
Abstract
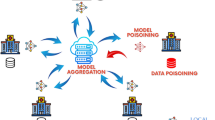
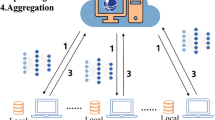
In highly regulated domains such as finance and healthcare, where stringent data-sharing constraints pose substantial obstacles, federated learning (FL) has emerged as a transformative paradigm in distributed machine learning, facilitating collaborative model training, preserving data decentralization and upholding governance standards. Despite its advantages, FL is vulnerable to poisoning attacks during central model aggregation, prompting the development of Byzantine-robust FL systems that use robust aggregation rules to counter malicious attacks. However, neural network models in such systems are susceptible to unintentionally memorizing and revealing individual training instances, thereby introducing substantial information leakage risks, as adversaries may exploit this vulnerability to reconstruct sensitive data through model outputs transmitted over the air. Existing solutions fall short of providing a viable Byzantine-robust FL system that is completely secure against information leakage and is computationally efficient. To address these concerns, we propose Lancelot, an efficient and effective Byzantine-robust FL framework that uses fully homomorphic encryption to safeguard against malicious client activities. Lancelot introduces a mask-based encrypted sorting mechanism that overcomes the limitations of multiplication depth in ciphertext sorting with zero information leakage. It incorporates cryptographic enhancements like lazy relinearization, dynamic hoisting and GPU acceleration to ensure practical computational efficiency. Extensive experiments demonstrate that Lancelot surpasses existing approaches, achieving a 20-fold enhancement in processing speed.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$32.99 / 30 days
cancel any time
Subscribe to this journal
Receive 12 digital issues and online access to articles
$119.00 per year
only $9.92 per issue
Buy this article
- Purchase on SpringerLink
- Instant access to the full article PDF.
USD 39.95
Prices may be subject to local taxes which are calculated during checkout





Similar content being viewed by others
Data availability
The MNIST dataset is available at https://www.kaggle.com/datasets/hojjatk/mnist-dataset. The FMNIST dataset is available via GitHub at https://github.com/zalandoresearch/fashion-mnist. The CIFAR-10 dataset is available at https://www.cs.toronto.edu/~kriz/cifar.html. The SVHN dataset is available at http://ufldl.stanford.edu/housenumbers/. The MedMNIST dataset is available at https://medmnist.com/. The MosMedData dataset is available at https://mosmed.ai/datasets/covid19_1110. The ImageNet dataset is available at https://www.image-net.org/. Source data are provided with this paper.
Code availability
All code necessary to run the public portion of the experiment is available via GitHub at https://github.com/siyang-jiang/Lancelot and via Zenodo at https://doi.org/10.5281/zenodo.16022526 (ref. 65). The code is licensed using the MIT license.
References
Accountability Act Health insurance portability and accountability act of 1996. Public Law 104, 191 (1996).
European Parliament & Council. General data protection regulation. Off. J. Eur. Union L 119, 1–88 (2016).
Sav, S. et al. POSEIDON: privacy-preserving federated neural network learning. In 28th Annual Network and Distributed System Security Symposium (NDSS 2021) https://doi.org/10.14722/ndss.2021.24119 (The Internet Society, 2021).
Mendelsohn, S. et al. sfkit: a web-based toolkit for secure and federated genomic analysis. Nucleic Acids Res. 51, W535–W541 (2023).
Biggio, B., Nelson, B. & Laskov, P. Poisoning attacks against support vector machines. In Proc. 29th International Conference on Machine Learning 1467–1474 (Omnipress, 2012).
Xie, C., Huang, K., Chen, P. & Li, B. DBA: distributed backdoor attacks against federated learning. In Proc. 7th International Conference on Learning Representations https://openreview.net/pdf?id=rkgyS0VFvr (ICLR, 2020).
Zhang, Y., Zeng, D., Luo, J., Xu, Z. & King, I. A survey of trustworthy federated learning with perspectives on security, robustness, and privacy. In Proc. ACM Web Conference 2023 Companion 1167–1176 (ACM, 2023).
Alkhunaizi, N., Kamzolov, D., Takáč, M. & Nandakumar, K. Suppressing poisoning attacks on federated learning for medical imaging. In Proc. 25th International Conference on Medical Image Computing and Computer-Assisted Intervention 673–683 (Springer, 2022).
