
Abstract
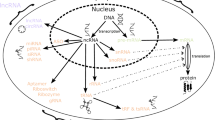
To address the rapid growth of scientific publications and data in biomedical research, knowledge graphs (KGs) have become a critical tool for integrating large volumes of heterogeneous data to enable efficient information retrieval and automated knowledge discovery. However, transforming unstructured scientific literature into KGs remains a significant challenge, with previous methods unable to achieve human-level accuracy. Here we used an information extraction pipeline that won first place in the LitCoin Natural Language Processing Challenge (2022) to construct a large-scale KG named iKraph using all PubMed abstracts. The extracted information matches human expert annotations and significantly exceeds the content of manually curated public databases. To enhance the KG’s comprehensiveness, we integrated relation data from 40 public databases and relation information inferred from high-throughput genomics data. This KG facilitates rigorous performance evaluation of automated knowledge discovery, which was infeasible in previous studies. We designed an interpretable, probabilistic-based inference method to identify indirect causal relations and applied it to real-time COVID-19 drug repurposing from March 2020 to May 2023. Our method identified around 1,200 candidate drugs in the first 4 months, with one-third of those discovered in the first 2 months later supported by clinical trials or PubMed publications. These outcomes are very challenging to attain through alternative approaches that lack a thorough understanding of the existing literature. A cloud-based platform (https://biokde.insilicom.com) was developed for academic users to access this rich structured data and associated tools.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$32.99 / 30 days
cancel any time
Subscribe to this journal
Receive 12 digital issues and online access to articles
$119.00 per year
only $9.92 per issue
Buy this article
- Purchase on SpringerLink
- Instant access to the full article PDF.
USD 39.95
Prices may be subject to local taxes which are calculated during checkout





Similar content being viewed by others


Data availability
The datasets used in this study are available on the GitHub repository at https://github.com/myinsilicom/iKraph (ref. 97). Due to size limitations, additional large datasets can be accessed via Zenodo at https://doi.org/10.5281/ZENODO.14846820 (ref. 98). We used the BioRED dataset to train our NER and relation extraction models, and the BioRED dataset can be accessed through https://ftp.ncbi.nlm.nih.gov/pub/lu/BioRED/. The complete KG is hosted on the cloud-based platform: https://www.biokde.com. The downloadable version of the complete iKraph can be accessed via Zenodo at https://doi.org/10.5281/ZENODO.14846820 (ref. 98). Source data are provided with this paper.
Code availability
The code and datasets generated during this study can be found via the GitHub repository at https://github.com/myinsilicom/iKraph (ref. 97).
References
Kitano, H. Nobel Turing Challenge: creating the engine for scientific discovery. npj Syst. Biol. Appl. 7, 29 (2021).
Li, L. et al. Real-world data medical knowledge graph: construction and applications. Artif. Intell. Med. 103, 101817 (2020).
Yu, S. et al. BIOS: An algorithmically generated biomedical knowledge graph. Preprint at https://arxiv.org/abs/2203.09975 (2022)
Nicholson, D. N. & Greene, C. S. Constructing knowledge graphs and their biomedical applications. Comput. Struct. Biotechnol. J. 18, 1414–1428 (2020).
Gao, Z., Ding, P. & Xu, R. KG-Predict: a knowledge graph computational framework for drug repurposing. J. Biomed. Inform. 132, 104133 (2022).
Li, N. et al. KGHC: a knowledge graph for hepatocellular carcinoma. BMC Med. Inf. Decis. Making 20, 135 (2020).
Ernst, P., Siu, A. & Weikum, G. KnowLife: a versatile approach for constructing a large knowledge graph for biomedical sciences. BMC Bioinf. 16, 157 (2015).
Zheng, S. et al. PharmKG: a dedicated knowledge graph benchmark for biomedical data mining. Briefings Bioinform. 22, bbaa344 (2021).
Petasis, G. et al. Using machine learning to maintain rule-based named-entity recognition and classification systems. In Proc. 39th Annual Meeting on Association for Computational Linguistics: ACL ’01 426–433 (Association for Computational Linguistics, 2001).
