
Abstract
Correlative live-cell imaging of landmark organelles—such as nuclei, nucleoli, cell membranes, nuclear envelope and lipid droplets—is critical for systems cell biology and drug discovery. However, achieving this with molecular labels alone remains challenging. Virtual staining of multiple organelles and cell states from label-free images with deep neural networks is an emerging solution. Virtual staining frees the light spectrum for imaging molecular sensors, photomanipulation or other tasks. Current methods for virtual staining of landmark organelles often fail in the presence of nuisance variations in imaging, culture conditions and cell types. Here we address this with Cytoland, a collection of models for robust virtual staining of landmark organelles across diverse imaging parameters, cell states and types. These models were trained with self-supervised and supervised pre-training using a flexible convolutional architecture (UNeXt2) and augmentations inspired by image formation of light microscopes. Cytoland models enable virtual staining of nuclei and membranes across multiple cell types—including human cell lines, zebrafish neuromasts, induced pluripotent stem cells (iPSCs) and iPSC-derived neurons—under a range of imaging conditions. We assess models using intensity, segmentation and application-specific measurements obtained from virtually and experimentally stained nuclei and membranes. These models rescue missing labels, correct non-uniform labelling and mitigate photobleaching. We share multiple pre-trained models, open-source software (VisCy) for training, inference and deployment, and the datasets.
Similar content being viewed by others

Main
Building predictive models of dynamic cell systems requires analysis of the interactions of cells and organelles1,2,3,4,5,6. Genetic tagging with multiple fluorescent proteins is a current standard for multiplexed imaging of organelle dynamics7,8. Despite advances in cell engineering technologies, labelling multiple organelles with fluorescent proteins is labour-intensive and limits the throughput. For example, imaging of the emergence of cell types during the development of the zebrafish9,10 requires tracking individual cell types and developmental signals. But, engineering embryos that express multiple fluorescent reporters for developmental signalling, cell type, nuclei and membranes is time-consuming. Fluorescent tags themselves, as well as phototoxicity caused by imaging multiple fluorescent channels, compromise cell health. Photobleaching of fluorophores limits the temporal resolution and the duration of experiments. These trade-offs are compounded in high-throughput experiments with diverse perturbations and cell types.
Virtual staining of label-free imaging data is an emerging solution to the challenges summarized above. Three-dimensional (3D) quantitative phase imaging (QPI) methods11,12,13,14,15,16,17 consistently visualize multiple landmark organelles—including nuclei, cell membranes, nucleoli, nuclear envelope and lipid droplets—in a single image. Quantitative polarization imaging methods measure the alignment and orientation of ordered organelles such as the cytoskeleton, and can be multiplexed with QPI11,13,18. Raman microscopy also reports several organelles based on relative concentrations of nucleic acids, amino acids and lipids19,20. If such physical and chemical properties of organelles are correlated with the distribution of the fluorescent markers, deep learning models can demultiplex organelles observed simultaneously by label-free contrast11,21,22,23,24. In contrast to training the models for segmentation of label-free images with human annotation, virtual staining bypasses the need for laborious and error-prone human annotations of organelles in 3D volumes and videos. Virtual staining of organelles and functional state of cells from label-free reflectance images has also been reported25. Beyond the analysis of cell dynamics, virtual staining is now widely used for rapid 3D histology from autofluorescence, optical coherence tomography and Raman microscopy26,27,28,29. If the organelles, cells or tissue architecture of interest are consistently encoded by label-free contrast, virtual stains are more reproducible than experimental stains28.
The above work suggests that virtual staining can indeed relax the longstanding multiplexing bottleneck in dynamic imaging. Then, why is virtual staining not yet a mainstream artificial intelligence tool for biological discovery and clinical diagnosis? One of the outstanding challenges24,30 is that current virtual staining models, like most deep neural networks, do not generalize to imaging parameters, cell states and cell types beyond the distribution of their training data. In this paper, we address this generalization gap with a collection of models, named Cytoland. The models reported in this paper jointly predict nuclei and cell membranes across imaging conditions, cell states and cell types.
This paper makes the following specific contributions. (1) Deconvolution and data augmentation strategies that make the virtual staining models invariant to nuisance changes in imaging parameters and variations in phase contrast without requiring additional experimental training data. (2) A two-step pre-training protocol that uses all label-free images and available pairs of label-free and fluorescence images for zero-shot generalization to new imaging parameters and label-free contrasts. (3) A pre-training/fine-tuning protocol for few-shot generalization of the virtual staining models to new cell states (for example, cell division, infection, developmental age) and cell types (human cell lines, stem cells, differentiated stem cells and zebrafish tissue) with minimal training data. (4) A scalable convolutional image translation architecture (UNeXt2). (5) Trained models for virtual staining of nuclei and membrane from widely deployable Zernike phase contrast or quantitative phase contrast data. We show that the combination of generalist virtual staining with off-the-shelf generalist fluorescence segmentation models enables reliable single-cell analysis. The Cytoland training protocol is implemented within our PyTorch-based open-source package, VisCy (https://github.com/mehta-lab/VisCy/)31. We assess the gains in performance due to architectural refinement, augmentation strategies and training protocols using a suite of metrics that include regression metrics, instance segmentation metrics and application-specific metrics.
Results
Architecture, training protocols, models and metrics
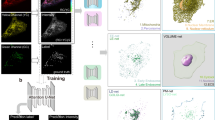
We focus on training the models with an accessible QPI method of phase from defocus11,32,33,34, which can be implemented on any wide-field microscope with a motorized z-stage. This method consists of acquiring a z-stack in transmission and deconvolving 3D phase density (Fig. 1a and ‘Preprocessing’ in Methods). We also deconvolved fluorescence volumes (Fig. 1a) to improve the sharpness of the predicted virtual stains. We developed the training protocol consisting of self-supervised (Fig. 1b) and supervised pre-training (Fig. 1c). During self-supervised pre-training, the phase images are randomly masked and the unmasked pixels are used to predict the masked pixels in each training patch (‘Model training’ in Methods), following the fully convolutional masked autoencoder (FCMAE) protocol35. During supervised pre-training, paired label-free and fluorescence images (Fig. 1c, orange and blue arrows) from many cell types and states are used. Furthermore, the training data were augmented with filters informed by the image formation of phase and fluorescence contrasts to generalize the model to a wide range of contrasts. Once a model is trained, only the label-free input is needed for inference (Fig. 1c, orange arrows). If needed, the model was fine-tuned with few paired phase and fluorescence images.

a–c, The training protocol consists of deconvolving phase and fluorescence density from bright-field and wide-field fluorescence volumes, based on models of the imaging system, to enhance contrast and consistency across datasets (a). Then, FCMAE pre-training is employed to initialize the UNeXt2 model’s weights without paired data or supervision (b). Subsequently, the second stage of pre-training trains the model with paired phase and fluorescence images of nuclei and plasma membrane, resulting in a generalist pre-trained virtual staining model (c). d, Virtually stained nuclei (blue) and membrane (orange) using VSCyto3D (HEK293T cells and iPSCs), VSNeuromast (zebrafish neuromasts) and VSCyto2D (A549 and BJ-5ta cells). Segmentation of nuclei (blue contours) and cell bodies (orange contours) using CellPose fluorescence segmentation models enables single-cell detection from phase images (greyscale). The neuromast X–Z slice is taken from the centre of the X–Y image. Scale bars, 25 µm. e–g, Application-specific evaluation metrics are used to rank and refine models, in addition to regression and instance segmentation metrics. These include morphological measurements for high-content screening (e), cell-state measurements for profiling dynamic cellular responses to infection (f) and cell-tracking measurements for studying organogenesis (g).
We developed a fully convolutional architecture that draws on the design principles of transformer models. We integrated the design choices from U-Net36, ConvNeXt v.235,37 and SparK38 architectures to develop a parameter-efficient and flexible architecture, named UNeXt2 (Fig. 1b,c, and Extended Data Figs. 1 and 2). The UNeXt2 architecture can be used for 2D, 3D and 2.5D11 image translation (‘Model architecture’ in Methods).
With the primary goal of accelerating single-cell phenotyping, we developed models for joint virtual staining of nuclei and cell membranes (Fig. 1d) that address distinct use cases:
-
VSCyto2D: 2D virtual staining for high-throughput screens across multiple cell lines, including HEK293T, A549 and BJ-5ta.
-
VSCyto3D: 3D virtual staining for organelle phenotyping across multiple cell lines, including HEK293T, A549 and human induced pluripotent stem cells (hiPSCs).
-
VSNeuromast: 3D virtual staining of zebrafish neuromasts for analysing cell growth and death during development.
In this paper, we also report additional computational experiments and models, summarized in Extended Data Table 1, to evaluate the training protocols.
In all of these applications, virtual staining and generalist segmentation models are used in tandem to segment the nuclei and cells from label-free images. Combination of QPI and complementary fluorescence reporters then enable phenotyping of functional states with single-cell resolution (Fig. 1e–g).
