
Abstract
Training of neural networks (NNs) has emerged as a major consumer of both computational and energy resources. Quantum computers were coined as a root to facilitate training, but no experimental evidence has been presented so far. Here we demonstrate that quantum annealing platforms, such as D-Wave, can enable fast and efficient training of classical NNs, which are then deployable on conventional hardware. From a physics perspective, NN training can be viewed as a dynamical phase transition: the system evolves from an initial spin glass state to a highly ordered, trained state. This process involves eliminating numerous undesired minima in its energy landscape. The advantage of annealing devices is their ability to rapidly find multiple deep states. We found that this quantum training achieves superior performance scaling compared to classical backpropagation methods, with a clearly higher scaling exponent (1.01 vs. 0.78). It may be further increased up to a factor of 2 with a fully coherent quantum platform using a variant of the Grover algorithm. Furthermore, we argue that even a modestly sized annealer can be beneficial to train a deep NN by being applied sequentially to a few layers at a time.
Similar content being viewed by others
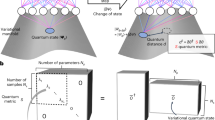

Introduction
Neural networks (NNs)1,2,3,4,5,6,7,8 have become one of the most transformative technologies, accelerating progress across multiple fields. A key factor in the success of neural networks7,8,9,10,11,12,13 is the development of efficient training methods. Techniques such as stochastic gradient descent14, backpropagation15, pre-training5, ReLU activation16, residual connections17 have paved the way for training deep NNs effectively, leading to groundbreaking applications, such as AI. Yet, this progress comes at extraordinary costs, as training state-of-the-art models now routinely requires massive computational and energy resources. Moreover, extrapolating current trends suggests even steeper future costs18. This motivates the search for fundamentally different training paradigms.
Meanwhile, quantum technologies have achieved critical milestones in recent years19,20,21,22,23,24. Of particular interest are quantum annealers, analog quantum computing devices engineered to exploit quantum coherent evolution to navigate glassy energy landscapes25,26,27,28,29,30,31,32,33,34,35. Modern quantum annealing architectures already approach 104 qubits33,35, with demonstrated advantage in optimizations35,36,37,38 and quantum dynamics simulations23,33.
Previous studies have explored the synergy between neural networks and quantum effects, including the use of quantum annealers for training restricted Boltzmann machines and deep belief networks39,40,41,42, the development of variational and circuit-based quantum neural networks43,44,45,46,47. Broader perspectives on quantum machine learning can be found in comprehensive reviews48. In this paper, we adopt a different perspective, which takes advantage of quantum annealers’ capability to rapidly map out low-energy landscapes of (e.g., classical) spin glass models. Here we show how one may take advantage of it to accelerate NNs training. Once trained, such NNs can be deployed on classical hardware, combining the advantages of quantum and classical computing.
The approach is based on the observation that the training process drives NNs through a phase transition from an initial glassy state to a highly ordered trained state49,50. The quantum dynamics facilitates such a transition due to its inherent ability to escape local minima33,38. It thus allows one to efficiently explore the hierarchical basin structure of the low-energy landscape38, which appears to be a key for accelerating NNs’ training. Being implemented on the D-Wave quantum annealer32,33, the quantum-assisted training algorithm demonstrates clear practical scaling advantages compared to classical training methods. Moreover, we show that a variant of Grover search algorithm51, known as amplitude amplification protocol52, implemented on a fully coherent quantum annealer, can further accelerate NNs’ training by potentially doubling the corresponding scaling exponent.
Methods
Neural network training
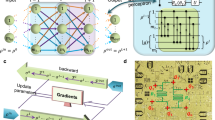
Here we explain the principal idea behind NN training strategy, amenable to be implemented on a quantum annealer. To be specific, consider a NN trained to recognize handwritten images of 0-9 digits. We adopted the architecture and image dataset (a subset of MNIST) as described in ref. 53. The network consists of three layers: one input layer, one hidden layer, and one output layer, see Fig. 1. The input layer contains 282 = 784 units, denoted by xa, where 0 ≤ xa ≤ 1 and a = 1, 2, …, 784, representing grayscale pixel values from handwritten images. The hidden layer consists of 120 units (implemented as qubits), denoted by \({s}_{i}^{h}\), where i = 1, 2, …, 120 and h designates the hidden layer, taking values of ± 1 after a measurement of qubits’ z-component. The output layer contains 40 units (also implemented as qubits), denoted by \({s}_{\alpha }^{o}\), here α = 1, 2, …40 and o stands for the output, also taking values of ± 1 upon z-measurement.

