\bf{p}}}}}}_{i}({t}_{k})=\{{{{{{\mathcal{L}}}}}}_{i}({t}_{k}),{{{{{\mathcal{V}}}}}}_{i}({t}_{k}),{{{{{\mathcal{S}}}}}}_{i}({t}_{k})\}\) and does not contain any agent-specific or global reward signals.
After integrating information about its local environment, pi(tk), the controller of each bead i computes, and then outputs an action, ai(tk) = {ϕi(tk), Δsi(tk)}, comprising a proposed active force, ϕi(tk), and an internal state update, si(tk+1) = si(tk) + Δsi(tk) (see Fig. 1b); this extends the purely state si-dependent inverse pattern formation task discussed in ref. 58 with local perception-action loops in a hydrodynamic environment. The proposed forces are limited to ϕi(tk) ∈ [−F0, F0] by clamping the controllers’ force outputs to ±F0, where F0 sets the force scale in our system and hence the maximum power consumption and bead velocities of the swimmer.
To model a force-free swimmer, we propose two different methods of how the mapping between the proposed forces ϕi(tk), and the actual active forces \({F}_{i}^{a}({t}_{k})\), is achieved: First, we interpret the proposed forces as pairwise arm forces ϕi(tk) and −ϕi(tk) applied between two consecutive beads i and i + 1, respectively (see Fig. 2a). This leads to the actual active forces \({F}_{i}^{a}({t}_{k})={\phi }_{i}({t}_{k})-{\phi }_{i-1}({t}_{k})\) for beads i = 1…, N, where we treat the swimmer’s “head” and “tail” separately by setting ϕN(tk) = 0 and introducing ϕ0(tk) = 0. This automatically ensures \({\sum }_{i = 1}^{N}{F}_{i}^{a}({t}_{k})=0\). In this sense, the proposed actions can be understood as local decisions to expand/contract muscles between the beads where the maximum local power input on a bead is constrained and set by the value of F0. Second, we assume that the proposed force ϕi(tk) of every controller directly targets the actual force applied to its associated bead, but, to fulfill the force-free condition, we subtract the mean \(\bar{\phi }({t}_{k})=\frac{1}{N}\mathop{\sum }_{j = 1}^{N}{\phi }_{j}({t}_{k})\) from every proposed force and arrive at \({F}_{i}^{a}({t}_{k})={\phi }_{i}({t}_{k})-\bar{\phi }({t}_{k})\) (see Fig. 2b). Hence the first approach ensures the global force-free condition via a series of locally annihilating pair-forces motivated by biological force dipole generation at small scales that cause the arms between the corresponding beads i and (i + 1) to contract or extend. In turn, the second approach regularizes the forces by collective feedback (via \(\bar{\phi }({t}_{k})\)) and can be interpreted as a mean-field approach that may be utilized by external controllers for artificial microswimmers63. Henceforth, we refer to the first scenario as type A, and to the second scenario as type B microswimmers, and alike for the corresponding self-navigation strategies or policies. We note that for both type A and B microswimmers the total force per bead is constrained to Fi(tk) ∈ [−2F0, 2F0], except for the first and last bead of type A which are only connected to a single muscle such that for type A swimmers F1(tk) and FN(tk) ∈ [−F0, F0].

a Schematics by interpreting the actions as force-pairs \({F}_{i}^{a}({t}_{k})={\phi }_{i}({t}_{k})-{\phi }_{i-1}({t}_{k})\) between neighboring beads (type A microswimmers). b Schematics by subtracting the global average \(\bar{\phi }({t}_{k})=\frac{1}{N}\mathop{\sum }_{i = 1}^{N}{\phi }_{i}({t}_{k})\) from every proposed, bead-specific action \({F}_{i}^{a}({t}_{k})=\left({\phi }_{i}({t}_{k})-\bar{\phi }({t}_{k})\right)\) (type B microswimmers).
Following RL terminology, we refer to the mapping between perceptions and actions of an agent (or here, synonymously, a controller) as its policy, πi: pi(tk) → ai(tk). In general, such a policy is a complicated and complex function of the input, and ANNs as universal function approximators64 are well-suited tools to parameterize these objects for arbitrary agents and environments (see Methods). Thus, we approximate the RL agent’s policy πi by an ANN, formally expressed as a function fθ( ⋅ ) with parameters θ, such that ai(tk) = fθ(pi(tk)). More specifically, we treat a single N-bead swimmer as a multi-agent system, each bead being equipped with a functionally identical but operationally independent ANN-based controller, fθ( ⋅ ). This renders the system reminiscent of a Neural Cellular Automaton60 (NCA) with the extension that the decentralized actions of all individual controllers give rise to a collective locomotion policy Π = {π1, …, πN} ≈ {fθ(p1(tk)), …, fθ(pN(tk))}, of the entire virtual organism (see also ref. 59). Here, only a single set of parameters θ is used for all N bead-specific agents, i.e., the same ANN controller is deployed to every bead; the states of the latter only differ in their initial conditions and subsequent input-output-history. For our purposes, this renders the optimization problem much more tractable compared to situations with a single centralized controller, \(\tilde{\Pi }\approx {\tilde{f}}_{\tilde{\theta }}({{{{{\bf{p}}}}}}_{1}({t}_{k}),\ldots ,{{{{{\bf{p}}}}}}_{N}({t}_{k}))\), especially for large swimmer morphologies.
Here, we aim at identifying optimal and robust swimming gaits for arbitrarily large N-bead swimmers, which translates to finding suitable ANN parameters, θ(opt), such that the bead-specific perception-action cycles, \({{{{{\bf{a}}}}}}_{i}({t}_{k})={f}_{{\theta }^{{{{{\rm{(opt)}}}}}}}({{{{{\bf{p}}}}}}_{i}({t}_{k}))\), collectively self-propel the multi-agent system efficiently in a certain direction. More specifically, the set of parameters θ comprises the weights and biases of the agent’s ANN-based controller, which we designed to be numerically feasible for our neuroevolution approach (see below): In stark contrast to traditional RL agents, with often more than tens or hundreds of thousands of parameters, we here utilize a predefined architecture inspired by refs. 58,65 with only 59 parameters (see the “Artificial neural network-based decentralized controllers” subsection in the “Methods”). Thus, we can utilize66 EAs, specifically a simple genetic algorithm67 discussed in the “Genetic algorithm and neuroevolution of single-agent policies with collective goals” subsection in the “Methods,” to adapt the ANN parameters (but not the ANN topology19) such that the entire N-bead swimmer’s mean center of mass (COM) velocity, \({v}_{T}=\frac{1}{N\,T}\left\vert \mathop{\sum }_{i = 1}^{N}\left({x}_{i}(T)-{x}_{i}(0)\right)\right\vert\), is maximized for a predefined swimming duration T = 400 − 800Δt, where Δt = 5 μR2/F0 is the time interval between two consecutive perception-action cycles of an RL agent. T is chosen sufficiently large to provide the respective N-bead swimmer enough time to approach a steady swimming state and to execute several swimming strokes, starting from randomized initial positions. Thus, we define the objective, i.e., the fitness score in terms of EAs, or the reward in terms of RL, as the mean COM velocity \(r={\langle {v}_{T}\rangle }_{{N}_{e}}\), averaged over Ne = 10 statistically independent episodes, and search for \({\theta }^{{{{{\rm{(opt)}}}}}}=\mathop{\max }_{\delta \theta }(r)\) through variation δθ of the parameters θ via EAs, as detailed in the “Genetic algorithm and neuroevolution of single-agent policies with collective goals” subsection in the “Methods”.
Individual, bead-specific decisions facilitate collective swimming of an N-bead swimmer
We utilize EAs to optimize the parameters of the ANN-based controllers (which are deployed to every bead in a specific morphology) for different realizations of our multi-agent microswimmer models. More specifically, we deploy morphologies ranging from N = 3 to N = 100 beads of type A and B microswimmers and train every swimmer of different size N for both types independently via EAs to self-propel by maximizing their respective fitness score r. For details on the utilized ANNs and the applied EA we refer to the “Modeling system-level decision-making with decentralized controllers” subsection in the “Results and Discussion” and to the “Methods”.
The training progress is presented in Fig. 1 exemplarily for type A microswimmers of different morphologies N, demonstrating that the proposed decentralized decision-making strategy is capable of facilitating fast system-level swimming gaits for all the considered swimmer sizes up to N = 100. Thus, our method removes the bottleneck for machine-learning navigation policies of large-scale microswimmers by employing computationally manageable local ANN-based perception-action loops of their bead-specific agents. To the best of our knowledge, this is the first time successful training of microswimmers with such a large number of degrees of freedom has been achieved.