We use Cellpose39 (‘Model evaluation’ in Methods) for segmenting the virtually stained nuclei and membrane (Fig. 1d). Joint virtual staining of nuclei and membranes provides complementary information for more accurate cell segmentation39. The Cellpose model requires substantial fine-tuning with QPI images but works well with virtually stained images of nuclei and cell membrane, primarily because the training set of Cellpose included only classical Zernike phase contrast40 and fluorescence data. As seen in Fig. 1d, virtually stained images are intrinsically denoised because the models cannot learn to predict random noise. This feature obviates the need to train additional denoising models, such as those in Cellpose341.
We assess the performance of the models using regression metrics (Pearson correlation coefficient (PCC)), instance segmentation metrics (average precision (AP)) and application-specific metrics (for example, cell count and cell area). Owing to the variations in experimental labelling and the need to fine-tune Cellpose models to new cell shapes, we cannot rely on experimental fluorescence images and segmentations obtained with Cellpose as absolute ground truth. For example, boundaries of BJ-5ta cells at low magnifications (Fig. 1b and Supplementary Fig. 1) are challenging to segment, because they have diverse shapes and can overlap axially. Therefore, this paper first compares the experimental and virtually stained images and their segmentations, and then quantifies the observations with metrics (‘Model evaluation’ in Methods). Model refinement and hyperparameter optimization are guided by application-driven metrics such as cell size of cultured cells and nuclei count in neuromasts (Fig. 1e–g), in addition to regression and segmentation metrics.
We explore the effect of deconvolution, physics-inspired data augmentation and training protocols on the robustness and generalization of virtual-staining models. Subsequent results describe each of these training protocols and our findings on the regime of generalization of the resulting models.
Robust virtual staining across phase microscopes
Nuisance variations in label-free images due to changes in phase contrast or optical aberrations degrade the performance of virtual-staining models. Generating sufficient experimental training data to address this generalization gap is onerous. We reasoned that deconvolving raw data and augmenting it using microscope image formation models could lead to robust virtual-staining models. These computational experiments led to the VS-HEK293T model (Extended Data Table 1).
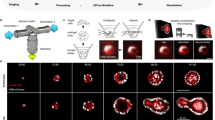
The effect of deconvolution was evaluated by training four virtual-staining models that translate between combinations of raw and deconvolved as shown in Fig. 2a. Deconvolution of raw intensities (‘Preprocessing’ in Methods) improves the contrast of biological structures in the image data. Deconvolution removes non-uniform illumination and suppresses phase variations due to the meniscus of fluid in imaging chambers. As shown in Fig. 2a, deconvolution of phase density from bright-field data11,32 and deconvolution of fluorescence density from raw fluorescence improves the contrast for organelles by enhancing the mid-band spatial frequencies that encode the structure of organelles. The deconvolved phase density also reports the local dry mass of the cells more consistently. In bright-field images, dense structures are transparent in focus, and brighter or darker relative to the background when out of focus. In the deconvolved phase-density images, the contrast is more uniform (Extended Data Fig. 3). The model trained to predict fluorescence density from phase density leads to the sharpest predictions of nuclei and membrane and the highest segmentation performance (Extended Data Fig. 3).

a, Deconvolution enhances contrast for virtual staining. Top to bottom: label-free input, fluorescence target and virtual staining prediction. Models are trained on pairs of raw or deconvolved label-free and fluorescence contrast modes. b, Predictions of nuclei and membrane from the phase image (first row) using models trained without augmentations (third row) are inconsistent with the experimental ground truth (second row), especially in the presence of noise (centre column) or at a different magnification (right column). The predictions using the models trained using spatial and intensity augmentations (see text for details) are invariant to noise and equivariant with magnification. The white box in the in-distribution column highlights the rescue of the lost fluorescence label. The white box in the higher-magnification column shows that the model with augmentations correctly predicts one large nucleus whereas the model trained without augmentation predicts two smaller nuclei. c, Data augmentation improves generalization to unseen modality. Virtual-staining models were trained to predict fluorescence density from phase density and then used to predict nuclei and plasma membrane from Zernike phase contrast image (left). The correlative raw fluorescence image (second from left) shows a low signal-to-noise ratio due to light loss in the phase contrast objective. Scale bars, 50 µm (a–c).
Interestingly, deconvolution has opposing effects on the segmentation and regression metrics. The AP improves because the deconvolution improves the localization of edges in the fluorescence density image, and the localization is preserved by virtual staining. The sharpening of the fluorescence target by deconvolution and subsequent smoothing by virtual staining (Extended Data Fig. 3) leads to a drop in the PCC between them, because PCC is sensitive to intensity differences in all pixels. The contrasting effects of the deconvolution on segmentation and regression metrics highlights the need for careful interpretation of metrics.
Data augmentations that account for the formation of natural and medical images have been important for robust representation learning42 and segmentation43. We augmented training data with spatial and intensity filters inspired by the image formation of microscopes to make the predictions of our models invariant to exposure, noise, the size of the illumination aperture and similar nuisance variations in imaging parameters. Figure 2b illustrates the images without and with such spatial and intensity augmentations (‘Data augmentations’ in Methods). The predictions (Fig. 2b, virtual staining with augmentations) and segmentations (Supplementary Fig. 1) across the test dataset become invariant to imaging parameters as we incorporate spatial and intensity augmentations inspired by image formation. As expected, the scaling augmentations make the model equivariant to magnification. The degree of perturbation to which the model is robust was assessed by simulating the blur and scaling of the input image. The VS-HEK293T model’s predictions are robust across a wide range of blur and contrast variation (Supplementary Fig. 2).
Fluorescent labelling is stochastic, especially when cells are engineered to express multiple fluorescent tags7. Sampling the patches from the training data in proportion to the degree of labelling makes the models robust to partial labelling as shown in Fig. 2b (white box). In fact, the VS-HEK293T model rescued labelling in the test dataset (Extended Data Fig. 4) where many cells were missing the experimental stain. Comparison of the 3D distribution of experimentally and virtually stained nuclei and membrane in a through-focus video (Supplementary Video 1) shows that virtual staining improves the uniformity of labelling of cell membrane.
We also explored whether the label-free input images can be augmented to mimic images from widely used Zernike phase contrast. Filters informed by the image formation of Zernike phase contrast were included in the augmentation pipeline. This strategy enabled generalization of the VS-HEK293T model to phase-contrast images (Fig. 2c) not seen during the training. The raw fluorescence images of labelled nuclei and membranes acquired with the phase-contrast objective were blurrier and noisier (Fig. 2c, raw fluorescence) than those acquired with the wide-field objective, because the phase ring in the phase-contrast objective filters fluorescence emission. Virtually stained nuclei and membranes (Fig. 2c, virtual staining with augmentation), and their segmentations (Extended Data Fig. 5), are sharper, because the model is optimized to output fluorescence density. This strategy also enabled synthesis of training datasets at ×20 magnification for training the VSCyto2D model (Fig. 1b and ‘Model training’ in Methods).
These results demonstrate a strategy to expand the regime of validity of virtual-staining models by acquiring the training data at high resolution and using physics-informed augmentations to synthesize lower-resolution or lower-contrast training data.
Few-shot generalization to new cell types
Next, we report generalization of robust virtual-staining models to new cell types with minimal new training data using a pre-training/fine-tuning paradigm. Collecting large amounts of paired label-free and fluorescence images across all cell types and cell states of interest is challenging. For example, consistent labelling of cell membranes requires genetically expressed peptides (for example, CAAX) that localize to cell membranes. Engineering cells to express genetic labels is time-consuming and challenging in cells that are not immortalized. As the landmark organelles show common morphological features across cell types, we reasoned that extending the pre-training/fine-tuning protocol developed for image classification35 to image translation can enable few-shot generalization of virtual-staining models to a new cell type.
We explored generalization of the models for virtual staining of nuclei and cell membranes in HEK293T and A549 to two new cell types: BJ-5ta, immortalized fibroblast cells used in toxicology research, and iPSC-derived neurons (iNeurons) used in neurobiology research. Virtual staining of BJ-5ta cells can accelerate image-based screening of cellular response to viral infection. Virtual staining of iNeurons can be used for label-free quality control of neuronal differentiation. Maintenance and differentiation of iPSCs takes weeks. Owing to high batch-to-batch variability, robust quality control is essential to ensure reproducible differentiations and measurements. Quality control of iNeurons involves evaluating the morphology of the cells to ensure that they exhibit the expected neuronal phenotype, including the presence of cell bodies and neurites. The neuronal phenotype is typically evaluated with the following morphological features: (1) cell bodies exhibit a characteristic round or polygonal shape with prototypical size and a centrally located nucleus; (2) mature neurons have neurites, including axons and dendrites.
The computational experiments described next use 2D images at lower magnification (‘Model training’ in Methods) common in image-based screens and result in the VSCyto2D model.