The input layer consists of 784 neurons, representing pixels of 28 × 28 MNIST images. The hidden and output layers, comprised of 120 and 40 neurons respectively, are encoded as qubits on the quantum annealer. Each neuron in the output layer represents a digit class (0–9), with the 4-fold error-correcting redundancy. An output layer qubit, measured as +1 indicates the corresponding digit class.
Connections from classical units in the input layer to quantum units in the hidden layer are implemented through local bias fields, hi:
where Wia matrix represents coupling strengths between them. Quantum units in the hidden and output layers are connected through couplings Jiα in the bare NN Hamiltonian,
where \({Z}_{i}^{h},{Z}_{\alpha }^{o}\) are Pauli-Z matrices acting on qubits \({s}_{i}^{h}\) and \({s}_{\alpha }^{o}\) respectively, and \({b}_{i}^{h}\) and \({b}_{\alpha }^{o}\) are bias parameters. Note that there are no couplings within the same layer. Hamiltonian of NN with an input image, x, is given by:
where the argument, [x], emphasizes its dependence on an input training or test image, x.
When the neural network has already been trained, it works in the following way. An input image, x, to be inferred, is encoded into the bias fields, hi[x], as in Eq. (1). One looks then for a 160-qubit configuration, \(\{{s}_{i}^{h},{s}_{\alpha }^{o}\}\), providing a ground (or a low-energy) state of the Hamiltonian H[x]. Specifically, the output part, \({s}_{\alpha }^{o}\), of the resulting ground state (spin configuration) is used to predict the image class, ỹ = 0, 1, …, 9. To this end the 40 output units are grouped into 10 groups by summing every four consecutive output values, forming a 10-component vector. A class predictor, ỹ, is given by a position of the maximum component in this vector. This 4-fold redundancy of the output layer serves as a simple majority-rule error-correcting mechanism.
As explained below, the fully trained neural network spin-Hamiltonian, H[x], is not a glass. Rather, it’s energy landscape contains a single (in case of the input image resembling one of training images) deep basin of attraction. Therefore, finding its ground state is a computationally easy task, which may be accomplished by, e.g., a simulated classical annealing. On the contrary, the training stage involves dealing with a glassy energy landscape. It can thus significantly benefit from using a quantum annealer, as explained below.
First we describe a training routine, known as equilibrium propagation54, which will be subsequently modified to take advantage of quantum capabilities. To train the NN, it introduces the nudge Hamiltonian, HN[x, y], which depends on a training image, x, and its apriori known class y = 0, 1, . . . , 9, as
where nα[y] is a nudge bias encoding the class, y, of each training image, x, as nα[y] = 1 for 4y < α ≤ 4(y + 1), and nα[y] = −1 otherwise.
The training process involves multiple updates of the network parameters. Initially, all parameters Wia, Jiα, \({b}_{i}^{h}\), \({b}_{\alpha }^{o}\) are chosen randomly. In our implementation, Wia is drawn from a uniform distribution over \(\left[-1/\sqrt{784},1/\sqrt{784}\right]\); Jiα is drawn from a uniform distribution over \(\left[-1/\sqrt{120},1/\sqrt{120}\right]\). The biases \({b}_{i}^{h}\), \({b}_{\alpha }^{o}\) are initialized to zero. In each update step, a training image, x, belonging to a class y, is randomly selected from the dataset. One then looks for two low-energy spin configurations: the first, \(\{{s}_{i}^{h},{s}_{\alpha }^{o}\}\), of the system Hamiltonian H[x], and the second, \(\{{s}_{i}^{h,N},{s}_{\alpha }^{o,N}\}\), of the nudge Hamiltonian HN[x, y]. The second step may be circumvented, as the strong nudge fixes \({s}_{\alpha }^{o,N}={n}_{\alpha }[y]\), while \({s}_{\alpha }^{o,h}\) is then simply determined by the sign of the local field as in Eq. (7). The parameters are updated based on the differences between these two spin configurations. Minimization of the loss function leads to the following update rules54:
where δW, δJ, δh, and δo are small positive learning rates.