Kim, J.-H. & Woodland, P.C. A rule-based named entity recognition system for speech input. In Proc. 6th International Conference on Spoken Language Processing (ICSLP 2000) (eds Yuan, B. et al.) 528–531 (International Speech Communication Association, 2000); https://doi.org/10.21437/ICSLP.2000-131
Miyao, Y., Sagae, K., Sætre, R., Matsuzaki, T. & Tsujii, J. Evaluating contributions of natural language parsers to protein–protein interaction extraction. Bioinformatics 25, 394–400 (2009).
Lee, J., Kim, S., Lee, S., Lee, K. & Kang, J. On the efficacy of per-relation basis performance evaluation for PPI extraction and a high-precision rule-based approach. BMC Med. Inf. Decis. Making 13, S7 (2013).
Raja, K., Subramani, S. & Natarajan, J. PPInterFinder—a mining tool for extracting causal relations on human proteins from literature. Database 2013, bas052 (2013).
Kim, J.-H., Kang, I.-H. & Choi, K.-S. Unsupervised named entity classification models and their ensembles. In Proc. 19th International Conference on Computational Linguistics (COLING 2002) (eds Tseng, S.-C. et al.) 1–7 (Association for Computational Linguistics, 2002); https://doi.org/10.3115/1072228.1072316
Li, L., Zhou, R. & Huang, D. Two-phase biomedical named entity recognition using CRFs. Comput. Biol. Chem. 33, 334–338 (2009).
Tikk, D., Thomas, P., Palaga, P., Hakenberg, J. & Leser, U. A comprehensive benchmark of kernel methods to extract protein–protein interactions from literature. PLoS Comput. Biol. 6, e1000837 (2010).
Bui, Q.-C., Katrenko, S. & Sloot, P. M. A. A hybrid approach to extract protein–protein interactions. Bioinformatics 27, 259–265 (2011).
Patra, R. & Saha, S. K. A kernel-based approach for biomedical named entity recognition. Sci. World J. 2013, 950796 (2013).
Hong, L. et al. A novel machine learning framework for automated biomedical relation extraction from large-scale literature repositories. Nat. Mach. Intell. 2, 347–355 (2020).
Zhang, H.-T., Huang, M.-L. & Zhu, X.-Y. A unified active learning framework for biomedical relation extraction. J. Comput. Sci. Technol. 27, 1302–1313 (2012).
Yu, K. et al. Automatic extraction of protein-protein interactions using grammatical relationship graph. BMC Med. Inf. Decis. Making 18, 42 (2018).
Chowdhary, R., Zhang, J. & Liu, J. S. Bayesian inference of protein–protein interactions from biological literature. Bioinformatics 25, 1536–1542 (2009).
Corbett, P. & Copestake, A. Cascaded classifiers for confidence-based chemical named entity recognition. BMC Bioinf. 9, S4 (2008).
Lung, P.-Y., He, Z., Zhao, T., Yu, D. & Zhang, J. Extracting chemical–protein interactions from literature using sentence structure analysis and feature engineering. Database 2019, bay138 (2019).
Bell, L., Chowdhary, R., Liu, J. S., Niu, X. & Zhang, J. Integrated bio-entity network: a system for biological knowledge discovery. PLoS ONE 6, e21474 (2011).
Kim, S., Yoon, J. & Yang, J. Kernel approaches for genic interaction extraction. Bioinformatics 24, 118–126 (2008).
Bell, L., Zhang, J., & Niu, X. Mixture of logistic models and an ensemble approach for protein-protein interaction extraction. In Proc. 2nd ACM Conference on Bioinformatics, Computational Biology and Biomedicine (eds Grossman, R. et al.) 371–375 (Association for Computing Machinery, 2011); https://doi.org/10.1145/2147805.2147853
Florian, R., Ittycheriah, A., Jing, H. & Zhang, T. Named entity recognition through classifier combination. In Proc. 7th Conf. Natural Language Learning at HLT-NAACL 2003 (CoNLL ’03) (eds Daelemans, W. et al.) 168–171 (Association for Computational Linguistics, 2003).
Leaman, R., Wei, C.-H. & Lu, Z. tmChem: a high performance approach for chemical named entity recognition and normalization. J. Cheminform. 7, S3 (2015).