Figure 3a illustrates the protocol, which uses images of HEK293T and A549 cells for pre-training virtual-staining models that are fine-tuned for virtual staining of BJ-5ta and iNeuron cells. The model is pre-trained in two steps. (1) The encoder and decoder weights are optimized with just phase images of HEK293T and A549 cells using the masked autoencoding task (Fig. 1b). (2) The encoder weights are transferred to a virtual-staining model that is pre-trained to predict fluorescent nuclei and cell membranes using HEK293T and A549 cells. Supplementary Video 4 shows that the model pre-trained with HEK293T and A549 datasets generalizes well to diverse cell morphologies of A549 cells throughout the cell cycle. After the pre-training, the model is fine-tuned with data acquired with a new cell type (BJ-5ta or iNeuron) that has a distinct morphology. The computational graphs of the models used for pre-training and fine-tuning are shown in Extended Data Fig. 2.

a, Flow chart of three training strategies to generalize the virtual-staining model pre-trained with A549 and HEK293T cells to the BJ-5ta cell type with limited training samples. The bounding boxes indicate strategies: blue, virtual-staining pre-training from scratch with paired images of BJ-5ta; orange, pre-training with paired images of HEK293T and A549, and fine-tuning with paired images of BJ-5ta; green, FCMAE pre-training with only the phase images of HEK293T and A549, virtual-staining pre-training with images of HEK293T and A549, and fine-tuning with paired images of BJ-5ta. The pre-training steps initialize model weights in the encoder (FCMAE) and decoder (virtual staining) of UNeXt2. b, Virtual-staining images of nuclei and membrane in BJ-5ta using the three models described in d. Performance scales with the increasing number of BJ-5ta FOVs used for fine-tuning. Scale bar, 50 µm. c, AP of instance segmentation and PCC between experimental and virtually stained nuclei and plasma membrane as a function of the number of FOVs used for the test dataset used for the training strategies shown in a. The pre-trained models show superior performance scaling relative to the number of BJ-5ta FOVs used for fine-tuning. Pre-trained models fine-tuned with fewer data can match or outperform models trained with more data from scratch. d, Virtual staining of iNeuron cells recovers the contrast needed for soma segmentation and neurite tracing. Cell membranes (magenta) and nuclei (green) staining are preprocessed to filter debris in cell culture and normalize contrast. Virtually stained nuclei and cell bodies are shown in blue and orange. The cyan arrows in the preprocessed fluorescence image point to white pixels where cell bodies and nuclei overlap. Soma segmentation is shown in colour-filled labels and neurite tracing is shown in white lines. Scale bars, 100 µm. e, Quantitative analysis of iNeuron segmentations. Similar number of soma per FOV, total neurite length and number of neurites per soma can be identified from virtual staining compared with experimental staining.
As a baseline, we evaluated the pre-training protocol with one cell type (HEK293T). The pre-training protocol slightly improves the visual sharpness of the predicted images (Extended Data Fig. 6a) and matches the accuracy of segmentation (Extended Data Fig. 6b) compared with the models trained from scratch with paired data.
Figure 3c reports few-shot generalization to BJ5-ta cells. The images (Fig. 3b) and segmentations (Extended Data Fig. 6c) show that the model fine-tuned with just 6 fields of view (FOVs) performs as well as the model trained from scratch with 110 FOVs. Visualization of the evolution of the predictions from the validation set (Supplementary Video 5) for the models trained with different training protocols show that pre-trained models produce useful predictions from the first epoch. Comparing the segmentation metrics for nuclei and membrane as a function of the number of training FOVs (Fig. 3c) confirms that pre-trained/fine-tuned models scale better, that is, generate more accurate predictions given the same amount of fine-tuning data, relative to the models trained from scratch.
We visualized the learned features (‘Model visualization’ in Methods) to assess the effect of training protocol on the mapping learned by the models. We find that the model pre-trained on phase images (Extended Data Fig. 7, columns 3 and 4, rows, encoder stages) learns a more regular representation of cell boundaries than the models trained on just the virtual-staining task (Extended Data Fig. 7, columns 1 and 2, rows, encoder stages).
Figure 3d reports fine-tuning of the VSCyto2D model to predict the soma and neurites of iNeurons from phase images. The images acquired with vital dyes (Fig. 3d, raw fluorescence) that stain nuclei and live cells were preprocessed (‘VSCyto2D’ in Methods) to suppress the dead cells. In this case, the cells that did not attach to the substrate at the start of differentiation died. The preprocessing step synthesizes clearer contrast (Fig. 3d, preprocessed) for neurites (magenta) and for soma (green). The preprocessed fluorescence data were used as a target for fine-tuning the VSCyto2D model. The fine-tuned model enables detection of soma and neurites (Fig. 3d, virtual staining) even in the presence of dead cells (Fig. 3d, phase). The utility of the virtual-staining model for quality control of differentiation is assessed by segmenting the soma and neurite from preprocessed fluorescence images or virtually stained images, and computing the following metrics of neuronal phenotype (Fig. 3e): number of live soma per FOV, total length of neurites within a FOV, and the number of neurites per soma. The features retrieved from virtually stained images corroborate the features retrieved from preprocessed fluorescence images. The model achieved this robustness with a training and validation set consisting of ~500 iNeurons, in contrast to ~11,000 HEK293T and A549 cells used during pre-training.
Taken together, the above results establish a training protocol for generalizing virtual staining models to new cell types.
3D virtual staining of nuclei, cell membranes and cell states
We extended the pre-training/fine-tuning protocols that led to VSCyto2D for volumetric virtual staining of cell morphology and states. We evaluated the possibility of predicting a cell-state reporter that is not directly recognizable from phase images by human vision. The reporter is a protein construct that is localized in the endoplasmic reticulum in healthy A549 cells, and translocates to the nucleus after being cleaved by the Zika virus (ZIKV) protease, acting as a ZIKV infection sensor. As this protein is not expected to directly alter the phase density, a virtual-staining model needs to recognize the underlying cell state (infection) from cell morphology to perform a non-random prediction.
We pooled phase images (‘VSCyto3D’ in Methods) from multiple cell types and cell states (healthy and virus-infected HEK293T and A549, and healthy iPSCs; ‘Training data pooling’ in Methods), and pre-trained a UNeXt2 model for the masked autoencoding task. We used an FCMAE pre-trained model to initialize 3D virtual-staining models for landmark organelles (VSCyto3D) and for a reporter of cell infection state (VS-infection).
VSCyto3D generalizes to diverse imaging conditions and sample variations. Although trained only on images from one of the imaging protocols (v.4.1) used at the Allen Institute5, VSCyto3D provides accurate predictions from phase images computed from a different imaging protocol (v.4.0) (Fig. 4a,b). The pre-trained model outperforms the virtual-staining model trained from scratch for downstream instance segmentation (Fig. 4b). Remarkably, the model generalizes zero-shot to iPSC images generated at the CZ Biohub (Fig. 4a). Such generalist models can accelerate the quality control of iPSC cultures and differentiation with label-free imaging.

a, Qualitative comparison of virtual-staining images of nuclei and plasma membrane in hiPSCs with and without pre-training. Scale bars, 25 µm. b, Pre-training improves segmentation from virtual staining. Measurement of the agreement between target labels and Cellpose segmentations obtained from the virtual-staining model trained from scratch (blue box), with label-free pre-training (orange box) and from fluorescence. AP@0.5 is the mean AP at IoU threshold of 0.5 for 20 test FOVs. The boxes show the median and interquartile range, the whiskers show the 12.5 and 87.5 percentiles, and the circles show outliers. c, Virtual staining of nuclei, plasma membrane and ZIKV viral sensor in A549 cells. The virtual-staining prediction of the infection sensor recapitulates the translocation pattern upon ZIKV infection seen in fluorescence imaging. The second row shows virtual staining of nuclei (blue) and plasma membrane (orange). HPI, hours post-infection. Scale bars, 50 µm.
Furthermore, VSCyto3D generalizes to A549 cells infected with ZIKV without paired training data (Fig. 4c), despite morphological differences in the phase images introduced by the cytopathic effects caused by infection. With nuclei and cell segmentation and tracking from virtual staining, imaging throughput can be improved to analyse dynamic subcellular response to viral infection at a large scale44. The VS-infection model reliably predicted the relocalization of the viral sensor due to infection from the 3D phase image (Fig. 4c and Supplementary Fig. 3). We also observed that the FCMAE-pre-trained model produces more accurate predictions (Fig. 4c).
Three-dimensional virtual staining of developing tissue
We explored the virtual staining of nuclei and cell membranes across the embryonic development using neuromasts of the zebrafish lateral line as a model organ. Three-dimensional shapes and textures of cells in neuromasts change throughout their development9,10. We developed VSNeuromast, a 3D virtual-staining model, and evaluated generalization across different developmental stages.
We followed the FCMAE and virtual-staining pre-training strategy (Fig. 3a) to train the VSNeuromast model. Training data were pooled from two developmental stages, consisting of phase images (‘VSNeuromast’ in Methods) and wide-field fluorescence microscope data. This model used the UNeXt2 model with 21 z-slices (Extended Data Fig. 2). The model was tested using an 8.5-hour time lapse of 5 neuromasts at a different developmental stage (Fig. 5a) on a different microscope to assess generalization across developmental stages. All the training data were acquired on a wide-field microscope and test data were acquired on a confocal microscope.