If the low-energy spin configuration sampled from H[x] is identical (or very close) to that from HN[x, y], it implies that the network already produces the correct output. In this case the parameter do not update. However, if the spin configuration from H[x] differs from the one sampled from HN[x, y], the update rules penalize this difference by increasing the energy of this incorrect spin configuration. As a result, the likelihood of sampling this spin configuration or its neighbors in the future trials decreases. Through repeated updates, the energy landscapes of H[x] and of HN[x, y] gradually align. Since the latter is engineered to enforce the output layer units to predict the proper class, y, the former inherits the same trait, without having the nudge bias, Eq. (4), (not known apriori for test images). Once this is achieved, the neural network is considered to be trained. Presenting NN with all images from the training set along with corresponding adjustments of the parameters, Eq. (5), is called a training epoch. Number of such epochs needed to fully train NN may range from dozens to thousands.
Understanding NN training mechanism
To better understand how NN develops its ability to classify images, we utilized D-Wave’s quantum annealer to sample low-energy spin configurations of (classical) Hamiltonians (3) and (4) using a quantum annealing protocol (specified below). We used a training set (1000 images, 100 per class) to train the NN for 13 epochs. At various stages of the training process we employed a test set (100 images total, 10 per class) to visualize the energy landscape of NN Hamiltonian, (3). To this end we sampled 100 low-energy spin configurations for each test image, x, 10,000 low-energy spin configurations in total. We then applied Multidimensional Scaling (MDS) using the scikit-learn library55, projecting high-dimensional spin configurations (hypercube with dimensionality N = 160) onto a two-dimensional plane. The MDS algorithm preserves the pairwise Hamming distances as closely as possible in the 2D representation.
Figure 2 shows the resulting 2D visualizations for 9 representative instances during the training history. Each point represents one of 104 low-energy spin configurations, color-coded by their output classes (0-9) (with gray points, labeled as class -1, indicating unclassified spin configurations in cases when the output vector does not have a single largest component). The evolution of the low-energy landscape illustrates the development of the NN from a random initialization stage toward a highly structured mature stage. As training progresses, the landscape develops 10 distinct well-separated low-energy basins, representing 10 classes. Correspondingly the NN’s recognition accuracy on the test set increases from 6% to 92%. It can be further increased with a few extra training epochs.

The development is visualized in (a) to (i) through low-energy states of H[x], sampled by the D-Wave annealer. Each subplot corresponds to a different training epoch, with the test accuracy indicated. For each image in the test set (100 images total, 10 per class), 100 low-energy spin configurations were sampled using fixed network weights at a given epoch. These 104 spin configurations are projected from the 160-dimensional hypercube onto 2D using multidimensional scaling (MDS), preserving Hamming distances. Points are color-coded by their output class (0−9); gray points (class−1) indicate unclassified spin configurations. The late stages clearly demonstrate the appearance of energy basins, with 9 of them needed to be cut off for any given training image, x.
Figure 3 gives a more detailed view of this process. The first row displays five examples of training images of the digit 7. Each image is fed into the NN and, as previously explained, low-energy spin configurations of the Hamiltonian H[x] with those images, x, belonging to the class y = 7, are sampled and plotted via the 2D MDS visualization. Dots are again color-coded according to their output class, \(\tilde{y}\). Notice that the latter may or may not be equal to 7, representing correct or incorrect recognition respectively. The second and third rows display low-energy spin configurations for a poorly-and a well-trained NN. Each column corresponds to the same input image shown in the first row. In the poorly trained network (second row), one observes a mixed distribution of spin configurations associated with multiple output classes. As training progresses, the low-energy spin configurations become more closely spaced and their output class is almost surely \(\tilde{y}=7\).

a Five representative 28 × 28 test images of digit 7. b Corresponding low-energy spin configurations sampled from a poorly trained network’s energy landscape. Points are color-coded by their inferred output class (\(\tilde{y}\)), showing a scattered distribution across several classes. c Same test on a well-trained network exhibits tight clustering and uniform output labels (\(\tilde{y}=7\)), showing that NN has developed a distinct energy basin for the digit 7. The legend applies to all the panels in (b) and (c).