Zhu, L., Liu, Z. & Han, S. Deep leakage from gradients. Adv. Neural Inf. Process. Syst. 32, 14747–14756 (2019).
Zhao, B., Mopuri, K. R. & Bilen, H. iDLG: improved deep leakage from gradients. Preprint at https://arxiv.org/abs/2001.02610 (2020).
Liu, J., Lou, J., Xiong, L., Liu, J. & Meng, X. Cross-silo federated learning with record-level personalized differential privacy. In Proc. 2024 ACM SIGSAC Conference on Computer and Communications Security 303–317 (ACM, 2024).
Liu, J., Lou, J., Xiong, L., Pei, J. & Sun, J. Dealer: an end-to-end model marketplace with differential privacy. Proc. VLDB Endow. 14, 957–969 (2021).
De, S., Berrada, L., Hayes, J., Smith, S. L. & Balle, B. Unlocking high-accuracy differentially private image classification through scale. Preprint at https://arxiv.org/abs/2204.13650 (2022).
Hayes, J., Balle, B. & Mahloujifar, S. Bounding training data reconstruction in DP-SGD. Adv. Neural Inf. Process. Syst. 36, 78696–78722 (2023).
Dwork, C. Differential privacy: a survey of results. In Proc. 5th International Conference on Theory and Applications of Models of Computation 1–19 (Springer, 2008).
Dwork, C., Tankala, P. & Zhang, L. Differentially private learning beyond the classical dimensionality regime. Preprint at https://arxiv.org/abs/2411.13682 (2024).
Bonawitz, K. A. et al. Practical secure aggregation for privacy-preserving machine learning. In Proc. 2017 ACM SIGSAC Conference on Computer and Communications Security 1175–1191 (ACM, 2017).
Mohammed, S. J. & Taha, D. B. Performance evaluation of RSA, ElGamal, and Paillier partial homomorphic encryption algorithms. In Proc. 2022 International Conference on Computer Science and Software Engineering 89–94 (IEEE, 2022).
Cheon, J. H., Kim, A., Kim, M. & Song, Y. Homomorphic encryption for arithmetic of approximate numbers. In Proc. 23rd International Conference on the Theory and Application of Cryptology and Information Security 409–437 (Springer, 2017).
Zhang, C. et al. BatchCrypt: efficient homomorphic encryption for cross-silo federated learning. In Proc. 2020 USENIX Annual Technical Conference 493–506 (USENIX Association, 2020).
Regev, O. On lattices, learning with errors, random linear codes, and cryptography. In Proc. 37th Annual ACM Symposium on Theory of Computing 84–93 (ACM, 2005).
Lai, F. et al. FedScale: benchmarking model and system performance of federated learning at scale. In Proc. 39th International Conference on Machine Learning 11814–11827 (PMLR, 2022).
Beutel, D. J. et al. Flower: a friendly federated learning research framework. Preprint at https://arxiv.org/abs/2007.14390 (2020).
Roth, H. R. et al. NVIDIA FLARE: federated learning from simulation to real-world. IEEE Data Eng. Bull. 46, 170–184 (2023).
Ludwig, H. et al. IBM federated learning: an enterprise framework white paper v0.1. Preprint at https://arxiv.org/abs/2007.10987 (2020).
He, C. et al. FedML: a research library and benchmark for federated machine learning. Preprint at https://arxiv.org/abs/2007.13518 (2020).
Blanchard, P., El Mhamdi, E. M., Guerraoui, R. & Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. In 31st Conference on Neural Information Processing Systems (NIPS 2017) https://proceedings.neurips.cc/paper_files/paper/2017/file/f4b9ec30ad9f68f89b29639786cb62ef-Paper.pdf (2017).
Yin, D., Chen, Y., Kannan, R. & Bartlett, P. Byzantine-robust distributed learning: towards optimal statistical rates. In Proc. 35th International Conference on Machine Learning 5650–5659 (PMLR, 2018).
Al Badawi, A. et al. OpenFHE: open-source fully homomorphic encryption library. In Proc. 10th Workshop on Encrypted Computing & Applied Homomorphic Cryptography 53–63 (ACM, 2022).