a, Time-lapse imaging of a zebrafish neuromast starting at 4 days post-fertilization (dpf) over 12 hours. Three representative timepoints are shown from imaging performed on a microscope system not included in the model’s training data. Phase (first row), experimentally stained nuclei and membrane (second row) and virtually stained nuclei and membrane using VSNeuromast (third row). The model is used to predict virtual staining and rescue missing nuclei and provides a more accurate read-out of the cell count and their locations than experimental staining. b, The model’s performance was quantitatively assessed using Pearson correlation plots across five neuromasts from the lateral line, comparing both fluorescence density and virtual-staining results for nuclei and membranes to highlight the precision of the fine-tuned model. The drop in the correlation matches the drop in intensity due to photobleaching, showing that virtual staining is robust to photobleaching effects. c, Mean photobleaching curves across five neuromasts showing experimental fluorescence (left) and virtual-staining (right) nuclei and membrane pairs. Virtual-staining nuclei and membranes show no photobleaching effects, extending imaging time. The shaded region indicates the standard deviation of the integrated intensity of single nuclei in a given frame. d, Comparison of experimental fluorescence and virtual-staining cell count after 3D segmentation and tracking of membranes. A fine-tuned Cellpose model and Ultrack were consistently applied across both modalities showing cell counts with comparable accuracy. Virtual staining reduces over- and under-segmentations, enhancing accuracy compared with experimental fluorescence. e, Prediction of cell death and tissue reorganization in experimentally stained and virtually stained nuclei and membrane. t, time in minutes since acquisition started; T, time in hours since acquisition started.
The VSNeuromast model achieved reliable 3D virtual staining of cell nuclei and membranes over time (Fig. 5a,c). The virtually stained neuromast nuclei and membrane show a more uniform intensity distribution compared with experimental fluorescence-stained counterparts. VSNeuromast predictions are smoother than the confocal fluorescence data as also reported by PCC (Fig. 5b). Nevertheless, the VSNeuromast model consistently predicted nuclei and cell membranes across developmental stages. Mean intensity measurements across five neuromasts over time showed the VSNeuromast model’s robustness to photobleaching, especially for the plasma membrane (Fig. 5c), where the decline in PCC (Fig. 5b) is correlated with the loss of experimental fluorescence intensity. Virtual staining extends imaging conditions and durations by overcoming photobleaching and phototoxicity. Additional fine-tuning with confocal fluorescence imaging can increase the sharpness of the VSNeuromast predictions, but is not needed for our end goal of counting and tracking cells during development, as discussed next.
We segmented and tracked45 cells from experimental and virtual stains (‘Model evaluation’ in Methods). We observe consistent cell counts from the predicted and experimental stains (Fig. 5d). Tracking helped filter extraneous segmentations (Supplementary Video 3 and Extended Data Fig. 8a). A comparative analysis of neuromast cell membrane counts using virtually stained and experimentally fluorescence-stained membranes revealed the model’s ability to rescue bleaching and rescue cells whose experimental staining may be weak (Supplementary Video 3). Weak labelling often leads to missed segmentation, and virtual staining consistently rescued them. In addition to accurate cell segmentation and tracking, VSNeuromast enabled detection of critical events such as cell division and cell death during tissue development (Fig. 5d and Supplementary Video 3). Interestingly, the VSNeuromast model virtually stained cells around the yolk, probably because the size and texture of these cells resembled neuromast cells. These cells could be easily filtered in post-processing (Extended Data Fig. 6). This finding suggests the potential to train a model capable of virtually staining all nuclei in zebrafish, provided that the phase images are acquired with sufficient resolution.
The features learned by the VSNeuromast model were interpreted by visualizing the feature maps learned by the encoder and decoder (‘Model visualization’ in Methods). The model represents shapes of nuclei, cell membranes and neuromast as seen from the principal components of the feature maps shown in Extended Data Fig. 9 for an example input image of a neuromast. An equivalent visualization of features of VS-HEK293T shows that the model represents shapes of nuclei and cell membranes.
The above data illustrate that robust virtual staining of nuclei and cell membranes can relax the challenges characteristic of in vivo time-lapse experiments such as photobleaching and phototoxicity, and unlock new longitudinal studies of embryonic development.
Limitations
The method reported above has led to Cytoland models that have already enabled high-throughput dynamic 3D imaging12, single-cell tracking45 and self-supervised modelling of dynamic cellular response to viral infection44. During the development of Cytoland models, we focused on generalization across cell cycle, infection cycle and organ development. Following are the key limitations of the methods and models reported in this paper.
We assessed the regime of robustness of VS-HEK293T model by varying the imaging conditions using both experimental (Fig. 2b and Supplementary Fig. 1) and synthetic test datasets (Supplementary Fig. 2). The model is robust to large perturbations to phase image, but the performance degrades when the contrast reduces by an order of magnitude. These tests indicate that the robust virtual staining of organelles encoded in low contrast may be challenging with the current approach, and require co-optimization with computational imaging methods.
The VSCyto2D model reliably predicts the shape of nuclei and plasma membrane over time in A549 cells (Supplementary Video 4), which is sufficient for segmentation (Fig. 1d) and tracking45. However, the predicted intensity of the individual cells fluctuates at high temporal frequency. This test indicates the need for explicit temporal regularization of predictions during inference or training.
While we report test datasets from multiple microscopes and cell types to evaluate the pre-trained generalist virtual-staining models (VSCyto3D, VSCyto2D and VSNeuromast), the evaluation of generalization is focused on cell cycle, infection cycle and developmental cycle. For example, VSCyto2D and VSCyto3D generalize to cell states captured infrequently during the cell cycle (mitotic events in Supplementary Video 4) and infection cycle (heterogeneous responses to infection in Fig. 4c). The generalization to rare cell morphologies in the presence of more diverse perturbations such as drug treatment or genetic perturbations needs to be evaluated with a well-controlled test dataset.
We explored the possibility to predict cell-state reporters with VS-infection (Fig. 4c). However, the quantitative comparison of the virtually stained and experimental reporters remains challenging owing to heterogeneous intensity levels in individual cells and the volumetric distribution of the signal. Measuring the nuclear and cytoplasmic intensity levels requires accurate volumetric segmentation and tracking of nuclei and cell bodies, which then allows single-cell-state classification over time. Here we assess the potential of downstream classification by evaluating the intensity differences between manually annotated infected and uninfected cells (Supplementary Fig. 3).
Conclusion and future work
Cytoland models enabled virtual staining of cellular landmarks across imaging conditions, cell states and cell types. The physics-informed data augmentations enabled zero-shot generalization of the 3D virtual-staining model to Zernike phase contrast without the need to acquire training data with this modality. These augmentations also made the model robust to nuisance factors such as non-uniform illumination and changes in numerical aperture. This robustness is critical for image-based screens that integrate data from diverse microscopes with varying imaging conditions and optical aberrations. The pre-training/fine-tuning protocol enabled few-shot generalization of the 2D and 3D virtual staining model to multiple cell types and cell states. Our strategy leverages the consistency of organelle shapes across different cell types and cell states, substantially reducing the data requirements for training robust virtual-staining models.
We reported a diverse set of evaluation metrics, including regression metrics, instance segmentation metrics and application-specific measurements to evaluate the models’ performance for real-world biological research. We also illustrate the limitations and the regime of validity of the key pre-trained models we report. Inspection of learned features suggests that the data augmentation strategies and training protocols enable the learning of the semantic mapping of cell structures between input and target imaging modalities. Further work on explainability methods for the accurate virtual staining of diverse cellular structures is timely to guide the development of generalist models.
This work paves the way for the following developments in virtual staining and its applications, improving the capabilities of Cytoland models. First, simulations with image formation models may further generalize the models to other phase-imaging modalities without the need to acquire new data. Second, the test-time augmentations may make predictions of our models even more robust. Third, the pre-training/fine-tuning strategy may be extended to train decoders for landmark organelles other than nuclei and cell membranes, such as nucleoli and lipid droplets. Fourth, the pre-training strategy can be used across developmental stages of zebrafish, enabling label-free tracking of cells across developing embryos. Finally, the training protocols developed for virtual staining can be adapted for segmentation models, potentially leading to joint virtual staining and segmentation models that offer even greater generalizability and accuracy.
Methods
Datasets
We combined public and in-house datasets to develop the proposed training strategies and the models. Extended Data Table 1 provides a summary of the datasets used for training and testing specific models. Details of cell culture and image acquisition can be found in Supplementary Note 1.
The phase-contrast images from the training and validation split of the LIVECell dataset40 were used for the FCMAE pre-training of VSCyto2D.
We used two subsets generated with different imaging protocols from the Allen Institute for Cell Science (AICS) iPSC dataset5 for training and testing VSCyto3D. We use all 3,446 FOVs from Pipeline 4.1 for training and a random subset of 20 FOVs from Pipeline 4 for testing.