Qu, J. et al. Triage of documents containing protein interactions affected by mutations using an NLP based machine learning approach. BMC Genomics 21, 773 (2020).
Nguyen, T. H. & Grishman, R. Relation extraction: perspective from convolutional neural networks. In Proc. 1st Workshop on Vector Space Modeling for Natural Language Processing (eds Blunsom, P. et al.) 39–48 (Association for Computational Linguistics, 2015).
He, D., Zhang, H., Hao, W., Zhang, R. & Cheng, K. A customized attention-based long short-term memory network for distant supervised relation extraction. Neural Comput. 29, 1964–1985 (2017).
Li, F., Zhang, M., Fu, G. & Ji, D. A neural joint model for entity and relation extraction from biomedical text. BMC Bioinf. 18, 198 (2017).
Crichton, G., Pyysalo, S., Chiu, B. & Korhonen, A. A neural network multi-task learning approach to biomedical named entity recognition. BMC Bioinf. 18, 368 (2017).
Luo, L. et al. An attention-based BiLSTM-CRF approach to document-level chemical named entity recognition. Bioinformatics 34, 1381–1388 (2018).
Guo, Z., Zhang, Y. & Lu, W. Attention guided graph convolutional networks for relation extraction. In Proc. 57th Annual Meeting of the Association for Computational Linguistics (eds Korhonen, A. et al.) 241–251 (Association for Computational Linguistics, 2019).
Gridach, M. Character-level neural network for biomedical named entity recognition. J. Biomed. Inform. 70, 85–91 (2017).
Lim, S. & Kang, J. Chemical–gene relation extraction using recursive neural network. Database 2018, bay060 (2018).
Gu, J., Sun, F., Qian, L. & Zhou, G. Chemical-induced disease relation extraction via convolutional neural network. Database 2017, bax024 (2017).
Habibi, M., Weber, L., Neves, M., Wiegandt, D. L. & Leser, U. Deep learning with word embeddings improves biomedical named entity recognition. Bioinformatics 33, i37–i48 (2017).
Liu, S. et al. Extracting chemical–protein relations using attention-based neural networks. Database 2018, bay102 (2018).
Wu, H. & Huang, J. Joint entity and relation extraction network with enhanced explicit and implicit semantic information. Appl. Sci. 12, 6231 (2022).
Akbik, A., Bergmann, T. & Vollgraf, R. Pooled contextualized embeddings for named entity recognition. In Proc. 2019 Conference of the North (eds Burstein, J. et al.) 724–728 (Association for Computational Linguistics, 2019).
Eberts, M. & Ulges, A. Span-based Joint Entity and Relation Extraction with Transformer Pre-Training (IOS, 2019).
Zhuang, L., Lin, W., Ya, S. & Zhao, J. A robustly optimized BERT pre-training approach with post-training. In Proc. 20th Chinese Natl. Conf. Computational Linguistics (eds Li, S. et al.) 1218–1227 (Chinese Information Processing Society of China, 2021); https://aclanthology.org/2021.ccl-1.108/
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proc. NAACL-HLT 2019 4171-4186 (Association for Computational Linguistics, 2019).
Nguyen, D. Q., Vu, T. & Nguyen, A. T. BERTweet: a pre-trained language model for English Tweets. In Proc. 2020 Conf. Empirical Methods in Natural Language Processing: System Demonstrations (eds Liu, Q. & Schlangen, D.) 9–14 (Association for Computational Linguistics, 2020); https://doi.org/10.18653/v1/2020.emnlp-demos.2
Lee, J. et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 36, 1234–1240 (2019).
Liang, C. et al. BOND: BERT-assisted open-domain named entity recognition with distant supervision. In Proc. 26th ACM SIGKDD Int. Conf. Knowledge Discovery & Data Mining (KDD ’20) (eds Gupta, R. et al.) 1054–1064 (Association for Computing Machinery, 2020); https://doi.org/10.1145/3394486.3403149
Wadden, D., Wennberg, U., Luan, Y. & Hajishirzi, H. Entity, relation, and event extraction with contextualized span representations. In Proc. 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) 5784–5789 (Association for Computational Linguistics, 2019).