Different strategies of autonomy: large-scale coordination enables fast swimming
Employing the learned policies of both type A and B microswimmers for different body sizes, i.e., the number of beads N, we determine the respective stroke-averaged COM velocities \(\bar{v}\), which increase monotonously with N as depicted in Fig. 3a, b. We normalize all velocities here with v0 = 2F0/(6πμR), i.e., the velocity of a bead dragged by an external force of strength 2F0. Type B swimmers are significantly faster compared to type A swimmers by almost one order of magnitude, especially for large N. As illustrated in Fig. 3a, for type A microswimmers with locally ensured force-free conditions, the mean COM velocity \(\bar{v}\) saturates with increasing N at \({\bar{v}}_{\max }/{v}_{0}\approx 0.03\) for N = 100. In contrast (c.f., Fig. 3b), the fastest type B microswimmer, again at N = 100, achieves a maximum COM velocity of \({\bar{v}}_{\max }/{v}_{0}\approx 0.15\).

a, b Stroke-averaged cennter of mass (COM) velocity, \(\bar{v}\), of different type A and B microswimmers, respectively, corresponding to their fitness score when optimized independently with evolutionary algorithms for N = 3 to N = 100 beads (see also Fig. 1c). Insets show COM trajectories, and \(({F}_{1}^{a},{F}_{3}^{a})\)- and (l1, l2)-phase-space plots for N = 3 (see blue circles). Typical bead-specific coordinate- (c, d) and force-trajectories (e, f) of an (N = 15)-bead type A and an (N = 100)-bead type B microswimmer, respectively (the examples, see red circles in (a, b), are chosen for illustrative purposes and are representative for all investigated N for both type A and B policies). See also Supplementary Movies 1-3. Insets in (c, d) detail the corresponding COM trajectories. For type A microswimmers (a, c, e), periodic localized waves of arm strokes travel through the body. In contrast, (b, d, f), large-scale collective body contractions allow large type B microswimmers to propagate much faster. Coordinate trajectories are normalized by the reference arm length L0 in the insets of (a, b), and by the total sum of the reference arm lengths LB = L0 × (N − 1) in (c–f).
The insets in Fig. 3a, b illustrate results for the well-studied three-bead swimmer (N = 3). First, they show the characteristic periodic 1-step-back-2-step-forward motion of the COM trajectory35. Second, the corresponding steady state phase space dynamics of the active forces on beads 1 and 3, \(({F}_{1}^{a},{F}_{3}^{a})\), and of the arm lengths (l1, l2), reiterating the periodic motion. Note that the force on bead 2 simply follows from \({F}_{2}^{a}=-{F}_{1}^{a}-{F}_{3}^{a}\). While both type A and B three-bead swimmers move at comparable speed, this is achieved with different policies, as can be seen by the different phase space curves (see also Supplementary Movie 1).
In Fig. 3c, d, we present trajectories of both the COM and bead-specific coordinates (top panels; respective insets emphasize the COM dynamics), and of the bead-specific proposed forces (bottom panels) for an (N = 15)-bead type A- and (N = 100)-bead type B microswimmer, respectively. These selected trajectories demonstrate the genuinely different swimming strategies for type A and B microswimmers (which have been optimized with the same EA settings).
In type A microswimmers (Fig. 3c), the pairwise arm forces induce periodic waves of arm contractions of relatively high frequency but small wavelength, which travel through and move forward the body of the N-bead microswimmer. For swimmers with a sufficiently large number of beads N this leads to a relatively smooth and linear COM motion (see inset in Fig. 3c).
In stark contrast, the fastest swimming strategies for type B microswimmers (Fig. 3d) assumes coordinated arm strokes across large fractions of their bodies, essentially contracting and extending almost the entire swimmer simultaneously, which is reflected in the oscillatory COM motion even for very large N (see inset in Fig. 3d). This large-scale coordination exceeds the capabilities of the locally interlocked policies of type A microswimmers and strikes us as an emergent phenomenon68 which—still based on purely local decision-making—is facilitated by the mean-field motivated feedback of the mean proposed force of all the agents in the system: type B microswimmers seemingly act as a single entity69, despite the fact that the precise number of constituents, N, is not important and can vary (see also Supplementary Movies 2 and 3).
As shown in Fig. 3d, typical emergent swimming gaits of the respective type B swimmers are reminiscent of the large amplitude contraction-wave based locomotion of crawling animals such as caterpillars70. Similarly, the crawling locomotion of crawling fly larvae had been optimized using RL recently71. In the context of locomotion in viscous fluids, large-amplitude traveling waves along the body have been discussed as an alternative swimming strategy of flagella-less organisms72,73.
Transferable evolved policies: decentralized decision-making generalizes to arbitrary morphologies
We have recently shown that biologically inspired NCA-based multi-agent policies—especially when evolved via evolutionary processes—can display behavior that is highly robust against structural and functional perturbations and exhibit increased generalizability, adaptability, and transferability58,74. We thus investigate here whether our decentralized locomotion policies, which are genuinely evolved for microswimmer bodies with exactly NT beads, generalize to morphological changes. More specifically, we carefully optimize ANN policies for a particular number of NT = 3 to 100 beads (as discussed above) and deploy them—without any retraining or further adaptation—into microswimmer bodies with a different number of N = 3 to 300 beads instead to evaluate the corresponding swimming velocities for such cross-policy environments.
As illustrated in Fig. 4a, b, we find that the vast majority of all policies that are most optimal for a particular value of NT are also highly effective in self-propelling microswimmers with N ≠ NT for both type A and B, respectively. This even holds for situations where NT ≪ N, such as NT = 3 and N = 300. We did not explicitly optimize for this property at all, but it is an emergent phenomenon of the inherent decentralized decision-making of the system. Thus, the collective nature of the proposed swimming policies renders the evolved locomotive strategies highly adaptive to morphological changes, irrespective of the specific number of beads N used during deployment. Only for a few situations which can occur when the number of beads N deviates significantly from the number of beads NT used during training, do not lead to successful swimming, in particular for type B microswimmers (Fig. 4b). In those cases the locally emerging periodic arm motion is lost and the beads are trapped in a resting state.

a, b: Stroke-averaged center of mass velocity \(\bar{v}\) of N-bead microswimmers deployed with policies optimized for NT (color-coded dotted lines) for type A and B microswimmers, respectively. The vast majority of the policies evolved for NT-beads generalize well to vastly different N-bead morphologies without further optimization (circle symbols mark utilized N, magenta × symbols illustrate training conditions where NT = N). (c) and (d): The mean angular velocity \(\bar{\omega }\) of the arm-length limit-cycle dynamics of the most optimal N-bead type A and B microswimmers, respectively (blue circles; fastest policies trained with NT-beads and deployed to N-bead microswimmers); magenta × symbols illustrate \(\bar{\omega }\) for the corresponding training conditions, N = NT. Similar to (c–f) show the mean cross-correlation time \(\bar{\tau }\) between neighboring arm lengths, and (g, h) show the corresponding (dimensionless) wavelength \(\bar{\lambda }\) (see columns in Fig. 3e, f at fixed time tk and see the “Transferable evolved policies: decentralized decision-making generalizes to arbitrary morphologies” subsection of the “Results and Discussion” for details) of type A and B microswimmers, respectively, as a function of N. Dashed lines indicate functional fits: (c) \(\bar{\omega }\approx a\ln N+b\) with a = −5.26 × 10−3rad/Δt and b = 1.13 × 10−1rad/Δt. (d) \(\bar{\omega }\approx \alpha {N}^{\beta }\) with α = 3.92 × 10−1rad/Δt and β = −8.19 × 10−1. e \(\bar{\tau }\approx 12.2\,\Delta t\). g \(\bar{\lambda }\approx a\ln N+b\) with a = 2.37 × 10−1 and b = 4.64. h \(\bar{\lambda }\approx \alpha {N}^{\beta }\) with α = 1.33 and β = 9.17 × 10−1. Error-bars in (c–h) represent the STD of \(\bar{\omega }\), \(\bar{\tau }\) and \(\bar{\lambda }=2\pi /(\bar{\omega }\bar{\tau })\) (see also “Swimming-gait analysis” subsection in the “Methods”) for all data points within a 3-sigma STD; error-bars in (c–d) are smaller than symbols.