Preprocessing
All internal datasets were acquired in uncompressed lossless formats (that is, OME-TIFF and ND-TIFF) and converted to OME-Zarr46 using iohub (https://github.com/czbiohub-sf/iohub)47. The public dataset was also converted to OME-Zarr from OME-TIFF stacks. The preprocessing, training and evaluation protocols below use OME-Zarr as input/output format to enable parallel processing and efficient storage.
Deconvolution
The reconstruction from bright-field and fluorescence stacks to phase density and fluorescence density was performed with the waveOrder package (https://github.com/mehta-lab/waveOrder)11,32,34.
The acquired bright-field and fluorescence stacks were modelled as filtered versions of the unknown specimen properties, phase density and fluorescence density, respectively. This blur was represented by a low pass optical transfer function in Fourier space and a point spread function in the real space, which were simulated using properly calibrated parameters of the imaging system (numerical apertures of imaging and illumination, wavelength of illumination and pixel size at the specimen plane). The simulated point spread functions were calibrated using images of beads and test targets. The simulated optical transfer functions were used to restore phase density and fluorescence density, respectively, from the bright-field and fluorescence stakes using a Tikhonov-regularized inverse filter. The regularization parameters for the inverse filter were chosen such that the contrast due to the cellular structure in the mid-band of the optical transfer function is maximized34.
Registration
The label-free and fluorescence channels were registered with biahub48. After registration, the resulting volumes were cropped to ZYX shape of (50, 2,044, 2,005) for the HEK293T Zernike phase contrast test dataset, (9, 2,048, 2,048) for A549, (12, 2,048, 2,009) for BJ-5ta and (26, 2,048, 2,007) for iNeuron. The neuromast datasets acquired with the wide-field fluorescence microscope were registered to the phase density channel and cropped to (107, 1,024, 1,024). The datasets acquired in the iSIM set-up were cropped to (81, 1,024, 1,024).
Additional preprocessing (iNeuron)
The fluorescence signal in iNeuron cells was further processed to improve contrast for virtual staining and segmentation. Paired 2D images were generated from each imaging volume.
For the calcein channel, the soma is much brighter than the neurites. The mean projection along the axial dimension and natural logarithm of one plus the input (‘log1p’) were applied to compress the dynamic range. The result was normalized so that the 99th percentile is 0 and the 99.99th percentile is 1, and then clipped to a range of 0 to 5.
To suppress fluorescence from dead cells in the Hoechst channel, the maximum projection of Hoechst volumes was multiplied with the mean projection of the raw calcein channel. The result was normalized so that the median is 0 and the 99.99th percentile is 1, and then clipped to a range of 0 to 5.
To match the shape of the fluorescence channels, a single Z-slice (at 8 µm from the bottom of the volumes) was taken from the phase channel as the input to virtual-staining models.
Model architecture
There is an active debate41,49,50,51 whether transformer models that use attention operations fundamentally outperform convolutional neural networks that rely on the inductive bias of shift equivariance for image translation and segmentation tasks. Systematic comparisons suggest that convolutional models perform as well as transformer models51,52 when a large compute budget is spent, and outperform the transformer models when a moderate compute budget is spent. Therefore, we opted to use a fully convolutional architecture for this work. We integrated the concepts from U-Net36, ConvNeXt v.235,37 and SparK38 to develop an architecture for 2D, 3D or 2.5D image translation. The module in the network that enables flexible choice of number of slices in the input stacks and output stacks is a projection module in the stem and head of the network (Extended Data Fig. 1). The body of the network is a U-Net-like hierarchical encoder and decoder with skip connections that learns a high-resolution mapping between input and output.
We chose the layers and blocks of the model as follows. We developed an asymmetric U-Net model with ConvNeXt v.235 blocks for both virtual staining (Extended Data Fig. 1) and FCMAE pre-training (Extended Data Fig. 2). The original ConvNeXt v.2 explored an asymmetric U-Net configuration for FCMAE pre-training and showed that it has identical fine-tuning performance on an image classification task. In the meantime, SparK38 used ConvNeXt v.1 blocks in the encoder and plain U-Net blocks in the decoder for its masked image modelling pre-training task. We use the ‘Tiny’ ConvNeXt v.2 backbone in the encoder. For FCMAE pre-training, 1 ConvNeXt v.2 block was employed per decoder stage. For virtual-staining models, each decoder stage consisted of 2 ConvNeXt v.2 blocks.
The UNeXt2 architecture provides 15 times more learnable parameters for 3D image translation than our previously published 2.5D U-Net at the same computational cost (Table 1). The efficiency gains are even more notable when compared with 3D U-Net. This approach enables the allocation of the available computing budget to train moderate-sized models faster or to train more expressive models that generalize to new imaging conditions and cell types. We evaluated a few different loss functions, shown in Supplementary Table 1. The models trained for joint prediction of nuclei and membranes are slightly more accurate than models trained for prediction of nuclei alone (Table 1).
Model training
Intensity statistics, including the mean, standard deviation and median, were calculated at the resolution of FOVs and at the resolution of the whole dataset by subsampling each FOV using square grid spacings of 32 pixels in each camera frame. These pre-computed metrics were then used to apply normalization transforms by subtracting the choice of median or mean and dividing by the interquartile range or standard deviation, respectively. This enables standardizing of the training data at the level of the whole dataset, at the level of each FOV and at the level of each patch11, depending on the use case.
Training objectives
The mixed image reconstruction loss53 was adapted as the training objective of the virtual-staining models: \({{\mathcal{L}}}^{{\rm{mix}}}=0.5 {{\mathcal{L}}}^{2.5{\rm{D}}\ {\rm{MS}}-{\rm{SSIM}}}+0.5 {{\mathcal{L}}}^{{{\mathcal{l}}}_{1}}.\) The first term \({{\mathcal{L}}}^{2.5{\rm{D}\ {\rm{MS}}-{\rm{SSIM}}}}\) is the multi-scale structural similarity index54 measured without downsampling along the depth dimension, and \({{\mathcal{L}}}^{{{\mathcal{l}}}_{1}}\) is the L1 distance (mean absolute error). The virtual-staining performance of different loss functions is compared in Supplementary Table 1.
The mean square error loss is used for FCMAE pre-training on label-free images, following the original implementation35.
Data augmentations
The data augmentations were performed with transformations from the MONAI library43. We used spatial (Supplementary Table 6) and intensity (Supplementary Table 7) augmentations during training to simulate geometric and contrast variations introduced by different imaging systems, and applied them either to both the source and target channels to achieve equivariance, or only to the target channel to achieve invariance.
Normalization
Normalization was performed at both training and evaluation time.
VS-HEK293T
For each channel, the image volume was subtracted by its dataset level median and divided by the dataset level interquartile range. As our Zernike phase contrast microscope generates inverted contrast compared with the quantitative phase, the Zernike phase images of HEK293T cells were additionally inverted after normalization.
VSCyto2D, VS-BJ5-ta, VS-iNeuron and VSCyto3D
Each image volume was independently normalized before being used for model input to account for differences in culture confluence and background fluorescence. The phase channel was normalized to zero mean and unit standard deviation, and the fluorescence channels were normalized to zero median and unit interquartile range. For the iNeuron dataset, normalization was only applied for only the phase channel as the fluorescence target was already preprocessed for contrast adjustment.
VSNeuromast
This model normalizes the label-free channel per FOV by subtracting the median and interquartile range.
Training data pooling
VSCyto2D
Image volumes of HEK293T cells were downsampled from the 63x dataset with ZYX average pooling ratios of (9, 3, 3). For the VSCyto2D model reported in Fig. 1, training data were sampled from the downsampled HEK293T dataset, the A549 dataset and the BJ-5ta dataset with equal weights.
VSCyto3D and VS-infection
During FCMAE pre-training, phase images of uninfected and OC43-infected HEK293T55, uninfected and ZIKV-infected A549, and the public iPSC dataset from AICS were used. This base model was used to initialize encoder weights for the VSCyto3D and VS-infection models. For VSCyto3D, phase and fluorescence images were sampled from the healthy HEK293T and A549 datasets, and the iPSC dataset from AICS.
VSNeuromast
The data used in our methods were pooled from four OME-Zarr stores, which contain neuromasts from 3 days post-fertilization (dpf), 6 dpf and 6.5 dpf stages. These stores include both the whole FOV and a centre-cropped version focused on the neuromast. For the cropped FOVs, a weighted cropping technique was applied to ensure the inclusion of training patches containing the neuromast. Conversely, the uncropped dataset employs an unweighted cropping method to incorporate additional contextual information. A high - content screening dataloader was developed to sample equally from the multiple datasets with variable length.
The time-lapse dataset were processed by registering the experimental fluorescence channels registered to the phase density channel and required downsampling of the data by the factor of 2.1 to match the pixel size between for the training and test set of VSNeuromast.
Training protocol
All models were trained on four graphics processing units with the distributed data parallel strategy. All FCMAE models were trained with a masking ratio of 0.5.
VS-HEK293T
Models were trained with a warmup-cosine-annealing schedule. A mini-batch size of 32 and base learning rate of 0.0002 was used. The training and validation patch ZYX size was (5, 384, 384). For testing the effect of deconvolution (Fig. 2b), models were trained for 100 epochs. For testing robustness to imaging conditions (Fig. 2d), models were trained for 50 epochs.