The lesson is that the training process can be viewed as a phase transition from a glassy phase (no explicit structure) to an ordered phase (a single deep basin for any image, x). (It is extremely important that images with distinct output classes produce such a deep basin in far-apart regions of the hypercube.) Such a transition makes the low energy spin configurations of the NN Hamiltonian loaded with an image, x, Eq. (3), to be concentrated within a narrow basin, having the same output class, \(\tilde{y}=y\), where y is the class of the image x. It achieves this goal by energetically penalizing all states with \(\tilde{y}\ne y\). The question is thus if and how a quantum annealer can accelerate such a training transition.
Quantum training algorithm
The main advantage of quantum hardware is its ability to produce low-energy states (as low as 0.1% above the ground state energy38) of Ising-like Hamiltonians, extremely fast (e.g., microseconds in case of D-Wave). Another useful feature is its ability to localize the search to specific parts of the hypercube. The latter capability is provided by the cyclic annealing protocol35,36,38. Unlike the more traditional forward annealing, it biasses the search to a vicinity of a chosen (so-called reference) state.
The Equilibrium Training algorithm, described above, looks for a low-energy spin configuration, \(\{{s}_{i}^{h},{s}_{\alpha }^{o}\}\), which needs to be sufficiently far from the nudge spin configuration \(\{{s}_{i}^{h,N},{s}_{\alpha }^{o,N}\}\), to generate evolution of NN parameters according to Eq. (5).
Before presenting the quantum extension of Equilibrium Propagation, it is useful to clarify the role of the so-called wrong spin configurations. For a given training image x with correct label y, the nudge Hamiltonian HN[x, y] enforces an output consistent with y. In contrast, the free Hamiltonian H[x] may yield low-energy spin configurations with incorrect outputs \(\tilde{y}\ne y\). These are the wrong spin configurations, located in spurious basins in the energy landscape which compete with the correct one. The training updates are precisely driven by the differences between the free spin configurations \(\{{s}_{i}^{h},{s}_{\alpha }^{o}\}\) and the nudge spin configuration \(\{{s}_{i}^{h,N},{s}_{\alpha }^{o,N}\}\). Whenever a wrong spin configuration is encountered, the update rules penalize it by raising its energy relative to the correct spin configuration, gradually suppressing its future occurrence.
With a quantum annealer, one can efficiently obtain not just a single low-energy spin configuration but a collection of m ≫ 1 spin configurations, \(\{{s}_{i}^{h,\gamma },{s}_{\alpha }^{o,\gamma }\}\) with γ = 1, 2, …, m, for a given training image x. By engineering the initial conditions of cyclic annealing, these configurations can be biased to explore wrong basins. To penalize all such configurations simultaneously, one substitutes
into Eq. (5). We refer to the resulting training scheme given by Eqs. (5)–(6) as the quantum propagation training algorithm.
Figure 2 shows exactly where are those configurations to penalize. They are in the 9 basins with wrong output classes, \(\tilde{y}\ne y\). Indeed, Fig. 4 illustrates how performance improves as the number of sampled spin configurations, m, increases during a fixed training epoch. All model parameters are initialized identically for each data point. A significant decrease in error rate is observed for m ≲ 10 and plateaus for larger m. To further optimize the training one should therefore look for m = 9 energy basins (low-energy spin configurations) within wrong basins. To this end one should initialize cyclic annealing from the reference spin configurations which are the nudge spin configurations of the 9 wrong basins. The latter are given by
where x is the currently presented image with the class y and \({\tilde{y}}^{\gamma }\ne y\) are 9 wrong output classes, γ = 1, …9.

It shows training error rate vs. number of training spin configurations m during the first epoch. The vertical red dashed line marks m0 = 10—the number of MNIST classes. Notable improvement in accuracy is observed when m ≲ m0. Saturation behavior beyond this point suggests formation of m0 class-labeled basins in the low-energy space.
Results
Benchmark
We benchmark the quantum propagation against classical backpropagation. To ensure fairness, both methods employ identical neural network architectures and best-practice settings. Classical training uses real-valued hidden and output units and ReLU activations in the hidden layer. Both methods use simple gradient descent to update parameters. Figure 5 shows the training error rate (1-accuracy) as a function of a number of training epochs in the log-log plot. It exhibits an algebraic relation,
where z is the scaling exponent indicating training efficiency. Blue triangles are data from the equilibrium propagation training, Eq. (5), the corresponding exponent is z = 0.64. This is worse than the conventional backpropagation technique (green squares, z = 0.78). Red dots represent quantum propagation(m = 20), exponent z = 1.01. The significantly larger exponent z = 1.01 for the quantum technique indicates superior performance and efficiency compared to both backpropagation and equilibrium propagation. Importantly, the scaling exponent z serves as a more meaningful performance metric than the raw accuracy alone, as it is unaffected by the computational overhead per parameter update. For a typical number of epochs (100 to 500), a conventional NN training process would require 3 to 4 times the resources to match quantum propagation performance. Additional testing under varied classical conditions did not match Quantum Propagation’s efficiency. Specifically, switching to sigmoid activations reduces z to 0.56, and increasing hidden units tenfold (from 120 to 1200 units) only marginally improves z to 0.84.