Moreover, the set of policies evolved and deployed for different bead numbers of NT and N, respectively, allows us to estimate a trend for optimal swimming gaits for large N: In steady state, the arm-lengths li(tk) of an arbitrary trained NT-bead swimmer describe limit cycle dynamics in an (N − 1)-dimensional phase space (c.f., Fig. 3). Then, all arms oscillate at the same angular velocity \(\bar{\omega }\) and exhibit the same cross-correlation times \(\bar{\tau }\) to their neighboring arms, where \({l}_{i+1}({t}_{k})={l}_{i}({t}_{k}-\bar{\tau })\), and we can express each of the i = 1, …, N arm lengths as a 2π-periodic function \({\hat{l}}_{i}(t)={f}_{\ell }\left((t-i\,\bar{\tau })\,\bar{\omega }+\phi \right)\), with the phase shift ϕ defining the initial conditions; for more details about \(\bar{\omega }\) and \(\bar{\tau }\) we refer to the “Swimming-gait analysis” subsection in the “Methods”. We can also write \({\hat{l}}_{i}(t)\) in the form of a wave equation as \({\hat{l}}_{i}(t)={f}_{\ell }\left(t\bar{\omega }+2\pi i/\bar{\lambda }+\phi \right)\), where the bead index i controls the “spatial” oscillations at a (dimensionless) wavelength \(\bar{\lambda }=\frac{2\pi }{\bar{\omega }\bar{\tau }}\) irrespective of the corresponding physical bead positions xi(tk). A careful analysis of different naive block-swimmer or waveform policies in the Supplementary Note 1 suggests that the found waveform parametrization obtained by the RL procedure is close to the optimum within our model assumptions for sufficiently large microswimmers. In particular, we find that the best policies for the proposed forces for the faster, sufficiently large type B microswimmers are well approximated by \({\phi }_{i}(t)={F}_{0}\,{\mbox{sign}}\,[\sin (\bar{\omega }t-2\pi i/\bar{\lambda })]\); the swimming speed is close to maximum by choosing for \(\bar{\omega }\) and \(\bar{\lambda }\) the respective values obtained from our RL procedure.
In Fig. 4c, e, g, we respectively present \(\bar{\omega }\), \(\bar{\tau }\), and \(\bar{\lambda }\) for the fastest type A microswimmers as a function of N (blue circles), additionally to the training conditions where N = NT (magenta “×” symbol). We can see that these quantities are almost independent of N, and we observe only weak logarithmic dependencies of \(\bar{\tau }\) and \(\bar{\lambda }\) (see Fig. 4 caption). In contrast, for type B see Fig. 4d, f, h, the angular velocity is approximately inverse to the swimmer length \(\bar{\omega } \sim {N}^{-1}\), and the wavelength almost linear to N, \(\bar{\lambda } \sim N\) (detailed fits see Fig. 4 caption). As a result, the evaluated \(\bar{\tau }\) values for type B microswimmers (Fig. 4f) are almost constant and the values are comparable to those of the type A microswimmer, but slightly decrease with N.
Large-scale coordination leads to efficient locomotion
In our approach, we limit the maximum forces on each of the beads and, thus, the maximum bead velocities. This procedure is somewhat similar as fixing the total power consumption of the swimmer. In previous optimization procedures on 3- and N-bead swimmers commonly the swimming efficiency is optimized75,76, where e.g., the power consumption of the entire swimmer is taken into account as a single, global quantity. In contrast, in our work, we set local constraints on the swimmer by limiting the forces on every bead. Although we hence did not optimize in our RL procedure for the hydrodynamic efficiency η of our swimmers, we measure η determined by refs. 1,75 \(\eta =6\pi \mu {R}_{{{{{\rm{eff}}}}}}{\bar{v}}^{2}/{{{{\mathcal{P}}}}}\) where \({{{{\mathcal{P}}}}}=\frac{1}{T}\int{\sum }_{i}{v}_{i}(t){F}_{i}(t){{{{\rm{d}}}}}t\) is the stroke-averaged power consumption, and Reff is the effective radius of our swimmers. There is no unique way to define Reff of our swimmer (see also the discussion in ref. 75), and it is hence not straightforward to compare Reff of swimmers of different size N. We choose here Reff = NR, which approximates the combined drag on all of the spheres, neglecting hydrodynamic interactions. The power consumption is naturally limited to be \({{{{\mathcal{P}}}}} \, < \, {{{{{\mathcal{P}}}}}}_{\max }\) with \({{{{{\mathcal{P}}}}}}_{\max }=2N{F}_{0}{v}_{0}=2N{F}_{0}^{2}/(6\pi \mu R)\), for both cases, type A and B; F0 and v0 are the force- and velocity-scale in our model, see the “Modeling system-level decision-making with decentralized controllers” subsection in the “Results and Discussion”. However, type B swimmers can exploit their higher freedom to adjust the forces on the beads compared to the arm-force-limited type A swimmer to locomote at higher speed, and hence at higher efficiency η. As seen in Fig. 5a, b for both type A and B swimmers, the efficiency increases with swimmer length N and levels off at large N. The efficiency is relatively low for all swimmer lengths N for type A swimmers, and is limited to ≈0.12%. In contrast, long type B swimmers can reach surprisingly high efficiencies of even ≈ 1.5% for N = 100, comparable to the efficiency of real existing microswimmers1.

a, b Hydrodynamic efficiency η of the most optimal N-bead type A and B microswimmers (blue circles), respectively; magenta × symbols emphasize the efficiency of microswimmers trained with N = NT. c, d stroke-averaged center of mass velocity per bead \(\bar{v}/N\) for the respective type A and B microswimmers. The insets show a power law decay, \((\bar{v}/{v}_{0})/N=\alpha \,{N}^{-\beta }\), with α = 2.34 × 10−2, β = 9.53 × 10−1 (c) and α = 2.83 × 10−2, β = 6.41 × 10−1 (d), (blue dots correspond to blue main-panel circle symbols, black dashed lines represent the repsective power law fits).
As discussed above, a larger microswimmer can swim faster due to the emergence of long-wavelength longitudinal waves. Indeed, it thus is not surprising that longer type B swimmers are faster than shorter ones. Animals typically scale their speed with their size77. Here we determine the swimmer speed per size \(\bar{v}/N\) depending on N as shown in Fig. 5c, d, where we identify a maximum for N = 4 for type A and at N = 8 for type B. Hence, these swimmers need the smallest amount of time to swim their own body size NL0 compared to swimmers of different N. For large N, \(\bar{v}/N\) decays with a power law (see inset Fig. 5c, d).
Robust- and failure tolerant locomotion and cargo transport without re-training
Since our evolved microswimmer policies show strong resilience even against significant morphological perturbations (see Fig. 4), we aim to investigate this operational plasticity even further: Exemplarily for the most optimal type A and B microswimmers with (N = 13), we systematically load the arms with extra passive “cargo” beads of variable radius Rc ∈ [0, 2R], and evaluate the dynamics of the corresponding loaded microswimmer consisting now of N = 13 + 1 beads, without retraining or further optimization.
These cargo beads can geometrically be located between two neighboring beads of the microswimmer, but remain functionally disjoint from the latter (cargo beads are not connected by arms to any body beads): when placed at an arm li, a cargo bead does not disrupt the exchange of information between the corresponding beads i and (i + 1) and thus does not affect the inputs of the respective bead-specific ANNs. Since cargo beads are passive elements, they do not propose active forces independently, \({F}_{c}^{a}({t}_{k})=0\), and are moved around solely by the hydrodynamic interaction with the other beads and the restoring spring forces of nearby beads. This ensures that a cargo bead is topologically fixed in the microswimmer’s body.
Figures 6a, b demonstrates, that our approach of utilizing decentralized, bead-specific controllers for N-bead microswimmer locomotion not only gives rise to highly robust self-propulsion policies (see the “Transferable evolved policies: decentralized decision-making generalizes to arbitrary morphologies” subsection in the “Results and Discussion”) but can also be used “out of the box” for cargo transport applications78: We show that both type A and B microswimmers are capable of swimming while having additional cargo beads of various sizes located at different internal positions, i.e., at different arms along their main axes. While the presence of cargo beads significantly restrains the neighboring beads from adapting the adjacent arm length, essentially locking the corresponding arm, the remaining functional beads self-propel the entire microswimmer effectively. We further emphasize that, in general, the swimming speed decreases with increasing cargo size, Rc.

a, b Stroke-averaged center of mass (COM) velocity \(\bar{v}\) in % (color-coded) of the maximum velocity \({v}_{\max }\) (c.f., respective left columns) of representative (N = 13)-bead type A and B microswimmer solutions, respectively, carrying a cargo bead of radius Rc ∈ [0, 2R] (horizontal axis) at different loading positions, i.e., at the respective arms l1 through lN−1 (vertical axis). For each panel, three selected trajectory plots (indicated by green frames in respective heatmaps) highlight the corresponding cargo-swimmers' single-bead- (red lines), COM- (black lines), and cargo bead trajectories (green lines) scaled by the total length of all arms LB = (N − 1)L0. c, d Similar to (a, b) but loading the respective (N = 13)-bead microswimmers with a total number of Nc = 1, …, (N − 1) cargo beads (vertical axis) of the same size, Rc (horizontal axis), where each cargo occupies a single arm li starting from i = 1, …, Nc (c.f., green cargo lines in designated example trajectories). Note, for the reference case, Rc = 0, we do not include any cargo beads in the simulations, thus, the corresponding velocity represents \({v}_{\max }\) for types A and B, respectively.