VSCyto2D, VS-BJ5-ta and VS-iNeuron
A training and validation patch ZYX size of (1, 256, 256), a mini-batch size of 32, automatic mixed precision and a 0.0002 base learning rate were used for all models. FCMAE pre-training was performed for 800 epochs. The mask patch size was 16. Both FCMAE and virtual-staining pre-training used a warmup-cosine-annealing schedule. For the VS-BJ5-ta experiments, the encoder weights were loaded from the FCMAE pre-trained models when applicable. The models were then trained for the virtual-staining task with the encoder weights either frozen or trainable. For testing data scaling with BJ-5ta, models were trained with constant learning rate. Six FOV models were trained for 6,400 epochs, 27 FOV models were trained for 1,600 epochs and 117 FOV models were trained for 400 epochs. For VS-iNeuron, the encoder weights were loaded from FCMAE pre-training. All model parameters were trained using a warmup-cosine-annealing schedule for 1,600 epochs.
VSCyto3D and VS-infection
A training and validation patch ZYX size of (15, 384, 384), automatic mixed precision and a 0.0002 base learning rate were used for all models. FCMAE pre-training used a mini-batch size of 80 for 800 epochs. The mask patch size was 32. VSCyto3D and VS-infection models have their encoder initialized from the FCMAE training above, and were trained for 100 epochs on the virtual-staining task, using 40 and 32 mini-batch sizes, respectively.
VSNeuromast
A training and validation patch ZYX size of (21, 384, 384), automatic mixed precision and a 0.0002 base learning rate were used for all models. FCMAE pre-training used a mini-batch size of 64 for 8,000 epochs. The mask patch size was 32. The virtual-staining pre-training step to get VSNeuromast used an encoder initialized from the FCMAE training, and was trained for another 65 epochs on the virtual-staining task, using a 32 mini-batch size.
Inference using trained models
For the 2D virtual-staining model VSCyto2D and its fine-tuned derivatives, each slice was predicted separately in a sliding window fashion.
For the 3D virtual-staining models (VS-HEK293T, VSCyto3D, VS-infection and VSNeuromast), a Z-sliding window of the model’s output depth and step size of 1 was used. The predictions from the overlapping windows were then average-blended.
Model evaluation
The correspondence between fluorescence and virtually stained nuclei and plasma membrane channels were measured with regression and segmentation metrics. We describe the segmentation models for each use case below. All segmentation models were also shared with the release of our pipeline, VisCy (‘Code availability’). In situations where the virtual stain rescues experimental stain (Extended Data Fig. 4), we manually curated the test FOVs to ensure that experimental fluorescence and its segmentation can be considered a benchmark. The instance segmentations were compared using the AP between segmented nuclei (or cell membranes) from fluorescence density images and from virtually stained images. An instance of a cell was considered to be true positive if the intersection over union (IoU) of both segmentations reached a threshold. We computed AP at IoU of 0.5 (AP@0.5) to evaluate the correspondence between instance segmentations at the coarse spatial scale and mean AP across IoU of 0.5–0.95 to evaluate the correspondence between instance segmentations at the finer spatial scales.
VS-HEK293T
Segmentation of H2B-mIFP fluorescence density and virtually stained nuclei was performed with a fine-tuned Cellpose ‘nuclei’ model (Supplementary Table 2). The nuclei segmentation masks were corrected by a human annotator. Segmentation of cells from CAAX-mScarlet fluorescence density and virtually stained plasma membrane was performed with the Cellpose ‘cyto3’ model (Supplementary Table 2). Owing to the loss of CAAX-mScarlet expression in some cells, positive phase density was blended with the CAAX-mScarlet fluorescence density to generate test segmentation targets. For the Zernike phase contrast test dataset, nuclei and cells were also segmented from the phase image using the Cellpose ‘nuclei’ and ‘cyto3’ models, in addition to segmentation from experimental fluorescence images.
PCC was computed between the virtual-staining prediction and fluorescence density images. AP@0.5 and mean AP of IoU thresholds from 0.5 to 0.95 at 0.05 interval (AP) was computed between segmentation masks generated from virtual-staining images and segmentation masks generated from fluorescence density images.
VSCyto2D, VS-BJ5-ta and VS-iNeuron
For HEK293T and A549, segmentation of fluorescence density images as well as virtual-staining prediction was performed with the ‘nuclei’ (nuclei) and ‘cyto3’ (cells) models in Cellpose. For BJ-5ta, the ‘nuclei’ model in Cellpose was used for nuclei segmentation and a fine-tuned ‘cyto3’ model was used for cell segmentation (Supplementary Table 3). The nuclei segmentation target was corrected by a human annotator. PCC was computed between the virtual-staining prediction and fluorescence density images. Average precision at IoU threshold of 0.5 (AP@0.5) as computed between segmentation masks generated from virtual-staining images and segmentation masks generated from fluorescence density images.
For iNeuron, the soma segmentation was performed with the ‘cyto3’ model in Cellpose (Supplementary Table 3). The neurites were traced from calcein fluorescence or virtual staining with scikit-image56, by multiplying the image with its Meijering-ridge-filtered57 signal, applying Otsu thresholding58, removing small objects and skeletonizing59. The total neurite length in each FOV was approximated by taking the sum of foreground pixels in the neurite traces. To count the number of neurites connected to each soma, the following steps were taken: (1) the soma foreground mask was first subtracted from the neurite traces; (2) the soma labels were then expanded for 6 pixels (~2 µm) without overlapping; and (3) the number of neurite segments intersecting with these expanded rings that were more than 100 pixels long were counted as belonging to the respective soma instances.
VSCyto3D
For the AICS iPSC dataset, segmentation of virtual-staining prediction was performed with the ‘nuclei’ (nuclei) and ‘cyto3’ (cells) models in Cellpose (Supplementary Table 4). Average precision at IoU threshold of 0.5 (AP@0.5) was computed between segmentation masks generated from virtual-staining images and segmentation masks published with the dataset (computationally generated from fluorescence images)5.
VSNeuromast
The nuclei and cell membranes of neuromasts were segmented using CellPose models, summarized in Supplementary Table 5. We refined the segmented cell instances using the Ultrack45 algorithm, which jointly optimizes the instance segmentation and tracking. The segmentation and tracking parameters were fine-tuned individually for the fluorescence and virtual-staining volumes for optimal detection of cells (Fig. 5d).
Model visualization
We visualize principal components of learned features as follows: each XY pixel in the output of a convolutional stage was treated as a sample with channel dimensions and decomposed into eight principal components. The top-three principal components were normalized individually and rendered as RGB values for visualization.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
Minimal datasets that illustrate the models are accessible from demos described in the ‘Code availability’ section and are maintained on our public server (https://public.czbiohub.org/comp.micro/viscy/VS_datasets/). All training and test datasets used for developing and evaluating the models reported in this paper are available via BioImage Archive: S-BIAD1702 (https://www.ebi.ac.uk/biostudies/BioImages/studies/S-BIAD1702). The datasets on BioImage Archive are organized by figures in this paper to make it easier to identify the datasets underlying specific results.
Code availability
The virtual-staining pipeline is implemented as part of an open-source Python package for single-cell phenotyping, named VisCy (a contraction of words ‘vision’ and ‘cell’), available at https://github.com/mehta-lab/VisCy/. We use PyTorch60 and PyTorch Lightning61 for computing framework, MONAI43 for data augmentation and PyTorch Image Models (timm)62 for network components. In addition, we implement custom data modules for reading and writing OME-Zarr stores during training and inference. The models referenced in the methods above are shared with releases and on the wiki of VisCy via GitHub31. A demo of the VSCyto2D model is available on HuggingFace at https://huggingface.co/spaces/compmicro-czb/Cytoland. The VSCyto2D, VSCyto3D and VSCyto-Neuromast models are available via the Chan Zuckerberg Initiative’s (CZI) Virtual Cell Platform at https://virtualcellmodels.cziscience.com/model/cytoland.
References
Kobayashi, H., Cheveralls, K. C., Leonetti, M. D. & Royer, L. A. Self-supervised deep learning encodes high-resolution features of protein subcellular localization. Nat. Methods 19, 995–1003 (2022).
Bray, M.-A. et al. Cell Painting, a high-content image-based assay for morphological profiling using multiplexed fluorescent dyes. Nat. Protoc. 11, 1757–1774 (2016).
Wu, Z. et al. DynaMorph: self-supervised learning of morphodynamic states of live cells. Mol. Biol. Cell 33, ar59 (2022).
Burgess, J. et al. Orientation-invariant autoencoders learn robust representations for shape profiling of cells and organelles. Nat. Commun. 15, 1022 (2024).
Viana, M. P. et al. Integrated intracellular organization and its variations in human iPS cells. Nature 613, 345–354 (2023).
Soelistyo, C. J., Vallardi, G., Charras, G. & Lowe, A. R. Learning biophysical determinants of cell fate with deep neural networks. Nat. Mach. Intell. 4, 636–644 (2022).