The data is shown on a log-log scale. Quantum Propagation (m = 20, red hexagons, z = 1.01) on D-Wave exhibits advantages scaling performance compared to Backpropagation (green squares, z = 0.78) and Equilibrium Propagation (also on D-Wave) (m = 1, blue triangles, z = 0.64).
Quantum coherent training
Equation (6) reminds an expectation value of corresponding Zh,o operators in a many-body quantum state \(\left\vert \psi \right\rangle\), which is a coherent superposition of m bit-string product states. Indeed, if
then Eq. (6) takes the form
At first glance, this does not provide any advantage, since to calculate the expectation values, one should run an annealing protocol multiple times and perform measurements of the corresponding z-components. This is exactly what Eq. (6) prescribes to begin with. Yet, there may be a significant benefit hidden here as explained below.
Consider a state \(\left\vert \psi \right\rangle\), reached upon a completion of a quantum annealing run, given by \(\left\vert \psi \right\rangle ={U}_{{{\rm{QA}}}}[x]\left\vert \psi (0)\right\rangle\), where an initial state, \(\left\vert \psi (0)\right\rangle\), may be, eg., the x-polarized product state, \(\left\vert \psi (0)\right\rangle ={\prod }_{i,\alpha }\left\vert {+}_{i},{+}_{\alpha }\right\rangle\). Here UQA[x] is a unitary quantum evolution operator describing forward annealing with the time-dependent Hamiltonian:
where \({X}_{j(\alpha )}^{h(o)}\) are Pauli-X’s acting on all qubits, s(0) = 0, while s(tf) = 1. The final state, \(\left\vert \psi \right\rangle =\left\vert \psi ({t}_{f})\right\rangle\), is a superposition of the two orthogonal components
where state \(\big\vert {\psi }_{y}\big\rangle\) has output qubits pointing to the correct class, y, of the presented image, x, and state \(\big\vert {\psi }_{\tilde{y}}\big\rangle\) has output qubits pointing to all 9 incorrect classes, \(\tilde{y}\ne y\). The corresponding amplitudes satisfy \(| {A}_{y}{| }^{2}+| {A}_{\tilde{y}}{| }^{2}=1\).
The goal of the training process is to make \(| {A}_{\tilde{y}}|\) as small as possible. As a result, during advanced training epochs \(| {A}_{\tilde{y}}| \ll 1\). This is a good news for operating NN, but is a very bad news for its further training. Indeed, the “correct” component, \(\big\vert {\psi }_{y}\big\rangle\), is identical (or very close) to the ground state, \(\big\vert {s}_{i}^{h,N},{s}_{\alpha }^{o,N}\big\rangle\), of the nudge Hamiltonian. As a result, it does not lead to any improvement of NN parameters, see Eq. (5). It is thus the “wrong” component, \(\big\vert {\psi }_{\tilde{y}}\big\rangle\), measured with the probability \(| {A}_{\tilde{y}}{| }^{2}\ll 1\), which contains all the information about energy basins to be cut off. Therefore the training process may be significantly accelerated if one can use \(\big\vert {\psi }_{\tilde{y}}\big\rangle\) component, instead of \(\left\vert \psi \right\rangle\) in Eqs. (10) and (5). The cyclic annealing with reference states, Eq. (7), is not efficient in late epochs, since the basin, defined by the correct class, y, is so much attractive that almost every cycle ends up in it, even if the initial reference state is chosen in a basin with \(\tilde{y}\ne y\).