Zhang, Z. et al. ERNIE: enhanced language representation with informative entities. In Proc. 57th Annual Meeting of the Association for Computational Linguistics (eds Korhonen, A. et al.) 1441–1451 (Association for Computational Linguistics, 2019).
Chang, H., Xu, H., van Genabith, J., Xiong, D. & Zan, H. JoinER-BART: joint entity and relation extraction with constrained decoding, representation reuse and fusion. IEEE/ACM Trans. Audio Speech Lang. Proc. https://doi.org/10.1109/TASLP.2023.3310879 (2023).
Yamada, I., Asai, A., Shindo, H., Takeda, H. & Matsumoto, Y. LUKE: deep contextualized entity representations with entity-aware self-attention. In Proc. the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (eds Webber, B. et al.) 6442–6454 (Association for Computational Linguistics, 2020).
Beltagy, I., Lo, K. & Cohan, A. SciBERT: a pretrained language model for scientific text. In Proc. 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (eds Inui, K. et al.) 3613–3618 (Association for Computational Linguistics, 2019).
Radford, A. et al. Language models are unsupervised multitask learners. OpenAI https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf (2019).
Radford, A., Narasimhan, K., Salimans, T. & Sutskever, I. Improving language understanding by generative pre-training. OpenAI https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (2018).
Brown, T. B. et al. Language models are few-shot learners. In Proc. 34th International Conference on Neural Information Processing Systems (eds Larochelle, H. et al.) Vol. 33, 1877–1901 (Curran Associates Inc., 2020).
Wei, X. et al. Zero-shot information extraction via chatting with ChatGPT. Preprint at https://arxiv.org/abs/2302.10205 (2023).
Pan, J. Z. et al. Large language models and knowledge graphs: opportunities and challenges. Trans. Graph Data Knowl. 1, 2:1–2:38 (2023).
Zhu, Y. et al. LLMs for knowledge graph construction and reasoning: recent capabilities and future opportunities. World Wide Web 27, 58 (2023).
Kandpal, N., Deng, H., Roberts, A., Wallace, E. & Raffel, C. Large language models struggle to learn long-tail knowledge. In Proc. 40th Int. Conf. Machine Learning (ICML 2023) (eds Krause, A. et al.) Vol. 202, 15708–15719 (PMLR, 2023); https://proceedings.mlr.press/v202/kandpal23a.html
Li, T., Hosseini, M. J., Weber, S. & Steedman, M. Language models are poor learners of directional inference. In Findings of the Association for Computational Linguistics: EMNLP 2022 (eds Goldberg, Y. et al.) 903–921 (Association for Computational Linguistics, 2022).
Elazar, Y. et al. Measuring and improving consistency in pretrained language models. Trans. Assoc. Comput. Ling. 9, 1012–1031 (2021).
Heinzerling, B. & Inui, K. Language models as knowledge bases: on entity representations, storage capacity, and paraphrased queries. In Proc. 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume (eds Merlo, P. et al.) 1772–1791 (Association for Computational Linguistics, 2021).
Zheng, Q., Guo, K. & Xu, L. A large-scale Chinese patent dataset for information extraction. Syst. Sci. Control Eng. 12, 2365328 (2024).
Stoica, G., Platanios, E. A. & Poczos, B. Re-TACRED: addressing shortcomings of the TACRED dataset. In Proc. AAAI Conf. Artif. Intell. Vol. 35, 13843–13850 (2021); https://doi.org/10.1609/aaai.v35i15.17631
Luan, Y., He, L., Ostendorf, M. & Hajishirzi, H. Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction. In Proc. 2018 Conference on Empirical Methods in Natural Language Processing (eds Riloff, E. et al.) 3219–3232 (Association for Computational Linguistics, 2018).
Wouters, O. J., McKee, M. & Luyten, J. Estimated research and development investment needed to bring a new medicine to market, 2009-2018. JAMA 323, 844 (2020).
Lovering, F., Bikker, J. & Humblet, C. Escape from flatland: increasing saturation as an approach to improving clinical success. J. Med. Chem. 52, 6752–6756 (2009).