Valm, A. M. et al. Applying systems-level spectral imaging and analysis to reveal the organelle interactome. Nature 546, 162–167 (2017).
Kumar, A. et al. Multispectral live-cell imaging with uncompromised spatiotemporal resolution. Preprint at bioRxiv https://doi.org/10.1101/2024.06.12.597784 (2024).
Jacobo, A., Dasgupta, A., Erzberger, A., Siletti, K. & Hudspeth, A. J. Notch-mediated determination of hair-bundle polarity in mechanosensory hair cells of the zebrafish lateral line. Curr. Biol. 29, 3579–3587.e7 (2019).
Hewitt, M. N., Cruz, I. A., Linbo, T. H. & Raible, D. W. Spherical harmonics analysis reveals cell shape-fate relationships in zebrafish lateral line neuromasts. Development 151, dev202251 (2024).
Guo, S.-M. et al. Revealing architectural order with quantitative label-free imaging and deep learning. eLife 9, e55502 (2020).
Ivanov, I. E. et al. Mantis: high-throughput 4D imaging and analysis of the molecular and physical architecture of cells. PNAS Nexus 3, pgae323 (2024).
Ivanov, I. E. et al. Correlative imaging of the spatio-angular dynamics of biological systems with multimodal instant polarization microscope. Biomed. Opt. Express 13, 3102–3119 (2022).
Park, Y., Depeursinge, C. & Popescu, G. Quantitative phase imaging in biomedicine. Nat. Photon. 12, 578 (2018).
Horstmeyer, R., Chung, J., Ou, X., Zheng, G. & Yang, C. Diffraction tomography with Fourier ptychography. Optica 3, 827–835 (2016).
Liba, O. et al. Speckle-modulating optical coherence tomography in living mice and humans. Nat. Commun. 8, 15845 (2017).
Jo, Y. et al. Label-free multiplexed microtomography of endogenous subcellular dynamics using generalizable deep learning. Nat. Cell Biol. 23, 1329–1337 (2021).
Yeh, L.-H. et al. Permittivity tensor imaging: modular label-free imaging of 3D dry mass and 3D orientation at high resolution. Nat. Methods https://doi.org/10.1038/s41592-024-02291-w (2024).
Ando, J., Palonpon, A. F., Sodeoka, M. & Fujita, K. High-speed Raman imaging of cellular processes. Curr. Opin. Chem. Biol. 33, 16–24 (2016).
Klein, K. et al. Label-free live-cell imaging with confocal Raman microscopy. Biophys. J. 102, 360–368 (2012).
Christiansen, E. M. et al. In silico labeling: predicting fluorescent labels in unlabeled images. Cell 173, 792–803.e19 (2018).
Ounkomol, C., Seshamani, S., Maleckar, M. M., Collman, F. & Johnson, G. R. Label-free prediction of three-dimensional fluorescence images from transmitted-light microscopy. Nat. Methods 15, 917 (2018).
Park, J. et al. Artificial intelligence-enabled quantitative phase imaging methods for life sciences. Nat. Methods 20, 1645–1660 (2023).
Kreiss, L. et al. Digital staining in optical microscopy using deep learning—a review. PhotoniX 4, 34 (2023).
Cheng, S. et al. Single-cell cytometry via multiplexed fluorescence prediction by label-free reflectance microscopy. Sci. Adv. 7, eabe0431 (2021).
Winetraub, Y. et al. Noninvasive virtual biopsy using micro-registered optical coherence tomography (OCT) in human subjects. Sci. Adv. 10, eadi5794 (2024).
Bai, B. et al. Deep learning-enabled virtual histological staining of biological samples. Light: Sci. Appl. 12, 57 (2023).
Li, Y. et al. Virtual histological staining of unlabeled autopsy tissue. Nat. Commun. 15, 1684 (2024).
Petersen, D. et al. Virtual staining of colon cancer tissue by label-free Raman micro-spectroscopy. Analyst 142, 1207–1215 (2017).
Elmalam, N., Ben Nedava, L. & Zaritsky, A. In silico labeling in cell biology: potential and limitations. Curr. Opin. Cell Biol. 89, 102378 (2024).
Liu, Z. et al. VisCy. Zenodo https://doi.org/10.5281/zenodo.15022187 (2025).
Soto, J. M., Rodrigo, J. A. & Alieva, T. Label-free quantitative 3D tomographic imaging for partially coherent light microscopy. Opt. Express 25, 15699–15712 (2017).
Chandler, T. et al. waveorder. Zenodo https://doi.org/10.5281/zenodo.15022105 (2025).
Chandler, T. et al. waveOrder: generalist framework for label-agnostic computational microscopy. Preprint at https://arxiv.org/abs/2412.09775 (2024).
Woo, S. et al. ConvNeXt V2: co-designing and scaling convnets with masked autoencoders. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 16133–16142 (2023).
Falk, T. et al. U-Net: deep learning for cell counting, detection, and morphometry. Nat. Methods 16, 67–70 (2019).
Liu, Z. et al. A ConvNet for the 2020s. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 11966–11976 (2022).
Tian, K. et al. Designing BERT for convolutional networks: sparse and hierarchical masked modeling. In Proc. International Conference on Learning Representations (ICLR) (2023).
Pachitariu, M. & Stringer, C. Cellpose 2.0: how to train your own model. Nat. Methods 19, 1634–1641 (2022).
Edlund, C. et al. LIVECell—a large-scale dataset for label-free live cell segmentation. Nat. Methods 18, 1038–1045 (2021).
Stringer, C. & Pachitariu, M. Cellpose3: one-click image restoration for improved cellular segmentation. Nat. Methods 22, 592–599 (2025).
Chen, T., Kornblith, S., Norouzi, M. & Hinton, G. A simple framework for contrastive learning of visual representations. In Proc. 37th International Conference on Machine Learning 1597–1607 (PMLR, 2020).
Cardoso, M. J. et al. MONAI: an open-source framework for deep learning in healthcare. Preprint at https://arxiv.org/abs/2211.02701 (2022).
Pradeep, S. et al. Contrastive learning of cell state dynamics in response to perturbations. Preprint at https://arxiv.org/abs/2410.11281 (2024).
Bragantini, J. et al. Ultrack: pushing the limits of cell tracking across biological scales. Preprint at bioRxiv https://doi.org/10.1101/2024.09.02.610652 (2024).
Moore, J. et al. OME-NGFF: a next-generation file format for expanding bioimaging data-access strategies. Nat. Methods 18, 1496–1498 (2021).
Liu, Z. et al. iohub. Zenodo https://doi.org/10.5281/zenodo.15022068 (2025).
Ivanov, I. E. et al. biahub. Zenodo https://doi.org/10.5281/zenodo.15022202 (2025).
Archit, A. et al. Segment anything for microscopy. Nat. Methods 22, 579–591 (2025).
Ma, J. et al. The multimodality cell segmentation challenge: toward universal solutions. Nat. Methods https://doi.org/10.1038/s41592-024-02233-6 (2024).
Stringer, C. & Pachitariu, M. Benchmarking cellular segmentation methods against Cellpose. Preprint at bioRxiv https://doi.org/10.1101/2024.04.06.587952 (2024).
Smith, S. L., Brock, A., Berrada, L. & De, S. ConvNets match vision transformers at scale. Preprint at https://arxiv.org/abs/2310.16764 (2023).
Zhao, H., Gallo, O., Frosio, I. & Kautz, J. Loss functions for image restoration with neural networks. IEEE Trans. Comput. Imaging 3, 47–57 (2017).
Wang, Z., Simoncelli, E. P. & Bovik, A. C. Multiscale structural similarity for image quality assessment. In The Thirty-Seventh Asilomar Conference on Signals, Systems & Computers, 2003 1398–1402 (IEEE, 2003); https://doi.org/10.1109/ACSSC.2003.1292216
Hein, M. Y. et al. Global organelle profiling reveals subcellular localization and remodeling at proteome scale. Cell 188, 1137–1155.e20 (2025).
Walt et al. scikit-image: image processing in Python. PeerJ 2, e453 (2014).
Meijering, E. et al. Design and validation of a tool for neurite tracing and analysis in fluorescence microscopy images. Cytometry A 58A, 167–176 (2004).
Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 9, 62–66 (1979).
Zhang, T. Y. & Suen, C. Y. A fast parallel algorithm for thinning digital patterns. Commun. ACM 27, 236–239 (1984).
Paszke, A. et al. PyTorch: an imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 32, 8024–8035 (2019).
Falcon, W. & The PyTorch Lightning team. PyTorch Lightning. Zenodo https://doi.org/10.5281/zenodo.3828935 (2019).
Wightman, R. et al. rwightman/pytorch-image-models. Zenodo https://doi.org/10.5281/zenodo.7618837 (2023).