Importantly, this can be achieved with the amplitude amplification procedure52,56,57,58, a generalization of the Grover search algorithm51, which generates a rotation
Engineering such a rotation requires order \(| {A}_{\tilde{y}}{| }^{-1}\gg 1\) applications of UQA[x] and \({U}_{{{\rm{QA}}}}^{{\dagger} }[x]\) operations, along with a control operation performed on ancilla coupled to the y-output qubits (\({U}_{{{\rm{QA}}}}^{{\dagger} }[x]\) operation is achieved by running the annealing in the reversed time direction, t → tf − t in Eq. (11)). This should be contrasted with the order \(| {A}_{\tilde{y}}{| }^{-2}\gg | {A}_{\tilde{y}}{| }^{-1}\) annealing runs, required by the straightforward application of Eqs. (10), (12) to observe the \(\big\vert {\psi }_{\tilde{y}}\big\rangle\) component.
As a result, the fully quantum coherent annealing protocol, which incorporates amplitude amplification52, may significantly further accelerate the training. Namely, it can potentially double the scaling exponent, z, in Eq. (8). We have not yet implemented such fully coherent protocol, since the D-Wave device is not expected to maintain coherence over multiple forward and backward runs of the annealing protocol. A smaller version of NN may be tested on a trapped ion platform57 which exhibits much longer coherence time.
Training deep neural networks
Finally we discuss a possibility of training deep NNs with L layers with a modest-sized quantum annealer. The neurons in neighboring layers l and l + 1 are connected through couplings \({J}_{{i}_{l}{i}_{l+1}}\) in the bare Hamiltonian of a deep NN,
where \({Z}_{{i}_{l}}^{l}\) are Pauli-Z matrices acting on qubits \({s}_{{i}_{l}}^{l}\) in layer l, and \({b}_{{i}_{l}}^{l}\) are bias parameters. The last layer, l = L, serves as the output layer. To train such deep NN, one looks again for two low-energy spin configurations \(\{{s}_{{i}_{l}}^{l}\}\) of the system Hamiltonian, H[x], and \(\{{s}_{{i}_{l}}^{l,N}\}\) of the nudge Hamiltonian, HN[x, y].
Due to the limited size of quantum annealers, one employs an active-layer sweep procedure. It calls for freezing all qubits along their total z-fields, except those in two (or more, depending on the capacity of the annealer) active layers. Starting from randomly initialized parameters, on the forward pass one allows layers l = 1, 2 to be unfrozen and uses the annealer to find their low-energy configuration. Next, with the updated values from layer l = 1, one freezes all layers except l = 2, 3, and repeat the annealing process for those two layers. Proceeding layer by layer, one sequentially update qubits up to the output layer L.
Then, the backward sweep is performed: first, one activates layers l = L, L − 1 only, and samples their m low-energy spin configurations from H[x] and one from HN[x, y]. These are used to update parameters in layers l = L, L − 1 via Quantum Propagation rules (5), (6). One then activates layers l = L − 1, L − 2 and repeats updating down to the layer l = 1. One full forward and backward pass constitutes a single update of the network parameters.
This way one only needs an annealer capable of accommodating two successive layer of a deep NN to take advantage of its ability to rapidly search for multiple low-energy spin configurations. This observation may allow already existing annealers to accelerate training of practical NNs.
Conclusions
We have shown that even a modest-size quantum annealer can significantly accelerate neural network training. The quantum propagation routine, suggested and implemented here with the D-Wave platform, exhibits a scaling exponent larger than both equilibrium propagation and backpropagation. Moreover, we argued that a fully coherent annealer may further increase the exponent by up to a factor of two. Finally, we discussed a strategy to benefit from quantum annealers with qubit numbers significantly smaller than the total number of neurons.
This work represents an initial step towards implementing quantum devices to accelerate NN training. The favorable scaling observed in our proof-of-principle experiments highlights the potential of quantum devices to surpass conventional training methods. Future directions naturally include larger datasets, deeper architectures, and systematic comparisons with state-of-the-art classical approaches on more challenging tasks. Equally exciting is the prospect of next-generation quantum annealers with longer coherence times, larger qubit counts, and enhanced connectivity, which may enable fully coherent training protocols. Ultimately, one may wonder: if quantum devices prove more effective at navigating complex energy landscapes and training neural networks for increasingly demanding tasks, could they open the door to forms of intelligence beyond what is practically attainable with purely classical methods?
Data availability
The data that support the findings of this study are provided in Supplementary Data.
Code availability
The code that supports the findings of this study is available from the corresponding author upon request.