Cui, L. et al. DETERRENT: knowledge guided graph attention network for detecting healthcare misinformation. In Proc. 26th ACM SIGKDD Int. Conf. Knowledge Discovery & Data Mining (KDD ’20) (eds Gupta, R. et al.) 492–502 (Association for Computing Machinery, 2020); https://doi.org/10.1145/3394486.3403092
Mohamed, S. K., Nounu, A. & Nováček, V. Biological applications of knowledge graph embedding models. Briefings Bioinform. 22, 1679–1693 (2021).
Wang, C., Yu, H. & Wan, F. Information retrieval technology based on knowledge graph. In Proc. 3rd Int. Conf. Advances in Materials, Mechatronics and Civil Engineering (ICAMMCE 2018) 291–296 (Atlantis Press, 2018); https://doi.org/10.2991/icammce-18.2018.65
Himmelstein, D. S. et al. Systematic integration of biomedical knowledge prioritizes drugs for repurposing. eLife 6, e26726 (2017).
Azuaje, F. Drug interaction networks: an introduction to translational and clinical applications. Cardiovascular Res. 97, 631–641 (2013).
Ye, H., Liu, Q. & Wei, J. Construction of drug network based on side effects and its application for drug repositioning. PLoS ONE 9, e87864 (2014).
Chen, H., Zhang, H., Zhang, Z., Cao, Y. & Tang, W. Network-based inference methods for drug repositioning. Comput. Math. Methods Med. 2015, 130620 (2015).
Luo, Y. et al. A network integration approach for drug-target interaction prediction and computational drug repositioning from heterogeneous information. Nat. Commun. 8, 573 (2017).
Islamaj, R., Lai, P.-T., Wei, C.-H., Luo, L. & Lu, Z. The overview of the BioRED (Biomedical Relation Extraction Dataset) track at BioCreative VIII. Zenodo https://doi.org/10.5281/ZENODO.10351131 (2023).
Luo, L., Lai, P.-T., Wei, C.-H., Arighi, C. N. & Lu, Z. BioRED: a rich biomedical relation extraction dataset. Briefings Bioinform. 23, bbac282 (2022).
Ahmed, F. et al. SperoPredictor: an integrated machine learning and molecular docking-based drug repurposing framework with use case of COVID-19. Front. Public Health 10, 902123 (2022).
Ahmed, F. et al. A comprehensive review of artificial intelligence and network based approaches to drug repurposing in Covid-19. Biomed. Pharmacother. 153, 113350 (2022).
Zhou, Y. et al. Network-based drug repurposing for novel coronavirus 2019-nCoV/SARS-CoV-2. Cell Disc. 6, 14 (2020).
Aghdam, R., Habibi, M. & Taheri, G. Using informative features in machine learning based method for COVID-19 drug repurposing. J. Cheminformatics 13, 70 (2021).
Belikov, A. V., Rzhetsky, A. & Evans, J. Prediction of robust scientific facts from literature. Nat. Mach. Intell. 4, 445–454 (2022).
Gu, Y. et al. Domain-specific language model pretraining for biomedical natural language processing. ACM Trans. Comput. Healthcare 3, 1–23 (2022).
Reimers, N. & Gurevych, I. Sentence-BERT: sentence embeddings using Siamese BERT-networks. In Proc. 2019 Conf. Empirical Methods in Natural Language Processing and the 9th Int. Joint Conf. Natural Language Processing (EMNLP-IJCNLP) 3982–3992 (Association for Computational Linguistics, 2019); https://doi.org/10.18653/v1/D19-1410
Liu, Y. et al. RoBERTa: a robustly optimized BERT pretraining approach. Preprint at http://arxiv.org/abs/1907.11692 (2019).
Raffel, C. et al. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 21, 1–67 (2020).
Peng, Y., Yan, S. & Lu, Z. Transfer learning in biomedical natural language processing: an evaluation of BERT and ELMo on ten benchmarking datasets. In Proc. 18th BioNLP Workshop and Shared Task (eds Demner-Fushman, D. et al.) 58–65 (Association for Computational Linguistics, 2019).
Alsentzer, E. et al. Publicly available clinical BERT embeddings. In Proc. 2nd Clinical Natural Language Processing Workshop (eds Rumshisky, A. et al.) 72–78 (Association for Computational Linguistics, 2019).