Next, we successively fill all arms of a single microswimmer from the left, l1, to the right, \({l}_{{N}_{c}}\), simultaneously with a total number of Nc = 1, …, (N − 1) cargo beads of equal radius Rc (one cargo per arm) and measure the speed of the correspondingly loaded (N + Nc)-bead microswimmers as a function of the number of loaded arms and cargo size. Both type A and B microswimmers are capable of transporting multiple cargo loads at once efficiently, as illustrated in Fig. 6c, d: they can carry up to ≈50–60% of their active beads N before the respective locomotion capabilities fail due to an increasing number of blocked arms. While we here fixed N = 13 to demonstrate cargo transport, it can be applied to different swimmer realizations, i.e., other morphologies and evolved policies: As shown in the Supplementary Note 2a, microswimmers of different size N display similarly behavior as shown in Fig. 6 for N = 13, rendering our system highly robust against such morphological defects.
Another potential morphological malfunction in our model is corrupting the information flow between selected neighboring beads. We thus choose a number of Nd links li between different neighboring beads i, j = i + 1 (c.f., Fig. 1), and intentionally set the corresponding contributions from bead j, i’s to bead i, j’s perception vectors pi(tk) and pj(tk) to zero before measuring the corresponding swimming velocities of different swimmer realizations; this will affect bead i’s measurements of the distance lj(tk)→0, velocity vj(tk)→0, and state sj(tk)→0 of the neighboring bead j, and vice-versa (see the “Modeling system-level decision-making with decentralized controllers” subsection in the “Results and Discussion” and the “Methods”).
As depicted in Fig. 7, the relative affected swimming velocity for type A and B microswimmers of size N effectively decreases linearly as a function of the fraction of blocked links Nd/(N − 1). In fact, the microswimmers can handle even a fraction of ≈50% blocked links while maintaining ⪅50% of their unaffected swimming speed.

a, b Relative swimming velocity \(\bar{v}/{v}_{\max }\) of type A and B microswimmers of different sizes N = NT (color-coded dashed lines) with blocked information flow between a fraction of Nd/(N − 1) randomly chosen neighboring beads (horizontal axis) averaged over at most 100 statistically independent simulations; \({v}_{\max }\) is the default velocity without blocked links, and colored circles emphasize the utilized fraction of blocked links. Error bars mark the STD for every data point.
Thus, our evolved navigation policies of the proposed microswimmer system not only show strong resilience against partly significant morphological changes of the swimmer’s body (see also Fig. 4), but even against functional alterations and failures of single or multiple actuators (c.f., blocked arms and links in Figs. 6 and 7). Moreover, the decentralized control paradigm in our microswimmer system is tolerant against various sources of noise, e.g., in the predicted action outputs, in the beads’ input perceptions, and in the presence of thermal noise added to the equations of motion, as detailed in the Supplementary Note 2b–d, respectively. In the former two cases, efficient locomotion is still possible for noise-to-signal ratios of 50% or even more. In the latter case, we add additive noise with diffusivity D, which allows for locomotion until Pe−1 = D/D0 = kBT/(2F0R) ~0.1 with D0 = Rv0, i.e., down to Péclet numbers Pe of \(\sim {{{{\mathcal{O}}}}}(1{0}^{1})\), therefore in the range of real microswimmer systems4. We emphasize that this goes well beyond what the swimmers experienced during training and is a clear sign of generalizability and robustness via collective decision-making79,80.
Conclusions
Our study demonstrates that machine learning of decentralized decision-making strategies of the distributed actuators in a composite in silico microswimmer can lead to highly efficient navigation policies of the entire organism that are, moreover, highly robust with respect to morphological changes or defects. More specifically, we treat each of the N beads of a generalized NG microswimmer model as an ANN-based agent that perceives information about its adjacent beads and whose actions induce activations of adjacent muscles. Via genetic algorithms, we have optimized such single-bead decision-making centers to collectively facilitate highly efficient swimming gaits on the system level of the NG swimmer.
In that way, we have identified locomotion strategies for increasingly large microswimmer bodies, ranging from N = 3 to N = 100, with hydrodynamic efficiencies of up to η ≈ 1.5%, close to that of real biological microswimmers; to the best of our knowledge, this is the first demonstration of successfully training an (N = 100)-bead microswimmer.
While having focused here on evolving swimming gaits for NG microswimmers of fixed morphologies, we report that the optimized decentralized locomotion policies generalize well without any further optimization towards partly severe morphological changes: policies optimized for an NT-bead microswimmer are in most cases also highly effective for (N ≠ NT)-bead morphologies, even if N ≫ NT or vice versa. This renders our approach robust and modular from both a physiological and information processing point of view58,59, going well beyond more traditional, in this sense much more brittle RL applications that are typically concerned with centralized controllers with a fixed number of inputs and outputs.
The limiting computational factor in our simulations is not the controller part, but the \({{{{\mathcal{O}}}}}({N}^{2})\) complexity of the hydrodynamic model, which could be leveraged by further modeling, numerical optimization, or hardware accelerators. However, the scalability of our approach allows us to generalize the optimized policies as a function of N, again overcoming limitations posed by traditional RL methods, and leveraging analytical investigations76 of the generalized NG model to the limit of N→∞.
As we demonstrate, the inherent robustness and increased structural and functional plasticity of the here investigated microswimmer locomotion policies, based on decentralized (collective) decision-making, make our system directly suitable for cargo transport applications without further optimization or fine-tuning. Since the here-proposed distributed ANN controllers and learning paradigm are not limited to integrating information of the local neighborhood of a single bead in an N-bead NG microswimmer, our approach can be extended to virtually arbitrary swimmer geometries and models. Thus, our approach represents a promising framework to develop autonomous cargo transport-78 or biomedically relevant drug-delivery systems7,8,9,10, especially when combined with chemotactic capabilities19. Our approach and results are thus of potential relevance for future experimental realization on autonomous soft intelligent microrobots81. While externally controlled 3-bead microswimmers at larger scale had been realized successfully82, autonomous microswimmers, in particular at smaller scales, are currently challenging to realize83. Our results offer insights into potential design principles for small-scale realizations of bead-based microswimmers with minimalistic controller architectures: Even individual body parts can all use the same controller with a pre-calculated policy, optimized for a specific number of body parts; we show that such controllers still work (i) if body parts are removed or added (ii) if some body parts fail to operate, and (iii) if they operate under noisy conditions that have not been experienced during training.
Owing to our 1D setup, drawing implications of our analysis for specific biological systems is not straightforward. In biological filaments used for microswimming, typically large-scale oscillations are induced, such as the beating of cilia and flagella. While we obtain similar large-scale oscillations via collective feedback in the type-B model, however in our case, deformations only occur through extensions and contractions in 1D, compared to the bending deformations in two or three dimensions of biological filaments. Applying our approach to systems beyond 1D is ongoing research and may allow us in the future to draw implications on more realistic biological systems.
Our interdisciplinary approach, integrating cutting-edge concepts from biology, biophysics, robotics, collective artificial intelligence, and artificial life84, offers a promising path to designing and understanding robust and fault-tolerant microswimmer policies that are computationally efficient. Reminiscent to the structural and functional plasticity of “real” biological matter85, we emphasize the inherent ability of our microswimmer policies to adapt without any retraining to functional perturbations or morphological changes “out of the box”. This resonates well with William James’ definition of intelligence44,86 of “achieving a fixed goal with variable means”, and raises philosophical questions about the nature of emergent individuality87 and the role of collective intelligence44 in multi-agent systems inspired by the multi-scale competency architecture of biology58,88,89.