References
McCulloch, W. S. & Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 5, 115–133 (1943).
Rosenblatt, F. The perceptron: a probabilistic model for information storage and organization in the brain. Psychol. Rev. 65, 386–408 (1958).
Hopfield, J. J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl Acad. Sci. USA 79, 2554–2558 (1982).
Hinton, G. E., Sejnowski, T. J. & Ackley, D. H.Boltzmann machines: Constraint satisfaction networks that learn (Carnegie-Mellon University, Department of Computer Science Pittsburgh, 1984).
Hinton, G. E., Osindero, S. & Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 18, 1527–1554 (2006).
Bengio, Y., Lamblin, P., Popovici, D. & Larochelle, H. Greedy Layer-Wise Training of Deep Networks. In Advances in Neural Information Processing Systems, vol. 19 (MIT Press, 2006).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems, vol. 25 (Curran Associates, Inc., 2012).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Goodfellow, I. J. et al. Generative adversarial nets. Adv. Neural. Inf. Process. Syst. 27 (2014).
Silver, D. et al. Mastering the game of Go with deep neural networks and tree search. Nature 529, 484–489 (2016).
Vaswani, A. et al. Attention is all you need. Adv. Neural. Inf. Process. Syst. 30 (2017).
Brown, T. et al. Language models are few-shot learners. In Advances in Neural Information Processing Systems, vol. 33, 1877–1901 (Curran Associates, Inc., 2020).
OpenAI. GPT-4 Technical Report (2024). arXiv:2303.08774.
Robbins, H. & Monro, S. A stochastic approximation method. Ann. Math. Stat. 22, 400–407 (1951).
Rumelhart, D. E., Hinton, G. E. & Williams, R. J. Learning representations by back-propagating errors. Nature 323, 533–536 (1986).
Glorot, X., Bordes, A. & Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, 315–323 (JMLR Workshop and Conference Proceedings, 2011).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778 (2016).
Kaplan, J. et al. Scaling laws for neural language models arXiv: 2001.08361 (2020).
Kim, Y. et al. Evidence for the utility of quantum computing before fault tolerance. Nature 618, 500–505 (2023).
Bluvstein, D. et al. Logical quantum processor based on reconfigurable atom arrays. Nature 626, 58–65 (2024).
Google Quantum AI and Collaborators. Quantum error correction below the surface code threshold. Nature 638, 920–926 (2025).
Gao, D. et al. Establishing a new benchmark in quantum computational advantage with 105-qubit Zuchongzhi 3.0 Processor. Phys. Rev. Lett. 134, 090601 (2025).
King, A. D. et al. Beyond-classical computation in quantum simulation. Science 388, 199–204 (2025).
Aboumrad, W. et al. Accelerating large-scale linear algebra using variational quantum imaginary time evolution arXiv:2503.13128 (2025).
Kadowaki, T. & Nishimori, H. Quantum annealing in the transverse Ising model. Phys. Rev. E 58, 5355–5363 (1998).
Brooke, J., Bitko, D., Rosenbaum, T. F. & Aeppli, G. Quantum annealing of a disordered magnet. Science 284, 779 (1999).
Farhi, E. et al. A quantum adiabatic evolution algorithm applied to random instances of an NP-complete problem. Science 292, 472–475 (2001).
Santoro, G. E., Martoňák, R., Tosatti, E. & Car, R. Theory of quantum annealing of an Ising spin glass. Science 295, 2427–2430 (2002).
Johnson, M. W. et al. Quantum annealing with manufactured spins. Nature 473, 194–198 (2011).
Jiang, S., Britt, K. A., McCaskey, A. J., Humble, T. S. & Kais, S. Quantum annealing for prime factorization. Sci. Rep. 8, 17667 (2018).
Criado, J. C. & Spannowsky, M. Qade: solving differential equations on quantum annealers. Quant. Sci. Technol. 8, 015021 (2022).
King, A. D. et al. Coherent quantum annealing in a programmable 2,000 qubit Ising chain. Nat. Phys. 18, 1324–1328 (2022).
King, A. D. et al. Quantum critical dynamics in a 5000-qubit programmable spin glass. Nature (2023).
Bernaschi, M., González-Adalid Pemartín, I., Martín-Mayor, V. & Parisi, G. The quantum transition of the two-dimensional Ising spin glass. Nature 631, 749–754 (2024).