Sohn, S., Comeau, D. C., Kim, W. & Wilbur, W. J. Abbreviation definition identification based on automatic precision estimates. BMC Bioinf. 9, 402 (2008).
Chandak, P., Huang, K. & Zitnik, M. Building a knowledge graph to enable precision medicine. Sci. Data 10, 67 (2023).
Zhou, Y. et al. TTD: Therapeutic Target Database describing target druggability information. Nucleic Acids Res. 52, D1465–D1477 (2023).
Ashburner, M. et al. Gene ontology: tool for the unification of biology. The Gene Ontology Consortium. Nat. Genet. 25, 25–29 (2000).
Gene Ontology Consortium et al. The Gene Ontology knowledgebase in 2023. Genetics 224, iyad031 (2023).
Wilks, C. et al. recount3: summaries and queries ffor large-scale RNA-seq expression and splicing. Genome Biol. 22, 323 (2021).
Zhang, Y. et al. myinsilicom/iKraph: 1.0.0. Zenodo https://doi.org/10.5281/ZENODO.14577964 (2024).
Zhang, Y. et al. iKraph: a comprehensive, large-scale biomedical knowledge graph for AI-powered, data-driven biomedical research. Zenodo https://doi.org/10.5281/ZENODO.14846820 (2025).
Acknowledgements
We thank the LitCoin NLP Challenge and BioCreative Challenge VIII BioRED track organizers for generating the valuable challenge dataset, which made the work possible. This research was partially supported by the NIH under grant no. R21LM014277 (J. Zhang), contract 75N91024C00007 (J. Zhang) and contract 75N93024C00034 (J. Zhang); by the National Science Foundation under grant nos. 2335357 (J. Zhang) and 2403911 (J. Zhang) and by the National Cancer Institute, NIH, under Prime Contract No. 75N91019D00024, Task Order No. 75N91024F00030 (J. Zhang). The content of this publication does not necessarily reflect the views or policies of the Department of Health and Human Services, nor does mention of trade names, commercial products or organizations imply endorsement by the US Government. The funders had no role in the study design, data collection and analysis, decision to publish or preparation of the paper.
Author information
Authors and Affiliations
Contributions
Y.Z., X.S., F.P., K.L., S.T., A.E., Q.H., W.W., Jianan Wang and Jian Wang collected data and developed models and pipelines. Y.Z., F.P. and J. Zhang analysed the data and developed methods. D.S., H.C., J. Zhou, E.Z., B.L., T.Z. and J. Zhang. developed the iExplore platform interface. K.Y. and J. Zhang conceptualized and designed the study. Y.Z., F.P., K.Y. and J. Zhang wrote the paper. X.Q., T.Z. and P.Z. provided consultation and paper revision. J. Zhang supervised the study and is the corresponding author.
Corresponding author
Ethics declarations
Competing interests
J. Zhang and T.Z. are owners of Insilicom LLC. The other authors declare no competing interests.
Peer review
Peer review information
Nature Machine Intelligence thanks James Evans and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information
Supplementary Methods sections 1–5, Discussion section 6, Figs. 1–3, Tables 1–4 and Box 1.
Source data
Source Data Fig. 1
Data used to generate the Venn plot, pie plot and line plot.
Source Data Fig. 2
Data used to generate the plot on repurposed drugs for COVID-19.
Source Data Fig. 3
Data used to generate the plot on repurposed drugs for cystic fibrosis.
Source Data Fig. 4
Data used to generate the plot on drug repurposing study on top ten common drugs and ten diseases.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhang, Y., Sui, X., Pan, F. et al. A comprehensive large-scale biomedical knowledge graph for AI-powered data-driven biomedical research. Nat Mach Intell 7, 602–614 (2025). https://doi.org/10.1038/s42256-025-01014-w
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s42256-025-01014-w
This article is cited by
-
Advancing active compound discovery for novel drug targets: insights from AI-driven approaches
Acta Pharmacologica Sinica (2025)
-
Vaner2: towards more general biomedical named entity recognition using multi-task large language model encoders
Health Information Science and Systems (2025)