Acknowledgements
Some of the computational experiments reported in this paper were informed by the discussions with participants of the advanced research course on Machine Learning for Microscopy Image Analysis at Marine Biological Lab (DL@MBL), Woods Hole. S.B.M. thanks fellow faculty A. Kreshuk, EMBL, Heidelberg, and A. Krull, University of Birmingham, for critical discussion of strategies. E.H.-M. thanks Ashesh, Human Technopole, Milan, for pair coding image translation models during DL@MBL 2023, and J. Bragantini for insightful tips and tricks on using Ultrack for cell tracking. We thank J. Byrum and G. Bell, Chan Zuckerberg Biohub, for their help with cell culture. We thank J. Hanks and W. Law from CZ Biohub’s Scientific Compute Platform for enabling access to the high-performance computing cluster for model training. We thank D. McCarthy, K. Rosario Cora, M. Weber Mendonça, E. Bezzi and C. Stolitzka from CZI’s Virtual Cell Platform for enabling deployment of models and datasets. We thank P. Chan and M. Zuckerberg for supporting the CZ Biohub. This research was funded by the Chan Zuckerberg Initiative through the Chan Zuckerberg Biohub, San Francisco. All authors were supported by the intramural programme of the Chan Zuckerberg Biohub, San Francisco. J.V.R. was supported by the DAAD (German Academic Exchange Service) IFI programme (international research stays for computer scientists) and the DFG (German research foundation) iMOL (interfacing image analysis and molecular life-science) project number 414985841, GRK 2566.
Author information
Authors and Affiliations
Contributions
Z.L., E.H.-M., S.P., J.V.R., I.E.I., H.O.W., T.L., A.B., R.M., C.L., A.J. and S.B.M. contributed imaging data for training and testing the models. Z.L., E.H.-M., S.P., C.F. and S.B.M. contributed to the development of the code for training models. Z.L. and E.H.-M trained and evaluated models reported in this paper with guidance from S.B.M. R.A., M.D.L., C.A., A.J. and S.B.M. supervised the research and informed the evaluation of the models. Z.L., E.H.-M. and S.B.M. wrote the paper with critical contributions from all co-authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Machine Intelligence thanks Lei Tian and Chengjia Wang for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 UNeXt2 network architecture illustrated with VSCyto3D.
The input image volume is projected to 2D feature map via the 3D stem, and a 2D U-Net encoder-decoder pair integrates information from multiple spatial scales, before projecting the 2D feature map back to the original 3D shape via the 3D head.
Extended Data Fig. 2 FCMAE pre-training for UNeXt2.
FCMAE network for self-supervised pre-training using VSCyto3D as an example.
Extended Data Fig. 3 Deconvolution improves contrast of fine features for virtual staining.
(a) Comparison of contrast in brightfield (BF) and fluorescence (FL) images with the corresponding deconvolution of the phase density and fluorescence density. We trained four virtual staining models that translate between raw and deconvolved versions of label-free and fluorescence contrasts (indicated by arrows). Scale bars: 10 µm. (b) The average precision (AP) and average precision at IoU =0.5 (AP@0.5) for nuclei segmented from experimentally and virtual stained images are shown for 12 test FOVs. Virtually stained images were predicted with four models indicated on the vertical axis. Instance segmentations of experimentally stained nuclei were proofread manually. Deconvolution of BF and FL volumes leads to more accurate segmentation of nuclei. We also assess how the phase and fluorescence density, deconvolved from brightfield (BF) and fluorescence (FL) volumes, respectively, affect the Pearson cross-correlation (PCC). The boxes show median and interquartile range, the whiskers show 12.5 and 87.5 percentiles, and the circles show outliers.
Extended Data Fig. 4 Virtual staining from phase rescues missing fluorescence labels.
Experimentally and virtually stained in HEK293T cells nuclei and membrane for the 75% aperture condition and corresponding segmentations. Scale bars: 50 µm.
Extended Data Fig. 5 Augmentation improves the virtual staining and segmentation of Zernike phase contrast images.
Cell and nuclei segmentation was performed using Zernike phase contrast, raw fluorescence, and virtual staining images. Virtual staining models trained with augmentations produced more accurate and higher resolution segmentations compared to the experimental phase contrast or fluorescence images. Scale bars represent 50 µm.
Extended Data Fig. 6 Illustrative predictions, segmentations, and metrics for training strategies described in Fig. 3a.
(a) Virtual staining of nuclei and membrane in HEK293T using models trained from scratch or pre-trained (FCMAE + virtual staining). Pre-training enhances the high-frequency features in predictions. Scale bar: 50 µm. (b) Training a model from scratch or with pre-training protocol leads to similar segmentation and regression performance for a single cell type (HEK293T) on a test set of 12 FOVs. PCC: Pearson correlation coefficient. AP@0.5: average precision at IoU =0.5. The boxes show median and interquartile range, the whiskers show 12.5 and 87.5 percentiles, and the circles show outliers. (c) Illustrative segmentations of virtually stained nuclei and membranes of BJ5-ta cells: models were trained with 6-FOVs or 110-FOVs according to the training strategies summarized in Fig. 3a.
Extended Data Fig. 7 Visualization of features learned by VSCyto2D.
Input, prediction, and intermediate feature maps of the 2DVSCyto and FCMAE models. The first 3 principal components of the feature map from each ConvNext stage are rendered as RGB values for an illustrative input image patch. (1) model trained from scratch on BJ-5ta; (2) model pre-trained on virtual staining of HEK-293T and A549, and then fine-tuned on BJ-5ta; (3) model pre-trained with FCMAE and virtual staining of HEK-293T and A549, and then fine-tuned on BJ-5ta; (4) FCMAE model of HEK-293T and A549, not trained for virtual staining. Scale bar: 50 µm.
Extended Data Fig. 8 Illustration of the workflow for processing predictions from VSNeuromast models.
(a) Workflow for testing the neuromast predictions. Images of neuromasts during preprocessing (denoising, deconvolution, registration) and postprocessing (segmentation and tracking) steps are also shown. (b) Post-processing is needed to distinguish virtually stained neuromast cells from non-neuromast cells. Phase, fluorescence and virtual staining pairs of the central and ventral slices depicting how the model generalizes to other cell types with similar morphology. (c) Processing pipeline to isolate the neuromasts from the whole FOV. The pipeline is used for generating the instance segmentations and performance metrics.
Extended Data Fig. 9 Visualization of features maps from VS-HEK293T (a) and VSNeuromast (b).
Features were computed for the central z-slice of phase, fluorescence target, and prediction volumes. The first 3 principal components of the feature map from each ConvNext stage are rendered as RGB values for an illustrative input image patch. Scale bars: 10 µm.
Supplementary information
Supplementary Information (download PDF )
Supplementary Note 1, Tables 1–7, Figs. 1–3 and captions for Videos 1–5.
Supplementary Video 1 (download MP4 )
Through-focus video of HEK293T cells: phase, experimentally stained nuclei (green) and membrane (magenta), virtually stained nuclei and membrane with VS-HEK293T. Scale bar, 25 µm.
Supplementary Video 2 (download MP4 )
Evolution of neuromast predictions during virtual-staining pre-training: the first three columns depict the 2D source (phase) and target (nuclei and membrane) pairs of three different FOVs from the validation dataset. The last two columns feature the virtually stained nuclei and membrane, respectively, across epochs.
Supplementary Video 3 (download MP4 )
Visualization of zebrafish neuromast dynamics using quantitative phase imaging, experimental fluorescence and virtual staining: the video shows both XY (at z = 7.5 µm) and XZ slices through the centre of the image over time. Top row: quantitative phase imaging, experimental fluorescence (nuclei in green, membrane in magenta) and virtually stained data (nuclei in blue, membrane in orange) are displayed side by side. Bottom row: comparison of 3D instance segmentations and cell tracking result of fluorescence and virtual staining, respectively. The Cellpose 3D membrane segmentations were used as a starting point for Ultrack tracking. Virtual staining enables longer cell tracking as it is more robust to photobleaching. Scale bars, XY 25 µm and XZ 5 µm.
Supplementary Video 4 (download MP4 )
Phase time-lapse images virtually stained with VSCyto2D: Cells were imaged every 30 minutes for 24 hours (nuclei in blue, membrane in orange). Scale bar, 100 µm.
Supplementary Video 5 (download MP4 )
Evolution of VSCyto2D predictions during fine-tuning on BJ-5ta cells: Illustrative patches of cells from the validation set are shown every four training epochs when fine-tuning a model that has been pre-trained with three different strategies—(top) without pre-training (from scratch), (middle) pretrained with paired phase and fluorescence images of HEK293T and A549 (end-to-end pretrained), (bottom) pretrained with masked autoencoder (FCMAE) and paired phase and fluorescence images of HEK293T and A549 cells. Left to right: phase input patch, nuclei fluorescence (Hoechst), membrane fluorescence (CellMask), nuclei prediction, membrane prediction. Pre-trained models start to produce correct predictions faster. Each image patch is 83.2 µm by 83.2 µm (256 pixels by 256 pixels).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, Z., Hirata-Miyasaki, E., Pradeep, S. et al. Robust virtual staining of landmark organelles with Cytoland. Nat Mach Intell 7, 901–915 (2025). https://doi.org/10.1038/s42256-025-01046-2
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s42256-025-01046-2