Zhang, H., Boothby, K. & Kamenev, A. Cyclic quantum annealing: searching for deep low-energy states in 5000-qubit spin glass. Sci. Rep. 14, 30784 (2024).
Wang, H., Yeh, H.-C. & Kamenev, A. Many-body localization enables iterative quantum optimization. Nat. Commun. 13, 5503 (2022).
Bauza, H. M. & Lidar, D. A. Scaling advantage in approximate optimization with quantum annealing. Phys. Rev. Lett. 134, 160601 (2025).
Zhang, H. & Kamenev, A. Computational complexity of three-dimensional Ising spin glass: Lessons from D-wave annealer. Phys. Rev. Res. 7, 033098 (2025).
Adachi, S. H. & Henderson, M. P. Application of quantum annealing to training of deep neural networks. arXiv:1510.06356 (2015).
Job, J. & Adachi, S. Systematic comparison of deep belief network training using quantum annealing vs. classical techniques. arXiv:2009.00134 (2020).
Dixit, V., Selvarajan, R., Alam, M. A., Humble, T. S. & Kais, S. Training restricted Boltzmann machines with a D-wave quantum annealer. Front. Phys. 9 (Frontiers, 2021).
Higham, C. F. & Bedford, A. Quantum deep learning by sampling neural nets with a quantum annealer. Sci. Rep. 13, 3939 (2023).
McClean, J. R., Boixo, S., Smelyanskiy, V. N., Babbush, R. & Neven, H. Barren plateaus in quantum neural network training landscapes. Nat. Commun. 9, 4812 (2018).
Lloyd, S. & Weedbrook, C. Quantum generative adversarial learning. Phys. Rev. Lett. 121, 040502 (2018).
Dendukuri, A. et al. Defining quantum neural networks via quantum time evolution arXiv: 1905.10912 (2020).
Senokosov, A., Sedykh, A., Sagingalieva, A., Kyriacou, B. & Melnikov, A. Quantum machine learning for image classification. Mach. Learn.: Sci. Technol. 5, 015040 (2024).
Barney, R., Lakhdar-Hamina, D. & Galitski, V. Natural quantization of neural networks arXiv:2503.15482 (2025).
Biamonte, J. et al. Quantum machine learning. Nature 549, 195–202 (2017).
Huang, H. Statistical Mechanics of Neural Networks (Springer Nature Singapore, 2021).
Barney, R., Winer, M. & Galitski, V. Neural Networks as Spin Models: From Glass to Hidden Order Through Training arXiv:2408.06421 (2024).
Grover, L. K. A fast quantum mechanical algorithm for database search In Proceedings of the twenty-eighth annual ACM symposium on Theory of computing, 212–219 (1996).
Brassard, G., Hoyer, P., Mosca, M. & Tapp, A. Quantum amplitude amplification and estimation. Quantum Comput. Quantum Inf. AMS Contemp. Math. 305, 53–74 (2002).
Laydevant, J., Marković, D. & Grollier, J. Training an Ising machine with equilibrium propagation. Nat. Commun. 15, 3671 (2024).
Scellier, B. & Bengio, Y. Equilibrium Propagation: Bridging the Gap between Energy-Based Models and Backpropagation. Front. Comput. Neurosci. 11 (2017).
Pedregosa, F. et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Yan, B. et al. Fixed-point oblivious quantum amplitude-amplification algorithm. Sci. Rep. 12, 14339 (2022).
Kikuchi, Y., Mc Keever, C., Coopmans, L., Lubasch, M. & Benedetti, M. Realization of quantum signal processing on a noisy quantum computer. npj Quantum Inf. 9, 1–12 (2023).
V, K. & Santhanam, M. S. Amplitude amplification and estimation using the atom-optics kicked rotor. Phys. Rev. A 111, 032601 (2025).
Acknowledgements
We are grateful to M. Amin, V. Galitski, and A. King for useful discussions. This work was supported by the NSF grant DMR-2338819.
Author information
Authors and Affiliations
Contributions
H.Z. and A.K. conceived the idea. H.Z. performed experiments. H.Z. and A.K. discussed the data and wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Communications Physics thanks the anonymous reviewers for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, H., Kamenev, A. Quantum sequel of neural network training. Commun Phys 8, 478 (2025). https://doi.org/10.1038/s42005-025-02384-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s42005-025-02384-8