Methods
Hydrodynamic interactions and numerical details for the N-bead swimmer model
The microswimmer consists of N hydrodynamically interacting beads located at positions xi(tk), i = 1, …, N, at time tk. The bead positions change over time by applying forces Fi(tk), consisting of active (\({F}_{i}^{a}({t}_{k})\)) and passive (\({F}_{i}^{r}({t}_{k})\)) contributions. At time tk, the velocities of the beads vi(tk) depend linearly on the applied forces through the mobility tensor \({{{{\mathcal{M}}}}}({t}_{k})\): \({v}_{i}({t}_{k})={\sum }_{j}{{{{{\mathcal{M}}}}}}_{ij}({t}_{k}){F}_{j}({t}_{k})\). Self-mobilities are given by Stokes' formula \({{{{{\mathcal{M}}}}}}_{ii}=1/(6\pi \mu R)\), while cross-mobilities describe hydrodynamic interactions, which we consider in the far-field limit in the Oseen approximation: \({{{{{\mathcal{M}}}}}}_{ij}({t}_{k})=1/(4\pi \mu | {x}_{i}({t}_{k})-{x}_{j}({t}_{k})| )\). Active forces \({F}_{i}^{a}({t}_{k})\) are applied as described in the main text. We apply passive harmonic spring forces as pairwise restoring forces \({F}_{i,i+1}^{r}({t}_{k})\) between beads i and i + 1. They depend on the arm length li(tk) between the beads and are applied if li(tk) < 0.7L0 such that \({F}_{i,i+1}^{r}({t}_{k})=k({l}_{i}({t}_{k})-0.7{L}_{0}) < 0\), or if li(tk) > 1.3L0 such that \({F}_{i,i+1}^{r}({t}_{k})=k({l}_{i}({t}_{k})-1.3{L}_{0}) > 0\), where k = 10F0/R is the spring constant. Every bead is potentially affected by restoring forces between both neighbor beads, resulting in a total restoring force \({F}_{i}^{r}({t}_{k})=-{F}_{i-1,i}^{r}({t}_{k})+{F}_{i,i+1}^{r}({t}_{k})\), except for the beads at the end, which only have a single neighbor bead where \({F}_{1}^{r}({t}_{k})={F}_{1,2}^{r}({t}_{k})\) and \({F}_{N}^{r}({t}_{k})=-{F}_{N-1,N}^{r}({t}_{k})\). This procedure limits the arm extensions, as can be seen for example, in the inset of Fig. 3a,b. Note, both the active and passive forces sum up to zero individually \({\sum }_{i}{F}_{i}^{r}({t}_{k})=0\) and \({\sum }_{i}{F}_{i}^{a}({t}_{k})\). The equations of motion of the microswimmer are then solved using a fourth-order Runge Kutta scheme using a sufficiently small time step dt = Δt/10, where we used F0 = 5, η = 1, R = 1 as numerical values in our simulation.
Artificial neural network-based decentralized controllers
Mimicking the flexible operations of biological neural circuits, ANNs consisting of interconnected Artificial Neurons (ANs) have become invaluable numerical tools for statistical learning applications90. Each AN takes a set of inputs, \({{{{\bf{x}}}}}\in {{\mathbb{R}}}^{n}\), and maps them onto a single output value, \(y\in {\mathbb{R}}\), through a weighted non-linear filter, y = σ(w ⋅ x + b), where the weights \({{{{\bf{w}}}}}\in {{\mathbb{R}}}^{n}\) represent the strengths of every individual input connection, and \(b\in {\mathbb{R}}\) is the bias, representing the AN’s firing threshold91.
ANNs are commonly organized into layers of ANNs. A Feed Forward (FF) ANN transforms an input, \({{{{{\bf{x}}}}}}^{(1)}\in {{\mathbb{R}}}^{{{{{{\rm{N}}}}}}_{{{{{\rm{0}}}}}}}\), through a series of hidden layers (i = 1, …, NL) to an output vector \({{{{{\bf{y}}}}}}^{({{{{\rm{out}}}}})}\in {{\mathbb{R}}}^{{N}_{{{{{\rm{L}}}}}}}\). Each layer’s output is calculated as \({{{{{\bf{y}}}}}}^{(i)}=\sigma \left({{{{{\mathcal{W}}}}}}^{(i)}\cdot {{{{{\bf{x}}}}}}^{(i)}+{{{{{\bf{b}}}}}}^{(i)}\right)\), where \({{{{{\mathcal{W}}}}}}^{(i)}=\{{w}_{jk}^{(i)}\}\in {{\mathbb{R}}}^{{{{{{\rm{N}}}}}}_{{{{{\rm{i}}}}}}\times {{{{{\rm{N}}}}}}_{{{{{\rm{i}}}}}-1}}\) is the weight matrix and \({{{{{\bf{b}}}}}}^{(i)}\in {{\mathbb{R}}}_{{{{{\rm{i}}}}}}^{{{{{\rm{N}}}}}}\) is the bias vector. In an FF ANN, the output of layer i becomes the input to the next deeper layer (i + 1) through successive dot products, until an output is generated. Training an ANN thus involves optimizing a set of parameters, \(\theta =\{{w}_{jk}^{(i)},{b}_{k}^{(i)}\}\), i.e., the entire network’s weights and biases, such that the ANN’s response to known inputs has minimal deviation from (typically predefined) desired outputs92,93.
Here, we utilize a single ANN that is independently deployed to every bead of an N-bead NG microswimmer to approximate a decentralized decision-making policy for autonomous locomotion of the entire virtual organism. Thus, each ANN-augmented bead represents an agent that is immersed in a chain of N single-bead agents comprising the body of an N-bead microswimmer (see Fig. 1). As detailed in Fig. 8, the bead-specific agents of the microswimmer successively perceive the states of their respective neighboring beads and integrate this local information to initiate swimming strokes locally, following a decentralized policy that self-propels the entire microswimmer in the hydrodynamic environment.

The detailing ANN architecture (inspired by ref. 58) emphasizes an ANN's perception, \({{{{{\bf{p}}}}}}_{{i}_{\nu }}\), of bead i's local neighborhood, ν = −1, 0, 1 (see the “Artificial neural network-based decentralized controllers” subsection of the “Methods”), followed by an embedding, \({{{{{\bf{p}}}}}}_{{i}_{\nu }}\to {\varepsilon }_{{i}_{\nu }}\), and concatenation layer in the sensory module that results in a bead-specific context matrix, \({{{{{\mathcal{C}}}}}}_{i}=({\varepsilon }_{{i}_{-1}},{\varepsilon }_{{i}_{0}},{\varepsilon }_{{i}_{+1}})\), based on which the policy module proposes an action, ai, comprising the proposed force, ϕi, and the cell-state update, Δsi. This step is performed by every bead independently at every successive time step, tk, to induce an update of the state of the microswimmer at times tk + 1 by considering the regularized forces, ϕi→Fi, in the equations of motion of the N-bead hydrodynamic environment, xi(tk)→xi(tk + 1), and performing a noisy (c.f., red wiggly arrow) cell-state update.
From the perspective of RL14, our approach can thus be considered a trainable multi-agent system that needs to utilize local communication and decision-making to achieve a target system-level outcome58. The goal is to identify a set of ANN parameters θ for the localized agents that facilitate such collective behavior, which we achieve here via58 EAs as detailed below.
Let us now specify the particular ANN architecture and the perception (ANN input) and action (ANN output) conventions that we utilize in this contribution (as illustrated in Fig. 8).
First, we define the neighborhood of a particular bead i = 1, …, N: In our example of a one-dimensional, linear N-bead swimmer, the direct neighbors of bead i are given by the beads i ± 1. To address each bead in this “i-neighborhood”, we introduce the index notation iν = i + ν with ν ∈ {−1, 0, 1}; i0 thus addresses bead i itself.
Second, we define the perception, or ANN input of bead i as \({{{{{\mathcal{P}}}}}}_{i}=\{{{{{{\bf{p}}}}}}_{{i}_{-1}},{{{{{\bf{p}}}}}}_{{i}_{0}},{{{{{\bf{p}}}}}}_{{i}_{-1}}\}\), a composite matrix containing local, neighbor iν-specific perceptions, \({{{{{\bf{p}}}}}}_{{i}_{\nu }}\), of bead i: We define the neighbor-specific perception as \({{{{{\bf{p}}}}}}_{{i}_{\nu }}=({l}_{{i}_{\nu }},{v}_{{i}_{\nu }},{{{{{\bf{s}}}}}}_{{i}_{\nu}})\), with bead iν-specific arm length to the neighboring beads \({l}_{{i}_{\nu }}=| {x}_{i}-{x}_{{i}_{\nu }}| \in {\mathbb{R}}\), bead velocity \({v}_{{i}_{\nu }}\in {\mathbb{R}}\), and an internal, vector-valued state \({{{{{\bf{s}}}}}}_{{i}_{\nu}}\in {{\mathbb{R}}}^{{n}_{{{{{\rm{ca}}}}}}}\) at time tk (see below); out-of-bound inputs for the head and tail beads are discarded by formally setting p0 = pN + 1 = 0 as we count i = 1, …, N.