Bhagoji, A. N., Chakraborty, S., Mittal, P. & Calo, S. Analyzing federated learning through an adversarial lens. In Proc. 36th International Conference on Machine Learning 634–643 (PMLR, 2019).
Cao, X. & Gong, N. Z. MPAF: model poisoning attacks to federated learning based on fake clients. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops 3396–3404 (IEEE, 2022).
Jiang, S., Shuai, X. & Xing, G. ArtFL: exploiting data resolution in federated learning for dynamic runtime inference via multi-scale training. In Proc. 23rd ACM/IEEE International Conference on Information Processing in Sensor Networks 27–38 (IEEE, 2024).
Yang, H. et al. Implementing and benchmarking word-wise homomorphic encryption schemes on GPU. Preprint at Cryptology ePrint Archive https://eprint.iacr.org/2023/049 (2023).
Deng, J. et al. ImageNet: a large-scale hierarchical image database. In Proc. 2009 IEEE Conference on Computer Vision and Pattern Recognition 248–255 (IEEE, 2009).
Morozov, S. P. et al. MosMedData: chest CT scans with COVID-19 related findings dataset. Preprint at https://arxiv.org/abs/2005.06465 (2020).
Geiping, J., Bauermeister, H., Dröge, H. & Moeller, M. Inverting gradients: how easy is it to break privacy in federated learning? In 34th Conference on Neural Information Processing Systems (NeurIPS 2020) https://proceedings.neurips.cc/paper/2020/file/c4ede56bbd98819ae6112b20ac6bf145-Paper.pdf (2020).
Hatamizadeh, A. et al. Do gradient inversion attacks make federated learning unsafe?. IEEE Trans. Med. Imaging 42, 2044–2056 (2023).
Feng, S. & Tramèr, F. Privacy backdoors: stealing data with corrupted pretrained models. In Proc. 41st International Conference on Machine Learning 13326–13364 (2024).
Li, B. & Micciancio, D. On the security of homomorphic encryption on approximate numbers. In Proc. 40th Annual International Conference on the Theory and Applications of Cryptographic Techniques 648–677 (Springer, 2021).
Cheon, J. H., Hong, S. & Kim, D. Remark on the security of CKKS scheme in practice. Preprint at Cryptology ePrint Archive https://eprint.iacr.org/2020/1581 (2020).
Hu, C., Chen, Z. & Larsson, E. G. Scheduling and aggregation design for asynchronous federated learning over wireless networks. IEEE J. Sel. Areas Commun. 41, 874–886 (2023).
Fan, B., Jiang, S., Su, X., Tarkoma, S. & Hui, P. A survey on model-heterogeneous federated learning: problems, methods, and prospects. In Proc. 2024 IEEE International Conference on Big Data 7725–7734 (IEEE, 2024).
Li, X. et al. ClassTer: mobile shift-robust personalized federated learning via class-wise clustering. IEEE Trans. Mob. Comput. 24, 2014–2028 (2025).
Lai, F., Zhu, X., Madhyastha, H. V. & Chowdhury, M. Oort: efficient federated learning via guided participant selection. In Proc. 15th USENIX Symposium on Operating Systems Design and Implementation 19–35 (USENIX Association, 2021).
Li, C., Zeng, X., Zhang, M. & Cao, Z. PyramidFL: a fine-grained client selection framework for efficient federated learning. In Proc. 28th Annual International Conference on Mobile Computing and Networking 158–171 (ACM, 2022).
Kim, S. et al. BTS: an accelerator for bootstrappable fully homomorphic encryption. In Proc. 49th Annual International Symposium on Computer Architecture 711–725 (ACM, 2022).
Pan, X. et al. Flagger: cooperative acceleration for large-scale cross-silo federated learning aggregation. In Proc. 51st ACM/IEEE Annual International Symposium on Computer Architecture 915–930 (IEEE, 2024).
Benaissa, A., Retiat, B., Cebere, B. & Belfedhal, A. E. TenSEAL: a library for encrypted tensor operations using homomorphic encryption. Preprint at https://arxiv.org/abs/2104.03152 (2021).
Halevi, S. & Shoup, V. Design and implementation of HElib: a homomorphic encryption library. Preprint at Cryptology ePrint Archive https://eprint.iacr.org/2020/1481 (2020).
CryptoLab Inc. HEAAN software library. GitHub https://github.com/kimandrik/HEAAN (2018).