The internal state of a bead is inspired by the cell state of a Cellular-94, or rather Neural Cellular Automaton60 (NCA) that can be utilized by each bead to memorize or exchange information with neighbors. Analogous to previous work58, we define the update of the internal state of a bead between two successive time steps as si(tk+1) = (si(tk) + Δsi(tk) + ξs), where we introduced a zero-centered Gaussian noise term of STD ξs = 2−5, increasing the robustness of evolved solutions58. Additionally, we clamp the elements of si(tk) to the interval [−1, 1] after each update. While in58 the internal cell states represent the entire environment for the unicellular agents, here, they only represent a subset of the beads’ state, explicitly extended by the physiological measurements in the hydrodynamic environment \({l}_{{i}_{\nu }}\) and \({v}_{{i}_{\nu }}\). While such a state-dependent decentralized policy is resilient against noise and morphological malfunctions (c.f., Figs. 6 and 7 and Supplementary Note 2), the internal states \({{{{{\bf{s}}}}}}_{{i}_{\nu }}\) assist the decision-making of the localized agents in the collective microswimmer via non-trivial exchange of information between neighboring beads (e.g., as self-orchestrated positional markers of the beads within the body, or as intrinsic pace-makers stabilizing dynamics, etc.). We find that at least a single hidden state \(\dim ({{{{\bf{s}}}}})\ge 1\) significantly improves the training efficiency on locomotion tasks, and while this might be the case for more complex environments, no further gains in swimming speed are expected in our system for \(\dim ({{{{\bf{s}}}}}) > 2\).
Third, we here utilize a fixed ANN architecture and deploy it to every single-bead agent, as illustrated in Fig. 8 (see ref. 58): we partition a bead’s ANN into a sensory module, \({f}_{\theta }^{(s)}(\cdot )\), and a policy module \({f}_{\theta }^{(c)}(\cdot )\). The sensory module maps each neighbor-specific input separately into a respective sensor embedding, \({\varepsilon }_{{i}_{\nu }}({t}_{k})={f}_{\theta }^{(s)}({{{{{\bf{p}}}}}}_{{i}_{\nu }}({t}_{k}))\in {{\mathbb{R}}}^{{n}_{{{{{\rm{embd}}}}}}}\), which are merged into a bead-specific context matrix \({{{{{\mathcal{C}}}}}}_{i}({t}_{k})=({\varepsilon }_{{i}_{-1}}({t}_{k}),{\varepsilon }_{{i}_{0}}({t}_{k}),{\varepsilon }_{{i}_{+1}}({t}_{k}))\). The subsequent policy module or controller ANN eventually outputs the action of the beads, \({{{{{\bf{a}}}}}}_{i}({t}_{k})={f}_{\theta }^{(c)}({{{{{\mathcal{C}}}}}}_{i}({t}_{k}))=({\phi }_{i},\Delta {{{{{\bf{s}}}}}}_{i})\), proposing a bead-specific force ϕi ∈ [−F0, F0] (to-be regularized, ϕ→Fi, such that ∑iFi = 0, see the “The N-bead swimmer model” and “Modeling system-level decision-making with decentralized controllers” subsections in the “Results and Discussion”) and an internal state update \(\Delta {{{{{\bf{s}}}}}}_{i}\in {{\mathbb{R}}}^{{n}_{{{{{\rm{ca}}}}}}}\).
Fourth, we specifically utilize a single-layer FF sensory module, \({f}_{\theta }^{(s)}(\cdot )\), with \(({N}_{0}^{(s)}=2+{n}_{{{{{\rm{ca}}}}}})\) input and \({N}_{1}^{(s)}={n}_{{{{{\rm{embd}}}}}}\) output neurons with a \(\tanh (\cdot )\) filter (the same network for all 3 neighbors). The (3 × nembd) context matrix, \({{{{{\mathcal{C}}}}}}_{i}\), is then flattened into a (3 nembd)-dimensional vector, which is processed by the policy module, \({f}_{\theta }^{(c)}(\cdot )\): again, a single FF layer with \({N}_{0}^{(c)}=3\,{n}_{{{{{\rm{embd}}}}}}\) and \(({N}_{1}^{(c)}=1+{n}_{{{{{\rm{ca}}}}}})\), followed by a clamping filter \({\sigma }^{(c)}(\cdot )=\max (\min (\cdot ,-1),1)\).
Fifth, we use nca = 2 and nembd = 4 in our simulations, resulting in \({N}_{0}^{(s)}\cdot ({N}_{1}^{(s)}+1)=20\) sensory module parameters, and \({N}_{0}^{(c)}\times ({N}_{1}^{(c)}+1)=39\) policy module parameters (accounting for the bias vectors), and thus in Nθ = 59 ANN parameters in total. These parameters were chosen to balance training performance and expected (near-)optimality of the results; any combination of nca, nembd≥1 is suitable for the presented system, but small values are not always sufficient to guarantee successful training behavior, and large values increase the number of ANN parameters.
Genetic algorithm and neuroevolution of single-agent policies with collective goals
Genetic Algorithms (GAs) are heuristic optimization techniques inspired by the process of natural selection. In GAs, a set (or a population) of size NP, \({{{{\bf{X}}}}}=\{{{{{{\mathbf{\theta }}}}}}_{1},\ldots ,{{{{{\mathbf{\theta }}}}}}_{{N}_{{{{{\rm{P}}}}}}}\}\), of sets of parameters (or individuals), \({{{{{\mathbf{\theta }}}}}}_{i}\in {{\mathbb{R}}}^{{N}_{\theta }}\), is maintained and modified over successive iterations (or generations) to optimize an arbitrary objective function (or a fitness score), \(r({{{{{\mathbf{\theta }}}}}}_{i}):{{\mathbb{R}}}^{{N}_{\theta }}\to {\mathbb{R}}\)58,66.
Many Genetic- or EA implementations have been proposed, which essentially follow the same biologically-inspired principles: Starting from an initial, often random population, high-quality individuals are selected (i) from the most recent generation for reproduction, depending on their associated fitness scores. Based on these selected high-fitness “parent” individuals, new “offspring” individuals are sampled, e.g., by genetic recombination (ii) of two mating parents, i, j, by randomly shuffling the elements (or genes) of their associated parameters, schematically expressed as θo = θi⨁θj. Such an offspring’s genome can be subjected to random mutations (iii), typically implemented by adding zero-centered Gaussian noise with a particular STD, ξθ, to the corresponding parameters, θo→θo + ξθ. The offspring then either replace (iv) existing individuals in the population or are discarded depending on their corresponding fitness score, r(θo). In that way, the population is successively updated and is thus guided towards high-fitness regions in the parameter space, \({{\mathbb{R}}}^{{N}_{\theta }}\), over many generations of successive reproduction cycles58,67.
Here, we utilize D. Ha’s “SimpleGA” implementation67 (following steps (i–iv) above) to optimize the ANN parameters, θ, of the single-bead agents of the here investigated N-bead microswimmers, see “The N-bead swimmer model” and “Modeling system-level decision-making with decentralized controllers” subsections of the “Results and Discussion,” and Figs. 1 and 8: After initializing the ANN parameters of a population of size NP = 128 by sampling from a zero-centered Gaussian of STD σθ = 0.1, we successively (i) select at each generation the best 10% of individuals for the reproduction cycle (ii, iii)—according to the fitness score r = 〈vT〉 that quantifies a swimmers mean center-of-mass velocity as detailed in the “Modeling system-level decision-making with decentralized controllers” subsection in the “Results and Discussion”—and (iv) replace the remaining 90% of the population with sampled offsprings; we fix the mutation rate in step (iii) to ξθ = 0.1 and typically perform multiple independent GA runs for 200–300 generations (see Fig. 1) each to ensure convergence of the evolved policies. For every parameter set θ (per run, and per generation), we evaluate the fitness score as the average fitness of 10 independent episodes, each lasting for T = (400–800) environmental time-steps. For every episode, we randomize the respective N-bead swimmer’s initial bead positions as \({x}_{i}(0) \sim {{{{\mathcal{N}}}}}(\mu =i\,{L}_{0},\sigma =R)\) drawn from a standard normal distribution centered around μ = i L0 with a STD of σ = R, and evaluate the episode fitness as mean center of mass velocity vT (see the “Modeling system-level decision-making with decentralized controllers” subsection in the “Results and Discussion”).
Swimming-gait analysis
In the “Transferable evolved policies: decentralized decision-making generalizes to arbitrary morphologies” subsection of the “Results and Discussion,” we define a 2π-period governing equation \({\hat{l}}_{i}(t)={f}_{\ell }\left((t-i\,\bar{\tau })\,\bar{\omega }+\phi \right)\) for the actual arm lengths li(tk) for both type A and B N-bead microswimmers as a function of the mean angular velocity \(\bar{\omega }=\bar{\omega} (N)\) and the mean neighbor arm cross-correlation time \(\bar{\tau }=\bar{\tau} (N)\). For all evolved type A and B microswimmer policies utilized in Fig. 4a and b, we thus evaluate the corresponding mean angular velocity as \(\bar{\omega }=\frac{1}{N-1}\mathop{\sum }_{i = 1}^{N-1}{\omega }_{i}\) by averaging the most dominant angular velocities ωi extracted for every arm length li(t) of a particular swimmer realization via Fourier transformation. We further define \(\bar{\tau }=\frac{1}{N-1}\mathop{\sum }_{i = 1}^{N-1}{\tau }_{i}\), with τi being the optimal time delay between neighboring arm lengths li(t) and li+1(t + τi) maximizing the overlap \(\frac{d}{d\tau }\int_{0}^{T}{l}_{i}(t){l}_{i+1}(t+\tau )\,dt{| }_{\tau = {\tau }_{i}}=0\).
Data availability
The data that support the plots within this paper and other findings of this study are available from the corresponding author upon request.
Code availability
The simulation code and output data are available upon reasonable request to the corresponding author.
References
Lauga, E. & Powers, T. R. The hydrodynamics of swimming microorganisms. Rep. Prog. Phys. 72, 096601 (2009).
Elgeti, J., Winkler, R. G. & Gompper, G. Physics of microswimmers-single particle motion and collective behavior: a review. Rep. Prog. Phys. 78, 56601 (2015).
Bechinger, C. et al. Active Brownian particles in complex and crowded environments. Rev. Mod. Phys. 88, 045006 (2016).
Zöttl, A. & Stark, H. Emergent behavior in active colloids. J. Phys. Condens Matter. 28, 253001 (2016).
Bray, D. Cell movements: from molecules to motility (Garland Science, 2000).
Wan, K. Y. Active oscillations in microscale navigation. Anim. Cogn. 26, 1837 (2023).
Jang, D., Jeong, J., Song, H. & Chung, S. K. Targeted drug delivery technology using untethered microrobots: A review. J. Micromech. Microeng, 29, 053002 (2019).
Singh, AjayVikram, Mohammad Hasan, P. L., Ansari, D. & Luch, A. Micro-nanorobots: important considerations when developing novel drug delivery platforms. Expert Opin. Drug Deliv. 16, 1259–1275 (2019).
Patra, D. et al. Intelligent, self-powered, drug delivery systems. Nanoscale 5, 1273–1283 (2013).
Kievit, F. M. & Zhang, M. Cancer nanotheranostics: improving imaging and therapy by targeted delivery across biological barriers. Adv. Mater. 23, H217–H247 (2011).
Brennen, C. & Winet, H. Fluid mechanics of propulsion by cilia and flagella. Ann. Rev. Fluid Mech. 9, 339–398 (1977).
Barry, N. P. & Bretscher, M. S. Dictyostelium amoebae and neutrophils can swim. Proc. Natl Acad. Sci. USA 107, 11376–11380 (2010).
Noselli, G., Beran, A., Arroyo, M. & DeSimone, A. Swimming Euglena respond to confinement with a behavioural change enabling effective crawling. Nat. Phys. 15, 496–502 (2019).
Sutton, R. S. & Barto, A. G. Reinforcement Learning: An Introduction (The MIT Press, 2018).
Nasiri, M., Löwen, H. & Liebchen, B. Optimal active particle navigation meets machine learning (a). EPL Europhys, Lett. 142 17001 (2023).
Zöttl, A. & Stark, H. Modeling active colloids: from active Brownian particles to hydrodynamic and chemical fields. Annu Rev. Condens Matter Phys. 14, 109–127 (2023).
Colabrese, S., Gustavsson, K., Celani, A. & Biferale, L. Flow navigation by smart microswimmers via reinforcement learning. Phys. Rev. Lett. 118, 1–5 (2017).
Schneider, E. & Stark, H. Optimal steering of a smart active particle. EPL 127, 64003 (2019).
Hartl, B., Hübl, M., Kahl, G. & Zöttl, A. Microswimmers learning chemotaxis with genetic algorithms. Proc. Natl Acad. Sci. USA 118, e2019683118 (2021).
Paz, S., Ausas, R. F., Carbajal, J. P. & Buscaglia, G. C. Chemoreception and chemotaxis of a three-sphere swimmer. Commun. Nonlinear Sci. Numer Simul. 117, 106909 (2023).
Rode, J., Novak, M. & Friedrich, B. M. Information theory of chemotactic agents using both spatial and temporal gradient sensing. Phys. Rev. X Life 2, 023012 (2024).
Alonso, A. & Kirkegaard, J. B. Learning optimal integration of spatial and temporal information in noisy chemotaxis. PNAS Nexus 3, 1–8 (2024).
Nasiri, M., Loran, E. & Liebchen, B. Smart active particles learn and transcend bacterial foraging strategies. Proc. Natl Acad. Sci. USA 121, 1–10 (2024).
Tsang, A. C. H., Tong, P. W., Nallan, S. & Pak, O. S. Self-learning how to swim at low Reynolds number. Phys. Rev. Fluids 5, 074101 (2020).
Zou, Z., Liu, Y., Young, Y. N., Pak, O. S. & Tsang, A. C. Gait switching and targeted navigation of microswimmers via deep reinforcement learning. Commun. Phys. 5, 1–9 (2022).
Qin, K., Zou, Z., Zhu, L. & Pak, O. S. Reinforcement learning of a multi-link swimmer at low Reynolds numbers. Phys. Fluids 35, 032003 (2023).
Zou, Z., Liu, Y., Tsang, A. C., Young, Y. N. & Pak, O. S. Adaptive micro-locomotion in a dynamically changing environment via context detection. Commun. Nonlinear Sci. Num. Simul. 128, 107666 (2024).
Jebellat, I., Jebellat, E., Amiri-Margavi, A., Vahidi-Moghaddam, A. & Nejat Pishkenari, H. A reinforcement learning approach to find optimal propulsion strategy for microrobots swimming at low Reynolds number. Robot Autonomous Syst. 175, 104659 (2024).
Lin, L.-S., Yasuda, K., Ishimoto, K. & Komura, S. Emergence of odd elasticity in a microswimmer using deep reinforcement learning. Phys. Rev. Res. 6, 033016 (2024).
Chiel, H. J. & Beer, R. D. The brain has a body: adaptive behavior emerges from interactions of nervous system, body and environment. Trends Neurosci. 20, 553–557 (1997).
Cohen, N. & Sanders, T. Nematode locomotion: dissecting the neuronal-environmental loop. Curr. Opin. Neurobiol. 25, 99–106 (2014).
Tornberg, A. K. & Shelley, M. J. Simulating the dynamics and interactions of flexible fibers in Stokes flows. J. Comput. Phys. 196, 8–40 (2004).
Gazzola, M., Dudte, L. H., McCormick, A. G. & Mahadevan, L. Forward and inverse problems in the mechanics of soft filaments. R. Soc. Open Sci. 5, 171628 (2018).
Russo, M. et al. Continuum robots: an overview. Adv. Intell. Syst. 5, 2200367 (2023).
Najafi, A. & Golestanian, R. Simple swimmer at low Reynolds number: three linked spheres. Phys. Rev. E 69, 062901 (2004).
Earl, D. J., Pooley, C. M., Ryder, J. F., Bredberg, I. & Yeomans, J. M. Modeling microscopic swimmers at low Reynolds number. J. Chem. Phys. 126, 064703 (2007).
Golestanian, R. & Ajdari, A. Analytic results for the three-sphere swimmer at low Reynolds number. Phys. Rev. E 77, 036308 (2008).
Walczak, C. E. & Nelson, D. L. Regulation of dynein-driven motility in cilia and flagella. Cell Motil. Cytoskeleton 27, 101–107 (1994).
Cass, J. F. & Bloomfield-Gadêlha, H. The reaction-diffusion basis of animated patterns in eukaryotic flagella. Nat. Commun. 14, 5638 (2023).
Renkawitz, J. et al. Nuclear positioning facilitates amoeboid migration along the path of least resistance. Nature 568, 546–550 (2019).
Reid, C. R., Latty, T., Dussutour, A. & Beekman, M. Slime mold uses an externalized spatial “memory" to navigate in complex environments. Proc. Natl. Acad. Sci. USA 109, 17490–17494 (2012).
Bonabeau, E., Dorigo, M. & Theraulaz, G. Swarm Intelligence from Natural to Artificial Systems. Santa Fe Institute Studies in the Sciences of Complexity (Oxford University Press, 1999).
Kennedy, J. Swarm Intelligence, 187–219 (Springer US, 2006).
McMillen, P. & Levin, M. Collective intelligence: a unifying concept for integrating biology across scales and substrates. Commun. Biol. 7, 378 (2024).
Stoy, K., Shen, W.-M. & Will, P. Using role-based control to produce locomotion in chain-type self-reconfigurable robots. IEEE/ASME Trans. Mechatron. 7, 410–417 (2002).
Kurokawa, H. et al. Self-reconfigurable m-tran structures and walker generation. Robot Auton. Syst. 54, 142–149 (2006).