Dutta, S., Innan, N., Yahia, S. B., Shafique, M. & Neira, D. E. B. MQFL-FHE: multimodal quantum federated learning framework with fully homomorphic encryption. Preprint at https://arxiv.org/abs/2412.01858 (2025).
Guo, Y. et al. Efficient and privacy-preserving federated learning based on full homomorphic encryption. Preprint at https://arxiv.org/abs/2403.11519 (2024).
Hu, C. & Li, B. MaskCrypt: federated learning with selective homomorphic encryption. IEEE Trans. Dependable Secur. Comput. 22, 221–233 (2025).
Jin, W. et al. FedML-HE: an efficient homomorphic-encryption-based privacy-preserving federated learning system. Preprint at https://arxiv.org/abs/2303.10837 (2024).
Ouyang, X. et al. ADMarker: a multi-modal federated learning system for monitoring digital biomarkers of Alzheimer’s disease. In Proc. 30th Annual International Conference on Mobile Computing and Networking 404–419 (ACM, 2024).
Zhang, Z. et al. LSFL: a lightweight and secure federated learning scheme for edge computing. IEEE Trans. Inf. Forensics Secur. 18, 365–379 (2023).
Zhang, Z. & Li, Y. NSPFL: a novel secure and privacy-preserving federated learning with data integrity auditing. IEEE Trans. Inf. Forensics Secur. 19, 4494–4506 (2024).
Xu, G. et al. Privacy-preserving federated deep learning with irregular users. IEEE Trans. Dependable Secure Comput. 19, 1364–1381 (2022).
Kim, M., Song, Y., Li, B. & Micciancio, D. Semi-parallel logistic regression for GWAS on encrypted data. BMC Med. Genomics 13, 99 (2020).
Froelicher, D. et al. Truly privacy-preserving federated analytics for precision medicine with multiparty homomorphic encryption. Nat. Commun. 12, 5910 (2021).
Froelicher, D. et al. Scalable and privacy-preserving federated principal component analysis. In Proc. 2023 IEEE Symposium on Security and Privacy 1908–1925 (IEEE, 2023).
Cho, H. et al. Secure and federated genome-wide association studies for biobank-scale datasets. Nat. Genet. 57, 809–814 (2025).
Halevi, S. & Shoup, V. Faster homomorphic linear transformations in HElib. In Proc. 38th International Cryptology Conference 93–120 (Springer, 2018).
Nelder, J. A. & Mead, R. A simplex method for function minimization. Comput. J. 7, 308–313 (1965).
Jiang, S. et al. Lancelot-Dev codebase. Zenodo https://doi.org/10.5281/zenodo.16022526 (2025).
Acknowledgements
This work is supported by the National Key R&D Program of China (2022YFB3103500), the Science and Technology Innovation Key R&D Program of Chongqing CSTB2025TIAD-STX0032, the fund which aims to improve scientific research capability of key construction disciplines in Guangdong province (2022ZDJS058), the National Natural Science Foundation of China (62132008 and U22B2030), the Hong Kong Research Grants Council (RGC) grant C4072-21G and the RGC under General Research Fund (number 14212924). We would also like to thank S. Shen, L. Jiang, W. Dai, and M. Ding for their valuable suggestions and support.
Author information
Authors and Affiliations
Contributions
S.J., H.Y., Q.X. and C.M. contributed to the motivation and framework design. S.J. led the development of the mask-based encrypted sorting algorithm, implemented most of the work and wrote a majority of the manuscript. H.Y. contributed to the CKKS implementation and provided expertise in cryptography. S.J. and Q.X. conducted the experiments and analysed the results. C.M., Z.L., S.W., T.X. and G.X. contributed to partial drafts of this manuscript. All authors reviewed and revised the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Machine Intelligence thanks Kim Miran, Yiyu Shi and Alexander Ziller for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information (download PDF )
Supplementary Sections 1–4 and References.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Jiang, S., Yang, H., Xie, Q. et al. Towards compute-efficient Byzantine-robust federated learning with fully homomorphic encryption. Nat Mach Intell 7, 1657–1668 (2025). https://doi.org/10.1038/s42256-025-01107-6
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s42256-025-01107-6
This article is cited by
-
Homomorphic encryption for secure healthcare artificial intelligence
Discover Artificial Intelligence (2026)