Bongard, J. Morphological change in machines accelerates the evolution of robust behavior. Proc. Natl. Acad. Sci. USA 108, 1234–1239 (2011).
Pathak, D., Lu, C., Darrell, T., Isola, P. & Efros, A. A. Learning to control self-assembling morphologies: a study of generalization via modularity. In Proc. Advances in Neural Information Processing Systems, vol. 32 (NIPS paper, 2019).
Kriegman, S., Blackiston, D., Levin, M. & Bongard, J. A scalable pipeline for designing reconfigurable organisms. Proc. Natl. Acad. Sci. USA 117, 1853–1859 (2020).
Bing, Z., Lemke, C., Cheng, L., Huang, K. & Knoll, A. Energy-efficient and damage-recovery slithering gait design for a snake-like robot based on reinforcement learning and inverse reinforcement learning. Neural Netw. 129, 323–333 (2020).
Bongard, J. Biologically inspired computing. Computer 42, 95–98 (2009).
Zhu, L., Kim, S.-J., Hara, M. & Aono, M. Remarkable problem-solving ability of unicellular amoeboid organism and its mechanism. R. Soc. Open Sci. 5, 180396 (2018).
Parsa, A. et al. Universal mechanical polycomputation in granular matter. In Proc. Genetic and Evolutionary Computation Conference, GECCO ’23, 193-201 (Association for Computing Machinery, 2023).
Monter, S., Heuthe, V.-L., Panizon, E. & Bechinger, C. Dynamics and risk sharing in groups of selfish individuals. J. Theor. Biol. 562, 111433 (2023).
Gupta, J. K., Egorov, M. & Kochenderfer, M. Cooperative multi-agent control using deep reinforcement learning. Lect. Notes Comput. Sci. 10642 LNAI, 66–83 (2017).
Peng, Z., Zhang, L. & Luo, T. Learning to communicate via supervised attentional message processing. In Proc. ACM International Conference Proceeding Series 11–16 (CASA, 2018).
Oroojlooy, A. & Hajinezhad, D. A review of cooperative multi-agent deep reinforcement learning. Appl. Intell. 53, 13677–13722 (2023).
Hartl, B., Risi, S. & Levin, M. Evolutionary implications of self-assembling cybernetic materials with collective problem-solving intelligence at multiple scales. Entropy 26, 532 (2024).
Pontes-Filho, S., Walker, K., Najarro, E., Nichele, S. & Risi, S. A unified substrate for body-brain co-evolution. In Proc. From Cells to Societies: Collective Learning across Scales. https://openreview.net/forum?id=BcgXSzk6b5 (2022).
Mordvintsev, A., Randazzo, E., Niklasson, E. & Levin, M. Growing neural cellular automata. Distill 5, 45740–45751(2020).
Li, X. & Yeh, A. G.-O. Neural-network-based cellular automata for simulating multiple land use changes using GIS. Int J. Geogr. Inf. Sci. 16, 323–343 (2002).
Kim, S. & Karila, S. J. Microhydrodynamics: Principles and Selected Applications (Dover Publications Inc., 2005).
Muiños-Landin, S., Fischer, A., Holubec, V. & Cichos, F. Reinforcement learning of artificial microswimmers. Sci. Robot 6, eabd9285 (2021).
Hornik, K., Stinchcombe, M. & White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 2, 359–366 (1989).
Tang, Y. & Ha, D. The sensory neuron as a transformer: permutation-invariant neural networks for reinforcement learning. In Beygelzimer, A., Dauphin, Y., Liang, P. & Vaughan, J. W. (eds.) Advances in Neural Information Processing Systems (IEEE, 2021).
Katoch, S., Chauhan, S. S. & Kumar, V. A review on genetic algorithm: past, present, and future. Multimedia Tools Appl. 80, 8091–8126 (2020).
Ha, D. Evolving stable strategies. blog.otoro.net (2017).
Anderson, P. W. More is different. Science 177, 393–396 (1972).
Levin, M. The computational boundary of a “self”: developmental bioelectricity drives multicellularity and scale-free cognition. Front. Psychol. 10, 2688 (2019).
van Griethuijsen, L. I. & Trimmer, B. A. Locomotion in caterpillars. Biol. Rev. 89, 656–670 (2014).
Mishra, S., Van Rees, W. M. & Mahadevan, L. Coordinated crawling via reinforcement learning. J. R. Soc. Interface 17, 20200198 (2020).
Ehlers, K. M., Samuel, A. D., Berg, H. C. & Montgomery, R. Do cyanobacteria swim using traveling surface waves? Proc. Natl. Acad. Sci. USA 93, 8340–8343 (1996).
Najafi, A. & Golestanian, R. Propulsion at low Reynolds number. J. Phys. Condens Matter. 17, S1203–S1208 (2005).
Manicka, S. & Levin, M. Minimal developmental computation: a causal network approach to understand morphogenetic pattern formation. Entropy 24, 107 (2022).
Nasouri, B., Vilfan, A. & Golestanian, R. Efficiency limits of the three-sphere swimmer. Phys. Rev. Fluids 4, 1–9 (2019).
Wang, Q. Optimal strokes of low reynolds number linked-sphere swimmers. Appl. Sci. 9, 4023 (2019).
Meyer-Vernet, N. & Rospars, J.-P. How fast do living organisms move: maximum speeds from bacteria to elephants and whales. Am. J. Phys. 83, 719–722 (2015).
Daddi-Moussa-Ider, A., Lisicki, M. & Mathijssen, A. J. Tuning the upstream swimming of microrobots by shape and cargo size. Phys. Rev. Appl. 14, 024071 (2020).
Alshiekh, M. et al. Safe reinforcement learning via shielding. In Proc. AAAI Conference on Artificial Intelligence 32 (AAAI, 2018).
Behzadan, V. & Munir, A. Vulnerability of deep reinforcement learning to policy induction attacks. In Perner, P. (ed.) Machine Learning and Data Mining in Pattern Recognition, 262–275 (Springer International Publishing, 2017).
Tsang, A. C. H., Demir, E., Ding, Y. & Pak, O. S. Roads to smart artificial microswimmers. Adv. Intell. Syst. 2, 1900137 (2020).
Grosjean, G. et al. Remote control of self-assembled microswimmers. Sci. Rep. 5, 1–8 (2015).
Baulin, V. A. et al. Intelligent soft matter: towards embodied intelligence. arXiv preprint arXiv:2502.13224 arXiv:2502.13224 (2025).
Langton, C. G. Artificial life: An overview (MIT Press, 1997).
Cooke, J. Scale of body pattern adjusts to available cell number in amphibian embryos. Nature 290, 775–778 (1981).
Fields, C. & Levin, M. Regulative development as a model for origin of life and artificial life studies. Biosystems 229, 104927 (2023).
Watson, R. A., Levin, M. & Buckley, C. L. Design for an individual: connectionist approaches to the evolutionary transitions in individuality. Front. Ecol. Evol. 10, 823588 (2022).
Levin, M. Darwin’s agential materials: evolutionary implications of multiscale competency in developmental biology. Cell. Mol. Life Sci. 80, 142 (2023).
Levin, M. Technological approach to mind everywhere: an experimentally-grounded framework for understanding diverse bodies and minds. Front. Syst. Neurosci. 16, 768201 (2022).
Goodfellow, I., Bengio, Y. & Courville, A. Deep Learning (MIT Press, 2016).
Minsky, M. & Papert, S. Perceptron: an introduction to computational geometry. MIT Press Camb. Expand. Ed. 19, 2 (1969).
Rumelhart, D. E., Hinton, G. E. & Williams, R. J. Learning representations by back-propagating errors. Nature 323, 533–536 (1986).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Von Neumann, J. & Burks, A. W. et al. Theory of self-reproducing automata. IEEE Trans. Neural Netw. 5, 3–14 (1966).
Acknowledgements
We thank Sebastian Risi and Santosh Manicka for helpful discussions. B.H. gratefully acknowledges an APART-MINT fellowship from the Austrian Academy of Sciences. M.L. gratefully acknowledges support via Grant 62212 from the John Templeton Foundation. The computational results presented have been achieved (in part) using the Vienna Scientific Cluster 5.
Author information
Authors and Affiliations
Contributions
B.H. and A.Z. designed the study and wrote the paper. BH developed the code and performed simulations. B.H. and A.Z. analyzed results. M.L. discussed results and reviewed and commented on the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Communications Physics thanks Yasemin Ozkan-Aydin and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hartl, B., Levin, M. & Zöttl, A. Neuroevolution of decentralized decision-making in \({\boldsymbol{N}}\)-bead swimmers leads to scalable and robust collective locomotion. Commun Phys 8, 194 (2025). https://doi.org/10.1038/s42005-025-02101-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s42005-025-02101-5
